A novel multiobjective evolutionary algorithm based on decomposition and multi-reference points strategy
Abstract
Many real-world optimization problems such as engineering design can be eventually modeled as the corresponding multiobjective optimization problems (MOPs) which must be solved to obtain approximate Pareto optimal fronts. Multiobjective evolutionary algorithm based on decomposition (MOEA/D) has been regarded as a significantly promising approach for solving MOPs. Recent studies have shown that MOEA/D with uniform weight vectors is well-suited to MOPs with regular Pareto optimal fronts, but its performance in terms of diversity usually deteriorates when solving MOPs with irregular Pareto optimal fronts. In this way, the solution set obtained by the algorithm can not provide more reasonable choices for decision makers. In order to efficiently overcome this drawback, we propose an improved MOEA/D algorithm by virtue of the well-known Pascoletti-Serafini scalarization method and a new strategy of multi-reference points. Specifically, this strategy consists of the setting and adaptation of reference points generated by the techniques of equidistant partition and projection. For performance assessment, the proposed algorithm is compared with existing four state-of-the-art multiobjective evolutionary algorithms on benchmark test problems with various types of Pareto optimal fronts. According to the experimental results, the proposed algorithm exhibits better diversity performance than that of the other compared algorithms. Finally, our algorithm is applied to two real-world MOPs in engineering optimization successfully.
keywords:
Evolutionary computations , Multiobjective optimization , Pascoletti-Serafini scalarization , Multi-reference points , Decomposition1 Introduction
The problems of simultaneously optimizing multiple conflicting objectives often arise in engineering, finance, transportation and many other fields; see [3, 46, 65, 7, 49]. These problems are called multiobjective optimization problems (MOPs). It is not possible mathematically to define a single optimal solution for a given MOP but we have a set of trade-offs, that is, a set of so-called Pareto optimal solutions in the decision space, which constitute the Pareto optimal set. The image of Pareto optimal set in objective space is known as the Pareto optimal front (POF). Finding the entire POF is very time-consuming since the POF of most MOPs is frequently composed of exponential or even an infinite number of solutions. Moreover, the decision makers may not be interested in having an unduly large number of solutions. Thus, a commonly-used technique in practice is to find a representative approximation of the true POF.
Over the past two decades, we have witnessed a large variety of methods for solving MOPs; see [41, 20, 59, 56, 58, 19, 18], the survey papers [32, 48, 21, 51, 38, 47] and the books [40, 9, 16, 43]. Among the various methods mentioned in the above literature, multiobjective evolutionary algorithms (MOEAs) have attracted tremendous attention by many researchers. A reasonable interpretation is that the population-based heuristic search mechanism makes a MOEA find a suitable approximation of the entire POF in a single run. Three goals of a MOEA summarized in [51] are - 1) to find a set of solutions as close as possible to the POF (known as convergence), 2) to find a well distributed set of solutions (known as diversity), 3) to cover the entire POF (known as coverage). In order to achieve these goals, several existing MOEAs can be broadly classified into three groups: Pareto dominance-based approaches (e.g., nondominated sorting genetic algorithm II (NSGA-II) [12]), indicator-based approaches (e.g., hypervolume estimation algorithm (HypE) [5]) and decomposition-based approaches (e.g., cellular multiobjective genetic algorithm (cMOGA) [42], MOEA/D [60]).
In the above-mentioned three groups, decomposition-based approaches have become increasingly popular recently. MOEA/D, proposed by [60], is the most well-known and effective method in decomposition-based MOEAs. The philosophy behind MOEA/D is that it decomposes a target MOP into a series of scalar optimization subproblems by means of a set of uniform weight vectors generated by the lattice method proposed by [10] and a scalarization method (or, decomposition method) such as Tchebycheff, and then solves these subproblems simultaneously by using an evolutionary algorithm and evolving a population of solutions. Although MOEA/D with even weight vectors is well-suited to MOPs with regular POFs (i.e., simplex-like, e.g., a triangle and a sphere), many recent studies [45, 34, 38] have suggested that its performance is often bottlenecked by MOPs with irregular POFs (e.g., disconnected, degenerate, inverted, highly nonlinear and badly scaled). From the variants (see the survey papers [51, 38, 55]) gestated by MOEA/D in the past a dozen years, it can be seen that the predefined uniform weight vectors and the scalarization approach in MOEA/D limit the diversity of population to a great extent. Therefore, the adjustment of weight vectors and the improvement of scalarization approach become two crucial ingredients in the variants of MOEA/D.
-
1.
Weight Vectors: The weight vectors determine the search directions and, to a certain extent, the distribution of the final solution set [38]. In MOEA/D [60], the weight vectors are predefined and cannot be changed during the search process. It is exciting that various interesting attempts [45, 23, 29, 8, 35, 15] have been made to adjust the weight vectors adaptively during the evolution process. For instance, -MOEA/D [29] uses a method called Pareto-adaptive weight vectors to automatically adjust the weight vectors via the geometrical features of the estimated POF. -MOEA/D is suitable for MOPs whose POFs have a symmetric shape, but deteriorates on MOPs with more complex POFs. DMOEA/D [23] adopts the technique of equidistant interpolation to adjust weight vectors after several generations according to the projection of the current nondominated solutions. MOEA/D-AWA [45] dynamically adjusts the weight vectors at the later stage of evolution. To be specific, MOEA/D-AWA periodically deletes weight vectors in crowed areas and adds ones in sparse areas. RVEA* [8] employs the preset weight vectors in the initialization and then uses random weight vectors to replace the invalid weight vectors associated with no solution in the evolutionary process. For the MOPs with different objective scales, [35] gave a new strategy to adjust the weight vectors. This strategy modifies the component of each weight vector by multiplying a factor, which corresponds to the range of associated objective values of solutions in current population.
-
2.
Scalarization Approaches: The scalarization method defines an improvement region or a contour line for every subproblem, which can significantly affect the search ability of the evolving population. In MOEA/D, the authors presented three kinds of scalarization methods, namely, weighted sum (WS), Tchebycheff (TCH) and penalty-based boundary intersection (PBI). However, the solutions obtained by these scalarization approaches with uniform weight vectors are not always uniformly distributed along POF and the performance of PBI is suffered from the penalty parameter. Moreover, the choice of scalarization method plays critical role in the performance of MOEA/D on a particular problem and it is not an easy task to choose an appropriate scalarization approach for different MOPs [51]. To alleviate these drawbacks, many different scalarizing functions have been proposed in the literature; see the survey papers [51, 55]. For example, [26] used the augmented weighted Tchebycheff within the framework of MOEA/D so as to cope with the problem of selecting a suitable scalarization method for a particular problem. [30] proposed the reverse Tchebycheff approach, which can deal with the problems with highly nonlinear and convex POFs. [57] investigated the search ability of scalarization method with different contour lines determined by the values and then introduced a Pareto adaptive scalarizing approximation to approach the optimal value at different search stages. [39] proposed the Tchebycheff scalarization approach with -norm constraint on direction vectors in which the experimental results show that this method is capable of obtaining high quality solutions.
These methods in the aforementioned literature improve the diversity of the final solution set obtained by corresponding algorithms to a certain extent. Unfortunately, the ability of scalarization function and the adjustment of weight vectors are still limited. In particular, for the MOP whose POF has the shape of highly nonlinearity and convexity, e.g., the hatch cover design problem [49] and GLT3 [23], these methods do not seem to be very effective. More importantly, we observe that various scalarization approaches introduced in MOEA/D and its variants all take into account the information on the weight vectors and the ideal point (see the scalarization approaches summarized in Table 1 of Subsection 2.2). From the geometric point of view, we attribute these methods to a category of “single-point and multi-directions”, as shown in Fig. 1 in Subsection 2.2. Herein, single-point stands for the ideal point or the nadir point and multi-directions denote a set of preset uniformly distributed weight vectors. The left part of Fig. 3 in Subsection 3.1 reveals that the diversity of the final solution set is vulnerable to this geometric phenomenon.
In order to essentially change this geometric phenomenon, an intuitive idea called “multi-points and single-direction” is proposed (see the right part of Fig. 3 in Subsection 3.1). As a result, the aforesaid scalarization method may no longer be applicable. Now, the question is whether there is a scalarization method without considering the weight vectors and the ideal point, and then matches this idea? Here, it is shown that the answer to this question is positive. The Pascoletti-Serafini (PS) scalarization method with additional constraints proposed by [44] does not rely on the weight vector and the ideal point. It has two parameters, i.e., reference point and direction, which by varying them in (-dimensional Euclidean space), all Pareto optimal solutions can be obtained for a given MOP. An advantage of the PS scalarization method is that it is very general in the sense that many other well-known and commonly-used scalarization methods such as the WS method, the -constraint method, the generalized WS method and the TCH method can be seen as a special case of it (see Section 2.5 in [16]). For researches on theories and applications of the PS method and its variants, we refer the interested readers to the literature [16, 17, 6, 33, 1, 14, 50] for more details. Note that [16] indicated that the optimal solution obtained by the PS scalarization method is the intersection point between the POF and the negative ordering cone along the line generated by reference point and direction. Therefore, in order to obtain a set of uniformly distributed solutions which can well approximate the true POF, the setting of the reference point and the direction in the PS scalarization approach is crucial.
In this paper, we propose a new multiobjective evolutionary algorithm based on decomposition and adaptive multi-reference points strategy, termed as MOEA/D-AMR, which performs well in diversity. The main contributions of this paper can be concluded as follows:
-
1.
Using a standard trick from mathematical programming, we equivalently transform the PS scalarization problem into a minimax optimization problem when each component of the direction is restricted to positive. Based on the proposed idea (i.e., “multi-points and single-direction”), a given MOP is decomposed into a series of the transformed minimax optimization subproblems.
-
2.
A strategy of setting multi-reference points is introduced. More specifically, the selection range of reference points is limited to a convex hull formed by the projection points of the vertices of the hypercube on a hyperplane and then the generation of reference points is realized by using two techniques including equidistant partition and projection.
-
3.
A multi-reference points adjustment strategy based on the obtained solutions in the later stage of evolution is proposed. This strategy can identify the promising reference points, delete unpromising ones and generate some new ones.
-
4.
We verify the diversity performance of the proposed algorithm by comparing it with four representative MOEAs on a series of benchmark multiobjective test problems with regular and irregular POFs. The proposed algorithm is used to solve two real-world MOPs in engineering optimization including the hatch cover design and the rocket injector design. The experimental results illustrate the effectiveness of our algorithm.
The rest of this paper is organized as follows. Section 2 gives some fundamental definitions related to multiobjective optimization and recalls several scalarization approaches. Section 3 discusses the motivation of the proposed algorithm and illustrates the details of its implemention. Algorithmic comparions and analysis on test problems are presented in Section 4, followed by applications on real-world MOPs in Section 5. Lastly, Section 6 concludes this paper and identifies some future plans.
2 Related works
We start with the descriptions of some basic concepts in multiobjective optimization. Then, we recall some scalarization methods used in MOEA/D framework. Finally, a brief review of the Pascoletti-Serafini scalarization method is presented.
2.1 Basic concepts
Throughtout this paper, for , where denotes the set of natural numbers, we use the symbols
Let be the nonnegative orthant of -dimensional Euclidean space , i.e,
We consider the following multiobjective optimization problem:
| (1) | ||||
where is a decision variable vector, is the decision (search) space, and are the lower and upper bounds of the -th decision variable , respectively. consists of real-valued objective functions , and is also called the objective space. Since these objectives conflict with one another, it is not possible to find a feasible point that minimizes all objective functions at the same time. Therefore, it is necessary to give a concept of optimality which described in [40].
Definition 2.1.
Remark 2.1.
It is obvious that if is a Pareto optimal solution of (1), then is a weakly Pareto optimal solution.
Definition 2.2.
If is a (weakly) Pareto optimal solution of (1), then is called a (weakly) Pareto optimal vector.
Definition 2.3.
The set of all Pareto optimal solutions is called the Pareto optimal set (POS). The set of all Pareto optimal vectors, , is called the Pareto optimal front (POF).
Definition 2.4.
A point is called an ideal point if for each .
Remark 2.2.
Note that we have in Definition 2.4 that for all , .
Definition 2.5.
A point is called a nadir point if for each .
2.2 Scalarization methods in MOEA/D framework
Let be a weight vector, i.e., and for all . The formulas of three traditional scalarization approaches (i.e., WS [40], TCH [40] and PBI [60]) and other six scalarization methods (i.e., the augmented Tchebycheff (a-TCH) [26], the modified Tchebycheff (m-TCH) [37], the reverse Tchebycheff (r-TCH) [30], scalarization [57], the multiplicative scalarizing function (MSF) [31] and the Tchebycheff with -norm constraint (-TCH) [39]) used in MOEA/D framework are summarized in Table 1. More scalarization approaches within the framework of MOEA/D can be found in the survey papers [51, 55].
| Scalarization | Formulas |
| WS | |
| TCH | |
| PBI | , , , |
| a-TCH | , |
| m-TCH | |
| r-TCH | |
| , | |
| MSF | |
| -TCH | , with and |
We select six representative scalarization methods from Table 1 to give some illustrations.
-
1.
WS method: The WS method is also called the linear scalarization. It is probably the most commonly used scalarization technique for MOPs in traditional mathematical programming. It associates every objective function with a weighting coefficient and optimizes real-valued function of weighted sum of the objectives. A major difficulty of this approach is that if the POF is not convex, then there does not exist any weight vector such that the solution lies in the nonconvex part.
-
2.
TCH method: This approach uses preference information received from a decision maker to find the Pareto optimal solution. The preference information consists of a weight vector and an ideal point. It is used as an scalarization method in MOEA/D for continuous MOPs, because it can deal with both convex POFs and concave POFs. It is noteworthy that the final solution set obtained by MOEA/D with the TCH approach is not well-distributed along the regular POFs.
-
3.
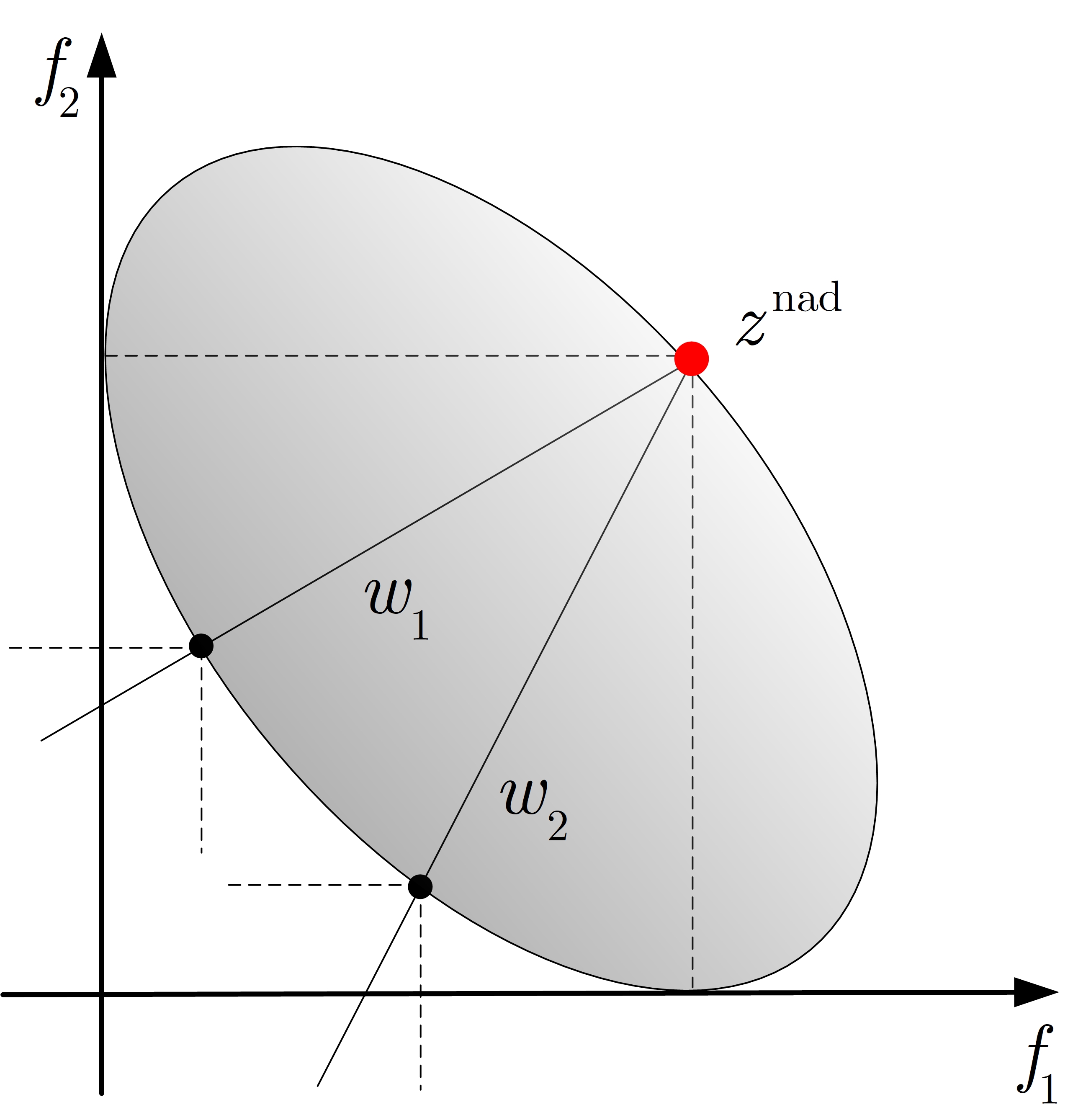
PBI method: This is a direction-based decomposition approach, which uses two distance to reflect the assessment of convergence measured by and diversity measured by of population in MOEA/D, respectively (see Fig. 1(c)). The penalty parameter in PBI is used to control the balance between convergence and diversity. A drawback of this method is that the penalty parameter is to be properly tuned.
-
4.
r-TCH method: It is an inverted version of the TCH method, which is determined by a weight vector and a nadir point (see Fig. 1(d)). Compared with the TCH approach, the r-TCH approach is superior in diversity when solving a MOP whose POF has a shape of highly nonlinearity and convexity. However, its performance deteriorates on MOPs with highly nonlinear and concave POFs.
-
5.
method: Contour curves of this method with different values are shown in Fig. 1(e). In this approach, there is a trade-off dependent on the value between the search ability of the method and its robustness on POF geometries [57]. As the value of increases, the search ability of the associated scalarization approach decreases. Therefore, a strategy called Pareto adaptive scalarizing approximation is introduced to determine the optimal value. The WS and TCH can be derived by setting and , respectively [57].
-
6.
MSF method: A main feature of the MSF approach is the shape or positioning of its contour lines, which play a key role in search ability. As compared with the method, the opening angle of contour lines of MSF approach is less than and it is controlled by the parameter . The geometric figure of this approach is depicted in Fig. 1(f). With the increasing of , the geometric figures become closer to the used weight vector. Clearly, when , the geometric figure overlaps with the weight vector and when , MSF degenerates to m-TCH.
When , the graphical interpretations of the six scalarization approaches and the positions of optimal solutions for subproblems are plotted in Fig. 1.





2.3 The Pascoletti-Serafini scalarization method
This subsection focuses on the scalarization method introduced by [44]. The scalar problem of the Pascoletti-Serafini (PS) scalarization method with respect to the ordering cone is defined as follows:
| (2) | ||||
| s.t. | ||||
where and are parameters selected from .
Remark 2.3.
- (i)
-
(ii)
Compared with the scalarization methods presented in Table 1, it is obvious that the PS method does not take into account the information on the weight vector and the ideal point or the nadir point.
The geometric interpretation of PS method presented in [16] or [33] is that the ordering cone is moved in the direction (or ) on the line starting in the point until the set is reduced to the empty set, where . The smallest value for which is the optimal value of (2). If the point pair is an optimal solution of (2), then with is an at least weakly Pareto optimal vector and by a variation of the parameters , all Pareto optimal vectors can be obtained. To have an intuitive glimpse of (2), we use the following Fig. 2 to give the graphical illustration of (2) in the case of .
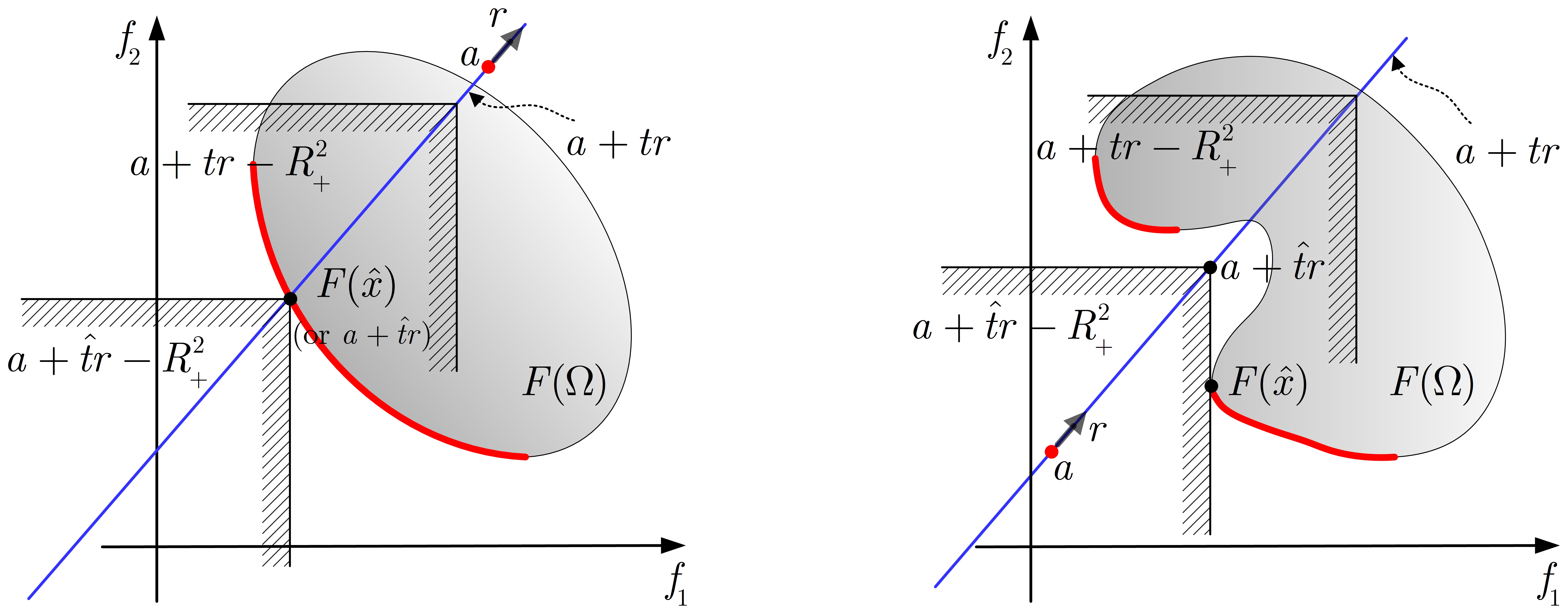
Some interesting properties of this scalarization approach can be found in [16]. Here we concentrate on the following major result (see Theorem 2.1(b) and (c) in [16]), which gives the relation of solutions between (1) and (2).
Theorem 2.1.
3 The proposed algorithm
In this section, the motivation on use of the PS method and an adaptive multi-reference points adjustment strategy for controlling the diversity is first discussed. Then we give specific answers to the questions proposed in motivation. Finally, the detailed implementation of the proposed algorithm is presented.
3.1 Motivation
It follows from these scalarization approaches given in Table 1 and the geometric interpretations shown in Fig. 1 that there is an interesting phenomenon, which we call “single-point and multi-directions”. This is attributed to the ideal point (or the nadir point) and the uniform weight vectors. Such a phenomenon results in the fact that the optimal solutions of all subproblems defined by uniform weight vectors in MOEA/D can form a good approximation for the regular POF. However, it usually leads to the unsatisfactory performance on solving MOPs with irregular POFs. Let us now take an example to illustrate this case. In the left part of Fig. 3, there are nine uniform weight vectors and an ideal point depicted by red solid point. The green, blue and red curves denote POF1, POF2 and POF3, respectively, and the black solid points stand for the optimal solutions for subproblems. It is clear to see that the solutions are roughly uniformly distributed along POF1 and POF2. However, when POF shape is highly nonlinear and convex like POF3 depicted in the left part of Fig. 3, uniform weighting strategy can not produce a set of evenly distributed solutions.

It can be said that the intersection points between a set of equidistant parallel lines and any curves are almost evenly distributed along the curves. Based on this fact, a fundamental idea comes up naturally: “multi-points and single-direction”. As shown in the right part of Fig. 3, there are nine equidistant parallel lines generated by nine red solid reference points and a direction. The black solid points are the intersection points between the nine equidistant parallel lines and three curves. Obviously, these intersection points are uniformly distributed along curve1–curve3.
Traces of this idea of studying the solutions involved in MOPs go back to the work of [10]. They proposed a direction-based decomposition approach, which is called normal boundary intersection (NBI). This approach can obtain the intersection points between the lower boundary part of the image set of the decision space and a series of straight lines defined by a normal vector and a group of evenly distributed points in the convex hull of individual minima (CHIM). Despite the intersection points generated by NBI are uniform, the method has limitations recognized by [10]. In particular, the NBI method may fail to cover the entire POF for problems with more than three objectives. In addition, this method can not guarantee the Pareto optimality of these intersection points. An advantage of the NBI method is that it is relatively insensitive to the scales of objective functions. [61] pointed out that NBI can not be easily used within MOEA/D framework because it has additional constraints. A meaningful attempt in their work is that they absorbed the strengthens of NBI and TCH, and introduced the NBI-style Tchebycheff method for biobjective optimization problem. We next briefly describe this method. Consider in (1) and let and be two extreme points of the POF of (1) in the objective space. The reference points , , are evenly distributed along the line segment linking and , i.e., , where for . Therefore, the -th NBI-style Tchebycheff scalarizing subproblem is
| (3) |
where and . The graphical illustation of the NBI-style Tchebycheff method is shown in Fig. 4. As we have seen, the optimal solutions to the above subproblems can be uniformly distributed along the POF. However, as pointed out by [34], the main weakness of the NBI-style Tchebycheff method is that it can not be extended to handle the MOPs with more than two objectives.

According to the descriptions in Subsection 2.3, it is worth mentioning that the setting of reference point and direction in the PS scalarization method is quite flexible. With the help of the flexibility of reference point and direction, [19] designed a new approximation algorithm to compute a box-coverage of the POF. We observe from their work that the reference points (the lower bounds of some boxes) and the directions (the differences between the lower bounds and the upper bounds of these boxes) are dynamically updated. Based on the flexibility of parameters in the PS scalarization method, the idea (i.e., “multi-points and single-direction”) and the decomposition strategy [60], the primary motivation of this paper is to decompose a target MOP into a number of PS scalar optimization subproblems which have different reference points and same direction, and optimize them simultaneously in a collaborative manner. For example, in the right part of Fig. 3, there are nine decomposed PS scalar optimization subproblems defined the reference points depicted by the red solid points and the same direction depicted by the dotted line. From the graphical illustration in Subsection 2.3, the black solid points are the optimal solutions of all subproblems and they are uniformly distributed. Although this way can approximate continuous POF very well, it may also face the same dilemma as MOEA/D [60], that is, the performance degrades on MOPs with discontinuous POF or even degenerate POF. Therefore, in our proposed algorithm, the reference points related to the subproblems can be properly adjusted to obtain better performance in diversity. Given the above-mentioned descriptions, three inevitable questions are:
-
(1)
How can we embed the PS scalarization method into the MOEA/D framework?
-
(2)
How to set the multi-reference points and the direction?
-
(3)
How to adaptively adjust the multi-reference points?
The following three subsections present the solutions for these questions.
3.2 The transformation of PS scalarization method
It is obvious that (2) cannot be easily used within the framework of decomposition-based multiobjective evolutionary algorithms since it introduces extra constraints. However, when , , (2) is equivalent to the following optimization problem:
| (4) | ||||
| s.t. | ||||
Note that, using a standard trick from mathematical programming, (4) can be rewritten as the following minimax optimization problem:
| (5) |
An advantage of (5) is that it can be used as a scalarizing function in MOEA/D framework. Obviously, Theorem 2.1 also holds for (5).
3.3 The setting of multi-reference points and direction
Our aim is to obtain a good approximation of the true POF for a given MOP by solving (5) for some parameters. From Remark 2.4, all Pareto optimal solutions of (1) can be obtained for a fixed by varying . However, it seems unnecessary to choose the parameters in the whole space . We observe that, Theorem 2.11 in [16] points out that the parameter only need to be varied in a hyperplane. We now present the result as follows:
Theorem 3.1.
Remark 3.2.
In order to make the proposed algorithm having better performance in diversity, we can choose as the normal vector of the hyperplane (i.e., ) and . More specifically, let and (note that this is not the only option). In this case, becomes the hyperplane
which passes through the origin. Then a set of reference points should be uniformly sampled on . In this way, different Pareto optimal solutions can be obtained by solving (5). This way of sampling reference points on the entire seems to be unwise, because it may lead to many redundant reference points. However, the range of true POFs of most test instances in the filed of evolutionary multiobjective optimization belong to . Now, it is assumed that is the set of projection points of all vertices of the hypercube on and let be the convex hull of . An example is shown in the left part of Fig. 5, and
The right part of Fig. 5 is the case of , i.e., and

Therefore, we only need to sample a set of uniformly distributed reference points on . It should be noted that in this paper the uniformly distributed reference points on are obtained by the following two steps:
-
(1)
Equidistant partition. When , we divide the interval on each axis into equal parts, and then base points are obtained. The left part of Fig. 6 shows an example consisting of 9 base points marked by the blue solid points for . When , we also divide on each axis into equal parts. Then the coordinates of these base points are exchanged and new base points are obtained (see the blue solid points in the left and middle parts of Fig. 7).
-
(2)
Projection. The base points are projected into the hyperplane , and then these projection points are regarded as the reference points. Obviously, the convex hull formed by these reference points is . The right part of Fig. 6 shows the 9 uniformly distributed reference points for and the right part of Fig. 7 shows an example consisting of 19 uniformly distributed reference points for .


We would like to emphasize that, if we consider the process of coordinate exchange for the case of , then we can obtain the same reference points. Hence, we omit this process here. The aforementioned method can also be used for . In general, the range of true POFs of some test problems and real-world MOPs is not necessarily belong to . It is apparent that the lines related to the reference points generated by the above-mentioned method cannot cover the whole POF. Herein, the normalization technique mentioned in [60] is adopted to tackle this issue. After normalization, all solutions in current generation are normalized to points in in the normalized objective space. Therefore, the update of solutions can be performed by the following scalar optimization subproblem:
| (6) |
Remark 3.3.
It is noteworthy that the objective normalization, as a transformation that maps the objective values from a scaled objective space onto the normalized objective space, changes the actual objective values, but does not affect the evaluation of by the scalarizing function value. Consequently, for and , the optimal solutions between (5) and (6) are equivalent.
Remark 3.4.
If the true ideal point and the true nadir point in (6) are not available, then we use the best value among all the examined solutions so far and worst value among the current population to assign values to and , respectively.
We conclude this subsection by giving a brief discussion between the way of generating weights in MOEA/D and the reference points generation technique in our method. In MOEA/D, a set of weights evenly distributed on -dimensional unit simplex is used, which is usually generated by the lattice method introduced in [10]. However, in our proposed method, the reference points uniformly distributed on the set , which are generated by the techniques of equidistant partition and projection. The set has a larger range than the simplex and can better cover the space from the diagonal perspective.
3.4 The adaptation of multi-reference points
It is noteworthy that a set of equidistant parallel lines generated by the aforesaid method can cover the whole space . However, if some straight lines, formed by the direction and some reference points, do not intersect the POF, then it follows from the geometric interpretation of the PS method in Subsection 2.3 that the same solution may be obtained for some subproblems or many solutions concentrate on the boundary or discontinuous location of the true POF. Taking Fig. 8(a) as an example, the subproblems related to the reference points , and have the same Pareto optimal vector . This issue greatly affects the performance of the algorithm.



To improve algorithmic performance, it is imperative to consider when, where and how to adjust the reference points. Early adjustment of reference points could be unnecessary and ineffective because the population does not provide a good approximation for POF at early generation. A better approach would be to trigger the adjustment only when the population has roughly reached the POF in later generation. Herein, we use the evolutionary rate to assist the reference points adaptation. When the ratio of iteration numbers to the maximal number of generations is , the adaptation of reference points will be started. In the context, a reference point is regarded as a promising one if it is associated with one or more solutions. On the other hand, a reference point is marked as unpromising if it is not associate with any solution, and then the marked unpromising reference point should be deleted. For example, for the discontinuous POF shown in Fig. 8(a), the six red solid reference points are promising and three blue solid are unpromising. Similarly, for the simplex POF shown in Fig. 8(b) and the degenerate POF shown in Fig. 8(c), there also exist some promising and unpromising reference points. Additional reference points should be generated by utilizing the promising ones so as to keep a prespecified number of reference points. Overall, the key ingredients of adaptive multi-reference points adjustment are how to identify the promising reference points and to add the new ones. The specific implementation schemes will be discussed detailedly in Subsection 3.5.4.
3.5 The description of MOEA/D-AMR
Based on the previous discussions, we are now in a position to propose a new algorithm called MOEA/D-AMR, which integrates the PS scalarization method and the adaptation of multi-reference points into the framework of MOEA/D-DE [36]. Its pseudo-code is presented in Algorithm 1.
Some important components of MOEA/D-AMR such as initialization (line 1 of Algorithm 1), reproduction and repair (lines 5–11 of Algorithm 1), update of solutions (lines 12–19 of Algorithm 1) and adjustment of multi-reference points (lines 21–29 of Algorithm 1) will be illustrated in detail in the following subsections.
3.5.1 Initialization
The first step is to create a set of reference points via the method introduced in Subsection 3.3. The set of all reference points is denoted by . Secondly, we compute the Euclidean distance between any two reference points and then work out the closest reference points to each reference point. For each , set the neighborhood index list , where are the closest reference points to . All the neighborhood index lists are defined as . Thirdly, an initial population , where is the population size, is generated by uniformly sampling from the decision space . The function values are calculated for every , and let . Finally, the ideal point is initialized by setting , .
3.5.2 Reproduction and repair
A probability parameter is used to choose a mating pool from either the neighborhood of solutions or the whole population (lines 5–9 in Algorithm 1). The diffential evolution (DE) mutation operator and the polynomial mutation (PM) operator are used in this paper to produce an offspring solution from , , which are also considered in MOEA/D-DE [36]. The DE operator generates a candidate solution by
where are randomly selected from the mating pool , is the -th component of , , is the scale factor, is the cross rate and is a uniform random number chosen from . The PM operator is applied to generate a solution from in the following way:
with
where the distribution index and the mutation rate are two control parameters. It is not always guaranteed that the new solution generated by reproduction belongs to the decision space . When a component of is out of the boundary of , a repair strategy is applied to such that , i.e.,
3.5.3 Update of solutions
After is generated, the procedure of updating solutions is performed, as shown in the lines 12–19 of Algorithm 1. First, the ideal point should be updated by , i.e., for any , if , then set (line 12 of Algorithm 1). Then the nadir point is calculated by for each . As mentioned in Remark 3.4, is the best value among all the examined solutions so far and is the worst value among the current population. Next, an index is randomly selected from and is subsequently deleted from (line 15 of Algorithm 1). Moreover, the individual is compared with the offspring based on the scalarization function defined in (6). If is better than according to their scalarizing function values, then is replaced with (line 17 of Algorithm 1). is used to count the number of solutions replaced by . If reaches the replacement size , then the procedure of updating solutions terminates (line 14 of Algorithm 1).
3.5.4 Adjustment of multi-reference points
As analyzed in Subsection 3.4, we need to adjust the reference points adaptively in the later process of algorithm. Therefore, the evolutionary rate is used to adaptively control evolutionary generations (line 21 of Algorithm 1). The adjustment strategy of multi-reference points consists of two parts:
For (i), we first need to give a distance criteria by virtue of the original reference points obtained by initialization process, i.e., the minimum distance between any two reference points in (lines 1–7 of Algorithm 2). Secondly, the current population is normalized by the ideal point and the nadir point obtained by line 12 of Algorithm 1, and then project the normalized points onto the set where the original reference points are located (line 9 of Algorithm 2). Here, we denote the set of all obtained projection points as the set . Thirdly, we need obtain a distance matrix , where stands for the distance between the -th reference point in and the -th projection point in (lines 10–14 of Algorithm 2). The next step is to find the minimum value of each row in matrix and to denote it as , . In other words, for each reference point in , we need to find a projection point closest to from and denote the distance between them as . Finally, if is less than , then the -th reference point is recognized as a promising reference point and it is stored in a new set , and its associated index and solution are preserved in and , respectively (lines 16–20 of Algorithm 2). To elaborate on the process, we explain it with an example.
In the left part of Fig. 9, the red solid points stand for all original reference points, the black solid points represent all normalized points and the blue solid points denote all projection points. The closest points to are , respectively. It is clear to see that and . Therefore, the reference points and are regarded as unpromising ones and they are subsequently dropped. The other reference points are marked as promising ones.

If the cardinality of obtained by Algorithm 2 is equal to , then all reference points are deemed as promising ones. Otherwise, some new reference points need to be generated by using the elements of . Put another way, Algorithm 3 needs to be executed.
Therefore, for (ii), firstly, we need find any two adjacent reference points in to form a point pair, and the set of all point pairs is denoted by where the elements do not repeat (line 4 of Algorithm 3). Next, we consider the following two cases:
Case 1. If is smaller than , then we randomly choose elements from and use the midpoint of these selected elements to form new reference points (lines 7–11 of Algorithm 3). For example, in the left part Fig. 9, we can obtain and the point pair set . Obviously, , then two elements are randomly selected from (we suppose that they are and ). Then . According to lines 9–10 of Algorithm 3, new reference points and are added into (see the right part of Fig. 9 and are marked by the green solid points).
Case 2. If is strictly bigger than , then all elements in need to be selected to generate new reference points, and then these newly generated points are added into . Next, according to the obtained set and line 4 of Algorithm 3, we reconstruct the point pair set and then repeat lines 13–17 until . For example, similar to the above analysis, we can obtain and the point pair set in the left part of Fig. 10.

Clearly, . At the first cycle, all elements in are selected to generate new reference points, i.e., and . After the first cycle, the reference points set becomes (see the middle part of Fig. 10) and the point pair set becomes . Obviously, and . At the second cycle, only one element is randomly selected from and it is assumed that . Therefore, a new reference point is added into (see the right part of Fig. 10).
4 Experimental studies
This section is devoted to the experimental studies for the verification of the performance of the proposed algorithm. We compare it with four existing state-of-the-art algorithms: MOEA/D-DE [36], NSGA-III [11], RVEA* [8] and MOEA/D-PaS [57]. MOEA/D-DE possesses the TCH scalarization method and it is a representative steady-state decomposition-based MOEA. NSGA-III is an extension of NSGA-II, which maintains the diversity of population via decomposition. The main characteristic of RVEA* is the adaptive strategy of weight vectors. MOEA/D-PaS is equipped with scalarization method and it uses a Pareto adaptive scalarizing approximation to obtain the optimal value. Before presenting the results, we first give the experimental settings in the next subsection.
4.1 Experimental settings
-
(1)
Benchmark problems. In this paper, a set of benchmark test problems with a variety of representative POFs is used. Moreover, we also construct two modified test problems based on ZDT1 [62] and IDTLZ2 [27]. The first test instance denoted as F1 has the following form:
where . The mathematical description of the second test problem is as follows:
where . Note that the parameter in the variant of ZDT1 (termed as mZDT1) introduced in [45] is set as and the variable space of DTLZ1 is set as . Other configures of all these problems are described in the corresponding literature. Table 3 provides a brief summary of these problems.
Table 3: Test Problems. and denote the number of objectives and decision variables, repectively. Problem The POF shape ZDT1 [62] mZDT1 [45] GLT3 [23] SCH1 [53] F1 ZDT3 [62] GLT1 [23] 30 30 10 1 30 30 10 Simplex-like, Convex Highly nonlinear, Concave Highly nonlinear (piecewise linear), Convex Highly nonlinear, Convex Highly nonlinear, Nonconvex-nonconcave Disconnected Disconnected DTLZ1 [13] DTLZ2 [13] DTLZ5 [13] VNT2 [54] DTLZ7 [13] IDTLZ1 [27] IDTLZ2 [27] F2 7 12 12 2 15 7 12 12 Simplex-like, Linear Simplex-like, Concave Degenerate, Concave Degenerate, Convex Disconnected Inverted , Linear Inverted, Concave Inverted, Highly concave -
(2)
Parameter settings. In MOEA/D-AMR, the number of division on each axis is for and for . Therefore, we set the population size as and 331 for biobjective and triobjective MOPs, respectively. To make all algorithms comparable, the population size for the other four algorithms are the same as MOEA/D-AMR and the initial weights are kept the same for the four compared algorithms. The maximum number of generations of all algorithms is set as on all the test problems. The other parameter settings of MOEA/D-AMR are listed as follows:
-
(a)
the neighborhood size: ;
-
(b)
the probability of selecting parent from the neighborhood: ;
-
(c)
the replacement size: ;
-
(d)
the control parameters in DE operator: and ;
-
(e)
the parameters in PM operator: and ;
-
(f)
the evolutionary rate: .
The parameters , , , , , and in MOEA/D-DE and MOEA/D-PaS share the same settings with the MOEA/D-AMR. The rate of change of penalty and the frequency of employing weight vector adaptation in RVEA* are set as and , respectively.
-
(a)
-
(3)
Performance metrics. Various performance metrics have been summarized in [4] for measure the quality of POF approximations. In this paper, two widely used performance metrics in MOEAs, the inverted generational distance (IGD) [64] and Hypervolume (HV) [63], are utilized to measure the obtained solution sets in terms of diversity. In the calculation of IGD, we select roughly 1000 scattered points evenly distributed in the true POF for all biobjective test problems and 5000 for the test problems with three objectives. All the objective function values are normalized by the ideal and nadir points of the POF before calculating HV metric. Then, the normalized HV value of the solution set is computed with a reference point . Every algorithm is run 30 times independently for each test problem. The mean and standard deviation values of the IGDs and HVs are calculated and listed in tables, where the results of best mean for each problem are highlighted with gray background. Furthermore, the Wilcoxon rank sum test with a significance level of 0.05 is adopted to perform statistics analysis on the experimental results, where the symbols ’’, ’’ and ’’ denote that the result of other algorithms is significantly better, statistically similar and significantly worse to that of MOEA/D-AMR, respectively.
4.2 Experimental results and analysis
The quantitative results on mean and standard deviation values of the performance indicators obtained by the five algorithms on these test instances are summarized in Tables 4.2 and 4.2.
| Property | Problem | MOEA/D-DE | NSGA-III | RVEA* | MOEA/D-PaS | MOEA/D-AMR | ||||||||||||||||||
| Simplex-like |
|
|
|
|
|
|
||||||||||||||||||
|
||||||||||||||||||||||||
| Degenerate |
|
|
|
|
|
|
||||||||||||||||||
|
||||||||||||||||||||||||
|
||||||||||||||||||||||||
| 0/1/14 | 2/2/11 | 0/5/10 | 0/1/14 | |||||||||||||||||||||
| Property | Problem | MOEA/D-DE | NSGA-III | RVEA* | MOEA/D-PaS | MOEA/D-AMR | ||||||||||||||||||
|
|
|
|
|||||||||||||||||||||
|
||||||||||||||||||||||||
| Degenerate |
|
|
|
|
|
|
||||||||||||||||||
|
||||||||||||||||||||||||
| Disconnected |
|
|
|
|
|
|
||||||||||||||||||
| 1/1/13 | 3/3/9 | 1/7/7 | 1/2/12 | |||||||||||||||||||||
In order to intuitively show the effectiveness of the proposed algorithm in diversity, the final solution sets with the median IGD values obtained by MOEA/D-DE, NSGA-III, RVEA*, MOEA/D-PaS and MOEA/D-AMR in 30 runs on these test problems are plotted. Since the POFs of these test problems have different properties, as stated in Table 3, we discuss these results in the following five different groups:
1) Simplex-like POFs: As can be observed from Fig. 11, MOEA/AMR can obtain more evenly distributed solutions than the other four compared algorithms on ZDT1. It is apparently that the solutions obtained by other compared algorithms are sparse in the upper left part and are crowded in the middle part. However, the HV results indicated in Table 4.2 show that MOEA/D-AMR is slightly inferior than NSGA-II, RVEA* and MOEA/D-PaS. As mentioned by [25], the optimal distribution of solutions for hypervolume maximization may not be even. Note that Algorithm 3 on ZDT1 is not triggered in our experiments since all the reference points are promising, i.e., in line 23 of Algorithm 1.

For DTLZ1 and DTLZ2, Figs. 12 and 13 suggest that the performance of NSGA-III is better than the other algorithms. This is confirmed by looking at the statistical results displayed in Tables 4.2 and 4.2. As described by [11], NSGA-III works very well on the two test problems. It is worth mentioning that MOEA/D-AMR is slightly worse than NSGA-III and RVEA* for DTLZ1 and DTLZ2. A reasonable explanation is that the creation of the additional reference points is based on the midpoint of two adjacent promising reference points. Therefore, many new reference points are embedded in the middle part of the original POF.


If we do not use the reference points update strategy in the proposed algorithm, as shown in Fig. 14, the final solution set is very uniform in the inner part of the POFs of DTLZ1 and DTLZ2, but several solutions converge to other subproblems or concentrate on the boundary of the POFs.


2) Highly nonlinear POFs: The test problems with highly nonlinear POFs shown in Table 3 can be classified three groups: the problem with a concave POF (i.e., mZDT1), the problems with a convex POF (i.e., SCH1 and GLT3) and the problem with a nonconvex-nonconcave POF (i.e., F1). For the first group, Fig. 15 shows that all the algorithms work well while MOEA/D-AMR performing slightly better than the other four compared algorithms. As for the second group, it is clear that only the proposed algorithm has an excellent performance in diversity and other four algorithms struggle in the location of sharp peak and long tail. For the third group, it follows from Fig. 18 that only MOEA/D-AMR can obtain a good performance in diversity. Overall, the highly nonlinear convex POF still poses a challenge to the corresponding method even if some adaptive strategies of weight vectors and scalarizing function are proposed.




3) Degenerated POFs: It follows from Tables 4.2 and 4.2 and Figs. 19 and 20 that the proposed algorithm has shown a significant advantage over its competitors on this group of problems. RVEA* performs better than the rest three algorithms as it has a weight vectors regeneration strategy. For this kind of problems, MOEA/D-PaS equipped with the adaptation strategy of scalarization function seems not so effective.


4) Inverted POFs: For MOEA/D-AMR, Figs. 21–23 illustrate that this group of problems has no effect on the algorithmic performance and the obtained solution set has a good coverage and diversity over the entire POF. For IDTLZ1 and IDTLZ2, a small amount of solutions in the inner part of POFs obtained by MOEA/D-DE and MOEA/PaS have a little uniformity, while most of the solutions locate in the boundary part of the POFs. By contrast, the solutions obtained by NSGA-III and RVEA* achieve a good coverage and poor diversity. On the constructed problem F2, the algorithms, i.e., MOEA/DE, NSGA-III, RVEA* and MOEA/D-PaS, are not very satisfactory and effective in coverage and diversity preservation.



5) Disconnected POFs: Figs. 24–26 show that the final solution set with the median IGD obtained by the five algorithms on ZDT3, GLT1 and DTLZ7, respectively. Togethering with Table 4.2, we can see that only MOEA/D-AMR can maintain a good distribution of the final solution set. For ZDT3 and GLT1, there are some solutions obtained by MOEA/D-DE and MOEA/D-PaS concentrate on the discontinuous position of the POFs. An interesting observation is that when looking at the HV results shown in Table 4.2, NSGA-III and MOEA/D-PaS perform the best on ZDT3 and GLT1, respectively. The most rational explanation is that the optimal distribution of solutions for hypervolume maximization may not be even [25].



5 Applications on real-world MOPs
As described in [49], many real-world MOPs have irregular POFs. To further assess the performance of the proposed algorithm, we consider two multiobjective engineering optimal design optimization problems shown in [49]. The performance is compared with other competitive algorithms presented in Section 4. Herein, we use the same parameter settings and performance metrics given in Subsection 4.1. Since the true POFs of the two practical problems are not known, we make use of the reference POFs of the two design problems provided in the supplementary website (https://github.com/ryojitanabe/reproblems) mentioned in [49] to give a performance assessment of these algorithms.
5.1 The hatch cover (HC) design problem
The design of HC was studied by [2] who gave a detailed analysis. It is designed with the weight of the cover as objective functions subject to four constraints. [49] indicated that the constraint functions of HC design problem can be simultaneously minimized. Thus, the original HC design problem is remodeled as a biobjective optimization problem with two variables in [49]. Mathematical formulation of the biobjective optimization problem is presented in (7), where the first objective is to minimize the weight of the hatch cover and the second objective is actually the sum of four constraint violations. The decision variables and denote the flange thickness (cm) and the beam height of the hatch cover (cm), respectively.
| (7) | ||||
where , , and . The parameters and their descriptions are shown in Table 6.
| Parameter | Description | Value | Unit |
| Calculated bending stresses | kg/cm2 | ||
| Maximum allowable bending stresses | 700 | kg/cm2 | |
| Calculated shearing stresses | kg/cm2 | ||
| Maximum allowable shearing stresses | 450 | kg/cm2 | |
| Deflections at the mid of cover | cm | ||
| Maximum allowable deflections | 1.5 | cm | |
| The buckling stresses of the flanges | kg/cm2 | ||
| Young Modulus | 700000 | kg/cm2 |
Fig. 27 shows that the graphical results of the final solution set obtained by MOEA/D-DE, NSGA-III, RVEA*, MOEA/D-PaS and MOEA/D-AMR on problem (7).

Obviously, the solution set obtained by MOEA/D-AMR has much better distribution than those of others, which can provide a more reasonable choice for decision makers. A large portion of solutions obtained by MOEA/D-DE, NSGA-III, RVEA* and MOEA/D-PaS concentrate on the middle part of the POF. As a result, much smaller value of IGD and much larger value of HV are obtained by the proposed algorithm (see Table 5.1). Hence, our algorithm significantly outperforms than that of other compared algorithms in terms of diversity and coverage.
| Problem | Metric | MOEA/D-DE | NSGA-III | RVEA* | MOEA/D-PaS | MOEA/D-AMR |
| HC | IGD | 8.8194e-0(2.98e-2) | 8.7709e-0(1.84e-2) | 9.9514e-0(1.83e-0) | 7.5090e-0(4.92e-1) | \markoverwith \ULon1.1498e-0(1.59e-2) |
| HV | 1.0536e-0(1.59e-5) | 1.0537e-0(5.55e-6) | 1.0536e-0(4.86e-4) | 1.0541e-0(2.06e-4) | \markoverwith \ULon1.0554e-0(5.49e-6) |
5.2 The rocket injector (RI) design problem
The improvement of performance and life are the two primary objectives of the injector design. The performance of the injector is expressed by the axial length of the thrust chamber, and the viability of the injector is related to the thermal field in the thrust chamber. A visual representation of the objectives is shown in [52, 22]. High temperature produce high thermal stress on the injector and thrust chamber, which will reduce the service life of components, but improve the performance of the injector. Consequently, the dual goal of maximizing the performance and the life was cast as a four objective design problem [52], i.e.,
is to minimize the maximum temperature of the injector face;
is to minimize the distance from the inlet;
is to minimize the maximum temperature on the post tip of the injector;
is to minimize the wall temperature at a distance three inches from the injector face.
Note that the objectives and were reported in [22] strongly correlated in the design space. Hence, was dropped from the objectives list and the optimization problem was formulated with the remaining three objectives. This reformulated problem is as follows:
| (8) | ||||
where
There are four design variables in this problem, which we need to make decisions. The four variables , , and describe the hydrogen flow angle, the hydrogen area, the oxygen area and the oxidizer post tip thickness, respectively.
The statistic results of the mean and standard deviation of IGD and HV metrics obtained by the five algorithms are shown in Table 5.2. It can be concluded that the proposed algorithm is clearly better than the other compared algorithms. Furthermore, we plot the final solution set of the median IGD value among 30 runs for each algorithm (see Fig. 28). As we have seen, the solutions obtained by MOEA/D-AMR are distributed more uniformly than those of other competitors.
| Problem | Metric | MOEA/D-DE | NSGA-III | RVEA* | MOEA/D-PaS | MOEA/D-AMR |
| RI | IGD | 4.3249e-2(3.17e-4) | 3.6629e-2(1.08e-3) | 3.6760e-2(4.94e-3) | 4.7835e-2(9.66e-4) | \markoverwith \ULon3.2578e-2(1.04e-3) |
| HV | 9.5235e-1(6.66e-5) | 9.4930e-1(1.23e-3) | 9.5079e-1(1.61e-3) | 9.4939e-1(6.61e-4) | \markoverwith \ULon9.5588e-1(2.33e-3) |

6 Conclusion and Future Work
In this paper, we have proposed a new algorithm named MOEA/D-AMR for enhancing the diversity of population in tacking some MOPs with regular and irregular POFs. Specifically, a scalarization approach, known as the Pascoletti-Serafini scalarization approach, has been introduced into the framework of MOEA/D-DE. More importantly, the Pascoletti-Serafini scalarization method has been equivalently transformed into a minimax formulation when restricting the direction to positive components. For the converted form, some scalarization methods such as TCH, -TCH and -TCH used in the framework of MOEA/D are its special cases intuitively based on the different selection of reference point and direction. Additionally, with the help of equidistant partitial and projection techniques, a new way of generating multi-reference points with relatively uniform distribution has been proposed. To avoid the occurrence of many unpromising reference points, that is, the solutions of the subproblems associated with these reference points converge to other subproblems, a strategy for adjusting the reference points has been suggested to tune the reference points in the later evolutionary stage. To assess the performance of the proposed algorithm, experimental comparisons have been conducted by comparing MOEAD/AMR with four state-of-the-art MOEAs, i.e., MOEA/D-DE, NSGA-III, RVEA* and MOEA/D-PaS, on several widely used test problems with different POFs and two real-world MOPs in engineering optimization. The experimental results have demonstrated that MOEAD/AMR is capable of obtaining superior or comparable performance to the other four state-of-the-art algorithms.
In the future, we would like to further investigate the following three issues. First, the proposed algorithm will be used to solve several many-objective optimization problems, which refers to the class of problems with four and more number of objectives. Note that the MOPs considered in this paper are all box-constrained problems. In fact, MOEA/D-AMR can easily incorporate some constraint-handling techniques such as the penalty function method reported in [28] to deal with the constrained MOPs via slightly modifying the repair operation of the proposed algorithm. We leave addressing this issue as our second research topic. It is worth pointing out that, in the proposed algorithm, we use the objective space normalization by means of the estimated ideal and nadir points updated adaptively during the evolutionary process. However, [24] pointed out that if the two points are inaccurately estimated, then the objective space normalization may deteriorate the performance of a MOEA. Therefore, an effective and robust normalization method should be embedded into the proposed algorithm, which is also our third future work.
References
- Akbari et al. [2018] Akbari, F., Ghaznavi, M., & Khorram, E. (2018). A revised Pascoletti-Serafini scalarization method for multiobjective optimization problems. Journal of Optimization Theory and Applications, 178, 560–590. https://doi.org/10.1007/s10957-018-1289-2.
- Amir & Hasegawa [1989] Amir, H. M., & Hasegawa, T. (1989). Nonlinear mixed-discrete structural optimization. Journal of Structural Engineering, 115, 626–646. https://doi.org/10.1061/(ASCE)0733-9445.
- Ashby [2000] Ashby, M. (2000). Multi-objective optimization in material design and selection. Acta Materialia, 48, 359–369. https://doi.org/10.1016/S1359-6454(99)00304-3.
- Audet et al. [2020] Audet, C., Bigeon, J., Cartier, D., Le Digabel, S., & Salomon, L. (2020). Performance indicators in multiobjective optimization. European Journal of Operational Research, 292, 397–422. https://doi.org/10.1016/j.ejor.2020.11.016.
- Bader & Zitzler [2011] Bader, J., & Zitzler, E. (2011). HypE: An algorithm for fast hypervolume-based many-objective optimization. Evolutionary Computation, 19, 45–76. https://doi.org/10.1162/EVCO_a_00009.
- Bortz et al. [2014] Bortz, M., Burger, J., Asprion, N., Blagov, S., Böttcher, R., Nowak, U., Scheithauer, A., Welke, R., Küfer, K.-H., & Hasse, H. (2014). Multi-criteria optimization in chemical process design and decision support by navigation on pareto sets. Computers Chemical Engineering, 60, 354–363. https://doi.org/10.1016/j.compchemeng.2013.09.015.
- Cheaitou & Cariou [2019] Cheaitou, A., & Cariou, P. (2019). Greening of maritime transportation: a multi-objective optimization approach. Annals of Operations Research, 273, 501–525. https://doi.org/10.1007/s10479-018-2786-2.
- Cheng et al. [2016] Cheng, R., Jin, Y., Olhofer, M., & Sendhoff, B. (2016). A reference vector guided evolutionary algorithm for many-objective optimization. IEEE Transactions on Evolutionary Computation, 20, 773–791. https://doi.org/10.1109/TEVC.2016.2519378.
- Coello et al. [2007] Coello, C. A. C., Lamont, G. B., & Van Veldhuizen, D. A. (2007). Evolutionary algorithms for solving multi-objective problems. Springer.
- Das & Dennis [1998] Das, I., & Dennis, J. E. (1998). Normal-boundary intersection: A new method for generating the Pareto surface in nonlinear multicriteria optimization problems. SIAM Journal on Optimization, 8, 631–657. https://doi.org/10.1137/S1052623496307510.
- Deb & Jain [2013] Deb, K., & Jain, H. (2013). An evolutionary many-objective optimization algorithm using reference-point-based nondominated sorting approach, part I: solving problems with box constraints. IEEE Transactions on Evolutionary Computation, 18, 577–601. https://doi.org/10.1109/TEVC.2013.2281535.
- Deb et al. [2002] Deb, K., Pratap, A., Agarwal, S., & Meyarivan, T. (2002). A fast and elitist multiobjective genetic algorithm: NSGA-II. IEEE Transactions on Evolutionary Computation, 6, 182–197. https://doi.org/10.1109/4235.996017.
- Deb et al. [2005] Deb, K., Thiele, L., Laumanns, M., & Zitzler, E. (2005). Scalable test problems for evolutionary multiobjective optimization. In Abraham A., Jain L., Goldberg R. (eds) Evolutionary Multiobjective Optimization. Advanced Information and Knowledge Processing (pp. 105–145). Springer, London. https://doi.org/10.1007/1-84628-137-7_6.
- Dolatnezhadsomarin & Khorram [2019] Dolatnezhadsomarin, A., & Khorram, E. (2019). Two efficient algorithms for constructing almost even approximations of the Pareto front in multi-objective optimization problems. Engineering Optimization, 51, 567–589. https://doi.org/10.1080/0305215X.2018.1479405.
- Dong et al. [2020] Dong, Z., Wang, X., & Tang, L. (2020). MOEA/D with a self-adaptive weight vector adjustment strategy based on chain segmentation. Information Sciences, 521, 209–230. https://doi.org/10.1016/j.ins.2020.02.056.
- Eichfelder [2008] Eichfelder, G. (2008). Adaptive scalarization methods in multiobjective optimization. Springer, Berlin.
- Eichfelder [2009] Eichfelder, G. (2009). An adaptive scalarization method in multiobjective optimization. SIAM Journal on Optimization, 19, 1694–1718. https://doi.org/10.1137/060672029.
- Eichfelder et al. [2021] Eichfelder, G., Kirst, P., Meng, L., & Stein, O. (2021). A general branch-and-bound framework for continuous global multiobjective optimization. Journal of Global Optimization, 80, 195–227. https://doi.org/10.1007/s10898-020-00984-y.
- Eichfelder & Warnow [2020] Eichfelder, G., & Warnow, L. (2020). An approximation algorithm for multi-objective optimization problems using a box-coverage, . https://www.optimization-online.org/DB_HTML/2020/10/8079.html.
- Fliege et al. [2009] Fliege, J., Graña Drummond, L. M., & Svaiter, B. F. (2009). Newton’s method for multiobjective optimization. SIAM Journal on Optimization, 20, 602–626. https://doi.org/10.1137/08071692X.
- Fukuda & Graña Drummond [2014] Fukuda, E. H., & Graña Drummond, L. M. (2014). A survey on multiobjective descent methods. Pesquisa Operacional, 34, 585–620. https://doi.org/10.1590/0101-7438.2014.034.03.0585.
- Goel et al. [2007] Goel, T., Vaidyanathan, R., Haftka, R. T., Shyy, W., Queipo, N. V., & Tucker, K. (2007). Response surface approximation of Pareto optimal front in multi-objective optimization. Computer Methods in Applied Mechanics and Engineering, 196, 879–893. https://doi.org/10.1016/j.cma.2006.07.010.
- Gu et al. [2012] Gu, F., Liu, H.-L., & Tan, K. C. (2012). A multiobjective evolutionary algorithm using dynamic weight design method. International Journal of Innovative Computing, Information and Control, 8, 3677–3688.
- He et al. [2021] He, L., Ishibuchi, H., Trivedi, A., Wang, H., Nan, Y., & Srinivasan, D. (2021). A survey of normalization methods in multiobjective evolutionary algorithms. IEEE Transactions on Evolutionary Computation, . doi:https://doi.org/10.1109/TEVC.2021.3076514.
- Ishibuchi et al. [2018] Ishibuchi, H., Imada, R., Setoguchi, Y., & Nojima, Y. (2018). How to specify a reference point in hypervolume calculation for fair performance comparison. Evolutionary Computation, 26, 411–440. https://doi.org/10.1162/evco_a_00226.
- Ishibuchi et al. [2010] Ishibuchi, H., Sakane, Y., Tsukamoto, N., & Nojima, Y. (2010). Simultaneous use of different scalarizing functions in MOEA/D. In Proceedings of the 12th Annual Conference on Genetic and Evolutionary Computation (pp. 519–526). https://doi.org/10.1145/1830483.1830577.
- Jain & Deb [2013] Jain, H., & Deb, K. (2013). An evolutionary many-objective optimization algorithm using reference-point based nondominated sorting approach, part II: Handling constraints and extending to an adaptive approach. IEEE Transactions on Evolutionary Computation, 18, 602–622. https://doi.org/10.1109/TEVC.2013.2281534.
- Jan & Zhang [2010] Jan, M. A., & Zhang, Q. (2010). MOEA/D for constrained multiobjective optimization: some preliminary experimental results. In 2010 UK Workshop on Computational Intelligence (UKCI) (pp. 1–6). https://doi.org/10.1109/UKCI.2010.5625585.
- Jiang et al. [2011] Jiang, S., Cai, Z., Zhang, J., & Ong, Y.-S. (2011). Multiobjective optimization by decomposition with Pareto-adaptive weight vectors. In 2011 Seventh International Conference on Natural Computation (pp. 1260–1264). volume 3. https://doi.org/10.1109/ICNC.2011.6022367.
- Jiang & Yang [2015] Jiang, S., & Yang, S. (2015). An improved multiobjective optimization evolutionary algorithm based on decomposition for complex Pareto fronts. IEEE Transactions on Cybernetics, 46, 421–437. https://doi.org/10.1109/TCYB.2015.2403131.
- Jiang et al. [2017] Jiang, S., Yang, S., Wang, Y., & Liu, X. (2017). Scalarizing functions in decomposition-based multiobjective evolutionary algorithms. IEEE Transactions on Evolutionary Computation, 22, 296–313. https://doi.org/10.1109/TEVC.2017.2707980.
- Jones et al. [2002] Jones, D. F., Mirrazavi, S. K., & Tamiz, M. (2002). Multi-objective meta-heuristics: An overview of the current state-of-the-art. European Journal of Operational Research, 137, 1–9. https://doi.org/10.1016/S0377-2217(01)00123-0.
- Khorram et al. [2014] Khorram, E., Khaledian, K., & Khaledyan, M. (2014). A numerical method for constructing the pareto front of multi-objective optimization problems. Journal of Computational and Applied Mathematics, 261, 158–171. https://doi.org/10.1016/j.cam.2013.11.007.
- Li et al. [2019a] Li, H., Deng, J., Zhang, Q., & Sun, J. (2019a). Adaptive epsilon dominance in decomposition-based multiobjective evolutionary algorithm. Swarm and Evolutionary Computation, 45, 52–67. https://doi.org/10.1016/j.swevo.2018.12.007.
- Li et al. [2019b] Li, H., Sun, J., Zhang, Q., & Shui, Y. (2019b). Adjustment of weight vectors of penalty-based boundary intersection method in MOEA/D. In Deb K. et al. (eds) Evolutionary Multi-Criterion Optimization. EMO 2019. Lecture Notes in Computer Science (pp. 91–100). https://doi.org/10.1007/978-3-030-12598-1_8.
- Li & Zhang [2009] Li, H., & Zhang, Q. (2009). Multiobjective optimization problems with complicated pareto sets, MOEA/D and NSGA-II. IEEE Transactions on Evolutionary Computation, 13, 284–302. https://doi.org/10.1109/TEVC.2008.925798.
- Li et al. [2013] Li, K., Zhang, Q., Kwong, S., Li, M., & Wang, R. (2013). Stable matching-based selection in evolutionary multiobjective optimization. IEEE Transactions on Evolutionary Computation, 18, 909–923. https://doi.org/10.1109/TEVC.2013.2293776.
- Ma et al. [2020] Ma, X., Yu, Y., Li, X., Qi, Y., & Zhu, Z. (2020). A survey of weight vector adjustment methods for decomposition-based multiobjective evolutionary algorithms. IEEE Transactions on Evolutionary Computation, 24, 634–649. https://doi.org/10.1109/TEVC.2020.2978158.
- Ma et al. [2017] Ma, X., Zhang, Q., Tian, G., Yang, J., & Zhu, Z. (2017). On Tchebycheff decomposition approaches for multiobjective evolutionary optimization. IEEE Transactions on Evolutionary Computation, 22, 226–244. https://doi.org/10.1109/TEVC.2017.2704118.
- Miettinen [2000] Miettinen, K. (2000). Nonlinear multiobjective optimization. Boston, MAA: Kluwer.
- Miglierina et al. [2008] Miglierina, E., Molho, E., & Recchioni, M. C. (2008). Box-constrained multi-objective optimization: a gradient-like method without “a priori” scalarization. European Journal of Operational Research, 188, 662–682. https://doi.org/10.1016/j.ejor.2007.05.015.
- Murata et al. [2001] Murata, T., Ishibuchi, H., & Gen, M. (2001). Specification of genetic search directions in cellular multi-objective genetic algorithms. In Zitzler E., Thiele L., Deb K., Coello Coello C.A., Corne D. (eds) Evolutionary Multi-Criterion Optimization. EMO 2001. Lecture Notes in Computer Science (pp. 82–95). volume 1993. https://doi.org/10.1007/3-540-44719-9_6.
- Pardalos et al. [2017] Pardalos, P. M., Zilinskas, A., & Zilinskas, J. (2017). Non-convex multi-objective optimization. Springer.
- Pascoletti & Serafini [1984] Pascoletti, A., & Serafini, P. (1984). Scalarizing vector optimization problems. Journal of Optimization Theory and Applications, 42, 499–524. https://doi.org/10.1007/BF00934564.
- Qi et al. [2014] Qi, Y., Ma, X., Liu, F., Jiao, L., Sun, J., & Wu, J. (2014). MOEA/D with adaptive weight adjustment. Evolutionary Computation, 22, 231–264. https://doi.org/10.1162/EVCO_a_00109.
- Rangaiah & Bonilla-Petriciolet [2013] Rangaiah, G. P., & Bonilla-Petriciolet, A. (2013). Multi-objective optimization in chemical engineering: developments and applications. John Wiley & Sons.
- Rojas-Gonzalez & Van Nieuwenhuyse [2020] Rojas-Gonzalez, S., & Van Nieuwenhuyse, I. (2020). A survey on kriging-based infill algorithms for multiobjective simulation optimization. Computers Operations Research, 116, 104869. https://doi.org/10.1016/j.cor.2019.104869.
- Ruzika & Wiecek [2005] Ruzika, S., & Wiecek, M. M. (2005). Approximation methods in multiobjective programming. Journal of Optimization Theory and Applications, 126, 473–501. https://doi.org/10.1007/s10957-005-5494-4.
- Tanabe & Ishibuchi [2020] Tanabe, R., & Ishibuchi, H. (2020). An easy-to-use real-world multi-objective optimization problem suite. Applied Soft Computing, 89, 106078. https://doi.org/10.1016/j.asoc.2020.106078.
- Tang & Yang [2021] Tang, L., & Yang, X. (2021). A modified direction approach for proper efficiency of multiobjective optimization. Optimization Methods and Software, 36, 653–668. https://doi.org/10.1080/10556788.2021.1891538.
- Trivedi et al. [2016] Trivedi, A., Srinivasan, D., Sanyal, K., & Ghosh, A. (2016). A survey of multiobjective evolutionary algorithms based on decomposition. IEEE Transactions on Evolutionary Computation, 21, 440–462. https://doi.org/10.1109/TEVC.2016.2608507.
- Vaidyanathan et al. [2003] Vaidyanathan, R., Tucker, K., Papila, N., & Shyy, W. (2003). CFD-based design optimization for single element rocket injector. In 41st Aerospace Sciences Meeting and Exhibit (pp. 1–21). https://doi.org/10.2514/6.2003-296.
- Valenzuela-Rendón et al. [1997] Valenzuela-Rendón, M., Uresti-Charre, E., & Monterrey, I. (1997). A non-generational genetic algorithm for multiobjective optimization. In Proceedings of the Seventh International Conference on Genetic Algorithms (pp. 658–665). Morgan Kaufmann.
- Vlennet et al. [1996] Vlennet, R., Fonteix, C., & Marc, I. (1996). Multicriteria optimization using a genetic algorithm for determining a Pareto set. International Journal of Systems Science, 27, 255–260. https://doi.org/10.1080/00207729608929211.
- Wang et al. [2020] Wang, J., Su, Y., Lin, Q., Ma, L., Gong, D., Li, J., & Ming, Z. (2020). A survey of decomposition approaches in multiobjective evolutionary algorithms. Neurocomputing, 408, 308–330. https://doi.org/10.1016/j.neucom.2020.01.114.
- Wang et al. [2015] Wang, R., Purshouse, R. C., Giagkiozis, I., & Fleming, P. J. (2015). The iPICEA-g: a new hybrid evolutionary multi-criteria decision making approach using the brushing technique. European Journal of Operational Research, 243, 442–453. https://doi.org/10.1016/j.ejor.2014.10.056.
- Wang et al. [2016] Wang, R., Zhang, Q., & Zhang, T. (2016). Decomposition-based algorithms using Pareto adaptive scalarizing methods. IEEE Transactions on Evolutionary Computation, 20, 821–837. https://doi.org/10.1109/TEVC.2016.2521175.
- Xu et al. [2018] Xu, Y., Ding, O., Qu, R., & Li, K. (2018). Hybrid multi-objective evolutionary algorithms based on decomposition for wireless sensor network coverage optimization. Applied Soft Computing, 68, 268–282. https://doi.org/10.1016/j.asoc.2018.03.053.
- Xu et al. [2013] Xu, Y., Qu, R., & Li, R. (2013). A simulated annealing based genetic local search algorithm for multi-objective multicast routing problems. Annals of Operations Research, 206, 527–555. https://doi.org/10.1007/s10479-013-1322-7.
- Zhang & Li [2007] Zhang, Q., & Li, H. (2007). MOEA/D: A multiobjective evolutionary algorithm based on decomposition. IEEE Transactions on Evolutionary Computation, 11, 712–731. https://doi.org/10.1109/TEVC.2007.892759.
- Zhang et al. [2010] Zhang, Q., Li, H., Maringer, D., & Tsang, E. (2010). MOEA/D with NBI-style tchebycheff approach for portfolio management. In IEEE Congress on Evolutionary Computation (pp. 1–8). https://doi.org/10.1109/CEC.2010.5586185.
- Zitzler et al. [2000] Zitzler, E., Deb, K., & Thiele, L. (2000). Comparison of multiobjective evolutionary algorithms: Empirical results. Evolutionary Computation, 8, 173–195. https://doi.org/10.1162/106365600568202.
- Zitzler & Thiele [1999] Zitzler, E., & Thiele, L. (1999). Multiobjective evolutionary algorithms: a comparative case study and the strength Pareto approach. IEEE Transactions on Evolutionary Computation, 3, 257–271. https://doi.org/10.1109/4235.797969.
- Zitzler et al. [2003] Zitzler, E., Thiele, L., Laumanns, M., Fonseca, C. M., & Da Fonseca, V. G. (2003). Performance assessment of multiobjective optimizers: An analysis and review. IEEE Transactions on Evolutionary Computation, 7, 117–132. https://doi.org/10.1109/TEVC.2003.810758.
- Zopounidis et al. [2015] Zopounidis, C., Galariotis, E., Doumpos, M., Sarri, S., & Andriosopoulos, K. (2015). Multiple criteria decision aiding for finance: An updated bibliographic survey. European Journal of Operational Research, 247, 339–348. https://doi.org/10.1016/j.ejor.2015.05.032.