∎
22email: [email protected] 33institutetext: Yuhui Liu44institutetext: School of Mathematics and Statistics, Wuhan University, Wuhan 430072, China
44email: [email protected] 55institutetext: Jerry Zhijian Yang66institutetext: School of Mathematics and Statistics, Wuhan University, Wuhan 430072, China
66email: [email protected] 77institutetext: Cheng Yuan88institutetext: School of Mathematics and Statistics, Wuhan University, Wuhan 430072, China
88email: [email protected]
A Stabilized Physics Informed Neural Networks Method for Wave Equations
Abstract
In this article, we propose a novel Stabilized Physics Informed Neural Networks method (SPINNs) for solving wave equations. In general, this method not only demonstrates theoretical convergence but also exhibits higher efficiency compared to the original PINNs. By replacing the norm with norm in the learning of initial condition and boundary condition, we theoretically proved that the error of solution can be upper bounded by the risk in SPINNs. Based on this, we decompose the error of SPINNs into approximation error, statistical error and optimization error. Furthermore, by applying the approximating theory of networks and the learning theory on Rademacher complexity, covering number and pseudo-dimension of neural networks, we present a systematical non-asymptotic convergence analysis on our method, which shows that the error of SPINNs can be well controlled if the number of training samples, depth and width of the deep neural networks have been appropriately chosen. Two illustrative numerical examples on 1-dimensional and 2-dimensional wave equations demonstrate that SPINNs can achieve a faster and better convergence than classical PINNs method.
Keywords:
PINNs neural network Wave equationsError analysisMSC:
68T07 65M12 62G051 Introduction
During the past few decades, numerical methods of Partial differential equations (PDEs) have been widely studied and applied in various fields of scientific computation brenner2007mathematical ; ciarlet2002finite ; Quarteroni2008Numerical ; Thomas2013Numerical . Among these, due to the central significance in solid mechanics, acoustics and electromagnetism, the numerical solution for wave equation attracts considerable attention, and a lot of work has been done to analyze the convergence rate, improve the solving efficiency and deal with practical problems such as boundary conditions. For many real problems with complex region, however, designing an efficient and accurate algorithms with practical absorbing boundary conditions is still difficult, especially for problems with irregular boundary. Furthermore, in high-dimensional case, many traditional methods may become even intractable due to the Curse of Dimensionality, which leads to an exponential increase in degree of freedom with the dimension of problem.
More recently, inspired by the great success of deep learning in fields of natural language processing and computational visions, solving PDEs with deep learning has become as a highly promising topic lagaris1998artificial ; anitescu2019artificial ; Berner2020Numerically ; han2018solving ; lu2021deepxde ; sirignano2018dgm . Several numerical schemes have been proposed to solve PDEs using neural networks, including the deep Ritz method (DRM) Weinan2017The , physics-informed neural networks (PINNs) raissi2019physics , weak adversarial neural networks(WANs) Yaohua2020weak and their extensions jagtap2020conservative ; npinns ; fpinns . Due to the simplicity and flexibility in its formulation, PINNs turns out to be the most concerned method. In the field of wave equations, researchers have successfully applied PINNs to the modeling of scattered acoustic fields wang2023acoustic , including transcranial ultrasound wave wang2023physics and seismic wave ding2023self . In these works, all of the authors observed an interesting phenomenon that training PINNs without any boundary constraints may lead to a solution under absorbing boundary condition. In another word, the waves obtained by PINNs without boundary loss will be naturally absorbed at the boundary. This phenomenon, in fact, greatly improves the application value of PINNs in wave simulation, especially for inverse scattering problems. On the other hand, although PINNs have been widely used in the simulation of waves, a rigorous numerical analysis of PINNs for wave equations and more efficient training strategy are still needed.
In this work, we propose the Stabilized Physics Informed Neural Networks (SPINNs) for simulation of waves. By replacing the norm in initial condition and boundary condition with norm, we obtain a stable PINNs method, in the sense that the error in solution can be upper bounded by the risk during training. It is worth mentioning that, in 2017 a similar idea called Sobolev Training has been proposed to improve the efficiency for regression czarnecki2017sobolev . Later in son2021sobolev and vlassis2021sobolev , the authors generalized this idea to the training of PINNs, with applications to heat equation, Burgers’ equation, Fokker-Planck equation and elasto-plasticity models. One main difference between our model and these works is that, we still use the norm, rather than norm for the residual and initial velocity in the loss of SPINNs. This designing, as we will demonstrate, turns out to be a sufficient condition to guarantee the stability, which also enables us to achieve a lower error with same and even less training samples. Furthermore, based on this stability, we firstly give a systematical convergence rate analysis of PINNs for wave equations. In general, our main contributions are summarized as follows:
Main contributions
We propose a novel Stabilized Physics Informed Neural Networks method (SPINNs) for solving wave equations, for which we prove that the error in solution can be bounded by the training risk.
We numerically show that SPINNs can achieve a faster and better convergence than original PINNs.
We present a systematical convergence analysis of SPINNs. According to our result, once the network depth, width, as well as the number of training samples have been appropriately chosen, the error between the numerical solution from SPINNs and the exact solution can be arbitrarily small in the norm
The rest of this paper is organized as follows. In Section 2, we describe the problem setting and introduce the SPINNs method. In Section 3, we study the convergence rate of the SPINNs method for solving wave equations. In Section 4, we present several numerical examples to illustrate the efficiency of SPINNs. Finally in Section 5 the main conclusion will be provided.
2 The Stabilized PINNs method
In this section, we would introduce a stabilized PINNs (SPINNs) method for solving the wave equation. For completeness, we first list the following notations of neural networks and function spaces we will use. After that, the formulation of SPINNs will be presented.
2.1 Preliminary
Let , we would call function a neural network if it is implemented by:
where , .And , is the active function. The hyper-parameters and are called the depth and the width of the network, respectively. Let be a set of activation functions and be a Banach space, the normed neural network function class can be defined as
Next, we introduce several standard function spaces, including the continuous function space and Sobolev space:
2.2 Stabilized PINNs for wave equations
Considering the following wave equation:
| (1) |
where , and . Through this article, we would assume this problems defines a unique solution: {assumption} Assume (1) has a unique strong solution .
Without loss of generality, we further assume that and their derivatives are bounded by a constant . Denote . Instead of solving problem (1) by traditional numerical methods, we turn to formulate (1) as a minimization problem on , with the loss functional being defined as:
| (2) |
Remark 1
Different from the original loss in PINNs, we adopt -norm in stead of -norm in the learning of initial position and boundary condition. This modification, as we will demonstrate, offers advantages in both theoretical analysis and numerical computation.
With assumption 2.2, we know that is also the unique minimizer of loss functional such that . Let and be the measure of and , namely, , and , then can be equivalently written as
| (3) |
where , , are uniform distribution on , and , respectively. To solve minimization of approximately, a Monte Carlo discrete version of will be used:
| (4) |
where , and are independent and identically distributed random samples according to the uniform distribution , and , respectively. With this approximation, we would solve the original problem (1) by using the empirical risk minimization:
| (5) |
where the admissible set refers to the deep neural network function class parameterized by . In this work, we will choose as the network function space, to ensure . More precisely,
will be given later to ensure the desired accuracy. The activation function is defined by
In practical, the minimizer of problem (5) is usually obtained through some optimization algorithm . We would denote the minimizer as .
3 Convergence analysis of SPINNs
In this section, we will present a systematical error analysis of SPINNs for wave equations. To begin with, we first review some basic notations and theorem in the PDEs theory on wave equations.
For wave equation, its total energy consists of two parts: kinetic energy and potential energy , both of which can be expressed by multiple integrals,
and their sum is called energy integral, the total energy of the wave equation (1) excluding a constant factor is denoted as,
| (6) |
Theorem 3.1 (Energy stability)
We denote , which stands for the square norm estimation of . We have the energy inequality as below.
Proof
See Appendix 6.1 for details.
3.1 Risk decomposition
By the definition of and , we can decompose the risk in SPINNs as
where is an arbitrarily element in . Since , and is an arbitrarily element in , we have:
Thus, we have decomposed the total risk into approximation error (), statistical error () and optimization error (). While the approximation error describes the expressive power of network, the statistical error is caused by the discretization of the Monte Carlo method and the optimization error represents performance of the solver we use. In this work, we compromisely assume that the neural network can be well trained such that , and leave the optimization error as future study. In this case, it can be found that .
3.2 Lower bound of risk
Next, based on the energy stability of wave equations, we shall present a lower bound of risk in SPINNs. As we will demonstrate later, the risk can be arbitrary small if the network and sample complexity have been well chosen, and thus we can assume . Let be the error between numerical solution and exact solution, we have
| (7) |
and . By applying theorem (3.1) to equation (7), we obtain
where we define . Combined this lower bound with previous risk decomposition, we can arrive at:
| (8) |
3.3 Approximation error
By applying the following lemma proved in our previous work, we can get the upper bound of approximation error:
Lemma 1
and , there exist a network with depth and width such that
Proof
A special case of Corollary 4.2 in AAM-39-239 .
Theorem 3.2
Under the Assumption 2.2 and the condition that , for any , if we choose the following neural network function class:
then the approximation error .
Proof
See Appendix 6.2 for details.
3.4 Statistical error
The following theorem demonstrates that with sufficiently large sample complexity, the statistical error can be well controlled:
Theorem 3.3
Let For any , if the number of samples satisfy:
where , , is an arbitrarily small number such that
then we have:
Proof
See Appendix 6.3 for details.
3.5 Convergence rate of SPINNs
With the preparation in last two sections on the bounds of approximation and statistical errors, we will give the main results in this section.
Theorem 3.4
Under the Assumption 2.2 and the condition that . For any , if we choose the parameterized neural network class
and let the number of samples be
where , is arbitrarily small such that
then we have:
Proof
By theorem 3.2, if we set the neural network function class as:
| (9) | |||||
the approximation error can be arbitrarily small:
| (10) |
Without loss of generality we assume that is small enough such that
By theorem 3.3, when the number of samples be:
| (11) |
where is an arbitrarily positive number and
| (12) |
we have:
| (13) |
Combining (8), (10) and (13) together, we get the final result:
| (14) |
4 Numerical Experiments
In this section, we would use SPINNs to solve wave equation in both one dimension and two dimension.
4.1 1D example
Consider the following 1D wave equation on from to :
| (15) |
For the training with SPINNs, we use a four-layer network with 64 neurons in each layer to approximate the solution. We choose the Adam algorithm to implement the minimization, and the initial learning rate is set as 1E-3.
As for sample complexity, we train SPINNs with 10000 interior points, 500 boundary points (250 for each end) and 250 initial points in each epoch, all of which are sampled according to a uniform distribution (see (a) in Figure 1). Further more, to obtain a better accuracy, we apply GAS method jiao2023gas as an adaptive sampling strategy. After every 250 epochs, we would adaptively add 600 inner points, 30 boundary points and 15 initial points based on a Gaussian mixture distribution. The GAS procedure will be repeated for 10 times. See jiao2023gas for more details. For evaluation, we use the central difference method with a fine mesh (, ) to obtain a reference solution (see (b) in Figure 1) , with which we can calculate the following relative error by using numerical integration:
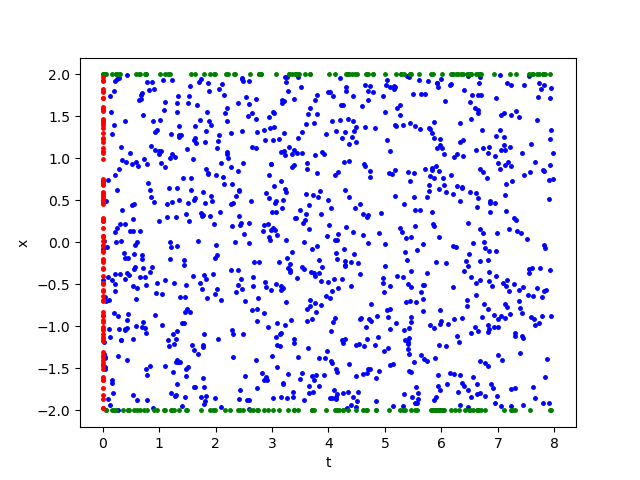
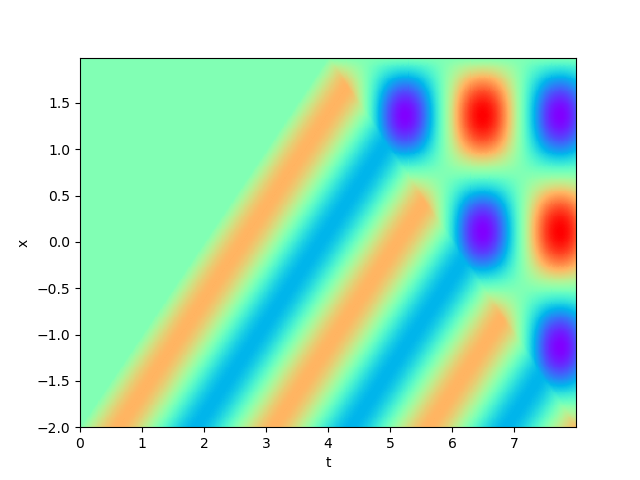
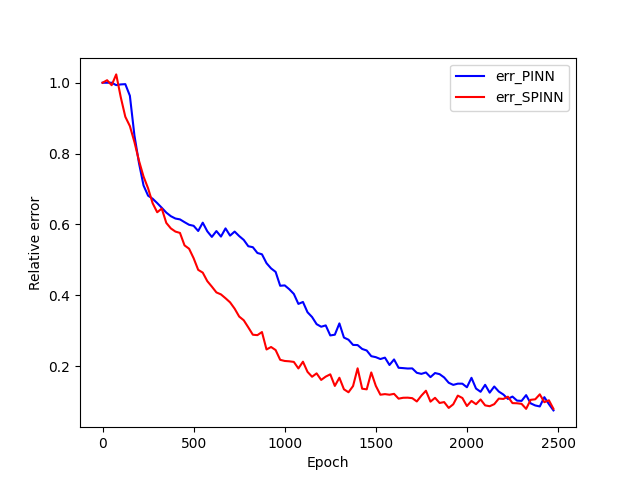
Figure 2 demonstrates the numerical result of PINNs and SPINNs for (15) after times of adaptive sampling by GAS. As we can see, the SPINNs method converges faster than the classical PINNs, e.g., after 5 times of adaptive sampling, SPINNs have already captured all the six peaks of standing waves generated by the superposition of reflected wave and right-traveling waves. Furthermore, we present the relative error of PINNs and SPINNs in Figure 3, which shows that our method can achieve a lower relative error at the early stage of training. On the other hand, with the times of adaptive sampling increasing, the classical PINNs can also arrive at a comparable accuracy, which has also been revealed by (g) in Figure 2. These results reflect the fact that training with SPINNs can speed up the convergence in solution, especially when the number of samples is relatively small.
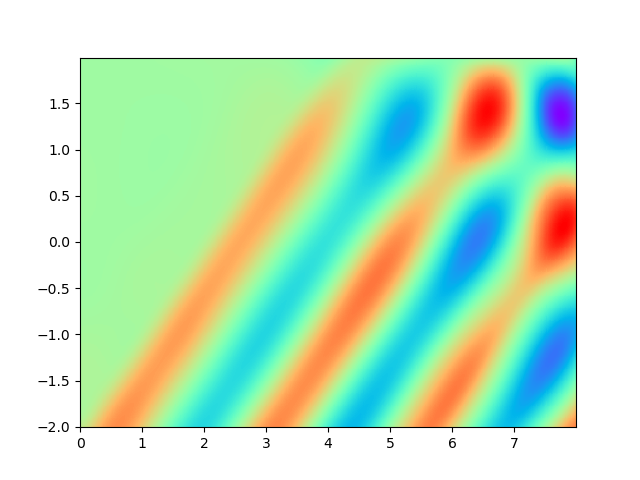
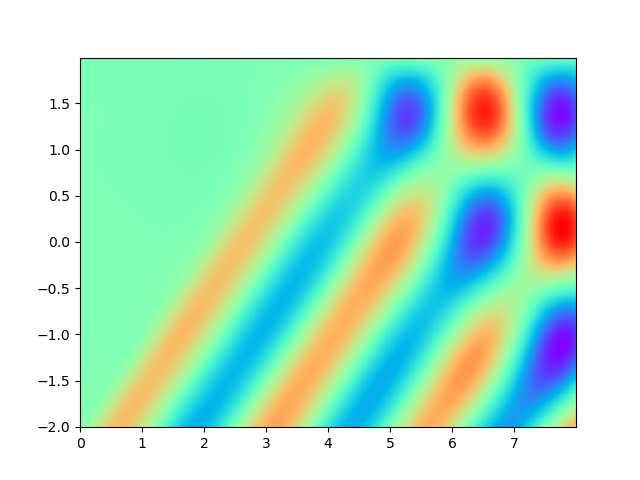
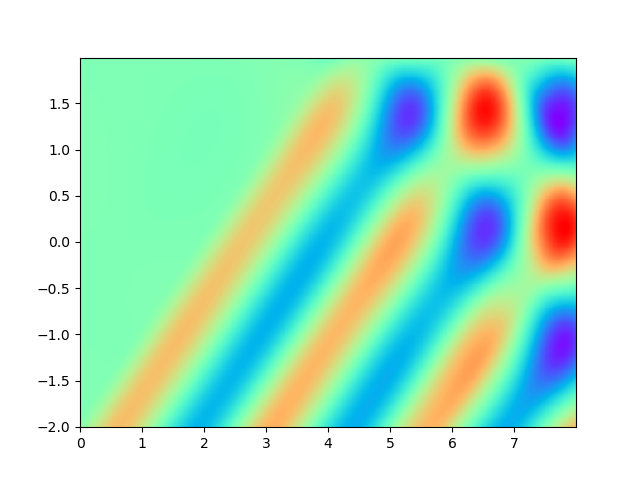
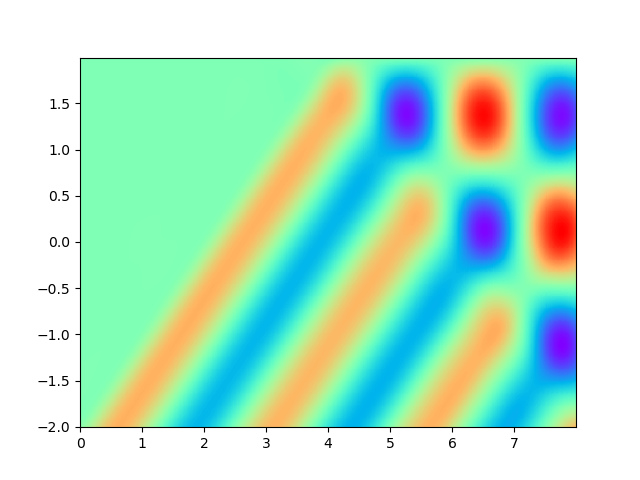
4.2 2D example
Consider the following 2D wave equation on from to :
| (16) |
For the training with SPINNs, based on the experiment, we choose a three-layer network with 512 neurons in each layer to approximate the solution. The optimization algorithm and the initial learning rate are kept as before.
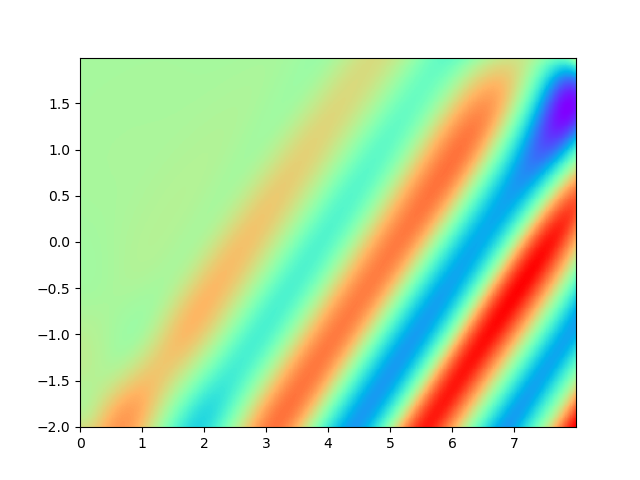
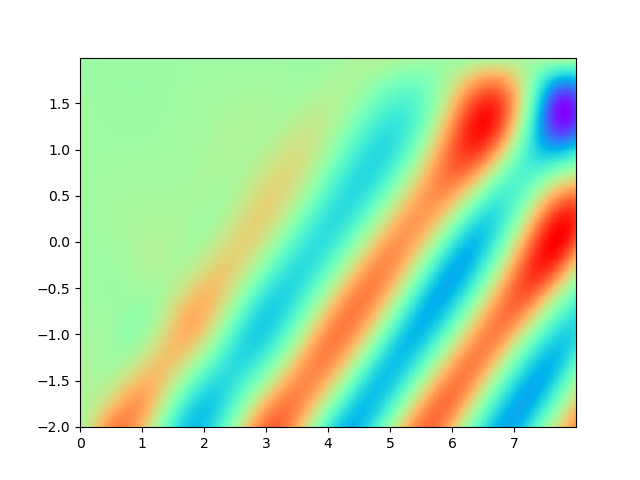
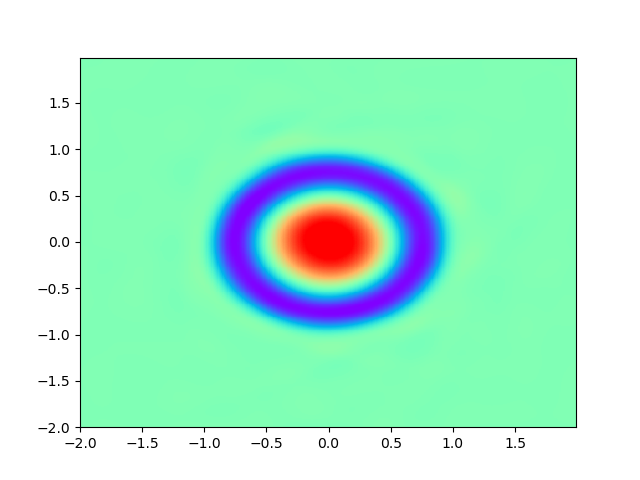
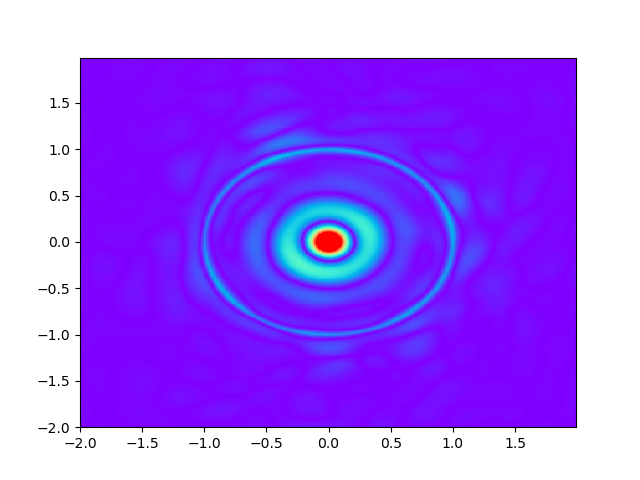
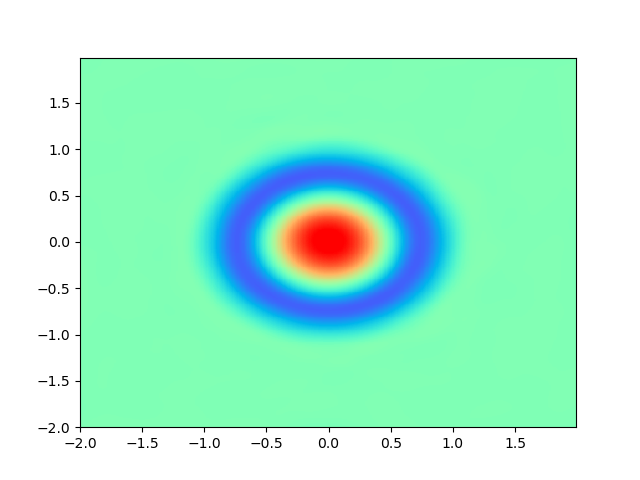
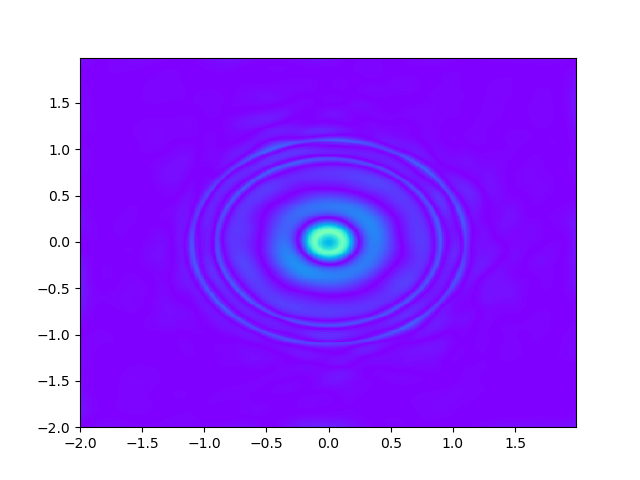
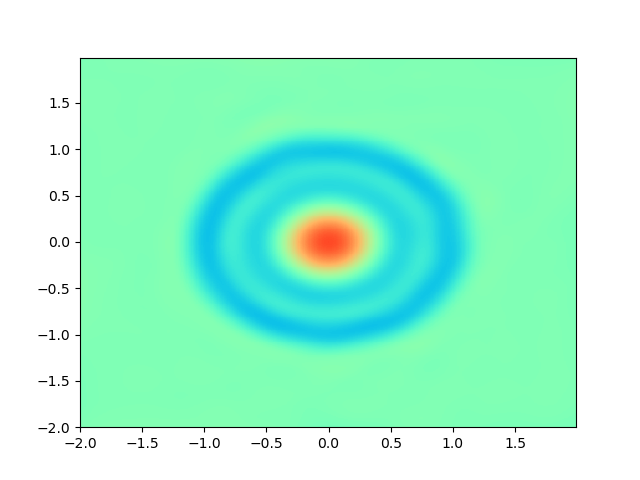
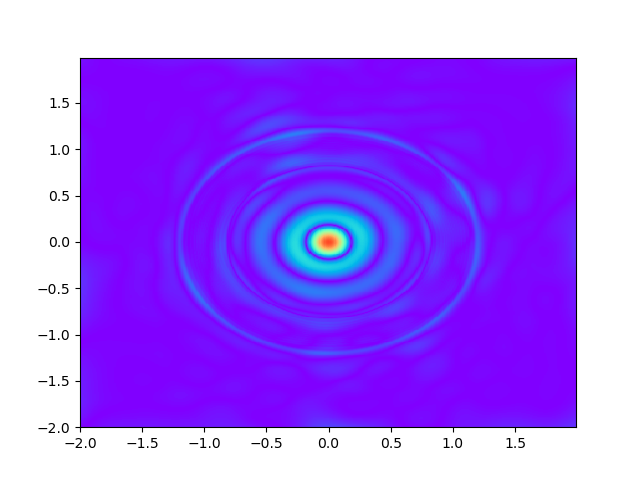
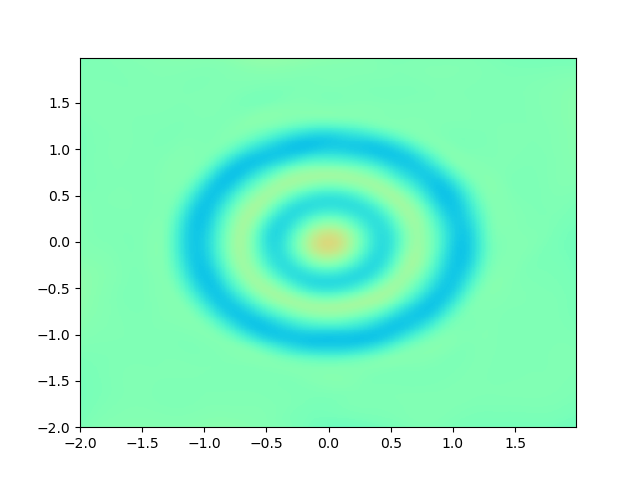
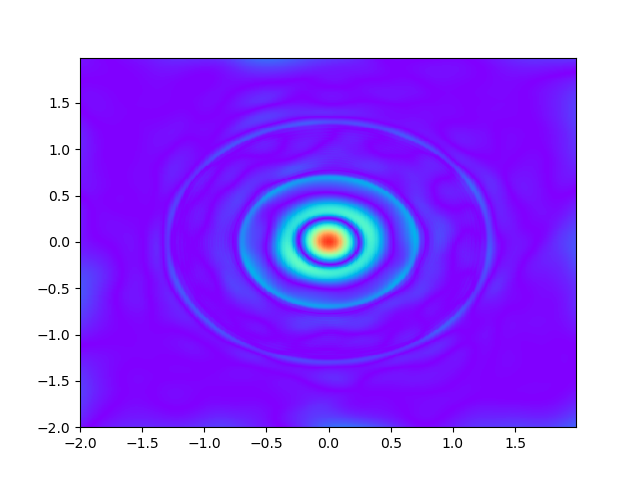
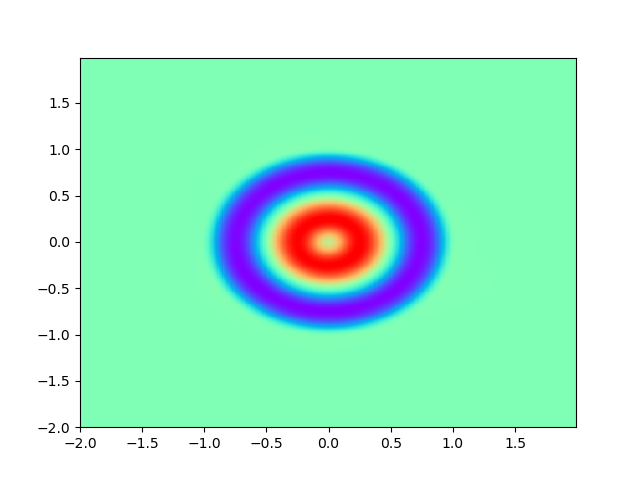
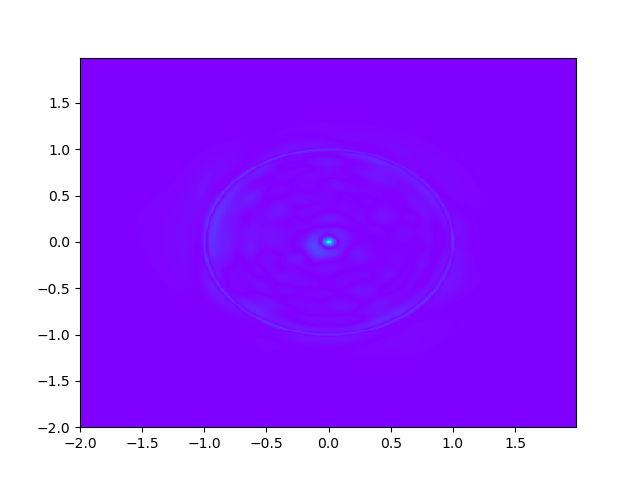
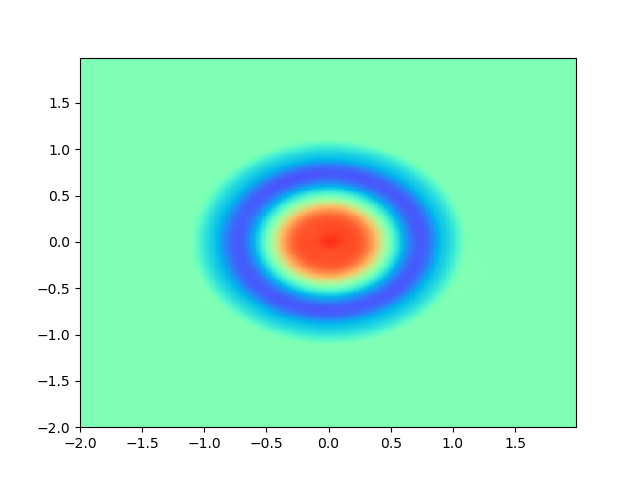
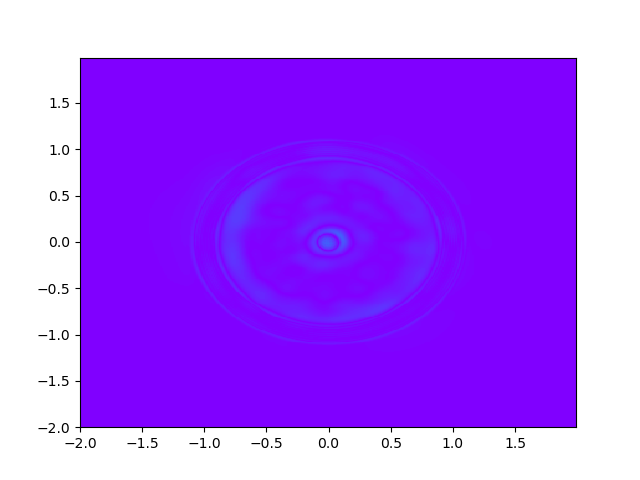
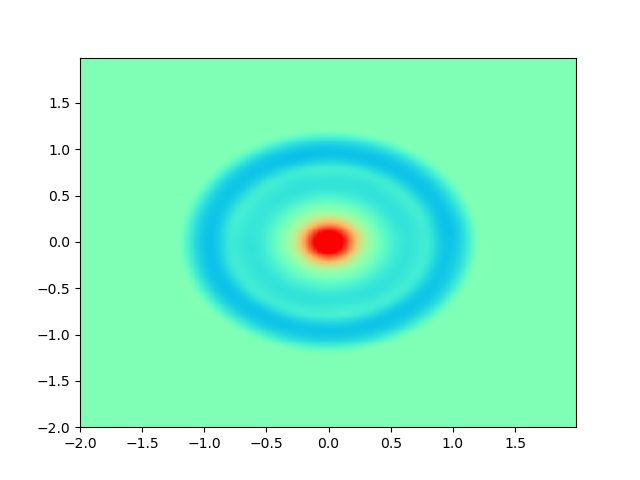
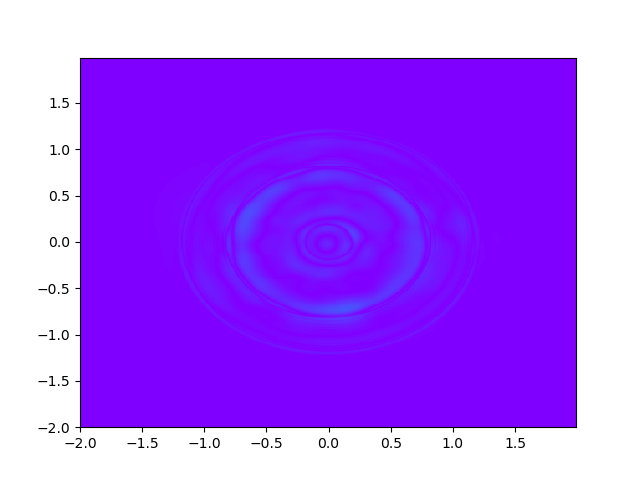
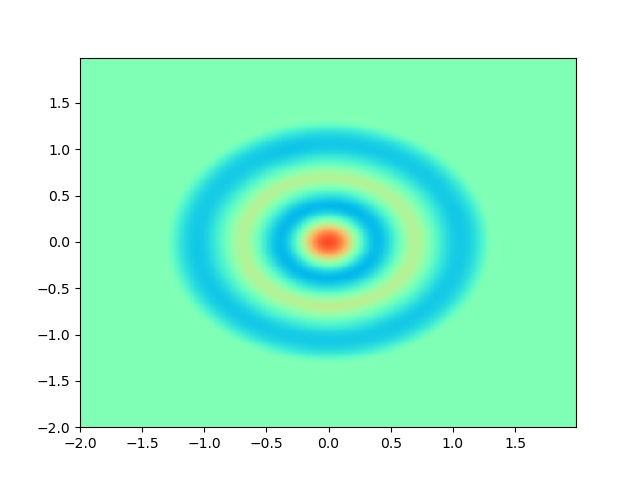
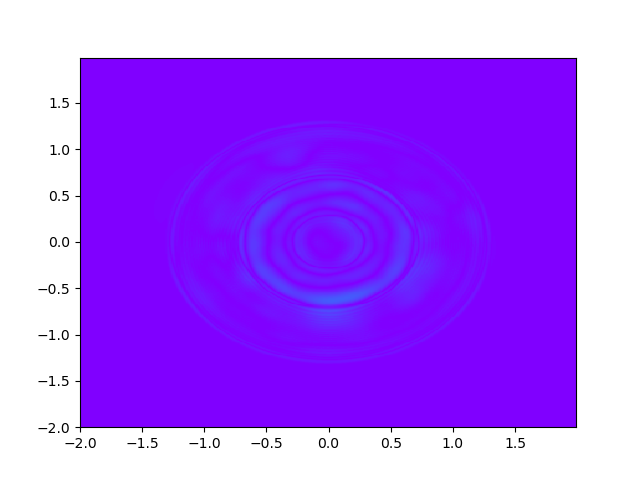
As for sample complexity, we train SPINNs with 2000 interior points, 4000 boundary points (1000 for each edge) and 1000 initial points in each epoch, all of which are sampled according to a uniform distribution. For evaluation, we use the central difference method with a fine mesh (, ) to obtain a reference solution , with which we can calculate the pointwise absolute error . As we can observe from Figure 4 and Figure 5, the SPINNs method can achieve a lower pointwise error, after training for same epochs. This superiority, in fact, can be understood as that learning with derivative information improves accuracy in the fitting of initial condition.
5 Conclusion
In this work, we propose a stabilized physics informed neural networks method SPINNs for wave equations. With some numerical analysis, we rigorously prove SPINNs is a stable learning method, in which the solution error can be well controlled by the loss term. Based on this, a non-asymptotic convergence rate of SPINNs is presented, which provide people with a solid theoretical foundation to use it. Furthermore, by applying SPINNs to the simulation of two wave propagation problems, we numerically demonstrate that SPINNs can achieve a higher training accuracy and efficiency, especially when the number of samples is limited. On the other hand, how to extend this method to more difficult situations such as high dimensional problems and how to handel the optimization error in our convergence analysis are still needed to be studied. We will leave these topics as our future research.
Acknowledgement
This work is supported by the National Key Research and Development Program of China (No.2020YFA0714200), by the National Nature Science Foundation of China (No.12371441, No.12301558, No.12125103, No.12071362), and by the Fundamental Research Funds for the Central Universities.
6 Appendix
6.1 Appendix for energy integral of wave equations
According to the Gaussian formula, we have
| (17) |
where is the unit outer normal vector. Combine (6) and (6.1),we have
| (18) |
Multiply both sides of the inequality (6.1) by ,
| (19) |
Then, integrating the equation (19) from 0 to t,
For any ,
| (20) |
is a constant that is only related to . Further we have
| (21) |
Multiply both sides of the above equation (21) by ,
| (22) |
Integrating the equation (22) from 0 to t,
| (23) |
For any ,
| (24) |
is a constant that is only related to . Combine (20) and (24),we have,
| (25) | |||
| (26) |
is a constant that is only related to .
6.2 Appendix for approximation error
6.3 Appendix for statistical error
We will give the precise computation on the upper bounds of statistical error in this section. To begin with, we first introduce several basic concepts and results in learning theory.
Definition 1
(Rademacher complexity) The Rademacher complexity of a set is defined by
where are i.i.d Rademacher variables with .
Let be a set and be a function class which maps to . Let be a probability distribution over and be i.i.d. samples from . The Rademacher complexity of associated with distribution and sample size is defined by
Lemma 2
Let be a set and be a probability distribution over . Let . Assume that and for all , then for any function class mapping to , there holds
where
Proof
See jiao2022rate for the proof.
Definition 2
(Covering number) Suppose that . For any ,let be an -cover of with respect to the distance , that is, for any , there exists a such that , where is defined by . The covering number is defined to be the minimum cardinality among all -cover of with respect to the distance .
Definition 3
(Uniform covering number) Suppose that is a class of functions from to . Given sample is defined by
The uniform covering number is defined by
Lemma 3
Let be a set and be a probability distribution over . Let ,and be a class of functions from to such that and the diameter of is less than ,i.e.,,. Then
Proof
This proof is base on the chaining method, see van1996weak .
Definition 4
(Pseudo-dimension) Let be a class of functions from to . Suppose that . We say that is pseudo-shattered by if there exists such that for any , there exists a satisfying
and we say that witnesses the shattering. The pseudo-dimension of , denoted as , is defined to be the maximum cardinality amoong all sets pseudo-shattered by .
Lemma 4 (Theorem 12.2 in Anthony1999Neural )
Let be a class of real functions from a domain to the bounded interval .Let . Then
which is less than for .
Next, to obtain the upper bound, we would decompose the statistical error into 24 terms by using triangle inequality:
where
and is the empirical version of . The following lemma states that each of these 24 terms can be controlled by the corresponding Rademacher complexity.
Lemma 5
Let be i.i.d samples from , then we have
for where:
Proof
The proof is based on the symmetrization technique, see lemma 4.3 in jiao2022rate for more details.
Lemma 6
Let . There holds
Proof
The proof is an application of proposition 4.2 in jiao2022rate . Take as an example, since , we have and . Notice the square operation can be implemented as , thus we get that .
Lemma 7 (Proposition 4.3 in jiao2022rate )
For any ,
Now we are ready to prove Theorem 3.3 on the statistical error.
Proof (The proof of Theorem 3.3)
For , when the sample numbers , we have
| (27) |
Let , then . Denoting:
we have:
| (28) |
Substitute (28) into (27) and choose , we have:
| (29) |
where
The last step above is due to lemma 7.
For , when the sample numbers , we can similarly prove that
| (30) |
where
For , when the sample numbers , we have
| (31) |
where
For , we have,
where is the standard deviation of . With the bound of , we can further obtain,
then we have,
Similarly, for ,
For ,
then we have,
Similarly, for ,
Hence, we have,
where are constants associated with dimensionality and bound . Hence, for any , if the number of samples satisfies:
where:
with restriction , , and is arbitrarily small. Then we have:
References
- (1) Susanne Brenner and Ridgway Scott. The mathematical theory of finite element methods, volume 15. Springer Science & Business Media, 2007.
- (2) Philippe G Ciarlet. The finite element method for elliptic problems. SIAM, 2002.
- (3) A. Quarteroni and A. Valli. Numerical Approximation of Partial Differential Equations, volume 23. Springer Science & Business Media, 2008.
- (4) J.W. Thomas. Numerical Partial Differential Equations: Finite Difference Methods, volume 22. Springer Science & Business Media, 2013.
- (5) Isaac E Lagaris, Aristidis Likas, and Dimitrios I Fotiadis. Artificial neural networks for solving ordinary and partial differential equations. IEEE transactions on neural networks, 9(5):987–1000, 1998.
- (6) Cosmin Anitescu, Elena Atroshchenko, Naif Alajlan, and Timon Rabczuk. Artificial neural network methods for the solution of second order boundary value problems. Computers, Materials & Continua, 59(1):345–359, 2019.
- (7) Julius Berner, Markus Dablander, and Philipp Grohs. Numerically solving parametric families of high-dimensional kolmogorov partial differential equations via deep learning. In Advances in Neural Information Processing Systems, volume 33, pages 16615–16627. Curran Associates, Inc., 2020.
- (8) Jiequn Han, Arnulf Jentzen, and E Weinan. Solving high-dimensional partial differential equations using deep learning. Proceedings of the National Academy of Sciences, 115(34):8505–8510, 2018.
- (9) Lu Lu, Xuhui Meng, Zhiping Mao, and George Em Karniadakis. Deepxde: A deep learning library for solving differential equations. SIAM Review, 63(1):208–228, 2021.
- (10) Justin Sirignano and Konstantinos Spiliopoulos. Dgm: A deep learning algorithm for solving partial differential equations. Journal of computational physics, 375:1339–1364, 2018.
- (11) E. Weinan and Ting Yu. The deep ritz method: A deep learning-based numerical algorithm for solving variational problems. Communications in Mathematics and Statistics, 6(1):1–12, 2017.
- (12) Maziar Raissi, Paris Perdikaris, and George E Karniadakis. Physics-informed neural networks: A deep learning framework for solving forward and inverse problems involving nonlinear partial differential equations. Journal of Computational Physics, 378:686–707, 2019.
- (13) Yaohua Zang, Gang Bao, Xiaojing Ye, and Haomin Zhou. Weak adversarial networks for high-dimensional partial differential equations. Journal of Computational Physics, 411:109409, 2020.
- (14) Ameya D Jagtap, Ehsan Kharazmi, and George Em Karniadakis. Conservative physics-informed neural networks on discrete domains for conservation laws: Applications to forward and inverse problems. Computer Methods in Applied Mechanics and Engineering, 365:113028, 2020.
- (15) G. Pang, M. D’Elia, M. Parks, and G.E. Karniadakis. npinns: Nonlocal physics-informed neural networks for a parametrized nonlocal universal laplacian operator. algorithms and applications. Journal of Computational Physics, 422:109760, 2020.
- (16) Guofei Pang, Lu Lu, and George Em Karniadakis. fpinns: Fractional physics-informed neural networks. SIAM Journal on Scientific Computing, 41(4):A2603–A2626, 2019.
- (17) Hao Wang, Jian Li, Linfeng Wang, Lin Liang, Zhoumo Zeng, and Yang Liu. On acoustic fields of complex scatters based on physics-informed neural networks. Ultrasonics, 128:106872, 2023.
- (18) Linfeng Wang, Hao Wang, Lin Liang, Jian Li, Zhoumo Zeng, and Yang Liu. Physics-informed neural networks for transcranial ultrasound wave propagation. Ultrasonics, 132:107026, 2023.
- (19) Yi Ding, Su Chen, Xiaojun Li, Suyang Wang, Shaokai Luan, and Hao Sun. Self-adaptive physics-driven deep learning for seismic wave modeling in complex topography. Engineering Applications of Artificial Intelligence, 123:106425, 2023.
- (20) Wojciech M Czarnecki, Simon Osindero, Max Jaderberg, Grzegorz Swirszcz, and Razvan Pascanu. Sobolev training for neural networks. Advances in neural information processing systems, 30, 2017.
- (21) Hwijae Son, Jin Woo Jang, Woo Jin Han, and Hyung Ju Hwang. Sobolev training for physics informed neural networks. Communications in Mathematical Sciences, 21:1679–1705, 2013.
- (22) Nikolaos N Vlassis and WaiChing Sun. Sobolev training of thermodynamic-informed neural networks for interpretable elasto-plasticity models with level set hardening. Computer Methods in Applied Mechanics and Engineering, 377:113695, 2021.
- (23) Yuling Jiao, Xiliang Lu, Jerry Zhijian Yang, Cheng Yuan, and Pingwen Zhang. Improved analysis of pinns: Alleviate the cod for compositional solutions. Annals of Applied Mathematics, 39(3):239–263, 2023.
- (24) Yuling Jiao, Di Li, Xiliang Lu, Jerry Zhijian Yang, and Cheng Yuan. Gas: A gaussian mixture distribution-based adaptive sampling method for pinns. arXiv preprint arXiv:2303.15849, 2023.
- (25) Yuling Jiao, Yanming Lai, Dingwei Li, Xiliang Lu, Fengru Wang, Jerry Zhijian Yang, et al. A rate of convergence of physics informed neural networks for the linear second order elliptic pdes. Communications in Computational Physics, 31(4):1272–1295, 2022.
- (26) Aad W Van Der Vaart, Adrianus Willem van der Vaart, Aad van der Vaart, and Jon Wellner. Weak convergence and empirical processes: with applications to statistics. Springer Science & Business Media, 1996.
- (27) Martin Anthony and Peter L. Bartlett. Neural network learning: Theoretical foundations. Ai Magazine, 22(2):99–100, 1999.