A Lightweight Solution of Industrial Computed Tomography with Convolutional Neural Network
Abstract
As an advanced non-destructive testing and quality control technique, industrial computed tomography (ICT) has found many applications in smart manufacturing. The existing ICT devices are usually bulky and involve mass data processing and transmission. It results in a low efficiency and cannot keep pace with smart manufacturing. In this paper, with the support from Internet of things (IoT) and convolutional neural network (CNN), we proposed a lightweight solution of ICT devices for smart manufacturing. It consists of efforts from two aspects: distributed hardware allocation and data reduction. At the first aspect, ICT devices are separated into four functional units: data acquisition, cloud storage, computing center and control terminals. They are distributed and interconnected by IoT. Only the data acquisition unit still remains in the production lines. This distribution not only slims the ICT device, but also permits the share of the same functional units. At the second aspect, in the data acquisition unit, sparse sampling strategy is adopted to reduce the raw data and singular value decomposition (SVD) is used to compress these data. They are then transmitted to the cloud storage. At the computing center, an ICT image reconstruction algorithm and a CNN are applied to these compressed sparse sampling data to obtain high quality CT images. The experiments with practical ICT data have been executed to demonstrate the validity of the proposed solution. The results indicate that this solution can achieve a drastic data reduction, a storage space save and an efficiency improvement without significant image degradation. The presented work has been helpful to push the applications of ICT in smart manufacturing.
Index Terms:
Industrial Computed Tomography, Smart Manufacturing, Industry Internet of Things, Singular Value Decomposition, Convolutional Neural Network.I Introduction
Idustrial computed tomography (ICT) has been widely applied to industries such as aerospace [1, 2], auto [3, 4] and microelectronic[5]. It generates nondestructively the high spatial resolution three dimensional (3D) mapping images of objects and enables an evaluation on the internal structures. ICT has played a key role to control the product quality in many fields since 1970s.
Smart manufacturing has been recently interested in ICT and many applications have been reported [6, 7, 8, 9]. Bauza et al. presented the realization of industry 4.0 with high speed ICT in high volume production [6]. Sagbas et al adopted ICT to execute nondestructive inspection of additive manufactured parts [8]. Akdogan et al applied ICT to re-engineering of manufacturing parts [9]. The ICT device is a complicated integrity and generally consists of system control, data acquisition, image reconstruction, data storage and drawback recognition. During the ICT scanning, mass X-ray projection and 3D image data is generated, processed and transmitted. Cone beam computed tomography (CBCT) with FDK (Feldkamp-Davis-Kress) [10] has been a common used ICT mode since it keeps a good balance between efficiency and quality. Typically, the generated data of a CBCT scanning can reach 10GB. So ICT is bulky, quite time-consuming and inefficient. It currently cannot satisfy the demand from smart manufacturing.
Internet of Things (IoT) is one of the drivers and foundations of data-driven innovations in smart manufacturing [11]. It forms a global information network composed of a large number of interconnected ”Things” (e.g., materials, sensors, equipments, people, products, and supply chain) [11]. By interconnecting these manufacturing things, IoT could achieve an effective digital integration of the entire manufacturing enterprise. Adopting IoT to separate and distribute the functional units can slim ICT device and let it be lightweight. Moreover, it can also make each functional unit more sophisticated and enable the share of the same functional units. However, the mass data transmission from ICT is a heavy burden and IoT cannot afford it. So it is necessary to reduce the ICT data to improve the transmission efficiency.
Sparse sampling is a good idea to reduce ICT data. However, ICT image reconstruction algorithms have a demand for the completeness of projection data. The ICT images suffer from artifacts since sparse sampling cannot meet this completeness condition. Developing the sparsity of the scanned objects, compress sensing can relax the completeness constraint and has been proved to be a powerful technique for sparse sampling image reconstruction [12]. Total variation(TV)[13] has also shown its ability in preserving edges and suppressing artifacts for sparse sampling image reconstruction. These techniques perform better than the conventional analytical algorithms, but they encounter some limits such as expensive time consumption and the complicated parameter selection.
The sparse sampling data still contains redundant information. It can be further compressed to save the storage space and improve the data transmission efficiency. The redundance lies on the the similarities in the neighboring pixels[14]. Compared with the visible light images, ICT images have much more redundancy due to the similarities of materials and structures of the inspected objects. The solution to address this problem is to compress the projection while maintaining acceptable image quality. Singular value decomposition (SVD) in image compression has attracted more and more interests [15]. SVD aims to find the low-rank approximation of the image matrix and represent it with much less data.
Sparse sampling and SVD can greatly reduce the ICT data, but they may lead to a degradation in ICT reconstruction images. Deep learning(DL) has been recently more and more popular and provides a possible solution for this degradation. As a typical DL technique, convolutional neural network(CNN) has been widely applied to image processing such as segmentation [16], super resolution[17] and restoration[18]. It has also found many applications in CT. Han et al reported a deep learning residual architecture for sparse sampling CT [19]. They first estimated the artifacts caused by the sparse sampling and then subtracted it from the CT image to obtain the artifact-free image. Jin et al developed a deep CNN for inverse problems in CT [20]. They combined multi-resolution decomposition with residual learning to remove the artifacts. Pelt et al proposed a mixed-scale dense CNN for image analysis [21].They adopted dilated convolutions to capture features at different image scales and densely connected all feature maps with each other. This architecture reduces parameters and avoids overfitting. Zhang et al [22] presented a sparse sampling CT reconstruction method by combining DenseNet [23] and deconvolution to remove the artifacts. Dong et al [24] reported a deep learning framework for CT with sparse-view projections. It is based on U-Net to estimate the complete projections from sparse-view projections. The above mentioned methods are based on 2D fan beam CT. For 3D CBCT, Jiang et al [25] proposed a symmetric residual convolutional neural network (SR-CNN). This architecture is able to reserve edges and structures in under-sampled CBCT images. Yang et al [26] adopted residual leaning network to suppress the streaking artifacts in sparse sampling CBCT and made a great progress.
In this paper, supported by IoT and CNN, we proposed a lightweight solution of ICT for smart manufacturing. It consists of efforts from two aspects: distributed hardware allocation and data reduction. First, the ICT device in the production line is simplified to be a data acquisition unit and all the other units are separated and distributed by IoT. It not only slims the ICT device, but also permits ICT devices from different production lines can share the same functional units. Moreover, the functional units will obtain space to develop to be more sophisticated and powerful. Second, sparse sampling strategy is adopted in the data acquisition unit to reduce the raw data and SVD is adopted to compress the raw data. The compressed data is then upload to the shared and distributed ICT units for further processing and storage. When image reconstruction is executed, the raw projection data is first recovered from the compressed data and reconstructed with FDK algorithm to generate the original CT images. A dense connection based CNN is then applied to the original CT images to remove the artifacts caused by sparse sampling and SVD. This CNN originates from the framework proposed by our group [27] and can reduce the number of parameters and achieve a high learning efficiency. In this article, we focus on data reduction. The distributed hardware allocation depends on IoT and will not be discussed in detail. The experiments with practical ICT data have been executed to demonstrate the validity of the proposed solution. The results indicate that this technique can achieve a drastic data reduction and an efficiency improvement without significant image degradation.
Briefly, the contributions in this article are as follow:
1) Present a lightweight solution of ICT for smart manufacturing.
2) Adopt distributed hardware allocation to slim ICT devices and permit the share of the same functional units.
3) Adopt sparse sampling strategy and SVD to reduce data.
4) Construct a CNN to deal with ICT image degradation.
II Methods
II-A Solution Overview
As illustrated in Fig.1, the proposed solution consists of four parts: field ICT devices, cloud storage, computing center and terminals. The cloud storage acts as a hub through which data and instructions are transmitted among other three parts. The field ICT devices are simplified to be data acquisition units and from different production lines. They receive the instructions from terminals and make response. They acquire, compress and transmit the compressed data to cloud storage. Other ICT units such as image reconstruction and drawbacks recognition are centralized to computing center. Terminals may be industrial computers or portable mobile devices such as smart phones and tablets. They control field devices and computing center, and have access to the ICT projection and image data saved at the cloud storage.
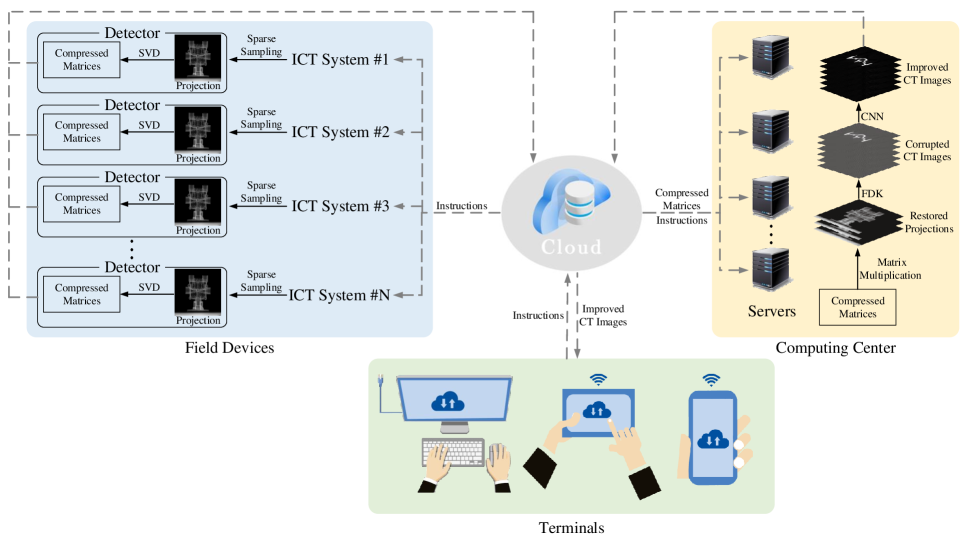
The field devices adopt sparse sampling strategy and SVD technique to reduce the raw projection data. Much less data is acquired in sparse sampling and the data acquisition time also greatly decreases. SVD is a linear matrix transformation used for image compression to remove the data redundancy. By applying SVD to the sparse sampling data and discarding lower singular values, the data could be approximated with three small size low-rank matrices and a great compression is obtained. It also saves the storage space. SVD can be implemented by hardware and easily embedded in the detector.
The computing center consists of a number of servers. They receive instructions from terminals and data from cloud storage and upload the improved CT images to cloud storage. The computing center performs three tasks: compressed projection restoration, image reconstruction and image improvement. First, the SVD compressed projections are restored. Then, FDK algorithm is applied to these restored projections to obtain the corrupted CT images. Finally, a CNN is applied to the corrupted CT images to remove the artifacts caused by sparse sampling and SVD compression. This CNN is based on densely connected pattern and U-Net. It keeps a good balance between the number of parameters and the performance.
This solution in Fig.1 implements distributed allocation of ICT functional units and data reduction. By distributed hardware allocation, ICT devices become slim and lightweight and the same functional units can be shared. Data reduction not only improves the transmission efficiency, but also save the storage space. So it provides a possible lightweight ICT solution for smart manufacturing.
II-B Neural Network
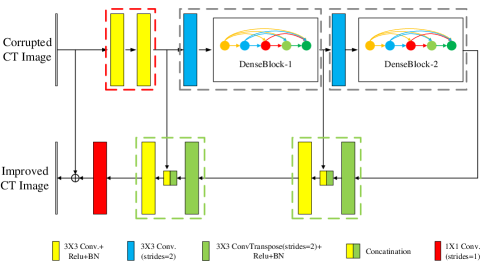
Depicted in Fig.2, the architecture of the CNN in Fig.1 is modified from the framework proposed by our group [27]. It takes advantages of U-Net [16] and DenseNet[23] to remove the artifacts caused by sparse sampling and SVD compression. As shown in Fig.2, the corrupted CT images are fed into the network and improved CT images are obtained. It consists of four kinds of function units as follow:
i)Two convolutional layers indicated by the two yellow solid rectangles surrounded by a red dashed line which are used to extract primary features.
ii)Two components surrounded by two grey dashed lines which contain down-sampling layers and DenseBlocks. The down-sampling is realized with convolutional layer with a stride of 2. These two components act as encoders and obtain multi-scale features.
iii)Two components surrounded by two green dashed lines which are used for decoding. They restore high resolution features from the low resolution features and concatenate them with lower level features.
iv)A convolutional layer with a filter size of indicated by the red solid rectangle. It compresses the stacked feature layers into one layer to keep the same size with the fed corrupted image.
As an example, the parameters of the network are listed in the Table I where the size of the fed corrupted CT image is pixels.
| Layers | Input Size | Ouput Size | ||
|---|---|---|---|---|
|
||||
|
||||
| Conv.(strides=2) | ||||
| DenseBlock-1 | ||||
| Conv.(strides=2) | ||||
| DenseBlock-2 | ||||
|
||||
| Concatenation | ||||
|
||||
|
||||
| Concatenation | ||||
|
||||
| Conv.(strides=1) | ||||
| Add | ||||
II-B1 Skip Connection
The CNN in Fig.2 contains two kinds of skip connections: element-wise addition between input and output in the form of residual learning [28] and feature concatenation among different stages.
The element-wise addition is formulated in (1), where represents the fed image, the nonlinear mapping of the network and the output of the network. This operation forces the network to recognize and remove the artifacts from the corrupted CT images, rather than remove the artifacts and build up the whole CT images at the same time. It simplifies the learning process.
| (1) |
Another skip connection is feature concatenation among different stages. It aims to integrate different levels of features. It is well known that DL naturally takes into account low, middle and higher level features. In the CNN in Fig.2, the high level features that contain wealth semantic information are hard to recover the spatial information. On the contrary, the low level features that contain less semantic information retain a good spatial accuracy. So the low level features are concatenated with high-level features to ensure a best result.
II-B2 DenseBlock
In the proposed solution, the CNN should be lightweight to obtain a high processing speed. We adopt DenseBlock technique to reduce the parameters. The structure of DenseBlock is shown in Fig.3. Each layer takes all preceding layers as input and passes its own features to all subsequent layers. The DenseBlock in Fig.3 contains four BN-Relu- Conv.(strides=1) layers. Compared with the preceding layer, each layer produces new features. Features from all the preceding layers are reused through dense connections. It could explore the full potential of the network and yield condensed models with higher parameter efficiency. Some researches have shown that a small number of features are sufficient for DenseBlock to obtain acceptable results. Densely connection discards redundant features and focuses on taking advantage of retained features, which dramatically reduces the number of parameters and improves the processing speed.
Moreover, densely connection makes the network easier to train since each layer in the same block can directly access the gradients from the cost function and the original input. It results in an implicit deep supervision [23]. Additionally, each layer generates only new features. The contribution to the final result from each one layer is controlled. It will overcome the problem of overfitting in a small batch training set.
The parameters of the DenseBlock in Fig.3 are listed in the Table II, where and represent the height and width of the features respectively.

| Layers | Input Size | Output Size | |
|---|---|---|---|
| 1 | BN-Relu- Conv. | ||
| Concatenation | |||
| 2 | BN-Relu- Conv. | ||
| Concatenation | |||
| 3 | BN-Relu- Conv. | ||
| Concatenation | |||
| 4 | BN-Relu- Conv. | ||
| Concatenation | |||
II-B3 Network Training
The network training is executed according to the following steps:
i)A set of corrupted CT images are matched with the corresponding ground truth into many pairs of training data. Each pair of training data includes a corrupted CT image obtained from restored projection and its corresponding ground truth obtained from the complete projection.
ii)These training data are fed into the CNN depicted in Fig.2 one pair by one pair to optimize the network.
iii)Repeat steps i) and ii) until the learning converges.
After training, the CNN is determined and ready to be used to obtain high quality CT images from the corrupted ones.
II-C Singular Value Decomposition
The SVD of the image matrix is formulated in (2). In this equation, and are the matrices with orthonormal columns. is the diagonal matrix. The vectors and are the left and right singular vectors of . The diagonal entries of are singular values of . As shown in (3), they are no less than zero and sorted by value descending.
| (2) |
| (3) |
Lower singular values contain negligible image information which can be discarded without significant image degradation. Thus, the image matrix could be approximated by the first singular values, as shown in (4). This approximation will reduce the storage space from bytes to bytes. The compression ratio (CR) given by (5) can be used to evaluate the compression performance.
| (4) |
| (5) |
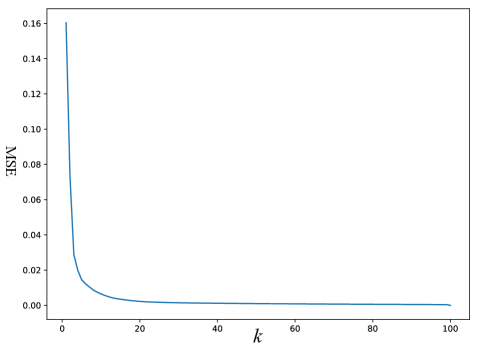
In ICT engineering applications, many objects are homogeneous and the internal structures are similar each other. Thus, the ICT projection data contains much more redundant information that is suitable for the compression with SVD. As an example, Fig.4 shows an ICT projection and its three compressed projections with different number of singular values. Fig.5 shows the curve of mean square error(MSE) between the original ICT projection and its compressed one with SVD. Along with the increase of value of , the MSE value descends rapidly. After the value of reaches 30, the MSE value has no visible change. It indicates that ICT projection can be approximated with the first singular values.

II-D FDK Reconstruction Algorithm
FDK is a CBCT reconstruction algorithm [10]. It has been the dominated technique in practical CBCT reconstruction. FDK algorithm has many extension versions and the one for a planar detector consists of the following three steps:
i)As shown in (6), weight the projection data. In this equation, represents the original projection data acquired by the detector element at the row and column under the sampling angle .
| (6) |
ii)As shown in (7), execute one-dimensional filtering on the weighted data in (6). In this equation, represents the ramp filter.
| (7) |
iii)As shown in (8), do back projection reconstruction. In this equation, represents the reconstruction volume and is the distance from X-ray source to detector.
| (8) |
| (9) |
FDK algorithm has high reconstruction speed and accuracy when the projection data is complete. However, dramatic image degradation will occur when it is applied to sparse sampling projection data.
III Experiments
III-A Data Preparation
The experimental data set is prepared by executing the CBCT scanning of two aluminum auto components, No.1 and No.2, with the ICT system developed by our group. These two components have different shapes and internal structures. The data set of the NO.1 component is for training and the data set of the NO.2 component is for testing.
The used ICT system plays as a data acquisition unit and consists of an 160 kV X-ray source, YTU160-D01, from YXLON company (Germany) and a 2D X-ray flat panel detector, XRD 1621, from PerkinElmer company (USA). The X-Ray source works with a tube voltage 120 and a tube current 2.0. The detector has an element size of 0.2 and works in an internal trigger mode. The field of view has a size of about .
The CBCT scanning angular increment is and totally 720 projections are acquired within . At each scanning angular position, a 2D projection image with a size of pixels is recorded by the 2D X-ray flat panel detector. So for each component, the projection data set has a size of pixels and occupies a storage space of 9.4263GB. It is complete for CT image reconstruction. Fig.4 shows one of the 2D projection images of the No.1 component.
The sparse sampling data set is obtained by extracting some projections from the complete data set. This extraction is with an equal angular interval named sparse sampling factor. In these experiments, the sparse sampling factor is set to be 12. The spare sampling CBCT projection data set has a size of pixels and occupies a storage space of 0.7855GB.
According to the SVD compression performance curve in Fig.5, the first 30 singular values are retained. With the sampling sparse factors 12, the compressed sparse sampling data set has a size of and just need a storage space of 0.0252GB. They will be transferred from the field ICT device to the cloud storage and fed to the computing center.
The 3D ICT volume image of each auto component consists of 460 2D cross section slice images with a size of pixels. They are generated by applying FDK algorithm to the projection data set at the computing center. The results from the complete projection data set with a size of pixels are treated as the ground truth.
Considering the spatial structure similarity of neighboring 2D cross section slices, in order to improve the learning efficiency and accuracy, only one of the neighboring 9 slices is selected for training. Totally, 50 slice images are selected from the 460 CT images of the No.1 auto component for training. We adopt some image transform operations such as rotation and translation to expand the training data set from 50 images to 550 images. All the 460 ICT slice images of the No.2 component are used for testing.
III-B Implementation
The CNN is implemented with Python 3.7.3 and Tensorflow 1.14.0. It runs on a workstation with a CPU Intel(R) Core(TM) i7-7700 HQ and a GPU Nvidia GTX 1060 with Max-Q Design 6GBytes.
As shown in (10), the loss function is based on the mean square error (MSE), where denotes the output image and represents the label image.
| (10) |
The network parameters are initialized using a Gaussian distribution with a mean value of zero and a standard deviation of , in which indicates the number of input units in each layer.
Adaptive momentum estimation (Adam) optimizer algorithm [29] is adopted to train the network. The initial learning rate is and gradually reduced to . All the models are trained for 100 epochs. It takes about 14 hours to complete the training. During testing, it takes about 0.8s to obtain an improved CT image.
III-C Quantitative Evaluation
The performance of the proposed solution need to be evaluated from two aspects: image quality and compression ratio.
For image quality evaluation, we select feature similarity (FSIM) [30] and information weighted SSIM (IW-SSIM) [31] as the indicators according to the research of Zhang et al[32].
The total compression ratio of this solution is calculated with (11). Here, and represent the height and width of projection, the number of retained singular values, the number of the sparse sampling projections.
| (11) | ||||
III-D Results
Fig.6 presents the 3D ICT images of the No.2 auto component before and after the improvement with CNN. It corresponds to the case with a sparse sampling factor 12 and the first 30 singular values. Compared with the ground truth, the one before the improvement with CNN has coarse surfaces and artifacts, caused by the sparse sampling and SVD compression and indicated by the red arrows in Fig.6. In the contrary, the one after the improvement with CNN has no visible artifacts.
Shown in Fig.7, one typical 2D cross section slice is selected from the 3D ICT image and a region of interest (ROI) is zoomed in for better visual observation and quantitative evaluation. As observed in the 3D images, the streak artifacts are quite visible in the 2D slices before the improvement with CNN. After the processing, the streak artifacts disappear from the 2D slice images.


Table III lists the FSIM and IW-SSIM values of presented images in Fig.7. Table IV lists the averaged FSIM and IW-SSIM values of all the testing slices. The FSIM and IW-SSIM values of the results after the processing of CNN are always greater than the ones before the processing. Table V presents the data compression ration in this experiment. It reaches 373.32 and indicates a tremendous data reduction.
The images in Figs.6 and 7 and the parameter values in Tables III, IV and V, demonstrate the validity of the sparse sampling, SVD compression, CNN restoration and the proposed lightweight solution of ICT for smart manufacturing. Within this solution, without significant image degradation, a drastic data reduction, a storage space save and an efficiency improvement are obtained.
| FSIM |
|
0.6575 | ||
|---|---|---|---|---|
|
0.9228 | |||
| IW-SSIM |
|
0.4019 | ||
|
0.9028 |
| FSIM |
|
0.7241 | ||
|---|---|---|---|---|
|
0.9258 | |||
| IW-SSIM |
|
0.4653 | ||
|
0.9006 |
| Sparse Sampling | SVD | Sparse Sampling and SVD | |
|---|---|---|---|
| CR | 12 | 31.11 | 373.32 |
IV Conclusion
In this paper, we proposed a lightweight solution of ICT devices for smart manufacturing with the support from IoT and CNN. Within this solution, ICT devices are separated into four function units. The data acquisition units remain in the production lines. Other three units are data storage, computing center and terminals and distributed by IoT. They are interconnecting and share instructions and data by IoT. It slims the ICT devices and enables the share of the same function units by the different production lines. This solution adopts sparse sampling to SVD compression technique to obtain a great data reduction. A compression ration about 300 can be achieved. It is helpful to improve the data transmission efficiency. The experimental results with auto components have demonstrate the validity of the proposed solution.
This solution depends on IoT and data compression techniques. Along with the develop of image processing and deep learning techniques, a greater data compression ratio can be obtained. Particularly, along with the application of the fifth generation of wireless communications technologies, IoT will have a revolutionary progress. They give a promising future to this solution.
Acknowledgment
We acknowledge support from the National Science and Technology Major Project of China (2018ZX04018001-006), National Natural Science Foundation of China (51975026), the Joint Fund of Research Utilizing Large-scale Scientific Facilities by National Natural Science Foundation of China and Chinese Academy of Science (U1932111).
References
- [1] J. Fu, Z. Liu, and J. Wang, “Multi-mounted x-ray computed tomography,” PloS one, vol. 11, no. 4, 2016.
- [2] J. Fu, J. Wang, W. Guo, and P. Peng, “Multi-mounted x-ray cone-beam computed tomography,” Nuclear Instruments and Methods in Physics Research Section A: Accelerators, Spectrometers, Detectors and Associated Equipment, vol. 888, pp. 119–125, 2018.
- [3] M. Barciewicz, A. Ryniewicz et al., “Computed tomography as a quality control technique in the 3d modelling of injection-moulded car system components,” Czasopismo Techniczne, vol. 2018, no. Volume 9, pp. 189–200, 2018.
- [4] S. Zheng, J. Vanderstelt, J. McDermid, and J. Kish, “Non-destructive investigation of aluminum alloy hemmed joints using neutron radiography and x-ray computed tomography,” NDT & E International, vol. 91, pp. 32–35, 2017.
- [5] N. Asadizanjani, M. Tehranipoor, and D. Forte, “Pcb reverse engineering using nondestructive x-ray tomography and advanced image processing,” IEEE Transactions on Components, Packaging and Manufacturing Technology, vol. 7, no. 2, pp. 292–299, 2017.
- [6] M. B. Bauza, J. Tenboer, M. Li, A. Lisovich, J. Zhou, D. Pratt, J. Edwards, H. Zhang, C. Turch, and R. Knebel, “Realization of industry 4.0 with high speed ct in high volume production,” CIRP Journal of Manufacturing Science and Technology, vol. 22, pp. 121–125, 2018.
- [7] T. Zikmund, J. Šalplachta, A. Zatočilová, A. Břínek, L. Pantělejev, R. Štěpánek, D. Koutnỳ, D. Paloušek, and J. Kaiser, “Computed tomography based procedure for reproducible porosity measurement of additive manufactured samples,” NDT & E International, vol. 103, pp. 111–118, 2019.
- [8] B. Sagbas and M. N. Durakbasa, “Industrial computed tomography for nondestructive inspection of additive manufactured parts,” in Proceedings of the International Symposium for Production Research 2019. Springer, 2019, pp. 481–490.
- [9] A. Akdogan, A. S. Vanli, and N. Durakbasa, “Re-engineering of manufacturing parts by computed tomography data,” in International Conference on Measurement and Quality Control-Cyber Physical Issue. Springer, 2019, pp. 114–121.
- [10] L. A. Feldkamp, L. C. Davis, and J. W. Kress, “Practical cone-beam algorithm,” Josa a, vol. 1, no. 6, pp. 612–619, 1984.
- [11] H. Yang, S. Kumara, S. T. Bukkapatnam, and F. Tsung, “The internet of things for smart manufacturing: A review,” IISE Transactions, vol. 51, no. 11, pp. 1190–1216, 2019.
- [12] C.-J. Hsieh, T.-K. Huang, T.-H. Hsieh, G.-H. Chen, K.-L. Shih, Z.-Y. Chen, J.-C. Chen, and W.-C. Chu, “Compressed sensing based ct reconstruction algorithm combined with modified canny edge detection,” Physics in Medicine & Biology, vol. 63, no. 15, p. 155011, 2018.
- [13] J. Rong, P. Gao, W. Liu, Q. Liao, C. Jiao, and H. Lu, “Prior image based anisotropic edge guided tv minimization for few-view ct reconstruction,” in 2014 IEEE Nuclear Science Symposium and Medical Imaging Conference (NSS/MIC). IEEE, 2014, pp. 1–4.
- [14] S. Kahu and R. Rahate, “Image compression using singular value decomposition,” International Journal of Advancements in Research & Technology, vol. 2, no. 8, pp. 244–248, 2013.
- [15] H. Prasantha, H. Shashidhara, and K. B. Murthy, “Image compression using svd,” in International Conference on Computational Intelligence and Multimedia Applications (ICCIMA 2007), vol. 3. IEEE, 2007, pp. 143–145.
- [16] O. Ronneberger, P. Fischer, and T. Brox, “U-net: Convolutional networks for biomedical image segmentation,” in International Conference on Medical image computing and computer-assisted intervention. Springer, 2015, pp. 234–241.
- [17] J. Yu, Y. Fan, J. Yang, N. Xu, Z. Wang, X. Wang, and T. Huang, “Wide activation for efficient and accurate image super-resolution,” arXiv preprint arXiv:1808.08718, 2018.
- [18] Y. Zhang, Y. Tian, Y. Kong, B. Zhong, and Y. Fu, “Residual dense network for image restoration,” IEEE Transactions on Pattern Analysis and Machine Intelligence, 2020.
- [19] Y. S. Han, J. Yoo, and J. C. Ye, “Deep residual learning for compressed sensing ct reconstruction via persistent homology analysis,” arXiv preprint arXiv:1611.06391, 2016.
- [20] K. H. Jin, M. T. McCann, E. Froustey, and M. Unser, “Deep convolutional neural network for inverse problems in imaging,” IEEE Transactions on Image Processing, vol. 26, no. 9, pp. 4509–4522, 2017.
- [21] D. M. Pelt and J. A. Sethian, “A mixed-scale dense convolutional neural network for image analysis,” Proceedings of the National Academy of Sciences, vol. 115, no. 2, pp. 254–259, 2018.
- [22] Z. Zhang, X. Liang, X. Dong, Y. Xie, and G. Cao, “A sparse-view ct reconstruction method based on combination of densenet and deconvolution,” IEEE transactions on medical imaging, vol. 37, no. 6, pp. 1407–1417, 2018.
- [23] G. Huang, Z. Liu, L. Van Der Maaten, and K. Q. Weinberger, “Densely connected convolutional networks,” in Proceedings of the IEEE conference on computer vision and pattern recognition, 2017, pp. 4700–4708.
- [24] J. Dong, J. Fu, and Z. He, “A deep learning reconstruction framework for x-ray computed tomography with incomplete data,” PloS one, vol. 14, no. 11, 2019.
- [25] Z. Jiang, Y. Chen, Y. Zhang, Y. Ge, F.-F. Yin, and L. Ren, “Augmentation of cbct reconstructed from under-sampled projections using deep learning,” IEEE transactions on medical imaging, vol. 38, no. 11, pp. 2705–2715, 2019.
- [26] F. Yang, D. Zhang, H. Zhang, K. Huang, Y. Du, and M. Teng, “Streaking artifacts suppression for cone-beam computed tomography with the residual learning in neural network,” Neurocomputing, vol. 378, pp. 65–78, 2020.
- [27] J. Fu, J. Dong, and F. Zhao, “A deep learning reconstruction framework for differential phase-contrast computed tomography with incomplete data,” IEEE Transactions on Image Processing, vol. 29, no. 1, pp. 2190–2202, 2019.
- [28] K. He, X. Zhang, S. Ren, and J. Sun, “Deep residual learning for image recognition,” in Proceedings of the IEEE conference on computer vision and pattern recognition, 2016, pp. 770–778.
- [29] D. P. Kingma and J. Ba, “Adam: A method for stochastic optimization,” arXiv preprint arXiv:1412.6980, 2014.
- [30] L. Zhang, L. Zhang, X. Mou, and D. Zhang, “Fsim: A feature similarity index for image quality assessment,” IEEE transactions on Image Processing, vol. 20, no. 8, pp. 2378–2386, 2011.
- [31] Z. Wang and Q. Li, “Information content weighting for perceptual image quality assessment,” IEEE Transactions on image processing, vol. 20, no. 5, pp. 1185–1198, 2010.
- [32] L. Zhang, L. Zhang, X. Mou, and D. Zhang, “A comprehensive evaluation of full reference image quality assessment algorithms,” in 2012 19th IEEE International Conference on Image Processing. IEEE, 2012, pp. 1477–1480.