[1]\fnmAsael Fabian \surMartínez
[1]\orgdivDepartment of Mathematics, \orgnameUniversidad Autónoma Metropolitana, \orgaddress\streetAv. San Rafael Atlixco 186, \cityMexico City, \postcode09340, \countryMexico
2]\orgdivIIMAS, \orgnameUniversidad Nacional Autónoma de México, \orgaddressCircuito Escolar S/N, \cityCiudad Universitaria, \postcode04510, \countryMexico
A model-based approach for clustering binned data
Abstract
Binned data often appears in different fields of research, and it is generated after summarizing the original data in a sequence of pairs of bins (or their midpoints) and frequencies. There may exist different reasons to only provide this summary, but more importantly, it is necessary being able to perform statistical analyses based only on it. We present a Bayesian nonparametric model for clustering applicable for binned data. Clusters are modeled via random partitions, and within them a model-based approach is assumed. Inferences are performed by a Markov chain Monte Carlo method and the complete proposal is tested using simulated and real data. Having particular interest in studying marine populations, we analyze samples of Lobatus (Strobus) gigas’ lengths and found the presence of up to three cohorts along the year.
keywords:
Bayesian nonparametrics, data augmentation, density estimation, grouped data, missing values, random partitions.1 Introduction
Data analysis often considers observations as continuous, but there are many situations where they are recorded with a very low precision during the data gathering process. This might happen since the data were measured with non high-precision instruments, due to their cost, or the lack of availability of an adequate measuring device. It could also be that the original data are only accesible in a summarized form, for simplicity or confidentiality reasons. In these and similar scenarios, assuming that the original observed data fall on an interval , they are only available after being processed as follows. First, the interval is divided into a series of non-overlapping subintervals, or bins, such that their union covers , and then, it is counted how many datapoints fall in each bin. Each bin is represented by its center , whose value can be its midpoint or some statistics such as the mean or median value. This data binning process produces a sequence of pairs representing the center and frequency, or number of observations, assigned to the corresponding bin , . We call binned data to this kind of datasets.
Binned data play important roles in fields such as biology, ecology, social sciences, economy, engineering, computing, and others. For statisticians, perhaps one of the most known example of binned data is the Fisher’s Iris dataset [21], consisting of samples from each of three species of Iris; each sample records five values: sepal length, sepal width, petal length, petal width and species. The variables for lengths and widths are clearly continuous but were recorded using only one decimal place. Another classic example appears in [55] as an example of finite mixture distributions, originally published by [6], where the lengths of snappers are reported as a frequency table. In this way, many biological or ecological studies collect data using a binned structure; see, for example, [3] for line transect sampling, a method used for estimating wildlife populations, and the references in [48] and [15] for cases of data binning in fishery. In socio-economic studies, data related to income or poverty are mainly available in binned form for developing countries, or due to the high cost of sharing the raw data (see Hajargasht et al. 32 and Eckernkemper and Gribisch 14 among others); similarly for schooling and child welfare (see, Guo 28 and Friedman et al. 19). It also happen that organizations wish to protect data confidentiality, security, and integrity, as explained by [1], so only binned data are made public.
On a different direction, there are cases where raw data are binned in order to avoid computational burdens, or to simplify further processing, like in [29] and [51]. Also, the process of binning has been used to filter some issues associated to the data-generating phenomena [31]. Finally, data might be originally collected in a binned form, like in survival analysis, where it is common to have interval-censored data, or in pattern recognition and machine learning problems, where color and feature histograms are the input data (see Cadez et al. 9 and the references therein for more details).
Although descriptive analysis or some elemental estimations might be performed using the binned data as is, these can be inaccurate by some kind of bias inherent to the data, and aiming to perform more elaborated or specific statistical analyses become more cumbersome. Among the literature, a wide range of methodologies have been proposed for the statistical treatment of binned data. For example, in parametric estimation, there are methods based on maximum likelihood [54, 15, 14], in the method of moments [32], or following Bayesian approaches [14]. When the data exhibit a more complex distribution, kernel density estimation proposals are widely used; they can be found, for example, in [52], [53], [5], [9], [36], [58], [49], [59], and [31]. A different approach is given by [39]. Another popular class of methods along this line is based on a modification of the EM algorithm [13] to handle missing data. Two extensions are given by [44] and [7], and have been used in mixture modeling by [8], [29], [51] and [1]. With regard to fully Bayesian methods designed for binned data, [40] propose a density estimation model, and [2] and [24] estimate the parameters for finite mixture models.
Motivated by the study of marine species in Quintana Roo coasts, we develop a Bayesian nonparametric methodology for estimating the underlying clustering structure based on collected data, available only in a binned form. Providing a clustering structure may allow to identify different cohorts in the population, and estimate some characteristics of interest. This information can subsequently be incorporated in growth models, a common tools for fisheries management (see, for example, Lorenzen 43).
Our proposed methodology, on the one hand, models heterogeneity in the data following a clustering perspective by means of random partitions [17, 37, 38], in particular, a modification of the distribution over partitions for the Dirichlet process [18] is used. On the other hand, data within groups are modeled under a probabilistic framework, also known as a model-based approach [23]. However, since the data is provided in a binned form, it is necessary to extend this framework; which we tackle by treating original data as missing values. Once the underlying clustering structure is estimated, we can easily estimate group’s parameters, as well as some other characteristics, like the distribution of the data. We test the performance of our methodology using simulated and real data. Finally, we analyze samples of the length of Lobatus (Strombus) gigas, collected at different times in Punta Gavilán, Quintana Roo.
2 Random partition models
For any dataset of elements, cluster analysis, also known as clustering, aims to provide an estimate of their grouping structure, say , which partitions into nonempty subsets , . Elements belonging to the same subset, or group in the context of clustering, have more similar characteristics among them than those in any other group. Given the importance of the task of clustering, many methodologies have been developed. Some of them cluster the elements according to their distance, in some sense, to the other elements in the same group or to some representative of the group; hierarchical clustering and the means algorithm are examples of these methods. Other approaches make use of a probabilistic component to associate the elements to a single group. There, it is assumed that each element is a realization of some random variable, so all elements belonging to the same group were generated from the same probability distribution ; this approach is known as model-based [23]. A common example of model-based methods are mixture models, i.e. convex linear combinations of probability distributions.
A different probabilistic approach for cluster analysis is based on random partitions. Early works on this topic can be traced back to [17] and [37, 38] for the study of population genetics, and, nowadays, they are widely used in Bayesian nonparametric models; see, e.g. [33] and [11] for a more extensive overview. A random partition is a random object taking values over the space generated by all the possible groupings of the elements, i.e. every possible value of . When they are combined with the model-based approach, we can determine the grouping structure underlying to a given dataset. By providing a probabilistic framework for all the possible groupings, we can have a priori and a posteriori probabilities for each possible value of , as well as some other estimates of interest. An example of this class of models is known as product partition models [30]. Throughout this work, we refer this approach for clustering as random partition models.
A natural way to describe random partition models is through Bayesian hierarchical models. Let us denote by the space of all the possible values of , in terms of the observations’ indices, and assume that the probability distribution for each group, , also called kernel, is the same and only its parameter, , varies, so . Then, the hierarchical model can be written as
| (1) | ||||
where and are prior distributions for the kernel parameters and the random partition, respectively.
The prior in Model (1) can be chosen such that, together with , both form a conjugate model. On the other hand, the prior for the random partition , seems less straightforward. For example, [30] defines partition distributions as proportional to the product of non-negative cohesion functions, , applied to each group in , i.e.
for all partition .
A different class of partition distributions arises when working with discrete almost surely (a.s.) random probability measures (RPMs), daily used tools in Bayesian nonparametrics; see, for instance, [50], [35]. Any sample of size from an a.s. discrete RPM , taking values in , is bounded to have ties with positive probability, and, as consequence, to form groups with distinct representative values, each one having frequency , with . Therefore, a partition distribution is obtained through
by letting , with the cardinality of . In the computation of the expression above, the expectation is with respect to the distribution of . The resulting class of distributions is known as exchangeable partition probability functions (EPPFs), where exchangeable stands for symmetric since it can be noticed that the probability is the same under permutations of the groups. Further, a priori, it does not matter what the sampled values of are in order to compute the probabilities, and more importantly, it can be seen that EPPF-based models also allow us to infer about the number of groups, denoted by the random variable . The Dirichlet process [18], the daily workhorse in Bayesian nonparametrics, is the canonical example for the distribution of , and its EPPF is given by
| (2) |
for some , where , and is the Pochhammer symbol. More general constructions can be found in, for example, [41, 42], [22] and [25].
2.1 Modeling binned data
Model (1) is designed to be used when the observations are all available, that is when each has been recorded with enough precision to be considered as a realization of some continuous random variable. However, if data are only available in a binned form, an additional treatment is required.
As defined in the Introduction, binned data are obtained after partitioning an interval , where the original observations fall, into non-overlapping subintervals , and recording the number of observations, , falling within each bin. Therefore, variables are non observable, and in order to still following a model-based approach, the observation-level hierarchy in Model (1) models a series of latent variables, and it needs to be modified as
| (3) |
where is an indicator variable associating each observation to the th bin; so , for , must be satisfied. This is a common approach in Bayesian methods dealing with missing values.
2.2 Sampling method
Making inferences from random partition models, like (1), can be done using some sampling schemes designed for mixture models; in our case, for the Dirichlet process mixture model (see, Escobar and West 16, Neal 46 or Ishwaran and James 35, just to mention a few examples). In some of them, a set of indicator variables associating observations and mixture components is introduced to make inferences, and there is a close relationship between this set and a random partition; a detailed discussion about it can be found in [26]. On a different direction, [20] propose a sampling method specifically designed for clustering, also based on the Dirichlet process mixture model.
Our model for binned data can use any of the mentioned sampling methods after adding the extra step given in Equation (3) for sampling the latent observations . We adopt the method of [20] since it simplifies the exploration of the whole space , where random partitions take values. Their approach is designed to cluster univariate observations by first ordering them. If observations and are clustered together, with , it is reasonable to assume that all observations in between should belong to the same cluster. As a consequence, the possible groupings are reduced from the th Bell number of choices, the cardinality of , to , with the sample size. See [20] and [45] for further details. We denote by this reduced space of possible groupings. After a partition is simulated, additional parameters, like those associated to each group, can be also sampled.
Taking the EPPF for the Dirichlet process, Equation (2), its restriction to leads to the following expression
Furthermore, regarding the bin-membership variables , they take the following particular structure under this restriction
with .
Therefore, we require to compute the posterior distribution of variables , , and , which are given by
Their corresponding full conditional distributions are given as follows. For the latent variables , ,
which is a -truncated version of with parameter . The notation indicates the vector without its th entry. Further, the posterior for the kernel parameters , , is
sampling from this distribution can be straightforward, for example using conjugate models.
Finally, there is the distribution for the -valued random partition, from which we can sample according to the details provided by [20]. Briefly, the Markov chain Monte Carlo (MCMC) scheme to draw samples for consists on the following steps. Assume the current value of has groups, and let be a proposed value; then
-
1.
the partition will have groups, where some non-singleton group was chosen and split into two groups;
-
2.
conversely, the partition will have groups, where two adjacent groups of were chosen and merged.
Each move is a Metropolis-Hastings step and is accepted accordingly. After a split/merge is performed, an additional step is done by updating the size of two adjacent groups, the so-called shuffle move. The details of each move for this scheme are provided in the Appendix of [45].
It is worth mentioning that our main interest is to infer about the clustering structure underlying the data, which corresponds to a point estimate for parameter , denoted by . Despite of the different estimators available in the literature (see, e.g. Dahl 10 and Wade and Ghahramani 57), we report the posterior modal partition due to its simplicity. Furthermore, due to the ordering restriction in the possible groupings, we will report partitions in terms of their groups’ sizes, for instance, means there are three groups, in terms of the indices: , , and .
Once the point estimate is computed, the estimation of kernel parameters can be done by taking all sampled values , at iteration , where the sampled partition , that is
where , and is the number of sampled values. Notice that following this approach, and taking advantage of the restriction induced by , there is no label switching issues; each individual sampled models the th group. Moreover, the estimated density can be also computed conditioned on as
with the size of group and the number of groups in , leading a simple and more interpretable mixture density model.
3 Model performance
We illustrate the performance of our model by using some datasets. In these cases, a normal density is set for modeling individual groups, i.e. , with unknown mean and precision, so , and a conjugate normal-gamma prior is chosen. Also, the restricted EPPF for the Dirichlet process is set for the prior over partitions, . Therefore, the model is
The full conditional distribution for the latent variables are, then, a -truncated normal distribution of parameters . For the kernel parameters , we have a normal-gamma distribution of parameters
with . Additionally, a gamma prior is assigned to the total mass parameter for the prior distribution of ; its posterior is a mixture of gamma distributions as explained in [16].
It is important to say that in many applications, the bins , for , are not provided, but only a representative value as explained in the Introduction. Without any further details, we assume the bins take the form , with , for , , and .
As a first example, a synthetic dataset is used. A sample of size is drawn from the following mixture of normal distributions
where the second parameter of the densities is expressed in terms of the variance. Given the sample, data was binned taking the interval , and bins where obtained, each one of length one, together with their frequencies. The histogram is depicted in Figure 1. The MCMC was run iterations long, discarding the firsts . Base measure parameters were set to and different values for were used, in particular , , and . Hyperparameters for the total mass parameter are set to . For each configuration, the posterior modal partition was computed, and conditioned on it, the density and groups’ parameters where also obtained. Figure 1 also displays the estimated density for each case.
When parameter , the estimated partition is , from which the mixing weights can be estimated by dividing each group size by the sample size, being them . Moreover, conditioned on , the estimated means are , and the standard deviations, ; the estimated density is the continuous line in Figure 1.
The other values for parameter allow us to see how it acts as a smoothing parameter. When , the posterior modal partition contains a few groups, three, and the estimated density is coarser or softer (dotted line in Figure 1) than the case . On the other hand, more groups are detected when taking , the posterior mode contains nine groups, and the estimated density follows closer all bin heights (dashed line in Figure 1).

The second dataset used corresponds to the measurements of the length, in inches, of snappers [6], referred in the Introduction. Figure 2 presents the histogram. The same three sampling schemes as before were used, and a similar behaviour is observed when the value of parameter varies. For the case , four groups are estimated, whose means are . It is worth mentioning that these estimates are similar to those presented in [55].
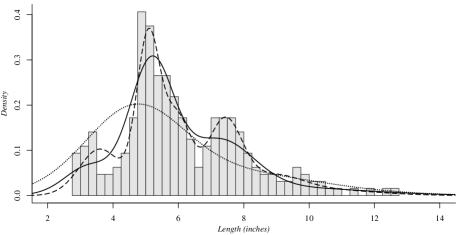
4 Cluster analysis of Lobatus (Strombus) gigas’ length samples
Studies of population demographics of marine resources are important for the management and to guarantee the sustainability of exploited marine populations. Fisheries management requires high quality estimates of length- and weight-at-age to incorporate such information in harvest and optimal management models (see, for example, Petitgas et al. 48 and Ogle and Isermann 47). Growth models commonly use length-at-age relationships obtained from modal progression analysis; see, e.g. [12]. Most bony fishes produce growth rings in their scales, which can be used to obtain length-at-age keys. Other marine resources, such as molluscs and shellfishes, do not produce growth rings and the usual way to obtain the length-at-age keys is through the analysis of modes from histograms constructed from samples from commercial catches or from field surveys. Estimating the number and the location of those modes is not always trivial due to the existence of size overlapping from different cohorts. In this section, we apply our proposed model to analyze the modal progression of Lobatus (Strombus) gigas using data collected at 10 points in time in Punta Gavilán, Quintana Roo, México. The data were binned using 10-millimeter intervals (Figure 3).
The method was run for each sample, one by date, taking iterations after discarding a first lot of . Base measure parameters were fixed ; regarding parameter , it was found that it has some relationship with the sample size, so a different value was chosen for each one. Figure 3 displays, for each sample, the modal estimated density (dashed line) together with its respective mixture components (continuous lines); Table 1 contains the estimated modal partition, and estimated posterior means and standard deviations given this partition.










| Date | Group size | Mean | Std. dev. |
|---|---|---|---|
| March 2010 | |||
| April 2010 | |||
| July 2010 | |||
| August 2010 | |||
| September 2010 | |||
| November 2010 | |||
| December 2010 | |||
| January 2011 | |||
| February 2011 | |||
| March 2011 |
The histograms and the estimated densities for each sample, as presented in Figure 3, show the presence of at least two groups (modes). It is believed that each mode corresponds to what is called a “year-class” in fisheries. The continuous growth process of L. gigas can be inferred from the displacement of the modal peaks to the right of the -axis. The posterior means in Table 1 show that for example, the mode at mm in March 2010 moved to mm in April 2010 and reached a value of mm in February 2011. A similar pattern can be tracked for other modes. Moreover, in March and September 2010, and in February 2011, a third mode appears at the left side of the histogram, which corresponds to the incorporation of a new cohort to the study area.
The modal progression obtained from the model we propose can also be incorporated in growth models, such as those by [27] and [56] (cf. Hernandez-Llamas and Ratkowsky 34 and Lorenzen 43). The resulting growth rates and parameters can be incorporated to stock and management assessment process to help resource managers to maintain a sustainable fishery for L. gigas. The method proposed here has the advantage of detecting the number of modal peaks and their location in an automatic way, unlike methods like [4], where the user has to detect the modes visually and guess their location. Other methods like kernel density estimation, the user relies on additional procedures for detecting the modal peaks.
5 Final remarks
The statistical analysis of binned data is of interest in different applied fields. We have presented a Bayesian nonparametric approach aiming, for univariate binned data exhibiting a complex structure, to perform cluster analysis together with parameter estimation for detected groups. In particular, we applied it to analyze samples of the length of L. gigas, detecting cohorts and their numerical characteristics.
Under a Bayesian perspective, the absence of the original observations was handled by a simple data augmentation mechanism for missing data, that is by incorporating an extra level in the hierarchical model. This approach places our method in the model-based paradigm, which allows to provide an estimated model for the individual groups. Furthermore, it is also possible to infer about the complete model, meaning using the complete mixture model, for example, through its estimated density. Even more, the usage of random partitions in the modeling let us to infer about the number of groups, a feature hardly available in other methodologies. Computationally, restricting their support to only consider clusters with no gaps, eases the exploration of the whole space of possible groupings during the posterior sampling.
The results obtained for the real dataset, L. gigas’ length, allows to understand the composition of the species at different times of the year. As explained, besides of automatically estimating the number of cohorts, our method do not require any extra procedure for detecting groups’ numeric characteristics, like the mean value. Also, all this information can be further explored by incorporating it in growth models, or similar tools; their results might be useful for resource management.
Finally, our model can be extended in several ways. It is straightforward handling non-homogeneous bins, i.e. bins having different lengths, or using another univariate data model for groups. Moreover, the extension to analyze data in higher dimensions mainly requires an appropriate sampling scheme of the truncated data distribution.
References
- \bibcommenthead
- AghahosseinaliShirazi et al. [2022] AghahosseinaliShirazi, Z., Silva, J.P.A.R., Souza, C.P.E.: Parameter estimation for grouped data using EM and MCEM algorithms. Communications in Statistics - Simulation and Computation, 1–22 (2022) https://doi.org/10.1080/03610918.2022.2108843
- Alston and Mengersen [2010] Alston, C.L., Mengersen, K.L.: Allowing for the effect of data binning in a Bayesian Normal mixture model. Computational Statistics & Data Analysis 54(4), 916–923 (2010)
- Burnham et al. [1980] Burnham, K.P., Anderson, D.R., Laake, J.L.: Estimation of density from line transect sampling of biological populations. Biometrical Journal 24(3) (1980) https://doi.org/10.1002/bimj.4710240306
- Bhattacharya [1967] Bhattacharya, C.G.: A Simple Method of Resolution of a Distribution into Gaussian Components. Biometrics 23(1), 115–135 (1967)
- Blower and Kelsall [2002] Blower, G., Kelsall, J.E.: Nonlinear Kernel Density Estimation for Binned Data: Convergence in Entropy. Bernoulli 8(4), 423–449 (2002)
- Cassie [1954] Cassie, R.M.: Some Uses of Probability Paper in the Analysis of Size Frequency Distributions. Marine and Freshwater Research 5(3), 513–522 (1954) https://doi.org/%****␣main.bbl␣Line␣125␣****10.1071/MF9540513
- Celeux and Diebolt [1988] Celeux, G., Diebolt, J.: A random imputation principle : the stochastic EM algorithm. Technical Report RR-0901, INRIA (1988)
- Chauveau [1995] Chauveau, D.: A stochastic EM algorithm for mixtures with censored data. Journal of Statistical Planning and Inference 46(1), 1–25 (1995)
- Cadez et al. [2002] Cadez, I.V., Smyth, P., McLachlan, G.J., McLaren, C.E.: Maximum Likelihood Estimation of Mixture Densities for Binned and Truncated Multivariate Data. Machine Learning 47(1), 7–34 (2002) https://doi.org/10.1023/A:1013679611503
- Dahl [2006] Dahl, D.B.: Model-Based Clustering for Expression Data via a Dirichlet Process Mixture Model. In: Do, K.-A., Müller, P., Vannucci, M. (eds.) Bayesian Inference for Gene Expression and Proteomics, pp. 201–218. Cambridge University Press, ??? (2006)
- De Blasi et al. [2015] De Blasi, P., Favaro, S., Lijoi, A., Mena, R.H., Prünster, I., Ruggiero, M.: Are Gibbs-Type Priors the Most Natural Generalization of the Dirichlet Process? IEEE Transactions on Pattern Analysis & Machine Intelligence 37(2), 212–229 (2015) https://doi.org/10.1109/TPAMI.2013.217
- Dippold et al. [2016] Dippold, D.A., Leaf, R.T., Hendon, J.R., Franks, J.S.: Estimation of the Length-at-Age Relationship of Mississippi’s Spotted Seatrout. Transactions of the American Fisheries Society 145(2), 295–304 (2016) https://doi.org/10.1080/00028487.2015.1121926
- Dempster et al. [1977] Dempster, A.P., Laird, N.M., Rubin, D.B.: Maximum Likelihood from Incomplete Data Via the EM Algorithm. Journal of the Royal Statistical Society: Series B (Methodological) 39(1), 1–22 (1977)
- Eckernkemper and Gribisch [2021] Eckernkemper, T., Gribisch, B.: Classical and Bayesian Inference for Income Distributions using Grouped Data. Oxford Bulletin of Economics and Statistics 83(1), 32–65 (2021) https://doi.org/10.1111/obes.12396
- Edwards et al. [2020] Edwards, A.M., Robinson, J.P.W., Blanchard, J.L., Baum, J.K., Plank, M.J.: Accounting for the bin structure of data removes bias when fitting size spectra. Marine Ecology Progress Series 636, 19–33 (2020) https://doi.org/10.3354/meps13230
- Escobar and West [1995] Escobar, M.D., West, M.: Bayesian Density Estimation and Inference Using Mixtures. Journal of the American Statistical Association 90(430), 577–588 (1995)
- Ewens [1972] Ewens, W.J.: The sampling theory of selectively neutral alleles. Theoretical Population Biology 3(1), 87–112 (1972)
- Ferguson [1973] Ferguson, T.S.: A Bayesian analysis of some nonparametric problems. The Annals of Statistics 1(2), 209–230 (1973)
- Friedman et al. [2018] Friedman, J., Graetz, N., Gakidou, E.: Improving the estimation of educational attainment: New methods for assessing average years of schooling from binned data. PLOS ONE 13(11), 1–15 (2018) https://doi.org/10.1371/journal.pone.0208019
- Fuentes-García et al. [2010] Fuentes-García, R., Mena, R.H., Walker, S.G.: A Probability for Classification Based on the Dirichlet Process Mixture Model. Journal of Classification 27, 389–403 (2010)
- Fisher [1936] Fisher, R.A.: The Use of Multiple Measurements in Taxonomic Problems. Annals of Eugenics 7(2), 179–188 (1936) https://doi.org/10.1111/j.1469-1809.1936.tb02137.x
- Favaro et al. [2016] Favaro, S., Lijoi, A., Nava, C., Nipoti, B., Prünster, I., Teh, Y.W.: On the Stick-Breaking Representation for Homogeneous NRMIs. Bayesian Analysis 11(3), 697–724 (2016)
- Fraley and Raftery [2002] Fraley, C., Raftery, A.E.: Model-Based Clustering, Discriminant Analysis, and Density Estimation. Journal of the American Statistical Association 97(458), 611–631 (2002)
- Gau et al. [2014] Gau, S.-L., Dieu Tapsoba, J., Lee, S.-M.: Bayesian approach for mixture models with grouped data. Computational Statistics 29(5), 1025–1043 (2014) https://doi.org/10.1007/s00180-013-0478-6
- Gil-Leyva and Mena [2023] Gil-Leyva, M.F., Mena, R.H.: Stick-breaking processes with exchangeable length variables. Journal of the American Statistical Association 118(541), 537–550 (2023)
- Gil Leyva Villa and Mena [2023] Gil Leyva Villa, M., Mena, R.H.: Stick-breaking processes with exchangeable length variables. Journal of the American Statistical Association 118(541), 537–550 (2023)
- Gompertz [1825] Gompertz, B.: XXIV. On the nature of the function expressive of the law of human mortality, and on a new mode of determining the value of life contingencies. In a letter to Francis Baily, Esq. F. R. S. &c. Philosophical Transactions of the Royal Society of London 115, 513–583 (1825) https://doi.org/10.1098/rstl.1825.0026
- Guo [2005] Guo, S.: Analyzing grouped data with hierarchical linear modeling. Children and Youth Services Review 27(6), 637–652 (2005) https://doi.org/10.1016/j.childyouth.2004.11.017
- Hamdan [2006] Hamdan, H.: Mixture model clustering of binned uncertain data: the classification approach. In: 2006 2nd International Conference on Information & Communication Technologies, vol. 1, pp. 1645–1650 (2006)
- Hartigan [1990] Hartigan, J.A.: Partition models. Communications in Statistics - Theory and Methods 19(8), 2745–2756 (1990) https://doi.org/10.1080/03610929008830345
- Hecht et al. [2023] Hecht, V., Dong, K., Rajesh, S., Shpilker, P., Wekhande, S., Shoresh, N.: Analyzing histone ChIP-seq data with a bin-based probability of being signal. PLOS Computational Biology 19(10), 1–19 (2023) https://doi.org/10.1371/journal.pcbi.1011568
- Hajargasht et al. [2012] Hajargasht, G., Griffiths, W.E., Brice, J., Rao, D.S.P., Duangkamon, C.: Inference for Income Distributions Using Grouped Data. Journal of Business & Economic Statistics 30(4), 563–575 (2012) https://doi.org/10.1080/07350015.2012.707590
- Hjort et al. [2010] Hjort, N.L., Holmes, C., Müller, P., Walker, S.G. (eds.): Bayesian Nonparametrics. Cambridge Series in Statistical and Probabilistic Mathematics. Cambridge University Press, ??? (2010)
- Hernandez-Llamas and Ratkowsky [2004] Hernandez-Llamas, A., Ratkowsky, D.A.: Growth of fishes, crustaceans and molluscs: estimation of the von Bertalanffy, Logistic, Gompertz and Richards curves and a new growth model. Marine Ecology Progress Series 282, 237–244 (2004) https://doi.org/10.3354/meps282237
- Ishwaran and James [2001] Ishwaran, H., James, L.F.: Gibbs sampling methods for stick-breaking priors. Journal of the American Statistical Association 96(453), 161–173 (2001)
- Jang and Loh [2010] Jang, W., Loh, J.M.: DENSITY ESTIMATION FOR GROUPED DATA WITH APPLICATION TO LINE TRANSECT SAMPLING. The Annals of Applied Statistics 4(2), 893–915 (2010)
- Kingman [1978a] Kingman, J.F.C.: Random Partitions in Population Genetics. Proceedings of the Royal Society of London. A. Mathematical and Physical Sciences 361(1704), 1–20 (1978)
- Kingman [1978b] Kingman, J.F.C.: The Representation of Partition Structures. Journal of the London Mathematical Society s2-18(2), 374–380 (1978)
- Koo and Kooperberg [2000] Koo, J.-Y., Kooperberg, C.: Logspline density estimation for binned data. Statistics & Probability Letters 46(2), 133–147 (2000) https://doi.org/10.1016/S0167-7152(99)00097-8
- Lambert and Eilers [2009] Lambert, P., Eilers, P.H.C.: Bayesian density estimation from grouped continuous data. Computational Statistics & Data Analysis 53(4), 1388–1399 (2009)
- Lijoi et al. [2007a] Lijoi, A., Mena, R.H., Prünster, I.: Bayesian Nonparametric Estimation of the Probability of Discovering New Species. Biometrika 94(4), 769–786 (2007) https://doi.org/10.1093/biomet/asm061
- Lijoi et al. [2007b] Lijoi, A., Mena, R.H., Prünster, I.: Controlling the Reinforcement in Bayesian Non-Parametric Mixture Models. Journal of the Royal Statistical Society Series B: Statistical Methodology 69(4), 715–740 (2007) https://doi.org/10.1111/j.1467-9868.2007.00609.x
- Lorenzen [2016] Lorenzen, K.: Toward a new paradigm for growth modeling in fisheries stock assessments: Embracing plasticity and its consequences. Fisheries Research 180, 4–22 (2016) https://doi.org/10.1016/j.fishres.2016.01.006
- McLachlan and Jones [1988] McLachlan, G.J., Jones, P.N.: Fitting mixture models to grouped and truncated data via the em algorithm. Biometrics 44(2), 571–578 (1988) https://doi.org/10.2307/2531869
- Martínez and Mena [2014] Martínez, A.F., Mena, R.H.: On a Nonparametric Change Point Detection Model in Markovian Regimes. Bayesian Analysis 9(4), 823–858 (2014)
- Neal [2000] Neal, R.M.: Markov chain sampling methods for Dirichlet process mixture models. Journal of Computational and Graphical Statistics 9(2), 249–265 (2000)
- Ogle and Isermann [2017] Ogle, D.H., Isermann, D.A.: Estimating Age at a Specified Length from the von Bertalanffy Growth Function. North American Journal of Fisheries Management 37(5), 1176–1180 (2017) https://doi.org/10.1080/02755947.2017.1342725
- Petitgas et al. [2011] Petitgas, P., Doray, M., Massé, J., Grellier, P.: Spatially explicit estimation of fish length histograms, with application to anchovy habitats in the Bay of Biscay. ICES Journal of Marine Science 68(10), 2086–2095 (2011) https://doi.org/10.1093/icesjms/fsr139
- Reyes et al. [2016] Reyes, M., Francisco-Fernández, M., Cao, R.: Nonparametric kernel density estimation for general grouped data. Journal of Nonparametric Statistics 28(2), 235–249 (2016) https://doi.org/10.1080/10485252.2016.1163348
- Regazzini et al. [2003] Regazzini, E., Lijoi, A., Prünster, I.: Distributional results for means of normalized random measures with independent increments. The Annals of Statistics 31(2), 560–585 (2003) https://doi.org/10.1214/aos/1051027881
- Samé et al. [2006] Samé, A., Ambroise, C., Govaert, G.: A classification EM algorithm for binned data. Computational Statistics & Data Analysis 51(2), 466–480 (2006) https://doi.org/10.1016/j.csda.2005.08.009
- Scott [1981] Scott, D.W.: Using Computer-Binned Data for Density Estimation. In: Eddy, W.F. (ed.) Computer Science and Statistics: Proceedings of the 13th Symposium on the Interface, pp. 292–294. Springer, ??? (1981)
- Scott and Sheather [1985] Scott, D.W., Sheather, S.J.: Kernel density estimation with binned data. Communications in Statistics - Theory and Methods 14(6), 1353–1359 (1985) https://doi.org/10.1080/03610928508828980
- Tarsitano [2005] Tarsitano, A.: Estimation of the Generalized Lambda Distribution Parameters for Grouped Data. Communications in Statistics - Theory and Methods 34(8), 1689–1709 (2005) https://doi.org/10.1081/STA-200066334
- Titterington et al. [1985] Titterington, D.M., Smith, A.F.M., Makov, U.E.: Statistical Analysis of Finite Mixture Distributions. Wiley, New York, ??? (1985)
- von Bertalanffy [1934] Bertalanffy, L.: Untersuchungen Über die gesetzlichkeit des wachstums : I. teil: Allgemeine grundlagen der theorie; mathematische und physiologische gesetzlichkeiten des wachstums bei wassertieren. Wilhelm Roux Arch Entwickl Mech Org 131(4), 613–652 (1934) https://doi.org/10.1007/BF00650112
- Wade and Ghahramani [2018] Wade, S., Ghahramani, Z.: Bayesian Cluster Analysis: Point Estimation and Credible Balls (with Discussion). Bayesian Analysis 13(2), 559–626 (2018)
- Wang and Wertelecki [2013] Wang, B., Wertelecki, W.: Density estimation for data with rounding errors. Computational Statistics & Data Analysis 65, 4–12 (2013)
- Xiao et al. [2016] Xiao, X., Mukherjee, A., Xie, M.: Estimation procedures for grouped data – a comparative study. Journal of Applied Statistics 43(11), 2110–2130 (2016) https://doi.org/10.1080/02664763.2015.1130801