A Convex Parameterization of Robust Recurrent Neural Networks
Abstract
Recurrent neural networks (RNNs) are a class of nonlinear dynamical systems often used to model sequence-to-sequence maps. RNNs have excellent expressive power but lack the stability or robustness guarantees that are necessary for many applications. In this paper, we formulate convex sets of RNNs with stability and robustness guarantees. The guarantees are derived using incremental quadratic constraints and can ensure global exponential stability of all solutions, and bounds on incremental gain (the Lipschitz constant of the learned sequence-to-sequence mapping). Using an implicit model structure, we construct a parametrization of RNNs that is jointly convex in the model parameters and stability certificate. We prove that this model structure includes all previously-proposed convex sets of stable RNNs as special cases, and also includes all stable linear dynamical systems. We illustrate the utility of the proposed model class in the context of non-linear system identification.
I INTRODUCTION
RNNs are state-space models incorporating neural networks that are frequently used in system identification and machine learning to model dynamical systems and other sequences-to-sequence mappings. It has long been observed that RNNs can be difficult to train in part due to model instability, referred to as the exploding gradients problem [1], and recent work shows that these models are often not robust to input perturbations [2]. These issues are related to long-standing concerns in control theory, i.e. stability and Lipschitz continuity solutions of dynamical systems [3].
There are many types of stability for nonlinear systems (e.g., RNNs). When learning dynamical systems with inputs, Lyapunov approaches are inappropriate as they require the construction of a Lyapunov function about a known stable solution. In machine learning and system identification, however, the goal is to simulate the learned model with new inputs, generating new solutions. Incremental stability [4] and contraction analysis [5] avoid this issue by showing stability for all inputs and trajectories.
Even if a model is stable, it is usually problematic if its output is very sensitive to small changes in the input. This sensitivity can be quantified by the model’s incremental gain. Finite incremental gain implies both boundedness and continuity of the input-output map [4]. Furthermore, the incremental gain bound is also a bound on the Lipschitz constant of the sequence-to-sequence mapping. In machine learning, the Lipschitz constant is used in proofs of generalization bounds [6], analysis of expressiveness [7] and guarantees of robustness to adversarial attacks [8, 9].
The problem of training models with stability or robustness guaranteed a-priori has seen significant attention for both linear [10, 11] and nonlinear [12, 13, 14] models. The main difficult comes from the non-convexity of most model structures and their stability certificates. Some methods deal with this difficulty by simply fixing the stability certificate and optimizing over the model parameters at significant cost to model expressibility [15]. It has recently been shown that implicit parametrizations allow joint convexity of the model and a stability certificate for linear [16], polynomial [12] and RNN [17] models. It has been observed that stability constraints serve as an effective regulariser and can improve generalisation performance [18, 17].
When a system is expressed in terms of a neural network, even the problem of analyzing the stability of known dynamics is difficult. A number of approaches have formulated LMI conditions [19, 20, 21] guaranteeing Lyapunov stability of a particular equilibrium. Recently, incremental quadratic constraints [3] have been recently applied to (non-recurrent) neural networks to develop the tightest bounds on the Lipschitz constant known to date [22].
Contributions: In this letter we propose a new convex parameterization of RNNs satisfying stability and robustness conditions. By treating RNNs as linear systems in feedback with a slope-restricted, element-wise nonlinearity, we can apply methods from robust control to develop stability conditions that are less conservative than prior methods. The proposed model set contains all previously published sets of stable RNNs, and all stable linear time-invariant (LTI) systems. Using implicit parameterizations with incremental quadratic constraints, we construct a set of models that is jointly convex in the model parameters, stability certificate and the multipliers required by the incremental quadratic constraint approach. Joint convexity in all parameters simplifies the training of stable models as constraints can be easily dealt with using penalty, barrier or projected gradient methods.
Notation. We use to denote the set of natural and real numbers, respectively. The set of all one-side sequences is denoted by . Superscript is omitted when it is clear from the context. For , is the value of the sequence at time . The notation denotes the standard 2-norm. The subset consists of all square-summable sequences, i.e., if and only if the norm is finite. Given a sequence , the norm of its truncation over with is written as . For matrices , we use and to mean is positive definite or positive semi-definite respectively and and to mean and respectively. The set of diagonal, positive definite matrices is denoted .
II Problem Formulation
We are interested in learning nonlinear state space models:
| (1) | |||
| (2) |
where is the state, is a known input and is the output. The functions are parametrized by and will be defined later. Given initial condition , the dynamical system (1), (2) can be provides a sequence-to-sequence mapping .
Definition 1.
This definition implies that initial conditions are forgotten, however, the outputs can still be sensitive to small perturbations in the input. In such cases, it is natural to measure system robustness in terms of the incremental -gain.
Definition 2.
Note that the above definition implies incremental stability since for all when . It also shows that all operators defined by (1) and (2) are Lipschitz continuous with Lipschitz constant , i.e. for any and all
| (4) |
The goal of this work is to construct a rich parametrization of the functions and in (1), (2), with robustness guarantees. We focus on two robustness guarantees in this work:
-
1.
A model set parametrized by is robust if for all the system has finite incremental -gain.
-
2.
A model set parameterized by is -robust if for all the system has an incremental -gain bound of .
III Robust RNNs
III-A Model Structure

We parameterize the functions (1), (2) as a feedback interconnection between a linear system and a static, memoryless nonlinear operator :
| (5) | |||
| (6) |
where with as the th component of the . This feedback interconnection is shown in Fig. 1. We assume that the slope of is restricted to the interval :
| (7) |
In the neural network literature, such functions are referred to as “activation functions”, and common choices (e.g. tanh, ReLU, sigmoid) are slope restricted [23].
The proposed model structure is highly expressive and contains many commonly used model structures. For instance, LTI systems are obtained when and . RNNs of the form [24]:
| (8) | |||
| (9) |
are obtained with the choice , , , , , , , and . This implies (5), (6) is a universal approximator for dynamical systems over bounded domains as [25].
Even for linear systems, the set of robust or -robust models is non-convex. Constructing a set of parameters for which (5), (6) is robust or -robust is further complicated by presence of the nonlinear activation function in . We will simplify the analysis by replacing with incremental quadratic constraints.
III-B Description of by Incremental Quadratic Constraints
III-C Convex Parametrization of Robust RNNs
Corresponding to the linear system (5), we introduce the following implicit, redundant parametrization:
| (12) |
where are the model parameters with invertible and is the incremental quadratic constraint multiplier from (11). The explicit system (5) can be easily constructed from (12) by inverting and . While the parameters and do not improve model expressiveness, the extra degrees of freedom will allow us to formulate sets of robust models that are jointly convex in the model parameters, stability certificate and multipliers.
To construct the set of stable robust models, we introduce the following convex constraint:
| (13) |
The set of Robust RNNs is then given by:
Since , (13) and (14) imply that which means that is invertible.
To construct a set of -robust models, we propose the following convex constraint:
| (14) |
The set of -robust RNNs is then given by:
Note that (13) and (14) are jointly convex in the model parameters, stability certificate, multipliers and the incremental gain bound .
Proof.
Proof.
Remark 1.
Theorem 1 and Theorem 2 actually imply a stronger form of stability. For , it is straightforward to show from the strict matrix inequalities that for some , which implies that the dynamics are contracting [5].
III-D Expressivity of the model set
To be able to learn models for a wide class of systems, it is beneficial to have as expressive a model set as possible. The main result regarding expressivity is that the Robust RNN set contains all contracting implicit RNNs (ci-RNNs) [17] and stable LTI models.
Theorem 3.
The Robust RNN set contains all stable LTI models of the form
| (15) |
Proof.
A necessary and sufficient condition for stability of (15) is the existence of some such that:
| (16) |
For any stable LTI system, the implicit RNN with such that , , , , and , and has the same dynamics and output. To see that that ,
for any . ∎
Remark 2.
Essentially the same proof technique but with the strict Bounded Real Lemma can be used to show that contains all LTI models with an norm of .
A ci-RNN [17] is an implicit model of the form:
| (17) |
such that the following contraction condition holds
| (18) |
where . The stable RNN (s-RNN), proposed in [15] is contained within the set of ci-RNNs when .
Theorem 4.
The Robust RNN set contains all ci-RNNs.
Proof.
For any ci-RNN, there is an implicit RNN with the same dynamics and output with such that , , , , , , , , , , and . By substituting into (5) and (6), we recover the dynamics and output of the ci-RNN in (17).
For this parameter choice, . To see this:
The remaining conditions , and follow by definition. ∎
IV Numerical Example
We will compare the proposed Robust RNN with the (Elman) RNN [24] described by (8), (9) with and Long Short Term Memory (LSTM) [26], which is a widely-used model class that was originally proposed to resolve issues related to stability. In addition, we compare to two previously-published stable model sets, the contracting implicit RNN (ci-RNN) [17] and stable RNN (sRNN) [15]. All models have a state dimension of 10 and all models except for the LSTM use a ReLU activation function. The LSTM is described by the following equations:
| (19) |
where , are the cell state and hidden state, is the input and is the Hadamard product and is the sigmoid function. The output is a linear function of the hidden state.
To generate data, we use a simulation of four coupled mass spring dampers. The goal is to identify a mapping from the force on the initial mass to the position of the final mass. Nonlinearity is introduced through the springs’ piecewise linear force profile
| (20) |
where is the spring constant for the th spring and is the displacement between the carts. A schematic is shown in Fig. 2. The masses are , the linear damping coefficients used are and spring constants used in (20) are .

We excite the system with a piecewise-constant input signal that changes value after an interval distributed uniformly in and takes values that are normally distributed with standard deviation . The measurements have Gaussian noise of approximately added. To generate data we simulate the system for seconds and sample the system at 5Hz to generate data points with an input signal characterized by and . The training data consists of 100 batches of length . We also generate a validation set with , and length that is used for early stopping. To test model performance, we generate test sets of length with and varying .
IV-A Training Procedure
We fit Robust RNNs by optimizing simulation error using stochastic gradient descent and logarithmic barrier functions to ensure strict feasibility of the robustness constraints. We use the ADAM optimizer [27] with an initial learning rate of to optimize the following objective function:
where are the LMIs to be satisfied and are the incremental quadratic constraint multipliers and and are the input and output for the th batch. A backtracking line search ensures strict feasibility throughout optimization. After 10 epochs without an improvement in validation performance, we decrease the learning rate by a factor of and decrease by a factor of . When reaches a final value of , we finish training. All code is written using Pytorch 1.60 and run on a standard desktop CPU. The code is available at the following link: https://github.com/imanchester/RobustRNN/.
IV-B Model Evaluation
Model quality of fit is measured using normalized simulation error:
| (21) |
where are the simulated and measured system outputs respectively. Model robustness is measured by approximately solving:
| (22) |
using gradient ascent. The value of is a lower bound on the true Lipschitz constant of the model.
IV-C Results
The validation performance versus number of epochs is shown in Fig. 3. Note that an epoch occurs after one complete pass through the training data. In this case, this corresponds to 100 batches and gradient descent steps. Each epoch training the Robust RNN takes twice as long as the LSTM due to the evaluation of the logarithmic barrier functions and the backtracking line search, however we will see that the model offers both stability/robustness guarantees and superior generalizability.
Figure 4 presents boxplots and a comparison of the medians for the performance of each model for a number of realizations of the input signal with varying . In each plot, there is a trough around corresponding to the training data distribution. For the LSTM and RNN, the model performance quickly degrades with varying . On the other hand, the stable models exhibit a much slower decline in performance. This supports the claim that model stability constraints can improve model generalization. The Robust RNN set uniformly outperforms all other models.
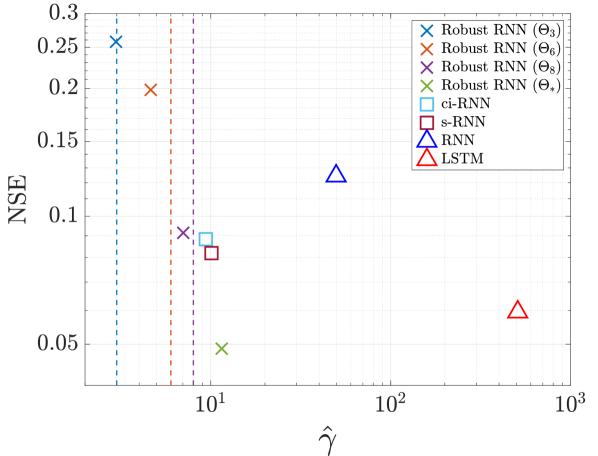
We have also plotted the worst case observed sensitivity versus median nominal test performance () in Fig. 5. The Robust RNNs show the best trade-off between nominal performance and robustness signified by the fact that they lie further in the lower left corner. For instance if we compare the LSTM with the Robust RNN (), we observe similar nominal performance, however the Robust RNN has a much smaller Lipschitz constant. Varying the incremental gain allows us to trade off between model performance and robustness. We can also observe in the figure that the guaranteed upper bounds are quite tight to the observed lower bounds on the Lipschitz constant, especially for the set .
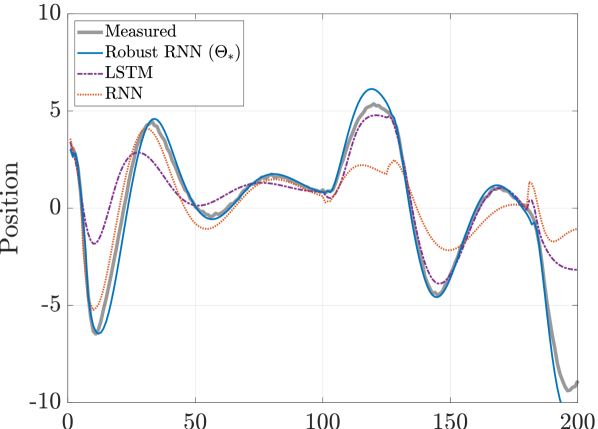
In Fig. 6, we have the model predictions for the RNN, LSTM and Robust RNN for a typical input with . We can see that even with the larger inputs, the Robust RNN continuous to accurately track the measured data. The predictions of the LSTM and RNN however deviate significantly from measured data for significant periods.







References
- [1] Y. Bengio, P. Simard, and P. Frasconi, “Learning long-term dependencies with gradient descent is difficult,” IEEE transactions on neural networks, vol. 5, no. 2, pp. 157–166, 1994.
- [2] M. Cheng, J. Yi, P.-Y. Chen, H. Zhang, and C.-J. Hsieh, “Seq2sick: Evaluating the robustness of sequence-to-sequence models with adversarial examples.” in Association for the Advancement of Artificial Intelligence, 2020, pp. 3601–3608.
- [3] G. Zames, “On the input-output stability of time-varying nonlinear feedback systems part one: Conditions derived using concepts of loop gain, conicity, and positivity,” IEEE Transactions on Automatic Control, vol. 11, no. 2, pp. 228–238, 1966.
- [4] C. A. Desoer and M. Vidyasagar, Feedback systems: input-output properties. SIAM, 1975, vol. 55.
- [5] W. Lohmiller and J.-J. E. Slotine, “On contraction analysis for non-linear systems,” Automatica, vol. 34, pp. 683–696, 1998.
- [6] P. L. Bartlett, D. J. Foster, and M. J. Telgarsky, “Spectrally-normalized margin bounds for neural networks,” in Advances in Neural Information Processing Systems, 2017, pp. 6240–6249.
- [7] S. Zhou and A. P. Schoellig, “An analysis of the expressiveness of deep neural network architectures based on their lipschitz constants,” arXiv preprint arXiv:1912.11511, 2019.
- [8] T. Huster, C.-Y. J. Chiang, and R. Chadha, “Limitations of the lipschitz constant as a defense against adversarial examples,” in Joint European Conference on Machine Learning and Knowledge Discovery in Databases. Springer, 2018, pp. 16–29.
- [9] H. Qian and M. N. Wegman, “L2-nonexpansive neural networks,” International Conference on Learning Representations (ICLR), 2019.
- [10] S. L. Lacy and D. S. Bernstein, “Subspace identification with guaranteed stability using constrained optimization,” IEEE Transactions on automatic control, vol. 48, no. 7, pp. 1259–1263, 2003.
- [11] D. N. Miller and R. A. De Callafon, “Subspace identification with eigenvalue constraints,” Automatica, vol. 49, no. 8, pp. 2468–2473, 2013.
- [12] M. M. Tobenkin, I. R. Manchester, and A. Megretski, “Convex parameterizations and fidelity bounds for nonlinear identification and reduced-order modelling,” IEEE Transactions on Automatic Control, vol. 62, no. 7, pp. 3679–3686, 2017.
- [13] J. Umlauft, A. Lederer, and S. Hirche, “Learning stable gaussian process state space models,” in 2017 American Control Conference (ACC). IEEE, 2017, pp. 1499–1504.
- [14] J. Z. Kolter and G. Manek, “Learning stable deep dynamics models,” in Advances in Neural Information Processing Systems 32. Curran Associates, Inc., 2019, pp. 11 128–11 136.
- [15] J. Miller and M. Hardt, “Stable recurrent models,” In Proceedings of International Conference on Learning Representations 2019, 2019.
- [16] J. Umenberger, J. Wågberg, I. R. Manchester, and T. B. Schön, “Maximum likelihood identification of stable linear dynamical systems,” Automatica, vol. 96, pp. 280–292, 2018.
- [17] M. Revay and I. R. Manchester, “Contracting implicit recurrent neural networks: Stable models with improved trainability,” Learning for Dynamics and Control (L4DC), 2020.
- [18] J. Umenberger and I. R. Manchester, “Specialized interior-point algorithm for stable nonlinear system identification,” IEEE Transactions on Automatic Control, vol. 64, no. 6, pp. 2442–2456, 2018.
- [19] E. Kaszkurewicz and A. Bhaya, Matrix Diagonal Stability in Systems and Computation. Birkhäuser Basel, 2000.
- [20] N. E. Barabanov and D. V. Prokhorov, “Stability analysis of discrete-time recurrent neural networks,” IEEE Transactions on Neural Networks, vol. 13, no. 2, pp. 292–303, Mar. 2002.
- [21] Y.-C. Chu and K. Glover, “Bounds of the induced norm and model reduction errors for systems with repeated scalar nonlinearities,” IEEE Transactions on Automatic Control, vol. 44, pp. 471–483, Mar. 1999.
- [22] M. Fazlyab, A. Robey, H. Hassani, M. Morari, and G. Pappas, “Efficient and accurate estimation of lipschitz constants for deep neural networks,” in Advances in Neural Information Processing Systems, 2019, pp. 11 423–11 434.
- [23] I. Goodfellow, Y. Bengio, and A. Courville, Deep learning. MIT press, 2016.
- [24] J. L. Elman, “Finding structure in time,” Cognitive science, vol. 14, no. 2, pp. 179–211, 1990.
- [25] A. Pinkus, “Approximation theory of the mlp model in neural networks,” Acta numerica, vol. 8, no. 1, pp. 143–195, 1999.
- [26] S. Hochreiter and J. Schmidhuber, “Long Short-Term Memory,” Neural computation, vol. 9, pp. 1735–1780, 1997.
- [27] D. P. Kingma and J. Ba, “Adam: A Method for Stochastic Optimization,” International Conference for Learning Representations (ICLR), Jan. 2017.