∎
22email: [email protected]
A novel meta-learning initialization method for physics-informed neural networks
Abstract
Physics-informed neural networks (PINNs) have been widely used to solve various scientific computing problems. However, large training costs limit PINNs for some real-time applications. Although some works have been proposed to improve the training efficiency of PINNs, few consider the influence of initialization. To this end, we propose a New Reptile initialization based Physics-Informed Neural Network (NRPINN). The original Reptile algorithm is a meta-learning initialization method based on labeled data. PINNs can be trained with less labeled data or even without any labeled data by adding partial differential equations (PDEs) as a penalty term into the loss function. Inspired by this idea, we propose the new Reptile initialization to sample more tasks from the parameterized PDEs and adapt the penalty term of the loss. The new Reptile initialization can acquire initialization parameters from related tasks by supervised, unsupervised, and semi-supervised learning. Then, PINNs with initialization parameters can efficiently solve PDEs. Besides, the new Reptile initialization can also be used for the variants of PINNs. Finally, we demonstrate and verify the NRPINN considering both forward problems, including solving Poisson, Burgers, and Schrödinger equations, as well as inverse problems, where unknown parameters in the PDEs are estimated. Experimental results show that the NRPINN training is much faster and achieves higher accuracy than PINNs with other initialization methods.
Keywords:
Physics-informed neural networks Partial differential equations Reptile initialization Accelerated training.1 Introduction
Recently, neural networks (NNs) have been successfully applied to the content of solving partial differential equations (PDEs) brink2020neural ; avrutskiy2020neural ; tartakovsky2018learning ; he2020physics ; chen2020physics . In particular, the physics-informed neural networks (PINNs) raissi2019physics ; raissi2020hidden is a general framework for solving both forward and inverse problems of PDEs. It is well suited for solving complex PDE-based physics problems in various domains, such as materialogy shukla2020physics , medical diagnosis sahli2020physics and hidden fluid mechanics mao2020physics , elastodynamics raissi2019deep , etc. PINNs encode the governing equation into loss function by adding a penalty term to constrain the space of admissible solutions. The problem of solving PDEs is transformed into an optimization problem of minimizing the loss function. Generally, training of a deep neural network model requires a vast number of labeled data, but the solutions of PDEs can be learned through a PINN model with less labeled data raissi2019physics ; zhang2020physics ; sun2020physics or even without any labeled data zhu2019physics ; sun2020surrogate . Besides, compared to numerical methods, such as finite difference method narasimhan1976integrated , wavelets method kumar2020efficient ; kumar2021fractional ; kumar2021wavelet and laplace transform method kumar2014new , the PINN is a mesh-free approach by utilizing automatic differentiation baydin2017automatic and avoids the curse of dimensionality poggio2017and ; grohs2018proof .
Large training cost is one of the main limitations of PINNs to run in real-time for solving real-life applications. Therefore, it is crucial to improve its training efficiency without sacrificing the performance. To improve the training efficiency of PINNs, D.Jagtap et al. jagtap2020adaptive ; jagtap2019locally introduced a scalable parameter in the activation function and it can be optimized during the optimization process. Inspired by works of D.Jagtap, Peng et al. peng2020accelerating proposed a variant called Prior Dictionary based PINNs to capture features provided by prior dictionaries. By modifying the structure of NNs, Sitzmann et al. sitzmann2020implicit used periodic activation functions for implicit neural representations and Tancik et al. tancik2020fourier added a simple Fourier feature mapping in the input of NNs to learn high-frequency functions in low-dimensional problem domains, which further speeds up the convergence. For accelerating the training of long-time integration, Meng et al. meng2020ppinn proposed a parareal PINN to decompose a long-time problem into many independent short-time problems. D.Jagtap et al. jagtap2020conservative ; jagtap2020extended proposed conservative PINNs and extended PINNs, where the computational domains are decomposed to achieve the speedup. A similar approach was proposed by Dwivedi et al. dwivedi2019distributed , where the authors decomposed the computational domain to many regular subdomains and installed a PINN in each subdomain. Those works mostly focus on modifying the structure of NNs or decomposing the computational domains. However, they have not considered the effect of network initialization for training efficiency and predicted solutions.
Chakraborty et al. chakraborty2020transfer and Goswami et al. goswami2020transfer introduced transfer learning to initialize PINNs for dealing with multi-fidelity problems and brittle fracture problem, respectively. But they have not considered designing efficient initialization algorithms for accelerating the training of PINNs. Recently, the meta-learning algorithms have received more and more attention on initialization rajeswaran2019meta ; smith2009cross ; finn2017meta ; finn2018probabilistic . In particular, the Model-Agnostic Meta-Learning (MAML) is an important meta-learning algorithm for the initialization. MAML was proposed by Finn et al. finn2017model to obtain the initialization parameters of NNs through training a variety of learning tasks. Although there is only a small amount of labeled training data, the model with MAML initialization converges well. Based on MAML, the Reptile algorithm proposed by Nichol et al. nichol2018first only uses the first-order information and achieves similar performance to the MAML. Compared to the MAML, the Reptile algorithm uses less computation and memory resources. The Reptile algorithm depends on labeled data to acquire initialization parameters through supervised learning. The amount of labeled data is limited in real-life applications, so the acceleration effect of the Reptile initialization is restricted. But PINNs are used with less labeled data or even without any labeled data. Inspired by this idea, the Reptile algorithm is promising to be extended for unsupervised and semi-supervised learning, which further improves the acceleration effect of initialization.
Initialization for PINNs is ignored in most works, where most researchers employed Xavier initialization glorot2010understanding . But a good initialization can endow PINNs with a good start to achieve fast convergence and improve accuracy. How to obtain a good initialization through modifying the Reptile algorithm is a problem to be discussed. In this paper, we explore those questions and our main contributions are:
-
1)
PINNs add PDEs as a penalty term into the loss function and then can be learned with less labeled data or even without any labeled data. Inspired by this idea, we propose the new Reptile initialization to sample more tasks from the parameterized partial differential equations and adapt the penalty term of the loss. Faced with only labeled data, no labeled data, or data both with and without labels, the new Reptile initialization acquires initialization parameters through supervised, unsupervised, and semi-supervised learning, further improving the acceleration effect of initialization.
-
2)
Based on the new Reptile initialization, we propose a new Reptile initialization based physics-informed neural network (NRPINN) algorithm to achieve fast convergence and high accuracy for PINNs. The advantages of using the NRPINN to approximate solutions of PDEs can be summarized as follows: (i) we use NRPINN to obtain the surrogate model of solutions. Forward evaluations of the surrogate model are extremely effective particularly for many-query and real-time applications; (ii) the NN is differentiable and derivative information can be easily obtained via automatic differentiation, which is a profitable feature for control or optimization problems. (iii) the training of the NRPINN is much faster and achieves higher accuracy than PINNs with other initialization methods. Besides, the new Reptile initialization can also be used for the variants of PINNs, such as PINNs with adaptive activation function jagtap2020adaptive ; jagtap2019locally .
-
3)
Based on the NRPINN algorithm, we study forward problems, e.g. Poisson, Burgers, and Schrödinger equations, as well as inverse problems, where unknown parameters in the PDEs are estimated. In addition to studying the effect of noisy data for prediction, we use the new Reptile initialization for a variant structure of PINNs.
The paper is structured as following sections. Problem statement and related work are presented in section 2. In section 3, after briefly introducing the key concepts of PINNs and Reptile, we present the NRPINN algorithm in detail. Numerical analysis of forward and inverse problems is conducted in section 4, where we discuss the results of PINNs with different initialization methods and the NRPINN. The conclusions of the paper are in Section 5.
2 Problem statement and related works
2.1 Problem statement
Generally, the parametrized and nonlinear PDEs is given by
| (1) | ||||
where is a nonlinear operator with the parameter , is the physical domain and is the boundary condition. For example, the nonlinear operator of the one-dimensional Burgers equation is given as , where the parameter is the viscosity coefficient.
In this work, we mainly consider solving the forward problems as well as inverse problems. The forward problem is solutions of PDEs to be inferred with the fixed parameter . For inverse problems, the unknown parameter is learned from the observed data. In addition, the solutions can be also inferred.
2.2 Related works
Recently, PINNs have been proven to be promising for solving PDEs or PDE-based systems sirignano2018dgm ; jagtap2020adaptive ; sun2020surrogate . However, training efficiency and prediction accuracy of PINNs are still a tremendous challenge. A few works focused on modifying the structure of NNs to speed up the convergence. D.Jagtap et al. jagtap2020adaptive ; jagtap2019locally employed a scalable hyper-parameter in the activation function, which changes dynamically during the process of optimizing the loss function. The PINN with the adaptive activation function had a more desirable feature for speeding up the convergence rate and improving the solution accuracy. KIM et al. kim2020fast presented a fast and accurate PINN ROM with a nonlinear manifold solution representation. The structure of NNs included two part, namely encoder and decoder. They trained a shallow masked encoder, where training data was from the full order model simulations. Then, the decoder was used as the nonlinear manifold solution representation. Merging prior information in the structure of NNs, Peng et al. peng2020accelerating proposed a Prior Dictionary based PINNs to capture features provided by dictionaries so as to speed up the convergence.
Some works were to decompose the computational domain for speeding up the convergence. D. Jagtap et al. jagtap2020conservative ; jagtap2020extended proposed conservative PINNs and extended PINNs to decompose the computational domain to several discrete sub-domains, where a shallow PINN was employed in each sub-domain. Inspired by works of D. Jagtap, Shukla et al. shukla2021parallel developed a distributed training framework for PINNs, where domain decomposition methods were used in space and time-space. The distributed framework combined the advantage of conservative PINNs and extended PINNs so as to accelerate the convergence. For solving the PDEs with long time integration, the time-space domain might become very large so that the training cost of NNs would become extremely expensive. To this end, Meng et al. meng2020ppinn proposed a parareal PINN to solve the long-time problem. They used a fast coarse-grained solver to decompose the long-time domain into many discrete short-time domains. Training several PINNs with many small-data sets was much faster than a PINN with a large-data set. The parareal PINN could achieve a significant speedup for PDEs with long-time integration. Combining domain decomposition and projection onto space of high-order polynomials, Kharazm et al. kharazmi2021hp introduced hp-variational PINNs to divide the computational space into the trial space and test space. Trial space was the space of NNs and test space represented the space of high order polynomials. The hp-variational PINNs learned from trial space and test space to accelerate the convergence and improve the solution accuracy.
Other works introduced transfer learning to accelerate the training of PINNs. Many physics systems could obtain high-fidelity and low-fidelity data. Generally, high-fidelity data was a large-data and low-fidelity data was a small-data set. To best use of two data sets, Chakraborty et al. chakraborty2020transfer proposed a novel multi-fidelity PINN. The low-fidelity data was first used to train a low-fidelity PINN. Then, they utilized high-fidelity data to obtain high-fidelity PINN by fine-tuning low-fidelity PINN. The multi-fidelity PINN provided a novel method to extract useful information from both low-fidelity and high-fidelity data. To solve brittle fracture problems, Goswami et al. goswami2020transfer introduced transfer learning to re-train the NN partially, instead of re-training the complete network. With this training method, the training efficiency was significantly enhanced. However, these methods ignored the acceleration effect of initialization. In most works, these existing initialization methods, such as Xavier and random initialization, did not use prior information. Therefore, how to use the prior information to endow PINNs with a good initialization is an open issue.
3 Methodology
3.1 Physics-informed neural networks
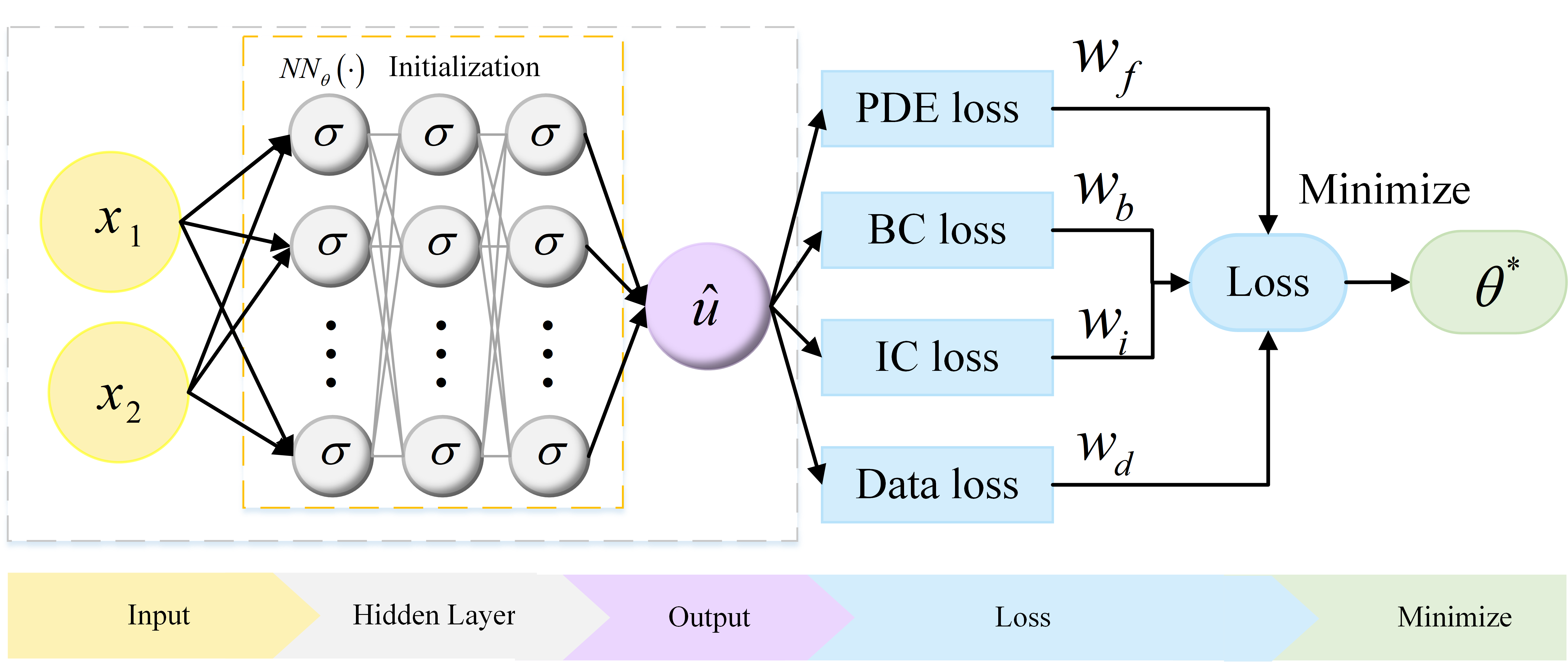
In this part, we first provide a brief overview of PINNs. Fig.1 is the schematic of a PINN. Let be a NN of depth , where denotes the vector of initialization of the NN. The NN has an input layer, hidden layers and an output layer, which is a mapping from into . We employ a Multi-Layer Perception (MLP) with the activation function .
To measure the difference between the NN and the physics constraints (governing equation and boundary condition), the left-hand-side of Eq.(1) is defined as , which is given by
| (2) |
The loss function includes partial differentiable structure loss (PDE loss), boundary value condition loss (BC loss), initial value condition loss (IC loss), and true value condition (Data loss) which are defined as
| (3) |
where
| (4) | ||||
and , , as well as are predefined hyper-parameters of weights. In this manuscript, we choose equal weights. , , , and denote the sets of residual points from PDE, initial value, boundary value, and real value, respectively. The denotes the output of NN and denotes the size of .
In the last step, the training procedure is to search for the best parameter of NN by minimizing the loss function , where automatic differentiation is used to minimize the highly nonlinear and non-convex loss function .
3.2 Reptile algorithm
MAML and Reptile are important algorithms for meta-learning initialization. Compared to MAML, the Reptile algorithm nichol2018first only performs stochastic gradient descent (SGD) bottou1991stochastic or Adam kingma2014adam (a gradient descent optimization algorithm) on each task once without twice like MAML, making less computation and memory resources, but the Reptile algorithm can achieve similar performance to MAML. The key of the Reptile algorithm is to obtain the initialization parameters so that the model can get the maximum performance of accuracy in the new task after updating the parameters through one or more gradient steps.
A detailed description of the Reptile algorithm is shown in Algorithm 1. The optimization problem of the Reptile is to find a set of initialization parameters . The learner constructs the corresponding loss through a sampled task . Each sampled task contains labeled data for classification or regression. For instance, a task might be a classification task from a labeled dataset with cats and dogs. Next, the learner finds parameters to minimize the loss after gradient steps. Then, the parameters are updated in the direction . In the last step, the parameters for Reptile initialization can be obtained by gradient updates under different tasks. The NN with initialization parameters for a new task can achieve the maximum performance of accuracy after a few gradient updates. The Reptile algorithm requires a large number of labeled data for supervised learning. However, when the amount of labeled data is limited, the initialization effect for accelerating convergence is restricted.
3.3 The New Reptile initialization based Physics-Informed Neural Network(NRPINN)
PINNs add PDEs as a penalty term into the loss function and then can be learned with less labeled data or even without any labeled data. Inspired by this idea, we propose the new Reptile initialization through modifying the task sampling process and the penalty term of the loss. The new Reptile initialization is extended from supervised learning to unsupervised and semi-supervised learning. To this end, we propose a new Reptile initialization based physics-informed neural network (NRPINN), which can achieve fast adapting and improve accuracy for the PINN. Our implementation is all done in Torch (version 1.4.0) using the Python application programming interface. According to the learning tasks in the new Reptile initialization, the NRPINN is divided into NRPINN with supervised learning (NRPINN-s), NRPINN with unsupervised learning (NRPINN-un) and NRPINN with semi-supervised learning (NRPINN-semi). The detailed description of the NRPINN is shown in Algorithm 2. We consider a MLP represented by with parameters . The PDE to be solved is in the general form
| (5) |
where is a nonlinear operator parametrized by the known parameter , and is a subset of . We summarize the prior information as two different information, namely high-order information and zero-order information. The two types of information can be represented as follows.
-
1)
The high-order information contains high-order derivative information of the solution , which is described by
(6) where is unknown and denotes the set of value. In other words, we consider the known parameter in Eq.(5) as variables to obtain the Eq.(6), which is called the high-order information of solution to be solved. Under high-order information, the governing equation with different is considered as a task.
-
2)
The zero-order information represents the solution under different can be obtained, where the solution is composed of labeled data. The zero-order information is given by
(7) where represents the set of the labeled data under different parameter . For the zero-order information, the solution under different parameter is considered as a task.
The two types of information can be regarded as tasks of the new Reptile initialization. There are three ways to acquire parameters: (i) when only the zero-order information can be obtained, the new Reptile initialization acquires parameters through the tasks with labeled data. (ii) when only the high-order information can be obtained, the new Reptile initialization acquires parameters through the tasks with unlabeled data. (iii) when the two types of information is obtained, the new Reptile initialization acquires parameters through the tasks with labeled and unlabeled data.
The procedure of the NRPINN algorithm is mainly divided into two parts, the new Reptile initialization and solving PDEs by PINNs. In the process of the new Reptile initialization, and represent the number of tasks for supervised and unsupervised learning, respectively. and represent the number of all tasks and updating all tasks. The new Reptile initialization is used for supervised, unsupervised, and semi-supervised learning. According to zero-order or high-order information, different types of tasks are obtained. Under each task, the difference between the three learning types is whether labeled data is used in the task sampling process. The three ways to learn from the tasks are as follows.
-
1)
For supervised learning when , we sample task from to obtain labeled data. Based on exact and predicted values, the loss function is confirmed.
-
2)
For unsupervised learning when , we sample task from and specify training points set and from PDE and boundary conditions. Based on the training data, the loss function about PDE and boundary condition is specified.
-
3)
For semi-supervised learning, task can be obtained from and , respectively. We consider the number of tasks for supervised learning and the remaining number of tasks is used for unsupervised learning.
Then, for the same task, the parameter is updated times by minimizing the loss function through SGD or Adam, which is described by . For different tasks, the parameter is updated in the direction to find the best parameters , and the update step size is a linear policy, .
The second part is the solving PDEs by PINNs. Through the new Reptile initialization, initialization parameters can be obtained. After loading the parameter , the NN is restricted to satisfy the physics constraints. Then the training sets , , and are specified for PDE, initial, boundary, and real data conditions. The loss by Eq.(3) is constructed to measure the discrepancy between the NN and the physics constraints. In the last step, the training procedure is to search for the best parameter by minimizing the loss function , where automatic differentiation is used to minimize the highly nonlinear and non-convex loss function . It is worth noting that the new Reptile initialization is used for initialization part, instead of changing the structure of the NN. Therefore, the new Reptile initialization can also be flexibly used for the variants of PINNs, such as PINNs with adaptive activation jagtap2020adaptive , parareal PINNs meng2020ppinn and conservative PINNs jagtap2020conservative , etc.
4 Numerical experiments
PDEs are the principle of describing many physical phenomena goufo2020similarities ; kumar2020analysis ; kumar2020study ; kumar2020chaotic . The NRPINN is a meshless method for PDE-based physics systems. To demonstrate and illustrate the performance of the NRPINN on different PDEs, we consider Poisson, Burgers, and Schrödinger equations, which have many real-life applications. Poisson equation is an elliptic PDE of broad utility in electrostatics, mechanical engineering, and theoretical physics fogolari2002poisson ; bates1987glossary ; pardoux2001poisson . Burgers equation is a fundamental PDE that appears in various areas of applied mathematics, such as nonlinear acoustics hamilton1998nonlinear , traffic flow may1990traffic , fluid mechanics munson2013fluid , etc. Schrödinger equation berezin2012schrodinger ; veeresha2020fractional is one of the fundamental equations of quantum mechanics griffiths2018introduction , which combines the concept of matter wave and wave equation to describe the motion of microscopic particles. Using NRPINN to solve these PDEs is important for modeling the large and complex PDE-based physics problems.
In this section, we will first consider solving forward and inverse problems by the NRPINN over PINNs with different initialization methods, where Xavier initialization glorot2010understanding is used by Raissi et al. raissi2019physics and other initialization methods are widespread use. The forward problems include one-dimensional Poisson, two-dimensional Poisson, Burgers, and Schrödinger equations. The inverse problem includes Burgers equations, where the clean and noisy data is used to identify the unknown parameters in the governing equations. Besides, the new Reptile initialization is used for PINNs with adaptive activation function jagtap2020adaptive .
4.1 Poisson equation
Poisson equation is represented by
| (8) |
where denotes Laplace operator and is penalty term.
4.1.1 One-dimensional Poisson equation
For one dimensional problem, the zero-order information is given by
| (9) |
where . denotes the solution under different parameters. Different tasks can be obtained from the zero-order information, and each task represents the solution under different parameters . The high-order information is given by
| (10) |
where and uniform [0,2]. Different tasks can also be obtained from the high-order information, and each task represents the governing equation under different parameters. In this case, we consider the following Poisson equation to be solved.
| (11) | ||||
where . The exact solution is smooth and has a linear term combining with two different frequency components, which is given by
| (12) |
We use four hidden layers with 50 neurons in each layer. The NRPINN mainly has two steps. In the part of the new Reptile initialization, we consider three types of the new Reptile initialization: (i) for supervised learning, we randomly select 4,000 tasks from the zero-order information. Then, we sample 2,000 training points under each task, confirm loss function , and use Adam to update the parameter 20 times with the learning rate of 0.001. (ii) for unsupervised learning, we randomly select 60 tasks from high-order information. Under each task, we sample 10,000 residual points from PDE as training points. Based on training points, the loss function is confirmed and Adam is used to update the parameter 1,000 times with the learning rate of 0.001. (iii) for semi-supervised learning, we select 100 tasks, of which half is used for supervised learning and the other half for unsupervised learning. In the part of solving PDEs by PINNs, the PINN with initialization parameters is used to solve the PDEs. We use 500 residual training points, two training data on the boundary, and 50 real data.
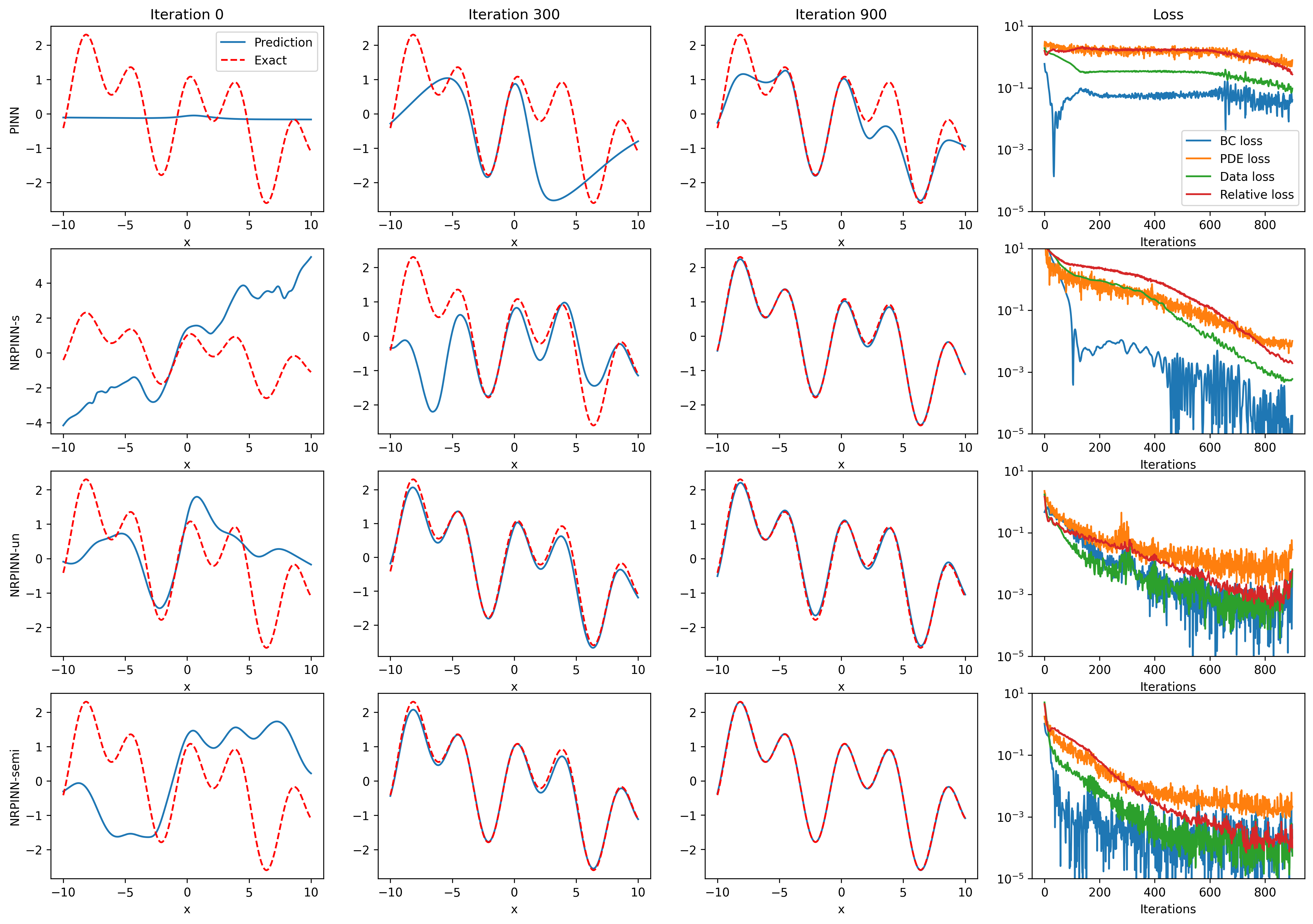
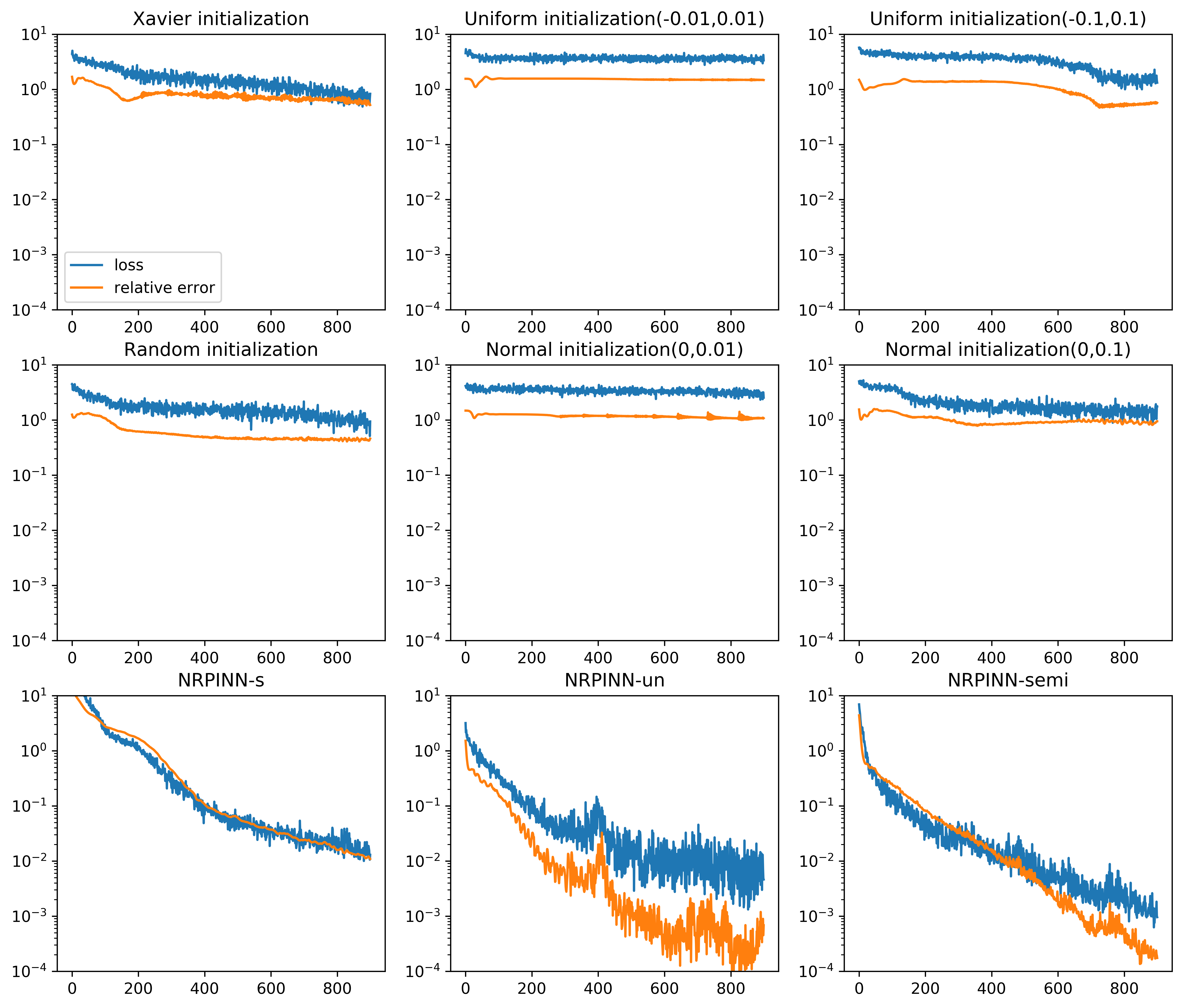
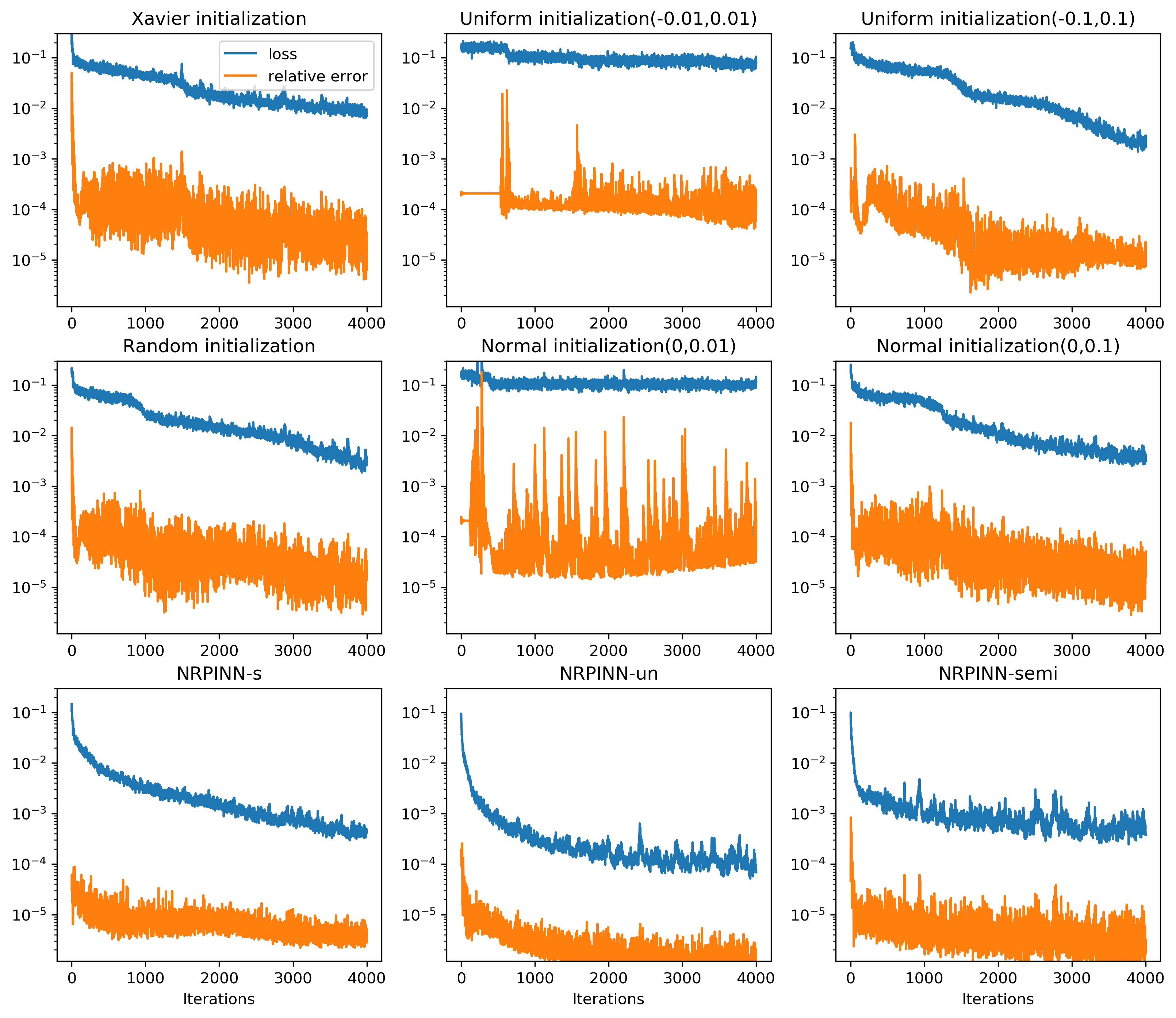
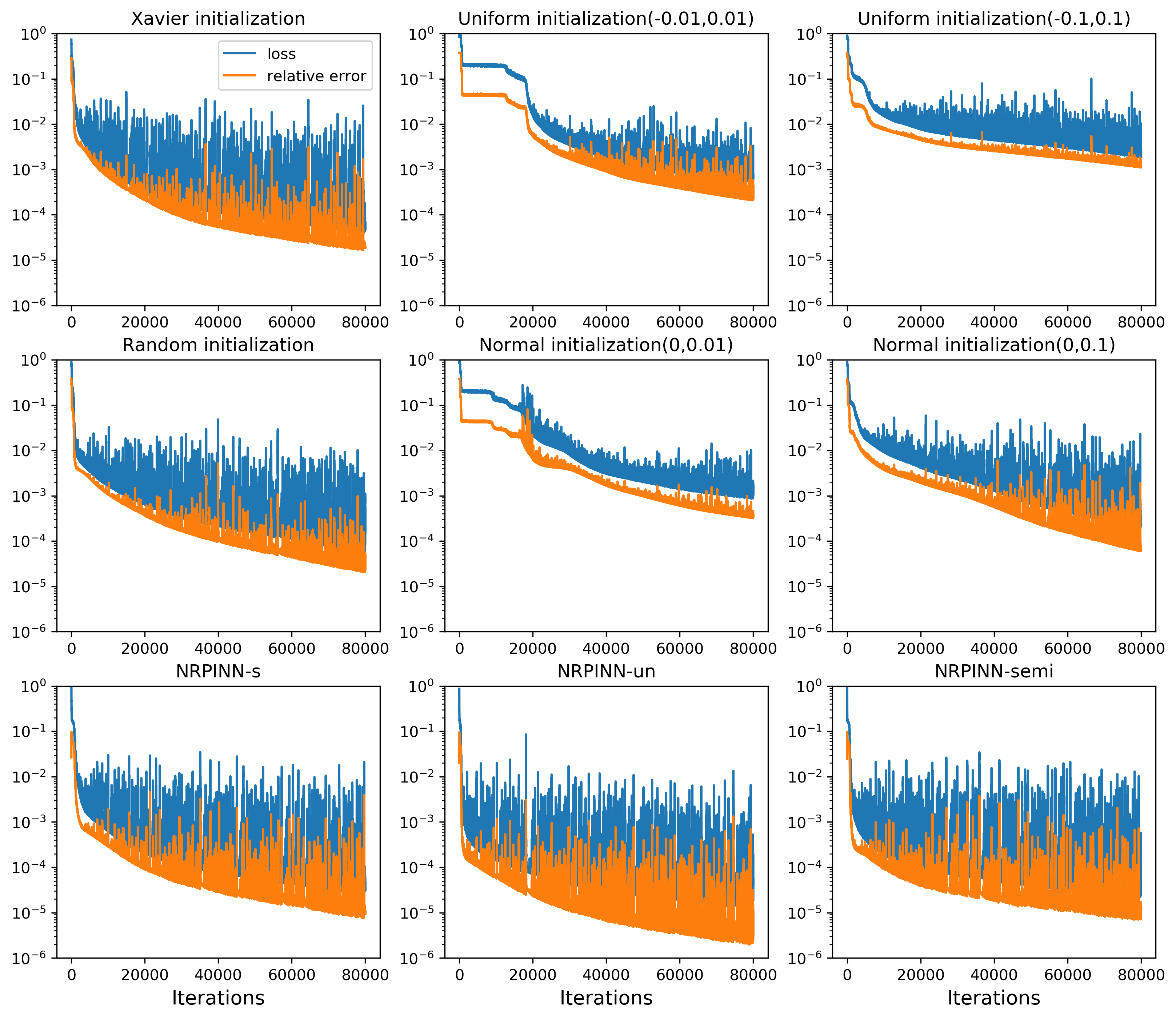
Fig.2 (top row) shows the result of PINNs by Xavier initialization, where the loss falls very slowly and reaches till 900 iterations and predicted loss is still high. Fig.2 (the last three rows) show the predicted solution at various iterations as well as the loss versus the number of iterations by the NRPINN with supervised (NRPINN-s), the NRPINN with unsupervised (NRPINN-un), and the NRPINN with semi-supervised learning (NRPINN-semi), respectively. The NRPINN-s, NRPINN-un, and NRPINN-semi accurately capture wave features in the solution quickly and different types of losses are very slow within iterations. The predicted loss (red line) of the NRPINN-s, NRPINN-un, and NRPINN-semi has converged to , which is significantly better than by the PINN with Xavier initialization. Fig.3 shows the history and relative loss with different initialization, where NRPINN-s, NRPINN-un, and NRPINN-semi outperform the PINN with other initialization methods. By contrast, the convergence performance of the PINN with uniform and normal distribution initialization is worst and the loss by Xavier initialization does not reach .
Table 1 shows the MAEs between predicted solutions and exact solutions for different initialization methods after 900 iterations. From the table, it can be noted that the MAEs of NRPINN-s, NRPINN-un, and NRPINN-semi are far less than other initialization methods. In particular, the MAE of the NRPINN-un tends to be , which is significantly better than by the PINN with the Xavier initialization. Overall, the NRPINN can endow the PINN with a better initialization.
| Initialization method | MAE |
|---|---|
| Xavier | 3.6731e-01 |
| Uniform(-0.01,0.01) | 1.7459 |
| Uniform(-0.1,0.1) | 1.7463 |
| Random | 5.0123e-01 |
| Normal(0,0.01) | 1.7400 |
| Normal(0,0.1) | 1.1109 |
| NRPINN-s | 2.8012e-02 |
| NRPINN-un | 5.1432e-04 |
| NRPINN-semi | 6.2110e-04 |
4.1.2 Two-dimensional Poisson equation
For two dimensional Poisson equation, it is represented by
| (13) | ||||
where represents the number of heat source and the heat source is generated by the following scheme as follows.
| (14) |
where , and .
In this case, the PDE to be solved is when and its parameters are shown in Table 2. Its numerical solution can be obtained through FEniCS dupont2003fenics , which is a popular open-source computing platform for solving PDEs. The numerical solution is shown in the Fig.4. The high-order information is the PDE with 1, 5 and 10 heat sources, which is given by
| (15) |
where and . Different tasks can be obtained from the high-order information, and each task represents the governing equation under different parameters. The zero-order information is the set of the numerical solution under different parameters , and . Different tasks can be obtained from the zero-order information, and each task represents the solution of Eq.(15) under different parameters. The numerical solution is obtained through FEniCS.
| 0.15 | 0.18 | 0.20 | 0.31 | 0.43 | 0.56 | 0.70 | 0.80 |
| 0.34 | 0.31 | 0.65 | 0.86 | 0.65 | 0.38 | 0.64 | 0.12 |
| 0.84 | 1.07 | 1.12 | 0.83 | 1.12 | 1.11 | 0.99 | 0.91 |
We use four hidden layers with 100 neurons in each layer. In the new Reptile initialization part, we consider three types of new Reptile initialization: (i) for supervised learning, we assume that 100 tasks can be obtained from the zero-order information. Then, we sample 4,000 training points under each task, confirm loss function , and use Adam to update the parameters of the NN 10,000 times with the learning rate of 0.001. (ii) for unsupervised learning, we randomly select 100 tasks from high-order information. Under each task, we sample 4,000 residual points from PDE as training points. Based on training points, the loss function is confirmed and Adam is used to update the parameter 10,000 times with the learning rate of 0.001. (iii) for semi-supervised learning, we select 100 tasks, of which half is used for supervised learning and the other half for unsupervised learning. In the part of solving PDEs by PINNs, the PINN with initialization parameters is used to solve the PDEs. We use 4,000 residual training points, 1,000 training data points on the boundary, and 0 real data.
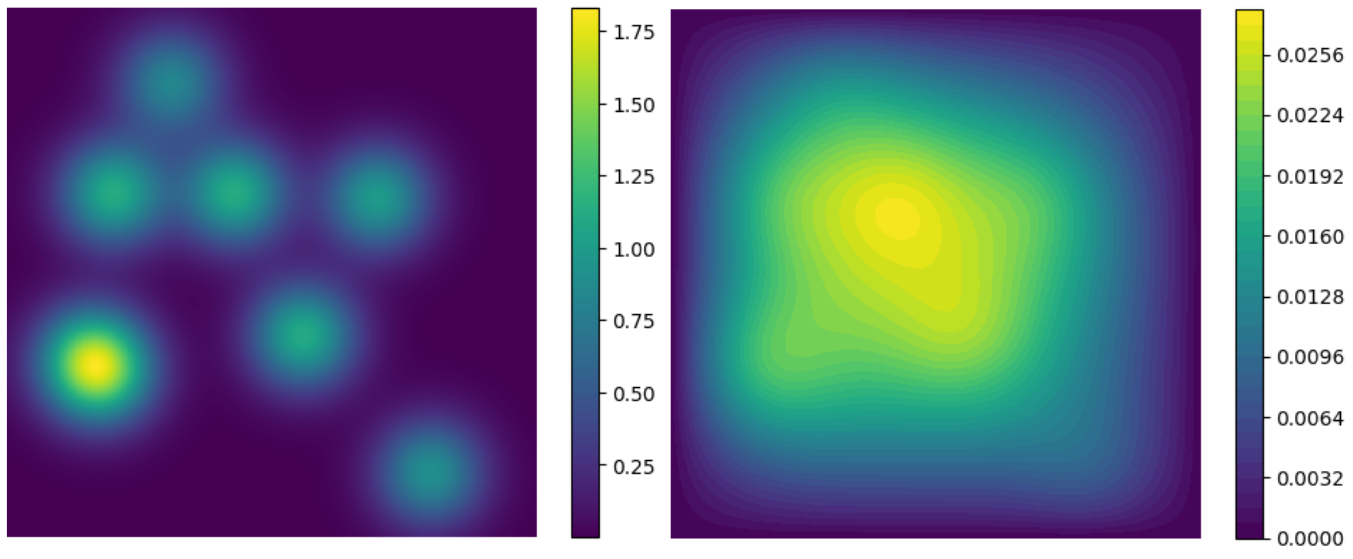
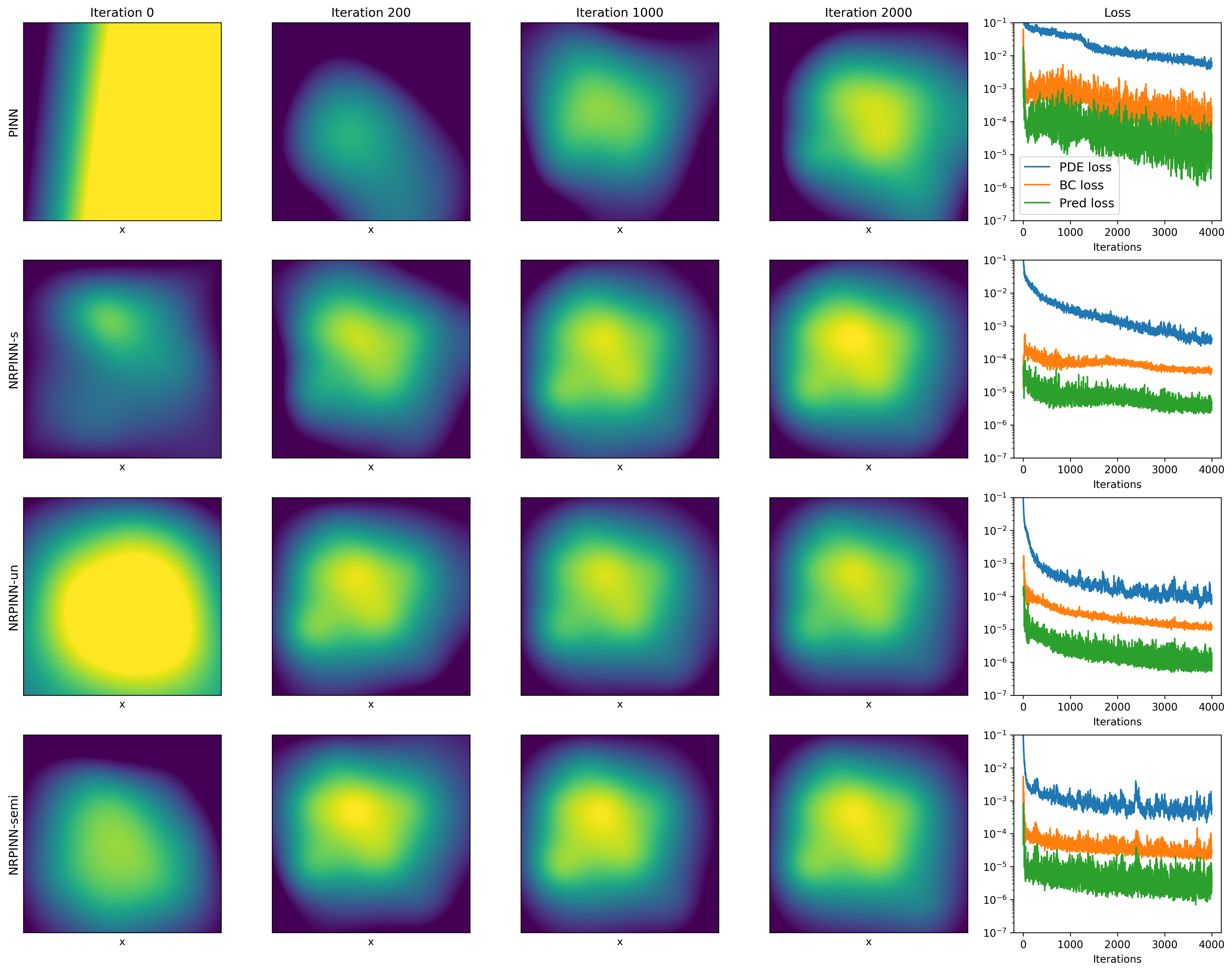
Fig.5 shows that the result of the PINN (the first row) with Xavier initialization and NRPINN-s, NRPINN-un, and NRPINN-semi (the last three rows). Obviously, even if PDEs with different heat sources are used as the tasks for NRPINN, the accuracy of NRPINN-s, NRPINN-un, and NRPINN-semi is visibly improved and the loss is clearly decreasing much fast. The training by NRPINN-un and NRPINN-semi has converged till 200 iteration. In the loss column, the predicted loss (green) denotes the relative error, where the predicted loss of NRPINN-un is lower 100 times over the PINN with Xavier initialization. The PDE loss as well as the BC loss of NRPINN-s, NRPINN-un, and NRPINN-semi converge faster than PINNs with the Xavier initialization. To analyze the effect of different initialization methods, Fig.6 shows the history and relative loss with different initializations, where NRPINN-s, NRPINN-un, and NRPINN-semi outperform the PINN with other initialization methods. Especially, the relative error by the NRPINN-un reaches , whose performance is best. In this case, Xavier initialization has similar to the random distribution initialization.
| Initialization method | MAE |
|---|---|
| Xavier | 1.6974036e-04 |
| Uniform(-0.01,0.01) | 1.4415e-04 |
| Uniform(-0.1,0.1) | 7.58242231e-05 |
| Random | 1.40351876e-05 |
| Normal(0,0.01) | 2.2043e-04 |
| Normal(0,0.1) | 5.07256991e-05 |
| NRPINN-s | 5.08864878e-06 |
| NRPINN-un | 6.44704471e-07 |
| NRPINN-semi | 3.15731108e-06 |
Table 3 shows the MAEs between prediction solutions and exact solutions for different initialization methods after 4,000 iterations. From the table, we can find that NRPINN achieves higher accuracy than the PINN with other initialization methods. In this case, the performance of the PINN with normal distribution initialization is better than Xavier initialization. However, the MAE of the NRPINN-un tends to be , which is significantly better than by the PINN with normal distribution initialization. In addition, the performances of NRPINN-s and NRPINN-semi are better than the PINN with normal distribution initialization.
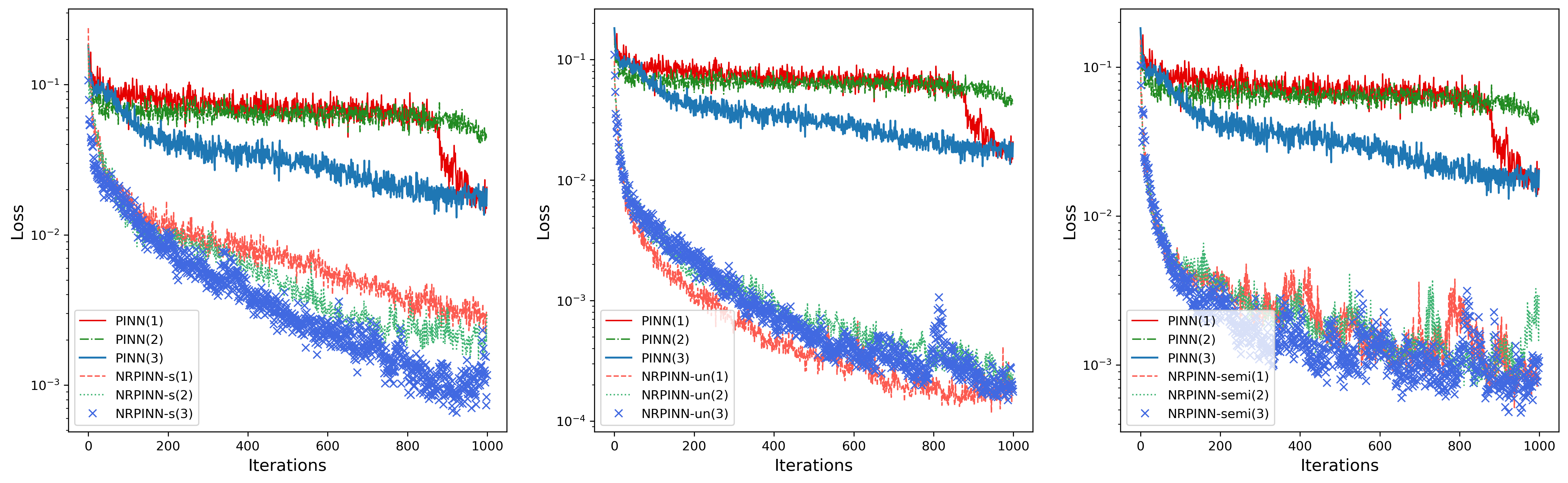
To further analyze the acceleration effect of the NRPINN for solving Eq.(13), the position of eight heat sources in the Fig.4 (left) is changed to obtain three PDEs. For illustration, we use NRPINN-s, NRPINN-un, and NRPINN-semi to solve another three PDEs and the experimental results shown in Fig.7. As Fig.7 shows, the training losses by NRPINN-s, NRPINN-un, and NRPINN-semi for the three PDEs are decreasing faster than the PINN with Xavier initialization. More apparently, the NRPINN can accelerate the training of any PDEs in the Eq.(14) and achieves similar acceleration effects for different PDEs. So one can see that NRPINN can efficiently solve a class of similar tasks.
4.2 Burgers equation
Before solving the Burgers equation, the high-order information is given by
| (16) | ||||
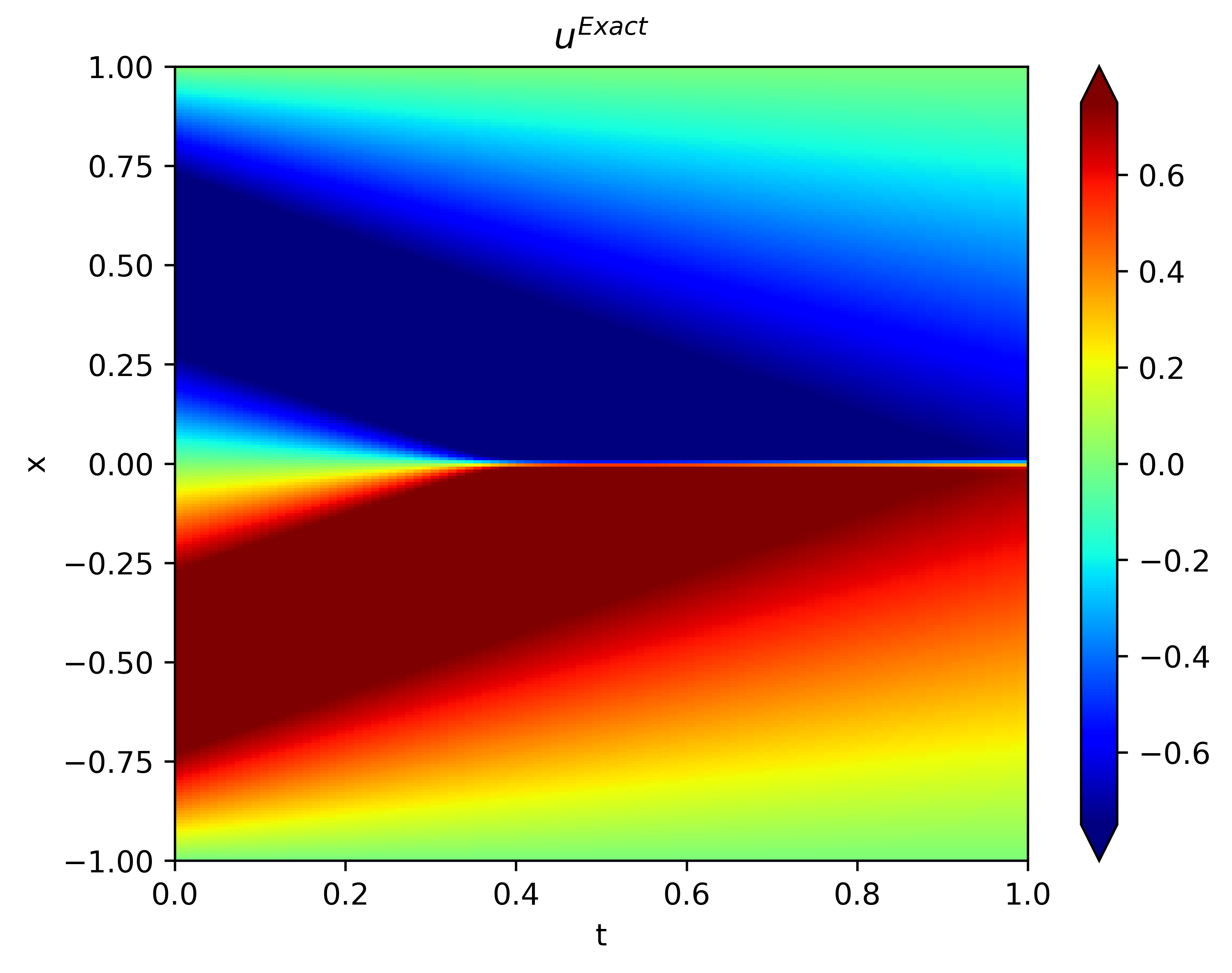
with viscous parameter . Each task obtained from the high-order information represents a governing equation in Eq.(16). The zero-order information is the set of numerical solutions under different . Each task obtained from the zero-order information represents the numerical solution under one value . In this case, the Burgers equation to be solved is when . The analytical solution can be obtained using the Hopf–Cole transformation and its graph is shown in Fig.8, see Basdevant et al. basdevant1986spectral for more details.
In this case, the number of hidden layers is eight and in each layer 20 neurons are used. In the new Reptile initialization part, we consider three types of new Reptile initialization: (i) for supervised learning, we assume that 20 tasks can be obtained from the zero-order information. Then, we sample 1,000 training points under each task, confirm loss function , and Adam is used to update the parameter 10,000 times with the learning rate of 0.001. (ii) for unsupervised learning, we randomly select 50 tasks, sample 1,000 residual points and 1,000 training points on the boundary, and update the parameters of the NN 10,000 times. (iii) for semi-supervised learning, we select 75 tasks, of which half is used for supervised learning and the other half for unsupervised learning. In the part of solving PDEs by PINNs, the PINN with initialization parameters is used to solve the PDEs. The number of residual training points is 10,000, the number of training data points on the boundary is 5,000, and the number of true data is 0.
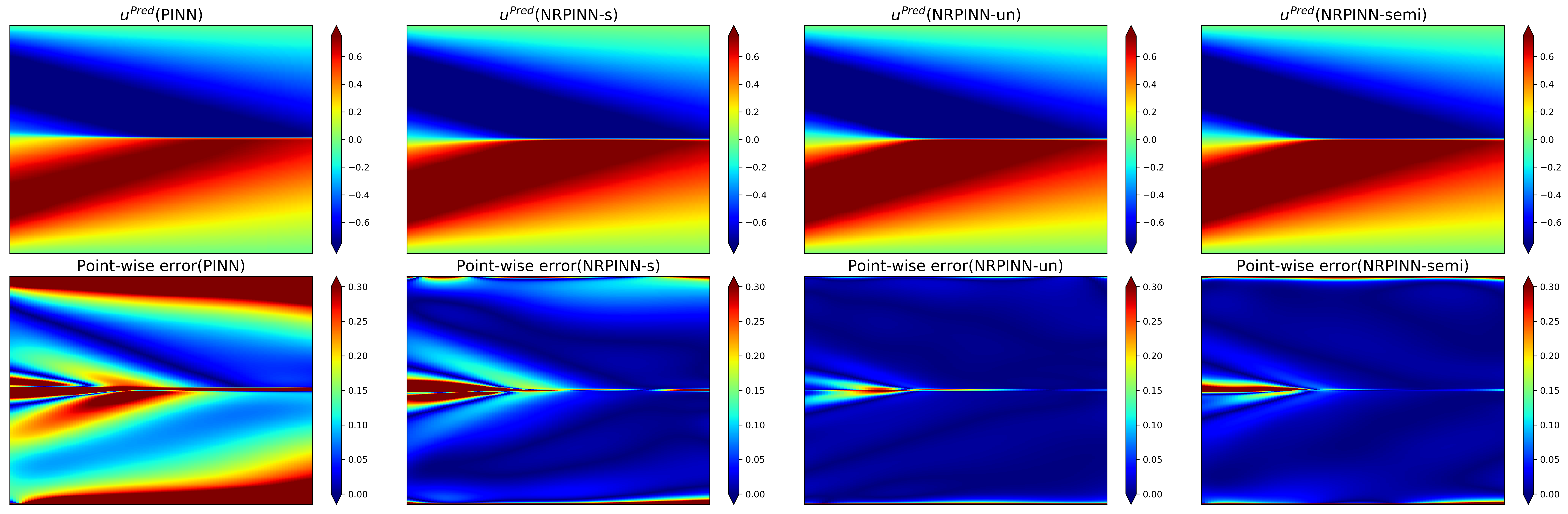
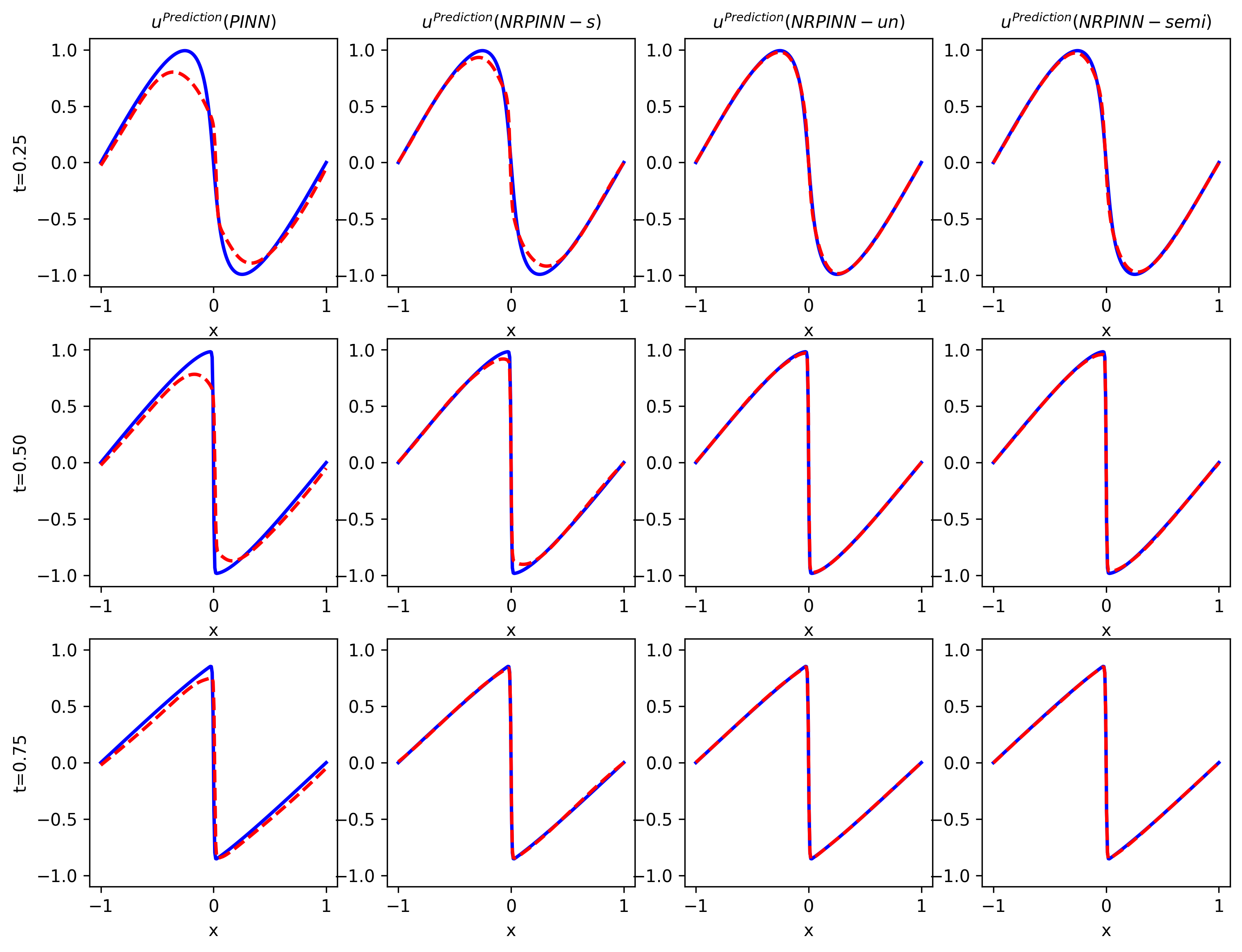
Fig.9 shows the predicted solution (top row) as well as the point-wise error (bottom row) by PINNs with Xavier initialization, NRPINN-s, NRPINN-un, and NRPINN-semi. NRPINN-s, NRPINN-un, and NRPINN-semi accurately capture all the dispersive waves in the solution and the point-wise errors in the entire domain are very low. In contrast, the PINN with Xavier initialization fails to predict the solution accuracy and its point-wise error is very high compared to NRPINN-s, NRPINN-un, and NRPINN-semi. Fig.10 gives the comparison of solutions by the PINN with Xavier initialization, NRPINN-s, NRPINN-un, and NRPINN-semi at various t locations. In the left column, Xavier initialization is used for the PINN and the right three columns present the results of NRPINN-s, NRPINN-un, and NRPINN-semi, where one can see that the accuracy of NRPINN-s, NRPINN-un, and NRPINN-semi over the PINN is significantly improved. Fig.11 shows the loss history and relative error over the number of iterations with different initializations methods. The loss and relative error of the NRPINN over the PINN with other initialization methods are visibly decreasing faster. The PINN with Xavier initialization outperforms other initializations methods but its loss and relative error reach , far less than the NRPINN-un.
Table 4 lists the MAEs between prediction solutions and exact solutions for different initialization methods after 2,000 iterations. The MAEs of NRPINN-s, NRPINN-un, and NRPINN-semi are far less than the PINN with other initialization methods. The performance of NRPINN-un is the best and the MAE of NRPINN-un tends to be . The MAE of the PINN with uniform distribution initialization tends to be , which is worse than NRPINN-s, NRPINN-un and NRPINN-semi.
| Initialization method | MAE |
|---|---|
| Xavier | 8.871e-03 |
| Uniform(-0.01,0.01) | 3.774e-01 |
| Uniform(-0.1,0.1) | 7.656e-02 |
| Random | 2.578e-02 |
| Normal(0,0.01) | 5.6194e-02 |
| Normal(0,0.1) | 3.3010e-02 |
| NRPINN-s | 1.3842e-03 |
| NRPINN-un | 8.582e-05 |
| NRPINN-semi | 1.7821e-04 |
4.3 Schrödinger equation
Before solving the Schrödinger equation, the high-order information is given by
| (17) |
where , and . Each task obtained from the high-order information represents a governing equation in Eq.(17). In this case, the Schrödinger equation to be solved is the PDE when and its graph is shown in Fig.12. Considering the Eq.17, we consider unsupervised learning for the new Reptile initialization. We use four hidden layers with 100 neurons in each layer. In the part of new Reptile initialization, we randomly select 100 tasks for unsupervised learning, sample 1,000 residual points and 1,000 training points on the boundary, and update the parameters 10,000 times. In the part of solving PDEs by PINNs, we consider 20,000 residual training points, 1,000 training data points on the boundary, and 0 real training data.
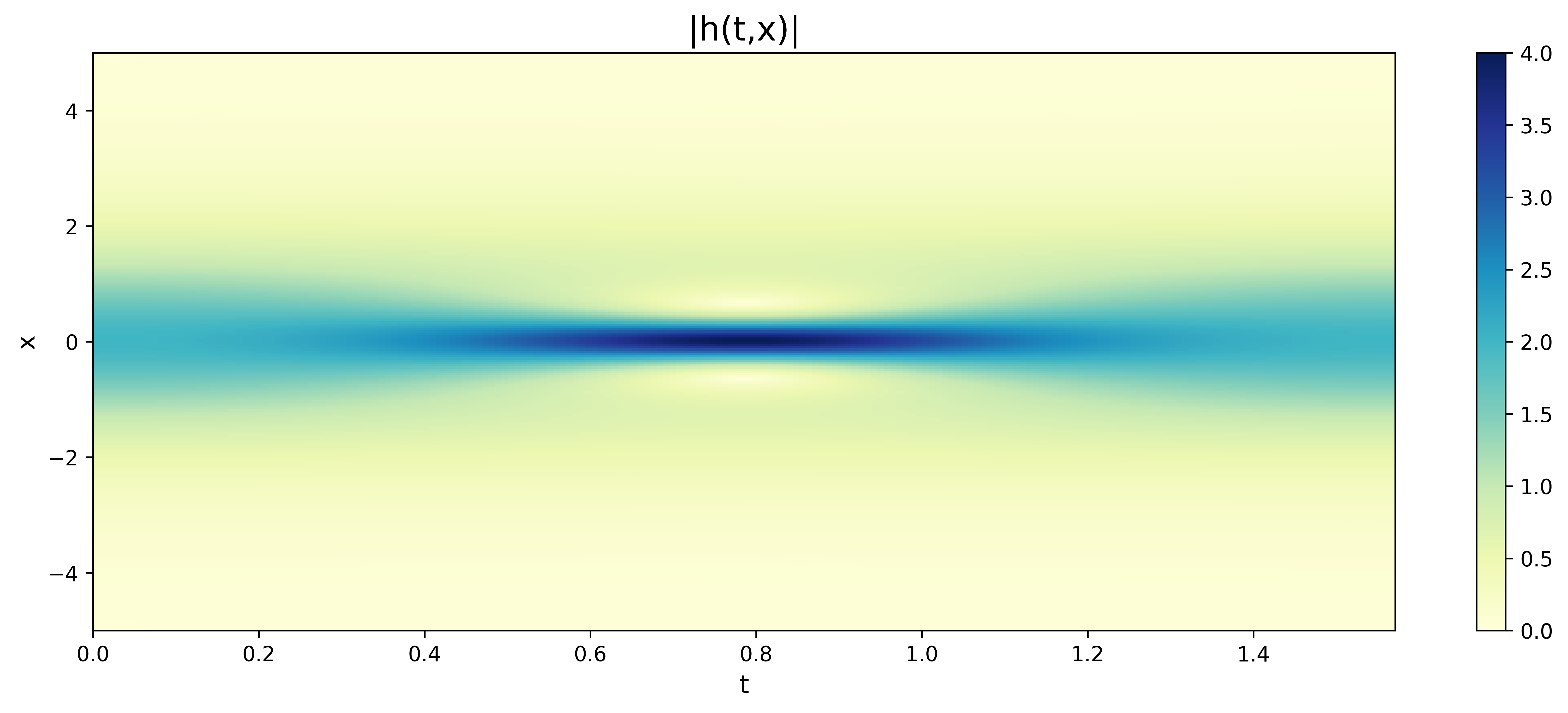
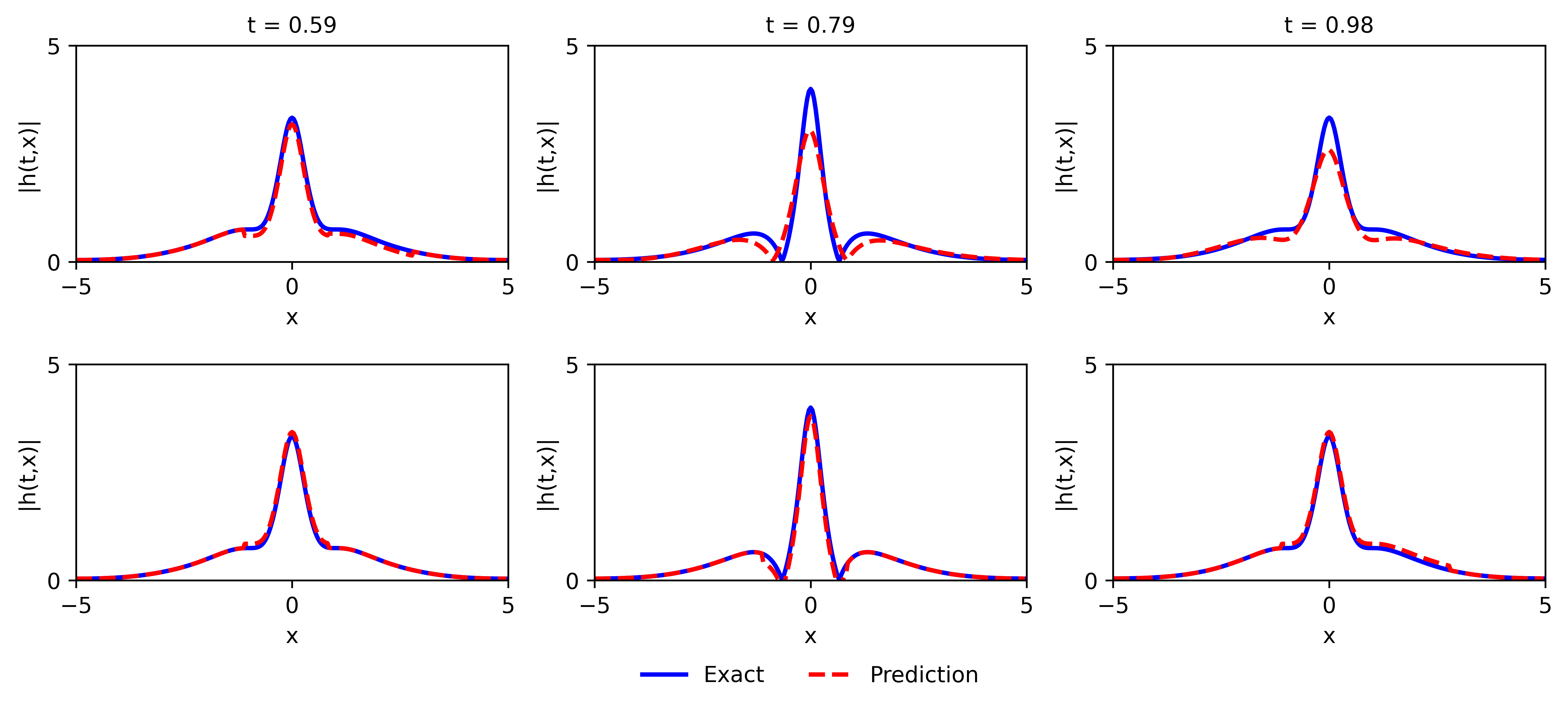
Fig.13 shows the predicted solution at various iterations, and the point-wise error at 30,000 iterations by the PINN (top row) with Xavier initialization and NRPINN-un (bottom row). Compared to the PINN, NRPINN-un accurately captures the feature of the solution faster and the point-wise error at 30,000 iterations in the entire domain is lower. Fig.14 gives the comparison of solution by the PINN and the NRPINN-un at . The top figure shows results of the PINN with Xavier initialization and the bottom figure presents results of NRPINN-un, where the accuracy of NRPINN-un over PINNs is visibly improved. Especially, the predicted solution at of PINNs is worst than NRPINN-un, which accords with points-wise error in Fig.14. Fig.15 shows the loss history and the relative error over the number of iterations for different initialization methods, where the loss and the relative error of NRPINN-un is decreasing faster over other initialization methods.
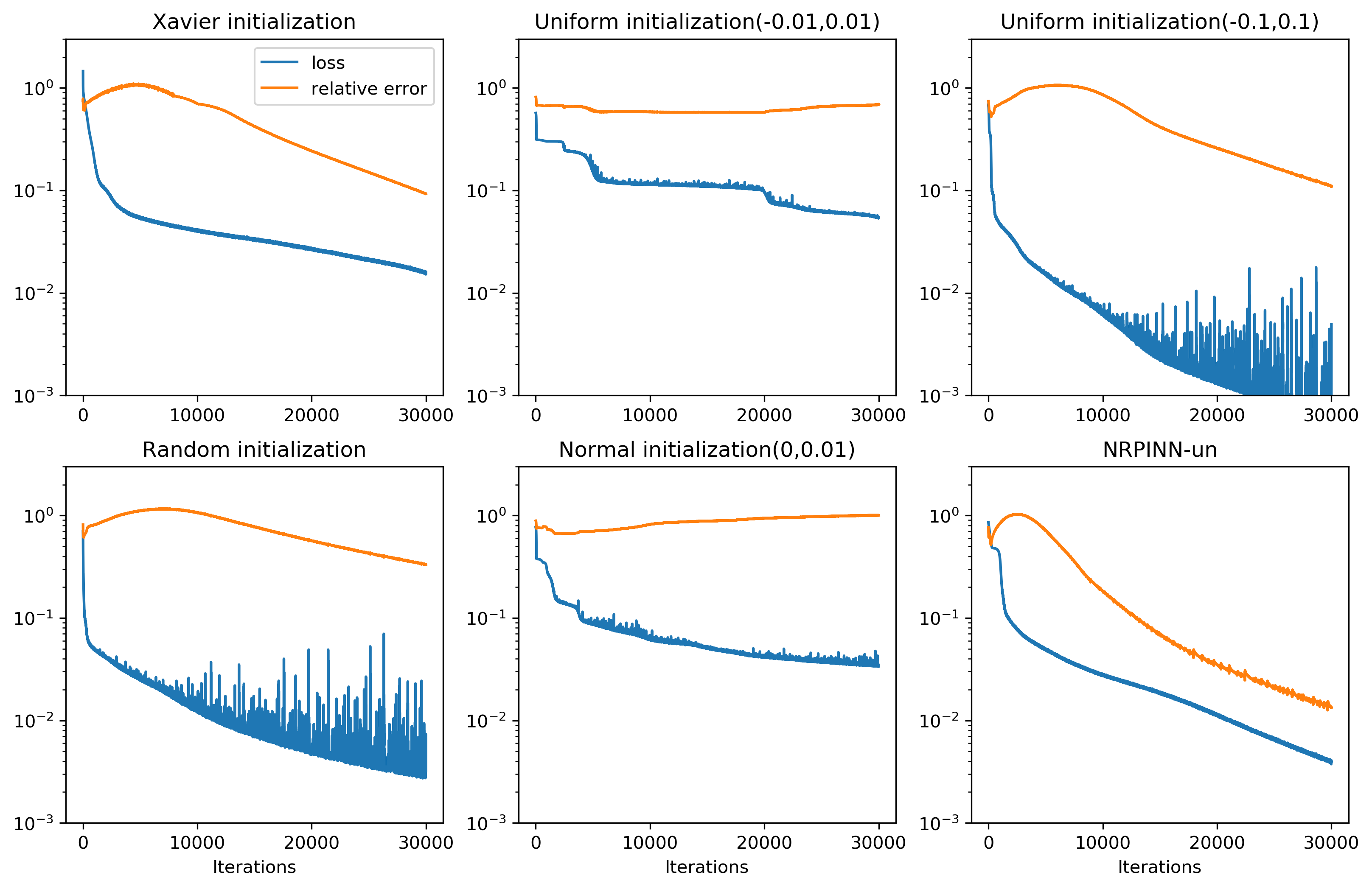
Table 5 lists the MAEs between prediction solutions and exact solutions for different initialization methods under 30,000 iterations. The MAE of the NRPINN-un tends to be , which is better than by the PINN with Xavier initialization. The PINN with uniform distribution initialization tends to be , which is far worse than by Xavier initialization method. In summary, the NRPINN endows the PINN with a good start to achieve higher accuracy.
| Initialization method | MAE |
|---|---|
| Xavier | 1.0742e-01 |
| Uniform(-0.01,0.01) | 6.9054e-01 |
| Uniform(-0.1,0.1) | 1.0934e-01 |
| Random | 3.3117e-01 |
| Normal(0,0.01) | 1.0060 |
| NRPINN-un | 1.3406e-02 |
4.4 Inverse problem for Burgers
In response to the lack of data, in this section, we consider quickly identifying the unknown parameters in the PDEs with a small amount of real data by NRPINN. The parameterized viscous Burgers equation is given by
| (18) |
where is hidden solution and is a parameterized nonlinear term. In this case, we consider solving the PDE when viscosity coefficient is equal to . Eq.18 can be considered as the high-order information for the new Reptile initialization. The zero-order information is the set of the solutions for different . The detailed experimental parameters setting for supervised, unsupervised, and semi-supervised learning are the same as section 4.2.
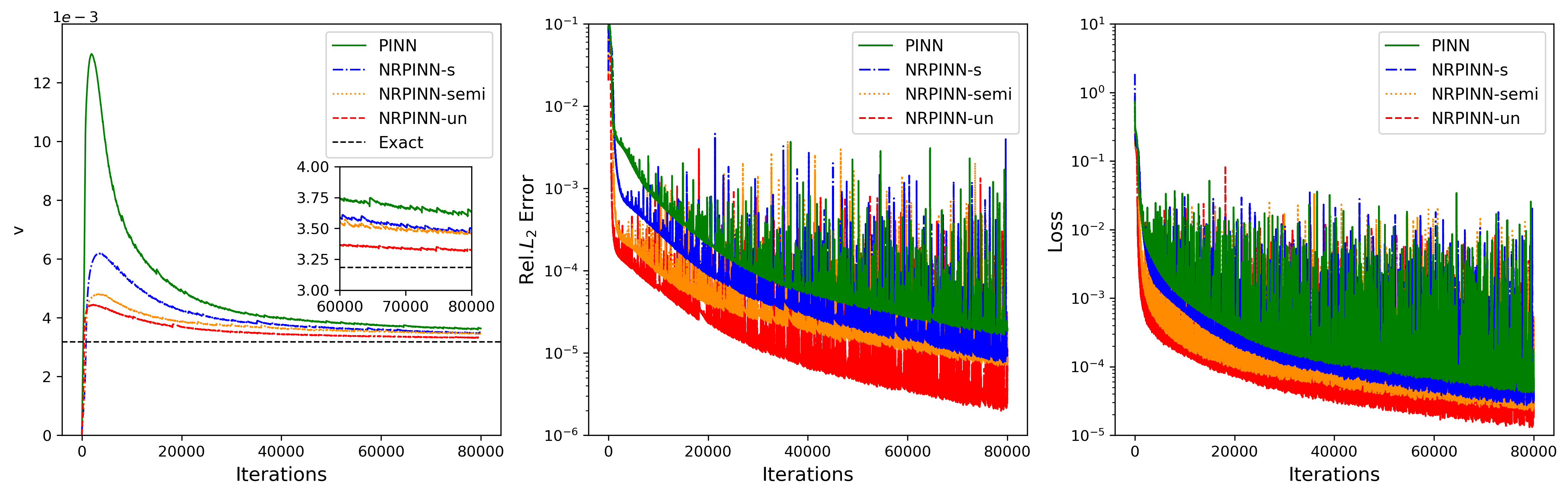
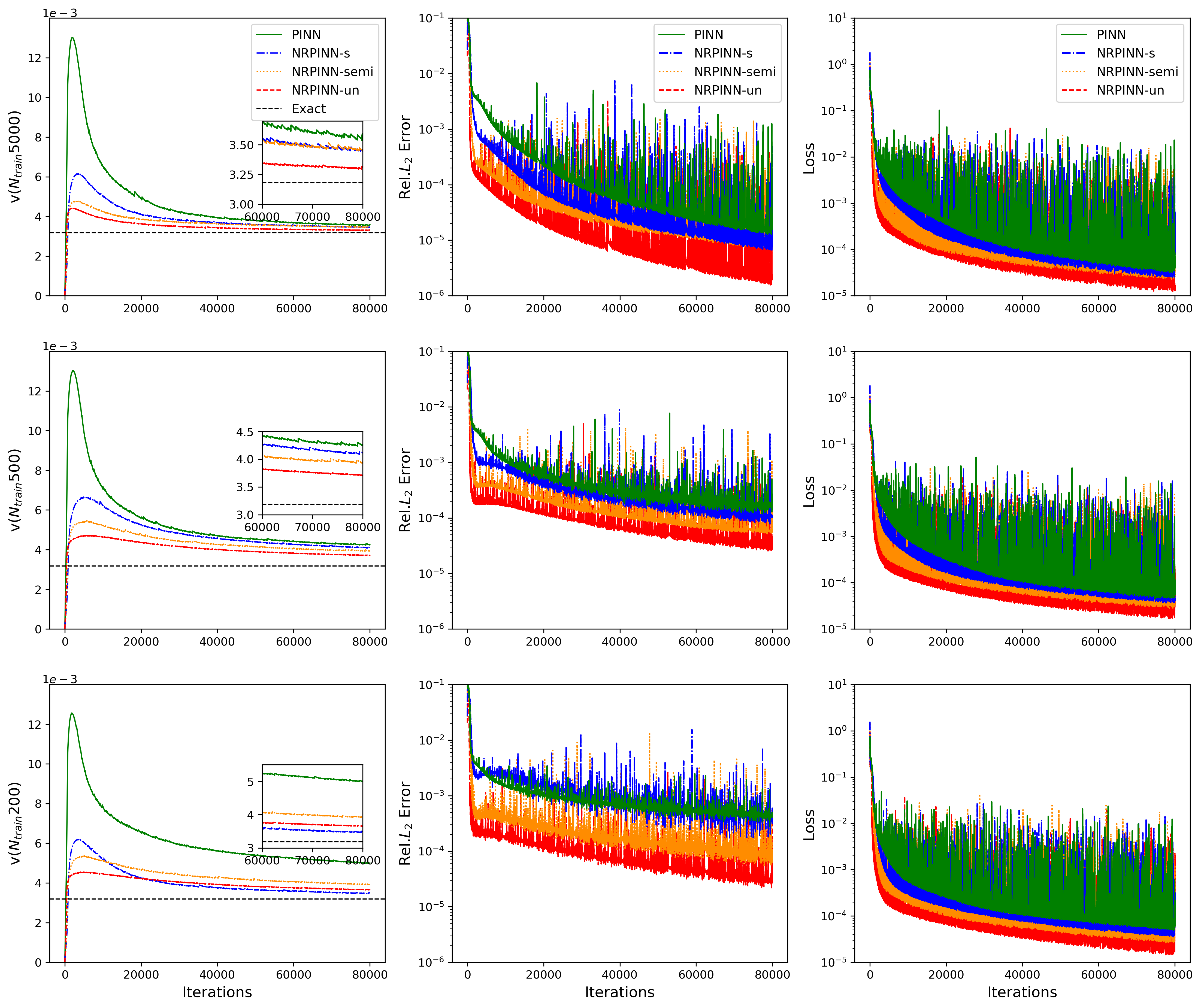
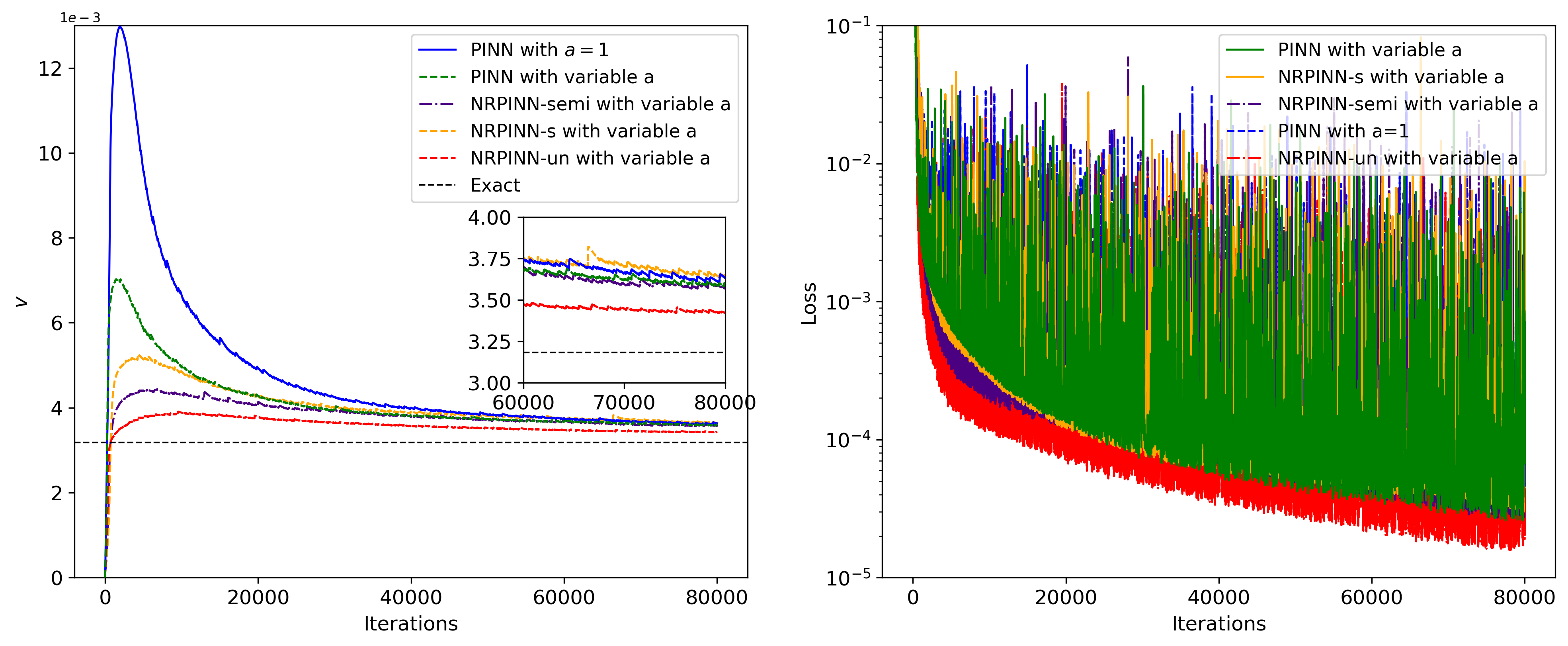
Fig.16 (left to right) shows the history, error, and loss versus number of iterations, respectively. In the left figure, the predicted by NRPINN-s, NRPINN-un, and NRPINN-semi visibly converge faster towards its exact value over the PINN. After 80,000 iterations, the predicted by NRPINN-s, NRPINN-un, and NRPINN-semi are , , and , respectively. The relative errors by NRPINN-s, NRPINN-un, and NRPINN-semi are , , and , whereas the predicted by the PINN with Xavier initialization is and the relative error is . To analyze the dependence by the PINN with Xavier initialization and NRPINN on real training data (), we use different number of real data. Fig.17 shows the history, error, and loss versus number of iterations with different real training data, where NRPINN-s, NRPINN-un, and NRPINN-semi always predict unknown parameters faster and achieve higher accuracy than the PINN with Xavier initialization. For is equal to , the predicted by the PINN is and the relative error is , whereas the relative error by NRPINN-s, NRPINN-un, and NRPINN-semi reaches , , and , respectively, where one can see that NRPINN maintains good predictive performance when the amount of real training data is small.
| 200 | 500 | |||||||||||
| Noise | clean | 1% | 2% | clean | 1% | 2% | ||||||
| PINN | 56.94% | 69.74% | 75.42% | 33.57% | 19.36% | 23.12% | ||||||
| NRPINN-s | 36.41% | 14.9%1 | 45.63% | 29.19% | 13.27% | 7.49% | ||||||
| NRPINN-un | 14.80% | 17.43% | 22.93% | 16.53% | 10.99% | 18.98% | ||||||
| NRPINN-semi | 23.32% | 12.38% | 22.77% | 24.11% | 19.77% | 18.10% | ||||||
| 5000 | 10000 | |||||||||||
| Noise | clean | 1% | 2% | clean | 1% | 2% | ||||||
| PINN | 12.79% | 23.59% | 21.27% | 14.13% | 20.26% | 21.15% | ||||||
| NRPINN-s | 8.62% | 10.55% | 10.32% | 9.85% | 9.44% | 8.55% | ||||||
| NRPINN-un | 4.12% | 6.97% | 5.23% | 4.46% | 5.59% | 5.51% | ||||||
| NRPINN-semi | 8.40% | 6.57% | 1.17% | 8.57% | 7.13% | 6.64% | ||||||
Fig.18 shows the history and relative loss with different initializations methods. The NRPINN has a better performance, which outperforms other initialization methods. Especially, the historical loss and relative error by NRPINN-un reach . In this case, the variation trend of Xavier initialization has similar to random distribution initialization. Fig.19 shows the history with clean data, , and noise data under 80,000 iterations. Whatever or noise data, NRPINN-s, NRPINN-un, and NRPINN-semi outperform the PINN with clean data, whose predicted is , and . Faced and noise data, the predicted by PINNs is and , far from the exact value . Fig.19 shows the historical loss with clean and noisy data, where NRPINN-s, NRPINN-un, NRPINN-semi achieve lower and faster historical losses than the PINN with Xavier initialization. Table 6 shows the relative error of predicted under the different number of noise data, where NRPINN-s, NRPINN-un, and NRPINN-semi achieve smaller errors than the PINN with Xavier initialization when a small number of real data is available. The new Reptile initialization is also used for the variants of PINNs. To demonstrate the new Reptile can be used for the variants of PINNs, we use new Reptile initialization for PINNs with adaptive activation function proposed by D.Jagtap et al. jagtap2020adaptive . Fig.21 shows the predicted and historical loss, where the PINN with variable outperform the PINN with . Apparently, the new Reptile initialization can also be used for PINNs with adaptive activation functions to accelerate training.
5 Conclusions
Designing a fast and accurate deep learning method is very important for solving a large and complex PDE-based physics problem. By introducing the meta-learning algorithm, we propose a new Reptile initialization based physics-informed neural network (NRPINN) to improve the training efficiency and predicted accuracy of PINNs. According to learning tasks in the new Reptile initialization, the NRPINN is divided into NRPINN-s, NRPINN-un and NRPINN-semi.
To support our claim, we examined our proposed algorithm for forward and inverse problems of both smooth solutions and sharp gradient solutions, including Poisson, Burgers and Schrödinger equations. In all cases, the decay of losses by NRPINN is much faster than PINNs with other initialization methods, and its corresponding mean relative errors between predicted and the exact solution by NRPINN are much lower than PINNs with other initialization methods. Besides, the new Reptile initialization is a general structure for PINNs, which is also used for variants of PINNs, such as PINNs with adaptive activation [24], parareal PINNs [29], and conservative PINNs [25], etc. In summary, the NRPINN reduces the training cost and improves the prediction accuracy.
There is one limitation in the current work. The NRPINN requires prior informations namely, high-order and zero-order information as the learning tasks of the new Reptile initialization. Therefore, NRPINN is not suitable for solving the problems where the prior information cannot be obtained. In future work, using transfer learning from related works to obtain a initialization may be another way to improve the performance of PINNs.
Acknowledgement
This work was supported in part by National Natural Science Foundation of China under Grant No.11725211 and 52005505.
Compliance with ethical standard Conflict
Conflict of interest The authors have no conflicts of interest that they are aware of.
References
- (1) Avrutskiy, V.I.: Neural networks catching up with finite differences in solving partial differential equations in higher dimensions. Neural. Comput. Appl. pp. 1–16 (2020)
- (2) Basdevant, C., Deville, M., Haldenwang, P., Lacroix, J., Ouazzani, J., Peyret, R., Orlandi, P., Patera, A.: Spectral and finite difference solutions of the burgers equation. Comput Fluids 14(1), 23–41 (1986)
- (3) Bates, R.L., Jackson, J.A.: Glossary of geology: American geological institute. Alexandria Va 788 (1987)
- (4) Baydin, A.G., Pearlmutter, B.A., Radul, A.A., Siskind, J.M.: Automatic differentiation in machine learning: a survey. J Mach Learn Res 18(1), 5595–5637 (2017)
- (5) Berezin, F.A., Shubin, M.: The Schrödinger Equation, vol. 66. Springer Science & Business Media (2012)
- (6) Bottou, L.: Stochastic gradient learning in neural networks. J. Neurosci. 91(8), 12 (1991)
- (7) Brink, A.R., Najera-Flores, D.A., Martinez, C.: The neural network collocation method for solving partial differential equations. Neural. Comput. Appl. pp. 1–18 (2020)
- (8) Chakraborty, S.: Transfer learning based multi-fidelity physics informed deep neural network. arXiv preprint arXiv:2005.10614 (2020)
- (9) Chen, Y., Lu, L., Karniadakis, G.E., Dal Negro, L.: Physics-informed neural networks for inverse problems in nano-optics and metamaterials. Opt. Express 28(8), 11618–11633 (2020)
- (10) Dupont, T., Hoffman, J., Johnson, C., Kirby, R.C., Larson, M.G., Logg, A., Scott, L.R.: The fenics project. Chalmers Finite Element Centre, Chalmers University of Technology (2003)
- (11) Dwivedi, V., Parashar, N., Srinivasan, B.: Distributed physics informed neural network for data-efficient solution to partial differential equations. arXiv preprint arXiv:1907.08967 (2019)
- (12) Finn, C., Abbeel, P., Levine, S.: Model-agnostic meta-learning for fast adaptation of deep networks. arXiv preprint arXiv:1703.03400 (2017)
- (13) Finn, C., Levine, S.: Meta-learning and universality: Deep representations and gradient descent can approximate any learning algorithm. arXiv preprint arXiv:1710.11622 (2017)
- (14) Finn, C., Xu, K., Levine, S.: Probabilistic model-agnostic meta-learning. In: NIPS, pp. 9516–9527 (2018)
- (15) Fogolari, F., Brigo, A., Molinari, H.: The poisson–boltzmann equation for biomolecular electrostatics: a tool for structural biology. JMR 15(6), 377–392 (2002)
- (16) Glorot, X., Bengio, Y.: Understanding the difficulty of training deep feedforward neural networks. In: Proceedings of the thirteenth international conference on artificial intelligence and statistics, pp. 249–256 (2010)
- (17) Goswami, S., Anitescu, C., Chakraborty, S., Rabczuk, T.: Transfer learning enhanced physics informed neural network for phase-field modeling of fracture. Theor. Appl. Fract. Mech. 106, 102447 (2020)
- (18) Goufo, E.F.D., Kumar, S., Mugisha, S.: Similarities in a fifth-order evolution equation with and with no singular kernel. Chaos Solitons Fractals 130, 109467 (2020)
- (19) Griffiths, D.J., Schroeter, D.F.: Introduction to quantum mechanics. Cambridge University Press (2018)
- (20) Grohs, P., Hornung, F., Jentzen, A., Von Wurstemberger, P.: A proof that artificial neural networks overcome the curse of dimensionality in the numerical approximation of black-scholes partial differential equations. arXiv preprint arXiv:1809.02362 (2018)
- (21) Hamilton, M.F., Blackstock, D.T., et al.: Nonlinear acoustics, vol. 237. Academic press San Diego (1998)
- (22) He, Q., Barajas-Solano, D., Tartakovsky, G., Tartakovsky, A.M.: Physics-informed neural networks for multiphysics data assimilation with application to subsurface transport. Adv Water Resour p. 103610 (2020)
- (23) Jagtap, A.D., Karniadakis, G.E.: Extended physics-informed neural networks (xpinns): A generalized space-time domain decomposition based deep learning framework for nonlinear partial differential equations. CiCP 28(5), 2002–2041 (2020)
- (24) Jagtap, A.D., Kawaguchi, K., Karniadakis, G.E.: Locally adaptive activation functions with slope recovery term for deep and physics-informed neural networks. arXiv preprint arXiv:1909.12228 (2019)
- (25) Jagtap, A.D., Kawaguchi, K., Karniadakis, G.E.: Adaptive activation functions accelerate convergence in deep and physics-informed neural networks. J.Comput.Phys. 404, 109136 (2020)
- (26) Jagtap, A.D., Kharazmi, E., Karniadakis, G.E.: Conservative physics-informed neural networks on discrete domains for conservation laws: Applications to forward and inverse problems. Comput Methods Appl Mech Eng 365, 113028 (2020)
- (27) Kharazmi, E., Zhang, Z., Karniadakis, G.E.: hp-vpinns: Variational physics-informed neural networks with domain decomposition. Comput Methods Appl Mech Eng 374, 113547 (2021)
- (28) Kim, Y., Choi, Y., Widemann, D., Zohdi, T.: A fast and accurate physics-informed neural network reduced order model with shallow masked autoencoder. arXiv preprint arXiv:2009.11990 (2020)
- (29) Kingma, D.P., Ba, J.: Adam: A method for stochastic optimization. arXiv preprint arXiv:1412.6980 (2014)
- (30) Kumar, S.: A new analytical modelling for fractional telegraph equation via laplace transform. Appl. Math. Model. 38(13), 3154–3163 (2014)
- (31) Kumar, S., Ahmadian, A., Kumar, R., Kumar, D., Singh, J., Baleanu, D., Salimi, M.: An efficient numerical method for fractional sir epidemic model of infectious disease by using bernstein wavelets. Mathematics 8(4), 558 (2020)
- (32) Kumar, S., Ghosh, S., Kumar, R., Jleli, M.: A fractional model for population dynamics of two interacting species by using spectral and hermite wavelets methods. Numer Methods Partial Differ Equ 37(2), 1652–1672 (2021)
- (33) Kumar, S., Ghosh, S., Samet, B., Goufo, E.F.D.: An analysis for heat equations arises in diffusion process using new yang-abdel-aty-cattani fractional operator. Math. Methods Appl. Sci. 43(9), 6062–6080 (2020)
- (34) Kumar, S., Kumar, R., Agarwal, R.P., Samet, B.: A study of fractional lotka-volterra population model using haar wavelet and adams-bashforth-moulton methods. Math. Methods Appl. Sci. 43(8), 5564–5578 (2020)
- (35) Kumar, S., Kumar, R., Cattani, C., Samet, B.: Chaotic behaviour of fractional predator-prey dynamical system. Chaos Solitons Fractals 135, 109811 (2020)
- (36) Kumar, S., Kumar, R., Osman, M., Samet, B.: A wavelet based numerical scheme for fractional order seir epidemic of measles by using genocchi polynomials. Numer Methods Partial Differ Equ 37(2), 1250–1268 (2021)
- (37) Mao, Z., Jagtap, A.D., Karniadakis, G.E.: Physics-informed neural networks for high-speed flows. Comput Methods Appl Mech Eng 360, 112789 (2020)
- (38) May, A.D.: Traffic flow fundamentals (1990)
- (39) Meng, X., Li, Z., Zhang, D., Karniadakis, G.E.: Ppinn: Parareal physics-informed neural network for time-dependent pdes. Comput Methods Appl Mech Eng 370, 113250 (2020)
- (40) Munson, B.R., Okiishi, T.H., Huebsch, W.W., Rothmayer, A.P.: Fluid mechanics. Wiley Singapore (2013)
- (41) Narasimhan, T., Witherspoon, P.: An integrated finite difference method for analyzing fluid flow in porous media. Water Resources Research 12(1), 57–64 (1976)
- (42) Nichol, A., Achiam, J., Schulman, J.: On first-order meta-learning algorithms. arXiv preprint arXiv:1803.02999 (2018)
- (43) Pardoux, E., Veretennikov, A.Y.: On the poisson equation and diffusion approximation. i. Ann Appl Probab pp. 1061–1085 (2001)
- (44) Peng, W., Zhou, W., Zhang, J., Yao, W.: Accelerating physics-informed neural network training with prior dictionaries. arXiv preprint arXiv:2004.08151 (2020)
- (45) Poggio, T., Mhaskar, H., Rosasco, L., Miranda, B., Liao, Q.: Why and when can deep-but not shallow-networks avoid the curse of dimensionality: a review. Int. J. Autom. Comput. 14(5), 503–519 (2017)
- (46) Raissi, M., Babaee, H., Givi, P.: Deep learning of turbulent scalar mixing. Phys. Rev. Fluid 4(12), 124501 (2019)
- (47) Raissi, M., Perdikaris, P., Karniadakis, G.E.: Physics-informed neural networks: A deep learning framework for solving forward and inverse problems involving nonlinear partial differential equations. J.Comput.Phys. 378, 686–707 (2019)
- (48) Raissi, M., Yazdani, A., Karniadakis, G.E.: Hidden fluid mechanics: Learning velocity and pressure fields from flow visualizations. Science 367(6481), 1026–1030 (2020)
- (49) Rajeswaran, A., Finn, C., Kakade, S.M., Levine, S.: Meta-learning with implicit gradients. In: NIPS, pp. 113–124 (2019)
- (50) Sahli Costabal, F., Yang, Y., Perdikaris, P., Hurtado, D.E., Kuhl, E.: Physics-informed neural networks for cardiac activation mapping. Front. Phys. 8, 42 (2020)
- (51) Shukla, K., Di Leoni, P.C., Blackshire, J., Sparkman, D., Karniadakis, G.E.: Physics-informed neural network for ultrasound nondestructive quantification of surface breaking cracks. arXiv preprint arXiv:2005.03596 (2020)
- (52) Shukla, K., Jagtap, A.D., Karniadakis, G.E.: Parallel physics-informed neural networks via domain decomposition. arXiv preprint arXiv:2104.10013 (2021)
- (53) Sirignano, J., Spiliopoulos, K.: Dgm: A deep learning algorithm for solving partial differential equations. J.Comput.Phys. 375, 1339–1364 (2018)
- (54) Sitzmann, V., Martel, J., Bergman, A., Lindell, D., Wetzstein, G.: Implicit neural representations with periodic activation functions. NIPS 33 (2020)
- (55) Smith-Miles, K.A.: Cross-disciplinary perspectives on meta-learning for algorithm selection. ACM COMPUT SURV 41(1), 1–25 (2009)
- (56) Sun, L., Gao, H., Pan, S., Wang, J.X.: Surrogate modeling for fluid flows based on physics-constrained deep learning without simulation data. Comput Methods Appl Mech Eng 361, 112732 (2020)
- (57) Sun, L., Wang, J.X.: Physics-constrained bayesian neural network for fluid flow reconstruction with sparse and noisy data. arXiv preprint arXiv:2001.05542 (2020)
- (58) Tancik, M., Srinivasan, P., Mildenhall, B., Fridovich-Keil, S., Raghavan, N., Singhal, U., Ramamoorthi, R., Barron, J., Ng, R.: Fourier features let networks learn high frequency functions in low dimensional domains. NIPS 33 (2020)
- (59) Tartakovsky, A.M., Marrero, C.O., Perdikaris, P., Tartakovsky, G.D., Barajas-Solano, D.: Learning parameters and constitutive relationships with physics informed deep neural networks. arXiv preprint arXiv:1808.03398 (2018)
- (60) Veeresha, P., Prakasha, D., Kumar, S.: A fractional model for propagation of classical optical solitons by using nonsingular derivative. Math. Methods Appl. Sci. (2020)
- (61) Zhang, R., Liu, Y., Sun, H.: Physics-guided convolutional neural network (phycnn) for data-driven seismic response modeling. Eng. Struct. 215, 110704 (2020)
- (62) Zhu, Y., Zabaras, N., Koutsourelakis, P.S., Perdikaris, P.: Physics-constrained deep learning for high-dimensional surrogate modeling and uncertainty quantification without labeled data. J.Comput.Phys. 394, 56–81 (2019)