A Survey of Sample-Efficient Deep Learning for Change Detection in Remote Sensing: Tasks, Strategies, and Challenges
Abstract
In the last decade, the rapid development of deep learning (DL) has made it possible to perform automatic, accurate, and robust Change Detection (CD) on large volumes of Remote Sensing Images (RSIs). However, despite advances in CD methods, their practical application in real-world contexts remains limited due to the diverse input data and the applicational context. For example, the collected RSIs can be time-series observations, and more informative results are required to indicate the time of change or the specific change category. Moreover, training a Deep Neural Network (DNN) requires a massive amount of training samples, whereas in many cases these samples are difficult to collect. To address these challenges, various specific CD methods have been developed considering different application scenarios and training resources. Additionally, recent advancements in image generation, self-supervision, and visual foundation models (VFMs) have opened up new approaches to address the ’data-hungry’ issue of DL-based CD. The development of these methods in broader application scenarios requires further investigation and discussion. Therefore, this article summarizes the literature methods for different CD tasks and the available strategies and techniques to train and deploy DL-based CD methods in sample-limited scenarios. We expect that this survey can provide new insights and inspiration for researchers in this field to develop more effective CD methods that can be applied in a wider range of contexts.
Index Terms—remote sensing, change detection, deep learning, supervised learning, visual foundation model.
I Introduction
Over the last 10 years, the emergence and success of Deep Learning (DL) techniques [1] have significantly advanced the field of Change Detection (CD) in Remote Sensing Images (RSIs). DL-based CD enables data-driven learning of specific changes of interest and, as a result, facilitates accurate and fully automatic processing of vast amounts of data. State-Of-The-Art (SOTA) methods [2, 3, 4] have reached an accuracy exceeding 90% in the metric across multiple benchmark datasets for CD, highlighting the remarkable identification capability of DL-based CD approaches.
Despite these advances, the translation of CD methods into practical real-world applications remains a significant challenge. This arises from the inherent diversity present in the input RSIs, as well as the wide variety of scenarios to conduct CD algorithms. For instance, the multi-temporal RSIs that CD methods process can exhibit significant heterogeneity or spatial misalignment [5], and more fine-grained information is required to indicate the time of change or the specific change category. This necessitates the development of CD methodologies that can operate effectively within such varied and intricate environments.
Moreover, training a robust Deep Neural Network (DNN) for CD requires extensive and accurately labeled datasets. In many real-world scenarios, the presence of such data is scarce. The construction of a CD training set requires the collection of RSIs with expansive region coverage and adequate temporal intervals to capture changes of interest [6]. For some small or rare types of change, it is often difficult to collect a sufficient number of training samples. This poses negative impacts on the efficacy and generalization of DL-based CD approaches.
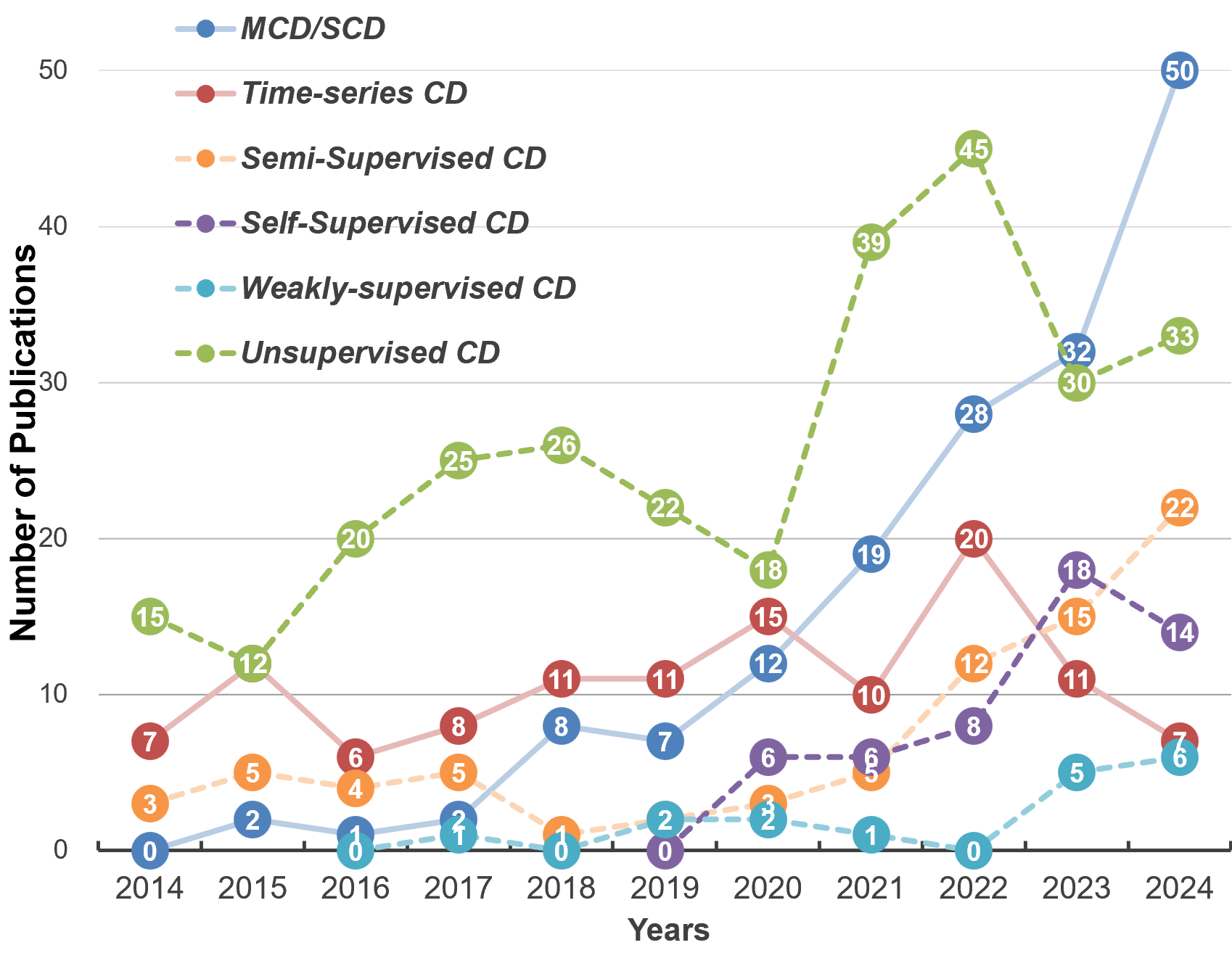
In response to these challenges, researchers have developed a variety of specialized CD methodologies that are customized to specific application contexts and training limitations. These methodologies encompass various subdivided CD tasks, each designed to meet the unique demands of a particular scenario. Concurrently, innovative training techniques and strategies have been introduced to mitigate the issue of ’data-hungry’ in training DNNs for CD. By exploring the underlying semantic context and multi-temporal correlations that are inherent to RSIs, the demand for extensive training labels can be reduced. Based on the different levels of supervision signals introduced, DL-based CD methods can be divided into several categories, such as fully supervised, semi-supervised, self-supervised, weakly supervised, and unsupervised. To display the dynamics in recent CD-related studies, in Fig.1 we present the number of publications associated with different CD tasks and supervision strategies. The statistics are obtained through a search at Web of Science 111https://www.webofscience.com/wos/ using related keywords while filtering the metadata to exclude those irrelevant to remote sensing. One can observe that there has been a rapid growth of interest in several CD topics, including multi-class CD, self-supervised CD, and semi-supervised CD. Additionally, some incomplete supervision settings have been rarely studied until very recent years (e.g., weakly supervised CD). These statistics indicate a trend of research focus in recent studies: as fully-supervised CD has already reached a high level of accuracy, an increasing number of investigations are being conducted on more challenging CD topics with incomplete supervision setups [7].
In light of these developments, there is a pressing need to comprehensively review and analyze the recent research on DL-based CD methods, particularly those tailored to diverse applicational contexts and incomplete supervision circumstances. This review aims to fill this gap by providing a detailed examination of the literature on CD tasks, which have been partitioned into specialized domains to address the unique challenges of each setting. In doing so, we expect to provide an in-depth understanding of the techniques and strategies employed to train and deploy DNN-based CD methods in real-world scenarios. Furthermore, we seek to identify gaps in the existing literature and highlight areas for future research, thus contributing to the multifaceted advancement and broader application of CD methodologies.
II CD Tasks
According to the granularity of results and the type of input images, CD in RSIs can be further divided into various sub-categories, including Binary CD (BCD), Multi-class CD/Semantic CD (MCD/SCD), and Time-series CD (TSCD). Fig.2 presents an overview of these different tasks. In the following, we summarize the benchmarks, applicational scope, and representative works related to each CD task.

II-A Binary CD
Background: BCD has been the most extensively studied CD task in the past few decades. Unless otherwise specified, BCD is also commonly abbreviated as CD in literature. As BCD has been comprehensively reviewed in existing literature, here we only provide a brief summary of the typical paradigms and representative work.
In the initial stages, DL-based BCD was seen as a segmentation task, where UNet-like Convolutional Neural Networks (CNNs) are employed to directly segment changes [8]. Let and denote a pair of RSIs obtained on the dates and , respectively. The general function of CD can be represented as:
| (1) |
where is the predicted change map, is the mapping function of a DNN with the trained parameters . Differently, Daudt et al. [9] proposed to first extract the temporal features, then model the change representations:
| (2) |
where and are two DNN encoders, is a DNN decoder. Under the circumstance that and exhibit homogeneity (e.g., collected by the same sensor or have similar spatial and spectral characteristics), and can be configured as siamese networks [9], i.e., share the same weight. This approach has been widely accepted as a paradigm for DL-based CD, as it allows effective exploitation of the temporal features.
Techniques: The major challenges in BCD are distinguishing semantic changes between seasonal changes and mitigating spatial misalignment as well as illumination differences. In CNN-based methods, channel-wise feature difference operations are commonly used to extract change features [9, 10]. Another common strategy is to leverage multiscale features to reduce the impact of redundant spatial details [11]. Multiscale binary supervisions are also introduced in [8] to align the embedding of change features. As an effective technique to aggregate global context, the attention mechanism is also widely used in CD of RSIs. Channel-wise attention is often used to improve the change representations [12, 13], while spatial attention is often used to exploit the long-range context dependencies [14, 15].
Another research focus in BCD is to model the temporal dependencies in pairs of RSIs. In [16] a multilayer RNN module is adopted to learn change probabilities. Graph convolutional networks are also an efficient technique to propagate Land Cover Land Use (LCLU) information to identify changes[17]. Recently, Vision Transformers (ViTs) [18, 19] have emerged and gained great research interests in the RS field [20, 21]. There are two strategies to utilize ViTs for CD in RSIs. The first is to replace CNN backbones with ViTs to extract temporal features, such as ChangeFormer[22] and ScratchFormer[23]. Meanwhile, ViTs can also be used to model the temporal dependencies. In BiT[2], a transformer encoder is employed to extract changes of interest, while two siamese transformer decoders are placed to refine the change maps. In CTD-Former[24], a cross-temporal transformer is proposed to interact between the different temporal branches.
II-B Multi-class CD/Semantic CD
Background: In BCD, the results only indicate location of the change, leaving out the detailed change type. This is often not informative enough to support RS applications. In contrast, multi-class CD (MCD) refers to the task of classifying changes into multiple predefined classes or categories [25]. On the other hand, semantic change detection (SCD) is introduced in recent DL-based CD literature to classify and represent the pre-event and after-event change classes [26, 27]. Although there are slight differences in the representation of results, both MCD and SCD enable a detailed analysis of the changed regions, e.g., identifying the major changes and calculating the proportion of each type of change. The results can further be represented in an occurrence matrix indicating pre-event and after-event LCLU classes, such as presented in Fig.2(b).
Architectures: MCD/SCD, with its provision of more detailed information, is indeed a more challenging task compared to BCD due to the need for modeling semantic information in particularly changed areas. According to the order of semantic modeling and CD, conventional methods for MCD can be roughly divided into two types, i.e. the post-classification comparison [28] and compound classification [29, 30]. In DL, it is feasible to perform multi-task learning by jointly using different training objectives. There are two types of deep architectures for MCD/SCD in RSIs. The first architecture applies the common CD architecture in Equation. (2), and fuses bi-temporal information to classify multiple change types [31, 32]. The second approach employs a joint learning paradigm to learn semantic features and change representations simultaneously through different network branches [26, 27]. This can be formulated as follows:
| (3) | ||||
where , , and are three DNN modules that project the temporal features into semantic maps and change map , respectively.
Techniques: The techniques used in MCD/SCD can be categorized into two types: i) spatio-temporal fusion [32, 33] and ii) semantic dependency modeling [34]. In [31], Mou et al. made an early attempt to employ DNNs for MCD. It is a joint CNN-RNN network where the CNN extracts semantic features, while the RNN models temporal dependencies to classify multi-class changes.
II-C Time-series CD
Background: Differently from common CD studies that analyze bi-temporal RSIs, Time-Series CD (TSCD) aims to capture changes that have occurred over multiple periods or across a series of temporal images. This can better characterize the dynamics of change [35] and discriminate between transient fluctuations and persistent changes, leading to more reliable and informative CD results. Conventional algorithms analyze the temporal curves to model the change patterns. Among these algorithms, trajectory classification models the trajectory in change regions, statistical boundary detects departure from common variations to detect changes, and regression models the long-term momentum in the observed regions[36]. Since these methods commonly do not consider spatial contexts, they are sensitive to noise and seasonal variations. Moreover, they have difficulty modeling complex or long-term change patterns.
Architectures: Due to the scarcity of training data, DL-based TSCD did not emerge until very recent years. An intuitive approach is to employ RNNs to model temporal variations in time-series observations, as RNNs were originally designed for sequence processing. In [37] Long-Short-Term Memory (LSTM) network, a more delicate type of RNN is first introduced to detect and predict the burned areas in forests. Experimental results reveal that LSTM can better model the nonlinear characteristics in temporal data. In [38] a temporal semantic segmentation method for time-series images is proposed. LSTM is employed to classify the spectral vectors into different LCLU types at different timestamps.
In these LSTM-based methods, the analysis is limited to the temporal dimension. Although the method in [38] involves analysis of the spatial consistency, this is conducted as post-processing to reduce noise and is not end-to-end trainable. To overcome this limitation and to consider the spatial context in time-series RSIs, in [39] LSTM is combined with a CNN for joint spatiotemporal analysis. A CNN is employed to project time-series RSIs into spatial features, followed by an LSTM to model the temporal dependencies. This can be formulated as:
III CD with Limited Samples

To advance DL in real-world CD applications, numerous studies have been conducted on training DNNs for CD in training sample-limited experimental setups in recent years. Depending on the strength of supervision introduced in the training, sample-efficient learning of CD DNNs can be divided into 4 categories, including semi-supervised (SMCD), weakly supervised CD (WSCD), self-supervised CD (SSCD), and unsupervised CD (UCD). For readers to easily comprehend the supervision strength in different learning settings, Fig.3 represents the data and annotations required in each taxonomy. For simplicity, some close supervision settings are merged. The few-shot CD and zero-shot CD are incorporated into SMCD and UCD, respectively.
Furthermore, Table.I summarizes various learning strategies and techniques in the literature. It is worth noting that many of these strategies can be applied to different supervision conditions. In the following, we elaborate on each supervision category and introduce the commonly used strategies, methodologies, and techniques.
| General Strategies | Specific Strategies | Methodologies & Techniques |
| Auxiliary regularization | Adversarial regularization | Entropy adversarial loss[41] |
| Adversarial change masking [42] | ||
| Consistency regularization | Temporal consistency [43, 44] | |
| Image perturbation consistency [45] | ||
| Feature perturbation consistency [46] | ||
| Perturbation consistency & sample selection [47, 48] | ||
| Pseudo supervision | Pseudo Labeling | Ensemble of multi-scale predictions [49] |
| Ensemble of historical predictions [50] | ||
| Ensemble of multi-model predictions [51] | ||
| Ensemble of multi-temporal predictions [34] [52] | ||
| Ensemble of teacher-student predictions [53] [54] | ||
| Uncertainty filtering | IoU voting [51] [50] | |
| Entropy measure [55] [56] | ||
| Similarity measure [34] [57] [58] | ||
| Class rebalancing [59] | ||
| Contrastive sampling [55] [60] | ||
| Pre-detection supervision | Image algebra methods [16, 61] | |
| Image transformation methods [62, 63] | ||
| Object-based image analysis [64] | ||
| Saliency detection [65] | ||
| Coarse-to-fine refinement | Change activation mapping | Multi-scale CAMs [66][67] |
| Mutual learning [68] | ||
| GradCAM++ [69] | ||
| Difference refinement | Difference clustering [70] | |
| Guided anisotropic diffusion [71] | ||
| CRF-RNN [72] | ||
| Change Masking & Classification [72] [73] | ||
| Representation learning | Graph representation | Super-pixel graph [74, 75, 76] |
| Feature graph [77] | ||
| Difference graph [78, 58] | ||
| Contrastive learning | Data augmentation [79, 80, 81] | |
| Multiple clues [82, 83, 84, 85, 86, 87, 88, 89] | ||
| Pseudo label contrast [90, 91, 92] | ||
| Masked image modeling | Large-scale MIM & fine-tuning [93][94] | |
| Contrastive mask image distillation [95] | ||
| Multi-modal MIM [96] | ||
| Generative representation | Autoencoder and its variants [97, 98, 99] | |
| Deep belief networks [100, 101] | ||
| Generative adversarial networks [102, 42] | ||
| Denoising diffusion probabilistic models [103] | ||
| Augmentation | Image augmentation | Background-mixed augmentation [104] |
| Pseudo change pair generation [105][106] | ||
| Patch exchange [107][106] | ||
| Change augmentation | Object masking & inpainting [108][109] | |
| Change instance generation [110][111] | ||
| Leveraging external knowledge | Leveraging VFMs | Fine-tuning VFMs [4, 112] |
| Prompt learning [113] | ||
| Transfer learning | Classifying VGGNet features [114, 115] | |
| Metric learning [116, 117] |
III-A Semi-supervised CD
Semi-supervised learning presupposes the availability of only a limited volume of labeled data for training. In scenarios where labeled samples are extremely scarce, this paradigm transitions into the domain of few-shot change detection. This necessitates intrinsic learning of the change patterns that can be generalized across diverse instances of change.
Pseudo Labeling: Pseudo labeling allows a DNN to generate pseudo labels for unlabeled data based on its predictions, thus effectively augmenting the training dataset. In segmentation-related tasks, pseudo labels can be obtained by thresholding the predictions of DNNs.
Since single DNN predictions may contain many errors, various methods combine multiple predictions to enhance the robustness of pseudo-labeling. In [49] pseudo labels are obtained by composing and voting multi-scale predictions. In [50], historical models are used during training to produce ensemble predictions. By calculating the mean Intersection over Union (IoU) in historical predictions, the reliable results are selected as pseudo labels to train the unlabeled data. The method in [51] utilizes multiple DNNs to produce multiple predictions and also performs IoU calculations to generate reliable labels. In [34] a cross-temporal pseudo-labeling technique is introduced. The semantic similarity between multitemporal predictions is calculated to select the high-confident pixels. In [53], a sophisticated cross-pseudo supervision method is proposed within the Teacher-Student (TS) learning paradigm. The knowledge learned in a teacher model is distilled to supervise the student models, and the predictions of multiple student models are composed to generate reliable pseudo labels. Kondmann et al. [54] employ an unsupervised method as the teacher model, subsequently train and fine-tune different CD models with pseudo labels from the teacher model. In [118], the method employs superpixel segmentation to create objects and enable self-supervised learning through object overlaps in bitemporal images. It produces and integrates multiscale object-level and pixel-level difference images and utilizes temporal prediction for SSCD.
The essence of pseudo-labeling is minimizing the errors and uncertainty in generated labels while enhancing guidance for critical cases. Therefore, it is important to measure the certainty of DNN predictions. If the pseudo labels are generated by multiple methods, the number of votes can be deemed the confidence score [54]. In [51] and [50] the certainty is measured through IoU in multiple predictions. For a single DNN prediction on unlabeled data, low entropy indicates high confidence, and entropy-based objectives are commonly used to filter uncertain predictions [55] [56]. In [57] similarity measures and uncertainty calculations are combined to map the pseudo CD labels. To improve the guidance for minor classes (i.e., changes), Hou et al. [59] cluster the extracted deep features to generate pseudo labels and rebalance the change/non-change instances in pseudo labels to strengthen the learning of minority class (i.e., changes). Furthermore, uncertain predictions also contain potential knowledge. In a contrastive learning paradigm, reliable and unreliable pixels can be sampled as positive and negative samples, thus improving the representation of temporal semantic features [55, 60].
Auxiliary regularization: To facilitate training on unlabeled data, a common strategy is to introduce auxiliary training objectives or regularization. This can constrict the optimization landscape and regularize DNNs to learn noise-resistant change representations. In [43] Ding et al. propose a temporal similarity regularization to optimize learning of temporal semantics in SCD. This objective drives DNNs to embed similar features in unchanged areas and different semantics in changed areas. In [4] it is extended with temperature regularization to model the implicit semantic latent in the BCD. In [52] temporal regularization is implemented in the form of mutual supervision with pseudo labels. In [44] a focal cosine loss is designed to align feature representations in unchanged areas for SSCD of hyperspectral images. It assigns greater weights to hard positive samples to emphasize the learning of critical samples.
In [41] adversarial learning is introduced to align the feature distributions of unlabeled data with the labeled data, thus promoting GT-like results. In [119], adversarial learning is introduced to learn consistent feature representations in bitemporal images. The CD results are then derived by clustering the different features.

Among auxiliary regularization-based approaches, Consistency Regularization (CR) is an effective strategy to enhance the model generalization. CR applies spatial or spectral perturbations to unlabeled data, training the model to reduce discrepancies between varying perturbations of the same image [120].
Bandara et al. [45] first introduce CR to WSCD, and extend perturbations from images to feature differences. A paradigm for CR is proposed in the context of WSCD, which involves different types of perturbations, such as random feature noising, random feature drop, feature cutout, and instance masking. Similarly, Yang et al. [46] extend the CR paradigm with dual stream feature-level perturbations, which greatly improves the generalization even with a very small proportion of training samples. A simplified paradigm of this CR learning under a teacher-student knowledge distillation framework is illustrated in Fig.4.
Building on top of the CR paradigm, many literature methods investigate to improve WSCD through advanced DNN designs and sample selection mechanisms. In [121], rotation augmentation is introduced in CR-based WSCD, and class-wise uncertainties are calculated to alleviate the class imbalance issue. Wang et al. [47] introduce a reliable sample selection mechanism that selects samples with stable historical predictions during training. In [122], a coarse-to-fine CD network with multiscale attention designs is designed as the backbone for CR-based WSCD. In [48] selection, trimming and merging of reliable instances is performed to enhance the robustness of extracted change instances. Hafner et al. consider multi-modal data as different views of the same regions and employ CR across different modalities to learn robust built-up changes [123].
Graph Representation: Graph neural networks (GNNs) are a family of DNNs that are adept at modeling relationships. Since GNNs can be trained with partial labels, they are well suited to semi-supervised learning settings [78, 74]. A crucial step in graph learning is graph construction. The literature methods can be categorized into superpixel-based [74, 75, 76], feature-based [77], and difference-based [78, 58] graph construction.
Liu et al. [78] first introduced graph learning in the context of SMCD. The differences between temporal features are calculated to construct change graphs, while adversarial learning is also introduced to train the graphs constructed with unlabeled data. Saha et al. construct change graphs with multi-temporal parcels, and propagate change information from labeled parcels to unlabeled ones through training iterations [74]. Tang et al. [58] employ a multi-scale Graph Convolutional Network (GCN) to capture long-range change context and generate pseudo labels with similarity metrics. In [75] a method for dynamic graph construction in SAR image CD is presented. It constructs graphs from three-channel pixel blocks and dynamically updates graph edges based on trained features. The method in [76] combines superpixel graph modeling and pixel-level CNN embedding for SMCD in hyperspectral images. It introduces a graph attention network (GAT) to capture temporal-spatial correlations via an affinity matrix and uses CNN layers to merge features to map changes. In [77], GAT is incorporated into a CR learning framework to learn robust multi-temporal graph representations. In [124] graph is employed to represent and cluster the change evolutions for unsupervised TSCD.
III-B Weakly supervised CD
While CD is a fine-grained segmentation task that requires pixel-level annotations, in the weakly supervised learning setting, only coarse-grained labels such as points, surrounding boxes, scribbles, and image categories are available. WSCD enables easy construction of a CD training set, as it does not require intensive human annotation. However, it does not mitigate the scarcity of change samples.
Most of the WSCD methods utilize image-level labels. The labels indicate either the image categories [66] or the image pair (change/nonchange [69]). Meanwhile, various types of coarse CD labels are also utilized in literature studies, including point labels [125], low-resolution labels [126], patch-wise labels [73] and box labels [127]. The differences in these supervisions derive different methodologies of utilizing and recovering spatial information. Two major categories of WSCD methodologies that correspond to image-level supervision and coarse CD supervision are change activation mapping and difference refinement, respectively.
Change activation Mapping: This strategy is frequently employed in WSCD to parse image-level label into spatial change representations. First, an image encoder is trained with image-level information, then the feature responses in the late layers, i.e., class activation maps (CAMs), are utilized to generate coarse pseudo labels. However, CAMs contain only coarse feature responses and do not indicate fine-grained change details. To improve the accuracy and robustness of CAMs, Cao et al. [66] ensemble multi-scale CAMs and propose a noise correction strategy to generate reliable pseudo labels. The method in [67] also adopts a multi-scale approach. It extracts more robust and accurate change probability maps through knowledge distillation and multi-scale sigmoid inference, as illustrated in Fig.5. The method in [68] introduces mutual learning between different time phases. It utilizes CAMs derived from the original image and the affine transformed image to improve the certainty of change mapping and incorporates contrastive learning to enlarge the distance between changed representations and unchanged representations. In [69] GradCAM++ is introduced to weight the multi-scale CAMs. It also leverages multi-scale and transformation consistency regularization to improve the quality of CAMs.

Difference Refinement: In comparison to image-level labels, coarse CD labels contain a certain degree of spatial information and thus can be utilized to train a coarse CD model. After mapping the differences, various kinds of techniques are developed to refine and highlight the salient change regions.
Several methods employ conventional machine learning methods to perform the refinement. In [126], the refinement is achieved through bitemporal comparison and morphological filtering operations. In [127], a candidate suppression algorithm is designed to reduce the overlapping box candidates and select the most confident candidate regions that indicate changes. In [70] temporal features are extracted by contrastive learning, and the mapping from difference image to CD result is achieved through PCA and K-Means algorithms.
In contrast to refinement on the CD results, several methods refine the labels to perform fine-grained supervision. The method in [128] first calculates a difference map through edge mapping and superpixel segmentation algorithms, then trains a denoising autoencoder to refine the pre-classification results. Fang et al. apply region growth on point labels and DNN predictions to expand the annotations and propose a consistency alignment objective to align the coarse and fine predictions [125]. In [71], the training of a CD CNN and the refinement of the results are carried out iteratively to reduce the errors in the noisy crowd-sourced labels. A guided anisotropic diffusion algorithm is introduced to filter the wrong predictions while preserving the edges.

Differently from these approaches, the method in [72] utilizes object-level class labels to perform WSCD. It first compares image pairs with a Siamese Unet and then masks the changed object to classify its category. To enable accurate masking of the changed object, a CRF-RNN (Conditional Random Fields as Recurrent Neural Network) layer is employed to integrate spatial details from the original image. Similarly to this object-masking approach, the method in [73] masks and re-segments superpixels as interesting instances (buildings), and utilizes a voting mechanism to classify the changed instances (damaged buildings).
III-C Self-supervised CD
Self-supervised learning exploits the inherent consistency within data to learn sensor-invariant and noise-resilient semantic representations. Leveraging the capability of self-supervised learning, SSCD learns to discriminate temporal variations in unlabeled RSIs. It is worth noting that SSCD can be regarded as a distinct subclass within the broader category of UCD, but they typically require extensive pre-training in the target domain. Additionally, many approaches employ SSCD for pretraining and still require fine-tuning on target datasets.
Contrastive Learning: This strategy constructs and compares positive and negative pairs to exploit the structure and relationships within unlabeled data. In CD, bi-temporal images are often utilized to construct the contrastive pairs. By maximizing the consistency among positive pairs and the difference among negative pairs through contrastive losses, DNNs are trained to exploit feature embeddings that can capture temporal similarities and discrepancies. Fig.6 illustrates a simplified paradigm of contrastive learning, where change pairs are constructed with cropped RSIs at the same and different locations. The mapping of pre-trained representations into CD results further categorizes two major types of methods: fine-tuning-based and thresholding-based.
The fine-tuning-based methods use CD labels to retrain based on the pre-trained model obtained from self-supervised methods. Common methods utilize data augmentation methods for comparative learning. The results of data augmentation based on the same sample are regarded as positive samples. Feng et al. [79] obtain a pre-trained model based on SimSiam and unlabeled samples. Multiple data augmentation methods are often combined to generate positive samples, and then the pre-trained model is directly fine-tuned [80] [81]. In addition to data augmentation, some studies construct contrastive learning by mining multiple clues, such as multi-level contrast and multi-feature contrast. Jiang et al. [82] design global-local contrastive learning, where global and local contrastive learning respectively implement instance-level and pixel-level discrimination tasks. Huang et al. [83] propose a soft contrastive loss function to improve the inadequate feature tolerance. In the downstream CD fine-tuning task, the features of different receptive fields are captured by a multiscale feature fusion module and combined with a two-domain residual attention block to obtain long-range dependencies on spectral and spatial dimensions. The method in [84] proposes a multilevel and multi-granularity feature extraction method and applies contrastive learning to obtain the pretrained model. A multilevel CD is performed by fine-tuning the network with limited samples.
The thresholding-based methods derive the CD map from dual feature maps using thresholding, thus no labeled samples are used for fine-tuning. Contrastive learning based on multiple clues has also been used in these methods. The method in [85] pretrains the model using a pseudo-siamese network and multiview images and then generates binary CD maps through feature distance measurement and thresholding. In [86], shifted RSI pairs are leveraged to train pseudo-siamese networks, performing pixel-level contrastive learning. Kuzu et al. [87] employ instance-level (BYOL, SimSiam) and pixel-level (PixPro, PixContrast) methods to derive pre-trained models and directly produce CD maps using DCVA. In [88], a multicue contrastive self-supervised learning framework is designed. Beyond mere data augmentation, this approach also constructs positive sample pairs from semantically similar local patches and temporally aligned patches. The preliminary change embeddings are then obtained from the affinity matrix. The method in [89] first performs contrastive learning on bitemporal RSIs, and then performs contrastive learning on early fusion and late fusion features. Meanwhile, pseudo label contrast has also been widely explored, which regards samples with the same class as positive pairs and samples with different classes as negative pairs. Saha et al. [90] employ deep clustering and contrastive learning for self-supervised pre-training. Adebayo [91] trains a classifier using land cover labels of available years to identify unchanged regions through post-classification comparisons. The pre-trained model is obtained through the BYOL method based on trusted unchanged regions. He et al. [92] employ clustering to obtain pseudo labels (non-changed, changed, and uncertain). Furthermore, this framework introduces a self-supervised triple loss, including changed and non-changed losses based on contrastive learning and an uncertain loss based on image reconstruction.
Masked Image Modeling: Masked Image Modeling (MIM) is a self-supervised reconstructive approach aims at learning generalized representations from extensive volumes of unlabeled data. Within the MIM paradigm, DNNs are trained to reconstruct masked image pixels or patches based on available unmasked image content. However, MIM does not provide task-specific feature representations and typically requires subsequent fine-tuning.
With large-scale pretraining using MIM, Sun et al. [93] constructed a foundational model for RS scenes and proved its improvements to BCD. Cui et al. [94] pre-train a network using multi-scale MIM and fine-tune it with labeled data. The model first processes images with convolutional structures and then extracts global information using transformers. The method in [95] combines contrastive learning and MIM in a self-distillation way, allowing effective representations with global semantic separability and local spatial perceptibility. Zhang et al. [96] propose a multi-modal pretraining framework. The DNNs learn visual representations through MIM, and align them with multi-modal data through contrastive learning. A temporal fusion transformer is also proposed to transfer the pre-trained model to CD.

Augmentation: Natural changes are infrequent and registered bitemporal RSIs are difficult to collect. To overcome these limitations, in [104] a background augmentation method is introduced for image-level WSCD. It augments samples under the guidance of background-exchanged images, enabling the model to learn intricate environmental variations.
Several literature studies resort to augmenting semantic changes with single-temporal RSIs in segmentation datasets. In [105], pseudo change pairs are constructed by randomly sampling labeled RSIs and mixing their semantic labels. This pseudo supervision is proved to generalize well on CD datasets without fine-tuning. In [107], Chen et al. propose a simple image patch exchange method to generate pseudo-multi-temporal images and pseudo labels from a wide range of single-temporal HR RSIs, facilitating the training of CD DNNs in a self-supervised manner. In [106], patches from other images are cut and pasted to create a pseudo-post-change image.
There are also several literature studies aiming to generate more diverse and realistic change pairs with instance-level augmentations. They commonly utilize instance labels in segmentation datasets to perform the creation or removal of synthetic changes, as illustrated in Fig.7. For example, Seo et al. [109] implement copy-pasting or removal-inpainting operations based on the labels of ground objects. Zheng et al. [111] first synthesize changes by copying or removing objects, then simulate temporal variations using a GAN. Zhu et al. [110] generate object segments with a GAN and employ Poisson blending to fuse them into background images. The resulting approach enables a few-shot CD in forest scenes. Quan et al. [108] generate pseudo-change pairs by masking the instances in labeled building segmentation datasets. After pretraining on these synthesized datasets, high accuracy is yielded with few amount of labeled data for fine-tuning.
III-D Unsupervised CD
UCD eliminates the necessity for prior training, allowing direct deployment of CD algorithms on unlabeled data. This significantly broadens the application scope of DL-based CD, representing a critical objective in the advancement of CD methodologies. However, unsupervised CD presents significant challenges for DL-based frameworks, as the training of DNNs requires task-specific objectives. To address the absence of explicit supervision in UCD, the literature identifies three principal strategies: generative representation, pre-detection supervision, and leveraging external knowledge.
Generative Representation: This approach uses generative models to extract features, eliminating the need for manually labeled data [129].
The model extracts feature maps from the original multi-temporal image for pixel-wise comparison to generate a difference map. A distance metric, such as the Euclidean distance, combined with a threshold segmentation algorithm, derives the final CD results. Prevalent deep generative models include auto-encoders (AE), deep belief networks (DBN), generative adversarial networks (GAN) [130], and denoising diffusion probabilistic models (DDPM) [131].
AEs are unsupervised learning models optimized by minimizing reconstruction errors. However, vanilla AEs tend to learn redundant information (e.g., simply replicating the input data) and encounter difficulties in deriving meaningful representations within a single-layer architecture. Consequently, various variants such as stacked AE (SAE), sparse AE, denoising AE (DAE), and variational AE (VAE) have been adapted for CD tasks.
In [132], an SAE-based algorithm for CD of HR RSIs employs a sparse representative sample selection strategy to reduce time complexity. Liu et al. [98] use an SAE with Fisher’s discriminant criterion for high-resolution SAR image CD to better distinguish between changed and unchanged features. In [133], SAE served as a predictor of hyperspectral anomaly CD. Touati [134] designed a multimodal CD (MMCD) framework based on anomaly detection, noting that changed regions often exhibit significant reconstruction losses in sparse AE. Lv et al. [135] used a contractive AE to minimize noise and extract deep features from superpixels for the SAR image CD. In [133], SAE served as a predictor of hyperspectral anomaly CD. Touati [134] designed an MMCD framework based on anomaly detection, noting that changed regions often exhibit significant reconstruction losses in a sparse AE. Lv et al. [135] employ a contractive AE to minimize noise and extract deep features from superpixels for the SAR image CD. In [136], a cross-resolution difference learning method involving two coupled AEs was developed for CD across images of varying resolutions.
Since DAEs help reduce the impact of noise on original images, they are widely used in SAR and MMCD [97, 137, 138, 139]. To mitigate the loss of spatial contextual information typically associated with vectoring operations in conventional AEs, convolutional layers have been incorporated into AEs, resulting in the development of convolutional AEs (CAEs) for CD. Bergamasco et al. [140] develop a CAE to learn multi-level difference features for multispectral CD. Wu et al. [141] add a commonality constraint to CAE for MMCD applications. Furthermore, to address spatial information loss in fully connected AEs, Wu et al. [142] propose a kernel principal component analysis (KPCA) convolution feature extraction model. A deep KPCA convolutional mapping network is designed following the layer-wise greedy training approach of SAE for both BCD and MCD in HR RSIs. Chen et al. [99] present a graph-based framework to model structural relationships for unsupervised multimodal CD. It employs dual-graph convolutional autoencoders to discern modality-agnostic nodes and edges within multimodal images.
DBNs are another type of classic unsupervised deep model with multiple layers of restricted Boltzmann machines (RBMs). Like SAE, DBNs are trained using a layer-wise greedy approach, enabling them to extract informative features from input images. Despite their potential, DBNs have seen relatively limited application in CD. Gong et al. [100] utilized pre-trained DBN weights as initial weights for a DNN to perform CD on SAR images. Zhao et al. [101] designed a DNN composed of two symmetric DBNs to learn the modality-invariant features for MMCD. Jia et al. [143] introduced a generalized Gamma DBN to learn features from different images, and Zhang et al. [144] compressed features extracted by DBN into a 2D polar domain for MCD on multispectral images.
As a prominent framework for approaching generative AI, GANs have also been widely applied in unsupervised CD. Lei et al. [102] apply GANs to learn representative features from hyperspectral images, achieving robust CD results. Saha et al. [145] develop a GAN-based method to learn deep change hypervectors for CD on multispectral images. Ren et al. [146] developed a GAN-based CD framework to mitigate the issues caused by unregistered objects in paired RSI. Wu et al. [42] propose an end-to-end unsupervised CD framework, jointly training a segmentor and a GAN with L1 constraints. Noh et al. [147] employ GANs for image reconstruction using single temporal images in training and bitemporal images in inference, identifying changed regions by high reconstruction losses. GANs demonstrate exceptional efficacy in MMCD owing to their advanced capabilities in image style transfer. One of the major types of unsupervised MMCD, modality translation methods, predominantly leverages GANs. For instance, Niu et al. [148] use a conditional GAN for modality translation between SAR and optical images, obtaining CD results through direct comparison of transformed images. Subsequent advances include sophisticated GAN architectures and training techniques for improved detection accuracy, such as cycle-consistent GAN [149, 150], CutMix [151], feature space alignment [152], and robust fusion-based CD strategies [153]. These approaches often incorporate pre-detection techniques to isolate changed regions for more stable modality translation results, aligning with the concepts we will discuss in the following subsection.
DDPMs, drawing inspiration from the principles of non-equilibrium thermodynamics, have garnered significant attention in generative artificial intelligence [131]. These models involve a diffusion process that gradually introduces random noise into the data, followed by a reverse diffusion process to reconstruct the desired data distribution from the noise. Training by reconstructing inputs makes DDPMs naturally suitable for feature extraction in CD tasks. Bandara et al. [103] first introduced DDPMs for CD. However, subsequent works focus mainly on fully supervised CD (FSCD) [154], while studies on UCD with DDPMs remain rare.

Pre-detection Supervision: Although unsupervised generative models do not require labeled data to extract features from images for CD, the lack of objectives during the feature extraction process may result in suboptimal and less informative features. Additionally, the absence of labeled data can limit the learning of more advanced DL models. To address these issues, pre-detection-based approaches first generate pseudo labels using traditional unsupervised CD algorithms, then train deep CD models with the pseudo labels. This strategy emulates supervised learning paradigms for training purposes while remaining
entirely unsupervised, as it does not depend on any pre-existing labeled data. Several early DL-based CD methods have adopted this strategy.
The effectiveness of pre-detection supervision depends on the accuracy of pre-detection algorithms. Thus, it is crucial to design or select algorithms that suit the characteristics of input images. Synthetic Aperture Radar (SAR) images, in particular, have been extensively studied due to their unique speckle noise. Gao et al. [62] developed an automatic CD algorithm using PCANet [155], which employs a Gabor wavelet transform and Fuzzy C-means clustering (FCM) to select the most reliable changed and unchanged samples from SAR images. These samples are then used to train the PCANet. Similarly, Gong et al. [100] proposed a deep neural network-based CD algorithm for SAR images that incorporates a pre-detection algorithm based on FCM to select the most representative samples. In another study, Gong et al. [156] introduced an unsupervised ternary CD algorithm where deep feature representations are learned from the difference image using an SAE, effectively suppressing image noise. Geng et al. [65] integrated saliency detection into CD for SAR images by designing a pre-detection algorithm to select representative and reliable samples for training the deep network. Additionally, Yang et al. [157] combined the concept of transfer learning with pre-detection methods to broaden the application scope of CD in SAR images. Liu et al. [158] proposed a locally restricted CNN that adds spatial constraints to the output layer, effectively reducing noise in Polarimetric SAR (PolSAR) images. This model was also supported by a pre-detection algorithm based on the statistical properties of PolSAR images.
Methods tailored for multispectral, hyperspectral, and high-resolution images have also been developed. Gong et al. [159, 160] leveraged the initial difference image generated by the CVA to provide a priori knowledge for sampling training data for GANs. Shi et al. [161] extended this approach to MCD. Du et al. [61] introduced a deep slow feature analysis (DSFA) model combined with a deep neural network to learn nonlinear features and emphasize changes. The authors employed a CVA-based pre-detection method to select samples from multispectral images for training the network. Song et al. [63] utilized PCA and image element unmixing algorithms to select training samples for a recurrent 3D fully convolutional network for binary and multiclass CD. In [162], pseudo-labels from BCD were employed to guide hyperspectral MCD. For high-resolution images, pre-detection algorithms need to focus more on the spatial information within the image. Gong et al. [64] developed a high-resolution CD algorithm based on superpixel segmentation and deep difference representation. This method achieved varying pre-detection results based on different superpixel features and implemented a voting mechanism to select reliable training samples from these results. Xu et al. [163] used SFA as a pre-detection algorithm to select reliable samples to train a stacked DAE for high resolution RSI CD.
Leveraging external knowledge: DNNs pre-trained on natural images are adept at extracting general visual features, which can be highly beneficial for the recognition tasks of RSIs. An early exploration by Saha et al. [114] utilized a CNN encoder pre-trained on natural optical images to extract bitemporal features, which were then pixel-wise compared to classify changes. Subsequently, Saha et al. [115] applied the pre-trained VGG network as a feature extractor for planetary CD. Bandara et al. [116] introduce multiple bitemporal constraints based on metric learning to transfer the inherent knowledge from pre-trained VGG networks to the RS target domain. The approach in [117] initially transfers deep features pre-trained on semantic segmentation datasets, then fine-tunes them with distance constraints and pseudo-change labels to enhance relevance. Furthermore, in [164], object-based image analysis was leveraged to refine feature extraction with a pre-trained CNN. To better tailor the features for the RS domain, a clustering function based on feature distance calculation was introduced in [165]. Yan et al. utilize multi-temporal remote sensing indices as domain knowledge to guide the contrastive learning of change representation [166].
Recently, Visual Foundation Models (VFMs) such as CLIP [167] and Segment Anything Model (SAM) [168] have emerged and gained significant research interest. VFMs, pre-trained on web-scale datasets, are designed to capture universal feature representations that can be generalized to a variety of downstream tasks. However, since these VFMs are generally trained with natural images, they exhibit certain biases in RS applications [169]. Considering spectral and temporal characteristics of RSIs, several RS foundation models (FMs) have been developed, including GFM [170], SpectralGPT [1] and SkySense [171]. These FMs enables training-free feature embedding on multi-spectral, multi-temporal, and multi-modal RS data, thereby supporting a variety of downstream tasks including CD. However, since these FMs are typically trained with the context intrinsic to RSIs, they do not consider the specific application context of CD tasks. Consequently, employing these models for CD still necessitates incorporating CD-specific modules and performing fully supervised fine-tuning.
Considering that FMs contain implicit knowledge of the image content, several recent methods have explored employing FMs to achieve sample-efficient CD. In [4], VFMs are adapted to the RS domain using a semantic latent aligning technique, demonstrating their sample efficiency. Fig.8 presents an overview of this approach, where the latent are aligned via temporal consistency regularization. In [112],
a side-adaption framework is proposed to inject the VFM knowledge into CD models. In [172], SAM is utilized to generate pseudo labels from vague change maps used as prompts. In [113], zero-shot CD is achieved by measuring the similarity of SAM-encoded features. In [173], Chen et al. employed SAM to achieve unsupervised CD between optical images and map data. Dong et al. [174] utilized CLIP to learn visual-language representations to improve CD accuracy.
| Sup. | Dataset | Method | Training data used | Training label used | Accuracy Metrics | ||
| OA (%) | IoU (%) | (%) | |||||
| FSCD | Levir | BIT [2] | 100% | 100% | 98.92 | 80.68 | 89.31 |
| SAM-CD[4] | 100% | 100% | 99.14 | 84.26 | 91.68 | ||
| ScratchF. [23] | 100% | 100% | 99.16 | 84.63 | 91.68 | ||
| Changer[3] | 100% | 100% | — | — | 92.06 | ||
| WHU | BIT [2] | 100% | 100% | 98.75 | 72.39 | 83.95 | |
| ScratchF. [23] | 100% | 100% | 99.37 | 84.97 | 91.87 | ||
| SAM-CD [4] | 100% | 100% | 99.60 | 91.15 | 95.37 | ||
| OSCD | FC-Siam-conc [9] | 100% | 100% | 94.07 | — | 45.20 | |
| FC-Siam-diff [9] | 100% | 100% | 94.86 | — | 48.86 | ||
| FC-EF [9] | 100% | 100% | 94.23 | — | 48.89 | ||
| ScratchF. [23] | 100% | 100% | 97.33 | 40.22 | 57.37 | ||
| FC-EF-Res [26] | 100% | 100% | 95.34 | — | 59.20 | ||
| SMCD | Levir | ECPS[53] | 5% 10% 20% 40% | 5% 10% 20% 40% | 98.59 98.74 98.70 98.85 | 75.56 77.63 78.06 79.30 | 86.06 87.40 87.68 88.46 |
| ST-RCL[121] | 5% 10% 20% 40% | 5% 10% 20% 40% | — | — | 87.11 88.75 89.46 89.77 | ||
| STCRNet[47] | 5% 10% 20% 40% | 5% 10% 20% 40% | — | 80.65 82.23 82.98 83.48 | 89.29 90.25 90.70 91.00 | ||
| UniMatch[46] | 5% 10% 20% 40% | 5% 10% 20% 40% | 80.88 81.73 82.04 82.25 | 89.43 89.95 90.13 90.26 | |||
| C2F-SemiCD[122] | 5% 10% 20% | 5% 10% 20% | 98.99 99.08 99.12 | 81.76 83.15 83.75 | 89.97 90.80 91.16 | ||
| ISCDNet[48] | 5% 10% 20% 40% | 5% 10% 20% 40% | — | 81.84 82.34 82.53 83.58 | 90.01 90.32 90.43 91.06 | ||
| WHU | UniMatch [46] | 5% 10% 20% 40% | 5% 10% 20% 40% | — | 75.15 77.30 81.64 82.13 | 85.81 87.20 90.95 91.26 | |
| STCRNet [47] | 5% 10% 20% 40% | 5% 10% 20% 40% | — | 77.03 81.91 83.40 83.93 | 87.03 90.06 90.95 91.26 | ||
| ST-RCL [121] | 5% 10% 20% 40% | 5% 10% 20% 40% | — | — | 87.80 88.00 89.29 83.84 | ||
| C2F-SemiCD [122] | 5% 10% 20% | 5% 10% 20% | 98.87 98.94 99.23 | 79.14 79.50 81.93 | 88.35 88.58 90.07 | ||
| ISCDNet [48] | 5% 10% 20% 40% | 5% 10% 20% 40% | — | 81.48 82.59 83.72 85.18 | 89.80 90.46 91.14 92.00 | ||
| OSCD | ECPS [53] | 5% 10% 20% 40% | 5% 10% 20% 40% | 87.12 88.13 88.59 88.98 | 37.05 37.69 40.31 41.44 | 54.07 54.75 57.46 58.60 | |
| WSCD | Levir | ICR-MJS[69] | 100% | image label | — | 67.41 | 50.84 |
| KD-MSI[67] | 100% | image label | 93.9 | 64.9 | 74.9 | ||
| CARGNet[125] | 100% | point label | 98.28 | 72.13 | 83.81 | ||
| WHU | ICR-MJS [69] | 100% | image label | — | 65.09 | 78.86 | |
| KD-MSI [67] | 100% | image label | 99.7 | 76.9 | 85.4 | ||
| OSCD | FCD-GAN [42] | 100% | box label | 91.38 | 21.28 | 35.08 | |
| SSCD | Levir | LGPNet [84] | 100% + ext. | 1% (FT) | — | 46.13 | 62.09 |
| DST-VGG [52] | 100% | 100% (FT) | 99.21 | 85.44 | 92.15 | ||
| RECM [175] | 100% + ext. | 100% (FT) | — | — | 92.77 | ||
| WHU | GLCL [82] | 100% | 100% (FT) | — | 90.29 | 90.54 | |
| DST-VGG [52] | 100% | 100% (FT) | 99.64 | 90.34 | 95.69 | ||
| OSCD | PixSSLs [86] | 100% + ext. | 0% | 95.70 | — | 53 | |
| DK-SSCD [166] | 100% | 0% | 95.54 | — | 55.69 | ||
| TD-SSCD [89] | 100% | 100% (FT) | 95.38 | — | 72.11 | ||
| UCD | Levir | Anychange[113] | 0% | 0% | — | — | 23.0 |
| DSFA [61] | 0% | 0% | 77.33 | — | 47.65 | ||
| DCVA [114] | 0% | 0% | 84.75 | — | 52.89 | ||
| SCM [147] | 100% | 0% | 88.80 | — | 62.80 | ||
| OSCD | DCVA [114] | 0% | 0% | 91.6 | — | 24.5 | |
| KPCA-MNet [142] | 0% | 0% | — | — | 30.2 | ||
| FLCG [176] | 100% | 0% | — | — | 32.1 | ||
| DMLCD [116] | 100% | 0% | 95.8 | — | 32.5 | ||
| DSFA [61] | 0% | 0% | 92.63 | — | 35.85 | ||
| Datasets | Resolution | Image size | Image | Change | Change | Highest (%) | ||||
| Pairs | Pixels | Instances | FSCD | SMCD (5%) | WSCD | SSCD (w/o. FT) | UCD | |||
| Levir | 0.5m | 1024×1024 | 637 | 30,913,975 | 31,333 | 92.06 [3] | 90.01[48] | 74.9 [69] | 62.80 [147] | |
| WHU | 0.3m | 32,507×15,354 | 1 | 21,352,815 | 2297 | 95.37 [4] | 89.80 [48] | 85.4 [67] | — | — |
| OSCD | 10m | 600×600 | 24 | 148,069 | 1048 | 59.20 [26] | 54.07 [53] | 35.08 [42] | 55.69 [166] | 35.85 [61] |
III-E Comparison of Accuracy
To elucidate the efficacy of the sample-efficient DL methodologies discussed, Table II presents a comparative analysis of the SOTA accuracy obtained on several benchmark CD datasets. The accuracy metrics include overall accuracy (OA), intersection over union (IoU), and , which are common in BCD. To facilitate comparison between different types of supervision, we select the most frequently used datasets in various tasks, including Levir [177], WHU [178], and OSCD [179]. It is important to acknowledge that there are significant variations in the experimental configurations of the methods being compared, a concern raised in [180]. Therefore, this table is intended solely to provide an intuitive assessment of the accuracy of SOTA.
To facilitate a comprehensive understanding of the training samples utilized across various methods, Table III presents the metadata of each CD benchmark. Overall, Levir and WHU are two VHR datasets with large image size and rich change samples. In contrast, OSCD has lower resolution and contains less training samples. To present an intuitive comparison of the SOTA accuracy across various learning paradigms, Table III also summarizes the highest scores achieved in each dataset.
Tables II and III clearly demonstrate that the accuracy of CD is highly dependent on the level of supervision during the training process. First, the CD accuracy on the Levir and WHU datasets is significantly higher than that on the OSCD dataset. This disparity is attributed to the richer set of change samples and the finer spatial resolution present in the Levir and WHU datasets. Second, the accuracy of FSCD and SSCD with fine-tuning (FT) is higher than that of SMCD, WSCD, UCD and SSCD without FT. Notably, the SSCD with FT marginally surpasses FSCD, which can be attributed to its extensive pre-training that effectively utilizes the image contexts as extra supervisions. This observed accuracy hierarchy aligns with the strong-to-weak supervision level in the different learning paradigms, as illustrated in Fig.3.
SMCD achieves the highest accuracy among sample-efficient CD approaches. Recent advances in SMCD ensure remarkably high accuracy with only a small proportion of training samples. For example, utilizing only 5% of the training data, the SOTA SMCD methods only see a minor reduction of 2% on the Levir and 0.6% on the OSCD datasets. However, it is important to note that even with this small portion of training data, SMCD still requires a substantial number of change samples. Based on the number of change instances detailed in Table II and through a rough estimate, SMCD typically requires more than 100 change samples on the Levir and WHU datasets.
The accuracy of WSCD is significantly influenced by the level of supervision applied. Compared to image-level labels, employing spatial labels (such as box or point labels) for training WSCD algorithms generally results in superior accuracy. For example, as tested on the Levir dataset, point label-supervised CD approach [125] has an advantage of exceeding 30% in compared to approaches that utilize image labels. Regarding image label-supervised SMCD, while a relatively high accuracy is attained (particularly on VHR datasets), it is important to note that training is carried out using patch labels rather than a complete RSI. As reported in [67] and [69], image labels are assigned to each pair of patches with 256256 pixels. Therefore, this type of SMCD still necessitates a certain degree of human intervention.
SSCD can be employed as either an approach to achieve label-free learning of change representations, or merely as a pretraining technique to initialize the DNN parameters. SSCD without FT is challenging, since the image contexts utilized in self-supervised learning are independent of the application contexts inherent in CD tasks. Most literature works adopt the latter strategy, that is, pre-training through self-supervision and fine-tuning with all available change samples. This strategy yields substantial accuracy improvements over the vanilla FSCD. The improvements are particularly significant on the OSCD dataset (up to 12% in [89]), which can be attributed to the scarcity of training samples within this dataset.
Meanwhile, SSCD without FT can be regarded as a distinct subset of UCD that utilizes self-supervised learning techniques. Most literature studies on UCD and label-free SSCD have been conducted on medium resolution datasets such as OSCD. They are commonly adopted for analysis of satellite images such as those collected by Sentinel and Landsat. Due to the fact that numerous experiments are performed on non-open benchmarks, it is challenging to assess the level of accuracy, and hence, these results are not presented in Table II. The highest metrics obtained on the OSCD dataset are 92.63% in OA and 35.85% in [61], exhibiting a reduction exceeding 23% in relative to FSCD. UCD (or label-free SSCD) is more challenging when applied to VHR datasets due to the increased spatial complexity. A reduction of approximately 30% in is noted when applied to the Levir dataset. One of the zero-shot CD approaches, Anychange [113], obtains an accuracy of 24.5% in , highlighting a substantial gap for further advancements.
In summary, sample-efficient CD methods have greatly reduced the dependence on a large volume of training samples, thereby achieving relatively high accuracy with a reduced number of samples or the utilization of weak labels. However, training CD algorithms without labels or using a very low level of supervision remains a challenge.
IV challenges and Future Trends
Despite the advanced methodologies and techniques developed, training DNNs for CD with very few samples remains challenging. This section presents an analysis of the remaining challenges and bottleneck problems in applying sample-efficient CD algorithms, along with a prospective overview of future developments in the field.
IV-A Challenges
Sample-efficient CD still encounters considerable challenges in mitigating the data dependency and in generalizing insights across diverse datasets without necessitating extensive fine-tuning. In the followings we analyse several principal obstacles.
IV-A1 Domain adaptability
RSIs collected by different sensors and platforms exhibit considerable variability in spatial resolution, imaging scale, and spectral patterns. Conventional machine learning methods derive different levels of analysis on pixel spectrals, local textures, and object contexts [181, 182]. Despite the capability of DL to facilitate end-to-end modeling of multilevel change patterns, these approaches still suffer from severe accuracy degradation when dealing with data from other domains. Although there are heterogeneous CD methods, they are constrained by trained domain transitions and face challenges in obtaining domain-invariant change representations.
The major reasons are two-fold: i) domain-specific network architectures. DL-based CD methods employ diversified DL techniques to perform intricate analysis on the informative attributes in different RS data. For instance, some methods employ spectral attention [44] and superpixel GNNs [183] for hyperspectral CD, while some other methods introduce low-level supervision [8, 128] and geometric perturbations [47] for CD in VHR RSIs. Although these designs yield significant accuracy enhancements within the training domains, they present substantial challenges when it comes to generalizing to novel domains. ii) Domain-coupled change learning. Typical CD approaches learn mappings of difference patterns specific to training domains. Although there exist domain-invariant change representation methods [165], they also neglect the intrinsic semantic transition mechanism in CD. Consequently, the resultant models struggle to differentiate between specific semantic changes and unknown domain variations.
IV-A2 Spatial and Temporal Complexity
Recent advancements in Earth Observation technologies enable dense time-series monitoring through the deployment of surveillance satellites and small satellite constellations. The improvement in temporal resolution benefits applications that require frequent observations, including environmental monitoring, urban management, and disaster alarm. However, DL-based analysis on time series CD is still in an early exploration phase, especially for the analysis of long-time series of HR images. Conventional methods address TSCD as a multidate LCLU classification task or analyze the trajectory of multi-temporal images [36]. This neglects the spatio-temporal context in HR data and may result in false alarms due to temporal variations (such as temporary occlusions and seasonal changes).
Additionally, few studies address the spatial misalignment that often occurs in multi-source RSIs. Observation platforms such as UAVs and surveillance satellites offer quick access to regions of interest due to shorter revisiting. However, these platforms differ greatly in imaging angles and geometric distortions [6]. Most CD studies require costly and time-consuming preprocessing operations to ensure strict spatial consistency, thereby constraining their applicability. To expand the applicability of CD techniques, there is a research gap in developing sample-efficient methodologies to address the spatial and temporal complexity in CD.
IV-A3 Unseen changes
Sample-efficient CD requires identification of changes that are absent from the training data. Unseen changes can be classified into two distinct types: (i) change instances that exhibit novel appearances yet remain within the established categories, a frequent occurrence in SMCD due to constrained usage of training data; and (ii) novel categories of changes that remain undefined, a common situation in SSCD and UCD while transferring domain knowledge into new datasets.
In BCD, the major challenge lies in distinguishing semantic changes amid temporal variations; whereas in MCD/SCD, the difficulties additionally encompass the identification of novel change categories. These challenges can be further amplified while encountering the previously mentioned obstacles including domain gap and spatio-temporal complexity. Generalization of CD insights into wider RS applications requires a profound understanding of the semantic transitions, as well as comprehension of the specific application contexts.
IV-B Future trends
IV-B1 Multi-temporal foundation models
Recent breakthroughs in generative image synthesis, self-supervision techniques, and VFMs are setting the stage for the next generation of CD algorithms [4, 113]. Although variable VFMs [168] and spectral foundation models [1, 171] have been established within the domains of computer vision and RS, the development of multi-temporal foundation models (TFMs) is crucial to achieve sample-efficient, sensor-agnostic, and eventually training-free CD within a unimodal framework.
TFMs are designed to capture temporal patterns and dynamic changes across multiple observations and subsequently utilizing the learned temporal knowledge to identify evolving trends. These models are designed to manage complex spatio-temporal dependencies within time-series RSIs, address data heterogeneity, and adapt to varying temporal intervals. They ensure scalability for extensive volumes of RS big data and create universal change representations by seamlessly integrating diverse sensor data across a range of resolutions and scales.
IV-B2 Few-shot and Zero-shot CD
As detailed in Sec.III-E, most literature studies on SMCD still require a considerable number of training samples to achieve accurate results. In real-world applications, collecting change samples is costly, especially when data is scarce or quick responses are necessary. Thus, developing few-shot and zero-shot CD algorithms is critical for deploying CD systems with minimal change samples.
Few-shot learning (FSL) aims to acquire generalized knowledge applicable across various tasks using only a few examples. Most of the literature methods on FSL follow the meta-learning framework proposed in [184]. This framework mimics the few-shot applicational scenarios, where the network learns to identify novel classes in the unlabeled data (query set) by utilizing the knowledge obtained from a few number of examples in the labeled data (support set). FSL allows DNNs to generalize to novel classes from a minimum of just one example, and has been investigated in the task of semantic segmentation [185].
Zero-shot learning (ZSL) uses data from known classes to train DNNs, enabling inference on unseen classes. Typical FSL methods map visual and semantic features to a common space for data-independent semantic alignment. Several problem settings have been further derived from ZSL to address various distinct application contexts [186]. These include: i) transductive ZSL, which uses unlabeled unseen data in training; ii) generalized ZSL, which involves classifying both seen and unseen classes; iii) domain adaptation, which adapts unseen targets to seen source domains; and iv) class-attribute association, which links unsupervised semantics to human-recognizable attributes.
Integrating FSL and ZSL into CD methods could remove the need for fine-tuning algorithms on target domains. However, the context of CD presents more severe challenges, such as data heterogeneity and reduced density of semantic contexts. Few-shot and zero-shot CD remain to be rarerly explored and requires further research investigations.
IV-B3 Interactive CD
In many practical cases, CD is closely associated with the specific application context, such as urban building changes or agricultural monitoring. Conventional DL-based CD implicitly learn these applicational contexts through training samples, which is challenging with scarce change samples. An alternative is to incorporate explicit human interactions to guide the active exploitation of the relevant change information. Two key interaction types are spatial and language interactions.
a. Spatial interactions. In various VFMs, user-generated input, such as points, scribbles, and rectangles, is encoded as spatial prompts to indicate the interesting objects to be extracted/segmented [168]. This approach can be expanded to CD tasks by incorporating bi-temporal annotations to specify the change objects of interest. This depends on the application of WSCD methodologies, which entails parsing weak spatial annotations into dense change predictions. Moreover, to minimize human effort and achieve the capability of ’clicking few and detecting many’, the incorporation of SMCD and continual learning techniques [187] is essential. The former facilitate the efficient use of sparse and scarce change annotations, while the latter allows for interactive refining and updating of annotations to specify the desired changes.
b. Language interactions. Recent developments in the fusion of language models with RS data analysis represent a new frontier in CD, offering innovative ways to interact with and interpret CD results. This approach includes: i) change captioning: describing the major changes in multi-temporal RSIs, ii) prompt-driven CD: selectively segment the changes of interested LCLU categories given user prompt such as keywords [174], and iii) visual question answering for CD: given questions concerning changes on RSIs, providing detailed and informative language answers. Language-driven CD offers a more intuitive interface between users and CD systems.
V Conclusions
Leveraging limited data to train DNNs with dense parameters has consistently been a bottleneck challenge in the deployment of DL algorithms. Recently, with the ongoing progress in DL methodologies such as image generation, self-supervised learning, and VFMs, there has been a growing increase in research attention towards sample-efficient CD.
CD has consistently been an important visual recognition task in RS applications. It can be classified into BCD, MCD/SCD, and TSCD, based on the granularity of the results and the number of observation dates. Sample-efficient change detection can be categorized into distinct learning paradigms based on the diversity in label forms and quantities. These paradigms encompass four principal types, including SMCD, WSCD, SSCD, and UCD. Each learning setting further derives diverse strategies and technologies specifically designed to overcome the unique challenges presented, which have been systematically reviewed and summarized in Table I. Moreover, to facilitate an intuitive comprehension of the SOTA performance in sample-efficient CD, a comparative analysis is performed across various learning settings with regard to change samples and the achieved accuracy. Finally, a critical analysis of the challenges encountered is provided, along with recommendations for potential future research directions.
In conclusion, the exploration of sample-efficient CD is still in an early stage of exploration. Although notable progress has been made in decreasing the dependence on extensive training samples, the challenge of performing CD with very scarce samples persists. There exists a substantial research gap in the development of CD methodologies to tackle more challenging CD scenarios, such as few-shot CD, image label-supervised WSCD, unsupervised CD (UCD), non-fine-tuned SSCD, and ultimately zero-shot CD.
Acknowledgement
This work was supported by the National Natural Science Foundation of China under Grant 42201443, Grant 42271350, and also supported by the International Partnership Program of the Chinese Academy of Sciences under Grant No.313GJHZ2023066FN. Danfeng Hong is the corresponding author.
References
- [1] D. Hong, B. Zhang, X. Li, Y. Li, C. Li, J. Yao, N. Yokoya, H. Li, P. Ghamisi, X. Jia, A. Plaza, P. Gamba, J. A. Benediktsson, and J. Chanussot, “Spectralgpt: Spectral remote sensing foundation model,” IEEE Transactions on Pattern Analysis and Machine Intelligence, vol. 46, no. 8, pp. 5227–5244, 2024.
- [2] H. Chen, Z. Qi, and Z. Shi, “Remote sensing image change detection with transformers,” IEEE Transactions on Geoscience and Remote Sensing, vol. 60, pp. 1–14, 2021.
- [3] S. Fang, K. Li, and Z. Li, “Changer: Feature interaction is what you need for change detection,” IEEE Transactions on Geoscience and Remote Sensing, vol. 61, pp. 1–11, 2023.
- [4] L. Ding, K. Zhu, D. Peng, H. Tang, K. Yang, and L. Bruzzone, “Adapting segment anything model for change detection in hr remote sensing images,” IEEE Transactions on Geoscience and Remote Sensing, vol. 62, pp. 1–11, 2024.
- [5] W. Shi, M. Zhang, R. Zhang, S. Chen, and Z. Zhan, “Change Detection Based on Artificial Intelligence: State-of-the-Art and Challenges,” Remote Sensing, vol. 12, no. 10, p. 1688.
- [6] L. Shen, Y. Lu, H. Chen, H. Wei, D. Xie, J. Yue, R. Chen, S. Lv, and B. Jiang, “S2looking: A satellite side-looking dataset for building change detection,” Remote Sensing, vol. 13, no. 24, p. 5094, 2021.
- [7] G. Cheng, Y. Huang, X. Li, S. Lyu, Z. Xu, Q. Zhao, and S. Xiang. Change Detection Methods for Remote Sensing in the Last Decade: A Comprehensive Review. [Online]. Available: http://arxiv.org/abs/2305.05813
- [8] D. Peng, Y. Zhang, and H. Guan, “End-to-end change detection for high resolution satellite images using improved unet++,” Remote Sensing, vol. 11, no. 11, p. 1382, 2019.
- [9] R. C. Daudt, B. Le Saux, and A. Boulch, “Fully convolutional siamese networks for change detection,” in 2018 25th IEEE International Conference on Image Processing (ICIP). IEEE, 2018, pp. 4063–4067.
- [10] M. Zhang and W. Shi, “A feature difference convolutional neural network-based change detection method,” IEEE Transactions on Geoscience and Remote Sensing, vol. 58, no. 10, pp. 7232–7246, 2020.
- [11] X. Hou, Y. Bai, Y. Li, C. Shang, and Q. Shen, “High-resolution triplet network with dynamic multiscale feature for change detection on satellite images,” ISPRS Journal of Photogrammetry and Remote Sensing, vol. 177, pp. 103–115, 2021.
- [12] Z. Li, C. Tang, L. Wang, and A. Y. Zomaya, “Remote sensing change detection via temporal feature interaction and guided refinement,” IEEE Transactions on Geoscience and Remote Sensing, vol. 60, pp. 1–11, 2022.
- [13] D. Peng, L. Bruzzone, Y. Zhang, H. Guan, and P. He, “Scdnet: A novel convolutional network for semantic change detection in high resolution optical remote sensing imagery,” International Journal of Applied Earth Observation and Geoinformation, vol. 103, p. 102465, 2021.
- [14] J. Chen, Z. Yuan, J. Peng, L. Chen, H. Huang, J. Zhu, Y. Liu, and H. Li, “Dasnet: Dual attentive fully convolutional siamese networks for change detection in high-resolution satellite images,” IEEE Journal of Selected Topics in Applied Earth Observations and Remote Sensing, vol. 14, pp. 1194–1206, 2020.
- [15] Q. Shi, M. Liu, S. Li, X. Liu, F. Wang, and L. Zhang, “A deeply supervised attention metric-based network and an open aerial image dataset for remote sensing change detection,” IEEE transactions on geoscience and remote sensing, vol. 60, pp. 1–16, 2021.
- [16] H. Chen, C. Wu, B. Du, L. Zhang, and L. Wang, “Change detection in multisource vhr images via deep siamese convolutional multiple-layers recurrent neural network,” IEEE Transactions on Geoscience and Remote Sensing, vol. 58, no. 4, pp. 2848–2864, 2019.
- [17] J. Wu, B. Li, Y. Qin, W. Ni, H. Zhang, R. Fu, and Y. Sun, “A multiscale graph convolutional network for change detection in homogeneous and heterogeneous remote sensing images,” International Journal of Applied Earth Observation and Geoinformation, vol. 105, p. 102615, 2021.
- [18] A. Dosovitskiy, L. Beyer, A. Kolesnikov, D. Weissenborn, X. Zhai, T. Unterthiner, M. Dehghani, M. Minderer, G. Heigold, S. Gelly et al., “An image is worth 16x16 words: Transformers for image recognition at scale,” arXiv preprint arXiv:2010.11929, 2020.
- [19] C. Li, B. Zhang, D. Hong, J. Zhou, G. Vivone, S. Li, and J. Chanussot, “Casformer: Cascaded transformers for fusion-aware computational hyperspectral imaging,” Information Fusion, vol. 108, p. 102408, 2024.
- [20] L. Ding, D. Lin, S. Lin, J. Zhang, X. Cui, Y. Wang, H. Tang, and L. Bruzzone, “Looking outside the window: Wide-context transformer for the semantic segmentation of high-resolution remote sensing images,” IEEE Transactions on Geoscience and Remote Sensing, vol. 60, pp. 1–13, 2022.
- [21] D. Hong, B. Zhang, H. Li, Y. Li, J. Yao, C. Li, M. Werner, J. Chanussot, A. Zipf, and X. X. Zhu, “Cross-city matters: A multimodal remote sensing benchmark dataset for cross-city semantic segmentation using high-resolution domain adaptation networks,” Remote Sensing of Environment, vol. 299, p. 113856, 2023.
- [22] P. Yuan, Q. Zhao, X. Zhao, X. Wang, X. Long, and Y. Zheng, “A transformer-based siamese network and an open optical dataset for semantic change detection of remote sensing images,” International Journal of Digital Earth, vol. 15, no. 1, pp. 1506–1525, 2022.
- [23] M. Noman, M. Fiaz, H. Cholakkal, S. Narayan, R. M. Anwer, S. Khan, and F. S. Khan, “Remote sensing change detection with transformers trained from scratch,” IEEE Transactions on Geoscience and Remote Sensing, 2024.
- [24] K. Zhang, X. Zhao, F. Zhang, L. Ding, J. Sun, and L. Bruzzone, “Relation changes matter: Cross-temporal difference transformer for change detection in remote sensing images,” IEEE Transactions on Geoscience and Remote Sensing, 2023.
- [25] F. Bovolo and L. Bruzzone, “The time variable in data fusion: A change detection perspective,” IEEE Geoscience and Remote Sensing Magazine, vol. 3, no. 3, pp. 8–26, 2015.
- [26] R. C. Daudt, B. Le Saux, A. Boulch, and Y. Gousseau, “Multitask learning for large-scale semantic change detection,” Computer Vision and Image Understanding, vol. 187, p. 102783, 2019.
- [27] K. Yang, G.-S. Xia, Z. Liu, B. Du, W. Yang, M. Pelillo, and L. Zhang, “Asymmetric siamese networks for semantic change detection in aerial images,” IEEE Transactions on Geoscience and Remote Sensing, vol. 60, pp. 1–18, 2021.
- [28] A. Singh, “Digital change detection techniques using remotely-sensed data,” Int. J. Remote Sensing, vol. 10, no. 6, pp. 989–1003, 1989.
- [29] L. Bruzzone and S. B. Serpico, “An iterative technique for the detection of land-cover transitions in multitemporal remote-sensing images,” IEEE transactions on geoscience and remote sensing, vol. 35, no. 4, pp. 858–867, 1997.
- [30] C. Wu, B. Du, X. Cui, and L. Zhang, “A post-classification change detection method based on iterative slow feature analysis and bayesian soft fusion,” Remote Sensing of Environment, vol. 199, pp. 241–255, 2017.
- [31] L. Mou, L. Bruzzone, and X. X. Zhu, “Learning spectral-spatial-temporal features via a recurrent convolutional neural network for change detection in multispectral imagery,” IEEE Transactions on Geoscience and Remote Sensing, vol. 57, no. 2, pp. 924–935, 2018.
- [32] Q. Zhu, X. Guo, W. Deng, S. Shi, Q. Guan, Y. Zhong, L. Zhang, and D. Li, “Land-Use/Land-Cover change detection based on a Siamese global learning framework for high spatial resolution remote sensing imagery,” ISPRS Journal of Photogrammetry and Remote Sensing, vol. 184, pp. 63–78.
- [33] Z. Zheng, Y. Zhong, S. Tian, A. Ma, and L. Zhang, “Changemask: Deep multi-task encoder-transformer-decoder architecture for semantic change detection,” ISPRS Journal of Photogrammetry and Remote Sensing, vol. 183, pp. 228–239, 2022.
- [34] L. Ding, J. Zhang, H. Guo, K. Zhang, B. Liu, and L. Bruzzone, “Joint spatio-temporal modeling for semantic change detection in remote sensing images,” IEEE Transactions on Geoscience and Remote Sensing, 2024.
- [35] W. Li, P. Ma, H. Wang, and C. Fang, “SAR-TSCC: A Novel Approach for Long Time Series SAR Image Change Detection and Pattern Analysis,” IEEE Transactions on Geoscience and Remote Sensing, vol. 61, pp. 1–16.
- [36] A. T. Stahl, R. Andrus, J. A. Hicke, A. T. Hudak, B. C. Bright, and A. J. Meddens, “Automated attribution of forest disturbance types from remote sensing data: A synthesis,” Remote Sensing of Environment, vol. 285, p. 113416.
- [37] Y. Yuan, L. Lin, L.-Z. Huo, Y.-L. Kong, Z.-G. Zhou, B. Wu, and Y. Jia, “Using An Attention-Based LSTM Encoder–Decoder Network for Near Real-Time Disturbance Detection,” IEEE Journal of Selected Topics in Applied Earth Observations and Remote Sensing, vol. 13, pp. 1819–1832.
- [38] H. He, J. Yan, D. Liang, Z. Sun, J. Li, and L. Wang, “Time-series land cover change detection using deep learning-based temporal semantic segmentation,” Remote Sensing of Environment, vol. 305, p. 114101.
- [39] O. Sefrin, F. M. Riese, and S. Keller, “Deep Learning for Land Cover Change Detection,” Remote Sensing, vol. 13, no. 1, p. 78.
- [40] S. Saha, F. Bovolo, and L. Bruzzone, “Change Detection in Image Time-Series Using Unsupervised LSTM,” IEEE Geoscience and Remote Sensing Letters, vol. 19, pp. 1–5.
- [41] D. Peng, L. Bruzzone, Y. Zhang, H. Guan, H. Ding, and X. Huang, “SemiCDNet: A Semisupervised Convolutional Neural Network for Change Detection in High Resolution Remote-Sensing Images,” IEEE Transactions on Geoscience and Remote Sensing, vol. 59, no. 7, pp. 5891–5906.
- [42] C. Wu, B. Du, and L. Zhang, “Fully Convolutional Change Detection Framework With Generative Adversarial Network for Unsupervised, Weakly Supervised and Regional Supervised Change Detection,” IEEE Transactions on Pattern Analysis and Machine Intelligence, vol. 45, no. 8, pp. 9774–9788, 2023.
- [43] L. Ding, H. Guo, S. Liu, L. Mou, J. Zhang, and L. Bruzzone, “Bi-temporal semantic reasoning for the semantic change detection in hr remote sensing images,” IEEE Transactions on Geoscience and Remote Sensing, vol. 60, pp. 1–14, 2022.
- [44] M. Hu, C. Wu, and L. Zhang, “Hypernet: Self-supervised hyperspectral spatial–spectral feature understanding network for hyperspectral change detection,” IEEE Transactions on Geoscience and Remote Sensing, vol. 60, pp. 1–17, 2022.
- [45] W. G. C. Bandara and V. M. Patel. Revisiting Consistency Regularization for Semi-supervised Change Detection in Remote Sensing Images. [Online]. Available: http://arxiv.org/abs/2204.08454
- [46] L. Yang, L. Qi, L. Feng, W. Zhang, and Y. Shi, “Revisiting Weak-to-Strong Consistency in Semi-Supervised Semantic Segmentation,” in 2023 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). IEEE, pp. 7236–7246.
- [47] L. Wang, M. Zhang, and W. Shi, “STCRNet: A Semi-Supervised Network Based on Self-Training and Consistency Regularization for Change Detection in VHR Remote Sensing Images,” vol. 17, pp. 2272–2282.
- [48] Y. Zuo, L. Li, X. Liu, Z. Gao, L. Jiao, F. Liu, and S. Yang, “Robust Instance-Based Semi-Supervised Learning Change Detection for Remote Sensing Images,” vol. 62, pp. 1–15.
- [49] J. Shi, T. Wu, H. Yu, A. K. Qin, G. Jeon, and Y. Lei, “Multi-layer composite autoencoders for semi-supervised change detection in heterogeneous remote sensing images,” vol. 66, no. 4, p. 140308.
- [50] J.-X. Wang, T. Li, S.-B. Chen, J. Tang, B. Luo, and R. C. Wilson, “Reliable Contrastive Learning for Semi-Supervised Change Detection in Remote Sensing Images,” IEEE Transactions on Geoscience and Remote Sensing, vol. 60, pp. 1–13.
- [51] S. Yuan, R. Zhong, C. Yang, Q. Li, and Y. Dong, “Dynamically Updated Semi-Supervised Change Detection Network Combining Cross-Supervision and Screening Algorithms,” vol. 62, pp. 1–14.
- [52] D. Zheng, Z. Wu, J. Liu, C.-C. Hung, and Z. Wei, “Detail enhanced change detection in vhr images using a self-supervised multi-scale hybrid network,” IEEE Journal of Selected Topics in Applied Earth Observations and Remote Sensing, 2024.
- [53] Y. Yang, X. Tang, J. Ma, X. Zhang, S. Pei, and L. Jiao, “Ecps: Cross pseudo supervision based on ensemble learning for semi-supervised remote sensing change detection,” IEEE Transactions on Geoscience and Remote Sensing, 2024.
- [54] L. Kondmann, S. Saha, and X. X. Zhu, “SemiSiROC: Semisupervised Change Detection With Optical Imagery and an Unsupervised Teacher Model,” vol. 16, pp. 3879–3891.
- [55] Y. Wang, H. Wang, Y. Shen, J. Fei, W. Li, G. Jin, L. Wu, R. Zhao, and X. Le, “Semi-Supervised Semantic Segmentation Using Unreliable Pseudo-Labels,” in 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). IEEE, pp. 4238–4247.
- [56] C. Sun, H. Chen, C. Du, and N. Jing, “SemiBuildingChange: A Semi-Supervised High-Resolution Remote Sensing Image Building Change Detection Method With a Pseudo Bitemporal Data Generator,” vol. 61, pp. 1–19.
- [57] X. Zhang, W. Shi, Z. Lv, and F. Peng, “Land Cover Change Detection from High-Resolution Remote Sensing Imagery Using Multitemporal Deep Feature Collaborative Learning and a Semi-supervised Chan–Vese Model,” vol. 11, no. 23, p. 2787.
- [58] X. Tang, H. Zhang, L. Mou, F. Liu, X. Zhang, X. X. Zhu, and L. Jiao, “An Unsupervised Remote Sensing Change Detection Method Based on Multiscale Graph Convolutional Network and Metric Learning,” IEEE Transactions on Geoscience and Remote Sensing, vol. 60, pp. 1–15.
- [59] X. Hou, Y. Bai, Y. Xie, H. Ge, Y. Li, C. Shang, and Q. Shen, “Deep collaborative learning with class-rebalancing for semi-supervised change detection in SAR images,” vol. 264, p. 110281.
- [60] X. Zhang, Y. Yang, L. Ran, L. Chen, K. Wang, L. Yu, P. Wang, and Y. Zhang, “Remote sensing image semantic change detection boosted by semi-supervised contrastive learning of semantic segmentation,” IEEE Transactions on Geoscience and Remote Sensing, 2024.
- [61] B. Du, L. Ru, C. Wu, and L. Zhang, “Unsupervised deep slow feature analysis for change detection in multi-temporal remote sensing images,” IEEE Transactions on Geoscience and Remote Sensing, vol. 57, no. 12, pp. 9976–9992, 2019.
- [62] F. Gao, J. Dong, B. Li, and Q. Xu, “Automatic change detection in synthetic aperture radar images based on pcanet,” IEEE Geoscience and Remote Sensing Letters, vol. 13, no. 12, pp. 1792–1796, 2016.
- [63] A. Song, J. Choi, Y. Han, and Y. Kim, “Change detection in hyperspectral images using recurrent 3d fully convolutional networks,” Remote Sensing, vol. 10, no. 11, 2018.
- [64] M. Gong, T. Zhan, P. Zhang, and Q. Miao, “Superpixel-based difference representation learning for change detection in multispectral remote sensing images,” IEEE Transactions on Geoscience and Remote Sensing, vol. 55, no. 5, pp. 2658–2673, 2017.
- [65] J. Geng, X. Ma, X. Zhou, and H. Wang, “Saliency-guided deep neural networks for sar image change detection,” IEEE Transactions on Geoscience and Remote Sensing, vol. 57, no. 10, pp. 7365–7377, 2019.
- [66] Y. Cao, X. Huang, and Q. Weng, “A multi-scale weakly supervised learning method with adaptive online noise correction for high-resolution change detection of built-up areas,” Remote Sensing of Environment, vol. 297, p. 113779.
- [67] B. Lu, C. Ding, J. Bi, and D. Song. Weakly Supervised Change Detection via Knowledge Distillation and Multiscale Sigmoid Inference. [Online]. Available: http://arxiv.org/abs/2403.05796
- [68] M. Zhao, X. Hu, L. Zhang, Q. Meng, Y. Chen, and L. Bruzzone, “Beyond Pixel-Level Annotation: Exploring Self-Supervised Learning for Change Detection With Image-Level Supervision,” IEEE Transactions on Geoscience and Remote Sensing, vol. 62, pp. 1–16.
- [69] Y. Dai, K. Zhao, L. Shen, S. Liu, X. Yan, and Z. Li, “A Siamese Network Combining Multiscale Joint Supervision and Improved Consistency Regularization for Weakly Supervised Building Change Detection,” IEEE Journal of Selected Topics in Applied Earth Observations and Remote Sensing, vol. 16, pp. 4963–4982.
- [70] I. Kalita, S. Karatsiolis, and A. Kamilaris, “Land Use Change Detection Using Deep Siamese Neural Networks and Weakly Supervised Learning,” in Computer Analysis of Images and Patterns, N. Tsapatsoulis, A. Panayides, T. Theocharides, A. Lanitis, C. Pattichis, and M. Vento, Eds. Springer International Publishing, vol. 13053, pp. 24–35.
- [71] R. C. Daudt, B. Le Saux, A. Boulch, and Y. Gousseau, “Weakly supervised change detection using guided anisotropic diffusion,” Machine Learning, vol. 112, no. 6, pp. 2211–2237, 2023.
- [72] P. Andermatt and R. Timofte, “A Weakly Supervised Convolutional Network for Change Segmentation and Classification,” in Computer Vision – ACCV 2020 Workshops, I. Sato and B. Han, Eds. Springer International Publishing, vol. 12628, pp. 103–119.
- [73] W. Qiao, L. Shen, Q. Wen, Q. Wen, S. Tang, and Z. Li, “Revolutionizing building damage detection: A novel weakly supervised approach using high-resolution remote sensing images,” International Journal of Digital Earth, vol. 17, no. 1, p. 2298245, 2024.
- [74] S. Saha, L. Mou, X. X. Zhu, F. Bovolo, and L. Bruzzone, “Semisupervised Change Detection Using Graph Convolutional Network,” IEEE Geoscience and Remote Sensing Letters, vol. 18, no. 4, pp. 607–611.
- [75] R. Wang, L. Wang, X. Wei, J.-W. Chen, and L. Jiao, “Dynamic graph-level neural network for sar image change detection,” IEEE Geoscience and Remote Sensing Letters, vol. 19, pp. 1–5, 2021.
- [76] T.-H. Lin and C.-H. Lin, “Hyperspectral change detection using semi-supervised graph neural network and convex deep learning,” IEEE Transactions on Geoscience and Remote Sensing, 2023.
- [77] C. Sun, J. Wu, H. Chen, and C. Du, “SemiSANet: A Semi-Supervised High-Resolution Remote Sensing Image Change Detection Model Using Siamese Networks with Graph Attention,” vol. 14, no. 12, p. 2801.
- [78] J. Liu, K. Chen, G. Xu, H. Li, M. Yan, W. Diao, and X. Sun, “Semi-Supervised Change Detection Based on Graphs with Generative Adversarial Networks,” in IGARSS 2019 - 2019 IEEE International Geoscience and Remote Sensing Symposium. IEEE, pp. 74–77.
- [79] W. Feng, F. Guan, J. Tu, C. Sun, and W. Xu, “Detection of changes in buildings in remote sensing images via self-supervised contrastive pre-training and historical geographic information system vector maps,” Remote Sensing, vol. 15, no. 24, p. 5670, 2023.
- [80] X. Ou, L. Liu, S. Tan, G. Zhang, W. Li, and B. Tu, “A hyperspectral image change detection framework with self-supervised contrastive learning pretrained model,” IEEE Journal of Selected Topics in Applied Earth Observations and Remote Sensing, vol. 15, pp. 7724–7740, 2022.
- [81] Y. Zou, T. Shen, Z. Chen, P. Chen, X. Yang, and L. Zan, “A transformer-based neural network with improved pyramid pooling module for change detection in ecological redline monitoring,” Remote Sensing, vol. 15, no. 3, p. 588, 2023.
- [82] F. Jiang, M. Gong, H. Zheng, T. Liu, M. Zhang, and J. Liu, “Self-supervised global–local contrastive learning for fine-grained change detection in vhr images,” IEEE Transactions on Geoscience and Remote Sensing, vol. 61, pp. 1–13, 2023.
- [83] Y. Huang, L. Zhang, W. Qi, C. Huang, and R. Song, “Contrastive self-supervised two-domain residual attention network with random augmentation pool for hyperspectral change detection,” Remote Sensing, vol. 15, no. 15, p. 3739, 2023.
- [84] C. Wang, S. Du, W. Sun, and D. Fan, “Self-supervised learning for high-resolution remote sensing images change detection with variational information bottleneck,” IEEE Journal of Selected Topics in Applied Earth Observations and Remote Sensing, 2023.
- [85] Y. Chen and L. Bruzzone, “Self-supervised change detection in multiview remote sensing images,” IEEE Transactions on Geoscience and Remote Sensing, vol. 60, pp. 1–12, 2021.
- [86] ——, “A self-supervised approach to pixel-level change detection in bi-temporal rs images,” IEEE Transactions on Geoscience and Remote Sensing, vol. 60, pp. 1–11, 2022.
- [87] R. S. Kuzu, O. Antropov, M. Molinier, C. O. Dumitru, S. Saha, and X. X. Zhu, “Forest disturbance detection via self-supervised and transfer learning with sentinel-1&2 images,” IEEE Journal of Selected Topics in Applied Earth Observations and Remote Sensing, 2024.
- [88] M. Yang, L. Jiao, F. Liu, B. Hou, S. Yang, Y. Zhang, and J. Wang, “Multicue contrastive self-supervised learning for change detection in remote sensing,” IEEE Transactions on Geoscience and Remote Sensing, vol. 61, pp. 1–14, 2023.
- [89] Y. Qu, J. Li, X. Huang, and D. Wen, “TD-SSCD: A Novel Network by Fusing Temporal and Differential Information for Self-Supervised Remote Sensing Image Change Detection,” vol. 61, pp. 1–15.
- [90] S. Saha, P. Ebel, and X. X. Zhu, “Self-supervised multisensor change detection,” IEEE Transactions on Geoscience and Remote Sensing, vol. 60, pp. 1–10, 2022.
- [91] A. D. Adebayo, C. Pelletier, S. Lang, and S. Valero, “Detecting land cover changes between satellite image time series by exploiting self-supervised representation learning capabilities,” in IGARSS 2023-2023 IEEE International Geoscience and Remote Sensing Symposium. IEEE, 2023, pp. 7168–7171.
- [92] H. Zong, E. Zhang, X. Li, and H. Zhang, “Multi-scale self-supervised sar image change detection based on wavelet transform,” IEEE Geoscience and Remote Sensing Letters, 2024.
- [93] X. Sun, P. Wang, W. Lu, Z. Zhu, X. Lu, Q. He, J. Li, X. Rong, Z. Yang, H. Chang et al., “Ringmo: A remote sensing foundation model with masked image modeling,” IEEE Transactions on Geoscience and Remote Sensing, 2022.
- [94] Y. Cui, Y. Zhuang, S. Dong, X. Zhang, P. Gao, H. Chen, and L. Chen, “Hybrid transformer network for change detection under self-supervised pretraining,” in IGARSS 2023-2023 IEEE International Geoscience and Remote Sensing Symposium. IEEE, 2023, pp. 6652–6655.
- [95] D. Muhtar, X. Zhang, P. Xiao, Z. Li, and F. Gu, “Cmid: A unified self-supervised learning framework for remote sensing image understanding,” IEEE Transactions on Geoscience and Remote Sensing, 2023.
- [96] Y. Zhang, Y. Zhao, Y. Dong, and B. Du, “Self-supervised pre-training via multi-modality images with transformer for change detection,” IEEE Transactions on Geoscience and Remote Sensing, 2023.
- [97] P. Zhang, M. Gong, L. Su, J. Liu, and Z. Li, “Change detection based on deep feature representation and mapping transformation for multi-spatial-resolution remote sensing images,” ISPRS Journal of Photogrammetry and Remote Sensing, vol. 116, pp. 24–41, 2016.
- [98] G. Liu, L. Li, L. Jiao, Y. Dong, and X. Li, “Stacked fisher autoencoder for sar change detection,” Pattern Recognition, vol. 96, p. 106971, 2019.
- [99] H. Chen, N. Yokoya, C. Wu, and B. Du, “Unsupervised multimodal change detection based on structural relationship graph representation learning,” IEEE Transactions on Geoscience and Remote Sensing, vol. 60, pp. 1–18, 2022.
- [100] M. Gong, J. Zhao, J. Liu, Q. Miao, and L. Jiao, “Change detection in synthetic aperture radar images based on deep neural networks,” IEEE Transactions on Neural Networks and Learning Systems, vol. 27, no. 1, pp. 125–138, 2016.
- [101] W. Zhao, Z. Wang, M. Gong, and J. Liu, “Discriminative feature learning for unsupervised change detection in heterogeneous images based on a coupled neural network,” IEEE Transactions on Geoscience and Remote Sensing, vol. 55, no. 12, pp. 7066–7080, 2017.
- [102] J. Lei, M. Li, W. Xie, Y. Li, and X. Jia, “Spectral mapping with adversarial learning for unsupervised hyperspectral change detection,” Neurocomputing, vol. 465, pp. 71–83, 2021.
- [103] W. G. C. Bandara, N. G. Nair, and V. M. Patel, “Ddpm-cd: Denoising diffusion probabilistic models as feature extractors for change detection,” 2024.
- [104] R. Huang, R. Wang, Q. Guo, J. Wei, Y. Zhang, W. Fan, and Y. Liu, “Background-Mixed Augmentation for Weakly Supervised Change Detection,” Proceedings of the AAAI Conference on Artificial Intelligence, vol. 37, no. 7, pp. 7919–7927.
- [105] Z. Zheng, A. Ma, L. Zhang, and Y. Zhong, “Change is Everywhere: Single-Temporal Supervised Object Change Detection in Remote Sensing Imagery,” in 2021 IEEE/CVF International Conference on Computer Vision (ICCV). IEEE, pp. 15 173–15 182.
- [106] S. Gao, K. Sun, W. Li, D. Li, Y. Tan, J. Wei, and W. Li, “A building change detection framework with patch-pairing single-temporal supervised learning and metric guided attention mechanism,” International Journal of Applied Earth Observation and Geoinformation, vol. 129, p. 103785, 2024.
- [107] H. Chen, J. Song, C. Wu, B. Du, and N. Yokoya, “Exchange means change: An unsupervised single-temporal change detection framework based on intra-and inter-image patch exchange,” ISPRS Journal of Photogrammetry and Remote Sensing, vol. 206, pp. 87–105, 2023.
- [108] Y. Quan, A. Yu, W. Guo, X. Lu, B. Jiang, S. Zheng, and P. He, “Unified building change detection pre-training method with masked semantic annotations,” International Journal of Applied Earth Observation and Geoinformation, vol. 120, p. 103346, 2023.
- [109] M. Seo, H. Lee, Y. Jeon, and J. Seo, “Self-Pair: Synthesizing Changes from Single Source for Object Change Detection in Remote Sensing Imagery,” in 2023 IEEE/CVF Winter Conference on Applications of Computer Vision (WACV). IEEE, pp. 6363–6372.
- [110] S. Zhu, W. Jing, P. Kang, M. Emam, and C. Li, “Data Augmentation and Few-Shot Change Detection in Forest Remote Sensing,” IEEE Journal of Selected Topics in Applied Earth Observations and Remote Sensing, vol. 16, pp. 5919–5934.
- [111] Z. Zheng, S. Tian, A. Ma, L. Zhang, and Y. Zhong, “Scalable Multi-Temporal Remote Sensing Change Data Generation via Simulating Stochastic Change Process,” in 2023 IEEE/CVF International Conference on Computer Vision (ICCV). IEEE, pp. 21 761–21 770.
- [112] K. Li, X. Cao, and D. Meng, “A new learning paradigm for foundation model-based remote-sensing change detection,” IEEE Transactions on Geoscience and Remote Sensing, vol. 62, pp. 1–12, 2024.
- [113] Z. Zheng, Y. Zhong, L. Zhang, and S. Ermon, “Segment any change,” arXiv preprint arXiv:2402.01188, 2024.
- [114] S. Saha, F. Bovolo, and L. Bruzzone, “Unsupervised deep change vector analysis for multiple-change detection in vhr images,” IEEE Transactions on Geoscience and Remote Sensing, vol. 57, no. 6, pp. 3677–3693, 2019.
- [115] S. Saha and X. X. Zhu, “Patch-level unsupervised planetary change detection,” IEEE Geoscience and Remote Sensing Letters, vol. 19, pp. 1–5, 2022.
- [116] W. G. C. Bandara and V. M. Patel, “Deep metric learning for unsupervised remote sensing change detection,” arXiv preprint arXiv:2303.09536, 2023.
- [117] J. Liu, K. Chen, G. Xu, X. Sun, M. Yan, W. Diao, and H. Han, “Convolutional Neural Network-Based Transfer Learning for Optical Aerial Images Change Detection,” IEEE Geoscience and Remote Sensing Letters, vol. 17, no. 1, pp. 127–131.
- [118] T. Zhan, M. Gong, X. Jiang, and E. Zhang, “S 3 net: Superpixel-guided self-supervised learning network for multitemporal image change detection,” IEEE Geoscience and Remote Sensing Letters, 2023.
- [119] H. Dong, W. Ma, Y. Wu, J. Zhang, and L. Jiao, “Self-supervised representation learning for remote sensing image change detection based on temporal prediction,” Remote Sensing, vol. 12, no. 11, p. 1868, 2020.
- [120] K. Sohn, D. Berthelot, N. Carlini, Z. Zhang, H. Zhang, C. A. Raffel, E. D. Cubuk, A. Kurakin, and C.-L. Li, “FixMatch: Simplifying Semi-Supervised Learning with Consistency and Confidence,” in Advances in Neural Information Processing Systems, vol. 33. Curran Associates, Inc., pp. 596–608. [Online]. Available: https://proceedings.neurips.cc/paper/2020/hash/06964dce9addb1c5cb5d6e3d9838f733-Abstract.html
- [121] X. Zhang, X. Huang, and J. Li, “Joint Self-Training and Rebalanced Consistency Learning for Semi-Supervised Change Detection,” vol. 61, pp. 1–13.
- [122] C. Han, M. Hu, and H. Chen, “C2F-SemiCD: A Coarse-to-Fine Semi-Supervised Change Detection Method Based on Consistency Regularization in High-Resolution Remote Sensing Images,” vol. 62.
- [123] S. Hafner, Y. Ban, and A. Nascetti, “Semi-Supervised Urban Change Detection Using Multi-Modal Sentinel-1 SAR and Sentinel-2 MSI Data,” vol. 15, no. 21, p. 5135.
- [124] E. Kalinicheva, D. Ienco, J. Sublime, and M. Trocan, “Unsupervised change detection analysis in satellite image time series using deep learning combined with graph-based approaches,” IEEE Journal of Selected Topics in Applied Earth Observations and Remote Sensing, vol. 13, pp. 1450–1466, 2020.
- [125] L. Fang, Y. Jiang, H. Yu, Y. Zhang, and J. Yue, “Point label meets remote sensing change detection: A consistency-aligned regional growth network,” IEEE Transactions on Geoscience and Remote Sensing, 2023.
- [126] Z. Zheng, Y. Liu, S. Tian, J. Wang, A. Ma, and Y. Zhong, “Weakly Supervised Semantic Change Detection via Label Refinement Framework,” in 2021 IEEE International Geoscience and Remote Sensing Symposium IGARSS. IEEE, pp. 2066–2069.
- [127] S. H. Khan, X. He, F. Porikli, and M. Bennamoun, “Forest Change Detection in Incomplete Satellite Images With Deep Neural Networks,” vol. 55, no. 9, pp. 5407–5423.
- [128] N. Lu, C. Chen, W. Shi, J. Zhang, and J. Ma, “Weakly Supervised Change Detection Based on Edge Mapping and SDAE Network in High-Resolution Remote Sensing Images,” vol. 12, no. 23, p. 3907.
- [129] D. Hong, C. Li, B. Zhang, N. Yokoya, J. A. Benediktsson, and J. Chanussot, “Multimodal artificial intelligence foundation models: Unleashing the power of remote sensing big data in earth observation,” The Innovation Geoscience, vol. 2, no. 1, p. 100055, 2024.
- [130] I. Goodfellow, J. Pouget-Abadie, M. Mirza, B. Xu, D. Warde-Farley, S. Ozair, A. Courville, and Y. Bengio, “Generative adversarial nets,” in Advances in Neural Information Processing Systems, vol. 27, 2014.
- [131] J. Ho, A. Jain, and P. Abbeel, “Denoising diffusion probabilistic models,” in Advances in Neural Information Processing Systems, vol. 33, 2020, pp. 6840–6851.
- [132] “Fast unsupervised deep fusion network for change detection of multitemporal sar images,” Neurocomputing, vol. 332, pp. 56–70, 2019.
- [133] M. Hu, C. Wu, L. Zhang, and B. Du, “Hyperspectral anomaly change detection based on autoencoder,” IEEE Journal of Selected Topics in Applied Earth Observations and Remote Sensing, vol. 14, pp. 3750–3762, 2021.
- [134] R. Touati, M. Mignotte, and M. Dahmane, “Anomaly feature learning for unsupervised change detection in heterogeneous images: A deep sparse residual model,” IEEE Journal of Selected Topics in Applied Earth Observations and Remote Sensing, vol. 13, pp. 588–600, 2020.
- [135] N. Lv, C. Chen, T. Qiu, and A. K. Sangaiah, “Deep learning and superpixel feature extraction based on contractive autoencoder for change detection in sar images,” IEEE Transactions on Industrial Informatics, vol. 14, no. 12, pp. 5530–5538, 2018.
- [136] X. Zheng, X. Chen, X. Lu, and B. Sun, “Unsupervised change detection by cross-resolution difference learning,” IEEE Transactions on Geoscience and Remote Sensing, vol. 60, pp. 1–16, 2022.
- [137] J. Liu, M. Gong, A. K. Qin, and P. Zhang, “A deep convolutional coupling network for change detection based on heterogeneous optical and radar images,” IEEE Trans. Neural Networks Learn. Syst., vol. 29, no. 3, pp. 545–559, 2018.
- [138] T. Zhan, M. Gong, J. Liu, and P. Zhang, “Iterative feature mapping network for detecting multiple changes in multi-source remote sensing images,” ISPRS Journal of Photogrammetry and Remote Sensing, vol. 146, pp. 38–51, 2018.
- [139] T. Zhan, M. Gong, X. Jiang, and S. Li, “Log-based transformation feature learning for change detection in heterogeneous images,” IEEE Geoscience and Remote Sensing Letters, vol. 15, no. 9, pp. 1352–1356, 2018.
- [140] L. Bergamasco, S. Saha, F. Bovolo, and L. Bruzzone, “Unsupervised change detection using convolutional-autoencoder multiresolution features,” IEEE Transactions on Geoscience and Remote Sensing, vol. 60, pp. 1–19, 2022.
- [141] Y. Wu, J. Li, Y. Yuan, A. K. Qin, Q.-G. Miao, and M.-G. Gong, “Commonality autoencoder: Learning common features for change detection from heterogeneous images,” IEEE Transactions on Neural Networks and Learning Systems, vol. 33, no. 9, pp. 4257–4270, 2022.
- [142] C. Wu, H. Chen, B. Du, and L. Zhang, “Unsupervised change detection in multitemporal vhr images based on deep kernel pca convolutional mapping network,” IEEE Transactions on Cybernetics, vol. 52, no. 11, pp. 12 084–12 098, 2022.
- [143] M. Jia and Z. Zhao, “Change detection in synthetic aperture radar images based on a generalized gamma deep belief networks,” Sensors, vol. 21, no. 24, 2021.
- [144] H. Zhang, M. Gong, P. Zhang, L. Su, and J. Shi, “Feature-level change detection using deep representation and feature change analysis for multispectral imagery,” IEEE Geoscience and Remote Sensing Letters, vol. 13, no. 11, pp. 1666–1670, 2016.
- [145] S. Saha, Y. T. Solano-Correa, F. Bovolo, and L. Bruzzone, “Unsupervised deep transfer learning-based change detection for hr multispectral images,” IEEE Geoscience and Remote Sensing Letters, vol. 18, no. 5, pp. 856–860, 2021.
- [146] C. Ren, X. Wang, J. Gao, X. Zhou, and H. Chen, “Unsupervised change detection in satellite images with generative adversarial network,” IEEE Transactions on Geoscience and Remote Sensing, vol. 59, no. 12, pp. 10 047–10 061, 2021.
- [147] H. Noh, J. Ju, M. Seo, J. Park, and D.-G. Choi, “Unsupervised change detection based on image reconstruction loss,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2022, pp. 1352–1361.
- [148] X. Niu, M. Gong, T. Zhan, and Y. Yang, “A conditional adversarial network for change detection in heterogeneous images,” IEEE Geoscience and Remote Sensing Letters, vol. 16, no. 1, pp. 45–49, 2019.
- [149] L. T. Luppino, M. Kampffmeyer, F. M. Bianchi, G. Moser, S. B. Serpico, R. Jenssen, and S. N. Anfinsen, “Deep image translation with an affinity-based change prior for unsupervised multimodal change detection,” IEEE Transactions on Geoscience and Remote Sensing, vol. 60, pp. 1–22, 2022.
- [150] Z.-G. Liu, Z.-W. Zhang, Q. Pan, and L.-B. Ning, “Unsupervised change detection from heterogeneous data based on image translation,” IEEE Transactions on Geoscience and Remote Sensing, vol. 60, pp. 1–13, 2022.
- [151] A. Radoi, “Generative adversarial networks under cutmix transformations for multimodal change detection,” IEEE Geoscience and Remote Sensing Letters, vol. 19, pp. 1–5, 2022.
- [152] L. T. Luppino, M. A. Hansen, M. Kampffmeyer, F. M. Bianchi, G. Moser, R. Jenssen, and S. N. Anfinsen, “Code-aligned autoencoders for unsupervised change detection in multimodal remote sensing images,” IEEE Transactions on Neural Networks and Learning Systems, vol. 35, no. 1, pp. 60–72, 2024.
- [153] J.-J. Wang, N. Dobigeon, M. Chabert, D.-C. Wang, T.-Z. Huang, and J. Huang, “Cd-gan: A robust fusion-based generative adversarial network for unsupervised remote sensing change detection with heterogeneous sensors,” Information Fusion, vol. 107, p. 102313, 2024.
- [154] Y. Wen, X. Ma, X. Zhang, and M.-O. Pun, “Gcd-ddpm: A generative change detection model based on difference-feature-guided ddpm,” IEEE Transactions on Geoscience and Remote Sensing, vol. 62, pp. 1–16, 2024.
- [155] T.-H. Chan, K. Jia, S. Gao, J. Lu, Z. Zeng, and Y. Ma, “Pcanet: A simple deep learning baseline for image classification?” IEEE Transactions on Image Processing, vol. 24, no. 12, pp. 5017–5032, 2015.
- [156] M. Gong, H. Yang, and P. Zhang, “Feature learning and change feature classification based on deep learning for ternary change detection in sar images,” ISPRS Journal of Photogrammetry and Remote Sensing, vol. 129, pp. 212–225, 2017.
- [157] M. Yang, L. Jiao, F. Liu, B. Hou, and S. Yang, “Transferred deep learning-based change detection in remote sensing images,” IEEE Transactions on Geoscience and Remote Sensing, vol. 57, no. 9, pp. 6960–6973, 2019.
- [158] F. Liu, L. Jiao, X. Tang, S. Yang, W. Ma, and B. Hou, “Local restricted convolutional neural network for change detection in polarimetric sar images,” IEEE Transactions on Neural Networks and Learning Systems, vol. 30, no. 3, pp. 818–833, 2019.
- [159] M. Gong, X. Niu, P. Zhang, and Z. Li, “Generative adversarial networks for change detection in multispectral imagery,” IEEE Geoscience and Remote Sensing Letters, vol. 14, no. 12, pp. 2310–2314, 2017.
- [160] M. Gong, Y. Yang, T. Zhan, X. Niu, and S. Li, “A generative discriminatory classified network for change detection in multispectral imagery,” IEEE Journal of Selected Topics in Applied Earth Observations and Remote Sensing, vol. 12, no. 1, pp. 321–333, 2019.
- [161] J. Shi, Z. Zhang, C. Tan, X. Liu, and Y. Lei, “Unsupervised multiple change detection in remote sensing images via generative representation learning network,” IEEE Geoscience and Remote Sensing Letters, vol. 19, pp. 1–5, 2022.
- [162] M. Hu, C. Wu, B. Du, and L. Zhang, “Binary change guided hyperspectral multiclass change detection,” IEEE Transactions on Image Processing, vol. 32, pp. 791–806, 2023.
- [163] J. Xv, B. Zhang, H. Guo, J. Lu, and Y. Lin, “Combining iterative slow feature analysis and deep feature learning for change detection in high-resolution remote sensing images,” Journal of Applied Remote Sensing, vol. 13, no. 2, p. 024506, 2019.
- [164] T. Zhan, M. Gong, X. Jiang, and W. Zhao, “Transfer learning-based bilinear convolutional networks for unsupervised change detection,” IEEE Geoscience and Remote Sensing Letters, vol. 19, pp. 1–5, 2022.
- [165] J. Sublime and E. Kalinicheva, “Automatic Post-Disaster Damage Mapping Using Deep-Learning Techniques for Change Detection: Case Study of the Tohoku Tsunami,” Remote Sensing, vol. 11, no. 9, p. 1123.
- [166] L. Yan, J. Yang, and J. Wang, “Domain Knowledge-Guided Self-Supervised Change Detection for Remote Sensing Images,” IEEE Journal of Selected Topics in Applied Earth Observations and Remote Sensing, vol. 16, pp. 4167–4179.
- [167] A. Radford, J. W. Kim, C. Hallacy, A. Ramesh, G. Goh, S. Agarwal, G. Sastry, A. Askell, P. Mishkin, J. Clark et al., “Learning transferable visual models from natural language supervision,” in International conference on machine learning. PMLR, 2021, pp. 8748–8763.
- [168] A. Kirillov, E. Mintun, N. Ravi, H. Mao, C. Rolland, L. Gustafson, T. Xiao, S. Whitehead, A. C. Berg, W.-Y. Lo, P. Dollar, and R. Girshick, “Segment anything,” in Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), October 2023, pp. 4015–4026.
- [169] W. Ji, J. Li, Q. Bi, T. Liu, W. Li, and L. Cheng, “Segment anything is not always perfect: An investigation of sam on different real-world applications,” 2024.
- [170] M. Mendieta, B. Han, X. Shi, Y. Zhu, and C. Chen, “Towards geospatial foundation models via continual pretraining,” in Proceedings of the IEEE/CVF International Conference on Computer Vision, 2023, pp. 16 806–16 816.
- [171] X. Guo, J. Lao, B. Dang, Y. Zhang, L. Yu, L. Ru, L. Zhong, Z. Huang, K. Wu, D. Hu et al., “Skysense: A multi-modal remote sensing foundation model towards universal interpretation for earth observation imagery,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2024, pp. 27 672–27 683.
- [172] L. Wang, M. Zhang, and W. Shi, “Cs-wscdnet: Class activation mapping and segment anything model-based framework for weakly supervised change detection,” IEEE Transactions on Geoscience and Remote Sensing, 2023.
- [173] H. Chen, J. Song, and N. Yokoya, “Change detection between optical remote sensing imagery and map data via segment anything model (sam),” arXiv preprint arXiv:2401.09019, 2024.
- [174] S. Dong, L. Wang, B. Du, and X. Meng, “Changeclip: Remote sensing change detection with multimodal vision-language representation learning,” ISPRS Journal of Photogrammetry and Remote Sensing, vol. 208, pp. 53–69, 2024.
- [175] Y. Zhang, Y. Zhao, Y. Dong, and B. Du, “Self-Supervised Pretraining via Multimodality Images With Transformer for Change Detection,” vol. 61, pp. 1–11.
- [176] U. Mall, B. Hariharan, and K. Bala, “Change event dataset for discovery from spatio-temporal remote sensing imagery,” in Advances in Neural Information Processing Systems, vol. 35, 2022, pp. 27 484–27 496.
- [177] H. Chen and Z. Shi, “A spatial-temporal attention-based method and a new dataset for remote sensing image change detection,” Remote Sensing, vol. 12, no. 10, 2020.
- [178] S. Ji, S. Wei, and M. Lu, “Fully convolutional networks for multisource building extraction from an open aerial and satellite imagery data set,” IEEE Transactions on geoscience and remote sensing, vol. 57, no. 1, pp. 574–586, 2018.
- [179] R. C. Daudt, B. Le Saux, A. Boulch, and Y. Gousseau, “Urban change detection for multispectral earth observation using convolutional neural networks,” in IGARSS 2018-2018 IEEE International Geoscience and Remote Sensing Symposium. Ieee, 2018, pp. 2115–2118.
- [180] I. Corley, C. Robinson, and A. Ortiz, “A change detection reality check,” arXiv preprint arXiv:2402.06994, 2024.
- [181] D. Wen, X. Huang, F. Bovolo, J. Li, X. Ke, A. Zhang, and J. A. Benediktsson, “Change detection from very-high-spatial-resolution optical remote sensing images: Methods, applications, and future directions,” IEEE Geoscience and Remote Sensing Magazine, vol. 9, no. 4, pp. 68–101, 2021.
- [182] Z. Lv, T. Liu, J. A. Benediktsson, and N. Falco, “Land Cover Change Detection Techniques: Very-high-resolution optical images: A review,” IEEE Geoscience and Remote Sensing Magazine, vol. 10, no. 1, pp. 44–63.
- [183] J. Qu, J. Zhao, W. Dong, S. Xiao, Y. Li, and Q. Du, “Feature mutual representation based graph domain adaptive network for unsupervised hyperspectral change detection,” IEEE Transactions on Geoscience and Remote Sensing, 2023.
- [184] O. Vinyals, C. Blundell, T. Lillicrap, D. Wierstra et al., “Matching networks for one shot learning,” Advances in neural information processing systems, vol. 29, 2016.
- [185] C. Lang, G. Cheng, B. Tu, and J. Han, “Learning what not to segment: A new perspective on few-shot segmentation,” in Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2022, pp. 8057–8067.
- [186] S. Rahman, S. Khan, and N. Barnes, “Polarity loss: Improving visual-semantic alignment for zero-shot detection,” IEEE Transactions on Neural Networks and Learning Systems, 2022.
- [187] A. Douillard, Y. Chen, A. Dapogny, and M. Cord, “Plop: Learning without forgetting for continual semantic segmentation,” in Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2021, pp. 4040–4050.
| Lei Ding ([email protected]) received his MS’s degree in Photogrammetry and Remote Sensing from the Information Engineering University (Zhengzhou, China), and his PhD (cum laude) in Communication and Information Technologies from the University of Trento (Trento, Italy). He is currently a Lecturer at the Information Engineering University. Since 2024, he has been a Post-doctoral Fellow at the Aerospace Information Research Institute, Chinese Academy of Sciences, Beijing, China. His research interests are related to the intelligent interpretation of remote sensing data. |
| Danfeng Hong (IEEE Senior Member, [email protected]) received the Dr. -Ing degree (summa cum laude) from the Signal Processing in Earth Observation (SiPEO), Technical University of Munich (TUM), Munich, Germany, in 2019. Since 2022, he has been a Full Professor with the Aerospace Information Research Institute, Chinese Academy of Sciences. His research interests include Artificial Intelligence, Multimodal, Foundation Models, and Earth Observation. Dr. Hong serves as an Associate Editor for the IEEE Transactions on Image Processing (TIP) and the IEEE Transactions on Geoscience and Remote Sensing (TGRS). He is also an Editorial Board Member for Information Fusion and the ISPRS Journal of Photogrammetry and Remote Sensing. He has received several prestigious awards, including the Jose Bioucas Dias Award (2021) and Paul Gader Award (2024) at WHISPERS for outstanding papers, respectively, the Remote Sensing Young Investigator Award (2022), the IEEE GRSS Early Career Award (2022), and the “2023 China’s Intelligent Computing Innovators” award (the only recipient in AI for Earth Science) by MIT Technology Review (2024). He has been recognized as a Highly Cited Researcher by Clarivate Analytics in 2022, 2023, and 2024. |
| Maofan Zhao ([email protected]) is currently pursuing a Ph.D. degree at the Aerospace Information Research Institute, Chinese Academy of Sciences, Beijing, China. From 2021 to 2023, he was a Visiting Ph.D. student at the University of Trento, Trento, Italy. His research interests include remote sensing image analysis, deep learning and urban remote sensing. |
| Hongruixuan Chen (IEEE Student Member, [email protected]) received the M.E. degree in photogrammetry and remote sensing from State Key Laboratory of Information Engineering in Surveying, Mapping, and Remote Sensing, Wuhan University, Wuhan, China, in 2022. He is currently pursuing the Ph.D. degree with the Graduate School of Frontier Science, The University of Tokyo, Chiba, Japan. His research fields include deep learning, domain adaptation, and multimodal remote sensing image interpretation and analysis. |
| Chenyu Li ([email protected]) received the B.S. and M.S. degrees from the School of Transportation, Southeast University, Nanjing, China, in 2018 and 2021, respectively. She is currently pursuing her Ph.D. degree from the Department of Mathematics at Southeast University, Nanjing, China, and is also a joint Ph.D. student at the Aerospace Information Research Institute, Chinese Academy of Sciences, Beijing, China. Her research interests include interpretable artificial intelligence, big Earth data forecasting, foundation models, and hyperspectral imaging. |
| Jie Deng received the Ph.D. degree in agronomy from China Agricultural University, Beijing, China, in 2023. Since 2023, he has been working as a Post-Doctoral Researcher with the College of Plant Protection, China Agricultural University. His main research areas include plant disease epidemiology, quantitative inversion of crop diseases based on imaging remote sensing, and yield prediction. |
| Naoto Yokoya (IEEE Member, [email protected]) is currently an Associate Professor at The University of Tokyo, Japan, and he leads the Geoinformatics Team at the RIKEN Center for Advanced Intelligence Project, Tokyo. His research is focused on the development of image processing, data fusion, and machine learning algorithms for understanding remote sensing images, with applications to disaster management and environmental assessment. |
| Lorenzo Bruzzone (IEEE Fellow, [email protected]) received his M.S. degree in electronic engineering (summa cum laude) and his Ph.D. degree in telecommunications from the University of Genoa, Italy, in 1993 and 1998, respectively. Currently, he is with the Department of Information Engineering and Computer Science, University of Trento, Italy. Dr. Bruzzone is the founder and the director of the Remote Sensing Laboratory in the Department of Information Engineering and Computer Science, University of Trento. His research interests include remote sensing, radar and SAR, signal processing, machine learning, and pattern recognition. |
| Jocelyn Chanussot (IEEE Fellow, [email protected]) received the M.Sc. degree in electrical engineering from the Grenoble Institute of Technology (Grenoble INP), Grenoble, France, in 1995, and the Ph.D. degree from the Université de Savoie, Annecy, France, in 1998. From 1999 to 2023, he has been with Grenoble INP, where he was a Professor of signal and image processing. He is currently a Research Director with INRIA, Grenoble. His research interests include image analysis, hyperspectral remote sensing, data fusion, machine learning, and artificial intelligence. He has been a visiting scholar at Stanford University (USA), KTH (Sweden) and NUS (Singapore). Since 2013, he is an Adjunct Professor of the University of Iceland. In 2015-2017, he was a visiting professor at the University of California, Los Angeles (UCLA). He holds the AXA chair in remote sensing and is an Adjunct professor at the Chinese Academy of Sciences, Aerospace Information research Institute, Beijing, China. Dr. Chanussot is the founding President of the IEEE Geoscience and Remote Sensing French chapter (2007-2010) which received the 2010 IEEE GRSS Chapter Excellence Award. He was the Vice-President of the IEEE Geoscience and Remote Sensing Society, in charge of meetings and symposia (2017-2019). He is an Associate Editor for the IEEE Transactions on Geoscience and Remote Sensing, the IEEE Transactions on Image Processing, and the Proceedings of the IEEE. He was the Editor-in-Chief of the IEEE Journal of Selected Topics in Applied Earth Observations and Remote Sensing (2011-2015). In 2014 he served as a Guest Editor for the IEEE Signal Processing Magazine. He is a Fellow of the IEEE, an ELLIS Fellow, a Fellow of AAIA, a member of the Institut Universitaire de France (2012-2017,) and a Highly Cited Researcher (Clarivate Analytics/Thomson Reuters, since 2018). |