A Multi-view Perspective of Self-supervised Learning
Abstract.
As a newly emerging unsupervised learning paradigm, self-supervised learning (SSL) recently gained widespread attention in many fields such as computer vision and natural language processing. SSL aims to reduce the dependence on large amounts of annotated data in these fields, and its key is to create a pretext task without manual data annotation. Though the effectiveness of SSL has been verified in most tasks, its essence has not been well understood yet, making the design of existing pretext tasks depend more on intuitive and heuristic, thus easily resulting in some invalid presettings. In fact, from a multi-view perspective, we can find that almost all of existing SSL tasks are mainly to perform explicit linear or nonlinear transformations on the given original (single view) data, thus forming multiple artificially-generated views (i.e., view augmentation of the data). However, unlike the traditional multi-view learning, SSL mostly introduces homogeneous view data with same dimensions while exploits the views’ own labels as proxy supervised signals for feature learning. As a preliminary attempt, this paper therefore borrows such a perspective to explore the essence of SSL so as to gain some insights into the design of pretext task. Specifically, we decouple a class of popular pretext tasks into a combination of view augmentation of the data (VAD) and view label classification (VLC), and design a simple yet effective verification framework to explore the impact of these two parts on SSL’s performance. Our experiments empirically uncover that it is VAD rather than generally considered VLC that dominates the performance of such SSLs.
1. Introduction
Due to the powerful learning representation ability, deep convolutional neural networks (CNNs) (LeCun et al., 1998) have made breakthroughs in such areas as computer vision and natural language processing. At present, training a powerful CNNs often requires a large number of annotated/labeled instances, however, collecting such data in numerous practical tasks is time-consuming and expensive. In contrast, unlabeled data is cheap and easily accessible. Therefore, research on the effective use of such data is already a hot issue (Denton and Birodkar, 2017). In recent years, a new learning paradigm that automatically generates supervisory signals according to some attributes of data to guide feature learning—self-supervised learning (SSL) (Tung et al., 2017) is receiving increasingly more attention.
In SSL, a pretext with pseudo labels is first designed for CNNs to solve, where the pseudo labels are automatically generated based on some attributes of data without manual annotation. After the pretext task finished, the learned feature representation can be further transferred to downstream tasks as pre-trained models, making them obtain better starting points of solution (Jing and Tian, 2019). Thus the pretext task plays a key role, and many pretext tasks have been proposed such as in-painting (Pathak et al., 2016), patch context and jigsaw puzzles (Doersch et al., 2015; Noroozi and Favaro, 2016), rotation (Gidaris et al., 2018), color permutation (Lee et al., 2019), and so on. In particular, due to easy implementation and computational efficiency, the rotation pretext task has been more widely extended to multiple learning scenarios like domain adaptation (Sun et al., 2019), generative adversarial networks (GANs) (Chen et al., 2019), out-of-distribution detection (Hendrycks et al., 2019). Besides, as an auxiliary learning task, some researchers recently also have applied it to other learning tasks such as cross-modal learning task (Song et al., 2019) and face representation task (Röthlingshöfer et al., 2019), etc.

Although the effectiveness of SSL has been verified in most tasks, the essence of such effectiveness has not been quite clear yet. In fact, almost all existing pretext tasks are designed based more on intuitive and heuristic, which restricts its further development. It is generally believed that the process of solving the pretext task captures the feature representation beneficial for downstream tasks (Jing and Tian, 2019). However, it is a fact that the pseudo labels of pretext tasks are usually not explicitly associated with the supervised lable/signal of downstream tasks. Thus a natural question is: how does it work effectively? From a multi-view perspective, we can find that existing pretext tasks are mainly to perform explicit linear or nonlinear transformation (i.e., self-supervised signals) on the given original (single view) data, thus forming multiple transformed views (i.e., view augmentation of the data), which interestingly falls just right into the multi-view learning framework of single view data (Wang et al., 2007, 2011). However, unlike the traditional multi-view learning (MVL), SSL mainly introduces homogeneous view data with same dimension while exploits the views’ own labels as proxy supervised signals to guide feature learning. Furthermore, though some researchers (Federici et al., 2020) also conceptually involved this perspective, they have neither discriminated the difference between MVL and SSL mentioned above nor explored the essence of SSL in depth. As a preliminary attempt, this paper therefore borrows such a perspective to explore the essence so as to provide some insights into the design of pretext task.
Specifically, we first decouple a class of popular pretext tasks (e.g., rotation, color permutation) into a combination of view augmentation of the data (VAD) and view label classification (VLC). Taking the rotation as an example, such a pretext task essentially 1) first performs a rotation transformation {} on the corresponding data, so as to generate multiple groups of transformed data, each group of data can be regarded as one-view new data generated from original data, all the groups form a set of so-called augmented multi-view data; 2) then predicts the rotation transformation of these data, i.e., view labels.
Further, a simple yet effective verification framework is designed to explore the impacts of VAD and VLC on SSL’s performance as shown in Figure 1. Concretely, we specially design a simple multi-view learning framework for SSL (SSL-MV), which assists the feature learning of the downstream task (original view) through the same tasks on the augmented views (i.e., VAD tasks), making it focus on VAD rather than VLC. Note that thanks to replacing VLC with VAD tasks, SSL-MV also enables an integrated inference combining the predictions from the augmented views, further improving the performance. In addition, as a contrast, a multi-task learning framework of SSL (SSL-MT) is also provided, which focuses on both VAD and VLC.
The rest of this paper is organized as follows. Section 2 simply reviews the recent SSL works. In Section 3, we focus on a class of popular pretext tasks (such as rotation, color permutation), and decouple them into a combination of view augmentation of the data (VAD) and view label classification (VLC) from a multi-view perspective. Then a simple yet effective verification framework is designed to help us to explore the essence of such SSL tasks. Experimental results and analyses on several benchmark datasets are reported in Section 4. Section 5 is a brief discussion, while Section 6 concludes this paper.

2. Related Work
As the key to SSL is the design of the pretext task, much of the research currently focuses more on designing new pretext tasks, thus developing a number of SSL methods. These methods use various cues from images or videos, etc. For example, some methods learn feature representation by solving the generations involving images or videos, such as image colorization (Zhang et al., 2016), image inpainting (Pathak et al., 2016), and video generation with GANs (Tulyakov et al., 2018), video prediction (Srivastava et al., 2015), etc. Some methods mainly adopt the image or video context information, such as jigsaw puzzles (Noroozi and Favaro, 2016), patch context (Doersch et al., 2015), geometry (Dosovitskiy et al., 2015; Li et al., 2019), counting (Noroozi et al., 2017), clustering (Caron et al., 2018), rotation (Gidaris et al., 2018), color permutation (Lee et al., 2019), and temporal order verification (Misra et al., 2016; Wei et al., 2018), sequence prediction (Lee et al., 2017a), etc. Furthermore, there are also some methods related to the automatic generation of free semantic label by traditional hardcode algorithms (Faktor and Irani, 2014) or by game engines (Ren and Jae Lee, 2018), such as semantic segmentation (Wang et al., 2020), contour detection (Ren and Jae Lee, 2018), relative depth prediction (Jiang et al., 2018), etc. For more details about these methods mentioned above, we refer the reader to (Jing and Tian, 2019).
| Dataset | # Class | # Training | # Testing |
|---|---|---|---|
| CIFAR10 | 10 | 50000 | 10000 |
| CIFAR100 | 100 | 50000 | 10000 |
| TinyImageNet | 200 | 100000 | 10000 |
| MIT67 | 67 | 5360 | 1340 |
In addition to exploring the design of pretext tasks, some researchers have also attempted to analyze the inherent advantages of SSL from other perspectives. From the perspective of CNNs’ structure, Kolesnikov et al. (Kolesnikov et al., 2019) studied the combination of multiple CNNs’ structures and multiple SSL pretext tasks, where they found that unlike supervised learning, the performance of SSL tasks depends significantly on the structure of CNNs used. Furthermore, they also experimentally show that the performance advantages obtained by the predecessor tasks do not always translate into the advantages in the feature representation of the downstream tasks, sometimes even worse. From the robust learning perspective, Hendrycks et al. (Hendrycks et al., 2019) found that SSL can improve robustness in a variety of ways, such as robustness to adversarial examples, label corruption, common input corruptions, while it also greatly benefits out-of-distribution detection (Hendrycks and Gimpel, 2016; Lee et al., 2017b) on difficult, near-distribution outliers.
From the data augmentation perspective, Lee et al. (Lee et al., 2019) reorganized various SSL strategies, where they mainly regarded SSL as a data augmentation technique and modeled the joint distribution of the original and self-supervised labels. Further, Federici et al. (Federici et al., 2020) empirically demonstrated the effectiveness of this kind of data augmentation under the multi-view information bottleneck framework they proposed. Besides, Keshav and Delattre (Keshav and Delattre, 2020) explored the crucial factors to avoid learning trivial solutions when constructing pretext tasks, while Kumar et al. (Kumar et al., 2020) investigated the SSL task combined with clustering, and provided the insight from data transformation perspective.
3. Proposed Frameworks
In this part, we focus on a class of popular pretext tasks such as rotation and color permutation, where we decouple them into a combination of view augmentation of the data (VAD) and view label classification (VLC), so as to explore whether VAD or VLC dominates the performance of such SSL. Specifically, two implementation pipelines of SSL, i.e., SSL-MT and SSL-MV, are designed, respectively, where SSL-MT focused on both VAD and VLC, while SSL-MV concentrates only on VAD. The more details about them will be provided in the following parts.
Notation. Let denote the training set, where is the corresponding label and is the number of classes. Let represent the shared feature extractor, be the cross-entropy loss function, and be the individual classifier. Furthermore, let denote the augmented sample using a transformation (self-supervision label), where , and denotes the identical transformation.

3.1. Multi-task pipeline of SSL
Most existing SSL methods usually adopt the two-step strategy, where they first solve a pretext task, i.e., predicting which transformation (self-supervised/view label) is applied to the original sample , then transfer the learned feature representation to downstream tasks. However, since the self-supervised label is usually not explicitly associated with the supervised label of downstream tasks, thus the performance of such implementation pipeline currently lags behind fully supervised training, as reported in recent literature (Gidaris et al., 2018; Hendrycks et al., 2019). Therefore, to better explore the essence of SSL, we here adopt a multi-task pipeline to implement SSL. Specifically, we formulate the loss function as follows,
where the first term of the RHS of the equality (1) denotes the downstream task loss, while the second term is the pretext task loss. Many recent SSL works almost all adopted such a pipeline (Sun et al., 2019; Chen et al., 2019).
3.2. Multi-view pipeline of SSL
To effectively investigate whether VAD or VLC dominates SSL’s performance, we specially design a simple yet effective multi-view learning framework for SSL as shown in Figure 2, which assists the feature learning of downstream tasks (original view) through the same supervised learning task on the augmented views (VAD Tasks). Further, we define the following loss function:
| (2) |
Different from SSL-MT which focuses on both VAD and VLC, SSL-MV only pays attention to VAD. Furthermore, from the multi-task perspective, SSL-MV essentially replaces the VLC in SSL-MT with VAD tasks. Note that, intuitively, such tasks are more helpful for the feature learning of downstream tasks, since they are closer to the downstream task compared to the VLC tasks. Additionally, SSL-MV actually also enables an integrated inference combining the predictions from the different augmented views, consequently further improving the performance as validated in our experiments below.
4. Experiments and Analysis
4.1. Settings
Datasets and models. In this paper, we evaluate our learning framework on several commonly used benchmark datasets: CIFAR10/100 (Krizhevsky et al., 2009), Tiny-ImageNet (https://tiny-imagenet.herokuapp.com/), and a fine-grained dataset MIT67 (Quattoni and Torralba, 2009). Moreover, Table 1 describes the details of these datasets. For the CNN models used, we refer to (Lee et al., 2019): 32-layer Reset for CIFAR, 18-layer ResNet for Tiny-ImageNet and MIT67.
Training Details. For all benchmark datasets, we use SGD with learning rate 0.1, momentum 0.9. For CIFAR10/100, we set weight decay to , and train for 200 epoches with batch size of 128. For Tiny-ImageNet, we set weight decay of , and train for 100 epoches with batch size of 64 (limited by the GPU capacity). For MIT67, we set weight decay of , and train for 180 epoches with batch size of 32 as suggested by (Lee et al., 2019). We decay the learning rate by the constant factor of 0.1 at 50% and 75% epoches. Furthermore, for SDA+AI, SDA+AG and the standard supervised learning, we follow the same settings in (Lee et al., 2019).
Choices of pretext tasks. As we use image classification as the downstream task, where using the entire image as input is important. Therefore, similar to (Lee et al., 2019), we here focus on two pretext tasks of such SSL, i.e., rotation and color permutation. For rotation, we adopt four commonly used transformations, i.e., , while six transformations for color permutation, i.e., {RGB, RBG, GRB, GBR, BRG, BGR} as visualized in Figure 3. Note that though we here mainly carry out experimental studies based on both rotation and color permutation, some drawn conclusions can give insights of the essence of SSL.
4.2. Shared block experiment
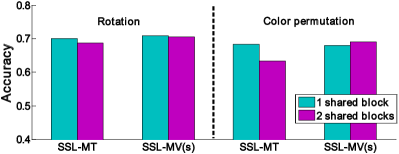
Generally, the shallow layers of CNNs can capture general low-level features like edges, corners, etc, while deeper layers capture task-related high-level features (Jing and Tian, 2019). This subsection reports the impact of sharing different numbers of blocks on performance. Taking CIFAR100 as an example, Figure 4 shows the corresponding results. For SSL-MT, its performance is negatively correlated with the number of shared blocks, which is consistent with the previous general conclusion. However, for SSL-MV(s), its performance of sharing two blocks is at least equal to that of sharing one block, which is probably because the VAD tasks in SSL-MV are closer to downstream tasks than the VLC task in SSL-MT. Additionally, for color permutation, though sharing more layers improves the performance of SSL-MV(s) (67.99% vs 69.09%), on the other hand, the performance of SSL-MV(e) decreases (76.32% vs 75.11%). For the sake of fairness, all experiments in this paper share the first block of the corresponding CNNs.
| Dataset \Method | Supervised | SDA+SI | SSL-MT | SSL-MV(s) | SDA+AG | SSL-MV(e) | |
|---|---|---|---|---|---|---|---|
| CIFAR10 | Rotation | 92.39 | 92.50 | 93.81 | 93.47 | 94.50 | 95.18 |
| CIFAR100 | 68.27 | 68.68 | 70.11 | 70.89 | 74.14 | 77.26 | |
| TinyImageNet | 63.11 | 63.99 | 64.08 | 64.37 | 66.95 | 69.51 | |
| MIT67 | 54.75 | - | 59.18 | 58.28 | 64.85 | 61.49 | |
| CIFAR10 | Color permutation | 92.39 | - | 92.42 | 93.52 | 92.51 | 95.01 |
| CIFAR100 | 68.27 | - | 68.30 | 67.99 | 69.14 | 76.32 | |
| TinyImageNet | 63.11 | - | 64.47 | 64.25 | 64.15 | 70.51 | |
| MIT67 | 54.75 | - | 54.93 | 57.24 | 59.99 | 60.30 | |
4.3. Main Results
To investigate whether whether VAD or VLC dominates the performance of SSL, we here focus most on the comparison between SSL-MT and SSL-MV. In addition, for SSL-MV, it has a single inference (SSL-MV(s)) and an aggregated inference (SSL-MV(e)). Thus in order to further demonstrate the advantages of SSL-MV, we also respectively report their comparison with SDA + SI (a single inference) and SDA + AG (an aggregated inference) in (Lee et al., 2019), a latest work closed to our SSL-MV. Moreover, we report the results of the standard supervised learning as a baseline. Table 2 shows the results.
Observation 1: Compared to the standard supervised learning, SSL-MT and SSL-MV achieve significant performance improvements on almost all datasets, which demonstrates that such pretext tasks indeed benefit the feature learning for the downstream tasks.
Observation 2: No matter whether it is rotation or color permutation, SSL-MV(s) achieves at least comparable performance to SSL-MT on all benchmark datasets, which fully indicates that it is VAD rather than generally considered VLC that dominates the performance of such SSL, since it has been replaced by the VAD tasks. This also inspires us to further improve the performance of SSL by generating richer data views, such as using transform composition, which will be discussed in subsection 4.5
| Color permutation | Views | SSL-MT | SSL-MV | |
|---|---|---|---|---|
| SSL-MV(s) | SSL-MV(e) | |||
| RGB | 1 | 68.27 | 68.27 | |
| RGB,GBR,BRG | 3 | 69.54 | 66.99 | 73.84 |
| RGB,GRB,BGR | 3 | 69.24 | 69.69 | 73.89 |
| RGB,RBG,GRB,GBR,BRG,BGR | 6 | 68.30 | 67.99 | 76.32 |
Observation 3: Compared to the single inference, our aggregated inference (SSL-MV(e)) achieves the best performance on all datasets. This demonstrates that the transforms from such pretext tasks indeed enrich the diversity of the original data, which in turn leads to the diversity of the classifiers, consequently further improving the performance (Krawczyk et al., 2017). Besides, both SSL-MV(s) and SSL-MV(e) are significantly ahead of SDA+SI and SDA+AG, respectively, on almost all datasets. This seems to validate our previous conjecture, i.e., there may be potentially unfavorable competition between the original and self-supervised labels in such a modeling of (Lee et al., 2019). Note that, although the VAD tasks also compete with the downstream tasks, the resulting competition has eased due to the closeness between these tasks.
Observation 4: The performance of SSL-MV(s) lags behind the standard supervised learning on CIFAR100, and we conjecture that some view(s) of VAD may confuse the shared feature extractor. In other words, some augmented view(s) may introduce severe distribution drift. As shown in Figure 3, taking the bird as an example, the newly generated GBR and BRG images have visually shifted greatly from the original RGB images. Especially, when these images have largely color overlap with other kinds of birds, it is easy to confuse the classifiers. To verify our conjecture, we further conduct the color permutation experiments in subsection 4.4.
Remark. Note that, this paper focuses on the exploration of the essence of SSL, and to better study this issue, we specially design such a simple yet effective multi-view learning framework for SSL. Although the single inference, especially aggregated inference of this framework has achieved impressive performance as reported above, this framework currently is not scalable and difficult to be directly deployed into practical applications.
| Rotation | Sharpness | Views | SSL-MV | |
|---|---|---|---|---|
| SSL-MV(s) | SSL-MV(e) | |||
| 1 | 68.27 | |||
| 2 | 70.87 | 75.08 | ||
| 4 | 70.89 | 77.26 | ||
| 4 | 69.36 | 75.87 | ||
| 8 | 69.39 | 77.69 | ||
| 16 | 69.17 | 77.72 | ||
4.4. Color permutation experiment
In this subsection, we specifically perform the color permutation experiments to verify our claims in subsection 4.3, and the results are reported in Table 3. As we conjectured, SSL-MV(s) lags behind the standard supervised learning when the augmented views GBR and BRG are used to assist the feature learning of the downstream task. In contrast, when GRB and BGR are used, the performance of SSL-MV(s) is significantly better than that of the standard supervised learning, indicating that the distribution drift on the latter is smaller than the former. Similarly, SSL-MV(s) performs slightly better than SSL-MT when using GRB and BGR, whereas it lags behind SSL-MT when using GBR and BRG, which also indicates that VLC is necessary when the samples are sensitive to the corresponding transformation (color permutation here). Interestingly, though the distribution drift of some augmented view data interferes with the feature learning of downstream tasks to some extent, the performance of aggregated inference (SSL-MV(e)) is positively correlated with the number of augmented views.
4.5. Composed transformations
As mentioned in subsection 4.3, VAD dominates the performance of such SSL discussed in this paper, which inspires us to further improve the performance of SSL by generating richer data views, such as through transform composition. As a preliminary exploration, an extended experiment on the composed transformations containing rotation and an image enhancement transformation, i.e., , is carried out in this subsection. The parameter controls the sharpness of an image, where returns a blurred image, while returns the original image. Specifically, we adopt four transformations, and the corresponding results are reported in Table 4.
For SSL-MV(s), although its performance improves with the increase of augmented view data, it is not positively correlated to the number of the augmented views. One possible reason is that some augmented views of VAD drift too much and confuse the shared feature extractor as discussed above. Nonetheless, such augmented view data greatly increase the diversity of the original data, making our aggregated inference (SSL-MV(e)) achieve better performance.
5. Discussion
From the multi-view perspective, this paper revisits a class of popular SSL methods as an attempt to preliminarily explore the essence of SSL, where we find it is VAD rather than generally considered VLC plays a crucial role in boosting performance for downstream tasks. Please note that unlike traditional data augmentation and multi-view learning, SSL also considers the so-attached self-supervised labels. Furthermore, to our best knowledge, the theoretical exploration of SSL currently is almost blank as well. Thus, from the above explorations, it seems that we can draw on the existing multi-view learning theory (Wang and Zhou, 2017) to compensate this issue, and further expand SSL by the following typical strategies:
-
(1)
Generate more diverse self-supervised signals/labels. For example, through richer transformation compositions: composed/nested/hierarchical operations on data examples.
-
(2)
Establish a unified learning framework of self-supervised learning and multi-view learning.
Additionally, inspired by the effective use of self-supervised signals in SSL, exploring the use of view labels in existing multi-view learning is also worth further in-depth discussion.
6. Conclusion
In this paper, we revisit SSL from the multi-view perspective as an attempt to explore its essence, where we decouple a class of popular pretext tasks into a combination of view data augmentation (VAD) and view label classification (VLC), empirically revealing that it is VAD rather than generally considered VLC that dominates the performance of such SSL. Furthermore, we also give some insights about SSL, hoping to benefit the researchers in this community.
References
- (1)
- Caron et al. (2018) Mathilde Caron, Piotr Bojanowski, Armand Joulin, and Matthijs Douze. 2018. Deep clustering for unsupervised learning of visual features. In Proceedings of the European Conference on Computer Vision (ECCV). 132–149.
- Chen et al. (2019) Ting Chen, Xiaohua Zhai, Marvin Ritter, Mario Lucic, and Neil Houlsby. 2019. Self-Supervised GANs via Auxiliary Rotation Loss. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 12154–12163.
- Denton and Birodkar (2017) Emily L Denton and vighnesh Birodkar. 2017. Unsupervised learning of disentangled representations from video. In Advances in neural information processing systems. 4414–4423.
- Doersch et al. (2015) Carl Doersch, Abhinav Gupta, and Alexei A Efros. 2015. Unsupervised visual representation learning by context prediction. In Proceedings of the IEEE International Conference on Computer Vision. 1422–1430.
- Dosovitskiy et al. (2015) Alexey Dosovitskiy, Philipp Fischer, Jost Tobias Springenberg, Martin Riedmiller, and Thomas Brox. 2015. Discriminative unsupervised feature learning with exemplar convolutional neural networks. IEEE transactions on pattern analysis and machine intelligence 38, 9 (2015), 1734–1747.
- Faktor and Irani (2014) Alon Faktor and Michal Irani. 2014. Video Segmentation by Non-Local Consensus voting.. In BMVC, Vol. 2. 8.
- Federici et al. (2020) Marco Federici, Anjan Dutta, Patrick Forré, Nate Kushman, and Zeynep Akata. 2020. Learning Robust Representations via Multi-View Information Bottleneck. arXiv preprint arXiv:2002.07017 (2020).
- Gidaris et al. (2018) Spyros Gidaris, Praveer Singh, and Nikos Komodakis. 2018. Unsupervised representation learning by predicting image rotations. arXiv preprint arXiv:1803.07728 (2018).
- Hendrycks and Gimpel (2016) Dan Hendrycks and Kevin Gimpel. 2016. A baseline for detecting misclassified and out-of-distribution examples in neural networks. arXiv preprint arXiv:1610.02136 (2016).
- Hendrycks et al. (2019) Dan Hendrycks, Mantas Mazeika, Saurav Kadavath, and Dawn Song. 2019. Using self-supervised learning can improve model robustness and uncertainty. In Advances in Neural Information Processing Systems. 15637–15648.
- Jiang et al. (2018) Huaizu Jiang, Gustav Larsson, Michael Maire Greg Shakhnarovich, and Erik Learned-Miller. 2018. Self-supervised relative depth learning for urban scene understanding. In Proceedings of the European Conference on Computer Vision (ECCV). 19–35.
- Jing and Tian (2019) Longlong Jing and Yingli Tian. 2019. Self-supervised visual feature learning with deep neural networks: A survey. arXiv preprint arXiv:1902.06162 (2019).
- Keshav and Delattre (2020) Vishal Keshav and Fabien Delattre. 2020. Self-supervised visual feature learning with curriculum. arXiv preprint arXiv:2001.05634 (2020).
- Kolesnikov et al. (2019) Alexander Kolesnikov, Xiaohua Zhai, and Lucas Beyer. 2019. Revisiting self-supervised visual representation learning. arXiv preprint arXiv:1901.09005 (2019).
- Krawczyk et al. (2017) Bartosz Krawczyk, Leandro L Minku, João Gama, Jerzy Stefanowski, and Michał Woźniak. 2017. Ensemble learning for data stream analysis: A survey. Information Fusion 37 (2017), 132–156.
- Krizhevsky et al. (2009) Alex Krizhevsky, Geoffrey Hinton, et al. 2009. Learning multiple layers of features from tiny images. Technical Report. Citeseer.
- Kumar et al. (2020) Abhimanu Kumar, Aniket Anand Deshmukh, Urun Dogan, Denis Charles, and Eren Manavoglu. 2020. Data Transformation Insights in Self-supervision with Clustering Tasks. arXiv preprint arXiv:2002.07384 (2020).
- LeCun et al. (1998) Yann LeCun, Léon Bottou, Yoshua Bengio, Patrick Haffner, et al. 1998. Gradient-based learning applied to document recognition. Proc. IEEE 86, 11 (1998), 2278–2324.
- Lee et al. (2019) Hankook Lee, Sung Ju Hwang, and Jinwoo Shin. 2019. Rethinking Data Augmentation: Self-Supervision and Self-Distillation. arXiv preprint arXiv:1910.05872 (2019).
- Lee et al. (2017a) Hsin-Ying Lee, Jia-Bin Huang, Maneesh Singh, and Ming-Hsuan Yang. 2017a. Unsupervised representation learning by sorting sequences. In Proceedings of the IEEE International Conference on Computer Vision. 667–676.
- Lee et al. (2017b) Kimin Lee, Honglak Lee, Kibok Lee, and Jinwoo Shin. 2017b. Training confidence-calibrated classifiers for detecting out-of-distribution samples. arXiv preprint arXiv:1711.09325 (2017).
- Li et al. (2019) Junnan Li, Jianquan Liu, Yongkang Wong, Shoji Nishimura, and Mohan S Kankanhalli. 2019. Self-supervised Representation Learning Using 360° Data. In Proceedings of the 27th ACM International Conference on Multimedia. 998–1006.
- Misra et al. (2016) Ishan Misra, C Lawrence Zitnick, and Martial Hebert. 2016. Shuffle and learn: unsupervised learning using temporal order verification. In European Conference on Computer Vision. Springer, 527–544.
- Noroozi and Favaro (2016) Mehdi Noroozi and Paolo Favaro. 2016. Unsupervised learning of visual representations by solving jigsaw puzzles. In European Conference on Computer Vision. Springer, 69–84.
- Noroozi et al. (2017) Mehdi Noroozi, Hamed Pirsiavash, and Paolo Favaro. 2017. Representation learning by learning to count. In Proceedings of the IEEE International Conference on Computer Vision. 5898–5906.
- Pathak et al. (2016) Deepak Pathak, Philipp Krahenbuhl, Jeff Donahue, Trevor Darrell, and Alexei A Efros. 2016. Context encoders: Feature learning by inpainting. In Proceedings of the IEEE conference on computer vision and pattern recognition. 2536–2544.
- Quattoni and Torralba (2009) Ariadna Quattoni and Antonio Torralba. 2009. Recognizing indoor scenes. In 2009 IEEE Conference on Computer Vision and Pattern Recognition. IEEE, 413–420.
- Ren and Jae Lee (2018) Zhongzheng Ren and Yong Jae Lee. 2018. Cross-domain self-supervised multi-task feature learning using synthetic imagery. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 762–771.
- Röthlingshöfer et al. (2019) Veith Röthlingshöfer, Vivek Sharma, and Rainer Stiefelhagen. 2019. Self-supervised Face-Grouping on Graphs. In Proceedings of the 27th ACM International Conference on Multimedia. 247–256.
- Song et al. (2019) Yuqing Song, Shizhe Chen, Yida Zhao, and Qin Jin. 2019. Unpaired Cross-lingual Image Caption Generation with Self-Supervised Rewards. In Proceedings of the 27th ACM International Conference on Multimedia. 784–792.
- Srivastava et al. (2015) Nitish Srivastava, Elman Mansimov, and Ruslan Salakhudinov. 2015. Unsupervised learning of video representations using lstms. In International conference on machine learning. 843–852.
- Sun et al. (2019) Yu Sun, Eric Tzeng, Trevor Darrell, and Alexei A Efros. 2019. Unsupervised Domain Adaptation through Self-Supervision. arXiv preprint arXiv:1909.11825 (2019).
- Tulyakov et al. (2018) Sergey Tulyakov, Ming-Yu Liu, Xiaodong Yang, and Jan Kautz. 2018. Mocogan: Decomposing motion and content for video generation. In Proceedings of the IEEE conference on computer vision and pattern recognition. 1526–1535.
- Tung et al. (2017) Hsiao-Yu Tung, Hsiao-Wei Tung, Ersin Yumer, and Katerina Fragkiadaki. 2017. Self-supervised learning of motion capture. In Advances in Neural Information Processing Systems. 5236–5246.
- Wang and Zhou (2017) Wei Wang and Zhi-Hua Zhou. 2017. Theoretical foundation of co-training and disagreement-based algorithms. arXiv preprint arXiv:1708.04403 (2017).
- Wang et al. (2020) Yude Wang, Jie Zhang, Meina Kan, Shiguang Shan, and Xilin Chen. 2020. Self-supervised Equivariant Attention Mechanism for Weakly Supervised Semantic Segmentation. arXiv preprint arXiv:2004.04581 (2020).
- Wang et al. (2011) Zhe Wang, Songcan Chen, and Daqi Gao. 2011. A novel multi-view learning developed from single-view patterns. Pattern Recognition 44, 10-11 (2011), 2395–2413.
- Wang et al. (2007) Zhe Wang, Songcan Chen, and Tingkai Sun. 2007. MultiK-MHKS: a novel multiple kernel learning algorithm. IEEE Transactions on Pattern Analysis and Machine Intelligence 30, 2 (2007), 348–353.
- Wei et al. (2018) Donglai Wei, Joseph J Lim, Andrew Zisserman, and William T Freeman. 2018. Learning and using the arrow of time. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 8052–8060.
- Zhang et al. (2016) Richard Zhang, Phillip Isola, and Alexei A Efros. 2016. Colorful image colorization. In European conference on computer vision. Springer, 649–666.