A Survey on 3D Skeleton-based Action Recognition Using Learning Method
Abstract
3D skeleton-based action recognition (3D SAR) has gained significant attention within the computer vision community, owing to the inherent advantages offered by skeleton data. As a result, a plethora of impressive works, including those based on conventional handcrafted features and learned feature extraction methods, have been conducted over the years. However, prior surveys on action recognition have primarily focused on video or RGB data-dominated approaches, with limited coverage of reviews related to skeleton data. Furthermore, despite the extensive application of deep learning methods in this field, there has been a notable absence of research that provides an introductory or comprehensive review from the perspective of deep learning architectures. To address these limitations, this survey first underscores the importance of action recognition and emphasizes the significance of 3D skeleton data as a valuable modality. Subsequently, we provide a comprehensive introduction to mainstream action recognition techniques based on four fundamental deep architectures, i.e., Recurrent Neural Networks (RNNs), Convolutional Neural Networks (CNNs), Graph Convolutional Network (GCN), and Transformers. All methods with the corresponding architectures are then presented in a data-driven manner with detailed discussion. Finally, we offer insights into the current largest 3D skeleton dataset, NTU-RGB+D, and its new edition, NTU-RGB+D 120, along with an overview of several top-performing algorithms on these datasets. To the best of our knowledge, this research represents the first comprehensive discussion of deep learning-based action recognition using 3D skeleton data.
1 Introduction

Action analysis, a pivotal and vigorously researched topic in the field of computer vision, has been under investigation for several decades [117, 102, 143, 116]. The ability to recognize actions is of paramount importance, as it enables us to understand how humans interact with their surroundings and express their emotions [60, 70]. This recognition can be applied across a wide range of domains, including intelligent surveillance systems, human-computer interaction, virtual reality, and robotics [136, 137, 11]. In recent years, the field of skeleton-based action recognition has made significant strides, surpassing conventional hand-crafted methods. This progress has been chiefly driven by substantial advancements in deep learning methodologies. [84, 83, 71, 127, 61, 97, 99, 145, 118, 73].
Traditionally, action recognition has relied on various data modalities, such as RGB image sequences [58, 28, 101, 62, 98], the depth image sequences [123, 1], videos, or a fusion of these modalities (e.g., RGB combined with the optical flow) [93, 27, 110, 30, 34]. These approaches have yielded impressive results through various techniques. Compared to skeleton data, which offers a detailed topological representation of the human body through joints and bones, these alternative modalities often prove computationally intensive and less robust when confronted with complex backgrounds and variable conditions. This includes challenges posed by variations in body scales, viewpoints, and motion speeds [38, 59].
Furthermore, the availability of sensors like the Microsoft Kinect [144] and advanced human pose estimation algorithms [20, 129, 8, 146] has facilitated the acquisition of accurate 3D skeleton data [92]. Figure 1 provides a visual representation of human skeleton data. In this case, 25 body joints are captured for a given human body. Skeleton sequences possess several advantages over other modalities, characterized by three notable features: 1) Intra-frame spatial information, where strong correlations exist between joints and their adjacent nodes, enabling the extraction of rich structural information. 2) Inter-frame temporal information, which captures strong and clear temporal correlations between frames of each body joint, enhancing the potential for action recognition. 3) A co-occurrence relationship between spatial and temporal domains when considering joints and bones, offering a holistic perspective. These unique attributes have catalyzed substantial research endeavors in human action recognition and detection. The escalating integration of skeleton data is anticipated to pervade diverse applications in the field.
The recognition of human actions using skeleton sequences predominantly hinges on a temporal dimension, transforming it into both a spatial and temporal information modeling challenge. As a result, traditional approaches in skeleton-based methods focus on extracting motion patterns from these sequences, prompting extensive research into handcrafted features. [105, 36, 34, 149, 113, 133]. These features often entail capturing the relative 3D rotations and translations among different joints or body parts [71, 104]. However, it has become evident that handcrafted features perform well only on specific datasets [111], highlighting the challenge that features tailored for one dataset may not be transferable to others. This issue hampers the generalization and broader application of action recognition algorithms.
With the remarkable development and outstanding performance of deep learning methods in various computer vision tasks, such as image classification [42, 22] and object detection [9, 152], the application of deep learning to skeleton data for action recognition has gained prominence. Nowadays, deep learning techniques utilizing Recurrent Neural Networks (RNNs) [48], Convolutional Neural Networks (CNNs) [17], Graph Convolutional Networks (GCNs), and Transformer-based methods have emerged in this field [126, 90]. Figure 2 provides an overview of the general pipeline for 3D skeleton-based action recognition (3D SAR) using deep learning, starting from raw RGB sequences or videos and culminating in action category prediction. RNN-based methods leverage skeleton sequences as natural time series data, treating joint coordinates as sequential vectors, aligning well with the RNN’s capacity for processing time series information. To enhance the learning of temporal context within skeleton sequences, variants like Long Short-Term Memory (LSTM) and Gated Recurrent Unit (GRU) have been employed. Meanwhile, CNNs complement RNN-based techniques, as they excel at capturing spatial cues in the input data, which RNNs may lack. Additionally, a relatively recent approach, the GCNs has gained attention for its ability to model skeleton data in a natural topological graph structure, with joints and bones as vertices and edges, respectively, offering advantages over alternative formats like images or sequences. Transformer-based methods [109, 150, 79, 153, 2, 132] capture the spatial-temporal relation of the input 3D skeleton data mainly based on its core multi-head self-attention mechanism (MSA).

All these three kinds of deep learning-based architectures have already gained unprecedented performance, but most review works just focus on traditional techniques or deep learning-based methods just with the RGB image or RGB-D data method. Ronald Poppe et al. [81] firstly addressed the basic challenges and characteristics of this domain and then gave a detailed illumination of basic action classification methods about direct classification and temporal state-space models. Daniel and Remi et al. [119] showed an overall overview of the action representation only in both spatial and temporal domains. Though the methods mentioned above provide some inspiration that may be used for input data pre-processing, neither skeleton sequence nor deep learning strategies were taken into account. Recently, Wu et al. [121] and Herath et al. [32] offered a summary of deep learning-based video classification and captioning tasks, in which the fundamental structure of CNN, as well as RNNs, were introduced, and the latter made a clarification about common deep architectures and quantitative analysis for action recognition. To our best knowledge, [75] is the first work recently giving an in-depth study in 3D SAR, which concludes this issue from the action representation to the classification methods, in the meantime, it also offers some commonly used datasets such as UCF, MHAD, MSR daily activity 3D, etc. [25, 77, 107, 72], while it doesn’t cover the emerging GCN based methods. Finally, [111] proposed a new review based on Kinect-dataset-based action recognition algorithms, which organized a thorough comparison of those Kinect-dataset-based techniques with various types of input data including RGB, Depth, RGB+Depth, and skeleton sequences. [96] presented an overview of the action recognition across all the data modalities but without presenting the Transformer-based methods. In addition, all these works mentioned above also ignore the differences and motivations among CNN-based, RNN-based, GCN-based, and Transformer-based methods, especially when taking the 3D skeleton sequences into account.
To address these issues comprehensively, this survey aims to provide a detailed summary of 3D SAR employing four fundamental deep learning architectures: RNNs, CNNs, GCNs, and Transformers. Additionally, we delve into the motivations behind the choice of these models and offer insights into potential future directions for research in this field.
In summary, our study encompasses four key contributions:
-
•
A comprehensive introduction about the superiority of 3D skeleton sequence data and characteristics of three kinds of fundamental deep architectures are presented in a detailed and clear manner, and a general pipeline in 3D SAR using deep learning methods is illustrated.
-
•
Within each type of deep architecture, numerous contemporary methods leveraging skeleton data are introduced, focusing on data-driven approaches. These encompass spatial-temporal modeling, innovative skeleton data representation, and methods for co-occurrence feature learning.
-
•
The discussion begins by addressing the latest challenging datasets, notably the NTU-RGB+D 120, along with an exploration of several top-ranked methods. Subsequently, it delves into envisaged future directions in this domain.
-
•
The initial study comprehensively examines four foundational deep architectures, encompassing RNN-based, CNN-based, GCN-based, and Transformer-based methods within the domain of 3D SAR.
2 3D SAR With Deep Learning
While existing surveys have offered comprehensive comparisons of action recognition techniques based on RGB or skeleton data, they often lack a detailed examination from the perspective of neural networks. To bridge this gap, we provide a concise introduction to the fundamental properties of each architecture (Section 2.1). Then our survey provides an exhaustive discussion and comparison of RNN-based (Section 2.2), CNN-based (Section 2.3), GCN-based (Section 2.4), and Transformer-based (Section 2.5) methods for 3D skeleton-based action recognition. We will explore these methods in-depth, highlighting their strengths and weaknesses, and introduce several latest related works as case studies, focusing on specific limitations or classic spatial-temporal modeling challenges associated with these neural network models.
2.1 Preliminaries: Basic Properties of RNNs, CNNs, GCNs, and Transformers
Before delving into the specifics of each method, we provide a brief overview of the fundamental architecture, outlining their respective advantages, disadvantages, and coarse selection criteria under the 3D SAR setting.
RNNs. RNNs are ideal for capturing temporal dependencies in sequences of joint movements over time and are suited for modeling action sequences due to their ability to retain temporal information. However, RNNs are also vulnerable to long-term dependencies, potentially missing complex relationships in lengthy sequences, and are computationally inefficient due to sequential processing, leading to longer training times for large-scale datasets.
CNNs. CNNs are not only effective in capturing spatial patterns from the joint coordinates, recognizing spatial features within individual frames of the 3D skeleton data but also great for local spatial relationships among joints. However, CNNs are limited to capturing temporal evolution in sequences, potentially missing out on the temporal dynamics crucial for action recognition.
GCNs. GCNs are designed to manage graph-structured data such as skeletal joint connections in action recognition, enabling the learning of relationships between joints and their connectivity while integrating spatial and temporal information. However, GCNs can be sensitive to noisy or irregular connections among joints, potentially impacting recognition accuracy, particularly in complex actions.
Transformers. Transformers is not only efficient at capturing long-range dependencies without the vanishing/exploding gradient issue but also Versatile in handling multiple modalities and learning global relationships. However, it’s also computationally intensive due to attention mechanisms, potentially requiring substantial computational resources. What’s more, compared to RNNs, it is also limited to sequential locality

(a)

(b)
2.2 RNN-Based Methods
Recursive connections within the RNN structure are established by feeding the output of the previous time step as the input to the current time step, as demonstrated in prior work [139]. This approach is known to be effective for processing sequential data. In a similar vein, models like the standard RNN, LSTM, and GRU were introduced to address limitations such as gradient-related issues and the modeling of long-term temporal dependencies that were present in the standard RNN.
From the first aspect, spatial-temporal modeling can be seen as the principle in action recognition tasks. Due to the weakness of the spatial modeling ability of RNN-based architecture, the performance of some related methods generally could not gain a competitive result [120, 147, 54]. Recently, Hong et al. [106] proposed a novel two-stream RNN architecture to model both temporal dynamics and spatial configurations for skeleton data. Figure 3 shows the framework of their work. An exchange of the skeleton axes was applied for the data level pre-processing for the spatial dominant learning. Unlike [106], Jun et al. [63] stepped into the traversal method of a given skeleton sequence to acquire the hidden relationship of both domains. Compared with the general method which arranges joints in a simple chain so that ignores the kinetic dependency relations between adjacent joints, the mentioned tree-structure-based traversal would not add false connections between body joints when their relation is not strong enough. Then, using an LSTM with a trusted gate treat the input discriminately, through which, if the tree-structured input unit is reliable, the memory cell will be updated by importing input latent spatial information. Inspirited by the property of CNN, which is extremely suitable for spatial modeling. Li et al.[49] incorporated an attention RNN with a CNN model to enhance the complexity of spatial-temporal modeling. Initially, they introduced a temporal attention module within a residual learning module, allowing for the recalibration of temporal attention across frames within a skeleton sequence. Subsequently, they applied a spatial-temporal convolutional module to this first module, treating the calibrated joint sequences as images. Furthermore, in the work by Lin et al.[50], an attention recurrent relation LSTM network was employed. This network combines a recurrent relation network for spatial features with a multi-layer LSTM to capture temporal features within skeleton sequences.
The second aspect involves the network structure, serving as a solution to address the limitations of standard RNNs. While RNNs are inherently suitable for sequence data, they often suffer from well-known problems like gradient exploding and vanishing. Although LSTM and GRU have alleviated these issues to some extent, the use of hyperbolic tangent and sigmoid activation functions can still result in gradient decay across layers. In response, new types of RNN architectures have been proposed [5, 47, 52]. Shuai et al. [52] introduced an independently recurrent neural network (IndRNN) designed to address gradient exploding and vanishing problems, making it feasible and more robust to construct longer and deeper RNNs for high-level semantic feature learning. This modification for RNNs is not limited to skeleton-based action recognition but can also find applications in other domains, such as language modeling. In the IndRNN structure, neurons in one layer operate independently of each other, enabling the processing of much longer sequences.

(a)
(b)
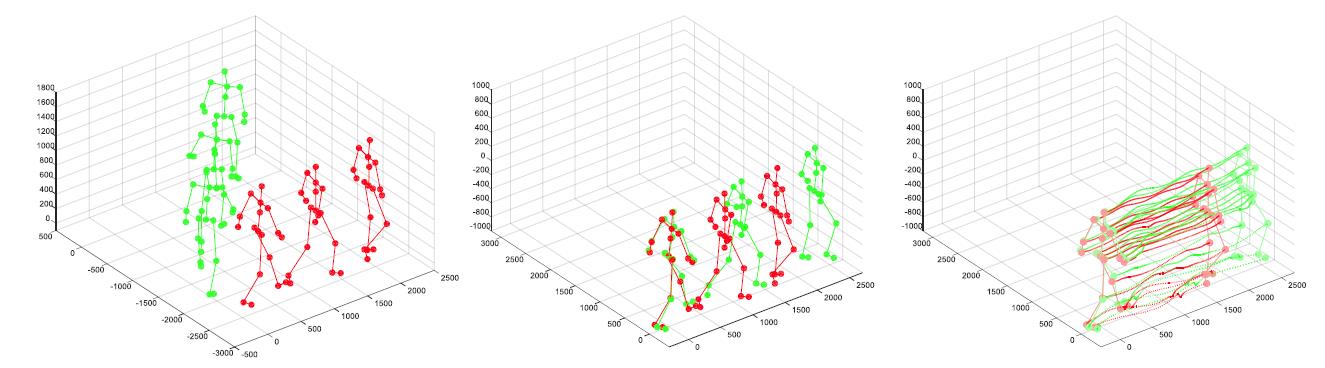
Finally, the third aspect is the data-driven. In the consideration that not all joints are informative for an action analysis, [65] add global context-aware attention to LSTM networks, which selectively focus on the informative joints in a skeleton sequence. Figure 4 illustrates the visualization of the proposed method, from the figure we can conclude that the more informative joints are addressed with a red circle color area, indicating those joints are more important for this special action. In addition, because the skeletons provided by datasets or depth sensors are not perfect, which would affect the result of an action recognition task, [44] transform skeletons into another coordinate system for the robustness to scale, rotation and translation first and then extract salient motion features from the transformed data instead of sending the raw skeleton data to LSTM. Figure 4(b) shows the feature representation process.
Numerous valuable works have utilized RNN-based methods to address challenges related to large viewpoint changes and the relationships among joints within a single skeleton frame. However, it’s essential to acknowledge that in specific modeling aspects, RNN-based methods may exhibit limitations compared to CNN-based approaches. In the following sections, we delve into an intriguing question: how do CNN-based methods perform temporal modeling, and how can they strike the right balance between spatial and temporal information in action recognition?

(a)

(b)
2.3 CNN-Based Methods
While convolutional neural networks (CNNs) offer efficient and effective high-level semantic cue learning, they are primarily tailored for regular image tasks. However, action recognition from skeleton sequences presents a distinct challenge due to its inherent time-dependent nature. Achieving the right balance and maximizing the utilization of both spatial and temporal information within a CNN-based architecture remains a challenging endeavor.
Typically, from the spatial-temporal modeling aspect, most of the CNN-based methods explored the representation of 3D skeleton sequences, Specifically, to accommodate the input requirements of CNNs, 3D-skeleton sequence data undergoes the transformation from a vector sequence to a pseudo-image format. However, achieving a suitable representation that effectively combines both spatial and temporal information can be challenging. Consequently, many researchers opt to encode skeleton joints into multiple 2D pseudo-images, which are subsequently fed into CNNs to facilitate the learning of informative features [21, 125]. Wang et al. [112] proposed the Joint Trajectory Maps (JTM), which represent spatial configuration and dynamics of joint trajectories into three texture images through color encoding. However, this kind of method is a little complicated and also loses importance during the mapping procedure. To tackle this shortcoming, Li et al. [4] used a translation-scale invariant image mapping strategy which firstly divided human skeleton joints in each frame into five main parts according to the human physical structure, then those parts were mapped to 2D form. This method makes the skeleton image consist of both temporal information and spatial information. However, though the performance was improved, there is no reason to take skeleton joints as isolated points, cause in the real world, imitate connection exists among our body, for example, when waiting for the hands, not only the joints directly within the hand should be taken into account, but also other parts such as shoulders and legs are considerable. Li et al. [55] proposed the shape-motion representation from geometric algebra, which addressed the importance of both joints and bones and fully utilized the information provided by the skeleton sequence. Similarly, [71] also use the enhanced skeleton visualization to represent the skeleton data, and Carlos et al. [7] also proposed a new representation named SkeleMotion based on motion information that encodes the temporal dynamics by explicitly computing the magnitude and orientation values of the skeleton joints. Figure 5 (a) shows the shape-motion representation proposed by [55] while Figure 5 (b) illustrate the SkeleMotion representation. What’s more, similarly to SkeleMotion, [6] uses the framework of SkeleMotion but is based on tree structure and reference joints for a skeleton image representation.
Commonly, CNN-based methods represent a skeleton sequence as an image by encoding temporal dynamics and skeleton joints as rows and columns, respectively. However, this simplistic approach may limit the model’s ability to capture co-occurrence features, as it considers only neighboring joints within the convolutional kernel and may overlook latent correlations involving all joints. Consequently, CNNs might fail to learn the corresponding and useful features. In response to this limitation, Chao et al. [10] introduced an end-to-end framework designed to learn co-occurrence features through a hierarchical methodology. This approach gradually aggregates different levels of contextual information, beginning with the independent encoding of point-level information, which is then assembled into semantic representations within both temporal and spatial domains.
Besides explorations in the representation of 3D skeleton sequences, there also exist some other problems in CNN-based techniques. For example, to find a balance between the model size and the corresponding inference efficiency, DD-Net [127] was proposed to model double feature and double motion via CNN for efficient solutions. Kim et al. [95] proposed to use the temporal CNN (TCN) for modeling the interpretable spatio-temporal cues [43]. As a result, the point-level feature of each joint is learned. In addition, two-stream and three-stream CNN-based heavy models are also proposed for improving the representation learning ability for spatial-temporal modeling [85]. So the skeleton-based action recognition using CNN is still an open problem waiting for researchers to dig in.
2.4 GCN-Based Methods
Drawing inspiration from the inherent topological graph structure of human 3D-skeleton data, distinct from the sequential vector or pseudo-image treatments in RNN-based or CNN-based methods. Recently the Graph Convolution Network has been adopted in this task frequently due to the effective representation of the graph structure data. Generally, two kinds of graph-related neural networks can be found, i.e., the graph and recurrent neural networks, and graph and convolutional neural networks (GCNs). In this survey, we mainly pay attention to the latter. This focus yielded compelling results, as evidenced by the performance of the GCN-based method on the rank board. Furthermore, merely encoding the skeleton sequence into a vector or 2D grid fails to fully capture the interdependence among correlated joints from the skeleton’s perspective. Conversely, GCNs present adaptability to diverse structures, such as the skeleton graph. Nonetheless, the principal challenge within GCN-based approaches persists in the handling of skeleton data, particularly in structuring the original data into a coherent graph format. Yan et al. [126] first presented a novel model, the spatial-temporal graph convolutional networks (ST-GCN), for skeleton-based action recognition. Specifically, the approach first involved the creation of a spatial-temporal graph, wherein the joints functioned as graph vertices, establishing inherent connections within the human body structure and across temporal sequences as the graph edges. Following this step, the ST-GCN’s higher-level feature maps on the graph underwent classification using a standard Softmax classifier, assigning them to their respective action categories. This work has notably directed attention towards employing GCNs for skeleton-based action recognition, resulting in a surge of recent related research [88, 142, 15, 18, 24, 148].

Built upon GCNs, two main common aspects are explored, i.e., more representative manner for the construction of the skeleton data and more effective designs of the GCN-based model [46, 51].
From the first aspect, [51] proposed the Action-Structural Graph Convolutional Networks (AS-GCN) could not only recognize a person’s action but also use a multi-task learning strategy to output a prediction of the subject’s next possible pose. The constructed graph in this work can capture richer dependencies among joints by two modules called Actional Links and Structural Links. Figure 6 shows the feature learning and its generalized skeleton graph of AS-GCN. Multi-task learning strategy used in this work may be a promising direction because the target task would be improved by the other task as a complementary. To capture and enhance richer feature representations, Shi et al. [88] introduced the 2s-AGCN, which incorporates an adaptive topology graph. This approach allows for automatic updates leveraging the neural network’s backpropagation algorithm, effectively enhancing the characterization of joint connection strengths. Liu et al. [74] proposes MS-G3D which constructs a unified spatial-temporal graph. This big spatial-temporal graph is composed of several subgraphs, and each subgraph represents the spatial relationships of joints on a certain frame. This form of the adjacent matrix can effectively model the relationship between different joints in different frames. Similarly, there are also a lot of following-up methods proposed for constructing more representative graphs [115, 31, 45].
From the second aspect, traditional GCNs operate as straight feed-forward networks, limiting low-level layers’ access to semantic information from higher-level layers. To address this, Yang et al. [128] introduce the Feedback Graph Convolutional Network (FGCN) aimed at incrementally acquiring global spatial-temporal features. Departing from direct manipulation of the complete skeleton sequence, FGCN adopts a multi-stage temporal sampling strategy to sparsely extract a sequence of input clips from the skeleton data. Furthermore, Bian et al. [3] introduces a structural knowledge distillation scheme aimed at mitigating accuracy loss resulting from low-quality data, thereby enhancing the model’s resilience to incomplete skeleton sequences. Fang et al. [26] presents the spatial-temporal slow-fast graph convolutional network (STSF-GCN), which conceptualizes skeleton data akin to a unified spatial-temporal topology, reminiscent of MS-G3D.
From the preceding introduction and discussion, it’s evident that the predominant concern revolves around data-driven approaches, seeking to uncover latent insights within 3D skeleton sequence data. In the realm of GCN-based action recognition, the central query persists: ’How do we extract this latent information?’ This question remains an ongoing challenge. Particularly noteworthy is the inherent temporal-spatial correlation within the skeleton data itself. The optimal utilization of these two aspects warrants further exploration. There remains substantial potential for enhancing their effectiveness, calling for deeper investigation and innovative strategies to maximize their utilization.
2.5 Transformer-Based Methods
Transformers [103] demonstrated their overwhelming power on a broad range of language tasks (e.g., text classification, machine translation, or question answering [103, 41]), and the vision community follows it closely and extends it for vision tasks, such as image classification [22, 100, 82], object detection [9, 152], segmentation [131], image restoration [12, 56], and point cloud registration [76, 35, 114]. The emergence of transformer algorithms marks a pivotal shift in point-centric research. These transformer-based methods are gradually challenging the dominance of GCN methods, showcasing promising advancements in computational efficiency and accuracy. Upon analysis, we firmly believe that transformer-based approaches retain robust potential and are poised to become the mainstream technique in the future.
The core module in Transformer, multi-head self-attentions (MSAs) [103, 22] aggregate sequential tokens with normalized attention as: where , and are query, key and value matrices, respectively. is the dimension of query and key, and is the -th output token. This step usually represents the context relation computation and update of the overall 3D skeleton features. Building upon the MSA from the Transformer for solving the 3D-SAR problem, there are lots of transformer architecture-based solutions are proposed
In particular, Cho et al. [19] proposed a novel model called Self-Attention Network (SAN) that completely utilizes the self-attention mechanism to model spatial-temporal correlations. Shi et al. [89] proposed a decoupled spatial-temporal attention network (DSTA-Net) that contains spatial-temporal attention decoupling, decoupled position encoding, and global spatial regularization. DSTA-Net decouples the skeleton data into four streams, namely, spatial-temporal stream, spatial stream, slow-temporal stream, and fast-temporal stream, each data stream focuses on expressing a particular aspect of the action. Plizzari et al. [80] proposed a novel Spatial-Temporal Transformer network (ST-TR) in which the spatial self-attention module and temporal self-attention module are used to capture the correlation between different nodes in a frame and the dynamic relationship between the same node in the whole frames. To handle action sequences of varying lengths proficiently, Ibh et al. [37] proposed TemPose which leaves out the padded temporal and interaction tokens in the attention map. At the same time, Tempose codes the position of the player and the position of the badminton ball to predict the action class together.
| NTU-RGB+D dataset | |||||
| Rank | Paper | Year | Accuracy (C-View) | Accuracy (C-Subject) | Method |
| 1 | Wang et al. [109] | 2023 | 98.7 | 94.8 | Two-stream Transformer |
| 2 | Duan et al. [23] | 2022 | 97.5 | 93.2 | Dynamic group GCN |
| 3 | Liu et al. [68] | 2023 | 96.8 | 92.8 | Temporal decoupling GCN |
| 4 | Zhou et al. [150] | 2022 | 96.5 | 92.9 | Transformer |
| 5 | Chen et al. [14] | 2021 | 96.8 | 92.4 | Topology refinement GCN |
| 6 | Zeng et al. [135] | 2021 | 96.7 | 91.6 | Skeletal GCN |
| 7 | Liu et al. [74] | 2020 | 96.2 | 91.5 | Disentangling and unifying GCN |
| 8 | Ye et al. [130] | 2020 | 96.0 | 91.5 | Dynamic GCN |
| 9 | Shi et al. [87] | 2019 | 96.1 | 89.9 | Directed graph neural networks |
| 10 | Shi et al. [88] | 2018 | 95.1 | 88.5 | Two-stream adaptive GCN |
| 11 | Zhang et al. [140] | 2018 | 95.0 | 89.2 | LSTM based RNN |
| 12 | Si et al. [91] | 2019 | 95.0 | 89.2 | AGC-LSTM(Joints&Part) |
| 13 | Hu et al. [33] | 2018 | 94.9 | 89.1 | Non-local S-T + frequency attention |
| 14 | Li et al. [51] | 2019 | 94.2 | 86.8 | GCN |
| 15 | Liang et al. [57] | 2019 | 93.7 | 88.6 | 3S-CNN + multi-task ensemble learning |
| 16 | Song et al. [94] | 2019 | 93.5 | 85.9 | Richly activated GCN |
| 17 | Zhang et al. [141] | 2019 | 93.4 | 86.6 | Semantics-guided GCN |
| 18 | Xie et al. [49] | 2018 | 93.2 | 82.7 | RNN+CNN+Attention |
| NTU-RGB+D 120 dataset | |||||
| Rank | Paper | Year | Accuracy (C-Subject) | Accuracy (C-Setup) | Method |
| 1 | Wang et al. [109] | 2023 | 92.0 | 93.8 | Two-stream Transformer |
| 2 | Xu et al. [124] | 2023 | 90.7 | 91.8 | Language Knowledge-Assisted |
| 3 | Zhou et al. [150] | 2022 | 89.9 | 91.3 | Transformer |
| 4 | Duan et al. [23] | 2022 | 89.6 | 91.3 | Dynamic group GCN |
| 5 | Chen et al. [14] | 2021 | 88.9 | 90.6 | Topology refinement GCN |
| 6 | Chen et al. [13] | 2021 | 88.2 | 89.3 | Spatial-Temporal GCN |
| 7 | Liu et al. [74] | 2020 | 86.9 | 88.4 | Disentangling and unifying GCN |
| 8 | Cheng et al. [16] | 2020 | 85.9 | 87.6 | Shift GCN |
| 9 | Caetano et al. [6] | 2019 | 67.9 | 62.8 | Tree Structure + CNN |
| 10 | Caetano et al. [7] | 2019 | 67.7 | 66.9 | SkeleMotion |
| 11 | Liu et al. [69] | 2018 | 64.6 | 66.9 | Body Pose Evolution Map |
| 12 | Ke et al. [40] | 2018 | 62.2 | 61.8 | Multi-Task CNN with RotClips |
| 13 | Liu et al. [64] | 2017 | 61.2 | 63.3 | Two-Stream Attention LSTM |
| 14 | Liu et al. [71] | 2017 | 60.3 | 63.2 | Skeleton Visualization (Single Stream) |
| 15 | Jun et al. [67] | 2019 | 59.9 | 62.4 | Online+Dilated CNN |
| 16 | Ke et al. [39] | 2017 | 58.4 | 57.9 | Multi-Task Learning CNN |
| 17 | Jun et al. [65] | 2017 | 58.3 | 59.2 | Global Context-Aware Attention LSTM |
| 18 | Jun et al. [63] | 2016 | 55.7 | 57.9 | Spatio-Temporal LSTM |
The Transformer-based approach effectively mitigates the issue of solely concentrating on local information and excels in capturing extensive dependencies over long sequences. When applied to tasks involving skeleton-based human behavior recognition, the Transformer architecture demonstrates adeptness in capturing temporal relationships. However, its efficacy in modeling spatial relationships remains constrained due to limitations in capturing and encoding the intricate high-dimensional semantic information inherent in skeleton data [151, 122]. Simultaneously, numerous approaches have emerged that amalgamate the Transformer with GCNs or CNNs, thereby forming hybrid architectures. These models are designed with the aspiration of harnessing the strengths inherent in each fundamental architecture. By combining the Transformer’s capabilities with the specialized strengths of RNNs, CNNs, or GCNs, these hybrid models aim to achieve a more comprehensive and powerful framework for diverse tasks [134, 150, 138, 29].
3 Latest Datasets And Performance
Skeleton sequence datases such as MSRAAction3D [53], 3D Action Pairs [78], and MSR Daily Activity3D [107] have be analysed in lots of previous surveys [75, 32, 111]. In this survey, we mainly address the following two recent datasets, NTU-RGB+D [86] and NTU-RGB+D 120 [66].
The NTU-RBG+D dataset, introduced in 2016, stands as a significant resource, comprising 56,880 video samples gathered through Microsoft Kinect-v2. This dataset holds a prominent position as one of the largest collections available for skeleton-based action recognition. It furnishes the 3D spatial coordinates of 25 joints for each human depicted in an action, as illustrated in Figure 1 (a). For assessing the proposed methods, two evaluation protocols are suggested: Cross-Subject and Cross-View. The Cross-Subject setting involves 40,320 samples, with 16,560 allocated for training and evaluation, employing a split of 40 subjects into training and evaluation groups. In the case of Cross-View, comprising 37,920 and 18,960 samples, the evaluation uses camera 1 while training is conducted using cameras 2 and 3. Recently, an extended version of the original NTU-RGB+D dataset known as NTU-RGB+D 120 has been introduced. This extended dataset comprises 120 action classes and encompasses a total of 114,480 skeleton sequences, significantly expanding the scope. Additionally, the viewpoints have increased to 155.
In Table 1 and Table 2, we present the performance of recent skeleton-based techniques relevant to NTU-RGB + D and NTU-RGB + D 120 datasets, respectively. Note that in NTU-RGB+D, ’CS’ stands for Cross-Subject, and ’CV’ stands for Cross-View. For NTU-RGB + D120, there are two settings, i.e., Cross-Subject (C-Subject), and Cross-Setup (C-Setup).
Based on the observation of the performance of these two datasets, we find that it’s evident that existing algorithms have achieved impressive performances in the original NTU-RGB+D dataset. However, the newer NTU-RGB+D 120 poses a significant challenge, indicating that further advancements are needed to effectively address this more complex dataset. It’s worth noting that the GCN-based methods achieved the leading results compared to the other two architectures. In addition to the very fundamental architectures (i.e., RNNs, CNNs, and GCN), the most recent Transformer [103] based methods also show their promising performance on both datasets. It’s also easy to find that a hybrid Transformer and other architectures also further boost the overall performance of the 3D-SAR.
4 Discussion
Considering the performance and attributes of the aforementioned deep architectures, several critical points warrant further discussion concerning the criteria for architecture selection. In terms of accuracy and robustness, GCNs demonstrate potential excellence by adeptly capturing spatial and temporal relationships among joints. RNNs exhibit proficiency in capturing temporal dynamics, while CNNs excel in identifying spatial features. When evaluating computational efficiency, CNNs boast faster processing capabilities owing to their parallel processing nature, contrasting with RNNs’ slower sequential processing. Additionally, RNNs tend to excel in recognizing fine-grained actions, where temporal dependencies play a crucial role, while CNNs may better suit the recognition of gross motor actions based on spatial configurations. Considering factors like dataset size and hardware resources, the choice becomes more adaptable, contingent on the final model’s scale. The size of the dataset and available computational resources for training become pivotal considerations, as different architectures might entail varying requirements. In summary, when recognizing actions reliant on temporal sequences, RNNs prove suitable for capturing the nuanced temporal dynamics within joint movements. In contrast, CNNs excel in identifying static spatial features and local patterns among joint positions. However, for comprehensive action recognition, leveraging both spatial and temporal relationships among joints, GCNs offer a beneficial approach when dealing with 3D skeletal data.
A possible in-practical solution can be also proposed to integrate not only one architecture but also a combination of them. This may make the final model absorb the advantages of each fundamental architecture. Furthermore, beyond the choice of deep architectures, the trajectory of 3D skeleton action recognition (SAR) navigation is a crucial consideration. Building upon our earlier discussions, we deduce that long-term action recognition, optimizing 3D-skeleton sequence representations, and achieving real-time operation remain significant open challenges. Moreover, annotating action labels for given 3D skeleton data remains exceptionally labor-intensive. Exploring avenues such as unsupervised or weakly-supervised strategies, along with zero-shot learning, may pave the way forward.
5 Conclusion
This paper presents an exploration of action recognition using 3D skeleton sequence data, employing four distinct neural network architectures. It underscores the concept of action recognition, highlights the advantages of skeleton data, and delves into the characteristics of various deep architectures. Unlike prior reviews, our study pioneers a data-driven approach, providing comprehensive insights into deep learning methodologies, encompassing the latest algorithms spanning RNN-based, CNN-based, GCN-based, and Transformer-based techniques. Specifically, our focus on RNN and CNN-based methods centers on addressing spatial-temporal information by leveraging skeleton data representations and intricately designed network architectures. In the case of GCN-based approaches, our emphasis lies in harnessing joint and bone correlations to their fullest extent. Furthermore, the burgeoning Transformer architecture has garnered significant attention, often employed in conjunction with other architectures for action recognition tasks. Our analysis reveals that a fundamental challenge across diverse learning structures lies in effectively extracting pertinent information from 3D skeleton data. The topology graph emerges as the most intuitive representation of human skeleton joints, a notion substantiated by the performance metrics observed in datasets like NTU-RGB+D. However, this doesn’t negate the suitability of CNN or RNN-based methods for this task. On the contrary, the introduction of innovative strategies, such as multi-task learning, shows promise for substantial improvements, particularly in cross-view or cross-subject evaluation protocols. Nevertheless, achieving further accuracy enhancements on datasets like NTU-RGB+D presents increasing difficulty due to the already high-performance levels attained. Hence, redirecting focus towards more challenging datasets, such as the enhanced NTU-RGB+D 120 dataset, or exploring other fine-grained human action datasets becomes imperative. Finally, we delve into an exhaustive discussion on the selection of foundational deep architectures and explore potential future pathways in 3D skeleton-based action recognition.
6 Acknowledgements
This work was supported by National Natural Science Foundation of China (No. 62203476), Natural Science Foundation of Shenzhen (No. JCYJ20230807120801002). Data are available upon reasonable request.
References
- Baek et al. [2016] Seungryul Baek, Zhiyuan Shi, Masato Kawade, and Tae-Kyun Kim. Kinematic-layout-aware random forests for depth-based action recognition. arXiv preprint arXiv:1607.06972, 2016.
- Bai et al. [2021] Dianchun Bai, Tie Liu, Xinghua Han, and Hongyu Yi. Application research on optimization algorithm of semg gesture recognition based on light cnn+ lstm model. Cyborg and bionic systems, 2021.
- Bian et al. [2021] Cunling Bian, Wei Feng, Liang Wan, and Song Wang. Structural knowledge distillation for efficient skeleton-based action recognition. IEEE Transactions on Image Processing, 30:2963–2976, 2021.
- Bo et al. [2017] Li Bo, Yuchao Dai, Xuelian Cheng, Huahui Chen, and Mingyi He. Skeleton based action recognition using translation-scale invariant image mapping and multi-scale deep cnn. In IEEE International Conference on Multimedia & Expo Workshops, 2017.
- Bradbury et al. [2016] James Bradbury, Stephen Merity, Caiming Xiong, and Richard Socher. Quasi-recurrent neural networks. In International Conference on Learning Representations, 2016.
- Caetano et al. [2019a] Carlos Caetano, François Brémond, and William Robson Schwartz. Skeleton image representation for 3d action recognition based on tree structure and reference joints. In 2019 32nd SIBGRAPI conference on graphics, patterns and images (SIBGRAPI), pages 16–23. IEEE, 2019a.
- Caetano et al. [2019b] Carlos Caetano, Jessica Sena, François Brémond, Jefersson A Dos Santos, and William Robson Schwartz. Skelemotion: A new representation of skeleton joint sequences based on motion information for 3d action recognition. In 2019 16th IEEE international conference on advanced video and signal based surveillance (AVSS), pages 1–8. IEEE, 2019b.
- Cao et al. [2018] Zhe Cao, Gines Hidalgo, Tomas Simon, Shih-En Wei, and Yaser Sheikh. OpenPose: realtime multi-person 2D pose estimation using Part Affinity Fields. In arXiv preprint arXiv:1812.08008, 2018.
- Carion et al. [2020] Nicolas Carion, Francisco Massa, Gabriel Synnaeve, Nicolas Usunier, Alexander Kirillov, and Sergey Zagoruyko. End-to-end object detection with transformers. In European Conference on Computer Vision (ECCV), 2020.
- Chao et al. [2018] Li Chao, Qiaoyong Zhong, Xie Di, and Shiliang Pu. Co-occurrence feature learning from skeleton data for action recognition and detection with hierarchical aggregation. 2018.
- Chen et al. [2020] Chen Chen, Mengyuan Liu, Xiandong Meng, Wanpeng Xiao, and Qi Ju. Refinedetlite: A lightweight one-stage object detection framework for cpu-only devices. In IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops, pages 700–701, 2020.
- Chen et al. [2021a] Hanting Chen, Yunhe Wang, Tianyu Guo, Chang Xu, Yiping Deng, Zhenhua Liu, Siwei Ma, Chunjing Xu, Chao Xu, and Wen Gao. Pre-trained image processing transformer. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2021a.
- Chen et al. [2021b] Tailin Chen, Desen Zhou, Jian Wang, Shidong Wang, Yu Guan, Xuming He, and Errui Ding. Learning multi-granular spatio-temporal graph network for skeleton-based action recognition. In Proceedings of the 29th ACM international conference on multimedia, pages 4334–4342, 2021b.
- Chen et al. [2021c] Yuxin Chen, Ziqi Zhang, Chunfeng Yuan, Bing Li, Ying Deng, and Weiming Hu. Channel-wise topology refinement graph convolution for skeleton-based action recognition. In Proceedings of the IEEE/CVF international conference on computer vision, pages 13359–13368, 2021c.
- Cheng et al. [2020a] Ke Cheng, Yifan Zhang, Congqi Cao, Lei Shi, Jian Cheng, and Hanqing Lu. Decoupling gcn with dropgraph module for skeleton-based action recognition. In Computer Vision–ECCV 2020: 16th European Conference, Glasgow, UK, August 23–28, 2020, Proceedings, Part XXIV 16, pages 536–553, 2020a.
- Cheng et al. [2020b] Ke Cheng, Yifan Zhang, Xiangyu He, Weihan Chen, Jian Cheng, and Hanqing Lu. Skeleton-based action recognition with shift graph convolutional network. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 183–192, 2020b.
- Chéron et al. [2015] Guilhem Chéron, Ivan Laptev, and Cordelia Schmid. P-cnn: Pose-based cnn features for action recognition. In Proceedings of the IEEE international conference on computer vision, pages 3218–3226, 2015.
- Chi et al. [2022] Hyung-gun Chi, Myoung Hoon Ha, Seunggeun Chi, Sang Wan Lee, Qixing Huang, and Karthik Ramani. Infogcn: Representation learning for human skeleton-based action recognition. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 20186–20196, 2022.
- Cho et al. [2020] Sangwoo Cho, Muhammad Maqbool, Fei Liu, and Hassan Foroosh. Self-attention network for skeleton-based human action recognition. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, pages 635–644, 2020.
- Chu et al. [2017] Xiao Chu, Wei Yang, Wanli Ouyang, Cheng Ma, Alan L Yuille, and Xiaogang Wang. Multi-context attention for human pose estimation. In Proceedings of the IEEE conference on computer vision and pattern recognition, pages 1831–1840, 2017.
- Ding et al. [2017] Zewei Ding, Pichao Wang, Philip O Ogunbona, and Wanqing Li. Investigation of different skeleton features for cnn-based 3d action recognition. In 2017 IEEE International conference on multimedia & expo workshops (ICMEW), pages 617–622. IEEE, 2017.
- Dosovitskiy et al. [2020] Alexey Dosovitskiy, Lucas Beyer, Alexander Kolesnikov, Dirk Weissenborn, Xiaohua Zhai, Thomas Unterthiner, Mostafa Dehghani, Matthias Minderer, Georg Heigold, Sylvain Gelly, et al. An image is worth 16x16 words: Transformers for image recognition at scale. In International Conference on Learning Representations (ICLR), 2020.
- Duan et al. [2022a] Haodong Duan, Jiaqi Wang, Kai Chen, and Dahua Lin. Dg-stgcn: dynamic spatial-temporal modeling for skeleton-based action recognition. arXiv preprint arXiv:2210.05895, 2022a.
- Duan et al. [2022b] Haodong Duan, Yue Zhao, Kai Chen, Dahua Lin, and Bo Dai. Revisiting skeleton-based action recognition. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 2969–2978, 2022b.
- Ellis et al. [2013] Ellis, Chris, Masood, Syed Zain, Tappen, F Marshall, LaViola, J Joseph, Jr, and Sukthankar. Exploring the trade-off between accuracy and observational latency in;action recognition. International Journal of Computer Vision, 101(3):420–436, 2013.
- Fang et al. [2022] Zheng Fang, Xiongwei Zhang, Tieyong Cao, Yunfei Zheng, and Meng Sun. Spatial-temporal slowfast graph convolutional network for skeleton-based action recognition. IET Computer Vision, 16(3):205–217, 2022.
- Feichtenhofer et al. [2016] Christoph Feichtenhofer, Axel Pinz, and Andrew Zisserman. Convolutional two-stream network fusion for video action recognition. In Proceedings of the IEEE conference on computer vision and pattern recognition, pages 1933–1941, 2016.
- Feichtenhofer et al. [2019] Christoph Feichtenhofer, Haoqi Fan, Jitendra Malik, and Kaiming He. Slowfast networks for video recognition. In Proceedings of the IEEE/CVF international conference on computer vision, pages 6202–6211, 2019.
- Gao et al. [2022] Zhimin Gao, Peitao Wang, Pei Lv, Xiaoheng Jiang, Qidong Liu, Pichao Wang, Mingliang Xu, and Wanqing Li. Focal and global spatial-temporal transformer for skeleton-based action recognition. In Proceedings of the Asian Conference on Computer Vision, pages 382–398, 2022.
- Gu et al. [2013] Ye Gu, Weihua Sheng, Yongsheng Ou, Meiqin Liu, and Senlin Zhang. Human action recognition with contextual constraints using a rgb-d sensor. In 2013 IEEE International Conference on Robotics and Biomimetics (ROBIO), pages 674–679. IEEE, 2013.
- Hao et al. [2021] Xiaoke Hao, Jie Li, Yingchun Guo, Tao Jiang, and Ming Yu. Hypergraph neural network for skeleton-based action recognition. IEEE Transactions on Image Processing, 30:2263–2275, 2021.
- Herath et al. [2017] Samitha Herath, Mehrtash Harandi, and Fatih Porikli. Going deeper into action recognition: A survey. Image and vision computing, 60:4–21, 2017.
- Hu et al. [2019] Guyue Hu, Bo Cui, and Shan Yu. Skeleton-based action recognition with synchronous local and non-local spatio-temporal learning and frequency attention. In 2019 IEEE International Conference on Multimedia and Expo (ICME), pages 1216–1221. IEEE, 2019.
- Hu et al. [2015] Jian-Fang Hu, Wei-Shi Zheng, Jianhuang Lai, and Jianguo Zhang. Jointly learning heterogeneous features for rgb-d activity recognition. In Proceedings of the IEEE conference on computer vision and pattern recognition, pages 5344–5352, 2015.
- Huang et al. [2023] Xiaoshui Huang, Guofeng Mei, and Jian Zhang. Cross-source point cloud registration: Challenges, progress and prospects. Neurocomputing, page 126383, 2023.
- Hussein et al. [2013] Mohamed E Hussein, Marwan Torki, Mohammad A Gowayyed, and Motaz El-Saban. Human action recognition using a temporal hierarchy of covariance descriptors on 3d joint locations. In Twenty-third international joint conference on artificial intelligence, 2013.
- Ibh et al. [2023] Magnus Ibh, Stella Grasshof, Dan Witzner, and Pascal Madeleine. Tempose: A new skeleton-based transformer model designed for fine-grained motion recognition in badminton. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 5198–5207, 2023.
- Johansson [1973] Gunnar Johansson. Visual perception of biological motion and a model for its analysis. Perception & psychophysics, 14:201–211, 1973.
- Ke et al. [2017] Qiuhong Ke, Mohammed Bennamoun, Senjian An, Ferdous Sohel, and Farid Boussaid. A new representation of skeleton sequences for 3d action recognition. In Proceedings of the IEEE conference on computer vision and pattern recognition, pages 3288–3297, 2017.
- Ke et al. [2018] Qiuhong Ke, Mohammed Bennamoun, Senjian An, Ferdous Sohel, and Farid Boussaid. Learning clip representations for skeleton-based 3d action recognition. IEEE Transactions on Image Processing, 27(6):2842–2855, 2018.
- Khan et al. [2022] Salman Khan, Muzammal Naseer, Munawar Hayat, Syed Waqas Zamir, Fahad Shahbaz Khan, and Mubarak Shah. Transformers in vision: A survey. ACM computing surveys (CSUR), 54(10s):1–41, 2022.
- Krizhevsky et al. [2012] Alex Krizhevsky, Ilya Sutskever, and Geoffrey E Hinton. Imagenet classification with deep convolutional neural networks. Advances in neural information processing systems, 25, 2012.
- Lea et al. [2017] Colin Lea, Michael D Flynn, Rene Vidal, Austin Reiter, and Gregory D Hager. Temporal convolutional networks for action segmentation and detection. In proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 156–165, 2017.
- Lee et al. [2017] Inwoong Lee, Doyoung Kim, Seoungyoon Kang, and Sanghoon Lee. Ensemble deep learning for skeleton-based action recognition using temporal sliding lstm networks. In Proceedings of the IEEE international conference on computer vision, pages 1012–1020, 2017.
- Lee et al. [2023] Jungho Lee, Minhyeok Lee, Dogyoon Lee, and Sangyoun Lee. Hierarchically decomposed graph convolutional networks for skeleton-based action recognition. In Proceedings of the IEEE/CVF International Conference on Computer Vision, pages 10444–10453, 2023.
- Lei et al. [2019] Shi Lei, Zhang Yifan, Cheng Jian, and Lu Hanqing. Two-stream adaptive graph convolutional networks for skeleton-based action recognition. In IEEE Conference on Computer Vision & Pattern Recognition, 2019.
- Lei et al. [2018] Tao Lei, Yu Zhang, and Yoav Artzi. Training rnns as fast as cnns. 2018.
- Lev et al. [2016] Guy Lev, Gil Sadeh, Benjamin Klein, and Lior Wolf. Rnn fisher vectors for action recognition and image annotation. In Computer Vision–ECCV 2016: 14th European Conference, Amsterdam, The Netherlands, October 11-14, 2016, Proceedings, Part VI 14, pages 833–850. Springer, 2016.
- Li et al. [2021] Ce Li, Chunyu Xie, Baochang Zhang, Jungong Han, Xiantong Zhen, and Jie Chen. Memory attention networks for skeleton-based action recognition. IEEE Transactions on Neural Networks and Learning Systems, 33(9):4800–4814, 2021.
- Li et al. [2018a] Lin Li, Wu Zheng, Zhaoxiang Zhang, Yan Huang, and Liang Wang. Skeleton-based relational modeling for action recognition. arXiv preprint arXiv:1805.02556, 1(2):3, 2018a.
- Li et al. [2019a] Maosen Li, Siheng Chen, Xu Chen, Ya Zhang, Yanfeng Wang, and Qi Tian. Actional-structural graph convolutional networks for skeleton-based action recognition. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 3595–3603, 2019a.
- Li et al. [2018b] Shuai Li, Wanqing Li, Chris Cook, Ce Zhu, and Yanbo Gao. Independently recurrent neural network (indrnn): Building a longer and deeper rnn. In Proceedings of the IEEE conference on computer vision and pattern recognition, pages 5457–5466, 2018b.
- Li et al. [2010] Wanqing Li, Zhengyou Zhang, and Zicheng Liu. Action recognition based on a bag of 3d points. In Computer Vision & Pattern Recognition Workshops, 2010.
- Li et al. [2017] Wenbo Li, Longyin Wen, Ming-Ching Chang, Ser Nam Lim, and Siwei Lyu. Adaptive rnn tree for large-scale human action recognition. In Proceedings of the IEEE international conference on computer vision, pages 1444–1452, 2017.
- Li et al. [2019b] Yanshan Li, Rongjie Xia, Xing Liu, and Qinghua Huang. Learning shape-motion representations from geometric algebra spatio-temporal model for skeleton-based action recognition. In 2019 IEEE international conference on multimedia and Expo (ICME), pages 1066–1071. IEEE, 2019b.
- Li et al. [2023] Yawei Li, Yuchen Fan, Xiaoyu Xiang, Denis Demandolx, Rakesh Ranjan, Radu Timofte, and Luc Van Gool. Efficient and explicit modelling of image hierarchies for image restoration. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 18278–18289, 2023.
- Liang et al. [2019] Duohan Liang, Guoliang Fan, Guangfeng Lin, Wanjun Chen, Xiaorong Pan, and Hong Zhu. Three-stream convolutional neural network with multi-task and ensemble learning for 3d action recognition. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition workshops, pages 1–7, 2019.
- Lin et al. [2018] Ji Lin, Chuang Gan, and Song Han. Temporal shift module for efficient video understanding. arXiv preprint arXiv:1811.08383, 2018.
- Liu et al. [2023a] Chang Liu, Mengyi Zhao, Bin Ren, Mengyuan Liu, and Nicu Sebe. Spatio-temporal graph diffusion for text-driven human motion generation. In British Machine Vision Conference, 2023a.
- Liu et al. [2015] Hong Liu, Lu Tian, Mengyuan Liu, and Hao Tang. Sdm-bsm: A fusing depth scheme for human action recognition. In IEEE International Conference on Image Processing (ICIP), pages 4674–4678, 2015.
- Liu et al. [2017a] Hong Liu, Juanhui Tu, and Mengyuan Liu. Two-stream 3d convolutional neural network for skeleton-based action recognition. arXiv preprint arXiv:1705.08106, 2017a.
- Liu et al. [2020a] Hong Liu, Bin Ren, Mengyuan Liu, and Runwei Ding. Grouped temporal enhancement module for human action recognition. In 2020 IEEE International Conference on Image Processing (ICIP), pages 1801–1805. IEEE, 2020a.
- Liu et al. [2016] Jun Liu, Amir Shahroudy, Dong Xu, and Gang Wang. Spatio-temporal lstm with trust gates for 3d human action recognition. In Computer Vision–ECCV 2016: 14th European Conference, Amsterdam, The Netherlands, October 11-14, 2016, Proceedings, Part III 14, pages 816–833. Springer, 2016.
- Liu et al. [2017b] Jun Liu, Gang Wang, Ling-Yu Duan, Kamila Abdiyeva, and Alex C Kot. Skeleton-based human action recognition with global context-aware attention lstm networks. IEEE Transactions on Image Processing, 27(4):1586–1599, 2017b.
- Liu et al. [2017c] Jun Liu, Gang Wang, Ping Hu, Ling-Yu Duan, and Alex C Kot. Global context-aware attention lstm networks for 3d action recognition. In Proceedings of the IEEE conference on computer vision and pattern recognition, pages 1647–1656, 2017c.
- Liu et al. [2019a] Jun Liu, Amir Shahroudy, Mauricio Perez, Gang Wang, Ling-Yu Duan, and Alex C Kot. Ntu rgb+ d 120: A large-scale benchmark for 3d human activity understanding. IEEE transactions on pattern analysis and machine intelligence, 42(10):2684–2701, 2019a.
- Liu et al. [2019b] Jun Liu, Amir Shahroudy, Gang Wang, Ling-Yu Duan, and Alex Kot Chichung. Skeleton-based online action prediction using scale selection network. IEEE transactions on pattern analysis and machine intelligence, 2019b.
- Liu et al. [2023b] Jinfu Liu, Xinshun Wang, Can Wang, Yuan Gao, and Mengyuan Liu. Temporal decoupling graph convolutional network for skeleton-based gesture recognition. IEEE Transactions on Multimedia, 2023b.
- Liu and Yuan [2018] Mengyuan Liu and Junsong Yuan. Recognizing human actions as the evolution of pose estimation maps. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 1159–1168, 2018.
- Liu et al. [2017d] Mengyuan Liu, Qinqin He, and Hong Liu. Fusing shape and motion matrices for view invariant action recognition using 3d skeletons. In IEEE International Conference on Image Processing (ICIP), pages 3670–3674, 2017d.
- Liu et al. [2017e] Mengyuan Liu, Hong Liu, and Chen Chen. Enhanced skeleton visualization for view invariant human action recognition. Pattern Recognition, 68:346–362, 2017e.
- Liu et al. [2022] Mengyuan Liu, Fanyang Meng, and Yongsheng Liang. Generalized pose decoupled network for unsupervised 3d skeleton sequence-based action representation learning. Cyborg and Bionic Systems, 2022:0002, 2022.
- Liu et al. [2023c] Mengyuan Liu, Fanyang Meng, Chen Chen, and Songtao Wu. Novel motion patterns matter for practical skeleton-based action recognition. In AAAI Conference on Artificial Intelligence (AAAI), 2023c.
- Liu et al. [2020b] Ziyu Liu, Hongwen Zhang, Zhenghao Chen, Zhiyong Wang, and Wanli Ouyang. Disentangling and unifying graph convolutions for skeleton-based action recognition. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 143–152, 2020b.
- [75] Liliana Lo Presti and Marco La Cascia. 3d skeleton-based human action classification: A survey. Pattern Recognition.
- Mei et al. [2023] Guofeng Mei, Fabio Poiesi, Cristiano Saltori, Jian Zhang, Elisa Ricci, and Nicu Sebe. Overlap-guided gaussian mixture models for point cloud registration. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, pages 4511–4520, 2023.
- Ofli et al. [2013] Ferda Ofli, Rizwan Chaudhry, Gregorij Kurillo, René Vidal, and Ruzena Bajcsy. Berkeley mhad: A comprehensive multimodal human action database. In Applications of Computer Vision, 2013.
- Oreifej and Liu [2013] Omar Oreifej and Zicheng Liu. Hon4d: Histogram of oriented 4d normals for activity recognition from depth sequences. In IEEE Conference on Computer Vision & Pattern Recognition, 2013.
- Plizzari et al. [2021a] Chiara Plizzari, Marco Cannici, and Matteo Matteucci. Skeleton-based action recognition via spatial and temporal transformer networks. Computer Vision and Image Understanding, 208:103219, 2021a.
- Plizzari et al. [2021b] Chiara Plizzari, Marco Cannici, and Matteo Matteucci. Spatial temporal transformer network for skeleton-based action recognition. In Pattern Recognition. ICPR International Workshops and Challenges: Virtual Event, January 10–15, 2021, Proceedings, Part III, pages 694–701. Springer, 2021b.
- Poppe [2010] Ronald Poppe. A survey on vision-based human action recognition. Image and vision computing, 28(6):976–990, 2010.
- Ren et al. [2023a] Bin Ren, Yahui Liu, Yue Song, Wei Bi, Rita Cucchiara, Nicu Sebe, and Wei Wang. Masked jigsaw puzzle: A versatile position embedding for vision transformers. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 20382–20391, 2023a.
- Ren et al. [2023b] Bin Ren, Hao Tang, Fanyang Meng, Runwei Ding, Philip HS Torr, and Nicu Sebe. Cloth interactive transformer for virtual try-on. ACM Transactions on Multimedia Computing, Communications and Applications, 2023b.
- Ren et al. [2011] Zhou Ren, Jingjing Meng, Junsong Yuan, and Zhengyou Zhang. Robust hand gesture recognition with kinect sensor. In Proceedings of the 19th ACM international conference on Multimedia, pages 759–760, 2011.
- Ruiz et al. [2017] Alejandro Hernandez Ruiz, Lorenzo Porzi, Samuel Rota Bulò, and Francesc Moreno-Noguer. 3d cnns on distance matrices for human action recognition. In the 2017 ACM, 2017.
- Shahroudy et al. [2016] Amir Shahroudy, Jun Liu, Tian-Tsong Ng, and Gang Wang. Ntu rgb+ d: A large scale dataset for 3d human activity analysis. In Proceedings of the IEEE conference on computer vision and pattern recognition, pages 1010–1019, 2016.
- Shi et al. [2019a] Lei Shi, Yifan Zhang, Jian Cheng, and Hanqing Lu. Skeleton-based action recognition with directed graph neural networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 7912–7921, 2019a.
- Shi et al. [2019b] Lei Shi, Yifan Zhang, Jian Cheng, and Hanqing Lu. Two-stream adaptive graph convolutional networks for skeleton-based action recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 12026–12035, 2019b.
- Shi et al. [2020] Lei Shi, Yifan Zhang, Jian Cheng, and Hanqing Lu. Decoupled spatial-temporal attention network for skeleton-based action-gesture recognition. In Proceedings of the Asian Conference on Computer Vision, 2020.
- Si et al. [2018] Chenyang Si, Ya Jing, Wei Wang, Liang Wang, and Tieniu Tan. Skeleton-based action recognition with spatial reasoning and temporal stack learning. In Proceedings of the European conference on computer vision (ECCV), pages 103–118, 2018.
- Si et al. [2019a] Chenyang Si, Wentao Chen, Wei Wang, Liang Wang, and Tieniu Tan. An attention enhanced graph convolutional lstm network for skeleton-based action recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 1227–1236, 2019a.
- Si et al. [2019b] Chenyang Si, Wentao Chen, Wei Wang, Liang Wang, and Tieniu Tan. An attention enhanced graph convolutional lstm network for skeleton-based action recognition. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 1227–1236, 2019b.
- Simonyan and Zisserman [2014] Karen Simonyan and Andrew Zisserman. Two-stream convolutional networks for action recognition in videos. Advances in neural information processing systems, 27, 2014.
- Song et al. [2019] Yi-Fan Song, Zhang Zhang, and Liang Wang. Richlt activated graph convolutional network for action recognition with incomplete skeletons. arXiv preprint arXiv:1905.06774, 2019.
- Soo Kim and Reiter [2017] Tae Soo Kim and Austin Reiter. Interpretable 3d human action analysis with temporal convolutional networks. In Proceedings of the IEEE conference on computer vision and pattern recognition workshops, pages 20–28, 2017.
- Sun et al. [2022] Zehua Sun, Qiuhong Ke, Hossein Rahmani, Mohammed Bennamoun, Gang Wang, and Jun Liu. Human action recognition from various data modalities: A review. IEEE transactions on pattern analysis and machine intelligence, 2022.
- Tang et al. [2023] Hao Tang, Lei Ding, Songsong Wu, Bin Ren, Nicu Sebe, and Paolo Rota. Deep unsupervised key frame extraction for efficient video classification. ACM Transactions on Multimedia Computing, Communications and Applications, 19(3):1–17, 2023.
- Thatipelli et al. [2022] Anirudh Thatipelli, Sanath Narayan, Salman Khan, Rao Muhammad Anwer, Fahad Shahbaz Khan, and Bernard Ghanem. Spatio-temporal relation modeling for few-shot action recognition. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 19958–19967, 2022.
- Theodoridis and Hu [2007] Theodoros Theodoridis and Huosheng Hu. Action classification of 3d human models using dynamic anns for mobile robot surveillance. In 2007 IEEE International Conference on Robotics and Biomimetics (ROBIO), pages 371–376. IEEE, 2007.
- Touvron et al. [2021] Hugo Touvron, Matthieu Cord, Matthijs Douze, Francisco Massa, Alexandre Sablayrolles, and Herve Jegou. Training data-efficient image transformers & distillation through attention. In International Conference on Machine Learning (ICML), 2021.
- Tran et al. [2018] Du Tran, Heng Wang, Lorenzo Torresani, Jamie Ray, Yann LeCun, and Manohar Paluri. A closer look at spatiotemporal convolutions for action recognition. In Proceedings of the IEEE conference on Computer Vision and Pattern Recognition, pages 6450–6459, 2018.
- Tu et al. [2023] Zhigang Tu, Yuanzhong Liu, Yan Zhang, Qizi Mu, and Junsong Yuan. Dtcm: Joint optimization of dark enhancement and action recognition in videos. IEEE Transactions on Image Processing, 2023.
- Vaswani et al. [2017] Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N Gomez, Łukasz Kaiser, and Illia Polosukhin. Attention is all you need. In Advances in Neural Information Processing Systems (NeurIPS), 2017.
- Vemulapalli and Chellapa [2016] Raviteja Vemulapalli and Rama Chellapa. Rolling rotations for recognizing human actions from 3d skeletal data. In Proceedings of the IEEE conference on computer vision and pattern recognition, pages 4471–4479, 2016.
- Vemulapalli et al. [2014] Raviteja Vemulapalli, Felipe Arrate, and Rama Chellappa. Human action recognition by representing 3d skeletons as points in a lie group. In Proceedings of the IEEE conference on computer vision and pattern recognition, pages 588–595, 2014.
- Wang and Wang [2017] Hongsong Wang and Liang Wang. Modeling temporal dynamics and spatial configurations of actions using two-stream recurrent neural networks. In Proceedings of the IEEE conference on computer vision and pattern recognition, pages 499–508, 2017.
- Wang et al. [2012] Jiang Wang, Zicheng Liu, Ying Wu, and Junsong Yuan. Mining actionlet ensemble for action recognition with depth cameras. In Computer Vision and Pattern Recognition (CVPR), 2012 IEEE Conference on, 2012.
- Wang et al. [2014] Jiang Wang, Xiaohan Nie, Yin Xia, Ying Wu, and Song-Chun Zhu. Cross-view action modeling, learning and recognition. In Proceedings of the IEEE conference on computer vision and pattern recognition, pages 2649–2656, 2014.
- Wang and Koniusz [2023] Lei Wang and Piotr Koniusz. 3mformer: Multi-order multi-mode transformer for skeletal action recognition. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 5620–5631, 2023.
- Wang et al. [2016a] Limin Wang, Yuanjun Xiong, Zhe Wang, Yu Qiao, Dahua Lin, Xiaoou Tang, and Luc Van Gool. Temporal segment networks: Towards good practices for deep action recognition. In European conference on computer vision, pages 20–36. Springer, 2016a.
- Wang et al. [2019] Lei Wang, Du Q Huynh, and Piotr Koniusz. A comparative review of recent kinect-based action recognition algorithms. IEEE Transactions on Image Processing, 29:15–28, 2019.
- Wang et al. [2016b] Pichao Wang, Wanqing Li, Chuankun Li, and Yonghong Hou. Action recognition based on joint trajectory maps with convolutional neural networks. In Acm on Multimedia Conference, 2016b.
- Wang et al. [2023a] Ti Wang, Hong Liu, Runwei Ding, Wenhao Li, Yingxuan You, and Xia Li. Interweaved graph and attention network for 3d human pose estimation. In ICASSP 2023-2023 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), pages 1–5. IEEE, 2023a.
- Wang et al. [2023b] Weijie Wang, Guofeng Mei, Bin Ren, Xiaoshui Huang, Fabio Poiesi, Luc Van Gool, Nicu Sebe, and Bruno Lepri. Zero-shot point cloud registration. arXiv preprint arXiv:2312.03032, 2023b.
- Wang et al. [2022] Xuanhan Wang, Yan Dai, Lianli Gao, and Jingkuan Song. Skeleton-based action recognition via adaptive cross-form learning. In Proceedings of the 30th ACM International Conference on Multimedia, pages 1670–1678, 2022.
- Wang et al. [2024] Xinshun Wang, Wanying Zhang, Can Wang, Yuan Gao, and Mengyuan Liu. Dynamic dense graph convolutional network for skeleton-based human motion prediction. IEEE Transactions on Image Processing, 2024.
- Wang et al. [2023c] Yong Wang, Hongbo Kang, Doudou Wu, Wenming Yang, and Longbin Zhang. Global and local spatio-temporal encoder for 3d human pose estimation. IEEE Transactions on Multimedia, 2023c.
- Wang et al. [2023d] Yuxuan Wang, Ye Tian, Jinying Zhu, Haotian She, Yinlai Jiang, Zhihong Jiang, and Hiroshi Yokoi. A hand gesture recognition strategy based on virtual dimension increase of emg. Cyborg and Bionic Systems, 2023d.
- Weinland et al. [2011] Daniel Weinland, Remi Ronfard, and Edmond Boyer. A survey of vision-based methods for action representation, segmentation and recognition. Computer vision and image understanding, 115(2):224–241, 2011.
- Wu and Shao [2014] Di Wu and Ling Shao. Leveraging hierarchical parametric networks for skeletal joints based action segmentation and recognition. In Proceedings of the IEEE conference on computer vision and pattern recognition, pages 724–731, 2014.
- Wu et al. [2017] Zuxuan Wu, Ting Yao, Yanwei Fu, and Yu-Gang Jiang. Deep learning for video classification and captioning. In Frontiers of multimedia research, pages 3–29. 2017.
- Xiang et al. [2023] Wangmeng Xiang, Chao Li, Yuxuan Zhou, Biao Wang, and Lei Zhang. Generative action description prompts for skeleton-based action recognition. In Proceedings of the IEEE/CVF International Conference on Computer Vision, pages 10276–10285, 2023.
- Xu et al. [2017] Chi Xu, Lakshmi Narasimhan Govindarajan, Yu Zhang, and Li Cheng. Lie-x: Depth image based articulated object pose estimation, tracking, and action recognition on lie groups. International Journal of Computer Vision, 123:454–478, 2017.
- Xu et al. [2023] Haojun Xu, Yan Gao, Zheng Hui, Jie Li, and Xinbo Gao. Language knowledge-assisted representation learning for skeleton-based action recognition. arXiv preprint arXiv:2305.12398, 2023.
- Xu et al. [2018] Yangyang Xu, Jun Cheng, Lei Wang, Haiying Xia, Feng Liu, and Dapeng Tao. Ensemble one-dimensional convolution neural networks for skeleton-based action recognition. IEEE Signal Processing Letters, 25(7):1044–1048, 2018.
- Yan et al. [2018] Sijie Yan, Yuanjun Xiong, and Dahua Lin. Spatial temporal graph convolutional networks for skeleton-based action recognition. In Proceedings of the AAAI conference on artificial intelligence, 2018.
- Yang et al. [2019] Fan Yang, Yang Wu, Sakriani Sakti, and Satoshi Nakamura. Make skeleton-based action recognition model smaller, faster and better. In Proceedings of the ACM multimedia asia, pages 1–6. 2019.
- Yang et al. [2021] Hao Yang, Dan Yan, Li Zhang, Yunda Sun, Dong Li, and Stephen J Maybank. Feedback graph convolutional network for skeleton-based action recognition. IEEE Transactions on Image Processing, 31:164–175, 2021.
- Yang et al. [2016] Wei Yang, Wanli Ouyang, Hongsheng Li, and Xiaogang Wang. End-to-end learning of deformable mixture of parts and deep convolutional neural networks for human pose estimation. In Proceedings of the IEEE conference on computer vision and pattern recognition, pages 3073–3082, 2016.
- Ye et al. [2020] Fanfan Ye, Shiliang Pu, Qiaoyong Zhong, Chao Li, Di Xie, and Huiming Tang. Dynamic gcn: Context-enriched topology learning for skeleton-based action recognition. In Proceedings of the 28th ACM international conference on multimedia, pages 55–63, 2020.
- Ye et al. [2019] Linwei Ye, Mrigank Rochan, Zhi Liu, and Yang Wang. Cross-modal self-attention network for referring image segmentation. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 10502–10511, 2019.
- You et al. [2023a] Yingxuan You, Hong Liu, Xia Li, Wenhao Li, Ti Wang, and Runwei Ding. Gator: Graph-aware transformer with motion-disentangled regression for human mesh recovery from a 2d pose. In ICASSP 2023-2023 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), pages 1–5. IEEE, 2023a.
- You et al. [2023b] Yingxuan You, Hong Liu, Ti Wang, Wenhao Li, Runwei Ding, and Xia Li. Co-evolution of pose and mesh for 3d human body estimation from video. In Proceedings of the IEEE/CVF International Conference on Computer Vision, pages 14963–14973, 2023b.
- Yuan et al. [2022] Lin Yuan, Zhen He, Qiang Wang, Leiyang Xu, and Xiang Ma. Spatial transformer network with transfer learning for small-scale fine-grained skeleton-based tai chi action recognition. In IECON 2022–48th Annual Conference of the IEEE Industrial Electronics Society, pages 1–6. IEEE, 2022.
- Zeng et al. [2021] Ailing Zeng, Xiao Sun, Lei Yang, Nanxuan Zhao, Minhao Liu, and Qiang Xu. Learning skeletal graph neural networks for hard 3d pose estimation. In Proceedings of the IEEE/CVF international conference on computer vision, pages 11436–11445, 2021.
- Zhang et al. [2012] Fang-Lue Zhang, Ming-Ming Cheng, Jiaya Jia, and Shi-Min Hu. Imageadmixture: Putting together dissimilar objects from groups. IEEE Transactions on Visualization and Computer Graphics, 18(11):1849–1857, 2012.
- Zhang et al. [2018a] Fang-Lue Zhang, Xian Wu, Rui-Long Li, Jue Wang, Zhao-Heng Zheng, and Shi-Min Hu. Detecting and removing visual distractors for video aesthetic enhancement. IEEE Transactions on Multimedia, 20(8):1987–1999, 2018a.
- Zhang et al. [2022] Jiaxu Zhang, Yifan Jia, Wei Xie, and Zhigang Tu. Zoom transformer for skeleton-based group activity recognition. IEEE Transactions on Circuits and Systems for Video Technology, 32(12):8646–8659, 2022.
- Zhang et al. [2018b] Pengfei Zhang, Jianru Xue, Cuiling Lan, Wenjun Zeng, Zhanning Gao, and Nanning Zheng. Adding attentiveness to the neurons in recurrent neural networks. In proceedings of the European conference on computer vision (ECCV), pages 135–151, 2018b.
- Zhang et al. [2019a] Pengfei Zhang, Cuiling Lan, Junliang Xing, Wenjun Zeng, Jianru Xue, and Nanning Zheng. View adaptive neural networks for high performance skeleton-based human action recognition. IEEE transactions on pattern analysis and machine intelligence, 2019a.
- Zhang et al. [2019b] Pengfei Zhang, Cuiling Lan, Wenjun Zeng, Jianru Xue, and Nanning Zheng. Semantics-guided neural networks for efficient skeleton-based human action recognition. arXiv preprint arXiv:1904.01189, 2019b.
- Zhang et al. [2020] Pengfei Zhang, Cuiling Lan, Wenjun Zeng, Junliang Xing, Jianru Xue, and Nanning Zheng. Semantics-guided neural networks for efficient skeleton-based human action recognition. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 1112–1121, 2020.
- Zhang et al. [2024] Yi Zhang, Xinhua Xu, Youjun Zhao, Yuhang Wen, Zixuan Tang, and Mengyuan Liu. Facial prior guided micro-expression generation. IEEE Transactions on Image Processing, 2024.
- Zhang [2012] Zhengyou Zhang. Microsoft kinect sensor and its effect. IEEE multimedia, 19(2):4–10, 2012.
- Zhao et al. [2023a] Mengyi Zhao, Mengyuan Liu, Bin Ren, Shuling Dai, and Nicu Sebe. Modiff: Action-conditioned 3d motion generation with denoising diffusion probabilistic models. arXiv preprint arXiv:2301.03949, 2023a.
- Zhao et al. [2023b] Qitao Zhao, Ce Zheng, Mengyuan Liu, and Chen Chen. A single 2d pose with context is worth hundreds for 3d human pose estimation. In Thirty-seventh Conference on Neural Information Processing Systems, 2023b.
- Zhao et al. [2017] Rui Zhao, Haider Ali, and Patrick Van der Smagt. Two-stream rnn/cnn for action recognition in 3d videos. In 2017 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), pages 4260–4267. IEEE, 2017.
- Zhou et al. [2023] Huanyu Zhou, Qingjie Liu, and Yunhong Wang. Learning discriminative representations for skeleton based action recognition. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 10608–10617, 2023.
- Zhou et al. [2009] Qiaoyun Zhou, Shiqi Yu, Xinyu Wu, Qiao Gao, Chongguo Li, and Yangsheng Xu. Hmms-based human action recognition for an intelligent household surveillance robot. In 2009 IEEE International Conference on Robotics and Biomimetics (ROBIO), pages 2295–2300. IEEE, 2009.
- Zhou et al. [2022] Yuxuan Zhou, Zhi-Qi Cheng, Chao Li, Yanwen Fang, Yifeng Geng, Xuansong Xie, and Margret Keuper. Hypergraph transformer for skeleton-based action recognition. arXiv preprint arXiv:2211.09590, 2022.
- Zhu et al. [2023a] Wentao Zhu, Xiaoxuan Ma, Zhaoyang Liu, Libin Liu, Wayne Wu, and Yizhou Wang. Motionbert: A unified perspective on learning human motion representations. In Proceedings of the IEEE/CVF International Conference on Computer Vision, pages 15085–15099, 2023a.
- Zhu et al. [2021] Xizhou Zhu, Weijie Su, Lewei Lu, Bin Li, Xiaogang Wang, and Jifeng Dai. Deformable detr: Deformable transformers for end-to-end object detection. In International Conference on Learning Representations (ICLR), 2021.
- Zhu et al. [2023b] Xiaoyu Zhu, Po-Yao Huang, Junwei Liang, Celso M de Melo, and Alexander G Hauptmann. Stmt: A spatial-temporal mesh transformer for mocap-based action recognition. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 1526–1536, 2023b.