A Lagrangian Dual-based Theory-guided Deep Neural Network
Abstract
The theory-guided neural network (TgNN) is a kind of method which improves the effectiveness and efficiency of neural network architectures by incorporating scientific knowledge or physical information. Despite its great success, the theory-guided (deep) neural network possesses certain limits when maintaining a tradeoff between training data and domain knowledge during the training process. In this paper, the Lagrangian dual-based TgNN (TgNN-LD) is proposed to improve the effectiveness of TgNN. We convert the original loss function into a constrained form with fewer items, in which partial differential equations (PDEs), engineering controls (ECs), and expert knowledge (EK) are regarded as constraints, with one Lagrangian variable per constraint. These Lagrangian variables are incorporated to achieve an equitable tradeoff between observation data and corresponding constraints, in order to improve prediction accuracy, and conserve time and computational resources adjusted by an ad-hoc procedure. To investigate the performance of the proposed method, the original TgNN model with a set of optimized weight values adjusted by ad-hoc procedures is compared on a subsurface flow problem, with their L2 error, R square (R2), and computational time being analyzed. Experimental results demonstrate the superiority of the Lagrangian dual-based TgNN.
Index Terms:
theory-guided neural network; Lagrangian dual; weights adjustment; tradeoff.I Introduction
The deep neural network (DNN) has achieved significant breakthroughs in various scientific and industrial fields [1, 2, 3, 4]. Like most data-driven models in artificial intelligence [5], they are also dependent on a large amount of training data. However, the cost and the difficulty of collecting data in some areas, especially in energy-related fields, hinders the development of (deep) neural networks. To further increase their generalization, theory-guided data science models, which bridge scientific problems and complex physical phenomena, have gained increased popularity in recent years [6, 7, 8].
As a successful representative, the theory-guided neural network framework, also called a physical-informed neural network framework or an informed deep learning framework, which incorporates the theory (e.g., governing equations, other physical constraints, engineering controls, and expert knowledge) into (deep) neural network training, has been applied to construct the prediction model, especially in industries with limited training data [6, 7]. Herein, the theory may refer to scientific laws and engineering theories [6], which can be regarded as a kind of prior knowledge. Such knowledge is combined with training data to improve training performance during the learning process. In the loss function, they are usually transformed into regularization terms and added up with the training term [9]. Owing to the existence of theory, predictions obtained by TgNN take physical feasibility and knowledge beyond the regimes covered with the training data into account. As a result, TgNN can obtain a training model with better generalization, and can achieve higher accuracy than the traditional DNN [1, 7].
Although the introduction of theory expands the application of data-driven models, the tradeoff between observation data and theory should be equitable. Herein, we first provide its theory-incorporated mathematical formulation, as shown in Eq.1:
| (1) | ||||
where and denote the weight and mean square error for -th term, respectively; and , where the term refers to the observation data or training data. The remaining terms are the added theory in the (D)NN model. The governing equations consist of terms , , , , and , referring to partial differential equations, initial conditions, boundary conditions, engineering control, and engineering knowledge, respectively. Each weight term represents the importance of the corresponding term in the loss function. In addition, only the might the values of these terms be at different scales, but their physical meanings and dimensional units can also be distinct. Therefore, balancing the tradeoff among these terms is critical.
If viewing these weight variables as neural architecture parameters, the gradient of is calculated as from Eq.1, i.e., a constant nonnegative value, making continuously decrease until negative infinity with the increase of iterations at the stage of back-propagation [10, 11]. Therefore, due to the existence of theory, i.e., regularization terms in the loss function, it is difficult to determine the weights of each term in comparison with the training data term. If set inappropriately, it is highly possible to increase the training time, or even impede the convergence of the optimizer, contributing to an inaccurate training model. Consequently, the adjustment of these weight values is essential. In most existing literature, researchers often adjust these values by experience [6, 9, 8]. However, if these weights are not at the same scale, this will inevitably create a heavy burden on researchers and place a constraint on the ability to conserve human time.
Recently, babysitting or evolutionary computation based techniques [12], such as grid search [13, 14] and genetic algorithm [15, 16], have achieved rising popularity for hyper-parameter optimization [17, 18, 19]. If TgNN first generates an initial set of weights, followed by comparing and repeating this searching process until the most suitable set of weight values is found or the stopping criterion is met, the training time will be absolutely extended. In contrast, if the search for optimized weight values can be incorporated into the training process, the training time may be shortened.
In recent years, Lagrangian dual approaches have been widely combined with the (deep) neural network to improve the latter’s ability when dealing with problems with constraints [20, 21, 22, 23]. Ferdinando et al. pointed out that Lagrangian duality can bring significant benefits for applications in which the learning task must enforce constraints on the predictor itself, such as in energy systems, gas networks, transprecision computing, among others [20]. Walker et al. incorporated the Lagrangian dual approach into laboratory and prospective observational studies [24]. Gan et al. developed a Lagrangian dual-based DNN framework for trajectory simulation [23]. Pundir and Raman proposed a dual deep learning method for image-based smoke detection [25]. The above contributions can improve the performance of the original deep neural network framework and provide more accurate predictive training models.
Having realized this, we propose the Lagrangian dual-based TgNN (TgNN-LD) to provide theoretical guidance for the adjustment of weight values in the loss function of the theory-guided neural network framework. In our method, the Lagrangian dual framework is incorporated into the TgNN training model, and controls the update of weights with the purpose of automatically changing the weight values and producing accurate predictive results within limited training time. Moreover, to better set forth our approach, we select a subsurface flow problem as a test case in the experiment.
The reminder of this paper proceeds as follows. Section II briefly describes the mathematical formulation of the TgNN model, followed by details of the proposed method. The experimental settings with the investigation of corresponding results are provided in Section III and IV, respectively. Finally, Section V concludes the paper and suggests directions for future research.
II Proposed Method
In this paper, we consider the following optimization problem:
| (2) | ||||
since the initial condition (IC) and boundary condition (BC), which impose restrictions for the decision space, can be regarded as a part of the data term. The values of , , and have a great impact on the optimization results. As discussed previously, not only might the values of these terms be at different scales, but their physical meanings and dimensional units can also be dissimilar. As a consequence, by introducing the formation of Eq.2, is expected to achieve a normalized balance between training data and the other terms. If it is inappropriately assigned, however, the prediction accuracy will be diminished, and both training time and computational cost will markedly increase. To theoretically determine the weight values and maintain the balance of each term in TgNN, we propose the Lagrangian dual-based TgNN framework.
II-A Problem description
We first introduce the following mathematical descriptions of governing equations of the underlying physical problem:
| (3) |
| (4) |
| (5) |
where and denote the spatial and temporal domain, respectively, with as the spatial boundaries; and represent a differential operator and its spatial derivatives, respectively, of ; is a forcing term; and and are two other operators which define the initial and boundary conditions, respectively.
As discussed in Eq.1, TgNN incorporates theory into DNN by the summation of corresponding terms. It is constructed based on the following six general parts shown in Eq.6:
| (6) |
where needs to approach to 0, representing the residual of the partial differential Eq.3; denotes the collocation points of the residual function with the size of , which can be randomly chosen because no labels are needed for these points; is the approximation of a solution obtained by the (deep) neural network; represents the numbers of training data; and denote the collocation points for the evaluation of initial and boundary conditions, respectively; and and denote the collocation points of engineering control and knowledge, respectively.
II-B Problem transformation
Having realized the mathematical description of each term, we then convert the original loss function of the TgNN model, which incorporates scientific knowledge and engineering controls, to be re-written as Eq.7:
| (7) |
Following this, a Lagrangian duality framework [20], which incorporates a Lagrangian dual approach into the learning task, is employed to learn this constrained optimization problem and approximate minimizer . Given three multipliers, , , and , corresponding to per constraint, consider the Lagrangian loss function
| (8) |
where can be written as:
| (9) |
According to [20], the previous Lagrangian loss function with respect to multipliers , can then be transformed into a function with the purpose of finding the , which can minimize the Lagrangian loss function, solving the optimization problem shown as follows:
| (10) |
Herein, we denote an approximation of the approximated optimizer as , which can be produced by an optimizer (in our paper, we use Adam) during the training process.
Next, the above problem is transformed by the Lagrangian dual approach into searching the required optimal multipliers for a max-min problem shown as follows:
| (11) |
The same as [20], we denote this approximation as .
To summarize [20], the repeated calculation and search process by the Lagrangian dual framework adhere to the following steps:
(a) Learn ;
(b) Let , where denotes the -th training sample, and refers to the label;
(c) .
where and refer to the update step size and the current iteration, respectively. In our problem, we recommend , and we utilize in our experiment.
III Experimental Settings
In this section, we take a 2-D unsteady-state single phase subsurface flow problem [9] as the test case to investigate the performance of the proposed Lagrangian dual-based TgNN.
III-A Parameter settings and scenario description
The governing equation of the subsurface flow problem in our experiment can be written as Eq.12:
| (12) | ||||
where is the hydraulic head that needs to be predicted; and and are the specific storage and the hydraulic conductivity field, respectively. When is approximate with the neural network, , the residual of the governing equation of flow can be written as:
| (13) | ||||
In Eq.13, the partial derivatives of can be calculated in the network while the partial derivatives of are, in general, required to be computed by numerical difference. Herein, we view the hydraulic conductivity field as a heterogeneous parameter field, i.e., a random field following a specific distribution with corresponding covariance [9]. Since its covariance is known, the Karhunen-Loeve expansion (KLE) is utilized to parameterize this kind of heterogeneous model. As a result, the residual of the governing equation can be re-written as Eq.14:
| (14) | ||||
where represents the hydraulic conductivity field with as the -th independent random variable of the field . For the sake of fairness, the settings of our experiments remain the same as those in [9], listed in Tab.LABEL:tab:settings. MODFLOW software is adopted to perform the simulations to obtain the required training dataset.
| a square domain | evenly divided into grid blocks | |||
| length in both directions of domain |
|
|||
| specific storage | ||||
| the total simulation time | ( denotes any consistent time unit) | |||
| each time step | (50 time steps in total) | |||
| the correlation length of the field | ||||
| hydraulic conductivity field settings |
|
|||
| initial conditions |
|
|||
| prescribed heads |
|
|||
| the log hydraulic conductivity |
|
III-B Compared methods
Wang et al. determined a set of values for TgNN via an ad-hoc procedure, which is [9], for this particular problem. To investigate whether there are improvements in predictive accuracy, we utilize this weight setting as one of the compared methods and denote this case as TgNN. In addition, for comparison, we also take a naive approach by setting the weights equally as and denote this case as TgNN-1.
IV Comparisons and Results
This section first evaluates the predictive accuracy of the proposed Lagrangian dual-based TgNN framework on a subsurface flow problem, in comparison with TgNN and TgNN-1. Subsequently, we reduce the training epochs to observe whether the efficiency can be improved with less training time. Changes of Lagrangian multipliers are then recorded with their final values being assigned into the loss function to compare predictive performances obtained by dynamic adjustment and fixed values. Furthermore, different levels of noise are added into the training data to observe the effect on the predictive results caused by noise. Finally, the stopping criterion is substituted with a dynamic epoch, which has a relationship with changes of loss values, to control the training process.
First, the distribution of the hydraulic conductivity field is provided in Fig.1.(a) with the reference hydraulic head at in Fig.1.(b).


IV-A Predictive accuracy
We first compare the above three methods with the number of iterations of 2000. Tab.LABEL:tab:table2 provides the results of error L2 and R2, as well as the training time, with the best result per measure metric being marked in bold.
| Error L2 | R2 | Training time/s | |
| TgNN-LD | 2.0833E-04 | 9.9532E-01 | 204.3223 |
| TgNN | 3.5648E-04 | 9.8735E-01 | 195.3986 |
| TgNN-1 | 4.5596E-04 | 9.7931E-01 | 186.2980 |
As shown in Tab.LABEL:tab:table2, TgNN-LD can obtain the best error L2 and R2 results, which are obviously smaller and larger than the other two, respectively. It is worth noting that its training time seems lightly inferior among all three methods, probably due to the extra computation brought by the introduction of three Lagrangian multipliers. However, in comparison with TgNN-1 without any human adjustment, our proposed TgNN-LD achieves much better error L2 and R2 results. Moreover, compared to TgNN, in which the weights are adjusted by expertise, our method can not only save babysitting time in the preliminary stage of determining a better set of weights, but produce superior results, as well.
In order to observe the changing trend of each loss, we plot the loss values versus iterations for each method, as shown in Fig.2. Since TgNN places more emphasis on the PDE term, herein, we only provide changes of the total loss (denoted as ), the data term (denoted as ), and the PDE term (denoted as ).
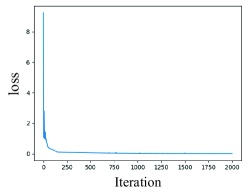











It can be seen from Fig.2 that TgNN-LD can obtain losses with less fluctuation, and TgNN takes second place, and TgNN-1 achieves the worst results. The most remarkable difference lies in changes of , which corresponds to the PDE term. The proposed TgNN-LD exhibits much more stable states whereas there are many shocks in both TgNN and TgNN-1. Indeed, in terms of both smoothness and the number of iterations, TgNN-LD achieves superior performance.
Fig.3 compares the correlation between the reference and predicted hydraulic head with the iteration number of 2000. Fig.4 provides prediction results of TgNN-LD, TgNN, and TgNN-1. From these figures, it can be clearly seen that the prediction of TgNN-LD matches the reference values well and are superior to the predictions of the other two.






IV-B Reduced training epochs
From Figs.2.(j)-(l), it can be observed that when the number of iterations is approximately 1750, three losses are approaching to converge, suggesting that the number of iterations could be reduced to shorten the training time. To verify its effect, we set different numbers of iterations to test our method. The related results are presented in Tab.III.
| Number of iterations | Error L2 | R2 | Training time/s |
| 1500 | 3.5398E-04 | 9.8753E-01 | 149.6769 |
| 1700 | 2.4923E-04 | 9.9382E-01 | 159.2913 |
| 1750 | 1.9887E-04 | 9.9606E-01 | 164.3937 |
| 1800 | 2.3961E-04 | 9.9429E-01 | 168.9544 |
| 2000 | 2.0833E-04 | 9.9532E-01 | 204.3223 |
As shown in Tab.III, when the number of iteration is 1750, even though the training time is 15s longer than that obtained with the iteration number of 1500, the error L2 and R2 results exhibit the best performance among the compared sets. Especially, in comparison with a result iteration number of 2000, the training time almost decreases by 20%, while the error L2 and R2 results are superior.
IV-C Changes of Lagrangian multipliers
To further investigate the effect of Lagrangian multipliers under different iteration values, we plot their changes with iterations, as shown in Fig.5, where Lambda, Lambda1, and Lambda2 refer to , , and , respectively.












It can be seen from Fig.5 that these Lagrangian multipliers cannot converge to a fixed value, irrespective of the number of iterations, which is rooted in randomly selected seeds leading to various initial values. Tab.IV lists their final values with respect to different settings of iterations.
| Number of iterations | |||
| 1700 | 7.7076E+00 | 8.5914E-01 | 1.1813E+00 |
| 1750 | 9.9854E+00 | 8.6531E-01 | 2.6842E+00 |
| 1800 | 8.8720E+00 | 8.6241E-01 | 9.9864E-01 |
| 2000 | 8.1127E+00 | 2.8652E-01 | 1.0940E+00 |
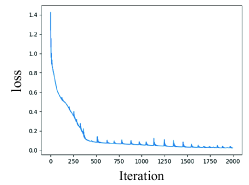
We then take one set of multipliers (8.1127E+00, 2.8652E-01, and 1.0940E+00) into Eq.1 and keep them the same during the whole training stage to further verify the above conclusion. Related results are shown in Fig.6. From Fig.6, it can be seen that the predictive results obtained by fixed multipliers’ values are not as good as the ones obtained by dynamic changing multipliers.




IV-D Predicting the future response from noisy data
To investigate the robustness of our proposed method, we add noise with the following formulation into the training data [9]
| (15) |
where , , and denote the maximal difference obtained at location during the entire monitoring process, the noise level, and a uniform variable ranging from -1 to 1.
Figs.7-9 show the predictive results obtained by TgNN-LD, TgNN, and TgNN-1 under noise levels of 5%, 10%, and 20%, respectively, with their error L2 and R2 results listed in Tab.V. From Figs.7-9 and Tab.V, it can be found that TgNN-LD can always obtain the best results among the three methods on correlation between the reference and predicted hydraulic head when noise exists. Moreover, it can also achieve the best results on the error L2 and R2 results. Although the training time obtained by TgNN-LD under different noise levels seems slightly longer than the other two, comparisons between the prediction and reference demonstrate the improvement of incorporating the Lagrangian dual approach.
| noise level | L2 error | R2 | Training time/s | |
| TgNN-LD | 2.2848E-04 | 9.9481E-01 | 206.9471 | |
| TgNN | 4.9887E-04 | 9.7524E-01 | 204.6485 | |
| TgNN-1 | 6.4963E-04 | 9.5802E-01 | 201.8772 | |
| TgNN-LD | 2.6835E-04 | 9.9285E-01 | 208.6079 | |
| TgNN | 4.9018E-04 | 9.7614E-01 | 202.5091 | |
| TgNN-1 | 5.6168E-04 | 9.6867E-01 | 205.8537 | |
| TgNN-LD | 3.6974E-04 | 9.8652E-01 | 204.9997 | |
| TgNN | 5.5094E-04 | 9.7007E-01 | 204.1725 | |
| TgNN-1 | 7.2383E-04 | 9.4833E-01 | 204.9317 |


















IV-E Training under the dynamic epoch
To investigate the predictive performance more deeply, we substitute the stopping criterion, i.e., a fixed number of iterations, with a dynamic epoch, which has a close relationship with changes of loss values. From Fig.2, it can be seen that the training process has usually already converged with the iteration number of 2000. Therefore, we set the total number of epoch, denoted as , as 2000. The dynamic epoch is denoted as .
In our experiment, we maintain a time window with the length of . For per obtained loss value, we compare whether loss values in the current time window are less than a threshold, . If this criterion is satisfied, we stop the iteration and output the predictive results. Herein, we recommend and . Tab.VI lists a number of good prediction results under the dynamic epoch obtained by TgNN-LD, with their results on correlation between reference and prediction and prediction versus reference being presented in Fig.10. From the numerical results in Tab.VI, it seems that TgNN-LD can come to convergence by a dynamic stopping epoch.
| stopping epoch | error L2 | R2 | Training time/s |
| 1712 | 2.0178E-04 | 0.995948184 | 164.2439 |
| 1810 | 2.0807E-04 | 0.99569132 | 204.4629 |
| 1829 | 2.1342E-04 | 0.995467097 | 203.6778 |






V Conclusion
In this paper, we propose a Lagrangian dual-based TgNN framework to assist in balancing training data and theory in the TgNN model. It provides theoretical guidance for the update of weights for the theory-guided neural network framework. Lagrangian duality is incorporated into TgNN to automatically determine the weight values for each term and maintain an excellent tradeoff between them. The subsurface flow problem is investigated as a test case. Experimental results demonstrate that the proposed method can increase the predictive accuracy and produce a superior training model compared to that obtained by an ad-hoc procedure within limited computational time.
In the future, we would like to combine the proposed Lagrangian dual-based TgNN framework with more informed deep learning approaches, such as TgNN with weak-form constraints. It can also be utilized to solve more application problems, such as the two-phase flow problem in energy engineering, to enhance the training ability of TgNN and achieve accurate predictions.
References
- [1] D. Silver, A. Huang, C. J. Maddison, A. Guez, L. Sifre, G. van den Driessche, J. Schrittwieser, I. Antonoglou, V. Panneershelvam, M. Lanctot, S. Dieleman, D. Grewe, J. Nham, N. Kalchbrenner, I. Sutskever, T. Lillicrap, M. Leach, K. Kavukcuoglu, T. Graepel, and D. Hassabis, “Mastering the game of Go with deep neural networks and tree search,” Nature, vol. 529, no. 7587, pp. 484–489, JAN 2016.
- [2] Y. Chen, X. Sun, and Y. Jin, “Communication-efficient federated deep learning with layerwise asynchronous model update and temporally weighted aggregation,” IEEE Transactions on Neural Networks and Learning Systems, DEC 2019. [Online]. Available: 10.1109/TNNLS.2019.2953131
- [3] Y. Chen, J. Zhang, and C. K. Yeo, “Network anomaly detection using federated deep autoencoding gaussian mixture model,” in International Conference on Machine Learning for Networking, APR 2019. [Online]. Available: 10.1007/978-3-030-45778-5_1
- [4] M. Tan, B. Chen, R. Pang, V. Vasudevan, M. Sandier, A. Howard, and Q. V. Le, “MnasNet: Platform-aware neural architecture search for mobile,” in IEEE Conference on Computer Vision and Pattern Recognition, JUN 2019, pp. 2815–2823.
- [5] T. Hong, Z. Wang, X. Luo, and W. Zhang, “State-of-the-art on research and applications of machine learning in the building life cycle,” Energy And Buildings, vol. 212, APR 2020. [Online]. Available: 10.1016/j.enbuild.2020.109831
- [6] A. Karpatne, G. Atluri, J. H. Faghmous, M. Steinbach, A. Banerjee, A. Ganguly, S. Shekhar, N. Samatova, and V. Kumar, “Theory-guided data science: A new paradigm for scientific discovery from data,” IEEE Transactions on Knowledge and Data Engineering, vol. 29, no. 10, pp. 2318–2331, JAN 2017.
- [7] A. Karpatne, W. Watkins, J. Read, and V. Kumar, “Physics-guided neural networks (pgnn): An application in lake temperature modeling,” 2017. [Online]. Available: arXiv:1710.11431
- [8] M. Raissi, P. Perdikaris, and G. E. Karniadakis, “Physics-informed neural networks: A deep learning framework for solving forward and inverse problems involving nonlinear partial differential equations,” Journal Of Computational Physics, vol. 378, pp. 686–707, FEB 2019.
- [9] N. Wang, D. Zhang, H. Chang, and H. Li, “Deep learning of subsurface flow via theory-guided neural network,” Journal Of Hydrology, vol. 584, MAY 2020. [Online]. Available: 10.1016/j.jhydrol.2020.124700
- [10] B. Zoph, V. Vasudevan, J. Shlens, and Q. V. Le, “Learning transferable architectures for scalable image recognition,” in IEEE Conference on Computer Vision and Pattern Recognition, JUN 2018, pp. 8697–8710.
- [11] Y. Chen, X. Sun, and Y. Hu, “Federated learning assisted interactive eda with dual probabilistic models for personalized search,” in International Conference on Swarm Intelligence, JUL 2019, pp. 374–383.
- [12] X. Wang, Y. Jin, S. Schmitt, and M. Olhofer, “An adaptive Bayesian approach to surrogate-assisted evolutionary multi-objective optimization,” Information Sciences, vol. 519, pp. 317–331, MAY 2020.
- [13] H. A. Fayed and A. F. Atiya, “Speed up grid-search for parameter selection of support vector machines,” Applied Soft Computing, vol. 80, pp. 202–210, JUL 2019.
- [14] H. Chen, Z. Liu, K. Cai, L. Xu, and A. Chen, “Grid search parametric optimization for FT-NIR quantitative analysis of solid soluble content in strawberry samples,” Vibrational Spectroscopy, vol. 94, pp. 7–15, JAN 2018.
- [15] J.-H. Han, D.-J. Choi, S.-U. Park, and S.-K. Hong, “Hyperparameter optimization using a genetic algorithm considering verification time in a convolutional neural network,” Journal Of Electrical Engineering & Technology, vol. 15, no. 2, pp. 721–726, MAR 2020.
- [16] F. J. Martinez-de Pison, R. Gonzalez-Sendino, A. Aldama, J. Ferreiro-Cabello, and E. Fraile-Garcia, “Hybrid methodology based on Bayesian optimization and GA-PARSIMONY to search for parsimony models by combining hyperparameter optimization and feature selection,” Neurocomputing, vol. 354, no. SI, pp. 20–26, AUG 2019.
- [17] D. Sun, H. Wen, D. Wang, and J. Xu, “A random forest model of landslide susceptibility mapping based on hyperparameter optimization using bayes algorithm,” Geomorphology, vol. 362, AUG 2020. [Online]. Available: 10.1016/j.geomorph.2020.107201
- [18] Y. Yao, J. Cao, and Z. Ma, “A cost-effective deadline-constrained scheduling strategy for a hyperparameter optimization workflow for machine learning algorithms,” in International Conference on Service-Oriented Computing, NOV 2018, pp. 870–878.
- [19] J. Bergstra and Y. Bengio, “Random search for hyper-parameter optimization,” The Journal of Machine Learning Research, vol. 13, pp. 281–305, MAR 2012.
- [20] F. Fioretto, P. V. Hentenryck, T. W. Mak, C. Tran, F. Baldo, and M. Lombardi, “Lagrangian duality for constrained deep learning,” 2020. [Online]. Available: arXiv:2001.09394
- [21] M. Lombardi, F. Baldo, A. Borghesi, and M. Milano, “An analysis of regularized approaches for constrained machine learning,” 2020. [Online]. Available: arXiv:2005.10674
- [22] A. Borghesi, F. Baldo, and M. Milano, “Improving deep learning models via constraint-based domain knowledge: a brief survey,” 2020. [Online]. Available: arXiv:2005.10691
- [23] J. Gan, P. Liu, and R. K. Chakrabarty, “Deep learning enabled lagrangian particle trajectory simulation,” Journal Of Aerosol Science, vol. 139, JAN 2020. [Online]. Available: 10.1016/j.jaerosci.2019.105468
- [24] B. N. Walker, J. M. Rehg, A. Kalra, R. M. Winters, P. Drews, J. Dascalu, E. O. David, and A. Dascalu, “Dermoscopy diagnosis of cancerous lesions utilizing dual deep learning algorithms via visual and audio (sonification) outputs: Laboratory and prospective observational studies,” Ebiomedicine, vol. 40, pp. 176–183, FEB 2019.
- [25] A. S. Pundir and B. Raman, “Dual deep learning model for image based smoke detection,” Fire Technology, vol. 55, no. 6, pp. 2419–2442, NOV 2019.