A Self-Learning Disturbance Observer for Nonlinear Systems in Feedback-Error Learning Scheme
Abstract
This paper represents a novel online self-learning disturbance observer (SLDO) by benefiting from the combination of a type-2 neuro-fuzzy structure (T2NFS), feedback-error learning scheme and sliding mode control (SMC) theory. The SLDO is developed within a framework of feedback-error learning scheme in which a conventional estimation law and a T2NFS work in parallel. In this scheme, the latter learns uncertainties and becomes the leading estimator whereas the former provides the learning error to the T2NFS for learning system dynamics. A learning algorithm established on SMC theory is derived for an interval type-2 fuzzy logic system. In addition to the stability of the learning algorithm, the stability of the SLDO and the stability of the overall system are proven in the presence of time-varying disturbances. Thanks to learning process by the T2NFS, the simulation results show that the SLDO is able to estimate time-varying disturbances precisely as distinct from the basic nonlinear disturbance observer (BNDO) so that the controller based on the SLDO ensures robust control performance for systems with time-varying uncertainties, and maintains nominal performance in the absence of uncertainties.
keywords:
Disturbance observer, neural networks, neuro-fuzzy structure, online learning algorithm, robustness, sliding mode control, type-2 fuzzy logic systems, uncertainty.1 Introduction
One of the most essential requirements for controllers is to be insensitive to uncertainties. Many control methods have been proposed to handle different types of uncertainties, (e.g. control (Glover and Doyle, 1988; Gahinet and Apkarian, 1994), sliding mode control (SMC) (Slotine et al., 1991; Li et al., 2013; Xu et al., 2014), adaptive control (Sun et al., 2013a, b; He et al., 2014; Yao et al., 2015), etc…). In control, uncertainties must be bounded in -norm. This implies that disturbances must disappear suddenly and completely. However, this is not a realistic assumption for real-time applications. In SMC theory, integral SMC controller is proposed in the presence of uncertainties. It is a well known fact that the integral action may cause unwanted effects such as, large settling time and overshoots. Moreover, adaptive control systems may not have an ability to control uncertain systems with highly changing parameters (Chen et al., 2015). As an alternative method, disturbance observers (DOs) have been proposed since they are very crucial for control of systems due to the fact that uncertainties extensively exist in practice and are extremely difficult to be modeled. These uncertainties, such as parameter variations, noise, unmodeled dynamics and interactions between subsystems, must be taken for the controller design into account to have a capability of getting robustness. For this purpose, different DOs have been designed in literature to obtain robust control performance for systems (Chen et al., 2000b, a, 2016).
In DO based control approaches, the model uncertainties and external disturbances are merged into one term and a control law contains the estimated disturbance value by a DO. The aims are to achieve performance specifications while stabilizing the system considering the nominal model of the system and remove the disturbance effect on the system (Chen, 2004; Yang et al., 2013; Ginoya et al., 2014). A nonlinear dynamics inversion control method was designed for the longitudinal autopilot of a missile in (Chen, 2003). It was reported that the control method exhibit poor performance in case of unknown uncertainties while a basic nonlinear DO (BNDO) based nonlinear dynamics inversion control approach ensured robust performance against uncertainty. The same BNDO has been used to design a robust SMC controller for systems with mismatched uncertainties (Yang et al., 2013). The main drawback in these studies, the BNDO is only be able to estimate time-invariant disturbances. If disturbances are time-varying, then the BNDO gives bias estimates. Furthermore, there are well known nonlinear observers, such as extended Kalman filter (EKF), particle filtering and nonlinear moving horizon estimation methods. EKF works well if linear approximation is valid and noise on measurements is small (Haseltine et al., 2005). Besides, particle filter and nonlinear moving horizon estimation methods require very large computation time (Daum, 2005). For this reason, an observer, computationally cheap, is required to be able to estimate time-varying disturbances.
Type-2 fuzzy logic systems (T2FLSs) are proposed as the extended versions of type-1 fuzzy logic systems (T1FLSs) in literature (Kayacan et al., 2010; Castillo et al., 2012; Lee et al., 2015). It allows us to have more degrees of freedom for design than their type-1 counterparts so that it results in better capability of handling uncertainty (Castro et al., 2011; Castro and Castillo, 2013; Lee et al., 2014; Rubio-Solis and Panoutsos, 2015; Zaheer et al., 2015). Type-2 fuzzy sets are especially preferred as the decision of the position of the membership functions (MFs) precisely is a very troublesome task (Liang et al., 2000; Castillo et al., 2013). However, the computational complexity of generalized type-2 fuzzy sets is very high. For this reason, the interval type-2 fuzzy sets were proposed to decrease computation time and made it feasible in real-time applications (Liang and Mendel, 2000; Maldonado et al., 2013; Lin et al., 2014; Chang and Chan, 2014; Castillo et al., 2014; Zaheer et al., 2015; Wagner et al., 2015).
Neuro-fuzzy structures as a model-free method have been widely used for control and identification of systems in literature. It is well know that the stability of systems controlled by model-free controllers cannot be proven. Therefore, the feedback-error learning scheme has been proposed for neuro-fuzzy structures to guarantee the global asymptotic stability of the system in a compact space (Efe et al., 2000). SMC achieves robustness to parametric uncertainty and high-frequency unmodeled dynamics; therefore, the SMC theory-based learning algorithms for neuro-fuzzy structures have been proposed to ensure the robustness of the overall system (Kaynak et al., 2001; Yu and Kaynak, 2009). Moreover, they ensure faster convergence rate than the traditional learning methods, such as gradient descent, Levenberg-Marquardt and particle swarm optimization, because they are computationally simple. There are numerous examples for SMC theory-based learning algorithms for artificial neural networks, type-1 and type-2 neuro-fuzzy structures (Topalov et al., 2009; Kayacan et al., 2012).
The main contribution of this paper is to develop a novel online SLDO, which can learn the disturbance behavior of systems in time-varying case as distinct from basic nonlinear DOs (BNDOs), be solved in the range of millisecond, and robust against uncertainties. For this purpose, the T2NFS in feedback-error learning scheme is proposed due to fact that they are very suitable techniques for adaptive learning. Additionally, computationally efficient sliding mode learning algorithm is used as the training algorithm of the T2NFS because it is a powerful approach for the stability issue. Consequently, the use of the combination of T2NFS, feedback-error learning scheme and sliding mode control theory harmoniously allow to better handle uncertainties.
The major contributions of this paper are as follows:
-
1.
The first major contribution is that a novel estimation approach in the feedback-error learning scheme is developed for disturbance observer design for the first-time.
-
2.
The second major contribution is that the stability of the training algorithm has been always proven for feedback-error learning methods in literature. In this paper, in addition to the proof of the training algorithm, the overall system stability is proven considering the dynamics of the proposed SLDO by adding a robust term. To the best knowledge of the author, this is also the first-time such a stability analysis is ever proven.
The minor contributions of this paper are as follows:
-
1.
The first minor contribution is that the developed SLDO is solved within milliseconds; therefore, the required computation time for the SLDO is significantly less than other methods, such as particle filter and nonlinear moving horizon estimation methods.
-
2.
The second minor contribution is that the learning rate of SMC theory-based learning algorithm for the T2NFS is adaptive so that it is possible to estimate the disturbance without the knowledge about the upper bound of the disturbance and its derivatives.
The paper consists of six sections: The formulation of the BNDO is given in Section 2. The SLDO benefiting from the T2NFS is developed in Section 3. The T2NFS and online learning algorithm established on SMC theory are respectively represented in Sections 3.1 and 3.2. The stability of the SLDO is proven in Section 3.3. The controller design and the stability of the system are given in Section 4. The simulation results are represented in Sections 5. Finally, the paper is summarized in Section 6.
2 Basic Nonlinear Disturbance Observer
A number of physical systems, such as robots, spacecrafts and mechanical systems, are generally described by second-order differential equations. A second-order nonlinear system is written in the following form:
| (1) |
where is the state vector, is the control input, is the disturbance, is the disturbance coefficients vector, and are the nonlinear system dynamics.
The disturbance in (1) is not measurable in practice. Therefore, it is required to be estimated in practice to obtain robust control performance of systems. The following basic nonlinear disturbance observer (BNDO) dynamics have been proposed in (Chen, 2003; Yang et al., 2013) as follows:
| (2) |
where , and denote respectively the internal state, proportional observer gain and estimated disturbance. By taking time derivative of the estimated disturbance considering (2), the time derivative of the estimated disturbance is obtained as:
| (3) |
If the time derivative of the actual disturbance is added into (3), the error dynamics of the BNDO are obtained as follows:
| (4) |
where is the disturbance error.
Assumption 1
The time derivative of the actual disturbance is bounded and .
If Assumption 1 is satisfied, then (2) is obtained as follows:
| (5) |
Lemma 1
Lemma 1 implies that the estimated disturbance by the BNDO is able to track the actual disturbance of the system in (1) asymptotically in case Assumption 1 is satisfied.
Remark 1
If the time derivative of the actual disturbance is not equal to zero, the error dynamics of th BNDO cannot converge to zero so that BNDO gives bias. Therefore, there exists always difference between the estimated and true values of the disturbance. Similar observers have been designed in literature and the same drawback has been reported in (Chen, 2003; Yang et al., 2013).
3 Self-learning Disturbance Observer
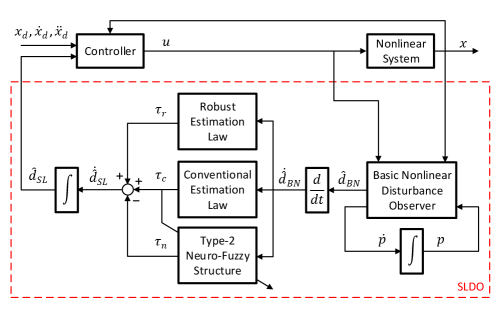
BNDOs cannot give unbiased estimation results in case of time-varying disturbances; therefore, a fast, computationally efficient, adaptive and robust disturbance observer is required. A novel estimation law is proposed as follows:
| (6) |
where , and denote respectively the outputs of the conventional estimation law, robust term and T2NFS. The schematic diagram of the SLDO is illustrated in Fig 1. As seen, the BNDO is working in series with the feedback-error learning algorithm in which the conventional and robust estimation laws work in parallel with T2NFS.
The conventional estimation law used in this paper is defined as follows:
| (7) |
where denotes the time derivative of the estimated value of the disturbance by the BNDO, and denote the proportional and derivative gain vectors, and and are positive, i.e. .
The robust estimation law is written as follows:
| (8) |
is positive, i.e. , and denotes the robust gain vector.
3.1 Type-2 Neuro-Fuzzy Structure
An interval type-2 Takagi-Sugeno-Kang (TSK) fuzzy if-then rule is written as:
| (9) |
where and denote the inputs while and denote type-2 fuzzy sets for inputs. The function is the output of the rules and the total number of the rules are equal to in which and are the total number of the inputs.
The upper and lower Gaussian membership functions for type-2 fuzzy logic systems are written as follows:
| (10) |
| (11) |
| (12) |
| (13) |
where denote respectively the lower and upper mean, and the lower and upper standard deviation of the membership functions. These parameters are adjustable for the T2NFS.
The lower and upper membership functions and of A2-C0 fuzzy system employed in this paper are determined for every signal. Then, the firing strength of rules are calculated as follows:
| (14) |
The output of the every fuzzy rule is a linear function formulated in (9). The output of the network is formulated below:
| (15) |
where and are the normalized firing strengths of the lower and upper output signals of the neuron are written as follows:
| (16) |
The design parameter weights the participation of the lower and upper firing levels and is generally set to . In this paper, it is formulated as a time-varying parameter in the next subsection.
The vectors are defined as::
where these normalized firing strengths are between and , i.e. and . In addition, and .
3.2 SMC Theory-based Learning Algorithm
The sliding surface is formulated as follows:
| (17) |
where is the output of the conventional estimation law and used as a sliding surface. It is to be noted that the sliding surface is used as learning error to train the SMC theory-based learning algorithm.
The adaptation rules of the T2NFS parameters are given by the following equations:
| (18) |
| (19) |
| (20) |
| (21) |
| (22) |
| (23) |
| (24) |
| (25) |
| (26) |
| (27) |
| (28) |
where and denote respectively the learning rate and the coefficient of the adaptation for the learning rate, and they must be positive, i.e. .
Theorem 1 (Stability of the learning algorithm)
Proof 1
The Lyapunov function is written as follows:
| (29) |
By taking the time derivative of the Lyapunov function in (29), it is obtained as follows:
| (30) |
If the (28) is inserted into the equation above:
| (31) |
The calculation of in (63) is inserted into (31), it is obtained as follows:
| (32) |
If (17) is inserted into the equation above:
| (33) |
If it is assumed that and are upper bounded by and , (33) is obtained as follows:
| (34) | |||||
As stated in Theorem 1, if the final value of the learning rate is large enough, i.e. , then the time derivative of the Lyapunov function is negative, i.e. so that the SMC theory-based learning algorithm is stable and will converge to zero in finite time.
Remark 2
Since the adaptation rules in (28) are enforced, the final value of the learning rate of the T2NFS is determined during the adaptation of learning rate, and it is able to reach large values to make learning algorithm stable. This is a superiority of the proposed approach in this study as distinct from previous studies in which the upper bounds are needed to be foreknown.
3.3 Stability Analysis
The error dynamics for the SLDO are obtained by adding the actual disturbance rate into the estimated disturbance rate in (36) and considering the calculated time derivative of the estimated disturbance by BNDO in (3):
| (37) |
By taking the time derivative of (3.3), it is obtained as follows:
| (38) |
As calculated in (63), is inserted into (38);
| (39) |
If in (7) is inserted into (17), the sliding surface is obtained as follows:
| (40) |
where is the slope of the sliding surface. The time derivative of the sliding surface is obtained as
| (41) |
Theorem 2 (Stability of the SLDO)
The estimation law in (6) is employed as a DO, the closed-loop error dynamics for the SLDO are stable if the robust gain is equal to , i.e. , and the final value of the learning rate of T2NFS is large enough, where the acceleration of the actual disturbance is upper bounded by .
Proof 2
The Lyapunov function is written as follows:
| (42) |
By taking the time derivative of the Lyapunov function above considering (28), it is obtained as
| (43) |
If the time derivative of the sliding surface is inserted into the aforementioned equation, it is obtained as follows:
| (44) |
It is obtained considering (3)
| (45) |
(39) is inserted into (45), it is obtained as follows:
| (46) |
If it is assumed that is upper bounded by :
| (47) | |||||
| (48) |
As stated in Theorem 2, if is equal to , i.e. , and the final value of the learning algorithm is large enough, i.e. , then the time derivative of the Lyapunov function is negative, i.e. , so that the SLDO is stable.
Remark 4
The main advantage of the SLDO is to be able to prove the stability in case of not only time-invariant disturbances, such as BNDOs, but also time-varying disturbances.
4 Controller Design
The control objective is to find a control law so that the system states can track a desired trajectory. One of the most commonly used method for nonlinear systems is feedback linearization control (FLC). The traditional FLC method for nonlinear systems is formulated considering a second-order nonlinear system in (1) where there exists no disturbance:
| (49) |
where the controller coefficients are positive, i.e. . If the control law in (49) is applied to the system in (1), the closed-loop error dynamics are obtained as follows:
| (50) |
where and .
Lemma 2
(Khalil and Grizzle, 1996): If a nonlinear system is input-to-state stable and the input satisfies , then the state satisfies .
Remark 5
As seen in (50), if the disturbance is different from zero, the closed-loop error dynamics cannot converge to zero in finite time. This shows that the traditional FLC is sensitive to disturbances.
The FLC based on the SLDO by taking the estimated disturbance value into account is formulated as follows:
| (51) |
If the control law in (51) is applied to the system in (1), the closed-loop error dynamics are obtained as follows:
| (52) |
where . As stated in Theorem 2, the disturbance error dynamics for the SLDO can converge to zero asymptotically. As stated in Lemma 2, if the disturbance error satisfies , then the system error satisfies . As a result, the closed-loop error dynamics of the system can converge to zero asymptotically in finite time under the control law in (51) if the controller coefficients and are positive, i.e. .
5 Simulation Studies
The following nonlinear system, i.e., chaotic Duffing oscillator, is considered for the simulation studies (Hsu, 2012):
| (53) |
where , and as can be seen from (1).
The desired states values are defined as . The initial conditions on the states of the system and the controller coefficients are respectively selected as and , . Since the disturbance coefficient vector in (5) is equal to , the proportional, derivative and robust gains for DOs must be positive, i.e., . The proportional gain is selected as while the derivative gain is selected as . As stated in Theorem 2, since the robust gain must be equal to , i.e. , the robust gain is selected as . The coefficient to adjust the learning rate for the SLDO is selected as . The initial conditions on the learning rate and parameter are set to and , respectively. To benchmark different disturbance observers in the presence and absence of uncertainties, no disturbance is imposed on the system at the beginning, a step external disturbance is imposed on the system at second and a sinusoidal external disturbance is imposed on the system at second as formulated below:
| (54) |
In simulation studies, the control performance of the FLC based on the SLDO is firstly compared with the traditional FLC and the FLC based on the BNDO. Then, the SLDO is analyzed under noisy conditions and compared with its type-1 counterpart. Throughout simulation studies, the sampling time is set to second while the number of membership functions are selected as . In the presence of plant uncertainties, the adaptation of the learning rate of sliding mode learning algorithm must be a robust adaptation law to avoid having infinite values. Therefore, a dead-zone has been proposed in literature to handle this problem. In this paper, if the sliding surface is smaller than the dead-zone parameter , i.e., , then the learning rate is not updated.
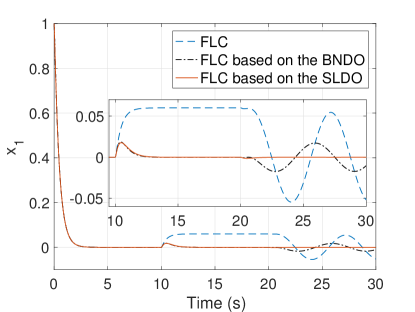
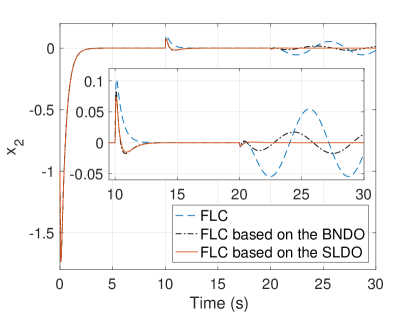
The states responses are shown in Figs. 2(a) and 2(b). Firstly, the FLC controller can control the system without steady-state error while there exists no disturbance on the system. However, after the disturbances are imposed on the system, it is observed that it is not robust against any external disturbance and gives steady-state error as seen in Fig. 2(a) and stated in Remark 5. Secondly, the FLC based on the BNDO can control the system without any steady-state error while there exist no disturbance and a time-invariant disturbance. However, it is seen that it is not robust against a time-varying disturbance as stated in Remark 1. Thirdly, the FLC based on the SLDO can control system without steady-state error and it is robust against time-invariant and time-varying disturbances. Moreover, the FLCs based on the BNDO and SLDO maintain the nominal performance while there exists no disturbance between t=0-10 seconds as stated in Remark 6.
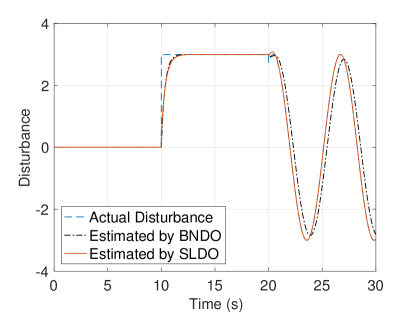
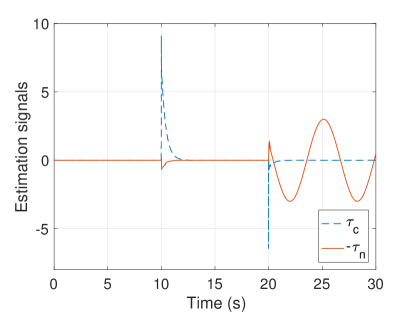
The actual and estimated disturbances are shown in Fig. 2(c). As can be observed, the SLDO can estimate time-varying disturbances while BNDO is only able to estimate only time-invariant disturbances as stated in Remark 4. This fact results in the robust control performance of the FLC based on the SLDO against time-varying uncertainties. Thanks to learning process by the feedback-error learning algorithm, the T2NFS takes the overall estimation signal while the conventional estimation signal converges to zero in finite time as shown in Fig. 2(d). Inasmuch as the total generated estimation signal by the feedback-error learning structure is equal to , the output of the T2NFS is multiplied by in Fig. 2(d) not to cause the reader to become perplexed. The T2NFS becomes the leading estimator after a short time period. The output of the conventional estimation law becomes nonzero only during the time intervals when the T2NFS is learning.
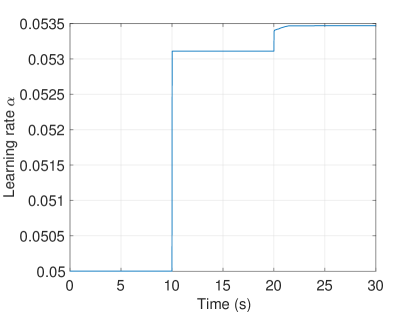
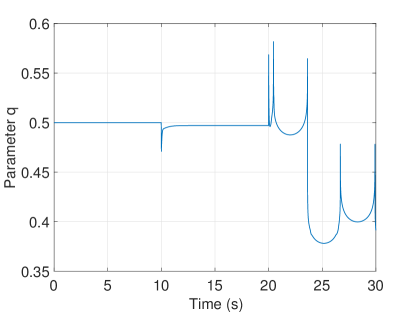
The adaptation of the learning rate is shown in Fig 2(e). As seen, the initial condition on the learning rate is set to and the learning rate is constant while the output of the conventional estimation law is equal to zero due to the fact that learning is not required. When the disturbances are imposed on the system, the learning rate is increasing for a short time period till becomes zero. Moreover, the adaptation of the parameter is shown in Fig. 2(f). The initial condition on the parameter is set to , which is the general case. Thanks to the adaptation rule in (27), the proportion of the upper and lower membership functions is adjusted throughout the simulations.
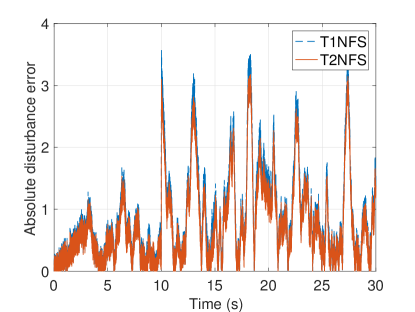
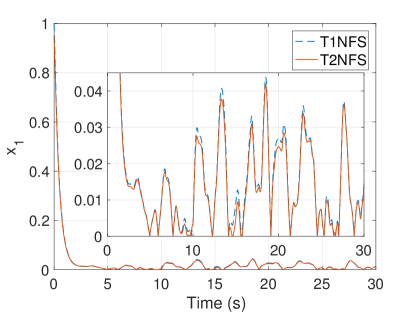
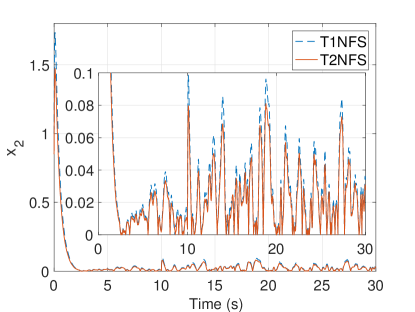
Type-2 fuzzy membership functions are used in the proposed estimation structure and it is possible to downgrade them to type-1 counterparts by equalizing the upper and lower values of parameters in (18)-(25). In literature, it is claimed that the type-2 fuzzy logic system gives better performance than its type-1 counterpart in the presence of noise and uncertainty in the system. The initial conditions on the states of the system are set to . In order to compare the performance of T2NFS with its type-1 counterpart under noisy conditions, the actual disturbance with different noise levels , which are equal to , and , is applied the system. The mean squared errors for the different noise levels are given in Table 1. As seen from this table, the T2NFS gives less error than the type-1 neuro-fuzzy structure (T1NFS) and the performance of T2NFS is more remarkable while the noise level is increasing. Figure 3(a) shows the absolute disturbance error responses with a noise level of for T1NFS and T2NFS. As can be observed, T2NFS gives less disturbance error when compared to its type-1 counterpart. Moreover, the system states under noisy condition are shown in Figs. 3(b) and 3(c). The FLC with the SLDO based on T2NFS exhibits better control performance. These results verify previous results seen in (Mendel, 2000; Hsiao et al., 2008; Khanesar et al., 2011). Type-2 fuzzy systems have more degrees of freedom so that they have capability of dealing with noisy measurements and uncertainties in the system more effectively.
| 20 (dB) | 40 (dB) | 60 (dB) | |
|---|---|---|---|
| T1NFS | 1.3112 | 0.0288 | 0.0034 |
| T2NFS | 1.2352 | 0.0276 | 0.0033 |
| Decrease in Disturbance Error | 6.14 % | 4.35 % | 3.03 % |
The simulations are executed on the computer, which is equipped with GHz Intel Core i CPU and GB of RAM. It is to be noted that the sampling and simulation times are set to and seconds in the sense that total number of sample is equal to . The total required computation time is calculated as seconds so that the required computation time for each sampling time instant is around millisecond. The required computation time of the sliding mode learning algorithm is significantly lower than the one of the other methods, such as gradient descent, Levenberg-Marquardt, particle swarm optimization and extended Kalman filter (Kayacan et al., 2015a). The reason is that the sliding mode learning algorithm does not contain any high-order matrices, matrix manipulations or calculations of the partial derivatives. Moreover, particle filter becomes infeasible in real-time due to large number of states and moving horizon estimation requires solving nonlinear optimization problem which results in large computation times (Daum, 2005). Recent developed numerical methods have reduced required computation times for solving nonlinear optimization problems around 5 milliseconds. However, even this is 25 times more than our proposed algorithms in the paper (Kayacan et al., 2015b). Therefore, it can be concluded that the proposed method in this paper is more practical in real-time applications.
6 Conclusion
A novel SLDO is developed by benefiting from the T2NFS with online sliding mode learning algorithm in feedback-error learning scheme. In addition to the stability of the SMC-theory learning algorithm, the stability of the SLDO by taking the system dynamics into account and the stability of the FLC based on the SLDO are proven by using separation principle. The simulations results show that the traditional FLC is sensitive to disturbances and the FLC based on the BNDO is only robust to time-invariant disturbance while the FLC based on the SLDO is robust against any kind of disturbances by performing precise online estimation of the immeasurable time-varying disturbances. Moreover, the FLC based on the SLDO maintains the nominal control performance in the absence of uncertainties. Thanks to online sliding mode learning algorithm, the parameters of the T2NFS are spontaneously adjusted to learn disturbances and this makes systems robust to cope with uncertainties. Moreover, the developed SMC-theory based learning algorithm requires significantly less computation time than the traditional ones, e.g. gradient descent and evolutionary training algorithms, so that it is more practical in real-time applications.
Appendix A Calculation of
By taking the time derivative of (10)-(13), the following equations are obtained as:
| (55) |
where
| (56) |
It is obtained from (A)
| (57) |
By taking the time derivative of (16), the following equations are obtained as follows:
| (58) |
Since ,
| (59) | |||||
where
Similarly, it is readily obtained that:
| (60) |
where
The time derivative of (15) is obtained to find as follows:
| (61) | |||||
Acknowledgement
The information, data, or work presented herein was funded in part by the Advanced Research Projects Agency-Energy (ARPA-E), U.S. Department of Energy, under Award Number DE-AR0000598.
References
- Castillo et al. (2013) Castillo, O., Castro, J.R., Melin, P., Rodriguez-Diaz, A., 2013. Universal approximation of a class of interval type-2 fuzzy neural networks in nonlinear identification. Advances in Fuzzy Systems doi:10.1155/2013/136214.
- Castillo et al. (2014) Castillo, O., Castro, J.R., Melin, P., Rodriguez-Diaz, A., 2014. Application of interval type-2 fuzzy neural networks in non-linear identification and time series prediction. Soft Computing 18, 1213–1224.
- Castillo et al. (2012) Castillo, O., Martínez-Marroquín, R., Melin, P., Valdez, F., Soria, J., 2012. Comparative study of bio-inspired algorithms applied to the optimization of type-1 and type-2 fuzzy controllers for an autonomous mobile robot. Information Sciences 192, 19 – 38.
- Castro and Castillo (2013) Castro, J.R., Castillo, O., 2013. A class of interval type-2 fuzzy neural networks illustrated with application to non-linear identification, in: The 2013 International Joint Conference on Neural Networks (IJCNN), pp. 1–6. doi:10.1109/IJCNN.2013.6706738.
- Castro et al. (2011) Castro, J.R., Castillo, O., Melin, P., Mendoza, O., Rodriguez-Diaz, A., 2011. An Interval Type-2 Fuzzy Neural Network for Chaotic Time Series Prediction with Cross-Validation and Akaike Test. Springer Berlin Heidelberg, Berlin, Heidelberg. pp. 269–285.
- Chang and Chan (2014) Chang, Y.H., Chan, W.S., 2014. Adaptive dynamic surface control for uncertain nonlinear systems with interval type-2 fuzzy neural networks. IEEE Transactions on Cybernetics 44, 293–304.
- Chen et al. (2015) Chen, F., Jiang, R., Wen, C., Su, R., 2015. Self-repairing control of a helicopter with input time delay via adaptive global sliding mode control and quantum logic. Information Sciences 316, 123 – 131. doi:http://dx.doi.org/10.1016/j.ins.2015.04.023. nature-Inspired Algorithms for Large Scale Global Optimization.
- Chen (2003) Chen, W.H., 2003. Nonlinear disturbance observer-enhanced dynamic inversion control of missiles. Journal of Guidance, Control, and Dynamics 26, 161–166.
- Chen (2004) Chen, W.H., 2004. Disturbance observer based control for nonlinear systems. Mechatronics, IEEE/ASME Transactions on 9, 706–710. doi:10.1109/TMECH.2004.839034.
- Chen et al. (2000a) Chen, W.H., Ballance, D., Gawthrop, P., O’Reilly, J., 2000a. A nonlinear disturbance observer for robotic manipulators. Industrial Electronics, IEEE Transactions on 47, 932–938. doi:10.1109/41.857974.
- Chen et al. (2016) Chen, W.H., Yang, J., Guo, L., Li, S., 2016. Disturbance-observer-based control and related methods: An overview. IEEE Transactions on Industrial Electronics 63, 1083–1095. doi:10.1109/TIE.2015.2478397.
- Chen et al. (2000b) Chen, X., Komada, S., Fukuda, T., 2000b. Design of a nonlinear disturbance observer. Industrial Electronics, IEEE Transactions on 47, 429–437. doi:10.1109/41.836359.
- Daum (2005) Daum, F., 2005. Nonlinear filters: beyond the kalman filter. IEEE Aerospace and Electronic Systems Magazine 20, 57–69. doi:10.1109/MAES.2005.1499276.
- Efe et al. (2000) Efe, M.O., Kaynak, O., Yu, X., 2000. Sliding mode control of a three degrees of freedom anthropoid robot by driving the controller parameters to an equivalent regime. Journal of Dynamic Systems, Measurement, and Control 122, 632–640.
- Gahinet and Apkarian (1994) Gahinet, P., Apkarian, P., 1994. A linear matrix inequality approach to control. International Journal of Robust and Nonlinear Control 4, 421–448. doi:10.1002/rnc.4590040403.
- Ginoya et al. (2014) Ginoya, D., Shendge, P., Phadke, S., 2014. Sliding mode control for mismatched uncertain systems using an extended disturbance observer. Industrial Electronics, IEEE Transactions on 61, 1983–1992. doi:10.1109/TIE.2013.2271597.
- Glover and Doyle (1988) Glover, K., Doyle, J.C., 1988. State-space formulae for all stabilizing controllers that satisfy an -norm bound and relations to relations to risk sensitivity. Systems & Control Letters 11, 167 – 172. doi:http://dx.doi.org/10.1016/0167-6911(88)90055-2.
- Haseltine et al. (2005) Haseltine, E.L., , Rawlings*, J.B., 2005. Critical evaluation of extended kalman filtering and moving-horizon estimation. Industrial & Engineering Chemistry Research 44, 2451–2460. doi:10.1021/ie034308l.
- He et al. (2014) He, W., Zhang, S., Ge, S., 2014. Adaptive control of a flexible crane system with the boundary output constraint. Industrial Electronics, IEEE Transactions on 61, 4126–4133. doi:10.1109/TIE.2013.2288200.
- Hsiao et al. (2008) Hsiao, M.Y., Li, T.H.S., Lee, J.Z., Chao, C.H., Tsai, S.H., 2008. Design of interval type-2 fuzzy sliding-mode controller. Information Sciences 178, 1696 – 1716.
- Hsu (2012) Hsu, C.F., 2012. Adaptive dynamic {CMAC} neural control of nonlinear chaotic systems with {L2} tracking performance. Engineering Applications of Artificial Intelligence 25, 997 – 1008. URL: //www.sciencedirect.com/science/article/pii/S0952197612000826, doi:http://dx.doi.org/10.1016/j.engappai.2012.03.014.
- Kayacan et al. (2015a) Kayacan, E., Kayacan, E., Khanesar, M., 2015a. Identification of nonlinear dynamic systems using type-2 fuzzy neural networks - a novel learning algorithm and a comparative study. Industrial Electronics, IEEE Transactions on 62, 1716–1724. doi:10.1109/TIE.2014.2345353.
- Kayacan et al. (2015b) Kayacan, E., Kayacan, E., Ramon, H., Saeys, W., 2015b. Learning in centralized nonlinear model predictive control: Application to an autonomous tractor-trailer system. Control Systems Technology, IEEE Transactions on 23, 197–205. doi:10.1109/TCST.2014.2321514.
- Kayacan et al. (2010) Kayacan, E., Kaynak, O., Abiyev, R., Tørresen, J., Høvin, M., Glette, K., 2010. Design of an adaptive interval type-2 fuzzy logic controller for the position control of a servo system with an intelligent sensor, in: International Conference on Fuzzy Systems, pp. 1–8.
- Kayacan et al. (2012) Kayacan, E., Saeys, W., Kayacan, E., Ramon, H., Kaynak, O., 2012. Intelligent control of a tractor-implement system using type-2 fuzzy neural networks, in: 2012 IEEE International Conference on Fuzzy Systems, pp. 1–8.
- Kaynak et al. (2001) Kaynak, O., Erbatur, K., Ertugnrl, M., 2001. The fusion of computationally intelligent methodologies and sliding-mode control-a survey. IEEE Transactions on Industrial Electronics 48, 4–17. doi:10.1109/41.904539.
- Khalil and Grizzle (1996) Khalil, H.K., Grizzle, J., 1996. Nonlinear systems. volume 3. Prentice hall New Jersey.
- Khanesar et al. (2011) Khanesar, M., Kayacan, E., Teshnehlab, M., Kaynak, O., 2011. Analysis of the noise reduction property of type-2 fuzzy logic systems using a novel type-2 membership function. IEEE Transactions o nSystems, Man, and Cybernetics, Part B: Cybernetics 41, 1395–1406.
- Lee et al. (2014) Lee, C.H., Chang, F.Y., Lin, C.M., 2014. An efficient interval type-2 fuzzy cmac for chaos time-series prediction and synchronization. IEEE Transactions on Cybernetics 44, 329–341. doi:10.1109/TCYB.2013.2254113.
- Lee et al. (2015) Lee, C.S., Wang, M.H., Wu, M.J., Teytaud, O., Yen, S.J., 2015. T2fs-based adaptive linguistic assessment system for semantic analysis and human performance evaluation on game of go. IEEE Transactions on Fuzzy Systems 23, 400–420. doi:10.1109/TFUZZ.2014.2312989.
- Li et al. (2013) Li, H., Yu, J., Hilton, C., Liu, H., 2013. Adaptive sliding-mode control for nonlinear active suspension vehicle systems using T-S fuzzy approach. Industrial Electronics, IEEE Transactions on 60, 3328–3338. doi:10.1109/TIE.2012.2202354.
- Liang et al. (2000) Liang, Q., Karnik, N., Mendel, J., 2000. Connection admission control in atm networks using survey-based type-2 fuzzy logic systems. IEEE Transactions on Systems, Man, and Cybernetics, Part C: Applications and Reviews 30, 329–339.
- Liang and Mendel (2000) Liang, Q., Mendel, J., 2000. Interval type-2 fuzzy logic systems: theory and design. IEEE Transactions on Fuzzy Systems 8, 535–550.
- Lin et al. (2014) Lin, Y.Y., Liao, S.H., Chang, J.Y., Lin, C.T., 2014. Simplified interval type-2 fuzzy neural networks. IEEE Transactions on Neural Networks and Learning Systems 25, 959–969.
- Maldonado et al. (2013) Maldonado, Y., Castillo, O., Melin, P., 2013. Particle swarm optimization of interval type-2 fuzzy systems for FPGA applications. Applied Soft Computing 13, 496 – 508.
- Mendel (2000) Mendel, J.M., 2000. Uncertainty, fuzzy logic, and signal processing. Signal Processing 80, 913 – 933.
- Rubio-Solis and Panoutsos (2015) Rubio-Solis, A., Panoutsos, G., 2015. Interval type-2 radial basis function neural network: A modeling framework. IEEE Transactions on Fuzzy Systems 23, 457–473. doi:10.1109/TFUZZ.2014.2315656.
- Slotine et al. (1991) Slotine, J.J.E., Li, W., et al., 1991. Applied nonlinear control. volume 199. Prentice-Hall Englewood Cliffs, NJ.
- Sun et al. (2013a) Sun, W., Gao, H., Yao, B., 2013a. Adaptive robust vibration control of full-car active suspensions with electrohydraulic actuators. Control Systems Technology, IEEE Transactions on 21, 2417–2422. doi:10.1109/TCST.2012.2237174.
- Sun et al. (2013b) Sun, W., Zhao, Z., Gao, H., 2013b. Saturated adaptive robust control for active suspension systems. Industrial Electronics, IEEE Transactions on 60, 3889–3896. doi:10.1109/TIE.2012.2206340.
- Topalov et al. (2009) Topalov, A.V., Kayacan, E., Oniz, Y., Kaynak, O., 2009. Adaptive neuro-fuzzy control with sliding mode learning algorithm: Application to antilock braking system, in: 2009 7th Asian Control Conference, pp. 784–789.
- Wagner et al. (2015) Wagner, C., Miller, S., Garibaldi, J., Anderson, D., Havens, T., 2015. From interval-valued data to general type-2 fuzzy sets. IEEE Transactions on Fuzzy Systems 23, 248–269. doi:10.1109/TFUZZ.2014.2310734.
- Xu et al. (2014) Xu, J.X., Guo, Z.Q., Lee, T.H., 2014. Design and implementation of integral sliding-mode control on an underactuated two-wheeled mobile robot. Industrial Electronics, IEEE Transactions on 61, 3671–3681. doi:10.1109/TIE.2013.2282594.
- Yang et al. (2013) Yang, J., Li, S., Yu, X., 2013. Sliding-mode control for systems with mismatched uncertainties via a disturbance observer. Industrial Electronics, IEEE Transactions on 60, 160–169. doi:10.1109/TIE.2012.2183841.
- Yao et al. (2015) Yao, J., Deng, W., Jiao, Z., 2015. Adaptive control of hydraulic actuators with lugre model-based friction compensation. Industrial Electronics, IEEE Transactions on 62, 6469–6477. doi:10.1109/TIE.2015.2423660.
- Yu and Kaynak (2009) Yu, X., Kaynak, O., 2009. Sliding-mode control with soft computing: A survey. IEEE Transactions on Industrial Electronics 56, 3275–3285. doi:10.1109/TIE.2009.2027531.
- Zaheer et al. (2015) Zaheer, S.A., Choi, S.H., Jung, C.Y., Kim, J.H., 2015. A modular implementation scheme for nonsingleton type-2 fuzzy logic systems with input uncertainties. IEEE/ASME Transactions on Mechatronics 20, 3182–3193. doi:10.1109/TMECH.2015.2411853.