A Convergence Theory Towards Practical
Over-parameterized Deep Neural Networks
Abstract
Deep neural networks’ remarkable ability to correctly fit training data when optimized by gradient-based algorithms is yet to be fully understood. Recent theoretical results explain the convergence for ReLU networks that are wider than those used in practice by orders of magnitude. In this work, we take a step towards closing the gap between theory and practice by significantly improving the known theoretical bounds on both the network width and the convergence time. We show that convergence to a global minimum is guaranteed for networks with widths quadratic in the sample size and linear in their depth at a time logarithmic in both. Our analysis and convergence bounds are derived via the construction of a surrogate network with fixed activation patterns that can be transformed at any time to an equivalent ReLU network of a reasonable size. This construction can be viewed as a novel technique to accelerate training, while its tight finite-width equivalence to Neural Tangent Kernel (NTK) suggests it can be utilized to study generalization as well.
1 Introduction
Deep neural networks have achieved remarkable success in machine learning applications of different fields such as computer vision [Voulodimos et al., 2018], speech recognition [Hinton et al., 2012], and natural language processing [Devlin et al., 2018]. Much of this success is yet to be fully explained. One of the existing gaps is the network’s trainability, its ability to perfectly fit training data when initialized randomly and trained by first-order methods. Modern deep networks are commonly equipped with rectified linear unit (ReLU) activations [Xu et al., 2015], forming highly non-convex and non-smooth optimization problems. Such optimization problems are known to be generally computationally infeasible [Livni et al., 2014], and NP-hard in some cases [Blum and Rivest, 1989]. Nevertheless, in practice, trainability is often achieved in various tasks. Such empirical findings were summarized by Zhang et al. [2016]: “Deep neural networks easily fit (random) labels”.
Previous theoretical works focused on networks’ expressivity [Bengio and Delalleau, 2011, Cohen et al., 2016], the existence of a solution that perfectly fits training data, therefore necessary for trainability. As it has been shown that even shallow nonlinear networks are universal approximators [Hornik et al., 1989], a better understanding of the power of depth was desired [Eldan and Shamir, 2016, Liang and Srikant, 2016, Telgarsky, 2015]. One conclusion is that increased depth allows exponentially more efficient representations, thus per parameter, deep networks can approximate a richer class of functions than shallow ones [Cohen et al., 2016, Liang and Srikant, 2016]. However, a recent work by Yun et al. [2019] provided tighter expressivity bounds on ReLU networks, showing that datasets of training examples can be perfectly expressed by a -layer ReLU network with parameters. This does not explain the sizes of practical neural networks that are typically over-parameterized and exceed the training data’s size. It appears that expressivity can provide only a limited explanation for the overparameterization of modern neural networks, which keep growing deeper and wider in search of state-of-the-art results [Zagoruyko and Komodakis, 2016, Huang et al., 2019, Ridnik et al., 2020].
Important insights regarding trainability emerged from the analysis of simplified variants of neural networks. Deep linear networks are of special interest since increased depth does not affect their expressiveness, only changes their optimization landscape. Therefore the effects of increased width and depth on the training process can be isolated and carefully studied in this setting. Arora et al. [2018a] proved that trainability is attained at a linear rate under proper initialization as long as the network is wide enough. Arora et al. [2018b] showed that training with gradient-descent could be accelerated by increasing the network’s depth. Their empirical evaluations supported the existence of a similar outcome in deep nonlinear networks as well. Another simplified variant with further insights is overparameterized shallow nonlinear networks, typically with a single hidden layer. Du and Lee [2018] proved that for a quadratic activation function all local minima are global minima. Safran and Shamir [2018] showed that ReLU networks suffer from spurious local minima, which can be drastically reduced by overparameterization. Oymak and Soltanolkotabi [2020] achieved trainability where the proportion between the number of hidden units and training examples depends on the activation: for smooth ones it is while for ReLU it is significantly larger, . Additional works examined the unique dynamics of ReLU activation during the training and their relation to gradient-descent optimization [Li and Liang, 2018, Arora et al., 2019b].
The analysis of deep ReLU networks is more challenging, as additional problems emerge with increased depth. Exploding and vanishing gradient [Hanin, 2018] and bias shifts [Clevert et al., 2015] are shared with additional activations, while the dying ReLUs problem, causing them to remain inactive permanently, is unique [Lu et al., 2019]. While in practice those problems are solved by the introduction of additional tensor transformations [Ioffe and Szegedy, 2015, He et al., 2016b], their theoretical understanding remains limited. Correspondingly, existing trainability guarantees for deep ReLU networks are considerably weaker compared with shallow networks. Du et al. [2019] required a minimal network width which scales exponentially with its depth and polynomially with the number of examples . More recent works [Zou et al., 2018, Allen-Zhu et al., 2019] improved the dependencies to be high-order polynomials, and correspondingly. The best known result, by Zou and Gu [2019], required a network width of , which is still prohibitively large compared to practice. For instance, training their network with layers [He et al., 2016b] over the common ImageNet dataset [Krizhevsky et al., 2017] requires a network of parameters, while the largest one reported contains only [Brown et al., 2020].
In this work, we take a step towards closing the gap between theory and practice. We develop a novel technique to analyze the trainability of overparameterized deep neural networks and provide convergence guarantees under size requirements that are significantly milder than previously known. The network width required by our analysis for trainability scales only quadratically with , enabling for the first time empirical evaluation of the theoretical bounds, and bridging previous empirical results related to overparameterization. In addition, the required width by our theory is linear with , paving the way for a better understanding of the behavior of deep neural networks of practical depths. Finally, the number of training iterations for reaching global minima by our theory is logarithmic in , significantly smaller than previous theoretical results and similar to leading practical applications (e.g., BiT [Kolesnikov et al., 2019]). A full comparison with previous methods can be found in Table 1.
A key novelty of our analysis is the construction of a surrogate network, named Gated ReLU or GReLU, illustrated in Figure 1. The activation patterns of GReLU, i.e. which entries output zero [Hanin and Rolnick, 2019b], are determined at initialization and kept fixed during training. They are set by a random transformation of the input, independent of the network initialization. Therefore, GReLU networks are immune to two main problems of training ReLU networks, dying ReLUs and bias shifts, while still enjoying the advantages of ReLU activation. We first prove tighter bounds on the width and convergence time for training GReLU networks, then show that they can be transformed to equivalent ReLU networks with train accuracy. We further investigate the proposed technique and derive a finite-width Neural Tangent Kernel equivalence with a improved condition on the network width. Finally, we empirically validate the effectiveness of our technique with datasets of different domains and practical network sizes.
Our main contribution can be summarized as follows
-
•
We show that a randomly initialized deep ReLU network of depth and width trained over samples of dimension , reaches -error global minimum for regression in a logarithmic number of iterations, . For comparison, the previous state-of-the-art result by Zou and Gu [2019] required , .
-
•
To achieve that, we propose a novel technique of training a surrogate network with fixed activation patterns that can be transformed to its equivalent ReLU network at any point. It is immune to bias-shifts and dying-ReLU problems and converges faster without affecting generalization, as we empirically demonstrate.
-
•
We derive an NTK equivalence for GReLU networks with width linear in , connecting the regimes of practical networks and kernel methods for the first time (improving by Huang and Yau [2020]). This connection allows utilizing NTK-driven theoretic discoveries for practical neural networks, most notably generalization theory.
The remainder of this paper is organized as follows. In section 2 we state the problem setup and introduce our technique. Our main theoretical result is covered in section 3, followed by additional properties of the proposed technique in Section 4. In section 5 we provide a proof sketch of the main theory, and in section 6 we empirically demonstrate its properties and effectiveness. Section 7 contains additional related work. Finally, section 8 concludes our work.
2 Preliminaries
In this section we introduce the main problem and the novel
setup which is used to solve it.
Notations:
we denote the Euclidean norm of vector by or , and the Kronecker product and Frobenius inner-product for matrices by , respectively. We denote by , matrix minimal and maximal eigenvalues.
We use the shorthand to denote the set and .
We denote the positive part of a vector by and
its indicator vector by . Matrix column-wise vectorization is denoted by . For two sequences , we denote if there exist a constant such that , and if a constant satisfies . In addition, we denote to hide logarithmic factors.
Finally, we denote the normal and chi-square distributions by respectively.
2.1 Problem Setup
Let , be training examples, with . Note that a different linear mapping is used for each training example as our goal is to fit a nonlinear objective . We assume for convenience and without loss of generality that the input data is normalized, . The data is used for training a fully-connected neural network with hidden layers and neurons on each layer.
We propose a novel network structure named GReLU, as illustrated in Figure 1,
which improves the optimization, leading to tighter trainability bounds.
The key idea of this construction is to decouple the activation patterns from the weight tuning. The role of the activation patterns is to make sure different input samples propagate through different paths, while the role of the weights is to fit the output with high accuracy.
Therefore, GReLU is composed of two parts, one consists of the weights that are trained, while the other defines the data-dependent activations of the ReLU gates. It is independently initialized and then remains fixed.
In Section 4.1, we show that a GReLU network has an equivalent ReLU network, and those can be switched at any point.
All layers are initialized with independent Gaussian distributions for :
Then, only the layers (blue blocks) are trained, while (red blocks) remain fixed during training. The activations are computed based on the random weights of as follows,
This implies that the activations do not change during training. Note that while previous works also used fixed initial and final layers e.g. [Allen-Zhu et al., 2019, Zou and Gu, 2019], the introduction of as fixed activation layers is novel.
We denote the th layer at iteration by , and the concatenation of all layers by . Since the activations are fixed in time and change per example, the full network applied on example is the following matrix,
| (1) |
Following previous works [Allen-Zhu et al., 2019, Du et al., 2019, Oymak and Soltanolkotabi, 2020], we focus here for the sake of brevity on the task of regression with the square loss,
| (2) |
The loss is minimized by gradient-descent with a constant learning rate . Our proofs can be extended to other tasks and loss functions such as classification with cross-entropy, similarly to [Allen-Zhu et al., 2019, Zou et al., 2018] and omitted for readability.
Finally, our analysis requires two further definitions. The intermediate transform for is defined as:
| (3) |
and, the maximal variation from initialization of the network’s trained layers is:
| (4) |

3 Main Theory
In this section, we present our main theoretical results. We start with making the following assumptions on the training data.
Assumption 1 (non-degenerate input).
Every two distinct examples satisfy .
Assumption 2 (common regression labels).
Labels are bounded: .
Both assumptions hold for typical datasets and are stated in order to simplify the derivation. Assumption 2 is more relaxed than corresponding assumptions in previous works of labels bounded by a constant due to the overparameterization (), enabling the network handle large outputs better. We are ready to state the main result, guaranteeing a linear-rate convergence to a global minimum.
Theorem 1.
Suppose a deep neural network of depth is trained by gradient-descent with learning rate under the scheme in Section 2.1, and with a width that satisfies,
Then, with a probability of at least over the random initialization, the network reaches -error within a number of iterations,
The proof appears in Section 10.4.
Theorem 1 improves previous known results [Zou et al., 2018, Allen-Zhu et al., 2019, Du et al., 2018, Zou and Gu, 2019] by orders of magnitude, as can be seen in Table 1.
Specifically, it takes a step towards closing the gap between existing theory and practice, with required widths that can be used in practice for the first time.
The dependence of on the depth is linear, offering a significant improvement over the previous tightest bound of [Zou and Gu, 2019]. The bound on the number of iterations is logarithmic in the number of train examples, similarly to current common practice. For example, BiT [Kolesnikov et al., 2019, Sec. 3.3] obtained SotA results on CIFAR-10/100 and ImageNet with a similar adjustment of the number of training epochs to the dataset size.
An interesting question is whether the bounds we prove on and are tight. The empirical evaluation presented in Figure 3(a) suggests they might be. We show that on a synthetic problem, fully-connected ReLU and GReLU networks with widths , which is below our bound, do not converge to zero loss, while those with do.
Next, we make two important remarks that further compare the above theoretical results with previous work.
Remark 1.
The majority of works on the trainability of overparameterized networks focus on simplified shallow -hidden layer networks (e.g. [Zou and Gu, 2019, Du et al., 2018, Wu et al., 2019, Oymak and Soltanolkotabi, 2020, Song and Yang, 2019, Li and Liang, 2018]). Our focus is on the more challenging practical deep networks, and Theorem 1 requires a minimal depth . Our analysis, however, can be extended to -hidden layer networks with the same dependencies on the number of train samples, i.e., . According to our knowledge, these dependencies improve all previous results on shallow networks.
Remark 2.
The proposed GReLU construction is used here to prove bounds on optimization. However, we believe it could be used as a technical tool for better understanding the generalization of deep neural networks. Previous works offered convergence guarantees on networks with practically infinite width. Empirical results show a poor generalization ability for such networks [Arora et al., 2019a, Li et al., 2019] when compared to mildly overparameterized ones [Srivastava et al., 2015, Noy et al., 2020, Nayman et al., 2019] over various datasets. Tighter bounds on the network size are possibly key to capture the training dynamics of deep neural networks, and to further improve those from a theoretic perspective. We leave this to future work.
4 Properties
In this section, we discuss the properties of the suggested technique. It complements the former section by providing intuition on why we are able to achieve the rates in Theorem 1, which are more similar to sizes used in practice.
First, it is important to note that modern state-of-the-art models are not based on fully-connected networks but rather on improved architectures. A classic example is the improved optimization achieved by residual connections [He et al., 2016a]. Neural networks equipped with residual connections typically retain an improved empirical performance for a relatively small degradation in runtime [Monti et al., 2018]. However, Previous theoretical works on trainability of residual networks do not share those improvements [Allen-Zhu et al., 2019, Du et al., 2018]. Few works have shown that a residual network can be transformed to its equivalent network with no residual connections (e.g. [Monti et al., 2018]).
Similarly to residual networks, GReLU networks offer appealing properties regarding the optimization of deep networks (Section 4.3), and can be mapped to their equivalent ReLU networks at any time (Section 4.1). Unlike residual networks, GReLU networks are based on theoretical guarantees (Sections 3, 4.2), and actually accelerate the network runtime as discussed in Section 4.4.
4.1 ReLU Network Equivalence
ReLU networks are extensively studied theoretically due to their dominating empirical performance regarding both optimization and generalization. While this work studies optimization, the following equivalence between GReLU and ReLU networks is important to infer on the generalization ability of the proposed technique.
Theorem 2.
Let be an overparameterized GReLU network of depth and width , trained for steps. Then, a unique equivalent ReLU network of the same sizes can be obtained, with identical intermediate and output values over the train set.
The proof appears in Section 10.7 and is done by construction of the equivalent ReLU network. The equivalent networks have an identical training footprint, in the sense that every intermediate feature map of any train example is identical for both, leading to identical predictions and training loss.This offers a dual view on GReLUs: a technique to improve and accelerate the training of ReLU networks. A good analogy is Batch Normalization, used to smooth the optimization landscape [Santurkar et al., 2018], and can be absorbed at any time into the previous layers [Krishnamoorthi, 2018, (20)-(21)] Notice that a ReLU network can be also trained as a GReLU network at any time by fixing its activation pattern, and using the scheme in section 2.1 with .
We note that while our proof uses the Moore–Penrose pseudo inverse for clarity, modern least-squares solvers [Lacotte and Pilanci, 2019] provide similar results more efficiently, so the overall complexity of our method stays the same. In other words, training according to Theorem 1 and then switching to the equivalent ReLU network results in a trained ReLU network with an -error in operations, as stands for the number of trained network parameters.
4.2 Neural Tangent Kernel Equivalence
The introduction of the Neural Tangent Kernel (NTK) [Jacot et al., 2018] offered a new perspective on deep learning, with insights on different aspects of neural networks training. Followup works analyzed the behavior of neural networks in the infinite-width regime, where neural networks roughly become equivalent to linear models with the NTK. An important result by Allen-Zhu et al. [2019], extended this equivalence to finite-width networks for . Huang and Yau [2020] reduced the sample-size dependency to , still prohibitively large for practical use.
In this section, we derive a corresponding finite-width NTK equivalence, with a width that is linear in the sample-size. Closing this gap between theory and practice offers advantages for both:
- 1.
-
2.
Theory: NTK-driven theoretic insights can be utilized effectively for neural networks of practical sizes. Those insights relate to loss landscapes, implicit regularization, training dynamics and generalization theory [Belkin et al., 2018b, Cao and Gu, 2019, Belkin et al., 2018a, Li et al., 2019, Huang et al., 2020, Liang et al., 2020].
The analysis of Theorem 1 bounds the maximal variation of the network’s layers with a probability of at least as follows,
| (5) |
for some small number . Let be any solution which satisfies,
Denote the difference , and notice that .
Define the NTK and the NTK objective [Jacot et al., 2018, Allen-Zhu et al., 2019] of the initialized network for the -th output, , respectively,
| (6) |
Jacot et al. [2018] proved that for an infinite , the dynamic NTK and NTK are in fact equivalent as . Allen-Zhu et al. [Allen-Zhu et al., 2019] showed a high-order polynomial bound on this equivalence. We further improve their results by stating a tighter bound on for our setting.
Theorem 3.
For every , , and , with probability of at least over the initialization of we have,
| (7) |
with the ratio
Corollary 4.
For every , , and , with probability of at least ,
| (8) |
Proofs can be found in Sections (10.5-10.6). Theorem 3 guarantees that the difference between gradients is negligible compared to their norms, thus the
NTK is a good approximation for the dynamic one. For simplicity, we state the result per single output dimension , while it holds for outputs of dimension as well.
For comparison, the corresponding ratio by Allen-Zhu et al. [2019] is significantly worse: .
More Specifically, equipped with the width required by Theorem 1, the guaranteed ratio by Theorem 3 is negligible even for small problems .
The more regular trajectory of GReLU gradients compared to ReLU gradients
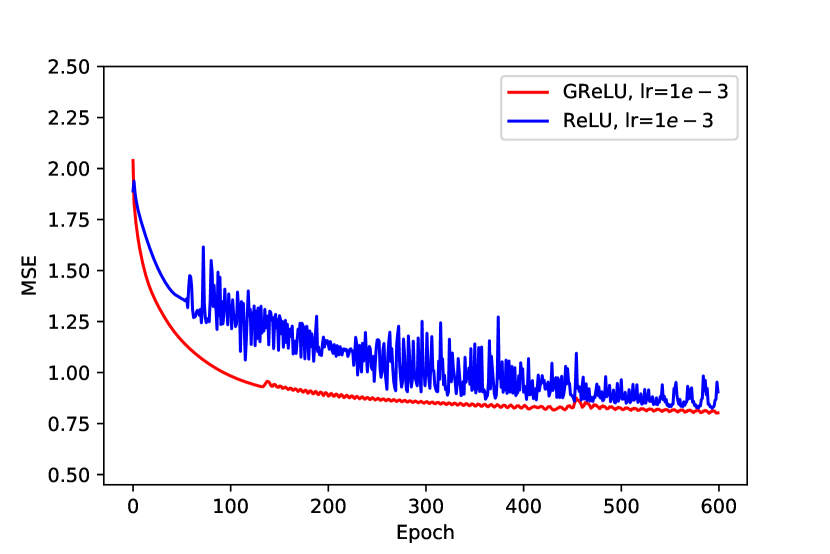
can be also seen in experiments with smaller network widths, as demonstrated in Figure 2(b).
4.3 Improved Gradient Optimization
Modern state-of-the-art models are modified versions of fully-connected networks, offering improved optimization
with additional layers [He et al., 2016b, Ioffe and Szegedy, 2015, Bachlechner et al., 2020], activations [Clevert et al., 2015, Xu et al., 2015] and training schemes [Zagoruyko and Komodakis, 2017, Jia et al., 2017].
Those are mostly aimed at solving problems that arise when training plain deep ReLU networks. It is important to note that ReLU networks often do not achieve small training error without such modifications.
Two of the most studied problems of ReLU networks are bias shifts (mean shifts) [Clevert et al., 2015] and dying ReLUs [Lu et al., 2019].
Bias shifts affect networks equipped with activations of non-zero mean. Specifically, ReLU is a non-negative function,
leading to increasingly positively-biased layer outputs in ReLU networks, a problem that grows with depth, .
Reduced bias shifts were shown to speed up the learning by bringing the normal gradient closer to the unit natural gradient [Clevert et al., 2015].
Interestingly, GReLUs do not suffer from bias shifts, as negative values are passed as well, and the fixed activations of different layers are independent.
Dying ReLUs refers to the problem of ReLU neurons become inactive and only output for any input. This problem also grows with depth, as Lu et al. [Lu et al., 2019] show that a deep enough ReLU network will eventually become a constant function.
Considering a GReLU network, given the initial network is properly initialized (i.e., not ’born dead’), it is guaranteed that no neurons will die during training due to its fixed activation pattern.
Remark 3.
GReLU networks are immune to the problems of bias-shifts and dying-ReLUs.
These properties essentially lead to better back-propagation of gradients during training and corresponding faster convergence to global minima under milder requirements on the networks’ depths.
4.4 Faster Train and Inference Iterations
Theorem 1 guarantees a faster convergence to global minima in terms of the number of iterations. We now explain how a straightforward implementation of a GReLU network leads to an additional approximated shorter iteration time compared to its equivalent ReLU network, for both train and inference.
Train: consider a single GReLU train step as described in Figure 1. Since the activations are fixed, a binary lookup table of size is made once and used to calculate only the values related to active ReLU entries, which are around due to the proposed initialization of , leading to approximately of the FLOPS of a fully-connected network of the same dimensions111Acceleration is achieved without additional implementation, as Pytorch and Tensorflow automatically skip backward-propagation calculations of such zeroed gradients..
Inference: A non-negative matrix approximation (NMA) [Tandon and Sra, 2010] is used to replace each matrix with smaller ones with respective sizes and , for . The total FLOPS count is therefore proportional to . While this approximation is not covered by our theory, experiments with yielded the desired acceleration without any accuracy degradation. This result leads to a general insight.
Remark 4.
Our technique for accelerated inference can be used to accelerate any neural network with ReLU activation. Given network layers , simply transition to the GReLU architecture described in Figure 1 with, , then use NMA approximation, .
Additional modifications can be applied for further acceleration with minimal inference variation, like binarized matrices [Hubara et al., 2016]. Those exceed our scope and are left as future work.
5 Main Theory Proof Sketch
Calculating the gradient of over , denoted by , is straightforward,
| (9) |
where
| (10) |
and we set . Those represent the network partition and will be referred to as sub-networks. Notice that . We now calculate the difference between and .
Lemma 1.
where
| (11) | ||||
| (12) |
Lemma 1 breaks a single gradient step into terms. The first term on the left represents the impact of example onto itself, where the next term (11) represents its impact by other examples and has a key role in our analysis. Our technique of fixed activations enables a more careful optimization of this term, followed by improved guarantees. The last term (12) stands for higher-order dependencies between different weights, i.e. the impact of a change in some weights over the change of others, as a result of optimizing all weights in parallel. It negatively affects the optimization and should be minimized. The next lemma deals with the loss change.
Lemma 2.
For any set of positive numbers , we have
| (13) |
where
We wish to bound the right-hand side with a value as negative as possible. The first term of (13) is proportional to the loss (2). Thus negative values can lead to an exponential loss decay, i.e. linear-rate convergence: .
In order to minimize , two properties are desired:
(a) The eigenvalues of the squared weight matrices are concentrated, that is the ratio between the minimal and maximal eigenvalues is independent of the problem’s parameters. (b) The covariance between sub-networks of different examples is much smaller than the covariance of the same examples.
The second term of (13) represents high-order dependencies between gradients and is positive, restricting the learning rate from being too high.
Next, we assume the following inequalities which satisfy (a),(b) hold with a high probability,
| (14) | |||
| (15) | |||
| (16) | |||
| (17) |
where , and are auxiliary parameters. Assumptions (14,15) are related to property (a), while (16, 17) guarantee property (b). We will show that the above bounds hold with a high probability under the proposed initialization and the fixed activation patterns defined in Section 2. Using those assumptions, we state the following lemma.
Lemma 3.
This inequality indicates a linear-rate convergence with rate . The proof of Theorem 1 follows directly from (19). Proofs for the validity of the above assumptions with high probability are based on concentration bounds for sufficiently overparameterized networks under the unique initialization proposed in Section 2, and are quite technical.
Theorem 5 validates (14,15) by bounding the ratio between the maximal and minimal eigenvalues of the squared weight matrices with a small constant for all . Theorem 6 utilizes the fixed activation patterns to show a small covariance between sub-networks of different examples as required by (16,17).
Both theorems hold for small enough maximal variation from initialization (4), which is achieved
by sufficient network overparameterization, as shown in Theorem 1.
6 Experiments
In this section, we provide empirical validation of our theoretical results, as well as further testing on complementary setups. We wish to answer the following questions:
-
1.
Is the theoretical guarantee of Theorem 1 tight, or can it be further improved?
-
2.
How well do GReLU networks train and generalize compared to ReLU networks?
-
3.
What is the difference between the training dynamics of GReLU and ReLU when optimized with gradient-descent?
The next sections are dedicated to discuss these questions. For fairness, we compare networks with the same width and depth, initialization described in Section 2, and trained by gradient descent with a constant learning rate for each train. The term MSE refers to the sum of squared errors described in (2). Since the theory covers general setups, it often uses small learning rate values to fit all setups, while in practice larger values can be utilized for faster convergence. Therefore, we experiment with a variety of learning rates according to the task. In addition, in all the experiments we optimize with batch gradient-descent due to hardware constraints. We pick the largest possible batch size per experiment.



6.1 Lower Trainability Bound
To answer question 1, we experiment on a synthetic dataset, in order to control the number of examples and their dimension to fit the theory under GPU memory constraints. We generate a regression problem with the following complex version of the Ackley function [Potter and De Jong, 1994],
We generate random vectors and labels, and use -layers networks for both ReLU and GReLU, with various widths. Each experiment is repeated 5 times with different random seeds.
The results of the different runs appear in Figure 2(a). To have a fair comparison between the different settings, we proceed as follows. For the experiment corresponding to the theoretical width in Theorem 1, we plot a curve where every entry is computed by taking the maximal MSE over the 5 runs. For lower widths, and , we plot the minimal MSE over the corresponding runs. All runs with our theoretical width converged to zero error, for both ReLU and GReLU. In contrast, none of the runs with lower width converged, for both networks. Since the theory guarantees convergence for any data distribution, these results provide some empirical support that Theorem 1 is tight.
We acknowledge that training with significantly smaller learning rates (e.g., ) would correspond to longer and impractical convergence times, but possibly would allow narrower networks to converge as well. In addition, while we focus on fully-connected networks, modern architectures like ResNets were empirically shown to converge with smaller widths (channels) for specific tasks. Improved theoretic guarantees for these architectures via GReLU technique are interesting for future work.
6.2 Optimization and Generalization in Practical Scenarios



In this section, in order to answer question 2, we evaluate the training of ReLU and GReLU networks in more practical scenarios, by experimenting with sub-theoretic widths on two popular datasets from different domains, input dimensions and structures:
CIFAR-10 the popular image classification dataset, with
and .
We transform each classification to a scalar regression by calculating the squared loss between the one-hot dimensional vector encoding its correct label and the output logits of the network.
| Architecture | ReLU | GRelu |
| Depth , Width k | ||
| Depth , Width k | ||
| Depth , Width k |
SGEMM the well known CPU kernel-performance regression dataset222https://archive.ics.uci.edu/ml/datasets/SGEMM+GPU+kernel+performance [Nugteren and Codreanu, 2015]. It contains samples of dimension , measuring CPU runtime of matrix products. SGEMM experiments demonstrate a similar behavior to CIFAR-10, and appear in Section 9 of the supplementary material.
We initialize both networks with the same trainable weights and additional for GReLU, and train them with a fixed learning rate of . The results presented in Table 2 show that all variants of GReLU converged to near zero losses. Conversely, ReLU variants improved with increased depth, but did not reach similar losses. Possibly deeper ReLU networks with fine-tuned learning rates schemes would reach near zero losses as well. The loss progression of different variants is plotted in Figure 3(a). The GReLU networks (blue) converge with higher rates as well.
We proceed to evaluate the GReLUReLU scheme proposed in Section 4.1. While this paper is focused on optimization, comparing the empirical generalization of this scheme against traditional ReLU network is intriguing. For a fair and simple comparison with no additional hyper-parameters to tune, we train both networks with RandAugment [Cubuk et al., 2020] to avoid overfitting. We train the variants for epochs, and transform the GReLU to its equivalent ReLU network exactly in the middle. Results on train and test set (additional examples) appear in Figures (3(b),3(c)). The train loss of the GReLU variant is continuous at epoch , as guaranteed by Theorem 2, and comparable to the ReLU variant. However, on the test set a significant loss drop can be seen as a result of the transform, leading to an improved performance of the GReLU network. Since GReLU is transformed to a ReLU network with minimal -norm, the transform effectively acts as a ridge-regularization step. While the final loss is similar, we note that the GReLU training is almost twice as fast, as explained in Section 4.4. This can be used for further improvement.
6.3 Training Dynamics
To answer question 3, we start with a comparison of the optimization trajectories of the networks. Regular trajectories are favored due to typically smoother corresponding optimization landscapes. Acceleration methods like gradient-descent with momentum [Qian, 1999] provide more regular trajectories and are commonly used. During a full train with each network with , we compute the norm between consecutive gradients, , and present the results in Figure 2(b). The gradient differences of the GReLU network are smaller than the ones of the ReLU network, and
gradually decrease along the convergence to the global optima.
This provides an additional empirical validation of the relatively larger learning rates allowed by our theory. In addition, this empirical evaluation matches the tighter bound on the gradients difference guaranteed by theorem 3. The gradient differences of the ReLU network increase monotonically along the training, with highly irregular trajectories that match the relatively high variation of the losses in Figure 5.
To better understand the behaviour of the ReLU network, we conduct an additional experiment, of calculating the change in its activation patterns along the training. More specifically, we present the mean Hamming distance between its activation patterns at consecutive epochs. The distance is computed across all ReLU activations over a selected validation set.
The results are illustrated in Figure 2(c) and are quite surprising: a large portion of the activations, , changes every epoch and keep increasing along the run. This result complements the previous one by showing some instability of the ReLU network.
We point out that some level of change in activation patterns along the optimization possibly contributes to the generalization via implicit regularization.
In such case, a hybrid version of the GReLU network that allows gradual, controlled changes of its activation patterns is an interesting future direction to be pursued.
7 Related Work
Neural network overparameterization has been extensively studied under different assumptions over the training data and network architecture.
For the simplified case of well-separated data, Ji and Telgarsky [2018] showed that a poly-logarithmic width is sufficient to guarantee convergence in two-layer networks, and Chen et al. [2019] extended the result to deep networks using the NTRF function class by Cao and Gu [2019]. For mixtures of well-separated distributions, Li and Liang [2018] proved that when training two-layer networks with width proportional to a high-order polynomial in the parameters of the problem with SGD, small train and generalization errors are achievable. Other common assumptions include Gaussian input [Brutzkus and Globerson, 2017, Zhong et al., 2017, Li and Yuan, 2017], independet activations [Choromanska et al., 2015, Kawaguchi, 2016], and output generated by a teacher-network [Li and Yuan, 2017, Zhang et al., 2019b, Brutzkus and Globerson, 2017]. In our work, only a mild assumption of non-degenerate input is used.
overparameterization of special neural networks is varied across the analysis of linear networks [Kawaguchi, 2016, Arora et al., 2018a, Bartlett et al., 2018], smooth activations [Du and Lee, 2018, Kawaguchi and Huang, 2019], and shallow networks [Du and Lee, 2018, Oymak and Soltanolkotabi, 2020]. For deep linear networks, Kawaguchi [2016] proved that all local minima are global minima. Arora et al. [2018a] proved trainability for deep linear networks of minimal width, generalizing result by Bartlett et al. [2018] on residual linear networks.
Du and Lee [2018] considered neural networks with smooth activations, and showed that
in overparameterized shallow networks with quadratic activation, all local minima are global minima.
Kawaguchi and Huang [2019] showed that when only the output layer is trained, i.e. least squares estimate with gradient descent, tighter bounds on network width are achievable.
Such training assumptions are rarely used in practice due to poor generalization.
Considering one-hidden-layer networks, Du et al. [2018] showed that under the assumption of non-degenerate population Gram matrix, gradient-descent converges to a globally optimal solution.
Oymak and Soltanolkotabi [2020] stated the current tightest bound on the width of shallow networks for different activation functions. For the ReLU activation, the bound we derive for deep networks improves theirs over shallow networks as well.
We focus on the general setting of deep networks equipped with ReLU activation, as typically used in practice.
Similar works [Zou et al., 2018, Du et al., 2019, Allen-Zhu et al., 2019, Zou and Gu, 2019] require unrealistic overparameterization conditions, namely a minimal width proportional to the size of the dataset in the power of [Zou and Gu, 2019, Allen-Zhu et al., 2019, Zou et al., 2018], and the depth of the network in the power of - [Zou and Gu, 2019, Zou et al., 2018] or exponential dependency [Du et al., 2019].
Our work improves the current tightest bound [Zou and Gu, 2019] by a factor of , with a corresponding significant decrease in convergence time, from polynomial to logarithmic in the parameters of the problem.
Optimization landscape of deep networks under different assumptions is an active line of research.
A few works showed that ReLU networks have bad local minima [Venturi et al., 2018, Safran and Shamir, 2018, Swirszcz et al., 2016, Yun et al., 2017] due to ”dead regions”, even for random input data and labels created according to a planted model [Yun et al., 2017, Safran and Shamir, 2018],
a property which is not shared with smooth activations [Liang et al., 2018, Du and Lee, 2018, Soltanolkotabi et al., 2018]. Specifically, Hardt and Ma [2016] showed
that deep linear residual networks have no spurious local minima.
Training dynamics of ReLU networks and their activation patterns were studied by few recent works [Hanin and Rolnick, 2019a, b, Li and Liang, 2018].
Hanin and Rolnick [2019b] showed that the average number of patterns along the training is significantly smaller than the possible one and only weakly depends on the depth. We study a single random pattern, entirely decoupled from depth.
Li and Liang [2018] studied ”pseudo gradients” for shallow networks, close in spirit with the fixed ReLU activations suggested by our work. They showed that unless the generalization error is small, pseudo gradients remain large, providing motivation for fixing activation patterns from a generalization perspective. Furthermore, they showed that pseudo gradients could be coupled with original gradients for most cases when the network is sufficiently overparameterized.
Neural Tangent Kernel regression has been shown to describe the evolution of infinitely wide fully-connected networks when trained with gradient descent [Jacot et al., 2018]. Additional works provided corresponding kernels for residual [Huang et al., 2020] and convolutional networks [Li et al., 2019], allowing to study the training dynamics of those in functional space.
Few works [Belkin et al., 2018b, Cao and Gu, 2019, Belkin et al., 2018a, Liang et al., 2020] analyzed NTK for explaining properties for deep neural networks, most notably their trainability and generalizability.
An important result by Allen-Zhu et al. [2019] extended the NTK equivalence to deep networks of finite width. We provide an improved condition on the required width for this equivalence to hold.
8 Conclusions and Future Work
In this paper we proposed a novel technique for studying overparameterized deep ReLU networks which leads to state-of-the-art guarantees on trainability. Both the required network size and convergence time significantly improve previous theory and can be tested in practice for the first time. Further theoretical and empirical analysis provide insights on the optimization of neural networks with first-order methods. Our analysis and proof technique can be extended to additional setups such as optimization with stochastic gradient-descent, cross-entropy loss, and other network architectures such as convolutional and residual networks similarly to [Zhang et al., 2019a, Allen-Zhu et al., 2019, Du et al., 2018]. Our encouraging empirical results motivate analyzing additional variants like Gated-CNNs and Gated-ResNets. Our improved finite-width NTK equivalence enables studying neural networks of practical sizes using kernel theory, potentially leading to a better understanding of learning dynamics and generalization.
Acknowledgements
We would like to thank Assaf Hallak, Tal Ridnik, Avi Ben-Cohen, Yushun Zhang and Itamar Friedman for their feedbacks and productive discussions.
References
- Allen-Zhu et al. [2019] Zeyuan Allen-Zhu, Yuanzhi Li, and Zhao Song. A convergence theory for deep learning via over-parameterization. In International Conference on Machine Learning, pages 242–252, 2019.
- Arora et al. [2018a] Sanjeev Arora, Nadav Cohen, Noah Golowich, and Wei Hu. A convergence analysis of gradient descent for deep linear neural networks. arXiv preprint arXiv:1810.02281, 2018a.
- Arora et al. [2018b] Sanjeev Arora, Nadav Cohen, and Elad Hazan. On the optimization of deep networks: Implicit acceleration by overparameterization. arXiv preprint arXiv:1802.06509, 2018b.
- Arora et al. [2019a] Sanjeev Arora, Simon S Du, Wei Hu, Zhiyuan Li, Russ R Salakhutdinov, and Ruosong Wang. On exact computation with an infinitely wide neural net. In Advances in Neural Information Processing Systems, pages 8141–8150, 2019a.
- Arora et al. [2019b] Sanjeev Arora, Simon S Du, Wei Hu, Zhiyuan Li, and Ruosong Wang. Fine-grained analysis of optimization and generalization for overparameterized two-layer neural networks. arXiv preprint arXiv:1901.08584, 2019b.
- Bachlechner et al. [2020] Thomas Bachlechner, Bodhisattwa Prasad Majumder, Huanru Henry Mao, Garrison W Cottrell, and Julian McAuley. Rezero is all you need: Fast convergence at large depth. arXiv preprint arXiv:2003.04887, 2020.
- Bartlett et al. [2018] Peter Bartlett, Dave Helmbold, and Philip Long. Gradient descent with identity initialization efficiently learns positive definite linear transformations by deep residual networks. In International conference on machine learning, pages 521–530. PMLR, 2018.
- Belkin et al. [2018a] Mikhail Belkin, Daniel J Hsu, and Partha Mitra. Overfitting or perfect fitting? risk bounds for classification and regression rules that interpolate. In Advances in neural information processing systems, pages 2300–2311, 2018a.
- Belkin et al. [2018b] Mikhail Belkin, Siyuan Ma, and Soumik Mandal. To understand deep learning we need to understand kernel learning. arXiv preprint arXiv:1802.01396, 2018b.
- Bengio and Delalleau [2011] Yoshua Bengio and Olivier Delalleau. On the expressive power of deep architectures. In International Conference on Algorithmic Learning Theory, pages 18–36. Springer, 2011.
- Blum and Rivest [1989] Avrim Blum and Ronald L Rivest. Training a 3-node neural network is np-complete. In Advances in neural information processing systems, pages 494–501, 1989.
- Brown et al. [2020] Tom B Brown, Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared Kaplan, Prafulla Dhariwal, Arvind Neelakantan, Pranav Shyam, Girish Sastry, Amanda Askell, et al. Language models are few-shot learners. arXiv preprint arXiv:2005.14165, 2020.
- Brutzkus and Globerson [2017] Alon Brutzkus and Amir Globerson. Globally optimal gradient descent for a convnet with gaussian inputs. arXiv preprint arXiv:1702.07966, 2017.
- Cao and Gu [2019] Yuan Cao and Quanquan Gu. Generalization bounds of stochastic gradient descent for wide and deep neural networks. In Advances in Neural Information Processing Systems, pages 10836–10846, 2019.
- Chen et al. [2019] Zixiang Chen, Yuan Cao, Difan Zou, and Quanquan Gu. How much over-parameterization is sufficient to learn deep relu networks? arXiv preprint arXiv:1911.12360, 2019.
- Choromanska et al. [2015] Anna Choromanska, Mikael Henaff, Michael Mathieu, Gérard Ben Arous, and Yann LeCun. The loss surfaces of multilayer networks. In Artificial intelligence and statistics, pages 192–204, 2015.
- Clevert et al. [2015] Djork-Arné Clevert, Thomas Unterthiner, and Sepp Hochreiter. Fast and accurate deep network learning by exponential linear units (elus). arXiv preprint arXiv:1511.07289, 2015.
- Cohen et al. [2016] Nadav Cohen, Or Sharir, and Amnon Shashua. On the expressive power of deep learning: A tensor analysis. In Conference on learning theory, pages 698–728, 2016.
- Cubuk et al. [2020] Ekin D Cubuk, Barret Zoph, Jonathon Shlens, and Quoc V Le. Randaugment: Practical automated data augmentation with a reduced search space. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops, pages 702–703, 2020.
- Devlin et al. [2018] Jacob Devlin, Ming-Wei Chang, Kenton Lee, and Kristina Toutanova. Bert: Pre-training of deep bidirectional transformers for language understanding. arXiv preprint arXiv:1810.04805, 2018.
- Du et al. [2019] Simon Du, Jason Lee, Haochuan Li, Liwei Wang, and Xiyu Zhai. Gradient descent finds global minima of deep neural networks. In International Conference on Machine Learning, pages 1675–1685, 2019.
- Du and Lee [2018] Simon S Du and Jason D Lee. On the power of over-parametrization in neural networks with quadratic activation. arXiv preprint arXiv:1803.01206, 2018.
- Du et al. [2018] Simon S Du, Xiyu Zhai, Barnabas Poczos, and Aarti Singh. Gradient descent provably optimizes over-parameterized neural networks. arXiv preprint arXiv:1810.02054, 2018.
- Eldan and Shamir [2016] Ronen Eldan and Ohad Shamir. The power of depth for feedforward neural networks. In Conference on learning theory, pages 907–940, 2016.
- Geiger et al. [2020] Mario Geiger, Arthur Jacot, Stefano Spigler, Franck Gabriel, Levent Sagun, Stéphane d’Ascoli, Giulio Biroli, Clément Hongler, and Matthieu Wyart. Scaling description of generalization with number of parameters in deep learning. Journal of Statistical Mechanics: Theory and Experiment, 2020(2):023401, 2020.
- Hanin [2018] Boris Hanin. Which neural net architectures give rise to exploding and vanishing gradients? In Advances in Neural Information Processing Systems, pages 582–591, 2018.
- Hanin and Rolnick [2019a] Boris Hanin and David Rolnick. Complexity of linear regions in deep networks. arXiv preprint arXiv:1901.09021, 2019a.
- Hanin and Rolnick [2019b] Boris Hanin and David Rolnick. Deep relu networks have surprisingly few activation patterns. In Advances in Neural Information Processing Systems, pages 361–370, 2019b.
- Hardt and Ma [2016] Moritz Hardt and Tengyu Ma. Identity matters in deep learning. arXiv preprint arXiv:1611.04231, 2016.
- He et al. [2016a] Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun. Deep residual learning for image recognition. In Proceedings of the IEEE conference on computer vision and pattern recognition, pages 770–778, 2016a.
- He et al. [2016b] Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun. Identity mappings in deep residual networks. In European conference on computer vision, pages 630–645. Springer, 2016b.
- Hinton et al. [2012] Geoffrey Hinton, Li Deng, Dong Yu, George E Dahl, Abdel-rahman Mohamed, Navdeep Jaitly, Andrew Senior, Vincent Vanhoucke, Patrick Nguyen, Tara N Sainath, et al. Deep neural networks for acoustic modeling in speech recognition: The shared views of four research groups. IEEE Signal processing magazine, 29(6):82–97, 2012.
- Hornik et al. [1989] Kurt Hornik, Maxwell Stinchcombe, Halbert White, et al. Multilayer feedforward networks are universal approximators. Neural networks, 2(5):359–366, 1989.
- Huang and Yau [2020] Jiaoyang Huang and Horng-Tzer Yau. Dynamics of deep neural networks and neural tangent hierarchy. In International Conference on Machine Learning, pages 4542–4551. PMLR, 2020.
- Huang et al. [2020] Kaixuan Huang, Yuqing Wang, Molei Tao, and Tuo Zhao. Why do deep residual networks generalize better than deep feedforward networks?–a neural tangent kernel perspective. arXiv preprint arXiv:2002.06262, 2020.
- Huang et al. [2019] Yanping Huang, Youlong Cheng, Ankur Bapna, Orhan Firat, Dehao Chen, Mia Chen, HyoukJoong Lee, Jiquan Ngiam, Quoc V Le, Yonghui Wu, et al. Gpipe: Efficient training of giant neural networks using pipeline parallelism. In Advances in neural information processing systems, pages 103–112, 2019.
- Hubara et al. [2016] Itay Hubara, Matthieu Courbariaux, Daniel Soudry, Ran El-Yaniv, and Yoshua Bengio. Binarized neural networks. Advances in neural information processing systems, 29:4107–4115, 2016.
- Ioffe and Szegedy [2015] Sergey Ioffe and Christian Szegedy. Batch normalization: Accelerating deep network training by reducing internal covariate shift. arXiv preprint arXiv:1502.03167, 2015.
- Jacot et al. [2018] Arthur Jacot, Franck Gabriel, and Clément Hongler. Neural tangent kernel: Convergence and generalization in neural networks. In Advances in neural information processing systems, pages 8571–8580, 2018.
- Ji and Telgarsky [2018] Ziwei Ji and Matus Telgarsky. Risk and parameter convergence of logistic regression. arXiv preprint arXiv:1803.07300, 2018.
- Jia et al. [2017] Kui Jia, Dacheng Tao, Shenghua Gao, and Xiangmin Xu. Improving training of deep neural networks via singular value bounding. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 4344–4352, 2017.
- Kawaguchi [2016] Kenji Kawaguchi. Deep learning without poor local minima. In Advances in neural information processing systems, pages 586–594, 2016.
- Kawaguchi and Huang [2019] Kenji Kawaguchi and Jiaoyang Huang. Gradient descent finds global minima for generalizable deep neural networks of practical sizes. In 2019 57th Annual Allerton Conference on Communication, Control, and Computing (Allerton), pages 92–99. IEEE, 2019.
- Kolesnikov et al. [2019] Alexander Kolesnikov, Lucas Beyer, Xiaohua Zhai, Joan Puigcerver, Jessica Yung, Sylvain Gelly, and Neil Houlsby. Big transfer (bit): General visual representation learning. arXiv preprint arXiv:1912.11370, 6:1, 2019.
- Krishnamoorthi [2018] Raghuraman Krishnamoorthi. Quantizing deep convolutional networks for efficient inference: A whitepaper. arXiv preprint arXiv:1806.08342, 2018.
- Krizhevsky et al. [2017] Alex Krizhevsky, Ilya Sutskever, and Geoffrey E Hinton. Imagenet classification with deep convolutional neural networks. Communications of the ACM, 60(6):84–90, 2017.
- Lacotte and Pilanci [2019] Jonathan Lacotte and Mert Pilanci. Faster least squares optimization. arXiv preprint arXiv:1911.02675, 2019.
- Laurent and Massart [2000] Beatrice Laurent and Pascal Massart. Adaptive estimation of a quadratic functional by model selection. Annals of Statistics, pages 1302–1338, 2000.
- Lee et al. [2020] Jaehoon Lee, Samuel S Schoenholz, Jeffrey Pennington, Ben Adlam, Lechao Xiao, Roman Novak, and Jascha Sohl-Dickstein. Finite versus infinite neural networks: an empirical study. arXiv preprint arXiv:2007.15801, 2020.
- Li and Liang [2018] Yuanzhi Li and Yingyu Liang. Learning overparameterized neural networks via stochastic gradient descent on structured data. In Advances in Neural Information Processing Systems, pages 8157–8166, 2018.
- Li and Yuan [2017] Yuanzhi Li and Yang Yuan. Convergence analysis of two-layer neural networks with relu activation. Advances in neural information processing systems, 30:597–607, 2017.
- Li et al. [2019] Zhiyuan Li, Ruosong Wang, Dingli Yu, Simon S Du, Wei Hu, Ruslan Salakhutdinov, and Sanjeev Arora. Enhanced convolutional neural tangent kernels. arXiv preprint arXiv:1911.00809, 2019.
- Liang and Srikant [2016] Shiyu Liang and Rayadurgam Srikant. Why deep neural networks for function approximation? arXiv preprint arXiv:1610.04161, 2016.
- Liang et al. [2018] Shiyu Liang, Ruoyu Sun, Yixuan Li, and Rayadurgam Srikant. Understanding the loss surface of neural networks for binary classification. arXiv preprint arXiv:1803.00909, 2018.
- Liang et al. [2020] Tengyuan Liang, Alexander Rakhlin, et al. Just interpolate: Kernel “ridgeless” regression can generalize. Annals of Statistics, 48(3):1329–1347, 2020.
- Livni et al. [2014] Roi Livni, Shai Shalev-Shwartz, and Ohad Shamir. On the computational efficiency of training neural networks. In Advances in neural information processing systems, pages 855–863, 2014.
- Lu et al. [2019] Lu Lu, Yeonjong Shin, Yanhui Su, and George Em Karniadakis. Dying relu and initialization: Theory and numerical examples. arXiv preprint arXiv:1903.06733, 2019.
- Monti et al. [2018] Ricardo Pio Monti, Sina Tootoonian, and Robin Cao. Avoiding degradation in deep feed-forward networks by phasing out skip-connections. In International Conference on Artificial Neural Networks, pages 447–456. Springer, 2018.
- Nayman et al. [2019] Niv Nayman, Asaf Noy, Tal Ridnik, Itamar Friedman, Rong Jin, and Lihi Zelnik. Xnas: Neural architecture search with expert advice. In Advances in Neural Information Processing Systems, pages 1977–1987, 2019.
- Noy et al. [2020] Asaf Noy, Niv Nayman, Tal Ridnik, Nadav Zamir, Sivan Doveh, Itamar Friedman, Raja Giryes, and Lihi Zelnik. Asap: Architecture search, anneal and prune. In International Conference on Artificial Intelligence and Statistics, pages 493–503. PMLR, 2020.
- Nugteren and Codreanu [2015] Cedric Nugteren and Valeriu Codreanu. Cltune: A generic auto-tuner for opencl kernels. In 2015 IEEE 9th International Symposium on Embedded Multicore/Many-core Systems-on-Chip, pages 195–202. IEEE, 2015.
- Oymak and Soltanolkotabi [2020] Samet Oymak and Mahdi Soltanolkotabi. Towards moderate overparameterization: global convergence guarantees for training shallow neural networks. IEEE Journal on Selected Areas in Information Theory, 2020.
- Pisier [1999] Gilles Pisier. The volume of convex bodies and Banach space geometry, volume 94. Cambridge University Press, 1999.
- Potter and De Jong [1994] Mitchell A Potter and Kenneth A De Jong. A cooperative coevolutionary approach to function optimization. In International Conference on Parallel Problem Solving from Nature, pages 249–257. Springer, 1994.
- Qian [1999] Ning Qian. On the momentum term in gradient descent learning algorithms. Neural networks, 12(1):145–151, 1999.
- Ridnik et al. [2020] Tal Ridnik, Hussam Lawen, Asaf Noy, and Itamar Friedman. Tresnet: High performance gpu-dedicated architecture. arXiv preprint arXiv:2003.13630, 2020.
- Safran and Shamir [2018] Itay Safran and Ohad Shamir. Spurious local minima are common in two-layer relu neural networks. In International Conference on Machine Learning, pages 4433–4441. PMLR, 2018.
- Santurkar et al. [2018] Shibani Santurkar, Dimitris Tsipras, Andrew Ilyas, and Aleksander Madry. How does batch normalization help optimization? arXiv preprint arXiv:1805.11604, 2018.
- Soltanolkotabi et al. [2018] Mahdi Soltanolkotabi, Adel Javanmard, and Jason D Lee. Theoretical insights into the optimization landscape of over-parameterized shallow neural networks. IEEE Transactions on Information Theory, 65(2):742–769, 2018.
- Song and Yang [2019] Zhao Song and Xin Yang. Quadratic suffices for over-parametrization via matrix chernoff bound. arXiv preprint arXiv:1906.03593, 2019.
- Srivastava et al. [2015] Rupesh K Srivastava, Klaus Greff, and Jürgen Schmidhuber. Training very deep networks. Advances in neural information processing systems, 28:2377–2385, 2015.
- Swirszcz et al. [2016] Grzegorz Swirszcz, Wojciech Marian Czarnecki, and Razvan Pascanu. Local minima in training of deep networks. ., 2016.
- Tandon and Sra [2010] Rashish Tandon and Suvrit Sra. Sparse nonnegative matrix approximation: new formulations and algorithms. ., 2010.
- Telgarsky [2015] Matus Telgarsky. Representation benefits of deep feedforward networks. arXiv preprint arXiv:1509.08101, 2015.
- Venturi et al. [2018] Luca Venturi, Afonso S Bandeira, and Joan Bruna. Spurious valleys in two-layer neural network optimization landscapes. arXiv preprint arXiv:1802.06384, 2018.
- Voulodimos et al. [2018] Athanasios Voulodimos, Nikolaos Doulamis, Anastasios Doulamis, and Eftychios Protopapadakis. Deep learning for computer vision: A brief review. Computational intelligence and neuroscience, 2018, 2018.
- Wu et al. [2019] Xiaoxia Wu, Simon S Du, and Rachel Ward. Global convergence of adaptive gradient methods for an over-parameterized neural network. arXiv preprint arXiv:1902.07111, 2019.
- Xiao et al. [2019] Lechao Xiao, Jeffrey Pennington, and Sam Schoenholz. Disentangling trainability and generalization in deep learning. ,, 2019.
- Xu et al. [2015] Bing Xu, Naiyan Wang, Tianqi Chen, and Mu Li. Empirical evaluation of rectified activations in convolutional network. arXiv preprint arXiv:1505.00853, 2015.
- Yun et al. [2017] Chulhee Yun, Suvrit Sra, and Ali Jadbabaie. Global optimality conditions for deep neural networks. arXiv preprint arXiv:1707.02444, 2017.
- Yun et al. [2019] Chulhee Yun, Suvrit Sra, and Ali Jadbabaie. Small relu networks are powerful memorizers: a tight analysis of memorization capacity. In Advances in Neural Information Processing Systems, pages 15558–15569, 2019.
- Zagoruyko and Komodakis [2016] Sergey Zagoruyko and Nikos Komodakis. Wide residual networks. arXiv preprint arXiv:1605.07146, 2016.
- Zagoruyko and Komodakis [2017] Sergey Zagoruyko and Nikos Komodakis. Diracnets: Training very deep neural networks without skip-connections. arXiv preprint arXiv:1706.00388, 2017.
- Zhang et al. [2016] Chiyuan Zhang, Samy Bengio, Moritz Hardt, Benjamin Recht, and Oriol Vinyals. Understanding deep learning requires rethinking generalization. arXiv preprint arXiv:1611.03530, 2016.
- Zhang et al. [2019a] Huishuai Zhang, Da Yu, Wei Chen, and Tie-Yan Liu. Training over-parameterized deep resnet is almost as easy as training a two-layer network. arXiv preprint arXiv:1903.07120, 2019a.
- Zhang et al. [2019b] Xiao Zhang, Yaodong Yu, Lingxiao Wang, and Quanquan Gu. Learning one-hidden-layer relu networks via gradient descent. In The 22nd International Conference on Artificial Intelligence and Statistics, pages 1524–1534. PMLR, 2019b.
- Zhong et al. [2017] Kai Zhong, Zhao Song, and Inderjit S Dhillon. Learning non-overlapping convolutional neural networks with multiple kernels. arXiv preprint arXiv:1711.03440, 2017.
- Zou and Gu [2019] Difan Zou and Quanquan Gu. An improved analysis of training over-parameterized deep neural networks. In Advances in Neural Information Processing Systems, pages 2055–2064, 2019.
- Zou et al. [2018] Difan Zou, Yuan Cao, Dongruo Zhou, and Quanquan Gu. Stochastic gradient descent optimizes over-parameterized deep relu networks. arxiv e-prints, art. arXiv preprint arXiv:1811.08888, 2018.
Appendix
9 Additional experiments on SGEMM dataset
We start with training networks of width and depth over SGEMM, and plot their losses along the training with varied learning rates in Figures 4(a) for the GReLU and 4(b) for the ReLU network. While for smaller rates results are quite similar, for larger ones the losses of the GReLU network decrease more monotonically and reach lower values. A comparison of high learning rates in Figure 5 shows that ReLU network oscillates with larger amplitudes towards higher loss values. The losses of the GReLU network decrease more monotonically, and reach smaller values with larger learning rates. Both networks do not reach zero loss, as their widths are smaller than required by our theory. We further test GReLU with a fixed learning rate for different widths and depths, and present the results in Figure 4(c). While both increased depth and width improve the results, deeper and narrower networks perform better for the same number of parameters. This result is consistent with similar comparisons of ReLU networks in previous works.





10 Proofs for Section 5
10.1 Proof of Lemma 1
Proof.
By the definition of in (1) we have
where (a) is due to the update of for any ; (b) uses the definition of in (12). In the above, we divide into two parts, with is proportional to and is proportional to . We can simplify as
We complete the proof by plugging in the expression of into the expression of . ∎
10.2 Proof of Lemma 2
Proof.
By the definition of loss function in (2), we have
| (20) |
For the first term in (10.2), by Lemma 1, we have
| (21) |
where the last equality is due to the facts that is a scalar and for any matrix and vectors . On the other hand, the first term in (10.2) will be
| (22) |
where for any matrices : (a) uses ; (b) uses ; (c) uses ; (d) uses . Define
| (23) | ||||
| (24) |
where is the Kronecker product. By plugging (10.2) into (10.2) and using the definitions in (23) and (24), we have
| (25) |
By using the fact that , we know that , which means that is symmetric. Thus we have
| (26) |
For the last term in (10.2),
| (27) |
where (a) uses the fact that for any matrix and vectors ; (b) uses the fact of definition of that . As a result, by (10.2) (26) (10.2) we have
| (28) |
We now handle the second term in (10.2), by Lemma 1 and using Cauchy-Schwarz inequality, we know
| (29) |
Since by using for any matrix and vector , we have
| (30) |
and
| (31) |
Hence, plugging (10.2) and (10.2) into (10.2), we have
| (32) |
where the last inequality uses
where the last equality is due to . We complete the proof by using Young’s inequality with to upper bound
| (33) |
and using the property of the eigenvalue of the Kronecker product of two symmetric matrices
| (34) |
∎
10.3 Proof for Lemma 3
Proof.
Using the assumption in (14), (15), (16) and (17), by setting ,
By choosing step size as , we have , and therefore
| (35) |
Next, we need to bound . Since , we want to bound . To this end, we first bound , i.e.
| (36) |
where (a) is due to for matrix ; (b) uses the facts that and for matrices ; (c) uses and . Since , then
| (37) |
where for any matrices : (a) uses ; (b) uses ; (c) uses ; (d) uses .
10.4 Proof for Theorem 1
Proof.
We start by restricting the network’s width and depth to values for which assumption (17) holds, that is . Revisiting (52), we need condition,
To meet the above condition, all the following should hold,
| (41) |
We thus need to bound . According to the setting, we know the number of iterations is
| (42) |
On the other hand,
where the second inequality uses (39) which assumes (9) and (16). Similarly to (51), the initial output of the network can be bounded with high probability in order to bound . With a probability
| (43) |
Where we also used Assumption (2) and . We now extract the required width from (41),
| (44) |
10.5 Proof for Theorem 3
Proof.
We start with the left-hand side, and denote for brevity . We will bound for every independently, and the final result follows,
Where we used the sub-multiplicativity of Frobenius norm, with,
According to Lemma 5, with a probability larger than , we have for all ,
Similar analysis can be applied to the other term, therefore,
The terms , follow independant distributions. Therefore by Laurent-Massart concentration bound [Laurent and Massart, 2000],
| (47) |
We can conclude, with a probability of at least ,
This term grows with due to the unique normalization of the network. We now show that it is negligible with respect to the NTK gradient in the right-hand side. Using theorem 5, probability of at least ,
Where we used the inequality of arithmetic and geometric means and multiplicativity of determinant for symmetric and positive semi-definite , i.e,
Combining both terms completes the proof. ∎
10.6 Proof for Corollary 4
10.7 Proof for Theorem 2
Proof.
In order to obtain a GReLU network from a ReLU network, we proceed as follows. First, let us define the following notations:
-
•
denotes the training example.
-
•
denotes the output feature map of the layer taken before the ReLU in the ReLU network on the training example, and is recursively defined as:
-
•
denotes the output feature map of the layer taken after the GReLU activation in the GReLU network on the training example, and is recursively defined as:
-
•
represents the feature map of the auxiliary network activating the GReLU gate on the training example, and is recursively defined as:
Matching the intermediate layer of the GReLU and ReLU network can be written as:
that is
that is equivalent to
| (48) |
Hence we proceed by recursion. Given that
we seek for that obeys equation (48). Denoting by the Moore–Penrose pseudo inverse, and by setting
| (49) |
equation (48) holds such that we have
The equivalence between (48) and (49) lays in the fact that the network is overparameterized such that . In this case has dimension and has dimension , and thus, (48) and (49) are equivalent.
∎
11 Main Theorems with Proofs
Theorem 5.
Choose which satisfies
| (50) |
With a probability at least , we have, for any , and
and
Thus, with a high probability, we have
Proof.
We will focus on first and similar analysis will be applied to . To bound , we will bound . Define , we have
According to Lemma 5, we have, with a probability , for any and any ,
Following the same analysis as in Lemma 5, we have, with a probability , we have
| (51) |
Combining the above results together, we have, with a probability ,
and
Since
we have, with a probability ,
Similar analysis applies to . ∎
Theorem 6.
Assume . With a probability , we have
where is an universal constant, and therefore
with
| (52) |
Proof.
To bound , we define and express as
According to Lemma 5, with a probability ,
As a result, with a probability , we have
where and the last step utilizes the assumption . Using the same analysis, we have, with a probability ,
Next we need to bound the spectral norm of . To this end, we will bound
Define
We have
where projects vector onto the direction of . Since is statistically independent from , by fixing and viewing as a random variable of , we have follow distribution, where
Using the property of Gaussian distribution, we have, with a probability ,
Since follows , with a probability , we have
Combining the above two results, with a probability ,
where the last step utilizes the fact and .
To bound , let be the set of indices of diagonal elements that are nonzero in both and . According to Lemma 4, with a probability , we have . Define . We have
Using the concentration of distribution, we have, with a probability
By combining the results for and , for a fixed normalized , , with a probability , we have
By combining the results over iterations, we have, with a probability , for fixed normalized and
We extend the result to any and by using the theory of covering number, and complete the proof by choosing .
To bound , follow the same analysis in above, we have
We expand as
With a probability , we have
With a probability
∎
12 Auxiliary Lemmas
Lemma 4.
Define
where is a Gaussian random matrix. Suppose , , and , where . Then, with a probability , we have
Proof.
Define that outputs when , and zero otherwise. We have
Since and are statistically independent, hence, with a probability ,
and therefore,
We proceed to bound . First, each element of follows a Gaussian distribution , where . Similarly, each element follows a distribution , where . Using the concentration inequality of distribution, we have, with a probability ,
Using the properties of Gaussian distribution, we have
As a result, we have
Using the standard concentration inequality, we have, with a probability ,
and therefore, with a probability , we have
∎
Lemma 5.
With a probability at least , for any and any , we have
Proof.
To bound , we will bound . To this end, we divide into components of equal size, denoted by . We furthermore introduce to include the th component of with everything else padded with zeros. As a result,
where (a) uses the fact that for any and Cauchy-Schwarz inequality that since ; (b) holds since one constraint for maximization is removed. We fix and consider a fixed . We will prove the following high probability bound by induction
| (53) |
where is a introduced parameter related to the failure probability. For , we have
It is easy to show that follows the distribution of with degree of . Using the concentration of distribution, we have
Hence, with a probability , when , we have
As a result, for a fixed , for any and , with a probability , we have
| (54) |
Since , the above bound can be simplified as
| (55) |
where we uses two inequalities: for and for .
To bound for any , we introduce as an appropriate -net of . Using the well known property of appropriate -net, we have
| (56) |
where (a) is due to ; (b) is due to ; (c) is due to the the property of appropriate -net. Since [Pisier, 1999], by taking the union bound, we have, with probability at least ,
By choosing with , we have, with a probability at least
| (57) |
and therefore, with a probability , for any , we have
| (58) |
∎
Lemma 6.
For any sequences and , we have
| (59) | |||
| (60) |
where the notation means .