A Novel U-Net Architecture for Denoising of Real-world Noise Corrupted Phonocardiogram Signal
Abstract.
The bio-acoustic information contained within heart sound signals are utilized by physicians world-wide for auscultation purpose. However, the heart sounds are inherently susceptible to noise contamination. Various sources of noises like lung sound, coughing, sneezing, and other background noises are involved in such contamination. Such corruption of the heart sound signal often leads to inconclusive or false diagnosis. To address this issue, we have proposed a novel U-Net based deep neural network architecture for denoising of phonocardiogram (PCG) signal in this paper. For the design, development and validation of the proposed architecture, a novel approach of synthesizing real-world noise corrupted PCG signals have been proposed. For the purpose, an open-access real-world noise sample dataset and an open-access PCG dataset has been utilized. The performance of the proposed denoising methodology has been evaluated on the synthesized noisy PCG dataset. The performance of the proposed algorithm has been compared with existing state-of-the-art (SoA) denoising algorithms qualitatively and quantitatively. The proposed denoising technique has shown improvement in performance as comparison to the SoAs.
1. introduction
The pumping action of the heart circulates blood throughout the body. During the circulation the opening and closing of the heart valves gives rise to the heart sounds. The four fundamental heart sounds are: 1) first heart sound (S1), 2) second heart sound (S2), 3) systolic interval and 4) diastolic interval. The heart sound is heard by physician/clinician using stethoscope for auscultation purposes. However, owing to the characteristic low amplitude of the heart sound signal, it is naturally susceptible to ambient noises (leal2018noise, ). Sample recordings of a noisy and a clean PCG signals are plotted in Fig. 1(a) and Fig. 1(b) respectively.


It can be surmised from the figures that in the case of the noisy heart sound recording, the significant features of the signal become obfuscated due to the noise corruption. Under such a scenario, reliable auscultation become difficult even for the experts at places like out patients departments and non-clinical environments.
Thanks to the recent advances in artificial intelligence and machine learning techniques, an automatic diagnosis of different pathological conditions is possible from a PCG. However, noisy signals severely impact the performance of such algorithms as well. Hence, it can be concluded that denoising is an essential and practical pre-processing step required to ensure reliable auscultation/decision-making for human experts/machine driven algorithms.
The research complexity of denoising PCG corrupted with real-world noise arises due to 1) the wide gamut of naturally occurring noise sources that can corrupt the heart sound, and 2) the significant spectral overlap that exists between the heart sound spectrum and the noise spectrum.
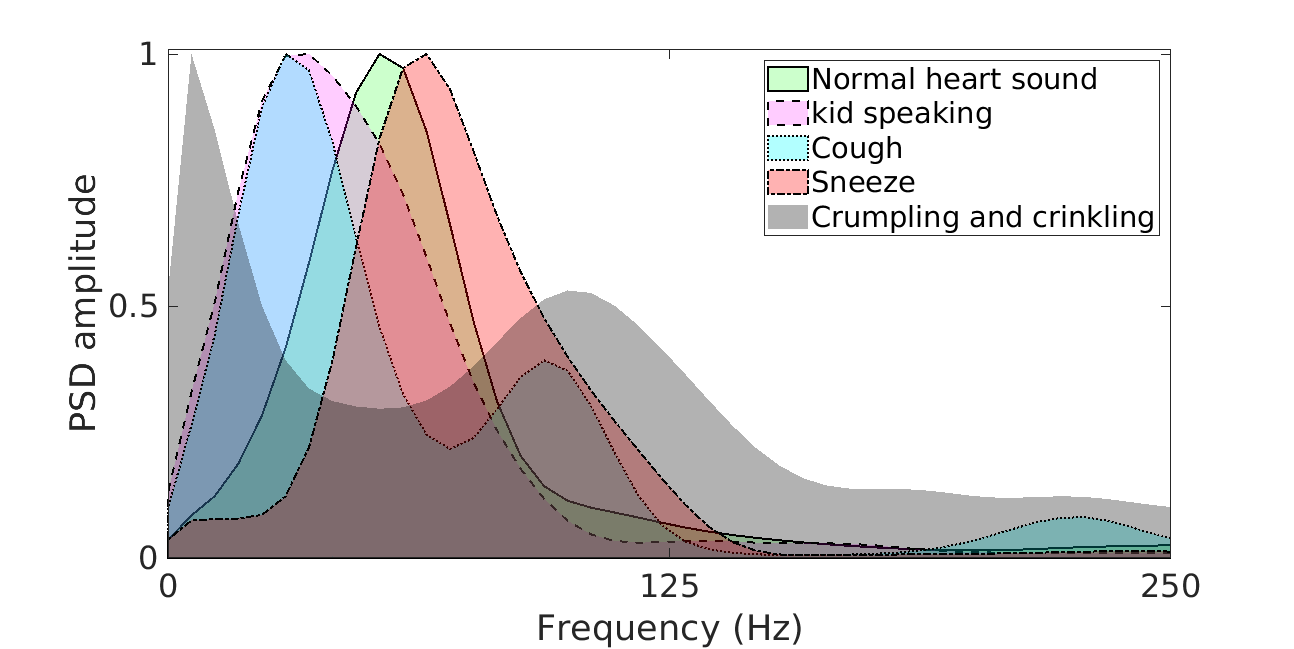
In Fig. 2 , the spectral plot of typical heart sound cycles, and other real-world noise samples like child speech, sneeze, cough, crumpling and crinkling are plotted. The significance of overlap between the spectrums as can be observed from the figure.
Two types of approaches for dealing with noisy heart sound signals exist in literature. In the first approach, the noisy part of the signal is identified and discarded. Such noisy segment identification is done based on signal quality metrics (springer2014signal, ). The other approaches modifies the noisy signal through some form of filtering like bandpass filtering (de2007automated, ), spectral subtraction (tosanguan2008modified, ; paul2006noise, ), etc. to retrieve the clean signal. However, due to the spectral overlap between the signal and noise spectrum such methods are largely ineffective (asmare2021can, ). Wavelet transform is another widely used technique used for denoising of heart sound (agrawal2013wavelet, ; messer2001optimal, ). However, the performances of such algorithms are highly sensitive to the setting of the thresholds (asmare2021can, ).
While all the existing state-of-the-art (SoA) heart sound denoising algorithms have reported effective denoising of noisy heart sound signals, most of those have considered only additive white gaussian (AWG) signal as the noise component (asmare2021can, ). This makes the reliability of such PCG denoising algorithms uncertain under real-world noise corruptions.
In order to address this research issue, the present research work proposes a deep learning architecture for denoising of PCG signals corrupted with real-world noise recordings.
The major contributions of the present research work are:
-
(1)
Development of a noisy PCG signal dataset based on real-world noise samples (child speak, cough, sneeze, crumpling and crinkling, hiss).
-
(2)
Development of a U-net based deep learning denoising architecture for reliable denoising of real-world noise corrupted heart sound signals.
-
(3)
Thorough evaluation of the proposed denoising architecture with simulated real-world noise corrupted PCG signal dataset as well as performance comparison with the existing SoA denosing algorithms.
The rest of the paper is organized as follows:
Section II presents the process for the synthesis of the real-world noise corrupted PCG signal dataset. Section III provides a detailed description of the proposed U-Net based denoising architecture. The evaluation of the proposed architecture and comparative analysis with existing SoA denosing techniques are presented in Section III followed by conclusion in Section IV.
2. dataset description
2.1. Heart sound dataset
For the present research work, a subset of the publicly available PASCAL heart sound dataset (Btraining_normal subset) (pascal-chsc-2011, ) has been utilized. The choice of the dataset was motivated by the availability of clean heart sound signals, which is the fundamental requirement of the present research endevour. The dataset consists of clean heart sound signals of varying lengths (between second and seconds). The signals are sampled at KHz and saved as audio files in wav format.
2.2. Real world noise sample dataset
In order to generate the noisy PCG recordings portions of real-world noise recordings have been used. The publicly available ARCA23K dataset (Iqbal2021, ) provides labeled real-world sound events. It consists of audio clips of varying lengths and along with annotations ( class labels). All the ARCA23K recordings are sampled at KHz and saved as audio files in wav format.
2.3. Noisy heart sound dataset synthesis
Among the labels of the ARCA23K dataset, only a subset of it has relevance (can be considered as noise) for heart sound corruption in a real-world setting. Hence, for the present work, we considered only those audio files that had one of the following labels as annotation: (1) Crumpling and crinkling, (2) Child speech and kid speaking, (3) hiss, (4) sneeze, and (5) cough. All such relevant noise recordings were resampled to KHz to match the sampling rate of the PASCAL heart sound recording. Now, the steps followed for mixing the down-sampled noise recordings with the clean PCG signals are enumerated as follows:
-
(1)
Random number of segments of varying lengths are generated from noise audio samples.
-
(2)
For each category of noise, the segments are randomly placed on a zero vector of length equal to the heart sound recording under consideration. This results in the generation of category-wise noise vectors.
-
(3)
The noise vectors are normalized between .
-
(4)
Now, the noise vectors are added sample-wise to the heart sound vector.
-
(5)
The resultant vector is again normalized between to generate the noisy heart sound vector.
| Noise category | # of segments | Mean (Sec) | Std (Sec) | Mode (Sec) |
|---|---|---|---|---|
| Child speech and kid speaking | 5892 | 0.76 | 0.76 | 0.29 |
| Hiss | 21719 | 0.64 | 0.68 | 0.37 |
| Crumpling and crinkling | 21569 | 0.62 | 0.66 | 0.11 |
| Cough | 5910 | 0.84 | 0.73 | 0.45 |
| Sneeze | 5892 | 0.84 | 0.73 | 0.25 |
Samples of the noise vectors generated following the above steps are shown in Fig. 3.





3. methodology
3.1. Pre-processing
Taking cognizance of the limited spectral bandwidth of a typical heart sound cycles (Fig. 2) each noisy PCG time series is down-sampled from KHz to Hz. Next, from the down-sampled signal, non-overlapping data-frames are extracted (window length = 1.5 seconds, rectangular window). Now each such 1-D dataframe is transformed to the time-frequency domain using short time Fourier transform (STFT). The STFT parameters used for the present application (samples per segment = , FFT points = , window = , scaling = , segment overlap= ). These are standard STFT parameters reported in research literature (grais2017two, ). This transformation generates the spectrum matrix () with dimension . The typical STFT frames generated for clean and noisy dataframes are shown in Fig. 4(a) and Fig. 4(b) respectively. Clear reflection of the noise corruption can be observed in Fig. 4(b). is further split into its real and imaginary matrix components. The component matrices are resized to and are concatenated along the third axis. The resulting matrix is fed into the deep neural network architecture discussed in the following section.


3.2. Proposed U-net based denoising approach
U-Net is a widely used fully convolutional deep neural network architecture. It has been widely applied in image segmentation (ronneberger2015u, ), image denoising (bao2020real, ) and restoration (aghabiglou2021projection, ). However, to the best of the knowledge of the authors, the present application of the U-Net architecture for the denoising of 1D physiological time series data is a novel application of U-Net. The U-Net has a similar architecture to that of the denoising autoencoder-decoder network. However, in U-Net, the presence of skip connections transfer the fine-grained information from the analysis path to the synthesis path. Such information allows the network to recostruct signals with accurate finer morphological details. This property of the U-Net is the motivation behind its choice as the learning model for the present application. For the purpose, the architecture proposed in (ronneberger2015u, ) has been utilized with minor modifications. The architecture can be referred to in (ronneberger2015u, ). The flow of the U-net architecture in the context of the present application is summarized as follows:
The input (as discussed in the preceeding subsection) is filtered by 2D convolution filters (number of filters are increased from to in steps) and downsampled using max-pooling() in steps to . This latent space is again filtered and upsampled for signal synthesis such that the output of the final layer dimension-wise matches the input. For the optimization of the tunable network parameters Nadam optimizer has been employed ( = , = , = , learning rate = ). The optimized function is the mean-squared error (mse). Further early-stopping criteria has been imposed upon the training to mitigate the curse of over-fitting. The batchsize is set to 128 and maximum epoch is set to 100. Further, batch normalization has been employed to limit the effect of over-fitting. Rectified linear unit (ReLU) function has been used as the non-linear activation function across all the layers of the network.
3.3. Post-processing
In the post-processing stage, the ouput spectrum frames are resized to () and then transformed back to the 1-D data frames using inverse STFT. Finally the frames are concatenated to obtain the denoised heart sound time series.
4. Results and discussion
The proposed architechture has been simulated in the Python environment using Pycharm IDE. The TensorFlow version used for the U-Net architecture realization is 2.7.4. From the clean PASCAL heart sound recordings, following the process already discussed (section II, subsection C), 4000 noisy recordings has been generated. The noisy recordings is further split into training, validation and test partitions in the ratio of 64:16:20. The split has been done at the subject level in order to ensure that data of none of the subjects is present in more that one partion. The real-world noisy heart sound data simulation and the deep learning training and testing is done in a computing device with 16 GB RAM, i5 8 core processor and 256 GB disk capacity. In addition to the evaluation of the proposed heart sound denoising architecture, the performance of the proposed architecture has been compared with a wavelet-thresholding (WT) (ghanbari2006new, ) based SoA technique and a baseline denoising auto-encoder (DAE) architecture (banerjee2022noise, ),(vincent2008extracting, ). respectively.
| (1) |
| (2) |
| (3) |
where is the clean PCG signal (target), is the noisy PCG signal and is the mean of .
| Method | Mean RMSE | Mean MAE | Mean SNR |
|---|---|---|---|
| Proposed | 0.7588 | 0.1063 | -2.4449 |
| WT based | 0.8772 | 0.1232 | -3.6469 |
| Baseline DAE based | 1.8818 | 0.2130 | -18.5644 |
The quantitative evaluation of the proposed denoising algorithm is done based on three metrics: root mean square error (RMSE), median absolute error (MAE) and signal to noise ratio (SNR). The mathematical representations of the three metrics are given in (1), (2) and (3). The performance of the proposed algorithm and the two SoA techniques in terms of the three metrics are reported in Table 2. From the reported metric values it can be observed that the proposed denoising architecture has performed better than the two SoAs comprehensively. In addition, for qualitative assessment, a sample of the test noisy heart sound signal and clean heart sound signal (target) are plotted in Fig. 5(b) and Fig. 5(a) respectively. The de-noised heart sound signals as obtained from the proposed denoising architecture is plotted in Fig. 5(c). Further, the denoised time series as obtained from the SoAs (WT and DAE) are plotted in Fig. 5(e) and Fig. 5(e) respectively. It can be observed that the proposed methodology is able to effectively remove the real-world noises from the noisy signal while preserving the S1 and S2 characteristics. The wavelet based approach has introduced a narrow band of noise along the time series as well as thinned out the S1, S2 peaks thereby impacting its audio characteristics. The DAE based method has failed to perform any effective noise cleaning.





5. CONCLUSIONS
Heart sounds signal are in general vulnerable to ambient noises and hence denoising is considered as a critical pre-processing step in the subsequent analysis for potential disease diagnosis. Simulating such noise-contaminated PCG signal is challenging and the existing denoising approaches use AWG as the noise source for data corruption. A machine learning model trained on such data is less likely to generalize in practical scenario. In this paper, we propose a novel pipeline for simulating realistic noisy PCG signals. Further, we propose a novel U-Net based PCG denoising algorithm that can reliably reconstruct both the amplitude and the phase information of the PCG data from realistic noisy PCG recordings. The realistic noisy PCG signals synthesized has been used to training the proposed deep learning model. Our experiments on publicly available dataset and subsequent quantitative and qualitative analysis and comparison with other existing SoA denoising algorithms clearly indicates the efficacy of the proposed approach.
Denoising is a critical application for any PCG recording device front-end. Therefore, our future works would be to optimize the model for effective deployment on low-powered embedded platforms.
References
- [1] Adriana Leal, Diogo Nunes, Ricardo Couceiro, Jorge Henriques, Paulo Carvalho, Isabel Quintal, and César Teixeira. Noise detection in phonocardiograms by exploring similarities in spectral features. Biomedical Signal Processing and Control, 44:154–167, 2018.
- [2] David B Springer, Thomas Brennan, LJ Zühlke, Hassan Y Abdelrahman, Ntobeko Ntusi, Gari D Clifford, Bongani M Mayosi, and Lionel Tarassenko. Signal quality classification of mobile phone-recorded phonocardiogram signals. In 2014 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), pages 1335–1339. IEEE, 2014.
- [3] Jacques P De Vos and Mike M Blanckenberg. Automated pediatric cardiac auscultation. IEEE Transactions on Biomedical Engineering, 54(2):244–252, 2007.
- [4] Thanut Tosanguan, Robert J Dickinson, and Emmanuel M Drakakis. Modified spectral subtraction for de-noising heart sounds: Interference suppression via spectral comparison. In 2008 IEEE Biomedical Circuits and Systems Conference, pages 29–32. IEEE, 2008.
- [5] Anindya S Paul, Eric A Wan, and Alex T Nelson. Noise reduction for heart sounds using a modified minimum-mean squared error estimator with ecg gating. In 2006 International Conference of the IEEE Engineering in Medicine and Biology Society, pages 3385–3390. IEEE, 2006.
- [6] Melkamu Hunegnaw Asmare, Frehiwot Woldehanna, Luc Janssens, and Bart Vanrumste. Can heart sound denoising be beneficial in phonocardiogram classification tasksf. In 2021 43rd Annual International Conference of the IEEE Engineering in Medicine & Biology Society (EMBC), pages 354–358. IEEE, 2021.
- [7] Kritika Agrawal, Abhinash Kumar Jha, Shealini Sharma, Ayush Kumar, and Vijay S Chourasia. Wavelet subband dependent thresholding for denoising of phonocardiographic signals. In 2013 Signal Processing: Algorithms, Architectures, Arrangements, and Applications (SPA), pages 158–162. IEEE, 2013.
- [8] Sheila R Messer, John Agzarian, and Derek Abbott. Optimal wavelet denoising for phonocardiograms. Microelectronics journal, 32(12):931–941, 2001.
- [9] P. Bentley, G. Nordehn, M. Coimbra, and S. Mannor. The PASCAL Classifying Heart Sounds Challenge 2011 (CHSC2011) Results. http://www.peterjbentley.com/heartchallenge/index.html.
- [10] T. Iqbal, Y. Cao, A. Bailey, M. D. Plumbley, and W. Wang. ARCA23K: An audio dataset for investigating open-set label noise. In Proceedings of the Detection and Classification of Acoustic Scenes and Events 2021 Workshop (DCASE2021), pages 201–205, Barcelona, Spain, 2021.
- [11] Emad M Grais, Gerard Roma, Andrew JR Simpson, and Mark D Plumbley. Two-stage single-channel audio source separation using deep neural networks. IEEE/ACM Transactions on Audio, Speech, and Language Processing, 25(9):1773–1783, 2017.
- [12] Olaf Ronneberger, Philipp Fischer, and Thomas Brox. U-net: Convolutional networks for biomedical image segmentation. In Medical Image Computing and Computer-Assisted Intervention–MICCAI 2015: 18th International Conference, Munich, Germany, October 5-9, 2015, Proceedings, Part III 18, pages 234–241. Springer, 2015.
- [13] Long Bao, Zengli Yang, Shuangquan Wang, Dongwoon Bai, and Jungwon Lee. Real image denoising based on multi-scale residual dense block and cascaded u-net with block-connection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops, pages 448–449, 2020.
- [14] Amir Aghabiglou and Ender M Eksioglu. Projection-based cascaded u-net model for mr image reconstruction. Computer Methods and Programs in Biomedicine, 207:106151, 2021.
- [15] Yasser Ghanbari and Mohammad Reza Karami-Mollaei. A new approach for speech enhancement based on the adaptive thresholding of the wavelet packets. Speech communication, 48(8):927–940, 2006.
- [16] Rohan Banerjee, Ayan Mukherjee, and Avik Ghose. Noise cleaning of ecg on edge device using convolutional sparse contractive autoencoder. In 2022 IEEE International Conference on Pervasive Computing and Communications Workshops and other Affiliated Events (PerCom Workshops), pages 491–496. IEEE, 2022.
- [17] Pascal Vincent, Hugo Larochelle, Yoshua Bengio, and Pierre-Antoine Manzagol. Extracting and composing robust features with denoising autoencoders. In Proceedings of the 25th international conference on Machine learning, pages 1096–1103, 2008.