A Simplified Framework for Contrastive Learning for Node Representations
Abstract
Contrastive learning has recently established itself as a powerful self-supervised learning framework for extracting rich and versatile data representations. Broadly speaking, contrastive learning relies on a data augmentation scheme to generate two versions of the input data and learns low-dimensional representations by maximizing a normalized temperature-scaled cross entropy loss (NT-Xent) to identify augmented samples corresponding to the same original entity (Chen et al., 2020). In this paper, we investigate the potential of deploying contrastive learning in combination with Graph Neural Networks (Scarselli et al., 2008) for embedding nodes in a graph. Specifically, we show that the quality of the resulting embeddings and training time can be significantly improved by a simple column-wise postprocessing of the embedding matrix, instead of the row-wise postprocessing via multilayer perceptrons (MLPs) that is adopted by the majority of peer methods. This modification yields improvements in downstream classification tasks of up to 1.5% and even beats existing state-of-the-art approaches on 6 out of 8 different benchmarks. We justify our choices of postprocessing by revisiting the “alignment vs. uniformity paradigm” of Wang and Isola (2020), and show that column-wise post-processing improves both “alignment” and “uniformity” of the embeddings.
1 Introduction
| Method | Target | MI-Estimator | Proj/Pred head | Asymmetric | Negative samples |
| DGI | N-G | ✓ | - | - | ✓ |
| MVGRL | N-G | ✓ | ✓ | ✓ | ✓ |
| BGRL | N-N | - | ✓ | ✓ | - |
| CCA-SSG | F-F | - | - | - | - |
| GRACE | N-N | - | ✓ | - | ✓ |
| CLNR (Ours) | N-N | - | - | - | ✓ |
Contrastive learning has become one of the most popular self-supervised methods for learning rich and versatile data representations — a success largely owing to its impressive performance across domains ranging from image classification (Chen et al., 2020; Grill et al., 2020; He et al., 2020; Hjelm et al., 2018; Oord et al., 2018a; Tian et al., 2020) to sequence modeling (Kong et al., 2019; Oord et al., 2018b; Wu et al., 2020a) and adversarial learning (Ho and Nvasconcelos, 2020; Grill et al., 2020). By and large, contrastive learning’s general outline consists in generating two (or more) perturbed versions of the data and in subsequently learning to recognize representations from “positive pair” (i.e. embeddings corresponding to the same original entity) and to embed them close to one another in the embedding space. Conversely, “negative pairs” (i.e. embeddings corresponding to different original entity) are encouraged to lie farther apart. Remarkably, this simple “model-free” learning of differences (Gutmann et al., 2022) between data views has been shown to achieve state-of-the-art performance in many downstream supervised tasks when combined with a simple linear classifier (Chen et al., 2020). This result is quite surprising as the method performs well not only relative to other unsupervised embedding algorithms, but also to supervised end-to-end methods whose primary aim is to learn embeddings tailored to a particular task.
Contrastive Learning for Graphs. Inspired by its success across various machine learning applications, contrastive learning has more recently been adopted by the graph representation learning community. In this case, contrastive learning is usually coupled with Graph Neural Networks (GNNs) (Scarselli et al., 2008; Kipf and Welling, 2016a; Zhou et al., 2020; Wu et al., 2020b) to learn a new class of node embeddings. Current contrastive methods for graphs can be classified into two categories, depending on which mutual information seeks to be maximized.
1. Local-to-global mutual information maximization, such as those used by Deep Graph InfoMax (DGI) (Velickovic et al., 2019) and Multi-View Graph Representation Learning (MVGRL) (Hassani and Khasahmadi, 2020). These methods seek to learn node embeddings by maximizing the mutual information between representations of the original data at different scales: DGI considers the mutual information between local (node) representations obtained by passing the original graph through a GNN encoder and a global graph embedding obtained by summing all local representations. Negative samples are generated by a corruption function separately. MVGRL, on the other hand, leverages diffusion processes to generate additional graphs and obtain corresponding additional pairs of node and graph representations. A pair of node and graph representations from different graph are considered as negative pairs. Both DGI and MVGRL use mutual information estimator parameterized by a neural network to obtain probability score for each local and global representation pair. More specifically, letting and denote the original and the corrupted graphs respectively, the DGI loss writes as:
where is a mutual information estimator parameterized by MLPs, is the summary vector of the original graph, and , are node representations from the original graph and its corrupted version respectively with and .
2. Local-to-local mutual information maximization, such as Graph Contrastive Representation Learning (GRACE) (Zhu et al., 2020) and its extension, Graph Contrastive representation learning with Adaptive augmentation (GCA) (Zhu et al., 2021). Contrary to the previous approaches, these methods directly define similarity scores using the dot product between node pairs and foregoes the need for a parameterized mutual information estimator. These methods typically project their node representations onto the unit hypersphere, which is known to improve training stability and is more easily separable by downstream linear classifiers. GRACE and GCA generate two views of the original graph by randomly perturbing both edges and features (typically through a combination of random edge deletions and feature masking). Note that perturbations here are used to generate alternative versions of the same data rather than negative examples. Node representations are then learned through the maximization of a normalized temperature-scaled cross entropy loss (NT-Xent) (Chen et al., 2020) between node pairs, which amounts to solving a classification problem: for each node, in each version of the data, the algorithm seeks to recognize the embeddings from the same original node amongst all other embeddings in both versions of the graph. The objective function is provided in Equations (2) and (3). Despite the impressive performance showed by GRACE and GCA, they suffer from a few drawbacks. Both methods rely on row-wise postprocessing of a raw embedding matrix via a MLP with a nonlinear activation function. This choice was first inspired by the method’s vision counterpart (Chen et al., 2020) where it was empirically shown that utilizing a 2-layers MLPs with a nonlinear activation function after the ResNet (He et al., 2016) improved the expressive power and quality of representations compared to those with a linear activation function or without postprocessing step. However, the use of additional postprocessing via MLPs considerably complexifies the model architecture and its effect on the resulting representations is still ill-understood.
Non-contrastive Learning for Graphs. The previous set of methods have some computational difficulties when processing large graph as the evaluation of the normalizing factor for each node requires the computation of pairwise cosine similarities between all negative pairs. Consequently, newer methods such as Bootstrapped Graph Latents (BGRL) (Thakoor et al., 2021) and Canonical Correlation Analysis inspired Self-Supervised Learning on Graphs (CCA-SSG) (Zhang et al., 2021) propose to leverage non-contrastive objectives which do not incorporate the negative samples. In CCA-SSG, for instance, the goal is to directly minimize the distance between positive pairs, while additionally decorrelating features in different dimensions. The objective function writes as:
where are node representation matrix of two perturbed versions of the original graph, be the hyperparameter, and denotes the Frobenius norm. In consequences, both BGRL and CCA-SSG enjoy low computational complexities by disregarding any computations with negative samples. However, BGRL requires additional components such as exponential moving average (EMA) and Stop-Gradient — making the method both more expensive and harder to interpret. Although CCA-SSG relies on a simple and symmetric architecture without additional components, this feature-wise contrastive method typically requires larger embedding dimension to improve the quality of its representations.
Contributions. The contributions of our paper are threefold. (1) We propose a simplified framework for contrastive learning for node representations and refer to our method as Contrastive Learning for Node Representations (CLNR). CLNR follows the core structure of GRACE (Zhu et al., 2020) and GCA (Zhu et al., 2021) which generate two views of an input graph via random data augmentation, use a shared GNN encoder, and find node representations by maximizing the NT-Xent loss (Chen et al., 2020). In contrast to GRACE and GCA, CLNR simplifies the model architecture by replacing row-wise postprocessing of a node representation matrix via a MLPs with a simple column-wise standardization. We show this substitution considerably improves the quality of representations and model training time. (2) We provide a finer understanding on the effect of various postprocessing steps and justify our choice of postprocessing (column-wise standardization) by revisiting the “alignment and uniformity paradigm” of Wang and Isola (2020) which was proposed to analyze the quality of representations on the unit hypersphere. (3) We provide experimental evidence of the quality of the induced node embeddings by using them as input for downstream classification. We show that CLNR provides superior results compared to state-of-the-art approaches, including CCA-SSG and GRACE.
Notations. For a given graph , is the feature matrix and is the adjacency matrix. Here, denotes the number of nodes in the graph , while denotes the feature dimension.
Structure of the paper. We introduce the general contrastive learning framework for node representations and propose our simplified framework in Section 2. Experiments are given in Section 3 and discussion on various postprocessing step is provided in Section 4. Additional experiments are present in Section 5 and conclusions are presented in Section 6.
2 Contrastive Learning for Node Representations
We begin by presenting the general framework for contrastive learning for node embddings, and focus on studying the choice of the embedding postprocessing.
2.1 Model Framework
Graph Augmentations. We follow the standard pipeline for random graph augmentation developed by Zhu et al. (2020), which comprises two components: (1) edge dropping and (2) feature masking. This procedure thus relies on two distinct hyperparameters: the “edge drop rate” (that is, the Bernoulli probability for each edge to be dropped, independently from all the others), and the “feature mask rate” (or probability that each element of the feature matrix to be masked, independently from the others). This set of perturbations allow the generation of two alternative versions of the same input graph at each epoch. Let us denote these two versions as with and with .
Shared GNN Encoder. We embed the nodes in both and in Euclidean space using a shared Graph Neural Network (GNN) (Scarselli et al., 2008). Let be the shared GNN encoder. We denote the raw embedding matrices by and where and denotes the embedding dimension.
Postprocessing Step. The outcome of the previous convolution step is a set of raw embedding matrices and for the two versions of the input graph. Empirical evidence shows that further postprocessing of these raw embeddings can greatly improve their expressive power. Usual options include:
- (1) Row-wise Postprocessing,
-
in which case each node embedding is processed independently of the others. Let be a 2-layers MLPs with a nonlinear activation function. The final node embedding matrices for each of the two versions of the data can be written as and . Such is the setting adopted for instance by GRACE (Zhu et al., 2020), which closely follows the architecture of SimCLR (Chen et al., 2020). The latter showed that adding a 2-layers MLPs with a non-linear activation function to the ResNet (He et al., 2016) outperformed other choices such as MLPs with a linear activation function or the one without postprocessing for vision tasks (Chen et al., 2020; Bachman et al., 2019).
- (2) Column-wise Postprocessing
-
— and more specifically, column-wise standardization, in which case each dimension of the raw embeddings is centered and rescaled. Therefore, each node embedding is processed along with others in a batch, and no longer independently. This type of processing mechanism is referred to as “batch normalization” (BN) in the deep learning literature (Ioffe and Szegedy, 2015; Santurkar et al., 2018; Bjorck et al., 2018). When training deep neural networks (DNNs), BN is typically used before the activation function between layers to standardize inputs. BN was initially proposed to alleviate internal covariate shift, defined as the shift in the distribution of network activations caused by the change in network parameters during training (Ioffe and Szegedy, 2015). BN was subsequently found to improve speed and stability of the model’s training and generalization accuracy by smoothing the optimization landscape (Santurkar et al., 2018) and allowing faster learning rates (Bjorck et al., 2018). Here, we propose a new way of using BN as a postprocessing step in self-supervised contrastive learning. We posit indeed that the row-wise MLPs postprocessing used in usual methods overly complexifies the architecture of the algorithm with no clear gain in performance. Rather, in Sections 3 and 4, we will show that the column-wise BN postprocessing results in better representations and this result is supported by recent findings in the contrastive learning literature of alignment and uniformity paradigm (Wang and Isola, 2020). We refer to the contrastive learning framework with this choice of postprocessing as Contrastive Learning method for Node Representations (CLNR). The final node embeddings can be written as follows:
(1) where for any matrix , and and and .
Projection onto Hypersphere. Regardless of the choice of postprocessing, the embeddings are then finally projected onto the unit hypersphere. This final step stems from the substantial deep learning literature (Bojanowski and Joulin, 2017; Chen et al., 2020; Davidson et al., 2018; Meng et al., 2019; Xu and Durrett, 2018). This normalization of the final embedding matrices (e.g., and ) is indeed known to improve the stability of learning process (Wang and Isola, 2020; Xu and Durrett, 2018), and makes the embeddings more easily separable by downstream linear classifiers.
Contrastive Loss Function.
We use the contrastive objective from Zhu et al. (2020), which is called “NT-Xent loss” where the term was first used in Chen et al. (2020). Contrary to GRACE — which computes the cosine similarities of all pairs of nodes in the graph —, we randomly subsample nodes at each epoch and only compute the cosine similarity between these nodes. This allows the method to scale well for a large graph with no expenses in accuracy if is sufficiently large. For each node in the random mini-batch, we let and be the -th row of and respectively. Then, for each , if is the target node, is viewed as a positive pair, and and where are naturally considered as negative pairs. Note that the first negative pairs are from inter-view nodes, and the second negative pairs are from intra-view nodes. Let be the cosine similarity function (defined as ). Our objective function takes the following explicit form:
| (2) |
where denotes the temperature parameter. It is worth noting that in general, . Therefore, taking the average over all possible pairs, the final objective to be maximized is given by
| (3) |
3 Experiments
In this section, we showcase the potential of our simplified framework for node constrative learning by deploying it on a number real-life datasets and comparing it against existing peer methods.
Real-life Datasets. We evaluate the quality of our node representations using a node classification task on real-life data. We consider eight node classification benchmarks: Cora, CiteSeer, Pubmed, Amazon Computers, Amazon Photo, Coauthor CS, Coauthor Physics, ogbn-arxiv. The first seven benchmarks are used in Yang et al. (2016) and Shchur et al. (2018), and ogbn-arxiv is from the Open Graph Benchmark datasets (Hu et al., 2020). We adopt the public splits for the citation network datasets (Cora, Citeseer, Pubmed), and 1:1:8 train/validation/test splits for Amazon and Coauthor network datasets (Amazon Computer, Amazon Photo, Coauthor CS, Coauthor Physics). Details of the datasets are given in Appendix A.1.
Experimental Setup. We follow the evaluation protocol suggested by Velickovic et al. (2019), which consists of two stages: 1) Pretraining and 2) Linear evaluation. First, we begin by training a GNN encoder using the NT-Xent loss described in Equation (2), thereby yielding node embeddings for the entire graph. We then fit a simple linear classifier on a subset of nodes (training set). We then evaluate the classification accuracy on the remaining nodes (test set). All experiments are done with Pytorch and Pytorch Geometric module on GPU with 16 GB memory.
| Methods | Input | Cora | CiteSeer | PubMed | Computers | Photo | CS | Physics | ogbn-arxiv |
| GAE | X, A | 71.50.4 | 65.80.4 | 72.10.5 | 85.30.2 | 91.60.1 | 90.00.7 | 94.90.1 | 52.570.1 |
| DGI | X, A | 82.30.6 | 71.80.7 | 76.80.6 | 84.00.5 | 91.60.2 | 92.20.6 | 94.50.5 | 67.950.6 |
| MVGRL | X, A, S | 83.50.4 | 73.30.5 | 80.10.7 | 87.50.1 | 91.70.1 | 92.10.1 | 95.30.1 | OOM |
| CCA-SSG | X, A | 84.20.4 | 73.10.3 | 81.60.4 | 88.70.3 | 93.10.1 | 93.30.2 | 95.40.1 | 60.5 0.2 |
| BGRL | X, A | 82.11.0 | 71.80.5 | 80.61.0 | 89.00.4 | 92.70.4 | 92.00.2 | 94.50.3 | 70.30.1 |
| GRACE | X, A | 83.60.8 | 71.81.1 | 81.60.9 | 89.10.4 | 93.30.4 | 93.60.3 | 95.30.1 | 69.8 0.1 |
| CLNR | X, A | 84.30.6 | 73.10.7 | 83.0 0.6 | 89.50.4 | 93.20.3 | 93.80.2 | 95.50.1 | 70.4 0.3 |
| GCN | X, A, Y | 81.50.7 | 70.30.7 | 79.00.3 | 86.50.5 | 92.40.2 | 93.00.3 | 95.70.2 | 71.70.3 |
| GAT | X, A, Y | 83.00.7 | 72.50.7 | 79.00.3 | 86.90.3 | 92.60.4 | 92.30.2 | 95.50.2 | 71.70.3 |
Implementation Details. For this first set of experiments, we took our graph encoder to be a standard 2-layers GCN model (Kipf and Welling, 2016a) with the same hidden and output dimensions across all datasets except CiteSeer, Coauthor CS, and ogbn-arxiv. As in Zhang et al. (2021), we observed 1-layer GCN is better for CiteSeer and 2-layers MLPs is better for Coautor CS than using 2-layers GCN. We use a 3-layers GCN for ogbn-arxiv due to the difficulty of the task (40 classes are in ogbn-arxiv, compared to less than 15 classes in the others). For the second stage, we use a simple logistic regression as a linear classifier. We utilize the Adam optimizer (Kingma and Ba, 2014). We run 20 random initializations on both model parameters and data splits, and report the mean accuracy along with a standard deviation. Additional details regarding hyperparameter tuning are provided in Appendix A.2.
Results. For fair comparison, we provide a consistent training setting across all methods: we use an Adam optimizer and a simple logistic regression without regularization for all methods and for all benchmark datasets. Table 2 provides the comparison between CLNR and existing peer methods by reporting the mean classification accuracy (and standard deviation). We first focus on comparisons between CLNR (column-wise postprocessing) and GRACE (row-wise postprocessing). We can see that CLNR outperforms GRACE up to 1.5% throughout all benchmark datasets — with the exception of Photo. This shows that column-wise postprocessing achieves better representations than row-wise postprocessing in general. We also compare the performance of CLNR against other existing methods. In particular, we compare CLNR with one classical unsupervised model: GAE (Kipf and Welling, 2016b), five self-supervised models: DGI (Velickovic et al., 2019), MVGRL (Hassani and Khasahmadi, 2020), BGRL (Thakoor et al., 2021), CCA-SSG (Zhang et al., 2021), and two supervised baselines: GCN (Kipf and Welling, 2016a) and GAT (Veličković et al., 2017). From Table 2, we observe that CLNR outperforms all other unsupervised and self-supervised methods on all benchmarks except CiteSeer, where MVGRL is superior. CLNR even outperforms two supervised baselines, GCN and GAT, by up to 1 to 4% on all benchmark datasets except Coauthor Physics and ogbn-arxiv. On the other hand, among methods using non-contrastive losses, CCA-SSG outperforms BGRL on all benchmark datasets except Computer and ogbn-arxiv.
Training Time. It is also worth emphasizing that CLNR typically needs smaller number of epochs to generate the best node representations. This is due to other advantage of batch normalization which allows a higher learning rate and make the optimization landscape smoother, hence, accelerating model training. Moreover, CLNR does not need to learn additional parameters in a MLPs. Table 3 shows the comparison between GRACE and CLNR in terms of model training time. We observe that CLNR is up to 20 times faster in training than GRACE.
| Model | Dataset | Training time |
| CLNR | ogbn-arxiv | 2879.75s |
| GRACE | ogbn-arxiv | 7286.71s |
| CLNR | Photo | 7.87s |
| GRACE | Photo | 143.25s |
| CLNR | Computers | 25.62s |
| GRACE | Computers | 104.59s |
| CLNR | PubMed | 134.51s |
| GRACE | PubMed | 538.75s |
4 Revisiting the “Alignment vs. Uniformity Paradigm”
In this section, we propose to delve deeper in the comparison between CLNR and GRACE, and try to explain the superiority of the embeddings obtainted by CLNR.
To this end, we revisit the “alignment and uniformity paradigm” proposed by Wang and Isola (2020).
Alignment vs. Uniformity. Noting the success of mapping features to the unit hypersphere and restricting their analysis to those, Wang and Isola (2020) propose an analysis of contrastive losses in terms of two quantities: (a) Alignment, which quantifies how close representations from positive pairs (i.e. embeddings corresponding to the same entity) are mapped to one another:
| (4) |
In the previous expression, denotes the embedding for the nodes, is any positive exponent (usually chosen to be equal to 2); And (b) uniformity, defined as the logarithm of the average pairwise Gaussian potential:
| (5) |
Uniformity essentially measures uniformly distributed the features are on the unit sphere. Wang and Isola (2020) indeed posit that data distributions that are more uniformly spread on the hypersphere preserve more information. They then proceed to show that the NT-Xent loss can asymptotically be written as the sum of a uniformity and an alignment term, so that it optimizes for both. Building off of these observations, the authors suggest that explicitly optimizing for both uniformity and alignment might yield better results than using the classical negative cross-entropy loss. However, the weighted loss that they propose has the disadvantage of introducing yet another parameter that has to be cross-validated for.









Batch Normalization to Enhance Uniformity. Wang and Isola (2020) empirically shows that better representations achieve lower value of alignment and uniformity metrics. Leveraging these insights, we explain the success of our batch normalization by its ability to enhance the uniformity of the representation. Indeed, batch normalization has the effect of scaling all dimensions of the embedding space — thereby making all embedding directions comparable and the embedding space, isotropic. Such standardization is in fact routine procedure for other unsupervised learning techniques, including principal component analysis, to prevent one dimension of the data from overpowering the others (Hastie et al., 2009). Similarly here, we posit that BN stabilizes the contribution of each dimension and allows for an easier optimization of uniformity. We posit that this batch normalization is sufficient to encourage the uniformity that Wang and Isola (2020) showed to be beneficial for embedding quality, and has the significant advantage of not requiring hyperparameter tuning.
To provide empirical evidence for this phenomenon and clearly see the effect of each postprocessing, we additionally consider the following variants:
- nCLNR:
-
We first compare the CLNR and GRACE to a counterpart (which we call nCLNR) that uses the identity mapping as postprocessing (i.e., no postprocessing is used). This will serve as our ablation benchmark to verify the importance of the postprocessing step.
- dCLNR:
-
Building off of the rich literature on the topic in DNNs, another choice of column-wise postprocessing consists in using decorrelated batch normalization (dBN) (Huang et al., 2018). dBN expands on the previous standardization technique, and further enforces features in different dimension to be uncorrelated. This holds the promise of further allowing a better conditioning the Hessian, but in standard literature, is often considered too costly to implement. To enrich our discussion, we also consider dBN postprocessing step, and refer to the contrastive learning framework with this choice of postprocessing as dCLNR.
- GCLNR:
-
This last variant corresponds to a postprocessing that uses a 2-layers MLPs with nonlinear activation function followed by column-wise standardization (i.e., both row-wise and column-wise postprocessing are used).






We begin by plotting the learned representations on Cora dataset using GRACE and our method, CLNR in Figure 1. As expected, our batch-normalization-based method significantly improved the uniformity of the learned representations.
Figure 2 shows the alignment (Equation (4)) vs uniformity (Equation (5)) metrics achieved for each of the methods on 6 different datasets. We observe that sole CLNR is located in left-bottom side of nCLNR (no postprocessing) for 5 out of 6 benchmark datasets. This implies that column-wise postprocessing improves both alignment and uniformity compared to the one without postprocessing. On the other hand, GRACE is shown consistently at the right-bottom corner of the figures. This implies that row-wise postprocessing focuses on improving alignment of representations at the expense of losing significant amount of uniformity. The only exception is Photo where GRACE is also located in left-bottom side of nCLNR and exhibits better node classification accuracy compared to CLNR. We might expect that GCLNR which uses both row-wise and column-wise postprocessing improve the quality of representations compared with the ones using just one of them. Interestingly, we observe that GCLNR is consistently located at the middle of CLNR and GRACE which implies that we can not fully recover the uniformity by column-wise postprocessing once the row-wise postprocessing is done. Surprisingly, dCLNR which additionally decorrelates different features has a similar value of alignment and uniformity metrics
with nCLNR.









5 Additional Experiments
We conclude this paper with a discussion on the additional benefits of CLNR compared to existing approaches. We focus this discussion on two points: (a) efficiency of the embedding method (as measured by the accuracy of downstream node classifiers as a function of the embedding size) and (b) robustness to perturbations. Throughout this discussion, we include in the comparison a non-contrastive competitor, CCA-SSG (Zhang et al., 2021) due to its impressive performance and scalability.
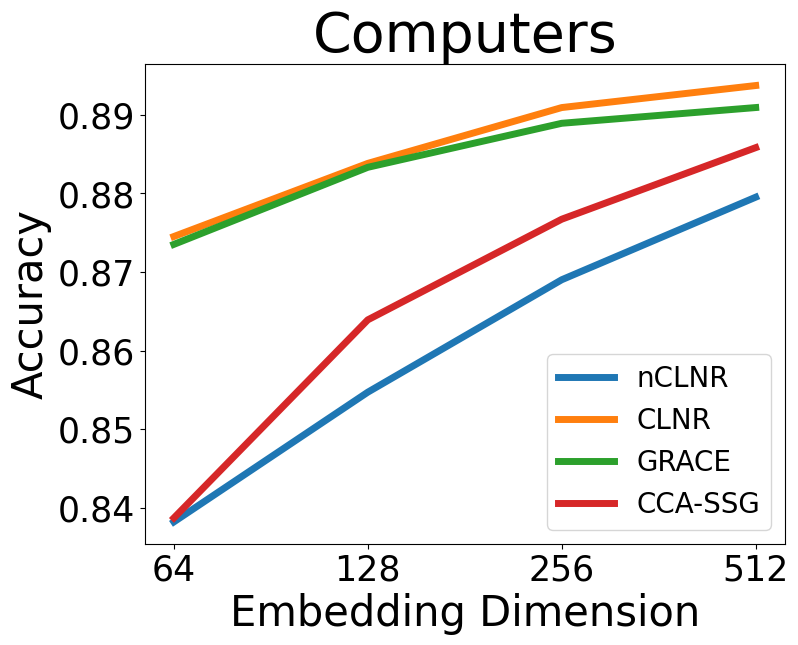
Efficiency of Embedding. We now study the effect of embedding dimension on the quality of node representations.
From Figure 3, we observe that CLNR shows consistent competitive performance across all embedding dimensions on all benchmark datasets. GRACE also shows good performance across all embedding dimensions on all benchmark datasets except CiteSeer. Conversely, we observe that nCLNR which does not postprocess the raw embeddings and CCA-SSG which uses a non-contrastive loss are considerably more sensitive to the dimension.
Robustness of Methods.
Finally, we compare nCLNR, CLNR, GRACE, and CCA-SSG in terms of robustness on edge perturbation. Let be the number of edges in an input graph . For given we generate adjacency matrix noise containing number of random undirected edges. We then generate a perturbed adjacency matrix with and we train GCN encoder with the perturbed graph instead of . The results are summarized in Figure 4. Figure 4 shows node classification accuracy of the four models on 5 benchmark datasets along with an increasing value of . We observe that CLNR consistently outperforms all other methods on all benchmark datasets except CiteSeer.
6 Conclusion
We have introduced self-supervised contrastive learning for node representations (CLNR), a simplified but powerful method for learning effective node representations. By replacing the expensive MLP-based row-wise postprocessing of GRACE (Zhu et al., 2020) with a simple batch normalization, we simplify the architecture of existing contrastive learning methods based on NT-Xent loss and considerably its performance, scalability and robustness. To explain this success, we revisit the alignment and uniformity paradigm. We provided empirical evidence that the column-wise postprocessing was sufficient to improve both alignment and uniformity of the embeddings, while row-wise postprocessing improves the alignment of node representations at the expense of losing significant amounts of uniformity.
References
- Bachman et al. (2019) P. Bachman, R. D. Hjelm, and W. Buchwalter. Learning representations by maximizing mutual information across views. Advances in neural information processing systems, 32, 2019.
- Bjorck et al. (2018) N. Bjorck, C. P. Gomes, B. Selman, and K. Q. Weinberger. Understanding batch normalization. Advances in neural information processing systems, 31, 2018.
- Bojanowski and Joulin (2017) P. Bojanowski and A. Joulin. Unsupervised learning by predicting noise. In International Conference on Machine Learning, pages 517–526. PMLR, 2017.
- Caliński and Harabasz (1974) T. Caliński and J. Harabasz. A dendrite method for cluster analysis. Communications in Statistics-theory and Methods, 3(1):1–27, 1974.
- Chen et al. (2020) T. Chen, S. Kornblith, M. Norouzi, and G. Hinton. A simple framework for contrastive learning of visual representations. In International conference on machine learning, pages 1597–1607. PMLR, 2020.
- Davidson et al. (2018) T. R. Davidson, L. Falorsi, N. De Cao, T. Kipf, and J. M. Tomczak. Hyperspherical variational auto-encoders. arXiv preprint arXiv:1804.00891, 2018.
- Davies and Bouldin (1979) D. L. Davies and D. W. Bouldin. A cluster separation measure. IEEE transactions on pattern analysis and machine intelligence, (2):224–227, 1979.
- Grill et al. (2020) J.-B. Grill, F. Strub, F. Altché, C. Tallec, P. Richemond, E. Buchatskaya, C. Doersch, B. Avila Pires, Z. Guo, M. Gheshlaghi Azar, et al. Bootstrap your own latent-a new approach to self-supervised learning. Advances in neural information processing systems, 33:21271–21284, 2020.
- Gutmann et al. (2022) M. U. Gutmann, S. Kleinegesse, and B. Rhodes. Statistical applications of contrastive learning. Behaviormetrika, pages 1–25, 2022.
- Hassani and Khasahmadi (2020) K. Hassani and A. H. Khasahmadi. Contrastive multi-view representation learning on graphs. In International Conference on Machine Learning, pages 4116–4126. PMLR, 2020.
- Hastie et al. (2009) T. Hastie, R. Tibshirani, J. H. Friedman, and J. H. Friedman. The elements of statistical learning: data mining, inference, and prediction, volume 2. Springer, 2009.
- He et al. (2016) K. He, X. Zhang, S. Ren, and J. Sun. Deep residual learning for image recognition. In Proceedings of the IEEE conference on computer vision and pattern recognition, pages 770–778, 2016.
- He et al. (2020) K. He, H. Fan, Y. Wu, S. Xie, and R. Girshick. Momentum contrast for unsupervised visual representation learning. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 9729–9738, 2020.
- Hjelm et al. (2018) R. D. Hjelm, A. Fedorov, S. Lavoie-Marchildon, K. Grewal, P. Bachman, A. Trischler, and Y. Bengio. Learning deep representations by mutual information estimation and maximization. arXiv preprint arXiv:1808.06670, 2018.
- Ho and Nvasconcelos (2020) C.-H. Ho and N. Nvasconcelos. Contrastive learning with adversarial examples. Advances in Neural Information Processing Systems, 33:17081–17093, 2020.
- Hu et al. (2020) W. Hu, M. Fey, M. Zitnik, Y. Dong, H. Ren, B. Liu, M. Catasta, and J. Leskovec. Open graph benchmark: Datasets for machine learning on graphs. Advances in neural information processing systems, 33:22118–22133, 2020.
- Huang et al. (2018) L. Huang, D. Yang, B. Lang, and J. Deng. Decorrelated batch normalization. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 791–800, 2018.
- Ioffe and Szegedy (2015) S. Ioffe and C. Szegedy. Batch normalization: Accelerating deep network training by reducing internal covariate shift. In International conference on machine learning, pages 448–456. PMLR, 2015.
- Kingma and Ba (2014) D. P. Kingma and J. Ba. Adam: A method for stochastic optimization. arXiv preprint arXiv:1412.6980, 2014.
- Kipf and Welling (2016a) T. N. Kipf and M. Welling. Semi-supervised classification with graph convolutional networks. arXiv preprint arXiv:1609.02907, 2016a.
- Kipf and Welling (2016b) T. N. Kipf and M. Welling. Variational graph auto-encoders. arXiv preprint arXiv:1611.07308, 2016b.
- Kong et al. (2019) L. Kong, C. d. M. d’Autume, W. Ling, L. Yu, Z. Dai, and D. Yogatama. A mutual information maximization perspective of language representation learning. arXiv preprint arXiv:1910.08350, 2019.
- McAuley et al. (2015) J. McAuley, C. Targett, Q. Shi, and A. Van Den Hengel. Image-based recommendations on styles and substitutes. In Proceedings of the 38th international ACM SIGIR conference on research and development in information retrieval, pages 43–52, 2015.
- Meng et al. (2019) Y. Meng, J. Huang, G. Wang, C. Zhang, H. Zhuang, L. Kaplan, and J. Han. Spherical text embedding. Advances in neural information processing systems, 32, 2019.
- Oord et al. (2018a) A. v. d. Oord, Y. Li, and O. Vinyals. Representation learning with contrastive predictive coding. arXiv preprint arXiv:1807.03748, 2018a.
- Oord et al. (2018b) A. v. d. Oord, Y. Li, and O. Vinyals. Representation learning with contrastive predictive coding. arXiv preprint arXiv:1807.03748, 2018b.
- Rousseeuw (1987) P. J. Rousseeuw. Silhouettes: a graphical aid to the interpretation and validation of cluster analysis. Journal of computational and applied mathematics, 20:53–65, 1987.
- Santurkar et al. (2018) S. Santurkar, D. Tsipras, A. Ilyas, and A. Madry. How does batch normalization help optimization? Advances in neural information processing systems, 31, 2018.
- Scarselli et al. (2008) F. Scarselli, M. Gori, A. C. Tsoi, M. Hagenbuchner, and G. Monfardini. The graph neural network model. IEEE transactions on neural networks, 20(1):61–80, 2008.
- Sen et al. (2008) P. Sen, G. Namata, M. Bilgic, L. Getoor, B. Galligher, and T. Eliassi-Rad. Collective classification in network data. AI magazine, 29(3):93–93, 2008.
- Shchur et al. (2018) O. Shchur, M. Mumme, A. Bojchevski, and S. Günnemann. Pitfalls of graph neural network evaluation. 2018.
- Sinha et al. (2015) A. Sinha, Z. Shen, Y. Song, H. Ma, D. Eide, B.-J. Hsu, and K. Wang. An overview of microsoft academic service (mas) and applications. In Proceedings of the 24th international conference on world wide web, pages 243–246, 2015.
- Thakoor et al. (2021) S. Thakoor, C. Tallec, M. G. Azar, M. Azabou, E. L. Dyer, R. Munos, P. Veličković, and M. Valko. Large-scale representation learning on graphs via bootstrapping. arXiv preprint arXiv:2102.06514, 2021.
- Tian et al. (2020) Y. Tian, D. Krishnan, and P. Isola. Contrastive multiview coding. In European conference on computer vision, pages 776–794. Springer, 2020.
- Veličković et al. (2017) P. Veličković, G. Cucurull, A. Casanova, A. Romero, P. Lio, and Y. Bengio. Graph attention networks. arXiv preprint arXiv:1710.10903, 2017.
- Velickovic et al. (2019) P. Velickovic, W. Fedus, W. L. Hamilton, P. Liò, Y. Bengio, and R. D. Hjelm. Deep graph infomax. ICLR (Poster), 2(3):4, 2019.
- Wang et al. (2020) K. Wang, Z. Shen, C. Huang, C.-H. Wu, Y. Dong, and A. Kanakia. Microsoft academic graph: When experts are not enough. Quantitative Science Studies, 1(1):396–413, 2020.
- Wang and Isola (2020) T. Wang and P. Isola. Understanding contrastive representation learning through alignment and uniformity on the hypersphere. In International Conference on Machine Learning, pages 9929–9939. PMLR, 2020.
- Wu et al. (2020a) Z. Wu, S. Wang, J. Gu, M. Khabsa, F. Sun, and H. Ma. Clear: Contrastive learning for sentence representation. arXiv preprint arXiv:2012.15466, 2020a.
- Wu et al. (2020b) Z. Wu, S. Pan, F. Chen, G. Long, C. Zhang, and S. Y. Philip. A comprehensive survey on graph neural networks. IEEE transactions on neural networks and learning systems, 32(1):4–24, 2020b.
- Xu and Durrett (2018) J. Xu and G. Durrett. Spherical latent spaces for stable variational autoencoders. arXiv preprint arXiv:1808.10805, 2018.
- Yang et al. (2016) Z. Yang, W. W. Cohen, and R. Salakhutdinov. Revisiting semi-supervised learning with graph embeddings. 2016.
- Zhang et al. (2021) H. Zhang, Q. Wu, J. Yan, D. Wipf, and P. S. Yu. From canonical correlation analysis to self-supervised graph neural networks. Advances in Neural Information Processing Systems, 34:76–89, 2021.
- Zhou et al. (2020) J. Zhou, G. Cui, S. Hu, Z. Zhang, C. Yang, Z. Liu, L. Wang, C. Li, and M. Sun. Graph neural networks: A review of methods and applications. AI Open, 1:57–81, 2020.
- Zhu et al. (2020) Y. Zhu, Y. Xu, F. Yu, Q. Liu, S. Wu, and L. Wang. Deep graph contrastive representation learning. arXiv preprint arXiv:2006.04131, 2020.
- Zhu et al. (2021) Y. Zhu, Y. Xu, F. Yu, Q. Liu, S. Wu, and L. Wang. Graph contrastive learning with adaptive augmentation. In Proceedings of the Web Conference 2021, pages 2069–2080, 2021.
Appendix A IMPLEMENTATION DETAILS
A.1 Datasets
We consider eight node-classification benchmarks to evaluate our models: Cora, CiteSeer, PubMed, Amazon Computers, Amazon Photo, Coauthor CS, Coauthor Physics, ogbn-arxiv. For all experiments, we use the processed version of the datasets provided by Pytorch Geometric. We provide brief description of the datasets as follows:
Cora, CiteSeer, PubMed. A citation network where nodes represent scientific papers and edges mean citations between pairs of paper (Sen et al., 2008).
Amazon Computers, Amazon Photo. The Amazon co-purchase network where nodes represent goods and edges mean being pairs of goods frequently purchased together (McAuley et al., 2015).
Coauthor CS, Coauthor Physics. The Microsoft Academic network where nodes represent authors and edges mean authors who have co-authored a paper (Sinha et al., 2015).
Ogbn-arxiv. The citation network between all Computer Science (CS) ARXIV papers indexed by MAG where nodes represent ARXIV papers and directed edges mean one paper cites another one (Wang et al., 2020; Hu et al., 2020).
Further details of the datasets are presented in Table 4.
| Dataset | Nodes | Edges | Feature dimension | Classes |
| Cora | 2,708 | 10,556 | 1,433 | 7 |
| CiteSeer | 3,327 | 9,104 | 3,703 | 6 |
| PubMed | 19,717 | 88,648 | 500 | 3 |
| Computers | 13,752 | 491,722 | 767 | 10 |
| Photo | 7,650 | 238,162 | 745 | 8 |
| CS | 18,333 | 163,788 | 6,805 | 15 |
| Physics | 34,493 | 495,924 | 8,415 | 5 |
| ogbn-arxiv | 169,343 | 1,166,243 | 128 | 40 |
A.2 Hyper-parameters
For all datasets, all hyper-parameters are choosen by small grid search. In particular, we fix the temperature parameter and due to large search space. We provide all details of hyper-parameters that are used in our experiments on the eight benchmarks in Table 5.
| Dataset | Epoch | layers | embedding dimension | lr1 | wd1 | lr2 | wd2 | |||
| Cora | 50 | 2 | 512 | 0.5 | 1e-3 | 0 | 0.2 | 0.5 | 5e-3 | 1e-4 |
| CiteSeer | 50 | 1 | 512 | 0.5 | 1e-3 | 0 | 0.2 | 0.5 | 1e-2 | 1e-2 |
| PubMed | 600 | 2 | 512 | 0.5 | 1e-3 | 0 | 0.3 | 0.5 | 1e-2 | 1e-4 |
| Computers | 200 | 2 | 512 | 0.5 | 1e-3 | 0 | 0.0 | 0.5 | 1e-2 | 1e-4 |
| Photo | 100 | 2 | 512 | 0.5 | 1e-3 | 0 | 0.0 | 0.5 | 1e-2 | 1e-4 |
| CS | 600 | 2 | 512 | 0.5 | 1e-3 | 0 | 0.3 | 0.1 | 5e-3 | 1e-2 |
| Physics | 50 | 2 | 512 | 0.5 | 1e-3 | 0 | 0.2 | 0.4 | 5e-3 | 1e-4 |
| ogbn-arxiv | 5000 | 3 | 512 | 0.5 | 1e-2 | 0 | 0.0 | 0.5 | 1e-2 | 1e-4 |
Appendix B FURTHER NODE EMBEDDING COMPARISONS
B.1 Clustering Score
We further evaluate the quality of node embedding by examining three clustering scores: Silhouette Coefficient, Davies-Bouldin index, Calinski-Harabasz score (Rousseeuw, 1987; Davies and Bouldin, 1979; Caliński and Harabasz, 1974). We consider three methods: CLNR, GRACE, CCA-SSG. We provide brief description of three clustering scores as follows:
Silhouette coefficient. Let us denote Silhouette coefficient for -th node as and Silhouette coefficient over all nodes as where is the number of nodes. For each node , Silhouette coefficient is calculated by where is the mean intra-cluster distance and is the mean nearest-cluster distance that -th node is not a part of. The best and worst value that attains are 1 and -1 respectively. indicates overlapping clusters.
Davies-Boulding index. Let us denote Davies-Boulding index as . Davies-Boulding index is calculated by where is the number of classes and where is the average distance between each node and the centroid of -th cluster, and is the distance between the centroids of -th and -th cluster. Small value of indicates well-separated clusters.
Calinski-Harabasz score. Let us denote Calinski-Harabasz score as . Calinski-Harabasz score is calculated by where is the trace of the between group dispersion matrix, is the trace of the within-cluster dispersion matrix, is the number of classes, and is the number of nodes. Higher score indicates dense and well-separated clusters.
Clustering scores for CLNR, GRACE, and CCA-SSG on Cora dataset are summarized in Table 6. We observe that CLNR achieves the best Silhouette coefficient and CCA-SSG achieves the best Davies-Boulding index and Calinski-Harabasz score. Moreover, all clustering scores for CLNR are higher than those of GRACE.
| Methods | |||
| CLNR | 0.105 | 2.248 | 63.066 |
| GRACE | 0.041 | 2.686 | 49.503 |
| CCA-SSG | 0.089 | 2.002 | 70.760 |