[1]\fnmMarcus \surHoerger
[1]\orgdivSchool of Mathematics & Physics, \orgnameThe University of Queensland, \orgaddress\cityBrisbane, \postcode4072, \stateQLD, \countryAustralia
A Flow-Based Generative Model for Rare-Event Simulation
Abstract
Solving decision problems in complex, stochastic environments is often achieved by estimating the expected outcome of decisions via Monte Carlo sampling. However, sampling may overlook rare, but important events, which can severely impact the decision making process. We present a method in which a Normalizing Flow generative model is trained to simulate samples directly from a conditional distribution given that a rare event occurs. By utilizing Coupling Flows, our model can, in principle, approximate any sampling distribution arbitrarily well. By combining the approximation method with Importance Sampling, highly accurate estimates of complicated integrals and expectations can be obtained. We include several examples to demonstrate how the method can be used for efficient sampling and estimation, even in high-dimensional and rare-event settings. We illustrate that by simulating directly from a rare-event distribution significant insight can be gained into the way rare events happen.
keywords:
normalizing flows, neural networks, rare events, simulation1 Introduction
Many decision problems in complex, stochastic environments (Kochenderfer, \APACyear2015) are nowadays solved by estimating the expected outcome of decisions via Monte Carlo simulations (Kroese \BOthers., \APACyear2011, \APACyear2019; Liu, \APACyear2004). The success of Monte Carlo methods is due to their simplicity, flexibility, and scalability. However, in many problem domains, the occurrence of rare but important events — events that happen with a very small probability, say less than — severely impairs their efficiency, for the reason that such events do not show up often in a typical simulation run (Arief \BOthers., \APACyear2021). On the other hand, failing to consider such rare events can lead to decisions with potentially catastrophic outcomes, e.g., hazardous behaviour of autonomous cars. By using well-known variance reduction techniques such as Importance Sampling (Kroese \BOthers., \APACyear2011; Bucklew, \APACyear2004) it is possible to sometimes dramatically increase the efficiency of the standard Monte Carlo method. Nevertheless, there are few efficient methods available that give insights into how a system behaves under a rare event. An important research goal is thus to find methods that simulate a random process conditionally on the occurrence of a rare event. In this case, the target sampling distribution is the distribution of the original process conditioned on the rare event occurring. More broadly, for both estimation and sampling problems, the challenge is to identify a “good” sampling distribution that closely approximates a target distribution. Certain approximation methods, such as the Cross-Entropy method (de Boer \BOthers., \APACyear2005; Rubinstein \BBA Kroese, \APACyear2017), train a parametric model by minimizing the cross-entropy between a distribution family and the target distribution. However, typical parametric models are often not flexible enough to efficiently capture all the complexity of many interesting systems. Botev \BOthers. (\APACyear2007) introduced a Generalized Cross-entropy method, which approximates the target distribution in a non-parametric way. However, the quality of the results is determined by various hyper-parameters, which require expertise to tune.
While many standard methods can identify sampling distributions of sufficient quality to estimate rare-event probabilities and related quantities of interest, extremely good approximations to the target conditional distribution are required to be able to explore the behaviour of the simulated system under rare-event conditions. This can occasionally be achieved by strategically selecting very specific distribution families using problem-specific information, but this has been difficult to achieve with conventional simulation methods. Therefore, it is desirable to have a more general approach that can closely approximate any target distribution without relying on problem-specific knowledge. Gibson \BBA Kroese (\APACyear2022) recently introduced a framework for rare-event simulation using neural networks that aimed to achieve this. In that framework two Multilayer Perceptrons are trained simultaneously: the first being a generative model to represent the sampling distribution, and the second to approximate the probability distribution of the first. While the framework had some success in one-dimensional problems, the reliance on a second network and probability density estimation convoluted the training process and made scaling to higher-dimensional problems difficult. Ardizzone \BOthers. (\APACyear2019) and Falkner \BOthers. (\APACyear2022) explore the use of normalizing flows for rare event sampling in the context of image generation and Boltzmann generators. The approach in Ardizzone \BOthers. (\APACyear2019) requires a conditioning network to be pre-trained and embedded into the normalizing flows architecture. Falkner \BOthers. (\APACyear2022) embeds a bias variable into the flow to learn distributions that are biased towards the region of interest. However, such bias variables can be difficult to construct for more complex problems. In contrast, our model is trained end-to-end and without having to introduce a conditioning variable.
We present a new framework, inspired by Gibson \BBA Kroese (\APACyear2022), in which a Normalizing Flows generative model is trained to learn the optimal sampling distribution and used to estimate quantities such as the rare-event probability. The highly expressive nature of some Normalizing Flows architectures, trained using standard deep learning training algorithms, massively expands the range of learnable distributions, while the invertibility of Normalizing Flows allows the exact generative probability density to be computed without the need of a second network. In Section 2 we present the background theory and a description of the training algorithm, and in Section 3 we present several examples of rare-event simulation using this method. The source-code of our method is available at https://github.com/hoergems/rare-event-simulation-normalizing-flows.
2 Theory
The theory of rare-event simulation (Juneja \BBA Shahabuddin, \APACyear2006; Rubino \BBA Tuffin, \APACyear2009; Bucklew, \APACyear2004), Importance Sampling (Glynn \BBA Iglehart, \APACyear1989; Tokdar \BBA Kass, \APACyear2010; Neal, \APACyear2001) and Normalizing Flows (Kobyzev \BOthers., \APACyear2021; Papamakarios \BOthers., \APACyear2021; Rezende \BBA Mohamed, \APACyear2015) is well established. In this section we review the relevant background, formulate the foundation of our method, and present the training procedure.
2.1 Rare-Event Simulation and Importance Sampling
First let us introduce a mathematical basis for rare-event simulation and Importance Sampling. Consider a random object (e.g., random variable, random vector, or stochastic process), , taking values in some space, , with probability density function, , that represents the result of a simulation experiment. Running simulations corresponds to sampling . We consider rare events of the form , where is the set of simulation outcomes that satisfy a predicate for some performance function and level parameter . The probability of the rare event can thus be written as
where is very small, but not 0. Here, is an indicator function that is 1 when and 0 otherwise, and represents the expected value. The expected number of simulations to sample a single rare event is , so simulating rare events by sampling directly quickly becomes computationally infeasible the rarer the event is. Therefore, other techniques, such as Importance Sampling become necessary to simulate and analyse rare events.
In particular, suppose that is sampled from a probability density function and that we wish to estimate the quantity
via “crude” Monte Carlo: Simulate independently from , and estimate via the sample average . The idea of Importance Sampling is to change the probability distribution under which the simulation takes place. However, computing the expected value of a function of while using a different sampling density , requires a correction factor of the likelihood ratio ,
| (1) |
where and represent the expected values under the two probability models. This relationship allows an unbiased estimate of to be computed by sampling from instead of , via
where is an independent and identically distributed (iid) sample from . Note that any choice for is allowed, as long as when . The optimal sampling distribution for estimating in this way is thus the distribution that minimizes the variance of the estimator . When is strictly positive (or strictly negative), choosing the probability density
| (2) |
yields in fact a zero-variance estimator, because then . As a special case, an unbiased estimator of the rare-event probability can be computed as
| (3) |
and the optimal sampling density is just the original density truncated to the rare-event region :
| (4) |
More generally, if we want to estimate the expectation of conditional on , that is,
| (5) |
then can be estimated via
| (6) |
In this case, the optimal Importance Sampling density is
| (7) |
2.2 Normalizing Flows
If it is possible to approximate the target density (e.g., the optimal Importance Sampling density) closely, then we are able to compute certain quantities of interest (e.g., or with low variance. Normalizing Flows is a generative model that can closely approximate a wide variety of probability densities. Suppose the random object, , can be mapped to another random object, , taking values in some space of the same dimensionality, and vice versa, via invertible differentiable functions and , so that
where is a vector representing all, if any, parameters. If, under the target density, maps to a random object that has a simple base distribution, such as a (multivariate) normal or uniform distribution, then the target distribution can be sampled indirectly by sampling from the base distribution and mapping the result using . The name of such a generative model is derived from the idea that a sequence of invertible differentiable transformations can map even a very complex probability distribution to a simple base distribution, thereby forming a ‘normalizing flow’. The construction of the ‘flow’ relies on the principle that any composition of invertible differentiable functions will also be invertible and differentiable.
In what follows, we assume that is a subset of and that and are “continuous” random variables; more precisely, that they have probability densities and with respect to the Lebesgue measure on . Since is differentiable, the probability density function can be expressed in terms of the probability density function via the relation
| (8) |
or, in terms of :
| (9) |
Here, is Jacobian matrix of and the absolute value of its determinant is the Jacobian of , and similar for . If is a composition of other invertible differentiable functions,
then we can use the chain rule to combine the Jacobians as a product,
Therefore, analogous to a feed-forward neural network, the full Jacobian can be computed during a single pass as is computed. A similar result holds for the inverse: . Functional composition increases the complexity of the model while maintaining the accessibility of the Jacobian. In this way, Normalizing Flows provides the opportunity for highly expressible generative models, with computationally tractable density functions. As will be discussed in Section 2.4, training the model to learn a target density from a given function, rather than via training data, requires the ability to compute as a differentiable function. Therefore, using a Normalizing Flows model improves and simplifies the framework introduced by Gibson \BBA Kroese (\APACyear2022) by eliminating the need to train a second neural network to approximate the density function via kernel density estimation.
2.3 Coupling Flows
Coupling Flows, first introduced by Dinh \BOthers. (\APACyear2015), is a family of Normalizing Flows which have been shown to be universal approximators of arbitrary invertible differentiable functions when composed appropriately (Teshima \BOthers., \APACyear2020). A single Coupling Flows unit splits into two vectors, and , as well as into and . It then transforms one part via an invertible differentiable function, , called the coupling function, which contains parameters determined by the other partition. The relationship between the second part and the coupling function parameters, called the conditioner, , does not need to be invertible, since this part is not transformed and is accessible when computing the inverse. This means functions with many learnable parameters, like neural networks, can be used to capture interesting and complex dependencies between variables. Figure 1 illustrates the structure of a Coupling Flow models and its inverse.
The Coupling Flow can be expressed mathematically as:
Note that the parameters of the flow are contained in the conditioner, . Since the -partition does not transform, the Jacobian of the full transformation is just the Jacobian of the coupling function; that is,
The coupling function is often chosen to be a simple affine transformation (Dinh \BOthers., \APACyear2015, \APACyear2016; Kingma \BBA Dhariwal, \APACyear2018). Instead, we base our coupling function on the rational function proposed by Ziegler \BBA Rush (\APACyear2019):
| (10) |
This function has five parameters when applied elementwise. However, separate parameters can be used for each dimension in the partition. For additional complexity, the coupling function can also be a composition of these rational functions, . In this case the total number of parameters in the coupling function is five multiplied by the number of compositions multiplied by the number of dimension in . We choose the conditioner function to be a Multilayer Perceptron, with an input dimensionality to match and an output dimensionality to match the number of parameters in the coupling function.
In order for eq. 10 to define an invertible function, some restrictions have to be placed on the parameters. Choosing
ensures that the function in eq. 10 is a strictly increasing invertible function. We enforce these constraints, following Ziegler and Rush, by processing the output of the conditioner Multilayer Perceptron,
where primed letters denote unconstrained outputs of the conditioner function. The factor of 0.95 in the expression for helps improve stability by precluding barely invertible functions that can exist near the bound . While we do not need to compute the inverse in our method, it can be calculated as the real solution to a cubic equation.
A single coupling flow unit does not transform the -partition. So, functional composition is necessary to obtain a general approximation. To achieve this, the dimensions of each coupling flow unit are split differently to ensure that all dimensions have to opportunity to ‘influence’ all other dimensions, thereby capturing any dependencies between all dimensions. In practice, we permute the dimensions between Coupling Flow units, while fixing the partitioned dimensions. The permutation of dimensions can be viewed as special case of a linear transformation, where the transformation matrix is a permutation of the rows of the identity matrix. The Jacobian matrix of a linear transformation is equal to the transformation matrix. So, the Jacobian is just 1 and is trivial to include in the probability density calculations of eq. 8 and eq. 9.
2.4 Objective and Training
Choosing an appropriate Normalizing Flows model architecture allows any density to be approximated arbitrarily well if the correct parameters can be identified. We use a form of stochastic gradient descent to iteratively tune the parameters of the model to minimize the Kullback–Leibler (KL) divergence between the model density, say, and a known target function, , that is proportional to the target probability density function. That is, we minimize
| (11) |
Note that a model density that minimizes eq. 11 also minimizes the KL divergence between and the actual (normalized) target density. The advantage of using eq. 11 is that the normalization constant of the target density does not need to be known. This motivates the following minimization program:111Actually, the first term in this objective corresponds to the negative differential entropy of the base density and does not depend on any parameters, so could be omitted. However, we keep it to make interpreting the loss a little simpler.
| (12) |
which corresponds to choosing parameters to minimize the KL divergence between the Normalizing Flows generative density and a target density whose probability density function is proportional to . The expression can be derived by substituting from eq. 9 into eq. 11 and taking the expectation with respect to the base density. The minimum KL divergence is zero, when the two densities are identical, so the minimum value of this objective is the negative natural logarithm of the normalization constant of . For example, if , then the minimum value of the objective function is . The objective function values can be estimated via
| (13) |
where is an iid sample of the base density.
The objective function marks a clear distinction between how we train a Normalizing Flows generative model using a target function, and how they are typically trained using a data set. In other works, such as by Dinh \BOthers. (\APACyear2015), Normalizing Flows are trained to learn the density of a data set by maximizing the log-likelihood of the sampled data. While this can be considered equivalent to minimizing the KL divergence, the training process involves sampling the data set, which corresponds to sampling , and then moving in the ‘normalizing’ direction with to solve the maximization program:
After the model is trained, new data can be generated by sampling and moving in the ‘generating’ direction using . Therefore, in the data-focused case, it is essential to be able to compute both transformations, and . However, in the context of rare-event simulation, we do not have access to training data, but a target function that is proportional to a target probability density, and all training occurs in the ‘generating’ direction. Therefore, computing is not required (although must still be invertible in principle). Algorithm 1 outlines our training procedure.
2.5 Conditional Target Densities
As previously shown in eq. 4 and eq. 7, when estimating rare-event probabilities and other quantity conditioned on a rare event, the target density includes an indicator function, . However, the term, in the objective function in eq. 12 requires each value of the target function value to be strictly positive. To circumvent this problem, we reuse the solution presented by Gibson \BBA Kroese (\APACyear2022), to approximate by defining a strictly positive penalty factor,
| (14) |
which is a positive approximation of when and is the complement set of . The approximation is more accurate the larger the value of and is exact in the limit . Figure 2 illustrates the convergence of the approximation.

Therefore, if the target density includes the indicator function as a factor, we replace it with the penalty factor with appropriate performance function, . For example, if the aim is to estimate from eq. 5, then the target function would be of the form
Note that in this case
so learning a conditional density by including the penalty factor in the target function is equivalent to learning the unconditional target and including an additional penalty term in the objective that penalizes samples outside the rare-event region. In this way, can be interpreted as the weight of the penalty. For our experiments we choose .
3 Results
In this section we look at how well Normalizing Flows models can learn various target functions using several practical examples.
3.1 Truncated Normal Density
Firstly we consider a very simple one-dimensional example of a truncated normal density. Let have a standard normal distribution: and consider the rare-event region . An obvious choice for the performance function is , so if the goal is to estimate the rare-event probability , then the target function is
A Coupling Flow is unsuitable for a one-dimensional problem, so we use a composition of three rational functions from eq. 10, containing a total of 15 parameters. Choosing a batch size of , a learning rate of , a weight decay parameter of and , the model was trained via Algorithm 1 and the Adam gradient descent optimizer (Kingma \BBA Ba, \APACyear2017) for 30,000 iterations. Figure 3 illustrates how the model converges towards the truncated normal target density, with threshold parameter .




Using a sample of 1,000 points, eq. 3 gives us an estimate 0.00134576 of the rare-event probability , which is about 0.3% error from the true value of about 0.0013499. From the same sample, the sample standard deviation is about 0.000261. We can estimate the minimum sample size needed for a 1% standard error by
where is the sample standard deviation of the summand in eq. 3. Using a crude Monte Carlo estimator, the relative standard error should be , requiring a much larger sample size of about for a 1% standard error.
The learned density is not exactly identical to the target conditional density, but is very close. To quantify how good the approximation is, we can estimate the KL divergence between the target density and the learned density using
In this example the KL divergence is estimated to be with a standard error of using sample size 10,000.
3.2 Two-Dimensional Exponential Density
Secondly, we try another example from Gibson \BBA Kroese (\APACyear2022) of a two-dimensional exponential density. In particular, in this example the probability density function of is:
and the rare-event region is , with performance function, . To estimate , the target function is
This time we choose a flow model composed of six Coupling Flows, interlaced with dimension permutations, followed by an elementwise exponential function. The exponentiation ensures that the generated points are positive. The coupling function in each Coupling Flow is a composition of two rational functions of the form in eq. 10. The conditioner in each Coupling Flow is a linear transformation plus a constant vector. Therefore, the total number of learnable parameters is 60. Figure 4 shows the structure of this model via a flow chart.
The model was trained for 100,000 iterations with a learning rate of 0.0001, a weight decay of constant of 0.0001, and a batch size of 10,000. When , . After training, with a sample size of 1,000 the estimated constant is , with standard deviation of about giving a relative standard error of 0.40%. Achieving a comparable standard error using a crude Mote Carlo estimator would require a sample size of more than . Figure 5 shows how well the model learned the target density by including a scatter plot of a sample of points as well as comparing the learned probability density with the target probability density. The KL-divergence is estimated to be about 0.011 with 9.7% standard error using sample size of 10,000.


3.3 Bridge Network
This third example comes from Chapter 9 of Kroese \BOthers. (\APACyear2011). In this example, we increase the number of dimensions to five, each corresponding to a random edge length in a bridge network, shown in Figure 6. The graph contains five edges and four nodes, where the length of each edge is uniformly distributed and the goal is to identify the expected shortest path from node to node . Specifically, we wish to estimate the expected length of the shortest path from to ; that is, the expectation in eq. 1, with and
In this case , so the optimal Importance Sampling density that minimizes the variance in estimating is . Therefore, the target function is .
The space of allowed values in this example is , so it is reasonable to choose a model architecture in which the domains and co-domains of each composed flow unit is . To achieve this we choose a uniform base distribution, . Additionally, the model is composed of five Coupling Flows and dimension permutation pairs. In each permutation the dimensions are cycled via . The dimensions are partitioned so the coupling function transforms the first three dimensions. The coupling function of each Coupling Flow is a rational function based on eq. 10 with separate parameters for each dimension. The conditioner, like the previous example, is a linear transformation. Figure 7 uses a flow chart to illustrate the structure of this model. The parameters in the coupling functions of each Coupling Flow unit contain additional constraints to ensure that and , thereby preserving the domain of at each flow component.
The model was trained with a learning rate of 0.0001, weight decay parameter of 0.0001, batch size 10,000 for 300,000 iterations. The scatter plot in Figure 8 compares the learned probability density of with the optimal sampling density given by eq. 2. The learned density forms a fairly good approximation of the optimal sampling density with a KL divergence of about 0.0017 with 29% standard error (using sample of 10,000). The histograms in Figure 8 compare the densities of the summands of the Importance Sampling estimator from eq. 1 and the crude Monte Carlo estimator, being the sample mean of . In this example both methods provide accurate estimates of the expected minimum path length. Typical values of the crude Monte Carlo and IS estimators are 0.9272 with a standard relative error of and 0.9301 with a standard relative error of . While both values agree with the theoretical value of , the IS estimator reduces the variance by a factor of about 65.


3.4 Conditional Bridge Network
In this example we continue with the bridge network, but now consider the rare event that the shortest path includes three edges, passing through the middle, rather than just two. That is, the shortest path is either or . The rare-event region can be defined by choosing
and . That is, the penalty depends on the difference between the shortest ‘inner’ path ( or ) and the shortest ‘outer’ path ( or ).
The exact same model was reused, but trained across 500,000 iterations with the penalty factor included in the target function. In this way, the goal is to estimate the expected shortest path length of the distribution conditioned on the shortest path being or . The rare event probability can be estimated using eq. 3 with a sample size of 10,000 to be about 0.0346 with a standard relative error of . This corresponds to a variance reduction in a factor of about 17 compared to the crude Monte Carlo estimate. The conditional expected shortest path length can now be estimated via eq. 6 as 0.913 with a standard relative error of .
By learning an approximation of the conditional distribution, we can explore the likely conditions required to generate the rare event. Figure 9 compares scatter plots between the learned unconditional and the conditional distributions. The unconditional distribution is not too different from the original uniform distribution, with the exception of and . This is the expected result since the path, , with path length , is the most likely to be the shortest. However, the learned conditional distribution is significantly different to the original uniform distribution. From the scatter plots it is clear that is almost always short, and and have a strong negative correlation. Therefore, we can conclude that the most likely conditions for the shortest path to be one that passes through the middle edge, is that the middle edge is short, and that exactly one of bottom two edges is short. This is congruent with expectations since a long middle edge would likely make the total path length longer than both of the outer paths, if both bottom edges were short then the middle edge would be bypassed, and if both bottom edges were long, then the shortest path would likely be across the top.


3.5 Asian Call Option
In this section we look at stock price models and expected pricing of call options. This example, from Chapter 15 of Kroese \BOthers. (\APACyear2011), specifically looks at estimating the expected Asian call option of a stock whose undiscounted price, , at time can be modelled by the Stochastic Differential Equation (SDE)
where the drift, , is the risk-free rate of return, is a Wiener process and is the volatility. This SDE is solved by
The average stock price across the interval can be approximated by
where the time has been discretized into equal intervals of ,
and . The discounted payoff at time of the Asian option is
where and the superscript denotes the ramp function. Since is a Wiener process, , where is the identity matrix of appropriate dimensionality. If the goal is to estimate the expected discounted payoff then, according to eq. 2, the optimal sampling distribution should include a factor of . However, the objective eq. 12 requires the target function to be non-zero at all sampled values. Therefore, we introduce the following approximation
which is a strictly positive continuously differentiable function that is exact in the limit . In our experiments we choose . Therefore, the target function is
We chose the base distribution to be and the normalizing flow to be comprised of six coupling flow units with equal partition sizes. The dimensions were permuted after each coupling flow unit. Figure 10 illustrates the normalizing flows structure.
The parameters used in this example were , , , , and . The model was trained for 30000 steps with a batch size of 1000, learning rate of 0.0001 and weight decay of 0.0001. Figure 11 compares the histograms of the crude Monte Carlo and importance sampling estimator summands. Using a sample of 10000, the crude estimator is about 5.3432 with a standard relative error of , and the importance sampling estimator is about 5.3580 with a standard relative error of . This corresponds to a variance reduction of about a factor of 4.4.
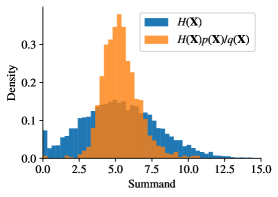
Let us explore the rare event in which the discounted payoff exceeds 14, with performance function and . In this case the goal is to explore how this rare event occurs and to estimate the probability of the rare event. Therefore, the target function is just the probability density function of the Wiener process multiplied by the penalty factor,
This time the model was trained for 100000 iterations. With a sample of 10000 the crude and IS estimators are about 0.0022 with relative error, and 0.0015797 with relative error respectively. This corresponds to a variance reduction of a factor of about 2100. Using the estimated normalization constant of 0.0015797 the KL divergence between the learnt density and the target density is about 0.15157 with a standard relative error of indicating that the learnt distribution is very close to the target conditional distribution. Figure 12 illustrates the strong linear relationship between the learnt log density and the target unconditional density, and compares the distributions of the simulated discounted Asian options.
 |
 |
Since the learnt distribution is a decent approximation of the conditional distribution, we can use the simulated trajectories to gain insights into how high performing options can occur. Figure 13 shows typical stock prices across time when simulating using the original probability measure and the learnt probability measure. In the first instance the average value is largely static, increasing very slowly, while the variance grows across time. However, conditioning the simulation on achieving a discounted payoff of at least 14 changes the trend unexpectedly. Rather than a steady growth in stock price across the whole time interval, most of the stock price growth occurs by . Additionally, the variance is fairly constant over time during this growth time, mostly growing near the end. This result is also visible in the covariance matrix of the stock price, illustrated in figure 14. Under the original probability distribution the stock price near maturity depends little on the early prices, and the variance grows roughly linearly with time. However, under the learnt probability distribution, the variance in stock price is largely constant until a short time before maturity. Additionally, there is a small correlation between early stock prices and late stock prices. This could indicate that
 |
 |

3.6 Double Slit Experiment
In this example we test our method on a high-dimensional problem. A dimensionless particle traverses an unbounded -dimensional environment for a maximum duration of , which is discretized into time steps, where . The environment consists of a barrier with two slits, located at and . The width of both slits is . Additionally, the environment contains a vertical screen located at . The aim of the particle is to reach the screen while simultaneously passing through one of the two slits. At time step , the particle starts at the -position . Given a random vector , where is the -dimensional identity matrix, the position of the particle at time step evolves according to
| (15) |
where is the -th component vector of . The path of the particle induced by is then the sequence of points , with defined according to eq. 15.
Let be the density of . Our goal is to learn a sampling density that is proportional to truncated to the rare-event region , where is an outcome of . The performance function is defined as follows. Suppose is is the time step where is closest to the screen; that is,
where is the -coordinate of the particle at time step . Additionally, let be the first step where , i.e., where the particle crosses . The performance function of an outcome of , with path , and outcomes and of and is then defined as
| (16) |
where
| (17) |
The functions and in section 3.6 measure the distances of the -coordinate (i.e., ) of point to the slits and the operator in eq. 16 ensures that only the minimum distance to the slits contributes to the performance function. Note that the definitions of and imply that a path successfully crosses a slit if , even if the path touches the barrier from to . In case the particle does not cross , we set both and to . The function is an additional penalty term which penalizes the -coordinate of the point (i.e., ) to be on the left-hand side of the screen.
With the performance function in eq. 16, the target function is defined as
| (18) |
with . For the base distribution, we chose a Gaussian Mixture Model () consisting of two -dimensional component distributions and with equal weights, where and . This bimodal mixture model helps in learning the correct bimodal target density. The normalizing flow is composed of twenty coupling flow units with equal partition sizes. The dimensions are permuted after each coupling flow unit. Figure 15 illustrates the normalizing flow.
In our experiments we set , , , and . We then trained three normalizing flows using , and , where each flow was trained for iterations with a batch size of , learning rate of and weight decay of .

Figure 16 (left) shows the double slit environment with paths simulated using the learned normalizing flows for (red paths), (green paths) and (blue paths). We additionally used samples for each to test the capability of the models in generating paths that successfully pass through one of the slits and hit the screen at . In our tests, the success rate was , and for , and respectively, which shows that the learnt distributions are close to the conditional target distribution, even when the base and target distributions are -dimensional. We additionally investigate how the marginal distributions of the paths at look like. Figure 16 (right) shows the histogram of the -positions of paths at for (red), (green) and (blue) respectively. We can see that for all values of , the distributions at the screen closely match each other. This is both desired and expected, due to the scaling factor for the variance of the conditional target densities.
4 Conclusion
Monte Carlo methods are important tools for decision making under uncertainty. However, rare events pose significant challenges for standard Monte Carlo methods, due to the low probability of sampling such events. In this paper, we propose a framework for rare-event simulation. Our framework uses a normalizing flow based generative model to learn optimal importance sampling distributions, including conditional distributions. The model is trained using standard gradient descent techniques to minimize the KL divergence between the model density and a function that is proportional to the target density. Empirical evaluations in several domains demonstrate that our framework is able to closely approximate complicated distributions, even in high-dimensional (up to -dimensional) rare-event settings. Simultaneously, our framework demonstrates substantial improvements in sample efficiency compared to standard Monte Carlo methods. Given these properties, we believe that combining our framework with Monte Carlo based methods for decision making under uncertainty is a fruitful avenue for future research.
Supplementary information The source-code of our framework and the examples is publicly available at https://github.com/hoergems/rare-event-simulation-normalizing-flows.
Acknowledgements We thank Wei Jiang for helpful discussions. This work is supported by the Australian Research Council Centre of Excellence for Mathematical and Statistical Frontiers (ACEMS) CE140100049 grant and the Australian Research Council (ARC) Discovery Project 200101049.
References
- \bibcommenthead
- Ardizzone \BOthers. (\APACyear2019) \APACinsertmetastarardizzone2019guided{APACrefauthors}Ardizzone, L., Lüth, C., Kruse, J., Rother, C.\BCBL Köthe, U. \APACrefYearMonthDay2019. \APACrefbtitleGuided Image Generation with Conditional Invertible Neural Networks. Guided image generation with conditional invertible neural networks. \APACaddressPublisherarXiv. {APACrefURL} https://doi.org/10.48550/arXiv.1907.02392 \PrintBackRefs\CurrentBib
- Arief \BOthers. (\APACyear2021) \APACinsertmetastararief2021certifiable{APACrefauthors}Arief, M., Bai, Y., Ding, W., He, S., Huang, Z., Lam, H.\BCBL Zhao, D. \APACrefYearMonthDay2021. \APACrefbtitleCertifiable Deep Importance Sampling for Rare-Event Simulation of Black-Box Systems. Certifiable deep importance sampling for rare-event simulation of black-box systems. \APACaddressPublisherarXiv. {APACrefURL} https://doi.org/10.48550/arXiv.2111.02204 \PrintBackRefs\CurrentBib
- Botev \BOthers. (\APACyear2007) \APACinsertmetastarbotev2007generalized{APACrefauthors}Botev, Z.I., Kroese, D.P.\BCBL Taimre, T. \APACrefYearMonthDay2007. \BBOQ\APACrefatitleGeneralized Cross-entropy Methods with Applications to Rare-event Simulation and Optimization Generalized cross-entropy methods with applications to rare-event simulation and optimization.\BBCQ \APACjournalVolNumPagesSimulation8311785–806, {APACrefDOI} https://doi.org/10.1177/0037549707087067 \PrintBackRefs\CurrentBib
- Bucklew (\APACyear2004) \APACinsertmetastarBucklewJames2004ItRE{APACrefauthors}Bucklew, J. \APACrefYear2004. \APACrefbtitleIntroduction to Rare Event Simulation Introduction to rare event simulation. \APACaddressPublisherSpringer. \PrintBackRefs\CurrentBib
- de Boer \BOthers. (\APACyear2005) \APACinsertmetastardeBoer2005{APACrefauthors}de Boer, P\BHBIT., Kroese, D.P., Mannor, S.\BCBL Rubinstein, R.Y. \APACrefYearMonthDay2005. \BBOQ\APACrefatitleA Tutorial on the Cross-Entropy Method A tutorial on the cross-entropy method.\BBCQ \APACjournalVolNumPagesAnnals of Operations Research134119–67, {APACrefDOI} https://doi.org/10.1007/s10479-005-5724-z \PrintBackRefs\CurrentBib
- Dinh \BOthers. (\APACyear2015) \APACinsertmetastarDinh2015{APACrefauthors}Dinh, L., Krueger, D.\BCBL Bengio, Y. \APACrefYearMonthDay2015. \APACrefbtitleNICE: Non-linear Independent Components Estimation. Nice: Non-linear independent components estimation. \APACaddressPublisherarXiv. {APACrefURL} https://doi.org/10.48550/arXiv.1410.8516 \PrintBackRefs\CurrentBib
- Dinh \BOthers. (\APACyear2016) \APACinsertmetastarDinh2016{APACrefauthors}Dinh, L., Sohl-Dickstein, J.\BCBL Bengio, S. \APACrefYearMonthDay2016. \APACrefbtitleDensity estimation using Real NVP. Density estimation using real NVP. \APACaddressPublisherarXiv. {APACrefURL} https://doi.org/10.48550/arXiv.1605.08803 \PrintBackRefs\CurrentBib
- Falkner \BOthers. (\APACyear2022) \APACinsertmetastarfalkner2022conditioning{APACrefauthors}Falkner, S., Coretti, A., Romano, S., Geissler, P.\BCBL Dellago, C. \APACrefYearMonthDay2022. \APACrefbtitleConditioning Normalizing Flows for Rare Event Sampling. Conditioning normalizing flows for rare event sampling. \APACaddressPublisherarXiv. {APACrefURL} https://doi.org/10.48550/arXiv.2207.14530 \PrintBackRefs\CurrentBib
- Gibson \BBA Kroese (\APACyear2022) \APACinsertmetastarGibson2022{APACrefauthors}Gibson, L.J.\BCBT \BBA Kroese, D.P. \APACrefYearMonthDay2022. \BBOQ\APACrefatitleRare-Event Simulation via Neural Networks Rare-event simulation via neural networks.\BBCQ \APACrefbtitleAdvances in Modeling and Simulation. Advances in modeling and simulation. \APACaddressPublisherSpringer. \APACrefnoteIn Press \PrintBackRefs\CurrentBib
- Glynn \BBA Iglehart (\APACyear1989) \APACinsertmetastarGlynn1989{APACrefauthors}Glynn, P.W.\BCBT \BBA Iglehart, D.L. \APACrefYearMonthDay1989. \BBOQ\APACrefatitleImportance Sampling for Stochastic Simulations Importance sampling for stochastic simulations.\BBCQ \APACjournalVolNumPagesManagement Science35111367-1392, {APACrefDOI} https://doi.org/10.1287/mnsc.35.11.1367 \PrintBackRefs\CurrentBib
- Juneja \BBA Shahabuddin (\APACyear2006) \APACinsertmetastarJUNEJA2006291{APACrefauthors}Juneja, S.\BCBT \BBA Shahabuddin, P. \APACrefYearMonthDay2006. \BBOQ\APACrefatitleChapter 11 Rare-Event Simulation Techniques: An Introduction and Recent Advances Chapter 11 rare-event simulation techniques: An introduction and recent advances.\BBCQ S.G. Henderson \BBA B.L. Nelson (\BEDS), \APACrefbtitleSimulation Simulation (\BPGS 291–350). \APACaddressPublisherElsevier. \PrintBackRefs\CurrentBib
- Kingma \BBA Ba (\APACyear2017) \APACinsertmetastarkingma2017adam{APACrefauthors}Kingma, D.P.\BCBT \BBA Ba, J. \APACrefYearMonthDay2017. \APACrefbtitleAdam: A Method for Stochastic Optimization. Adam: A method for stochastic optimization. \APACaddressPublisherarXiv. {APACrefURL} https://doi.org/10.48550/arXiv.1412.6980 \PrintBackRefs\CurrentBib
- Kingma \BBA Dhariwal (\APACyear2018) \APACinsertmetastarNEURIPS2018_d139db6a{APACrefauthors}Kingma, D.P.\BCBT \BBA Dhariwal, P. \APACrefYearMonthDay2018. \BBOQ\APACrefatitleGlow: Generative Flow with Invertible 1x1 Convolutions Glow: Generative flow with invertible 1x1 convolutions.\BBCQ S. Bengio, H. Wallach, H. Larochelle, K. Grauman, N. Cesa-Bianchi\BCBL \BBA R. Garnett (\BEDS), \APACrefbtitleAdvances in Neural Information Processing Systems Advances in neural information processing systems (\BVOL 31). \APACaddressPublisherCurran Associates. \PrintBackRefs\CurrentBib
- Kobyzev \BOthers. (\APACyear2021) \APACinsertmetastarKobyzev2020{APACrefauthors}Kobyzev, I., Prince, S.J.\BCBL Brubaker, M.A. \APACrefYearMonthDay2021. \BBOQ\APACrefatitleNormalizing Flows: An Introduction and Review of Current Methods Normalizing flows: An introduction and review of current methods.\BBCQ \APACjournalVolNumPagesIEEE Transactions on Pattern Analysis and Machine Intelligence43113964–3979, {APACrefDOI} https://doi.org/10.1109/TPAMI.2020.2992934 \PrintBackRefs\CurrentBib
- Kochenderfer (\APACyear2015) \APACinsertmetastarKochenderfer2015decision{APACrefauthors}Kochenderfer, M.J. \APACrefYear2015. \APACrefbtitleDecision Making Under Uncertainty: Theory and Application Decision Making Under Uncertainty: Theory and Application. \APACaddressPublisherMIT Press. \PrintBackRefs\CurrentBib
- Kroese \BOthers. (\APACyear2019) \APACinsertmetastarkroese2019data{APACrefauthors}Kroese, D.P., Botev, Z.I., Taimre, T.\BCBL Vaisman, R. \APACrefYear2019. \APACrefbtitleData Science and Machine Learning: Mathematical and Statistical Methods Data science and machine learning: Mathematical and statistical methods. \APACaddressPublisherChapman and Hall/CRC. \PrintBackRefs\CurrentBib
- Kroese \BOthers. (\APACyear2011) \APACinsertmetastarkroese2013handbook{APACrefauthors}Kroese, D.P., Taimre, T.\BCBL Botev, Z.I. \APACrefYear2011. \APACrefbtitleHandbook of Monte Carlo Methods Handbook of Monte Carlo methods. \APACaddressPublisherJohn Wiley & Sons. \PrintBackRefs\CurrentBib
- Liu (\APACyear2004) \APACinsertmetastarliu2001monte{APACrefauthors}Liu, J.S. \APACrefYear2004. \APACrefbtitleMonte Carlo Strategies in Scientific Computing Monte Carlo strategies in scientific computing. \APACaddressPublisherSpringer. \PrintBackRefs\CurrentBib
- Neal (\APACyear2001) \APACinsertmetastarNeal2001{APACrefauthors}Neal, R.M. \APACrefYearMonthDay2001. \BBOQ\APACrefatitleAnnealed Importance Sampling Annealed importance sampling.\BBCQ \APACjournalVolNumPagesStatistics and Computing112125-139, {APACrefDOI} https://doi.org/10.1023/A:1008923215028 \PrintBackRefs\CurrentBib
- Papamakarios \BOthers. (\APACyear2021) \APACinsertmetastarpapamakarios2021normalizing{APACrefauthors}Papamakarios, G., Nalisnick, E.T., Rezende, D.J., Mohamed, S.\BCBL Lakshminarayanan, B. \APACrefYearMonthDay2021. \BBOQ\APACrefatitleNormalizing Flows for Probabilistic Modeling and Inference Normalizing flows for probabilistic modeling and inference.\BBCQ \APACjournalVolNumPagesThe Journal of Machine Learning Research22571–64, {APACrefURL} http://jmlr.org/papers/v22/19-1028.html \PrintBackRefs\CurrentBib
- Rezende \BBA Mohamed (\APACyear2015) \APACinsertmetastarRezende2015{APACrefauthors}Rezende, D.\BCBT \BBA Mohamed, S. \APACrefYearMonthDay2015. \BBOQ\APACrefatitleVariational Inference with Normalizing Flows Variational inference with normalizing flows.\BBCQ F. Bach \BBA D. Blei (\BEDS), \APACrefbtitleProceedings of the 32nd International Conference on Machine Learning Proceedings of the 32nd international conference on machine learning (\BVOL 37, \BPGS 1530–1538). \APACaddressPublisherPMLR. \PrintBackRefs\CurrentBib
- Rubino \BBA Tuffin (\APACyear2009) \APACinsertmetastarRubino2009{APACrefauthors}Rubino, G.\BCBT \BBA Tuffin, B. \APACrefYear2009. \APACrefbtitleRare Event Simulation using Monte Carlo Methods Rare event simulation using Monte Carlo methods. \APACaddressPublisherJohn Wiley & Sons. \PrintBackRefs\CurrentBib
- Rubinstein \BBA Kroese (\APACyear2017) \APACinsertmetastarrubinstein2016simulation{APACrefauthors}Rubinstein, R.Y.\BCBT \BBA Kroese, D.P. \APACrefYear2017. \APACrefbtitleSimulation and the Monte Carlo Method Simulation and the Monte Carlo method. \APACaddressPublisherJohn Wiley & Sons. \PrintBackRefs\CurrentBib
- Teshima \BOthers. (\APACyear2020) \APACinsertmetastarTakeshi2020{APACrefauthors}Teshima, T., Ishikawa, I., Tojo, K., Oono, K., Ikeda, M.\BCBL Sugiyama, M. \APACrefYearMonthDay2020. \APACrefbtitleCoupling-based Invertible Neural Networks Are Universal Diffeomorphism Approximators. Coupling-based invertible neural networks are universal diffeomorphism approximators. \APACaddressPublisherarXiv. {APACrefURL} https://doi.org/10.48550/arXiv.2006.11469 \PrintBackRefs\CurrentBib
- Tokdar \BBA Kass (\APACyear2010) \APACinsertmetastarTokdar2010{APACrefauthors}Tokdar, S.T.\BCBT \BBA Kass, R.E. \APACrefYearMonthDay2010. \BBOQ\APACrefatitleImportance Sampling: A Review Importance sampling: A review.\BBCQ \APACjournalVolNumPagesWIREs Computational Statistics2154-60, {APACrefDOI} https://doi.org/10.1002/wics.56 \PrintBackRefs\CurrentBib
- Ziegler \BBA Rush (\APACyear2019) \APACinsertmetastarziegler2019{APACrefauthors}Ziegler, Z.\BCBT \BBA Rush, A. \APACrefYearMonthDay2019. \BBOQ\APACrefatitleLatent Normalizing Flows for Discrete Sequences Latent normalizing flows for discrete sequences.\BBCQ K. Chaudhuri \BBA R. Salakhutdinov (\BEDS), \APACrefbtitleProceedings of the 36th International Conference on Machine Learning Proceedings of the 36th international conference on machine learning (\BVOL 97, \BPGS 7673–7682). \APACaddressPublisherPMLR. \PrintBackRefs\CurrentBib