A Survey on Multi-modal Summarization
Abstract.
The new era of technology has brought us to the point where it is convenient for people to share their opinions over an abundance of platforms. These platforms have a provision for the users to express themselves in multiple forms of representations, including text, images, videos, and audio. This, however, makes it difficult for users to obtain all the key information about a topic, making the task of automatic multi-modal summarization (MMS) essential. In this paper, we present a comprehensive survey of the existing research in the area of MMS, covering various modalities like text, image, audio, and video. Apart from highlighting the different evaluation metrics and datasets used for the MMS task, our work also discusses the current challenges and future directions in this field.
1. Introduction
Everyday, the Internet is flooded with tons of new information coming from multiple sources. Due to the technological advancements, people can now share information in multiple formats with various modes of communication to be used at their disposal. This alarmingly increasing amount of content on the Internet makes it difficult for the users to receive useful information from the torrent of sources, necessitating research on the task of multi-modal summarization (MMS). Various studies have shown that including multi-modal data as input can indeed help improve the summary quality (Jangra et al., 2020b; Li et al., 2017). Zhu et al. (2018) claimed that on an average having a pictorial summary can improve the user satisfaction by 12.4% over a plain text summary. The fact that nearly every content sharing platform has a provision to accompany an opinion or fact in multiple media forms, and every mobile phone has the feature to deliver that kind of facility are indicative of the superiority of a multi-modal means of communication in terms of ease in conveying and understanding information.
Information in the form of multi-modal inputs has been leveraged in many tasks other than summarization including multi-modal machine translation (Specia, 2018; Caglayan et al., 2019; Huang et al., 2016; Elliott, 2018; Elliott et al., 2017), multi-modal movement prediction (Wang et al., 2018; Kirchner et al., 2014; Cui et al., 2019), multi-modal question answering (Singh et al., 2021), multi-modal lexico-semantic classification (Jha et al., 2022), multi-modal keyword extraction (Verma et al., 2022), product classification in e-commerce (Zahavy et al., 2016), multi-modal interactive artificial intelligence frameworks (Kim et al., 2018), multi-modal emoji prediction (Barbieri et al., 2018; Coman et al., 2018), multi-modal frame identification (Botschen et al., 2018), multi-modal financial risk forecasting (Sawhney et al., 2020; Li et al., 2020b), multi-modal sentiment analysis (Yadav and Vishwakarma, 2020; Morency et al., 2011; Rosas et al., 2013), multi-modal named identity recognition (Moon et al., 2018b; Arshad et al., 2019; Zhang et al., 2018; Moon et al., 2018a; Yu et al., 2020; Suman et al., 2020), multi-modal video description generation (Ramanishka et al., 2016; Hori et al., 2017, 2018), multi-modal product title compression (Miao et al., 2020) and multi-modal biometric authentication (Snelick et al., 2005; Fierrez-Aguilar et al., 2005; Indovina et al., 2003). The shear number of application possibilities for multi-modal information processing and retrieval tasks are quite impressive. Research on multi-modality can also be utilized in other closely related research problems like image-captioning (Chen and Zhuge, 2019, 2020), image-to-image translation (Huang et al., 2018), seismic pavement testing (Ryden et al., 2004), aesthetic assessment (Zhang et al., 2014; Kostoulas et al., 2017; Liu and Jiang, 2020), and visual question-answering (Kim et al., 2016a).
Text summarization is one of the oldest problems in the fields of natural language processing (NLP) and information retrieval (IR), that has attracted various researchers due to its challenging nature and potential for many applications. Research on text summarization can be traced back to more than six decades in the past (Luhn, 1958). The NLP and IR community have tackled research in text summarization for multiple applications by developing myriad of techniques and model architectures (See et al., 2017; Chen and Bansal, 2018; Jangra et al., 2020a; Liu et al., 2022). As an extension to this, the problem of multi-modal summarization adds another angle by incorporating visual and aural aspects into the mix, making the task more challenging and interesting to tackle. This extension of incorporating multiple modalities into a summarization problem expands the breadth of the problem, leading to wider application range for the task. In recent years, multi-modal summarization has experienced many new developments, including release of new datasets, advancements in techniques to tackle the MMS task, as well as proposals of more appropriate evaluation metrics. The idea of multi-modal summarization is a rather flexible one, embracing a broad range of possibilities for the input and output modalities, and also making it difficult to apprehend existing works on the MMS task with knowledge of uni-modal summarization techniques alone. This necessitates a survey on multi-modal summarization.
The MMS task, just like any uni-modal summarization task, is a demanding one, and existence of multiple correct solutions makes it very challenging. Humans creating a multi-modal summary have to use their prior understanding and external knowledge to produce the content. Establishing computer systems to mimic this behaviour becomes difficult given their inherent lack of human perception and knowledge, making the problem of automatic multi-modal summarization a non-trivial but interesting task.
Although quite a few survey papers were written for uni-modal summarization tasks including surveys on text summarization (Yao et al., 2017; Gambhir and Gupta, 2017; Tas and Kiyani, 2007; Nenkova and McKeown, 2012; Gupta and Lehal, 2010; Jain et al., 2022a) and video summarization (Kini and Pai, 2019; Sebastian and Puthiyidam, 2015; Money and Agius, 2008; Hussain et al., 2020; Basavarajaiah and Sharma, 2019), and a few survey papers covering multi-modal research (Baltrušaitis et al., 2018; Soleymani et al., 2017; Atrey et al., 2010; Jaimes and Sebe, 2007; Ramachandram and Taylor, 2017; Sebe et al., 2005). However, to the best of our knowledge, we are the first to present a survey on multi-modal summarization. The closest work to ours is the work on multi-dimensional summarization by Zhuge (2016), who proposes the method for summarization of things in cyber-physical society through a multi-dimensional lens of semantic computing. However, our survey is distinct from that work as Zhuge (2016) focuses on how understanding human behaviour, psychology, and advances in cognitive sciences can help to improve the current summarization systems in the emerging cyber-physical society while in this manuscript we mostly focus on the direct applications and techniques adopted by the research community to tackle the MMS task. Through this manuscript, we unify and systematize the information presented in related works, including the datasets, methodology, and evaluation techniques. With this survey, we aim to assist researchers familiarize with various techniques and resources available to proceed with research in the area of multi-modal summarization.
The rest of the paper is structured as follows: We formally define the MMS task in Section 2. In Section 3, we provide an extensive organization of existing works. In Section 4, we give an overview about the techniques used for the task of MMS. In Section 5 we introduce the datasets available for the MMS task and evaluation techniques devised for the evaluation of multi-modal summaries, respectively. We discuss about possibilities of future work in Section 7 and conclude our paper in Section 8.
2. Multi-modal Summarization task
In this section we formally define what classifies as a multi-modal summarization task. Before formalizing the multi-modal summarization we broadly define the term summarization111In this paper, summarization stands for automatic summarization unless specified otherwise.. According to Wikipedia222https://en.wikipedia.org/wiki/Automatic_summarization, automatic summarization is “the process of shortening a set of data computationally, to create an abstract that represents the most important or relevant information within the original content.” Formally, summarization is the process of obtaining the set such that , where is the output summary, is the input data, and function is the summarization function.
The multi-modal summarization task can be defined as a summarization task that takes more than one mode of information representation (termed as modality) as input, and depends on information sharing across different modalities to generate the final summary. Mathematically speaking, when the input dataset can be broken down into several partially disjoint sets of different modality information , where and several pairs of for such that the shared latent information between is not , then the task of obtaining the set is known as multi-modal summarization333The reason for restricting for the task definition is limitation of current techniques, that are unable to successfully generate modalities other than text for multi-modal summarization. Even though there have been some recent breakthroughs in text-to-image generation (like Open AI’s DALL-E (Ramesh et al., 2021)), and text-to-speech synthesis (like Google’s Duplex (Leviathan and Matias, 2018)); they still lack the level of integrity and robustness to be used in a real-world application like MMS.. If for , then the output summary is multi-modal; otherwise, the output is a uni-modal summary.
In this survey, we mainly focus on recent works that have natural language as the central modality444We believe that the MMS models that have video as the central modality tend to be closely related to the task of video summarization., where a central modality (or key modality) is selected according to the intuition: ”For any information processing task in multi-modal scenarios, including content summarization, amongst all the modalities, there is often a preferable mode of representation based on the significance and ability to fulfill the task” (Jangra et al., 2021). Other modalities that aid the central modality to convey information are termed as adjacent modalities.
Various aspects of multi-modal summarization: Literature has explored the MMS task for myriad of reasons and motives, and doing so, has lead to different challenges and variants of the task. Some of the most prominent and interesting ones are discussed below:
-
•
Combined complementary-supplementary multi-modal summarization task (CCS-MMS) (Jangra et al., 2021): Jangra et al. (2021) proposed the CCS-MMS task of generating a multi-modal summary that considers text as the central modality, and images, audio and videos as the adjacent modality. The task is to generate the multi-modal summary such that it consists of both supplementary and complementary enhancements, which are defined as follows:
-
–
Supplementary enhancement: When the adjacent modalities reinforce the facts and ideas presented in the central modality, the adjacent modalities are termed as supplementary enhancements.
-
–
Complementary enhancement: When the adjacent modalities complete the information by providing additional but relevant information that is not covered in the central modality, the adjacent modalities are termed as complementary enhancements.
-
–
-
•
Summarization objectives: We can distinguish prior work based on summarization objectives they have used. For instance, Li et al. (2017) uses weighted sum of three sub-modular objective functions to create an extractive text summarization system that is guided by multi-modal inputs. The chosen submodular functions are - salience of input text, image information covered by text summary, and non-redundancy in input text. Jangra et al. (2020b) uses a single objective function for an ILP setup, that is the weighted average of uni-modal salience, and cross-modal correspondence. Jangra et al. (2020c) proposes two different sets of multi-modal objectives for the task of extractive multi-modal summary generation - a) summarization-based objective, and b) clustering-based objectives. For summarization-based objectives, they use the following three objectives - i) Salience(txt) / Redundancy(txt), ii) Salience(img) / Redundancy(img), and iii) cross-modal correspondence; while for clustering-based objectives, they use PBM (Pakhira et al., 2004), a popular cluster validity index (a function of cluster compactness and separation) to evaluate the uni-modal clusters of image and text, giving the following set of objectives - i) PBM(txt), PBM(img), and cross-modal correspondence. Almost all the neural networks based multi-modal summarization frameworks (Li et al., 2018a; Palaskar et al., 2019; Chen and Zhuge, 2018a, b) on the other hand use the standard negative log-likelihood function over the output vocabulary as the training objective. Some works also use textual and visual coverage loss to prevent over-attending the input as well (Li et al., 2018a; Zhu et al., 2018).
-
•
Multi-modal social media event summarization: Various works have been conducted on the social media data that consists of opinions and experiences of a diverse set of population. Tiwari et al. (2018) proposes the problem of summarizing asynchronous information from multiple social media platforms like Twitter, Instagram, and Flickr to generate a summary of event that is widely covered by users of these platforms extensively. Bian et al. (2013) propose multi-modal summarization of trending topics in microblogs. They use Sina Weibo555http://www.weibo.com/ microblogs for the experimentation, which is a very popular microblogging platform in China. Qian et al. (2018) uses the Weibo platform information to summarize disaster events like train crash and earthquakes.
3. Organization of existing work
Different attempts have been made to solve the MMS task, and thus it is important to categorize the existing works to get a better understanding of the task. We categorize the prior works into three broad categories, depending upon encoding the input, the model architecture, and decoding the output. We have also illustrated these categorizations through a generic model diagram in Figure 1. A detailed pictorial representation of the taxonomy is shown in Figure 2 and a comprehensive study is provided in Table 2 (note that if some classifications are not marked in the table, then either the information about that category was not present, or is not applicable.).

3.1. On the basis of encoding the input
A multi-modal summarization task is highly driven by the kind of input it is given. Due to this dependency on diverse input modalities, the feature extraction and encoding strategies also differ for different multi-modal summarization systems. Existing works can be distinguished from others on the basis of the type of input and its encoding strategy in the following categories:
Multi-modal Diversity (MMD): Different combinations of input (text, image,video & audio) involve different preprocessing and encoding strategies. We can classify the existing works depending on the combination of modalities in which the input is represented. Various combinations within the input modalities like text-image (Zhu et al., 2018; Li et al., 2018a; Chen and Zhuge, 2018a), text-video (Fu et al., 2020; Li et al., 2020a), audio-video666Note that audio-video and text-audio-video works are grouped together since in most of the existing works, automatic speech transcription is performed to obtain the textual modality part of data in the pre-processing step. (Erol et al., 2003; Evangelopoulos et al., 2013), and text-image-audio-video (UzZaman et al., 2011; Li et al., 2017; Jangra et al., 2020b, c, 2021) have been explored in the literature of MMS. The different feature extraction strategies for individual modalities are described in Section 3.1.1.
Input Text Multiplicity (ITM): Since a major focus of this survey is on MMS tasks with text as the central modality, the number of text documents in input can also be one way of categorizing the related works. Depending upon whether the textual input is single-document (Chen and Zhuge, 2018b; Li et al., 2018a; Zhu et al., 2018) or multi-document (Li et al., 2017; Jangra et al., 2020b, c, 2021), the input preprocessing and the overall summarization strategies might differ. Having multiple documents makes the task a lot more challenging, since the degree of redundant information in input becomes a lot more prominent, making the data somewhat more noisy (Ma et al., 2020).
Multi-modal Synchronization (MMSy)777Note that the term synchronization is mostly used when there is a continuous media in consideration.: Synchronization refers to the interaction of two or more things at the same time or rate. For multi-modal summarization, having a synchronized input indicates that the multiple modalities have a coordination in terms of information flow, making them convey information in unison. We then classify input as synchronous (Erol et al., 2003; Evangelopoulos et al., 2013) and asynchronous (Li et al., 2017; Jangra et al., 2020b, c; Tjondronegoro et al., 2011; Jangra et al., 2021).
Domain Specificity (DS): Domain can be defined as the specific area of cognition that is covered by any data, and depending upon the extent of domain coverage, we can classify works as domain-specific or generic. The approach to summarize a domain-specific input can differ from the generic input greatly, since feature extraction in the former can be very particular in nature while not so in the latter, impacting the overall techniques immensely. Most of the news summarization tasks (Jangra et al., 2020c; Zhu et al., 2018; Li et al., 2017; Chen and Zhuge, 2018a; Jangra et al., 2021) are generic in nature, since news covers information about almost all the domains; whereas movie summarization (Evangelopoulos et al., 2013), sports event summarization for tennis (Tjondronegoro et al., 2011) and soccer (Sanabria et al., 2019), meetings recording summarization (Erol et al., 2003), tutorial summarization (Libovickỳ et al., 2018), social media event summarization (Tiwari et al., 2018) are examples of domain specific tasks.

3.1.1. Feature Extraction Strategies
In a multi-modal setting, pre-processing & feature extraction becomes vital step, since it involves extracting features from different modalities. Each input modality has been dealt with using modal-specific feature-extraction techniques. Even though some works tend to learn the semantic representation of data using their own proposed models, nearly all follow the same steps for feature extraction. Since the related works have different sets of input modalities, we describe feature extraction techniques for each modality individually.
Text: Traditionally, before the era of deep learning, Term Frequency-Document Inverse Frequency (TF-IDF) (Salton, 1989) was used to identify relevant text segments (Erol et al., 2003; Tjondronegoro et al., 2011; Evangelopoulos et al., 2013). Due to significant advancements in feature extraction, almost all the MMS tasks in the past five years either use pre-trained embeddings like word2vec (Mikolov et al., 2013) or Glove (Pennington et al., 2014). These pre-trained embeddings utilize the fact that the semantic information of a word is related to its contextual neighbors for training. Some works also train similar embeddings on their own datasets (Zhu et al., 2018, 2020a) (refer to Feature Extraction in Section 4.1.1). Some works also adopt different pre-processing steps, depending upon the task specifications. For example, Tiwari et al. (2018) applied a normalizer to handle the concept of expressive lengthening dealing with microblog datasets. Even though current MMS systems have not yet adopted them, it is worth mentioning Transformer-based word representations (Vaswani et al., 2017) like BERT, etc. that have achieved state-of-the-art performance in the vast majority of NLP and vision tasks. This achievement can be credited to their fast training due to parallelization, and ability to pre-train the language models on unlabelled corpora. We even have multi-lingual embeddings like LabSE (Feng et al., 2020), and multi-modal text-image embeddings like UNITER (Chen et al., 2020), VilBERT (Lu et al., 2019), VisualBERT (Li et al., 2019), Pixel-BERT (Huang et al., 2020), etc.
| Pre-trained network | Works using this framework |
|---|---|
| VGGNet (Simonyan and Zisserman, 2015) | Li et al. (2017), Li et al. (2018a), Zhu et al. (2018), Chen and Zhuge (2018a), Zhu et al. (2020a), Jangra et al. (2020b), Jangra et al. (2020c), Chen and Zhuge (2018b), Modani et al. (2016), Jangra et al. (2021) |
| ResNet (He et al., 2016) | Fu et al. (2020), Li et al. (2020a), Li et al. (2020c) |
| GoogleNet (Szegedy et al., 2015) | Sanabria et al. (2019) |
Images: Images, unlike text, are non-sequential and have a two-dimensional contextual span. Convolutional neural network (CNN) based deep neural network models have proven to be very promising in feature extraction tasks, but training these models requires large datasets, making it difficult to train features on MMS datasets. Hence, most of the existing works use pre-trained networks (e.g., ResNet (He et al., 2016), VGGNet (Simonyan and Zisserman, 2015), GoogleNet (Szegedy et al., 2015)) trained on large image classification datasets like ImageNet (Deng et al., 2009). The technique of extracting local features (containing information about a confined patch of image) along with global features has shown promise in the MMS task as well (Zhu et al., 2018). A detailed list of frameworks that use pre-trained deep learning networks can be found in Table 1. Tiwari et al. (2018) uses Speeded-Up Robust Features (SURF) for each image, following a bag-of-word approach to creating a visual vocabulary. Chen and Zhuge (2018b) handle images by first extracting the Scale Invariant Feature Transform (SIFT) features. These SIFT features are fed to a hierarchical quantization module (Qian et al., 2014) to obtain a 10,000-dimensional bag of the visual histogram. Having been inspired by the success of self-attention and Transformers (Vaswani et al., 2017) in effectively modeling textual sequences, researchers in computer vision have adopted the techniques like self-attention, unsupervised pre-training, parallelizability of transformer architecture, etc. to better model the image representations888The readers are encouraged to read the extensive survey provided by Khan et al. (2021).. In order to adopt the self-attention layer dedicated to text sequences, Parmar et al. (2018) proposed a framework that restricts the self-attention to the local neighborhoods, thus significantly increasing the size of images that the model can process, despite maintaining larger receptive fields per layer than a CNN framework. Dosovitskiy et al. (2020) illustrated that usage of self-attention in conjunction with CNNs is not required, and a pure transformer applied to the sequence of image patches can also perform well on image classification tasks. Touvron et al. (2021) developed and optimized deep image transformer frameworks that do not saturate early with more depth.
To the best of our knowledge, none of the existing multi-modal summarization works use image transformers to encode the images. Since these large-scale models have a lot more capability to store more learned patterns from large-scale datasets due to the huge parameter space, they are bound to improve the overall summarization process by aiding in better image understanding.
Audio and video: Audio and video are usually present together as a single synchronized continuous media, and hence we discuss the pre-processing techniques used to extract features from them simultaneously. Continuous media has been processed in many diverse ways. Since audios and videos are susceptible to noise, it becomes of utmost importance to detect relevant segments before proceeding to the training phase999Note that some deep neural models like Fu et al. (2020) or Li et al. (2020a) prefer to encode individual frames using CNNs, and then use trainable RNNs to encode temporal information in videos. This CNN-RNN framework is not part of pre-processing, but instead, it belongs to the main model since these layers are also affected during training.. While some works have adopted a naïve sliding window approach, making equal length cuts and further experimenting on these segments (Erol et al., 2003), quite a few have done a modal conversion, changing the information media using automatic speech transcription to generate speech transcriptions and extracting key-frames from video using techniques like boundary shot-detection (Jangra et al., 2020c, b; Li et al., 2017; Tjondronegoro et al., 2011; Jangra et al., 2021). Some works have also taken into account the nature of the dataset, and performed semantic segmentation, getting better segment slices. For example, Tjondronegoro et al. (2011) worked on a tennis dataset and used the information that the umpire requires the audience to remain quiet during the match point, performing segmentation consisting of a segment that begins with low audio activity followed by high audio energy levels as a result of the cheering and the commentary. If the audio and video are converted into another modality, then their pre-processing follows the same procedure as the new modalities, whereas, in the case of segmentation, various metrics like acoustic confidence, audio magnitude, sound localization for audio, motion detection, and Spatio-temporal features driven by intensity, color, and orientation for video have been explored to determine the salience and relevance of segments depending upon the task at hand (Erol et al., 2003; Li et al., 2017; Evangelopoulos et al., 2013).
Cross-modal correspondence: Although the majority of works train their own shared embedding space for multiple modalities using the information from the target datasets (Li et al., 2018a; Zhu et al., 2018; Libovickỳ et al., 2018), quite a few works (Jangra et al., 2020c, b; Li et al., 2017; Modani et al., 2016; Jangra et al., 2021) also tend to use pre-trained neural network models (Wang et al., 2016; Karpathy et al., 2014) trained on the image-caption datasets like Pascal1k (Rashtchian et al., 2010), Flickr8k (Hodosh et al., 2013), Flick30k (Young et al., 2014) etc. to leverage the information overlap amongst different modalities. This becomes a necessity for small datasets that are mostly used for extractive summarization. However even these pre-trained models cannot process raw data, and hence the text and image inputs are first pre-processed to desired embedding formats and then are fed to these models with pre-trained weights. For example, Wang et al. (2016) required a 6,000-dimensional sentence vector and 4,096-dimensional image vector generated by applying Principal Component Analysis (PCA) (Pearson, 1901) to the 18,000-dimensional output from the Hybrid Gaussian Laplacian mixture model (HGLMM) (Klein et al., 2014) and extracting the weights from the final fully connected layer, , from VGGNet (Simonyan and Zisserman, 2015), respectively. In recent years, various Transformer-based (Vaswani et al., 2017) models have also been developed to correlate semantic information across textual and visual modalities. These BERT (Devlin et al., 2019) inspired models include ViLBERT (Lu et al., 2019), VisualBERT (Li et al., 2019), VideoBERT (Sun et al., 2019), VLP (Zhou et al., 2020), Pixel-BERT (Huang et al., 2020) etc. to name a few. There has also been some video-text representation learning like (Lin et al., 2021) and (Patrick et al., 2020) that can be used to summarize multi-modal content with continuous modalities. However, none of the recent works on multi-modal summarization has utilized these transformer-based techniques in their system pipelines.
Domain specific techniques: Most of the systems proposed to solve the problem of multi-modal summarization are generic and can be adapted to other domains and problem statements as well. But, there do exist some works that benefit from the external knowledge of particular domains and problem settings to create better-performing systems. For instance, Tjondronegoro et al. (2011) utilizes the fact that in tennis, the umpire always requires spectators to be silent before a serve, until the end of the point. The authors also pointed out that the end of the point is usually marked by a loud cheer from the supporters of the players in the audience. They used this fact to perform smooth segmentation of tennis clips using audio energy levels to indicate the start and end positions of a segment. Similar to this, Sanabria et al. (2019) utilized atomic events in a game of soccer like a pass, goal, dribble, etc. to segment the video, which is later connected together to generate the summary. Other than sports, such domain-specific solutions have also been adopted in other domains. For example, Erol et al. (2003), when summarizing meeting recordings of a conference room, seeks out some visual activity like “someone entering the room” or “someone standing up to write something on a whiteboard” to detect some event likely to contain relevant information. In a different domain setting, people have benefited from other data pre-processing strategies, for instance, Li et al. (2020c) extracts various key aspects of products like “environmentally friendly refrigerators” or “energy efficient freezers” to generate a captivating summary for Chinese e-commerce products.
3.2. On the basis of method
A lot of various approaches have been developed to solve the MMS task, and we can organize the existing works on the basis of proposed methodologies as follows:
Learning process (LP): A lot of work has been done in both supervised learning (Zhu et al., 2020a; Libovickỳ et al., 2018; Chen and Zhuge, 2018b; Zhu et al., 2018; Li et al., 2018a) and unsupervised learning (Jangra et al., 2020c, b; Erol et al., 2003; Evangelopoulos et al., 2013; Li et al., 2017; Jangra et al., 2021). It can be observed that a large fraction of supervised techniques adopt deep neural networks to tackle the problem (Li et al., 2018a; Chen and Zhuge, 2018a; Zhu et al., 2018; Libovickỳ et al., 2018), whereas in unsupervised techniques a large diversity of techniques have been adopted including deep neural networks (Chen and Zhuge, 2018b), integer linear programming (Jangra et al., 2020b), differential evolution (Jangra et al., 2020c, 2021), submodular optimization (Li et al., 2017) etc.
Handling of continuous media (HCM): We can also distinguish between works depending upon how the proposed models handle continuous media (audio and video in this case). There are three broad distinctions possible, a) extracting-information, where the model extracts information from continuous media to get a discrete representation (Jangra et al., 2020c, b; Li et al., 2017; Jangra et al., 2021), b) semantic-segmentation, where a logical technique is proposed to slice out the continuous media (Tjondronegoro et al., 2011; Evangelopoulos et al., 2013, 2009), and c) sliding window, when a naïve fixed window based modeling is performed (Erol et al., 2003).
Notion of importance (NI): One of the most significant distinctions would be the notion of importance used to generate the final summary. A diverse set of objectives ranging from interestingness (Tjondronegoro et al., 2011), redundancy (Li et al., 2017), cluster validity index (Jangra et al., 2020c), acoustic energy / visual illumination (Evangelopoulos et al., 2009, 2013), and social popularity (Sahuguet and Huet, 2013) have been explored in attempt to solve the MMS task.
Cross-modal information exchange (CIE): The most important part of a MMS model is the ability to extract and share information across multiple modalities. Most of the works either adopt a proximity-based approach (Xu et al., 2013; Erol et al., 2003), a pre-trained model on image-caption pairs based corpora for information overlap (Jangra et al., 2020c, b; Li et al., 2017; Jangra et al., 2021), or learn the semantic overlap over uni-modal embeddings (Li et al., 2018a; Zhu et al., 2018, 2020a; Chen and Zhuge, 2018b, a).
Algorithms (A): The algorithm for the multimodal summarization task varies from traditional multiobjective optimization strategies to modern deep learning-based approaches. We can classify the existing works based on the different algorithms as Neural models (NN), Integer Linear Programming based models (ILP), Submodular Optimization-based models (SO), Nature-Inspired Algorithm based models (NIA), Graph-based models (G), and other algorithms (Oth). We have discussed these different methods in detail in Section 4.1. The other algorithms comprise different clustering-based, LDA (Blei et al., 2003) - based and audio-video analysis-based techniques which were earlier used for performing multimodal summarization.
3.3. On the basis of decoding the output
The summarization objective decides the desired type of output. For different summarization objectives, the type of output and decoding method vary. Depending on the type of output and the decoding method, we can categorize the existing works on the following basis:
Content intensity (CI): The degree to which an output summary elaborates on a concept can hugely impact the overall modeling. The output summary can either be informative, having detailed information about the input topic (Libovickỳ et al., 2018; Yan et al., 2012), or indicative, only hinting at the most relevant information (Zhu et al., 2018; Chen and Zhuge, 2018a).
Text Summarization Type (TST): The most widely discussed distinction for text summarization works is the distinction of extractive vs abstractive. Abstractive summarization systems generally use a beam search or greedy search mechanism for decoding the output summary. While extractive systems during decoding use some scoring mechanism to identify the salient, non-redundant, and readable elements from the input for the final output. Depending on the nature of an output text summary, we can also classify the works in MMS tasks (containing text in the output) into extractive MMS (Jangra et al., 2020c, b; Chen and Zhuge, 2018b; Li et al., 2017; Jangra et al., 2021) and abstractive MMS (Zhu et al., 2020a; Chen and Zhuge, 2018a; Zhu et al., 2018; Li et al., 2018a)101010Note that other modalities beside text have been so far subject to only extractive approaches in MMS researches..
Multi-modal expressivity (MME): Whether the output is uni-modal (comprising of one modality) (Libovickỳ et al., 2018; Li et al., 2018a; Chen and Zhuge, 2018b; Li et al., 2017; Evangelopoulos et al., 2013) or multi-modal (comprising of multiple modalities) (Jangra et al., 2020c, b; Zhu et al., 2020a; Chen and Zhuge, 2018a; Zhu et al., 2018; Tjondronegoro et al., 2011; Jangra et al., 2021) is a major classification for the existing work. Mostly the systems producing multimodal output involve some post-processing steps for selecting the final output elements from the non-central modalities.
Central modality (CM): Based on central-modality (defined in Section 2), existing works can also be distinguished depending on the base modality around which the final output, as well as the model, are formulated. A large portion of the prior work adopts either a text-centric approach (Jangra et al., 2020b; Libovickỳ et al., 2018; Chen and Zhuge, 2018a; Zhu et al., 2018; Li et al., 2018a, 2017; Jangra et al., 2021) or a video-centric111111Here audio is assumed to be a part of video since in all the existing works video and audio are synchronous to each other. approach (Sahuguet and Huet, 2013; Evangelopoulos et al., 2013; Tjondronegoro et al., 2011; Erol et al., 2003). Few of the decoding methods followed popularly in neural models have been discussed in detail in Section 4.1.1.
| Input Based | Output Based | Method Based | ||||||||||||||||||||||||||||
| Papers | MMD | ITM | MMSy | DS | CI | TST | MME | CM | LP | HCM | NI | CIE | A | |||||||||||||||||
|
Text |
Images |
Audio |
Video |
Single-doc |
Multi-doc |
Sync |
Async |
Domain Specific |
Generic |
Informative |
Indicative |
Abstractive |
Extractive |
Uni-modal |
Multi-modal |
Text |
Video |
Unsupervised |
Supervised |
Extracting info |
Semantic seg |
Sliding window |
Redundancy based |
Interestingness |
Other |
Image Caption |
Proximity |
Uni-modal embedding |
Algorithms |
|
| Erol et al. (2003) | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | Oth | ||||||||||||||||
| Tjondronegoro et al. (2011) | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | Oth | ||||||||||||||||
| UzZaman et al. (2011) | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | Oth | |||||||||||||||||||
| Evangelopoulos et al. (2013) | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | Oth | ||||||||||||||||
| Li et al. (2017) | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | SO, G | ||||||||||||||
| Li et al. (2018a) | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | NN | |||||||||||||||||
| Zhu et al. (2018) | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | NN | |||||||||||||||||
| Chen and Zhuge (2018a) | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | NN | |||||||||||||||||
| Libovickỳ et al. (2018) | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | NN | |||||||||||||||
| Palaskar et al. (2019) | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | NN | |||||||||||||||
| Zhu et al. (2020a) | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | NN | |||||||||||||||||
| Jangra et al. (2020b) | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ILP | ||||||||||||||
| Jangra et al. (2020c) | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | NIA | ||||||||||||||
| Jangra et al. (2021) | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | NIA | ||||||||||||||
| Xu et al. (2013) | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | NIA | |||||||||||||||||
| Sahuguet and Huet (2013) | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | Oth | |||||||||||||||
| Tiwari et al. (2018) | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | SO | |||||||||||||||||
| Bian et al. (2013) | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | Oth | |||||||||||||||||||
| Yan et al. (2012) | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | G | |||||||||||||||||||
| Qian et al. (2019) | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | Oth | ||||||||||||||||||
| Chen and Zhuge (2018b) | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | NN | |||||||||||||||||
| Evangelopoulos et al. (2009) | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | Oth | ||||||||||||||||
| Bian et al. (2014) | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | Oth | |||||||||||||||||||
| Fu et al. (2020) | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | NN | |||||||||||||||
| Li et al. (2020a) | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | NN | |||||||||||||||
| Li et al. (2020c) | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | NN | |||||||||||||||||
| Modani et al. (2016) | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | SO, G | |||||||||||||||||
| Sanabria et al. (2019) | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | NN | |||||||||||||
4. Overview of Methods
A lot of works have attempted to solve the MMS task using supervised and unsupervised techniques. In this section, we attempt to describe the MMS frameworks in a generalized manner, elucidating the nuances of different approaches. Since the variety of inputs, outputs and techniques that were used span a large spectrum of possibilities, we describe each one individually. We have broken down this section into three stages, pre-processing, main model, and post-processing.

4.1. Main Model
A lot of different techniques have been adopted to perform the MMS task using extracted features. Figure 3 illustrates the analysis of techniques adopted by researchers to solve the MMS task. We have tried to cover almost all the recent architectures that mainly focus on text-centric output summaries. In the approaches that have text as the central modality, the adjacent modalities are treated as a supplement to the text summaries, often getting selected at the post-processing step (Section 4.2).
4.1.1. Neural Models
A few extractive summarization models (Chen and Zhuge, 2018b) and almost all of the abstractive text summarization based MMS architectures (Li et al., 2018a; Zhu et al., 2018; Chen and Zhuge, 2018a; Libovickỳ et al., 2018; Zhu et al., 2020a) use Neural Networks (NN) in one form or another. Obtaining annotated dataset with sufficient instances to train these supervised techniques is the most difficult step for any Deep learning based MMS framework. The existing datasets satisfying these conditions belong to news domain, and have text-image type input (refer to datasets #4, #5, #6, #7, #19 in Table 3) or text-audio-video type input (refer to datasets #17, #18 in Table 3). All these frameworks utilize the effectiveness of seq2seq RNN models for language processing and generation, and encoding temporal aspects in videos; CNN networks are also adopted to encode discrete visual information in form of images (Zhu et al., 2018; Chen and Zhuge, 2018a) and video frames (Li et al., 2020a; Fu et al., 2020). All the neural models have an encoder-decoder architecture at their heart, having three key elements: 1) a feature extraction module (encoder), 2) a summary generation module (decoder), and 3) a multi-modal fusion module. Fig. 4 describes a generic neural model to generate text-image121212We formulate text-image summaries in our generic model since the existing neural models only output text (Li et al., 2018a; Chen and Zhuge, 2018b; Fu et al., 2020) or text-image (Li et al., 2020a; Zhu et al., 2020a; Chen and Zhuge, 2018a; Zhu et al., 2018) output. summaries for multi-modal input.

Feature Extraction (Encoder): Encoder is a generic term that entails both textual encoders as well as visual encoders. Various encoders have been explored to encode contextual information in textual modality, ranging from sentence-level encoders (Li et al., 2018a) to hierarchical document level encoders (Chen and Zhuge, 2018a) with Long Short Term Memory (LSTM) units (Hochreiter and Schmidhuber, 1997) or Gated Recurrent Units (GRU) (Cho et al., 2014) as the underlying RNN architecture. Most of the visual encoders do not train the parameter weights from scratch, but rather prefer to use CNN based pre-trained embeddings (refer to Section 3.1.1). However, notably, in order to capture the contextual information of images, Chen and Zhuge (2018a) used a bi-directional GRU unit to encode information from multiple images (encoded using VGGNet (Simonyan and Zisserman, 2015)) into one context vector, which is a unique approach for discrete image inputs. However, this RNN-CNN based encoding strategy is very standard approach adopted to encoding video input. Fu et al. (2020) and Li et al. (2020a) in their respective works use pre-trained CNNs to encode individual frames, and then feed them as input to randomly initialized bi-directional RNNs to capture the temporal dependencies across these frames. Libovickỳ et al. (2018) and Palaskar et al. (2019) use ResNeXt-101 3D Convolutional Neural Network (Hara et al., 2018) trained to recognize 400 diverse human actions on the Kinetics dataset (Kay et al., 2017) to tackle the problem of generating text summaries for tutorial videos from How2 dataset (Sanabria et al., 2018).
Multi-modal fusion strategies: A lot of fusion techniques have been developed in the field of MMS. However, most of the works that take text-image based inputs focus on multi-modal attention to facilitate a smooth information flow across the two modalities. Attention strategies has proven to be a very useful technique to help discard noise and focus on relevant information (Vaswani et al., 2017). The attention mechanism has been adopted by all the neural models that attempt to solve the MMS task. It has been applied to modal-specific information (uni-modal attention), as well as at the information sharing step in form of multi-modal attention to determine the degree of involvement of a specific modality for each input individually. Li et al. (2018a) proposed the hierarchical multi-modal attention for the first time to solve the task of multi-modal summarization of long sentences. The attention module comprises of individual text and image attention layers, followed by a subsequent layer of modality attention layer. Although multi-modal attention has shown great promise in text-image summarization tasks, it itself is not sufficient for text-video-audio summarization tasks (Li et al., 2020a). Hence, to overcome this weakness, Fu et al. (2020) proposed bi-hop attention as an extension of bi-linear attention (Kim et al., 2016b), and Li et al. (2020a) developed a novel conditional self-attention mechanism module to capture local semantic information of video conditioned on the input text information. Both of these techniques were backed empirically, and established state-of-the-art in their respective problems.
Decoder: Depending on the encoding strategy used, the textual decoders also vary from plain unidirectional RNN (Zhu et al., 2018) generating a word at a time to hierarchical RNN decoders (Chen and Zhuge, 2018a) performing this step in multiple levels of granularity. Although a vast majority of neural models focus only on generating textual summary using multi-modal information as input (Li et al., 2018a; Libovickỳ et al., 2018; Chen and Zhuge, 2018b; Palaskar et al., 2019; Li et al., 2020c), some work also output images as an supplement to the generated summary (Zhu et al., 2018; Chen and Zhuge, 2018a; Li et al., 2020a; Zhu et al., 2020a; Fu et al., 2020); reinforcing the textual information and improving the user experience. These works either use a post-processing strategy to select the image(s) to become a part of final multi-modal summary (Zhu et al., 2018; Chen and Zhuge, 2018a), or they incorporate this functionality in their proposed model (Zhu et al., 2020a; Fu et al., 2020; Li et al., 2020a). All the three frameworks that have implicit text-image summary generation characteristic adapt the final loss to be a weighted average of text generation loss together with the image selection loss. Zhu et al. (2020a) treats the image selection as a classification task and adopts cross-entropy loss to train the image selector. Fu et al. (2020) also treats the image selection process as a classification problem, and adopts an unsupervised learning technique that uses RL methods (Zhou et al., 2017). The proposed technique uses representativeness and diversity as the two reward functions for the RL learning. Li et al. (2020a) perceives the proposes a cover frame selector131313Model proposed by Li et al. (2020a) only selects one image per input, chosen from the video frames. that selects one image based on the hierarchical CNN-RNN based video encoding conditioned on article semantics using a conditional self-attention module. Li et al. (2020a) uses pairwise hinge loss to measure the loss during the model training.
Although the encoder-decoder model acts as the basic skeleton for the neural models solving MMS task, a lot of variations have been made, depending upon the input and output specifics. Zhu et al. (2018) proposes a visual coverage mechanism to mitigate the repetition of visual information. Li et al. (2018a) uses two image filters, namely image attention filter and image context filter to avoid noise introduction, filtering out useful information. Zhu et al. (2020a) proposes a multi-modal objective function, that generates multi-modal summary at the end of this step, avoiding any statistical post-processing step for image selection. Fu et al. (2020) utilizes the fact that audio and video are synchronous, and audio can easily be converted to textual format, utilizing these speech transcriptions as the the bridge across the asynchronous modalities of text and video. They also formulate various fusion techniques including early fusion (concatenation of multi-modal embeddings), tensor fusion (Zadeh et al., 2017), and late fusion (Liu et al., 2018) to enhance the information representation in the latent space.
4.1.2. ILP-based Models
Integer linear programming (ILP) has been used for text summarization in the past (Alguliev et al., 2010; Galanis et al., 2012), primarily for extractive summarization. Jangra et al. (2020b) has shown that if properly formulated, ILP can also be used to tackle the MMS task. More specifically, Jangra et al. (2020b) attempt to solve the problem of generating multi-modal summaries from a multi-document multi-modal news dataset by extracting necessary sentences, images and videos. They propose a Joint Integer Linear Programming framework that optimizes weighted average of uni-modal salience and cross-modal correspondence. The model takes pre-trained joint embedding of sentences and images as input, and performs a shared clustering, generating text clusters and image clusters. A recommendation-based setting is used to create the most optimal clusters. The text cluster centers are chosen to be the extractive text summary, and a multi-modal summary containing text, images and videos is generated at the post-processing step.
4.1.3. Submodular Optimization based Models
Sub-modular functions have been quite useful for text summarization tasks (Lin and Bilmes, 2010; Sipos et al., 2012) thanks to their assurance that the local optima is never worse than (63%) of the global optima (Nemhauser et al., 1978). A greedy algorithm having time complexity of is sufficient to optimize the functions. Tiwari et al. (2018), Li et al. (2017), and Modani et al. (2016) have also utilized these properties of submodular functions in order to solve the MMS task. Tiwari et al. (2018) uses coverage, novelty and significance as the submodular functions to extract the most significant documents for the task of timeline generation of a social media event in a multi-modal setting. Li et al. (2017) proposes a linear combination of submodular functions (salience of text, redundancy and visual coverage in this case) under a budget constraint to obtain near-optimal solutions at a sentence level to obtain an extractive text summary using news input comprising of text, images, videos and audio. Modani et al. (Modani et al., 2016) uses a weighted sum of five submodular functions (coverage of input text/images, diversity of text/images in final summary, and coherence of text part and image part of the final summary) to generate a summary comprising of text and images.
4.1.4. Nature Inspired Algorithms
Genetic algorithms (Saini et al., 2019a) and other nature inspired meta-heuristic optimization algorithms like the Grey Wolf Optimizer (Mirjalili et al., 2014) and Water Cycle algorithm (Eskandar et al., 2012) have shown great promise for extractive text summarization (Saini et al., 2019b). Jangra et al. (2020c) has illustrated that such algorithms can also be useful in multi-modal scenarios by experimenting with a multi-objective setting using differential evolution as the underlying guidance strategy. For the multi-objective optimization setup, the authors have proposed two different sets of objectives: one redundancy based (including uni-modal salience, redundancy and cross-modal correspondence) and one using cluster validity indices (PBM index (Pakhira et al., 2004) was used in this case). Both of these settings have performed better than the baselines. The optimization setup outputs the top most suitable sentences and images, which follow similar post-processing procedure as Jangra et al. (2020b). Jangra et al. (2021) on the other hand used Grey Wolf Optimizer (Mirjalili et al., 2014) based multi-objective optimization strategy to obtain the combined complementary-supplementary multi-modal summaries. The proposed approach was split into two key steps: a) global coverage text format (GCTF) - obtaining extractive text summaries using Grey Wolf Optimizer over all the input modalities in a clustering setup, b) visual enhanced text summaries (VETS) - using one-shot population based strategy to enhance the obtained text summaries with visual modalities to obtain the complementary and supplementary enhancements in a data-driven manner. The overall pipeline adopted similar pre-processing and post-processing steps as Jangra et al. (2020c).
4.1.5. Graph based Models
Graph based techniques have been widely adopted in extractive text summarization frameworks (Mihalcea, 2004; Mihalcea and Tarau, 2004; Erkan and Radev, 2004; Modani et al., 2015). These techniques involve graph formulation of text documents where nodes are represented by document sentences and the edge weights are formulated using similarity across two sentences. Extending this idea to a multi-modal set up, Modani et al. (Modani et al., 2016) proposed a graph based approach to generate text-image summaries. A graph was constructed using content segments (representing either sentences or images) as the nodes, and each node is given a weight depending on its information content. For sentences, this weight is computed as the sum of #nouns, #adverbs, #adjectives, #verbs, and half the #pronouns, while an images node’s weight is given by the average similarity score with all other image segments. An edge weight for an edge connecting two sentences is computed as the cosine similarity of sentence embeddings (evaluated using auto-encoders), edge weight connecting two images is computed as the cosine similarity of image embeddings (evaluated using VGGNet (Simonyan and Zisserman, 2015)) and the edge weight connecting a sentence and an image is computed as the cosine similarity of sentence embedding and image embedding projected in a shared vector space (using Deep Fragment embeddings (Karpathy et al., 2014)). After graph construction, an iterative greedy strategy (Modani et al., 2015) is adopted to select appropriate content segments and generate the text-image summary.
Li et al. (Li et al., 2017) also use a graph based technique to evaluate the salience of text to generate an extractive text summary using multi-modal input (containing text documents, images, videos). A guided LexRank (Erkan and Radev, 2004) was proposed to evaluate the salience score of the text unit (comprising of document sentences and speech transcriptions). The guidance strategy proposed by Li et al. (Li et al., 2017) had bidirectional connections for sentences belonging to documents, but only unidirectional connections were made for speech transcriptions with only outward edges to follow on their assumption that speech transcriptions might not always be grammatically correct, and hence should only be used for guidance and not for summary generation. This textual score was then used as a submodular function for the final model (refer to Sec 4.1.3).
4.2. Post-processing
Most of the existing works are not capable of generating multi-modal summaries141414Although, all the surveyed methods are ”multi-modal summarization” approaches, i.e. they all summarize multi-modal information, however, most of them summarize it to generate uni-modal outputs.. The systems that do generate multi-modal summaries either have an inbuilt system capable to generating multi-modal output (mainly by generating text using seq2seq mechanisms and selecting relevant images) (Li et al., 2020a; Zhu et al., 2020a) or they adopt some post-processing steps to obtain the visual and vocal supplements of the generated textual summaries (Jangra et al., 2020b; Zhu et al., 2018). Neural network models that use multi-modal attention mechanisms to determine the relevance of modality for each input case have been used for selecting the most suitable image (Zhu et al., 2018; Chen and Zhuge, 2018a). More precisely, the visual coverage scores (after the last decoding step), i.e. the summation of attention values while generating the text summary, are used to determine the most relevant images. Depending upon the needs of the task, a single image (Zhu et al., 2018) as well as multiple images (Chen and Zhuge, 2018b) can be extracted to supplement the text.




Jangra et al. (2020b) proposes a text-image-video summary generation task, which as the name suggests, outputs all possible modalities in the final summary. Having extracted most important sentences and images (containing video key-frames as well) using the ILP framework, the images are separated from the key-frames, and are supplemented with other images from the input set that have a moderate similarity, with a pre-determined threshold and upper bound to avoid noisy and redundant information. Cosine similarity of global image features is used as the underlying similarity matrix in this case. A weighted average of verbal scores and visual scores is used to determine the most suitable video for the multi-modal summary. verbal score is defined as the information overlap between speech transcriptions and generated text summary, while the visual score is defined as the information overlap between the key-frames of a video with the generated image summary.
5. Datasets and Evaluation Techniques
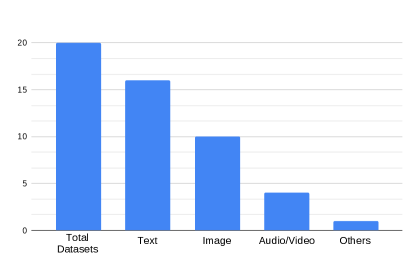
Due to the flexible nature of the MMS task, with a large variety of input-output modalities, the MMS task does not have a standard dataset used as a common evaluation benchmark for all approaches to this date. Nonetheless, we have collected information about datasets used in the previous works, and a comprehensive study of 20 datasets can be found at Table 3. It was found that out of these 21 datasets, 12 datasets are of news-related origin (Jangra et al., 2020b; Li et al., 2018a; Zhu et al., 2018; Fu et al., 2020; Yan et al., 2012), and including the dataset on video tutorials by Sanabria et al. (2018), there are 13 datasets that are domain-independent, thus suitable to test out domain generic models. 6 out of the 21 datasets produce text-only summaries using multi-modal input; out of these six datasets, 2 datasets’ output comprises of extracted text summaries (Chen and Zhuge, 2018b; Li et al., 2017) and 4 datasets’ output contains abstractive summaries (Li et al., 2018a, 2020c; Fu et al., 2020; Sanabria et al., 2018). One the other hand, there are 8 datasets that output text-image summaries, which can further be divided into 6 extractive text-image summary generation datasets (Xu et al., 2013; Tiwari et al., 2018; Bian et al., 2013) and 2 abstractive text-image summary generation datasets (Li et al., 2020a; Chen and Zhuge, 2018a). Datasets #19 ((Jangra et al., 2020b)) and #20 ((Jangra et al., 2021)) are the only two datasets that comprise of text, image, audio and video in the output. However, these datasets are small, and thus limited to extractive summarization techniques. Meanwhile, dataset #20 ((Jangra et al., 2021)) is the only existing dataset that comprises of both complementary and supplementary enhancements in the multi-modal summary (refer to Section 2 for the definition). Out of the 21 datasets, 17 datasets contain text in the multi-modal summary, 11 contain images as well, 3 comprises solely of audio-video outputs (Evangelopoulos et al., 2009, 2013; Sanabria et al., 2019), and 1 dataset has a fixed template151515Tjondronegoro et al. (2011) focusing on summarizing tennis matches, and thus the output has a fixed template comprising of three different summarization tasks: a) summarization of entire tournament, b) summarization of a match and c) summarization of a tennis player. as output (Tjondronegoro et al., 2011). Of these 17 text-containing datasets, 10 datasets contain extractive text summaries (Xu et al., 2013; Tiwari et al., 2018; Bian et al., 2013; Jangra et al., 2020b) and the rest 7 datasets contain abstractive summaries (Li et al., 2020a; Chen and Zhuge, 2018a; Fu et al., 2020; Sanabria et al., 2018). It is interesting to note that 5 out of these 7 abstractive datasets belong to the news-domain (Li et al., 2020a; Chen and Zhuge, 2018a; Fu et al., 2020; Li et al., 2018a; Zhu et al., 2018), while the other two focus on e-commerce product summarization (Li et al., 2020c) and tutorial summarization (Sanabria et al., 2018).Out of the datasets only (Li et al., 2017; Sanabria et al., 2018; Jangra et al., 2021; Zhu et al., 2018) of them are publicly available.



Depending on the input, we can also divide the 20 datasets based on the presence/absence of video in the input. There are 10 datasets that contain videos, whereas the rest 11 mostly work with text-image inputs. Due to the nature of this survey (the main focus on text modality), all 21 datasets in consideration contain text as input. A majority of these text sources are single documents (Li et al., 2020a; Chen and Zhuge, 2018a; Li et al., 2020c; Zhu et al., 2018), but there are 6 datasets that have multiple documents in the input (Li et al., 2017; Jangra et al., 2020b; Xu et al., 2013; Bian et al., 2013, 2014; Jangra et al., 2021). Sanabria et al. (2019), Evangelopoulos et al. (2009) and Evangelopoulos et al. (2013) however do not contain text documents, but the speech transcriptions from corresponding audio inputs. While most of these datasets comprise of multi-sentence summaries generated from input documents, Li et al. (2018a) contains a single sentence as the source as well as the reference summary. Most of these datasets use English-based text and audio, but there are 3 datasets that contain Chinese text (Bian et al., 2013; Li et al., 2017; Bian et al., 2014; Li et al., 2020a).
There are some datasets that have inputs other than text, image, audio and video. For instance, Tiwari et al. (2018) and Yan et al. (2012) contain temporal information about the dataset for the task of multi-modal timelines generation. Qian et al. (2018) also utilize user information including demographics like gender, birthday, user profile (short biography), and other information including user name, nickname, number of followers, number of microblogs posted, profile registration time, and user’s level of interests in different topics for generating summaries of an event based on social media content. Detailed plots for selected statistics on the datasets covered in this study can be found at Figure 5.
| ID & Paper | Used In Paper | Input Modalities | Output Modalities | Data Statistics | Domain |
|---|---|---|---|---|---|
| #1: Li et al. (2018a) (2018) | (Li et al., 2018a) | T, I | TA | 66,000 triplets (sentence, image and summary) | News |
| #2: Zhu et al. (2018)(2018)* | (Zhu et al., 2018, 2020a) | T, I | TA, I | 313k documents, 2.0m images | News |
| #3: Chen and Zhuge (2018a) (2018) | (Chen and Zhuge, 2018a) | T, I | TA, I | 219k documents | News |
| #4: Xu et al. (2013) (2013) | (Xu et al., 2013) | T, I | TE, I | 8 topics (each containing 150+ documents) | News |
| #5: Bian et al. (2013) (2013) | (Bian et al., 2013) | TC, I | TE, I | 10 topics (127k microblogs and 48k images) | Social Media |
| #6: Bian et al. (2014) (2014) | (Bian et al., 2014) | TC, I | TE, I | 20 topics (310k documents, 114k images) | Social Media |
| #7: Li et al. (2020c) (2020) | (Li et al., 2020c) | TC, I | TA | 1,375,453 instances from home appliances, clothing, and cases & bags categories | E-commerce |
| #8: Chen and Zhuge (2018b) (2018) | (Chen and Zhuge, 2018b) | T, A | TE | - | News |
| #9: Tiwari et al. (2018) (2018) | (Tiwari et al., 2018) | T, I, TM | TE, I | 6 topics | Social Media |
| #10: Yan et al. (2012) (2012) | (Yan et al., 2012) | T, I, TM | TE, I | 4 topics (6k documents, 2k images) | News |
| #11: Qian et al. (2019) (2019) | (Qian et al., 2019) | T, I, U | TE, I | 12 topics (9.1m documents, 2.2m users, 15m images) | News (disasters) |
| #12: Tjondronegoro et al. (2011) (2011) | (Tjondronegoro et al., 2011) | T, A, V | TF | 66 hrs video (33 matches), 1,250 articles related to Australian Open 2010 tennis tournament | Sports (Tennis) |
| #13: Sanabria et al. (2018) (2018)* | (Libovickỳ et al., 2018) | T, A, V | TA | 2,000 hrs video | Multiple domains |
| #14: Fu et al. (2020) (2020) | (Fu et al., 2020) | T, A, V | TA | 1970 articles from Daily Mail (avg. video length 81.96 secs), and 203 articles from CNN (avg. video length 368.19 secs) | News |
| #15: Li et al. (2020a) (2020) | (Li et al., 2020a) | T, A, V | TA, I | 184,920 articles (Weibo) with avg. video duration 1 min, avg. article length 96.84 words, avg. summary length 11.19 words | News |
| #16: Sanabria et al. (2019) (2019) | (Sanabria et al., 2019) | T, A, V | A, V | 20 complete soccer games from 2017-2018 season of French Ligue 1 | Sports (Soccer / Football) |
| #17: Evangelopoulos et al. (2009) (2009) | (Evangelopoulos et al., 2009) | T, A, V | A, V | 3 movie segments (5-7 min each) | Movies |
| #18: Evangelopoulos et al. (2013) (2013) | (Evangelopoulos et al., 2013) | T, A, V | A, V | 7 half hour segments of movies | Movies |
| #19: Jangra et al. (2020b) (2020) | (Jangra et al., 2020b, c) | T, I, A, V | TE, I, A, V | 25 topics (500 documents, 151 images, 139 videos) | News |
| #20: Jangra et al. (2021) (2021)* | (Jangra et al., 2021) | T, I, A, V | TE, I, A, V | 25 topics (contains complementary and supplementary multi-modal references) | News |
| #21: Li et al. (2017) (2017)* | (Li et al., 2017) | T, TC, I, A, V | TE | 25 documents in English, 25 documents in Chinese | News |
These datasets span a wide variety of domains, including sports like tennis (Tjondronegoro et al., 2011) and football (Sanabria et al., 2019), movies (Evangelopoulos et al., 2009, 2013), social media-based information (Bian et al., 2013, 2014; Tiwari et al., 2018), e-commerce (Li et al., 2020c). In the coming days, we are likely bound to see more large-scale domain specific datasets to advance this field.
Although there have been a lot of innovative attempts in solving the MMS task, the same does not go for the evaluation techniques used to showcase the quality of generated summaries. Most of the existing works use uni-modal evaluation metrics, including ROUGE scores (Lin, 2004) to evaluate the text summaries, accuracy and precision-recall based metrics to evaluate the image and video parts of generated summaries. A few works have also reported True Positives and False Positives as well (Sahuguet and Huet, 2013). The best way to evaluate the quality of a summary is to perform extensive human evaluations. Various techniques have been used to get the best user performance evaluations including the quiz method (Erol et al., 2003), and user-satisfaction test (Zhu et al., 2018). These manual evaluation techniques are mainly of two kinds: a) simple scoring of summary quality based on input (Zhu et al., 2020a, 2018; Jangra et al., 2021), and b) answering the questions based on input to quantify the information retention of input data instance (Li et al., 2020a). However, one major issue with these manual evaluations is that they cannot be conducted for the entire dataset, and are hence performed on a subset of the test dataset. There are a lot of uncertainties involving this subset, as well as the mental conditions of the human evaluators while performing these quality checks. Hence it can be unreliable to compare two results of separate human evaluation experiments, even for the same task.
5.1. Text Summary Evaluation Techniques
Since the scope of this work is mostly limited to text-centric MMS techniques, it is important to discuss evaluation of text summaries separately and in tandem to other modalities. Even though quite a few MMS works generate uni-modal text summaries from multi-modal inputs (Li et al., 2018a, 2017; Libovickỳ et al., 2018), they still use very basic string based n-gram overlap metrics like ROUGE (Lin, 2004) to conduct the evaluation. Through this survey, we want to direct the researchers to not just focus on ROUGE, but also look at other aspects of text summarization as well. For instance, Fabbri et al. (2021) proposes four key-characteristics that an ideal summary must have:
-
(1)
Coherence the quality of smooth transition between different summary sentences such that sentences are not completely unrelated or completely same.
-
(2)
Consistency the factual correctness of summary with respect to input document.
-
(3)
Fluency the grammatical correctness and readability of sentences.
-
(4)
Relevance the ability of a summary to capture important and relevant information from the input document.
Fabbri et al. (2021) also illustrated how ROUGE is not capable of gauging the quality of generated summaries by doing an n-gram overlap with human written reference summaries. There are other metrics out there that use more advanced strategies to do the evaluation, such as n-gram based metric like WIDAR (Jain et al., 2022b), embedding-based metrics like ROUGE-WE (Ng and Abrecht, 2015), MoverScore (Zhao et al., 2019) and Sentence Mover Similarity (SMS) (Clark et al., 2019) or neural model-based metrics like BERTScore (Zhang* et al., 2020), SUPERT (Gao et al., 2020), BIANC (Vasilyev and Bohannon, 2021) and S3 (Peyrard et al., 2017). These evaluation metrics have been proven to be empirically better at captivating the above-mentioned characteristics of a summary (Fabbri et al., 2021), and hence upcoming research works should also report performance on some of these metrics along with ROUGE to have more accurate analysis of the generated summaries.
5.2. Multi-modal Summary Evaluation Techniques
In an attempt to evaluate the multi-modal summaries, Zhu et al. (2018) proposes a multi-modal automatic evaluation (MMAE) technique that jointly considers uni-modal salience and cross-modal relevance. In their case, the final summary comprises of text and images, and the final objective function is formulated as a mapping of three objective functions: 1) salience of text, 2) salience of images, and 3) text-image relevance. This mapping function is learnt using supervised techniques (Linear Regression, Logistic Regression and Multi-layer Perceptron in their case) to minimize training loss with human judgement scores. Although the metric seems promising, there are a lot of conditions that must be met in order to perform the evaluation.
The MMAE metric does not effectively evaluate the information integrity161616Information integrity is the dependability or trustworthiness of information. In context of a multi-modal summary evaluation task, it refers to the ability to make a judgement that is unbiased towards any modality (i.e. an ideal evaluation metric does not give higher importance to information from one modality (e.g. text) over other modality (e.g. images)). of a multi-modal summary, since it uses uni-modal salience scores as a feature in the overall judgement making process, leading to a cognitive bias. Zhu et al. (2020a) improves upon this by proposing an evaluation metric based on joint multi-modal representation (termed as MMAE++), projecting the generated summaries and the ground truth summaries into a joint semantic space. In contrast to other multi-modal evaluation metrics, they attempt to look at the multi-modal summaries as a whole entity, than a combination of piece-wise significant elements. A neural network based model is used to train this joint representation. Images of two image caption pairs are swapped to obtain two image-text pairs that are semantically close to each other to obtain the training data for joint representation automatically. The evaluation model is trained using a multi-modal attention mechanism (Li et al., 2018a) to fuse the text and image vectors, using max-margin loss as loss function.
Modani et al. (2016) propose a novel evaluation technique termed by them as Multimedia Summary Quality (MuSQ). Just like other multi-modal summarization metrics described above, MuSQ is also limited to text-image summaries. However, unlike the majority of previous evaluation metrics for multi-modal summarization or document summarization techniques (Ermakova et al., 2019), MuSQ does not require a ground truth to evaluate the quality of generated summary. MuSQ is a naive coverage based evaluation metric denoted as , and is defined as:
| (1) | |||
| (2) | |||
| (3) | |||
| (4) |
where denotes the degree of coverage of input text document by text summary , denotes the degree of coverage of input images by the image summary . measures the cohesion across the text sentences and images of final multi-modal summary. and are respectively the individual reward values for each input sentence and input image that denote the extent of information content in each content fragment (a text sentence or an image).
| Metric name & corresponding paper | Pros & Cons |
|---|---|
| Multi-modal Automatic Evaluation (MMAE). Zhu et al. (2018) | Advantages |
| - MMAE shows high correlation with human judgement scores. | |
| Disadvantages | |
| - Requires a substantial manually annotated dataset. | |
| - Might perform ambiguously‡ for evaluation of other new domains. | |
| MMAE++. Zhu et al. (2020a) | Advantages |
| - Utilizes joint multi-modal representation of sentence-image pairs to better improve the correlation scores over MMAE metric (Zhu et al., 2018). | |
| Disadvantages | |
| - Requires a substantial manually annotated dataset. | |
| - Might perform ambiguously1 for evaluation of other new domains. | |
| Multimedia Summary Quality (MuSQ). Modani et al. (2016) | Advantages |
| - Does not require manually created gold summaries. | |
| Disadvantages | |
| - The technique is very naive, and only considers coverage of input information and text-image cohesiveness. | |
| - The metric output is not normalized. Hence the evaluation scores are highly sensitive to the cardinality of input text sentences and input images. |
-
1
Here ”might perform ambiguously” refers to the fact that since model-based metrics are biased towards the training data, it is hard to determine how well would they perform on unseen domains. For instance, if the model is trained on news summarization dataset, and the task is to evaluate medical report summaries, then the model performance cannot be determined without further experiments.
To sum up, only a handful of works have focused on the evaluation of multi-modal summaries. Even the proposed evaluation metrics have a lot of drawbacks. The evaluation metrics proposed by Zhu et al. (2018) and Zhu et al. (2020a) require a large human evaluation score-based training data to learn the parameter weights. Since these metrics are highly dependent on the human-annotated dataset, the quality of this dataset can compromise the evaluation process if the training dataset is restrictive in domain coverage or is of poor quality. It also becomes difficult to generalize these metrics since they depend on the domain of training data. The evaluation technique proposed by Modani et al. (2016), although independent from gold summaries, is too naive, and has its own drawbacks. The evaluation metric is not normalized, and hence shows great variation when comparing the results of two input data instances with different sizes.
Overall, the discussed strategies have their own pros and cons; however, there is a great scope for future improvement in the area of ‘evaluation techniques for multi-modal summaries’ (refer to Section 7).
For population based techniques (Jangra et al., 2020c, 2021), the best score across multiple solutions were reported in this work.
| Paper | Dataset No. | Domain | Text score (ROUGE) | Image score | ME | |||||
|---|---|---|---|---|---|---|---|---|---|---|
| R-1 | R-2 | R-L | R-SU4 | Precision | Recall | MAP | ||||
| Li et al. (2017) (EXT) | Li et al. (2017) (English) | News | 0.442 | 0.133 | N.A | 0.187 | N.A | N.A | N.A | ✓ |
| Li et al. (2017) (Chinese) | 0.414 | 0.125 | N.A | 0.173 | N.A | N.A | N.A | ✓ | ||
| Li et al. (2018a) (ABS) | Li et al. (2018a) | News | 0.472 | 0.248 | 0.444 | N.A | N.A | N.A | N.A | |
| Zhu et al. (2018) (ABS) | Zhu et al. (2018) | News | 0.408 | 0.1827 | 0.377 | N.A | 0.624 | N.A | N.A | ✓ |
| Zhu et al. (2020a) (ABS) | Zhu et al. (2018) | 0.411 | 0.183 | 0.378 | N.A | 0.654 | N.A | N.A | ✓ | |
| Chen and Zhuge (2018b) (EXT) | Chen and Zhuge (2018b) | News | 0.271 | 0.125 | 0.156 | N.A | N.A | N.A | N.A | |
| Chen and Zhuge (2018a) (ABS) | Chen and Zhuge (2018a) | News | 0.326 | 0.120 | 0.238 | N.A | N.A | 0.4978 | N.A | |
| Libovickỳ et al. (2018) (ABS) | Sanabria et al. (2018) | Multi-domain | N.A | N.A | 0.549 | N.A | N.A | N.A | N.A | ✓ |
| Jangra et al. (2020b) (EXT) | Jangra et al. (2020b) | News | 0.260 | 0.074 | 0.226 | N.A | 0.599 | 0.38 | N.A | |
| Jangra et al. (2020c) (EXT) | Jangra et al. (2020b) | 0.420 | 0.167 | 0.390 | N.A | 0.767 | 0.982 | N.A | ||
| Jangra et al. (2021) (EXT) | Jangra et al. (2021) | News | 0.556 | 0.256 | 0.473 | N.A | 0.620 | 0.720 | N.A | ✓ |
| Xu et al. (2013) (EXT) | Xu et al. (2013) | News | 0.369 | 0.097 | N.A | N.A | N.A | N.A | N.A | |
| Bian et al. (2013) (EXT) | Bian et al. (2013) | Social Media | 0.507 | 0.303 | N.A | 0.232 | N.A | N.A | N.A | |
| Yan et al. (2012) (EXT) | Yan et al. (2012) | News | 0.442 | 0.109 | 0.320 | N.A | N.A | N.A | N.A | |
| Bian et al. (2014) (EXT) | Bian et al. (2014) (social trends) | Social Media | 0.504 | 0.307 | N.A | 0.235 | N.A | N.A | N.A | |
| Bian et al. (2014) (product events) | 0.478 | 0.279 | N.A | 0.187 | N.A | N.A | N.A | |||
| Fu et al. (2020) (EXT) | Fu et al. (2020) (DailyMail) | News | 0.417 | 0.186 | 0.317 | N.A | N.A | N.A | N.A | ✓ |
| Fu et al. (2020) (CNN) | 0.278 | 0.088 | 0.187 | N.A | N.A | N.A | N.A | ✓ | ||
| Li et al. (2020a) (ABS) | Li et al. (2020a) | News | 0.251 | 0.096 | 0.232 | N.A | N.A | N.A | 0.654 | ✓ |
| Li et al. (2020c) (ABS) | Li et al. (2020c) (Home Appliances) | E-commerce | 0.344 | 0.125 | 0.224 | N.A | N.A | N.A | N.A | ✓ |
| Li et al. (2020c) (Clothing) | 0.319 | 0.111 | 0.215 | N.A | N.A | N.A | N.A | ✓ | ||
| Li et al. (2020c) (Cases & Bags) | 0.338 | 0.125 | 0.224 | N.A | N.A | N.A | N.A | ✓ | ||
6. Results and Discussion
Since the MMS task is quite broad, covering multiple sub-problem statements, it is difficult to compare models due to the lack of a standard evaluation metric (refer to Section 5). We are then restricted to presenting the results using uni-modal evaluation techniques like ROUGE scores (Lin, 2004) for text summaries, and precision-recall scores for image summaries. In Section 3, we have described the diversity of works done so far, with some working on timeline generation (Tiwari et al., 2018; Xu et al., 2013; Sahuguet and Huet, 2013), while others working on generic news summarization (Jangra et al., 2020c; Zhu et al., 2018); making it difficult to conduct a fair comparison of different architectures171717Note that we only display the results that have text as the central modality (refer to Section 2).. Even comparing two models that have a very similar settings like Zhu et al. (2018) and Chen and Zhuge (2018a) (both are trained on large scale abstractive news summarization datasets), is not adequate because datasets #5 and #7 have different sizes of training data (refer to Table 3). Other such example is of Fu et al. (2020) and Li et al. (2020a), both these works intake text-video inputs; however Fu et al. (2020) is trained on English dataset with 2k instances, and Li et al. (2020a) is trained on Chinese dataset with 1,84k instances (refer to Table 3). Nonetheless, we attempted to give the readers an overview of the potential of existing architectures. There are a few observations that can be made even with these constraints. We can observe that the abstractive summarization models go neck-to-neck with extractive summarization models, even though extractive summarization models have an advantage of keeping the basic grammatical syntax intact, illustrating the advancement in neural summarization models in the MMS task. An extensive study can be found in Table 5.
There exist some works that share a common dataset to illustrate the efficacy of their proposed model architectures. For instance, Zhu et al. (2018) and Zhu et al. (2020a) share a common dataset (dataset #2). Both the works produce competitive results, with Zhu et al. (2020a) outperforming Zhu et al. (2018) by small difference in all modalities. It can also be observed from the results of Li et al. (2017) that the input language does not affect the quality of summary at all. Results for both English and Chinese datasets (refer to dataset #3 in Table 3) are close, and the difference can be accredited to non-overlapping content across the two datasets. We can also observe from the results by Fu et al. (2020) that neural models require large datasets to perform better. The CNN part of dataset only comprises of 200 data instances, while the DailyMail part of dataset comprises of 1970 instances. The authors also suggest that the larger size of videos in CNN data leads to worse performance, even though the underlying learning strategies are the same.
Some datasets are also an extension of existing ones; for instance, dataset #19 ((Jangra et al., 2020b)) was extended from dataset #21 *(Li et al., 2017)) by incorporating images and videos in the references, while dataset #20 ((Jangra et al., 2021)) was extended from dataset #19 ((Jangra et al., 2020b)) by introducing complementary and supplementary enhancements for the multi-modal references. Therefore all four works share the same reference summaries. Hence even though the other modalities differ, the works can be partially compared with each other for the text modality. From this, it can be deduced that the two-step approach proposed by (Jangra et al., 2021) that first generates the Global Coverage Text Format summary (GCTF) using grey-wolf optimizer on a multi-objective optimization setup, and then enhances this by using other modalities outperforms all the prior works; illustrating the power of population based techniques. The submodular optimization (Li et al., 2017) is able to outperform the Genetic Algorithm technique (Jangra et al., 2020c), which is again a population based-technique by some margin, which we believe can be credited to both, the ability of sub-modular optimization as well as the trade-off for a the multi-modal summary generation framework. Since Li et al. (2017) only-generates text, while Jangra et al. (2020c) generates a multi-modal output comprising of text, images, and videos; there might be some trade-off to improve quality of other modalities over text. Since Jangra et al. (2020b) and Jangra et al. (2020c) both present their works on the same dataset (dataset #19), and it is evident that the population-based genetic algorithm proposed in Jangra et al. (2020c) produces better summaries as compared to the single point optimization strategy using integer linear programming proposed in Jangra et al. (2020b), both in terms of text as well as image output. For the video output181818Since dataset #19 ((Jangra et al., 2020b)) and #20 ((Jangra et al., 2021)) are the only datasets which contain text and video in the output, we have reported the results in text instead of making another column in Table 5. It should also be noted that accuracy is used to evaluate the video summary, because both of these datasets restrict a single video in the output summary. Since dataset #20 is extended from dataset #19 they both share the same text and video outputs. Jangra et al. (2020c) and Jangra et al. (2020b) performed equally well with an accuracy of 44%, while Jangra et al. (2021) was able to obtain video accuracy of 64% (in contrast to the average accuracy of 16% for random selection over 10 attempts).
Out of the 17 works reported in Table 5, 8 have performed some sort of manual evaluation along with automatic evaluation to produce a clearer picture about the performance of various summarization strategies. Through these experiments, prior works have statistically shown how the presence of multi-modal information can not only aid the uni-modal summarization process, but improve the overall user experience. Li et al. (2020a) has shown that an output containing text and images increases user satisfaction by 12.4% in juxtaposition to text summaries. Jangra et al. (2021) also illustrate that having visual cues in a text summary helps improve the overall satisfaction by 22%, makes the topic 19% more fascinating, and helps users understand the topic better by 14.5%. Jangra et al. (2021) also empirically justify through manual annotations that a multi-modal summary should have both complementary and supplementary enhancements to improve the user experience.
7. Future Work
The MMS task is relatively new, and the work done so far has only scratched the surface of what this field has to offer. In this section we discuss the future scope of the MMS task, including some possible improvements in existing works, as well as some possible new directions.
7.1. Scope of improvement
Better fusion of multi-modal information: Almost all the works discussed in this survey adopt a late-joint representation approach, where uni-modal information is extracted beforehand, and the information-sharing across multiple modalities takes place at a later stage. These works either use a pre-trained model on image captions (Simonyan and Zisserman, 2015) or train the multi-modal correspondence in a naïve way, using a neural multi-modal attention mechanism. However Liu et al. (2020) have proposed a multi-stage fusion approach with a fusion forget gate module for solving the task of multimodal summarization in videos. Their proposed approach tries to improve the interaction between multiple modalities to complete the missing information of each modality. Further they have also introduced a forget gate to suppress the flow of unecessary multimodal noise. Using this approach the model was able to outperform the Palaskar et al. (2019) model 8.3 BLEU-4 points, 7.4 ROUGEL points and 3.9 METEOR points in the How2 (Sanabria et al., 2018) dataset. Although these techniques are able to capture the essence of semantic overlap across modalities, there is still room for improvement in fusion modeling.
Better evaluation metrics (for multi-modal summaries): Most of the existing works use uni-modal evaluation techniques like ROUGE scores (Lin, 2004) for text, and precision-recall based metrics for images and videos. The multi-modal evaluation metrics proposed by Zhu et al. (2018) and Zhu et al. (2020a) have shown some promise, but they require a large set of human evaluation scores of generated summaries for training to determine the parameter values, making them unfit as a universal metric, especially when the summaries to be evaluated are from different domains than the data the models were trained on. These proposed evaluation metrics are also very specific as they work only for text-image based multi-modal summaries. Hence the community still lacks an evaluation metric that could judge the quality of a summary comprising of multiple summaries. Even the standard text summarization metrics have some inherent shortcomings, as illustrated by the survey performed by ter Hoeve et al. (2020). They illustrated that even though these metrics are able to cover up basic concepts like informativeness, fluency, succinctness and factuality; they still lack other important aspects like usefulness as discovered by the survey conducted on users who frequently use automatic summarization mechanisms. In order to improve the overall user satisfaction, similar techniques should be incorporated for the evaluation of multi-modal summarization systems as well.
More datasets All the datasets proposed in the community till date are mostly centered towards the news domain, even though there are multiple potential applications in other domains like medical report summarization, tutorial summarization, simplification summarization, slogan generation etc. which could benefit from multi-modal information. There are also potential new research areas that can be explored, but due to the lack of dataset availability, the community is unable to pursue research in these fields. Some of these are: explainable MMS, sentiment lossless MMS, multi-lingual MMS, data-stream MMS, large-scale MMS of long documents etc.
Complementary and Supplementary MMS: It is well established fact that multi-modal systems improve the user experience and help paint a clearer picture of topics or events discussed in input documents (Li et al., 2020a; Jangra et al., 2021). However, there does not exist any system that can generate the complementary and supplementary multi-modal summaries together. A large majority of research work today focus on developing supplementary multi-modal summaries (Zhu et al., 2018; Chen and Zhuge, 2018a). There also exists some works that generate complementary multi-modal summaries as well (Li et al., 2020a). Jangra et al. (2021) also illustrated how an ideal multi-modal summary should comprise of both complementary and supplementary enhancements.
But the concepts of complementary and supplementary enhancements should not be limited to visual modalities over textual central modality as proposed in Jangra et al. (2021). For instance, summarizing articles with user opinion from the comments section can be a great application191919This task can be considered multi-modal if we extend the notion of modality to something more generic; however, since the scope of this survey is limited to the distinction in modality being the form of representing information, we do not consider such works in great detail.. Even though this is a text-only task, the concepts of complementary and supplementary enhancements can be extended to cover up comments that cover vivid perspectives, in both favor and against the information presented in the article.
No abstractive complementary-supplementary MMS framework or application has been proposed in the community so far, and hence the exploration potential in this is quite vast.
7.2. New directions
Manually generated dataset for evaluation of MMS evaluation metrics : There is a need of some human annotated datasets to evaluate the performance of existing and upcoming evaluation metrics. There have been some works in text summarization that can be used to draw out some parallels; for instance, Fabbri et al. (2021) releases the SummEval dataset that gives out human annotation scores for 1600 article documents scored by 11 annotators in four key-characteristics of a summary - consistency, coherence, fluency and relevance. Similar work is also needed in the MMS, where, other than uni-modal aspects, the ability to judge the cross-modal information correspondence also should be taken into account.
Explainable and Controlled MMS: Maynez et al. (2020) showed that automated abstractive summarization models suffer from the problem of hallucinations and often generate fictional content. Explainable and Controlled MMS refers to the process of developing summarization systems where we do not treat these automated systems as black boxes generating summaries; Rather we have the power to understand and control the output of these models so as to produce content of our desired type. Even though existing MMS summarization frameworks have shown substantial improvement in the recent few years, it is still a mystery how each modality is handled and understood to obtain the final summaries. This calls for more explainable systems that also output some meta-data in tandem with the summaries to better understand the functioning of these models. Attention mechanism (Bahdanau et al., 2016) is one way to get better insights in the model working. In the context of text summarization, Haonan et al. (2020) proposed a select and generate strategy where elements are first extracted from a document based on informativeness, novelty, and relevance and then an abstractor generates an abstractive summary using the extracted elements. Their extractor module features an interaction matrix to explain the selection logic and by changing the thresholds of the model one can control the final summary quality.
In the multimodal context, Shang et al. (2022) proposed DGExplain which exploits the cross-modal association between the news of multiple modalities and the user comments to detect misinformation. Explainable and controlled multimodal summarization systems can be built using this kind of explainable framework to detect and filter incorrect content and summarize the true facts. Mukherjee et al. (2022) proposed a multi-tasking approach to generate topic-aware multimodal summaries. Their proposed model aims to embed topic awareness in both the visual and textual outputs. Thus, these kinds of models are stepping stones towards developing systems that are able to control the information flow from different modalities in input and output.
Application-oriented MMS: We can use different MMS techniques to leverage the output of various tasks like product description generation, product review summarization, multi-modal microblog summarization, education material summarization, medical report summarization and simplification of any multi-modal content. For each of these tasks, earlier text-only (Chen et al., 2019; Yu et al., 2016; Ali et al., 2020) or image-only (Somasundaram and Alli, 2017) summarization methods were majorly used. However, Li et al. (2020c) showed that the quality of e-commerce product descriptions could be improved by incorporating visual information and textual descriptions of a product during the summarization process. Delbrouck et al. (2021) utilized the visual features from the x-rays associated with the radiology reports to improve the medical report summarization quality.
During any natural disaster, people post relevant content on microblogging websites, which concerned authorities could use for rescue operations. Saini et al. (2021) proposed a multi-modal approach to summarize these posts utilizing both the textual and visual aspects of the post to improve the summary quality. Recently, educational content has been multi-modal, comprising video, audio and text. We believe that educational material summary quality can be significantly enhanced if information from all of these modalities is utilized during the summarization process (Khullar and Arora, 2020). All of these recent works highlight the ability of MMS to combine the knowledge from various modalities to produce superior-quality summaries. Hence making it a more robust choice over the traditional uni-modality-based methods for multiple applications in future.
Sentiment/Emotion Lossless MMS: The point of a summary is to provide users with the information that they’d gain from reading the entire document; and an ideal summary would not only do that, but also elicit the same sentiments that the user would feel when reading the entire document. Gulshan et al. (2019) proposes an extractive text summarization framework that attempts to retain the sentiment of input in the generated summary. This task would be very relevant in few domains like story summarization, novel summarization etc. where the users tend to empathize with the content in the summary. Khan and Fu (2021) proposed a transformer based architecture to perform aspect based multimodal sentiment analysis. In future we can combine ideas from aspect based summarization systems (Li et al., 2020c) and multimodal aspect based sentiment recognition frameworks to gnerate sentiment aware MMS. When working with multi-modal data, this becomes even more challenging and interesting since various additional flavors of sentiment can be obtained from different modalities; and in some cases some modalities can fill the lack of sentiment in others. For instance, in a news article covering an earthquake, the text tends to be objective and devoid of subjective and sentiment-bearing expressions in order to remain professional, but the images and videos are able to convey these sentiments and emotions conveniently. Hence we believe that this kind of multi-modal summarization would help move current systems one step further in an attempt to obtain ideal summaries202020Note that this problem would be mostly restrictive to single-document summarization tasks (with some exceptions), since multiple articles tend to cover different aspects of a topic, often leading to conflicting opinions, and hence conflicting sentiments and emotions. There the problem statement can be changed to providing an unbiased and sentiment-less summary to be faithful to the users..
Multi-lingual MMS: Multi-modal information has proven to be useful for multi-modal neural machine translation tasks (Specia, 2018; Qian et al., 2018), and it has been a highly debated question whether language affects visual perception, a universal form of perception, shared by all individuals (Vulchanova et al., 2019). The fact that this question remains open till this date speaks volumes about how multi-modal information can prove to be useful for multi-lingual summarization tasks, if harnessed properly.
Data-stream MMS: Data-stream summarization, also known as update summarization or online summarization or dynamic summarization has been explored in great extent in the automatic text summarization community (Saggion and Poibeau, 2013; Gupta et al., 2016; Zhan et al., 2009; Hu et al., 2017; Tsai et al., 2020; Liu et al., 2015; Takamura et al., 2011; Shou et al., 2013). Data-stream summarization is used in situations where the input information is not static, and accordingly the summarization system needs to dynamically keep the summary up-to-date with the latest information. It is a challenging problem as it requires the summary to retain the key-highlights from past events, while being consistent and fluent with the most recent events as well. Data stream summarization has been used for various applications like social media content summarization (Liu et al., 2015; Shou et al., 2013), review summarization (Gupta et al., 2016; Zhan et al., 2009; Hu et al., 2017; Tsai et al., 2020), etc.
With the world moving towards multi-modal information representation, there is a need to make these models robust and adaptive to multi-modal information. A few of these are discussed in the ‘Application-oriented MMS’ part of this section.
Query-based MMS: A lot of work has been done in query based text summarization (Rahman and Borah, 2019; Litvak and Vanetik, 2017), but there is no existing research on query-based summarization in a multi-modal setting. Since it has been shown that visual content can help improve the quality of experience (Zhu et al., 2018), we believe that query-based summarization setup, that has a user-interaction, could really be improved by introducing multi-modal form of information.
MMS at scale: Although some work has been done on generic datasets in terms of domain coverage (Jangra et al., 2020c; Zhu et al., 2018; Li et al., 2017; Chen and Zhuge, 2018a), most of the existing works have been performed in a protective environment with some pre-defined notions of input and output formats. In order to produce a large-scale ready-to-use MMS framework, a more generic setup is required, that has better generalization and high adaptive capabilities.
MMS with user interaction: Inspired from query-chain summarization frameworks (Baumel et al., 2014), there is a possibility of a multi-modal summarization based on user interaction, which could help improve the overall user satisfaction.
8. Conclusion
Due to the improving technology, it has become convenient for people to create and share information in multiple modalities, a feat that was not possible a decade ago. As a result of this advancement, the need for multi-modal summarization is increasing. We present a survey to help familiarize users with techniques and challenges present for the MMS task. In this manuscript, we formally define the task of multi-modal summarization, and we also provide an extensive categorization of existing works depending upon various input, output and technique related details. We then include a comprehensive description of datasets used to tackle the MMS task. Moreover, we also briefly describe various techniques used to solve the MMS task, along with the evaluation metrics used to judge the quality of summaries produced. Finally, we also provide a few possible directions that research in MMS can take. We hope that this survey paper will significantly promote research in multi-modal summarization.
References
- (1)
- Alguliev et al. (2010) Rasim Alguliev, Ramiz Aliguliyev, and Makrufa Hajirahimova. 2010. Multi-document summarization model based on integer linear programming. Intelligent Control and Automation 1, 02 (2010), 105.
- Ali et al. (2020) Syed Muhammad Ali, Zeinab Noorian, Ebrahim Bagheri, Chen Ding, and Feras Al-Obeidat. 2020. Topic and sentiment aware microblog summarization for twitter. Journal of Intelligent Information Systems 54, 1 (2020), 129–156.
- Arshad et al. (2019) Omer Arshad, Ignazio Gallo, Shah Nawaz, and Alessandro Calefati. 2019. Aiding intra-text representations with visual context for multimodal named entity recognition. In 2019 International Conference on Document Analysis and Recognition (ICDAR). IEEE, 337–342.
- Atrey et al. (2010) Pradeep K Atrey, M Anwar Hossain, Abdulmotaleb El Saddik, and Mohan S Kankanhalli. 2010. Multimodal fusion for multimedia analysis: a survey. Multimedia systems 16, 6 (2010), 345–379.
- Bahdanau et al. (2016) Dzmitry Bahdanau, Kyunghyun Cho, and Yoshua Bengio. 2016. Neural Machine Translation by Jointly Learning to Align and Translate. arXiv:1409.0473 [cs.CL]
- Baltrušaitis et al. (2018) Tadas Baltrušaitis, Chaitanya Ahuja, and Louis-Philippe Morency. 2018. Multimodal machine learning: A survey and taxonomy. IEEE transactions on pattern analysis and machine intelligence 41, 2 (2018), 423–443.
- Barbieri et al. (2018) Francesco Barbieri, Miguel Ballesteros, Francesco Ronzano, and Horacio Saggion. 2018. Multimodal emoji prediction. arXiv preprint arXiv:1803.02392 (2018).
- Basavarajaiah and Sharma (2019) Madhushree Basavarajaiah and Priyanka Sharma. 2019. Survey of Compressed Domain Video Summarization Techniques. ACM Computing Surveys (CSUR) 52, 6 (2019), 1–29.
- Baumel et al. (2014) Tal Baumel, Raphael Cohen, and Michael Elhadad. 2014. Query-chain focused summarization. In Proceedings of the 52nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 913–922.
- Bian et al. (2013) Jingwen Bian, Yang Yang, and Tat-Seng Chua. 2013. Multimedia summarization for trending topics in microblogs. In Proceedings of the 22nd ACM international conference on Information & Knowledge Management. 1807–1812.
- Bian et al. (2014) Jingwen Bian, Yang Yang, Hanwang Zhang, and Tat-Seng Chua. 2014. Multimedia summarization for social events in microblog stream. IEEE Transactions on multimedia 17, 2 (2014), 216–228.
- Blei et al. (2003) David M Blei, Andrew Y Ng, and Michael I Jordan. 2003. Latent dirichlet allocation. Journal of machine Learning research 3, Jan (2003), 993–1022.
- Botschen et al. (2018) Teresa Botschen, Iryna Gurevych, Jan-Christoph Klie, Hatem Mousselly-Sergieh, and Stefan Roth. 2018. Multimodal frame identification with multilingual evaluation. In Proceedings of the 2018 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long Papers). 1481–1491.
- Caglayan et al. (2019) Ozan Caglayan, Pranava Madhyastha, Lucia Specia, and Loïc Barrault. 2019. Probing the need for visual context in multimodal machine translation. arXiv preprint arXiv:1903.08678 (2019).
- Chen et al. (2010) Fan Chen, Christophe De Vleeschouwer, H Duxans Barrobés, J Gregorio Escalada, and David Conejero. 2010. Automatic summarization of audio-visual soccer feeds. In 2010 IEEE International Conference on Multimedia and Expo. IEEE, 837–842.
- Chen and Zhuge (2018a) Jingqiang Chen and Hai Zhuge. 2018a. Abstractive Text-Image Summarization Using Multi-Modal Attentional Hierarchical RNN. In Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing. 4046–4056.
- Chen and Zhuge (2018b) Jingqiang Chen and Hai Zhuge. 2018b. Extractive Text-Image Summarization Using Multi-Modal RNN. In 2018 14th International Conference on Semantics, Knowledge and Grids (SKG). IEEE, 245–248.
- Chen and Zhuge (2019) Jingqiang Chen and Hai Zhuge. 2019. News Image Captioning Based on Text Summarization Using Image as Query. In 2019 15th International Conference on Semantics, Knowledge and Grids (SKG). IEEE, 123–126.
- Chen and Zhuge (2020) Jingqiang Chen and Hai Zhuge. 2020. A news image captioning approach based on multimodal pointer-generator network. Concurrency and Computation: Practice and Experience (2020), e5721.
- Chen et al. (2019) Qibin Chen, Junyang Lin, Yichang Zhang, Hongxia Yang, Jingren Zhou, and Jie Tang. 2019. Towards knowledge-based personalized product description generation in e-commerce. In Proceedings of the 25th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining. 3040–3050.
- Chen and Bansal (2018) Yen-Chun Chen and Mohit Bansal. 2018. Fast Abstractive Summarization with Reinforce-Selected Sentence Rewriting. In Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 675–686.
- Chen et al. (2020) Yen-Chun Chen, Linjie Li, Licheng Yu, Ahmed El Kholy, Faisal Ahmed, Zhe Gan, Yu Cheng, and Jingjing Liu. 2020. UNITER: UNiversal Image-TExt Representation Learning. arXiv:1909.11740 [cs.CV]
- Cho et al. (2014) Kyunghyun Cho, Bart van Merriënboer, Caglar Gulcehre, Dzmitry Bahdanau, Fethi Bougares, Holger Schwenk, and Yoshua Bengio. 2014. Learning Phrase Representations using RNN Encoder–Decoder for Statistical Machine Translation. In Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing (EMNLP). 1724–1734.
- Clark et al. (2019) Elizabeth Clark, Asli Celikyilmaz, and Noah A. Smith. 2019. Sentence Mover’s Similarity: Automatic Evaluation for Multi-Sentence Texts. In Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics. Association for Computational Linguistics, Florence, Italy. https://doi.org/10.18653/v1/P19-1264
- Coman et al. (2018) Andrei Catalin Coman, Yaroslav Nechaev, and Giacomo Zara. 2018. Predicting emoji exploiting multimodal data: FBK participation in ITAmoji task. EVALITA Evaluation of NLP and Speech Tools for Italian 12 (2018), 135.
- Cui et al. (2019) Henggang Cui, Vladan Radosavljevic, Fang-Chieh Chou, Tsung-Han Lin, Thi Nguyen, Tzu-Kuo Huang, Jeff Schneider, and Nemanja Djuric. 2019. Multimodal trajectory predictions for autonomous driving using deep convolutional networks. In 2019 International Conference on Robotics and Automation (ICRA). IEEE, 2090–2096.
- Delbrouck et al. (2021) Jean-Benoit Delbrouck, Cassie Zhang, and Daniel Rubin. 2021. QIAI at MEDIQA 2021: Multimodal Radiology Report Summarization. In Proceedings of the 20th Workshop on Biomedical Language Processing. 285–290.
- Deng et al. (2009) Jia Deng, Wei Dong, Richard Socher, Li-Jia Li, Kai Li, and Li Fei-Fei. 2009. Imagenet: A large-scale hierarchical image database. In 2009 IEEE conference on computer vision and pattern recognition. Ieee, 248–255.
- Devlin et al. (2019) Jacob Devlin, Ming-Wei Chang, Kenton Lee, and Kristina Toutanova. 2019. BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding. In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers). Association for Computational Linguistics, Minneapolis, Minnesota, 4171–4186. https://doi.org/10.18653/v1/N19-1423
- Dosovitskiy et al. (2020) Alexey Dosovitskiy, Lucas Beyer, Alexander Kolesnikov, Dirk Weissenborn, Xiaohua Zhai, Thomas Unterthiner, Mostafa Dehghani, Matthias Minderer, Georg Heigold, Sylvain Gelly, et al. 2020. An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale. In International Conference on Learning Representations.
- Elliott (2018) Desmond Elliott. 2018. Adversarial evaluation of multimodal machine translation. In Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing. 2974–2978.
- Elliott et al. (2017) Desmond Elliott, Stella Frank, Loïc Barrault, Fethi Bougares, and Lucia Specia. 2017. Findings of the second shared task on multimodal machine translation and multilingual image description. arXiv preprint arXiv:1710.07177 (2017).
- Erkan and Radev (2004) Günes Erkan and Dragomir R Radev. 2004. Lexrank: Graph-based lexical centrality as salience in text summarization. Jour. of artif. intel. res. 22 (2004), 457–479.
- Ermakova et al. (2019) Liana Ermakova, Jean Valère Cossu, and Josiane Mothe. 2019. A survey on evaluation of summarization methods. Information Processing & Management 56, 5 (2019), 1794–1814.
- Erol et al. (2003) Berna Erol, D-S Lee, and Jonathan Hull. 2003. Multimodal summarization of meeting recordings. In 2003 International Conference on Multimedia and Expo. ICME’03. Proceedings (Cat. No. 03TH8698), Vol. 3. IEEE, III–25.
- Eskandar et al. (2012) Hadi Eskandar, Ali Sadollah, Ardeshir Bahreininejad, and Mohd Hamdi. 2012. Water cycle algorithm–A novel metaheuristic optimization method for solving constrained engineering optimization problems. Computers & Structures 110 (2012), 151–166.
- Evangelopoulos et al. (2008) Georgios Evangelopoulos, Konstantinos Rapantzikos, Alexandros Potamianos, Petros Maragos, A Zlatintsi, and Yannis Avrithis. 2008. Movie summarization based on audiovisual saliency detection. In 2008 15th IEEE International Conference on Image Processing. IEEE, 2528–2531.
- Evangelopoulos et al. (2013) Georgios Evangelopoulos, Athanasia Zlatintsi, Alexandros Potamianos, Petros Maragos, Konstantinos Rapantzikos, Georgios Skoumas, and Yannis Avrithis. 2013. Multimodal saliency and fusion for movie summarization based on aural, visual, and textual attention. IEEE Transactions on Multimedia 15, 7 (2013), 1553–1568.
- Evangelopoulos et al. (2009) Georgios Evangelopoulos, Athanasia Zlatintsi, Georgios Skoumas, Konstantinos Rapantzikos, Alexandros Potamianos, Petros Maragos, and Yannis Avrithis. 2009. Video event detection and summarization using audio, visual and text saliency. In 2009 IEEE International Conference on Acoustics, Speech and Signal Processing. IEEE, 3553–3556.
- Fabbri et al. (2021) A. R. Fabbri, Wojciech Kryscinski, Bryan McCann, R. Socher, and Dragomir Radev. 2021. SummEval: Re-evaluating Summarization Evaluation. Transactions of the Association for Computational Linguistics 9 (2021), 391–409.
- Feng et al. (2020) Fangxiaoyu Feng, Yinfei Yang, Daniel Cer, Naveen Arivazhagan, and Wei Wang. 2020. Language-agnostic BERT Sentence Embedding. arXiv:2007.01852 [cs.CL]
- Fierrez-Aguilar et al. (2005) Julian Fierrez-Aguilar, Javier Ortega-Garcia, Joaquin Gonzalez-Rodriguez, and Josef Bigun. 2005. Discriminative multimodal biometric authentication based on quality measures. Pattern recognition 38, 5 (2005), 777–779.
- Fu et al. (2020) Xiyan Fu, Jun Wang, and Zhenglu Yang. 2020. Multi-modal Summarization for Video-containing Documents. arXiv preprint arXiv:2009.08018 (2020).
- Galanis et al. (2012) Dimitrios Galanis, Gerasimos Lampouras, and Ion Androutsopoulos. 2012. Extractive multi-document summarization with integer linear programming and support vector regression. In Proceedings of COLING 2012. 911–926.
- Gambhir and Gupta (2017) Mahak Gambhir and Vishal Gupta. 2017. Recent automatic text summarization techniques: a survey. Artificial Intelligence Review 47, 1 (2017), 1–66.
- Gao et al. (2020) Yang Gao, Wei Zhao, and Steffen Eger. 2020. SUPERT: Towards New Frontiers in Unsupervised Evaluation Metrics for Multi-Document Summarization. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics. Association for Computational Linguistics, Online. https://doi.org/10.18653/v1/2020.acl-main.124
- Gulshan et al. (2019) Varun Gulshan, Renu P. Rajan, Kasumi Widner, Derek Wu, Peter Wubbels, Tyler Rhodes, Kira Whitehouse, Marc Coram, Greg Corrado, Kim Ramasamy, Rajiv Raman, Lily Peng, and Dale R. Webster. 2019. Performance of a Deep-Learning Algorithm vs Manual Grading for Detecting Diabetic Retinopathy in India. JAMA Ophthalmology 137, 9 (09 2019), 987–993. https://doi.org/10.1001/jamaophthalmol.2019.2004
- Gupta et al. (2016) Pankaj Gupta, Ritu Tiwari, and Nirmal Robert. 2016. Sentiment analysis and text summarization of online reviews: A survey. In 2016 International Conference on Communication and Signal Processing (ICCSP). IEEE, 0241–0245.
- Gupta and Lehal (2010) Vishal Gupta and Gurpreet Singh Lehal. 2010. A survey of text summarization extractive techniques. Journal of emerging technologies in web intelligence 2, 3 (2010), 258–268.
- Haonan et al. (2020) Wang Haonan, Gao Yang, Bai Yu, Mirella Lapata, and Huang Heyan. 2020. Exploring Explainable Selection to Control Abstractive Summarization. arXiv preprint arXiv:2004.11779 (2020).
- Hara et al. (2018) Kensho Hara, Hirokatsu Kataoka, and Yutaka Satoh. 2018. Can spatiotemporal 3d cnns retrace the history of 2d cnns and imagenet?. In Proceedings of the IEEE conference on Computer Vision and Pattern Recognition. 6546–6555.
- He et al. (2016) Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun. 2016. Deep residual learning for image recognition. In Proceedings of the IEEE conference on computer vision and pattern recognition. 770–778.
- Hochreiter and Schmidhuber (1997) Sepp Hochreiter and Jürgen Schmidhuber. 1997. Long short-term memory. Neural computation 9, 8 (1997), 1735–1780.
- Hodosh et al. (2013) Micah Hodosh, Peter Young, and Julia Hockenmaier. 2013. Framing image description as a ranking task: Data, models and evaluation metrics. Journal of Artificial Intelligence Research 47 (2013), 853–899.
- Hori et al. (2017) Chiori Hori, Takaaki Hori, Teng-Yok Lee, Ziming Zhang, Bret Harsham, John R Hershey, Tim K Marks, and Kazuhiko Sumi. 2017. Attention-based multimodal fusion for video description. In Proceedings of the IEEE international conference on computer vision. 4193–4202.
- Hori et al. (2018) Chiori Hori, Takaaki Hori, Gordon Wichern, Jue Wang, Teng-yok Lee, Anoop Cherian, and Tim K Marks. 2018. Multimodal Attention for Fusion of Audio and Spatiotemporal Features for Video Description.. In CVPR Workshops. 2528–2531.
- Hu et al. (2017) Ya-Han Hu, Yen-Liang Chen, and Hui-Ling Chou. 2017. Opinion mining from online hotel reviews–a text summarization approach. Information Processing & Management 53, 2 (2017), 436–449.
- Huang et al. (2016) Po-Yao Huang, Frederick Liu, Sz-Rung Shiang, Jean Oh, and Chris Dyer. 2016. Attention-based multimodal neural machine translation. In Proceedings of the First Conference on Machine Translation: Volume 2, Shared Task Papers. 639–645.
- Huang et al. (2018) Xun Huang, Ming-Yu Liu, Serge Belongie, and Jan Kautz. 2018. Multimodal unsupervised image-to-image translation. In Proceedings of the European Conference on Computer Vision (ECCV). 172–189.
- Huang et al. (2020) Zhicheng Huang, Zhaoyang Zeng, Bei Liu, Dongmei Fu, and Jianlong Fu. 2020. Pixel-bert: Aligning image pixels with text by deep multi-modal transformers. arXiv preprint arXiv:2004.00849 (2020).
- Hussain et al. (2020) Tanveer Hussain, Khan Muhammad, Weiping Ding, Jaime Lloret, Sung Wook Baik, and Victor Hugo C de Albuquerque. 2020. A comprehensive survey of multi-view video summarization. Pattern Recognition 109 (2020), 107567.
- Indovina et al. (2003) M Indovina, U Uludag, R Snelick, A Mink, and A Jain. 2003. Multimodal biometric authentication methods: a COTS approach. In Proc. of Workshop on Multimodal User Authentication. Citeseer, 99–106.
- Jaimes and Sebe (2007) Alejandro Jaimes and Nicu Sebe. 2007. Multimodal human–computer interaction: A survey. Computer vision and image understanding 108, 1-2 (2007), 116–134.
- Jain et al. (2022a) Raghav Jain, Anubhav Jangra, Sriparna Saha, and Adam Jatowt. 2022a. A Survey on Medical Document Summarization. arXiv preprint arXiv:2212.01669 (2022).
- Jain et al. (2022b) Raghav Jain, Vaibhav Mavi, Anubhav Jangra, and Sriparna Saha. 2022b. WIDAR - Weighted Input Document Augmented ROUGE. In Advances in Information Retrieval: 44th European Conference on IR Research, ECIR 2022, Stavanger, Norway, April 10–14, 2022, Proceedings, Part I (Stavanger, Norway). Springer-Verlag, Berlin, Heidelberg, 304–321. https://doi.org/10.1007/978-3-030-99736-6_21
- Jangra et al. (2020a) Anubhav Jangra, Raghav Jain, Vaibhav Mavi, Sriparna Saha, and Pushpak Bhattacharyya. 2020a. Semantic Extractor-Paraphraser based Abstractive Summarization. In Proceedings of the 17th International Conference on Natural Language Processing (ICON). 191–199.
- Jangra et al. (2020b) Anubhav Jangra, Adam Jatowt, Mohammad Hasanuzzaman, and Sriparna Saha. 2020b. Text-Image-Video Summary Generation Using Joint Integer Linear Programming. In European Conference on Information Retrieval. Springer, 190–198.
- Jangra et al. (2020c) Anubhav Jangra, Sriparna Saha, Adam Jatowt, and Mohammad Hasanuzzaman. 2020c. Multi-Modal Summary Generation Using Multi-Objective Optimization (SIGIR ’20). Association for Computing Machinery, New York, NY, USA, 1745–1748. https://doi.org/10.1145/3397271.3401232
- Jangra et al. (2021) Anubhav Jangra, Sriparna Saha, Adam Jatowt, and Mohammed Hasanuzzaman. 2021. Multi-Modal Supplementary-Complementary Summarization Using Multi-Objective Optimization. Association for Computing Machinery, New York, NY, USA, 818–828. https://doi.org/10.1145/3404835.3462877
- Javed et al. (2022) Hira Javed, MM Sufyan Beg, and Nadeem Akhtar. 2022. Multimodal Summarization: A Concise Review. In Proceedings of the International Conference on Computational Intelligence and Sustainable Technologies. Springer, 613–623.
- Jha et al. (2022) Prince Jha, Gaël Dias, Alexis Lechervy, Jose G Moreno, Anubhav Jangra, Sebastião Pais, and Sriparna Saha. 2022. Combining Vision and Language Representations for Patch-based Identification of Lexico-Semantic Relations. In Proceedings of the 30th ACM International Conference on Multimedia. 4406–4415.
- Karpathy et al. (2014) Andrej Karpathy, Armand Joulin, and Li F Fei-Fei. 2014. Deep fragment embeddings for bidirectional image sentence mapping. In Advances in neural information processing systems. 1889–1897.
- Kato (2021) Tsuneaki Kato. 2021. Multi-modal Summarization. In Evaluating Information Retrieval and Access Tasks. Springer, Singapore, 71–82.
- Kay et al. (2017) Will Kay, Joao Carreira, Karen Simonyan, Brian Zhang, Chloe Hillier, Sudheendra Vijayanarasimhan, Fabio Viola, Tim Green, Trevor Back, Paul Natsev, et al. 2017. The kinetics human action video dataset. arXiv preprint arXiv:1705.06950 (2017).
- Khan et al. (2021) Salman Khan, Muzammal Naseer, Munawar Hayat, Syed Waqas Zamir, Fahad Shahbaz Khan, and Mubarak Shah. 2021. Transformers in vision: A survey. arXiv preprint arXiv:2101.01169 (2021).
- Khan and Fu (2021) Zaid Khan and Yun Raymond Fu. 2021. Exploiting BERT for Multimodal Target Sentiment Classification through Input Space Translation. Proceedings of the 29th ACM International Conference on Multimedia (2021).
- Khullar and Arora (2020) Aman Khullar and Udit Arora. 2020. MAST: Multimodal abstractive summarization with trimodal hierarchical attention. arXiv preprint arXiv:2010.08021 (2020).
- Kim et al. (2016a) Jin-Hwa Kim, Sang-Woo Lee, Donghyun Kwak, Min-Oh Heo, Jeonghee Kim, Jung-Woo Ha, and Byoung-Tak Zhang. 2016a. Multimodal residual learning for visual qa. Advances in neural information processing systems 29 (2016), 361–369.
- Kim et al. (2016b) Jin-Hwa Kim, Kyoung-Woon On, Woosang Lim, Jeonghee Kim, Jung-Woo Ha, and Byoung-Tak Zhang. 2016b. Hadamard product for low-rank bilinear pooling. arXiv preprint arXiv:1610.04325 (2016).
- Kim et al. (2018) Sujeong Kim, David Salter, Luke DeLuccia, Kilho Son, Mohamed R Amer, and Amir Tamrakar. 2018. SMILEE: Symmetric multi-modal interactions with language-gesture enabled (AI) embodiment. In Proceedings of the 2018 Conference of the North American Chapter of the Association for Computational Linguistics: Demonstrations. 86–90.
- Kini and Pai (2019) Mahesh Kini and Karthik Pai. 2019. A Survey on Video Summarization Techniques. In 2019 Innovations in Power and Advanced Computing Technologies (i-PACT), Vol. 1. IEEE, 1–5.
- Kirchner et al. (2014) Elsa Andrea Kirchner, Marc Tabie, and Anett Seeland. 2014. Multimodal movement prediction-towards an individual assistance of patients. PloS one 9, 1 (2014), e85060.
- Klein et al. (2014) Benjamin Klein, Guy Lev, Gil Sadeh, and Lior Wolf. 2014. Fisher vectors derived from hybrid gaussian-laplacian mixture models for image annotation. arXiv preprint arXiv:1411.7399 (2014).
- Kostoulas et al. (2017) Theodoros Kostoulas, Guillaume Chanel, Michal Muszynski, Patrizia Lombardo, and Thierry Pun. 2017. Films, affective computing and aesthetic experience: Identifying emotional and aesthetic highlights from multimodal signals in a social setting. Frontiers in ICT 4 (2017), 11.
- Leviathan and Matias (2018) Yaniv Leviathan and Yossi Matias. 2018. Google Duplex: An AI system for accomplishing real-world tasks over the phone. (2018).
- Li et al. (2020c) Haoran Li, Peng Yuan, Song Xu, Youzheng Wu, Xiaodong He, and Bowen Zhou. 2020c. Aspect-Aware Multimodal Summarization for Chinese E-Commerce Products.. In AAAI. 8188–8195.
- Li et al. (2018a) Haoran Li, Junnan Zhu, Tianshang Liu, Jiajun Zhang, and Chengqing Zong. 2018a. Multi-modal Sentence Summarization with Modality Attention and Image Filtering. In Proceedings of the Twenty-Seventh International Joint Conference on Artificial Intelligence, IJCAI-18. International Joint Conferences on Artificial Intelligence Organization, 4152–4158. https://doi.org/10.24963/ijcai.2018/577
- Li et al. (2017) Haoran Li, Junnan Zhu, Cong Ma, Jiajun Zhang, and Chengqing Zong. 2017. Multi-modal summarization for asynchronous collection of text, image, audio and video. In Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing. 1092–1102.
- Li et al. (2018b) Haoran Li, Junnan Zhu, Cong Ma, Jiajun Zhang, and Chengqing Zong. 2018b. Read, watch, listen, and summarize: Multi-modal summarization for asynchronous text, image, audio and video. IEEE Transactions on Knowledge and Data Engineering 31, 5 (2018), 996–1009.
- Li et al. (2020b) Jiazheng Li, Linyi Yang, Barry Smyth, and Ruihai Dong. 2020b. MAEC: A Multimodal Aligned Earnings Conference Call Dataset for Financial Risk Prediction. In Proceedings of the 29th ACM International Conference on Information & Knowledge Management. 3063–3070.
- Li et al. (2019) Liunian Harold Li, Mark Yatskar, Da Yin, Cho-Jui Hsieh, and Kai-Wei Chang. 2019. Visualbert: A simple and performant baseline for vision and language. arXiv preprint arXiv:1908.03557 (2019).
- Li et al. (2020a) Mingzhe Li, Xiuying Chen, Shen Gao, Zhangming Chan, Dongyan Zhao, and Rui Yan. 2020a. VMSMO: Learning to Generate Multimodal Summary for Video-based News Articles. arXiv preprint arXiv:2010.05406 (2020).
- Libovickỳ et al. (2018) Jindrich Libovickỳ, Shruti Palaskar, Spandana Gella, and Florian Metze. 2018. Multimodal Abstractive Summarization for Open-Domain Videos. In Proceedings of the Workshop on Visually Grounded Interaction and Language (ViGIL). NIPS.
- Lin (2004) Chin-Yew Lin. 2004. ROUGE: A Package for Automatic Evaluation of Summaries. In Text Summarization Branches Out. Association for Computational Linguistics, Barcelona, Spain, 74–81. https://www.aclweb.org/anthology/W04-1013
- Lin and Bilmes (2010) Hui Lin and Jeff Bilmes. 2010. Multi-document summarization via budgeted maximization of submodular functions. In Human Language Technologies: The 2010 Annual Conference of the North American Chapter of the Association for Computational Linguistics. 912–920.
- Lin et al. (2021) Xudong Lin, Gedas Bertasius, Jue Wang, Shih-Fu Chang, Devi Parikh, and Lorenzo Torresani. 2021. VX2TEXT: End-to-End Learning of Video-Based Text Generation From Multimodal Inputs. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 7005–7015.
- Litvak and Vanetik (2017) Marina Litvak and Natalia Vanetik. 2017. Query-based summarization using MDL principle. In Proceedings of the multiling 2017 workshop on summarization and summary evaluation across source types and genres. 22–31.
- Liu et al. (2015) Cheng-Ying Liu, Ming-Syan Chen, and Chi-Yao Tseng. 2015. Incrests: Towards real-time incremental short text summarization on comment streams from social network services. IEEE Transactions on Knowledge and Data Engineering 27, 11 (2015), 2986–3000.
- Liu et al. (2018) Kuan Liu, Yanen Li, Ning Xu, and Prem Natarajan. 2018. Learn to combine modalities in multimodal deep learning. arXiv preprint arXiv:1805.11730 (2018).
- Liu et al. (2020) Nayu Liu, Xian Sun, Hongfeng Yu, Wenkai Zhang, and Guangluan Xu. 2020. Multistage Fusion with Forget Gate for Multimodal Summarization in Open-Domain Videos. In Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP). Association for Computational Linguistics, Online, 1834–1845. https://doi.org/10.18653/v1/2020.emnlp-main.144
- Liu and Jiang (2020) Xin Liu and Yujia Jiang. 2020. Aesthetic assessment of website design based on multimodal fusion. Future Generation Computer Systems (2020).
- Liu et al. (2022) Yixin Liu, Pengfei Liu, Dragomir Radev, and Graham Neubig. 2022. BRIO: Bringing Order to Abstractive Summarization. In Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 2890–2903.
- Lu et al. (2019) Jiasen Lu, Dhruv Batra, Devi Parikh, and Stefan Lee. 2019. Vilbert: Pretraining task-agnostic visiolinguistic representations for vision-and-language tasks. In Advances in Neural Information Processing Systems. 13–23.
- Luhn (1958) Hans Peter Luhn. 1958. The automatic creation of literature abstracts. IBM Journal of research and development 2, 2 (1958), 159–165.
- Ma et al. (2020) Congbo Ma, Wei Emma Zhang, Mingyu Guo, Hu Wang, and Quan Z. Sheng. 2020. Multi-document Summarization via Deep Learning Techniques: A Survey. arXiv:2011.04843 [cs.CL]
- Maynez et al. (2020) Joshua Maynez, Shashi Narayan, Bernd Bohnet, and Ryan McDonald. 2020. On faithfulness and factuality in abstractive summarization. arXiv preprint arXiv:2005.00661 (2020).
- Miao et al. (2020) Lianhai Miao, Da Cao, Juntao Li, and Weili Guan. 2020. Multi-modal product title compression. Information Processing & Management 57, 1 (2020), 102123.
- Mihalcea (2004) Rada Mihalcea. 2004. Graph-based ranking algorithms for sentence extraction, applied to text summarization. In Proceedings of the ACL Interactive Poster and Demonstration Sessions. 170–173.
- Mihalcea and Tarau (2004) Rada Mihalcea and Paul Tarau. 2004. Textrank: Bringing order into text. In Proceedings of the 2004 conference on empirical methods in natural language processing. 404–411.
- Mikolov et al. (2013) Tomas Mikolov, Ilya Sutskever, Kai Chen, Greg S Corrado, and Jeff Dean. 2013. Distributed representations of words and phrases and their compositionality. In Advances in neural information processing systems. 3111–3119.
- Mirjalili et al. (2014) Seyedali Mirjalili, Seyed Mohammad Mirjalili, and Andrew Lewis. 2014. Grey wolf optimizer. Advances in engineering software 69 (2014), 46–61.
- Modani et al. (2015) Natwar Modani, Elham Khabiri, Harini Srinivasan, and James Caverlee. 2015. Creating diverse product review summaries: a graph approach. In International Conference on Web Information Systems Engineering. Springer, 169–184.
- Modani et al. (2016) Natwar Modani, Pranav Maneriker, Gaurush Hiranandani, Atanu R Sinha, Vaishnavi Subramanian, Shivani Gupta, et al. 2016. Summarizing multimedia content. In International Conference on Web Information Systems Engineering. Springer, 340–348.
- Money and Agius (2008) Arthur G Money and Harry Agius. 2008. Video summarisation: A conceptual framework and survey of the state of the art. Journal of visual communication and image representation 19, 2 (2008), 121–143.
- Moon et al. (2018a) Seungwhan Moon, Leonardo Neves, and Vitor Carvalho. 2018a. Multimodal named entity disambiguation for noisy social media posts. In Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 2000–2008.
- Moon et al. (2018b) Seungwhan Moon, Leonardo Neves, and Vitor Carvalho. 2018b. Multimodal named entity recognition for short social media posts. arXiv preprint arXiv:1802.07862 (2018).
- Morency et al. (2011) Louis-Philippe Morency, Rada Mihalcea, and Payal Doshi. 2011. Towards multimodal sentiment analysis: Harvesting opinions from the web. In Proceedings of the 13th international conference on multimodal interfaces. 169–176.
- Mukherjee et al. (2022) Sourajit Mukherjee, Anubhav Jangra, Sriparna Saha, and Adam Jatowt. 2022. Topic-aware Multimodal Summarization. In Findings of the Association for Computational Linguistics: AACL-IJCNLP 2022. 387–398.
- Nemhauser et al. (1978) George L Nemhauser, Laurence A Wolsey, and Marshall L Fisher. 1978. An analysis of approximations for maximizing submodular set functions—I. Mathematical programming 14, 1 (1978), 265–294.
- Nenkova and McKeown (2012) Ani Nenkova and Kathleen McKeown. 2012. A survey of text summarization techniques. In Mining text data. Springer, 43–76.
- Ng and Abrecht (2015) Jun-Ping Ng and Viktoria Abrecht. 2015. Better Summarization Evaluation with Word Embeddings for ROUGE. In Proceedings of the 2015 Conference on Empirical Methods in Natural Language Processing. Association for Computational Linguistics, Lisbon, Portugal, 1925–1930. https://doi.org/10.18653/v1/D15-1222
- Oskouie et al. (2014) Payam Oskouie, Sara Alipour, and Amir-Masoud Eftekhari-Moghadam. 2014. Multimodal feature extraction and fusion for semantic mining of soccer video: a survey. Artificial Intelligence Review 42, 2 (2014), 173–210.
- Pakhira et al. (2004) Malay K Pakhira, Sanghamitra Bandyopadhyay, and Ujjwal Maulik. 2004. Validity index for crisp and fuzzy clusters. Pattern recognition 37, 3 (2004), 487–501.
- Palaskar et al. (2019) Shruti Palaskar, Jindrich Libovickỳ, Spandana Gella, and Florian Metze. 2019. Multimodal abstractive summarization for how2 videos. arXiv preprint arXiv:1906.07901 (2019).
- Parmar et al. (2018) Niki Parmar, Ashish Vaswani, Jakob Uszkoreit, Lukasz Kaiser, Noam Shazeer, Alexander Ku, and Dustin Tran. 2018. Image transformer. In International Conference on Machine Learning. PMLR, 4055–4064.
- Patrick et al. (2020) Mandela Patrick, Po-Yao Huang, Yuki Asano, Florian Metze, Alexander Hauptmann, Joao Henriques, and Andrea Vedaldi. 2020. Support-set bottlenecks for video-text representation learning. arXiv preprint arXiv:2010.02824 (2020).
- Pearson (1901) Karl Pearson. 1901. LIII. On lines and planes of closest fit to systems of points in space. The London, Edinburgh, and Dublin Philosophical Magazine and Journal of Science 2, 11 (1901), 559–572.
- Pennington et al. (2014) Jeffrey Pennington, Richard Socher, and Christopher D Manning. 2014. Glove: Global vectors for word representation. In Proceedings of the 2014 conference on empirical methods in natural language processing (EMNLP). 1532–1543.
- Peyrard et al. (2017) Maxime Peyrard, Teresa Botschen, and Iryna Gurevych. 2017. Learning to Score System Summaries for Better Content Selection Evaluation.. In Proceedings of the Workshop on New Frontiers in Summarization. Association for Computational Linguistics, Copenhagen, Denmark. https://doi.org/10.18653/v1/W17-4510
- Qian et al. (2019) Xueming Qian, Mingdi Li, Yayun Ren, and Shuhui Jiang. 2019. Social media based event summarization by user–text–image co-clustering. Knowledge-Based Systems 164 (2019), 107–121.
- Qian et al. (2014) Xueming Qian, Yao Xue, Xiyu Yang, Yuan Yan Tang, Xingsong Hou, and Tao Mei. 2014. Landmark summarization with diverse viewpoints. IEEE Transactions on Circuits and Systems for Video Technology 25, 11 (2014), 1857–1869.
- Qian et al. (2018) Xin Qian, Ziyi Zhong, and Jieli Zhou. 2018. Multimodal machine translation with reinforcement learning. arXiv preprint arXiv:1805.02356 (2018).
- Rahman and Borah (2019) Nazreena Rahman and Bhogeswar Borah. 2019. Improvement of query-based text summarization using word sense disambiguation. Complex & Intelligent Systems (2019), 1–11.
- Ramachandram and Taylor (2017) Dhanesh Ramachandram and Graham W Taylor. 2017. Deep multimodal learning: A survey on recent advances and trends. IEEE Signal Processing Magazine 34, 6 (2017), 96–108.
- Ramanishka et al. (2016) Vasili Ramanishka, Abir Das, Dong Huk Park, Subhashini Venugopalan, Lisa Anne Hendricks, Marcus Rohrbach, and Kate Saenko. 2016. Multimodal video description. In Proceedings of the 24th ACM international conference on Multimedia. 1092–1096.
- Ramesh et al. (2021) Aditya Ramesh, Mikhail Pavlov, Gabriel Goh, Scott Gray, Chelsea Voss, Alec Radford, Mark Chen, and Ilya Sutskever. 2021. Zero-Shot Text-to-Image Generation. arXiv:2102.12092 [cs.CV]
- Rashtchian et al. (2010) Cyrus Rashtchian, Peter Young, Micah Hodosh, and Julia Hockenmaier. 2010. Collecting image annotations using amazon’s mechanical turk. In Proceedings of the NAACL HLT 2010 Workshop on Creating Speech and Language Data with Amazon’s Mechanical Turk. 139–147.
- Rosas et al. (2013) Verónica Pérez Rosas, Rada Mihalcea, and Louis-Philippe Morency. 2013. Multimodal sentiment analysis of spanish online videos. IEEE Intelligent Systems 28, 3 (2013), 38–45.
- Ryden et al. (2004) Nils Ryden, Choon B Park, Peter Ulriksen, and Richard D Miller. 2004. Multimodal approach to seismic pavement testing. Journal of geotechnical and geoenvironmental engineering 130, 6 (2004), 636–645.
- Saggion and Poibeau (2013) Horacio Saggion and Thierry Poibeau. 2013. Automatic text summarization: Past, present and future. In Multi-source, multilingual information extraction and summarization. Springer, 3–21.
- Sahuguet and Huet (2013) Mathilde Sahuguet and Benoit Huet. 2013. Socially motivated multimedia topic timeline summarization. In Proceedings of the 2nd international workshop on Socially-aware multimedia. 19–24.
- Saini et al. (2021) Naveen Saini, Sriparna Saha, Pushpak Bhattacharyya, Shubhankar Mrinal, and Santosh Kumar Mishra. 2021. On multimodal microblog summarization. IEEE Transactions on Computational Social Systems 9, 5 (2021), 1317–1329.
- Saini et al. (2019a) Naveen Saini, Sriparna Saha, Dhiraj Chakraborty, and Pushpak Bhattacharyya. 2019a. Extractive single document summarization using binary differential evolution: Optimization of different sentence quality measures. PloS one 14, 11 (2019), e0223477.
- Saini et al. (2019b) Naveen Saini, Sriparna Saha, Anubhav Jangra, and Pushpak Bhattacharyya. 2019b. Extractive single document summarization using multi-objective optimization: Exploring self-organized differential evolution, grey wolf optimizer and water cycle algorithm. Knowledge-Based Systems 164 (2019), 45–67.
- Salton (1989) Gerard Salton. 1989. Automatic text processing: The transformation, analysis, and retrieval of. Reading: Addison-Wesley 169 (1989).
- Sanabria et al. (2019) Melissa Sanabria, Frédéric Precioso, and Thomas Menguy. 2019. A Deep Architecture for Multimodal Summarization of Soccer Games. In Proceedings Proceedings of the 2nd International Workshop on Multimedia Content Analysis in Sports. 16–24.
- Sanabria et al. (2018) Ramon Sanabria, Ozan Caglayan, Shruti Palaskar, Desmond Elliott, Loïc Barrault, Lucia Specia, and Florian Metze. 2018. How2: a large-scale dataset for multimodal language understanding. arXiv preprint arXiv:1811.00347 (2018).
- Sawhney et al. (2020) Ramit Sawhney, Puneet Mathur, Ayush Mangal, Piyush Khanna, Rajiv Ratn Shah, and Roger Zimmermann. 2020. Multimodal multi-task financial risk forecasting. In Proceedings of the 28th ACM International Conference on Multimedia. 456–465.
- Sebastian and Puthiyidam (2015) Tinumol Sebastian and Jiby J Puthiyidam. 2015. A survey on video summarization techniques. Int. J. Comput. Appl 132, 13 (2015), 30–32.
- Sebe et al. (2005) Nicu Sebe, Ira Cohen, Theo Gevers, and Thomas S Huang. 2005. Multimodal approaches for emotion recognition: a survey. In Internet Imaging VI, Vol. 5670. International Society for Optics and Photonics, 56–67.
- See et al. (2017) Abigail See, Peter J. Liu, and Christopher D. Manning. 2017. Get To The Point: Summarization with Pointer-Generator Networks. CoRR abs/1704.04368 (2017). arXiv:1704.04368 http://arxiv.org/abs/1704.04368
- Shang et al. (2022) Lanyu Shang, Ziyi Kou, Yang Zhang, and Dong Wang. 2022. A Duo-generative Approach to Explainable Multimodal COVID-19 Misinformation Detection. In Proceedings of the ACM Web Conference 2022. 3623–3631.
- Shou et al. (2013) Lidan Shou, Zhenhua Wang, Ke Chen, and Gang Chen. 2013. Sumblr: continuous summarization of evolving tweet streams. In Proceedings of the 36th international ACM SIGIR conference on Research and development in information retrieval. 533–542.
- Simonyan and Zisserman (2015) Karen Simonyan and Andrew Zisserman. 2015. Very Deep Convolutional Networks for Large-Scale Image Recognition. In International Conference on Learning Representations.
- Singh et al. (2021) Hrituraj Singh, Anshul Nasery, Denil Mehta, Aishwarya Agarwal, Jatin Lamba, and Balaji Vasan Srinivasan. 2021. Mimoqa: Multimodal input multimodal output question answering. In Proceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies. 5317–5332.
- Sipos et al. (2012) Ruben Sipos, Pannaga Shivaswamy, and Thorsten Joachims. 2012. Large-margin learning of submodular summarization models. In Proceedings of the 13th Conference of the European Chapter of the Association for Computational Linguistics. 224–233.
- Snelick et al. (2005) Robert Snelick, Umut Uludag, Alan Mink, Mike Indovina, and Anil Jain. 2005. Large-scale evaluation of multimodal biometric authentication using state-of-the-art systems. IEEE transactions on pattern analysis and machine intelligence 27, 3 (2005), 450–455.
- Soleymani et al. (2017) Mohammad Soleymani, David Garcia, Brendan Jou, Björn Schuller, Shih-Fu Chang, and Maja Pantic. 2017. A survey of multimodal sentiment analysis. Image and Vision Computing 65 (2017), 3–14.
- Somasundaram and Alli (2017) SK Somasundaram and P Alli. 2017. A machine learning ensemble classifier for early prediction of diabetic retinopathy. Journal of Medical Systems 41, 12 (2017), 1–12.
- Specia (2018) Lucia Specia. 2018. Multi-modal Context Modelling for Machine Translation. (2018).
- Suman et al. (2020) Chanchal Suman, Saichethan Miriyala Reddy, Sriparna Saha, and Pushpak Bhattacharyya. 2020. Why pay more? A simple and efficient named entity recognition system for tweets. Expert Systems with Applications (2020), 114101.
- Sun et al. (2019) Chen Sun, Austin Myers, Carl Vondrick, Kevin Murphy, and Cordelia Schmid. 2019. Videobert: A joint model for video and language representation learning. In Proceedings of the IEEE International Conference on Computer Vision. 7464–7473.
- Szegedy et al. (2015) Christian Szegedy, Wei Liu, Yangqing Jia, Pierre Sermanet, Scott Reed, Dragomir Anguelov, Dumitru Erhan, Vincent Vanhoucke, and Andrew Rabinovich. 2015. Going deeper with convolutions. In Proceedings of the IEEE conference on computer vision and pattern recognition. 1–9.
- Takamura et al. (2011) Hiroya Takamura, Hikaru Yokono, and Manabu Okumura. 2011. Summarizing a document stream. In European conference on information retrieval. Springer, 177–188.
- Tas and Kiyani (2007) Oguzhan Tas and Farzad Kiyani. 2007. A survey automatic text summarization. PressAcademia Procedia 5, 1 (2007), 205–213.
- ter Hoeve et al. (2020) Maartje ter Hoeve, Julia Kiseleva, and Maarten de Rijke. 2020. What Makes a Good Summary? Reconsidering the Focus of Automatic Summarization. arXiv preprint arXiv:2012.07619 (2020).
- Tiwari et al. (2018) Akanksha Tiwari, Christian Von Der Weth, and Mohan S Kankanhalli. 2018. Multimodal Multiplatform Social Media Event Summarization. ACM Transactions on Multimedia Computing, Communications, and Applications (TOMM) 14, 2s (2018), 1–23.
- Tjondronegoro et al. (2011) Dian Tjondronegoro, Xiaohui Tao, Johannes Sasongko, and Cher Han Lau. 2011. Multi-modal summarization of key events and top players in sports tournament videos. In Applications of Computer Vision (WACV), 2011 IEEE Workshop on. IEEE, 471–478.
- Touvron et al. (2021) Hugo Touvron, Matthieu Cord, Alexandre Sablayrolles, Gabriel Synnaeve, and Hervé Jégou. 2021. Going deeper with image transformers. arXiv preprint arXiv:2103.17239 (2021).
- Tsai et al. (2020) Chih-Fong Tsai, Kuanchin Chen, Ya-Han Hu, and Wei-Kai Chen. 2020. Improving text summarization of online hotel reviews with review helpfulness and sentiment. Tourism Management 80 (2020), 104122.
- UzZaman et al. (2011) Naushad UzZaman, Jeffrey P Bigham, and James F Allen. 2011. Multimodal summarization of complex sentences. In Proceedings of the 16th international conference on Intelligent user interfaces. ACM, 43–52.
- Vasilyev and Bohannon (2021) Oleg Vasilyev and John Bohannon. 2021. Is Human Scoring the Best Criteria for Summary Evaluation?. In Findings of the Association for Computational Linguistics: ACL-IJCNLP 2021. Association for Computational Linguistics, Online. https://doi.org/10.18653/v1/2021.findings-acl.192
- Vaswani et al. (2017) Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N Gomez, Łukasz Kaiser, and Illia Polosukhin. 2017. Attention is all you need. In Advances in neural information processing systems. 5998–6008.
- Verma et al. (2022) Yash Verma, Anubhav Jangra, Sriparna Saha, Adam Jatowt, and Dwaipayan Roy. 2022. MAKED: Multi-lingual Automatic Keyword Extraction Dataset. In Proceedings of the Thirteenth Language Resources and Evaluation Conference. 6170–6179.
- Vulchanova et al. (2019) Mila Vulchanova, Valentin Vulchanov, Isabella Fritz, and Evelyn A Milburn. 2019. Language and perception: introduction to the special issue speakers and listeners in the visual world. Journal of Cultural Cognitive Science (2019), 1–10.
- Wang et al. (2016) Liwei Wang, Yin Li, and Svetlana Lazebnik. 2016. Learning deep structure-preserving image-text embeddings. In Proceedings of the IEEE conference on computer vision and pattern recognition. 5005–5013.
- Wang et al. (2018) Nancy XR Wang, Ali Farhadi, Rajesh PN Rao, and Bingni W Brunton. 2018. AJILE movement prediction: Multimodal deep learning for natural human neural recordings and video. In Thirty-Second AAAI Conference on Artificial Intelligence.
- Xu et al. (2013) Shize Xu, Liang Kong, and Yan Zhang. 2013. A cross-media evolutionary timeline generation framework based on iterative recommendation. In Proceedings of the 3rd ACM conference on International conference on multimedia retrieval. 73–80.
- Yadav and Vishwakarma (2020) Ashima Yadav and Dinesh Kumar Vishwakarma. 2020. A Deep Multi-Level Attentive network for Multimodal Sentiment Analysis. arXiv preprint arXiv:2012.08256 (2020).
- Yan et al. (2012) Rui Yan, Xiaojun Wan, Mirella Lapata, Wayne Xin Zhao, Pu-Jen Cheng, and Xiaoming Li. 2012. Visualizing timelines: Evolutionary summarization via iterative reinforcement between text and image streams. In Proceedings of the 21st ACM international conference on Information and knowledge management. 275–284.
- Yao et al. (2017) Jin-ge Yao, Xiaojun Wan, and Jianguo Xiao. 2017. Recent advances in document summarization. Knowledge and Information Systems 53, 2 (2017), 297–336.
- Young et al. (2014) Peter Young, Alice Lai, Micah Hodosh, and Julia Hockenmaier. 2014. From image descriptions to visual denotations: New similarity metrics for semantic inference over event descriptions. Transactions of the Association for Computational Linguistics 2 (2014), 67–78.
- Yu et al. (2020) Jianfei Yu, Jing Jiang, Li Yang, and Rui Xia. 2020. Improving multimodal named entity recognition via entity span detection with unified multimodal transformer. Association for Computational Linguistics.
- Yu et al. (2016) Naitong Yu, Minlie Huang, Yuanyuan Shi, and Xiaoyan Zhu. 2016. Product review summarization by exploiting phrase properties. In Proceedings of COLING 2016, the 26th International Conference on Computational Linguistics: Technical Papers. 1113–1124.
- Zadeh et al. (2017) Amir Zadeh, Minghai Chen, Soujanya Poria, Erik Cambria, and Louis-Philippe Morency. 2017. Tensor fusion network for multimodal sentiment analysis. arXiv preprint arXiv:1707.07250 (2017).
- Zahavy et al. (2016) Tom Zahavy, Alessandro Magnani, Abhinandan Krishnan, and Shie Mannor. 2016. Is a picture worth a thousand words? A Deep Multi-Modal Fusion Architecture for Product Classification in e-commerce. arXiv preprint arXiv:1611.09534 (2016).
- Zhan et al. (2009) Jiaming Zhan, Han Tong Loh, and Ying Liu. 2009. Gather customer concerns from online product reviews–A text summarization approach. Expert Systems with Applications 36, 2 (2009), 2107–2115.
- Zhang et al. (2014) Luming Zhang, Yue Gao, Chao Zhang, Hanwang Zhang, Qi Tian, and Roger Zimmermann. 2014. Perception-guided multimodal feature fusion for photo aesthetics assessment. In Proceedings of the 22nd ACM international conference on Multimedia. 237–246.
- Zhang et al. (2018) Qi Zhang, Jinlan Fu, Xiaoyu Liu, and Xuanjing Huang. 2018. Adaptive Co-attention Network for Named Entity Recognition in Tweets.. In AAAI. 5674–5681.
- Zhang* et al. (2020) Tianyi Zhang*, Varsha Kishore*, Felix Wu*, Kilian Q. Weinberger, and Yoav Artzi. 2020. BERTScore: Evaluating Text Generation with BERT. In International Conference on Learning Representations. https://openreview.net/forum?id=SkeHuCVFDr
- Zhao et al. (2019) Wei Zhao, Maxime Peyrard, Fei Liu, Yang Gao, Christian M. Meyer, and Steffen Eger. 2019. MoverScore: Text Generation Evaluating with Contextualized Embeddings and Earth Mover Distance. In Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP). Association for Computational Linguistics, Hong Kong, China, 563–578. https://doi.org/10.18653/v1/D19-1053
- Zhou et al. (2017) Kaiyang Zhou, Yu Qiao, and Tao Xiang. 2017. Deep reinforcement learning for unsupervised video summarization with diversity-representativeness reward. arXiv preprint arXiv:1801.00054 (2017).
- Zhou et al. (2020) Luowei Zhou, Hamid Palangi, Lei Zhang, Houdong Hu, Jason J Corso, and Jianfeng Gao. 2020. Unified Vision-Language Pre-Training for Image Captioning and VQA.. In AAAI. 13041–13049.
- Zhu et al. (2018) Junnan Zhu, Haoran Li, Tianshang Liu, Yu Zhou, Jiajun Zhang, and Chengqing Zong. 2018. MSMO: Multimodal Summarization with Multimodal Output. In Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing. 4154–4164.
- Zhu et al. (2020a) Junnan Zhu, Yu Zhou, Jiajun Zhang, Haoran Li, Chengqing Zong, and Changliang Li. 2020a. Multimodal Summarization with Guidance of Multimodal Reference. In Proceedings of the AAAI Conference on Artificial Intelligence, Vol. 34. 9749–9756.
- Zhu et al. (2020b) Junnan Zhu, Yu Zhou, Jiajun Zhang, Haoran Li, Chengqing Zong, and Changliang Li. 2020b. Multimodal summarization with guidance of multimodal reference. In Proceedings of the AAAI Conference on Artificial Intelligence, Vol. 34. 9749–9756.
- Zhuge (2016) Hai Zhuge. 2016. Multi-dimensional summarization in cyber-physical society. Morgan Kaufmann.
- Zlatintsi et al. (2017) Athanasia Zlatintsi, Petros Koutras, Georgios Evangelopoulos, Nikolaos Malandrakis, Niki Efthymiou, Katerina Pastra, Alexandros Potamianos, and Petros Maragos. 2017. COGNIMUSE: A multimodal video database annotated with saliency, events, semantics and emotion with application to summarization. EURASIP Journal on Image and Video Processing 2017, 1 (2017), 1–24.