A Multi-Strategy based Pre-Training Method for Cold-Start Recommendation
Abstract.
Cold-start issue is a fundamental challenge in Recommender System. The recent self-supervised learning (SSL) on Graph Neural Networks (GNNs) model, PT-GNN, pre-trains the GNN model to reconstruct the cold-start embeddings and has shown great potential for cold-start recommendation. However, due to the over-smoothing problem, PT-GNN can only capture up to 3-order relation, which can not provide much useful auxiliary information to depict the target cold-start user or item. Besides, the embedding reconstruction task only considers the intra-correlations within the subgraph of users and items, while ignoring the inter-correlations across different subgraphs. To solve the above challenges, we propose a multi-strategy based pre-training method for cold-start recommendation (MPT), which extends PT-GNN from the perspective of model architecture and pretext tasks to improve the cold-start recommendation performance111This paper is the extension of our previously published conference version (Hao et al., 2021).. Specifically, in terms of the model architecture, in addition to the short-range dependencies of users and items captured by the GNN encoder, we introduce a Transformer encoder to capture long-range dependencies. In terms of the pretext task, in addition to considering the intra-correlations of users and items by the embedding reconstruction task, we add embedding contrastive learning task to capture inter-correlations of users and items. We train the GNN and Transformer encoders on these pretext tasks under the meta-learning setting to simulate the real cold-start scenario, making the model easily and rapidly being adapted to new cold-start users and items. Experiments on three public recommendation datasets show the superiority of the proposed MPT model against the vanilla GNN models, the pre-training GNN model on user/item embedding inference and the recommendation task.
1. Introduction
As an intelligent system, Recommender System (RS) (He et al., 2017, 2020; Linden et al., 2003) has been built successfully in recent years, and aims to alleviate the information overload problem. The most popular algorithm in RS is collaborative filtering, which uses either matrix factorization (Linden et al., 2003) or neural collaborative filtering (He et al., 2017) to learn the user/item embeddings. However, due to the sparse interactions of the cold-start users/items, it is difficult to learn high-quality embeddings for these cold-start users/items.
To address the cold-start issue, researchers propose to incorporate the side information such as knowledge graphs (KGs) (Wang et al., 2019d, a) or the contents of users/items (Yin et al., 2014, 2017; Chen et al., 2020b) to enhance the representations of users/items. However, the contents are not always available, and it is not easy to link the items to the entities in KGs due to the incompleteness and ambiguities of the entities. Another research line is to adopt the Graph Neural Networks (GNNs) such as GraphSAGE (Hamilton et al., 2017), NGCF (Wang et al., 2019b) and LightGCN (He et al., 2020) to solve the problem. The basic idea is to incorporate the high-order neighbors to enhance the embeddings of the cold-start users/items. However, the GNN models for recommendation can not thoroughly solve the cold-start problem, as the embeddings of the cold-start users/items aren’t explicitly optimized, and the cold-start neighbors have not been considered in these GNNs.
In our previous work, we propose - (Hao et al., 2021), which pre-trains the GNN model to reconstruct the user/item embeddings under the meta-learning setting (Vinyals et al., 2016). To further reduce the impact from the cold-start neighbors, - incorporates a self-attention based meta aggregator to enhance the aggregation ability of each graph convolution step, and an adaptive neighbor sampler to select proper high-order neighbors according to the feedbacks from the GNN model.
However, - still suffers from the following challenges: 1) In terms of the model architecture, - suffers from lacking the ability to capture long-range dependencies. Existing researches such as Chen et al. (Chen and Wong, 2020) pointed out that GNN can only capture up to 3-hop neighbors due to the overfitting and over-smoothing problems (He et al., 2020). However, in the cold-start scenario, both low-order neighbors (, where is the convolution layer) and high-order neighbors () are important to the target cold-start user/item. On one hand, the low-order neighbors are crucial for representing the target cold-start users/items, as the first-order neighbors directly reflect the user’s preference or the item’s target audience, and the second-order neighbors directly reflect the signals of the collaborative users/items. On the other hand, due to the extremely sparse interactions of the cold-start users/items, the first- and second-order neighbors are insufficient to represent a user or an item. Thus, for the target users/items, it is crucial to capture not only the short-range dependencies from their low-order neighbors, but also the long-range dependencies from their high-order neighbors. Nevertheless, due to the limitation of the network structure, most of the existing GNN models can only capture the short-range dependencies, which inspires the first research question: how to capture both short- and long-range dependencies of users/items? 2) In terms of the pretext task, - only considers the intra-correlations within the subgraph of the target user or item, but ignores the inter-correlations between the subgraphs of different users or items. More concretely, given a target cold-start user or item, - samples its high-order neighbors to form a subgraph, and leverages the subgraph itself to reconstruct the cold-start embedding. Essentially, the embedding reconstruction task is a generative task, which focuses on exploring intra-correlations between nodes in a subgraph. On the contrary, some recent pre-training GNN models (e.g., GCC (Qiu et al., 2020), GraphCL (You et al., 2020)) depending on the contrastive learning mechanism, can capture the similarities of nodes between different subgraphs, i.e., the inter-correlations. Thus, this inspires the second research question: how to capture the inter-correlations of the target cold-start users/items in addition to the intra-correlations?

Present work. We propose a Multi-strategy based Pre-Training method for cold-start recommendation (), which extends - from the perspective of model architecture and pretext tasks to improve the cold-start recommendation performance. The improvements over - are shown in Fig. 1.
First, in terms of the model architecture, in addition to the original GNN encoder which captures the short-range dependencies from the user-item edges in the user-item graph, we introduce a Transformer encoder to capture the long-range dependencies from the user-item paths, which can be extracted by performing random walk (Perozzi et al., 2014) starting from the target user or item in the user-item graph. The multi-head self-attention mechanism in the Transformer attends nodes in different positions in a path (Vaswani et al., 2017), which can explicitly capture the long-range dependencies between users and items. Besides, we change the RL-based neighbor sampling strategy in the original GNN encoder into a simple yet effective dynamic sampling strategy, which can reduce the time complexity of the neighbor sampling process.
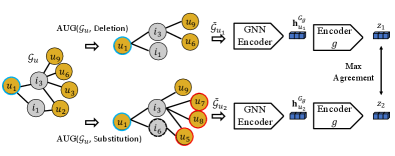
Second, in terms of the pretext task, in addition to the original embedding reconstruction task which considers the intra-correlations within the subgraph of the target user or item, we add embedding contrastive learning (Wu et al., 2018) task to capture the inter-correlations across the subgraphs or paths of different users or items. Specifically, we first augment a concerned subgraph or path by deleting or replacing the nodes in it. Then we treat the augmented subgraphs or paths of the concerned user or item as its positive counterparts, and those of other users or items as the negative counterparts. By contrastive learning upon the set of the positive and negative instances, we can pull the similar user or item embeddings together while pulling away dissimilar embeddings.
We train the GNN and Transformer encoders by the reconstruction and contrastive learning pretext tasks under the meta-learning setting (Vinyals et al., 2016) to simulate the cold-start scenario. Specifically, following -, we first pick the users/items with sufficient interactions as the target users/items, and learn their ground-truth embeddings on the observed abundant interactions. Then for each target user/item, in order to simulate the cold-start scenario, we mask other neighbors and only maintain first-order neighbors, based on which we form the user-item subgraph and use random walk (Perozzi et al., 2014) to generate the paths of the target user or item. Next we perform graph convolution multiple steps upon the user-item subgraph or self-attention mechanism upon the path to obtain the target user/item embeddings. Finally, we optimize the model parameters with the reconstruction and contrastive losses.
We adopt the pre-training & fine-tuning paradigm (Qiu et al., 2020) to train . During the pre-training stage, in order to capture the correlations of users and items from different views (i.e., the short- and long-range dependencies, the intra- and inter-correlations), we assign each pretext task an independent set of initialized embeddings, and train these tasks independently. During the fine-tuning state, we fuse the pre-trained embeddings from each pretext task and fine-tune the encoders by the downstream recommendation task. The contributions can be summarized as:
-
•
We extend - from the perspective of model architecture. In addition to the short-range dependencies of users and items captured by the GNN encoder, we add a Transformer encoder to capture long-range dependencies.
-
•
We extend - from the perspective of pretext tasks. In addition to considering the intra-correlations of users and items by the embedding reconstruction task, we add embedding contrastive learning task to capture inter-correlations of users and items.
-
•
Experiments on both intrinsic embedding evaluation and extrinsic downstream tasks demonstrate the superiority of our proposed model against the state-of-the-art GNN model and the original proposed -.
2. Preliminaries
In this section, we first define the problem and then introduce the original proposed - .
2.1. Notation and Problem Definition
Bipartite Graph. We denote the user-item bipartite graph as , where is the set of users and is the set of items. denotes the set of edges that connect the users and items. Notation denotes the -order neighbors of user . When ignoring the superscript, denotes the first-order neighbors of . and are defined similarly for items.
User-Item Path. The user-item path is generated by the random walk strategy from the user-item interaction data, and has the same node distribution with the graph , as Perozzi et al. (Perozzi et al., 2014) proposed. Formally, there exists two types of paths: = or = , where denotes the node type is user and denotes the node type is item.
Problem Definition. Let be the encoding function that maps the users or items to -dimension real-valued vectors. We denote a user and an item with initial embeddings and , respectively. Given the bipartite graph or the path , we aim to pre-train the encoding function that is able to be applied to the downstream recommendation task to improve its performance. Note that for simplicity, in the following sections, we mainly take user embedding as an example to explain the proposed model, as item embedding can be explained in the same way.
2.2. A Brief Review of PT-GNN
The basic idea of - is to leverage the vanilla GNN model as the encoder to reconstruct the target cold-start embeddings to explicitly improve their embedding quality. To further reduce the impact from the cold-start neighbors, - incorporates a self-attention based meta aggregator to enhance the aggregation ability of each graph convolution step, and an adaptive neighbor sampler to select proper high-order neighbors according to the feedbacks from the GNN model.
2.2.1. Basic Pre-training GNN Model
The basic pre-training GNN model reconstructs the cold-start embeddings under the meta-learning setting (Vinyals et al., 2016) to simulate the cold-start scenario. Specifically, for each target user , we mask some neighbors and only maintains at most neighbors ( is empirically selected as a small number, e.g., =3) at the -th layer. Based on which we perform graph convolution multiple steps to predict the target user embedding. Take GraphSAGE (Hamilton et al., 2017) as the backbone GNN model as an example, the graph convolution process at the -th layer is:
| (1) |
where is the refined user embedding at the -th convolution step, is the previous user embedding ( is the initialized embedding). is the averaged embedding of the neighbors, in which the neighbors are sampled by the random sampling strategy. is the sigmoid function, is the parameter matrix, and is the concatenate operation.
We perform graph convolution -1 steps, aggregate the refined embeddings of the first-order neighbors to obtain the smoothed embedding , and transform it into the target embedding , i.e., , . Then we calculate the cosine similarity between the predicted embedding and the ground-truth embedding to optimize the parameters of the GNN model:
| (2) |
where the ground-truth embedding is learned by any recommender algorithms (e.g., NCF (He et al., 2017), LightGCN (He et al., 2020)222They are good enough to learn high-quality user/item embeddings from the abundant interactions, and we will discuss it in Section 5.3.1), is the model parameters. Similarly, we can obtain the item embedding and optimize model parameters by (Eq. (2)).
2.2.2. Enhanced Pre-training Model: PT-GNN
The basic pre-training strategy has two problems. On one hand, it can not explicitly deal with the high-order cold-start neighbors during the graph convolution process. On the other hand, the GNN sampling strategies such as random sampling (Hamilton et al., 2017) or importance sampling (Chen et al., 2018) strategies may fail to sample high-order relevant cold-start neighbors due to their sparse interactions.
To solve the first challenge, we incorporate a meta aggregator to enhance the aggregation ability of each graph convolution step. Specifically, the meta aggregator uses self-attention mechanism (Vaswani et al., 2017) to encode the initial embeddings of the first-order neighbors for as input, and outputs the meta embedding for . The process is:
| (3) |
We use the same cosine similarity described in Eq. (2) to measure the similarity between the predicted meta embedding and the ground truth embedding .
To solve the second challenge, we propose an adaptive neighbor sampler to select proper high-order neighbors according to the feedbacks from the GNN model. The adaptive neighbor sampler is formalized as a hierarchical Markov Sequential Decision Process, which sequentially samples from the low-order neighbors to the high-order neighbors and results in at most neighbors in the -th layer for each target user . After sampling the neighbors of the former layers, the GNN model accepts the sampled neighbors to produce the reward, which denotes whether the sampled neighbors are reasonable or not. Through maximizing the expected reward from the GNN model, the adaptive neighbor sampler can sample proper high-order neighbors. Once the meta aggregator and the adaptive neighbor sampler are trained, the meta embedding and the averaged sampled neighbor embedding at the -th layer are added into each graph convolution step in Eq. (1):
| (4) |
For the target user , Eq. (4) is repeated steps to obtain the embeddings for its first-order neighbors, then the predicted embedding is obtained by averaging the first-order embeddings. Finally, Eq. (2) is used to optimize the parameters of the pre-training GNN model. The pre-training parameter set , where is the parameters of the vanilla GNN, is the parameters of the meta aggregator and is the parameters of the neighbor sampler. The item embedding can be obtained in a similar way.
2.2.3. Downstream Recommendation Task
We fine-tune - in the downstream recommendation task. Specifically, for each target user and his neighbors of different order, we first use the pre-trained adaptive neighbor sampler to sample proper high-order neighbors , and then use the pre-trained meta aggregator to produce the user embedding . The item embedding can be obtained in the same way. Then we transform the embeddings to calculate the relevance score between a user and an item, i.e., with parameters . Finally, we adopt the BPR loss (He et al., 2020) to optimize and fine-tune :
| (5) |
However, as shown in Fig. 1, due to the limitation of the GNN model, - can only capture the short-range dependencies of users and items; besides, the embedding reconstruction task only focuses on exploring the intra-correlations within the subgraph of the target user or item. Therefore, it is necessary to fully capture both short- and long-range dependencies of users and items, and both intra- and inter-correlations of users or items.



3. The Proposed Model MPT
We propose a novel Multi-strategy based Pre-Training method (), which extends - from the perspective of model architecture and pretext tasks. Specifically, in terms of the model architecture, in addition to using the GNN encoder to capture the short-range dependencies of users and items, we introduce a Transformer encoder to capture long-range dependencies. In terms of the pretext task, in addition to considering the intra-correlations of users and items by the embedding reconstruction task, we add embedding contrastive learning task to capture inter-correlations of users and items. Hence, by combining each architecture and each pretext task, there are four different implementations of pretext tasks, as shown in Fig. 2. We detail each pretext task implementation in Section 3.1 - Section 3.4, and then present the overall model training process in Section 3.5. Finally, we analyze the time complexity of the pretext task implementation in Section 3.6.
3.1. Reconstruction with GNN Encoder
In this pretext task, we primarily follow the original PT-GNN model to reconstruct the user embedding, as proposed in Section 2.2. We modify PT-GNN in terms of its neighbor sampling strategy to reduce the time complexity.
The adaptive neighbor sampling strategy in - suffers from the slow convergence issue, as it is essentially a Monte-Carlo based policy gradient strategy (REINFORCE) (Sutton et al., 1999; Williams, 1992), and has the complex action-state trajectories for the entire neighbor sampling process. To solve this problem, inspired by the dynamic sampling theory that uses the current model itself to sample instances (Burges, 2010; Zhang et al., 2013), we propose the dynamic sampling strategy, which samples from the low-order neighbors to the high-order neighbors according to the enhanced embeddings of the target user and each neighbor. The enhanced embedding for the target user (or each neighbor) is obtained by concatenating the meta embedding produced by the meta aggregator in PT-GNN (Section 2.2.2) and the current trained embedding. The meta embedding enables considering the cold-start characteristics of the neighbors, and the current trained embedding enables dynamically selecting proper neighbors. Formally, at the -th layer, the sampling process is:
| (6) | |||||
where is the concatenate operation, is the cosine similarity between the enhanced target user embedding and the enhanced -th neighbor embedding , and are the meta embeddings produced by the meta aggregator, and are the current trained user embedding, is the top relevant neighbors. is the operation that selects top neighbor embeddings with top cosine similarity. Compared with the adaptive sampling strategy in -, the proposed dynamic sampling strategy not only speeds up the model convergence, but also has competitive performance. As it does not need multiple sampling process, and considers the cold-start characteristics of the neighbors during the sampling process. Notably, the training process of the dynamic sampling strategy is not a fully end-to-end fashion. In each training epoch, we first select relevant neighbors as the sampled neighbors for each target node according to Eq. (6), and then we can obtain the adjacency matrix of the user-item graph. Next, we perform the graph convolution operation to reconstruct the target node embedding to optimize the model parameters. Finally, the updated current node embedding, together with the fixed meta node embedding produced by the meta aggregator are used in the next training epoch, which enables dynamically sampling proper neighbors.
Once the neighbors are sampled, at the -th layer, we use the meta embedding , the previous user embedding and the averaged dynamically sampled neighbor embedding to perform graph convolution, as shown in Eq. (4). Then we perform graph convolution steps to obtain the predicted user embedding , and use Eq. (2) to optimize the model parameters. Fig. 2(a) shows this task, and the objective function is as follows:
| (7) |
3.2. Contrastive Learning with GNN Encoder
In this pretext task, we propose to contrast the user embedding produced by the GNN encoder across subgraphs, as shown in Fig. 2(b). Similar as -, we also train this task under the meta-learning setting to simulate the cold-start scenario. Specifically, we also select users with abundant interactions, randomly select at most () neighbors at layer to form the subgraph . Then we perform contrastive learning (CL) upon to learn the representations of users. In the following part, we first present the four components in the CL framework and then detail the key component, i.e., the data augmentation operation.
-
•
An augmentation module augments the user subgraph by deleting or replacing the users or items in it, which results in two random augmentations = and = , where and are two random seeds. In this paper, we evaluate the individual data augmentation operation, i.e., performing either deletion or substitution operation. We leave the compositional data augmentation operation as the future work.
-
•
A GNN encoder performs the graph convolution steps using Eq. (4) to generate the representation of the target user for each augmented subgraph. i.e., and .
-
•
A neural network encoder maps the encoded augmentations and into two vectors , . This operation is the same with SimCLR (Chen et al., 2020a), as its observation that adding a nonlinear projection head can significantly improve the representation quality.
-
•
A contrastive learning loss module maximizes the agreement between positive augmentation pair in the set . We construct the set by randomly augmenting twice for all users in a mini-batch (assuming is with size ), which gets a set with size . The two variants from the same original user form the positive pair, while all the other instances from the same mini-batch are regarded as negative samples for them. Then the contrastive loss for a positive pair is defined as:
(8) where is the indicator function to judge whether , is a temperature parameter, and denotes the cosine similarity of two vector and . The overall contrastive loss defined in a mini-batch is:
(9) where is a indicator function returns 1 when and is a positive pair, returns 0 otherwise, is the parameters of the CL framework.
The key method in CL is the data augmentation strategy. In recommender system, since each neighbor may play an essential role in expressing the user profile, it remains unknown whether data augmentation would benefit the representation learning and what kind of data augmentation could be useful. To answer these questions, we explore and test two basic augmentations, deletion and substitution. We believe there exist more potential augmentations, which we will leave for future exploration.
-
•
Deletion. At each layer , we random select % users or items and delete them. If a parent user or item is deleted, its child users or items are all deleted.
-
•
Substitution. At each layer , we randomly select % users or items. For each user or item in the selected list, we randomly replace or with one of its parent’s interacted first-order neighbors. Note that in order to illustrate the two data augmentation strategies, we present the deletion and substitution operations in Fig. 2(b), but in practice we perform individual data augmentation strategy, i.e., performing either deletion or substitution operation, and analyze whether the substitution or deletion ratio used for the target user (or target item) can affect the recommendation performance in Section 5.3.3.
Once the CL framework is trained, we leave out other parts and only maintain the parameters of the trained GNN encoder. When a new cold-start user comes in, same as Section 3.1, the GNN encoder performs graph convolution steps to obtain the enhanced embedding .
3.3. Reconstruction with Transformer Encoder
In this pretext task, we propose using Transformer encoder to reconstruct the embeddings of target users in the user-item path, as shown in Fig. 2(c). This pretext task is also trained under the meta-learning setting. Specifically, similar to -, we first choose abundant users and use any recommender algorithms to learn their ground-truth embeddings. Then for each user, we sample () neighbors, based on which, we use random walk (Perozzi et al., 2014) to obtain the user-item path = (or = ) with path length . Finally, we mask the target user in the input path with special tokens “[mask]”, and use Transformer encoder to predict the target user embedding.
Formally, given an original path =, where each node in represents the initial user embedding or the initial item embedding . We first construct a corrupted path by replacing the target user token in to a special symbol ”[mask]” (suppose the target user is at the -th position in ). Then we use Transformer encoder to map the input path into a sequence of hidden vectors . Finally, we fetch the -th embedding in to predict the ground-truth embedding, and use cosine similarity to optimize the parameters of the Transformer encoder. For simplicity, we use notation to represent the -th predicted embedding, i.e., = . The objective function is:
| (10) |
Once the Transformer encoder is trained, we can use it to predict the cold-start embedding. When a new cold-start user with his interacted neighbors comes in, we first use random walk to generate the path set , where in the -th path , is in the -th position. Then we replace with the ”[mask]” signal to generate the corrupted path . Next we feed all the corrupted paths into the Transformer encoder, obtain the predicted user embeddings . Finally, we average these predicted embeddings to obtain the final user embedding .
3.4. Contrastive Learning with Transformer Encoder
In this task, we propose to contrast the user embedding produced by the Transformer encoder across different paths, as shown in Fig. 2(d). We train this task under the meta-learning setting. Same as Section 3.3, we choose abundant users, sample () order neighbors, and use random walk to obtain the path . Then we perform the CL framework to learn the cold-start user embedding:
-
•
An augmentation module augments the path = by randomly deleting or replacing the users or items in it, i.e., = and = . Similar to Section 3.2, we evaluate the individual data augmentation operation.
-
•
A Transformer encoder accepts , as input, and encodes the target user from two augmented paths into latent vectors, i.e., = and = .
-
•
A neural network encoder that maps the encoded augmentations and into two vectors = , = .
-
•
A contrastive learning loss module maximizes the agreement between positive augmentation pair in the set . Same as Section 3.2, we also construct the set by randomly augmenting twice for all users in a mini-batch to get a set with size , use the two variants from the same original user as positive pair, use all the other instances from the same mini-batch as negative samples, and use Eq. (8) as the contrastive loss for a positive pair. Similar to Eq. (9), the overall contrastive loss defined in a mini-batch is:
(11) where is the parameters of the CL framework.
The data augmentation strategies are as follows:
-
•
Deletion. For each path , we random select % users and items and delete them.
-
•
Substitution. For each path , we randomly select % users and items. For each user or item in the selected list, we randomly replace or with one of its parent’s interacted first-order neighbors. Note that in order to illustrate the two data augmentation strategies, we present the deletion and substitution operations in Fig. 2(d), but in practice we perform individual data augmentation strategy, i.e., performing either deletion or substitution operation, and analyze whether the substitution or deletion ratio used for the target user (or target item) can affect the recommendation performance in Section 5.3.3. Note that we perform individual data augmentation strategy, i.e., performing either deletion or substitution operation, and analyze whether the substitution or deletion ratio used for the target user (or target item) can affect the recommendation performance in Section 5.3.3.
Once the CL framework is trained, we leave out other parts and only maintain the parameters of the Transformer encoder. When a new cold-start user with his interacted neighbors comes in, same as Section 3.3, we generate the path set , use Transformer encoder to obtain the encoded embeddings , and average these embeddings to obtain the final embedding .
3.5. Model Pre-training & Fine-tuning Process
We adopt the pre-training and fine-tuning paradigm (Qiu et al., 2020) to train the GNN and Transformer encoders.
During the pre-training stage, we independently train each pretext task using the objective functions Eq. (7), Eq. (9), Eq. (10) and Eq. (11) to optimize the parameters . We assign each pretext task an independent set of initialized user and item embeddings, and do not share embeddings for these pretext tasks. Therefore, we can train these pretext tasks in a fully parallel way.
During the fine-tuning process, we initialize the GNN and Transformer encoders with the trained parameters, and fine-tune them via the downstream recommendation task. Specifically, for each target cold-start user and his interacted neighbors of each order, we first use the trained GNN and Transformer encoders corresponding to each pretext task to generate the user embedding , , and . Then we concatenate the generated embeddings and transform them into the final user embedding:
| (12) |
where is the parameter matrix. We generate the final item embedding in a similar way. Next we calculate the relevance score as the inner product of user and item final embeddings, i.e., . Finally, we use BPR loss defined in Eq. (5) to optimize and fine-tune .
3.6. Discussions
As we can see, the GNN and Transformer encoders are the main components of the pretext tasks. For the GNN encoder, the time complexity is , where represents the time complexity of the layer-wise propagation of the GNN model, and represents the time complexity of the sampling strategy. Since different GNN model has different time complexity , we select classic GNN models and show their . LightGCN (He et al., 2020): , NGCF (Wang et al., 2019b): , GCMC (van den Berg et al., 2018):, GraphSAGE (Hamilton et al., 2017): , where denotes the number of nonzero entries in the Laplacian matrix, is the number of totally sampled instances and is the embedding size. We present the time complexity of dynamic sampling strategy = and the adaptive sampling strategy = , where is the number of convergent epochs, is the sampling times. Compared with adaptive sampling strategy, the dynamic strategy does not need multiple sampling time , and has fewer convergent epochs , thus has smaller time complexity. For the Transformer encoder, the time complexity is , where is the length of the user-item path.
4. Experiments
Following PT-GNN (Hao et al., 2021), we conduct intrinsic evaluation task to evaluate the quality of user/item embeddings, and extrinsic task to evaluate the cold-start recommendation performance. We answer the following research questions:
-
•
RQ1: How does perform embedding inference and cold-start recommendation compared with the state-of-the-art GNN and pre-training GNN models?
-
•
RQ2: What are the benefits of performing pretext tasks in both intrinsic and extrinsic evaluation?
-
•
RQ3: How do different settings influence the effectiveness of the proposed model?
4.1. Experimental Settings
4.1.1. Datasets
We select on three public datasets MovieLens-1M (Ml-1M)333https://grouplens.org/datasets/movielens/ (Harper and Konstan, 2016), MOOCs444http://moocdata.cn/data/course-recommendation (Zhang et al., 2019) and Gowalla555https://snap.stanford.edu/data/loc-gowalla.html (Liang et al., 2016). Table 1 illustrates the statistics of these datasets.
| Dataset | #Users | #Items | #Interactions | #Sparse Ratio |
|---|---|---|---|---|
| MovieLens-1M | 6,040 | 3,706 | 1,000,209 | 4.47% |
| MOOCs | 82,535 | 1,302 | 458,453 | 0.42% |
| Gowalla | 29,858 | 40,981 | 1,027,370 | 0.08% |
4.1.2. Comparison Methods
We select three types of baselines, including the neural collaborative filtering model, the GNN models and the self-supervised graph learning models.
-
•
NCF (He et al., 2017): is a neural collaborative filtering model which uses multi-layer perceptron and matrix factorization to learn the representations of users/items.
- •
- •
- •
-
•
LightGCN (He et al., 2020): discards the feature transformation and nonlinear activation functions in NGCF.
-
•
SGL (Wu et al., 2021): contrasts the node representation within the graphs from multiple views, where node dropout, edge dropout and random walk are adopted to generate these views. We find edge dropout has the best performance.
-
•
PT-GNN (Hao et al., 2021): takes the embedding reconstruction as the pretext task to explicitly improve the embedding quality.
For each vanilla GNN model (e.g., GCMC, NGCF), notation means we apply GNN in -, and notation means we apply GNN in . Since SGL adopts multi-task learning paradigm for recommendation, for fair comparison, we compare it in the extrinsic recommendation task and use notation - to denote it.
4.1.3. Intrinsic and Extrinsic Settings.
Following - (Hao et al., 2021), we divide each dataset into the meta-training set and the meta-test set . We train and evaluate the proposed model in the intrinsic user/item embedding inference task on . Once the the proposed model is trained, we fine-tune it in the extrinsic task and evaluate its performance on . We select the users/items from each dataset with sufficient interactions as the target users/items in , as the intrinsic evaluation needs the ground-truth embeddings of users/items inferred from the sufficient interactions. In the cold-start user scenario, we divide the users with the number of the direct interacted items (first-order neighbors) more than into and leave the rest users into . We set as 25, 10 and 25 for the dataset Ml-1M, MOOCs and Gowalla, respectively. Similarly, in the cold-start item scenario, we divide the items with the number of the direct interacted users (first-order neighbors) more than into and leave the rest items into , where we set as 15, 10 and 15 for Ml-1M, MOOCs and Gowalla, respectively. We set as 3 and 8 in the intrinsic task, and 8 in the extrinsic task. By default, we set as 32, the learning rate as 0.003, as 4, as 6, as 0.2, as 0.2 and as 0.2.
4.1.4. Intrinsic Evaluations: Embedding Inference
We conduct the intrinsic evaluation task, which aims to infer the embeddings of cold-start users and items by the proposed model. Both the evaluations on user embedding inference and item embedding inference are performed.
Training and Test Settings. Following - (Hao et al., 2021), we perform intrinsic evaluation on . Specifically, same as -, we train NCF (He et al., 2017) to get the ground-truth embeddings for the target users/items in . We also explore whether is sensitive to the ground-truth embedding generated by other models such as LightGCN (He et al., 2020). We randomly split into the training set and the test set with a ratio of 7:3. To mimic the cold-start users/items on , we randomly keep neighbors for each user/item, which results in at most neighbors () for each target user/item. Thus is changed into .
We train NCF transductively on the merged dataset and . We train the vanilla GNN models by BPR loss (He et al., 2020) on . We train - on , where we first perform Eq. (4) -1 steps to obtain the refined first-order neighbors, and then average them to reconstruct the target embedding; finally we use Eq. (2) to measure the quality of the predicted embedding. We train on , where we first perform four pretext tasks by Eq. (7), Eq. (9), Eq. (10) and Eq. (11), and then use Eq. (12) to fuse the generated embeddings; finally we use Eq. (2) to measure the quality of the fused embedding. Note that the embeddings in all the models are randomly initialized. We use cosine similarity to measure the agreement between the ground-truth and predicted embeddings, due to its popularity as an indicator for the semantic similarity between embeddings.
| Methods | Ml-1M (user) | MOOCs (user) | Gowalla(user) | Ml-1M (item) | MOOCs (item) | Gowalla(item) | ||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 3-shot | 8-shot | 3-shot | 8-shot | 3-shot | 8-shot | 3-shot | 8-shot | 3-shot | 8-shot | 3-shot | 8-shot | |
| 0.490 | 0.533 | 0.451 | 0.469 | 0.521 | 0.558 | 0.436 | 0.496 | 0.482 | 0.513 | 0.482 | 0.491 | |
| 0.518 | 0.557 | 0.542 | 0.564 | 0.552 | 0.567 | 0.558 | 0.573 | 0.558 | 0.591 | 0.556 | 0.599 | |
| 0.659 | 0.689 | 0.651 | 0.669 | 0.663 | 0.692 | 0.734 | 0.745 | 0.658 | 0.668 | 0.668 | 0.676 | |
| 0.690 | 0.698 | 0.668 | 0.673 | 0.687 | 0.695 | 0.741 | 0.748 | 0.661 | 0.669 | 0.673 | 0.683 | |
| 0.513 | 0.534 | 0.546 | 0.569 | 0.546 | 0.562 | 0.559 | 0.566 | 0.554 | 0.558 | 0.553 | 0.557 | |
| 0.600 | 0.625 | 0.750 | 0.765 | 0.716 | 0.734 | 0.725 | 0.733 | 0.607 | 0.615 | 0.650 | 0.667 | |
| 0.629 | 0.632 | 0.782 | 0.790 | 0.741 | 0.748 | 0.744 | 0.764 | 0.608 | 0.616 | 0.675 | 0.681 | |
| 0.534 | 0.554 | 0.531 | 0.547 | 0.541 | 0.557 | 0.511 | 0.516 | 0.503 | 0.509 | 0.503 | 0.506 | |
| 0.591 | 0.618 | 0.541 | 0.573 | 0.552 | 0.574 | 0.584 | 0.596 | 0.549 | 0.560 | 0.576 | 0.591 | |
| 0.645 | 0.650 | 0.598 | 0.601 | 0.582 | 0.589 | 0.609 | 0.613 | 0.606 | 0.611 | 0.590 | 0.594 | |
| 0.549 | 0.569 | 0.530 | 0.534 | 0.581 | 0.592 | 0.600 | 0.631 | 0.590 | 0.616 | 0.606 | 0.622 | |
| 0.636 | 0.644 | 0.646 | 0.654 | 0.614 | 0.617 | 0.691 | 0.701 | 0.667 | 0.676 | 0.693 | 0.701 | |
| 0.641 | 0.647 | 0.652 | 0.657 | 0.695 | 0.700 | 0.699 | 0.704 | 0.669 | 0.691 | 0.768 | 0.774 | |
4.1.5. Extrinsic Evaluation: Recommendation
We apply the pre-training GNN model into the downstream recommendation task and evaluate its performance.
Training and Testing Settings. We consider the scenario of the cold-start users and use the meta-test set to perform recommendation. For each user in , we select top % (%=0.2 by default) of his interacted items in chronological order into the training set , and leave the rest items into the test set . We pre-train our model on and fine-tune it on according to Section 3.5.
The vanilla GNN and the NCF models are trained by the BPR loss on and . For each user in , we calculate his relevance score to each of the rest 1-% items. We adopt Recall@ and NDCG@ as the metrics to evaluate the items ranked by the relevance scores. By default, we set as 20 for Ml-1M, MOOCs and Gowalla.
5. Experimental Results
5.1. Performance Comparison (RQ1)
5.1.1. Overall Performance Comparison
We report the overall performance of intrinsic embedding inference and extrinsic recommendation tasks in Table 2 and Table 3. We find that:
-
•
(denoted as ) is better than NCF and the vanilla GNN model, which indicates the effectiveness of the pre-training strategy. Compared with the pre-training model - (denoted as ) and SGL (denoted as -), also performs better than them. This indicates the superiority of simultaneously considering the intra- and inter- correlations of nodes as well as the short- and long-range dependencies of nodes.
-
•
In Table 2, when decreases from 8 to 3, the performance of all the baseline methods drops by a large scale, while drops a little. This indicates is able to learn high-quality embeddings for users or items that have extremely sparse interactions.
-
•
In the intrinsic task (Cf. Table 2), we notice that most models perform generally better on the item embedding inference task than the user embedding inference task. The reason is that the users in have more interacted neighbors than the items in , thus the learned ground-truth user embedding shows much more diversity than the learned ground-truth item embedding, and only use (K is small) neighbors to learn the user embedding is more difficult than learning the item embedding. To validate our point of view, we calculate the average number of interacted neighbors of users and items in among these three datasets. In ML-1M, MOOCs and Gowalla, when the layer size , the users interact with an average of 178.26, 134.90 and 178.27 items, while the items interact with an average of 32.14, 15.75 and 32.14 users. When the layer size gets larger, the interacted neighbors’ number of users and items show the same trend. The results indicate the abundant users have much more interacted neighbors than the abundant items, which verifies the above analysis.
-
•
Aligning Table 2 and Table 3, we notice that using GCMC, LigtGCN as the backbone GNN model can always obtain better performance than using PinSage and NGCF. The possible reason is that compared with PinSage and NGCF, GCMC and LightGCN have discarded the complex feature transformation operation, which will contribute to learn high-quality embeddings and better recommendation performance. This phenomena is consistent with LightGCN’s (He et al., 2020) findings.
| Methods | Ml-1M | MOOCs | Gowalla | |||
|---|---|---|---|---|---|---|
| Recall | NDCG | Recall | NDCG | Recall | NDCG | |
| 0.004 | 0.009 | 0.132 | 0.087 | 0.039 | 0.013 | |
| 0.006 | 0.012 | 0.085 | 0.066 | 0.003 | 0.011 | |
| - | 0.040 | 0.033 | 0.172 | 0.086 | 0.011 | 0.021 |
| 0.047 | 0.038 | 0.150 | 0.089 | 0.008 | 0.019 | |
| 0.054 | 0.036 | 0.182 | 0.099 | 0.045 | 0.021 | |
| 0.008 | 0.006 | 0.232 | 0.172 | 0.006 | 0.033 | |
| - | 0.038 | 0.037 | 0.239 | 0.177 | 0.033 | 0.035 |
| 0.044 | 0.041 | 0.248 | 0.187 | 0.018 | 0.032 | |
| 0.071 | 0.076 | 0.272 | 0.212 | 0.065 | 0.043 | |
| 0.052 | 0.058 | 0.208 | 0.171 | 0.009 | 0.013 | |
| - | 0.062 | 0.079 | 0.216 | 0.177 | 0.028 | 0.014 |
| 0.064 | 0.071 | 0.217 | 0.181 | 0.037 | 0.014 | |
| 0.083 | 0.077 | 0.241 | 0.208 | 0.047 | 0.016 | |
| 0.058 | 0.064 | 0.217 | 0.169 | 0.011 | 0.023 | |
| - | 0.066 | 0.077 | 0.275 | 0.178 | 0.034 | 0.028 |
| 0.078 | 0.071 | 0.308 | 0.184 | 0.049 | 0.031 | |
| 0.094 | 0.101 | 0.346 | 0.223 | 0.051 | 0.036 | |

5.1.2. Interacted Number and Sparse Rate Analysis
It is still unclear how does handle the cold-start users with different interacted items and sparse rate %. To this end, we change the interaction number in the range of and the sparse rate % in the range of , select LightGCN as the backbone GNN model and report the cold-start recommendation performance on MOOCs dataset in Fig. 3. The smaller and % are, the cold-start users in have fewer interactions. We find that:
-
•
(denoted as ) is consistently superior to all the other baselines, which justifies the superiority of in handling cold-start recommendation with different and %.
-
•
When decreases from 15 to 5, has a larger improvement compared with other baselines, which verifies its capability to solve the cold-start users with extremely sparse interactions.
-
•
When % decreases from 60% to 20%, has a larger improvement compared with other baselines, which again verifies the superiority of in handling cold-start users with different sparse rate.
5.2. Ablation Study (RQ2)


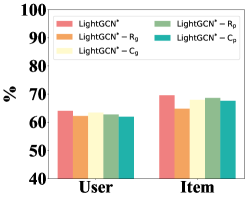



5.2.1. Impact of Pretext Tasks
It is still not clear which part of the pretext tasks is responsible for the good performance in . To answer this question, we apply LightGCN in , perform individual or compositional pretext tasks, report the performance of intrinsic and extrinsic task in Fig. 4, where notation , , and denote the pretext task of reconstruction with GNN (only use the objective function Eq. (7)), contrastive learning with GNN (only use the objective function Eq. (9)), reconstruction with Transformer (only use the objective function Eq. (10)) and contrastive learning with Transformer (only use the objective function Eq. (11)), respectively; notation - means we only discard reconstruction task with GNN encoder and use the other three pretext tasks (use the objective functions Eq. (9), Eq. (10) and Eq. (11)) as the variant model. Other variant models are named in a similar way. Aligning Table 2 with Fig. 4, we find that:
-
•
Combining all the pretext tasks can benefit both embedding quality and recommendation performance. This indicates simultaneously consider intra- and inter-correlations of users and items can benefit cold-start representation learning and recommendation.
-
•
Compared with other variant models, performing the contrastive learning task with the GNN or Transformer encoder independently, or performing the contrastive learning task with both the GNN and Transformer encoder leads poor performance in the intrinsic task, but has satisfactory performance in the recommendation task. The reason is that contrastive learning does not focus on predicting the target embedding, but can capture the inter-correlations of users or items, and thus can benefit the recommendation task.




| Dataset | Ml-1M | MOOCs | |||
|---|---|---|---|---|---|
| Method | Avg. Sampling Time | Avg. Training Time | Avg. Sampling Time | Avg. Training Time | |
| 0.56s | 201.02s | 2.78s | 237.63s | ||
| 6.56s | 204.64s | 2.86s | 240.12s | ||
| 134.64s | 205.13s | 160.37s | 241.75s | ||
| 8.93s | 205.76s | 3.20s | 240.67s | ||
5.2.2. Impact of the Sampling Strategy
We study the effect of the proposed dynamic sampling strategy. In this paper, we compare four variants of the LightGCN model: that adaptively samples neighbors (Hao et al., 2021), that samples neighbors according to the importance sampling strategy (Chen et al., 2018), that randomly samples neighbors (Hamilton et al., 2017) and that dynamically samples neighbors. Notably, for fair comparison, for each target node, at the -th layer, the number of the sampled neighbors are at most . We report the average sampling time and the average training time per epoch (the average training time includes the training time of all the four pretext tasks, but does not include the neighbor sampling time) for these sampling strategies on MOOCs and Ml-1M in Table 4, and report the recommendation performance on MOOCs and Ml-1M in Fig. 5. We find that:
-
•
The sampling time of the proposed dynamic sampling strategy is in the same magnitude with the importance sampling strategy and the random sampling strategy, which is totally acceptable. While the adaptive sampling strategy takes too much sampling time, since it adopts a Monte-Carlo based policy gradient strategy, and has the complex action-state trajectories for the entire neighbor sampling process. Besides, we report the average training time in each epoch and find that the training time of all the variant models is almost the same, since each variant model performs the same pretext tasks., i.e., the graph convolution operation in the GNN encoder and self-attention operation in the Transformer encoder. By aligning Table 4 and Fig. 5, we find that has a quick convergence speed.
-
•
Although the adaptive sampling strategy has competitive performance than the random and importance sampling strategies, it has slow convergence speed due to the complex RL-based sampling process.
-
•
Compared with the other sampling strategies, the proposed dynamic sampling strategy not only has the best performance, but also has quick convergence speed.
5.3. Study of MPT (RQ3)
5.3.1. Effect of Ground-truth Embedding
As mentioned in Section 2, when performing embedding reconstruction with GNN and Transformer encoders, we choose NCF to learn the ground-truth embeddings. However, one may consider whether ’s performance is sensitive to the ground-truth embedding. To this end, we use the baseline GNN models to learn the ground-truth embeddings, and only perform embedding reconstruction task with LightGCN or Transformer. For NCF, we concatenate embeddings produced by both the MLP and GMF modules as ground-truth embeddings. While for PinSage, GCMC, NGCF and LightGCN, we combine the embeddings obtained at each layer to form the ground-truth matrix, i.e., + + , where is the concatenated user-item embedding matrix at -th convolution step. Fig. 6(a) and Fig. 6(b) shows the recommendation performance using LightGCN and Transformer encoder, respectively. Suffix +, +, +, + and + denote that the ground-truth embeddings are obtained by NCF, LightGCN, GCMC, PinSage and NGCF, respectively. We find that:
-
•
All the models that equipped with different ground-truth embeddings achieve almost the same performance. This indicates our model is not sensitive to the ground-truth embeddings, as the NCF and vanilla GNN models are good enough to learn high-quality user or item embeddings from the abundant interactions.
-
•
Besides, when LightGCN is used to obtain the ground-truth embeddings (denoted as + and +), we can obtain marginal performance gain compared with other variant models.




5.3.2. Effect of Data Augmentation
To understand the effects of individual or compositional data augmentations in the contrastive learning (CL) task using GNNs or Transformer encoder, we investigate the performance of CL pretext tasks in when applying augmentations individually or in pairs. We report the performance in Fig. 7. Notation , and mean we apply LightGCN into the CL task and use deletion, substitution and their combinations, respectively; Notation , and denote we use Transformer encoder into the CL task and use deletion, substitution and their combinations, respectively. We find that:
-
•
Composing augmentations can lead to better recommendation performance than performing individual data augmentation.
- •






5.3.3. Effect of Hyperparameters
We move on to study different designs of the layer depth , the deletion ratio %, the substitution ratio % and the user-item path length in . Due to the space limitation, we omit the results on MOOCs and Gowalla which have a similar trend to Ml-1M.
-
•
We only perform embedding reconstruction with GNNs in , and report the results in Fig. 8. We find that the performance first increases and then drops when increasing from 1 to 4. The peak point is 3 at most cases. This indicates GNN can only capture short-range dependencies, which is consistent with LightGCN’s (He et al., 2020) finding.
-
•
We only perform embedding reconstruction with Transformer encoder in , and report the results in Fig. 9. We find that the performance first improves when the path length increases from 3 to 8, and then drops from 8 to 10. This indicates Transformer encoder is good at capturing long-range rather than short-range dependencies of nodes.
-
•
We perform contrastive learning with LightGCN and contrastive learning with Transformer encoder under different deletion ratio % and substitution % independently, and report the recommendation results in Fig 10. Based on the results, we find that the recommendation performance is not sensitive to the substitution ratio % but is a little bit sensitive to the deletion ratio %. In terms of the deletion ratio %, the recommendation performance first increases and then drops. The peak point is around 0.2-0.3 for most cases. The reason is that when we perform the substitution operation, we randomly replace or with one of its parent’s interacted first-order neighbors, thus the replaced nodes can still reflect its parent’s characteristic to some extent. However, once the deletion ratio gets larger (e.g., 0.9), it will result in a highly skewed graph structure, which can not bring much useful collaborative signals to the target node.




6. Related Work
Self-supervised Learning with GNNs. The recent advance on self-supervised learning for recommendation has received much attention (Yu et al., 2022a; Qiu et al., 2022; Yu et al., 2021a; Xia et al., 2021b, a), where self-supervised learning with GNNs aim to find the correlation of nodes in the graph itself, so as to alleviate the data sparsity issue in graphs (Hu et al., 2020; Qiu et al., 2020; Velickovic et al., 2019; Chen et al., 2019; Sun et al., 2020; You et al., 2020; Yu et al., 2022b, 2021b). More recently, some researchers explore pre-training GNNs on user-item graphs for recommendation. For example, - (Hao et al., 2021) reconstructs embeddings under the meta-learning setting. SGL (Wu et al., 2021) contrasts node representation by node dropout, edge dropout and random walk data augmentation operations. PMGT (Liu et al., 2021) reconstructs graph structure and node feature using side information. GCN-P/COM-P (Meng et al., 2021) learns the representations of entities constructed from the side information. However, these methods suffer from ineffective long-range dependency problem, as the GNN model can only capture low-order correlations of nodes. Besides, the pretext tasks of these methods consider either intra-correlations (Hao et al., 2021; Liu et al., 2021; Meng et al., 2021) or inter-correlations (Wu et al., 2021) of nodes, rather than both. Further, the side information is not always available, making it difficult to construct the pretext tasks. To solve the above problems, we propose , which considers both short- and long-range dependencies of nodes, and both intra- and inter-correlations of nodes.
Cold-start Recommendation. Cold-start recommendation is an intractable problem in Recommender System. Some researchers try to incorporate the side information such as knowledge graphs (KGs) (Wang et al., 2019d, a) or the contents of users/items (Yin et al., 2014, 2017; Chen et al., 2020b; Yin et al., 2019, 2020; Wang et al., 2019c; Gharibshah et al., 2020) to enhance the representations of users/items. However, the contents are not always available and it is difficult to align the users/items with the entities in KGs. Another research line is to explicitly improve the quality of cold-start users/items, which uses either meta-learning (Finn et al., 2017; Munkhdalai and Yu, 2017; Vinyals et al., 2016; Snell et al., 2017) or the graph neural networks (GNNs) (Ying et al., 2018; Wang et al., 2019b; He et al., 2020; Yin et al., 2020) for recommendation. However, the meta learning technique does not explicitly address the high-order neighbors of the cold-start users/items. The GNNs do not explicitly address the high-order cold-start users/items, which can not thoroughly improve the embedding quality of the cold-start users/items.
7. Conclusion
We propose a multi-strategy based pre-training method, , which extends PT-GNN from the perspective of model architecture and pretext tasks to improve the cold-start recommendation performance. Specifically, in addition to the short-range dependencies of nodes captured by the GNN encoder, we add a transformer encoder to capture long-range dependencies. In addition to considering the intra-correlations of nodes by the embedding reconstruction task, we add embedding contrastive learning task to capture inter-correlations of nodes. Experiments on three datasets demonstrate the effectiveness of our proposed model against the vanilla GNN and pre-training GNN models.
ACKNOWLEDGMENTS
This work is supported by National Key Research & Develop Plan (Grant No. 2018YFB1004401), National Natural Science Foundation of China (Grant No. 62072460, 62076245, 62172424), Beijing Natural Science Foundation (Grant No. 4212022), Australian Research Council Future Fellowship (Grant No. FT210100624) and Discovery Project (Grant No. DP190101985).
References
- (1)
- Burges (2010) Christopher JC Burges. 2010. From ranknet to lambdarank to lambdamart: An overview. Learning 11, 23-581 (2010), 81.
- Chen et al. (2019) Hongxu Chen, Hongzhi Yin, Tong Chen, Quoc Viet Hung Nguyen, Wen-Chih Peng, and Xue Li. 2019. Exploiting Centrality Information with Graph Convolutions for Network Representation Learning. In ICDE’19. IEEE, 590–601.
- Chen et al. (2020b) Hongxu Chen, Hongzhi Yin, Xiangguo Sun, Tong Chen, Bogdan Gabrys, and Katarzyna Musial. 2020b. Multi-level Graph Convolutional Networks for Cross-platform Anchor Link Prediction. In SIGKDD’20. ACM, 1503–1511.
- Chen et al. (2018) Jie Chen, Tengfei Ma, and Cao Xiao. 2018. FastGCN: Fast Learning with Graph Convolutional Networks via Importance Sampling. In ICLR’ 18.
- Chen et al. (2020a) Ting Chen, Simon Kornblith, Mohammad Norouzi, and Geoffrey E. Hinton. 2020a. A Simple Framework for Contrastive Learning of Visual Representations. In ICML’20 (Proceedings of Machine Learning Research, Vol. 119). PMLR, 1597–1607.
- Chen and Wong (2020) Tianwen Chen and Raymond Chi-Wing Wong. 2020. Handling Information Loss of Graph Neural Networks for Session-based Recommendation. In SIGKDD’20. ACM, 1172–1180.
- Finn et al. (2017) Chelsea Finn, Pieter Abbeel, and Sergey Levine. 2017. Model-Agnostic Meta-Learning for Fast Adaptation of Deep Networks. In ICML’17, Vol. 70. 1126–1135.
- Gharibshah et al. (2020) Zhabiz Gharibshah, Xingquan Zhu, Arthur Hainline, and Michael Conway. 2020. Deep Learning for User Interest and Response Prediction in Online Display Advertising. Data Sci. Eng. 5, 1 (2020), 12–26.
- Gilmer et al. (2017) Justin Gilmer, Samuel S. Schoenholz, Patrick F. Riley, Oriol Vinyals, and George E. Dahl. 2017. Neural Message Passing for Quantum Chemistry. In ICML’17 (Proceedings of Machine Learning Research, Vol. 70). PMLR, 1263–1272.
- Hamilton et al. (2017) William L. Hamilton, Zhitao Ying, and Jure Leskovec. 2017. Inductive Representation Learning on Large Graphs. In NeurlPS’17. 1024–1034.
- Hao et al. (2021) Bowen Hao, Jing Zhang, Hongzhi Yin, Cuiping Li, and Hong Chen. 2021. Pre-Training Graph Neural Networks for Cold-Start Users and Items Representation. In WSDM’21. ACM, 265–273.
- Harper and Konstan (2016) F. Maxwell Harper and Joseph A. Konstan. 2016. The MovieLens Datasets: History and Context. ACM Trans. Interact. Intell. Syst. (2016), 19:1–19:19.
- He et al. (2020) Xiangnan He, Kuan Deng, Xiang Wang, Yan Li, Yongdong Zhang, and Meng Wang. 2020. LightGCN: Simplifying and Powering Graph Convolution Network for Recommendation. In SIGIR’20.
- He et al. (2017) Xiangnan He, Lizi Liao, Hanwang Zhang, Liqiang Nie, Xia Hu, and Tat-Seng Chua. 2017. Neural Collaborative Filtering. In WWW’17. 173–182.
- Hu et al. (2020) Ziniu Hu, Yuxiao Dong, Kuansan Wang, Kai-Wei Chang, and Yizhou Sun. 2020. GPT-GNN: Generative Pre-Training of Graph Neural Networks. In SIGKDD’20.
- Kipf and Welling (2017) Thomas N. Kipf and Max Welling. 2017. Semi-Supervised Classification with Graph Convolutional Networks. In ICLR’17.
- Liang et al. (2016) Dawen Liang, Laurent Charlin, James McInerney, and David M. Blei. 2016. Modeling User Exposure in Recommendation. In WWW’16. ACM, 951–961.
- Linden et al. (2003) Greg Linden, Brent Smith, and Jeremy York. 2003. Amazon.com Recommendations: Item-to-Item Collaborative Filtering. IEEE Internet Comput. (2003), 76–80.
- Liu et al. (2021) Yong Liu, Susen Yang, Chenyi Lei, Guoxin Wang, Haihong Tang, Juyong Zhang, Aixin Sun, and Chunyan Miao. 2021. Pre-training Graph Transformer with Multimodal Side Information for Recommendation. In MM’21. ACM, 2853–2861.
- Meng et al. (2021) Zaiqiao Meng, Siwei Liu, Craig Macdonald, and Iadh Ounis. 2021. Graph Neural Pre-training for Enhancing Recommendations using Side Information. CoRR abs/2107.03936 (2021). https://arxiv.org/abs/2107.03936
- Munkhdalai and Yu (2017) Tsendsuren Munkhdalai and Hong Yu. 2017. Meta Networks. In ICML’17 (Proceedings of Machine Learning Research, Vol. 70), Doina Precup and Yee Whye Teh (Eds.). 2554–2563.
- Perozzi et al. (2014) Bryan Perozzi, Rami Al-Rfou, and Steven Skiena. 2014. DeepWalk: online learning of social representations. In SIGKDD’14. ACM, 701–710.
- Qiu et al. (2020) Jiezhong Qiu, Qibin Chen, Yuxiao Dong, Jing Zhang, Hongxia Yang, Ming Ding, Kuansan Wang, and Jie Tang. 2020. GCC: Graph Contrastive Coding for Graph Neural Network Pre-Training. In SIGKDD’20.
- Qiu et al. (2022) Ruihong Qiu, Zi Huang, Hongzhi Yin, and Zijian Wang. 2022. Contrastive Learning for Representation Degeneration Problem in Sequential Recommendation. In WSDM’22. ACM, 813–823.
- Snell et al. (2017) Jake Snell, Kevin Swersky, and Richard S. Zemel. 2017. Prototypical Networks for Few-shot Learning. In NeurlPS’17. 4077–4087.
- Sun et al. (2020) Fan-Yun Sun, Jordan Hoffmann, Vikas Verma, and Jian Tang. 2020. InfoGraph: Unsupervised and Semi-supervised Graph-Level Representation Learning via Mutual Information Maximization. In ICLR’20.
- Sutton et al. (1999) Richard S. Sutton, David A. McAllester, Satinder P. Singh, and Yishay Mansour. 1999. Policy Gradient Methods for Reinforcement Learning with Function Approximation. In NeurIPS’99. 1057–1063.
- van den Berg et al. (2018) Rianne van den Berg, Thomas N. Kipf, and Max Welling. 2018. Graph Convolutional Matrix Completion. In SIGKDD’18. ACM.
- Vaswani et al. (2017) Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N. Gomez, Lukasz Kaiser, and Illia Polosukhin. 2017. Attention is All you Need. In NeurlPS’17. 5998–6008.
- Velickovic et al. (2019) Petar Velickovic, William Fedus, William L Hamilton, Pietro Liò, Yoshua Bengio, and R Devon Hjelm. 2019. Deep Graph Infomax. In ICLR’19.
- Vinyals et al. (2016) Oriol Vinyals, Charles Blundell, Tim Lillicrap, Koray Kavukcuoglu, and Daan Wierstra. 2016. Matching Networks for One Shot Learning. In NeurlPS’16. 3630–3638.
- Wang et al. (2019d) Hongwei Wang, Fuzheng Zhang, Miao Zhao, Wenjie Li, Xing Xie, and Minyi Guo. 2019d. Multi-Task Feature Learning for Knowledge Graph Enhanced Recommendation. In WWW’ 19. 2000–2010.
- Wang et al. (2019c) Qinyong Wang, Hongzhi Yin, Hao Wang, Quoc Viet Hung Nguyen, Zi Huang, and Lizhen Cui. 2019c. Enhancing Collaborative Filtering with Generative Augmentation. In SIGKDD’19. ACM, 548–556.
- Wang et al. (2019a) Xiang Wang, Xiangnan He, Yixin Cao, Meng Liu, and Tat-Seng Chua. 2019a. KGAT: Knowledge Graph Attention Network for Recommendation. In SIGKDD’19. 950–958.
- Wang et al. (2019b) Xiang Wang, Xiangnan He, Meng Wang, Fuli Feng, and Tat-Seng Chua. 2019b. Neural Graph Collaborative Filtering. In SIGIR’19. 165–174.
- Williams (1992) Ronald J. Williams. 1992. Simple Statistical Gradient-Following Algorithms for Connectionist Reinforcement Learning. Mach. Learn. 8, 229–256.
- Wu et al. (2021) Jiancan Wu, Xiang Wang, Fuli Feng, Xiangnan He, Liang Chen, Jianxun Lian, and Xing Xie. 2021. Self-supervised Graph Learning for Recommendation. In SIGIR’21. ACM, 726–735.
- Wu et al. (2018) Zhirong Wu, Yuanjun Xiong, Stella X. Yu, and Dahua Lin. 2018. Unsupervised Feature Learning via Non-Parametric Instance Discrimination. In CVPR’18. Computer Vision Foundation / IEEE Computer Society, 3733–3742.
- Xia et al. (2021a) Xin Xia, Hongzhi Yin, Junliang Yu, Yingxia Shao, and Lizhen Cui. 2021a. Self-Supervised Graph Co-Training for Session-based Recommendation. In CIKM’21. ACM, 2180–2190.
- Xia et al. (2021b) Xin Xia, Hongzhi Yin, Junliang Yu, Qinyong Wang, Lizhen Cui, and Xiangliang Zhang. 2021b. Self-Supervised Hypergraph Convolutional Networks for Session-based Recommendation. In AAAI’21. AAAI Press, 4503–4511.
- Yin et al. (2014) Hongzhi Yin, Bin Cui, Yizhou Sun, Zhiting Hu, and Ling Chen. 2014. LCARS: A Spatial Item Recommender System. TOIS’14 32, 3 (2014), 11:1–11:37.
- Yin et al. (2019) Hongzhi Yin, Qinyong Wang, Kai Zheng, Zhixu Li, Jiali Yang, and Xiaofang Zhou. 2019. Social Influence-Based Group Representation Learning for Group Recommendation. In ICDE’19. IEEE, 566–577.
- Yin et al. (2020) Hongzhi Yin, Qinyong Wang, Kai Zheng, Zhixu Li, and Xiaofang Zhou. 2020. Overcoming Data Sparsity in Group Recommendation. IEEE Trans. Knowl. Data Eng. (2020).
- Yin et al. (2017) Hongzhi Yin, Weiqing Wang, Hao Wang, Ling Chen, and Xiaofang Zhou. 2017. Spatial-Aware Hierarchical Collaborative Deep Learning for POI Recommendation. IEEE Trans. Knowl. Data Eng. 19, 11 (2017), 2537–2551.
- Ying et al. (2018) Rex Ying, Ruining He, Kaifeng Chen, Pong Eksombatchai, William L. Hamilton, and Jure Leskovec. 2018. Graph Convolutional Neural Networks for Web-Scale Recommender Systems. In SIGKDD”18. 974–983.
- You et al. (2020) Yuning You, Tianlong Chen, Yongduo Sui, Ting Chen, Zhangyang Wang, and Yang Shen. 2020. Graph Contrastive Learning with Augmentations. In NeurIPS’20.
- Yu et al. (2021a) Junliang Yu, Hongzhi Yin, Min Gao, Xin Xia, Xiangliang Zhang, and Nguyen Quoc Viet Hung. 2021a. Socially-Aware Self-Supervised Tri-Training for Recommendation. In SIGKDD’21. ACM, 2084–2092.
- Yu et al. (2021b) Junliang Yu, Hongzhi Yin, Jundong Li, Qinyong Wang, Nguyen Quoc Viet Hung, and Xiangliang Zhang. 2021b. Self-Supervised Multi-Channel Hypergraph Convolutional Network for Social Recommendation. In WWW’21. ACM / IW3C2, 413–424.
- Yu et al. (2022a) Junliang Yu, Hongzhi Yin, Xin Xia, Tong Chen, Jundong Li, and Zi Huang. 2022a. Self-Supervised Learning for Recommender Systems: A Survey. CoRR abs/2203.15876 (2022). https://doi.org/10.48550/arXiv.2203.15876
- Yu et al. (2022b) Junliang Yu, Hongzhi Yin, Xin Xia, Lizhen Cui Tong Chen, and Quoc Viet Hung Nguyen. 2022b. Are Graph Augmentations Necessary? Simple Graph Contrastive Learning for Recommendation. In SIGIR’22.
- Zhang et al. (2019) Jing Zhang, Bowen Hao, Bo Chen, Cuiping Li, Hong Chen, and Jimeng Sun. 2019. Hierarchical Reinforcement Learning for Course Recommendation in MOOCs. In AAAI’19. 435–442.
- Zhang et al. (2013) Weinan Zhang, Tianqi Chen, Jun Wang, and Yong Yu. 2013. Optimizing top-n collaborative filtering via dynamic negative item sampling. In SIGIR’13. ACM, 785–788.