Disclaimer. This work has been submitted to the IEEE for possible publication. Copyright may be transferred without notice, after which this version may no longer be accessible.
A Real-Time Predictive Pedestrian Collision Warning Service for Cooperative Intelligent Transportation Systems Using 3D Pose Estimation
Abstract
Minimizing traffic accidents between vehicles and pedestrians is one of the primary research goals in intelligent transportation systems. To achieve the goal, pedestrian orientation recognition and prediction of pedestrian’s crossing or not-crossing intention play a central role. Contemporary approaches do not guarantee satisfactory performance due to limited field-of-view, lack of generalization, and high computational complexity. To overcome these limitations, we propose a real-time predictive pedestrian collision warning service (P2CWS) for two tasks: pedestrian orientation recognition ( FPS) and intention prediction ( FPS). Our framework obtains satisfying generalization over multiple sites because of the proposed site-independent features. At the center of the feature extraction lies 3D pose estimation. The 3D pose analysis enables robust and accurate recognition of pedestrian orientations and prediction of intentions over multiple sites. The proposed vision framework realizes % accuracy in the behavior recognition task on the TUD dataset without any training process and % accuracy in intention prediction on our dataset achieving new state-of-the-art performance. To contribute to the corresponding research community, we make our source codes public which are available at https://github.com/Uehwan/VisionForPedestrian
Index Terms:
Cyber Physical System (CPS), Intelligent Transportation system (ITS), Advanced Driving Assistant Systems (ADAS), Automatic Emergency Braking Systems, Pedestrian, Pedestrian Intention, Pose Estimation.I Introduction
Advances in the technology of autonomous driving and advanced driving assistant systems (ADAS) would transform the way the current transportation system works and integrate into people’s daily lives in the near future [1, 2, 3]. An ideal transportation system enhances the transportation convenience for both drivers and pedestrians but will put more effort into improving safety. Mainly, the system will focus on minimizing traffic accidents between vehicles and pedestrians since the traffic accidents between them could often result in fatalities [4]. In preventing vehicle and pedestrian accidents and securing safety, pedestrian orientation recognition and crossing intention prediction play a vital role as emergency braking 0.16 second in advance could reduce the severity of accident injuries down to 50% [5, 6].
However, contemporary warning service preventing collision between pedestrian and vehicle possess a few limitations. First, the existing in-vehicle sensor-based methods may overlook upcoming collision risks due to the limited field-of-view (FoV) and distance range. In-vehicle sensors such as Radar and Lidar allow the detection of pedestrians around vehicles, which restricts the effectiveness of collision-warning. Even in-vehicle sensors recognize possible collisions, they would not secure enough time space to handle the risks.
Next, conventional cooperative-intelligent transportation systems (C-ITS), an infrastructure equipped with sensors in various areas such as roads, power poles and traffic light poles, hardly guarantee a real-time operation and generality over multiple sites. Such algorithms integrate multiple deep-learning modules for detection and other data processing steps; the resulting complicated software architectures slow down the overall computation time. Moreover, pevious research groups have developed algorithms specific to their study sites [7, 8]; their methods require retraining in new sites for deployment.
To overcome the limitations mentioned above, we propose a real-time predictive pedestrian collision warning service (P2CWS) for C-ITS using 3D pose estimation. The proposed P2CWS utilizes the existing sensors at intersections, which do not entail visibility obstruction, to recognize pedestrian orientations and predict corssing-or-not-crossing intention. Therefore, the proposed P2CWS does not suffer from limited FoV. Moreover, we propose to take advantage of 3D pose estimation in designing P2CWS. The pose analysis with 3D pose estimation becomes more accurate than that of 2D pose estimation since 3D pose estimation employs a 3D human body model as a knowledge base and temporal context within videos. Subsequently, 3D pose estimation allows precise analysis of pedestrian body orientation as well as prediction of pedestrian intention. The proposed pedestrian analysis based on 3D pose estimation simplifies the data processing process and achieves real-time operation; the usage of the generic 3D pose features enables generalization over multiple sites.
Specifically, we deduce three categories of information for pedestrian intention prediction: 1) pedestrian features, 2) vehicle-to- pedestrian (V2P) interactions, and 3) environmental contexts. The pedestrian features represent the characteristics of the pedestrian of interest and consist of orientation features, the group size, and the speed of the pedestrian. Next, the V2P interactions describe the effect of the nearby vehicle on the pedestrian’s decision-making and include the distance and angle between them and the vehicle’s speed. Moreover, the environmental contexts illustrate the contextual information and comprise crosswalk distance, angle, the pedestrian’s location semantics. Furthermore, we approximate the physical dimensions, i.e., the distance between objects, utilizing a knowledge-base of average object heights. 2D images do not contain full information for physical dimensions; thus, it is difficult to reconstruct the 3D dimensions. We propose to resolve the 3D dimension reconstruction with the knowledge-base. Finally, we predict the pedestrian’s crossing or not-crossing intention utilizing the features extracted.
In summary, the contributions of our work are as follows:
-
1.
P2CWS Framework Utilizing Vision Sensors at Intersections : We propose a collision warning framework which could function at multiple sites and guarantee real-time operation.
-
2.
Pedestrian Crossing Intention Prediction : We propose strategy is not to detect crossing pedestrian only, but to recognize crossing intention considering information such as pedestrian features, vehicle to pedestrian (V2P) interaction, environmental contexts.
-
3.
Real-Time Operation and Verification at Multiple Sites: The proposed vision framework guarantees a real-time operation on a modern processing unit ( 30 FPS) and we verify the performance and the universality of the proposed vision framework at multiple study sites.
-
4.
Open Source: We contribute to the corresponding research community by making the source codes of the proposed vision framework public.
The rest of this manuscript is organized as follows. Section II reviews conventional research outcomes relevant to the proposed vision framework and compare them. Section III describes the proposed P2CWS framework. Sections IV and V illustrate the feature extraction and pedestrian intention prediction processes in detail. Section VI delineates the evaluation settings for performance verification and the experiment results with corresponding analysis follow in Section VII. Section VIII discusses future research direction for further improvement of the proposed framework and concluding remarks follow in Section IX.
II Related Works
In this section, we review previous research outcomes relevant to the proposed P2CWS framework and the two tasks. We discuss the main ideas and limitations of previous works and compare them with the proposed framework.
II-A Cooperative-Intelligent Transport System
Cooperative-Intelligent Transportation Systems (C-ITS) collect and provide information in both directions between vehicles and road-side infra-structures [9]; in general, C-ITS utilizes on-board-unit (OBU) installed on vehicles and vision, radar and Lidar sensors on the road-side for information processing. C-ITS allows vehicles and transportation infra-structures to inter-connect, share information and coordinate pertinent actions [10]. Representative services of C-ITS includes slow-vehicle, pedestrian collision and abnormal condition on the road (accidents and construction) warning services.
It is true that the initial installation of OBU and setting of transportation infra-structures for C-ITS. However, C-ITS can secure time to preemptively respond to risks that occur far from the subject vehicle and generate accurate information regarding the hazardous area—minimizing traffic accidents. Therefore, various countries such as Europe, the United States, Republic of Korea and Japan are currently conducting C-ITS demonstration projects to compensates for blind spots that drivers cannot detect by in-vehicle sensors through infrastructure sensors installed on the roadside [11, 12, 13].
II-B Pedestrian Collision Warning Service
Among C-ITS services, the pedestrian collision warning service aims to improve pedestrian safety at intersections or road sections. The pedestrian collision warning service implemented in the demonstration projects in various regions by applying the C-ITS standard acquires image data from a camera installed on the road-side such as crosswalks, and streams the image data to the image processing unit. The image processing unit analyzes the received image data to detect possible collisions and transmit collision warning messages to nearby vehicles through the vehicle-to-everything (V2X) server and RSU. However, due to the large amount of streaming data and the communication latency, simplification of software architecture and processing speed beyond real-time operation have become a critical concern [14].
II-C Pedestrian Crossing Intention Prediction
Prediction of pedestrian’s intention is under active research to realize intelligent transportation systems and autonomous driving. Especially, it plays a key role in realizing a pedestrian collision warning service. One of the works has utilized pedestrian’s demographic information, such as gender and age, and the movement of pedestrians to predict the intention [5]. Although such demographic information could help infer pedestrian’s intention, pedestrian’s demographic information is not always available and straightforward to recognize.
On one hand, hand-crafted features or statistical model design still perform better than deep neural networks in certain environments [15, 5] since a sufficient amount of data for training large deep neural networks is not available in the area of the pedestrian intention prediction task. On the other hand, deep neural networks trained on large public datasets could replace sub-modules of intention prediction systems [7, 1]. Although such methods can guarantee solid performance in predefined environments, they can hardly generalize to multiple sites and they in general require a fine-tuning process to get deployed in new sites.
Another stream of research incorporates deep-learning methods to maximize the performance [8, 16, 17]. At the current state, the resulting algorithms assume specific situations such as evacuations and thus do not generalize to common transportation scenarios. Moreover, an intention prediction algorithm in signalized environments takes the signal and elapsed time of the signal phase into account in addition to environmental context, vehicle features and pedestrian characteristics [18]. The work, however, does not guarantee universality over multiple sites. The work that is most relevant to our framework estimates 2D pose for predicting pedestrian intention [7]. However, the performance of intention prediction based on 2D pose degrades in the cases of occlusions and view variations.
II-D Human Pose Estimation
Human pose estimation algorithms include two main categories: 2D and 3D pose estimations. Both 2D and 3D pose estimation algorithms take in RGB images and estimate the pose of humans within the images. The surge of deep-learning has resolved the limitations of classical methods in 2D human pose estimation [19, 20, 21]. The research on 2D pose estimation with deep-learning has become feasible with the collection of corresponding datasets [22, 23]. The most widely used COCO dataset contains over 200,000 images and 250,000 person instances with the labels of 17 keypoints.
The request for 3D coordinates of human joints has triggered the development of 3D pose estimation algorithms [24, 25, 26]. Exemplary applications of 3D pose estimation encompass AR/VR, human computer interaction, computer graphics and human action understanding. The research on 3D pose estimation has become active with the collection of large datasets [27, 28, 25], which is similar to the case of 2D pose estimation. Recent 3D pose estimation methods have incorporated pre-trained 3D human models [29, 30]. Incorporation of 3D human models improves the performance significantly and enables 3D pose estimation to overcome harsh conditions such as occlusions and view variations due to the injection of additional knowledge-base.
III Predictive Pedestrian Collision Warning Service
In this section, we describe the proposed predictive pedestrian collision warning service (P2CWS) framework architecture.
III-A Service Overview

We designed the P2CWS framework to alert dangerous behaviors of pedestrians to vehicle drivers approaching intersections. Fig. 1 shows the overview of P2CWS. P2CWS require three hardware components: On-Board Unit (OBU) on vehicles, Road-Side Units (RSU), and CCTV installed at an intersection. For detecting pedestrians in real traffic scenes, we consider a camera (CCTV) as a sensor. P2CWS resides on RSU and consists of a real-time vision framework and a crossing intention prediction system. The overall data flow of P2CWS is as follows. The installed camera at an intersection shoots a fixed site including pedestrians before crossing the crosswalk, and collects a sequence of images at every 0.033 second (30 FPS). It transmits the collected image sequences to RSU. The OBU on each vehicle gather their own vehicles’ location data while uploading their locations to RSU. If RSU receives no information from OBU, the vision framework of P2CWS extracts the position and speed information of the vehicle. The real-time vision framework of P2CWS processes collected information and extracts features with which the crossing intention prediction system predicts the intention of pedestrians.
Implementing the P2CWS demands a high level of real-time data processing and transmission techniques. There are still a number of issues associated with the application of wireless cellular communication in practice, such as latency, reliability, data delivery ratio, and GPS accuracy of smartphones in vehicles. The main focus of our work is on studying a machine learning-based collision warning rather than on dealing with the communication problems—we do not consider such communication issues. Therefore, we develop the machine learning-based collision warning system under the assumption that P2CWS receives traffic information with acceptable latency and deliberated accuracy.
III-B Collision Warning Strategy

Fig. 2 displays the concept of collision warning provided by P2CWS. P2CWS extracts features of pedestrians, vehicles and other contexts every 0.033 seconds. Then, the crossing intention prediction system recognizes the pedestrian’s crossing intention to warn drivers approaching the intersection of possible collisions. Since the paths of vehicles are available, P2CWS could predict possible collisions. Moreover, P2CWS aims to predict the future crossing intention in 1.5 seconds.
IV Real-time vision framework
We describe the real-time vision framework for feature extracting in this section. The proposed real-time vision framework allows effective and efficient Prediction of crossing intention.
IV-A System Overview

Fig.3 illustrates the overall architecture of the proposed vision framework. The input sequence of images first passes through the object detection and object tracking modules which recognize object semantics and object identities. Then, the human pose estimation and orientation estimation modules extract pose and orientation features of pedestrians. Meanwhile, a set of first image frames goes through the semantic segmentation module for the analysis of environmental semantics. After extracting the environmental semantics, the semantic segmentation module becomes idle. Moreover, the distance measure module estimates distances between entities. After all the features necessary for the intention prediction get extracted, the process of intention prediction begins.
IV-B Pose Estimation


The proposed framework estimates both 3D and 2D poses of pedestrians (Fig. 4). For 3D pose estimation, the proposed framework utilizes one of the off-the-shelf 3D pose estimation algorithms [26] and we propose to derive 2D poses from the estimated 3D poses.
IV-B1 3D Pose Estimation
The 3D pose estimation algorithm first yields the Skinned Multi-Person Linear Model (SMPL) parameters [31]. Then, the algorithm computes 49 joint locations in a normalized 3D space from the body vertices using a pre-trained linear regressor as follows:
| (1) |
where represents the SMPL model, and denote body-pose and body-shape parameters of the SMPL model, respectively and stands for the pre-trained linear regressor. We filter out redundant and non-effective joints and employ 14 joint positions for our study.
IV-B2 2D Pose Estimation
Once we have evaluated the 3D poses of the pedestrians in scenes, 2D pose estimation becomes a straight-forward process of projecting the estimated 3D poses into the image planes; projecting each 3D point of 3D poses generates the corresponding 2D points of 2D poses. Applying camera geometry operations projects 3D points into an image plane [32] as follows:
| (2) |
where and represent a point in a 3D space and the corresponding 2D point on the image plane, respectively, and denote rotation and translation matrices, respectively, and and stand for a camera intrinsic matrix and a perspective scale factor, respectively.
IV-C Pedestrian Orientation
We define two categories of pedestrian orientation: head orientation and body orientation. By defining two types of orientation, we can specifically analyze the orientation of pedestrians. Moreover, we use line equations in the vector form to represent orientation.
IV-C1 Head Orientation
We define the head orientation as the line passing through the middle point of the left and right eyes and the middle point of head-top and jaw as follows:
| (3) |
where is a line parameter. The example usages of the head orientation include the analysis of the pedestrian field of view.
IV-C2 Body Orientation
We define the body orientation as the line perpendicular to the plane containing the left and right shoulders, and mid-hip joint which passes through the middle point of the three joints as follows:
| (4) |
The example applications of the body orientation encompass the analysis of the paths pedestrians are taking.
IV-D Distance Measure
Distances between objects offer a key context for the interpretation of interactions between the objects. Since 2D imaging modalities hinder the exact recovery of the 3D dimensions without prior knowledge [33], we linearly approximate distances from 2D images using a knowledge-base of object dimensions as follows:
| (5) |
where and denote the measured height in pixels and the mean height of an object from the knowledge-base, respectively, represents the position of an object on the 2D image plane, and and refer to object identities, respectively. Table I displays the knowledge-base of the mean heights of the objects involved in our study. After measuring distances, we normalize them by where is a normalization factor.
| Object | Person | Cyclist | Car | Bus | Truck |
| m | m | m | m | m | |
V Pedestrian Crossing Intention Prediction
We illustrate the proposed intention prediction method in this section. The proposed intention prediction method consists of a feature extraction process and a classification process.
V-A Algorithm Overview
Table II and Fig. 5 summarize the features for intention prediction. We propose to extract three categories of features: pedestrian features, V2P interactions and environmental contexts. The pedestrian features derive the characteristic of pedestrians in three feature vectors (3D pose, group size and speed). The V2P interactions represent the effect of vehicles on pedestrians’ intention (distance, angle and speed). Last, the environmental contexts stand for the encoding of environment information (distance to a crosswalk, angle with a crosswalk and location of pedestrian). In total, we deal with nine types of features.
| Type | Name | Notation | Dimension | Norm. Factor | Description |
| Pedestrian Features | 3D Pose | Concatenation of fourteen 3D pose joints | |||
| Group Size | Number of pedestrians in the group boundary | ||||
| Speed | Moving speed of the pedestrian of interest | ||||
| V2P Interactions | Distance | Distance to the closest approaching vehicle from the pedestrian | |||
| Angle | Angle between the pedestrian and the vehicle | ||||
| Speed | Speed of the vehicle | ||||
| Environmental Contexts | Distance | Distance to the closest crosswalk entrance from the pedestrian | |||
| Angle | Angle between the crosswalk entrance and the pedestrian | ||||
| Location | Pedestrian location semantics | ||||

V-B Pedestrian Features
V-B1 3D Pose Feature
We select 14 keypoints relevant for pedestrian movements rather than using all the keypoints extracted [34]. Fig. 4 highlights the selected keypoints with orange circles. Other keypoints minimally vary over pedestrian movements thus offers less meaningful information. We concatenate the normalized 3D positions of 14 keypoints and form the 3D pose feature as follows:
| (6) |
V-B2 Group Size
As the size of the group that contains the pedestrian of interest affects the pedestrian decision making, we count the number of nearby pedestrians within a group boundary. We define the group boundary as a circle with 5m diameter centered at the pedestrian of interest. We normalize the group size by dividing it by before feeding it into a classifier.
V-B3 Speed
We measure the speed of a pedestrian as follows:
| (7) |
where is the position of the hip joint at time . We track the position of the hip joint since it is the center of a body. In addition, we use for a stable measurement of speed. For normalization before feeding into a classifier, we divide the measured speed by .
V-C Vehicle-to-Pedestrian (V2P) Interactions
We categorize vehicles into two groups: approaching or non-approaching. The distances between the pedestrian of interest and the approaching vehicles decrease () over time and the distances increase () in the case of non-approaching vehicles. We only consider the closest approaching vehicle for the analysis of V2P interactions. This analysis setting simplifies the analysis process and the subsequent approaching vehicles get into consideration after the closest approaching vehicle becomes a non-approaching vehicle.
V-C1 Distance
The decision making of crossing or not-crossing highly depends on the distance to the approaching vehicles. Thus, we take the distance into account: the distance between the pedestrian of interest and the closest approaching vehicle. For the calculation of the distance using (5), we utilize the hip joint position of the pedestrian and the middle front position of the vehicle. We normalize the distance by dividing the measured distance by .
V-C2 Angle
We measure the angle between the pedestrian body orientation and the vehicle direction vector for the angle feature. The body orientation accounts for the actual direction of a pedestrian’s movement and we evaluate the vehicle direction as . Since the perpendicular geometry between the pedestrian and the vehicle leads to a collision while the parallel movements of the two entities do not, we design the angle feature as follows:
| (8) |
V-C3 Speed of Vehicle
We measure the speed of a vehicle as follows:
| (9) |
Since vehicles tend to move much faster than pedestrians, we compensate the scale variation by calculating the aspect ratio twice. For normalization, we apply division by .
V-D Environment Context
V-D1 Crosswalk Context
For the crosswalk context, we calculate the distance and the angle between the pedestrian and the closest crosswalk entrance. For the distance, we consider the middle point of the crosswalk and to approximate the actual dimension from the pixel distance. For the angle, we measure as (8). We define the direction of a crosswalk entrance () with the line vector defining the crosswalk entrance.
V-D2 Location Semantics
Since the current location of a pedestrian affects the crossing or not-crossing intention, we extract location semantics as one of environmental contexts. To extract semantics, we sample pixels from the nearby pixels of left and right toe joints, respectively. Among the pixels, the dominant semantic label becomes the location semantic of a pedestrian. We assign a specific number to each label to encode semantics.
V-E Intention Prediction
For intention prediction, the feature at time step becomes
| (10) |
We input a set of features from a specific length of time span (temporal context) to a classifier and retrieve the intention prediction result at different future time steps. We sample 15 features per second to account for the case when detectors fail to recognize entities. Furthermore, we could attach the current state information (crossing or not-crossing) at each time step to .
VI Experimental Settings
In this section, we delineate the experiment settings and methods for performance verification of the proposed ㅖ2ㅊㅉㄴ framework in two tasks: pedestrian orientation recognition and intention prediction tasks.
VI-A Pedestrian Orientation Recognition
VI-A1 Dataset
We use the TUD multi-view pedestrian dataset [35] to evaluate the performance of pedestrian orientation recognition. The dataset consists of a total of 5,228 pedestrian images (refer to Fig. 6 for sample images) and includes three subsets: training (4,732 images), validation (290 images) and test (309 images) sets. We only utilize the test set for the evaluation since the proposed vision framework functions in general cases and does not require a training step for pedestrian orientation recognition. The dataset provides the bounding boxes and the ground-truth orientation of each pedestrian ranging from to [36].

VI-A2 Performance Metrics
We compute four metrics for quantitative analysis and comparison of performance: Accuracy , Accuracy , Mean Absolute Error (MAE) and Frames-per-Second (FPS). On the one hand, the accuracy metrics are defined as follows:
| (11) |
where represents the number of test images, and denote the ground-truth and estimated orientations, respectively, is an indicator function for a set , and . On the other hand, MAE is defined as follows:
| (12) |
VI-A3 Baselines
We employ eight baseline algorithms to compare the performance of pedestrian orientation recognition (Table III). Three out of the eight involve convolutional neural networks for orientation recognition, and others involve hand-crafted features. In addition, we include the human accuracy to indicate the gap between the current state of the art and the desired performance.
VI-A4 Implementation Details
We compute the pedestrian orientation using (4) and do not consider the head orientation as the TUD dataset does not. To convert the pedestrian orientation vector to an angle ranging from to , we measure the angle between the body orientation vector and the vector () using the inner product operation. The angles increase in the clockwise direction and the angles in the third and fourth quaternions of the 2D plane range from to . When calculating errors, we select the minimum values between and to account for the discontinuity between and despite their sameness.
VI-B Intention Prediction
VI-B1 Dataset
For the training and evaluation of the proposed pedestrian intention prediction algorithm, we have collected a pedestrian crossing or not-crossing (PCNC) dataset. The dataset contains 51 scenes acquired from 15 study sites and includes 64 pedestrians (refer to Fig. 6 for sample images). We set the acquisition environment to RGB images at 30 FPS and a 1,9201,080 resolution. We have labeled the crossing and not-crossing states of pedestrians for all collected image frames.
VI-B2 Performance Metrics
We assess the performance of pedestrian intention prediction with two widely adopted metrics: accuracy and F1 score. The accuracy metric defined as computes the ratio of correctly predicted observation to the total observations and the F1 scores defined as computes the weighted average of precision and recall.
VI-B3 Baselines
We employ three types of classifiers and compare their performance on the intention prediction task: Feed-Forward Neural Networks (FFNN), Gated Recurrent Unit (GRU) [37] and the encoder of transformer model [38]. The baseline models except for the FFNN model intrinsically entail temporal modeling. The input size at each time step is for the two temporal models, while it is for FFNN where is the number of time steps as temporal context. The output size is for each time step accounting for crossing and not-crossing.
VI-B4 Ablation Study
First, we set the temporal context length as sec and let the classifiers predict the intention at the sec future time step. Then, we vary the model size to investigate its effect on performance. For each model we modify the number of layers () from and to and the number of hidden units () from and to . For the transformer model, we set the number of heads as in all cases.
Once we have found the best configuration for each model, we vary the length of the temporal context from sec to sec with the sec step size to investigate the effect of temporal context on performance. In addition, we design the classifiers to predict the intention at different future time steps (from sec to sec with the step size of sec) to examine how much classifiers can predict the future intentions. Last, we study the effect of the multi-task learning scheme [39], where a classifier simultaneously predicts intentions at multiple time steps.
VI-B5 Implementation Details
We employ Yolov3 [40] as an object detector, SORT [41] as an object tracker and HRNetV2 [42] as a semantic segmentation module. Employing other detectors and trackers did not result in dramatic performance difference. Furthermore, we split the PCNC dataset into train (50 pedestrians), validation (7 pedestrians) and test (7 pedestrians) sets. We divide the dataset by scenes rather than mixing and splitting by percentage to examine if the proposed intention prediction method could perform robustly with unseen data. We stop the training procedure when the performance on the validation set starts to decrease.
VII Results and Analysis
In this section, we present the experiment results in a set of different conditions, analyze the effect of various design choices, and establish the effectiveness of the proposed vision framework.
VII-A Pedestrian Orientation Recognition
| Method | Performance Metrics | ||||
| Name | Features | Accuracy | Accuracy | MAE | FPS |
| Human Accuracy | - | - | |||
| HOG+SVM (cost-relax) | Hand-crafted | - | - | - | |
| HOG+LogReg | Hand-crafted | - | - | ||
| CNN-based Method | CNN-based | - | - | ||
| HOG+KRF | Hand-crafted | - | |||
| HSSR | Hand-crafted | - | |||
| HOG+AKRF-VW | Hand-crafted | - | |||
| CNN + Mean-shift | CNN-based | - | |||
| Coarse-to-fine Deep Learning [43] | CNN-based | 72.4 | |||
| Ours | CNN-based | 89.3 | 100.53 | ||


Table III summarizes the comparative study results. The proposed vision framework outperforms or performs on par with baselines in the orientation recognition task. One thing to note is that our method does not involve any training or fine-tuning steps for orientation recognition with the TUD dataset, and we obtain the result solely with (4). This fact ensures the generality of the proposed pedestrian orientation recognition method and indicates that our method is free from the issue of overfitting. Other methods involve the process of fine-tuning for performance maximization, which could cause overfitting.
Next, our method seems to reveal weak performance in catching tiny details, although the proposed method entails much lower computational complexity (higher FPS) and displays superior performance on the overall view. The Accuracy of our method is not satisfactory compared to the performance in other metrics. We presume that the axis for measuring orientation angles might not match between the one provided by the TUD dataset and ours. Since our method measures orientations in a normalized 3D space and the TUD dataset has been annotated using 2D images, developing a calibration method for the measurement axis would result in performance enhancement in the Accuracy metric.
Moreover, our method can recognize the body orientation when pedestrians do not stand up straight while other baseline methods function with the assumption of the straight pose. The TUD dataset contains only the straight pose cases, and baseline methods trained or fine-tuned on the dataset would fail with other pedestrian postures. In a similar vein, we could easily extend our method to perform other tasks, unlike baseline methods, due to its extraction of generic 3D pose features. The example tasks our method can be extended to include pedestrian movement analysis, pedestrian action recognition, and tracking pedestrians’ views.
Fig. 7 illustrates the distribution of absolute errors and the cumulation of absolute errors per angle. The maximum and minimum of the absolute errors are and , respectively, and the number of samples decreases with the increment of the absolute error. Next, the cumulation of errors distributes uniformly over angles despite a few peaks, such as the peaks at and . The uniform distribution demonstrates that our method recognizes orientations without a bias.
VII-B Intention Prediction
| Architecture | with State Info. | without State Info. | ||||||||||
| Accuracy | F1 Score | Accuracy | F1 Score | |||||||||
| FFNN | 2 | |||||||||||
| 3 | ||||||||||||
| 4 | ||||||||||||
| GRU | 2 | |||||||||||
| 3 | ||||||||||||
| 4 | ||||||||||||
| Transformer | 2 | |||||||||||
| 3 | ||||||||||||
| 4 | ||||||||||||
Table IV summarizes the ablation study result (prediction of the intention at sec given sec context). Among the three models (FFNN, GRU and transformer), the GRU model performed the best, achieving % accuracy given the state information and % accuracy without the state information. With the state information given, all the models performed satisfactorily and the performance gaps between models were marginal. This indicates the importance of the current state information for predicting the future intention of pedestrians. The state information allowed the models to predict future intentions with a small number of model parameters.
However, there seemed to exist a performance limit that models could achieve even when the state information was given. The limit might have arisen from the data discrepancy between training and test sets. Since we had divided the dataset by the scenes rather than mixing the data and splitting by percentage, the train set would not enable models to learn a few features necessary for the perfect performance. We can overcome this limit by collecting more data, which we will conduct as future work.
Next, increasing the model size did not necessarily lead to performance enhancement. The best performing model configurations (, ) were (, ), (, ) and (, ) for FFNN, GRU and transformer, respectively. At some points, models stopped improving the performance, although we increased the number of model parameters. In other words, making models wider and deeper could result in performance improvement until the performance saturation points. As we collect more data, we would be able to experiment with wider and deeper models and investigate the effect of the model size on the performance more accurately.


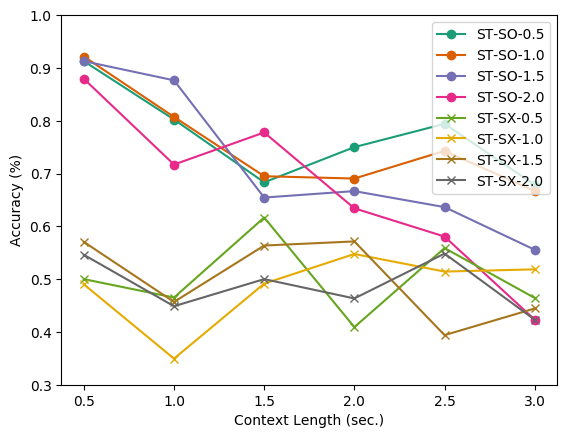



Fig. 8 illustrates the effect of the context lengths on the performance of predicting future intentions at various time steps. First of all, injecting more extended contexts did not improve the accuracy of the intention prediction task. In contrast, more extended contexts tended to degrade performance. We presume the short-term context plays a crucial role while the long-term context rapidly becomes obsolete in the intention prediction task. In the context of the transportation systems, the fact that the prediction of pedestrians’ intention requires only short-term contexts could benefit the design of safety systems.
Furthermore, the multi-task learning setting did not consistently improve performance (the second row in Fig. 8). In the case of GRU, the multi-task learning setting helped the models to enhance the performance with the state information given, but the performance decreased in other cases. We surmise two rationales for this phenomenon: 1) predictions of intentions at different future time steps are independent to some degree, which hinders the extraction of common features or 2) the collected data was not enough to take advantage of the multi-task learning setting.
VIII Discussion
The proposed P2CWS framework recognizes pedestrian behaviors and predicts crossing or not-crossing intention in real-time using 3D pose estimation. Since the framework extracts site-independent features for the two tasks, it displays robust performance in multiple environments. Specifically, we demonstrated the proposed vision framework’s state-of-the-art performance in pedestrian behavior recognition without any training and in intention prediction in multiple study sites. Despite its effectiveness, however, there still remain a few future works for further improvement of the performance of the proposed vision framework.
First of all, the current P2CWS framework implicitly analyzes the gaze of pedestrians, but in future studies, we can enhance the performance by explicitly analyzing the gaze. The pedestrian’s gaze contains a lot of information regarding the pedestrian’s future behavior. For example, whether a pedestrian has seen an oncoming vehicle determines whether a pedestrian crosses a crosswalk. Also, if a pedestrian approaches a crosswalk and frequently looks around, we can infer that the pedestrian is preparing to cross with a high probability. If an advanced vision framework tracks and analyzes the head orientation proposed in this study in real-time, it can predict pedestrians’ behavior with higher accuracy.
Next, we can improve the performance by replacing individual modules with enhanced modules in the future since we designed the proposed vision framework in a modular manner. As the available data increases, the performance of deep learning-based detectors and trackers is steadily improving. Therefore, we can maximize the performance of the proposed vision framework through continuous updates. Although the currently proposed vision framework guarantees persistence and scalability to some extent, future studies can further improve the software architecture to ensure persistence and scalability more strongly. Through this architectural improvement, it will become possible to reduce the computational complexity and realize higher accuracy.
In addition, we can extend the framework to consider multiple pedestrians and multiple vehicles simultaneously. The current vision framework focuses on the intention prediction of a single pedestrian. The current vision framework can still predict the intention of multiple pedestrians through iterative analysis, but it may cause inefficiency in terms of computational complexity. In the following study, we can expand the P2CWS framework to consider multiple vehicles simultaneously and predict the intention of multiple pedestrians. This expansion will reduce the amount of computation and increase accuracy by considering interactions between entities more effectively. To this end, future research will entail the process of designing a deep neural architecture that can analyze a variable number of entities.
Last but not least, we can enhance performance through an end-to-end architecture design. Since the present P2CWS framework is modular, one can consider that the current P2CWS framework was designed through human knowledge. This design method is similar to hand-crafted features. If we replace the architecture from hand-engineered to end-to-end designs, we can expect performance advancement through feature learning. In future studies, we can maximize performance through such end-to-end designs. We can implement such end-to-end designs using image-based generative adversarial networks (GAN).
IX Conclusion
In this work, we proposed a real-time P2CWS framework for two central tasks in intelligent transportation systems: pedestrian orientation recognition and crossing or not-crossing intention prediction. The proposed P2CWS framework extracts site-independent features to ensure generalization over multiple sites. 3D pose estimation plays a crucial role in the feature extraction process. 3D pose estimation allows robust and accurate analysis of pedestrian orientation and crossing or not-crossing intention since it incorporates a 3D human body model as a knowledge base and temporal context within the video. We demonstrated the effectiveness of 3D pose estimation in the pedestrian behavior recognition task using the TUD dataset. The proposed pedestrian behavior recognition approach renewed the state-of-the-art performance without any finetuning process (% % in Accuracy ) and computational efficiency ( FPS FPS). Furthermore, we proposed three categories of features for the intention prediction task: pedestrian features, vehicle-to-pedestrian (V2P) interactions, and environmental contexts. We verified the efficacy of the proposed approach at multiple study sites, and the proposed approach displayed % prediction accuracy.
References
- [1] S. Neogi, M. Hoy, K. Dang, H. Yu, and J. Dauwels, “Context model for pedestrian intention prediction using factored latent-dynamic conditional random fields,” IEEE Transactions on Intelligent Transportation Systems, Early Access, 2020.
- [2] X. Wang, X. Zheng, W. Chen, and F.-Y. Wang, “Visual human-computer interactions for intelligent vehicles and intelligent transportation systems: The state of the art and future directions,” IEEE Transactions on Systems, Man, and Cybernetics: Systems, 2020.
- [3] X. Xu, L. Zuo, X. Li, L. Qian, J. Ren, and Z. Sun, “A reinforcement learning approach to autonomous decision making of intelligent vehicles on highways,” IEEE Transactions on Systems, Man, and Cybernetics: Systems, vol. 50, no. 10, pp. 3884–3897, 2018.
- [4] M. Goldhammer, S. Köhler, S. Zernetsch, K. Doll, B. Sick, and K. Dietmayer, “Intentions of vulnerable road users–detection and forecasting by means of machine learning,” IEEE Transactions on Intelligent Transportation Systems, Early Access, 2019.
- [5] X. Zhang, H. Chen, W. Yang, W. Jin, and W. Zhu, “Pedestrian path prediction for autonomous driving at un-signalized crosswalk using w/cdm and msfm,” IEEE Transactions on Intelligent Transportation Systems, Early Access, 2020.
- [6] G. Li, G. Kou, and Y. Peng, “A group decision making model for integrating heterogeneous information,” IEEE Transactions on Systems, Man, and Cybernetics: Systems, vol. 48, no. 6, pp. 982–992, 2016.
- [7] Z. Fang and A. M. López, “Intention recognition of pedestrians and cyclists by 2d pose estimation,” IEEE Transactions on Intelligent Transportation Systems, Early Access, 2019.
- [8] K. Saleh, M. Hossny, and S. Nahavandi, “Contextual recurrent predictive model for long-term intent prediction of vulnerable road users,” IEEE Transactions on Intelligent Transportation Systems, Early Access, 2019.
- [9] L. Chen and C. Englund, “Cooperative its—eu standards to accelerate cooperative mobility,” in 2014 International Conference on Connected Vehicles and Expo (ICCVE). IEEE, 2014, pp. 681–686.
- [10] M. Autili, L. Chen, C. Englund, C. Pompilio, and M. Tivoli, “Cooperative intelligent transport systems: Choreography-based urban traffic coordination,” IEEE Transactions on Intelligent Transportation Systems, vol. 22, no. 4, pp. 2088–2099, 2021.
- [11] M. Lu, O. Turetken, O. E. Adali, J. Castells, R. Blokpoel, and P. Grefen, “C-its (cooperative intelligent transport systems) deployment in europe: challenges and key findings,” in 25th ITS World Congress, Copenhagen, Denmark, 2018, pp. 17–21.
- [12] M. Lu, J. Castells, P. Hofman, R. Blokpoel, and A. Vallejo, “Pan-european deployment of c-its: The way forward,” in Proceedings of the 26th World Congress on Intelligent Transport Systems, Singapore, 2019, pp. 21–25.
- [13] L.-W. Chen and P.-C. Chou, “Big-cca: Beacon-less, infrastructure-less, and gps-less cooperative collision avoidance based on vehicular sensor networks,” IEEE Transactions on Systems, Man, and Cybernetics: Systems, vol. 46, no. 11, pp. 1518–1528, 2015.
- [14] J. W. Park, J. W. Baek, S. Lee, W. Seo, and D.-W. Seo, “Edge camera based c-its pedestrian collision avoidance warning system,” The Journal of The Korea Institute of Intelligent Transport Systems, vol. 18, no. 6, pp. 176–190, 2019.
- [15] E. Rehder, H. Kloeden, and C. Stiller, “Head detection and orientation estimation for pedestrian safety,” in 17th International IEEE Conference on Intelligent Transportation Systems (ITSC). IEEE, 2014, pp. 2292–2297.
- [16] X. Song, K. Chen, X. Li, J. Sun, B. Hou, Y. Cui, B. Zhang, G. Xiong, and Z. Wang, “Pedestrian trajectory prediction based on deep convolutional lstm network,” IEEE Transactions on Intelligent Transportation Systems, Early Access, 2020.
- [17] S. Yang, W. Wang, C. Liu, and W. Deng, “Scene understanding in deep learning-based end-to-end controllers for autonomous vehicles,” IEEE Transactions on Systems, Man, and Cybernetics: Systems, vol. 49, no. 1, pp. 53–63, 2018.
- [18] Y. Gu, Y. Hashimoto, L.-T. Hsu, M. Iryo-Asano, and S. Kamijo, “Human-like motion planning model for driving in signalized intersections,” IATSS research, vol. 41, no. 3, pp. 129–139, 2017.
- [19] Z. Cao, T. Simon, S.-E. Wei, and Y. Sheikh, “Realtime multi-person 2d pose estimation using part affinity fields,” in Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 2017, pp. 7291–7299.
- [20] B. Xiao, H. Wu, and Y. Wei, “Simple baselines for human pose estimation and tracking,” in Proceedings of the European Conference on Computer Vision (ECCV), 2018, pp. 466–481.
- [21] K. Sun, B. Xiao, D. Liu, and J. Wang, “Deep high-resolution representation learning for human pose estimation,” in Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 2019, pp. 5693–5703.
- [22] T.-Y. Lin, M. Maire, S. Belongie, J. Hays, P. Perona, D. Ramanan, P. Dollár, and C. L. Zitnick, “Microsoft coco: Common objects in context,” in Proceedings of the European Conference on Computer Vision (ECCV). Springer, 2014, pp. 740–755.
- [23] M. Andriluka, U. Iqbal, E. Insafutdinov, L. Pishchulin, A. Milan, J. Gall, and B. Schiele, “Posetrack: A benchmark for human pose estimation and tracking,” in Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 2018, pp. 5167–5176.
- [24] J. Martinez, R. Hossain, J. Romero, and J. J. Little, “A simple yet effective baseline for 3d human pose estimation,” in Proceedings of the IEEE International Conference on Computer Vision, 2017, pp. 2640–2649.
- [25] R. Alp Güler, N. Neverova, and I. Kokkinos, “Densepose: Dense human pose estimation in the wild,” in Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 2018, pp. 7297–7306.
- [26] M. Kocabas, N. Athanasiou, and M. J. Black, “Vibe: Video inference for human body pose and shape estimation,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2020, pp. 5253–5263.
- [27] C. Ionescu, D. Papava, V. Olaru, and C. Sminchisescu, “Human3. 6m: Large scale datasets and predictive methods for 3d human sensing in natural environments,” IEEE Transactions on Pattern Analysis and Machine Intelligence, vol. 36, no. 7, pp. 1325–1339, 2014.
- [28] D. Mehta, H. Rhodin, D. Casas, P. Fua, O. Sotnychenko, W. Xu, and C. Theobalt, “Monocular 3d human pose estimation in the wild using improved cnn supervision,” in 2017 International Conference on 3D Vision (3DV). IEEE, 2017, pp. 506–516.
- [29] M. Loper, N. Mahmood, J. Romero, G. Pons-Moll, and M. J. Black, “Smpl: A skinned multi-person linear model,” ACM Transactions on Graphics (TOG), vol. 34, no. 6, pp. 1–16, 2015.
- [30] L. Pishchulin, S. Wuhrer, T. Helten, C. Theobalt, and B. Schiele, “Building statistical shape spaces for 3d human modeling,” Pattern Recognition, vol. 67, pp. 276–286, 2017.
- [31] A. Kanazawa, M. J. Black, D. W. Jacobs, and J. Malik, “End-to-end recovery of human shape and pose,” in Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 2018, pp. 7122–7131.
- [32] U.-H. Kim, J.-M. Park, T.-J. Song, and J.-H. Kim, “3-d scene graph: A sparse and semantic representation of physical environments for intelligent agents,” IEEE Transactions on Cybernetics, Early Access, 2019.
- [33] U.-H. Kim, S. Kim, and J.-H. Kim, “Simvodis: Simultaneous visual odometry, object detection, and instance segmentation,” IEEE Transactions on Pattern Analysis and Machine Intelligence, Early Access, 2020.
- [34] R. Q. Mínguez, I. P. Alonso, D. Fernández-Llorca, and M. Á. Sotelo, “Pedestrian path, pose, and intention prediction through gaussian process dynamical models and pedestrian activity recognition,” IEEE Transactions on Intelligent Transportation Systems, vol. 20, no. 5, pp. 1803–1814, 2019.
- [35] M. Andriluka, S. Roth, and B. Schiele, “Monocular 3d pose estimation and tracking by detection,” in Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. IEEE, 2010, pp. 623–630.
- [36] K. Hara and R. Chellappa, “Growing regression tree forests by classification for continuous object pose estimation,” International Journal of Computer Vision, vol. 122, no. 2, pp. 292–312, 2017.
- [37] J. Chung, C. Gulcehre, K. Cho, and Y. Bengio, “Empirical evaluation of gated recurrent neural networks on sequence modeling,” arXiv preprint arXiv:1412.3555, 2014.
- [38] A. Vaswani, N. Shazeer, N. Parmar, J. Uszkoreit, L. Jones, A. N. Gomez, Ł. Kaiser, and I. Polosukhin, “Attention is all you need,” in Advances in Neural Information Processing Systems, 2017, pp. 5998–6008.
- [39] S. Ruder, “An overview of multi-task learning in deep neural networks,” arXiv preprint arXiv:1706.05098, 2017.
- [40] J. Redmon and A. Farhadi, “Yolov3: An incremental improvement,” arXiv preprint arXiv:1804.02767, 2018.
- [41] A. Bewley, Z. Ge, L. Ott, F. Ramos, and B. Upcroft, “Simple online and realtime tracking,” in 2016 IEEE International Conference on Image Processing (ICIP). IEEE, 2016, pp. 3464–3468.
- [42] J. Wang, K. Sun, T. Cheng, B. Jiang, C. Deng, Y. Zhao, D. Liu, Y. Mu, M. Tan, X. Wang et al., “Deep high-resolution representation learning for visual recognition,” IEEE Transactions on Pattern Analysis and Machine Intelligence, Early Access, 2020.
- [43] S.-S. Kim, I.-Y. Gwak, and S.-W. Lee, “Coarse-to-fine deep learning of continuous pedestrian orientation based on spatial co-occurrence feature,” IEEE Transactions on Intelligent Transportation Systems, vol. 21, no. 6, pp. 2522–2533, 2020.
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/c7fc72de-969e-42ce-8b23-62412de17a0d/photo_uhkim.jpg) |
Ue-Hwan Kim received the Ph.D, M.S. and B.S. degrees in Electrical Engineering from Korea Advanced Institute of Science and Technology (KAIST), Daejeon, Korea, in 2020, 2015 and 2013, respectively. Since 2021, he has been with the AI Graduate School, GIST, Korea, where he is leading the Autonomous Computing Systems Lab as an assistant professor. His current research interests include visual perception, service robots, intelligent transportation systems, cognitive IoT, computational memory systems, and learning algorithms. |
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/c7fc72de-969e-42ce-8b23-62412de17a0d/photo_dhka.jpg) |
Dongho Ka received the Ph.D degree in Civil and Environmental Engineering in 2021 and the M.S. and B.S. degrees in Industrial and Systems Engineering in 2017 and 2015 from KAIST, Daejeon, Korea, in 2017 and 2015, respectively. His current research interests include system engineering, cooperative-intelligent transport systems, AI mobility, and pedestrian behavior analysis. |
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/c7fc72de-969e-42ce-8b23-62412de17a0d/photo_hsyeo.jpg) |
Hwasoo Yeo received the B.S. degree in civil engineering from Seoul National University, Seoul, in 1996, and the M.S. and Ph.D. degrees in civil and environmental engineering from the University of California at Berkeley, Berkeley, CA, USA, in 2008. He is currently an Associate Professor with the Department of Civil and Environmental Engineering, KAIST. His current research interests include AI mobility, traffic flow and traffic operations, and intelligent transportation systems. |
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/c7fc72de-969e-42ce-8b23-62412de17a0d/photo_jhkim.jpg) |
Jong-Hwan Kim (F’09) received the Ph.D. degree in electronics engineering from Seoul National University, Korea, in 1987. Since 1988, he has been with the School of Electrical Engineering, KAIST, Korea, where he is leading the Robot Intelligence Technology Laboratory as KT Endowed Chair Professor. Dr. Kim is the Director for both of KoYoung-KAIST AI Joint Research Center and Machine Intelligence and Robotics Multi-Sponsored Research and Education Platform. His research interests include intelligence technology, machine intelligence learning, and AI robots. He has authored five books and ten edited books, and around 450 refereed papers in technical journals and conference proceedings. |