A New Class of Non-Central Dirichlet Distributions
Abstract
In the present paper new light is shed on the non-central extensions of the Dirichlet distribution. Due to several probabilistic and inferential properties and to the easiness of parameter interpretation, the Dirichlet distribution proves the most well-known and widespread model on the unitary simplex. However, despite its many good features, such distribution is inadequate for modeling the data portions next to the vertices of the support due to the strictness of the limiting values of its joint density. To replace this gap, a new class of distributions, called Conditional Non-central Dirichlet, is presented herein. This new model stands out for being a more easily tractable version of the existing Non-central Dirichlet distribution which maintains the ability of this latter to capture the tails of the data by allowing its own density to have arbitrary positive and finite limits.
Keywords: Unitary simplex; finite limits of the density; mixture representation; perturbation representation; simulation; computational efficiency.
MSC 2010 subject classifications: 62E15
1 Introduction
Thanks to its simplicity and good mathematical properties, the Dirichlet distribution has historically represented the first tool for modeling data on the unitary simplex, this latter being the subset of , , given by
| (1) |
and corresponding to the Real interval for . Such data typically consist of components which represent parts of a whole and naturally arise in many areas of application such as medical, biological and social sciences. In this regard, a comprehensive review of the great variety of disciplines in which the above distribution has been employed is provided for example by [Ng et al. (2011)]. Despite its several statistical properties fundamental for the analysis of this type of data, one of the weakest points of the Dirichlet family lies in the poorness of its parametrization. Amongst others, this fact implies low flexibility of the density at the vertices of Eq. (1). More precisely, only the -th component of the parameter vector is devoted to modeling the limiting value of the Dirichlet density at the -th vertex of the simplex, this latter being the Real vector whose elements are all equal to zero except for the -th element which is one. This characteristic feature necessarily restricts the applicative potential of such distribution. In fact, the Dirichlet density tipically performs the identification of the tails of the data in an unsatisfactory way by showing limits equal to 0 or in the cases that positive finite limits would be more appropriate instead.
Several generalizations of the Dirichlet distribution have been proposed in the literature. However, only a few of them enable to overcome the aforementioned limitation of the Dirichlet by allowing their densities to take on arbitrary positive and finite limits which are potentially apt to properly model the data portions lying in the neighborhood of the vertices of the support. Specifically, the bivariate extension of the Kummer-Beta distribution [Bran-Cardona et al. (2011)] and the Non-central Dirichlet distribution [Sánchez et al. (2006)] are right worthy of consideration in the above sense due to the major flexibility achieved by the limiting values of their densities by means of richer parametrizations. As a matter of fact, due to its further parameter, the density of the former model shows a more flexible behavior than the Dirichlet at the vertices of the unit simplex, whereas the density of the latter, despite its analytical hardness and poor interpretability, enables to fully overcome the above mentioned drawback of the Dirichlet thanks to its additional vector of non-centrality parameters.
That said, the present paper sheds new light on the variety of the probabilistic models on the unitary simplex which accommodate for a more sophisticated structure for the limits of the density by proposing a new non-central generalization of the Dirichlet distribution. This novel model, called Conditional Non-central Dirichlet, can be considered as a more tractable analogue of the existing Non-central Dirichlet model. In fact, the former preserves the ability of the latter to potentially capture the tails of the data by letting its density have arbitrary positive and finite limits and, at the same time, offers the advantage of having a density function which is more straightforward and easily handeable than the existing non-central one.
More precisely, our work is organized as follows. Section 2 provides the mathematical tool kit, which essentially hinges on the notions of ascending factorial and generalized hypergeometric function. A glance at the unit simplex distributions involved in the definition and the analysis of the new model is given as well; particular attention is focused on the limiting values of the densities of such models on varying the parameter vector. An in-depth study of the novel model is carried out in Section 3. Specifically, this latter is properly specified in Subsection 3.1, where definition, distribution and theoretical properties are discussed in detail. In this regard, the Conditional Non-central Dirichlet density is proved to exhibit the same complex mixture type structure as the standard non-central one; however, from its perturbation representation, the greater tractability and interpretability of this new density surprisingly emerge. Then, an investigation of the mixing distribution of the mixture type form of the new Non-central Dirichlet density is reported in Subsection 3.2. Evidences of the similarities between the new and the standard non-central models are provided in Subsections 3.3 and 3.4, where some representations of the new model are presented and significant plots of its density are displayed, respectively. In particular, a special focus is given to the case of unitary shape parameters, under which the density of the new model shows the attractive feature of taking on arbitrary positive and finite limits at the vertices of the unit simplex. Subsection 3.5 derives a closed-form expression for the mixed raw moments, whereas the identifiability of the model is tackled in Subsection 3.6. In Section 4 an application to a real data set highlights the potential of the new model with respect to the aforementioned alternative ones. In conclusion, Section 5 contains some final remarks and Section 6 provides an appendix which bears an implementation in the programming enviromnment R of the multiple infinite sum involved in the perturbation representation of the standard Non-central Dirichlet density.
2 Preliminaries
This section is intended to briefly review the probabilistic models involved in the present study. However, first of all we shall provide the mathematical tool kit that paves the way for a thorough analysis of the new distribution we are going to define. In this regard, it is essential remembering that
| (2) |
is the -th ascending factorial or Pochhammer’s symbol of [Johnson et al. (2005)], where indicates the number of terms and denotes the gamma function. Some interesting properties of the above notion are listed in the following. Firstly, by additively decomposing into , in light of Eq. (2) one has that
| (3) |
Then, the ratio of two ascending factorials of can be expressed as
| (4) |
whereas the following expansion holds true for the Pochhammer’s symbol of a binomial:
| (5) |
By virtue of the foregoing concept, the generalized hypergeometric function with upper parameters and lower parameters, , can be accordingly defined as
| (6) |
for more details on the convergence of the hypergeometric series in Eq. (6) as well as for further results and properties of , the reader is recommended referring to [Srivastava and Karlsson (1985)]. In this regard, the special case of Eq. (6) corresponding to and , namely
| (7) |
plays a prominent role in the analysis of the new model at study. Hence, some features of this latter that make it an extremely regular function are emphasised herein. Specifically, the function in Eq. (7) is increasing in with values in for any given and decreasing in for any given as well as its first derivative with respect to . Finally, another important special case of Eq. (6) is
| (8) |
which is otherwise called Kummer’s confluent hypergeometric function; this latter satisfies the following transformation:
| (9) |
which is known as Kummer’s First Theorem.
That said, denoting independence by , we remember that the -dimensional Dirichlet model with vector of shape parameters , , , denoted by , is defined as follows:
| (13) | |||||
| (14) | |||||
[Kotz et al. (2000)] and its joint density function is given by
| (15) |
where and is specified in Eq. (1). For the ends of this paper it is useful bearing in mind that, in the notation of Eq. (14), the Dirichlet distribution can be also obtained as conditional distribution of given , the former being independent of the latter by virtue of a characterizing property of independent Gamma random variables [Lukacs (1955)]. The relevance of this property is remarkable; therefore, it is made explicit in the following.
Property 2.1 ([Lukacs (1955)] Characterizing property of independent Gamma random variables)
Let , be two nondegenerate and positive random variables and suppose that they are independently distributed. The random variables and , for every , are independently distributed if and only if both and has Gamma distributions with the same scale parameter.
Clearly, Property 2.1 is valid also in the case that the number of the involved independent Gamma random variables is greater than two. In particular, by setting the common scale parameter of these latter equal to , such property holds true also for any finite number of independent Chi-Squared random variables.
Now let equal 2. The Dirichlet density, despite the great variety of shapes reachable by it on varying the shape parameters, shows poor flexibility at the vertices of the unit simplex. In this regard, the limiting values of the density of are as follows:
| (21) | |||||
| (27) | |||||
| (33) | |||||
where the symbol indicates that the corresponding limit does not exist because depends on the direction followed to reach the accumulation point under consideration. From Eq. (33) it is noticeable that the limiting value at the -th vertex of the simplex, when different from 0 or , depends only on the -th shape parameter under unitary values for the remaining ones. Such state gets worse if for every ; in fact, in this latter case the bivariate Dirichlet density reduces to the Uniform on and all its limiting values equal 2. Finally, by Eq. (2), the mixed raw moment of order of the distribution can be stated as
| (34) |
The bivariate Kummer-Beta distribution is the first generalization of the Dirichlet taken into account herein. This model is briefly recalled in the following for what is of interest in the present analysis; however, for further results and properties, the reader can be referred to [Bran-Cardona et al. (2011)]. Specifically, a bidimensional random vector is said to follow a bivariate Kummer-Beta distribution with shape parameters , , and additional parameter , denoted by , if its joint density can be expressed as the following infinite mixture of Dirichlet densities weighted by the probabilities obtained by normalizing the terms of the infinite sum in Eq. (8) where , , :
| (35) | |||||
By simple computations, Eq. (35) can be equivalently stated in terms of the following perturbation of the bivariate Dirichlet density:
which, in turn, by Eq. (9), can be rewritten in the final form reported by the above cited reference:
| (36) | |||||
Under unitary shape parameters the behavior of the KB 2 density at the vertices of the unit simplex turns out to be more flexible than that of the bivariate Dirichlet thanks to its additional parameter . More precisely, the limits of the KB 2 density take on the following values:
where the symbol indicates that the corresponding limit does not exist because depends on the direction followed to reach the accumulation point under consideration.
The non-central extension of the Chi-Squared model [Johnson et al. (1995)] represents the main ingredient for the definition and the analysis of the existing Non-central Dirichlet distribution, this latter being the second generalization of the Dirichlet considered in the present paper. Specifically, a Non-central Chi-Squared random variable with degrees of freedom and non-centrality parameter , denoted by , can be characterized by means of the following mixture representation:
| (43) |
the case corresponding to the distribution. Moreover, such a random variable can be additively decomposed into two independent parts, a central one with degrees of freedom and a purely non-central one with non-centrality parameter , namely
| (44) |
By virtue of Eq. (44), the random variable is said to have a Purely Non-central Chi-Squared distribution with non-centrality parameter . Indeed, we shall denote it by , its number of degrees of freedom being equal to zero [Siegel (1979)]. By Eq. (43), the density function of can be expressed as
| (45) |
i.e. as the infinite series of the densities, , weighted by the probabilities of . In this regard, the case is of prominent interest in the present setting; in fact, in this case the density in Eq. (45) exhibits a flexible limiting behavior on varying the non-centrality parameter by allowing its limit at to take on the following expression:
| (46) |
Finally, the Non-central Chi-Squared distribution is reproductive with respect to both the number of degrees of freedom and the non-centrality parameter; specifically:
| (47) |
That said, the -dimensional Non-central Dirichlet model with vector of shape parameters and vector of non-centrality parameters , , , denoted by , can be easily defined by replacing the ’s by in Eq. (14) as follows:
| (51) | |||||
| (52) | |||||
[Sánchez et al. (2006)]. The density function of the distribution can be simply derived by following the next arguments; in this regard, let:
| (53) | |||||
Then, in the notation of Eq. (52), by Eq. (43) the conditional distribution of given is of the type , ; therefore, by Eq. (14):
| (54) |
which is the mixture representation of the NcDir distribution. Hence, the joint density of can be stated as
| (55) |
i.e. as the multiple infinite series of the densities, , weighted by the joint probabilities of the random vector defined in Eq. (53). Moreover, the function in Eq. (55) can be equivalently expressed in terms of perturbation of the corresponding central case as follows:
| (56) | |||||
where
| (57) |
is the -dimensional () generalization of the Humbert’s confluent hypergeometric function [Srivastava and Karlsson (1985)]. Unfortunately, the perturbation representation of the Non-central Dirichlet density in Eq. (56) highlights the uneasy tractability and interpretability of this latter. Indeed, regardless of the constant term, the Dirichlet density is perturbed by a function in variables given by the sum of the multiple power series in Eq. (57), that, as far as we know, cannot be reduced to a more easily tractable analytical form. In this regard, the code of a routine implemented in the programming environment R for the computation of the function in Eq. (57) with is provided in the appendix contained in Section 6.
Now let equal 2. By simple computations it is easy to see that, despite its poor tractability from a mathematical standpoint, the limiting values of the NcDir 2 density interestingly take on the following simple expressions:
Hence, thanks to its richer parametrization based on three non-centrality parameters, the density of the bivariate Non-central Dirichlet distribution enables to overcome the aforementioned limitations of the Dirichlet by allowing its own limits at the vertices of the unit simplex to have arbitrary positive and finite values under unitary shape parameters. This feature, which results from the flexibility of the limit at 0 of the Non-central Chi-Squared density previously noticed in Eq. (46), makes the NcDir model potentially apt to properly capture the data portions having values next to the vertices of the support.
3 A new Non-central Dirichlet model
3.1 Definition and distribution
The above recalled characterizing property of independent Gamma random variables is no longer valid in the non-central setting. This fact covers a key role in the present paper and, more specifically, is assumed as the starting point in the derivation of the new family of non-central generalizations of the Dirichlet distribution we are interested in. Indeed, in the notation of Eq. (52), a new Non-central Dirichlet model can be achieved by conditioning the existing one on the sum of the independent Non-central Chi-Squared random variables involved in its definition. Such a model is thus distributed according to the conditional distribution of given ; moreover, as is not independent of , this distribution must be different from the except for , this latter case corresponding to the Dirichlet. In this regard, the conditional density of given can be obtained for any fixed by mixing the conditional density of given with respect to the conditional probability mass function of given . As is conditionally independent of given by Property 2.1, in light of Eq. (54) we have that , while a direct application of Bayes’ Theorem shows that:
| (66) | |||||
| (67) | |||||
Therefore, by incorporating the conditioning value in the ’s, without loss of generality we are led to the following definitions.
Definition 3.1 (-variate Conditional Non-central Dirichlet distribution)
The -variate Conditional Non-central Dirichlet distribution with vector of shape parameters and vector of non-centrality parameters , denoted by , is the distribution of the -dimensional random vector defined as follows:
| (71) | |||||
| (72) | |||||
Definition 3.2 (-variate Mixture Weight distribution)
The -variate Mixture Weight distribution with shape parameter and vector of non-centrality parameters , denoted by , is the distribution of the -dimensional random vector obtained as follows:
| (78) | |||||
| (79) | |||||
The special case of Eq. (79) where is set equal to leads to a random vector degenerate at . By Eq. (67) and in view of the foregoing arguments, the joint probability mass function of the distribution takes on the following form:
| (83) | |||||
Therefore, the density function of can be accordingly expressed as follows:
| (84) |
i.e. as the multiple infinite series of the densities, , weighted by the joint probabilities of the random vector in Eq. (83). Hence, the CNcDir density shows the same mixture type form as the NcDir one; the only difference lies in the mixing distribution, given by the MW for the former and the Multi-Poisson for the latter. In this regard, an overview of the properties of the multivariate Mixture Weight distribution is deferred to the next subsection. More interestingly, by simple computations it is easy to see that the CNcDir density turns out to be equivalently stated in terms of the following perturbation of the corresponding central case:
| (85) | |||||
From Eq. (85) the major tractability and interpretability of the CNcDir density over the NcDir one prove evident. Contrarily to the standard non-central case where the perturbing factor of the Dirichlet density shows an inner structure that is too complex to be handled analytically, with reference to the density of the conditional model the perturbing effect can be clearly noticed for each value of the parameter vector. More precisely, in Eq. (85), regardless of the constant term, the Dirichlet density is perturbed by the product of generalized hypergeometric functions which show perfectly symmetric behaviors. Specifically, as gets higher, , the corresponding function gives more weight to the tail of the Dirichlet density relative to the -th vertex of the unit simplex; moreover, the less is the corresponding shape parameter , the larger is the extent of this phenomenon.
The Conditional Non-central Dirichlet model shares with the Dirichlet and the existing Non-central Dirichlet some important properties that are discussed below.
The first one is the closure under permutation, an apparently trivial property which expresses the fact that the CNcDir distribution treats all its components in a completely symmetric way.
Proposition 3.1 (Closure under permutation)
Let where , and be a permutation of . Then, where and .
Proof.
The proof directly follows from the definition of the model at study in Eq. (72) by applying the permutation to the ’s. ∎
Then, like the Dirichlet and the Non-central Dirichlet, the present model satisfies the aggregation property, which is crucial to the derivation of the results established in the following.
Proposition 3.2 (Aggregation property)
Let where , . Let be a partition of , . Then:
| (86) |
Proof.
By suitably resorting to Proposition 3.2, the -dimensional marginals of the -dimensional Conditional Non-central Dirichlet model can be simply achieved for every . Specifically, like the Dirichlet and the existing Non-central Dirichlet models, the Conditional Non-central Dirichlet is closed under marginalization and simple relationships hold between the parameters of the joint and the marginal distributions. In particular, the univariate marginals are of Conditional Doubly Non-central Beta (CDNcB) type, this latter being the analogue of the CNcDir on the Real interval . In this regard, a first analysis and an in-depth study of the CDNcB distribution are given in [Ongaro and Orsi (2015)] and [Orsi (2021)], respectively. In the following, only the univariate and bivariate marginals are made explicit but as far as the investigation of the -dimensional marginals, , is concerned, similar results apply.
Proposition 3.3 (Univariate and bivariate marginals)
Let . Then, for every , :
| (87) |
| (88) |
Proof.
Another consequence of the aggregation property is about the distribution of the sum of the components of a CNcDir random vector.
Proposition 3.4 (Sum of the components)
Let where , . Then, .
Proof.
The proof ensues from Proposition 3.2 by setting and taking , . ∎
We end this subsection pointing out that, unlike the standard Non-central Dirichlet case, the Conditional Non-central Dirichlet distribution is closed under conditioning after normalization.
Proposition 3.5 (Closure under normalized conditioning)
Let where , . Let and , . Then, the normalized conditional distribution of given is:
| (92) | |||||
Proof.
By setting and taking for every , in Eq. (86), one has , where , , and . For every , the conditional density of given admits the following expression:
Now consider the -dimensional random vector defined by the following linear transformation:
note that the conditional density of this latter given takes on the form of
| (93) | |||||
where . Clearly, Eq. (93) corresponds to the density of the distribution in Eq. (92). ∎
3.2 Mixing distribution
The -variate Mixture Weight distribution specified in Eq. (83) plays the role of mixing distribution in the mixture type form of the CNcDir density. Such model represents the generalization to dimensions of the , this latter being the mixing distribution in the mixture type form of the CDNcB density. Hence, the properties of the distribution illustrated in the present subsection are extensions of the ones of the bivariate case, an in-depth study of which is provided in [Orsi (2021)].
First of all, the distribution is closed under permutation and the non-centrality parameters of the permuted random vector are obtained by applying the same permutation to the original ones.
Proposition 3.6 (Closure under permutation)
Let where and be a permutation of . Then, where .
Proof.
The proof directly follows from the definition of the model at study in Eq. (79) by applying the permutation to the ’s. ∎
Proposition 3.6 fully expresses the symmetric nature of the distribution, implying that the particular choice of its components does not affect any of the following results.
The distribution under consideration is not closed under marginalization, but it is closed under conditioning.
Proposition 3.7 (Marginals and conditionals)
Let . Then, for every , the marginal probability mass function of is
and the conditional distribution of given is
Proof.
The proof is straightforward and is omitted. ∎
The sum of the components of belongs to the univariate Mixture Weight family.
Proposition 3.8 (Sum of the components)
Let . Then:
| (95) |
Proof.
Despite the differences existing between their joint probability mass functions, the and the share the same conditional distribution given the sum of their components.
Proposition 3.9 (Conditional distribution given the sum of the components)
Let where and . Then:
| (96) |
Proof.
Finally, the distribution can be simulated by first generating the random variable according to Eq. (95) and then the -variate Multinomial distribution in Eq. (96). In particular, the former can be easily simulated by using, for example, the Inverse-Transform method [Law and Kelton (2000)]. Specifically, after generating a realization from a Uniform random variable on the Real interval , an exact realization from the random variable is obtainable by taking the generalized inverse of its distribution function in , i.e. .
3.3 Representations
In the present subsection a number of fundamental representations of the Conditional Non-central Dirichlet model are provided, disclosing its remarkable tractability.
The first one is the mixture representation, which summarizes the arguments leading to Definitions 3.1 and 3.2.
Proposition 3.10 (Mixture representation)
Let and . Then:
| (97) |
Proof.
The proof is straightforward and is omitted. ∎
Proposition 3.10 proves significant in several respects. Indeed, the above representation constitutes a valid practical method for generating from a Conditional Non-central Dirichlet random vector. Specifically, the algorithm to obtain a realization from the model using such a representation requires to first generate from the distribution and then from the conditional distribution in Eq. (97). In particular, the former operation can be accomplished by following the lines made explicit in the previous subsection. In this regard, an interesting restatement of the combination of the two aforementioned generation steps is provided by the following result, which shows that, conditionally on , the density of the model of interest is given by a mixture of Dirichlet densities weighted by the Multinomial probabilities in Eq. (96).
Proposition 3.11 (Conditional density given )
Let , and . Then, the conditional density of given is
| (101) | |||||
Proof.
Finally, the mixture representation in Eq. (97) leads to the following representation of the CNcDir model in terms of unconditional composition.
Proposition 3.12 (Unconditional composition type representation)
Let and , with . Then:
-
i)
,
-
ii)
, , where , , are mutually independent.
Proof.
The proof is straightforward and is omitted. ∎
The issue of generating from the Conditional Non-central Dirichlet model can be also addressed by resorting to i) in Proposition 3.12. Specifically, the simulation methods based on the mixture representation and on the above unconditional composition type representation differ only in the way that the Dirichlet distribution is generated: directly by the former and via Chi-Squareds by the latter. Moreover, from ii) in Proposition 3.12 it is noticeable that the ’s play the same role as the Non-central Chi-Squared random variables involved in the definition of the standard Non-central Dirichlet model. Hence, the present representation guides us to view the CNcDir model as an analogue of the NcDir one. Indeed, like the ’s in Eq. (44), the ’s can be additively decomposed into two independent parts, a central one and a purely non-central one. Moreover, by resorting to the ’s, the following generalization of the independence relationship stated in Property 2.1 holds true.
Proposition 3.13 (Conditional independence)
Let and with . Furthermore, let be defined as in Proposition 3.12 with . Then, and are conditionally independent given .
Proof.
The ingredients of the representation of the CNcDir model in Proposition 3.12 can be analogously defined as follows:
hence, by Eq. (47):
| (102) |
where denotes equality in distribution. By Property 2.1, and are independent conditionally on and therefore, given this latter, the joint distribution of factores into the marginal distributions of and . That said, the proof follows by noting that the joint density of factores into the marginal densities of and ; indeed, under Eq. (102):
where , and the density is given in Eq. (101). ∎
3.4 Density plots
In this subsection we shall focus on the case in order to make it possible the graphical depiction of the joint density of the model of interest.
A key advantage of the distribution over the bivariate Dirichlet is the much larger variety of shapes reachable by the density of the former on varying the non-centrality parameters. In this regard, some significant plots of the bivariate CNcDir density are displayed in Figure 1 for selected values of the parameter vector.



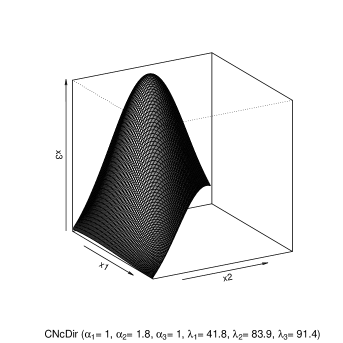
Specifically, the main attraction of the CNcDir 2 distribution lies in the following feature. When at least two shape parameters are set equal to one, the three non-centrality parameters control the height of the density at the vertices of the unit simplex by allowing the limits of this latter to have arbitrary positive and finite values. That said, the limiting values of the bivariate Conditional Non-central Dirichlet density are established herein.
Proposition 3.14 (Limiting values of the bivariate density)
Let . Then:
where the symbol indicates that the corresponding limit does not exist because depends on the direction followed to reach the accumulation point under consideration.
The surface representing the density function of the CNcDir 2 distribution is depicted in Figure 2 for shape parameters equal one and selected values of the non-centrality parameters. The above mentioned feature of the density at study can be clearly detected from these plots.

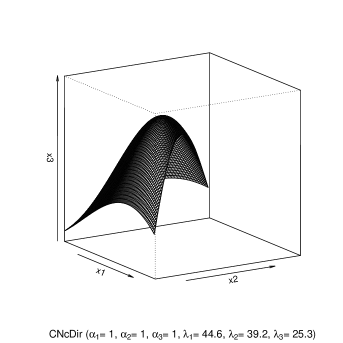


All the elements that enable us to affirm that the CNcDir distribution preserves the applicative potential of the NcDir one are finally at hand. Indeed, there exist deep similarities between the varieties of shapes reachable by the two densities in the case that, under the same values for the shape parameters, the non-centrality parameters of the Conditional model are assigned much higher values than those used for the existing one. In light of the mixture representations of the two models, in fact, the differences between such distributions can be entirely explained by the differences existing between their respective mixing distributions. In light of Eq. (96), these latter are completely due to the differences between the sums of their components and , the probability mass functions of which depend on by means of . By virtue of the arguments put forward in [Orsi (2021)] (Section 4) with reference to the comparison between the Conditional and the standard Doubly Non-central Beta distributions, the link between the values of and can be understood by comparing their modes as functions of . Specifically, for a given value of the mode of , one can find the value relative to which produces similar mode; as shown in the above cited reference, this value is much larger than the one relative to and gets even larger when increases.
3.5 Moments
For the sake of simplicity, in all the present subsection we shall focus on the case ; however, by virtue of Eq. (88), the results derived herein also apply for any two-dimensional marginal of the CNcDir model with .
By analogy with the form of the density in Eq. (84) and by Eq. (34), for every , the mixed raw moment of order of can be stated as
| (111) | |||||
| (112) | |||||
i.e. as the multiple infinite series of the mixed raw moments of order of the distributions weighted by the probabilities. Moreover, by Eq. (3), Eq. (112) can be equivalently expressed as the following doubly infinite sum of generalized hypergeometric functions with one numerator parameter and two denominator parameters:
| (113) | |||||
Unfortunately, the above formulas are computationally cumbersome. Hence, in the following we shall provide an interesting general expression for the quantity at study that allows the computation of this latter to be reduced from the doubly infinite sum in Eq. (113) to a surprisingly simple form given by a doubly finite sum.
Proposition 3.15 (Mixed raw moments of the bivariate distribution)
The mixed raw moment of order of admits the following expression:
| (116) | |||||
| (117) | |||||
Proof.
Let have a distribution conditionally on with , . By Eq. (101), one has:
| (118) | |||||
in light of Eq. (5):
so that one obtains:
where:
| (120) | |||||
By Eq. (2), for every , :
| (121) |
under Eq. (121), Eq. (120) can be thus rewritten as follows:
| (122) | |||||
In carrying out the prove, reference must be made to Ljunggren’s Identity, namely
| (123) |
which is (3.18) in [Gould (1972)]. By the special case of Eq. (123) where , , , , , the final sum in Eq. (122) can be equivalently expressed as
so that, for every , , Eq. (122) can be restated as
| (124) | |||||
Under the special case of Eq. (123) where , , , , , Eq. (124) can be rewritten in the form of
| (125) | |||||
so that, by Eqs. (118), (LABEL:eq:mom.dim1b) and (125), conditionally on , the mixed raw moment of interest takes on the following expression:
| (126) | |||||
applying the law of iterated expectations to Eq. (126) finally leads to:
| (127) | |||||
Since for , , one has:
so that Eq. (127) is equivalent to:
then, by Eqs. (2) and (7), setting yields:
and, by observing that:
one can obtain:
| (128) | |||||
By setting , and by Eq. (5), each of the two final sums in Eq. (128) turns out to be tantamount to:
| (129) | |||||
hence, by Eq. (129), Eq. (128) can be stated in the following form:
| (130) | |||||
Eq. (130) can be finally exhibited in the form reported in Eq. (117) by noting that:
Hence, the formula of the mixed raw moment of order of the distribution can be obtained by taking in Eq. (117) as follows:
| (131) | |||||
This latter can be algebraically manipulated with the aim to reduce the number of distinct functions appearing in it. More precisely, in carrying out the computations, reference must be made to the recurrence identity
which holds for consecutive values of the denominator parameter of and is easy to verify upon noting that, by Eq. (3), for every . Specifically, the aforementioned improvement of Eq. (131) depends on three functions instead of four and is given by
3.6 Identifiability
Before facing the applicative issues included in the next section, in the present subsection we briefly discuss the identifiability of the CNcDir model.
Proposition 3.16 (Identifiability)
Let and where , , and . Then, if and only if and .
Proof.
We need to show that if then and , the converse being obvious. Clearly, if , then for every . By Eq. (87), and ; therefore, the proof follows from the identifiability of the CDNcB model ([Orsi (2021)], Section 7). ∎
4 Applications
The potential of the CNcDir model is now illustrated by means of an application to a real data set. To this end we turned our attention to the Cartesian coordinates of the locations of 584 longleaf pine trees (Pinus palustris) placed in a metre region within Southern Georgia (USA). This data set was originally collected and analyzed by [Platt et al. (1988)], was later quoted in [Rathbun et al. (1994)] and finally was made available by [Baddeley et al. (2020)] as part of the package “spatstat.data” in the programming environment R. More precisely, in a comparative perspective, the four distributions on the unit simplex considered in the present paper were fitted to the data set obtained as follows. The above region was rescaled to the unit square and cut by the diagonal joining the vertices and into two congruent triangles; hence, the aforementioned analysis was carried out on the subset of locations lying in the interior of the upper triangle after undergoing the transformation that mapped this latter into the unit simplex in (see Figure 3).

What is of interest to us is to check if the evidence suggests that the data portions having values next to the vertices of are large enough to let the densities of such models take on positive and finite limits as tends to , and . Hence, the problem at study can be formalized by testing the hypotheses that all three shape parameters of each model or two of them, at the very least, are unitary.
That said, the method of Maximum-Likelihood (ML) was applied in order to derive the estimates for the parameter vectors of all the above models. In this regard, let be a sequence of independent random vectors with identical distribution depending on an unknown parameter vector . First, suppose that , ; by Eq. (15), given the observed sample , the log-likelihood function for the parameter vector of the model is
| (132) | |||||
By taking , , in light of Eqs. (36) and (132), given the observed sample , the log-likelihood function for the parameter vector of the model is
Now let , ; by Eqs. (56) and (132), given the observed sample , the log-likelihood function for the parameter vector of the model is
where, in light of Eqs. (3) and (57), by means of simple computations, the above specified function can be expressed as
| (133) | |||||
i.e. as a doubly infinite sum of weighted Kummer’s confluent hypergeometric functions. This formula can be usefully adopted as a natural basis for implementing such a function in any statistical package where the generalized hypergeometric function is already implemented. In this regard, the code of a possible implementation in R of the algorithm in Eq. (133) is proposed in Section 6. Similar reasonings clearly apply as far as the computation of the function with is concerned.
Finally, let , ; by Eqs. (85) and (132), given the observed sample , the log-likelihood function for the parameter vector of the model is
Under well known regularity conditions, the ML estimator for the parameter vector has an asymptotic multivariate Normal distribution with mean vector and covariance matrix which can be approximated by the inverse of the observed information matrix , being the ML estimate for . The maximization of the above log-likelihoods was numerically accomplished by using the built-in-function optim available in the statistical software R. The global maximum of the log-likelihoods is ensured to be actually achieved by using a wide range of starting values for the estimates of the parameters in the optimization algorithm.
The null hypotheses () , , and are issued towards all the models at study with the aim to verify if the tails of the data corresponding to all three vertices of the unit simplex or to a few couples of them are valuable enough to be captured by the densities of the aforementioned distributions. If all the above hypotheses are rejected, the model with all the parameters to be estimated is chosen; otherwise, in case of non-rejection of at least one of them, the model corresponding to the highest -value is selected amongst the non-rejected ones with fewest parameters. Such hypotheses can be easily verified by means of a suitable Likelihood Ratio (LR) test with asymptotic Chi-Squared distribution. The construction of such LR test requires the unconstrained maximization of the log-likelihoods as well as the constrained maximization of these latter under the hypotheses of interest. Specifically, the LR statistic is given by , where and are, respectively, the maximum of the log-likelihood under and the maximum of the unrestricted log-likelihood. This statistic can be used to check if the fit of the models with two or three shape parameters set equal to 1 is statistically superior to the one of the model containing all the parameters. According to Wilks’ theorem [Wilks (1938)], on varying the sample, describes the random variable , the distribution of which has been approximated by a Chi-Squared with number of degrees of freedom equal to the number of parameters fixed by .
Details of the LR tests carried out herein are listed in Table 1, which indicates that the CNcDir and the NcDir models are the only for which the null hypothesis is not rejected with the highest value; therefore, their densities allow for the tails of the data corresponding to all three vertices of to be captured. On the contrary, none of the four hypotheses at study is significantly supported by the data with reference to the remaining models; hence, all three shape parameters of these models are estimated. In this regard, the ML estimates for the parameters of the chosen models and the asymptotic standard errors of the corresponding estimators are reported in Table 2.
| Model | df | -value | ||||
|---|---|---|---|---|---|---|
| 262.0291 | 262.7820 | 1.5058 | 3 | 0.6809 | ||
| 262.3874 | 0.7892 | 2 | 0.6739 | |||
| 262.0826 | 1.3988 | 0.4969 | ||||
| 262.1861 | 1.1918 | 0.5511 | ||||
| 262.7941 | 263.8433 | 2.0984 | 3 | 0.5522 | ||
| 263.0525 | 1.5816 | 2 | 0.4535 | |||
| 262.9253 | 1.8360 | 0.3993 | ||||
| 263.1430 | 1.4006 | 0.4964 | ||||
| 239.8289 | 255.2603 | 30.8628 | 3 | |||
| 240.7546 | 29.0114 | 2 | ||||
| 243.9976 | 22.5254 | |||||
| 240.3968 | 29.7270 | |||||
| 239.8813 | 255.3020 | 30.8414 | 3 | |||
| 245.2593 | 20.0854 | 2 | ||||
| 244.5826 | 21.4388 | |||||
| 240.4078 | 29.7884 |
| Model | ML estimate (SE) | Model | ML estimate (SE) | ||
|---|---|---|---|---|---|
| 1 | 1 | ||||
| 1 | 1 | ||||
| 1 | 1 | ||||
| 42.7802 (8.5087) | 3.0478 (0.4093) | ||||
| 48.7569 (9.3385) | 3.4644 (0.4382) | ||||
| 44.1538 (8.6944) | 3.1084 (0.4121) | ||||
| 1.2671 (0.0717) | 1.2810 (0.0870) | ||||
| 1.3594 (0.0772) | 1.3748 (0.0944) | ||||
| 1.2818 (0.0726) | 1.2543 (0.1187) | ||||
| 0.1884 (0.6519) | |||||
Moreover, the graphical depiction of the fitted densities of the four models under consideration is displayed in Figure 4, from which it is remarkable how much similar are the fitting of the two-dimensional CNcDir and NcDir densities on the one hand (top left and top right panels) and of the two-dimensional Dir and KB densities from the other (bottom left and bottom right panels). In particular, it is noticeable how much comparable are the abilities of the two non-central densities to identify the presence of the data portions next to the vertices of the unit simplex on one side and the behaviors of the two remaining densities on the other, which show all zero limits despite the four-parameter structure of the two-dimensional KB.




The main lesson to be learnt from the results reported herein is an essential equivalence between the CNcDir and the NcDir models. However, the fitting of the former is computationally less demanding than the one of the latter. Indeed, the amount of execution time that the CNcDir model enables to save with regard to the maximization of the log-likelihood is remarkable. This raises the question of further investigating the computational performances of the two models on the basis of efficiency arguments regarding the time to accomplish the Maximum-Likelihood fitting. In this respect, series of random values were generated from each of the two above models for selected combinations of the series size and of the parameter vector in the case . Then, the machine-time spent to fit the two models was measured for each replication and means and standard deviations were computed for this latter within each stratum. Hence, the null hypothesis of non-inferiority of the true mean of the CNcDir fitting time with respect to the one of the NcDir is checked by using the one-tailed test for large samples. The results of the above described simulation study are listed in Table 3, from which we conclude that the Conditional model is beyond doubt to be preferred to the existing one for the major computational efficiency this permits in carrying out inferences based on the Maximum-Likelihood theory. More precisely, the obtained founds suggest that on average the NcDir fitting is approximately of the order of 90 times slower than the one of the CNcDir model.
| Time (′′) | |||||
|---|---|---|---|---|---|
| 1.8 | 0.7 | 0.9053 (0.5852) | 1.3360 (1.0834) | 1.5253 (1.2979) | |
| 1.2 | 1.0 | 54.5803 (41.8910) | 72.9673 (76.5182) | 107.7123 (126.4231) | |
| 1.5 | 0.9 | -value | |||
| 0.7 | 4.6 | 1.0907 (0.8587) | 1.7207 (1.0176) | 1.3610 (0.9568) | |
| 1.3 | 0.5 | 72.3550 (93.5070) | 110.6507 (138.8951) | 105.8680 (89.4877) | |
| 1.9 | 3.8 | -value | |||
| 2.1 | 0.8 | 1.1537 (0.6813) | 1.2613 (0.9024) | 1.4517 (0.7845) | |
| 0.2 | 2.9 | 91.0197 (88.6285) | 142.1647 (101.2835) | 172.0060 (98.3391) | |
| 0.6 | 4.2 | -value | |||
| 0.8 | 2.4 | 0.7337 (0.3396) | 1.0263 (0.5822) | 1.2010 (0.6801) | |
| 0.9 | 1.7 | 82.7857 (86.6345) | 121.7610 (71.8105) | 158.0427 (78.6970) | |
| 0.4 | 2.8 | -value | |||
5 Conclusions
In this paper a new non-central extension of the Dirichlet model was obtained by conditioning the existing Non-central Dirichlet on the sum of the Non-central Chi-Squared random variables involved in its definition. The resulting Conditional Non-central Dirichlet distribution represents the multivariate generalization of the Conditional Doubly Non-central Beta one, namely the new non-central version of the Beta distribution which has been recently studied by [Orsi (2021)]. An in-depth analysis of this new multidimensional model was carried out herein in order to highlight similarities and differences with the existing one. Specifically, despite the densities of the new and the standard Non-central Dirichlet distributions share the same complex mixture type form, from the comparison between their perturbation representations the surprisingly greater tractability and interpretability of the former over the latter emerge. Hence, the Conditional Non-central Dirichlet distribution enables to overcome the strong analytical and mathematical limitations affecting the existing Non-central Dirichlet by exhibiting a substantially simpler density function than that of the latter. At the same time, the new non-central generalization of the Dirichlet model preserves the applicative potential of the existing one by allowing its density to take on arbitrary positive and finite limits which enables to properly capture the data portions next to the vertices of the support. These are the reasons why we hope this model may attract a wide range of applications in statistics.
6 Appendix
In the present section we shall propose a possible translation into R code of the algorithm specified in Eq. (133) to compute the generalization to three dimensions of the Humbert’s confluent hypergeometric function. In light of Eq. (56), this issue is instrumental in assessing the bivariate Non-central Dirichlet density. Specifically, the present implementation consists of two routines. The first routine, named psi2.3, implements the external infinite sum in Eq. (133). This routine internally calls the other one, named intpsi2.3, which computes the Humbert’s confluent hypergeometric function as infinite sum of Kummer’s confluent hypergeometric functions. The two routines share the same following arguments:
-
•
x1, x2: vectors of the first and of the second components of the data on ;
-
•
shape1, shape2, shape3: the three shape parameters , , of the bivariate Non-central Dirichlet density;
-
•
ncp1, ncp2, ncp3: the three non-centrality parameters , , of the bivariate Non-central Dirichlet density;
-
•
tol: tolerance, where zero means keeping on the iterations until the additional terms do not change the partial sum of the infinite series under consideration;
-
•
maxiter: maximum number of iterations to perform;
-
•
debug: Boolean, where TRUE means returning debugging information whereas FALSE means returning only the final evaluation.
The code of the first routine is as follows:
psi2.3<-
function(x1,x2,shape1,shape2,shape3,ncp1,ncp2,ncp3,tol,maxiter,debug) {
L=c(shape1,shape2,shape3)
S=sum(L)
y1=(ncp1/2)*x1
coef<-1
temp<-intpsi2.3(x1=x1,x2=x2,shape1=shape1,shape2=shape2,shape3=shape3,
ncp1=ncp1,ncp2=ncp2,ncp3=ncp3,tol=tol,maxiter=maxiter,debug=debug)
out<-NULL
for(n in seq_len(maxiter)) {
coef<-coef*((S/L[1])*y1/n)
fac<-coef*
intpsi2.3(x1=x1,x2=x2,shape1=shape1+n,shape2=shape2,shape3=shape3,
ncp1=ncp1,ncp2=ncp2,ncp3=ncp3,tol=tol,maxiter=maxiter,debug=debug)
series<-temp+fac
if(debug) {
out<-c(out,fac)
}
if(hypergeo::isgood(series-temp,tol)) {
if(debug) {
return(list(series,out))
}
else {
return(series)
}
}
temp<-series
S<-S+1
L[1]<-L[1]+1
}
if(debug) {
return(list(series,out))
}
}
The code of the second routine is as follows:
intpsi2.3<-
function(x1,x2,shape1,shape2,shape3,ncp1,ncp2,ncp3,tol,maxiter,debug) {
L=c(shape1,shape2,shape3)
S=sum(L)
y2=(ncp2/2)*x2
y3=(ncp3/2)*(1-x1-x2)
coef<-1
temp<-hypergeo::genhypergeo(U=S,L=L[3],z=y3,tol=tol,maxiter=maxiter,
check_mod=TRUE,polynomial=FALSE,debug=FALSE)
out<-NULL
for(m in seq_len(maxiter)) {
coef<-coef*((S/L[2])*y2/m)
fac<-coef*hypergeo::genhypergeo(U=S+1,L=L[3],z=y3,tol=tol,
maxiter=maxiter,check_mod=TRUE,polynomial=FALSE,debug=FALSE)
series<-temp+fac
if(debug) {
out<-c(out,fac)
}
if(hypergeo::isgood(series-temp,tol)) {
if(debug) {
return(list(series,out))
}
else {
return(series)
}
}
temp<-series
S<-S+1
L[2]<-L[2]+1
}
if(debug) {
return(list(series,out))
}
}
References
- [Baddeley et al. (2020)] Baddeley, A., Turner, R. and Rubak, E. 2020. spatstat.data: datasets for ’spatstat’. R package version 1.4-3, https://cran.r-project.org/web/packages/spatstat.data/index.html.
- [Bran-Cardona et al. (2011)] Bran-Cardona, P. A., Orozco-Castaeda, J. M. and Nagar, D. K. 2011. Bivariate Generalization of the Kummer-Beta Distribution. Revista Colombiana de Estadística 34:(3) 497-512.
- [Gould (1972)] Gould, H. W. 1972. Combinatorial Identities. Morgantown (WV): Morgantown Printing and Binding Company.
- [Johnson et al. (1995)] Johnson, N. L., Kotz, S. and Balakrishnan, N. 1995. Vol. 2 of Continuous Univariate Distributions, 2nd edn. New York: John Wiley & Sons.
- [Johnson et al. (2005)] Johnson, N. L., Kemp, A. W. and Kotz, S. 2005. Univariate Discrete Distributions, 3rd edn. Hoboken (NJ): John Wiley & Sons.
- [Kotz et al. (2000)] Kotz, S., Balakrishnan, N. and Johnson, N. L. 2000. Vol. 1 of Continuous Multivariate Distributions: Models and Applications, 2nd edn. New York: John Wiley & Sons.
- [Law and Kelton (2000)] Law, A. M. and Kelton, W. D. 2000. Simulation Modeling and Analysis, 3rd edn. Boston: McGraw Hill.
- [Lukacs (1955)] Lukacs, E. 1955. A Characterization of the Gamma Distribution. Annals of Mathematical Statistics 26:(2) 319-324.
- [Ng et al. (2011)] Ng, K. W., Tian, G.-L., Tang, M.-L. 2011. Dirichlet and Related Distributions: Theory, Methods and Applications. Wiley Series in Probability and Statistics.
- [Ongaro and Orsi (2015)] Ongaro, A. and Orsi, C. 2015. Some Results on Non-central Beta Distributions. Statistica 75:(1) 85-100.
- [Orsi (2021)] Orsi, C. 2021. On the Conditional Non-central Beta Distribution. Accepted for publication at Statistica Neerlandica on 01 May 2021, doi:10.1111/stan.12249.
- [Platt et al. (1988)] Platt, W. J., Evans, G. W. and Rathbun, S. L. 1988. The Population Dynamics of a Long-Lived Conifer (Pinus palustris). The American Naturalist, 131:(4) 491-525
- [Rathbun et al. (1994)] Rathbun, S. L. and Cressie, N. 1994. A Space-Time Survival Point Process for a Longleaf Pine Forest in Southern Georgia. Journal of the American Statistical Association, 89:(428) 1164-1173
- [Sánchez et al. (2006)] Sánchez, L. E., Nagar, D. K., Gupta, A. K. 2006. Properties of Noncentral Dirichlet Distributions. Computers and Mathematics with Applications, 52:(12) 1671-1682
- [Siegel (1979)] Siegel, A. F. 1979. The Noncentral Chi-Squared Distribution with Zero Degrees of Freedom and Testing for Uniformity. Biometrika, 66:(2) 381-386
- [Srivastava and Karlsson (1985)] Srivastava, H. M. and Karlsson, W. 1985. Multiple Gaussian Hypergeometric Series. Chichester (UK): Ellis Horwood.
- [Wilks (1938)] Wilks, S. S. 1938. The Large-Sample Distribution of the Likelihood Ratio for Testing Composite Hypotheses. Annals of Mathematical Statistics, 9:(1) 60