A Residual Solver and Its Unfolding Neural Network for Total Variation Regularized Models
Abstract
This paper proposes to solve the Total Variation regularized models by finding the residual between the input and the unknown optimal solution. After analyzing a previous method, we developed a new iterative algorithm, named as Residual Solver, which implicitly solves the model in gradient domain. We theoretically prove the uniqueness of the gradient field in our algorithm. We further numerically confirm that the residual solver can reach the same global optimal solutions as the classical method on 500 natural images. Moreover, we unfold our iterative algorithm into a convolution neural network (named as Residual Solver Network). This network is unsupervised and can be considered as an “enhanced version” of our iterative algorithm. Finally, both the proposed algorithm and neural network are successfully applied on several problems to demonstrate their effectiveness and efficiency, including image smoothing, denoising, and biomedical image reconstruction. The proposed network is general and can be applied to solve other total variation regularized models.
Index Terms:
TV; residual; network; rsnet; solverI Introduction
Various image processing and computer vision tasks are ill-posed, such as image denoising, biomedical image reconstruction, image smoothing, segmentation, object recognition, etc. The illness comes from the fact that it is impossible to recover the ground truth without making any assumption about it. For example, in the image denoising task, it is impossible to tell if a pixel intensity contains noise or not without making any assumption about the ground truth. Another example is the image smoothing. It is not clear what should be smoothed out without any prior knowledge. In the biomedical image reconstruction, the input signal and the desired output even do not work in the same space. And the illness comes from the fact that there are not enough observations available due to physical limitations, such as dose restriction, equipment angle limitation, temperature requirement, pressure condition, etc.
Although ill-posed problems are common, solving these problems is challenging. Usually, there are many solutions that satisfy the constraints in the ill-posed problems. In mathematical words, the solution space is too large to find the desired one solution. Moreover, the computational cost for such problems is usually very high. Therefore, it is not realistic to search the full solution space in practice.
To solve such ill-posed problems, a prior or an assumption about the ground truth must be imposed, reducing the solution space or even making the solution unique. For example, the well-known total variation regularization leads to a piecewise constant signal [1]. The ground truth signal might be assumed to be piecewise linear, leading to the famous guided filter [2]. The ground truth might be assumed to be a minimal surface, leading to the area regularization [3, 4, 5]. The ground truth might be assumed to be piecewise developable, leading to the Gaussian curvature regularization [6, 7]. Different assumptions usually lead to different resulting images, which visually reflects the imposed priors. For example, the well-known total variation regularization will make the resulting image piecewise constant, which is known as staircase artifacts. These artifacts reflect the imposed prior. Such prior is usually imposed by a regularization term, which is a mathematical model for the imposed prior or assumption.
The same prior or assumption, however, might have several different regularization forms because it can be modeled by different mathematical formula with various accuracy and computation complexity. For example, the well-known gradient distribution prior can be modeled by Gaussian distribution, Hyper Laplace distribution [8] or the derivative of function [9, 10], etc. These models impose the same gradient distribution prior, but they have different approximation accuracy and different optimization properties, such as convexity, fast computation, explicit gradient formula, etc.
I-A Total Variation Regularization
Among all regularization terms, Total Variation (TV) might be the most popular one because of its simplicity and effectiveness [1]. Assuming the unknown ground truth signal is where is the spatial coordinate, the traditional total variation regularization term is
| (1) |
where is the gradient operator and indicates the standard norm. This term is isotropic when and becomes anisotropic when . Choosing which norm is problem specific. In the rest of this paper, we use because it has been shown preserving edges better in many practical applications [10].
Although there are some variants of TV, such as spatial weighted TV and norm TV (Hyper Laplace), the standard TV with norm still is the most popular regularization term. The reasons come from three aspects. First, from optimization point of view, this term is convex. This means the global optimal solution is unique. And the convex optimization algorithms can be used for this term. Second, the norm is a simple computation operation. Thus, it can be efficiently computed and evaluated in practice. Third, the anisotropy property of this term is important in preserving edges in image processing. In general, preserving edges is always preferred in many image processing tasks.
When TV is used as the regularization term, many image processing problems, such as denoising, segmentation, inpainting and fusion, etc, can be formulated as the following minimization problem:
| (2) |
where is an imaging matrix, is the unknown signal to be estimated, is a spatial coordinate, is the observed signal and is a scalar that balances the imaging and the TV prior ( usually is related with noise level). The imaging matrix models a linear imaging process, such as blurring, down sampling, up sampling, etc. A linear matrix already covers a large range of image processing problems.
I-B Iterative Solvers
Many solvers have been developed for this model (Equation 2). The earliest iterative scheme was proposed in [1]. This method is slow due to the stability constraints in the time step size. To accelerate the optimization procedure, a number of alternative methods have been proposed. One popular method is primal dual solver [11, 12]. Primal dual method simultaneously finds the optimal solution for this model and its dual, improving the numerical stability. Another technique is to split the imaging model and the TV regularization, by introducing a variable :
| (3) |
This new model can be solved by alternating direction method of multipliers (ADMM) [13], split Bregman [14], etc. Equation 2 can also be solved by Iterative Shrinkage and Thresholding Algorithm (ISTA) [15]. These methods are based on nonlinear partial differential equations and thus time consuming, compared with recently developed neural network solvers.
I-C Neural Network Solvers
With the development of deep learning, several neural networks have been proposed to solve Eq. 2. One of the earliest work is the Learned ISTA (LISTA), which unfolds the ISTA as neural networks to perform the optimization algorithm [16]. One layer in the network corresponds to one iteration in ISTA. Different from ISTA, all the parameters in LISTA implicitly communicate with each other during the training process. Such communication can be considered as high order scheme from the partial differential equation point of view. Therefore, the network can solve the problem within a small number of layers, in contrast with the large number of iterations in iterative algorithm ISTA.
ISTA-net is another extension of ISTA [17]. It unfolds the ISTA but keeps the symmetric network structure, requiring the encoding and decoding are inverse functions for each other. Such constraint makes the network invertable, leading to better numerical stability than LISTA.
Another unfolding method is the primal dual network, which unfolds the primal dual iteration for Eq. 2 [18]. It has been shown converging much faster than the original primal dual iteration.
ADMM-net unfolds the classical ADMM iteration, leading to a neural network representation [19]. It first trains one layer. Then it fixes this layer, adds another layer and only trains the new added layer. By repeating this procedure, it shows good performance for MRI reconstruction problem. In this network, after 10 layers, adding more layers does not improve the result anymore.
Recently, a CNN based image reconstruction method for inverse problem is proposed in [20]. It shows that neural networks are very efficient in solving image reconstruction problems thanks to the parameter communication between different layers.
In general, neural network methods are more efficient than the iterative algorithms because of two reasons. First, the parameters in the neural networks can communicate with each other during the training process. This corresponds to the high order scheme from partial differential equation point of view. Second, the parameters in the neural networks are more adaptive to the training data. In contrast, the operations in the iterative algorithms are independent from the input image. As a result, the neural network usually only needs a small number of layers to solve Eq. 2 (computational efficiency).
I-D Motivations and Contributions
Most of these neural network algorithms are supervised, requiring the ground truth to be explicitly given. Such requirement is not easily satisfied in most practical applications. This motivates us to develop an unsupervised neural network. Our contributions fall in following two aspects:
-
•
We develop a new iterative algorithm that solves the Eq. 2. Instead of directly finding the optimal solution, we find its related residual (details will be explained in later sections). Therefore, our solver is called Residual Solver (RS).
-
•
We unfold the proposed iterative residual solver into a neural network and our network is unsupervised. Therefore, it can be trained without knowing the optimal solution. Another advantage of our network is that it can be trained on low resolution images but applied on high resolution images. Our experiments confirm this property.
II Mathematical Background
Equation 2 can be solved by many algorithms as mentioned in previous sections. Here, we give the general procedure that solves Eq. 2 and then a typical algorithm for solving the bottleneck sub problem in this procedure.
In general, Eq. 2 can be solved by the following iteration (proximal gradient method [21])
| (4) | |||||
| (5) | |||||
| (6) |
where is a parameter, is the scaled dual variable and is the iteration index. The initial values are and .
II-A Dual First Iteration
Since this procedure is iterative, we can modify this iteration by updating the dual variable first, leading to a more efficient algorithm
| (7) | |||||
| (8) | |||||
| (9) |
In this new iteration, the term in Eq. 8 can be considered as extrapolation. And we also avoid the matrix multiplication with in Eq. 4. In fact, Eq. 8 is simpler to compute, compared with Eq. 4. Thus, it is faster in practice.
II-B The Bottleneck
In both iteration methods, Eq. 9 is the computation bottleneck. This equation is known as the standard ROF model [1]. Many algorithms have been developed to efficiently solve Eq. 9. Among these algorithms, following iteration was proposed in [22]
| (10) | |||||
| (11) |
where is a scalar parameter, is an inner iteration index, corresponds to the gradient field, , and function is defined as
| (12) |
This iteration can theoretically guarantee the numerical convergence and has shown good performance in theory and practice [22]. We refer this algorithm as FastSolver (FS) in this paper.
This function proposed in FS is the residual of the well-known operation. As shown in Fig. 1, function plus function equals the identity function. Their difference forms a nonlinear transfer function that also appears in deep learning community. Moreover, the function is similar with several well-known activation functions from neural network field, such as sigmoid, , soft sign, etc.

Until Section IV-D, we will focus on this bottleneck problem (Eq. 9). We will show a residual solver for this problem. Then we will unfold this iterative solver into a neural network, which is an enhanced version of the iterative solver. In Section IV-D, we will show how to embed this neural network into a larger network for the general TV regularized models.
III Residual Solver
In this paper, we modify above iteration from [22], leading to a faster iterative algorithm. In FastSolver, during each iteration, has to be explicitly computed by Eq. 11 since it is needed in Eq. 10. Explicitly computing and its gradient adds extra computation burden for this algorithm. As shown in the following section, this computation can be avoided by finding the residual between the input and the optimal solution. Our method does not explicitly compute or its gradient.
Different from previous approaches, we propose a residual representation of Eq. 9 and perform the optimization in gradient domain. Moreover, our method does not explicitly compute during the optimization procedure.
Specifically, from Eq. 11 we have
| (13) |
Taking above equation into Eq. 10, we get
| (14) |
For a given , the optimal solution is a fixed point for this equation. After finding , the optimal solution can be obtained by Eq. 11
| (15) |
In Eq. 15, is the residual between input and its optimal solution . Since only the residual is solved, we call our method as Residual Solver (RS). And the residual term is defined as
| (16) |
Clearly, the residual is unique if is unique for given . This algorithm is summarized in Algorithm 1.
Our RS is computationally efficient. In RS, during the iteration in Eq. 14, only one vector field has to be updated. And the two computation operations, and can be efficiently performed, making RS faster. This is numerically confirmed in later section.
III-A Uniqueness of
To show that our RS is numerical stable, we need to find a unique vector field for the unique residual . It is well-known that Eq. 9 is convex [1]. Therefore, its optimal solution is unique, leading to the uniqueness of the residual . Although the vector field is not unique, it belongs to a unique set in terms of divergence equivalency
| (17) |
This set is convex because is a linear operation. Let be a scalar. Then, for any and in this set, since , we have
| (18) |
This result indicates that this unique set is a convex set.
Since the ground truth image has bounded intensity values (usually or ), is also bounded (). Therefore, we can require .
Thank to the bounded norm and convexity, we can obtain a unique solution if we add an additional constraint, such as minimizing . More specifically, we have
| (19) |
Thanks to the convexity of , is unique.
In practice, we always initialize . This initialization leads to the unique since it is the “minimum” vector field in this convex set. We observed that the same input always find the same vector field in practice.
The convexity of the solution set and uniqueness of vector field provide the theoretical guarantees for our RS. They also reveal the numerical stability of our RS, which is confirmed in following experiment on BSDS500 data set.
III-B Convergence to the Optimal Solution
Our RS can reach the optimal solution. We run RS and FS with 200 iterations on 500 natural images from BSDS500 data set. Then we compute their final loss function value for each image, respectively. For the same image, we compute the loss function value difference. The distribution of such differences for all 500 images is shown in Fig. 2 (a). The average difference is about . The negative values indicate that our residual solver always reaches lower energy level for these images. The results confirm that RS can reach the optimal solution.
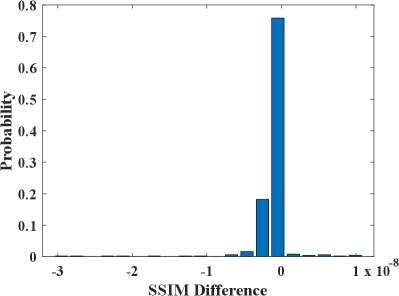
We also compute the SSIM between the original and processed images. For FastSolver and RS, the SSIM difference is small () and its distribution is shown in Fig. 2 (b).

In addition, our RS runs faster. The average running time of RS and FastSolver for the 500 color images on the same hardware with the same iteration number is 0.89 seconds and 1.07 seconds, respectively. This indicates that our RS can reduce about of the running time.
III-C Properties
This new residual solver has three important properties:
-
•
implicit: Our RS does not require to compute during the iteration. In contrast, has to be explicitly computed in Eq. 11 for each iteration in FastSolver.
-
•
gradient domain: Our RS solves the problem in the gradient domain, which is different from previous methods that work in the intensity domain.
-
•
fast: In Eq. 14, is fixed during the inner iterations. Therefore, can be computed before the loop, which reduces about running time in practice.
IV Residual Solver Network
In this paper, we propose a new network, based on the residual solver in the previous section. Inspired by the neural network development in the past few years (Section I-C), we unfold the RS algorithm into a neural network, called RSnet, which can be considered as an “enhanced” version of our iterative algorithm.
The enhancement comes from two aspects. First, there are only two components in RS, covering the and axis direction respectively. In contrast, RSnet uses more channels (eight, sixteen or thirty two), which cover more orientations (including the and directions). Second, the operations (gradient and divergence) in RS are independent from the input. In contrast, these operations in RSnet are learned from training data set and thus more adaptive in solving this problem. Therefore, RS iterative algorithm can be considered as a special case of RSnet with two channels and fixed convolution kernels. And RSnet is an “enhanced” version of RS.

IV-A Network Architecture
First, the gradient operator for is relaxed to a convolution kernel in our neural network. And this convolution kernel is shared among each unfolding block. Second, the linear operator ( is the identity matrix) for in Eq. 14 is relaxed to a convolution kernel. But it is not shared for the network blocks in order to improve the neural network’s capacity. Finally, the operator in Eq. 15 is relaxed to a convolution kernel. The network architecture is shown in Fig. 3. One block corresponds to one iteration in RS.
In this network, is the input for our neural network. The convolution of is shared for all blocks, which is shown in shaded blue. The step symbol indicates the activation function, which is implemented by clip operation. The indicates a convolution kernel that is not shared between blocks. The initial is the same as the iterative algorithm. Different from previous related neural networks, our network does not adopt any Batch Normalization. Therefore, it can be trained on low resolution images but applied on high resolution images.
The proposed RSnet has three important features:
-
•
Our network is unsupervised. It does not require the ground truth images. It is suitable for practical applications where the ground truth is unknown, such as biomedical image reconstruction.
-
•
Our network can be trained on low resolution images but applied on high resolution images. This property is important for training process on hardware with limited memory. Our designed loss function is independent from image resolution and our network does not contain any batch normalization nor drop out layer.
-
•
The result from our network is comparable with the counterpart from classical iterative algorithms. As shown in Section IV-B, we can set the parameter in our loss function for this network such that results from our method are comparable with the counterpart from classical iterative algorithms.
IV-B The Loss Function
Here, we propose a loss function that is independent from the image resolution. Although Eq. 2 is well-known from the literature, it depends on the resolution of input image because the is for the whole image rather than for each pixel. To relax this constraint, we propose to use following loss function (normalized version) for our neural network
| (20) |
This loss function is independent from the image resolution. Therefore, this loss function is comparable for different resolution images. In contrast, Eq. 2 is NOT comparable for images with different resolution. When we compare the energy levels between iterative algorithms and our neural network method, we simply scale them by the total number of pixels (). With this loss function and our network architecture, our neural network can be trained on low resolution images but applied on high resolution images. This property is different from traditional neural networks that involve batch normalization layers or drop out layers. They can only deal with the same resolution images (training and inference images must have the same resolution).






IV-C Training on Natural Images
We randomly crop 10,000 image patches with resolution from 500 natural images in the BSDS dataset [23]. Each patch is turned into gray scale. Eighty percent of these patches are used as training set and the rest is the validation set. During training, we fix , all kernel size is set to , learning rate is 0.0003, batch size is 64, and the epoch number is 3000. We increase the number of block from 3 to 20 and set the number of channels as 8, 16 and 32, respectively.
After training, the final loss function values are shown in Fig. 4. When increasing the number of blocks or the number of channels, the loss is reduced after training. After some value, increasing the them does not improve the result anymore. As comparison, the loss function value for the optimal solutions from FastSolver is 126. This result shows that our neural network can reach the optimal results.
Keeping in mind the complexity of network and the effectiveness, we fix the number of block as 10 and the number of channel as 16 in the rest of our paper. This configuration leads to 21K learnable parameters. Such small number of parameters can be easily trained with a modern GPU hardware.
The loss function values are compared with the counterpart from FastSolver. The distribution of their difference is shown in Fig. 5 (a). We further compare their SSIM difference and the distribution is shown in Fig. 5 (b). RSnet keeps more structural information (Fig. 5 (b)).
Some learned convolution kernels are visualized in Fig. 6. These kernels already contain the classical gradient and divergence operators. Therefore, this network is an enhanced version of our iterative algorithm that only has gradient and divergence operators. As a result, this network has better performance in some applications (Section V-B).
RSnet takes only 0.064 second for each color image with 481321 resolution from BSDS500 data set on a GTX 1080 Ti GPU card. In contrast, the average running time of RS and FastSolver is 0.89 seconds and 1.07 seconds, respectively.
IV-D Embedding RSnet into Other Networks
We have shown the residual solver and its unfolding RSnet that can efficiently solve the bottleneck problem in TV regularized models.
In this section, we show how to embed RSnet into a larger network that can solve the general total variation regularized models (Eq. 2). More specifically, we unfold the dual first iteration algorithm (Eq. 7 to Eq. 9) into a neural network, which contains RSnet as a sub network for Eq. 9. The network structure is shown in Fig. 7.

V Applications
In this section, the proposed RS and RSnet are applied in three scenarios, image smoothing, image denoising and ultrasonic image reconstruction. In image smoothing, we show that RS and RSnet can reach the optimal solution as the classical FastSolver [22]. This experiment also confirms that RSnet can be trained on low resolution images () but used on other resolution images ( in this case). In image denoising, we show that RSnet can get better results because it is an enhanced version of RS. In this scenario, we directly adopt the already trained RSnet from the image smoothing problem and apply it on noisy images, showing the transferring ability of RSnet. In the ultrasonic image reconstruction, we show that RS and RSnet can be used for a global operation, not limited in local operations, such as smoothing and denoising. In all these scenarios, we compared the RS and RSnet results with the counterpart from the FastSolver [22]. In all these applications, we use Eq. 20 as the loss function and set . All the experiments are performed on a GTX 1080 Ti GPU.
V-A Image smoothing
In image smoothing, we show that RS and RSnet can reach the optimal solution as FastSolver [22]. This experiment also confirms that RSnet can be trained on low resolution images but applied on other resolution images.
In image smoothing, the imaging matrix is simply the identity matrix. We apply FastSolver, RS or RSnet on 500 color images from BSDS dataset. And the algorithms perform on each color channel separately. The iteration number of FastSolver and RS is set to 200. The RSnet is trained on 10,000 image patches with resolution , but applied on or resolution images. Two examples from the data set are shown in Fig. 8. As can be told from Fig. 8, the smoothing results are comparable. To evaluate the quality of these results, structural similarity index measure (SSIM) is used to calculate the similarity between the input and the output images [24].


















For these two examples, we also calculate the energy for both methods with first 20 iterations. The results are shown in Fig. 9. RS converges faster than FastSolver at the first few iterations. We observed that this fact is also true for other images from the BSDS500 data set. This is because the operations in RS are independent from the image content.
























V-B Image denoising
In this experiment, we show the transferring ability of RSnet. We train our network on the noise free image patches with resolution , but apply the trained network on noisy images with higher resolution. This indicates that the learned RSnet can be transferred for other tasks. We add noises with Gaussian distribution () on the images from BSDS dataset. We apply FastSolver, RS and RSnet on these noisy images, respectively.
Two examples are shown in Fig. 10. As can be seen in Fig. 10, the results of FastSolver and RS are comparable but the result from RSnet is better. PSNR is calculated to show this quantitatively. There are two reasons for this. First, RSnet is an enhanced version of RS because RSnet has multi channels (16 in our case) while RS only has two channels (gradient operator). Second, RSnet was trained on the noise free images, which make the learned parameters produce similar results.
We evaluate the denoising performance on 500 images of the dataset. In Fig. 11(a) and (b), we show the difference of the converged energy between RS, RSnet and FastSolver, respectively. We show the difference of their PSNR in Fig. 11 (c) and (d), respectively . As can be seen, RS can converge to a smaller energy than FastSolver. Although RSnet gets higher energy, it can reach better PSNR. In this application, RSnet has the best performance due to the two reasons mentioned above.
V-C Ultrasonic image reconstruction
In previous experiments, we have shown the performance of RS and RSnet on the problems where pixels are only affected by their local neighbors. In this section, we use our RS and RSnet to reconstruct ultrasonic images where each pixel has an influence on all other pixels (global behavior).
The imaging principle of ultrasound is shown in Fig. 12 (a) and the imaging domain is discretized, shown in Fig. 12 (b). The average speed of sound in human tissue is 1540 meters per second. We denote the contrast speed of sound image as and then the speed of sound is . Letting denote the sound wave traveling path, we can calculate its traveling time by
| (21) |
Letting be the time delay compared with the average speed , we can get the total time delay
| (22) |
In practice, can be discretized on a mesh grid to form an imaging matrix (see Fig. 12 (b)). And the time delay can be measured by an ultrasound device.






To recover the (and ), we minimize following model
| (23) |
where is a weight parameter since the uncertainty of each pixel along and axes are different [25]. We set according to this work.
We use FastSolver, RS and RSnet to solve this problem, respectively. We generate 500 simulated images as ground truth. To generate one image, we first generate a random region number and then generate random seeds in 2D. We use Voronoi diagram to obtain regions from these seeds. Then, we give each region a random number in . For such image, according to the discretization in Fig. 12 (b), we obtain the corresponding observations.
Our RSnet is trained on the same 10,000 natural image patches with resolution (the same data set as described in previous sections), but the loss function is changed to Eq. 23. The learning rate, batch size, epoch, etc. are the same as described in previous sections. This also shows the transfer property of RSnet since the training data set is natural images but the testing data set is piecewise constant biomedical images.
Two examples are shown in Fig. 13, including the ground truth, observation and the reconstruction results from FastSolver, RS and RSnet, respectively. The reconstructed results from FastSolver and RS are almost the same since they reach the same global optimal solution. To evaluate the quality of the results, PSNR and SSIM are calculated and the values are shown in Fig. 13.
The reconstruction results have some issue at left and right boundaries, which is indicated by red arrows. The reason is that the ultrasound device does not have enough samples in the left and right boarder regions. This issue is not caused by solving algorithms but is the limitation from hardware. In practice, such boundary regions should be removed from the reconstructed images and the central region is the main concern.
In this application, RSnet can achieve real time performance, much faster than the other two iterative algorithms because of the small number of blocks. Therefore, RSnet can be used in real-time imaging in our future work.
VI Conclusion
We have developed a new algorithm for solving the total variation models, called residual solver. It works in gradient domain and implicitly optimizes the model. This new algorithm runs faster than the well-known fast solver [22] and can reach the same global optimal solution. Its efficiency and effectiveness has been numerically confirmed by several experiments, including image smoothing, denoising and biomedical image reconstruction.
Moreover, we unfold the new algorithm into a neural network. Our network is unsupervised and thus can be trained without knowing the ground truth. Our network does not contain any batch normalization or drop out layers. Therefore, it can be trained on low resolution images but applied on high resolution images. Our numerical experiments have confirmed this property. The results from our network can be compared with the counterpart from iterative algorithms because they use the same loss function.
A small number of blocks in our neural network can reach the global optimal solutions. This property is different from iterative algorithms, such as FastSolver and RS, which require a large number of iterations to converge. Thanks to the high performance, our network is suitable for many real-time applications in practice. Such high performance might lead to real-time high resolution video processing algorithms.
We believe that the proposed RS and RSnet can be applied on a large range of image processing problems for several reasons. First, the loss function is well established in the field and has been shown successful in the past decades. Therefore, the proposed solvers can be applied on a large range of applications. Second, our RS and RSnet can reach the global optimal solutions, as confirmed in this paper. RS is suitable for tasks with high accuracy requirement. RSnet is suitable for real-time applications.
In future work, we will investigate their applications in the tasks where total variation is used as regularization, for example, image deblurring [26], inpainting [27], image smoothing [5], super resolution, image curvature optimization [4], dehazing [28], image fusion, motion estimation [29], computed tomography in X-ray imaging [30], etc.
Acknowledgment
This work was supported in part by the National Natural Science Foundation of China under Grant 61907031.
References
- [1] L. I. Rudin, S. Osher, and E. Fatemi, “Nonlinear total variation based noise removal algorithms,” Physica D, vol. 60, no. 1, pp. 259–268, 1992.
- [2] K. He, J. Sun, and X. Tang, “Guided image filtering,” ECCV 2010, pp. 1–14, 2010.
- [3] Y. Gong, “Bernstein filter: A new solver for mean curvature regularized models,” in 2016 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), 2016, pp. 1701–1705.
- [4] Y. Gong and I. F. Sbalzarini, “Curvature filters efficiently reduce certain variational energies,” IEEE Transactions on Image Processing, vol. 26, no. 4, pp. 1786–1798, 2017.
- [5] Y. Gong and O. Goksel, “Weighted mean curvature,” Signal Processing, vol. 164, pp. 329 – 339, 2019. [Online]. Available: http://www.sciencedirect.com/science/article/pii/S0165168419302282
- [6] Y. Gong and I. F. Sbalzarini, “Local weighted Gaussian curvature for image processing,” Intl. Conf. Image Proc. (ICIP), pp. 534–538, 2013.
- [7] Y. Gong, Q. Wang, C. Yang, Y. Gao, and C. Li, “Symmetry detection for multi-object using local polar coordinate,” Lecture Notes in Computer Science, vol. 5702, p. 277, 2009.
- [8] D. Krishnan and R. Fergus, “Fast image deconvolution using hyper-Laplacian priors,” Adv. Neural Inform. Proc. Sys., vol. 22, pp. 1–9, 2009.
- [9] Y. Gong and I. F. Sbalzarini, “Image enhancement by gradient distribution specification,” in In Proc. Workshop ”Emerging Topics in Image Enhancement and Restoration”, 12th Asian Conference on Computer Vision, Singapore, Nov 2014, pp. w7–p3.
- [10] Y. Gong and I. Sbalzarini, “A natural-scene gradient distribution prior and its application in light-microscopy image processing,” Selected Topics in Signal Processing, IEEE Journal of, vol. 10, no. 1, pp. 99–114, 2016.
- [11] T. F. Chan, G. H. Golub, and P. Mulet, “A nonlinear primal-dual method for total variation-based image restoration,” SIAM J. Sci. Comput., vol. 20, no. 6, pp. 1964–1977, May 1999. [Online]. Available: http://dx.doi.org/10.1137/S1064827596299767
- [12] A. Chambolle and T. Pock, “A first-order primal-dual algorithm for convex problems with applications to imaging,” Journal of Mathematical Imaging and Vision, vol. 40, pp. 120–145, 2011.
- [13] B. Wahlberg, S. Boyd, M. Annergren, and Y. Wang, “An admm algorithm for a class of total variation regularized estimation problems,” 2012.
- [14] T. Goldstein and S. Osher, “The split Bregman method for L1-regularized problems,” SIAM J. Imaging Sci., vol. 2, no. 2, pp. 323–343, 2009.
- [15] A. Beck and M. Teboulle, “A fast iterative shrinkage-thresholding algorithm for linear inverse problems,” SIAM journal on imaging sciences, vol. 2, no. 1, pp. 183–202, 2009.
- [16] K. Gregor and Y. LeCun, “Learning fast approximations of sparse coding,” in Proceedings of the 27th International Conference on Machine Learning (ICML-10), 2010, pp. 399–406.
- [17] J. Zhang and B. Ghanem, “Ista-net: Interpretable optimization-inspired deep network for image compressive sensing,” 2017.
- [18] J. Adler and O. Öktem, “Learned primal-dual reconstruction,” IEEE Transactions on Medical Imaging, 2018.
- [19] J. Sun, H. Li, Z. Xu et al., “Deep admm-net for compressive sensing mri,” in Advances in Neural Information Processing Systems, 2016, pp. 10–18.
- [20] K. H. Jin, M. T. McCann, E. Froustey, and M. Unser, “Deep convolutional neural network for inverse problems in imaging,” IEEE Transactions on Image Processing, vol. 26, no. 9, pp. 4509–4522, 2017.
- [21] S. Boyd, N. Parikh, E. Chu, B. Peleato, and J. Eckstein, Distributed Optimization and Statistical Learning via the Alternating Direction Method of Multipliers, 2011.
- [22] R.-Q. Jia and H. Zhao, “A fast algorithm for the total variation model of image denoising,” Advances in Computational Mathematics, vol. 33, no. 2, pp. 231–241, 2010.
- [23] P. Arbelaez, M.Maire, C. Fowlkes., and J. Malik, “Contour detection and hierarchical image segmentation.” IEEE TPAMI, 33:898–916, May 2011.
- [24] Z. Wang, A. Bovik, H. Sheikh, and E. Simoncelli, “Image quality assessment: from error visibility to structural similarity,” Image Processing, IEEE Transactions on, vol. 13, no. 4, pp. 600–612, 2004.
- [25] S. J. Sanabria and O. Goksel, “Hand-held sound-speed imaging based on ultrasound reflector delineation,” in International Conference on Medical Image Computing and Computer-Assisted Intervention. Springer, 2016, pp. 568–576.
- [26] Y. Gong, B. Liu, X. Hou, and G. Qiu, “Sub-window box filter,” in Proc. IEEE Visual Communications and Image Processing (VCIP), Dec. 2018, pp. 1–4.
- [27] H. Yin, Y. Gong, and G. Qiu, “Side window filtering,” in The IEEE Conference on Computer Vision and Pattern Recognition (CVPR), June 2019.
- [28] ——, “Side window guided filtering,” Signal Processing, vol. 165, pp. 315 – 330, 2019.
- [29] Y. Gong, “Mean curvature is a good regularization for image processing,” IEEE Transactions on Circuits and Systems for Video Technology, vol. 29, no. 8, pp. 2205–2214, Aug. 2019.
- [30] Y. Gong, H. Yin, J. Liu, B. Liu, and G. Qiu, “Soft tissue removal in x-ray images by half window dark channel prior,” in 2019 IEEE International Conference on Image Processing (ICIP), Sep. 2019, pp. 3576–3580.