A Deep Learning Approach for Imbalanced Tabular Data in Advertiser Prospecting: A Case of Direct Mail Prospecting
Abstract.
Acquiring new customers is a vital process for growing businesses. Prospecting is the process of identifying and marketing to potential customers using methods ranging from online digital advertising, linear television, out of home, and direct mail. Despite the rapid growth in digital advertising (particularly social and search), research shows that direct mail remains one of the most effective ways to acquire new customers. However, there is a notable gap in the application of modern machine learning techniques within the direct mail space, which could significantly enhance targeting and personalization strategies. Methodologies deployed through direct mail are the focus of this paper.
In this paper, we propose a supervised learning approach for identifying new customers, i.e., prospecting, which comprises how we define labels for our data and rank potential customers. The casting of prospecting to a supervised learning problem leads to imbalanced tabular data. The current state-of-the-art approach for tabular data is an ensemble of tree-based methods like random forest and XGBoost. We propose a deep learning framework for tabular imbalanced data. This framework is designed to tackle large imbalanced datasets with vast number of numerical and categorical features. Our framework comprises two components: an autoencoder and a feed-forward neural network. We demonstrate the effectiveness of our framework through a transparent real-world case study of prospecting in direct mail advertising. Our results show that our proposed deep learning framework outperforms the state of the art tree-based random forest approach when applied in the real-world.
1. Introduction
Companies and brands use advertising for different purposes; acquiring new customers, creating brand awareness, introducing new products , and so forth. To achieve these goals, advertisers use different mediums such as email, TV, newspaper, direct mail, online advertisement, etc. Each of these techniques has its own pros and cons. Email advertising campaigns and surveys are less costly to send but have lower success compared to say for example direct mail advertising and surveys (Shih and Fan, 2008; Dooley, 2022). Previous research has shown that direct mail advertisement is better for brand recall since it requires less cognitive effort to process than digital media (Dooley, 2022). We focus on direct mail advertising in this paper.
Direct mail has two types of advertising: customer relationship management (CRM) and prospecting. Customer relationship management uses ads to stay in touch with and motivate customers to make future purchases. The goal when prospecting is to find new customers for the company by using targeted ads. Potential customers are unknown when prospecting, therefore the potential universe that ads can be served to is large (e.g., in the US, we have around million households (Duffin, 2022)). Budget limitations and the desire for profitable ad campaigns will necessitate a more targeted approach. Therefore, it is essential to have an efficient framework to acquire new customers with the minimum budget spent.
Even though direct mail advertising is one of the most effective ways to acquire new customers, to the best of our knowledge, machine learning has not been widely used and studied in direct mail advertising. In this paper, we focus on direct mail advertising, specifically on prospecting. Prospecting is challenging since an advertiser must identify new potential customers and target them. To identify and target new customers, we propose an approach that models the problem as a supervised learning task. In our proposed framework, we discuss in detail how we define labels and rank the customers throughout the population. Our proposed approach has delivered strong production performance for a variety of different Fortune 500 companies. Casting the problem of direct mail advertising as a supervised learning problem results in a tabular imbalanced input dataset (which is when the size of different classes or groups are not equal). The majority of classes’ distributions can dominate the training process, which will result in poor performance for minority classes.
Previous research corroborated the fact that random forest, XGBoost, and ensemble methods are the first choice in practice and industry due to their simplicity and better performance when working with tabular data (Grinsztajn et al., 2022). In addition to using one of these known methods for inference on tabular data (random forest), we propose our deep learning architecture for inference on tabular data.
Developing state-of-the-art deep learning methods for tabular data is an active area of research. While performance benchmarks are common for image, language, and audio data, they are not as readily available for tabular data. There have been some ad-hoc attempts to propose new approaches, such as (Somepalli et al., 2021; Huang et al., 2020). These methods lack extensive evaluation for different datasets and domains. Tabular data also does not have large real-world datasets, as in image and language, to test models. Publicly available datasets are small and do not reflect real-world scenarios.
We propose a deep learning framework for tabular imbalanced data. We show that its performance is state-of-the-art for tabular data, matching the performance of random forest for the case of direct mail advertising. We also investigate how our proposed solution works in real-world applications of ad serving in the context of direct mail.
Our proposed framework is general and can be applied to any binary classification task for tabular imbalanced data and can be used for both numerical and categorical data. We will illustrate how we cast the problem of prospecting new customers as a binary classification and provide a natural way we can define labels. Finally, we investigate a real-world case study of prospecting via direct mail. In our real-world case study, we show how our proposed framework outperforms an optimized tree-based model over several campaigns.
The rest of this paper is organized as follows: In Section 2, we go over the literature on deep learning models for tabular data. In Section 3, we propose how we model this problem as a supervised learning task and our deep learning framework, which is followed by our experimental results and real-world implementation in Section 4. In Section 5, we discuss the proposed model as well as its limitations and underlying assumptions. Finally, we conclude the paper in Section 6.
2. Related Work
Deep learning methods for tabular data can be divided into three categories: data transformation, specialized architectures, and regularization techniques (Borisov et al., 2022). Data transformation methods convert categorical and numerical data to an input that a deep learning model can effectively process. This can include transforming tabular data into a format similar to an image that captures spatial dependencies, as demonstrated by the successful use of convolutional neural networks in image analysis (Zhu et al., 2021; Sun et al., 2019). This approach has been applied to gene expression profiles and molecular descriptions of drugs, both of which have feature dependencies. However, it may not work well for independent features or when dependencies cannot be captured. Another approach is to use an encoder representation of data such as VIME (Yoon et al., 2020) to find a new and informative representation of the data for predictive tasks. This has been shown to improve performance compared to baseline models like XGBoost (Chen and Guestrin, 2016), but is limited to continuous data (Somepalli et al., 2021). In our framework, we use both the encoder representation and raw representation of data. Note that before now all of these methods have only been tested on small datasets and not yet shown to be scalable to real-world applications.
The majority of the work in this field is concentrated in specialized architectures for tabular data. One approach combines classic machine learning methods, often decision trees, with neural networks (Cheng et al., 2016; Frosst and Hinton, 2017; Luo et al., 2020; Guo et al., 2017). For example, Frosst and Hinton (Frosst and Hinton, 2017) use the outputs of a deep neural network and the ground truth labels to train soft decision trees, which are highly interpretable but sacrifice accuracy. Another specialized architecture is network-on-network (NON) (Luo et al., 2020) which consists of three components: a field-wise network, an across-field network, and an operation fusion network. Each column has its own field-wise network to extract specific information. The optimal operations are chosen by the across-field network and connected by the operation fusion network. For datasets with many features, training individual networks for every column and optimizing operations can be computationally intensive and time-consuming.
Transformers, previously used successfully in other domains, have been applied to tabular data as well. One such architecture is TabNet (Arik and Pfister, 2021). TabNet uses sequential decision steps to encode features and determine relevant ones for each sample using sparse learned masks. Despite good performance, some inconsistencies in explanations have been noted (Borisov et al., 2022).
The third category of methods for tabular data focuses on regularization techniques (Valdes et al., 2021; Fiedler, 2021; Lounici et al., 2021; Shavitt and Segal, 2018). Regularization is necessary due to the extreme flexibility of deep learning models for tabular data that can sometimes lead to overfitting. A Regularization Learning Network (RLN) (Shavitt and Segal, 2018) was proposed to address the observation that a single feature in tabular data can significantly impact the prediction. A RLN is made more efficient and sparse by using regularization coefficients to control the weight of each feature. This approach uses a new ”counterfactual loss” to improve performance and the resulting sparse network can also be used for feature importance analysis. The evaluation of a RLN relies mainly on numerical datasets and does not address categorical data.
In many real-world datasets such as the prospecting case in our study, the number of features and samples are extensive and contain both categorical and numerical data. Additionally, imbalanced datasets are often encountered in these problems. Hence, using specialized regularization techniques for tabular data is not appropriate. Furthermore, due to the large size of these datasets, we aim to implement a fast-training architecture that maintains high performance. While one-time training might be feasible for some tasks, training a prospecting model must occur independently and from scratch for each company. To address these challenges we present our framework utilizing an autoencoder and feed-forward prediction network.
3. Proposed Framework
In this section, we present our machine learning approach for prospecting in advertising by formulating it as a supervised learning problem and introducing our deep learning architecture.
Our proposed framework is based on deep learning for tabular data, which has been compared to tree-based methods such as random forests in previous studies, e.g., (Grinsztajn et al., 2022). Deep learning approaches have yet to outperform tree-based methods for small to medium-sized datasets but our problem of prospecting has some key differences to previous theoretical work. First, our datasets are much larger. Second, our datasets are imbalanced, whereas previous conclusions were made from balanced datasets. Third, a deep learning framework provides more options for future optimizations in prospecting, such as fine-tuning the model with transfer learning.
3.1. Prospecting
The goal of prospecting is twofold: first, to find new customers for a company, and second, to prioritize potential customers in an order that minimizes the cost of the prospecting campaign. To achieve these goals, we propose a supervised learning solution.
Each company has a record of its previous customers who have purchased one of their products. For each of these customers, a set of features can be created, ranging from demographic information to spending habits and interests. The set of features is both numerical and categorical. This list of customers and their features is referred to as an audience. The type of features that are useful for one product or service being advertised may differ from another. Although creating these features for a customer is not the focus of this paper, some companies, such as Epsilon (Inc., 2023b), Visa (Inc., 2023e), Mastercard (Inc., 2023d), Acxiom (Inc., 2023a), and Experian (Inc., 2023c) provide such data while abiding by privacy laws and best practices. Further discussion on privacy considerations can be found in Section 5.3.
The process of creating features for a company’s universe, or the population it is targeting for ads, is similar to creating features for its previous customers. The universe can vary based on the company’s marketing goals, ranging from a city to a country or multiple countries. In this framework, the entire US population is used as an example in experimental results. However, this framework is general and not limited by the size of the universe. The population, after excluding the company’s existing audience of customers, consists of a mix of potential new customers and individuals who are not as likely to become new customers. The size of the population is usually much larger compared to the audience, with the US population being around three hundred million while the size of the audience is typically not more than one million consumers.
We model targeted advertisements as a binary classification problem. Therefore, we define two classes: Class 1, which consists of customers in the company’s audience list, and Class 0, which consists of a sample of the population minus the audience. We use these two classes to train a model, which is then used to classify the rest of the population and determine the target audience for the ads. It is possible that some individuals in the Class 0 sample are actually potential customers and should be labeled as Class 1. However, due to the small proportion of customers in the population, the number of incorrect Class 0 labels is negligible and is not expected to significantly impact the performance of our proposed framework. The important aspect of our Class 0 labels is that they represent a sample of the universe.
When we sample data from our population minus our audience, there are two considerations:
-
•
Sample size
-
•
Sampling method.
We aim to balance the size of our sample with the population. On one hand, the sample needs to be large enough to be representative of the non-customer portion of the population. On the other hand, a sample that is too large may contain an increased number of instances with the wrong negative label. This would result in a highly imbalanced dataset that is harder to train a supervised learning model on. We choose a sample size that strikes a balance between being representative and not so large the quantity of false negatives approaches the size of the audience. The actual sample size is chosen through experimentation while taking into account the imbalance in the dataset.
There are several methods to sample from the population minus the audience. In this paper we choose to sample uniformly from the entire population without any restrictions.
3.2. Framework
In this subsection, we introduce our proposed deep-learning architecture for tabular data. Figure 1 shows the detail of our proposed architecture. Our proposed architecture consists of two main components: (1) the autoencoder creates an encoded representation of data to distinguish between the minority class and the majority class, and (2) the feed-forward prediction neural network that uses the combination of encoded representation of data and data itself for final prediction. It is worth mentioning that in our feed-forward prediction neural network, we use a customized loss function for our imbalanced dataset, which we cover in more detail in Section 3.2.2.

3.2.1. Autoencoder
An autoencoder is a type of unsupervised neural network designed to learn an efficient representation of unlabeled data. It consists of two parts: an encoding network and a decoding network.
Encoding: The encoding network takes in the input sample and compresses it into a lower dimensional representation through a series of linear and non-linear transformations.
| (1) |
where is encoding neural network with weight parameters .
Decoding: The decoding network then takes the encoded representation and tries to reconstruct the original input by applying a reverse process of linear and non-linear transformations.
| (2) |
where is the reconstructed output and is decoding neural network with weight parameters .
The objective of the autoencoder is to minimize the reconstruction error between the original input and the reconstructed output. The autoencoder achieves that by minimizing the distance between and .
| (3) |
where in this case is a measure of Euclidean distance.
This process helps in learning compact and meaningful representations of the input data that can be useful for further analysis. In our case, we use the learned encoding to train a supervised learning model for the task of targeted direct mail advertisements.
3.2.2. Feed-Forward Prediction Network
Our feed-forward neural network uses the concatenation of our raw features and the encoded version of these features as input. This concatenated input is then used to build a classification model to predict the final class label.
| (4) |
| (5) |
where denotes the input features to the feed-forward neural network, i.e., the concatenation of input features and the encoded features. The weight parameters of the feed-forward neural network are represented by , and the predicted probability of label is represented by .
Cost Function. Imbalanced data, where different classes have varying sizes, is a common challenge in machine learning. There are several approaches to address this issue, such as re-sampling or cost-sensitive mechanisms. Over-sampling involves repeating samples from the minority class or generating new samples via methods like interpolating neighboring samples (Chawla et al., 2002) or data augmentation using generative models (Antoniou et al., 2017). Other approaches involve assigning weights to each sample’s loss based on the data distribution (Kahn and Marshall, 1953; Khan et al., 2017), and the most common method is to select weights for each class as the inverse of the class frequency (Huang et al., 2016). A more advanced approach to weight selection involves learning weights from a balanced sample of data (Kamani et al., 2020). In this paper, we focus on the latter approach of assigning weights to the sample’s loss function and using the inverse of the class frequency for weight selection.
Since we are modeling the prospecting scenario as a classification problem, we use binary cross entropy for our loss function. During training, our objective is to minimize the following loss function:
| (6) |
where is the number of samples in training. is the actual label of sample and is the model prediction probability for sample . Note that and are the weight parameters of class and class , respectively, which we choose as the inverse of the class frequency.
3.3. Random Forest vs Our Framework
The current state-of-the-art approach for classification in tabular data favors tree-based models such as random forest and XGBoost for small to medium datasets (around 10K samples) (Grinsztajn et al., 2022). However, in many practical applications, the datasets are much larger, often exceeding 100K samples and sometimes reaching millions, as is the case in our study of prospecting via direct mail. In this study, we compare the real-world performance of our proposed deep learning framework, consisting of an autoencoder and feed-forward neural network, to a random forest model regarding conversion rate and found that our framework outperformed the random forest.
As mentioned earlier, tree-based algorithms provide state-of-the-art performance for tabular data (Grinsztajn et al., 2022). In (Grinsztajn et al., 2022), Grinsztajn et al. compare tree-based algorithms like random forest with other approaches and different datasets thoroughly and show that tree-based approaches outperform deep learning and other traditional methods. As a result of this previous work, we only compare our proposed framework to the random forest model in our evaluation.
4. Experimental Results
In this section, we present the experimental results of our proposed framework for addressing the issue of prospecting in imbalanced datasets using real-world data. First, we provide a brief overview of our datasets, including their creation and evaluation criteria. Next, we describe the process of finalizing the proposed model structure and hyperparameter tuning through experimentation. We also discuss the selection of sample size. Finally, we evaluate the performance of our proposed model in a real-world scenario.
4.1. Dataset
Each country has its own privacy laws. Since we are a company based in the United States, we restrict ourselves to the United States’ privacy laws. However, our proposed method is general and can be used in other countries. The data we use for our experiments is provided by companies like Acxiom and Experian, which offer features for each individual or household and are compliant with federal and state privacy laws and best practices. To protect the privacy of individuals, the data provided was de-identified during the model development process. For a further discussion on privacy, see Section 5.3.
While these data providers supply the features for our input, they do not provide the labels for our binary classification. As mentioned earlier, each company seeking to do prospecting provides a list of their customers, i.e., the audience. We use this list to create the label 1 data by combining it with the features provided by data providers like Acxiom (Inc., 2023a) and Experian (Inc., 2023c). To create the label 0 data, we sample from the population that is not included in the audience list. By combining both label 0 and label 1 data, we create our dataset. The term ”ratio” is used to denote the sample size in relation to the audience size. For example, a ratio of 4 means that the sample size is equal to 4 times the audience size.
In our experimental results, we use audience lists from six companies, referred to as , , , , , and , to build our dataset, train the model, and evaluate the proposed model. However, for confidentiality reasons, the actual names of these six advertisers are not disclosed. In the following sections, we provide a general description of these companies without revealing their specific identities.
-
•
Company : An apparel company with an audience size of .
-
•
Company : An apparel company mainly for women specialized for swim and fitness with an audience size of .
-
•
Company : A health related company and with an audience size of .
-
•
Company : A sustainable lifestyle essentials brand for women with an audience size of .
-
•
Company : A home services company with an audience size of .
-
•
Company : A home decor company with an audience size of .
Note that the audiences of these six companies vary in terms of both size and product type. We select these companies to demonstrate the effectiveness of our proposed framework across different product verticals. To show how this framework can be generalized, we use companies , , , and for training, model building, and hyperparameter tuning. Then, we evaluate the performance of our finalized framework in a real-world scenario using companies and .
For consistency, we use the same data provider throughout the experiment. However, we do not disclose which provider we used among those mentioned.
We evaluate our proposed framework in two ways. First, we use traditional evaluation metrics such as accuracy, precision, recall, and the score. Since our data is imbalanced, we focus on precision, recall, and the score, which is a weighted harmonic mean of precision and recall. We split our dataset into training and testing sets, and evaluate the performance of our model based on these metrics. Recall is particularly important when prospecting because we do not want to miss any potential customers. Therefore, we consider the score which places more emphasis on recall.
Second, we evaluate our proposed framework in a real-world direct mail scenario. Based on our trained model, we measure the number of consumers exposed to a direct mail ad who then make a purchase within a specific time frame (attribution window). These results are presented in Section 4.5.
Our proposed deep learning structure consists of two parts: an autoencoder and a feed-forward neural network. To train the framework, we first train the autoencoder alone to ensure that the encoder produces good compact representations of the input features. Then, we use the trained autoencoder in the framework and freeze its weights during the training of the feed-forward neural network.
This separate training and freezing of the autoencoder has several benefits. First, it is faster to train the autoencoder alone than it is to simultaneously train both the feed-forward neural network and the autoencoder using a joint loss function. Second, we found that using the pre-trained autoencoder and fine-tuning it during the training process of the feed-forward neural network does not result in improved performance. Finally, jointly training the autoencoder and the feed-forward neural network would introduce an additional hyper-parameter to tune, i.e., a weight parameter specifying the contribution of each loss function, which we aim to avoid for simplicity.
4.2. Architecture and Hyper-parameters
| Company A | Company B | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| Size | Train-Test | Accuracy | Precision | Recall | Size | Train-Test | Accuracy | Precision | Recall | ||
| 16 | Train | 16 | Train | ||||||||
| 16 | Test | 16 | Test | ||||||||
| 32 | Train | 32 | Train | ||||||||
| 32 | Test | 32 | Test | ||||||||
| 64 | Train | 64 | Train | ||||||||
| 64 | Test | 64 | Test | ||||||||
| 128 | Train | 128 | Train | ||||||||
| 128 | Test | 128 | Test | ||||||||
| Company C | Company D | ||||||||||
| Size | Train-Test | Accuracy | Precision | Recall | Size | Train-Test | Accuracy | Precision | Recall | ||
| 16 | Train | 16 | Train | ||||||||
| 16 | Test | 16 | Test | ||||||||
| 32 | Train | 32 | Train | ||||||||
| 32 | Test | 32 | Test | ||||||||
| 64 | Train | 64 | Train | ||||||||
| 64 | Test | 64 | Test | ||||||||
| 128 | Train | 128 | Train | ||||||||
| 128 | Test | 128 | Test | ||||||||
Our architecture comprises two parts: an autoencoder and a feed-forward neural network. First, we determine the optimal encoded size for the autoencoder. We use a symmetrical structure for the encoder and decoder, with the first hidden layer in the encoder having 256 neurons and each subsequent layer size being halved until we reach the desired encoded size. We then reconstruct the input from the encoded output and compare the decoder output to the original input using Euclidean distance. We have 734 input features, so an encoded representation less than 16 may not be sufficient and a representation larger than 128 may not be compact enough. Thus, we consider encoded output sizes of 16, 32, 64, and 128. We compare the precision, recall, and measures for these four sizes and choose the size with the best performance without overfitting. For the training of our autoencoder, we use the Adam optimizer and train for 100 epochs until the distance metric plateaus. Based on the results, we select an encoded size of 32 for our encoder. The results for the four sizes are shown in Table 1. We choose an encoded size of 32 as the measure is slightly better for this size.
Our proposed deep learning framework shows different levels of performance for different companies in terms of recall and precision. For example, companies and have lower precision values (below ) compared to companies B and D (above ). The same is true for recall values, with companies B and D having about higher recall compared to companies A and C. One reason for this variation is the difference in products offered by these companies, some of which have more general products that can be purchased by a larger customer base, making it more challenging to build specific prospecting models. As a result, our framework tends to produce more false positives (lower precision) to ensure that no potential customers are missed (high recall). Additionally, all four companies have an imbalanced dataset with varying class frequencies, which affects the weight assigned to each sample in the loss function. This leads to a reasonable rate of true positives while having a tendency to predict more positives and higher weights for class 1 predictions, resulting in more false positives.
The second component, the feed-forward neural network, takes as input the concatenation of the input features (734) and the output of the encoder (32). We test three different network architectures to find the best one for our problem.
The first architecture (architecture 512) has 512 neurons in the first layer and each subsequent layer reduces the number of neurons by half until reaching 64 neurons. The second architecture (architecture 2048) starts with 2048 neurons in the first layer and reduces the number of neurons by half in each subsequent layer until 64 neurons. The third architecture (architecture 4096) has 4096 neurons in the first layer followed by 64 neurons. All three architectures have a final layer of 1 neuron for binary prediction. Batch normalization, the ReLU function, and dropout (Srivastava et al., 2014) are used in all layers of these three architectures.
Due to space limitations, we do not cover in detail the performance of these three structures. However, the performance of these architectures was evaluated in the same manner as the autoencoder evaluation to determine which one provides the best performance while also having low overfitting and reasonable training time. As a result, we select architecture in our framework.
In our model, we use a dropout probability of 0.5. For the optimizer, we test Adam, AdamW (Loshchilov and Hutter, 2017), and SGD with momentum (Sutskever et al., 2013). Based on our results, we observe that SGD with momentum gives the best performance with lower overfitting. We select a learning rate of 0.0001 with a momentum of 0.92. We use a training batch size of 256 and train for 100 epochs.
4.3. Ratio
The ratio of the sample size to the target audience size is investigated in this section. The dataset for our prospecting task is created by using a sample of the population excluding the target audience as the negative class (label 0). We call the size of the sample relative to the audience size the ratio. When the ratio is greater than 1, the dataset becomes imbalanced, meaning that the number of samples with label 0 exceeds the number of samples with label 1. To prevent the majority class (label 0) from dominating the learning process and lowering the accuracy of the minority class (label 1), weights are assigned to each sample’s loss based on the inverse of the class frequency. The results for this investigation can be seen in Figure 2 (see Tables 6, 7, 8, and 9 in Appendix A for both training and test results).


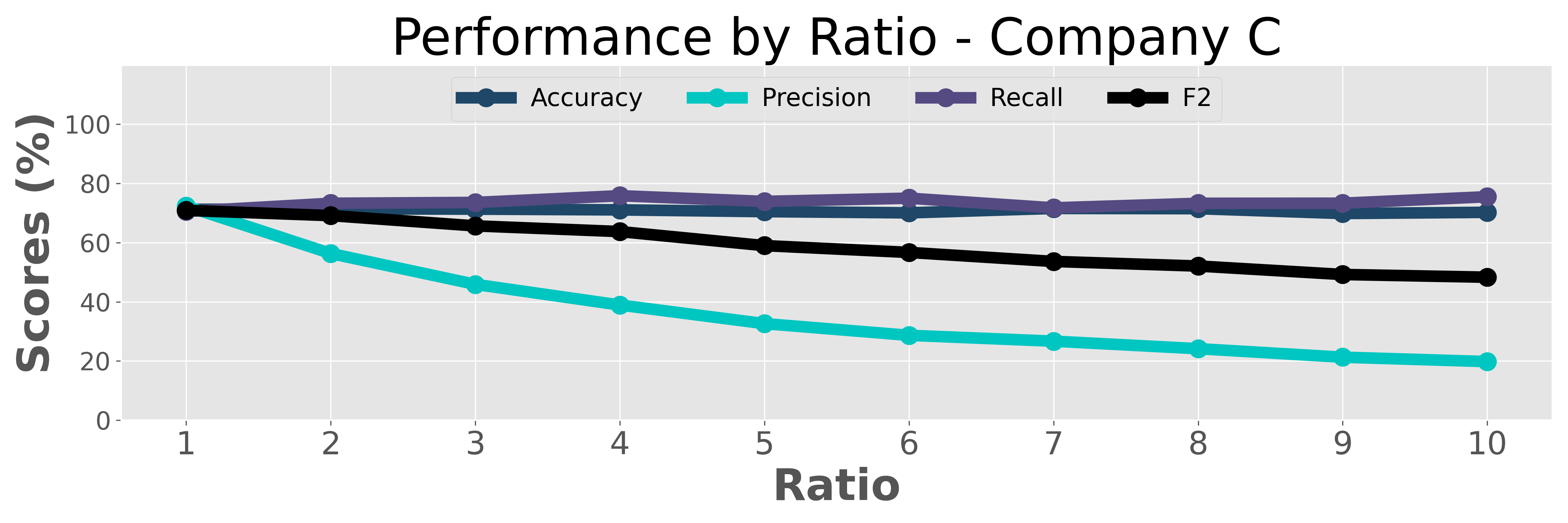

According to the results in the figure, as the ratio increases the precision for both the test and training sets decreases. This outcome is expected because as the ratio increases, there are more samples for class with label . The weight factor (inverse of class frequency) in the loss function yields more positive predictions to maintain a high recall value, but also results in more false positives, which is undesirable. However, the more data we use for training the more generalizable we make the model. Therefore, when choosing the ratio, it is important to balance these two factors and opt for a higher ratio as long as the precision does not excessively degrade.
As mentioned previously, ratios and are not chosen as they lead to small datasets, which limit the model’s ability to generalize. Additionally, precision values for ratios greater than are too low. Hence, we focus on ratios , , and and do extensive analysis for these three ratios, see Table 2 for test performance and Table 3 for training set performance. For companies , , and , the highest recall is achieved with a ratio of . Although company has better recall with ratio , the difference is minimal and the recall value for ratio is very close. Despite a slight decrease in precision when increasing the ratio from to , we still opt for ratio as it offers a higher recall and a larger dataset, which is more ideal for our real-world testing with variable audience sizes.
| Company A | Company B | ||||||||
|---|---|---|---|---|---|---|---|---|---|
| Ratio | Accuracy | Precision | Recall | Ratio | Accuracy | Precision | Recall | ||
| 3 | |||||||||
| 4 | 4 | ||||||||
| 5 | 5 | ||||||||
| Company C | Company D | ||||||||
| Ratio | Accuracy | Precision | Recall | Ratio | Accuracy | Precision | Recall | ||
| 3 | 3 | ||||||||
| 4 | 4 | ||||||||
| 5 | 5 | ||||||||
| Company A | Company B | ||||||||
|---|---|---|---|---|---|---|---|---|---|
| Ratio | Accuracy | Precision | Recall | Ratio | Accuracy | Precision | Recall | ||
| 3 | |||||||||
| 4 | 4 | ||||||||
| 5 | 5 | ||||||||
| Company C | Company D | ||||||||
| Ratio | Accuracy | Precision | Recall | Ratio | Accuracy | Precision | Recall | ||
| 3 | 3 | ||||||||
| 4 | 4 | ||||||||
| 5 | 5 | ||||||||
4.4. Random Forest Comparison
Table 4 shows a comparison of precision, recall, and score for our proposed deep learning framework (denoted as DL-AE) and random forest (denoted as RF) for four different companies, i.e., companies , , , and . Our framework outperforms random forest in terms of recall and score for all four companies, while random forest provides better precision. As we prioritize recall over precision, our framework is considered more suitable for our use case. The performance of both frameworks varies based on the company, which is dependent on the product and its audience. These results coupled with the conversion rate analysis demonstrate that our proposed deep learning framework outperforms random forest in real-world scenarios.
| Company | Method | Accuracy | Precision | Recall | |
|---|---|---|---|---|---|
| RF | |||||
| DL-AE | |||||
| RF | |||||
| DL-AE | |||||
| RF | |||||
| DL-AE | |||||
| RF | |||||
| DL-AE |
Since the focus of this paper is on proposing the deep learning method for tabular data, we do not provide the details of how we tune our random forest framework. In this paper, we only provide the parameters of our random forest model; however, similar to deep learning, we have done rigorous testing in order to find the best parameters for our random forest framework. The depth of our random forest model ranges from 9-18, with 200-500 trees, and a minimum between 5 - .01 percent (training data size) instances per node.
4.5. Real-World Performance
In this section, we evaluate our proposed framework in the real world. We aim to see how our proposed framework works for prospecting via direct mail. In a prospecting campaign, the specific number of mail pieces that are sent to different households is determined by the company’s budget and referred to as the campaign’s reach. The number of targeted households that end up purchasing a product from that company within a specified time window (attribution window) are considered converters. Each individual transaction from one of these converters is considered a conversion. To calculate the performance for a prospecting campaign, we are mainly interested in the conversion rate (denoted by CVR), or the number of conversions (denoted by #CNV) divided by the reach.
The output of our proposed framework gives a probability for each sample showing the likelihood of that sample being a prospecting customer. Based on these probabilities, we can rank the whole population and distribute reach according to this ranking. In other words, the ranking shows the priority that a household would have during a campaign mailing.
We evaluated the real-world performance of two companies, i.e., Company and Company . These companies were selected as they are distinct from those used in the development and testing of our framework. This serves to demonstrate the generality of our framework and its ability to be applied to different products and audiences. Moreover, Company operates in the home services sector, while Company is in the home decoration sector.
In our Evaluation, we have tested different audiences within each company for both our proposed deep learning framework, which is denoted by DL-AE, and random forest, denoted by RF in Table 5. Testing different audiences with different sizes for a company will lead us to find new potential customers since each audience consists of a special sector of the company’s customers.
| Company | Method | Audience | Reach | #CNV | CVR |
|---|---|---|---|---|---|
| DL-AE | |||||
| RF | |||||
| DL-AE | |||||
| RF | |||||
| DL-AE | 119,076 | 3,679 | 3.09% | ||
| RF | 77,385 | 2,245 | 2.90% | ||
| DL-AE | 61,881 | 2,003 | 3.24% | ||
| RF | 91,658 | 2,771 | 3.02% |
In Table 5, the size of audience and are and respectively. For company , audience and size are and . For privacy reasons for these companies, we do not reveal the difference between these audiences except for their size.
As we can see in Table 5, the real-world performance of our proposed framework is better than the random forest.
In addition to considering the conversion rate of a couple of campaigns for some companies, we consider the performance of company for multiple campaigns over the course of 6 months and compare how often our proposed architecture performs better than RF in practice. Over the course of 6 months, we have run 46 campaigns for this company, and the reach ranges from 20,000 to 500,00 based on the goal of the campaign and budget for that specific campaign. When evaluating the performance of 46 different campaigns using conversion rate, our proposed DL framework outperformed the random forest model 30 times and matched random forest performance 9 times. In production, the random forest model only performed better than our proposed DL framework 7 times. The above analysis corroborates the consistent performance of our proposed DL approach over time compared to the random forest, which is known as the best choice for tabular data.
5. Discussion and Limitations
In this section, we discuss some implications of our work and some limitations.
5.1. Label and Ground Truth
To address the issue of prospecting, we selected our label by randomly sampling from the population excluding current customers. While some individuals in this sample may have never been exposed to the product, making it uncertain if they are truly label , we chose this method as it is infeasible to determine with certainty whether an individual will never purchase the product. There is a possibility that they may become customers in the future. The random sample from across the entire United States allows us to conceptually learn how our client’s customers compare to the average American.
Additionally, testing our framework in the real world and calculating conversions does not necessarily indicate that non-converters are not customers. It only shows that they didn’t choose to purchase the product during the current attribution window. Factors such as a different attribution window, increased ad exposure, altered messaging, or alternative offers may influence their decision to convert in the future.
It is important to note that there is no standard conversion rate that is considered acceptable. Conversion rates vary depending on a company’s marketing goals, which can change from company to company and season to season. Whether the conversion rate of a specific campaign is reasonable depends on the company’s objectives and current market conditions.
5.2. Interpretability
Given the uncertainty surrounding label , we evaluate the interpretability of our model using Shapley values (Lundberg and Lee, 2017). We calculate the impact of individual features on the prediction for a set of samples ranked at the top of our model’s predictions. This analysis demonstrates that features related to the product have the greatest impact on the prediction. In other words, we aim to confirm that our model is functioning correctly and picking up relevant product-related features. Our analysis suggests that the uncertainty regarding label does not negatively impact the accuracy of our model. However, due to proprietary data restrictions from our data providers, we cannot reveal the specific features or products involved. We only mention this investigation to ensure that our model is functioning correctly.
5.3. Privacy
During our model development and evaluation, we utilized a set of features from a single data provider source. To maintain privacy and comply with regulations, we have taken the following precautions:
-
(1)
We only used data from large, publicly traded commercial data providers with established privacy and compliance processes. We did not combine this data with any other publicly accessible sources.
-
(2)
All data used in our model development and evaluation was anonymized.
-
(3)
We did not use any sensitive personal information such as health records, credit card information, race, etc.
-
(4)
We are in compliance with regulations outlined in the California Consumer Privacy Act (CCPA) (of California Department of Justice, 2023) which gives consumers the right to know, delete, opt-out, and the right to non-discrimination regarding the information collected by a business.
6. Conclusion
This paper presents a novel deep learning framework for handling imbalanced tabular data in an applied real world scenario. The framework consists of two components: an autoencoder and a feed-forward neural network, which are designed to efficiently handle large datasets with numerous features. The performance of the proposed framework is evaluated through a real-world case study of direct mail prospecting advertisement. The study investigates important architecture selections such as the encoder size, feed-forward neural network architecture, and ratio, and compares the performance of the proposed model to that of a tree-based random forest model. The results show that the proposed framework outperforms the random forest in traditional metrics such as precision and recall, as well as in real-world performance in the prospecting campaign.
The proposed framework is general in nature and could be applied to other binary classification tasks. The authors intend to further explore this potential in future work by evaluating the framework on different tasks with varying feature sizes and numbers, and comparing its performance to tree-based models like random forest and XGBoost.
References
- (1)
- Antoniou et al. (2017) Antreas Antoniou, Amos Storkey, and Harrison Edwards. 2017. Data augmentation generative adversarial networks. arXiv preprint arXiv:1711.04340 (2017).
- Arik and Pfister (2021) Sercan Ö Arik and Tomas Pfister. 2021. Tabnet: Attentive interpretable tabular learning. In Proceedings of the AAAI Conference on Artificial Intelligence, Vol. 35. 6679–6687.
- Borisov et al. (2022) Vadim Borisov, Tobias Leemann, Kathrin Seßler, Johannes Haug, Martin Pawelczyk, and Gjergji Kasneci. 2022. Deep neural networks and tabular data: A survey. IEEE Transactions on Neural Networks and Learning Systems (2022).
- Chawla et al. (2002) Nitesh V Chawla, Kevin W Bowyer, Lawrence O Hall, and W Philip Kegelmeyer. 2002. SMOTE: synthetic minority over-sampling technique. Journal of artificial intelligence research 16 (2002), 321–357.
- Chen and Guestrin (2016) Tianqi Chen and Carlos Guestrin. 2016. Xgboost: A scalable tree boosting system. In Proceedings of the 22nd acm sigkdd international conference on knowledge discovery and data mining. 785–794.
- Cheng et al. (2016) Heng-Tze Cheng, Levent Koc, Jeremiah Harmsen, Tal Shaked, Tushar Chandra, Hrishi Aradhye, Glen Anderson, Greg Corrado, Wei Chai, Mustafa Ispir, et al. 2016. Wide & deep learning for recommender systems. In Proceedings of the 1st workshop on deep learning for recommender systems. 7–10.
- Dooley (2022) Roger Dooley. 2022. Paper Beats Digital In Many Ways, According To Neuroscience. https://www.forbes.com/sites/rogerdooley/2015/09/16/paper-vs-digital/?sh=4e33c42033c3. [Online; accessed 2-June-2024].
- Duffin (2022) Erin Duffin. 2022. Number of households in the U.S. from 1960 to 2022. https://www.statista.com/statistics/183635/number-of-households-in-the-us/. [Online; accessed 4-June-2024].
- Fiedler (2021) James Fiedler. 2021. Simple modifications to improve tabular neural networks. arXiv preprint arXiv:2108.03214 (2021).
- Frosst and Hinton (2017) Nicholas Frosst and Geoffrey Hinton. 2017. Distilling a neural network into a soft decision tree. arXiv preprint arXiv:1711.09784 (2017).
- Grinsztajn et al. (2022) Leo Grinsztajn, Edouard Oyallon, and Gael Varoquaux. 2022. Why do tree-based models still outperform deep learning on typical tabular data?. In Thirty-sixth Conference on Neural Information Processing Systems Datasets and Benchmarks Track.
- Guo et al. (2017) Huifeng Guo, Ruiming Tang, Yunming Ye, Zhenguo Li, and Xiuqiang He. 2017. DeepFM: a factorization-machine based neural network for CTR prediction. arXiv preprint arXiv:1703.04247 (2017).
- Huang et al. (2016) Chen Huang, Yining Li, Chen Change Loy, and Xiaoou Tang. 2016. Learning deep representation for imbalanced classification. In Proceedings of the IEEE conference on computer vision and pattern recognition. 5375–5384.
- Huang et al. (2020) Xin Huang, Ashish Khetan, Milan Cvitkovic, and Zohar Karnin. 2020. Tabtransformer: Tabular data modeling using contextual embeddings. arXiv preprint arXiv:2012.06678 (2020).
- Inc. (2023a) Acxiom Inc. 2023a. ACXIOM. https://www.acxiom.com/. [Online; accessed 3-June-2024].
- Inc. (2023b) Epsilon Inc. 2023b. Epsilon. https://www.epsilon.com/us. [Online; accessed 4-June-2024].
- Inc. (2023c) Experian Inc. 2023c. EXPERIAN. https://www.experian.com/. [Online; accessed 4-June-2024].
- Inc. (2023d) Mastercard Inc. 2023d. Mastercard. https://www.mastercard.us/en-us.html. [Online; accessed 3-June-2024].
- Inc. (2023e) Visa Inc. 2023e. VISA. https://usa.visa.com/. [Online; accessed 4-June-2024].
- Kahn and Marshall (1953) Herman Kahn and Andy W Marshall. 1953. Methods of reducing sample size in Monte Carlo computations. Journal of the Operations Research Society of America 1, 5 (1953), 263–278.
- Kamani et al. (2020) Mohammad Mahdi Kamani, Sadegh Farhang, Mehrdad Mahdavi, and James Z Wang. 2020. Targeted data-driven regularization for out-of-distribution generalization. In Proceedings of the 26th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining. 882–891.
- Khan et al. (2017) Salman H Khan, Munawar Hayat, Mohammed Bennamoun, Ferdous A Sohel, and Roberto Togneri. 2017. Cost-sensitive learning of deep feature representations from imbalanced data. IEEE transactions on neural networks and learning systems 29, 8 (2017), 3573–3587.
- Loshchilov and Hutter (2017) Ilya Loshchilov and Frank Hutter. 2017. Decoupled weight decay regularization. arXiv preprint arXiv:1711.05101 (2017).
- Lounici et al. (2021) Karim Lounici, Katia Meziani, and Benjamin Riu. 2021. Muddling label regularization: Deep learning for tabular datasets. arXiv preprint arXiv:2106.04462 (2021).
- Lundberg and Lee (2017) Scott M Lundberg and Su-In Lee. 2017. A unified approach to interpreting model predictions. Advances in neural information processing systems 30 (2017).
- Luo et al. (2020) Yuanfei Luo, Hao Zhou, Wei-Wei Tu, Yuqiang Chen, Wenyuan Dai, and Qiang Yang. 2020. Network on network for tabular data classification in real-world applications. In Proceedings of the 43rd International ACM SIGIR Conference on Research and Development in Information Retrieval. 2317–2326.
- of California Department of Justice (2023) State of California Department of Justice. 2023. California Consumer Privacy Act (CCPA). https://oag.ca.gov/privacy/ccpa. [Online; accessed 4-June-2024].
- Shavitt and Segal (2018) Ira Shavitt and Eran Segal. 2018. Regularization learning networks: deep learning for tabular datasets. Advances in Neural Information Processing Systems 31 (2018).
- Shih and Fan (2008) Tse-Hua Shih and Xitao Fan. 2008. Comparing response rates from web and mail surveys: A meta-analysis. Field methods 20, 3 (2008), 249–271.
- Somepalli et al. (2021) Gowthami Somepalli, Micah Goldblum, Avi Schwarzschild, C Bayan Bruss, and Tom Goldstein. 2021. Saint: Improved neural networks for tabular data via row attention and contrastive pre-training. arXiv preprint arXiv:2106.01342 (2021).
- Srivastava et al. (2014) Nitish Srivastava, Geoffrey Hinton, Alex Krizhevsky, Ilya Sutskever, and Ruslan Salakhutdinov. 2014. Dropout: a simple way to prevent neural networks from overfitting. The journal of machine learning research 15, 1 (2014), 1929–1958.
- Sun et al. (2019) Baohua Sun, Lin Yang, Wenhan Zhang, Michael Lin, Patrick Dong, Charles Young, and Jason Dong. 2019. Supertml: Two-dimensional word embedding for the precognition on structured tabular data. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops. 0–0.
- Sutskever et al. (2013) Ilya Sutskever, James Martens, George Dahl, and Geoffrey Hinton. 2013. On the importance of initialization and momentum in deep learning. In International conference on machine learning. PMLR, 1139–1147.
- Valdes et al. (2021) Gilmer Valdes, Wilmer Arbelo, Yannet Interian, and Jerome H Friedman. 2021. Lockout: Sparse regularization of neural networks. arXiv preprint arXiv:2107.07160 (2021).
- Yoon et al. (2020) Jinsung Yoon, Yao Zhang, James Jordon, and Mihaela van der Schaar. 2020. Vime: Extending the success of self-and semi-supervised learning to tabular domain. Advances in Neural Information Processing Systems 33 (2020), 11033–11043.
- Zhu et al. (2021) Yitan Zhu, Thomas Brettin, Fangfang Xia, Alexander Partin, Maulik Shukla, Hyunseung Yoo, Yvonne A Evrard, James H Doroshow, and Rick L Stevens. 2021. Converting tabular data into images for deep learning with convolutional neural networks. Scientific reports 11, 1 (2021), 11325.
Appendix A Ratio Selections
| Ratio | Train-Test | Accuracy | Precision | Recall | |
|---|---|---|---|---|---|
| Train | |||||
| Test | |||||
| Train | |||||
| Test | |||||
| Train | |||||
| Test | |||||
| Train | |||||
| Test | |||||
| Train | |||||
| Test | |||||
| Train | |||||
| Test | |||||
| Train | |||||
| Test | |||||
| Train | |||||
| Test | |||||
| Train | |||||
| Test | |||||
| Train | |||||
| Test |
| Ratio | Train-Test | Accuracy | Precision | Recall | |
|---|---|---|---|---|---|
| Train | |||||
| Test | |||||
| Train | |||||
| Test | |||||
| Train | |||||
| Test | |||||
| Train | |||||
| Test | |||||
| Train | |||||
| Test | |||||
| Train | |||||
| Test | |||||
| Train | |||||
| Test | |||||
| Train | |||||
| Test | |||||
| Train | |||||
| Test | |||||
| Train | |||||
| Test |
| Ratio | Train-Test | Accuracy | Precision | Recall | |
|---|---|---|---|---|---|
| Train | |||||
| Test | |||||
| Train | |||||
| Test | |||||
| Train | |||||
| Test | |||||
| Train | |||||
| Test | |||||
| Train | |||||
| Test | |||||
| Train | |||||
| Test | |||||
| Train | |||||
| Test | |||||
| Train | |||||
| Test | |||||
| Train | |||||
| Test | |||||
| Train | |||||
| Test |
| Ratio | Train-Test | Accuracy | Precision | Recall | |
|---|---|---|---|---|---|
| Train | |||||
| Test | |||||
| Train | |||||
| Test | |||||
| Train | |||||
| Test | |||||
| Train | |||||
| Test | |||||
| Train | |||||
| Test | |||||
| Train | |||||
| Test | |||||
| Train | |||||
| Test | |||||
| Train | |||||
| Test | |||||
| Train | |||||
| Test | |||||
| Train | |||||
| Test |