A GAN-based Approach for Mitigating Inference Attacks in Smart Home Environment
Abstract
The proliferation of smart, connected, always listening devices have introduced significant privacy risks to users in a smart home environment. Beyond the notable risk of eavesdropping, intruders can adopt machine learning techniques to infer sensitive information from audio recordings on these devices, resulting in a new dimension of privacy concerns and attack variables to smart home users. Techniques such as sound masking and microphone jamming have been effectively used to prevent eavesdroppers from listening in to private conversations. In this study, we explore the problem of adversaries spying on smart home users to infer sensitive information with the aid of machine learning techniques. We then analyze the role of randomness in the effectiveness of sound masking for mitigating sensitive information leakage. We propose a Generative Adversarial Network (GAN) based approach for privacy preservation in smart homes which generates random noise to distort the unwanted machine learning-based inference. Our experimental results demonstrate that GANs can be used to generate more effective sound masking noise signals which exhibit more randomness and effectively mitigate deep learning-based inference attacks while preserving the semantics of the audio samples.
Index terms - privacy, IoT, generative adversarial networks, information leakage, smart home
I Introduction
The presence of ”always listening” devices in a user’s environment poses significant privacy concerns, as an adversary may leverage these devices to eavesdrop on a user’s private conversations. With the proliferation of IoT smart home devices, the number of microphone bearing devices in residential homes has increased exponentially over the past decade resulting in an increased attack surface for adversaries. A typical case study in [1] showed that researchers with minimal coding effort converted an Amazon Echo smart speaker into a spy device for eavesdropping on homeowners. Similar studies [2] [3] have suggested a wide range of adversaries including IoT platform owners, app developers, device manufacturers and solution providers.
The ability of GANs to create high dimensional data has been researched [4]. In this study, we seek to correlate the relationship between high dimensional data in GAN generated audio samples and increased randomness.
The use of sound masking noise signals has been an important technique in protecting user privacy against eavesdroppers who attempt to gain unauthorized access to users’ private conversations. One recommended approach for protecting user privacy in smart homes from always listening devices is the use of sound masking by adding white noise to audio signals [5]. White noise includes all frequencies at equal energy. However, it is more desirable to generate audio signals that sound more comfortable to listeners. As such, only the specific frequency spectrum that are required to increase privacy are produced with resultant minimal distraction.
Providers and vendors of smart home IoT devices have argued that connected, always listening devices such as Amazon Echo speakers implement a temporary buffer [6] that prevents the device from continuously recording user conversations. In addition, users can review and delete their voice recordings either through the app or by voice commands. While these techniques are a reasonable proposition, their effectiveness is not yet proven in preserving user privacy, especially since the attack surface increases with Internet connectivity and accessibility to various third-party apps. Moreover, this requires having a complete trust in several providers (hardware, software, etc.) and the insiders within the organization, which may not be guaranteed all the time.
In this study, we explore risks beyond eavesdropping and consider information leakage in smart home environments. An information leakage attack provides a larger attack surface because the adversary can deduce or infer sensitive information with the aid of computation and machine learning techniques. For example, an adversary can infer that there is an infant child in the home, can infer the race and gender of the occupants, or activities being performed in a home by merely running inference attacks on the smart home devices [7] [8].
Sound-based inference attacks may provide greater incentives to adversaries. For example, they can get thousands of users to download an app, and infer certain sensitive information such as behavioral patterns for a large number of people, which can then be used for commercial purposes such as advertising and sales targeting [9]. An adversary may also use such information for more malicious purposes, which could jeopardise the safety of the smart home occupants, such as inferring home occupancy and planning a robbery attack [10].
Our contributions from this study are twofold. In our first contribution, we demonstrate that GAN generated noise results in better performance in mitigating machine learning-based information leakage inference in smart home environments due to the increased randomness in the GAN noise. We show the relationship between randomness in audio signals and the effectiveness of a sound-masking noise signal in preventing sensitive information leakage.
For our second contribution, we introduce a novel Generative Adversarial Network (GAN) structure for producing sound-masking noise signals that are proven to be truly random. We adopt existing frameworks for measuring the randomness element in discrete signals and demonstrate that the GAN based audio noise signals have more entropy-based randomness compared to digitally generated white noise signals.
The novelty of our research is demonstrated in the following ways. To the best of our knowledge, this is the first study to investigate the use of GAN-based noise for mitigating sound-based privacy leakage inference attacks targeted against smart home environments.
Also, this is the first study to the best of our knowledge to investigate the effect of randomness in the ability of a sound masking noise signal to mitigate sensitive information leakage. Our findings show that information leakage mitigation is strongly correlated with the randomness element in the sound masking audio signal.
We further demonstrate that GANs can generate noise signals which can effectively mitigate sound-based privacy inference attacks while maintaining the semantics of the audio signal, as shown in section VII-C.
II Related Work
Existing research work for privacy preservation / information leakage prevention with noise distortion has focused on signal jamming – to distort the signal and prevent an eavesdropper from listening. No existing solution has utilized generative adversarial networks to create the noise distortion. Similar work [11] has also used ultrasonic transmission to jam nearby microphones .
Lei et al. [12] proposed the use of a physical presence based access control mechanism which ensures that physical presence is detected before activating the ”wake word” in voice assistants as a security measure or before accepting voice commands from a voice-activated digital assistant. While this technique is effective, a carefully crafted malware can effectively fool this safeguard [13]. In addition, the presence of a home occupant is not a deterrent for an intruder who is deploying and executing malware remotely since the malicious app will most likely operate saliently and quietly. The authors in [14] proposed a Doppler radar-based liveliness detector to prevent spoofing attacks on voice assistants and ensure a human is present before accepting voice commands. The work of [15] proposes a framework that implements a solution that jams the device microphone until the user issues a voice command.
Authors in [16] [17] discussed the limitations of GANs in that it learns the data distribution from the dataset and tends to remember the training samples, which can be used to infer sensitive information from the dataset. The authors thus propose approaches to incorporate privacy preservation techniques into the structure of the GAN.
Researchers have investigated the use of noise audio signals for privacy preservation in smart environments, such as in [18], where a noise generator was proposed for preserving privacy in smart tactical platforms. In [19], researchers exploited the use of audio masking for preventing sensitive information leakage in smartphones.
The feasibility of inferring sensitive information in smart homes has been studied from numerous contexts. In [20], user activities such as walking, sleeping etc. could be inferred by observing the network traffic in a smart home. Even when such traffic is encrypted as in [21], an adversary can still perform information leakage attacks on the smart home, compromising user privacy and confidentiality.
Several attempts have been made to explore the usage of GAN’s in network security. [22] proposed the use of GAN’s for defending against adversarial attacks in network security.
From our literature review, we observed that no published work had explored the use of Generative Adversarial Networks (GANs) to generate audio noise signals to mitigate audio inference attacks in smart home environments. Our research, therefore, seeks to close this gap.
III Problem Statement and Proposed Solution
Several users have installed various IoT devices to make their homes smarter. These devices are always connected, measuring, and collecting data about the environment. An adversary can use the information from those sensors to infer sensitive information about the occupants of the home. This raises significant privacy concerns. For example, researchers have been able to infer the TV content of home users by listening to the sound from the TV [23].
While it is easy for someone who is familiar with the movie to tell just by listening to the audio sound if the person is in close proximity to the home, the proliferation of smart, connected devices that are always listening creates a larger attack surface. This means that IoT devices or smartphones could be accessed remotely without the owners’ authorization or consent to deduce and infer such sensitive content. We term this for the scope of this study, as an inference attack.
As machine learning algorithms are becoming more sophisticated, adversaries will utilize machine learning and deep learning techniques to compromise the privacy of smart home users. In one of such attack variations, an adversary could seek to intercept digital voice assistants, which are very common in many smart home environments and are incorporated into various devices, such as smart speakers, smart refrigerators, and smartphones. In order to prevent sensitive information leakage from digital voice assistants, which are heavily integrated into smart home devices, we need to understand how an adversary can achieve such information leakage and the risk associated with it as well as the consequences of such leakage.
III-A What is an Inference Attack?
In the context of this study, an inference attack occurs when an external party infers sensitive information from data that they have access to [20]. Deep neural networks (DNN) are widely used for various audio processing tasks which fall under two broad categories of audio analysis and audio synthesis/transformation [24]. Our study represents a borderline between these two categories where we draw a distinction between the two categories and differentiate between audio recognition and audio inference. In this study we focus on audio inference aspects whereby our target is not to recognize what was said, but what could be inferred from what was said. Fig. 1 illustrates the difference between eavesdropping and inference.

Consider a similar case scenario in which a user downloads a malicious app which exploits the ”always listening” capability of a smart device and then runs a script to infer the user’s movie preferences. This is also an example of an information leakage attack.
III-B MaskGAN: Our Proposed Solution
In our proposed solution, we utilize Generative Adversarial Networks (GANs) [25] to generate sound masking audio noise to mitigate the information leakage as a result of the machine learning-based inference. More details about the MaskGAN structure is provided in section V-D. The advantage of our proposed solution is twofold. First, GANs due to the lack of a deterministic bias [25] can generate synthetic data samples that are truly random. Our objective in this study is to investigate if the noise generated by MaskGAN can mitigate information leakage while preserving the semantics of the audio as shown in the results section VII. The second advantage is that our solution is independent of the smart home device manufacturer, vendor or solution provider and is completely within the control of the user. We ensure that the noise generated by the MaskGAN does not exceed a sound intensity of 45db which is within the comfort zone for human hearing [26].
In this study, we seek to understand the role which randomness plays in sound masking privacy preservation. We conduct experiments to determine if our GAN-based approach for generating sound masking noise signals can produce audio noise signals that exhibit more randomness compared to white noise.
III-C Research Questions
Our study seeks to answer the following research questions.
1. Are GAN-generated noise samples effective for information leakage prevention in smart home environments to deter various adversaries from inferring sensitive information from user conversations?
2. Can GAN-generated noise samples be used to deter adversaries from inferring sensitive information from smart home devices, while maintaining the semantics of the audio samples?
3. Are GAN-generated noise samples more random compared to white noise? What role does randomness play in improving the ability of privacy-preserving sound masking techniques to prevent the risk of inferring sensitive information from ”always listening” smart home devices?
Our findings to these three research questions are reported in the results section VII.
IV Threat Model
The threat model in our study assumes an information leakage scenario in which an adversary accesses audio files from an ”always listening” connected device in a smart home, and infers sensitive information such as user demographics or activities of the home occupants. Fig. 2 illustrates our threat model.

We assume the adversary is anyone other than the legitimate owner of the smart home device’s data. The adversary could be a device manufacturer, an insider, an authorized third-party app developer, an unauthorized intruder such as one who deploys a malicious app, or a possible state actor as discussed in [27]. The adversaries have different capabilities but it is assumed that all adversaries can access the smart home device either physically or remotely. The threat model illustrated in Fig. 2 illustrates an unauthorized third-party adversary who deploys a malicious app onto the smart device either through physical access or through a phishing attack. The malicious app compromises any existing protection e.g., the temporary buffer which prevents the smart device from continuously recording conversations [6].
Different adversaries follow the same pattern of attack against the end-user with the same end goal - in which sensitive information the smart device user has not given consent to, is inferred and ultimately used for the adversary’s gain. We note that there are various capabilities for the different adversaries, and various types of attacks that can be launched by each of the adversaries based on their capabilities such as eavesdropping, inference attacks or other malicious purposes. For the scope of this study, however, we focus only on inference attacks, in which the adversary applies machine learning techniques to infer sensitive information from the audio recordings from those devices.
It is also assumed that the adversary has full knowledge of the model in what could be referred to as a white box attack. The adversary gains access to the recordings and carries out an inference attack on the recorded conversation. In our experimental approach, three different Deep Neural Network (DNN) models namely the Convolutional Neural Network (CNN), Recurrent Neural Network (RNN) and the Convolutional Recurrent Neural Network (CRNN), were used to infer sensitive information from the audio recordings.
V Solution Overview
Generative adversarial networks (GAN’s) [25] belong to the set of unsupervised deep learning algorithms known as generative models which learn the underlying hidden structure of given data without specifying a target value. Generative models typically generate synthetic inputs , given an input data , by learning the intrinsic distribution function of the input data. In contrast to discriminative models which tend to model the conditional probability distribution function , for a given function , generative models are direct density implicit models which model without attributing the probability distribution function.
V-A Audio Features Representation
Feature representation of the audio signal plays an important role in the deep learning model’s ability to infer sensitive information from an audio sample. We consider the task of feature representation for this study different from that of audio classification tasks since the features that serve best for audio classification might not adequately suffice for inferring sensitive information [28]. As a basic foundation, the upper layers of a DNN are best suited for performing feature extraction. In contrast, the lower layers are established to perform class discrimination [29] to output the target class. While it is possible to use Mel frequency cepstral coefficients (MFCCs) for the acoustic feature representation, since our study utilizes deep learning models, this approach is ignored because spatial information is lost from the MFCC.
An alternative representation known as the spectrogram consists of a temporal sequence of spectra. It can be obtained by omitting the Discrete Cosine Transform (DCT) to yield the log-mel spectrum [24]. Fig. 3 shows an illustration of spectrogram images for an audio sample in our dataset and a white noise sample that was generated for our experiment.

Even though the spectrograms are similar to images, the approach for audio processing using DNN’s is considered to be different from image classification due to the variation in value distribution for audio samples as compared to image samples.
We desist from using the time-domain waveform samples of the audio representation since they do not capture sufficient spatial information which is crucial for our machine learning model and technique.
V-B Neural Network Models
In the past, it was common practice to model and analyze audio signals using Gaussian mixture due to their mathematical elegance [24]. However, in recent times, Deep Neural Networks (DNNs) have shown to be more accurate for audio processing and classification tasks [30]. In this study we examine the performance of three types of neural network models namely - Convolutional Neural Network (CNN), Recurrent Neural Network (RNN), and Convolutional Recurrent Neural Network (CRNN) for our task of inferring sensitive information from audio samples.
A Convolutional Neural Network (CNN) consists of a series of convolutional layers that are passed through pooling layers, followed by one or more dense layers. Since our study is based on spectral input features from the Mel spectrogram, a 2-dimensional time-frequency convolution is used for computing the feature maps, which are further downsampled by the pooling layers. The optimal parameters for the CNN are obtained experimentally based on the validation error observed during the training process. Recurrent Neural Networks (RNN), are well suited for sequence modeling tasks such as audio processing [31] due to the fact that they intrinsically model the temporal dependency in the input features. A Convolutional Recurrent Neural Network (CRNN) [32] is an extension of the CNN in which an RNN is implemented to process the output of a CNN. While the purpose of the convolutional layers is to perform feature extraction, the recurrent layers enable the model to make sense of the longer temporal context.
The audio samples are all processed into 16bit, 48kHz .wav format before being converted into spectrogram images. After the audio samples are pre-processed into spectrogram images, spectral feature extraction is carried out and the input is then fed into the Deep Neural Network (DNN) classifiers. Fig. 4 shows a diagrammatic representation of the solution architecture.

V-C Noise Generation Methodology
Our solution is based on the premise that GAN generated noise, when combined with audio recordings from the smart home device, reduces the effectiveness of machine learning based inference from the audio recordings. This enhances smart home user privacy from various forms of adversaries with varying capabilities discussed in the preceding paragraph. Our results from section VII highlight more details on this.
The GAN noise signal is generated by an external device that is permanently in the smart home user’s environment and constantly producing noise signals which when combined with audio recordings from the smart home device, prevents an adversary from inferring sensitive information from the audio recordings. The noise amplitude of the external noise generator is audible for human perception but it should not exceed the acceptable noise threshold for human comfort.
In this study, we evaluate the effectiveness of the GAN noise with white noise. The white noise is generated with a python script using the same hardware for generating the GAN noise. In our evaluation, both noise samples are produced at the same amplitude to ensure consistency in the results.
V-D MaskGAN Overview
In the original GAN setup introduced by [25], GANs were used to generate synthetic data samples by taking as input, statistically independent noise samples. To the best of our knowledge, GANs have not been used to generate random noise signals. We choose to implement GANs in our approach to create audio samples as against other generative models such as Variable Autoencoders (VAE) because GANs do not introduce any deterministic bias and work better with discrete latent variables [25].
Our solution which we refer to as MaskGAN is an adaptation of Deep Convolutional Generative Adversarial Networks (DCGAN) [33]. DCGANs are a notable architecture for adversarial image generation in which a transposed convolution operation is implemented for creating high-resolution images from low-resolution feature maps. Since DCGAN ouputs 64x64 pixel images, we add two additional layers to produce two seconds of audio at 16KHz. Furthermore, the 2-dimensional convolutions are flattened into 1-dimensional with the stride factors increased twofold.
Our proposed MaskGAN structure consists of two models as shown in Fig 5. The first model known as the generator tries to generate new and synthetic audio samples that are identical to the target white noise audio sample. The second model known as the discriminator performs an adversary role by trying to detect if the synthetic audio sample is real or fake, hence helping to improve the knowledge of the generator until the generator eventually succeeds in creating some synthetic audio sample which is realistic and as indistinguishable from the actual white noise audio sample as possible.

The generator model is represented as while the discriminator model is represented as where represents the input audio samples and represents the generated synthetic samples. The weights of the neural network also known as parameters are represented as . The parameters of the generator are updated to maximize the probability that the synthetic audio is classified as the real audio dataset. The loss function of the generator network seeks to maximize . With regards to the discriminator, the parameters are optimized to maximize the probability that the synthetic noise audio samples are classified as real audio samples. Hence, the loss function of the discriminator, seeks to maximize the function while minimizing the function .
The minmax game between the generator and the discriminator is represented as a value function , whereby the generator seeks to maximize the probability that its output is classified as real. In contrast, the objective of the discriminator is to minimize this probability.
The input to the MaskGAN model is a random seed and the target output is a white noise signal that has been generated from our python code. After several iterations, the generative model finally arrives at a synthetic noise signal that is indistinguishable from the digital white noise signal, based on the assessment of the discriminative model.
V-E Dataset, Developmental Tools, Hardware and Software
For our experimental work, we used a standalone desktop PC running windows 10 Education OS. The hardware components consist of an AMD Ryzen 7 2700X processor at 3.70GHz with 32GB of RAM and 1TB SSD storage. The graphics card is a standalone GPU - NVIDIA GeForce RTX 2080 TI with 11GB RAM.
All software development was carried out using publicly available and open-source tools. The software code was written in Python programming language using the Spyder Integrated Development Environment (IDE), which is part of the ”Anaconda software distribution”. For the deep learning framework, we used the Google TensorFlow v2 deep learning framework.
The three datasets we used represent the three inference attack case scenarios that were explored in this study, namely music genre inference (MGI), user demographics inference (UDI), and speech emotion inference (SEI). The datasets used are publicly available, and details of each dataset are further discussed in section VII-A.
VI Experimental Approach
Assuming the smart home has devices that are equipped with always-listening capabilities. As discussed in section IV above, these devices could be harnessed by an adversary to leak sensitive information from the occupants of the home. Our experiments seek to deter such leakage inference attacks using truly random noise generated by a GAN neural network model which we term as MaskGAN. The first subsection describes our approach for generating audio noise with increased randomness using our GAN solution. The next subsection VI-B describes our approach for measuring the randomness of the GAN generated noise and performing a comparison to the white noise using two different runs tests methods. In the 3rd subsection VI-C, we describe how we perform the inference attacks for three different scenarios using three different datasets and for each dataset, three different neural network models are utilized. In this step, the original audio dataset is used without adding any form of noise mitigation. In the next subsection VI-D, we discuss our approach to mitigate the leakage of sensitive information via inference attacks with the use of the noise generated by the GAN and white noise. In the final subsection VI-E we discuss the different metrics we utilize for evaluating our methodology and results.
Since this paper focuses on information leakage from smart homes rather than eavesdropping, our case study scenarios and dataset selection best reflect this context. For example, rather than selecting datasets for automatic speech recognition such as [34], we instead select datasets in which information inference is sought from the audio samples. In our ”semantic preservation factor” evaluation metrics in section VI-E2, we discuss our approach to experientially highlight the difference between both contexts and report our results in section VII-C. For our case study, we consider the possibility of an adversary seeking to infer what genre of music the occupants of a home prefers to listen to and therefore provide targeted ads to the user. The second case scenario demonstrates an adversary who infers the user demographics such as race and gender of the home occupants, while the 3rd case scenario discusses an adversary who seeks to infer the emotion of the home occupants. The adversary achieves this sensitive information leakage or inference attacks using machine learning or deep learning techniques applied to the audio recordings. Other possible adversary scenarios may include the possibility to allow speech recognition while blocking out contextual information leakage.
VI-A Generate Noise Signals with GAN
The first step in our experimental approach entails using the GAN structure described in section V-D to create noise samples using white noise as the target output. As illustrated in Fig. 5, the generative model produces audio samples from a random seed and learns to improve as the discriminator determines how close the audio sample is to the white noise signal. The amplitude of the generated GAN noise does not exceed 45db in order to remain with the human comfort level as specified in [26]
VI-B Measuring the degree of Randomness in Noise Signals
In the second step of our experimental approach, we compute the degree of randomness of the original sample, the white noise and the GAN noise. In this section, we use two different non-parametric approaches in determining the degree of randomness of the audio samples.
Each audio sample is represented as a matrix of integers, with the shape representing the dimensions. For the scope of our study, we focus on notable runs tests in which upward and downward run counts are carried out for a sequence of variables, by floating the integers of the audio samples represented as an integer matrix.
Two measures of randomness namely the Wald-wolfowitz runs test [35] and the Cox-stuart test [36] are used to measure and compare the degree of randomness between the three audio signals. The results are reported in sections VI-B1 and VI-B2.
VI-B1 Wald-wolfowitz Runs tests
The wald-wolfowitz runs tests [35] considers each integer in the integer matrix representation of the audio sample as observations with a median value. A measure of the expected runs and the variance are computed respectively below to establish the statistical ratio. The equation below from [35]
| (1) |
which represents the number of runs in the representation of the audio file corresponding to its size.
VI-B2 Cox-stuart Test
The Cox-Stuart test [36] focuses on randomness based on negative or positive tests in data. Taking into consideration the sum of positive signs for an integer matrix representing each audio sample, a p-value is taken as a cumulative probability function for a binomial distribution of the dataset. The integer matrix representation of the dataset is grouped into pairs with the sign computed. The sign test in the equation below is used to determine if there is a trend in randomness as observed in the integer matrix representation of the audio sample. The equation below from [36]
| (2) |
Thus, the p-value with a count of the positive comparisons forms the statistical ratio for the degree of randomness.
Outcome of the Runs Test for Randomness: For each runs test, we compute the average across the entire dataset for each inference attack case scenario mentioned in section V-E. We repeat the process of the runs test computation for each of the datasets with the white noise added and also with the GAN noise added. First, we compute the degree of randomness in the original audio sample. We then compare the degree of randomness with the audio sample superimposed with the white noise sample as well as the audio sample superimposed with the GAN noise. Figures 6, 7 and 8 show the results of the randomness tests. The results show that on a scale of 0-1, the audio sample overlaid with the GAN noise shows more randomness based on both runs test compared to the original dataset as well as the dataset with the white noise.



VI-C Perform Inference Attacks on Original Audio Samples
Machine learning-based audio profiling of voice recordings from always listening devices can be used to infer sensitive information from a smart home user ’s environment. We experiment with a total of three publicly available datasets, to explore three types of inference attacks to leak out sensitive information about the occupants of a home.
VI-C1 Inferring User Music Listening Preferences from Smart Listening Devices
We use the Free Music Archive Dataset [37] which is an open and easily accessible dataset suitable for evaluating several tasks in music information retrieval (MIR). It consists of full-length and high-quality audio which includes metadata, tags. The dataset consists of 106,574 tracks from 16,341 artists and 14,854 albums, arranged in a hierarchical taxonomy of 161 genres.
VI-C2 Inferring User Demographics from Smart Listening Devices
This task involves inferring three basic user demographics context from audio files, namely age, gender and race. The dataset used is the Mozilla common voice dataset [38], which consists of about 51,000 voice recording samples. We use all three DNN architectures to perform multi-class, multi-label classification.
VI-C3 Inferring Emotional Content from Smart Listening Devices
In the third step of our experimental approach, we explore the feasibility of an adversary to infer emotional context from a user’s private conversations. As earlier discussed, monetary motives such as targeted advertisements may be a factor for such an adversary in implementing this form of inference attack. For this case scenario, the Ryerson Audio-Visual Database of Emotional Speech and Song (RAVDESS) [39] is used.
VI-D Mitigate Sound Inference Attacks
Our methodology entails the superimposition of the original audio samples with some form of external audio noise to prevent an adversary from inferring unwarranted sensitive information from audio recordings. The external noise is generated in with two methods. For the first method, white noise is generated. The second method entails the use of a Generative Adversarial Network (GAN) architecture, which forms the basis of our proposed solution.
VI-E Evaluation
We evaluate the effectiveness of our solution based on three metrics. The mitigated inference accuracy (MIA), the semantic preservation factor (SPF), and randomness to mitigation relationship (RTMR). First, we establish a benchmark assessment which we report in section VII-A as the Baseline Inference Accuracy (BIA). We then proceed to evaluate our proposed solution based on the metrics described below.
VI-E1 Mitigated Inference Accuracy
The mitigated inference accuracy (MIA) denotes the prediction accuracy of the DNN model in inferring sensitive information from an audio dataset when the sound masking noise has been applied. We report this metric for all inference scenarios using the three different DNN architectures described in the study.
VI-E2 Semantic Preservation Factor
The semantic preservation factor (SPF) represents the attribute of the sound masking signal to preserve the semantics of the audio content. We use a different dataset for this experimental setup with the three DNN models to compare the SPF of both white noise and the GAN noise.
VI-E3 Randomness to Mitigation Relationship
The third evaluation metric compares the randomness in the GAN noise and white noise with the mitigation inference accuracy. For both the white noise and the GAN noise, we calculate the element of the randomness in the audio dataset when each noise sample is added, compared to the effect of the inference mitigation that was achieved.
VII Results
In this section, we report our experimental findings based on our three evaluation criteria discussed in section VI-E . In the first subsection VII-A, we establish the effectiveness of the inference attack on all three datasets. In the next results section VII-B, we compare the effect of both the GAN noise as well as the white noise in mitigating inference attacks for all three case scenarios. In the next results section VII-C, we show results which demonstrate that the GAN noise is more effective in preserving the semantics of the audio compared to the white noise. In the final results section VII-D, we show how the randomness for both the white noise and the GAN noise correlates with the mitigated inference accuracy for all three case scenarios.
VII-A Baseline Inference Accuracy
In the first experiment, we conduct a baseline assessment of the inference attacks against all 3 datasets for the 3 case scenarios we considered. All 3 machine learning techniques were effective in inferring information from the audio dataset with a highest achievable inference of 82% from the CRNN model for the user demographic inference (UDI). as shown in Fig. 9. The figures reported are the best results achieved based on K-fold cross validation which was used to determine the optimal parameter settings of the neural network models.
VII-A1 Music Genre Inference (MGI)
As part of privacy considerations and in the context of user privacy, a user’s preferences for music listening may be chosen not to be shared with external parties without their consent. An adversary may however want to infer this information for example for monetary purposes such as targeted advertisement without the user’s consent. The ability of an adversary to infer this information is demonstrated using the Free Music Archive dataset [37]. We confirm using three different Deep neural network architectures that the music genre can be correctly inferred with an accuracy of up to 67%.
VII-A2 User Demographics Inference (UDI)
We explore the feasibility of an adversary to infer user demographic data such as age, accent and gender from audio dataset using the Mozilla Common Voice dataset [38]. The dataset consists of about 51,000 voice recording samples of humans in 18 different languages. Our DNN models identify the demographic qualities of the speaker with an accuracy of 74%, 71% and 89% respectively. When all demographic properties are combined, an accuracy of 82% is achieved.
VII-A3 Speech Emotion Inference (SEI)
In our third privacy inference case scenario, we examine the ability of an adversary to infer the emotion of users from a given dataset. We use the Ryerson Audio-Visual Database of Emotional Speech and Song (RAVDESS) [39] which consists 7356 audio samples of 12 female and 12 male professional actors. Each of the actors is tasked with speaking out two lexically matched statements using a neutral North American accent. The dataset is labeled to distinguish a total of 7 different emotions including calm, happy, sad, angry, fearful, surprise, and disgust expressions.

VII-B Mitigated Inference Accuracy
In this section, we test the privacy preservation hypothesis of the GAN noise capability in preventing sensitive information leakage in smart homes. We seek to determine if the GAN noise is more effective than white noise in preserving the privacy of smart home devices. Our results show that the noise generated by GAN results in over 45% reduction in sensitive information leakage from smart home devices while maintaining the semantics of the audio.
VII-B1 Mitigated Inference Accuracy (White Noise)
In our next experiment, we tested the ability of the DNN to correctly infer sensitive information from the dataset for the case scenarios discussed above. We notice very little difference in the ability of the white noise when combined with the original audio to mitigate against information leakage. When compared to the BIA results in section VII-A, the maximum decrease in inference that was observed when the white noise was added was less than 11% as shown in Fig. 10.

VII-B2 Mitigated Inference Accuracy (GAN Noise)
In our third experiment, we combine the GAN generated noise with the original audio and repeat the inference attack using the 3 DNN models. When compared to the BIA results in section VII-A, we observe up to a maximum of 45% decrease in inference accuracy when the GAN generated noise is added to the original audio sample as shown in Fig. 11.

VII-C Semantic Preservation Factor

In our fourth experiment, we demonstrate the ability of the GAN noise to preserve the semantics of the audio while effectively mitigating information leakage attacks. A visual representation of the results is show in Fig. 12 We performed speech recognition classification using the google speech commands dataset [34]. This fourth dataset was selected since the dataset was collected and labeled for recognizing the content of the speech. Unlike the other 3 datasets which were used in the inference attack discussed in section VI-C, this dataset is more appropriate for deducing the content of the speech. The other 3 datasets were not used for semantic experiment since they were not collected and labelled for speech classification tasks. The result of the experiment shows that the GAN noise has less impact on the DNN speech recognition classifier compared to the white noise as shown in Fig. 13. Hence, we confirm that the GAN noise does indeed preserve the utility of the device by deterring inference attack yet, maintaining the semantics of the conversation.

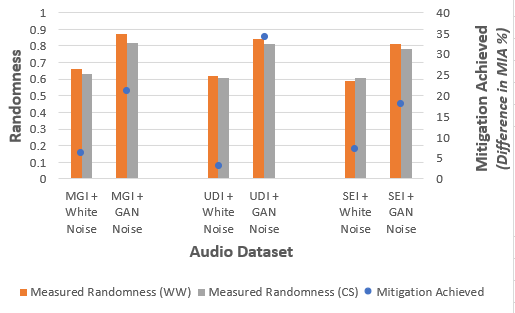
VII-D Randomness to Mitigation Relationship
We evaluated the relationship between randomness and the mitigation inference accuracy (MIA) in each inference attack case scenario. The result as illustrated in Fig. 14 shows that the higher the degree of randomness, the higher the mitigation effect that the noise exhibits in deterring the inference attack. The mitigation achieved is calculated as the difference in the MIA for each case scenario with the white noise as well as the GAN noise. The GAN noise, having more randomness compared to the white noise is proven to have a higher mitigation effect.
VIII Discussion
VIII-A White Noise and Randomness
White noise is known to exhibit statistical characteristics that are similar to randomly generated numbers. To be considered as truly random, we expect the entity to be in fact unpredictable; but the possibility of a white noise generator to exhibit true randomness in the sense of unpredictability is questionable. Speicher et al. [40] noted that patterns can be noted in pseudo random generated white noise, based on the fact that is contains possibly predictable elements for example, a linear congruential random generator, which is typical algorithm used for producing digital noise output. Tzeng et al. [41] argued that it is best to treat randomness as a property of the process that generates the signal of the white noise, not of the white noise itself.
Hence, we establish that white noise with its pseudorandom property is thus limited in the ability as an effective measure in privacy preservation for use in audio masking for preventing sensitive information leakage attacks.
The ability of generative adversarial networks to create high dimensional data has been researched [4] and the relationship of this high dimensionality to randomness is an object of interest. As the generator model in the GAN continuously learns to produce data samples which the adversary (discriminator) cannot predict, the randomness element in its output improves, as demonstrated in our results. Our solution entails the use of a generative model that has learnt to produce realistic noise samples of a given dataset from low-dimensional, random latent vectors.
Several recent efforts have been made to generate sound using Generative Adversarial Networks including the use of CycleGAN by [42]. Their approach augments an existing audio sample with emotions and can also convert speeches between emotional variations e.g. convert an angry speech into a sad speech.
We differentiate our work from other studies such as [43] which use adversarial attacks to mitigate speech recognition i.e. the use of machine learning systems to determine the identity of the speaker. In this specific study, a state of the art deep neural network (DNN) known as X-vector was tested. By adding a carefully crafted inconspicuous noise to the original audio, their attack method was successful in fooling the DNN into making false predictions. The solution goes further to incorporate room impulse response (RIR) estimates while training the adversarial examples to demonstrate the effectiveness for both digital attacks as well as over-the-air attacks.
VIII-B Mitigating Privacy Inference Leakage in Digital Space Vs. Physical Space
Sound masking in the context of this study occurs in the physical space and is more practical oriented. Factors such as the room impulse ratio is considered in deploying real and tangible audio signals to mitigate unwanted sensitive information leakage due to machine learning inference. Traditionally, there have been several ways of attacking speech recognition systems. Adversarial examples, for instance the work of Carlini and Wagner [44] could impact a speech recognition system to misclassify by adding a carefully crafted perturbation. This adversarial attack method was tested against speech recognition only, but not tested against speech inference. Furthermore, their attack was proven to be effective in the digital space. Similar studies [45] [44] have proposed solutions mostly against automatic speaker recognition in the digital space. In our threat model, we considered various adversaries, including the manufacturer or solution developer who controls the digital space and therefore, implementing a solution within the digital space will be ineffective against such adversaries.
Also, the work of Fuxun Yu et al [46] introduced ”MASKER”, a solution which introduces human imperceptible adversarial perturbation into real time audio signals with significant increase in the word error rate (WER). Their work focused on mobile platforms and was not tested to work against digital voice assistants or smart home environments. Also, the solution is primarily effective only in the digital space and was not tested as an over-the-air solution.
Our method focuses on a solution that is implemented within the physical space. Since the user can perceive the sound generated, we ensure that this sound is within the audible comfort zone for human hearing of less than 45db [26]. We tested with various amplitudes of audio signal and determined that as the amplitude increases, the effectiveness also increases. However, compared to the original audio as well as the white noise, our GAN generated noise achieves better mitigation based on several metrics.
We show that speech recognition and sound-based inference have varying and different and unique characteristics and adversarial noise techniques should be considered differently. Refer to Fig. 1 where we illustrate the difference between eavesdropping and inference attacks.
Conclusion
We proposed a novel method for mitigating sensitive information leakage in smart home environments. We highlighted a threat model whereby an adversary deploys a machine learning based inference attack on connected, always listening devices such as smart phones or smart speakers.
Our solution is based on a generative deep learning model known as the Generative Adversarial Networks (GAN). We established from our experiments that GAN based audio samples have increased randomness compared to white noise. Also, when used for sound masking purposes, GAN generated noise can effectively mitigate machine learning based inference attacks in smart home environments while preserving the semantics of the audio conversation.
acknowledgement
This work was supported by the Natural Sciences and Engineering Research Council of Canada (NSERC) through the NSERC Discovery Grant program.
References
- [1] Checkmarx, “Amazon Echo - Alexa Leveraged as a Silent Eavesdropper,” 2018.
- [2] J. Lau, B. Zimmerman, and F. Schaub, “Alexa, are you listening? privacy perceptions, concerns and privacy-seeking behaviors with smart speakers,” Proceedings of the ACM on Human-Computer Interaction, vol. 2, no. CSCW, pp. 1–31, 2018.
- [3] E. Zeng, S. Mare, and F. Roesner, “End user security and privacy concerns with smart homes,” in Thirteenth Symposium on Usable Privacy and Security (SOUPS 2017), pp. 65–80, 2017.
- [4] M. De Bernardi, M. Khouzani, and P. Malacaria, “Pseudo-random number generation using generative adversarial networks,” in Joint European Conference on Machine Learning and Knowledge Discovery in Databases, pp. 191–200, Springer, 2018.
- [5] J. Jiang, Y. Li, X. Ma, P. Zhang, Y. Fan, and Q. Hao, “Research on noise quality in anti-eavesdropping system based on acoustic masking,” in 2017 International Conference on Wireless Communications, Signal Processing and Networking (WiSPNET), pp. 823–827, IEEE, 2017.
- [6] S. Godwin, B. Glendenning, and K. Gagneja, “Future security of smart speaker and iot smart home devices,” in 2019 Fifth Conference on Mobile and Secure Services (MobiSecServ), pp. 1–6, IEEE, 2019.
- [7] J. Bugeja, A. Jacobsson, and P. Davidsson, “On privacy and security challenges in smart connected homes,” in 2016 European Intelligence and Security Informatics Conference (EISIC), pp. 172–175, IEEE, 2016.
- [8] N. Apthorpe, D. Y. Huang, D. Reisman, A. Narayanan, and N. Feamster, “Keeping the smart home private with smart (er) iot traffic shaping,” Proceedings on Privacy Enhancing Technologies, vol. 2019, no. 3, pp. 128–148, 2019.
- [9] D. Y. Huang, N. Apthorpe, G. Acar, F. Li, and N. Feamster, “Iot inspector: Crowdsourcing labeled network traffic from smart home devices at scale,” arXiv preprint arXiv:1909.09848, 2019.
- [10] D. Bastos, M. Shackleton, and F. El-Moussa, “Internet of things: A survey of technologies and security risks in smart home and city environments,” 2018.
- [11] Y. Chen, H. Li, S.-Y. Teng, S. Nagels, Z. Li, P. Lopes, B. Y. Zhao, and H. Zheng, “Wearable microphone jamming,” in Proceedings of the 2020 CHI Conference on Human Factors in Computing Systems, pp. 1–12, 2020.
- [12] X. Lei, G.-H. Tu, A. X. Liu, K. Ali, C.-Y. Li, and T. Xie, “The insecurity of home digital voice assistants–amazon alexa as a case study,” arXiv preprint arXiv:1712.03327, 2017.
- [13] N. An, A. Duff, M. Noorani, S. Weber, and S. Mancoridis, “Malware anomaly detection on virtual assistants,” in 2018 13th International Conference on Malicious and Unwanted Software (MALWARE), pp. 124–131, IEEE, 2018.
- [14] L. Zhang, S. Tan, and J. Yang, “Hearing your voice is not enough: An articulatory gesture based liveness detection for voice authentication,” in Proceedings of the 2017 ACM SIGSAC Conference on Computer and Communications Security, CCS ’17, (New York, NY, USA), p. 57–71, Association for Computing Machinery, 2017.
- [15] C. Gao, V. Chandrasekaran, K. Fawaz, and S. Banerjee, “Traversing the quagmire that is privacy in your smart home,” in Proceedings of the 2018 Workshop on IoT Security and Privacy, pp. 22–28, 2018.
- [16] Y. Liu, J. Peng, J. J. Yu, and Y. Wu, “Ppgan: Privacy-preserving generative adversarial network,” arXiv preprint arXiv:1910.02007, 2019.
- [17] L. Frigerio, A. S. de Oliveira, L. Gomez, and P. Duverger, “Differentially private generative adversarial networks for time series, continuous, and discrete open data,” in IFIP International Conference on ICT Systems Security and Privacy Protection, pp. 151–164, Springer, 2019.
- [18] A. Asatilla and D.-S. Kim, “Information protection by noise generator for tactical smart platforms,” in 2018 3rd International Conference On Internet of Things: Smart Innovation and Usages (IoT-SIU), pp. 1–6, IEEE, 2018.
- [19] Y.-C. Tung and K. G. Shin, “Exploiting sound masking for audio privacy in smartphones,” in Proceedings of the 2019 ACM Asia Conference on Computer and Communications Security, pp. 257–268, 2019.
- [20] B. Copos, K. Levitt, M. Bishop, and J. Rowe, “Is anybody home? inferring activity from smart home network traffic,” in 2016 IEEE Security and Privacy Workshops (SPW), pp. 245–251, IEEE, 2016.
- [21] N. Apthorpe, D. Reisman, S. Sundaresan, A. Narayanan, and N. Feamster, “Spying on the smart home: Privacy attacks and defenses on encrypted iot traffic,” arXiv preprint arXiv:1708.05044, 2017.
- [22] M. Usama, M. Asim, S. Latif, J. Qadir, et al., “Generative adversarial networks for launching and thwarting adversarial attacks on network intrusion detection systems,” in 2019 15th International Wireless Communications & Mobile Computing Conference (IWCMC), pp. 78–83, IEEE, 2019.
- [23] Y. Xu, J.-M. Frahm, and F. Monrose, “Watching the watchers: Automatically inferring tv content from outdoor light effusions,” in Proceedings of the 2014 ACM SIGSAC Conference on Computer and Communications Security, pp. 418–428, 2014.
- [24] H. Purwins, B. Li, T. Virtanen, J. Schlüter, S.-Y. Chang, and T. Sainath, “Deep learning for audio signal processing,” IEEE Journal of Selected Topics in Signal Processing, vol. 13, no. 2, pp. 206–219, 2019.
- [25] I. Goodfellow, J. Pouget-Abadie, M. Mirza, B. Xu, D. Warde-Farley, S. Ozair, A. Courville, and Y. Bengio, “Generative adversarial nets,” in Advances in neural information processing systems, pp. 2672–2680, 2014.
- [26] W. Fincher and M. Boduch, “Standards of human comfort: relative and absolute,” 2009.
- [27] L. Cauley, “Nsa has massive database of americans’ phone calls,” USA today, vol. 11, no. 06, 2006.
- [28] U. Avci, G. Akkurt, and D. Unay, “A pattern mining approach in feature extraction for emotion recognition from speech,” in International Conference on Speech and Computer, pp. 54–63, Springer, 2019.
- [29] A.-r. Mohamed, G. Hinton, and G. Penn, “Understanding how deep belief networks perform acoustic modelling,” in 2012 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), pp. 4273–4276, IEEE, 2012.
- [30] G. Hinton, L. Deng, D. Yu, G. E. Dahl, A.-r. Mohamed, N. Jaitly, A. Senior, V. Vanhoucke, P. Nguyen, T. N. Sainath, et al., “Deep neural networks for acoustic modeling in speech recognition: The shared views of four research groups,” IEEE Signal processing magazine, vol. 29, no. 6, pp. 82–97, 2012.
- [31] Z. C. Lipton, J. Berkowitz, and C. Elkan, “A critical review of recurrent neural networks for sequence learning,” arXiv preprint arXiv:1506.00019, 2015.
- [32] K. Choi, G. Fazekas, M. Sandler, and K. Cho, “Convolutional recurrent neural networks for music classification,” in 2017 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), pp. 2392–2396, IEEE, 2017.
- [33] A. Radford, L. Metz, and S. Chintala, “Unsupervised representation learning with deep convolutional generative adversarial networks,” in 4th International Conference on Learning Representations, ICLR 2016, San Juan, Puerto Rico, May 2-4, 2016, Conference Track Proceedings (Y. Bengio and Y. LeCun, eds.), 2016.
- [34] P. Warden, “Speech Commands: A Dataset for Limited-Vocabulary Speech Recognition,” ArXiv e-prints, Apr. 2018.
- [35] A. Wald and J. Wolfowitz, “On a test whether two samples are from the same population,” The Annals of Mathematical Statistics, vol. 11, no. 2, pp. 147–162, 1940.
- [36] D. R. Cox and A. Stuart, “Some quick sign tests for trend in location and dispersion,” Biometrika, vol. 42, no. 1/2, pp. 80–95, 1955.
- [37] M. Defferrard, K. Benzi, P. Vandergheynst, and X. Bresson, “Fma: A dataset for music analysis,” arXiv preprint arXiv:1612.01840, 2016.
- [38] R. Ardila, M. Branson, K. Davis, M. Henretty, M. Kohler, J. Meyer, R. Morais, L. Saunders, F. M. Tyers, and G. Weber, “Common voice: A massively-multilingual speech corpus,” arXiv preprint arXiv:1912.06670, 2019.
- [39] S. R. Livingstone and F. A. Russo, “The ryerson audio-visual database of emotional speech and song (ravdess): A dynamic, multimodal set of facial and vocal expressions in north american english,” PloS one, vol. 13, no. 5, 2018.
- [40] R. Speicher, “A new example of ‘independence’and ‘white noise’,” Probability theory and related fields, vol. 84, no. 2, pp. 141–159, 1990.
- [41] S. Tzeng and L.-Y. Wei, “Parallel white noise generation on a gpu via cryptographic hash,” in Proceedings of the 2008 symposium on Interactive 3D graphics and games, pp. 79–87, 2008.
- [42] T. Asakura, S. Akama, E. Shimokawara, T. Yamaguchi, and S. Yamamoto, “Emotional speech generator by using generative adversarial networks,” in Proceedings of the Tenth International Symposium on Information and Communication Technology, pp. 9–14, 2019.
- [43] Z. Li, C. Shi, Y. Xie, J. Liu, B. Yuan, and Y. Chen, “Practical adversarial attacks against speaker recognition systems,” in Proceedings of the 21st International Workshop on Mobile Computing Systems and Applications, pp. 9–14, 2020.
- [44] N. Carlini and D. Wagner, “Audio adversarial examples: Targeted attacks on speech-to-text,” in 2018 IEEE Security and Privacy Workshops (SPW), pp. 1–7, IEEE, 2018.
- [45] M. Alzantot, B. Balaji, and M. Srivastava, “Did you hear that? adversarial examples against automatic speech recognition,” arXiv preprint arXiv:1801.00554, 2018.
- [46] F. Yu, Z. Xu, C. Liu, and X. Chen, “Masker: Adaptive mobile security enhancement against automatic speech recognition in eavesdropping,” in Proceedings of the 56th Annual Design Automation Conference 2019, pp. 1–6, 2019.