A Distributed Deep Reinforcement Learning Technique for Application Placement in Edge and Fog Computing Environments
Abstract
Fog/Edge computing is a novel computing paradigm supporting resource-constrained Internet of Things (IoT) devices by placement of their tasks on edge and/or cloud servers. Recently, several Deep Reinforcement Learning (DRL)-based placement techniques have been proposed in fog/edge computing environments, which are only suitable for centralized setups. The training of well-performed DRL agents requires manifold training data while obtaining training data is costly. Hence, these centralized DRL-based techniques lack generalizability and quick adaptability, thus failing to efficiently tackle application placement problems. Moreover, many IoT applications are modeled as Directed Acyclic Graphs (DAGs) with diverse topologies. Satisfying dependencies of DAG-based IoT applications incur additional constraints and increase the complexity of placement problem. To overcome these challenges, we propose an actor-critic-based distributed application placement technique, working based on the IMPortance weighted Actor-Learner Architectures (IMPALA). IMPALA is known for efficient distributed experience trajectory generation that significantly reduces exploration costs of agents. Besides, it uses an adaptive off-policy correction method for faster convergence to optimal solutions. Our technique uses recurrent layers to capture temporal behaviors of input data and a replay buffer to improve the sample efficiency. The performance results, obtained from simulation and testbed experiments, demonstrate that our technique significantly improves execution cost of IoT applications up to 30% compared to its counterparts.
Index Terms:
Fog Computing, Edge Computing, Deep Reinforcement Learning, Application Placement, Internet of Things (IoT).1 Introduction
In recent years, new computing and communication technologies have rapidly advanced, leading to the proliferation of smart Internet of Things (IoT) devices (e.g., sensors, smartphones, cameras, vehicles) [1]. These advancements empower IoT devices to run a multitude of resource-hungry and latency-sensitive IoT applications. These emerging IoT applications increasingly demand computing, storage, and communication resources for the execution [2]. Also, the execution of such resource-hungry applications requires a significant amount of energy consumption. Hence, limited computing, storage, and battery capacity of IoT devices, directly affect the performance of IoT applications and user experience [3].
The Cloud computing paradigm, as a centralized solution, is one of the main enablers of the IoT, providing unlimited and elastic remote computing and storage resources for the execution of computation-intensive IoT applications [4]. All/some computation-intensive constituent parts (e.g., service, modules, tasks) of IoT applications can be placed (i.e., offloaded) on remote Cloud Servers (CSs) for execution and storage in order to reduce the execution time of IoT applications and energy consumption of IoT devices [5, 6]. However, due to low bandwidth and high communication latency between IoT devices and CSs, the requirements of latency-sensitive IoT applications cannot be efficiently satisfied [7]. Besides, low bandwidth and high latency of CSs may incur more energy consumption for IoT devices due to higher active communication time with CSs. To improve the high communication latency and low bandwidth of CSs, fog computing paradigm, as a distributed solution, has emerged. In fog computing, heterogeneous Fog Servers (FSs) are distributed in the proximity of IoT devices, through which IoT devices can access the computing and storage resources with higher bandwidth and less communication latency, compared to CSs [8]. However, these FSs usually have limited resources (e.g., CPU, RAM) in comparison to CSs. In our view, edge computing harnesses only distributed edge resources at the proximity of IoT devices while fog computing harnesses both edge and cloud resources to address the requirements of both computation-intensive and latency-sensitive IoT applications (although some works use these terms interchangeably).
In real-world scenarios, many IoT applications (e.g., face recognition [9], smart healthcare [10], and augmented reality [11]) are modeled as a Directed Acyclic Graph (DAG), in which nodes and edges represent tasks and data communication among dependent tasks, respectively. These DAG-based IoT applications incur higher complexity and constraints when making placement decisions for the execution of IoT applications. Hence, placement/offloading of IoT applications, comprised of dependent tasks, on/to suitable servers with the minimum execution time and energy consumption is an important and yet challenging problem in fog computing. Many heuristics, approximation, and rule-based solutions are proposed for this NP-hard problem [12, 13, 14]. Although these techniques work well in general cases, they heavily rely on comprehensive knowledge about the IoT applications and resource providers (e.g., CSs or FSs). The fog computing environment is stochastic in several aspects, such as arrival rate of application placement requests, dependency among tasks, number of tasks per IoT application, resource requirements of applications, and available remote resources, just to mention a few. Therefore, heuristic-based techniques cannot efficiently adapt to constant changes in the fog computing environments [15].
Deep Reinforcement Learning (DRL) provides a promising solution by combining Reinforcement Learning (RL) with Deep Neural Network (DNN). Since DRL agents can accurately learn the optimal policy and long-term rewards without prior knowledge of the system [16], they help solve complex problems in dynamic and stochastic environments such as fog computing, especially when the state space is so large [15, 17]. Although the effectiveness of DRL techniques is shown in several works [18, 19, 20, 21, 22], there are yet several challenges for practical realizations of these techniques in fog computing environments. In DRL, the agent interacts with the environment using trial and error (i.e., exploration) and records the trajectories of experiences (i.e., sequences of states, actions, and rewards) in large quantities with high diversity. These experience trajectories are used to learn the optimal policy in the training phase. In complex environments, such as fog computing, DRL agents require a large number of interactions with the environment to obtain sufficient trajectories of experience to capture the properties of the environment. Therefore, the exploration cost of agents increases. Obviously, it negatively affects the user experience in the fog computing environment, because the training of the DRL agents in such complex environments is a time-consuming process. The centralized DRL agents used in fog computing environments are not suitable for the highly distributed and stochastic environments [23]. Hence, a key problem is how to adapt distributed DRL techniques to efficiently perform in fog computing environments. Considering the distributed nature of fog computing environments, the application placement engines can be placed on different FSs, that work in parallel and efficiently produce diverse experience trajectories with less exploration costs. However, other challenges may arise such as how these trajectories can be efficiently and practically used to learn the optimal policy.
To address the aforementioned challenges, we propose an EXperience-sharing Distributed Deep Reinforcement Learning-based application placement technique, called -DDRL, to efficiently capture complex dynamics of DAG-based IoT applications and FSs’ resources. The -DDRL uses IMPortance weighted Actor-Learner Architectures (IMPALA), proposed by Espeholt et al. [24], which is a distributed DRL agent that uses an actor-learner framework to learn the optimal policy. In IMPALA, several actors interact with the environments in parallel and produce diverse experience trajectories in a timely manner. Then, these experience trajectories are periodically forwarded to the learner for the training and learning of the optimal policy. After each policy update of the learner, actors reset their parameters with the learner’s one and independently continue their explorations. As a result of this distributed and collaborative experience-sharing between actors and learners, the exploration costs reduce significantly, and the experience trajectories are efficiently reused. However, due to decoupled acting and learning, a policy gap between actors and learners arises, which can be corrected by V-trace off-policy correction method [24]. Moreover, we use Recurrent Neural Networks (RNN) to accurately identify the temporal patterns across different features of the input. Finally, the -DDRL uses experience replay to break the strong correlation between generated experience trajectories and improve sample efficiency.
The main contributions of this paper are summarized as follows:
-
•
A weighted cost model for application placement of DAG-based IoT applications is proposed to minimize the execution time of IoT applications and energy consumption of IoT devices. Then, this weighted cost model is adapted to be used in DRL-based techniques.
-
•
A pre-scheduling technique is put forward to define an execution order for dependent tasks within each DAG-based IoT application.
-
•
We propose a dynamic and distributed DRL-based application placement technique for complex and stochastic fog computing environments, working based on the IMPALA framework. Our technique uses RNN to capture complex patterns across different features of the input. Moreover, it uses an experience replay buffer which remarkably helps sampling efficiency and breaks the strong correlation between experience trajectories.
-
•
We conduct simulation and testbed experiments using a wide range of synthetic DAGs, derived from the real-world IoT applications, to cover diverse application dependency models, task numbers, and execution costs. Also, the performance of our technique is compared with two state-of-the-art DRL techniques, called Double Deep Q Learning (Double-DQN), and Proximal Policy Optimization (PPO), and a greedy-based heuristic.
The rest of the paper is organized as follows. Relevant DRL-based application placement techniques in edge and fog computing environments are discussed in Section 2. The system model and problem formulations are presented in Section 3. Section 4 describes the DRL-based model and its main concepts. Section 5 presents our proposed distributed DRL-based application placement framework. We evaluate the performance of our technique and compare it with state-of-the-art techniques in Section 6. Finally, Section 7 concludes the paper and draws future works.
2 Related Work
Considering the large number of works in application placement techniques, in this section, related works for DRL-based application placement techniques in fog/edge computing environments are studied. However, detailed related works for the non-learning-based application placement techniques and frameworks are available in [3, 25, 26].
DRL-based works are first divided into edge computing and fog computing. Edge computing works only consider the resources in the proximity of IoT users while fog computing ones take advantage of both edge resources and remote cloud resources. Hence, the heterogeneity of resources is higher in the fog computing works, which leads to higher complexity for DRL-based application placement techniques to identify the features of the environments. Besides, works are further categorized into independent and dependent categories based on the dependency model of their IoT applications’ granularity (e.g., tasks, modules). In IoT applications with dependent tasks (i.e., DAGs), each task can be executed only when its parent tasks finish their execution, while tasks of independent IoT applications do not have such constraints for execution. Therefore, works in the dependent category have more constraints, and hence the DRL agent requires specific considerations compared to works in the independent category to efficiently learn the optimal policy.
2.1 Edge Computing
In the independent category, Huang et al. [27] proposed a DRL-based offloading algorithm to minimize the system cost, in which parallel computing is used to speed up the computation of a single edge server. Min et al. [28] proposed a fast deep Q-network (DQN) based offloading scheme, combining the deep learning and hotbooting techniques to improve the learning speed of Q-learning. Huang et al. [18] proposed a quantized-based DRL method to optimize the system energy consumption for faster processing of IoT devices’ requests. Chen et al. [19] proposed a double DQN-based algorithm to minimize the energy consumption and execution time of independent tasks of IoT applications. Huang et al. [20] also proposed a DRL-based offloading framework based on DQN that jointly considers offloading decisions and resource allocations. Chen et al. [29] proposed a joint offloading framework with DRL to make an offloading decision based on the information of applications’ tasks and network conditions where the training data is generated from the searching process of the Monte Carlo tree search algorithm. Lu et al. [21] proposed a Deep Deterministic Policy Gradients (DDPG)-based algorithm for computation offloading of multiple IoT users to a single edge server to improve the quality of experience of users. To improve the convergence of the DQN algorithm in an edge computing environment, Xiong et al. [30] proposed a DQN-based algorithm combined with multiple replay memories to minimize the execution time of one IoT application. Qiu et al. [31] studied the distributed DRL in an edge computing environment with a single edge server to minimize the energy cost of running IoT applications, consisted of independent tasks. To obtain this goal, they combined deep neuro-evolution and policy gradient to improve the convergence results.
In the dependent category, Wang et al. [16] proposed a meta reinforcement learning algorithm based on the Proximal Policy Optimization (PPO). The main goal of this work is to minimize the execution time of dependent IoT applications, situated in the proximity of a single edge server.
2.2 Fog Computing
In the independent category, Gazori et al. [32] targeted task scheduling of independent IoT applications to minimize long-term service delay and system cost. To obtain this, they used a double DQN-based scheduling algorithm combined with an experience replay buffer. Tuli et al. [23] proposed Asynchronous-Advantage-Actor-Critic (A3C) learning-based technique combined with Recurrent Neural Network (RNN) for the scheduling of independent IoT applications to minimize total system cost.
In the dependent category, Lu et al. [33] proposed a DQN-based algorithm to minimize the overall system cost. Although they consider dependencies among constituent parts of each IoT application, they only consider the sequential dependency model among tasks of an IoT application, where there are no tasks for parallel execution.
2.3 A Qualitative Comparison
| Techniques | Category | Application Properties | Architectural Properties | Application Placement Engine Properties | |||||||||||||
| Main Method | Task Priority | Decision Parameters | |||||||||||||||
| Dependency | Task Number | Heterogeneity | IoT Device Layer | Edge/Fog Layer | Multi Cloud | Time | Energy | Weighted | |||||||||
| Number |
|
Number | Heterogeneity | ||||||||||||||
|
Edge Computing | Independent | Multiple | Heterogeneous | Multiple | Homogeneous | Single | Homogeneous | _ | ✓ | |||||||
|
Single | Homogeneous | Multiple | Heterogeneous | Single | Homogeneous | _ | ✓ | |||||||||
|
Single | Homogeneous | Single | Homogeneous | Multiple | Heterogeneous | DQN | ✓ | |||||||||
|
Single | Heterogeneous | Multiple | Heterogeneous | Single | Homogeneous |
|
✓ | ✓ | ||||||||
|
Multiple | Heterogeneous | Multiple | Heterogeneous | Single | Homogeneous | DQN | ✓ | ✓ | ✓ | |||||||
|
Single | Heterogeneous | Multiple | Heterogeneous | Multiple | Heterogeneous | MCTS | ✓ | ✓ | ||||||||
|
Multiple | Heterogeneous | Multiple | Heterogeneous | Single | Homogeneous | DDPG | ✓ | ✓ | ✓ | |||||||
|
Multiple | Heterogeneous | Multiple | Homogeneous | Single | Homogeneous | DQN | ✓ | |||||||||
|
Multiple | Heterogeneous | Multiple | Heterogeneous | Single | Homogeneous |
|
✓ | |||||||||
|
Dependent | Multiple | Heterogeneous | Multiple | Heterogeneous | Single | Homogeneous | PPO | ✓ | ✓ | |||||||
|
Fog Computing | Independent | Multiple | Heterogeneous | Multiple | Heterogeneous | Multiple | Heterogeneous |
|
✓ | |||||||
|
Multiple | Heterogeneous | Multiple | Heterogeneous | Multiple | Heterogeneous | A3C | ✓ | ✓ | ✓ | |||||||
|
Dependent | Multiple | Heterogeneous | Multiple | Homogeneous | Multiple | Heterogeneous | DQN | ✓ | ||||||||
|
Multiple | Heterogeneous | Multiple | Heterogeneous | Multiple | Heterogeneous | ✓ | IMPALA | ✓ | ✓ | ✓ | ✓ | |||||
Table I identifies and compares the main elements of related works with ours in terms of their IoT application, architectural, and application placement engine properties. In the IoT application section, the dependency model of each proposal is studied, which can be either independent or dependent. Moreover, we study how each proposal models IoT applications in terms of the number of tasks and heterogeneity. This demonstrates whether IoT applications consist of homogeneous or heterogeneous tasks in terms of their computation and data flow. In the architectural properties, the attributes of IoT devices, fog/edge servers, and cloud servers are studied. For IoT devices, the overall number of devices and their type of requests are identified. The heterogeneous request type shows that each device has a different number of requests with various requirements compared to other IoT devices. For edge/fog servers, the number of deployed servers between IoT devices and cloud servers and the heterogeneity of their resources are studied. Moreover, the multi-cloud shows either these works consider different cloud service providers with heterogeneous resources or not. In the application placement engine, the main employed DRL methods are identified. Besides, it is studied either these works consider any mechanism to provide priority for the execution of tasks or not. Finally, the decision parameters of these DRL-based techniques are identified.
Considering DRL-based application placement techniques in edge and fog computing and their identified properties, the environment with multiple heterogeneous IoT devices, heterogeneous FSs, and heterogeneous multi CSs has the highest number of features. Moreover, DAG-based IoT applications incur more constraints on DRL agents as they need to consider the dependency among tasks within each IoT application. The exploration cost of DRL agents increases as the number of features and complexity of the environment increases. It negatively affects the training and convergence time of DRL techniques, and accordingly users’ experience. To address these issues, we propose a distributed DRL technique based on the IMPALA architecture, called -DDRL, in which several actors independently interact with fog computing environments and create experience trajectories in parallel. Then, these distributed experience trajectories are forwarded to the learner for training and policy updates. This significantly reduces the exploration and training costs of centralized DRL techniques. Furthermore, since the learner directly uses the batches of experience trajectories of distributed actors, rather than gradients with respect to the parameters of the policy (similar to how the A3C algorithm works), it can more efficiently learn and identify the features of input data [24]. Also, the transmission of gradients among actors and learners is more expensive in terms of data exchange size and time (similar to how A3C works) in comparison to sharing trajectories of experience. Hence, experience-sharing DRL techniques such as IMPALA are more practical and data-efficient in highly distributed and stochastic environments [24], such as fog computing. Since the policy used to generate the trajectories of experiences in distributed actors can lag behind the policy of the learner in the time of gradient calculations, a V-trace off-policy actor-critic algorithm is used to correct this discrepancy. Besides, to capture the temporal behavior of input data, we embed RNN layers in the network of actors and learners. Moreover, -DDRL uses a replay buffer to improve the sample efficiency for training.
3 System Model and Problem Formulation
Figure 1 represents an overview of our system model in fog computing. IoT devices send their application placement requests to brokers, situated at the edge of the network to be accessed with less latency and higher bandwidth [34, 3]. For each arriving application request, the broker makes a placement decision based on the corresponding DAG of the IoT application, its constraints, and the system status. Accordingly, each task of an IoT application may be assigned to the IoT device for the local execution or one of heterogeneous FSs or CSs for the execution.

3.1 IoT Application
Each IoT applications is modeled as a DAG of its tasks, where depicts vertex set of one application, in which denotes the th task. Moreover, represents edge set, in which denotes there is a data flow between (i.e., parent), (i.e., child) and hence, cannot be executed before . Accordingly, for each task , a predecessor task set is defined, containing all tasks that should be executed before . Moreover, for each DAG , exit tasks are referred to tasks without any children.
The amount of CPU cycles, required for the processing of each task, is represented as , while the required amount of RAM for processing of each task is . Moreover, the weight on each edge illustrates the amount of data that task sends as its output to task as its input.
3.2 Problem Formulation
Each task of an IoT application can either be executed locally on the IoT device or on one of the FSs or CSs. We define the set of all available servers as where . Each server is represented as where shows the type of server (IoT device (), FSs (), CSs ()) and denotes the server index. Therefore, the placement configuration of task , belonging to an IoT application, can be defined as:
| (1) |
and accordingly, the placement configuration of an IoT application is defined as the set of placement configurations for all of its tasks:
| (2) |
We consider that tasks of an IoT application are sorted in a sequence so that all parent tasks are scheduled for the execution before their children. Hence, the dependencies among tasks are satisfied. Besides, among tasks that can be executed in parallel (i.e., tasks that all of their dependencies are satisfied), the is an indicator function to demonstrate whether the task is on the critical path of the IoT application or not [35] (i.e., a path containing vertices and edges that incurs the highest execution cost).
3.2.1 Execution time model
The execution time of each task depends on the availability time of required input data for that task and its processing time on the assigned server :
| (3) |
where depends on the required CPU cycles for that task and the processing speed of the corresponding assigned server , calculated as follows:
| (4) |
The is calculated as the maximum time that the required input data for the execution of task become available on the corresponding assigned server (i.e., ) from its parent tasks:
| (5) | |||
where shows the current bandwidth (i.e., data rate) between the servers to which and are assigned, respectively. Moreover, demonstrates the communication latency between two servers. The is equal to if (i.e., same assigned servers) or 1, otherwise. Since fog computing environments are heterogeneous and stochastic, the , , and may be different among IoT devices, FSs, and CSs.
The main goal of the execution time model is to find the best-possible placement configuration for the IoT application so that its execution time becomes minimized. Assuming an IoT application consists of tasks, the execution time model is defined as:
| (6) |
where is if task is on the critical path and otherwise. Due to the parallel execution of some tasks, only the execution time of tasks on the critical path is considered, which incurs the highest execution time and involves the execution time of other parallel tasks as well.
3.2.2 Energy consumption model
We only consider the energy consumption of IoT devices in this work since FSs and CSs are usually connected to constant power supplies [7]. From the IoT devices’ perspective, the energy consumption that execution of each task incurs depends on the amount of energy the IoT device consumes until the required input data for that task becomes ready plus the required energy for the processing of that task :
| (7) |
where depends whether the task is assigned to the IoT device for local execution or not. Hence, we define an IoT Server identifier to show whether the refers to an IoT device () or other servers (). Accordingly, the is calculated as what follows:
| (10) |
If the task is assigned to the IoT device (i.e., ), the energy consumption of the IoT device is equal to the amount of time that it processes the task multiplied by the CPU power of IoT device . However, if the task is assigned to the other servers for processing (i.e., ), the energy consumption of the IoT device depends on its idle time and corresponding idle power .
The depends on the assigned servers to current task (i.e., ) and its predecessors, and is calculated as what follows:
| (15) |
where and demonstrates whether the current task and/or its parent task in each edge are assigned to the IoT device or not, respectively. It is important to note that the transmission energy consumption for each edge in DAG is only considered when one of the tasks is placed on the IoT device. Hence, if the current task is assigned to the IoT device (i.e., ), the depends on the . However, if the current task is not assigned to the IoT device (i.e., ), it is possible that the predecessor tasks of the current task (i.e., ) are previously assigned to the IoT device, and hence the IoT device should forward the data to the server on which the current task is assigned (which incurs energy consumption). If none of the tasks are assigned to the IoT device for local execution, the IoT device is in its idle state. Besides, , represent the transmission power of the IoT device and its idle time, respectively. Similar to [7, 36, 37], we used constant values for , , however, these parameters also can be dynamically configured.
The main goal of the energy consumption model is to find the best-possible placement configuration for the IoT application so that its energy consumption becomes minimized. Assuming an IoT application consists of tasks, the energy consumption model is defined as:
| (16) |
3.2.3 Weighted cost model
The weighted execution cost of task is defined based on its assigned server :
| (17) |
where and refer to the execution time and energy consumption for the execution of task . Moreover, the and are control parameters to represent the importance of decision parameters in weighted execution cost of each task. Also, the weighted cost of each task can be changed to execution time or energy consumption cost of each task by assigning or , respectively.
Finally, the goal of weighted cost model is to find the best placement configuration for tasks of an IoT application while minimizing the weighted cost of parameters. In this work, we consider execution time of IoT applications and energy consumption of IoT devices as decision parameters, however, this weighted cost can be extended using other decision parameters. The weighted cost model is defined as:
| (18) |
| (19) | |||
| (20) | |||
| (21) | |||
| (22) |
where , are obtained from Eq. 6 and Eq. 16, respectively. Besides, and are control parameters for execution time and energy consumption, by which the weighted cost model can be tuned. denotes that each task can only be assigned to one server at a time for processing. Moreover, states that the task can only be executed after the execution of its predecessors, and hence the cumulative execution cost of is always larger or equal to execution cost of its predecessors’ tasks [7]. Besides, states that the assigned server to the task should have sufficient amount of available RAM for the processing. Also, defines a constraint on the values of control parameters. These constraints are also valid for execution time and energy consumption models. Moreover, the weighted cost model can be changed to execution time or energy consumption model by assigning or , respectively.
Since the application placement problem in heterogeneous environments is an NP-hard problem [31], the problem’s complexity grows exponentially as the number of heterogeneous servers and/or the number of tasks within an IoT application increases. Thus, the optimal policy of the application placement problem cannot be obtained in polynomial time by iterative approaches. The existing application placement techniques are mostly based on heuristics, rule-based policies, and approximation algorithms [16, 23]. Such techniques work well in general cases, however, they cannot fully adapt to dynamic computing environments where the effective parameters of workloads and computational resources continuously change [16, 38]. To address these issues, DRL-based scheduling/placement algorithms are promising avenues for dynamic optimizations of the system [15, 23].


4 Deep Reinforcement Learning Model
The DRL is a general framework that incorporates deep learning to solve decision-making problems with high-dimensional inputs. Formally, learning problems in DRL can be modeled as Markov Decision Processes (MDP), which is extensively used in sequential stochastic decision making problems. A learning problem can be defined by a tuple , in which and denote the state and action spaces, respectively. illustrates the state transition probability, and is a reward function. Finally, is a discount factor, determining the importance of future rewards. We suppose that the time horizon is separated into multiple time periods, called time steps . The DRL agent interacts with the environment, and in each time step , it perceives the current state of the environment , and selects an action based on its policy , mapping states to actions. Considering the selected action , the agent receives a reward from the environment, and it can perceive the next state . The main goal of the agent is to find a policy in order to maximize the expected total of future discounted reward [24]:
| (23) |
where is the reward at time step , and is the generated action at time step by following the policy . Moreover, when DNN is used to approximate the function, the parameters are denoted as .
Considering the application placement in fog computing environments, we define the main concept of the DRL for our problem as what follows:
-
•
State space : In our application placement problem, the state is the observations of the agent from the heterogeneous fog computing environment. Thus, the state at time step () consists of information about all heterogeneous servers (such as processing speed of CPU, number of CPU cores, CPU utilization, access Bandwidth (i.e., data rate) of servers, access latency of servers, and CPU, transmission, and idle power consumption values of IoT device). For the rest of the servers, their power consumption values are ignored as we only consider energy consumption from IoT devices’ perspective [7]. If for each server we have features to represent its information, the feature vector of all servers at time step () can be presented as:
(24) where shows the th feature of the server . Moreover, contains the information about the current task to be processed within a DAG of an IoT application (such as computation requirements of the task, required RAM, amount of output data per parent task, and current placement configuration of all tasks). Since we consider that tasks are sorted and their dependencies are satisfied before their execution, the current placement configuration of tasks contains the information regarding assigned servers to all previous tasks. The values of unprocessed tasks are set to . If we assume that each task has features, the feature vector of task () can be represented as:
(25) where shows the th feature of the task . Thus, the system space can be defined as:
(26) -
•
Action space : Actions are assignments of available servers to tasks of an IoT application. Therefore, the action at time step () is equal to assigning a server to the current task . Considering the placement configuration of each task in Section 3.2, can be defined as:
(27) Thus, the action space can be defined as the set of all available servers, presented as follows:
(28) -
•
Reward function : The goal is to minimize the weighted cost model, defined in Eq. 18. To obtain this, we consider Eq. 17 as the weighted cost of each task and define the as the negative value of Eq. 17 if the task can be executed (). Moreover, we define a constant value, which is usually a very large negative number [31]. Furthermore, the value can be dynamically set based on the goal of the optimization problem and environmental variables. If the selected action by the agent (i.e., server assignment for the current task) cannot be performed due to any reason (), the reward becomes equal to . Accordingly, is defined as:
(31)
5 Distributed DRL-based Framework
To address the challenges of DAG-based application placement in the heterogeneous fog computing environment, the -DDRL works based on an actor-critic framework, aiming at taking advantage of both value-based and policy-based techniques while minimizing their drawbacks [35].
Actor-critic framework
In an actor-critic framework, the policy is directly parameterized, denoted as , and the is updated by calculating the gradient ascent on the variance of the expected total future discounted reward (i.e, ) and the learned state-value function under policy (i.e., ) [35]. The actor interacts with the environment and receives state , outputs the action based on , and receives the reward and next state . The critic, on the other hand, uses rewards to evaluate the current policy based on the Temporal Difference (TD) error between current reward and the estimation of the value function . Both actor and critic use DNNs as their function approximators, which are trained separately. To improve the selection probability of better actions by the actor, the parameters of the actor network are updated using the feedback of the TD-error, while the network parameters of the critic network are updated to achieve better value estimation. While the actor-critic frameworks work very well in long-term performance optimizations, their learning speeds are slow and they incur huge exploration costs, especially in problems with high dimensional-state space [31]. The distributed learning techniques in which diverse trajectories are generated in parallel can greatly improve the exploration costs and learning speed of actor-critic frameworks.
The -DDRL works based on an actor-learner framework, in which the process of generating experience trajectories is separated from learning the parameters of and . Fig 2(a) demonstrates a high-level overview of learner and actors. The distributed actors in fog computing environments, which can be multiple CPUs within a broker (i.e., FS) or different brokers, interact with their fog computing environments. Arriving application placement requests to each broker are queued in the based on the First-In-First-Out (FIFO) policy. As Fig 2(b) depicts, brokers performs pre-scheduling phase for each IoT application. Then, based on features of available servers and current task of selected IoT application, each broker pre-processes the current state and makes an application placement decision. Each broker periodically sends its local experience trajectories to the learner. Besides, the learner updates the target policy based on collection of received trajectories from different brokers and past trajectories stored in the replay buffer. After each policy update of the learner, brokers update their local policy with the policy of the learner .
The -DDRL is divided into two phases: pre-scheduling and application placement technique. In the pre-scheduling, tasks of the received IoT application are ranked and sorted in a sequence for the execution. Afterward, for each task of an IoT application, -DDRL makes a placement decision to minimize the execution cost of the IoT application.
5.1 -DDRL: Pre-scheduling Phase
IoT applications are heterogeneous in terms of the number of tasks per application, the dependency model, and corresponding weights of vertices and edges. Considering the dependency model of an IoT application, tasks should be sorted for execution, so that task cannot be executed before any task . Furthermore, there are several tasks that can be executed in parallel, and the order of execution of such parallel tasks are also important and may affect the execution cost of an IoT application. Figure 3 shows a sample IoT application, dependencies among tasks, and parallel tasks with the same colors in each row.

Whenever a broker receives a DAG-based IoT application request from a user, it creates a sequence of tasks for the execution while considering above-mentioned challenges. Tasks within the IoT application are ranked based on the non-increasing order of their rank value. The rank value of a task is defined as:
| (35) |
where shows the average weighted execution cost of task on considering different servers. The rank is calculated recursively by traversing the DAG of the application, starting from the exit module. Using the rank function, the tasks on the critical path of DAG (i.e., ) can also be identified. Hence, not only does the rank function satisfy the dependency among tasks, but it also defines an execution order for tasks that can be executed in parallel. To achieve this, it gives higher priority to tasks that incur higher total execution costs among parallel tasks.
5.2 -DDRL: Application Placement Phase
If we assume that each broker makes placement decisions for tasks of IoT applications, using their local policy , for steps in the time horizon starting at time , algorithm 1 shows how brokers perform application placement decisions and generate experience trajectories. Each broker performs the following steps: At the beginning of each trajectory, the broker updates its policy with the policy of the learner (line 3). When broker starts making placement decisions for tasks of a new IoT application (i.e., when the flag-init=), it receives the current IoT application from the (contains all received application requests to this broker) (line 6). Then, the broker performs the pre-scheduling to obtain the sorted list of application’ tasks based on the Eq. 35 (line 7). Next, the system state is generated using the initial state of the IoT application and available servers (line 8). Moreover, the broker changes the flag-init to , indicating that in the subsequent steps there is no need to re-calculate the ranking and initial state of the (line 9), and the broker only requires to obtain the current state of the environment based on Eq. 26 (line 11). The current state of the broker’s environment consists of feature vectors of servers and the current task of IoT application . The current task of each IoT application is obtained from the ordered sequence of tasks . Then, the broker pre-processes and normalizes values of the current state (line 13). Considering and current policy , an application placement decision (i.e., the assignment of a server for the processing of the current task) is made (line 14). The current task is then forwarded to the assigned server (based on ) for processing. After the execution of the task, the broker receives the reward of this action, which is the negative value of the weighted execution cost of this task Eq. 31 (line 15). The next state of the environment is then created using the function (line 16). Then, the broker creates an experience tuple (,,,) and stores it in its local experience batch buffer (line 17). When the broker finishes assignment of servers to all tasks of the current IoT application , meaning the application placement is done for the current IoT application, the total weighted execution cost of this IoT application is calculated using Eq. 18 (line 19). Moreover, the broker sets flag-init to so that the next IoT application in the queue of this broker can be served (line 20). After steps, each broker forwards its experience batch buffer to the learner (lines 23-25). The learner periodically updates its policy (i.e., ) on batches of experience trajectories, collected from several brokers.
Since policies of brokers are updated based on the learner’s policy (trained on trajectories of different brokers), each broker gets the benefit of trajectories generated by other brokers. It significantly reduces the exploration cost of each broker, and also provides brokers with a more accurate local policy . Furthermore, the -DDRL uses an experience-sharing approach, which significantly reduces communication overhead between brokers and learners, in comparison to gradient-sharing techniques such as A3C [24].
Due to the gap between the policy of broker (when generating new decisions) and the policy of the learner in the training time (when the learner estimates the gradients), the learner in the -DDRL uses the off-policy correction method, called V-trace [24], to correct this discrepancy.
-
•
V-trace off-policy correction method: We assume that each broker generates an experience trajectory for steps while following its local policy as . The value approximation of state , defined as -step V-trace target for , is as follows:
(36) where is a TD for , defined as:
(37) where and are truncated Importance Sampling (IS) weights, while . The and play different roles in the V-trace. The has a direct effect on the value function toward which we converge, while has a direct effect on speed of the convergence. Considering , the target policy of the learner can be defined as:
(38)
We consider: (1) the brokers generate trajectories while following policy , (2) the parameterized state-value function under as , (3) the current policy of learner is , and (4) the V-trace target is defined based on Eq. 36. The learner updates value parameters , at time step , in the direction of:
| (39) |
Moreover, the policy parameters are updated in the direction of the policy gradient using Adam optimization algorithm [39]:
| (40) |
Algorithm 2 summarizes the learners’ role in the -DDRL. The learner continuously receives and stores experience batches of brokers and updates the master Buffer until the training batch becomes full (line 4-10). Then, the learner optimizes the current target policy based on Eq. 39 and 40 (line 11). After policy update of the learner, brokers update their local policies with the latest policy of the learner (i.e., brokers set their policies to the new learner policy), and hence, new application placement decisions are made using the updated policy in the brokers. The learner in the -DDRL uses the replay buffer , which remarkably improves sample efficiency. The -DDRL can easily scale as the number of servers, IoT application requests, and brokers increases, which is a principal factor in highly distributed environments such as fog computing. If a new broker joins the environment, the broker updates its local policy with the latest policy of the learner, and hence it takes advantage of all trajectories that previously generated by other brokers. Besides, it generates new sets of trajectories which help to better diversify the trajectories of the learner. If the number of servers in the environment increases, distributed brokers quickly generate new sets of trajectories, and accordingly the learner can update its target policy promptly. Such a collaborative distributed broker-learner architecture not only significantly improves the exploration costs, but also improves the convergence speed. The other improvement in the -DDRL is using RNN layers since they can accurately identify highly non-linear patterns among different input features, resulting in significant speedup in the learner [40, 23].
5.3 Discussion on Resource Contention
In heterogeneous computing environments where multiple applications are forwarded to heterogeneous servers, resource contention for computing resources may occur. Let’s assume, there are three IoT applications named , , and while there are two servers (either at the edge or cloud) called and . The type of applications may be different from each other with different resource requirements, and the number of servers or their computing capability may differ so that resource contention occurs among IoT applications. Moreover, for the DAG-based IoT applications, consisting of several dependent tasks, another type of resource contention may happen among tasks of one IoT application.
One approach to solve the resource contention, either among different IoT applications or tasks of one application, is prioritization. In -DDRL, the FIFO policy is used to prioritize different IoT applications. These policies can be changed according to the targeted problem. Besides, for the tasks of one application, there are two important points to consider. In DAG-oriented IoT application, each task within the application can only be executed if its predecessor tasks are completed. However, for tasks that can be executed in parallel, a priority should be defined. In -DDRL, we use a rank function, Eq. 35, that prioritizes tasks of one IoT application while considering the dependency among tasks and the average execution cost of tasks. Such prioritization between different IoT applications and tasks of one IoT application help to solve the resource contention.
Moreover, the DRL agent receives the sequence of tasks based on the above-mentioned policies. So, these prioritization techniques are very important for the long-term reward, especially for DAG-based IoT applications having extra constraints. Without such prioritization, the DRL agent may converge to a good solution but the convergence time is significantly higher while in some scenarios the DRL agent even cannot converge to good solution. The DRL agent learns to assign the best server to each task while considering the tasks’ dependency model of an IoT application, resource requirements of each task, and available heterogeneous resources in the environment. That is, the DRL agent is considering the resource contention while assigning a server to each task, to minimize the execution cost of each task (based on short-term reward) and accordingly each IoT application (based on long-term reward).
6 Performance Evaluation
This section first describes the experimental setup, used to evaluate our technique and baseline algorithms. Next, the hyperparameters of our proposed technique -DDR are discussed. Finally, we study the performance of -DDRL and its counterparts in detail.
6.1 Experimental Setup
To evaluate the performance of the -DDRL, we use both simulation environment and testbed, which their specification are provided in what follows.
6.1.1 Simulation setup
We developed an event-driven simulation environment in Python using the OpenAI Gym [41] for the application placement in heterogeneous fog computing environments, similar to [16]. For each of the two learners, we set the number of brokers to , which have access to a set of servers, and make application placement decisions accordingly. Hence, we vectorized the fog computing environment, generated using OpenAI Gym, so that distributed brokers can interact with their fog computing environments and make application placement decisions in parallel. Unlike prior work [16, 31, 32, 33], we consider a heterogeneous fog computing environment consisting of IoT devices, resource-constrained FSs, and resource-rich CSs. In fog computing environment, we used the following server setup, unless it is stated in the experiments: two Raspberrypi 3B (Broadcom BCM2837 4 cores @1.2GHz, 1GB RAM)111https://www.raspberrypi.org/products/raspberry-pi-3-model-b, one Raspberrypi 4B (ARM Cortex-A72 4 cores @1.5GHz, 4GB RAM)222https://www.raspberrypi.org/products/raspberry-pi-4-model-b, and one Jetson Nano (ARM Cortex-A57 4 cores @1.43GHz, 4GB RAM, 128-core Maxwell GPU)333https://developer.nvidia.com/embedded/jetson-nano-developer-kit as heterogeneous FSs. Besides, to simulate a heterogeneous multi-cloud environment, we used specifications of six m3.large instances of Nectar Cloud infrastructure (AMD 8 cores @2GHz, 16GB RAM)444https://nectar.org.au/ and two instances of the University of Melbourne Horizon Cloud (Intel Xeon 8 cores @2.4GHz, 24GB RAM, NVIDIA P40 3GB RAM GPU)555https://people.eng.unimelb.edu.au/lucasjb/horizon/. For IoT devices, the server type is a single core @1GHz device embedded with 512MB RAM [16]. Besides, the power consumption of each IoT device in processing, idle, and transmission state is 0.5W, 0.002W, and 0.2W, respectively [7]. The bandwidth (i.e., data rate) and latency among different servers and IoT devices are also obtained based on average profiled values from testbed, similar to [23]. Hence, the latency of FSs and CSs are considered as 1ms and 10ms respectively, similar to [23]. The bandwidth between IoT devices and FSs is randomly selected between 10-12MB/s, while the bandwidth between IoT devices and FSs to the CSs is randomly selected between 4-8 MB/s, similar to [37]. Although we obtained these values based on testbed experiments, they are referred to some similar works as well to show the credibility of these values. Also, both and are set to 0.5, meaning that the importance of execution time and the energy consumption is equal in the results. However, these parameters can be adjusted based on the users’ requirements and network conditions.
Many real-world IoT applications can be modeled by DAGs with a different number of tasks and dependency models. Hence, we generated several synthetic DAG sets with a different number of tasks and dependency models to represent scenarios where IoT devices generate heterogeneous DAGs with different preferences, similar to [42, 16]. The dependency model of each DAG can be identified using three parameters: number of tasks within an application , that controls the width and heights of a DAG, and that identifies the number of edges between different levels of the DAG. Accordingly, we generated different DAG datasets, where each dataset contains 100 DAGs with a similar number of tasks, fat, and density while the weights are randomly selected to represent heterogeneous task requirements in IoT applications with the same DAG structure. To generate heterogeneous DAG datasets, we set task numbers , , and . To illustrate, one dataset of DAGs is , , and , containing 100 DAGs. Accordingly, for each task number , we have 25 different combinations of and , resulting in 25 different topologies and 2500 DAGs. Finally, the simulation experiments are all performed on an instance of Horizon Cloud with the above-mentioned specifications.
6.1.2 Testbed setup
To evaluate the performance of -DDRL in a real-world scenario, we created a testbed, similar to [31, 43]. The type of servers are the same as simulation setup while the number of servers of each type is as follows: two Raspberry pi 3B, one Raspberry pi 4B, one Jetson Nano, one instance of Horizon Cloud, and six m3.large instances of Nectar Cloud infrastructure). As IoT devices, we created several single-core VMs within a PC (HP Elitebook 840 G5 with Intel Core i7-8550U 8 cores @2GHz and 16GB RAM). These VMs are used to send application placement requests, using described DAG datasets, to the brokers. Moreover, to estimate the energy consumption of IoT devices, we used computing power, transmission power, and idle power as discussed in Section 6.1.1, similar to the approach in [31]. For the connectivity, we set up a virtual network using VPN among IoT devices, FSs, and CSs, as described in [26, 44]. Due to the limited CPU and RAM of the IoT devices’ VMs, they can send application placement requests, using a message-passing protocol (implemented using HTTP requests), to the broker that is the Jetson Nano in this testbed. The broker runs a multi-threaded server application that receives application placement requests from different IoT devices and puts them in the queue based on the FIFO policy. The broker dequeues the requests and makes placement decisions for the tasks according to its policy . According to the placement configuration for each IoT application, each server that receives a task for processing assigns that task to one of its threads for processing. The thread is kept busy according to the weight of task and processing speed of the server. After the execution of each task, the size of output results that should be forwarded to the children tasks is obtained based on the weights of the task’s outgoing edges in each DAG. Since weights of edges in each DAG (i.e., data to be transferred between tasks) are different, we generate files with different sizes to represent the weights on edges. Finally, the broker logs the execution cost of each IoT application and all of its constituent tasks in terms of selected evaluation metrics.
6.1.3 Baseline algorithms
We evaluate the performance of the -DDRL with a greedy heuristic algorithm, and two DRL-based techniques from the literature that proposed DRL-based solutions for DAG-based IoT applications. In what follows, we briefly describe how these techniques are implemented, while their detailed specifications are provided in Section 2.
-
•
PPO-RNN: It is the extended and adapted version of the technique proposed in [16]666https://github.com/linkpark/metarl-offloading. We extended this technique so that it can be used in multi-objective scenarios to minimize the weighted cost of execution. Besides, this technique is extended to be used in heterogeneous fog computing environments where several IoT devices, FSs, and CSs are available. This technique uses PPO as its DRL framework while the networks of the agent are wrapped by the RNN. Besides, we used the same hyperparameters as [16].
-
•
PPO-No-RNN: This technique is the same as PPO-RNN, while the networks are not wrapped by the RNNs.
-
•
Double-DQN: Many works in the literature uses standard Deep Q-Learning (DQN) based RL approach such as [33, 32, 18, 30]. We implemented the optimized Double-DQN technique with an adaptive exploration for application placement in heterogeneous fog computing environments777https://docs.ray.io/en/master/. The hyperparameters of this technique are set based on [33], which is a DQN-based application placement technique for DAG-based IoT applications.
-
•
Greedy: In this technique, tasks are greedily assigned to the servers if their execution cost is less than the estimated local execution cost, similar to [16].





6.2 -DDRL Hyperparameters
In the implementation of -DRRL, where the standard implementation of IMPALA is used888https://docs.ray.io/en/master/, the DNN structure of all agents is similar, consisting of two fully connected layers followed by two LSTM layers as recurrent layers. Moreover, we performed a grid search to tune hyperparameters. According to tuning experiments, we set the learning rate to , the discount factor to . Besides, values of and , controlling the performance of V-trace are set to [24] to obtain the best result. Table II summarizes the setting of hyperparameters.
| Parameter | Value | Parameter | Value |
| Fully Connected layers | 2 | Learning Rate | 0.01 |
| LSTM Layers | 2 | Discount Factor | 0.99 |
| Optimization Method | Adam | V-trace | 1 |
| Activation Function | Tanh | V-trace | 1 |
6.3 Performance Study
In this section, four experiments are conducted to evaluate and compare the performance of -DDRL with other techniques in terms of weighted execution cost, execution time of IoT applications, and energy consumption of IoT devices.
6.3.1 Execution cost vs policy update analysis
In this experiment, we study the performance of application placement techniques in different iterations of the policy updates. We consider two scenarios for datasets of IoT applications to analyze how efficiently these techniques can extract features of different datasets of IoT applications and optimize their target policy. In the first scenario, we consider the number of tasks within IoT applications . Hence, 25 datasets of IoT applications with the same task number and different and are used, among which 20 datasets are used for the training and 5 datasets are used for the evaluation. In the second scenario, for the training while for the evaluation . Therefore, the training and evaluation are performed on datasets with a different number of tasks. Fig 4 shows the obtained results of this study in terms of the average execution time of IoT applications, the energy consumption of IoT devices, and weighted cost for the above-mentioned two scenarios.
As Fig. 4 shows, the average execution cost of all techniques, except the greedy, decreases in different scenarios as the iteration number increases. However, the -DDRL converges faster and to better placement solutions in comparison to other techniques. This is mainly because the V-trace function embedded in the -DDRL uses n-step state-value approximation rather than 1-step state-value approximation [24], improving convergence speed of -DDRL to better solutions. Moreover, trajectories generated by distributed brokers are diverse, leading to a more efficient learning process. The execution cost of the greedy technique is fixed and does not change with different iteration numbers, but it can be used as a baseline technique to compare the performance of DRL-based techniques. The convergence speed of PPO-RNN and PPO-NO-RNN techniques is slower than the Double-DQN technique however, they finally converge to better placement solutions. In addition, the obtained results of the second scenario (Fig. 4(d), 4(e), 4(f)) shows that all DRL-based techniques has lower convergence speed in comparison to the obtained results of first scenario (Fig. 4(a), 4(b), 4(c)). However, still -DDRL outperforms other techniques in terms of execution time, energy consumption, and weighted cost. This proves that the -DDRL can more efficiently adapt itself with different DAG structures (i.e., task numbers, and dependency model), and hence it makes better application placement decisions in unforeseen scenarios.
6.3.2 System size analysis
In this experiment, the effect of different numbers of servers on application placement techniques is studied. The number of candidate servers has a direct effect on the complexity of application placement problems because the larger number of servers leads to a bigger search space. Hence, to analyze the performance of -DDRL, the default number of servers in this experiment is multiplied by two and four; i.e, we have 24 and 48 servers respectively. Moreover, in this experiment, the training and evaluation datasets are specified as the same as the first scenario in Section 6.3.1; i.e., a total of 25 datasets where and different and values. Due to the space limit and the fact that patterns for execution time, energy consumption, and weighted cost were roughly the same, only the obtained results from the weighted cost are provided in this experiment.
Fig. 5 shows the weighted cost of different techniques, where brokers in the system have access to 24 and 48 candidate servers when making application placement decisions. It is crystal clear that the weighted cost of the greedy technique is steady for 24 and 48 servers as the number of iterations increases. All DRL-based techniques perform better than greedy technique either when the number of servers is 24 or 48. Also, it can be seen that the weighted execution costs of techniques are higher when the number of servers is 48 than weighted costs when the servers’ number is 24. As the number of iterations increases, the DRL-based techniques can more accurately make placement decisions, leading to less weighted execution cost. However, the -DDRL always outperforms other techniques and converges faster to better solutions. It shows that the -DDRL has better scalability when the system size grows. This helps -DDRL to make better application placement decisions in a fewer number of iterations. Among other DRL-based techniques, PPO-RNN performs better than PPO-No-RNN and Double-DQN and makes better placement decisions as the iteration numbers increases.





6.3.3 Speedup and placement time overhead analysis
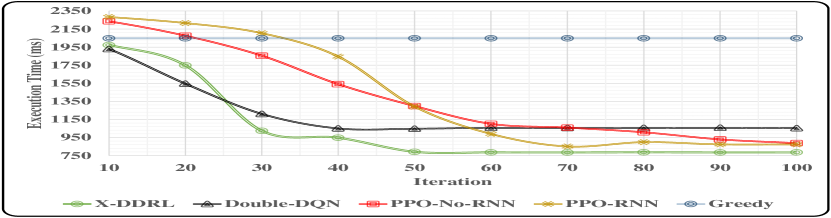
In this section, we study the speedup and placement time overhead of different DRL-based techniques. We follow the same experimental setup as the first scenario in Section 6.3.1. We define the average Placement Time Overhead (PTO) as the average required amount of time for each technique to make an application placement decision divided by the average local execution time of IoT applications on IoT devices. To obtain the local execution time of IoT applications on IoT devices, we assume that tasks within an IoT application are executed sequentially, similar to [7]. Besides, we define the time taken by the -DDRL technique with one broker to reach the value from the weighted execution cost as . The reason why is considered as the reference weighted execution cost is that this value is the minimum weighted execution cost that all DRL-based techniques can obtain. Moreover, the time taken by each technique to reach the reference weighted execution cost is defined as . Accordingly, similar to [23], the Speedup value of each technique () is defined as .
Fig 6 shows results of and for all DRL-based techniques. The placement time overhead of techniques using RNN (i.e., -DDRL and PPO-RNN) is usually higher than techniques that do not use RNN (i.e., Double-DQN, and PPO-No-RNN). The of the -DDRL is higher than other DRL-based techniques by less than 1% in the worst-case scenario, which is not significantly large. However, the obtained results of show that -DDRL performs 8 to 16 times faster than other techniques. Hence, considering the speedup performance and execution cost results of the -DDRL, its placement time overhead is negligible, and -DDRL can more efficiently perform application placement decisions compared to other techniques for heterogeneous fog computing environments.
6.3.4 Evaluation on Testbed
To evaluate the performance of -DDRL in real-world scenarios, we conducted experiments on the testbed whose configuration is discussed earlier in Section 6.1.2. In this experiment, for the training while for the evaluation .
Fig 7 shows the execution cost of different techniques in terms of execution time, energy consumption, and weighted cost by 95% confidence interval. It can be observed that, similar to the simulation results, -DDRL can outperform other techniques in terms of execution time, energy consumption, and weighted cost. Moreover, even after 100 iterations, where all techniques converged, there are no techniques that obtain better results in comparison to -DDRL. It demonstrates that not only does -DDRL converge faster, and its training time is significantly less than other techniques, but it also provides better results. As the results depict, the optimized Double-DQN technique converges faster than PPO-RNN and PPO-No-RNN, but it cannot obtain results as well as them. Overall, compared to converged results of other DRL-techniques, achieved results of -DDRL show an average performance gain up to 30%, 11%, and 24% in terms of execution time, energy consumption, and weighted cost, respectively.
7 Conclusions and Future Work
This paper proposes a distributed DRL-based technique, called -DDRL, to efficiently solve the application placement problem of DAG-based IoT applications in heterogeneous fog computing environments, where edge and cloud servers are collaboratively used. First, a weighted cost model for optimizing the execution time and energy consumption of IoT devices with DAG-based applications in heterogeneous fog computing environments is proposed. Besides, a pre-scheduling phase is used in the -DDRL, by which dependent tasks of each IoT application are prioritized for execution based on the dependency model of the DAG and their estimated execution cost. Moreover, we proposed an application placement phase, working based on the IMPALA framework for the training of distributed brokers, to efficiently make application placement decisions in a timely manner. Distinguished from existing works, the -DDRL can rapidly converge well-suited solutions in heterogeneous fog computing environments with a large number of servers and users. The effectiveness of -DDRL is analyzed through extensive simulation and testbed experiments while comparing with the state-of-the-art techniques in the literature. The obtained results indicate that -DDRL performs to times faster than other DRL-based techniques. Besides, compared to other DRL-based techniques, it achieves a performance gain up to 30%, 11%, and 24% in terms of execution time, energy consumption, and weighted cost, respectively.
As part of future work, we plan to extend our proposed weighted cost model to consider other aspects such as monetary cost, dynamic changes of transmission power, and total system cost. Moreover, we plan to apply mobility models in this scenario and adapt our proposed application placement technique accordingly.
Acknowledgment
We thank Shashikant Ilager, Amanda Jayanetti, and Samodha Pallewatta for their comments on improving this paper.
References
- [1] P. Hu, S. Dhelim, H. Ning, and T. Qiu, “Survey on fog computing: architecture, key technologies, applications and open issues,” Journal of Network and Computer Applications, vol. 98, pp. 27–42, 2017.
- [2] J. Wang, K. Liu, B. Li, T. Liu, R. Li, and Z. Han, “Delay-sensitive multi-period computation offloading with reliability guarantees in fog networks,” IEEE Transactions on Mobile Computing, vol. 19, no. 9, pp. 2062–2075, 2019.
- [3] M. Goudarzi, H. Wu, M. S. Palaniswami, and R. Buyya, “An application placement technique for concurrent IoT applications in edge and fog computing environments,” IEEE Transactions on Mobile Computing, vol. 20, no. 4, pp. 1298 – 1311, 2021.
- [4] S. Deng, Z. Xiang, J. Taheri, K. A. Mohammad, J. Yin, A. Zomaya, and S. Dustdar, “Optimal application deployment in resource constrained distributed edges,” IEEE Transactions on Mobile Computing, 2020.
- [5] S. Wang, Y. Guo, N. Zhang, P. Yang, A. Zhou, and X. S. Shen, “Delay-aware microservice coordination in mobile edge computing: A reinforcement learning approach,” IEEE Transactions on Mobile Computing, vol. 20, no. 4, pp. 939 – 951, 2021.
- [6] M. Goudarzi, M. Zamani, and A. T. Haghighat, “A fast hybrid multi-site computation offloading for mobile cloud computing,” Journal of Network and Computer Applications, vol. 80, pp. 219–231, 2017.
- [7] X. Xu, Q. Liu, Y. Luo, K. Peng, X. Zhang, S. Meng, and L. Qi, “A computation offloading method over big data for IoT-enabled cloud-edge computing,” Future Generation Computer Systems, vol. 95, pp. 522–533, 2019.
- [8] M. Goudarzi, M. Palaniswami, and R. Buyya, “A fog-driven dynamic resource allocation technique in ultra dense femtocell networks,” Journal of Network and Computer Applications, vol. 145, p. 102407, 2019.
- [9] M.-R. Ra, A. Sheth, L. Mummert, P. Pillai, D. Wetherall, and R. Govindan, “Odessa: enabling interactive perception applications on mobile devices,” in Proceedings of the 9th international conference on Mobile systems, applications, and services, 2011, pp. 43–56.
- [10] T. N. Gia, M. Jiang, A.-M. Rahmani, T. Westerlund, P. Liljeberg, and H. Tenhunen, “Fog computing in healthcare internet of things: A case study on ECG feature extraction,” in 2015 IEEE international conference on computer and information technology; ubiquitous computing and communications; dependable, autonomic and secure computing; pervasive intelligence and computing. IEEE, 2015, pp. 356–363.
- [11] A. Al-Shuwaili and O. Simeone, “Energy-efficient resource allocation for mobile edge computing-based augmented reality applications,” IEEE Wireless Communications Letters, vol. 6, no. 3, pp. 398–401, 2017.
- [12] A. Brogi and S. Forti, “Qos-aware deployment of IoT applications through the fog,” IEEE Internet of Things Journal, vol. 4, no. 5, pp. 1185–1192, 2017.
- [13] L. F. Bittencourt, J. Diaz-Montes, R. Buyya, O. F. Rana, and M. Parashar, “Mobility-aware application scheduling in fog computing,” IEEE Cloud Computing, vol. 4, no. 2, pp. 26–35, 2017.
- [14] M. Goudarzi, Z. Movahedi, and M. Nazari, “Mobile cloud computing: a multisite computation offloading,” in Proceedings of the 8th International Symposium on Telecommunications (IST). IEEE, 2016, pp. 660–665.
- [15] D. Jeff, “ML for system, system for ML, keynote talk in workshop on ML for systems, NIPS,” 2018.
- [16] J. Wang, J. Hu, G. Min, A. Y. Zomaya, and N. Georgalas, “Fast adaptive task offloading in edge computing based on meta reinforcement learning,” IEEE Transactions on Parallel and Distributed Systems, vol. 32, no. 1, pp. 242–253, 2020.
- [17] Q. Mao, F. Hu, and Q. Hao, “Deep learning for intelligent wireless networks: A comprehensive survey,” IEEE Communications Surveys & Tutorials, vol. 20, no. 4, pp. 2595–2621, 2018.
- [18] L. Huang, S. Bi, and Y.-J. A. Zhang, “Deep reinforcement learning for online computation offloading in wireless powered mobile-edge computing networks,” IEEE Transactions on Mobile Computing, vol. 19, no. 11, pp. 2581–2593, 2019.
- [19] X. Chen, H. Zhang, C. Wu, S. Mao, Y. Ji, and M. Bennis, “Optimized computation offloading performance in virtual edge computing systems via deep reinforcement learning,” IEEE Internet of Things Journal, vol. 6, no. 3, pp. 4005–4018, 2018.
- [20] L. Huang, X. Feng, C. Zhang, L. Qian, and Y. Wu, “Deep reinforcement learning-based joint task offloading and bandwidth allocation for multi-user mobile edge computing,” Digital Communications and Networks, vol. 5, no. 1, pp. 10–17, 2019.
- [21] H. Lu, X. He, M. Du, X. Ruan, Y. Sun, and K. Wang, “Edge QoE: Computation offloading with deep reinforcement learning for internet of things,” IEEE Internet of Things Journal, vol. 7, no. 10, pp. 9255 – 9265, 2020.
- [22] Y. Sun, M. Peng, Y. Zhou, Y. Huang, and S. Mao, “Application of machine learning in wireless networks: Key techniques and open issues,” IEEE Communications Surveys & Tutorials, vol. 21, no. 4, pp. 3072–3108, 2019.
- [23] S. Tuli, S. Ilager, K. Ramamohanarao, and R. Buyya, “Dynamic scheduling for stochastic edge-cloud computing environments using A3C learning and residual recurrent neural networks,” IEEE Transactions on Mobile Computing, 2020.
- [24] L. Espeholt, H. Soyer, R. Munos, K. Simonyan, V. Mnih, T. Ward, Y. Doron, V. Firoiu, T. Harley, I. Dunning et al., “IMPALA: Scalable distributed deep-rl with importance weighted actor-learner architectures,” in International Conference on Machine Learning. PMLR, 2018, pp. 1407–1416.
- [25] M. Goudarzi, M. Palaniswami, and R. Buyya, “A distributed application placement and migration management techniques for edge and fog computing environments,” arXiv preprint arXiv:2108.02328, 2021.
- [26] Q. Deng, M. Goudarzi, and R. Buyya, “FogBus2: a lightweight and distributed container-based framework for integration of IoT-enabled systems with edge and cloud computing,” in Proceedings of the International Workshop on Big Data in Emergent Distributed Environments, 2021, pp. 1–8.
- [27] L. Huang, X. Feng, A. Feng, Y. Huang, and L. P. Qian, “Distributed deep learning-based offloading for mobile edge computing networks,” Mobile Networks and Applications, pp. 1–8, 2018.
- [28] M. Min, L. Xiao, Y. Chen, P. Cheng, D. Wu, and W. Zhuang, “Learning-based computation offloading for IoT devices with energy harvesting,” IEEE Transactions on Vehicular Technology, vol. 68, no. 2, pp. 1930–1941, 2019.
- [29] J. Chen, S. Chen, Q. Wang, B. Cao, G. Feng, and J. Hu, “iRAF: A deep reinforcement learning approach for collaborative mobile edge computing IoT networks,” IEEE Internet of Things Journal, vol. 6, no. 4, pp. 7011–7024, 2019.
- [30] X. Xiong, K. Zheng, L. Lei, and L. Hou, “Resource allocation based on deep reinforcement learning in IoT edge computing,” IEEE Journal on Selected Areas in Communications, vol. 38, no. 6, pp. 1133–1146, 2020.
- [31] X. Qiu, W. Zhang, W. Chen, and Z. Zheng, “Distributed and collective deep reinforcement learning for computation offloading: A practical perspective,” IEEE Transactions on Parallel and Distributed Systems, vol. 32, no. 5, pp. 1085–1101, 2020.
- [32] P. Gazori, D. Rahbari, and M. Nickray, “Saving time and cost on the scheduling of fog-based IoT applications using deep reinforcement learning approach,” Future Generation Computer Systems, vol. 110, pp. 1098–1115, 2020.
- [33] H. Lu, C. Gu, F. Luo, W. Ding, and X. Liu, “Optimization of lightweight task offloading strategy for mobile edge computing based on deep reinforcement learning,” Future Generation Computer Systems, vol. 102, pp. 847–861, 2020.
- [34] R. Mahmud, R. Kotagiri, and R. Buyya, “Fog computing: A taxonomy, survey and future directions,” in Internet of everything. Springer, 2018, pp. 103–130.
- [35] Q. Qi, J. Wang, Z. Ma, H. Sun, Y. Cao, L. Zhang, and J. Liao, “Knowledge-driven service offloading decision for vehicular edge computing: A deep reinforcement learning approach,” IEEE Transactions on Vehicular Technology, vol. 68, no. 5, pp. 4192–4203, 2019.
- [36] S. E. Mahmoodi, R. Uma, and K. Subbalakshmi, “Optimal joint scheduling and cloud offloading for mobile applications,” IEEE Transactions on Cloud Computing, vol. 7, no. 2, pp. 301–313, 2016.
- [37] H. Wu, W. Knottenbelt, and K. Wolter, “An efficient application partitioning algorithm in mobile environments,” IEEE Transactions on Parallel and Distributed Systems, vol. 30, no. 7, pp. 1464–1480, 2019.
- [38] G. Fox, J. A. Glazier, J. Kadupitiya, V. Jadhao, M. Kim, J. Qiu, J. P. Sluka, E. Somogyi, M. Marathe, A. Adiga et al., “Learning everywhere: Pervasive machine learning for effective high-performance computation,” in 2019 IEEE International Parallel and Distributed Processing Symposium Workshops (IPDPSW). IEEE, 2019, pp. 422–429.
- [39] D. P. Kingma and J. Ba, “Adam: A method for stochastic optimization,” in Proceedings of the International Conference onLearning Representations (ICLR), 2015.
- [40] J. Appleyard, T. Kociskỳ, and P. Blunsom, “Optimizing performance of recurrent neural networks on GPUs. corr abs/1604.01946 (2016),” arXiv preprint arXiv:1604.01946, 2016.
- [41] G. Brockman, V. Cheung, L. Pettersson, J. Schneider, J. Schulman, J. Tang, and W. Zaremba, “OpenAI Gym,” arXiv preprint arXiv:1606.01540, 2016.
- [42] H. Arabnejad and J. G. Barbosa, “List scheduling algorithm for heterogeneous systems by an optimistic cost table,” IEEE Transactions on Parallel and Distributed Systems, vol. 25, no. 3, pp. 682–694, 2013.
- [43] M. Hu, L. Zhuang, D. Wu, Y. Zhou, X. Chen, and L. Xiao, “Learning driven computation offloading for asymmetrically informed edge computing,” IEEE Transactions on Parallel and Distributed Systems, vol. 30, no. 8, pp. 1802–1815, 2019.
- [44] M. Goudarzi, Q. Deng, and R. Buyya, “Resource management in edge and fog computing using fogbus2 framework,” arXiv preprint arXiv:2108.00591, 2021.
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/7ce4e124-f5a4-465b-8694-6788cac295f5/x16.jpg) |
Mohammad Goudarzi is working towards the Ph.D. degree at the Cloud Computing and Distributed Systems (CLOUDS) Laboratory, Department of Computing and Information Systems, the University of Melbourne, Australia. He was awarded the Melbourne International Research Scholarship (MIRS) supporting his studies. His research interests include Internet of Things (IoT), Fog Computing, Wireless Networks, and Distributed Systems. |
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/7ce4e124-f5a4-465b-8694-6788cac295f5/palani.jpg) |
Marimuthu Palaniswami is a Fellow of IEEE and past distinguished lecturer of the IEEE Computational Intelligence Society. He received his Ph.D. from the University of Newcastle, Australia before joining the University of Melbourne, where he is a Professor of Electrical Engineering. Previously, he was a Co-Director of Centre of Expertise on Networked Decision & Sensor Systems. He has published more than 500 refereed journal and conference papers, including 3 books, 10 edited volumes. |
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/7ce4e124-f5a4-465b-8694-6788cac295f5/rajkumar5.png) |
Rajkumar Buyya is a Redmond Barry Distinguished Professor and Director of the Cloud Computing and Distributed Systems (CLOUDS) Laboratory at the University of Melbourne, Australia. He has authored over 625 publications and seven text books including ”Mastering Cloud Computing” published by McGraw Hill, China Machine Press, and Morgan Kaufmann for Indian, Chinese and international markets respectively. He is one of the highly cited authors in computer science and software engineering worldwide (h-index=149, g-index=322, 116,000+ citations). |