A Survey on Recent Advances in Sequence Labeling from Deep Learning Models
Abstract
Sequence labeling (SL) is a fundamental research problem encompassing a variety of tasks, e.g., part-of-speech (POS) tagging, named entity recognition (NER), text chunking etc. Though prevalent and effective in many downstream applications (e.g., information retrieval, question answering and knowledge graph embedding), conventional sequence labeling approaches heavily rely on hand-crafted or language-specific features. Recently, deep learning has been employed for sequence labeling task due to its powerful capability in automatically learning complex features of instances and effectively yielding the stat-of-the-art performances. In this paper, we aim to present a comprehensive review of existing deep learning-based sequence labeling models, which consists of three related tasks, e.g., part-of-speech tagging, named entity recognition and text chunking. Then, we systematically present the existing approaches base on a scientific taxonomy, as well as the widely-used experimental datasets and popularly-adopted evaluation metrics in SL domain. Furthermore, we also present an in-depth analysis of different SL models on the factors that may affect the performance, and the future directions in SL domain.
Index Terms:
Sequence labeling, deep learning, natural language processing.I Introduction
Sequence labeling is a type of pattern recognition task in the important branch of natural language processing (NLP). From the perspective of linguistics, the smallest meaningful unit in a language is typically regarded as morpheme, and each sentence can thus be viewed as a sequence composed of morphemes. Accordingly, the sequence labeling problem in NLP domain can be formulate it as a task that aims at assigning labels to a category of morphemes that generally have similar roles within the grammatical structure of sentences and have similar grammatical properties, and the meanings of the assigned labels usually depend on the types of specific tasks, examples of classical tasks include part-of-speech (POS) tagging [71], named entity recognition (NER) [52], text chunking [65] and etc., which play a pivotal role in natural language understanding and can benefit a variety of downstream applications such as syntactic parsing [81], relation extraction [64] and entity coreference resolution [78] and etc., and hence has quickly gained massive attention.
Generally, conventional sequence labeling approaches are usually on the basis of classical machine learning technologies, e.g., Hidden Markov Models (HMM) [3] and Conditional Random Fields (CRFs) [51], which often heavily rely on hand-crafted features (e.g., whether a word is capitalized) or language-specific resources (e.g., gazetteers). Despite superior performance achieved, the requirement of the considerable amount of domain knowledge and efforts on feature engineering make them extremely difficult to extend to new areas. Over the past decade, the great success has been achieved by deep learning (DL) due to its powerful capability in automatically learning complex features of data. Hence, there already exist many efforts dedicated to research on how to exploit the representation learning capability of deep neural network for enhancing sequence labeling tasks, and many of these methods have successively advanced the state-of-the-art performances [8, 1, 19]. This trend motivates us to conduct a comprehensive survey to summarize the current status of deep learning techniques in the filed of sequence labeling. By comparing the choices of different deep learning architectures, we aim to identify the impacts on the model performance, making it convenient for subsequent researchers to better understand the advantages/disadvantages of such models.
Differences with former surveys. In literature, there have been numerous attempts to improve the performance of sequence labeling tasks using deep learning models. However, to the best of our knowledge, there are nearly none comprehensive surveys that provide an in-depth summary of existing neural network based methods or developments on part of this topic so far. Actually, in the past few years, several surveys have been presented on traditional approaches for sequence labeling. For example, Nguyen et al. [79] propose a systematic survey on machine learning based sequence labeling problems. Nadeau et al. [76] survey on the problem of named entity recognition and present an overview of the trend from hand-crafted rule-based algorithms to machine learning techniques. Kumar and Josan [49] conduct a short review on part-of-speech tagging for Indian language. In summary, the most reviews for sequence labeling mainly cover papers on traditional machine learning methods, rather than the recent applied techniques of deep learning (DL). Recently, two work [117, 54] present a good literature survey of the deep learning based models for named entity recognition (NER) problem, however it is solely a sub-task for sequence labeling. To the best of our knowledge, there has been so far no survey that can provide an exhaustive summary of recent research on DL-based sequence labeling methods. Given the increasing popularity of deep learning models in sequence labeling, a systematic survey will be of high academic and practical significance. We summarize and analyze these related works and over studies are covered in this survey.
Contributions of this survey. The goal of this survey is to thoroughly review the recent applied techniques of deep learning in the filed of sequence labeling (SL), and provides a panoramic view to enlighten and guide the researchers and practitioners in SL research community for quickly understanding and stepping into this area. Specifically, we present a comprehensive survey on deep learning-based SL techniques to systematically summarize the state-of-the-arts with a scientific taxonomy along three axes, i.e., embedding module, context encoder module, and inference module. In addition, we also present an overview on the experiment settings (i.e., dataset or evaluation metric) for commonly studied tasks in sequence labeling domain. Besides, we have discussed and compared the results give by the most representative models for analyzing the effects of different factors and architectures. Finally, we present readers with the challenges and open issues faced by current DL-based sequence labeling methods and outline future directions in this area.
Roadmap. The remaining of this paper is organized as follows: Section II introduces background of sequence labeling, consisting of several related tasks and traditional machine learning approaches. Section III presents deep learning models for sequence labeling based on our proposed taxonomy. Section IV summarizes the experimental settings (i.e., dataset and evaluation metric) for related tasks. Section V lists the results of different methods, followed by the discussion of the promising future directions. Finally, Section VII concludes this survey.
II Background
In this section, we first give an introduction of three widely-studied classical sequence labeling tasks, i.e., part-of-speech (POS) tagging, named entity recognition (NER) and text chunking. Then, we briefly introduce the traditional machine learning based techniques in sequence labeling domain.
II-A Classical Sequence Labeling Task
II-A1 Part-of-speech Tagging (POS)
POS receives a high degree of acceptance from both academia and industry, which is a standard sequence labeling task that aims at assigning a correct part-of-speech tag to each lexical item (a.k.a., word) such as noun (NN), verb (VB) and adjective (JJ). In general, part-of-speech (POS) tagging can also be viewed as a subclass division of all words in a language, which is thus also called a word class. The tagging system of part-of-speech tags is not usually uniform under different data set, e.g., PTB (Penn Treebank) [72], which includes different types of POS tags for word classification, such as for sentence “Mr. Jones is editor of the Journal”, it will be labeled with a sequence like ”NNP NNP VBZ NN IN DT NN”.
In fact, Part-of-speech can be regarded as a coarse-grained word cluster task, the goal of which is to label the form and syntactic information of words in a sentence, which is benefit for alleviating the sparseness of word-level features, and servers as an important pre-processing step in natural language processing domain for various subsequent tasks like semantic role labeling or syntax analysis.
II-A2 Named Entity Recognition (NER)
Name entity recognition (NER, a.k.a., named entity identification or entity chunking), is a well-known classical sequence labeling task, the goal of which is to identify named entities from text belonging to pre-defined categories, which generally consists of three major categories (i.e., entity, time, and numeric) and seven sub-categories (i.e., person name, organization, location, time, date, currency, and percentage). Particularly, in this paper we mainly focus on the NER problem in English language, and a widely-adopted English taxonomy is CoNLL2003 NER corpus [97], which is collected from Reuters News Corpus that includes four different types of named entities, i.e., person (PER), location (LOC), organization (ORG) and proper nouns (MISC).
Generally, the label of a word in NER is composed of two parts, i.e., “X-Y”, where “X” indicates the position of the labeled word and “Y” refers to the corresponding category within a pre-defined taxonomy. In particular, it may be labeled with a special label (e.g., “none”), if a word cannot be classified into any pre-defined category. Generally, the widely-adopted tagging scheme in the industry is BIOES system, that is, the word labeled “B” (Begin), “I” (Inside) and “E” (End) means that it is the first, middle or last word of a named entity phrase, respectively. The word labeled “0-” (Outside) means it does not belong to any named entity phrase and “S-” (Single) indicates it is the only word that represent an entity.
Named entity recognition is a very important task in natural language processing and is a basic technology for many high-level applications, such as search engine, question and answer systems, recommendation systems, translation systems, etc. Without loss of generality, we take machine translation as example to illustrate the importance of NER for various downstream tasks. In the process of translation, if the text contains named entity with a specific meaning, the translation system usually tends to translate multiple words that make up the named entity separately, resulting in blunt or even erroneous translation results. But if the named entity is identified first, the translation algorithm will have a better understanding of the word order and semantics of the text thus can output a better translation.
II-A3 Text Chunking
The goal of the text chunking task is to divide text into syntactically related non-overlapping groups of words, i.e., phrase, such as noun phrase, verb phrase, etc. The task can be essentially regarded as a sequence labeling problem that assign specific labels to words in sentences. Similar with NER, it can also adopt the BIOES tagging system. For example, the sentence “The little dog barked at the cat.” can be divided into the following phrases: “(The little dog) (barked at) (the cat)”. Therefore, with the BIOES tagging system, the label sequence corresponding to this sentence is “B-NP I-NP E-NP B-VP E-VP B-NP E-NP”, which means that “The little dog” and “the cat” are noun phrases and “barted at” is a verb phrase.
II-A4 Others
There have been many explorations into applying the sequence labeling framework to address other problems such as dependency parsing [105, 60], semantic role labeling [82, 107], answer selection [132, 56], text error detection [93, 92], document summarization [77], constituent parsing [24], sub-event detection [4], emotion detection in dialogues [102] and complex word identification [25].
II-B Traditional Machine Learning Based Approaches
The traditional statistical machine learning techniques are the primary method for early sequence labeling problems. Based on the carefully designed features to represent each training data, the machine learning algorithms are utilized to train the model from example inputs and their expected outputs, learning to make predictions for unseen samples. Common statistical machine learning techniques include Hidden Markov Models (HMM) [21], Support Vector Machines (SVM) [32], Maximum Entropy Models [41] and Conditional Random Fields (CRF) [51]. HMM is a statistical model used to describe a Markov process with implicit unknown states. Bikel et al. [7] propose the first HMM-based model for NER system, named IdentiFinder. This model is extended by Zhou and Su [131] and achieves better performance by assumimg mutual information independence rather than conditional probability independence of HMM.
SVM, which is alleged large margin classifier, is well-known for the good generalization capabilities and has been successfully applied to many pattern recognition problems. In the field of sequence labeling, Kudoh and Matsumoto [48] first propose to apply SVM classifier to the phrase chunking task and achieve the best performance at the time. Several subsequent studies using SVM for NER tasks are successively proposed [36, 59].
Ratnaparkhi [90] proposes the first maximum entropy model for part-of-speech tagging, and achieves great results. Some work for NER also adopt the maximum entry model [12, 5]. The maximum entropy markov model is further proposed [73], which obtains a certain degree of improvement compared with the original maximum entropy model. Lafferty et al. [51] point out that utilizing the maximum entropy model for sequence labeling may suffer from a label bias problem. The proposed CRF model has achieved significant improvement in part-of-speech tagging and named entity recognition tasks and has gradually become the mainstream method of sequence labeling tasks [74, 47].
III Deep Learning Based Models
| Ref | Embedding Module | Context Encoder | Inference Module | Tasks | ||
|---|---|---|---|---|---|---|
| external input | word embedding | character-level | ||||
| [71] | Glove | CNN | Bi-LSTM | CRF | POS, NER | |
| [8] | Word2vec | Bi-LSTM | Bi-LSTM | Softmax | POS | |
| [121] | Glove | Bi-LSTM | Bi-LSTM | CRF | POS | |
| [65] | Glove | Bi-LSTM+LM | Bi-LSTM | CRF | POS, NER, chunking | |
| [88] | Polyglot | Bi-LSTM | Bi-LSTM | CRF | POS | |
| [91] | Word2vec | Bi-LSTM | Bi-LSTM+LM | CRF | POS, NER, chunking | |
| [85] | Senna | CNN | Bi-LSTM+ pre LM | CRF | NER, chunking | |
| [1] | Pre LM emb | Glove | Bi-LSTM | Bi-LSTM | CRF | POS, NER, chunking |
| [127] | - | Bi-LSTM | Bi-LSTM | LSTM+Softmax | POS, NER | |
| [122] | Glove | Bi-LSTM+LM | Bi-LSTM | CRF+Semi-CRF | NER | |
| [126] | Spelling, gaz | Senna | MO-BiLSTM | Softmax | NER, chunking | |
| [26] | Word2vec | Bi-LSTM | Parallel Bi-LSTM | Softmax | NER | |
| [120] | Senna, Glove | Bi-GRU | Bi-GRU | CRF | POS, NER, chunking | |
| [62] | Trained on wikipedia | Bi-LSTM | Bi-LSTM | Softmax | POS | |
| [13] | Cap, lexicon | Senna | CNN | Bi-LSTM | CRF | NER |
| [92] | Word2vec | Bi-LSTM | Bi-LSTM | CRF | POS, NER, chunking | |
| [116] | Glove | InNet | Bi-LSTM | CRF | POS, NER, chunking | |
| [42] | Spelling, gaz | Senna | INN | Softmax | POS | |
| [108] | Glove | Bi-LSTM | EL-CRF | Citation field extraction | ||
| [37] | Trained with skip-gram | Bi-LSTM | Skip-chain CRF | Clinical entities detection | ||
| [115] | Word shapes, gaz | Glove | CNN | Bi-LSTM | CRF | NER |
| [17] | Gaz, cap | Senna | CNN | CRF | POS, NER, chunking, SRL | |
| [113] | Glove | CNN | Gated-CNN | CRF | NER | |
| [104] | Word2vec | ID-CNN | CRF | NER | ||
| [52] | Word2vec | Bi-LSTM | Bi-LSTM | CRF | NER | |
| [35] | Spelling, gaz | Senna | Bi-LSTM | CRF | POS, NER, chunking | |
| [99] | Word2vec | CNN | CNN | CRF | POS | |
| [124] | Senna | CNN | Bi-LSTM | Pointer network | Chunking, slot filling | |
| [130] | Word2vec | Bi-LSTM | LSTM | Entity relation extraction | ||
| [23] | LS vector, cap | SSKIP | Bi-LSTM | LSTM | CRF | NER |
| [103] | Word2vec | CNN | CNN | LSTM | NER | |
| [55] | Glove | Bi-GRU | Pointer network | Text segmentation | ||
| [27] | - | CNN | Bi-LSTM | Softmax | POS | |
| [20] | Word2vec, FastText | LSTM+attention | Bi-LSTM | Softmax | POS | |
| [34] | Glove | CNN | Bi-LSTM | NCRF transducers | POS, NER, chunking | |
| [40] | - | Bi-LSTM+AE | Bi-LSTM | softmax | POS | |
| [101] | Lexicons | Glove | CNN | Bi-LSTM | Segment-level CRF | NER |
| [10] | Glove | CNN | GRN+CNN | CRF | NER | |
| [114] | Glove | CNN | Bi-LSTM+SA | CRF | POS, NER, chunking | |
In this section, we survey deep learning based approaches for sequence labeling. We present the review with a scientific taxonomy that categorize existing works along three axes: embedding module, context encoder module, and inference module, of which three stages neural sequence labeling models often consists. The embedding module is the first stage that maps words into their distributed representations. The context encoder module extracts contextual features and the inference module predict labels and generate optimal label sequence as output of the model. In Table I, we make a brief overview of the deep learning based sequence labeling models with the aforementioned taxonomy. We list the different architectures that these work adopt in the three stages and the final column give the focused tasks.
III-A Embedding Module
The embedding module maps words into their distributed representations as the initial input of model. An embedding lookup table is usually required to convert the one-hot encoding of each word to a low dimensional real-valued dense vector, where each dimension represents a latent feature. In addition to pretrained word embeddings, character-level representations, hand-crafted features and sentence-level representations can also be part of the embedding module, supplementing features for the initial input from different perspectives.
III-A1 Pretrained Word Embeddings
Pretrained word embeddings that learned on a large corpus of unlabeled data has become a key component in many neural NLP models. Adopting it to initialize the embedding lookup table can achieve significant improvements over randomly initialized ones, since the syntactic and semantic information within language are captured during the pretraining process. There are many published pretrained word embeddings that have been widely used, such as Word2Vec, Senna, GloVe and etc.
Word2vec [75] is a popular method to compute vector representations of words, which provides two model architectures including the continuous bag-of-words and skip-gram. Santos et al. [99] use word2vec’s skip-gram method to train word embeddings and added to their sequence labeling model. Similarly, some work [91, 92, 20] initialize the word embeddings in their model with publicly available pretrained vectors that created using word2vec. Lample et al. [52] apply skip-n-gram [63] to pretrain their word embeddings, which is a variation of word2vec that accounts for word order. Gregoric et al. [26] follow their work and also used the same embeddings.
Collobert et al. [17] propose the “SENNA” architecture in 2011, which pioneers the idea of solving natural language processing tasks from the perspective of neural language model, and it also includes a construction method of pretrained word embeddings. Many subsequent work [85, 126, 13, 35, 119, 70] adopt SENNA word embeddings as the initial input of their sequence labeling models. Besides, Stanford’s publicly available GloVe embeddings [84] that trained on billion token corpus from Wikipedia and web text are also widely used and adopted by many work [71, 121, 65, 1, 122, 116, 55, 34, 10] to initilize their word embeddings.
The above pretrained word embedding methods only generate a single context-independent vector for each word, ignoring the modeling of polysemy problem. Recently, many approaches for learning contextual word representations [85, 86, 1] have been proposed, where bidirectional language models (LM) are trained on a large unlabeled corpus and the corresponding internal states are utilized to produce a word representation. And the representation of each word is dependent on its context. For instance, the generated embedding of the word “present” in “How many people were present at the meeting?” is different from that in “I’m not at all satisfied with the present situation”.
Peters et al. [85] propose pretrained contextual embeddings from bidirectional language models and added them to sequence labeling model, achieving pretty excellent performance on the task of NER and chunking. The method first pretrains the forward and backward neural language model separately with Bi-LSTM architecture on a large, unlabeled corpus. Then it removes the top softmax layer and concatenates the forward and backward LM embeddings to form bidirectional LM embeddings for every token in a given input sequence. Peters et al. extend their method [85] in [86] by introducing ELMo (Embeddings from Language Models) representations. Unlike previous approaches that just utilize the top LSTM layer, the ELMo representations are a linear combination of internal states of all bidirectional LM layers, where the weight of each layer is task-specific. By adding these representations to existing models, the method significantly improves the performance across a broad range of diverse NLP tasks [10, 34, 15].
Akbik et al. [1] propose a similar method to generate pretrained contextual word embeddings by adopting a bidirectional character-aware language model, which learns to predict the next and previous character instead of word.
Devlin et al. [19] propose a pretraining language representation model called BERT, which stands for Bidirectional Encoder Representations from Transformers. It obtains new state-of-the-art results on eleven tasks and causes a sensation in the NLP communities. The core idea of BERT is to pretrain deep bidirectional representations by jointly conditioning on both left and right context in all layers. Although the sequence labeling tasks can be addressed by fine-tuning the existing pre-trained BERT model, the output hidden states of BERT can also be taken as additional word embeddings to promote the performance of sequence labeling models [67, luo2020hierarchica].
By modeling the context information, the word representations produced by ELMo and BERT can encode rich semantic information. In addition to such context modeling, a recent work proposed by He et al. [31] provide a new kind of word embedding that is both context-aware and knowledge-aware, which encode the prior knowledge of entities from an external knowledge base. The proposed knowledge-graph augmented word representations significantly promotes the performance of NER in various domains.
III-A2 Character-level Representations
Although syntactic and semantic information are captured inside the pretrained word embeddings, the word morphological and shape information is normally ignored, which is extremely useful for many sequence labeling tasks like part-of-speech tagging. Recently, many researches learn the character-level representations of words through neural networks and incorporate them into the embedding module of models to exploit useful intra-word information, which can also tackle the out-of-vocabulary word problem effectively and has been verified to be helpful in numerous sequence labeling tasks. The two most common architectures to capture character-to-word representations are Convolutional Neural Networks(CNNs) and Recurrent Neural Networks(RNNs).
Convolutional Neural Networks.
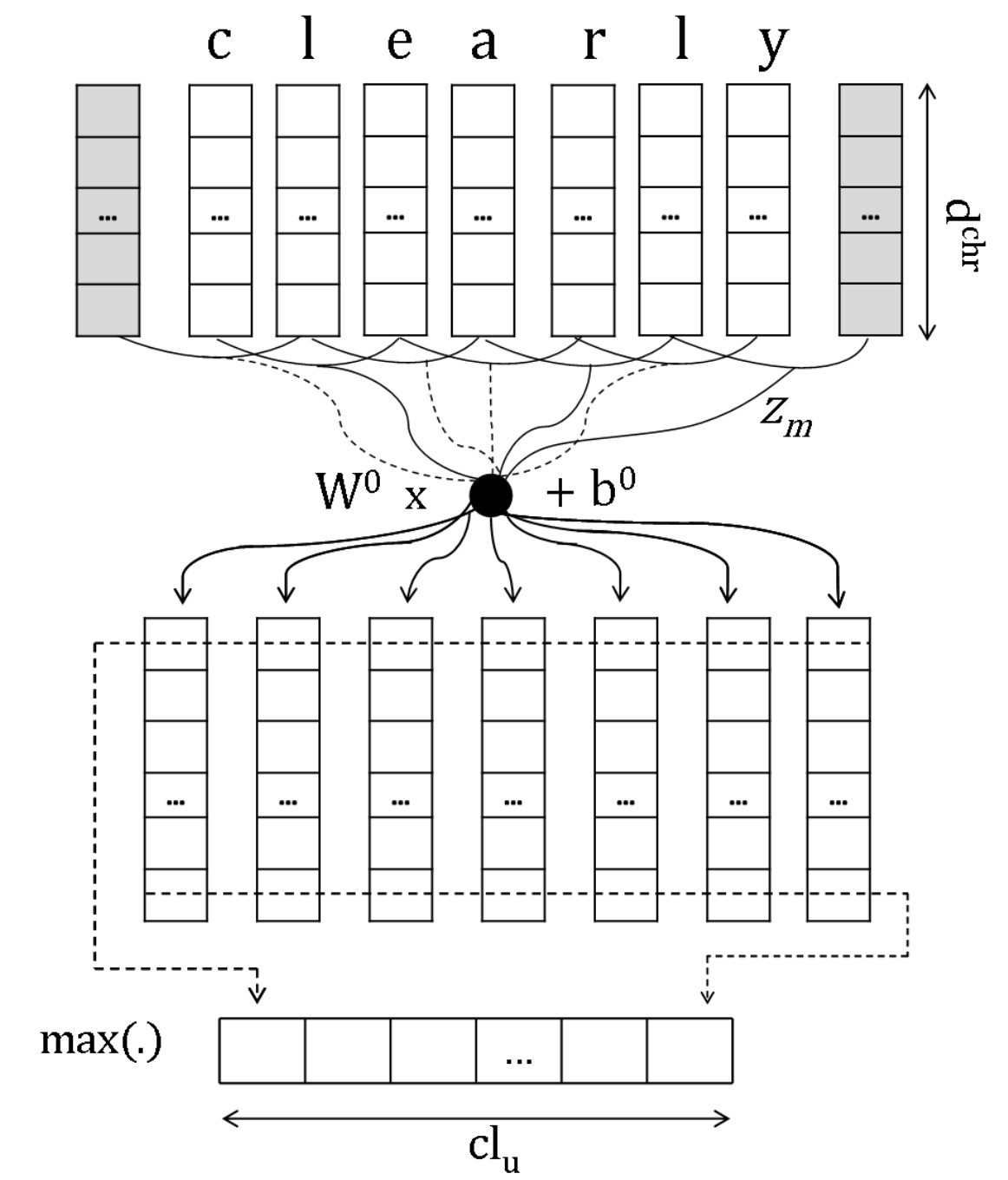
Santos and Zadrozny [99] initially propose the approach that using CNNs to learn character-level representations of words for sequence labeling, which is followed by many subsequent work [71, 13, 103, 10, 115, 15, 129]. The approach applies a convolutional operation to the sequence of character embeddings and produces local features of each character. Then a fixed-sized character-level embedding of the word is extracted by using the max over all character windows. The process is depicted in Fig 1.
Xin et al. [116] propose IntNet, a funnel-shaped wide convolutional neural network for learning character-level representations for sequence labeling. Unlike previous CNN-based character embedding approaches, this method delicately designs the convolutional block that comprises of several consecutive operations, and utilizes multiple convolutional layers in which feature maps are concatenated in every other ones. It helps the network to capture different levels of features and explore the full potential of CNNs to learn better internal structure of words. The proposed model achieves significant improvements over other character embedding models and obtains state-of-the-art performance on various sequence labeling datasets. Its main architecture can be shown in Fig 2.

Recurrent Neural Networks.
Ling et al. [62] propose a compositional character to word (C2W) model that uses bidirectional LSTMs (Bi-LSTM) to build word embeddings by taking the characters as atomic units. A forward and a backward LSTM processes the character embeddings sequence of a word in direct and reverse order. And the representaion for a word derived from its characters is obtained by combining the final states of the bidirectional LSTM. Illustration of the proposed method is shown in Fig 3. By exploiting the features in language effectively, the C2W model yields excellent results in language modeling and part-of-speech tagging. And many work [52, 127, 26, 121, 88] follow them to apply Bi-LSTM for obtaining character-level representations for sequence labeling. Similarly, Yang et al. [120] employ GRUs for the character embedding model instead of LSTM units.

Dozat et al. [20] propose a RNN based character-level model in which the character embeddings sequence of each word is fed into a unidirectional LSTM followed by an attention mechanism. The method first extracts the hidden state and cell state of each character from the LSTM and then computes linear attention over the hidden states. The output of attention is concatenated with cell state of the final character to form the character-level word embedding for their POS tagging model.
Kann et al. [40] propose a character-based recurrent sequence-to-sequence architecture, which connects the Bi-LSTM character encoding model to a LSTM based decoder that associated with an auxiliary objective (random string autoencoding, word autoencoding or lemmatization). The multi-task architecture introduces additional character-level supervision into the model, which helps them build a more robust neural POS taggers for low-resource languages.
Bohnet et al. [8] propose a novel sentence-level character model for learning context sensitive character-based representations of words. Unlike all aforementioned token-level character model, this method feeds all characters of a sentence into a Bi-LSTM layer and concatenates the forward and backward output vector of the first and last character in the word to form its final character-level representation. This strategy allows context information to be incorporated in the initial word embeddings before flowing into the context encoder module. Similarly, Liu et al. [65] also adopt the character-level Bi-LSTM that processes all characters of a sentence instead of a word. However, their proposed model focuses on extracting knowledge from raw texts by leveraging the neural language model to effectively extract character-level information. In particular, the forward and backward character-level LSTM would predict the next and previous word at word boundaries. In order to mediate the primary sequence labeling task and the auxiliary language model task, highway networks are further employed, which transform the output of the shared character-level layer into two different representations. One is used for language model and the other can be viewed as character-level representation that combined with the word embedding for sequence labeling model.
III-A3 Hand-crafted features
As aforementioned, enabled by the powerful capacity to extract features automatically, deep neural network based models have the advantage of not requiring complex feature engineering. However, before fully end-to-end deep learning models [71, 52] are proposed for sequence labeling tasks, feature engineering is typically utilized in neural models [17, 35, 13], where hand-crafted features such as word spelling features that can greatly benefits POS tagging and gazetteer features that are widly used in NER are represented as discrete vectors and then integrated to the embedding module. For example, Collobert et al. [17] utilize word suffix, gazetteer and capitalization features as well as cascading features that include tags from related tasks. Huang et al. [35] adopt designed spelling features (include word prefix and suffix features, capitalization feature etc.), context features (unigram, bi-gram and tri-gram features) and gazetteer features. Chiu and Nichols [13] use character-type, capitalization, and lexicon features.
In recent two years, there have been some work [115, 23, 94, 61, 66] that focus on incorporating manual features into neural models in a more effective manner and obtain significant further improvements for sequence labeling. Wu et al. [115] propose a hybrid neural model which combines a feature auto-encoder loss component to utilize hand-crafted features, and significantly outperforms existing competitive models on the task of NER. Exploited manual features include part-of-speech tags, word shapes and gazetteers. In particular, the auto-encoder auxiliary component takes hand-crafted features as input and learns to re-construct them into output, which helps the model to preserve important information stored in these features and thus enhances the primary sequence labeling task. Their proposed method has demonstrated the utility of hand-crafted features for named entity recognition on English data. However, designing such features for low-resource languages is challenging, because gazetteers in these languages are absent. To address this proplem, Rijhwani et al. [94] propose a method of ‘”soft gazetteers” that incorporates information from English knowledge bases through cross-lingual entity linking and create continuous-valued gazetteer features for low-resource languages.
Ghaddar et al. [23] propose a novel lexical representation (called Lexical Similarity i.e., (LS) vector) for NER, indicating that robust lexical features are quiet useful and can greatly benefit deep neural network architectures. The method first embeds words and named entity types into a joint low-dimensional vector space, which is trained from a Wikipedia corpus annotated with 120 fine-grained entity types. Then a 120-dimensional feature vector (i.e., LS vector) for each word is computed offline, where each dimension encodes the similarity of the word embedding with the embedding of an entity type. The LS vectors are finally incorporated into the embedding module of their neural NER model.
III-A4 Sentence-level Representations

Existing research [128] has proved that the global contextual information from the entire sentence is useful for modeling sequence, which is insufficiently captured at each token position in context encoder like Bi-LSTM. To solve this problem, some recent work [67, 68] have introduced sentence-level representations into the embedded module, that is, in addition to pretrained word embeddings and character-level representations, they also assign every word with a global representation learned from the entire sentence, which can be shown in Fig 4. Though these work propose different ways to get sentence representation, they all prove the superiority of adding it in the embedding module for the final performance of sequence labeling tasks.
III-B Context Encoder Module
Context dependency plays a significant role in sequence labeling tasks. The context encoder module extracts contextual features of each token and capture the context dependencies of given input sequence. Learned contextual representations will be passed into inference module for label prediction. There are three commonly used model architectures for context encoder module, i.e., RNN, CNN and Transformers.
III-B1 Recurrent Neural Network
Bi-LSTM is almost the most widely used context encoder architecture today. Concretely, it incorporates past/future contexts from both directions (forward/backward) to generate the hidden states of each token, and then jointly concatenate them to represent the global information of the entire sequence. While Hammerton [29] has studied utilizing LSTMs for NER tasks in the past, the lack of computing power limits the effectiveness of their model. With recent advances in deep learning, much research effort has been dedicated to using Bi-LSTM architecture and achieve excellent performance. Huang et al. [35] initially adopt Bi-LSTM to generate contextual representations of every word in their sequence labeling model, and produce state-of-the-art accuracy on POS tagging, chunking and NER data sets. Similarly, [127, 62, 71, 52, 13, 8, 121, 65, 88] also choose the same Bi-LSTM architecture for context encoding. Gated Recurrent Unit(GRU) is a variant of LSTM which also addresses long-dependency issues in RNN networks, and several work utilize Bi-GRU as their context encoder architecture [120, 55, 133].
Rei [91] propose a multitask learning method that equips the Bi-LSTM context encoder module with a auxiliary training objective, which learns to predict surrounding words for every word in the sentence. It shows that the language modeling objective provides consistent performance improvements on several sequence labeling benchmark, because it motivates the model to learn more general semantic and syntactic composition patterns of the language.
Zhang et al. [126] propose a new method called Multi-Order BiLSTM which combines low order and high order LSTMs together in order to learn more tag dependencies. The high order LSTMs predict multiple tags for the current token which contains not only the current tag but also the previous several tags. The model keeps the scalability to high order models with a pruning technique, and achieves the state-of-the-art result in chunking and highly competitive results in two NER datasets.
Ma et al. [69] propose a LSTM-based model for jointly training sentence-level classification and sequence labeling tasks, in which a modified LSTM structure is adopted as their context encoder module. In particular, the method employs a convolutional neural network before LSTM to extract features from both the context and previous tags of each word. Therefore, the input for LSTM is changed to include meaningful contextual and label information.
Most of the existing LSTM based methods use one or more stacked LSTM layers to extract context features of words. However, Gregoric et al. [26] present a different architecture which employs multiple parallel independent Bi-LSTM units across the same input and promotes diversity among them by employing an inter-model regularization term. It shows that the method reduces the total number of parameters in the model and achieves significant improvements on the CoNLL 2003 NER dataset compared to other previous methods.
Kazi et al. [42] propose a novel implicitly-defined neural network architecture for sequence labeling. In contrast to traditional recurrent neural networks, this work provides a different mechanism that each state is able to consider information in both directions. The method extends RNN by changing the definition of implicit hidden layer function:
where denotes the input of hidden layer, and is the hidden state of last and next time step, respectively. It forgoes the causality assumption used to formulate RNN and leads to an implicit set of equations for the entire sequence of hidden states. They compute them via an approximate Newton solve and apply the Krylov Subspace method [45]. The implicitly-defined neural network architecture helps to achieve improvements on problems with complex, long-distance dependencies.
Although Bi-LSTM has been widely adopted as context encoder architecture, there are still several natural limitations, such as the shallow connections between consecutive hidden states of RNNs. At each time step, BiLSTMs consume an incoming word and construct a new summary of the past subsequence. This process should be highly non-linear so that the hidden states can quickly adapt to variable inputs while still retaining useful summaries of the past [83]. Deep transition RNNs extend conventional RNNs by increasing the transition depth of consecutive hidden states [83]. Recently, Liu et al. [67] introduce the deep transition architecture for sequence labeling and achieve a significant performance improvement on the tasks of text chunking and NER. Besides, the way of sequentially processing inputs of RNN might limit the ability to capture the non-continuous relations over tokens within a sentence. To tackle the problem, a recent work proposed by Wei et al. [114] employs self-attention to provide complementary context information on the basis of Bi-LSTM. They propose a position-aware self-attention as well as a well-designed self-attentional context fusion network, aiming to explore the relative positional information of an input sequence for capturing the latent relations among tokens. It shows that the method achieves significant improvements on the tasks of POS, NER and chunking.
III-B2 Convolutional Neural Networks
Convolutional Neural Networks (CNNs) are another popular architecture for encoding context information in sequence labeling models. Compared to RNN, CNN based methods are considerably faster since it can fully leverage the GPU parallelism through the feed-forward structure. An initial work in this area is proposed by Collobert et al. [17]. The method employs a simple feed-forward neural network with a fixed-size sliding window over the input sequence embedding, which can be viewed as a simplified CNN without pooling layer. And this window approach is based on the assumption that the label of a word depends mainly on its neighbors. Santos et al. [99] follow their work and use similar structure for context feature extraction.
Shen et al. [103] propose a deep active learning based model for NER tasks. Their tagging model extracts context representations for each word using a CNN due to its strong efficiency, which is crucial for their iterative retraining scheme. The structure has two convolutional layers with kernels of width three, and it concatenates the representation at the last convolutional layer with the input embedding to form the output.
Wang et al. [113] employ stacked Gated Convolutional Neural Networks(GCNN) for named entity recognition, which extend the convolutional layer with gating mechanism. In particular, a gated convolutional layer can be written as
where denotes row convolution, is the input of this layer, are the parameters to be learned, is the sigmoid function and represents element-wise product.
Though relatively high efficiency, a major disadvantage of CNNs is that it has difficulties in capturing long-range dependencies in sequences due to the limited receptive fields, which makes fewer methods to perform sequence labeling tasks with CNNs than RNNs. In recent year, some CNN-based models modify traditional CNNs to better capture global context information and achieve excellent results for sequence labeling.
Strubell et al. [104] propose a Iterated Dilated Convolutional Neural Networks (ID-CNNs) method for the task of NER, which enables significant speed improvements while maintaining accuracy comparable to the state-of-the-arts. Dilated convolutions [123] operate on a sliding window of context like typical CNN layers, but the context need not be consecutive. The convolution is defined over a wider effective input width by skipping over several inputs at a time, and the effective input width can grow exponentially with the depth. Thus it can incorporate broader context into the representation of a token than typical CNN. Fig 5 shows the structure.

The proposed iterated dilated CNN architecture repeatedly applies the same block of dilated convolutions to token-wise representations. Repeatedly employing the same parameters prevents overfitting problem and provides the model desirable generalization capabilities.
Chen et al. [10] propose gated relation network(GRN) for NER, in which a gated relation layer that models the relationship between any two words is built on top of CNNs for capturing long-range context information. Specifically, it firstly computes the relation score vector between any two words,
where and denote the local context features from the CNN layer for the i-th and j-th word in the sequence, is the weight matrix and is the bias vector. Note that the relation score vector is of the same dimension as and . Then the corresponding global contextual representation for the ith word is obtained by performing a weighted-summing up operation, in which a gating mechanism is adopted for adaptively selecting other dependent words.
where is a gate using sigmoid function, and denotes element-wise multiplication. The proposed GRN model achieves significantly better performance than ID-CNN [104], owing to its stronger capacity to capture global context dependencies.
III-B3 Transformers
The Transformer model is proposed by Vaswani et al. [111] in 2017 and achieves excellent performance for Neural Machine Translation (NMT) tasks. The overall architecture is based solely on attention mechanisms to draw global dependencies between input, dispensing with recurrence and convolutions entirely. The initial proposed Transformer employs a sequence to sequence structure that comprises the encoder and decoder. But the subsequent research work often adopt the encoder part to serve as the feature extractor, thus our introduction here is limited to it.
The encoder is composed of a stack of several identical layers, which includes a multi-head self-attention mechanism and a position-wise fully connected feed-forward network. It employs a residual connection [30] around each of the two sub-layers to ease the training of deep neural network. And layer normalization [53] is applied after the residual connection to stabilize the activations of model.
Due to its superior performance, the Transformer is widely used in various NLP tasks and has achieved excellent results. However, in sequence labeling tasks, the Transformer encoder has been reported to perform poorly [28]. Recently, Yan et al. [118] analyze the properties of Transformer for exploring the reason why Transformer does not work well in sequence labeling tasks especially NER. Both the direction and relative distance information are important in the NER, but these information will lose when the sinusoidal position embedding is used in the vanilla Transformer. To address the problem, they propose TENER, an architecture adopting adapted Transformer Encoder by incorporating the direction and relative distance aware attention and the un-scaled attention, which can greatly boost the performance of Transformer encoder for NER. Star-Transformer is a lightweight alternative of Transformer proposed by Shao et al. [28]. It replaces the fully-connected structure with a star-shaped topology, in which every two non-adjacent nodes are connected through a shared relay node. The model complexity is reduced significantly, and it also achieved great improvements against the standard Transformer on various tasks including sequence labeling tasks.
III-C Inference Module
The inference module takes the representations from context encoder module as input, and generate the optimal label sequence.
III-C1 Softmax
The softmax function that also called normalized exponential function, is a generalization of logic functions and has been widely used in a variety of probability-based multi-classification methods. It maps a -dimensional vector into another -dimensional real vector such that each element has a range between and and the sum of all elements equals . The form of the function is usually given by the following formula
where .
Many models for sequence labeling treat the problem as a set of independent classification tasks, and utilize a softmax layer as a linear classifier to assign optimal label for each word in a sequence [8, 26, 62, 42, 27, 69, 43, 44]. Specifically, given the output representation of the context encoder at time step , the probability distribution of the t-th word’s label can be obtained by a fully connected layer and a final softmax function
where the weight matrix maps to the space of labels, is the dimension of and is the number of all possible labels.
III-C2 Conditional Random Fields
The above methods of independently inferring word labels in a given sequence ignore the dependencies between labels. Typically, the correct label to each word often depends on the choices of nearby elements. Therefore, it is necessary to consider the correlation between labels of adjacent neighborhoods to jointly decode the optimal label chain of the entire sequence. CRF model [45] has been proven to be powerful in learning the strong dependencies across output labels, thus most of the neural network-based models for sequence labeling employ CRF as the inference module [71, 121, 65, 88, 91, 85, 1, 125, 9, 22].
Specifically, let be the output of context encoder of the given sequence , the probability of generating the whole label sequence with regard to is
where is the set of possible label sequences for ; and indicate the weighted matrix and bias parameters corresponding to the label pair , respectively.
Semi-CRF.
Semi-Markov conditional random fields (semi-CRFs) [100] is an extension of conventional CRFs, in which labels are assigned to the segments of input sequence rather than to individual words. It extracts features of segments and models the transition between them, suitable for segment-level sequence labeling tasks such as named entity recognition and phrase chunking. Compared to CRFs, the advantage of semi-CRFs is that it can make full use of segment-level information to capture the internal properties of segments, and higher-order label dependencies can be taken into account. However, since it jointly learns to determine the length of each segment and the corresponding label, the time complexity becomes higher. Besides, more features is required for modeling segments with different lengths and automatically extracting meaningful segment-level features is an important issue for Semi-CRFs. With advances in deep learning, some models combining neural networks and Semi-CRFs for sequence labeling have been studied.
Kong et al. [46] propose Segmental Recurrent Neural Networks (SRNNs) for segment-level sequence labeling problems, which adopts a semi-CRF as the inference module and learns representations of segments through Bi-LSTM. Based on the recurrent nature of RNN, this method further designs a dynamic programming algorithm to reduce the time complexity. A parallel work Gated Recursive Semi-CRFs (grSemi-CRFs) proposed by Zhuo et al. [134] employs a Gated Recursive Convolutional Neural Network (grConv) [14] to extract segment features for semi-CRF. The grConv is a variant of recursive neural network that learns segment-level representations by constructing a pyramid-like structure and recursively combining adjacent segment vectors. The follow-up work proposed by Kemos et al. [43] utilize the same grConv architecture for extracting segment features in their neural semi-CRF model. It takes characters as the basic input unit but does not require any correct token boundaries, which is different from existing character-level models. The model is based on semi-CRF to jointly segment (tokenize) and label characters, being robust for languages with difficult or noisy tokenization. Sato et al. [101] design Segment-level Neural CRF for segment-level sequence labeling tasks. The method applies a CNN to obtain segment-level representations and constructs segment lattice to reduce search space.
The aforementioned models only adopt segment-level labels for segment score calculation and model training. An extension [122] proposed by Ye et al. demonstrates that incorporating word-level labels information can be beneficial for building semi-CRFs. The proposed Hybrid Semi-CRFs(HSCRF) model utilizes word-level and segment-level labels simultaneously to derive the segment scores. Besides, the methods of integrating CRF and HSCRF output layers into an unified network for jointly training and decoding are further presented. The Hybrid Semi-CRFs model is also adopted as baseline for subsequent work [66].
Skip-chain CRF. The Skip-chain CRF [106] is a variant of conventional linear chain CRF that captures long-range label dependencies by means of skip edges, which basically refers to edges between the label positions not adjacent to each other. However, the skip-chain CRF contains loop in graph structure, making the process of model training and inference intractable. Loop belief propagation that requires multiple iterations of messaging can be one of the approximate solutions, but is fairly time consuming for large neural network based models. In order to mitigate the problem, Jagannatha et al. [37] propose an approximate approach for computation of marginals which adopts recurrent units to model the messages. The proposed approximate neural skip-chain CRF model is used for enhancing the exact phrase detection of clinical entities.
Embedded-State Latent CRF. Thai et al. [108] design a novel embedded-state latent CRF for neural sequence labeling, which has more capacities in modeling non-local label dependencies that often neglected by conventional CRF. This method incorporates latent variables into the CRF model for capturing global constraints between labels and applies representation learning to the output space. In order to reduce the numbers of parameters and prevent overfitting, a parsimonious factorized parameter strategy to learn low-rank embedding matrices are further adopted.
NCRF transducers. Based on the similar motivation of modeling long-range dependencies between labels, Hu et al. [34] present a further extension and propose neural CRF transducers (NCRF transducers), which introduces RNN transducers to implement the edge potential in CRF model. The edge potential represents the score for current label by considering dependencies from all previous labels. Thus the proposed model can capture long-range label dependencies from the beginning up to each current position.
III-C3 Recurrent Neural Network

RNN is extremely suitable for feature extraction of sequential data, so it is widely used for encoding contextual information in sequence labeling models. Some studies demonstrate that RNN structure can also be adopted in the inference module for producing optimal label sequence. In addition to the learned representations output from context encoder, the information of former predicted labels also serves as an input. Thus the corresponding label of each word is generated based on both the features of input sequence and the previous predicted labels, making long-range label dependencies captured. However, unlike the global normalized CRF model, the RNN-based reasoning method greedily decodes the label from left to right, so it’s a local normalized model that might suffer from label bias and exposure bias problems [2].
Shen et al. [103] employ a LSTM layer on top of the context encoder for label decoding. As dipicted in Fig 6, the decoder LSTM takes the last generated label as well as the contextual representation of current word as inputs, and computes the hidden state which will be passed through softmax function to finally decode the label. Zheng et al. [130] adopt a similar LSTM structure as the inference module of their sequence labeling model.
Unlike the above two studies, Vaswani et al. [110] utilize a LSTM decoder that can be considered as parallel with the context encoder module. The LSTM only accepts the last label as input to produce a hidden state, which will be combined with the word context representation for label decoding. Zhang et al. [127] introduce a novel joint labeling strategy based on LSTM decoder. The output hidden state and contextual representation are not integrated before the labeling decision is made but independently estimate the labeling probability. Those two probabilities are then merged by weighted averaging to produce the final result. Specifically, a parameter is dynamically computed by a gate mechanism to adaptively balance the involvement of the two parts. Experiments show that the proposed label LSTM could significantly improve the performance.
Encoder-Decoder-Pointer Framework.

Zhai et al. [124] propose a neural sequence chunking model based on an encoder-decoder-pointer framework, which is suitable for tasks that need assign labels to meaningful chunks in sentences, such as phrase chunking and semantic role labeling. The architecture is illustrated in Fig 7. The proposed model divides original sequence labeling task into two steps: (1) Segmentation, identifying the scope of each chunk; (2) Labeling, treating each chunk as a complete unit to label. It adopts a pointer network [112] to process the segmentation by determining the ending point of each chunk and the LSTM decoder is utilized for labeling based on the segmentation results. The model proposed by Li et al. [55] also employs the similar architecture for their text segmentation model, where a seq2seq model equipped with pointer network is designed to infer the segment boundaries.
IV Evaluation Metrics and DataSets
As mentioned in Section II, three common related tasks of sequence labeling problems include POS tagging, NER, and chunking. In this section, we list some widely used datasets in Table II and will describe several most commonly used datasets of these three tasks, and introduce the corresponding evaluation metrics as well.
IV-A Datasets
| Task | Corpus | Year | URL |
| POS | Wall Street Journal(WSJ) | 2000 | https://catalog.ldc.upenn.edu/LDC2000T43/ |
| NEGRA German Corpus | 2006 | http://www.coli.uni-saarland.de/projects/sfb378/negra-corpus/ | |
| Rit-Twitter | 2011 | https://github.com/aritter/twitter_nlp | |
| Prague Dependency Treebank | 2012 - 2013 | http://ufal.mff.cuni.cz/pdt2.0/ | |
| Universal Dependency(UD) | 2015 - 2020 | https://universaldependencies.org | |
| NER | ACE | 2000 - 2008 | https://www.ldc.upenn.edu/collaborations/past-projects/ace |
| CoNLL02 | 2002 | https://www.clips.uantwerpen.be/conll2002/ner/ | |
| CoNLL03 | 2003 | https://www.clips.uantwerpen.be/conll2003/ner/ | |
| GENIA | 2004 | http://www.geniaproject.org/home | |
| OntoNotes | 2007 - 2012 | https://catalog.ldc.upenn.edu/LDC2013T19 | |
| WiNER | 2012 | http://rali.iro.umontreal.ca/rali/en/winer-wikipedia-for-ner | |
| W-NUT | 2015 - 2018 | http://noisy-text.github.io |
IV-A1 POS tagging
We will introduce three widely used datasets for part-of-speech tagging: WSJ, UD and Rit-Twitter.
WSJ. A standard dataset for POS tagging is the Wall Street Journal (WSJ) portion of the Penn Treebank [72] and a large number of work use it in their experiments. The dataset contains sections and classifies each word into different types of POS tags. A data split method used in [16] has become popular, in which sections - as training data, - as development data, and sections - as test data.
UD. Universal Dependencies (UD) is a project that is developing cross-linguistic grammatical annotation, which contains more than treebanks in over languages. Its original annotation scheme for part-of-speech tagging take the form of Google universal POS tag sets [87] that include language-independent tags. A recent version of UD [80] proposed a POS tag set that has 17 categories which partially overlap with those defined in [87], and annotations from it have been used by many recent work [88, 6, 121, 43] to evaluate their models.
Rit-Twitter. The Rit-Twitter dataset [95] is a benchmark for social media part-of-speech tagging which is comprised of tokens from Twitter. It adopts an extended version of the PTB tagset with several Twitter-specific tags includes: retweets, @usernames, #hashtags, and urls.
IV-A2 NER
We will introduce three widely used datasets for NER : CoNLL 2002, CoNLL 2003 and OntoNotes.
CoNLL 2002 CoNLL 2003. CoNLL 2002 [98] and CoNLL 2003 [97] are two shared tasks created for NER. Both of these datasets contains annotations from newswire text and are tagged with four different entities - PER (person), LOC (location), ORG (organization) and MISC (miscellaneous including all other types of entities). CoNLL02 focuses on two languages: Dutch and Spanish, while CoNLL03 on English and German. Among them, the English dataset of CoNLL03 is the most widely used for NER and lots of recent work report their performance on it.
OntoNotes. The OntoNotes project [33] was developed to annotate a large corpus from various genres in three languages (English, Chinese, and Arabic) with several layers of annotation, including named entities, coreference, part of speech, word sense, propositions, and syntactic parse trees. Regarding the NER dataset, the tag set consists of coarse entity types, containing subtypes and the whole dataset contains million tokens. There have been 5 versions so far, and the English dataset of the latest Release version [89] has been utilized by many recent NER work in their experiments.
IV-A3 Chunking
CoNLL 2000. The CoNLL 2000 shared task [96] dataset is widely used for text chunking. The dataset is based on the WSJ part of the Penn Treebank as corpus and the annotation consists of different labels including syntactic chunk types in addition to Other. Since it only includes training and test sets, many researchers [65, 85, 120] randomly sampled a part of sentences from training set as the development set.
IV-B Evaluation Metrics
Part-of-speech tagging systems are usually evaluated according to the token accuracy. And F1-score, the harmonic mean of precision and recall, is usually adopted as the evaluation metric of NER and chunking.
IV-B1 Accuracy
Accuracy depicts the ratio of the number of correctly classified instances and the total number of instances, which can be computed using the following equation
where denote True positive, True negative, False positive, False negative, respectively.
IV-B2 F1-score
F1-score indicates the fraction of correctly classified instances for each class within the dataset, which can be computed as follows
where is precision that is computed by , is recall that can be computed by , and denotes the total number of classes.
V Comparisons on Experimental Results of Various Techniques
| External resources | Method | Accuracy |
|---|---|---|
| None | Collobert et al. 2011 [17] | 97.29% |
| Santos et al. 2014 [99] | 97.32% | |
| Huang et al. 2015 [35] | 97.55% | |
| Ling et al. 2015 [62] | 97.78% | |
| Plank et al.2016 [88] | 97.22% | |
| Rei et al. 2016 [92] | 97.27% | |
| Vaswani et al. 2016 [110] | 97.40% | |
| Andor et al. 2016 [2] | 97.44% | |
| Ma and Hovy 2016 [71] | 97.55% | |
| Ma and Sun 2016 [70] | 97.56% | |
| Rei 2017 [91] | 97.43% | |
| Yang et al. 2017 [120] | 97.55% | |
| Kazi and Thompson 2017 [42] | 97.37% | |
| Bohnet et al. 2018 [8] | 97.96% | |
| Yasunaga et al. 2018 [121] | 97.55% | |
| Liu et al. 2018 [65] | 97.53% | |
| Zhang et al. 2018 [127] | 97.59% | |
| Xin et al. 2018 [116] | 97.58% | |
| Zhang et al. 2018 [128] | 97.55% | |
| Hu et al. 2019 [34] | 97.52% | |
| Cui et al. 2019 [18] | 97.65% | |
| Jiang et al. 2020 [39] | 97.7% | |
| Unlabeled Word Corpus | Akbik et al. 2018 [1] | 97.85% |
| Clark et al. 2018 [15] | 97.7% |
| External resources | Method | F1-score |
| None | Collobert et al. 2011 [17] | 88.67% |
| Kuru et al. 2016 [50] | 84.52% | |
| Chiu and Nichols 2016 [13] | 90.91% | |
| Lample et al. 2016 [52] | 90.94% | |
| Ma and Hovy 2016 [71] | 91.21% | |
| Rei 2017 [91] | 86.26% | |
| Strubell et al. 2017 [104] | 90.54% | |
| Zhang et al. 2017 [126] | 90.70% | |
| Tran et al. 2017 [109] | 91.23% | |
| Wang et al. 2017 [113] | 91.24% | |
| Sato et al. 2017 [101] | 91.28% | |
| Shen et al. 2018 [103] | 90.69% | |
| Zhang et al. 2018 [127] | 91.22% | |
| Liu et al. 2018 [65] | 91.24% | |
| Ye and Ling 2018 [122] | 91.38% | |
| Gregoric et al. 2018 [26] | 91.48% | |
| Zhang et al. 2018 [128] | 91.57% | |
| Xin et al. 2018 [116] | 91.64% | |
| Hu et al. 2019 [34] | 91.40% | |
| Chen et al. 2019 [10] | 91.44% | |
| Yan et al. 2019 [118] | 91.45% | |
| Liu et al. 2019 [67] | 91.96% | |
| Luo et al. 2020 [68] | 91.96% | |
| Jiang et al. 2020 [39] | 92.2% | |
| Li et al. 2020 [58] | 92.67% | |
| CoNLL00,WSJ | Yang et al. 2017 [120] | 91.26% |
| Gazetteers | Collobert et al. 2011 [17] | 89.59% |
| Huang et al. 2015 [35] | 90.10% | |
| Wu et al. 2018 [115] | 91.89% | |
| Liu et al. 2019 [66] | 92.75% | |
| Chen et al. 2020 [11] | 91.76% | |
| Lexicons | Chiu and Nichols 2016 [13] | 91.62% |
| Sato et al. 2017 [101] | 91.55% | |
| Ghaddar and Langlais 2018 [23] | 91.73% | |
| Unlabeled Word Corpus | Peters et al. 2017 [85] | 91.93% |
| Peters et al. 2018 [86] | 92.22% | |
| Devlin et al. 2018 [19] | 92.80% | |
| Akbik et al. 2018 [1] | 93.09% | |
| Clark et al. 2018 [15] | 92.6% | |
| Li et al. 2020 [57] | 93.04% | |
| LM emb | Tran et al. 2017 [109] | 91.69% |
| Chen et al. 2019 [10] | 92.34% | |
| Hu et al. 2019 [34] | 92.36% | |
| Liu et al. 2019 [67] | 93.47% | |
| Jiang et al. 2019 [38] | 93.47% | |
| Luo et al. 2019 [68] | 93.37% | |
| Knowledge Graph | He et al. 2020 [31] | 91.8% |
| External resources | Method | F1-score |
|---|---|---|
| None | Collobert et al. 2011 [17] | 94.32% |
| Huang et al. 2015 [35] | 94.46% | |
| Rei et al. 2016 [92] | 92.67% | |
| Rei 2017 [91] | 93.88% | |
| Zhai et al. 2017 [124] | 94.72% | |
| Sato et al. 2017 [101] | 94.84% | |
| Zhang et al. 2017 [126] | 95.01% | |
| Xin et al. 2018 [116] | 95.29% | |
| Hu et al. 2019 [34] | 95.14% | |
| Liu et al. 2019 [67] | 95.43% | |
| Chen et al. 2020 [11] | 95.45% | |
| Unlabeled Word Corpus | Peters et al. 2017 [85] | 96.37% |
| Akbik et al. 2018 [1] | 96.72% | |
| Clark et al. 2018 [15] | 97% | |
| LM emb | Liu et al. 2019 [67] | 97.3% |
| CoNLL03,WSJ | Yang et al. 2017 [120] | 95.41% |
While formal experimental evaluation is left out of the scope of this paper, we present a brief analysis of the experimental results of various techniques. For each of these three tasks, we choose one widely used dataset and report the performance of various models on the benchmark. The three datasets includes WSJ for POS, CoNLL 2003 NER and CoNLL 2000 chunking, and the results for these three tasks are given in Table III, Table IV and Table V, respectively. We also indicate whether the model makes use of external knowledge or resource in these tables.
As shown in Table III, different models have achieved relatively high performance (more than ) in terms of the accuracy of POS tagging. Among these work listed in the table, the Bi-LSTM-CNN-CRF model proposed by Ma and Hovy [71] has become a popular baseline for most subsequent work in this field, which is also the first end-to-end model for sequence labeling requiring no feature engineering or data preprocessing. The reported accuracy of Ma and Hovy is , and several studies in recent two years slightly outperform it by exploring different issues and building new models. For example, the model proposed by Zhang et al. [127] performs better with a improvement of , which takes the long range tag dependencies into consideration by incorporating a tag LSTM in their model. Besides, Bohnet et al. [8] achieves the state-of-the-art performance with accuracy by modeling the sentence-level context for initial character and word-based representations.
Table IV shows the results of different models on CoNLL 2003 NER datatsets. Compared with the POS tagging task, the overall score of NER task is lower, with most work between and , which indicates NER is more difficult than POS tagging. Among the work that utilize no external resources, Li et al. [58] performs best, with a average F1-score of . Their proposed model focuses on rare entities and applied novel techniques including local context reconstruction and delexicalized entity identification. We can observe that models which utilize external resources can generally achieve higher performance on all these three tasks, especially pretraining language models that using large unlabeled word corpus. But these models require a larger neural network that need huge computing resources and longer time for training.
VI The Promising Paths for Future Research
Although much success has been achieved in this filed, challenges still exist from different perspectives. In this section, we provide the following directions for further research in deep learning based sequence labeling.
Sequence labeling for low-resource data. Supervised learning algorithms including deep learning based models, rely on large annotated data for training. However, data annotations are expensive and often take a lot of time, leaving a big challenge in sequence labeling for many low-resource languages and specific resource-poor domains. Although some work have explored methods for this problem, there still exists a large scope for improvement. Future efforts could be dedicated on enhancing performance of sequence labeling on low-resource data by focusing on the following three research directions: (1) training a LM like BERT with the unlabeled corpus and finetune it with limited labeled corpus in a low-resource data; (2) providing more effective deep transfer learning models to transfer knowledge from one language or domain to another; (3) exploring appropriate data augmentation techniques to enlarge the available data for sequence labeling.
Scalability of deep learning based sequence labeling. Most neural models for sequence labeling do not scale well for large data, making it a challenge to build more scalable deep learning based sequence labeling models. The main reason for this is when the size of data grows, the parameters of models increase exponentially, leading to the high complexity of back propagation. While several models have achieved excellent performance with huge computing power, there exists need for developing approaches to balance model complexity and scalability. In addition, for pratical usage, its necessary to develop scalable methods for real-world applications.
Utilization of external resources. As discussed in Section V, the performance of neural sequence labeling models benefits significantly from external resources, including gazetteers, lexicons, large unlabeled word corpus, and etc. Though some research effort have been dedicated on this issue, how to effectively incorporate external resources in neural sequence labeling models remains to be explored.
VII Conclusions
This survey aims to thoroughly review applications of deep learning techniques in sequence labeling, and provides a panoramic view so that readers can build a comprehensive understanding of this area. We present a summary for the literature with a scientific taxonomy. In addition, we provide an overview of the datasets and evaluation metrics of the commonly studied tasks of sequence labeling problems. Besides, we also discuss and compare the results of different models and analyze the factors and different architectures that affect the performance. Finally, we present readers with the challenges and open issues faced by current methods and identify the future directions in this area. We hope that this survey can help to enlighten and guide the researchers, practitioners, and educators who are interested in sequence labeling.
References
- [1] Alan Akbik, Duncan Blythe, and Roland Vollgraf. Contextual string embeddings for sequence labeling. In COLING, pages 1638–1649, 2018.
- [2] Daniel Andor, Chris Alberti, David Weiss, Aliaksei Severyn, Alessandro Presta, Kuzman Ganchev, Slav Petrov, and Michael Collins. Globally normalized transition-based neural networks. arXiv preprint arXiv:1603.06042, 2016.
- [3] Leonard E Baum and Ted Petrie. Statistical inference for probabilistic functions of finite state markov chains. The annals of mathematical statistics, 37(6):1554–1563, 1966.
- [4] Giannis Bekoulis, Johannes Deleu, Thomas Demeester, and Chris Develder. Sub-event detection from twitter streams as a sequence labeling problem. NAACL, 2019.
- [5] Oliver Bender, Franz Josef Och, and Hermann Ney. Maximum entropy models for named entity recognition. In Proceedings of the seventh conference on Natural language learning at HLT-NAACL 2003-Volume 4, pages 148–151. Association for Computational Linguistics, 2003.
- [6] Gáabor Berend. Sparse coding of neural word embeddings for multilingual sequence labeling. Transactions of the Association for Computational Linguistics, 5:247–261, 2017.
- [7] Daniel M Bikel, Richard Schwartz, and Ralph M Weischedel. An algorithm that learns what’s in a name. Machine learning, 34(1-3):211–231, 1999.
- [8] Bernd Bohnet, Ryan McDonald, Goncalo Simoes, Daniel Andor, Emily Pitler, and Joshua Maynez. Morphosyntactic tagging with a meta-bilstm model over context sensitive token encodings. ACL, 2018.
- [9] Pengfei Cao, Yubo Chen, Kang Liu, Jun Zhao, and Shengping Liu. Adversarial transfer learning for chinese named entity recognition with self-attention mechanism. In Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing, pages 182–192, 2018.
- [10] Hui Chen, Zijia Lin, Guiguang Ding, Jianguang Lou, Yusen Zhang, and Borje Karlsson. Grn: Gated relation network to enhance convolutional neural network for named entity recognition. AAAI, 2019.
- [11] Luoxin Chen, Weitong Ruan, Xinyue Liu, and Jianhua Lu. Seqvat: Virtual adversarial training for semi-supervised sequence labeling. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, pages 8801–8811, 2020.
- [12] Hai Leong Chieu and Hwee Tou Ng. Named entity recognition: a maximum entropy approach using global information. In Proceedings of the 19th international conference on Computational linguistics-Volume 1, pages 1–7. Association for Computational Linguistics, 2002.
- [13] Jason PC Chiu and Eric Nichols. Named entity recognition with bidirectional lstm-cnns. Transactions of the Association for Computational Linguistics, 4:357–370, 2016.
- [14] Kyunghyun Cho, Bart Van Merriënboer, Dzmitry Bahdanau, and Yoshua Bengio. On the properties of neural machine translation: Encoder-decoder approaches. arXiv preprint arXiv:1409.1259, 2014.
- [15] Kevin Clark, Minh-Thang Luong, Christopher D Manning, and Quoc V Le. Semi-supervised sequence modeling with cross-view training. EMNLP, 2018.
- [16] Michael Collins. Discriminative training methods for hidden markov models: Theory and experiments with perceptron algorithms. In Proceedings of the ACL-02 conference on Empirical methods in natural language processing-Volume 10, pages 1–8. Association for Computational Linguistics, 2002.
- [17] Ronan Collobert, Koray Kavukcuoglu, Jason Weston, Leon Bottou, Pavel Kuksa, and Michael Karlen. Natural language processing (almost) from scratch. Journal of Machine Learning Research, 12(1):2493–2537, 2011.
- [18] Leyang Cui and Yue Zhang. Hierarchically-refined label attention network for sequence labeling. EMNLP, 2019.
- [19] Jacob Devlin, Ming-Wei Chang, Kenton Lee, and Kristina Toutanova. Bert: Pre-training of deep bidirectional transformers for language understanding. arXiv preprint arXiv:1810.04805, 2018.
- [20] Timothy Dozat, Peng Qi, and Christopher D Manning. Stanford’s graph-based neural dependency parser at the conll 2017 shared task. In Proceedings of the CoNLL 2017 Shared Task: Multilingual Parsing from Raw Text to Universal Dependencies, pages 20–30, 2017.
- [21] Sean R Eddy. Hidden markov models. Current opinion in structural biology, 6(3):361–365, 1996.
- [22] Xiaocheng Feng, Xiachong Feng, Bing Qin, Zhangyin Feng, and Ting Liu. Improving low resource named entity recognition using cross-lingual knowledge transfer. In IJCAI, pages 4071–4077, 2018.
- [23] Abbas Ghaddar and Philippe Langlais. Robust lexical features for improved neural network named-entity recognition. arXiv preprint arXiv:1806.03489, 2018.
- [24] Carlos Gómez-Rodríguez and David Vilares. Constituent parsing as sequence labeling. EMNLP, 2018.
- [25] Sian Gooding and Ekaterina Kochmar. Complex word identification as a sequence labelling task. ACL, 2019.
- [26] Andrej Zukov Gregoric, Yoram Bachrach, and Sam Coope. Named entity recognition with parallel recurrent neural networks. In Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 2: Short Papers), pages 69–74, 2018.
- [27] Tao Gui, Qi Zhang, Haoran Huang, Minlong Peng, and Xuanjing Huang. Part-of-speech tagging for twitter with adversarial neural networks. In Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pages 2411–2420, 2017.
- [28] Qipeng Guo, Xipeng Qiu, Pengfei Liu, Yunfan Shao, Xiangyang Xue, and Zheng Zhang. Star-transformer. NAACL, 2019.
- [29] James Hammerton. Named entity recognition with long short-term memory. In Proceedings of the seventh conference on Natural language learning at HLT-NAACL 2003-Volume 4, pages 172–175. Association for Computational Linguistics, 2003.
- [30] Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun. Deep residual learning for image recognition. In Proceedings of the IEEE conference on computer vision and pattern recognition, pages 770–778, 2016.
- [31] Qizhen He, Liang Wu, Yida Yin, and Heming Cai. Knowledge-graph augmented word representations for named entity recognition. AAAI, 2020.
- [32] Marti A. Hearst, Susan T Dumais, Edgar Osuna, John Platt, and Bernhard Scholkopf. Support vector machines. IEEE Intelligent Systems and their applications, 13(4):18–28, 1998.
- [33] Eduard Hovy, Mitchell Marcus, Martha Palmer, Lance Ramshaw, and Ralph Weischedel. Ontonotes: The 90% solution. In Proceedings of the human language technology conference of the NAACL, Companion Volume: Short Papers, 2006.
- [34] Kai Hu, Zhijian Ou, Min Hu, and Junlan Feng. Neural crf transducers for sequence labeling. In ICASSP 2019-2019 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), pages 2997–3001. IEEE, 2019.
- [35] Zhiheng Huang, Wei Xu, and Kai Yu. Bidirectional lstm-crf models for sequence tagging. Computer Science, 2015.
- [36] Hideki Isozaki and Hideto Kazawa. Efficient support vector classifiers for named entity recognition. In Proceedings of the 19th international conference on Computational linguistics-Volume 1, pages 1–7. Association for Computational Linguistics, 2002.
- [37] Abhyuday N Jagannatha and Hong Yu. Structured prediction models for rnn based sequence labeling in clinical text. In Proceedings of the conference on empirical methods in natural language processing. conference on empirical methods in natural language processing, volume 2016, page 856. NIH Public Access, 2016.
- [38] Yufan Jiang, Chi Hu, Tong Xiao, Chunliang Zhang, and Jingbo Zhu. Improved differentiable architecture search for language modeling and named entity recognition. In Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), pages 3576–3581, 2019.
- [39] Zhengbao Jiang, Wei Xu, Jun Araki, and Graham Neubig. Generalizing natural language analysis through span-relation representations. ACL, 2020.
- [40] Katharina Kann, Johannes Bjerva, Isabelle Augenstein, Barbara Plank, and Anders Søgaard. Character-level supervision for low-resource pos tagging. In Proceedings of the Workshop on Deep Learning Approaches for Low-Resource NLP, pages 1–11, 2018.
- [41] Jagat Narain Kapur. Maximum-entropy models in science and engineering. John Wiley & Sons, 1989.
- [42] Michaeel Kazi and Brian Thompson. Implicitly-defined neural networks for sequence labeling. In Proceedings of the 55th Annual Meeting of the Association for Computational Linguistics (Volume 2: Short Papers), pages 172–177, 2017.
- [43] Apostolos Kemos, Heike Adel, and Hinrich Schütze. Neural semi-markov conditional random fields for robust character-based part-of-speech tagging. arXiv preprint arXiv:1808.04208, 2018.
- [44] Joo-Kyung Kim, Young-Bum Kim, Ruhi Sarikaya, and Eric Fosler-Lussier. Cross-lingual transfer learning for pos tagging without cross-lingual resources. In Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, pages 2832–2838, 2017.
- [45] Dana A Knoll and David E Keyes. Jacobian-free newton–krylov methods: a survey of approaches and applications. Journal of Computational Physics, 193(2):357–397, 2004.
- [46] Lingpeng Kong, Chris Dyer, and Noah A Smith. Segmental recurrent neural networks. arXiv preprint arXiv:1511.06018, 2015.
- [47] Vijay Krishnan and Christopher D Manning. An effective two-stage model for exploiting non-local dependencies in named entity recognition. In Proceedings of the 21st International Conference on Computational Linguistics and the 44th annual meeting of the Association for Computational Linguistics, pages 1121–1128. Association for Computational Linguistics, 2006.
- [48] Taku Kudoh and Yuji Matsumoto. Use of support vector learning for chunk identification. In Fourth Conference on Computational Natural Language Learning and the Second Learning Language in Logic Workshop, 2000.
- [49] Dinesh Kumar and Gurpreet Singh Josan. Part of speech taggers for morphologically rich indian languages: a survey. International Journal of Computer Applications, 6(5):32–41, 2010.
- [50] Onur Kuru, Ozan Arkan Can, and Deniz Yuret. Charner: Character-level named entity recognition. In Proceedings of COLING 2016, the 26th International Conference on Computational Linguistics: Technical Papers, pages 911–921, 2016.
- [51] John Lafferty, Andrew McCallum, and Fernando CN Pereira. Conditional random fields: Probabilistic models for segmenting and labeling sequence data. In ICML, 2001.
- [52] Guillaume Lample, Miguel Ballesteros, Sandeep Subramanian, Kazuya Kawakami, and Chris Dyer. Neural architectures for named entity recognition. In NAACL, 2016.
- [53] Jimmy Lei Ba, Jamie Ryan Kiros, and Geoffrey E Hinton. Layer normalization. arXiv preprint arXiv:1607.06450, 2016.
- [54] Jing Li, Aixin Sun, Jianglei Han, and Chenliang Li. A survey on deep learning for named entity recognition. arXiv preprint arXiv:1812.09449, 2018.
- [55] Jing Li, Aixin Sun, and Shafiq Joty. Segbot: A generic neural text segmentation model with pointer network. In IJCAI, pages 4166–4172, 2018.
- [56] Peng Li, Wei Li, Zhengyan He, Xuguang Wang, Ying Cao, Jie Zhou, and Wei Xu. Dataset and neural recurrent sequence labeling model for open-domain factoid question answering. arXiv preprint arXiv:1607.06275, 2016.
- [57] Xiaoya Li, Jingrong Feng, Yuxian Meng, Qinghong Han, Fei Wu, and Jiwei Li. A unified mrc framework for named entity recognition. ACL, 2020.
- [58] Yangming Li, Han Li, Kaisheng Yao, and Xiaolong Li. Handling rare entities for neural sequence labeling. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, pages 6441–6451, 2020.
- [59] Yaoyong Li, Kalina Bontcheva, and Hamish Cunningham. Svm based learning system for information extraction. In International Workshop on Deterministic and Statistical Methods in Machine Learning, pages 319–339. Springer, 2004.
- [60] Zuchao Li, Jiaxun Cai, Shexia He, and Hai Zhao. Seq2seq dependency parsing. In Proceedings of the 27th International Conference on Computational Linguistics, pages 3203–3214, 2018.
- [61] Hongyu Lin, Yaojie Lu, Xianpei Han, Le Sun, Bin Dong, and Shanshan Jiang. Gazetteer-enhanced attentive neural networks for named entity recognition. In Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), pages 6233–6238, 2019.
- [62] Wang Ling, Tiago Luís, Luís Marujo, Ramón Fernandez Astudillo, Silvio Amir, Chris Dyer, Alan W Black, and Isabel Trancoso. Finding function in form: Compositional character models for open vocabulary word representation. arXiv preprint arXiv:1508.02096, 2015.
- [63] Wang Ling, Yulia Tsvetkov, Silvio Amir, Ramon Fermandez, Chris Dyer, Alan W Black, Isabel Trancoso, and Chu-Cheng Lin. Not all contexts are created equal: Better word representations with variable attention. In Proceedings of the 2015 Conference on Empirical Methods in Natural Language Processing, pages 1367–1372, 2015.
- [64] Liyuan Liu, Xiang Ren, Qi Zhu, Shi Zhi, Huan Gui, Heng Ji, and Jiawei Han. Heterogeneous supervision for relation extraction: A representation learning approach. In EMNLP, 2017.
- [65] Liyuan Liu, Jingbo Shang, Xiang Ren, Frank Fangzheng Xu, Huan Gui, Jian Peng, and Jiawei Han. Empower sequence labeling with task-aware neural language model. In AAAI, 2018.
- [66] Tianyu Liu, Jin-Ge Yao, and Chin-Yew Lin. Towards improving neural named entity recognition with gazetteers. In Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics, pages 5301–5307, 2019.
- [67] Yijin Liu, Fandong Meng, Jinchao Zhang, Jinan Xu, Yufeng Chen, and Jie Zhou. Gcdt: A global context enhanced deep transition architecture for sequence labeling. ACL, 2019.
- [68] Ying Luo, Fengshun Xiao, and Hai Zhao. Hierarchical contextualized representation for named entity recognition. In AAAI, pages 8441–8448, 2020.
- [69] Mingbo Ma, Kai Zhao, Liang Huang, Bing Xiang, and Bowen Zhou. Jointly trained sequential labeling and classification by sparse attention neural networks. arXiv preprint arXiv:1709.10191, 2017.
- [70] Shuming Ma and Xu Sun. A new recurrent neural crf for learning non-linear edge features. arXiv preprint arXiv:1611.04233, 2016.
- [71] Xuezhe Ma and Eduard Hovy. End-to-end sequence labeling via bi-directional lstm-cnns-crf. In ACL, 2016.
- [72] Mitchell Marcus, Beatrice Santorini, and Mary Ann Marcinkiewicz. Building a large annotated corpus of english: The penn treebank. 1993.
- [73] Andrew McCallum, Dayne Freitag, and Fernando CN Pereira. Maximum entropy markov models for information extraction and segmentation. In Icml, volume 17, pages 591–598, 2000.
- [74] Andrew McCallum and Wei Li. Early results for named entity recognition with conditional random fields, feature induction and web-enhanced lexicons. In Proceedings of the seventh conference on Natural language learning at HLT-NAACL 2003-Volume 4, pages 188–191. Association for Computational Linguistics, 2003.
- [75] Tomas Mikolov, Kai Chen, Greg Corrado, and Jeffrey Dean. Efficient estimation of word representations in vector space. arXiv preprint arXiv:1301.3781, 2013.
- [76] David Nadeau and Satoshi Sekine. A survey of named entity recognition and classification. Lingvisticae Investigationes, 30(1):3–26, 2007.
- [77] Ramesh Nallapati, Feifei Zhai, and Bowen Zhou. Summarunner: A recurrent neural network based sequence model for extractive summarization of documents. In Thirty-First AAAI Conference on Artificial Intelligence, 2017.
- [78] V. Ng. Supervised noun phrase coreference research: The first fifteen years. In ACL, 2010.
- [79] Nam Nguyen and Yunsong Guo. Comparisons of sequence labeling algorithms and extensions. In Proceedings of the 24th international conference on Machine learning, pages 681–688. ACM, 2007.
- [80] Joakim Nivre, Željko Agić, Maria Jesus Aranzabe, Masayuki Asahara, Aitziber Atutxa, Miguel Ballesteros, John Bauer, Kepa Bengoetxea, Riyaz Ahmad Bhat, Cristina Bosco, et al. Universal dependencies 1.2. 2015.
- [81] Joakim Nivre and Mario Scholz. Deterministic dependency parsing of english text. In COLING, page 64. Association for Computational Linguistics, 2004.
- [82] Jaehui Park. Selectively connected self-attentions for semantic role labeling. Applied Sciences, 9(8):1716, 2019.
- [83] Razvan Pascanu, Caglar Gulcehre, Kyunghyun Cho, and Yoshua Bengio. How to construct deep recurrent neural networks. ICLR, 2014.
- [84] Jeffrey Pennington, Richard Socher, and Christopher Manning. Glove: Global vectors for word representation. In Proceedings of the 2014 conference on empirical methods in natural language processing (EMNLP), pages 1532–1543, 2014.
- [85] Matthew E Peters, Waleed Ammar, Chandra Bhagavatula, and Russell Power. Semi-supervised sequence tagging with bidirectional language models. In ACL, 2017.
- [86] Matthew E. Peters, Mark Neumann, Mohit Iyyer, Matt Gardner, Christopher Clark, Kenton Lee, and Luke Zettlemoyer. Deep contextualized word representations. NAACL, 2018.
- [87] Slav Petrov, Dipanjan Das, and Ryan McDonald. A universal part-of-speech tagset. arXiv preprint arXiv:1104.2086, 2011.
- [88] Barbara Plank, Anders Søgaard, and Yoav Goldberg. Multilingual part-of-speech tagging with bidirectional long short-term memory models and auxiliary loss. ACL, 2016.
- [89] Sameer Pradhan, Alessandro Moschitti, Nianwen Xue, Hwee Tou Ng, Anders Björkelund, Olga Uryupina, Yuchen Zhang, and Zhi Zhong. Towards robust linguistic analysis using ontonotes. In Proceedings of the Seventeenth Conference on Computational Natural Language Learning, pages 143–152, 2013.
- [90] Adwait Ratnaparkhi. A maximum entropy model for part-of-speech tagging. In Conference on Empirical Methods in Natural Language Processing, 1996.
- [91] Marek Rei. Semi-supervised multitask learning for sequence labeling. In ACL, 2017.
- [92] Marek Rei, Gamal KO Crichton, and Sampo Pyysalo. Attending to characters in neural sequence labeling models. COLING, 2016.
- [93] Marek Rei and Helen Yannakoudakis. Compositional sequence labeling models for error detection in learner writing. arXiv preprint arXiv:1607.06153, 2016.
- [94] Shruti Rijhwani, Shuyan Zhou, Graham Neubig, and Jaime Carbonell. Soft gazetteers for low-resource named entity recognition. ACL, 2020.
- [95] Alan Ritter, Sam Clark, Oren Etzioni, et al. Named entity recognition in tweets: an experimental study. In Proceedings of the conference on empirical methods in natural language processing, pages 1524–1534. Association for Computational Linguistics, 2011.
- [96] Erik F Sang and Sabine Buchholz. Introduction to the conll-2000 shared task: Chunking. arXiv preprint cs/0009008, 2000.
- [97] Erik F Sang and Fien De Meulder. Introduction to the conll-2003 shared task: Language-independent named entity recognition. arXiv preprint cs/0306050, 2003.
- [98] Erik F. Tjong Kim Sang. Introduction to the conll-2002 shared task: Language-independent named entity recognition. Computer Science, pages 142–147, 2002.
- [99] Cicero Nogueira Dos Santos and Bianca Zadrozny. Learning character-level representations for part-of-speech tagging. In ICML, 2014.
- [100] Sunita Sarawagi and William W Cohen. Semi-markov conditional random fields for information extraction. In Advances in neural information processing systems, pages 1185–1192, 2005.
- [101] Motoki Sato, Hiroyuki Shindo, Ikuya Yamada, and Yuji Matsumoto. Segment-level neural conditional random fields for named entity recognition. In Proceedings of the Eighth International Joint Conference on Natural Language Processing (Volume 2: Short Papers), pages 97–102, 2017.
- [102] Rohit Saxena, Savita Bhat, and Niranjan Pedanekar. Emotionx-area66: Predicting emotions in dialogues using hierarchical attention network with sequence labeling. In Proceedings of the Sixth International Workshop on Natural Language Processing for Social Media, pages 50–55, 2018.
- [103] Yanyao Shen, Hyokun Yun, Zachary C Lipton, Yakov Kronrod, and Animashree Anandkumar. Deep active learning for named entity recognition. ICLR, 2018.
- [104] Emma Strubell, Patrick Verga, David Belanger, and Andrew McCallum. Fast and accurate entity recognition with iterated dilated convolutions. EMNLP, 2017.
- [105] Michalina Strzyz, David Vilares, and Carlos Gómez-Rodríguez. Viable dependency parsing as sequence labeling. NAACL, 2019.
- [106] Charles Sutton, Andrew McCallum, et al. An introduction to conditional random fields. Foundations and Trends® in Machine Learning, 4(4):267–373, 2012.
- [107] Zhixing Tan, Mingxuan Wang, Jun Xie, Yidong Chen, and Xiaodong Shi. Deep semantic role labeling with self-attention. In Thirty-Second AAAI Conference on Artificial Intelligence, 2018.
- [108] Dung Thai, Sree Harsha Ramesh, Shikhar Murty, Luke Vilnis, and Andrew McCallum. Embedded-state latent conditional random fields for sequence labeling. arXiv preprint arXiv:1809.10835, 2018.
- [109] Quan Tran, Andrew MacKinlay, and Antonio Jimeno Yepes. Named entity recognition with stack residual lstm and trainable bias decoding. arXiv preprint arXiv:1706.07598, 2017.
- [110] Ashish Vaswani, Yonatan Bisk, Kenji Sagae, and Ryan Musa. Supertagging with lstms. In Proceedings of the 2016 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, pages 232–237, 2016.
- [111] Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N Gomez, Łukasz Kaiser, and Illia Polosukhin. Attention is all you need. In NIPS, pages 5998–6008, 2017.
- [112] Oriol Vinyals, Meire Fortunato, and Navdeep Jaitly. Pointer networks. In Advances in Neural Information Processing Systems, pages 2692–2700, 2015.
- [113] Chunqi Wang, Wei Chen, and Bo Xu. Named entity recognition with gated convolutional neural networks. In Chinese Computational Linguistics and Natural Language Processing Based on Naturally Annotated Big Data, pages 110–121. Springer, 2017.
- [114] Wei Wei, Zanbo Wang, Xianling Mao, Guangyou Zhou, Pan Zhou, and Sheng Jiang. Position-aware self-attention based neural sequence labeling. Pattern Recognition, page 107636, 2020.
- [115] Minghao Wu, Fei Liu, and Trevor Cohn. Evaluating the utility of hand-crafted features in sequence labelling. arXiv preprint arXiv:1808.09075, 2018.
- [116] Yingwei Xin, Ethan Hart, Vibhuti Mahajan, and Jean-David Ruvini. Learning better internal structure of words for sequence labeling. EMNLP, 2018.
- [117] Vikas Yadav and Steven Bethard. A survey on recent advances in named entity recognition from deep learning models. In Proceedings of the 27th International Conference on Computational Linguistics, pages 2145–2158, 2018.
- [118] Hang Yan, Bocao Deng, Xiaonan Li, and Xipeng Qiu. Tener: Adapting transformer encoder for name entity recognition. arXiv preprint arXiv:1911.04474, 2019.
- [119] Zhilin Yang, Ruslan Salakhutdinov, and William Cohen. Multi-task cross-lingual sequence tagging from scratch. arXiv preprint arXiv:1603.06270, 2016.
- [120] Zhilin Yang, Ruslan Salakhutdinov, and William W Cohen. Transfer learning for sequence tagging with hierarchical recurrent networks. In ICLR, 2017.
- [121] Michihiro Yasunaga, Jungo Kasai, and Dragomir Radev. Robust multilingual part-of-speech tagging via adversarial training. In NAACL, 2018.
- [122] Zhi-Xiu Ye and Zhen-Hua Ling. Hybrid semi-markov crf for neural sequence labeling. ACL, 2018.
- [123] Fisher Yu and Vladlen Koltun. Multi-scale context aggregation by dilated convolutions. arXiv preprint arXiv:1511.07122, 2015.
- [124] Feifei Zhai, Saloni Potdar, Bing Xiang, and Bowen Zhou. Neural models for sequence chunking. In Thirty-First AAAI Conference on Artificial Intelligence, 2017.
- [125] Boliang Zhang, Di Lu, Xiaoman Pan, Ying Lin, Halidanmu Abudukelimu, Heng Ji, and Kevin Knight. Embracing non-traditional linguistic resources for low-resource language name tagging. In Proceedings of the Eighth International Joint Conference on Natural Language Processing (Volume 1: Long Papers), pages 362–372, 2017.
- [126] Yi Zhang, Xu Sun, Shuming Ma, Yang Yang, and Xuancheng Ren. Does higher order lstm have better accuracy for segmenting and labeling sequence data? In COLING, 2017.
- [127] Yuan Zhang, Hongshen Chen, Yihong Zhao, Qun Liu, and Dawei Yin. Learning tag dependencies for sequence tagging. In IJCAI, 2018.
- [128] Yue Zhang, Qi Liu, and Linfeng Song. Sentence-state lstm for text representation. ACL, 2018.
- [129] Sendong Zhao, Ting Liu, Sicheng Zhao, and Fei Wang. A neural multi-task learning framework to jointly model medical named entity recognition and normalization. CoRR, abs/1812.06081, 2019.
- [130] Suncong Zheng, Feng Wang, Hongyun Bao, Yuexing Hao, Peng Zhou, and Bo Xu. Joint extraction of entities and relations based on a novel tagging scheme. arXiv preprint arXiv:1706.05075, 2017.
- [131] GuoDong Zhou and Jian Su. Named entity recognition using an hmm-based chunk tagger. In proceedings of the 40th Annual Meeting on Association for Computational Linguistics, pages 473–480. Association for Computational Linguistics, 2002.
- [132] Xiaoqiang Zhou, Baotian Hu, Qingcai Chen, Buzhou Tang, and Xiaolong Wang. Answer sequence learning with neural networks for answer selection in community question answering. arXiv preprint arXiv:1506.06490, 2015.
- [133] Yuying Zhu, Guoxin Wang, and Börje F Karlsson. Can-ner: Convolutional attention network for chinese named entity recognition. NAACL, 2019.
- [134] Jingwei Zhuo, Yong Cao, Jun Zhu, Bo Zhang, and Zaiqing Nie. Segment-level sequence modeling using gated recursive semi-markov conditional random fields. In Proceedings of the 54th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), volume 1, pages 1413–1423, 2016.