A Lyapunov Function for the Combined System-Optimizer
Dynamics in Inexact Model Predictive Control
Abstract
In this paper, an asymptotic stability proof for a class of methods for inexact nonlinear model predictive control is presented. General Q-linearly convergent online optimization methods are considered and an asymptotic stability result is derived for the setting where a limited number of iterations of the optimizer are carried out per sampling time. Under the assumption of Lipschitz continuity of the solution, we explicitly construct a Lyapunov function for the combined system-optimizer dynamics, which shows that asymptotic stability can be obtained if the sampling time is sufficiently short. The results constitute an extension to existing attractivity results which hold in the simplified setting where inequality constraints are either not present or inactive in the region of attraction considered. Moreover, with respect to the established results on robust asymptotic stability of suboptimal model predictive control, we develop a framework that takes into account the optimizer’s dynamics and does not require decrease of the objective function across iterates. By extending these results, the gap between theory and practice of the standard real-time iteration strategy is bridged and asymptotic stability for a broader class of methods is guaranteed.
keywords:
predictive control, convergence of numerical methods, stability analysis, ,
1 Introduction
Nonlinear model predictive control (NMPC) is an advanced control technique that requires the solution of a series of nonlinear programs in order to evaluate an implicit control policy. Due to the potentially prohibitive computational burden associated with such computations, efficient methods for the solution of the underlying optimization problems are of crucial importance. For this reason, NMPC was first proposed and applied to systems with slow dynamics such as chemical processes in the 70s (see, e.g., [13]). The interest drawn in both industry and academia has driven in the past decades a quick progress in both algorithms and software implementations. At the same time, the computational power available on embedded control units has drastically increased leading to NMPC gradually becoming a viable solution for applications with much shorter sampling times (see, e.g., [18]).
In order to mitigate the computational requirements, many applications with high sampling rates rely on approximate feedback policies. Among other approaches, the real-time iteration (RTI) strategy proposed in [4] exploits a single iteration of a sequential quadratic programming (SQP) algorithm in order to compute an approximate solution of the current instance of the nonlinear parametric optimization problem. By using this solution to warmstart the SQP algorithm at the next sampling time, it is possible to track an optimal solution and eventually converge to it, as the system is steered to a steady state [6]. Attractivity proofs for the RTI strategy in slightly different settings, and under the assumption that inequality constraints are either absent or inactive in a neighborhood of the equilibrium, are presented in [5] and [6]. In the same spirit, similar algorithms that rely on a limited number of iterations are present in the literature. In [8], a general framework that covers methods with linear contraction in the objective function values is analyzed and an asymptotic stability proof is provided. The recent work in [11] addresses a more general setting where an SQP algorithm is used. A proof of local input-to-state stability is provided based on the assumption that a sufficiently high number of iterations is carried out per sampling time. In the convex setting, the works in [7] and [16] introduce stability results for relaxed barrier anytime methods and real-time projected gradient methods, respectively. Finally, the works in [15], [12] and, [1] analyze conditions under which suboptimal NMPC is stabilizing given that a feasible warmstart is available.
All of the above mentioned methods make use of a common idea. A limited number or, in the limit, a single iteration of an optimization algorithm are carried out in order to “track” the parametric optimal solution while reducing the computational footprint of the method. We will refer to these methods as real-time methods in order to make an explicit semantic connection with the well known RTI strategy [4].
Loosely speaking, the main challenge present in real-time approaches lies in the fact that the dynamics of the system and the ones of the optimizer interact with each other in a non-trivial way, as visualized in Figure 1. Although a formal definition of the system-optimizer dynamics requires the introduction of several concepts that we delay to Section 2, loosely speaking, for a given state and an approximate solution , the system is controlled using the control as feedback law and, and after the sampling time , it is steered to . Analogously, the optimizer generates a new approximate solution . We will refer to these coupled dynamics, with state , as , which will be formally defined in Definition 12.
1.1 Contribution and Outline
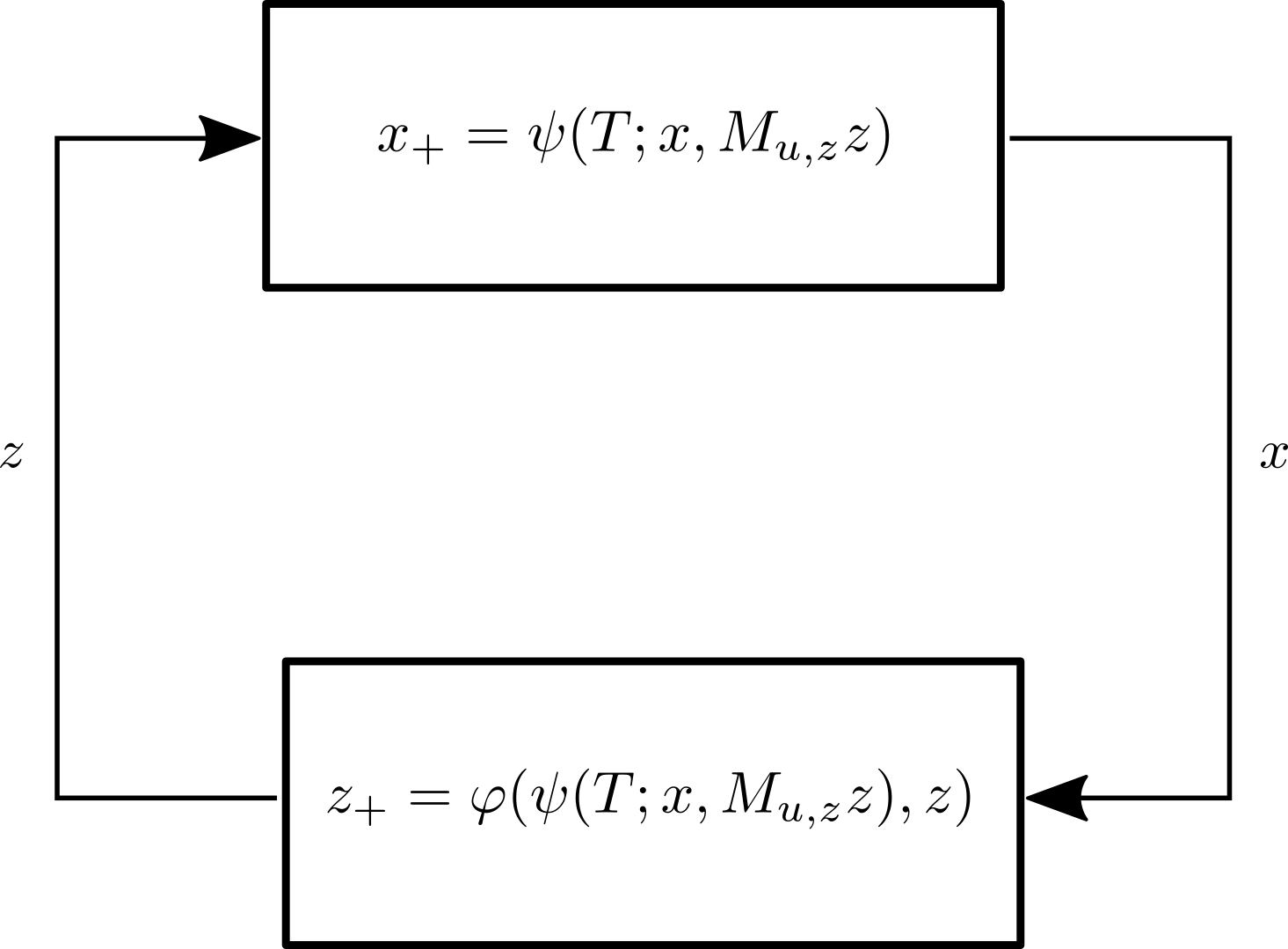
In this paper, we regard general real-time methods and establish asymptotic stability of the closed-loop system-optimizer dynamics . We assume that the exact solution to the underlying optimal control problems yields an asymptotically stable closed-loop system and that the iterates of the real-time method contract Q-linearly. Moreover, we assume that the primal-dual solution to the underlying parametric nonconvex program is Lipschitz continuous. Under these assumptions and the additional assumption that the sampling time of the closed-loop is sufficiently short, we show asymptotic stability of the system-optimizer dynamics by constructing a Lyapunov function for and the equilibrium in a neighborhood of .
In the setting of [15], [12], and [1], no regularity assumptions are required for the optimal solution and optimal value function, which are even allowed to be discontinuous. However, a decrease in the objective function is required in order for the optimizer’s iterates to be accepted. This condition is in general difficult to satisfy given that commonly used numerical methods do not generate feasible iterates and, for this reason, it is not easy to enforce decrease in the objective function. Although robust stability could still be guaranteed by shifting the warmstart (cf. [1]), the improved iterates might be rejected unnecessarily. Moreover, the optimizer’s dynamics are completely neglected. With respect to [15], [12], and [1], we propose in this work an analysis that, although requires stronger assumptions on the properties of the optimal solution, incorporates knowledge on the optimizer’s dynamics and does not require a decreasing cost.
Notice that attractivity proofs for the real-time iteration strategy are derived in [5] and [6] for a simplified setting where inequality constraints are not present or inactive in the entire region of attraction of the closed-loop system. In this sense, the present paper extends the results in [6] and [5] to a more general setting where active-set changes are allowed within the region of attraction. Moreover, asymptotic stability, rather than attractivity, is proved.
Finally, with respect to [11], we analyze how the behavior of the system-optimizer dynamics is affected by the sampling time, rather than by the number of optimizer’s iterations carried out. Additionally, we explicitly construct a Lyapunov function for the system-optimizer dynamics.
1.2 Notation
Throughout the paper we denote the Euclidean norm and the norm by and , respectively. We will sometimes write explicitly, to denote the Euclidean norm, when it improves clarity in the derivations. All vectors are column vectors and we denote the concatenation of two vectors by
| (1) |
We denote the derivative (gradient) of any function by and the Euclidean ball of radius centered at as . We use () to denote the space of strictly positive matrices (vectors) (i.e., the space of matrices (vectors) whose elements are real and strictly positive). With a slight abuse of notation we will sometimes write , to indicate that all the components of the vector are strictly positive. Analogously, we write () to denote the space of matrices (vectors) whose elements are nonnegative and use to indicate that all the components of the vector are nonnegative. We denote a vector whose components are all equal to 1 as and the identity matrix as . Finally, we denote the Minkowski sum of two sets and as .
2 System and Optimizer Dynamics
In this section, we will define the nominal dynamics that the system and optimizer state obey independently from each other. The nominal dynamics of the closed-loop system are assumed to be such that a Lyapunov function can be constructed if the exact solution to the underlying discretized optimal control problem is used as feedback law. Similarly, we will assume that certain contraction properties hold for the iterates generated by the optimizer if the parameter describing the current state of the system is held fixed.
2.1 System and optimizer dynamics
In order to study the interaction between the system to be controlled and the optimizer, we will first formally define their dynamics and describe the assumptions required for the stability analysis proposed.
2.1.1 System dynamics
The system under control obeys the following sampled-feedback closed-loop dynamics:
Definition 1 (System dynamics).
Let the following differential equation describe the dynamics of the system controlled using a constant input :
| (2) | ||||
Here, describes the trajectories of the system, denotes the state of the system at a given sampling instant and the corresponding constant input. We will refer to the strictly positive parameter as the sampling time associated with the corresponding discrete-time system
| (3) |
We will assume that a slightly tailored type of Lyapunov function is available for the closed-loop system controlled with a specific policy.
Assumption 2.
Let , and let be a continuous function. Let be a strictly positive constant and define
| (4) |
Assume that there exist positive constants , and such that, for any and any , the following hold:
| (5a) | ||||
| (5b) | ||||
Notice that Assumption 2, for a fixed boils down to the standard assumption for exponential asymptotic stability (see, e.g., Theorem 2.21 in [13]). Moreover, the dependency on in (5b) can be justified, for example, by assuming that a continuous-time Lyapunov function exists such that , for some positive constant and that is a sufficiently good approximation. Moreover, we make the following assumption which establishes additional regularity properties of the Lyapunov function.
Assumption 3.
Assume that is Lipschitz continuous over , i.e., there exists a constant such that
| (6) |
.
Remark 4.
Notice that a sufficient condition for Assumption 3 to hold is that is Lipschitz continuous over and that is Lipschitz continuous at . These conditions are satisfied, for example, by Lyapunov functions which are twice continuously differentiable at the origin if or simply Lipschitz continuous at the origin if .
The following proposition provides asymptotic stability of the closed-loop system obtained using the feedback policy .
Proposition 5 (Lyapunov stability).
The Lyapunov function defined in Assumption 2 guarantees that, if the ideal policy is employed, the resulting closed-loop system is (exponentially) asymptotically stable. In the following, we define the dynamics of the optimizer used to numerically compute approximations of for a given state .
2.1.2 Optimizer dynamics
We will assume that we dispose of a numerical method that defines what we will call the optimizer (or more generally a solver) that, for a given , can compute a vector from which we can compute through a linear map.
Assumption 6.
Assume that there exists a function and a matrix such that, for any , the following holds:
| (7) |
For simplicity of notation, we will assume further that .
Definition 7 (Optimizer dynamics).
Let the following discrete-time system describe the dynamics of the optimizer
| (8) |
where and represents the state of the optimizer.
Remark 8.
Notice that the optimizer dynamics (8) make use of the current approximate solution and a forward-simulated state . This setting corresponds, for example, to the case where a real-time iteration is carried out by solving a QP where the parameter is used as current state of the system. This amounts to assuming that either a perfect prediction of the system’s state is available ahead of time, or that instantaneous feedback can be delivered to the system. In both cases, small perturbations introduced by either model mismatch or feedback delay could be introduced explicitly. This goes however beyond the scope of the present work.
In order to leverage a certain type of contraction estimates, we will make the two following assumptions.
Assumption 9 (Lipschitz continuity).
Assume that there exist positive constants and such that, for any and any , the following holds
| (9) |
Moreover, we assume that .
Assumption 10 (Contraction).
There exist positive constants and such that, for any and any , the optimizer dynamics produce such that
| (10) |
The following lemma provides a way of quantifying the perturbation to the nominal contraction (10) due to changes in the value of across iterations of the optimizer.
Lemma 11.
Let Assumptions 9 and 10 hold. Then there exist strictly positive constants and such that, for any in , any in , and any in , we have that
| (11) | ||||
By choosing and such that they satisfy and , any in , any , and any , we have that . Hence, we can apply the contraction from Assumption 10 together with Lipschitz continuity of from Assumption 9 in order to write
| (12) | ||||||
which concludes the proof. ∎
2.2 Discussion of fundamental assumptions
Notice that the setting formalized by Assumptions 6, 9, and 10 does not require that is the optimal value function of a discretized optimal control problem nor of an optimization problem in general. We require instead that it is a Lyapunov function with some additional properties according to Assumptions 2 and 3. Similarly, needs not be the primal-dual solution to an optimization problem. We require instead that it is associated with the policy , i.e., for any , , that it is Lipschitz continuous and that the optimizer (or “solver” in general) can generate Q-linearly contracting iterates that converge to .
However, in order to make a more concrete connection with a classical setting, in NMPC we can often assume that is the optimal value function of a discretized version of a continuous-time optimal control problem. In this case, we can refer to the resulting parametric nonlinear program of the following form
| (13) |
where , for , and , for , describe the predicted states and inputs of the system to be controlled, respectively. The functions and describe the stage and terminal cost, respectively, and , , and describe the dynamics of the system, the stage, and terminal constraints, respectively.
The first-order optimality condition associated with (13) can be represented by a generalized equation (see, e.g., [14]), i.e.,
| (14) |
where denotes the primal-dual solution, is a vector-valued map and is a set-valued map denoting the normal cone to a convex set . Under proper regularity assumptions, we can then obtain that a single-valued localization of the solution map of the generalized equation must exist. Under the same assumptions, we can usually prove Lipschitz continuity of and Q-linear contraction of, for example, Newton-type iterations (cf. [9]), hence satisfying Assumptions 9 and 10. Notice that existence of a Lipschitz continuous single-valued localization of the solution map, does not require the solution map itself to be single-valued or Lipschitz continuous.
Similarly, using the standard argumentation for NMPC (see, e.g., [13]), we obtain that the feedback policy associated with the global solution to the underlying nonlinear programs is stabilizing and that the associated optimal value function is a Lyapunov function. In this way, Assumptions 2, 3, and 6 are satisfied. Note that, in this context, an aspect that remains somewhat unresolved is the fact that the standard argumentation for the stability analysis of NMPC requires that the global optimal solution is found by the optimizer. Hence, in order to be able to identify with the optimal value function it is necessary to assume that the single-valued localization attains the global minimum for all .
2.3 Combined system-optimizer dynamics
Proposition 5 and Lemma 11 provide key properties of the system and optimizer dynamics, respectively. In this section, we analyze the interaction between these two dynamical systems and how these properties are affected by such an interplay. To this end, let us define the following coupled system-optimizer dynamics.
Definition 12 (System-optimizer dynamics).
Let the following discrete-time system describe the coupled system-optimizer dynamics:
| (15) | ||||
or, in compact form
| (16) |
where and .
Our ultimate goal is to prove that, for a sufficiently short sampling time , the origin is a locally asymptotically stable equilibrium for (16). In order to describe the interaction between the two underlying subsystems, we analyze how the Lyapunov decrease (5b) and the error contraction (11) are affected.
2.3.1 Error contraction perturbation
In the following, we will specialize the result from Lemma 11 to the context where is determined by the evolution of the system to be controlled under the effect of the approximate policy. To this end, we make a general assumption on the behavior of the closed-loop system for a bounded value of the numerical error.
Assumption 13 (Lipschitz system dynamics).
Assume that and that positive finite constants , , and exist such that, for all , all , with , the following holds:
| (17) |
The following propositions establish bounds on the rate at which the state can change for given and .
Proposition 14.
Proposition 15.
Let Assumptions 9 and 13 hold. Then, there exist positive finite constants , and , such that for any , any , and any , the following holds:
| (20) |
Define and . Due to Proposition 14 we have that for any , any , and any , the following holds:
Hence, due to Assumption 9, we can write
such that the following holds:
| (21) | ||||
Finally, defining completes the proof. ∎
Using the bound from Proposition 15 together with the contraction from Lemma 11 we obtain the following perturbed contraction.
Proposition 16.
Then, for any such that and and any , the following holds:
| (23) |
where
| (24) |
Moreover, we also have . {pf} Due to Assumptions 2 and 13, given that and , we have for all if we additionally require that
| (25) |
which provides the first term in the definition of . Hence, for all , we can apply the contraction from Lemma 11:
| (26) | ||||
and applying the inequality from Proposition 15, we obtain
| (27) |
where
| (28) |
From this last inequality we see that in order to guarantee that , we must impose that
| (29) |
which provides the second term in the definition of .
Finally, since, for any , the following holds
| (30) |
we have that for any . ∎
Proposition 16 shows that under suitable assumptions and, in particular, for any , we can guarantee that the numerical error does not increase after one iteration of the optimizer.
In the following, we will make similar considerations for the behavior of across iterations.
2.3.2 Lyapunov decrease perturbation
Let us analyze the impact of the approximate feedback policy on the nominal Lyapunov contraction. Throughout the rest of the section, for the sake of notational simplicity, we will make use of the following shorthand:
| (31) |
to denote the value taken by the optimal cost at the state reached applying the suboptimal control action starting from . Similarly, we introduce
| (32) |
and
| (33) | ||||
to denote the numerical error attained at the “current” and at the next iteration of the optimizer, respectively, where the error is computed with respect to the exact solution associated with the “current” and next state of the system.
Proposition 17.
Let Assumptions 2, 3, 6, 9, 10, and 13 hold. Then, there exists a finite positive constant such that, for any , any , and any , the following holds:
| (34) |
where . {pf} Assumption 2 implies that, for any and any the following holds:
| (35) | ||||
Due to Assumption 3, for any , we can write
and defining we obtain
| (36) |
Together with Proposition 14, this implies that, for any , any , and any , we can write:
which implies
| (37) |
where . ∎
Using Proposition 17 we can formulate Lemma 19 below which establishes positive invariance of the following set for the system-optimizer dynamics (15).
Definition 18 (Invariant set).
Define the following set:
where
| (38) |
Lemma 19 (Invariance of ).
Let Assumptions 2, 3, 6, 9, 10, and 13 hold. Define
| (39) |
Then, for any and any , it holds that . Moreover, the following coupled inequalities hold:
| (40) | ||||
where . {pf} Given that and , we can apply the contraction from Proposition 17, such that
| (41) |
holds. Moreover, due to the definition of in (38), we have that since
| (42) | ||||
This implies that is in . Similarly, due to the fact that that and , we can apply the result from Proposition 15, which shows that
| (43) |
and
| (44) |
must hold. Using Assumption 2 in Equation (43), we obtain
| (45) |
Moreover, due to (39), we have that for any . ∎
Lemma 19 provides invariance of for the system-optimizer dynamics as well as a compact description of the interaction between the two underlying subsystems. In principle, we could study the behavior of the coupled contraction estimate by looking at the “worst-case” dynamics associated with (40):
| (46) | ||||
However, these dynamics are not Lipschitz continuous at the origin for and are for this reason non-trivial to analyze.
3 Asymptotic stability of the system-optimizer dynamics
In the following, we derive the main asymptotic stability result, which relies on a reformulation of the worst-case dynamics (46).
Proposition 20.
Let Assumptions 2, 3, 6, 9, 10, and 13 hold. Moreover, let . Then, for any and any , we have and the following holds:
| (47) | ||||
The fact that is a direct consequence of Lemma 19. Moreover, due to Assumption 3, the following holds, for any :
and, using the nominal Lyapunov contraction and Proposition 15, we obtain, for any , that
where . ∎
Unlike (46), the worst-case dynamics associated with (47) are not only Lipschitz continuous, but can also be cast as a linear positive system. We define the following dynamical system based on (47).
Definition 21 (Auxiliary dynamics).
Remark 22.
Given the definition of the auxiliary dynamics in Definition 21, for any , if and , then and . For this reason, intuitively, we can study the stability of the auxiliary dynamics and infer stability properties of the combined system-optimizer dynamics. This concept will be later formalized with the explicit construction of a Lyapunov function for the system-optimizer dynamics in Theorem 25.
We exploit properties of positive systems in order to construct an explicit linear Lyapunov function for the auxiliary dynamics which can be rewritten in the compact form
| (49) |
where
| (50) |
and . We will make use of the following result adapted from [10].
Theorem 23 (Stability of positive systems).
A positive discrete-time linear system of the form
| (51) |
where and , is asymptotically stable if there exist a strictly positive vector and a strictly positive constant such that
| (52) |
Moreover, the linear function is a Lyapunov function for (51) in and the following holds:
| (53) |
See Appendix B. ∎
Theorem 24.
The positive discrete-time linear system (49) is asymptotically stable if and only if the following condition is satisfied:
| (54) |
which holds for any sufficiently small sampling time . Moreover, the function , where
| (55) |
is a Lyapunov function for (48) in . {pf} In order to prove that is a Lyapunov function for (48) it suffices to apply Theorem 23. The system of inequalities
| (56) | ||||
admits a solution if
| (57) |
This condition can always be satisfied for a sufficiently small . In fact, it is easy to show that the limits for of the upper and lower bounds on are 0 and , respectively, such that, by continuity, there must exist a strictly positive constant such that (54) is satisfied for any . However, in order to make independent of , we note that, due to convexity, for any . Using this lower bound we can simplify the upper bound in (57) as
| (58) |
Choosing to be half of this upper bound, i.e., , we obtain that (57) is satisfied for any , which concludes the proof. ∎
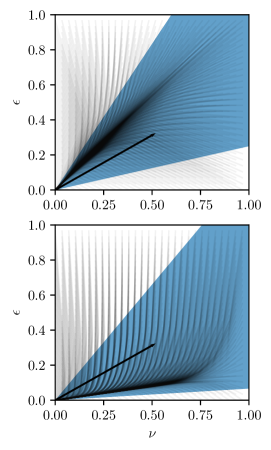
Theorem 24 shows that (exponential) asymptotic stability of the auxiliary dynamics holds under the condition that the sampling time satisfies inequality (54) for given , , , and . Figure 2 illustrates the meaning of Theorem 24 by showing the trajectories of the auxiliary system in a phase plot for fixed values of the parameters , and , two different values of the sampling time and for different initial conditions. In the following, we establish the main result of the section by exploiting the Lyapunov decrease established in Theorem 24 for the auxiliary dynamics to construct a Lyapunov function for the combined system-optimizer dynamics (16).
Theorem 25.
Let Assumptions 2, 3, 6, 9, 10, and 13 hold. Then, for any , the origin is an exponentially asymptotically stable equilibrium with region of attraction for the combined system-optimizer dynamics (16). In particular, the function
| (59) |
where is defined according to Theorem 24, is a Lyapunov function in for the system (16) and the origin . {pf} We can derive an upper bound for as follows:
| (60) | ||||
In order to derive a lower bound, we proceed as follows. Using the reverse triangle inequality and Lipschitz continuity of , we obtain
| (61) | ||||
If , then we can readily compute a lower bound:
| (62) | ||||
If instead , we define the auxiliary lower bound
| (63) |
Since , if we can show that can be lower bounded by a properly constructed function of , we can use this function to lower bound too. To this end, we first observe that, since we assumed that , for any such that , we have that
| (64) | ||||
where, for the minimization, we have used the fact that the objective is monotonically nonincreasing in such that the minimum is attained at the boundary of the interval for . Similarly, for any such that , we can use the fact that
Hence, we can conclude that
| (65) |
for any . Summing this last inequality and , we obtain
| (66) | ||||
Together with (62), we can define
| (67) |
and conclude that . Finally, the Lyapunov decrease can be derived. For given and , let and . Then the following holds.
| (68) | ||||
where we have used the norm due to the intermediate result in the proof of Theorem 23. Let denote the Lyapunov decrease. Using the same procedure used to derive the lower bound for , we can show that, if , we can write
Else, if , we can obtain the following bound:
Summing this last inequality and , we obtain
We define
| (69) |
and conclude that . Hence, we can define the functions and and the positive definite function , such that
| (70) | |||
i.e., is a Lyapunov function in for the system-optimizer dynamics and the equilibrium , for any . ∎
Theorem 25 shows that, for a sufficiently short sampling time , the system-optimizer dynamics in (15) are asymptotically exponentially stable and that is a Lyapunov function in . We observe that the obtained Lyapunov function is a positive linear combination of the ideal NMPC Lyapunov function and the error (which in turn is a Lyapunov function for the error dynamics). Loosely speaking, depending on the value of , gives more “importance” to either (for small values of ) or (for large values of ).
4 Illustrative example

We regard an optimal control problem of the form in (13) and define the continuous-time dynamics as
| (71) |
In order to compute an LQR-based terminal cost, the linearized dynamics are defined as
| (72) |
and discretized using exact discretization with piece-wise constant parametrization of the control trajectories:
where denotes the discretization time. We compute the solution to the discrete-time algebraic Riccati equation
where and such that the cost functionals can be defined as
| (73) |
and we impose simple bounds on the input .
We set the prediction horizon and discretize the resulting continuous-time optimal control problem using direct multiple shooting with shooting nodes. The Euler discretization is used for the cost integral and explicit RK4 is used to discretize the dynamics. In order to solve the resulting discretized optimal control problem, we use the standard RTI approach, with Gauss-Newton iterations and a fixed Levenberg-Marquardt-type term. A single SQP iteration per sampling time is carried out.
In order to compute an estimate for the constants involved in the definition of the Lyapunov function in Theorem 25, we regard six different initial conditions, and control the system using the feedback policy associated with the exact solution to the discretized optimal control problem. For every state in the obtained trajectories, we evaluate the optimal cost and the primal-dual optimal solution . With these values, we can estimate the constants in Assumption 2, the constant in Assumption 3 and the constant in Theorem 11. Moreover, for any state visited, we carry out a limited number of iterations of the optimizer in order to estimate the contraction rate . Choosing the sampling time , we obtain the estimates , and , such that the parameter involved in the definition of the Lyapunov function for the combined system-optimizer dynamics takes the value and we have . All the computations were carried out using CasADi [2] and its interface to Ipopt [17] and the code for the illustrative example is made available at https://github.com/zanellia/nmpc_system_optimizer_lyapunov.
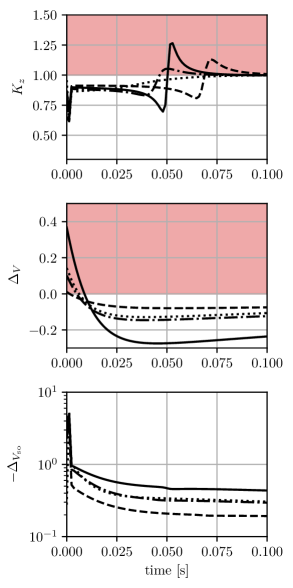
Figure 3 shows the state trajectories obtained controlling the system using the approximate feedback law starting from the selected initial conditions. Figure 4 shows the behavior of , and over time through the compact metrics
| (74) |
| (75) |
| (76) |
In particular, Figure 4 shows that, although the numerical error and the value function does not necessarily decrease over time, the constructed Lyapunov function does decrease.
5 Conclusions
In this paper, we presented a novel asymptotic stability results for inexact MPC relying on a limited number of iterations of an optimization algorithm. A class of optimization methods with Q-linearly convergent iterates has been regarded and, under the assumption that the ideal feedback law is stabilizing, we constructed a Lyapunov function for the system-optimizer dynamics. These results extend the attractivity proofs present in the literature which rely instead on the assumption that inequality constraints are either absent or inactive in the attraction region considered. Moreover, with respect to more general results on suboptimal MPC (cf. [15], [12], [1]), we analyzed the coupled system and optimizer dynamics and proved its asymptotic stability.
Future research will investigate how to relax the requirements of Lipschitz continuity of the solution localization and of Q-linear convergence.
References
- [1] D. A. Allan, C. N. Bates, M. J. Risbeck, and J. B. Rawlings. On the inherent robustness of optimal and suboptimal nonlinear MPC. Systems & Control Letters, 106:68–78, 2017.
- [2] J. A. E. Andersson, J. Gillis, G. Horn, J. B. Rawlings, and M. Diehl. CasADi: a software framework for nonlinear optimization and optimal control. Mathematical Programming Computation, pages 1–36, 2019.
- [3] H. Chen and F. Allgöwer. A quasi-infinite horizon nonlinear model predictive control scheme with guaranteed stability. Automatica, 34(10):1205–1218, 1998.
- [4] M. Diehl. Real-Time Optimization for Large Scale Nonlinear Processes, volume 920 of Fortschritt-Berichte VDI Reihe 8, Meß-, Steuerungs- und Regelungstechnik. VDI Verlag, Düsseldorf, 2002. PhD Thesis.
- [5] M. Diehl, R. Findeisen, and F. Allgöwer. A stabilizing real-time implementation of nonlinear model predictive control. In L. Biegler, O. Ghattas, M. Heinkenschloss, D. Keyes, and B. van Bloemen Waanders, editors, Real-Time and Online PDE-Constrained Optimization, pages 23–52. SIAM, 2007.
- [6] M. Diehl, R. Findeisen, F. Allgöwer, H. G. Bock, and J. P. Schlöder. Nominal stability of the real-time iteration scheme for nonlinear model predictive control. IEE Proc.-Control Theory Appl., 152(3):296–308, 2005.
- [7] C. Feller and C. Ebenbauer. Relaxed logarithmic barrier function based model predictive control of linear systems. IEEE Transactions on Automatic Control, 62(3):1223–1238, March 2017.
- [8] K. Graichen and A. Kugi. Stability and incremental improvement of suboptimal MPC without terminal constraints. IEEE Transactions on Automatic Control, 55(11):2576–2580, 2010.
- [9] N. H. Josephy. Newton’s method for generalized equations and the PIES energy model. PhD thesis, University of Wisconsin-Madison, 1979.
- [10] T. Kaczorek. The choice of the forms of Lyapunov functions for a positive 2D Roesser model. International Journal of Applied Mathematics and Computer Science, 17(4):471–475, Jan 2008.
- [11] D. Liao-McPherson, M. Nicotra, and I. Kolmanovsky. Time-distributed optimization for real-time model predictive control: Stability, robustness, and constraint satisfaction. Automatica, 117, 2020.
- [12] G. Pannocchia, J. Rawlings, and S. Wright. Conditions under which suboptimal nonlinear MPC is inherently robust. System & Control Letters, 60(9):747–755, 2011.
- [13] J. B. Rawlings, D. Q. Mayne, and M. M. Diehl. Model Predictive Control: Theory, Computation, and Design. Nob Hill, 2nd edition edition, 2017.
- [14] S. M. Robinson. Strongly Regular Generalized Equations. Mathematics of Operations Research, Vol. 5, No. 1 (Feb., 1980), pp. 43-62, 5:43–62, 1980.
- [15] P. O. M. Scokaert, D. Q. Mayne, and J.B. Rawlings. Suboptimal Model Predictive Control (Feasibility Implies Stability). IEEE Transactions on Automatic Control, 44(3):648–654, 1999.
- [16] R. Van Parys and G. Pipeleers. Real-time proximal gradient method for linear MPC. In Proceedings of the European Control Conference (ECC), Lymassol, Cyprus, 2018.
- [17] A. Wächter and L. Biegler. IPOPT - an Interior point optimizer. https://projects.coin-or.org/Ipopt, 2009.
- [18] A. Zanelli, J. Kullick, H. Eldeeb, G. Frison, C. Hackl, and M. Diehl. Continuous control set nonlinear model predictive control of reluctance synchronous machines. IEEE Transactions on Control Systems Technology, pages 1–12, February 2021.
Appendix A Proof of Proposition 3.2.16
In the following, we will use the shorthand . First, notice that
| (77) |
and that, due to continuity of with respect to , for all and all , there exists a , such that, for all , we have .
Using (77) and Assumption 13, we obtain that, for any , all and all , the following holds:
and, using the fact that ,
We can then apply the integral form of Grönwall’s Lemma in order to obtain
for any and all . Similarly, in order to prove the second inequality, we first notice that there must exist a such that, for all , for all and all such that and for all , we have . Hence, for any and all and all we can proceed as follows:
and, applying Gröonwall’s Lemma, we obtain
Finally, we pick and define and , such that
| (78) |
and
for any , all and any . ∎
Appendix B Proof of Theorem 3.2.25
It suffices to show that is a Lyapunov function for (51) in . Define and . The following inequalities hold:
and
which show that there exist functions and such that
| (79) |
Moreover, for any , we have that
| (80) | ||||
Hence, there exists a positive definite and continuous function such that, for any , the following holds
| (81) |
and , which concludes the proof. ∎