A Survey of Deep Learning for Low-Shot Object Detection
Abstract.
Object detection has achieved a huge breakthrough with deep neural networks and massive annotated data. However, current detection methods cannot be directly transferred to the scenario where the annotated data is scarce due to the severe overfitting problem. Although few-shot learning and zero-shot learning have been extensively explored in the field of image classification, it is indispensable to design new methods for object detection in the data-scarce scenario since object detection has an additional challenging localization task. Low-Shot Object Detection (LSOD) is an emerging research topic of detecting objects from a few or even no annotated samples, consisting of One-Shot Object Localization (OSOL), Few-Shot Object Detection (FSOD), and Zero-Shot Object Detection (ZSOD). This survey provides a comprehensive review of LSOD methods. First, we propose a thorough taxonomy of LSOD methods and analyze them systematically, comprising some extensional topics of LSOD (semi-supervised LSOD, weakly-supervised LSOD, and incremental LSOD). Then, we indicate the pros and cons of current LSOD methods with a comparison of their performance. Finally, we discuss the challenges and promising directions of LSOD to provide guidance for future works.
1. Introduction
Object detection is a fundamental yet challenging task in computer vision, aiming to locate objects of certain classes in images. It has been widely applied to many computer vision tasks like object tracking (Yilmaz et al., 2006; Wang et al., 2019b; Voigtlaender et al., 2019), autonomous driving (Grigorescu et al., 2020; Yurtsever et al., 2020), scene graph generation (Teng and Wang, 2021; Yang et al., 2018; Tang et al., 2020).
The general process of object detection is to predict classes for a set of bounding boxes (imaginary rectangles for reference in the image). Most traditional methods are slow since they generate the bounding boxes using brute force by sliding a window through the whole image. Viola-Jones (VJ) detector (Viola and Jones, 2001) first achieves real-time detection of human faces with three speed-up techniques: integral image, feature selection, and detection cascades. Later, histogram of oriented gradients (HOG) (Dalal and Triggs, 2005) is proposed, and many traditional object detectors adopt it for feature description. Deformable part-based model (DPM) (Felzenszwalb et al., 2008) is a representative traditional method. DPM divides an object detection task into several fine-grained detection tasks, then uses some part-filters to detect parts of an object and aggregates them for final prediction. Although people have made many improvements, traditional methods are restricted by their slow speed and low accuracy.
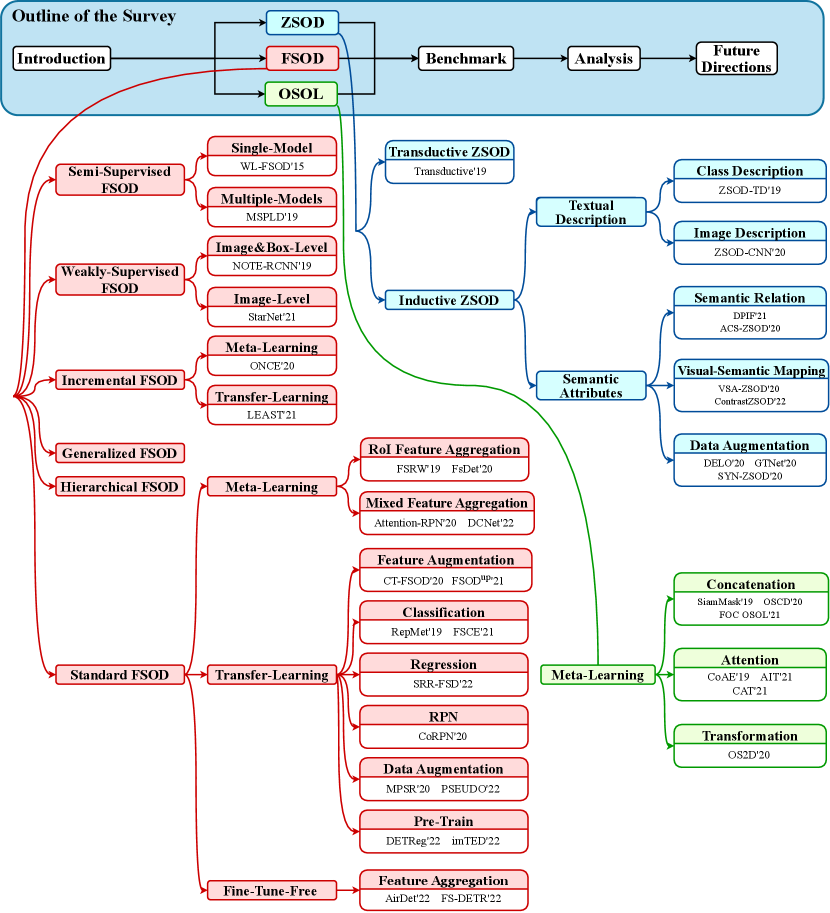
Compared with these traditional methods, deep-learning-based methods have significantly improved performance. Current deep detectors roughly consist of two-stage detectors and single-stage detectors. Two-stage detectors first generate region proposals (i.e., image regions which are more likely to contain objects) and next make predictions on them, following a similar framework to traditional methods. R-CNN (Girshick et al., 2014) is one of the earliest works of two-stage detectors. It uses selective search to obtain region proposals then extracts their features with a pre-trained CNN model for further classification and regression. Fast R-CNN (Girshick, 2015) improves R-CNN by using a region of interest (RoI) pooling layer to generate feature maps for region proposals from the integral feature map. Faster R-CNN (Ren et al., 2015) further proposes a region proposal network (RPN) to generate region proposals from the whole image feature map using anchors (i.e., pre-defined bounding boxes with specific height and width). However, the generation of region proposals requires high computation cost and storage costs. To mitigate this problem, single-stage detectors are proposed to combine these two stages. YOLO-style object detectors (Redmon and Farhadi, 2018; Bochkovskiy et al., 2020; Ge et al., 2021) are the representative works of single-stage detectors. Given the feature map extracted from the original image, YOLO-style detectors directly pre-define anchors with multiple scales over all locations of the image and predict the class probabilities, regression offsets and object confidence scores of each anchor. Single-stage detectors achieve higher speed, but they generally underperform two-stage detectors. Moreover, some methods like focal loss (Lin et al., 2017b) have been proposed to decrease the performance gap between single-stage and two-stage detectors. Recently, a transformer-based detector named DETR (Carion et al., 2020) has been proposed. DETR achieves end-to-end detection and has comparable performance to many classic detectors. Some extended methods (Zhu et al., 2021b; Dai et al., 2021) are proposed to mitigate the slow convergence problem of DETR.
However, these deep detectors tend to overfit when the training data is scarce and thus require abundant annotated data. In real life, it is hard to collect sufficient annotated data for some object classes due to the scarcity of these classes or special labeling costs, and current deep detectors are not competent in this situation. Therefore, the ability to detect objects from a few or even zero annotated samples is desired for modern detectors. To achieve this goal, Low-Shot Object Detection (LSOD) is introduced into object detection, including One-Shot Object Localization (OSOL), Few-Shot Object Detection (FSOD), Zero-Shot Object Detection (ZSOD). These three settings of LSOD mainly differ in the number of annotated samples for each category. Concretely, OSOL and FSOD tackle the situation that each object category has one or more annotated image samples, while ZSOD differentiates different classes according to the semantic information of each category instead of image samples.
OSOL and FSOD are developed following the mainstream scheme of few-shot learning (FSL). Few-shot learning divides the object classes into base classes with many annotated samples (denoted as base dataset) and novel classes with a few annotated samples (denoted as novel dataset). Note that the annotated samples and the test samples in novel classes are named as support samples and query samples, respectively. Few-shot learning requires to pre-train the model on the base dataset then uses the model to predict novel classes on the novel dataset for evaluation. Current few-shot learning methods are roughly categorized into meta-learning methods and transfer-learning methods. Meta-learning methods adopt a “learning-to-learn” mechanism, which defines multiple few-shot tasks on the base dataset to train the model, and enables the model to adapt to the real few-shot tasks quickly. Moreover, transfer-learning methods learn a good image representation by directly training the model on the base dataset, which is used for the novel dataset. Although meta-learning is a more natural approach to tackle the few-shot problem, Tian et al. (Tian et al., 2020) find that the baseline transfer-learning methods surpass some classic meta-learning methods, especially in the cross-domain few-shot learning. Current few-shot learning methods are mainly explored on the task of image classification. OSOL and FSOD are more challenging than few-shot image classification because object detection requires an extra task to locate the objects. As the branches of few-shot learning, OSOL and FSOD also inherit the core methods (meta-learning & transfer-learning) of it.
OSOL is a few-shot learning setting on object detection which locates objects using only one labeled image of each category in the image. Current OSOL methods all adopt the scheme of meta-learning following few-shot learning, where a large number of one-shot tasks are defined on the base dataset to train the model. OSOL has a strong guarantee that the model precisely knows the object classes contained in each test image. With this strong guarantee, the latest OSOL methods have achieved relatively high performance.
| Notation | Description | Notation | Description |
| Feature map of integral query image | Pool operation | ||
| Feature map of integral support image | Element-wise sum | ||
| The aggregated feature map of and | Channel-wise multiplication | ||
| The RoI feature map in the query image | Convolutional operation | ||
| The RoI feature vector in the query image | FC layer | ||
| The RoI semantic embedding in the query image | Softmax operation | ||
| The pooled feature vector | Sigmoid function | ||
| The aggregated feature vector of and | RELU function | ||
| The semantic embedding of class | The norm of a vector | ||
| The prediction score for class of a RoI | Concatenation operation | ||
| The absolute value of a vector |
However, OSOL setting is not realistic enough since the object classes in the test images are not pre-known in real life. Therefore, another few-shot setting on object detection is adopted by more papers, which is named Few-Shot Object Detection (FSOD). The major differences between FSOD and OSOL are as follows: (1) FSOD needs to predict the correct category of potential objects in the test image. (2) OSOL samples support images independently for each test image, FSOD samples the support images only once for all test images. (3) In FSOD, the number of labeled samples per category can be larger than one. Similar to methods on few-shot image classification, FSOD methods are categorized into two mainstream methods: meta-learning methods and transfer-learning methods. Early FSOD methods mainly adopt the meta-learning scheme. The core operation of meta-learning FSOD methods is to extract the features of a few annotated samples (support features) and aggregate them into the features of query images (query features) for guidance on the prediction of query images. This aggregation operation promotes the model to learn adequate information from a few annotated samples. Early meta-learning FSOD methods simply aggregate the support features with the features of RoIs (RoI features) in the query images. Afterwards, researchers find that the aggregation of integral features is essential for performance improvement since the shallow components in the model also require the information of annotated samples (e.g., the RPN component in Faster R-CNN needs the support features to filter out unmatched region proposals). Therefore, this survey categorizes meta-learning FSOD methods into RoI feature aggregation and mixed feature aggregation methods (“mixed” means using RoI feature aggregation and integral feature aggregation together). Unlike meta-learning methods, transfer-learning FSOD methods directly pre-train the detector on the base dataset and fine-tune it on the novel dataset. Early FSOD methods rarely adopt transfer-learning due to its poor performance. TFA (Wang et al., 2020a) subverts this cognition, which proposes a two-stage fine-tuning strategy to fine-tune the model and achieves better performance than contemporary meta-learning methods. In addition to the standard FSOD discussed above, other extensional settings like semi-supervised FSOD (Misra et al., 2015; Dong et al., 2019), weakly-supervised FSOD (Gao et al., 2019; Karlinsky et al., 2021) and incremental FSOD (Pérez-Rúa et al., 2020; Li et al., 2021a) are also explored by researchers and investigated in this survey.
ZSOD assigns abundant labeled samples to base classes, but it assigns no annotated image samples to novel classes. Instead, mainstream ZSOD allocates semantic attributes to each class (including base and novel classes), and it classifies object proposals according to their semantic similarities with different classes. Mainstream ZSOD methods include visual-semantic mapping methods, semantic relation methods, and data augmentation methods. Most early ZSOD methods belong to visual-semantic mapping methods. These methods aim to learn a visual-semantic function using the annotated samples of the base dataset, which projects visual features into semantic embeddings for comparison with class semantic attributes. Next, semantic relation methods utilize the semantic relation between different classes to make predictions. Moreover, data augmentation methods attempt to generate visual samples for novel classes and re-train the model. Besides the mainstream ZSOD setting described above, this survey discusses some rarely explored settings like transductive ZSOD and textual-description-based inductive ZSOD. Recently, with the emergence of large-scale cross-modal models (e.g., CLIP (Radford et al., 2021)), Open-Vocabulary Object Detection (OVD) attracts more and more research interest, which first trains a stronger visual-semantic mapping function for multiple classes and significantly improves the performance of the further ZSOD task.
The overview of this survey is illustrated in Figure 1. The preliminaries for meta-learning and transfer-learning are given in section 2. The more fine-grained categorization and analysis of methods for LSOD are described in section 3, section 4, section 5, section 6. The two popular datasets (MS COCO dataset (Lin et al., 2014) and PASCAL VOC dataset (Everingham et al., 2010)) and evaluation criteria of LSOD are described in section 7. The performance of current LSOD methods is summarized in section 8. The promising directions LSOD are discussed in section 9. Finally, section 10 concludes the contents of this survey. The key notations used in this survey are summarized in Table 1.
2. Preliminaries
2.1. Meta-Learning
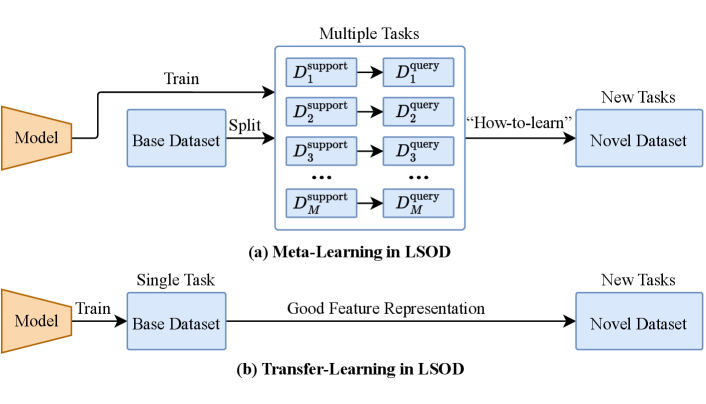
Meta-learning is a “learning-to-learn” (Thrun and Pratt, 1998; Hospedales et al., 2022) paradigm extended from the conventional “learning” paradigm. Conventional learning paradigm directly trains the model from scratch on the whole dataset as a single task. Differently, meta-learning learns the training pattern (e.g., parameter initialization) from multiple tasks, which is capable of generalizing across different tasks and facilitating the learning of new tasks. Therefore, meta-learning is suitable for quick adaptation of the model to the new tasks in few-shot learning. The framework of meta-learning is shown in Figure 2 (a), and a more detailed illustration is in section S1 of the supplementary online-only material.
2.2. Transfer-Learning
Transfer-learning methods aim to transfer the knowledge (good feature representation) from a related domain (named source domain) to the current domain (named target domain), in order to improve the performance of model on the target domain, as shown in Figure 2 (b). Traditional transfer-learning approaches include instance-based methods, feature-based methods, parameter-based methods, and relational-based methods (Zhuang et al., 2021).
For the transfer-learning methods in few-shot learning, the base dataset is viewed as the source domain, and the novel dataset is viewed as the target dataset. Tian et al. (Tian et al., 2020) find that simply transferring a strong feature extractor from the base dataset to the novel dataset outperforms many meta-learning methods on few-shot image classification, and many FSL methods follow this paradigm. Transfer-learning is not suitable for OSOL since the target domain consists of only one image for each task, yet it is widely adopted in FSOD after the emergence of TFA (Wang et al., 2020a).
3. One-Shot Object Localization
Task Settings. One-Shot Object Localization (OSOL) needs to locate objects in a query image according to only one support image for each novel class existing in this query image. The training dataset (base dataset ) of OSOL comprises abundant annotated instances of base classes , and the test dataset (novel dataset ) comprises instances of novel classes ( and are not intersected). Specifically, for each query image in , OSOL randomly samples a support image for each novel class existing in the image. Next, OSOL locates the novel objects in the query image according to the corresponding support image. The main difference from FSOD is that OSOL only requires a binary classification task to discriminate whether the potential object is foreground or background according to the given support image, while FSOD requires a multi-class classification task because FSOD doesn’t pre-know the classes of the existing objects in the query images.
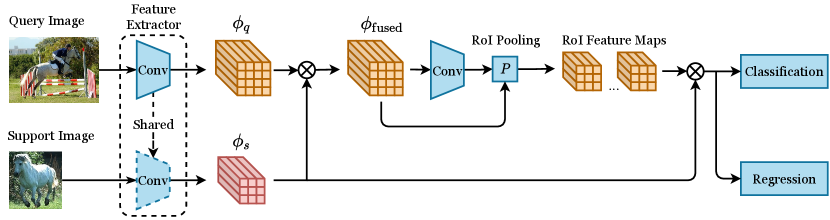
Framework of Current OSOL Methods. Some previous object tracking methods like SiamFC (Cen and Jung, 2018), SiamRPN (Li et al., 2018) are forerunners of OSOL, which are used for comparison with early OSOL methods. Current OSOL methods adopt the meta-learning scheme, and their framework is based on Faster R-CNN, as shown in Figure 3. First, they extract the integral features of the query image and the support image using the same convolutional backbone (named query features and support features, respectively), then conduct “integral feature aggregation” to generate a fused feature map by aggregating the query features with the support features. This fused feature map is fed into RPN and RoI layer to generate category-specific region proposals and the corresponding RoI features, respectively. Finally, these RoI features are used for the final classification and localization tasks. Furthermore, some methods additionally conduct “RoI feature aggregation” to further aggregate the RoI features with the support features.
Current OSOL methods mainly differ in the feature aggregation method, and this survey accordingly categorizes OSOL methods into concatenation-based methods, attention-based methods, and transformation-based methods. In the following sections, , and denote the query feature map, the RoI feature map and the support feature map, respectively. Note that , , , and are the channel and sizes of the feature maps.
3.1. Concatenation-Based Methods
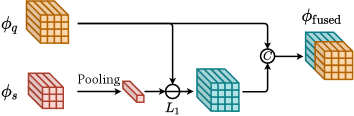
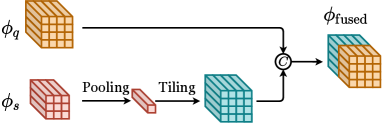
Concatenation-based methods simply adopt the concatenation operation to aggregate and , which are mainly adopted by early OSOL methods (SiamMask (Michaelis et al., 2018), OSCD (Fu et al., 2021), FOC OSOL (Yang et al., 2021a) and OSOLwT (Li et al., 2020c)), as shown in Figure 4.
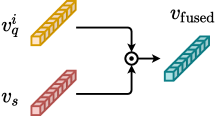
SiamMask (Michaelis et al., 2018). SiamMask is one of the early deep-learning-based methods for OSOL, which concatenates with the absolute difference between and the pooled embedding vector of to generate the aggregated feature map , as shown in Equation 1. In SiamMask, is directly used for further components (RPN, RoI layer) in Faster R-CNN without other modifications. SiamMask does not achieve satisfying performance since it tackles a segmentation task simultaneously. Nevertheless, as the first method for OSOL, SiamMask proposes a benchmark based on MS COCO dataset for performance comparison, pioneering many future works on OSOL and establishing a baseline for future work.
| (1) |
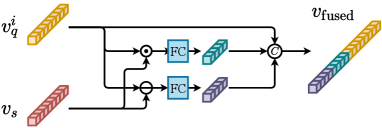
OSCD (Fu et al., 2021). Different from SiamMask, OSCD directly concatenates with the pooled embedding vector of to generate , as shown in Equation 2. Besides, OSCD further conducts RoI feature aggregation to leverage the information of to facilitate the prediction of RoIs, which concatenates the RoI feature map and in depth. OSCD proposes another OSOL benchmark based on PASCAL VOC dataset for evaluation, and it outperforms SiamFC and SiamRPN by a large margin on this benchmark.
| (2) |
OSOLwT (Li et al., 2020c) and FOC OSOL (Yang et al., 2021a). They add convolutional blocks into the concatenated features, which capture the relation between different feature units for performance improvement, as shown in Equation 3.
| (3) |
Discussion of Concatenation-Based Methods. Concatenation-based methods are mainly adopted by early OSOL methods. SiamMask and OSCD are the earliest concatenation-based methods for feature aggregation, while FOC OSOL and OSOLwT extend SiamMask and OSCD with convolutional blocks and some other elaborated training strategies. However, the limitation of concatenation-based methods is that they simply aggregate features without fully excavating the relation between different local parts of two feature maps, thus impairing the matching between the foreground parts of query feature map with support feature map.
3.2. Attention-Based Methods
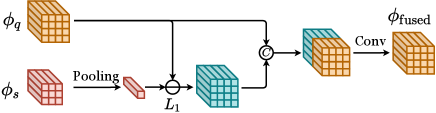
Attention-based methods take advantage of the correspondence between different parts of the support features and the query features, as shown in Figure 5.
CoAE (Hsieh et al., 2019). CoAE is the first attention-based OSOL method, which proposes two operations for integral feature aggregation: co-attention (ca) operation and co-excitation (ce) operation. The co-attention operation is implemented using the non-local operation (Wang et al., 2018) (an attention operation), which aggregates two feature maps according to their element-wise attention:
| (4) |
where denotes the non-local operation and . The co-excitation operation generates by aggregating with the pooled embedding vector of with a channel-wise multiplication:
| (5) |
CoAE adopts both these two operations for integral feature aggregation. Besides, CoAE proposes a proposal ranking loss to supervise RPN based on RoI feature aggregation. CoAE outperforms SiamMask on the MS COCO benchmark and OSCD on the PASCAL VOC benchmark, demonstrating the capacity of the attention mechanism on OSOL.
BHRL (Yang et al., 2022), ABA OSOL (Hsieh et al., 2023), ADA OSOL (Zhang et al., 2022a), and AUG OSOL (Du et al., 2022). These later methods follow the co-attention and co-excitation operations in CoAE with some elaborated modifications.
AIT (Chen et al., 2021a), CAT (Lin et al., 2021), SaFT (Zhao et al., 2022a). With the wide usage of transformers (Subakan et al., 2021) in computer vision, some methods (AIT, CAT, SaFT) adopt multi-head attention into OSOL for feature aggregation. These methods flatten the query feature map and the support feature map to be feature sequences and , then generates using multi-head attention to capture bidirectional correspondence between grids of them.
Discussion of Attention-Based Methods. Compared to attention-based methods with transformer, attention-based methods with co-attention require fewer extra parameters and less computation cost. However, CoAE is an early OSOL method, and the simple non-local operation is not enough for feature aggregation of current OSOL methods. Actually, recent methods of this type integrate co-attention with other elaborated operations to improve their performance. On the other hand, methods based on transformer significantly improve performance, and they can easily integrate other elaborated variants of transformer structure into this framework for further performance improvement. However, current transformer-based methods bring too much extra computation cost into model training. Therefore, the efficient transformer structure is expected to be adopted for the trade-off between performance and computation cost.
3.3. Transformation-Based Methods
OS2D (Osokin et al., 2020) proposes a transformation-based method for feature aggregation, which conducts feature map transformation to match query feature map and support feature map. Given the query feature map and the support feature map , OS2D first computes a 4D correlation matrix of shape which represents the correspondence between all pairs of locations from these two feature maps. Then, it uses a pre-trained TransformNet (Rocco et al., 2018) to generate a transformation matrix that spatially aligns the support feature map with the query feature map. Finally, the classification score of each location of the query feature map is obtained from the combination of the correlation matrix and the transformation matrix.
Discussion of OSOL Methods. To sum up, concatenation-based methods are easy to implement, and they require smaller computation cost, but they have poorer performance. Attention-based methods can capture the correspondence between support images and the foreground of query images, thus outperforming concatenation-based methods. The weakness of attention-based methods is that it is more complicated to implement them, and they require larger computation cost. Transformation-based methods make the decision process of OSOL more interpretable, but they require a large pre-trained model to capture the spatial correspondence between query and support images.
4. Standard Few-Shot Object Detection
Task Settings. The previous OSOL setting guarantees that every query image contains objects with the same category as the given support image, i.e., the model knows precisely the object classes contained in each test image. However, this setting is not realistic in the real world, and a more challenging LSOD setting, named Few-Shot Object Detection (FSOD), is adopted by more papers. This section first introduces the standard FSOD, and other FSOD settings (named extensional FSOD) are based on the standard FSOD, which will be analyzed in the later sections. Specifically, the base dataset () of standard FSOD consists of abundant annotated instances of base classes , and the novel dataset () consists of scarce annotated instances of novel classes ( and are not intersected). During testing, the model is evaluated on the test dataset comprising objects of both base classes and novel classes. The differences between FSOD and OSOL are as below:
-
(1)
Since OSOL precisely knows the object categories contained in each test image, it only requires a binary classification task to discriminate whether the potential object is foreground or background according to the given support image. In contrast, FSOD requires a multi-class classification task to predict the category of the potential object.
-
(2)
OSOL samples support images independently for each test image, FSOD samples the support images only once for all test images.
-
(3)
The shot number of support images per category can be larger than one in FSOD.
Method Categorization. Current standard FSOD methods can be categorized into fine-tune-based methods and fine-tune-free methods. Most methods are fine-tune-based methods, which require to fine-tune the model on the novel dataset for the significant improvement of performance. Early fine-tune-based methods adopt the scheme of meta-learning, and they also concentrate on the methods of feature aggregation as OSOL methods. Furthermore, the increased number of annotated samples opens up the possibility for standard FSOD methods to adopt the scheme of transfer-learning, which pre-trains an object detector on the base dataset and fine-tunes this pre-trained model for novel classes on the novel dataset. Early transfer-learning methods like LSTD (Chen et al., 2018) are outperformed by the meta-learning methods in that period until the emergence of TFA (Wang et al., 2020a). On the other hand, fine-tune-free methods aim to remove the fine-tuning step because fine-tuning step is not suitable for FSOD in real life for its nonnegligible computation cost. In this survey, the meta-learning methods are first analyzed since they are highly correlated to OSOL methods, then transfer-learning methods and fine-tune-free methods are analyzed later.
4.1. Meta-Learning Methods
Similar to OSOL, the meta-learning methods for standard FSOD first define a large number of few-shot detection tasks on the base dataset to train the model. The difference is that each few-shot task contains a query image and multiple support images since FSOD requires support images from all base classes for the multi-class classification task. Another difference is that meta-learning methods for standard FSOD have an additional fine-tuning stage that OSOL methods lack, which continues to meta-train the model by sampling support images from both base classes and novel classes for each few-shot task. The meta-learning framework of standard FSOD is similar to that of OSOL, which conducts “integral feature aggregation” and “RoI feature aggregation” to aggregate the query features with support features to incorporate the information of support images into the query image for prediction. Early meta-learning methods only conduct RoI feature aggregation, and later methods conduct both integral and RoI feature aggregation (named “mixed feature aggregation”) for better performance. Therefore, meta-learning methods for standard FSOD are categorized into RoI feature aggregation methods and mixed feature aggregation methods for a more explicit presentation in this survey.
4.1.1. RoI Feature Aggregation Methods
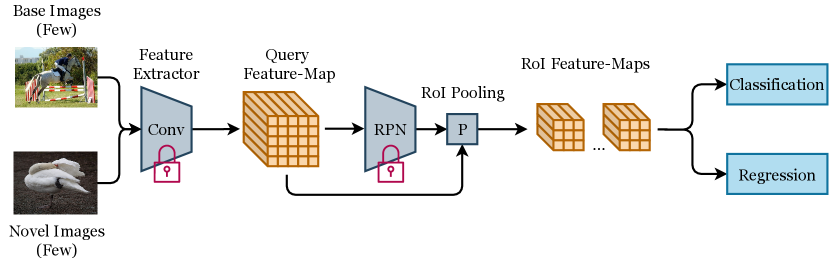
RoI feature aggregation methods aggregate the RoI features with support features to generate class-specific RoI features for the classification and regression tasks. Unlike OSOL methods that almost all adopt Faster R-CNN as the detection framework, early meta-learning methods explore RoI feature aggregation methods on both single-stage and two-stage detectors. These RoI feature aggregation methods can be categorized into two types according to the type of aggregated features: RoI feature-vector aggregation methods (FSRW (Kang et al., 2019), Meta R-CNN (Yan et al., 2019), CME (Li et al., 2021c), TIP (Li and Li, 2021), VFA (Han et al., 2023), FSOD-KT (Kim et al., 2020), GenDet (Liu et al., 2022a), FsDet (Xiao and Marlet, 2020), DRL (Liu et al., 2021b), and AFD-Net (Liu et al., 2021a)) and RoI feature-map aggregation methods (Attention-RPN (Fan et al., 2020), QA-FewDet (Han et al., 2021), KFSOD (Zhang et al., 2022d), PNSD (Zhang et al., 2020a), MM-FSOD (Han et al., 2022c), SQMG-FSOD (Zhang et al., 2021c), ICPE (Lu et al., 2022), DAnA-FasterRCNN (Chen et al., 2021b), TENET (Zhang et al., 2022c), Hierarchy-FasterRCNN (Park and Lee, 2022), IQ-SAM (Lee et al., 2022a), and Meta Faster R-CNN (Han et al., 2022a)).
The “RoI feature-vector aggregation methods” can be categorized into two types, which are first proposed by FSRW and FsDet, respectively.
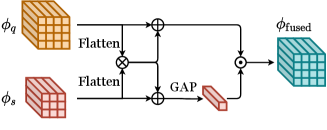
FSRW (Kang et al., 2019) is the first meta-learning method for standard FSOD based on the YOLOv2 detection framework. FSRW simply aggregates each feature vector at each pixel of the query feature map with the pooled embedding of the support feature map, aiming to highlight the important features corresponding to the support image using a simple element-wise multiplication:
| (6) |
The fused feature vector is used to predict the classification score (for the class that is from) and location regression, as shown in 6(a). Meta R-CNN (Yan et al., 2019), CME (Li et al., 2021c), TIP (Li and Li, 2021), VFA (Han et al., 2023), FSOD-KT (Kim et al., 2020) and GenDet (Liu et al., 2022a) follow this simple element-wise multiplication operation with other elaborated extensions.
FsDet (Xiao and Marlet, 2020) upgrades this simple element-wise multiplication operation to a more complex yet effective version, as shown in 6(b). Specifically, given the RoI feature vector and the support feature vector , the aggregated feature vector is calculated as the concatenation of their linearly transformed element-wise multiplication, subtraction and the original , as shown in Equation 7 ( denotes a fully-connected layer that reduces the dimension). With this extended aggregation method, FsDet outperforms Meta R-CNN on both MS COCO benchmark and PASCAL VOC benchmark.
| (7) |
AFD-Net (Liu et al., 2021a) and DRL (Liu et al., 2021b). These two methods follow FsDet in this RoI feature-vector aggregation method with some other modifications.
Unlike the above RoI feature-vector aggregation methods which concentrate on the aggregation of feature vectors, RoI feature-map aggregation methods focus on the aggregation of feature maps that preserves spatial information for better excavating the relation between query and support images. Some methods only adopt simple concatenation operation and element-wise operation for the feature map aggregation, while newly proposed methods tend to adopt attention operation for feature map aggregation.
Concatenation operation & element-wise operation for RoI feature-map aggregation. SQMG-FSOD (Zhang et al., 2021c) simply concatenates the RoI feature map with the support feature map for the RoI feature-map aggregation. While some methods (Attention-RPN (Fan et al., 2020), QA-FewDet (Han et al., 2021), KFSOD (Zhang et al., 2022d), PNSD (Zhang et al., 2020a), FCT (Han et al., 2022b), and MM-FSOD (Han et al., 2022c)) utilize a multi-relation head that adopt both concatenation operation and element-wise operation. Specifically, this multi-relation head consists of a global-relation head, a patch-relation head, and a local-relation head. The global-relation head concatenates and in depth with a pooling operation. The patch-relation head concatenates and with several convolutional blocks on it. And the local-relation head aggregates and by calculating the pixel-wise and depth-wise similarities between them. These methods conduct both integral and RoI feature aggregation, which will be specified later.
Attention operation for RoI feature-map aggregation. Some methods (ICPE (Lu et al., 2022), DAnA-FasterRCNN (Chen et al., 2021b), TENET (Zhang et al., 2022c), Hierarchy-FasterRCNN (Park and Lee, 2022), IQ-SAM (Lee et al., 2022a), and Meta Faster R-CNN (Han et al., 2022a)) adopt the attention operation to conduct RoI feature-map aggregation. Specifically, they calculate the aggregated feature map according to the similarity score (attention) between each pair of elements from and . In these methods, ICPE conducts only RoI feature aggregation with some proposed modifications. Specifically, it additionally incorporates the information of query images into support images before the final feature aggregation, and it adjusts the importance of different support images instead of treating them as equals. Other methods conduct both integral and RoI feature aggregation, which will be specified later.
Discussion of RoI Feature Aggregation Methods. RoI Feature Aggregation Methods are categorized into RoI feature-vector aggregation methods and RoI feature-map aggregation methods. RoI feature-vector aggregation methods are early meta-learning methods for FSOD, whose approaches are simple and limit their performance. On the other hand, RoI feature-map aggregation methods preserve spatial information of query and support samples, towards fully extracting the spatial relations between query and support features. Therefore, RoI feature-map aggregation methods can better discriminate features of different objects and achieve higher performance.
4.1.2. Mixed Feature Aggregation Methods
The above section discusses only the RoI feature aggregation, while most newly proposed methods (named “mixed feature aggregation methods”) additionally conduct integral feature aggregation to incorporate class-specific information into the shallow components of the detection model. The integral feature aggregation methods are mainly conducted on the feature-maps (not feature-vectors) and can be categorized into concatenation & element-wise operations (Attention-RPN (Fan et al., 2020), QA-FewDet (Han et al., 2021), KFSOD (Zhang et al., 2022d), PNSD (Zhang et al., 2020a), MM-FSOD (Han et al., 2022c), Meta Faster R-CNN (Han et al., 2022a)), convolutional operation (SQMG-FSOD (Zhang et al., 2021c)), and attention operation (DAnA-FasterRCNN (Chen et al., 2021b), TENET (Zhang et al., 2022c), Hierarchy-FasterRCNN (Park and Lee, 2022), IQ-SAM (Lee et al., 2022a), DCNet (Hu et al., 2021), Meta-DETR (Zhang et al., 2021b), FCT (Han et al., 2022b)).
Concatenation & element-wise operations for integral feature aggregation. Attention-RPN (Fan et al., 2020) conducts integral feature map aggregation by using as a kernel and sliding it across to compute similarities at each location. Specifically, the element at the location of the aggregated feature map is calculated in Equation 8 (note that ). Some methods (QA-FewDet (Han et al., 2021), KFSOD (Zhang et al., 2022d), PNSD (Zhang et al., 2020a), MM-FSOD (Han et al., 2022c), Meta Faster R-CNN (Han et al., 2022a)) follow this integral feature aggregation method with other extensions.
| (8) |
Convolutional operation for integral feature aggregation. SQMG-FSOD (Zhang et al., 2021c) proposes another integral feature aggregation method by generating convolutional kernels from support features and using the generated kernels to enhance query features. Furthermore, SQMG-FSOD not only learns a distance metric to compare RoI features and support features for filtering out irrelevant RoIs but also utilizes this metric to assign weights to support samples by comparing them with query images. Additionally, it proposes a hybrid loss to mitigate the false positive problem (i.e., some background RoIs are misclassified into objects).
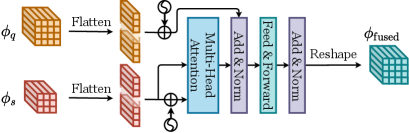
Attention operation for integral feature aggregation. Newly proposed methods (DCNet (Hu et al., 2021), DAnA-FasterRCNN (Chen et al., 2021b), TENET (Zhang et al., 2022c), Hierarchy-FasterRCNN (Park and Lee, 2022), IQ-SAM (Lee et al., 2022a), Meta-DETR (Zhang et al., 2021b), and FCT (Han et al., 2022b)) tend to adopt attention operation for integral feature aggregation. Attention operation aggregates two feature-maps using a similar manner as scaled dot-product attention (Subakan et al., 2021). It extracts the key map and the value map from the query image and the support image, respectively, then calculates the pixel-wise similarities between these two key maps and uses them to aggregate two value maps.
-
•
Meta-DETR also adopts attention operation for integral feature aggregation with a significant boost in performance. The major difference is that it adopts Deformable DETR (Zhu et al., 2021b) as the detection framework. DETR is an end-to-end transformer-based detector that eliminates anchor boxes in former detectors. Besides, Meta-DETR proposes a correlational aggregation module (CAM) that uses single-head attention to aggregate the query feature-maps with the support feature-maps. The aggregated features are finally fed into a class-agnostic transformer to predict object categories and locations.
-
•
Most of these methods aggregate the query and support features that are extracted from the backbone independently, while FCT surpasses this limit and instead aggregates the features in each layer of the ViT backbones, which achieves significant performance improvement. First, it splits query images and support images into image tokens and add position & branch embeddings into them (i.e., position embedding discriminates the position of the token, and branch embedding discriminates whether the token is from support image or query image). Next, it concatenates all query and support tokens into a sequence and feeds them into a transformer to generate the aggregated integral features.
Discussion of Mixed Feature Aggregation Methods. Compared to RoI feature aggregation methods, mixed feature aggregation methods additionally conduct integral feature aggregation to incorporate category-specific information into the shallow components (mainly RPN) of the detection model, which extracts more positive region proposals for the further classification & regression tasks and improves the performance. Mixed feature aggregation methods are categorized into three types: concatenation & element-wise operations, convolutional operation, and attention operation. Simple concatenation & element-wise operations are mostly adopted by early FSOD methods, which have poor performance and need to combine other components altogether for performance improvement. Convolutional operation is still simple, which cannot fully incorporate the information of support features into query features. Attention operation captures the relation between local regions in query feature maps and support feature maps, which better discriminates different local regions, and these methods overall achieve better performance.
4.1.3. Other Meta-Learning Methods
There are some other meta-learning methods that focus on issues other than the aggregation method of features, which are weight-prediction-based methods and metric-learning-based methods.
Weight-Prediction-Based Methods. MetaDet (Wang et al., 2019a) proposes a meta-learning method that learns to predict the weights of category-specific components of the model. MetaDet predicts category-specific (e.g., the classification and regression branches) weights for novel classes from few samples and fine-tunes the model on the novel dataset. Meta-RetinaNet (Li et al., 2020b) is another method which adopts RetinaNet as the detection framework and predicts the weights of the whole network.
Metric-Learning-Based Methods. IR-FSOD (Huang et al., 2021) directly learns to compare the similarity between the RoI features with support features from different classes to generate the classification scores. CAReD (Quan et al., 2022) also adds another metric learning branch for classification apart from the main classification branch.
4.2. Transfer-Learning Methods
Transfer-learning methods regard FSOD as a transfer-learning problem in which the source domain is the base dataset, and the target domain is the novel dataset. Current transfer-learning methods mainly adopt Faster R-CNN as the detection framework, consisting of two stages: base training and few-shot fine-tuning, as shown in Figure 7. The base training stage trains an object detector on the base dataset. After this stage, the object detector will obtain an effective feature extractor and achieve good performance on base classes. Then, in the few-shot fine-tuning stage, this pre-trained object detector will be fine-tuned on the novel dataset to detect novel classes. In this way, the common knowledge for feature extraction and proposal generation can be transferred from base classes to novel classes.

LSTD (Chen et al., 2018) is the first method to adopt the transfer-learning scheme for FSOD. It adopts Faster R-CNN as the detection framework with two regularization terms in the few-shot fine-tuning stage. Specifically, the first term suppresses background regions in the feature maps, and the second term promotes the fine-tuned model to generate similar predictions with the source model. Regrettably, the performance of LSTD is exceeded by the meta-learning methods during the same period.
TFA (Wang et al., 2020a) (Two-Stage Fine-tuning Approach) significantly improves the performance of transfer-learning methods based on the Faster R-CNN detection framework. In the base training stage, TFA pre-trains the model on the base dataset as previous transfer-learning methods. Then, in the few-shot fine-tuning stage, it freezes the main components of Faster R-CNN and only fine-tunes the last two layers (box classification and regression layers) of Faster R-CNN. The loss function used in the few-shot fine-tuning stage is the same as the base training stage but with a lower learning rate. The dataset used in the few-shot fine-tuning stage is a balanced dataset containing a few training samples of novel classes and a few selected training samples of base classes. This design retains the model’s detection ability for base classes and mitigates the problem that some objects of base classes are misclassified into novel classes. With this simple but effective training strategy, TFA outperforms early meta-learning methods like FSRW, MetaDet, and Meta R-CNN on both MS COCO benchmark and PASCAL VOC benchmark.
DeFRCN (Qiao et al., 2021) significantly improves the performance of TFA with two concise modifications: (1) DeFRCN assigns different importance values to the gradients from RPN module and R-CNN module, which is motivated by the viewpoint that RPN module and R-CNN module may learn paradoxically and the learning of these two modules should be decoupled. (2) DeFRCN utilizes a pre-trained classifier as an auxiliary branch for the classification of region proposals. DeFRCN further validates the effectiveness of transfer-learning methods for FSOD, and many methods are proposed following this transfer-learning paradigm. In this survey, transfer-learning methods are categorized into feature-augmentation-based methods, classification-based methods, regression-based methods, RPN-based methods, data-augmentation-based methods, and pre-train-based methods according to the detection stage they focus on.
4.2.1. Feature-Augmentation-Based Methods
Feature-augmentation-based methods focus on the feature extraction stage of an FSOD model. These methods apply different augmentations to the features, aiming to better transfer the features learned on the base dataset to the novel dataset. Current feature-augmentation-based methods can be categorized into three types: self-attention-based methods (CT-FSOD (Yang et al., 2020a), AttFDNet (Chen et al., 2020)), feature-discretization-based methods (SVD-FSOD (Wu et al., 2021b), KD-FSOD (Pei et al., 2022)), and feature-inheritance-based methods ( (Wu et al., 2021a), FADI (Cao et al., 2021)).
Self-Attention-Based Methods for Feature-Augmentation. Self-attention-based methods (CT-FSOD (Yang et al., 2020a), AttFDNet (Chen et al., 2020)) adopt self-attention to augment the extracted features.
Feature-Discretization-Based Methods for Feature-Augmentation. Feature-discretization-based methods (SVD-FSOD (Wu et al., 2021b), KD-FSOD (Pei et al., 2022)) discretize the feature-map by projecting each pixel of the feature-map into a learned codebook (i.e., replacing each pixel of the feature-map with its nearest code), thus enhancing the discrimination of features from different categories.
Feature-Inheritance-Based Methods for Feature-Augmentation. Feature-inheritance-based methods ( (Wu et al., 2021a), FADI (Cao et al., 2021)) inherit the features of base classes to the features of novel classes for augmentation, which mitigates the data scarcity problem of novel classes.
Discussion of Feature-Augmentation-Based Methods. Self-attention-based methods incorporate interpretability into the decision-making of FSOD through the attention heatmaps. However, self-attention-based methods are early FSOD methods, and the attention operations they adopt are primitive, restricting their performance.
Feature-discretization-based methods utilize feature discretization to enhance the discrimination of features from different categories, but they haven’t demonstrated the visual concepts that the discretized features represent. Besides, KD-FSOD requires an additional step to train an extra visual-word model and needs knowledge distillation to inherit the knowledge of this visual-word model into the few-shot detector, bringing a non-negligible burden into model training.
Feature-inheritance-based methods utilize the knowledge from base classes as “free lunch” to augment the features of novel classes with negligible cost. However, in the scenario that base classes and novel classes are not in the same domain, it is unclear whether these methods still work since base classes and novel classes share less common knowledge.
4.2.2. Classification-Based Methods
Classification-based methods aim to improve the classification branch of the detection model. Early classification-based methods focus on improving the main classification branch with some elaborated metric learning methods (RepMet (Karlinsky et al., 2019), NP-RepMet (Yang et al., 2020b), PNPDet (Zhang et al., 2021a), FSOD-KI (Yang et al., 2023)). New classification-based methods mostly propose another classification branch to assist the main classification branch, including additional-classifier-based methods (FSCN (Li et al., 2021e)), contrastive-learning-based methods (FSCE (Sun et al., 2021), FSRC (Shangguan et al., 2022), CoCo-RCNN (Ma et al., 2022)), knowledge-graph-based methods (KR-FSOD (Wang and Chen, 2022)), and semantic-infor-mation-based methods (SRR-FSOD (Zhu et al., 2021a)).
Metric Learning Methods for Classification. These methods (RepMet (Karlinsky et al., 2019), NP-RepMet (Yang et al., 2020b), PNPDet (Zhang et al., 2021a), FSOD-KI (Yang et al., 2023)) propose elaborated metric learning methods to directly improve the main classification branch.
Additional-Classifier-Based Methods for Classification. FSCN (Li et al., 2021e) proposes a few-shot correction network (FSCN) as an additional classification branch of the model, which makes class predictions for the cropped region proposals with a pre-trained image classifier. These classification scores are used to refine the classification scores from the main branch. Besides, this paper proposes a semi-supervised distractor utilization method to select unlabeled distractor proposals for novel classes and a confidence-guided dataset pruning (CGDP) method for filtering out training images containing unlabeled objects of novel-classes.
Contrastive-Learning-Based Methods for Classification. These methods (FSCE (Sun et al., 2021), CoCo-RCNN (Ma et al., 2022), FSRC (Shangguan et al., 2022)) adopt contrastive learning to assist the classification of region proposals.
-
•
FSCE introduces a contrastive loss to improve the classification performance of the model. FSCE proposes a contrastive loss function to maximize the similarity between objects of the same category and promote the distinctiveness of region proposals from different categories. This work is the first attempt to adopt contrastive learning into transfer-learning-based FSOD, which significantly improves the performance of the baseline TFA.
Knowledge-Graph-Based Methods for Classification. KR-FSOD (Wang and Chen, 2022) proposes an additional classification branch based on an external knowledge graph with potential objects as nodes. The model predicts the category of each potential object according to the information of its nearby objects, which is extracted from this external knowledge graph. KR-FSOD improves the performance by incorporating the external knowledge graph into the FSOD model.
Semantic-Information-Based Methods for Classification. SRR-FSOD (Zhu et al., 2021a) proposes an additional classification branch utilizing class semantic information to promote the classification, which utilizes the external semantic information into the FSOD model for higher performance. Specifically, SRR-FSOD projects the visual features into the semantic space using a linear projection. In this semantic space, multiple word embeddings are used as semantic embeddings to represent all base and novel classes. It generates class probabilities for the projected semantic embeddings by calculating the similarities between the projected visual features and the class semantic embeddings.
Discussion of Classification-Based Methods. Metric learning methods are early methods for FSOD with insufficient performance compared with the latest FSOD methods, indicating that simple modification on the RoI classifier is not enough for FSOD.
Additional-classifier-based method (FSCN) achieves a large performance improvement. However, it requires a pre-trained image classifier, resulting in an unfair comparison with other FSOD methods.
Contrastive-learning-based methods incur minimal additional cost during model training while yielding a substantial improvement in performance. Besides, they can be seamlessly integrated into other FSOD methods.
Knowledge-graph-based method (KR-FSOD) is well motivated, but the performance is currently not promising. Additionally, like FSCN, it cannot be readily applied to novel classes in real-world FSOD applications due to the unavailability of corresponding knowledge graphs.
Semantic-information-based method (SRR-FSOD) serves as a bridge between FSOD and zero-shot learning by incorporating class semantic information into the model. This approach has the potential for enhancing performance with the large-scale cross-modal models. Nevertheless, it may not be suitable for novel classes that haven’t been learned before.
4.2.3. Regression-Based Methods
Regression-based methods focus on improving the regression branch of detection model. SRR-FSD (Kim et al., 2022) proposes a refinement approach to improve the regression of region proposals in RPN. Specifically, SRR-FSD expands the regression branch into multiple successive regression heads. Each regression head receives the region proposals generated from the preceding regression head and continues to refine these region proposals for generating more positive samples.
Discussion of Regression-Based Methods. While the performance of the current regression-based method (SRR-FSD) is currently not ideal, it’s important to note that such methods are still rare, and there is ample opportunity for future exploration and improvement.
4.2.4. RPN-Based Methods
CoRPN (Zhang et al., 2020b) improves the RPN in Faster R-CNN for standard FSOD. CoRPN assumes that the RPN pre-trained on base classes will miss some objects of novel classes. Therefore, it uses multiple foreground-background classifiers in RPN instead of the original single one to mitigate this problem. During testing, a given proposal box is assigned with the score from the most certain RPN. During training, only the most certain RPN will get the gradient from the corresponding bounding box. CoRPN proposes a diversity loss to encourage the diversity of these RPNs and a cooperation loss to mitigate firm rejection of foreground proposals.
Discussion of RPN-Based Methods. RPN-based method (CoRPN) directly devises multiple RPNs to retrieve those missed novel objects, which addresses the problem that novel objects tend to be missed by the RPN trained on the base dataset. However, it is limited in R-CNN-based model, and it is unclear whether it still works when integrated into other FSOD models.
4.2.5. Data-Augmentation-Based Methods
Data-augmentation-methods aim to generate more samples for each novel class, thus directly tackling the data-scarce problem of few-shot setting. Current data augmentation methods can be divided into two categories: sample generation in the input-pixel space and sample generation in the feature space. The former type directly generates samples in the input-pixel space that are understandable and perceivable by humans, which can be further divided into multi-scale augmentation methods and novel-instance-mining methods. The latter type synthesizes more deep features for the novel classes, which can be further divided into distribution inheritance methods and generator-based methods.
Sample Generation In the Input-Pixel Space Multi-Scale Augmentation Methods. MPSR (Wu et al., 2020) and FSSP (Xu et al., 2021) both apply data augmentation to enrich the scales of positive samples.
-
•
MPSR claims that although feature pyramid network (FPN) (Lin et al., 2017a) may mitigate the scale variation issue, it cannot address the sparsity of scale distribution in FSOD. Therefore, MPSR proposes a strategy to directly augment the scales of objects in the input pixel space, which extracts each positive object independently and resizes them to multiple scales. The augmented multi-scale samples are fed into the RPN module and detection heads for training.
Sample Generation In the Input-Pixel Space Novel-Instance-Mining Methods. MINI (Cao et al., 2022), PSEUDO (Kaul et al., 2022), Decoupling (Gao et al., 2022a), and N-PME (Liu et al., 2022b) excavate the unlabeled novel objects in the dataset for data augmentation.
Sample Generation In the Feature Space Distribution Inheritance Methods. FSOD-KD (Zhao et al., 2022b), PDC (Li et al., 2022a), and FSOD-DIS (Wu et al., 2022) generate more novel features by transferring the feature distribution from the base dataset for data augmentation, which stem from the same few-shot learning method (Yang et al., 2021b). Specifically, these methods assume that the feature distribution of a class can be approximated as a Gaussian distribution and similar classes have similar feature distributions. Therefore, they calculate the feature distribution of base classes using their abundant samples and estimate the feature distribution of each novel class according to their nearest base classes. Finally, these methods sample more novel features from the estimated feature distribution and use them for training.
Sample Generation In the Feature Space Generator-Based Methods. Halluc (Zhang and Wang, 2021) aims to synthesize additional RoI features for novel classes. It proposes a simple hallucinator to generate hallucinated RoI features, implemented as a simple two-layer MLP. In the base-training stage, Halluc first trains a Faster R-CNN on the base dataset as regular object detection. Then, it freezes the parameters of the detector and pre-trains the hallucinator with a classification loss for the synthesized samples. Next, in the few-shot fine-tuning stage, Halluc unfreezes the parameters of detection heads (classification head & regression head) and adopts an EM-like algorithm to train the hallucinator and detection heads alternately. It is noted that this method shows impressive performance when the number of training samples is extremely small. However, its superiority over baseline methods such as TFA cannot be guaranteed as the number of training samples increases.
Discussion of Data-Augmentation-Based Methods. Methods for sample generation in the input-pixel space are categorized into multi-scale augmentation methods and novel instance mining methods. Multi-scale augmentation methods are effective data-augmentation methods for FSOD, and they are easy to implement. However, conducting data-augmentation only on the aspect of scale does not tackle the core of data-scarcity problem of FSOD, and they are early FSOD methods with insufficient performance. For the novel instance mining methods, it is true that on current FSOD benchmarks, many objects from novel classes indeed exist in the images without annotation. Capturing these objects effectively mitigates the data-scarcity problem in FSOD and significantly improves the performance. These methods have great potential to be integrated into other FSOD methods. However, this setting is not realistic. In real-life FSOD, it is not guaranteed that the images of the base dataset contain objects from novel classes.
Methods for sample generation in the feature space are categorized into two categories: distribution inheritance methods and generator-based methods. The former type effectively generates more samples for novel classes using the data distribution from the data-abundant base classes. It introduces no extra parameters and can be considered as a “free lunch” from the base dataset. However, it is not applicable in the real-world scenario that there is a significant difference between the data distribution of the base classes and novel classes. The latter type is more suitable for the scenario that base classes and novel classes differ a lot, but it introduces an extra generator which may increase the burden for model training.
4.2.6. Pre-Train-Based Methods
Almost all transfer-learning methods adopt a backbone pre-trained on ImageNet before the base training stage. Some methods (DETReg (Bar et al., 2022), imTED (Zhang et al., 2022b)) focus on improving this pre-training stage.
-
•
DETReg pre-trains a DETR model in an unsupervised manner. On the one hand, it uses Selective Search (Uijlings et al., 2013) to excavate object proposals and uses them to train the object localization branch of the model. On the other hand, it uses another pre-trained self-supervised model to generate object encodings and enforces the DETR model to mimic these object encodings.
-
•
imTED integrally migrates a pre-trained MAE model (He et al., 2022) to be a detection model. Concretely, imTED adds a region proposal network and a detection head into the MAE model following the design of Faster R-CNN. Besides, it proposes a multi-scale feature modulator to fuse multi-scale features extracted from a FPN (Lin et al., 2017a).
Discussion of Pre-Train-Based Methods. These methods explore the current FSOD problem in a new perspective that pursues a stronger backbone before the few-shot training stage, while current FSOD methods most simply adopt a backbone pre-trained with a classification task on ImageNet. Besides, the performance of these methods is significantly superior to other methods. However, these methods require a stronger pre-trained backbone (DETReg requires SwAV, and imTED requires MAE). Besides, these methods never clarify whether these stronger backbones cover the knowledge of novel classes in the FSOD setting, which will bring an unfair comparison with other FSOD methods.
4.3. Fine-Tune-Free Methods
Fine-tune-free methods focus on directly transferring the trained model from the base dataset to the novel dataset without fine-tuning. Existing fine-tune-free methods (AirDet (Li et al., 2022b), FS-DETR (Bulat et al., 2022)) adopt the scheme of meta-learning, and they also focus on the method of feature aggregation. Specifically, AirDet conducts integral feature aggregation with element-wise multiplication and concatenation operations, and it proposes to learn the weights of different support samples instead of treating them as equals. Besides, AirDet aggregates RoI features with support features for the regression branch. FS-DETR concatenates query features with support features into a common sequence and feeds it into the DETR model. FS-DETR proposes the learnable pseudo-class embeddings with the same shape as support features and adds them into support features to facilitate the model training.
Discussion of Fine-Tune-Free Methods. Fine-tune-free method requires less computation cost and are more suitable for real life. However, the performance of these methods is currently not ideal compared to the fine-tune-based methods.
5. Zero-Shot Object Detection
Zero-Shot Object Detection (ZSOD) is an extreme scenario of LSOD that novel classes do not contain any image sample. Concretely, the training dataset (base dataset ) of ZSOD consists of abundant annotated instances of base classes , and the test dataset (novel dataset ) does not consist of annotated instances of novel classes ( and are not intersected). As a substitute, ZSOD utilizes semantic information to assist in detecting objects of novel classes.
According to whether utilizing unlabeled test images for model training, this survey categorizes ZSOD into two domains: “transductive ZSOD” and “inductive ZSOD”. Inductive ZSOD is the mainstream of ZSOD, which does not require accessing the test images in advance. Differently, transductive ZSOD is rarely explored, which utilizes unlabeled test images to assist model training. Furthermore, inductive ZSOD is categorized according to the type of semantic information: semantic attributes and textual description. The former type utilizes the semantic attributes (word vector) as the auxiliary semantic information to represent each class. In contrast, the latter type utilizes the textual description (e.g., a description sentence for an image or a class) as the auxiliary semantic information. This section gives a comprehensive introduction to semantic-attributes-based inductive ZSOD (standard ZSOD). Textual-description-based inductive ZSOD and transductive ZSOD will be discussed in the later sections.
Current semantic-attributes-based inductive ZSOD methods adopt Faster R-CNN or YOLO-style model as the detection framework, as shown in Figure 8. Ankan Bansal et al. (Bansal et al., 2018) propose one of the earliest methods for semantic-attributes-based inductive ZSOD based on Faster R-CNN. This work first establishes a simple baseline built on Faster R-CNN, which uses a simple linear projection to project RoI features into semantic space and calculates the class probabilities of as the cosine similarities between the projected semantic embeddings and the semantic attributes of each class. As one of the earliest methods for ZSOD, this work sets up a benchmark adopted by many future works.
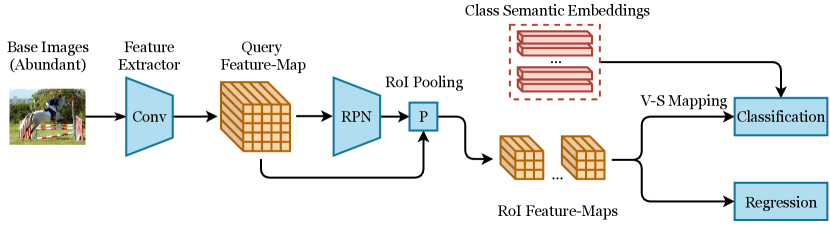
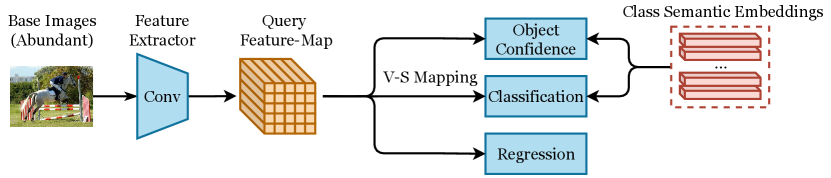
ZS-YOLO (Zhu et al., 2020b) is another early work for semantic-attributes-based inductive ZSOD based on YOLOv2. It projects each cell in the feature map into semantic embeddings for class prediction. Compared to the contemporaneous work (Bansal et al., 2018), ZS-YOLO adopts a different detection framework, and it does not require external training data and semantic embeddings of background class. However, these two methods are evaluated using different dataset settings, making it difficult to directly compare their performance.
As the forerunners of two mainstream detection frameworks for semantic-attributes-based inductive ZSOD, the above two methods (Bansal et al., 2018; Zhu et al., 2020b) are followed by many future works. The later methods mainly follow their framework with some extensions on different components of the framework. According to the modified components they focus on, this survey categorizes semantic-attributes-based inductive ZSOD methods into semantic relation methods, data augmentation methods, and visual-semantic mapping methods.
5.1. Semantic Relation Methods
Semantic relation methods utilize the semantic relation between classes to detect objects of novel classes, which are further categorized into base-novel class relation and super-class relation. Methods based on base-novel class relation utilize semantic similarities between base classes and novel classes to transfer knowledge from base classes to novel classes. Methods based on super-class relation assume that there is a hierarchical relationship among categories, i.e., some similar classes can be grouped into a super-class (e.g., bed, sofa, and chair can be grouped into furniture), and they utilize this hierarchical relationship to assist prediction.
5.1.1. Base-Novel Class Relation
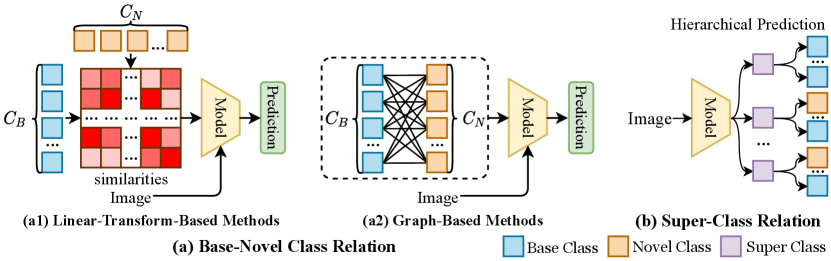
Methods based on base-novel class relation can be categorized into two types: linear-transform-based methods (TOPM-ZSOD (Shao et al., 2019), LSA-ZSOD (Wang et al., 2020b), DPIF (Li et al., 2021b)), and graph-based methods (SPGP (Yan et al., 2020), VSRG (Nie et al., 2022), CRF-ZSOD (Luo et al., 2020)). Linear-transform-based methods utilize the base-novel semantic relation to assist prediction through linear transforms of these semantic relations, and graph-based methods construct graphs with each node as a category, towards fully excavating the relation between base classes and novel classes through graph neural networks or conditional random fields.
Base-Novel Class Relation Linear-Transform-Based Methods. TOPM-ZSOD (Shao et al., 2019), LSA-ZSOD (Wang et al., 2020b), and DPIF (Li et al., 2021b) are all linear-transform-based methods to utilize base-novel class relation for ZSOD.
Base-Novel Class Relation Graph-Based Methods. SPGP (Yan et al., 2020), VSRG (Nie et al., 2022), and CRF-ZSOD (Luo et al., 2020) are graph-based methods to better excavate the relation between base and novel classes into the classification branch for higher performance.
Discussion of Methods Based on Base-Novel Class Relation. Linear-transform-based methods are simple approaches to directly utilize the base-novel semantic relation to assist prediction. However, linear transform does not fully excavate the base-novel relation for prediction, and it does not connect RoI features with the class semantic attributes together. Graph-based methods deeply excavate the relation between base classes and novel classes for prediction through graph neural networks or conditional random fields. Although they improve the performance through the graph structure modeling the relation between categories, they haven’t provided a quantitative analysis of whether the trained graph matches human intuition.
5.1.2. Super-Class Relation
Methods based on super-class relation (CG-ZSOD (Li et al., 2020a), JRLNC-ZSOD (Rahman et al., 2020b), ACS-ZSOD (Ma et al., 2020)) define some coarse-grained classes (super-classes) to cluster all classes into several groups, which separate the original classification problem into two sub-problems (coarse-grained classification and fine-grained classification).
Discussion of Methods Based on Super-Class Relation. These methods provide “free lunch” for the performance improvement of ZSOD, but they are unsuitable for situation where there is no hierarchical relationship between categories.
5.2. Visual-Semantic Mapping Methods
Visual-semantic mapping methods aim to find a proper mapping function to align visual features with the class semantic attributes. Visual-semantic mapping methods can be categorized into linear-projection-based methods (e.g., LSA-ZSOD (Wang et al., 2020b), DPIF (Li et al., 2021b), ZSDTR (Zheng and Cui, 2021)), weighted-combination-based methods (HRE-ZSOD (Demirel et al., 2018)), inverse-mapping methods (MS-ZSOD (Gupta et al., 2020), CCFA-ZSOD (Li et al., 2022c), SMFL-ZSOD (Li et al., 2021d)), auxiliary-loss-based methods (ContrastZSOD (Yan et al., 2022), VSA-ZSOD (Rahman et al., 2020a)), external-resource-based methods (CLIP-ZSOD (Xie and Zheng, 2022), BLC (Zheng et al., 2020)).
Linear-Projection-Based Methods. The earliest ZSOD method (Bansal et al., 2018) adopts this simplest visual-semantic mapping method that projects visual features into semantic space through a linear projection, which is followed by many ZSOD methods (e.g., LSA-ZSOD (Wang et al., 2020b), DPIF (Li et al., 2021b), ZSDTR (Zheng and Cui, 2021)). These methods are mostly based on CNN backbones, and only ZSDTR adopts DETR (Carion et al., 2020) (a vision-transformer-based detector) which projects the proposal encodings into semantic space.
Weighted-Combination-Based Methods. HRE-ZSOD (Demirel et al., 2018) calculates the semantic embeddings of the RoI feature as the weighted combination of different semantic attributes from all base classes according to their classification scores, as shown in Equation 9 ( denotes the probability that this RoI is predicted to be the base class ).
| (9) |
Inverse-Mapping Methods. Inverse-mapping methods (MS-ZSOD (Gupta et al., 2020), CCFA-ZSOD (Li et al., 2022c), SMFL-ZSOD (Li et al., 2021d)) conversely project class semantic attributes into visual space to align the class semantic attributes with the visual features.
Auxiliary-Loss-Based methods. Auxiliary-loss-based methods (ContrastZSOD (Yan et al., 2022), VSA-ZSOD (Rahman et al., 2020a)) propose some auxiliary losses to facilitate the visual-semantic mapping.
External-Resource-Based Methods. These methods utilize external resources (CLIP-ZSOD (Xie and Zheng, 2022), BLC (Zheng et al., 2020)) to better project visual features into semantic space. Specifically, CLIP-ZSOD utilizes a strong pre-trained CLIP model (Radford et al., 2021) for visual-semantic mapping, and BLC adopts external vocabulary for visual-semantic mapping.
5.3. Data Augmentation Methods
Data augmentation methods aim to generate multiple visual features for novel classes to mitigate the data-scarcity problem. The generated features are used to re-train the classifier of the detection model. Early data augmentation methods (DELO (Zhu et al., 2020a)) train a conditional generator with some auxiliary losses for data generalization, and later methods (GTNet (Zhao et al., 2020), SYN-ZSOD (Hayat et al., 2020), RSC-ZSOD (Sarma et al., 2022), RRFS-ZSOD (Huang et al., 2022)) all adopt GAN (generative adversarial network).
DELO (Zhu et al., 2020a) adopts a conditional generator to synthesize visual features for novel classes. Specifically, the generator consists of an encoder to extract the latent features of the corresponding semantic embeddings, and a decoder to synthesize the visual features from the latent features. DELO adopts the conditional VAE loss to train this generator, including a KL divergence loss and a reconstruction loss. Besides, it proposes three additional losses to encourage the consistency between the reconstructed visual features and the original visual features.
GTNet (Zhao et al., 2020), SYN-ZSOD (Hayat et al., 2020), RSC-ZSOD (Sarma et al., 2022), and RRFS-ZSOD (Huang et al., 2022). These methods all adopt GAN (generative adversarial network) to generate visual features for novel classes. The GAN consists of a generator to synthesize visual features and a discriminator to determine whether the visual features are synthesized or not. These methods propose some elaborated extensions on this framework respectively.
Discussion of Data Augmentation Methods. Data augmentation methods directly tackle the data-scarcity problem in ZSOD in an intuitive way. Actually, data augmentation methods can be seen as the inverse of visual-semantic mapping methods (i.e., mapping the class semantic attributes back into visual features). An important difference is that data augmentation methods incorporate intra-class variance into this mapping process, i.e., these methods generate different image features from different random noises for the same class. However, these methods can only synthesize visual features instead of visual samples (in the input pixel space), making it hard to interpret or visualize the synthesized samples. Besides, it is possible to substitute these methods by inverting the visual-semantic mapping functions.
6. Extensional Zero-Shot Object Detection
6.1. Open-Vocabulary Object Detection
Conventional ZSOD only learns to align visual features with semantic information for detection from a small set of base classes () and generalizes to the novel classes (), while Open-Vocabulary Object Detection (OVD) first accesses a much larger dataset (consisting of massive image-text pairs from multiple classes ) to train a stronger visual-semantic mapping function for multiple classes (intersecting with the base and novel classes for the later ZSOD task). We provide a detailed analysis of OVD in section S3 of the supplementary online-only material.
6.2. Textual-Description-Based Inductive ZSOD
Previous ZSOD methods use semantic attributes as semantic information to represent each class. Instead, textual-description-based methods use textual description as semantic information. Currently, only a few methods uncover textual-description-based inductive ZSOD, and they use different types of textual-description: class textual description (description text for each class) and image textual description (description text for each image).
Methods Based on Class Textual Description. ZSOD-TD (Li et al., 2019) adopts textual description to represent each class instead of semantic attributes (e.g., “stripe, equid” is used to describe zebra). ZSOD-TD projects the RoI features into semantic embeddings and makes predictions by comparing them with the features extracted from textual description.
Methods Based on Image Textual Description. In addition to the class textual description, ZSOD-CNN (Zhang et al., 2020c) adopts textual description to represent each image (e.g., “A bathroom with a sink and three towels.”), which also adopts Faster R-CNN as the detection framework. It uses a text CNN to extract text features, and concatenates the RoI features with the text features for further predictions. Besides, this method utilizes the OHEM technique to select hard samples for model training. During testing, it predicts the classification scores of novel classes according to those of base classes according to the semantic similarities between base and novel classes.
6.3. Transductive ZSOD
Transductive ZSOD (Rahman et al., 2019). Transductive ZSOD is an extended setting of inductive ZSOD, which incorporates unlabeled test images into model training. Rahman et al. (Rahman et al., 2019) propose the first work to uncover transductive ZSOD, which conducts transductive learning on a pre-trained ZSOD model. For transductive learning, it applies a pseudo-labeling paradigm on the unlabeled data, including a fixed pseudo-labeling step to generate fixed pseudo-labels for base classes using the pre-trained model, and a dynamic pseudo-labeling step to generate pseudo-labels for both base classes and novel classes iteratively. This work is the first to explore transductive learning on ZSOD, which shows promising potential for significant performance improvement, as other transductive methods in few-shot image classification.
7. Popular Benchmarks For Low-Shot Object Detection
7.1. Dataset Overview
In three settings (i.e., OSOL, FSOD, and ZSOD) of LSOD, the classes of the dataset are all split into two types: base classes with large labeled samples and novel classes with few or no labeled samples. The mainstream benchmarks for Low-Shot Object Detection are modified from widely-used object detection datasets like the PASCAL VOC dataset, MS COCO dataset. This survey summarizes the basic information of mainstream benchmarks for LSOD in Table 2 but omits some rarely-used benchmarks since they are not representative. In this table, the number of base classes, the number of novel classes, and the number of labeled samples per category for each benchmark are recorded. Moreover, split number denotes the number of category split schemes for each benchmark.
7.2. Evaluation Criteria
OSOL. OSOL has a guarantee that the model knows precisely the object classes contained in each test image. For each test image in the test stage, OSOL randomly samples one support image for each category existing in this image to locate the objects of this category and average their accuracy scores as the final results.
FSOD. Different from OSOL, FSOD methods randomly sample a small set of support samples for the whole test set instead of only one image. For the K-shot setting, some methods like LSTD (Chen et al., 2018) sample K support images for each novel category. This sampling strategy is not ideal since the number of objects in the images may differ. Current methods mostly sample K bounding boxes for each novel category instead, and this survey records the performance of FSOD methods under this setting. Early FSOD methods mostly adopt the support samples released by FSRW (Kang et al., 2019) for fair performance comparison, which are sampled only once. TFA (Wang et al., 2020a) samples support samples multiple times to obtain the average performance of the model. Currently, newly proposed FSOD methods mostly adopt this multiple sampling strategy to obtain more accurate performance.
ZSOD. ZSOD methods adopt two evaluation criteria for model performance comparison. The first criterion evaluates the model on a subset of test data that contains only objects of novel classes (ZSOD). The second setting, generalized ZSOD (GZSOD), evaluates the model on the complete test data, requiring the model to detect objects of both base classes and novel classes. Generalized ZSOD separately computes the mean average precision and recall of base classes and novel classes and uses a harmonic average to generate the average performance.
It is noted that the class semantic attributes for ZSOD are mainly borrowed from pre-trained word vectors or manually designed attributes: GloVe (300-dim) (Pennington et al., 2014), BERT (768-dim) (Devlin et al., 2019), word2vec (300-dim) (Mikolov et al., 2013), fastText (Bojanowski et al., 2017) and aPaY (64-dim) (Farhadi et al., 2009). Among them, aPaY contains manually designed attributes, and others contain pre-trained word vectors.
| LSOD Type | Dataset | Base Classes | Novel Classes | Shots Per Category | Split Number |
| OSOL | PASCAL VOC Dataset | 16 | 4 | 1 | 1 |
| MS COCO Dataset | 60 | 20 | 1 | 4 | |
| FSOD | PASCAL VOC Dataset | 15 | 5 | 1, 2, 3, 5, 10 | 3 |
| MS COCO Dataset | 60 | 20 | 10, 30 | 1 | |
| ZSOD | PASCAL VOC Dataset | 16 | 4 | 0 | 1 |
| MS COCO Dataset | 48 | 17 | 0 | 1 | |
| MS COCO Dataset | 65 | 15 | 0 | 1 |
7.3. Evaluation Metrics
Preliminaries for the calculation of evaluation metrics:
Intersection over Union (IoU). Intersection over Union (IoU) is a value that measures the degree of overlap between two bounding boxes. Specifically, let and respectively denote the area of overlap and union of two bounding boxes and , the IoU between them is calculated as . Two bounding boxes are considered to be matched if their IoU is larger than a pre-determined threshold .
The evaluation metrics for LSOD:
Precision. Precision is the fraction of correctly retrieved bounding boxes out of total retrieved bounding boxes.
Recall@K. In converse to Precision, Recall is the fraction of correctly retrieved bounding boxes out of total ground-truth bounding boxes (K denotes the number of total retrieved bounding boxes).
mAP50. AP50 (average precision with ) is the precision averaged over different levels of recall. Let denote the precision when “” is achieved, and AP50 is calculated averaged over some specific values of recall ( is usually selected), as shown in Equation 10. AP50 is calculated for each category and their results are averaged as the final mAP50 (mean average precision with ). Note that mAP50 is commonly adopted on the PASCAL VOC benchmark.
| (10) |
mAP. mAP is the extension of mAP50 that is averaged over ten IoU thresholds: , which is commonly adopted on the MS COCO benchmark.
8. Performance
This section demonstrates and analyzes the performance of different Low-Shot Object Detection methods on the most widely-used benchmarks.
8.1. One-Shot Object Localization
Table 3 lists the performance of current OSOL methods on the PASCAL VOC benchmark and the MS COCO benchmark (the results on the MS COCO benchmark are averaged over splits). SiamFC and SiamRPN are two methods initially proposed for video object tracking, which are the baselines for OSOL, and their performance is reasonably poor than authentic OSOL methods. SiamMask, OSCD, OSOLwT, and FOC OSOL use simple concatenation-based methods for feature aggregation with different modifications. These methods significantly outperform SiamFC & SiamRPN, but they have performance inferior to the attention-based methods, and FOC OSOL achieves the best performance among these methods on the PASCAL VOC benchmark. Differently, recently proposed methods (CoAE, ADA OSOL, AUG OSOL, AIT, CAT, BHRL, SaFT, ABA OSOL) most adopt the attention mechanism for feature aggregation, and CAT is the best method among them. Moreover, CAT (a transformer-based method) achieves points better than FOC OSOL on the PASCAL VOC benchmark, which indicates that attention-based methods are more promising for future One-Shot Object Localization.
| Type | Method | Detector (Backbone) | PASCAL VOC | MS COCO |
| Object Tracking Methods | SiamFC (2018) (Cen and Jung, 2018) | SNet & ENet (VGG-16) | 13.3 | N/A |
| SiamRPN (2018) (Li et al., 2018) | Faster R-CNN (AlexNet) | 14.2 | N/A | |
| Concatenation-Based Methods | SiamMask (2019) (Michaelis et al., 2018) | Faster R-CNN (R-50) | N/A | 16.8 |
| OSCD (2020) (Fu et al., 2021) | Faster R-CNN (AlexNet) | 52.1 | N/A | |
| OSOLwT (2020) (Li et al., 2020c) | Faster R-CNN (R-50) | 69.1 | N/A | |
| FOC OSOL (2021) (Yang et al., 2021a) | Faster R-CNN (R-50) | 71.0 | N/A | |
| Attention-Based Methods | CoAE (2019) (Hsieh et al., 2019) | Faster R-CNN (R-50) | 68.2 | 22.0 |
| ADA OSOL (2022) (Zhang et al., 2022a) | Faster R-CNN (R-50) | 72.3 | 23.6 | |
| AUG OSOL (2022) (Du et al., 2022) | Faster R-CNN (R-50) | 73.2 | 23.9 | |
| AIT (2021) (Chen et al., 2021a) | Faster R-CNN (R-50) | 73.1 | 24.3 | |
| BHRL (2022) (Yang et al., 2022) | Faster R-CNN (R-50) | 73.8 | 25.6 | |
| SaFT (2022) (Zhao et al., 2022a) | FCOS (Tian et al., 2019) (R-101) | 74.5 | 24.9 | |
| CAT (2021) (Lin et al., 2021) | Faster R-CNN (R-50) | 75.5 | 24.4 | |
| ABA OSOL (2023) (Hsieh et al., 2023) | Faster R-CNN (R-50) | 74.6 | 23.6 |
8.2. Few-Shot Object Detection
This subsection demonstrates the performance of standard Few-Shot Object Detection methods on two most commonly used benchmarks: PASCAL VOC benchmark and MS COCO benchmark. For a fair comparison, this survey only lists the performance of FSOD methods with released codes.
Table 4, Table 5 and Table 6 present the performance on novel classes of PASCAL VOC benchmark and MS COCO benchmark, respectively. Some conclusions can be summarized from these two tables: (1) The best-performing transfer-learning method have superior performance to the best performing meta-learning methods on the most commonly used backbone (ResNet-101). Specifically, FSOD-DIS (the best-performing transfer-learning method on ResNet-101) exceeds VFA (the best-performing meta-learning method on ResNet-101) on the MS COCO benchmark. (2) For meta-learning methods, mixed feature aggregation methods outperform RoI feature aggregation methods on two benchmarks overall. The reasons for this phenomenon is that mixed feature aggregation methods incorporate category-specific information into the shallow components (RPN, mainly) of the detection model, which directly guides the prediction of these components using the support information. (3) For transfer-learning methods, data augmentation methods (e.g., Halluc, PSEUDO, FSOD-DIS) show strong performance in an extremely few-shot condition (), demonstrating that data augmentation methods effectively tackle the data-scarcity problem in the extremely few-shot condition. (4) Methods on advanced backbones (FCT on PVTv2-B2-Li, Meta-DETR & DETReg on Def. DETR, PSEUDO on Swin-S, imTED on ViT-B) show significantly higher performance than methods on the regular backbone (ResNet-50 & ResNet-101), which point out a promising direction for the development of FSOD. (5) The performance ranking of a method can differ across these two benchmarks.
| Method | Detector (Backbone) | Novel Set 1 | Novel Set 2 | Novel Set 3 | |||||||||||||
| 1 | 2 | 3 | 5 | 10 | 1 | 2 | 3 | 5 | 10 | 1 | 2 | 3 | 5 | 10 | |||
| Meta-Learning | FSRW (2018) | YOLOv2 | 14.8 | 15.5 | 26.7 | 33.9 | 47.2 | 15.7 | 15.3 | 22.7 | 30.1 | 40.5 | 21.3 | 25.6 | 28.4 | 42.8 | 45.9 |
| Meta-RCNN (2019) | Faster R-CNN (R-101) | 19.9 | 25.5 | 35.0 | 45.7 | 51.5 | 10.4 | 19.4 | 29.6 | 34.8 | 45.4 | 14.3 | 18.2 | 27.5 | 41.2 | 48.1 | |
| FsDet (2020)⋆ | Faster R-CNN (R-101) | 24.2 | 35.3 | 42.2 | 49.1 | 57.4 | 21.6 | 24.6 | 31.9 | 37.0 | 45.7 | 21.2 | 30.0 | 37.2 | 43.8 | 49.6 | |
| DRL (2021)⋆ | Faster R-CNN (R-101) | 30.3 | 40.8 | 49.1 | 48.0 | 58.6 | 22.4 | 36.1 | 36.9 | 35.4 | 51.8 | 24.8 | 29.3 | 37.9 | 43.6 | 50.4 | |
| DCNet (2021)⋆ | Faster R-CNN (R-101) | 33.9 | 37.4 | 43.7 | 51.1 | 59.6 | 23.2 | 24.8 | 30.6 | 36.7 | 46.6 | 32.3 | 34.9 | 39.7 | 42.6 | 50.7 | |
| CME (2021) | YOLOv2 | 17.8 | 26.1 | 31.5 | 44.8 | 47.5 | 12.7 | 17.4 | 27.1 | 33.7 | 40.0 | 15.7 | 27.4 | 30.7 | 44.9 | 48.8 | |
| Meta-DETR (2022)⋆ | Def. DETR (R-101) | 35.1 | 49.0 | 53.2 | 57.4 | 62.0 | 27.9 | 32.3 | 38.4 | 43.2 | 51.8 | 34.9 | 41.8 | 47.1 | 54.1 | 58.2 | |
| QA-FewDet (2021) | Faster R-CNN (R-101) | 42.4 | 51.9 | 55.7 | 62.6 | 63.4 | 25.9 | 37.8 | 46.6 | 48.9 | 51.1 | 35.2 | 42.9 | 47.8 | 54.8 | 53.5 | |
| FCT (2022)⋆ | Faster R-CNN (PVTv2-B2-Li) | 38.5 | 49.6 | 53.5 | 59.8 | 64.3 | 25.9 | 34.2 | 40.1 | 44.9 | 47.4 | 34.7 | 43.9 | 49.3 | 53.1 | 56.3 | |
| VFA (2023) | Faster R-CNN (R-101) | 57.7 | 64.6 | 64.7 | 67.2 | 67.4 | 41.4 | 46.2 | 51.1 | 51.8 | 51.6 | 48.9 | 54.8 | 56.6 | 59.0 | 58.9 | |
| Transfer-Learning | TFA w/cos (2020) | Faster R-CNN (R-101) | 39.8 | 36.1 | 44.7 | 55.7 | 56.0 | 23.5 | 26.9 | 34.1 | 35.1 | 39.1 | 30.8 | 34.8 | 42.8 | 49.5 | 49.8 |
| Halluc (2021) | Faster R-CNN (R-101) | 47.0 | 44.9 | 46.5 | 54.7 | 54.7 | 26.3 | 31.8 | 37.4 | 37.4 | 41.2 | 40.4 | 42.1 | 43.3 | 51.4 | 49.6 | |
| MPSR (2020) | Faster R-CNN (R-101) | 41.7 | N/A | 51.4 | 55.2 | 61.8 | 24.4 | N/A | 39.2 | 39.9 | 47.8 | 35.6 | N/A | 42.3 | 48.0 | 49.7 | |
| Faster R-CNN (R-101) | 43.8 | 47.8 | 50.3 | 55.4 | 61.7 | 31.2 | 30.5 | 41.2 | 42.2 | 48.3 | 35.5 | 39.7 | 43.9 | 50.6 | 53.5 | ||
| FSCE (2021)⋆ | Faster R-CNN (R-101) | 32.9 | 44.0 | 46.8 | 52.9 | 59.7 | 23.7 | 30.6 | 38.4 | 46.0 | 48.5 | 22.6 | 33.4 | 39.5 | 47.3 | 54.0 | |
| DeFRCN (2021)⋆ | Faster R-CNN (R-101) | 40.2 | 53.6 | 58.2 | 63.6 | 66.5 | 29.5 | 39.7 | 43.4 | 48.1 | 52.8 | 35.0 | 38.3 | 52.9 | 57.7 | 60.8 | |
| FSOD-KI (2022) | Faster R-CNN (R-101) | 57.0 | 62.3 | 63.3 | 66.2 | 67.6 | 42.8 | 44.9 | 50.5 | 52.3 | 52.2 | 50.8 | 56.9 | 58.5 | 62.1 | 63.1 | |
| FSOD-KD (2022) | Faster R-CNN (R-101) | 46.7 | 53.1 | 53.8 | 61.0 | 62.1 | 30.1 | 34.2 | 41.6 | 41.9 | 44.8 | 41.0 | 46.0 | 47.2 | 55.4 | 55.6 | |
| FADI (2022) | Faster R-CNN (R-101) | 50.3 | 54.8 | 54.2 | 59.3 | 63.2 | 30.6 | 35.0 | 40.3 | 42.8 | 48.0 | 45.7 | 49.7 | 49.1 | 55.0 | 59.6 | |
| PSEUDO (2022) | Faster R-CNN (R-101) | 54.5 | 53.2 | 58.8 | 63.2 | 65.7 | 32.8 | 29.2 | 50.7 | 49.8 | 50.6 | 48.4 | 52.7 | 55.0 | 59.6 | 59.6 | |
| FSOD-DIS (2022) | Faster R-CNN (R-101) | 63.4 | 66.3 | 67.7 | 69.4 | 68.1 | 42.1 | 46.5 | 53.4 | 55.3 | 53.8 | 56.1 | 58.3 | 59.0 | 62.2 | 63.7 | |
| Method | Detector (Backbone) | 3 Novel Sets (Averaged) | |||||
| 1 | 2 | 3 | 5 | 10 | |||
| Meta-Learning | FSRW (2018) | YOLOv2 | 17.3 | 18.8 | 25.9 | 35.6 | 44.5 |
| Meta-RCNN (2019) | Faster R-CNN (R-101) | 14.9 | 21.0 | 30.7 | 40.6 | 48.3 | |
| FsDet (2020)⋆ | Faster R-CNN (R-101) | 22.3 | 30.0 | 37.1 | 43.3 | 50.9 | |
| DRL (2021)⋆ | Faster R-CNN (R-101) | 25.8 | 35.4 | 41.3 | 42.3 | 53.6 | |
| DCNet (2021)⋆ | Faster R-CNN (R-101) | 29.8 | 32.4 | 38.0 | 43.5 | 52.3 | |
| CME (2021) | YOLOv2 | 15.4 | 23.6 | 29.8 | 41.1 | 45.4 | |
| Meta-DETR (2022)⋆ | Def. DETR (R-101) | 32.6 | 41.0 | 46.2 | 51.6 | 57.3 | |
| QA-FewDet (2021) | Faster R-CNN (R-101) | 34.5 | 44.2 | 50.0 | 55.4 | 56.0 | |
| FCT (2022)⋆ | Faster R-CNN (PVTv2-B2-Li) | 33.0 | 42.6 | 47.6 | 52.6 | 56.0 | |
| VFA (2023) | Faster R-CNN (R-101) | 49.3 | 55.2 | 57.5 | 59.3 | 59.3 | |
| Transfer-Learning | TFA w/cos (2020) | Faster R-CNN (R-101) | 31.4 | 32.6 | 40.5 | 46.8 | 48.3 |
| Halluc (2021) | Faster R-CNN (R-101) | 37.9 | 39.6 | 42.4 | 47.8 | 48.5 | |
| MPSR (2020) | Faster R-CNN (R-101) | 33.9 | N/A | 44.3 | 47.7 | 53.1 | |
| Faster R-CNN (R-101) | 36.8 | 39.3 | 45.1 | 49.4 | 54.5 | ||
| FSCE (2021)⋆ | Faster R-CNN (R-101) | 26.4 | 36.0 | 41.6 | 48.7 | 54.1 | |
| DeFRCN (2021)⋆ | Faster R-CNN (R-101) | 34.9 | 43.9 | 51.5 | 56.5 | 60.0 | |
| FSOD-KI (2022) | Faster R-CNN (R-101) | 50.2 | 54.7 | 57.4 | 60.2 | 61.0 | |
| FSOD-KD (2022) | Faster R-CNN (R-101) | 39.3 | 44.4 | 47.5 | 52.8 | 54.2 | |
| FADI (2022) | Faster R-CNN (R-101) | 42.2 | 46.5 | 47.9 | 52.4 | 56.9 | |
| PSEUDO (2022) | Faster R-CNN (R-101) | 45.2 | 45.0 | 54.8 | 57.5 | 58.6 | |
| FSOD-DIS (2022) | Faster R-CNN (R-101) | 53.9 | 57.0 | 60.0 | 62.3 | 61.9 | |
8.3. Zero-Shot Object Detection
Table 7 and Table 8 demonstrate the performance of standard ZSOD methods under two evaluation protocols (ZSOD, GZSOD) on the most commonly used benchmark: MS COCO benchmark. Some trends can be found in this table. (1) Early ZSOD methods are not consistent in the choice of semantic attributes, and only a few of them are evaluated under the GZSOD protocol. Nevertheless, the newly proposed ZSOD methods mostly adopt word2vec as their semantic attributes and use both ZSOD protocol and GZSOD protocol to evaluate the model, which is more convenient for performance comparison. (2) The model performance of base-novel split is generally inferior to that of base-novel split, which is attributed to the fewer classes and samples in the base dataset. (3) Current data augmentation methods for ZSOD cannot achieve satisfying performance compared to the newly proposed ZSOD methods. However, data augmentation methods can outperform other methods when the shot number is small in FSOD, which is still promising in ZSOD. (4) The newly proposed ZSOD methods, such as CLIP-ZSOD, incorporate pre-trained cross-modal models like CLIP in their training process and achieve remarkable performance compared to state-of-the-art methods. This demonstrates the potential to transfer external foundation models in future ZSOD research, leading to even higher performance.
9. Promising Directions
9.1. Promising Directions for FSOD
Since FSOD extends OSOL by withdrawing the prior information of test images, this survey discusses the promising directions of FSOD to provide guidance for both FSOD and OSOL.
9.1.1. Efficient FSOD
FSOD models are generally modified from representative object detectors like Faster R-CNN, YOLO-style detectors. Current FSOD methods need to first pre-train these models on the data-abundant base dataset, then fine-tune them on the data-scarce novel dataset. The pre-training on the base dataset requires a large device cost and time cost similar to general object detection. Besides, current methods spend much time during the few-shot fine-tuning stage for the model to converge (usually more than epochs). The high computing cost of the model and long convergence time prevent FSOD from the real-life application. Therefore, lightweight and quickly-converged methods are required for future FSOD.
| Method | Backbone | 1 | 2 | 3 | 5 | 10 | 30 | |
| Meta-Learning | FSRW (2018) | YOLOv2 | N/A | N/A | N/A | N/A | 5.6 | 9.1 |
| Meta-RCNN (2019) | Faster R-CNN (R-101) | N/A | N/A | N/A | N/A | 8.7 | 12.4 | |
| FsDet (2020)⋆ | Faster R-CNN (R-101) | 4.5 | 6.6 | 7.2 | 10.7 | 12.5 | 14.7 | |
| Attention-RPN (2020) | Faster R-CNN (R-50) | 4.2 | 5.6 | 6.6 | 8.0 | 11.1 | 13.5 | |
| DRL (2021)⋆ | Faster R-CNN (R-101) | N/A | N/A | N/A | N/A | 11.9 | 14.6 | |
| DCNet (2021)⋆ | Faster R-CNN (R-101) | N/A | N/A | N/A | N/A | 12.8 | 18.6 | |
| CME (2021) | YOLOv2 | N/A | N/A | N/A | N/A | 15.1 | 16.9 | |
| Meta-DETR (2022)⋆ | Def. DETR (R-101) | 7.5 | N/A | 13.5 | 15.4 | 19.0 | 22.2 | |
| QA-FewDet (2021) | Faster R-CNN (R-101) | 4.9 | 7.6 | 8.4 | 9.7 | 11.6 | 16.5 | |
| DAnA-FasterRCNN (2021) | Faster R-CNN (R-50) | N/A | N/A | N/A | N/A | 18.6 | 21.6 | |
| Meta Faster R-CNN (2022) | Faster R-CNN (R-101) | 5.1 | 7.6 | 9.8 | 10.8 | 12.7 | 16.6 | |
| FCT (2022)⋆ | Faster R-CNN (PVTv2-B2-Li) | 5.1 | 7.2 | 9.8 | 12.0 | 15.3 | 20.2 | |
| VFA (2023) | Faster R-CNN (R-101) | N/A | N/A | N/A | N/A | 16.2 | 18.9 | |
| Transfer-Learning | TFA w/cos (2020) | Faster R-CNN (R-101) | 3.4 | 4.6 | 6.6 | 8.3 | 10.0 | 13.7 |
| Halluc (2021) | Faster R-CNN (R-101) | 4.4 | 5.6 | 7.2 | N/A | N/A | N/A | |
| MPSR (2020) | Faster R-CNN (R-101) | 2.3 | 3.5 | 5.2 | 6.7 | 9.8 | 14.1 | |
| Faster R-CNN (R-101) | N/A | N/A | N/A | N/A | 11.0 | 15.6 | ||
| FSCE (2021)⋆ | Faster R-CNN (R-101) | N/A | N/A | N/A | N/A | 11.9 | 16.4 | |
| DeFRCN (2021)⋆ | Faster R-CNN (R-101) | 4.8 | 8.5 | 10.7 | 13.6 | 16.8 | 21.2 | |
| N-PME (2022) | Faster R-CNN (R-101) | N/A | N/A | N/A | N/A | 10.6 | 14.1 | |
| FSOD-KI (2022) | Faster R-CNN (R-101) | N/A | N/A | N/A | N/A | 13.0 | 16.8 | |
| FSOD-KD (2022) | Faster R-CNN (R-101) | N/A | N/A | N/A | N/A | 12.5 | 17.1 | |
| FADI (2022) | Faster R-CNN (R-101) | N/A | N/A | N/A | N/A | 12.2 | 16.1 | |
| PSEUDO (2022) | Faster R-CNN (Swin-S) | N/A | N/A | N/A | N/A | 19.0 | 26.8 | |
| FSOD-DIS (2022) | Faster R-CNN (R-101) | 10.8 | 13.9 | 15.0 | 16.4 | 19.4 | 22.7 | |
| imTED (2022) | Faster R-CNN (ViT-B) | N/A | N/A | N/A | N/A | 22.5 | 30.2 | |
| DETReg (2022) | Def. DETR (R-50) | N/A | N/A | N/A | N/A | 25.0 | 30.0 |
| Method | Semantic | Detector (Backbone) | ZSOD | Seen | Unseen | HM | ||||
| mAP | Recall | mAP | Recall | mAP | Recall | mAP | Recall | |||
| SB (2018) (Bansal et al., 2018) | GloVe | Faster R-CNN (Inception) | 0.70 | 24.39 | N/A | N/A | N/A | N/A | N/A | N/A |
| DSES (2018) (Bansal et al., 2018) | GloVe | Faster R-CNN (Inception) | 0.54 | 27.19 | N/A | 15.02 | N/A | 15.32 | N/A | 15.17 |
| TOPM (2019) (Shao et al., 2019) | GloVe | YOLOv3 (DarkNet-53) | 15.43 | 39.20 | N/A | N/A | N/A | N/A | N/A | N/A |
| CG-ZSOD (2020) (Li et al., 2020a) | BERT | YOLOv3 (DarkNet-53) | 7.20 | N/A | N/A | N/A | N/A | N/A | N/A | N/A |
| GTNet (2020) (Zhao et al., 2020) | fastText | Faster R-CNN (R-101) | N/A | 44.6 | N/A | N/A | N/A | N/A | N/A | N/A |
| JRLNC-ZSOD (2020) (Rahman et al., 2020b) | word2vec | Faster R-CNN (R-50) | 5.05 | 12.27 | 13.93 | 20.42 | 2.55 | 12.42 | 4.31 | 15.45 |
| SPGP (2020) (Yan et al., 2020) | word2vec | Faster R-CNN (R-101) | N/A | 35.40 | N/A | N/A | N/A | N/A | N/A | N/A |
| VSA-ZSOD (2020) (Rahman et al., 2020a) | word2vec | RetinaNet (R-50) | 10.01 | 43.56 | 35.92 | 38.24 | 4.12 | 26.32 | 7.39 | 31.18 |
| MS-Zero++ (2020) (Gupta et al., 2020) | word2vec | Faster R-CNN (R-101) | N/A | N/A | 35.00 | N/A | 13.80 | 35.00 | 19.80 | N/A |
| BLC (2020) (Zheng et al., 2020) | word2vec | Faster R-CNN (R-50) | 10.60 | 48.87 | 42.10 | 57.56 | 4.50 | 46.39 | 8.20 | 51.37 |
| ZSI (2021) (Zheng et al., 2021) | word2vec | Faster R-CNN (R-101) | 11.40 | 53.90 | 46.51 | 70.76 | 4.83 | 53.85 | 8.75 | 61.16 |
| ZSDTR (2021) (Zheng and Cui, 2021) | word2vec | Def. DETR (R-50) | 10.40 | 48.50 | 48.53 | 74.31 | 5.62 | 48.44 | 9.45 | 60.53 |
| VSRG (2022) (Nie et al., 2022) | word2vec | Faster R-CNN (R-50) | 11.40 | 55.03 | 43.90 | 66.70 | 4.70 | 54.54 | 8.50 | 60.01 |
| ContrastZSOD (2022) (Yan et al., 2022) | word2vec | Faster R-CNN (R-101) | 12.50 | 52.40 | 45.10 | 65.70 | 6.30 | 52.40 | 11.10 | 58.30 |
| RRFS-ZSOD (2022) (Huang et al., 2022)) | fastText | Faster R-CNN (R-101) | 13.40 | 53.50 | 42.30 | 59.70 | 13.40 | 58.80 | 20.40 | 59.20 |
| CLIP-ZSOD (2022) (Xie and Zheng, 2022) | word2vec | YOLOv5 (CSPDarkNet-53) | 13.40 | 55.80 | 31.70 | 63.30 | 13.60 | 45.20 | 19.00 | 52.70 |
| Method | Semantic | Detector (Backbone) | ZSOD | Seen | Unseen | HM | ||||
| mAP | Recall | mAP | Recall | mAP | Recall | mAP | Recall | |||
| Transductive (2019) (Rahman et al., 2019) | word2vec | RetinaNet (R-50) | 14.57 | 48.15 | 28.78 | 54.14 | 14.05 | 37.16 | 18.89 | 44.07 |
| CG-ZSOD (2020) (Li et al., 2020a) | BERT | YOLOv3 (DarkNet-53) | 10.90 | N/A | N/A | N/A | N/A | N/A | N/A | N/A |
| LSA-ZSOD (2020) (Wang et al., 2020b) | aPaY | RetinaNet (R-50) | 13.55 | 37.78 | 34.18 | 40.32 | 13.42 | 38.73 | 19.27 | 39.51 |
| ACS-ZSOD (2020) (Ma et al., 2020) | aPaY | RetinaNet (R-50) | 15.34 | 47.83 | N/A | N/A | N/A | N/A | N/A | N/A |
| SYN-ZSOD (2020) (Hayat et al., 2020) | fastText | Faster R-CNN (R-101) | 19.00 | 54.00 | 36.90 | 57.70 | 19.00 | 53.90 | 25.08 | 55.74 |
| VSA-ZSOD (2020) (Rahman et al., 2020a) | word2vec | RetinaNet (R-50) | 12.40 | 37.72 | 34.07 | 36.38 | 12.40 | 37.16 | 18.18 | 36.76 |
| BLC (2020) (Zheng et al., 2020) | word2vec | Faster R-CNN (R-50) | 14.70 | 54.68 | 36.00 | 56.39 | 13.10 | 51.65 | 19.20 | 53.92 |
| ZSI (2021) (Zheng et al., 2021) | word2vec | Faster R-CNN (R-101) | 13.60 | 58.90 | 38.68 | 67.11 | 13.60 | 58.93 | 20.13 | 62.76 |
| ZSDTR (2021) (Zheng and Cui, 2021) | word2vec | Def. DETR (R-50) | 13.20 | 60.30 | 40.55 | 69.12 | 13.22 | 59.45 | 20.16 | 61.12 |
| DPIF (2021) (Li et al., 2021b) | word2vec | Faster R-CNN (R-50) | 19.82 | 55.73 | 29.82 | 56.68 | 19.46 | 38.70 | 23.55 | 46.00 |
| VSRG (2022) (Nie et al., 2022) | word2vec | Faster R-CNN (R-50) | 14.90 | 62.70 | 38.10 | 65.31 | 13.90 | 60.52 | 20.40 | 62.82 |
| RSC-ZSOD (2022) (Sarma et al., 2022) | word2vec | Faster R-CNN (R-101) | 20.10 | 65.10 | 37.40 | 58.60 | 20.10 | 64.00 | 26.15 | 61.18 |
| ContrastZSOD (2022) (Yan et al., 2022) | word2vec | Faster R-CNN (R-101) | 18.60 | 59.50 | 40.20 | 62.90 | 16.50 | 58.60 | 23.40 | 60.70 |
| RRFS-ZSOD (2022) (Huang et al., 2022)) | fastText | Faster R-CNN (R-101) | 19.80 | 62.30 | 37.40 | 58.60 | 19.80 | 61.80 | 26.00 | 60.20 |
| CLIP-ZSOD (2022) (Xie and Zheng, 2022) | word2vec | YOLOv5 (CSPDarkNet-53) | 18.30 | 69.50 | 31.70 | 61.00 | 17.90 | 65.20 | 22.90 | 63.00 |
| CCFA-ZSOD (2022) (Li et al., 2022c) | word2vec | RetinaNet (R-50) | 24.62 | 55.32 | 33.35 | 38.64 | 24.62 | 54.72 | 28.31 | 45.29 |
9.1.2. Cross-Domain FSOD
Almost all of the current FSOD methods are evaluated in the single-domain condition. Cross-domain few-shot learning is a more realistic setting that the data for base classes and novel classes are drawn from two domains. Some studies (Guo et al., 2020) on cross-domain few-shot image classification indicate that the few-shot method does not have consistent performance in the single-domain condition and cross-domain condition. For example, this paper demonstrates that although some meta-learning methods achieve better performance than fine-tuning methods in the single-domain condition, they significantly underperform even some simple fine-tuning methods in the cross-domain condition. Cross-domain few-shot object detection is a more complicated task than cross-domain few-shot image classification. Recently a few methods (Gao et al., 2022b; Lee et al., 2022b; Xiong and Liu, 2022) propose some benchmarks on cross-domain FSOD and set up some baselines for this area. Nevertheless, cross-domain FSOD deserves more exploration in the future for its practicality.
9.1.3. New Detection Framework for FSOD
Most of the current FSOD methods adopt Faster R-CNN as the detection framework. Some other powerful frameworks are worth exploring in the future. For example, vision transformer focuses more on holistic information of the image than local information, which can capture features missed by traditional CNN models. Currently, it has been widely applied in many other computer vision areas. In FSOD, the recently proposed Meta-DETR has improved the performance of FSOD to the SOTA on the MS COCO benchmark, which exceeds previous Faster R-CNN based detectors by several points. Therefore, the potential of vision transformer on FSOD still requires exploration.
9.2. Promising Directions for ZSOD
9.2.1. Combining Auxiliary Information for ZSOD
Combining information from an external source to assist ZSOD is a potential direction for performance improvement. Some ZSOD methods attempt to exploit the information of external classes (not intersecting with base classes and novel classes) to augment semantic attributes of base classes and novel classes. Moreover, some other ZSOD methods utilize an external word vocabulary to enhance the visual-semantic mapping. However, no ZSOD method delves into the utilization of external auxiliary information as a whole, which requires more attention in the future.
9.2.2. Large Cross-Modal Foundation Model for ZSOD
Recently some large pre-trained cross-modal model show incredibly strong performance in aligning the context semantic between images and their text descriptions. CLIP (Radford et al., 2021) is the representative work of these large cross-modal models. Specifically, CLIP pre-trains the model on a large-scale dataset comprising abundant image-text pairs. CLIP encodes the images and texts with two parallel transformer-based models and adopts a contrastive learning strategy for training. CLIP has the strong capacity of projecting images and texts into a common feature space, thus it can be directly transferred to the zero-shot scenario. Recently, CLIP has been widely adopted for open-vocabulary object detection.
9.2.3. ZSOD combined with FSOD
A more generic scenario may appear in real-life where only some novel classes have annotated samples, yet other novel classes have semantic attributes, which requires the combination of ZSOD and FSOD. Some methods have been proposed to tackle this scenario. For example, ASD (Rahman et al., 2020c) and UniT (Khandelwal et al., 2021) introduce an LSOD setting that the model makes predictions utilizing both semantic information and image samples. Moreover, UniT significantly improves the performance of FSOD with auxiliary semantic information. Therefore, this generalized setting has more practical significance for the application of LSOD in the future.
10. Conclusion
Enhancing the deep object detectors to quickly learn from very few or even zero samples is of great significance to future object detection. This paper conducts a comprehensive survey on Low-Shot Object Detection (LSOD), consisting of One-Shot Object Localization (OSOL), Few-Shot Object Detection (FSOD) and Zero-Shot Object Detection (ZSOD). In this survey, the emergence background and evolution history of LSOD are first reviewed. Then, current LSOD methods are analyzed systematically based on an explicit and complete taxonomy of these methods, including some extensional topics of LSOD. Moreover, the pros and cons of LSOD methods are indicated with a comparison of their performance. Finally, the challenges and promising directions of LSOD are discussed. Hopefully, this survey can promote future research on LSOD.
References
- (1)
- Bansal et al. (2018) Ankan Bansal, Karan Sikka, Gaurav Sharma, Rama Chellappa, and Ajay Divakaran. 2018. Zero-Shot Object Detection. In ECCV. Springer, 397–414.
- Bar et al. (2022) Amir Bar, Xin Wang, Vadim Kantorov, Colorado J. Reed, Roei Herzig, Gal Chechik, Anna Rohrbach, Trevor Darrell, and Amir Globerson. 2022. DETReg: Unsupervised Pretraining with Region Priors for Object Detection. In CVPR. IEEE, 14585–14595.
- Bochkovskiy et al. (2020) Alexey Bochkovskiy, Chien-Yao Wang, and Hong-Yuan Mark Liao. 2020. Yolov4: Optimal speed and accuracy of object detection. arXiv preprint arXiv:2004.10934 (2020).
- Bojanowski et al. (2017) Piotr Bojanowski, Edouard Grave, Armand Joulin, and Tomás Mikolov. 2017. Enriching Word Vectors with Subword Information. Trans. Assoc. Comput. Linguistics 5 (2017), 135–146.
- Bulat et al. (2022) Adrian Bulat, Ricardo Guerrero, Brais Martinez, and Georgios Tzimiropoulos. 2022. FS-DETR: Few-Shot DEtection TRansformer with prompting and without re-training. arXiv preprint arXiv:2210.04845 (2022).
- Cao et al. (2021) Yuhang Cao, Jiaqi Wang, Ying Jin, Tong Wu, Kai Chen, Ziwei Liu, and Dahua Lin. 2021. Few-Shot Object Detection via Association and DIscrimination. In NIPS. 16570–16581.
- Cao et al. (2022) Yuhang Cao, Jiaqi Wang, Yiqi Lin, and Dahua Lin. 2022. MINI: Mining Implicit Novel Instances for Few-Shot Object Detection. arXiv preprint arXiv:2205.03381 (2022).
- Carion et al. (2020) Nicolas Carion, Francisco Massa, Gabriel Synnaeve, Nicolas Usunier, Alexander Kirillov, and Sergey Zagoruyko. 2020. End-to-End Object Detection with Transformers. In ECCV. Springer, 213–229.
- Cen and Jung (2018) Miaobin Cen and Cheolkon Jung. 2018. Fully Convolutional Siamese Fusion Networks for Object Tracking. In ICIP. IEEE, 3718–3722.
- Chen et al. (2021a) Ding-Jie Chen, He-Yen Hsieh, and Tyng-Luh Liu. 2021a. Adaptive Image Transformer for One-Shot Object Detection. In CVPR. IEEE, 12247–12256.
- Chen et al. (2018) Hao Chen, Yali Wang, Guoyou Wang, and Yu Qiao. 2018. LSTD: A Low-Shot Transfer Detector for Object Detection. In AAAI. AAAI Press, 2836–2843.
- Chen et al. (2021b) Tung-I Chen, Yueh-Cheng Liu, Hung-Ting Su, Yu-Cheng Chang, Yu-Hsiang Lin, Jia-Fong Yeh, and Winston H Hsu. 2021b. Should I Look at the Head or the Tail? Dual-awareness Attention for Few-Shot Object Detection. arXiv preprint arXiv:2102.12152 (2021).
- Chen et al. (2020) Xianyu Chen, Ming Jiang, and Qi Zhao. 2020. Leveraging Bottom-Up and Top-Down Attention for Few-Shot Object Detection. arXiv preprint arXiv:2007.12104 (2020).
- Dai et al. (2021) Zhigang Dai, Bolun Cai, Yugeng Lin, and Junying Chen. 2021. UP-DETR: Unsupervised Pre-Training for Object Detection With Transformers. In CVPR. IEEE, 1601–1610.
- Dalal and Triggs (2005) Navneet Dalal and Bill Triggs. 2005. Histograms of Oriented Gradients for Human Detection. In CVPR. IEEE, 886–893.
- Demirel et al. (2018) Berkan Demirel, Ramazan Gokberk Cinbis, and Nazli Ikizler-Cinbis. 2018. Zero-Shot Object Detection by Hybrid Region Embedding. In BMVC. BMVA Press, 56.
- Devlin et al. (2019) Jacob Devlin, Ming-Wei Chang, Kenton Lee, and Kristina Toutanova. 2019. BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding. In NAACL-HLT. Association for Computational Linguistics, 4171–4186.
- Dong et al. (2019) Xuanyi Dong, Liang Zheng, Fan Ma, Yi Yang, and Deyu Meng. 2019. Few-Example Object Detection with Model Communication. TPAMI 41, 7 (2019), 1641–1654.
- Du et al. (2022) Yaoyang Du, Fang Liu, Licheng Jiao, Zehua Hao, Shuo Li, Xu Liu, and Jing Liu. 2022. Augmentative contrastive learning for one-shot object detection. Neurocomputing 513 (2022), 13–24.
- Everingham et al. (2010) Mark Everingham, Luc Van Gool, Christopher KI Williams, John Winn, and Andrew Zisserman. 2010. The pascal visual object classes (voc) challenge. IJCV 88, 2 (2010), 303–338.
- Fan et al. (2020) Qi Fan, Wei Zhuo, Chi-Keung Tang, and Yu-Wing Tai. 2020. Few-Shot Object Detection With Attention-RPN and Multi-Relation Detector. In CVPR. IEEE, 4012–4021.
- Farhadi et al. (2009) Ali Farhadi, Ian Endres, Derek Hoiem, and David A. Forsyth. 2009. Describing objects by their attributes. In CVPR 2009. IEEE Computer Society, 1778–1785.
- Felzenszwalb et al. (2008) Pedro F. Felzenszwalb, David A. McAllester, and Deva Ramanan. 2008. A discriminatively trained, multiscale, deformable part model. In CVPR. IEEE.
- Fu et al. (2021) Kun Fu, Tengfei Zhang, Yue Zhang, and Xian Sun. 2021. OSCD: A one-shot conditional object detection framework. Neurocomputing 425 (2021), 243–255.
- Gao et al. (2022a) Bin-Bin Gao, Xiaochen Chen, Zhongyi Huang, Congchong Nie, Jun Liu, Jinxiang Lai, Guannan Jiang, Xi Wang, and Chengjie Wang. 2022a. Decoupling Classifier for Boosting Few-shot Object Detection and Instance Segmentation. In NIPS.
- Gao et al. (2019) Jiyang Gao, Jiang Wang, Shengyang Dai, Li-Jia Li, and Ram Nevatia. 2019. NOTE-RCNN: NOise Tolerant Ensemble RCNN for Semi-Supervised Object Detection. In ICCV. IEEE, 9507–9516.
- Gao et al. (2022b) Yipeng Gao, Lingxiao Yang, Yunmu Huang, Song Xie, Shiyong Li, and Wei-Shi Zheng. 2022b. AcroFOD: An Adaptive Method for Cross-Domain Few-Shot Object Detection. In ECCV. Springer, 673–690.
- Ge et al. (2021) Zheng Ge, Songtao Liu, Feng Wang, Zeming Li, and Jian Sun. 2021. Yolox: Exceeding yolo series in 2021. arXiv preprint arXiv:2107.08430 (2021).
- Girshick (2015) Ross B. Girshick. 2015. Fast R-CNN. In ICCV. IEEE, 1440–1448.
- Girshick et al. (2014) Ross B. Girshick, Jeff Donahue, Trevor Darrell, and Jitendra Malik. 2014. Rich Feature Hierarchies for Accurate Object Detection and Semantic Segmentation. In CVPR. IEEE, 580–587.
- Grigorescu et al. (2020) Sorin Mihai Grigorescu, Bogdan Trasnea, Tiberiu T. Cocias, and Gigel Macesanu. 2020. A survey of deep learning techniques for autonomous driving. J. Field Robotics 37, 3 (2020), 362–386.
- Guo et al. (2020) Yunhui Guo, Noel Codella, Leonid Karlinsky, James V. Codella, John R. Smith, Kate Saenko, Tajana Rosing, and Rogério Feris. 2020. A Broader Study of Cross-Domain Few-Shot Learning. In ECCV. Springer, 124–141.
- Gupta et al. (2020) Dikshant Gupta, Aditya Anantharaman, Nehal Mamgain, Sowmya Kamath S., Vineeth N. Balasubramanian, and C. V. Jawahar. 2020. A Multi-Space Approach to Zero-Shot Object Detection. In WACV. IEEE, 1198–1206.
- Han et al. (2021) Guangxing Han, Yicheng He, Shiyuan Huang, Jiawei Ma, and Shih-Fu Chang. 2021. Query Adaptive Few-Shot Object Detection With Heterogeneous Graph Convolutional Networks. In ICCV. IEEE, 3263–3272.
- Han et al. (2022a) Guangxing Han, Shiyuan Huang, Jiawei Ma, Yicheng He, and Shih-Fu Chang. 2022a. Meta Faster R-CNN: Towards Accurate Few-Shot Object Detection with Attentive Feature Alignment. In AAAI. AAAI Press, 780–789.
- Han et al. (2022b) Guangxing Han, Jiawei Ma, Shiyuan Huang, Long Chen, and Shih-Fu Chang. 2022b. Few-Shot Object Detection with Fully Cross-Transformer. In CVPR. IEEE, 5311–5320.
- Han et al. (2022c) Guangxing Han, Jiawei Ma, Shiyuan Huang, Long Chen, Rama Chellappa, and Shih-Fu Chang. 2022c. Multimodal few-shot object detection with meta-learning based cross-modal prompting. arXiv preprint arXiv:2204.07841 (2022).
- Han et al. (2023) Jiaming Han, Yuqiang Ren, Jian Ding, Ke Yan, and Gui-Song Xia. 2023. Few-Shot Object Detection via Variational Feature Aggregation. arXiv preprint arXiv:2301.13411 (2023).
- Hayat et al. (2020) Nasir Hayat, Munawar Hayat, Shafin Rahman, Salman H. Khan, Syed Waqas Zamir, and Fahad Shahbaz Khan. 2020. Synthesizing the Unseen for Zero-Shot Object Detection. In ACCV. Springer, 155–170.
- He et al. (2022) Kaiming He, Xinlei Chen, Saining Xie, Yanghao Li, Piotr Dollár, and Ross B. Girshick. 2022. Masked Autoencoders Are Scalable Vision Learners. In CVPR. IEEE, 15979–15988.
- Hospedales et al. (2022) Timothy M. Hospedales, Antreas Antoniou, Paul Micaelli, and Amos J. Storkey. 2022. Meta-Learning in Neural Networks: A Survey. TPAMI 44, 9 (2022), 5149–5169.
- Hsieh et al. (2023) He-Yen Hsieh, Ding-Jie Chen, Cheng-Wei Chang, and Tyng-Luh Liu. 2023. Aggregating Bilateral Attention for Few-Shot Instance Localization. In WACV. IEEE, 6314–6323.
- Hsieh et al. (2019) Ting-I Hsieh, Yi-Chen Lo, Hwann-Tzong Chen, and Tyng-Luh Liu. 2019. One-Shot Object Detection with Co-Attention and Co-Excitation. In NIPS. 2721–2730.
- Hu et al. (2021) Hanzhe Hu, Shuai Bai, Aoxue Li, Jinshi Cui, and Liwei Wang. 2021. Dense Relation Distillation With Context-Aware Aggregation for Few-Shot Object Detection. In CVPR. IEEE, 10185–10194.
- Huang et al. (2021) Junying Huang, Fan Chen, Sibo Huang, and Dongyu Zhang. 2021. Instant Response Few-shot Object Detection with Meta Strategy and Explicit Localization Inference. arXiv preprint arXiv:2110.13377 (2021).
- Huang et al. (2022) Peiliang Huang, Junwei Han, De Cheng, and Dingwen Zhang. 2022. Robust Region Feature Synthesizer for Zero-Shot Object Detection. In CVPR. IEEE, 7612–7621.
- Kang et al. (2019) Bingyi Kang, Zhuang Liu, Xin Wang, Fisher Yu, Jiashi Feng, and Trevor Darrell. 2019. Few-Shot Object Detection via Feature Reweighting. In ICCV. IEEE, 8419–8428.
- Karlinsky et al. (2021) Leonid Karlinsky, Joseph Shtok, Amit Alfassy, Moshe Lichtenstein, Sivan Harary, Eli Schwartz, Sivan Doveh, Prasanna Sattigeri, Rogério Feris, Alex M. Bronstein, and Raja Giryes. 2021. StarNet: towards Weakly Supervised Few-Shot Object Detection. In AAAI. AAAI Press, 1743–1753.
- Karlinsky et al. (2019) Leonid Karlinsky, Joseph Shtok, Sivan Harary, Eli Schwartz, Amit Aides, Rogério Schmidt Feris, Raja Giryes, and Alexander M. Bronstein. 2019. RepMet: Representative-Based Metric Learning for Classification and Few-Shot Object Detection. In CVPR. IEEE, 5197–5206.
- Kaul et al. (2022) Prannay Kaul, Weidi Xie, and Andrew Zisserman. 2022. Label, Verify, Correct: A Simple Few Shot Object Detection Method. In CVPR. IEEE, 14217–14227.
- Khandelwal et al. (2021) Siddhesh Khandelwal, Raghav Goyal, and Leonid Sigal. 2021. UniT: Unified Knowledge Transfer for Any-Shot Object Detection and Segmentation. In CVPR. IEEE, 5951–5961.
- Kim et al. (2020) Geonuk Kim, Honggyu Jung, and Seong-Whan Lee. 2020. Few-Shot Object Detection via Knowledge Transfer. In SMC. IEEE, 3564–3569.
- Kim et al. (2022) Sueyeon Kim, Woo-Jeoung Nam, and Seong-Whan Lee. 2022. Few-Shot Object Detection with Proposal Balance Refinement. In ICPR. IEEE, 4700–4707.
- Lee et al. (2022a) Hojun Lee, Myunggi Lee, and Nojun Kwak. 2022a. Few-Shot Object Detection by Attending to Per-Sample-Prototype. In WACV. IEEE, 1101–1110.
- Lee et al. (2022b) Kibok Lee, Hao Yang, Satyaki Chakraborty, Zhaowei Cai, Gurumurthy Swaminathan, Avinash Ravichandran, and Onkar Dabeer. 2022b. Rethinking Few-Shot Object Detection on a Multi-Domain Benchmark. In ECCV. Springer, 366–382.
- Li and Li (2021) Aoxue Li and Zhenguo Li. 2021. Transformation Invariant Few-Shot Object Detection. In CVPR. IEEE, 3094–3102.
- Li et al. (2022a) Bohao Li, Chang Liu, Mengnan Shi, Xiaozhong Chen, Xiangyang Ji, and Qixiang Ye. 2022a. Proposal Distribution Calibration for Few-Shot Object Detection. arXiv preprint arXiv:2212.07618 (2022).
- Li et al. (2022b) Bowen Li, Chen Wang, Pranay Reddy, Seungchan Kim, and Sebastian A. Scherer. 2022b. AirDet: Few-Shot Detection Without Fine-Tuning for Autonomous Exploration. In ECCV. Springer, 427–444.
- Li et al. (2018) Bo Li, Junjie Yan, Wei Wu, Zheng Zhu, and Xiaolin Hu. 2018. High Performance Visual Tracking With Siamese Region Proposal Network. In CVPR. IEEE, 8971–8980.
- Li et al. (2021c) Bohao Li, Boyu Yang, Chang Liu, Feng Liu, Rongrong Ji, and Qixiang Ye. 2021c. Beyond Max-Margin: Class Margin Equilibrium for Few-Shot Object Detection. In CVPR. IEEE, 7363–7372.
- Li et al. (2022c) Haohe Li, Chong Wang, Shenghao Yu, Zheng Huo, Yujie Zheng, Li Dong, and Jiafei Wu. 2022c. Zero-Shot Object Detection with Partitioned Contrastive Feature Alignment. Research Square (2022). https://doi.org/10.21203/rs.3.rs-1770867/v1
- Li et al. (2021a) Pengyang Li, Yanan Li, and Donghui Wang. 2021a. Class-Incremental Few-Shot Object Detection. arXiv preprint arXiv:2105.07637 (2021).
- Li et al. (2021d) Qianzhong Li, Yujia Zhang, Shiying Sun, Xiaoguang Zhao, Kang Li, and Min Tan. 2021d. Rethinking semantic-visual alignment in zero-shot object detection via a softplus margin focal loss. Neurocomputing 449 (2021), 117–135.
- Li et al. (2020b) Shaoqi Li, Wenfeng Song, Shuai Li, Aimin Hao, and Hong Qin. 2020b. Meta-RetinaNet for Few-shot Object Detection. In BMVC. BMVA Press.
- Li et al. (2020c) Xiang Li, Lin Zhang, Yau Pun Chen, Yu-Wing Tai, and Chi-Keung Tang. 2020c. One-shot object detection without fine-tuning. arXiv preprint arXiv:2005.03819 (2020).
- Li et al. (2021b) Yanan Li, Pengyang Li, Han Cui, and Donghui Wang. 2021b. Inference Fusion with Associative Semantics for Unseen Object Detection. In AAAI. AAAI Press, 1993–2001.
- Li et al. (2020a) Yanan Li, Yilan Shao, and Donghui Wang. 2020a. Context-Guided Super-Class Inference for Zero-Shot Detection. In CVPR. IEEE, 4064–4068.
- Li et al. (2021e) Yiting Li, Haiyue Zhu, Yu Cheng, Wenxin Wang, Chek Sing Teo, Cheng Xiang, Prahlad Vadakkepat, and Tong Heng Lee. 2021e. Few-Shot Object Detection via Classification Refinement and Distractor Retreatment. In CVPR. IEEE, 15395–15403.
- Li et al. (2019) Zhihui Li, Lina Yao, Xiaoqin Zhang, Xianzhi Wang, Salil S. Kanhere, and Huaxiang Zhang. 2019. Zero-Shot Object Detection with Textual Descriptions. In AAAI. AAAI Press, 8690–8697.
- Lin et al. (2017a) Tsung-Yi Lin, Piotr Dollár, Ross B. Girshick, Kaiming He, Bharath Hariharan, and Serge J. Belongie. 2017a. Feature Pyramid Networks for Object Detection. In CVPR. IEEE, 936–944.
- Lin et al. (2017b) Tsung-Yi Lin, Priya Goyal, Ross B. Girshick, Kaiming He, and Piotr Dollár. 2017b. Focal Loss for Dense Object Detection. In ICCV. IEEE, 2999–3007.
- Lin et al. (2014) Tsung-Yi Lin, Michael Maire, Serge J. Belongie, James Hays, Pietro Perona, Deva Ramanan, Piotr Dollár, and C. Lawrence Zitnick. 2014. Microsoft COCO: Common Objects in Context. In ECCV. Springer, 740–755.
- Lin et al. (2021) Weidong Lin, Yuyan Deng, Yang Gao, Ning Wang, Jinghao Zhou, Lingqiao Liu, Lei Zhang, and Peng Wang. 2021. CAT: Cross-Attention Transformer for One-Shot Object Detection. arXiv preprint arXiv:2104.14984 (2021).
- Liu et al. (2021a) Longyao Liu, Bo Ma, Yulin Zhang, Xin Yi, and Haozhi Li. 2021a. AFD-Net: Adaptive Fully-Dual Network for Few-Shot Object Detection. In ACM MM. ACM, 2549–2557.
- Liu et al. (2022a) Liyang Liu, Bochao Wang, Zhanghui Kuang, Jing-Hao Xue, Yimin Chen, Wenming Yang, Qingmin Liao, and Wayne Zhang. 2022a. GenDet: Meta Learning to Generate Detectors From Few Shots. TNNLS 33, 8 (2022), 3448–3460.
- Liu et al. (2021b) Weijie Liu, Chong Wang, Haohe Li, Shenghao Yu, Jiangbo Qian, Jun Wang, and Jiafei Wu. 2021b. Dynamic relevance learning for few-shot object detection. arXiv preprint arXiv:2108.02235 (2021).
- Liu et al. (2022b) Weijie Liu, Chong Wang, Shenghao Yu, Chenchen Tao, Jun Wang, and Jiafei Wu. 2022b. Novel Instance Mining with Pseudo-Margin Evaluation for Few-Shot Object Detection. In ICASSP. IEEE, 2250–2254.
- Lu et al. (2022) Xiaonan Lu, Wenhui Diao, Yongqiang Mao, Junxi Li, Peijin Wang, Xian Sun, and Kun Fu. 2022. Breaking Immutable: Information-Coupled Prototype Elaboration for Few-Shot Object Detection. arXiv preprint arXiv:2211.14782 (2022).
- Luo et al. (2020) Ruotian Luo, Ning Zhang, Bohyung Han, and Linjie Yang. 2020. Context-Aware Zero-Shot Recognition. In AAAI. AAAI Press, 11709–11716.
- Ma et al. (2022) Jiawei Ma, Guangxing Han, Shiyuan Huang, Yuncong Yang, and Shih-Fu Chang. 2022. Few-Shot End-to-End Object Detection via Constantly Concentrated Encoding Across Heads. In ECCV. Springer, 57–73.
- Ma et al. (2020) Qiao-mei Ma, Chong Wang, Shenghao Yu, Ye Zheng, and Yuqi Li. 2020. Zero-Shot Object Detection With Attributes-Based Category Similarity. IEEE Trans. Circuits Syst. II Express Briefs 67-II, 5 (2020), 921–925.
- Michaelis et al. (2018) Claudio Michaelis, Ivan Ustyuzhaninov, Matthias Bethge, and Alexander S Ecker. 2018. One-shot instance segmentation. arXiv preprint arXiv:1811.11507 (2018).
- Mikolov et al. (2013) Tomás Mikolov, Kai Chen, Greg Corrado, and Jeffrey Dean. 2013. Efficient Estimation of Word Representations in Vector Space. In ICLR.
- Misra et al. (2015) Ishan Misra, Abhinav Shrivastava, and Martial Hebert. 2015. Watch and learn: Semi-supervised learning of object detectors from videos. In CVPR. IEEE, 3593–3602.
- Nie et al. (2022) Hui Nie, Ruiping Wang, and Xilin Chen. 2022. From Node to Graph: Joint Reasoning on Visual-Semantic Relational Graph for Zero-Shot Detection. In WACV. IEEE, 1648–1657.
- Osokin et al. (2020) Anton Osokin, Denis Sumin, and Vasily Lomakin. 2020. OS2D: One-Stage One-Shot Object Detection by Matching Anchor Features. In ECCV. Springer, 635–652.
- Park and Lee (2022) Dongwoo Park and Jongmin Lee. 2022. Hierarchical Attention Network for Few-Shot Object Detection via Meta-Contrastive Learning. arXiv preprint arXiv:2208.07039 (2022).
- Pei et al. (2022) Wenjie Pei, Shuang Wu, Dianwen Mei, Fanglin Chen, Jiandong Tian, and Guangming Lu. 2022. Few-Shot Object Detection by Knowledge Distillation Using Bag-of-Visual-Words Representations. In ECCV. Springer, 283–299.
- Pennington et al. (2014) Jeffrey Pennington, Richard Socher, and Christopher D. Manning. 2014. Glove: Global Vectors for Word Representation. In EMNLP. ACL, 1532–1543.
- Pérez-Rúa et al. (2020) Juan-Manuel Pérez-Rúa, Xiatian Zhu, Timothy M. Hospedales, and Tao Xiang. 2020. Incremental Few-Shot Object Detection. In CVPR. IEEE, 13843–13852.
- Qiao et al. (2021) Limeng Qiao, Yuxuan Zhao, Zhiyuan Li, Xi Qiu, Jianan Wu, and Chi Zhang. 2021. DeFRCN: Decoupled Faster R-CNN for Few-Shot Object Detection. In ICCV. IEEE, 8681–8690.
- Quan et al. (2022) Jianing Quan, Baozhen Ge, and Lei Chen. 2022. Cross attention redistribution with contrastive learning for few shot object detection. Displays 72 (2022), 102162.
- Radford et al. (2021) Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, Gretchen Krueger, and Ilya Sutskever. 2021. Learning Transferable Visual Models From Natural Language Supervision. In ICML. PMLR, 8748–8763.
- Rahman et al. (2019) Shafin Rahman, Salman H. Khan, and Nick Barnes. 2019. Transductive Learning for Zero-Shot Object Detection. In ICCV. IEEE, 6081–6090.
- Rahman et al. (2020a) Shafin Rahman, Salman H. Khan, and Nick Barnes. 2020a. Improved Visual-Semantic Alignment for Zero-Shot Object Detection. In AAAI. AAAI Press, 11932–11939.
- Rahman et al. (2020c) Shafin Rahman, Salman H. Khan, Nick Barnes, and Fahad Shahbaz Khan. 2020c. Any-Shot Object Detection. In ACCV. Springer, 89–106.
- Rahman et al. (2020b) Shafin Rahman, Salman H. Khan, and Fatih Porikli. 2020b. Zero-Shot Object Detection: Joint Recognition and Localization of Novel Concepts. IJCV 12 (2020), 2979–2999.
- Redmon and Farhadi (2018) Joseph Redmon and Ali Farhadi. 2018. Yolov3: An incremental improvement. arXiv preprint arXiv:1804.02767 (2018).
- Ren et al. (2015) Shaoqing Ren, Kaiming He, Ross B. Girshick, and Jian Sun. 2015. Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks. In NIPS. 91–99.
- Rocco et al. (2018) Ignacio Rocco, Relja Arandjelovic, and Josef Sivic. 2018. End-to-End Weakly-Supervised Semantic Alignment. In CVPR. IEEE, 6917–6925.
- Sarma et al. (2022) Sandipan Sarma, Sushil Kumar, and Arijit Sur. 2022. Resolving Semantic Confusions for Improved Zero-Shot Detection. arXiv preprint arXiv:2212.06097 (2022).
- Shangguan et al. (2022) Zeyu Shangguan, Lian Huai, Tong Liu, and Xingqun Jiang. 2022. Few-shot Object Detection with Refined Contrastive Learning. arXiv preprint arXiv:2211.13495 (2022).
- Shao et al. (2019) Yilan Shao, Yanan Li, and Donghui Wang. 2019. Zero-Shot Detection with Transferable Object Proposal Mechanism. In ICIP. IEEE, 3666–3670.
- Subakan et al. (2021) Cem Subakan, Mirco Ravanelli, Samuele Cornell, Mirko Bronzi, and Jianyuan Zhong. 2021. Attention Is All You Need In Speech Separation. In ICASSP. IEEE, 21–25.
- Sun et al. (2021) Bo Sun, Banghuai Li, Shengcai Cai, Ye Yuan, and Chi Zhang. 2021. FSCE: Few-Shot Object Detection via Contrastive Proposal Encoding. In CVPR. IEEE, 7352–7362.
- Tang et al. (2020) Kaihua Tang, Yulei Niu, Jianqiang Huang, Jiaxin Shi, and Hanwang Zhang. 2020. Unbiased Scene Graph Generation From Biased Training. In CVPR. IEEE, 3713–3722.
- Teng and Wang (2021) Yao Teng and Limin Wang. 2021. Structured Sparse R-CNN for Direct Scene Graph Generation. arXiv preprint arXiv:2106.10815 (2021).
- Thrun and Pratt (1998) Sebastian Thrun and Lorien Y. Pratt. 1998. Learning to Learn: Introduction and Overview. In Learning to Learn. Springer, 3–17.
- Tian et al. (2020) Yonglong Tian, Yue Wang, Dilip Krishnan, Joshua B Tenenbaum, and Phillip Isola. 2020. Rethinking few-shot image classification: a good embedding is all you need?. In ECCV. Springer, 266–282.
- Tian et al. (2019) Zhi Tian, Chunhua Shen, Hao Chen, and Tong He. 2019. FCOS: Fully Convolutional One-Stage Object Detection. In ICCV. IEEE, 9626–9635.
- Uijlings et al. (2013) Jasper R. R. Uijlings, Koen E. A. van de Sande, Theo Gevers, and Arnold W. M. Smeulders. 2013. Selective Search for Object Recognition. IJCV 104, 2 (2013), 154–171.
- Viola and Jones (2001) Paul A. Viola and Michael J. Jones. 2001. Rapid Object Detection using a Boosted Cascade of Simple Features. In CVPR. IEEE, 511–518.
- Voigtlaender et al. (2019) Paul Voigtlaender, Michael Krause, Aljosa Osep, Jonathon Luiten, Berin Balachandar Gnana Sekar, Andreas Geiger, and Bastian Leibe. 2019. MOTS: Multi-Object Tracking and Segmentation. In CVPR. IEEE, 7942–7951.
- Wang and Chen (2022) Jianwei Wang and Deyun Chen. 2022. Few-Shot Object Detection Method Based on Knowledge Reasoning. Electronics 11, 9 (2022), 1327.
- Wang et al. (2020b) Kang Wang, Lu Zhang, Yifan Tan, Jiajia Zhao, and Shuigeng Zhou. 2020b. Learning Latent Semantic Attributes for Zero-Shot Object Detection. In ICTAI. IEEE, 230–237.
- Wang et al. (2019b) Qiang Wang, Li Zhang, Luca Bertinetto, Weiming Hu, and Philip H. S. Torr. 2019b. Fast Online Object Tracking and Segmentation: A Unifying Approach. In CVPR. IEEE, 1328–1338.
- Wang et al. (2018) Xiaolong Wang, Ross Girshick, Abhinav Gupta, and Kaiming He. 2018. Non-local neural networks. In CVPR. IEEE, 7794–7803.
- Wang et al. (2020a) Xin Wang, Thomas E. Huang, Joseph Gonzalez, Trevor Darrell, and Fisher Yu. 2020a. Frustratingly Simple Few-Shot Object Detection. In ICML. 9919–9928.
- Wang et al. (2019a) Yu-Xiong Wang, Deva Ramanan, and Martial Hebert. 2019a. Meta-Learning to Detect Rare Objects. In ICCV. IEEE, 9924–9933.
- Wu et al. (2021a) Aming Wu, Yahong Han, Linchao Zhu, and Yi Yang. 2021a. Universal-Prototype Enhancing for Few-Shot Object Detection. In ICCV. IEEE, 9567–9576.
- Wu et al. (2021b) Aming Wu, Suqi Zhao, Cheng Deng, and Wei Liu. 2021b. Generalized and Discriminative Few-Shot Object Detection via SVD-Dictionary Enhancement. In NIPS. 6353–6364.
- Wu et al. (2020) Jiaxi Wu, Songtao Liu, Di Huang, and Yunhong Wang. 2020. Multi-scale Positive Sample Refinement for Few-Shot Object Detection. In ECCV. Springer, 456–472.
- Wu et al. (2022) Shuang Wu, Wenjie Pei, Dianwen Mei, Fanglin Chen, Jiandong Tian, and Guangming Lu. 2022. Multi-faceted Distillation of Base-Novel Commonality for Few-Shot Object Detection. In ECCV. Springer, 578–594.
- Xiao and Marlet (2020) Yang Xiao and Renaud Marlet. 2020. Few-Shot Object Detection and Viewpoint Estimation for Objects in the Wild. In ECCV. Springer, 192–210.
- Xie and Zheng (2022) Johnathan Xie and Shuai Zheng. 2022. Zero-shot Object Detection Through Vision-Language Embedding Alignment. In ICDM. IEEE, 1–15.
- Xiong and Liu (2022) Wuti Xiong and Li Liu. 2022. CD-FSOD: A Benchmark for Cross-domain Few-shot Object Detection. arXiv preprint arXiv:2210.05311 (2022).
- Xu et al. (2021) Honghui Xu, Xinqing Wang, Faming Shao, Baoguo Duan, and Peng Zhang. 2021. Few-Shot Object Detection via Sample Processing. IEEE Access 9 (2021), 29207–29221.
- Yan et al. (2022) Caixia Yan, Xiaojun Chang, Minnan Luo, Huan Liu, Xiaoqin Zhang, and Qinghua Zheng. 2022. Semantics-guided contrastive network for zero-shot object detection. TPAMI (2022).
- Yan et al. (2020) Caixia Yan, Qinghua Zheng, Xiaojun Chang, Minnan Luo, Chung-Hsing Yeh, and Alexander G. Hauptmann. 2020. Semantics-Preserving Graph Propagation for Zero-Shot Object Detection. TIP 29 (2020), 8163–8176.
- Yan et al. (2019) Xiaopeng Yan, Ziliang Chen, Anni Xu, Xiaoxi Wang, Xiaodan Liang, and Liang Lin. 2019. Meta R-CNN: Towards General Solver for Instance-Level Low-Shot Learning. In ICCV. IEEE, 9576–9585.
- Yang et al. (2022) Hanqing Yang, Sijia Cai, Hualian Sheng, Bing Deng, Jianqiang Huang, Xian-Sheng Hua, Yong Tang, and Yu Zhang. 2022. Balanced and Hierarchical Relation Learning for One-shot Object Detection. In CVPR. IEEE, 7581–7590.
- Yang et al. (2021a) Hanqing Yang, Yongliang Lin, Hong Zhang, Yu Zhang, and Bin Xu. 2021a. Towards improving classification power for one-shot object detection. Neurocomputing 455 (2021), 390–400.
- Yang et al. (2018) Jianwei Yang, Jiasen Lu, Stefan Lee, Dhruv Batra, and Devi Parikh. 2018. Graph R-CNN for Scene Graph Generation. In ECCV. Springer, 690–706.
- Yang et al. (2021b) Shuo Yang, Lu Liu, and Min Xu. 2021b. Free Lunch for Few-shot Learning: Distribution Calibration. In ICLR. OpenReview.net.
- Yang et al. (2020b) Yukuan Yang, Fangyun Wei, Miaojing Shi, and Guoqi Li. 2020b. Restoring Negative Information in Few-Shot Object Detection. In NIPS. 43–76.
- Yang et al. (2020a) Ze Yang, Yali Wang, Xianyu Chen, Jianzhuang Liu, and Yu Qiao. 2020a. Context-Transformer: Tackling Object Confusion for Few-Shot Detection. In AAAI. AAAI Press, 12653–12660.
- Yang et al. (2023) Ze Yang, Chi Zhang, Ruibo Li, Yi Xu, and Guosheng Lin. 2023. Efficient Few-Shot Object Detection via Knowledge Inheritance. TIP 32 (2023), 321–334.
- Yilmaz et al. (2006) Alper Yilmaz, Omar Javed, and Mubarak Shah. 2006. Object tracking: A survey. ACM Comput. Surv. 38, 4 (2006), 13.
- Yurtsever et al. (2020) Ekim Yurtsever, Jacob Lambert, Alexander Carballo, and Kazuya Takeda. 2020. A Survey of Autonomous Driving: Common Practices and Emerging Technologies. IEEE Access 8 (2020), 58443–58469.
- Zhang et al. (2021a) Gongjie Zhang, Kaiwen Cui, Rongliang Wu, Shijian Lu, and Yonghong Tian. 2021a. PNPDet: Efficient Few-shot Detection without Forgetting via Plug-and-Play Sub-networks. In WACV. IEEE, 3822–3831.
- Zhang et al. (2021b) Gongjie Zhang, Zhipeng Luo, Kaiwen Cui, and Shijian Lu. 2021b. Meta-detr: Few-shot object detection via unified image-level meta-learning. arXiv preprint arXiv:2103.11731 (2021).
- Zhang et al. (2020c) Licheng Zhang, Xianzhi Wang, Lina Yao, and Feng Zheng. 2020c. Zero-Shot Object Detection with Textual Descriptions Using Convolutional Neural Networks. In IJCNN. IEEE, 1–6.
- Zhang et al. (2021c) Lu Zhang, Shuigeng Zhou, Jihong Guan, and Ji Zhang. 2021c. Accurate Few-Shot Object Detection With Support-Query Mutual Guidance and Hybrid Loss. In CVPR. Computer Vision Foundation / IEEE, 14424–14432.
- Zhang et al. (2020a) Shan Zhang, Dawei Luo, Lei Wang, and Piotr Koniusz. 2020a. Few-Shot Object Detection by Second-Order Pooling. In ACCV. Springer, 369–387.
- Zhang et al. (2022c) Shan Zhang, Naila Murray, Lei Wang, and Piotr Koniusz. 2022c. Time-rEversed DiffusioN tEnsor Transformer: A New TENET of Few-Shot Object Detection. In ECCV. Springer, 310–328.
- Zhang et al. (2022d) Shan Zhang, Lei Wang, Naila Murray, and Piotr Koniusz. 2022d. Kernelized Few-shot Object Detection with Efficient Integral Aggregation. In CVPR. IEEE, 19185–19194.
- Zhang et al. (2022a) Wenwen Zhang, Chengdong Dong, Jun Zhang, Hangguan Shan, and Eryun Liu. 2022a. Adaptive context- and scale-aware aggregation with feature alignment for one-shot object detection. Neurocomputing 514 (2022), 216–230.
- Zhang and Wang (2021) Weilin Zhang and Yu-Xiong Wang. 2021. Hallucination Improves Few-Shot Object Detection. In CVPR. IEEE, 13008–13017.
- Zhang et al. (2020b) Weilin Zhang, Yu-Xiong Wang, and David A Forsyth. 2020b. Cooperating RPN’s Improve Few-Shot Object Detection. arXiv preprint arXiv:2011.10142 (2020).
- Zhang et al. (2022b) Xiaosong Zhang, Feng Liu, Zhiliang Peng, Zonghao Guo, Fang Wan, Xiangyang Ji, and Qixiang Ye. 2022b. Integral Migrating Pre-trained Transformer Encoder-decoders for Visual Object Detection. arXiv preprint arXiv:2205.09613 (2022).
- Zhao et al. (2020) Shizhen Zhao, Changxin Gao, Yuanjie Shao, Lerenhan Li, Changqian Yu, Zhong Ji, and Nong Sang. 2020. GTNet: Generative Transfer Network for Zero-Shot Object Detection. In AAAI. AAAI Press, 12967–12974.
- Zhao et al. (2022a) Yizhou Zhao, Xun Guo, and Yan Lu. 2022a. Semantic-aligned Fusion Transformer for One-shot Object Detection. In CVPR. IEEE, 7591–7601.
- Zhao et al. (2022b) Zhiyuan Zhao, Qingjie Liu, and Yunhong Wang. 2022b. Exploring Effective Knowledge Transfer for Few-shot Object Detection. In ACM MM. ACM, 6831–6839.
- Zheng and Cui (2021) Ye Zheng and Li Cui. 2021. Zero-Shot Object Detection With Transformers. In ICIP. IEEE, 444–448.
- Zheng et al. (2020) Ye Zheng, Ruoran Huang, Chuanqi Han, Xi Huang, and Li Cui. 2020. Background Learnable Cascade for Zero-Shot Object Detection. In ACCV. Springer, 107–123.
- Zheng et al. (2021) Ye Zheng, Jiahong Wu, Yongqiang Qin, Faen Zhang, and Li Cui. 2021. Zero-Shot Instance Segmentation. In CVPR. IEEE, 2593–2602.
- Zhu et al. (2021a) Chenchen Zhu, Fangyi Chen, Uzair Ahmed, Zhiqiang Shen, and Marios Savvides. 2021a. Semantic Relation Reasoning for Shot-Stable Few-Shot Object Detection. In CVPR. IEEE, 8782–8791.
- Zhu et al. (2020a) Pengkai Zhu, Hanxiao Wang, and Venkatesh Saligrama. 2020a. Don’t Even Look Once: Synthesizing Features for Zero-Shot Detection. In CVPR. IEEE, 11690–11699.
- Zhu et al. (2020b) Pengkai Zhu, Hanxiao Wang, and Venkatesh Saligrama. 2020b. Zero Shot Detection. IEEE Trans. Circuits Syst. Video Technol. 30, 4 (2020), 998–1010.
- Zhu et al. (2021b) Xizhou Zhu, Weijie Su, Lewei Lu, Bin Li, Xiaogang Wang, and Jifeng Dai. 2021b. Deformable DETR: Deformable Transformers for End-to-End Object Detection. In ICLR. OpenReview.net.
- Zhuang et al. (2021) Fuzhen Zhuang, Zhiyuan Qi, Keyu Duan, Dongbo Xi, Yongchun Zhu, Hengshu Zhu, Hui Xiong, and Qing He. 2021. A Comprehensive Survey on Transfer Learning. Proc. IEEE 109, 1 (2021), 43–76.