A neural net architecture based on principles of neural plasticity and development evolves to effectively catch prey in a simulated environment
Abstract
A profound challenge for A-Life is to construct agents whose behavior is ‘life-like’ in a deep way. We propose an architecture and approach to constructing networks driving artificial agents, using processes analogous to the processes that construct and sculpt the brains of animals. Furthermore, the instantiation of action is dynamic: the whole network responds in real-time to sensory inputs to activate effectors, rather than computing a representation of the optimal behavior and sending off an encoded representation to effector controllers. There are many parameters and we use an evolutionary algorithm to select them, in the context of a specific prey-capture task. We think this architecture may be useful for controlling small autonomous robots or drones, because it allows for a rapid response to changes in sensor inputs.
I introduction
One of the most profound challenges of research into artificial life (A-Life) is to construct agents whose behavior is generated in ways deeply analogous to the way an animal’s brain drives its motions. Many researchers argue for using neural networks to control behavior [1, 2, 3, 3] and some favor an approach that builds an ersatz nervous system, whose operations mimic aspects of an animal’s nervous system [4, 5, 6].
However, there is no consensus about how closely construction must hew to biology Furthermore, for large neural networks, the number of possible network configurations is so large that it is difficult to search for network constructions that drive adaptive or effective behavior. Evolutionary algorithms have a solid track record for solving problems with a large search space [7]. We introduce here an evolutionary approach to constructing a neural network controller for a small animat in a 2-dimensional world.
Our approach is distinctive in several ways. First, behavior will emerge through dynamic equilibria of the network and continuous feedback from the surroundings carried by a rich array of simple sensors, rather than having the network compute a representation of behavior, which is then implemented by mechanical systems. The network architecture will be recurrent feedback loops, analogous to loops between cortex and subcortical structures, such as thalamus and basal ganglia. Second, neurons will compete and oppose the actions of other neurons, so that the dynamic equilibrium may be rapidly altered as circumstances change. Third, each instance of a controller will be constructed by methods modeled on developmental processes in animal brains, as detailed below. To our knowledge, this is the most life-like approach yet taken to constructing A-life simulations.
II Methods
II.1 Animat Construction
Our system builds neural networks in three stages, modeled on neurobiology:
Node definition
Nodes are assigned random pseudo-locations in a 2D, 3D or 4D virtual space. Parameters define the probabilities of specific node classes at various locations within the virtual space, and within a class, the specific signals employed for further stages.
Coarse initial wiring
Projections are assigned with synaptic weights determined by the match between paired transmitter and receiver signals, in a manner intended to be analogous to how axons find distant targets through molecular interactions in the developing brain [8, 9]. In our prototype system the signals are determined by gradients in 2D virtual space determined by parameters.
Fine mapping
Learning
Experiences induce changes in synapses, in a Hebbian manner, contingent upon attaining food, mediated by neuromodulator (NM) signals. The intrinsically unstable Hebbian process is further stabilized in two ways: i) saturation of the plasticity signal, and ii) longer-term homeostatic mechanisms, both modeled on neurobiology [12, 13]. The processes of synapse generation at each stage are determined by a small number of parameters. During the subsequent learning stage, synaptic weights are periodically adjusted according to a pseudo-Hebbian learning rule, modulated by reward signals, whose parameters are set by genes.
II.2 Evaluation Task
The simulated world is a two dimensional plane, populated by two species of prey items, both of which move according to a Brownian Motion with a strong drift away from the animat, when the animat is within striking distance; their top speed is slightly less than the animat’s top speed. One prey species, comprising 1/3 of all prey, has more calories than the other; which species is to have more calories is chosen randomly in each generation, so that the genome cannot evolve to encode that value, but the animat must learn it in each generation. The fitness function for the animat is how many calories are captured per lifetime.
II.3 Simulation
The evolutionary algorithm was implemented by highly efficient special purpose open source software written in C++ that has been developed at MSU: MABE (Modular Agent Based Evolution framework) [14]. MABE allows researchers to combine different forms of cognitive substrates, tasks, selection methods and data collection methods to quickly develop digital neuroevolution experiments. MABE is ideally suited for this work since it allows parts of an experiment to be swapped without affecting other parts, which allows us to easily compare the behavior of the animat with other more popular methods of computational neuroevolution. Since the parameters that define the construction process and learning characteristics are continuous or integer-valued (with a large range of values), our mutation operator works by perturbing numerical values, rather than swapping symbols in a string. The size of perturbation is initially set to a plausible value about 10% of the range of values considered reasonable. See Appendix item I for the initial values of mutation and range used for the simulations described here.
III Results
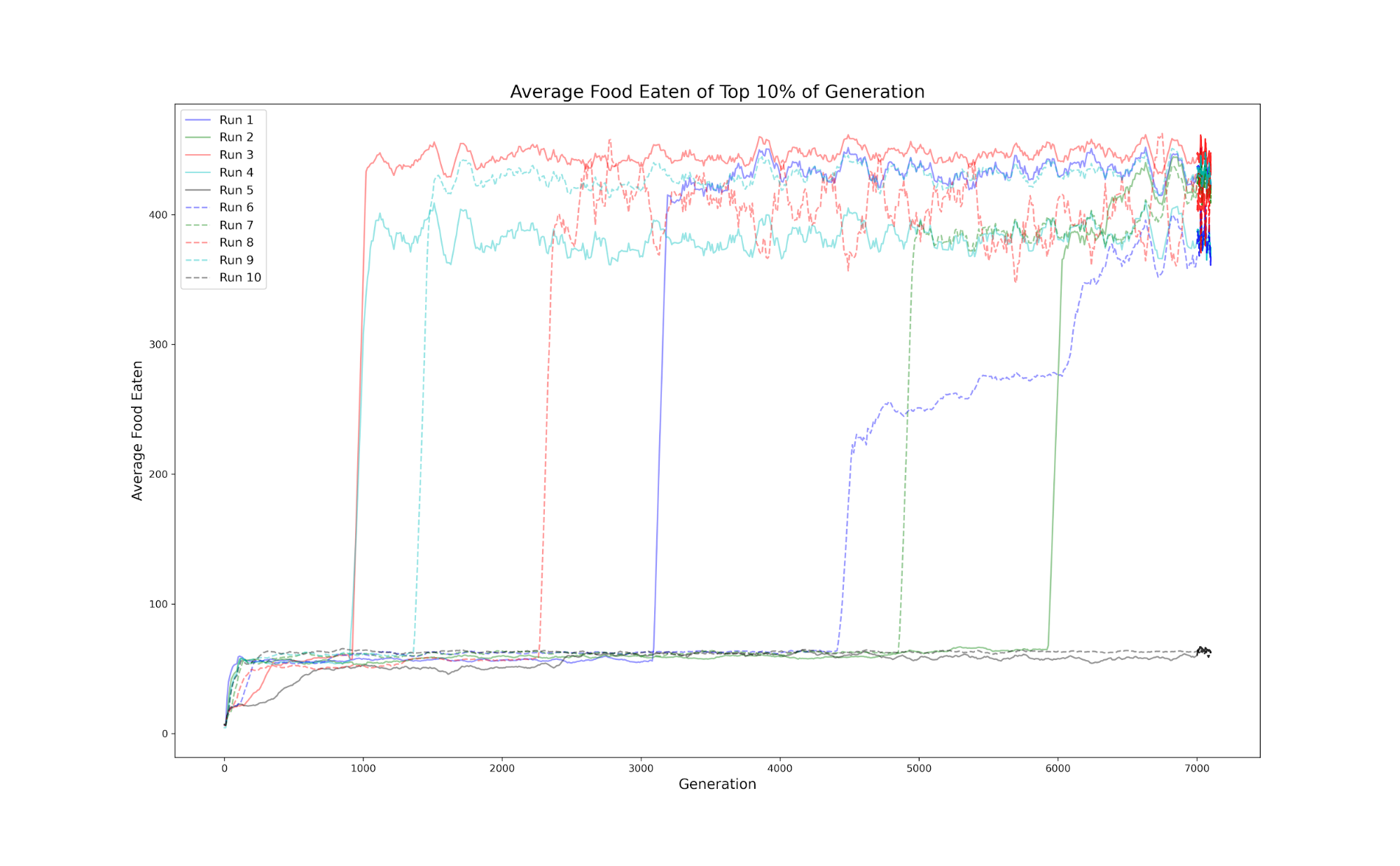
In our simulations, agents started by capturing an average of 2 or 3 food items in generation 1 and usually attained an average of 25 food items per 5 minutes simulated lifetime after 50 or 100 generations at which point their performance stabilized until several thousands of generations, at which point there typically was a rapid increase in fitness, which then plateaued at several hundred food items captured, while showing a strong preference for the high-calorie prey. After the second larger jump in most runs, in the stable population regime, agents ate an average of 282 prey items, with a standard deviation of 151. After performance of the top 10One issue for assessing performance, is how much the measure reflects the genome and how much it reflects (random) starting conditions. To test this we extracted 10 successful agents within the stable population regime, and then placed them in 100 random worlds, in which the starting location of the prey is randomly generated, we see that the distribution of food eaten for each agent throughout the random worlds (4) begins to look similar to the histogram of food eaten for all agents (successful or not) in the stable population regime. Looking at the histograms visualizing these count numbers, it’s easy to spot the pattern: the lackluster agents consume next to nothing, there is a relatively large gap in-between, then there is a larger group of well-performing agents arranged in a (left-skewed) normal distribution. The most successful agents were exceptional about identifying and chasing prey. These agents seemed to set and follow a trajectory for the nearest cluster of prey items, then after momentum carried the agent out of the group, they could loop back around or find the new nearest cluster of prey, which is an impressive behavior, as the agent moves quite quickly. The agent can traverse the entire range encompassing all 50 prey in 1 second of simulated time. This is in contrast to the behavior of agents before the jump, whose movement was characterized by a large, consistent looping pattern - a relatively successful strategy, but largely inefficient, which we termed “filter feeding.” Evolutionary theorists often ask how inevitable a specific evolutionary outcome is. Although so far the large majority of our simulations have found a stable high-performing population, the distributions of construction parameters (‘genes’) are very different from each other, any pair overlapping less than 1%. This indicates that even in this simple 22-parameter system a great many distinct possible optima, with comparable performance, may be found.
Acknowledgements.



References
- Richter et al. [2016] C. Richter, S. Jentzsch, R. Hostettler, J. A. Garrido, E. Ros, A. C. Knoll, F. Röhrbein, P. van der Smagt, and J. Conradt, Scalability in neural control of musculoskeletal robots, arXiv preprint arXiv:1601.04862 (2016).
- Amer et al. [2021] K. Amer, M. Samy, M. Shaker, and M. ElHelw, Deep convolutional neural network based autonomous drone navigation, in Thirteenth International Conference on Machine Vision, Vol. 11605 (SPIE, 2021) p. 16–24.
- Hole and Ahmad [2021] K. J. Hole and S. Ahmad, A thousand brains: toward biologically constrained ai, SN Applied Sciences 3, 743 (2021).
- Stanley et al. [2019] K. O. Stanley, J. Clune, J. Lehman, and R. Miikkulainen, Designing neural networks through neuroevolution, Nature Machine Intelligence 1, 24–35 (2019).
- Duarte et al. [2018] M. Duarte, J. Gomes, S. M. Oliveira, and A. L. Christensen, Evolution of repertoire-based control for robots with complex locomotor systems, IEEE Transactions on Evolutionary Computation 22, 314–328 (2018).
- Sheneman et al. [2019] L. Sheneman, J. Schossau, and A. Hintze, The evolution of neuroplasticity and the effect on integrated information, Entropy 21, 524 (2019).
- Goodman et al. [2011] E. D. Goodman, E. J. Rothwell, and R. C. Averill, Using concepts from biology to improve problem-solving methods, in Evolutionary and Bio-Inspired Computation: Theory and Applications V, Vol. 8059 (SPIE, 2011) p. 9–24.
- Hassan and Hiesinger [2015] B. A. Hassan and P. R. Hiesinger, Beyond molecular codes: Simple rules to wire complex brains, Cell 163, 285–291 (2015).
- Rubenstein and Rakic [2013] J. Rubenstein and P. Rakic, Cellular migration and formation of neuronal connections: comprehensive developmental neuroscience, Vol. 2 (Academic Press, 2013).
- Tiriac and Feller [2019] A. Tiriac and M. B. Feller, Embryonic neural activity wires the brain, Science 364, 933–934 (2019).
- Kerschensteiner [2014] D. Kerschensteiner, Spontaneous network activity and synaptic development, The Neuroscientist: A Review Journal Bringing Neurobiology, Neurology and Psychiatry 20, 272–290 (2014).
- Escobar and Derrick [2007] M. L. Escobar and B. Derrick, Long-term potentiation and depression as putative mechanisms for memory formation, Neural Plasticity and Memory: From Genes to Brain Imaging , 15 (2007).
- Turrigiano [2012] G. Turrigiano, Homeostatic synaptic plasticity: local and global mechanisms for stabilizing neuronal function, Cold Spring Harbor perspectives in biology 4, a005736 (2012).
- Bohm and Hintze [2017] C. Bohm and A. Hintze, Mabe (modular agent based evolver): A framework for digital evolution research, in ECAL 2017, the Fourteenth European Conference on Artificial Life (MIT Press, 2017) p. 76–83.
- Amunts et al. [2016] K. Amunts, C. Ebell, J. Muller, M. Telefont, A. Knoll, and T. Lippert, The human brain project: Creating a european research infrastructure to decode the human brain, Neuron 92, 574–581 (2016).