A Constrained Least-Squares Ghost Sample Points (CLS-GSP) Method for Differential Operators on Point Clouds
Abstract
We introduce a novel meshless method called the Constrained Least-Squares Ghost Sample Points (CLS-GSP) method for solving partial differential equations on irregular domains or manifolds represented by randomly generated sample points. Our approach involves two key innovations. Firstly, we locally reconstruct the underlying function using a linear combination of radial basis functions centered at a set of carefully chosen ghost sample points that are independent of the point cloud samples. Secondly, unlike conventional least-squares methods, which minimize the sum of squared differences from all sample points, we regularize the local reconstruction by imposing a hard constraint to ensure that the least-squares approximation precisely passes through the center. This simple yet effective constraint significantly enhances the diagonal dominance and conditioning of the resulting differential matrix. We provide analytical proofs demonstrating that our method consistently estimates the exact Laplacian. Additionally, we present various numerical examples showcasing the effectiveness of our proposed approach in solving the Laplace/Poisson equation and related eigenvalue problems.
1 Introduction
Classical numerical methods for partial differential equations (PDEs) usually rely on a structured computational mesh. Finite difference methods (FDM) and finite element methods (FEM), in particular, assume a certain degree of connectivity among sample points and necessitate the computational domain to be properly discretized or triangulated. Due to the connectivity between these sample points, mesh surgery or developing a robust remeshing strategy may be necessary for mesh adaptation, which can be challenging, especially in high dimensions.
Meshless methods [2, 34, 10, 27], therefore, present a more computationally attractive alternative when we lack control over the allocation of sample points or when obtaining a good discretization of the computational domain is problematic. These meshless methods can be roughly classified into two groups. The first group is the so-called generalized finite difference (GFD) methods [12, 14], which extend the traditional FDM based on classical Taylor’s expansion. Further studies on this method have been conducted in [3, 4]. A more popular group follows a similar approach but replaces the standard basis in Taylor’s expansion with radial basis functions (RBF) [18, 13, 5]. The idea is to locally represent the surface by interpolating the data points using a set of RBFs centered at each sample point. These RBF interpolation methods have demonstrated the ability to achieve spectral accuracy under certain assumptions regarding the form of the bases and the properties of the underlying functions [6, 15]. To expedite computations, the so-called radial basis function finite-differences (RBF-FD) method was proposed by [32, 31, 36]. The idea is to replace the global interpolation described above with a local interpolation, such that the reconstruction and derivative depend only on values in a small neighborhood around the center of the approximation. The first step of this approach is to gather a subset of sample points around the center using any standard algorithm such as K-nearest neighbors (KNN). Then, the global RBF approach is replaced by this smaller subset of points.
This paper extends the work developed in [38] and introduces a novel meshless method that offers several key advantages. Firstly, they exhibit robustness when given sample points are close to each other; the methods remain stable even if sample points become arbitrarily close or overlap. Secondly, they are local methods, meaning that the approximation to the difference operator depends only on sample points in a small neighborhood of the center. Therefore, the methods are computationally efficient and optimal in computational complexity. Finally, although the methods share some similarities with RBF methods, we must emphasize that our proposed methods differ from conventional RBF-type methods. Specifically, our methods do not interpolate data points but instead approximate the underlying function based on a least-squares approach.
We introduce our proposed approach as the constrained least-squares ghost sample points (CLS-GSP) method. It comprises two main components. Initially, we represent a local approximation as a linear combination of a set of RBFs. However, unlike typical RBF interpolation methods (or even RBF-FD methods), where the centers of these RBFs coincide with the sample locations, we suggest replacing these locations with a pre-chosen set of ghost sample points. These ghost sample points can be arbitrarily selected if they are well-separated around the center. This effectively mitigates the problem of co-linearity of the basis functions and the ill-conditioning of the coefficient matrix. To enhance the robustness of the algorithm, we propose replacing the interpolation problem with a least-squares problem, minimizing the sum of squared mismatches at all ghost sample points in the local reconstruction to the function value. This substitution allows for greater flexibility in the sampling locations, including the allowance for overlapping given sample points.
It is essential to reiterate again that our method differs from typical RBF interpolation approaches in that our reconstruction does not interpolate all function values but only at the center location where the local approximation is sought. This implies that spectral accuracy cannot be expected in our method. One might argue against replacing interpolation with least-squares fitting, which sacrifices this spectral accuracy. However, spectral accuracy is contingent upon certain conditions being met [16, 11], including the smoothness of the underlying function and the distribution of sample points. Addressing the first concern, one might consider only linear elliptic problems, which imply a smooth solution. However, regarding the second issue, we typically have less control over the distribution of the point cloud and can only assume that the sampling density satisfies certain regularity conditions. Our proposed approach, therefore, offers a simple alternative to approximate derivatives of a function with reasonable accuracy in many applications where these assumptions are not satisfied.
The second major component of our proposed method emphasizes the contribution of the function value at the center location of each reconstruction. Inspired by the approach developed in a series of studies [23, 22, 33], we observe that increasing the weighting at the center point in the least-squares (LS) reconstruction improves both the accuracy and the diagonal dominance of the differential matrix (DM). In this work, we propose a straightforward idea to enforce a hard constraint: the least-squares reconstruction must pass through the function value at the center location. This concept shares similarities with the local tangential lifting method [37], developed for estimating surface curvature and function derivatives on triangulated surfaces. This method has also been recently applied to approximate differential operators and solve PDEs on surfaces [8, 7, 9], albeit solely for triangulated surfaces, whereas we do not require any connectivity in the sampling points.
This paper is organized as follows. In Sections 2, we will discuss our proposed Least-Squares Ghost Sample Points (LS-GSP) and Constrained Least-Squares Ghost Sample Points (CLS-GSP) Methods. This section will provide a more detailed comparison of our approach with various methods. Some theoretical properties of these methods will be provided in Section 3. In particular, we will examine its consistency when approximating the standard Laplacian. Some numerical experiments are presented in Section 4 to demonstrate the effectiveness and robustness of our proposed approach. Finally, we provide a summary and conclusion in Section 5.
2 Our Proposed Methods
We introduce two new ideas for approximating differential operators on randomly distributed sample points. Firstly, in Section 2.1, we introduce the idea of ghost sample points and their use in function reconstruction based on least-squares. Like other LS methods, this approach does not guarantee that the local representation will pass through any data point, particularly the center point. Consequently, the approximation to the difference operator may be inconsistent with the exact value. Therefore, we propose a further enhancement called the constrained least-squares radial basis function method (CLS-GSP) in Section 2.2 to improve the reconstruction. Although we focus mostly on the two-dimensional case in the following discussions, generalizing to higher dimensions is straightforward.
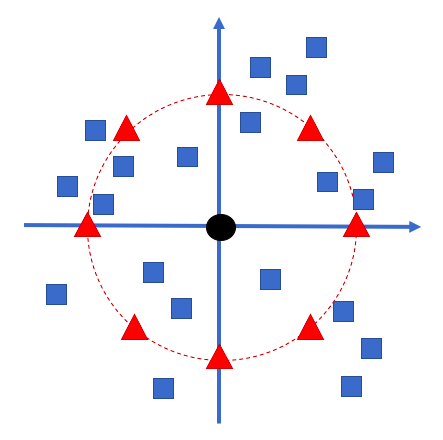
2.1 The Least-Squares Ghost Sample Points (LS-GSP) Method
Approximating a given differential operator at involves two primary steps. The first step entails introducing a set of ghost sample points, followed by a least-squares approximation based on RBF centered at these ghost sample points.
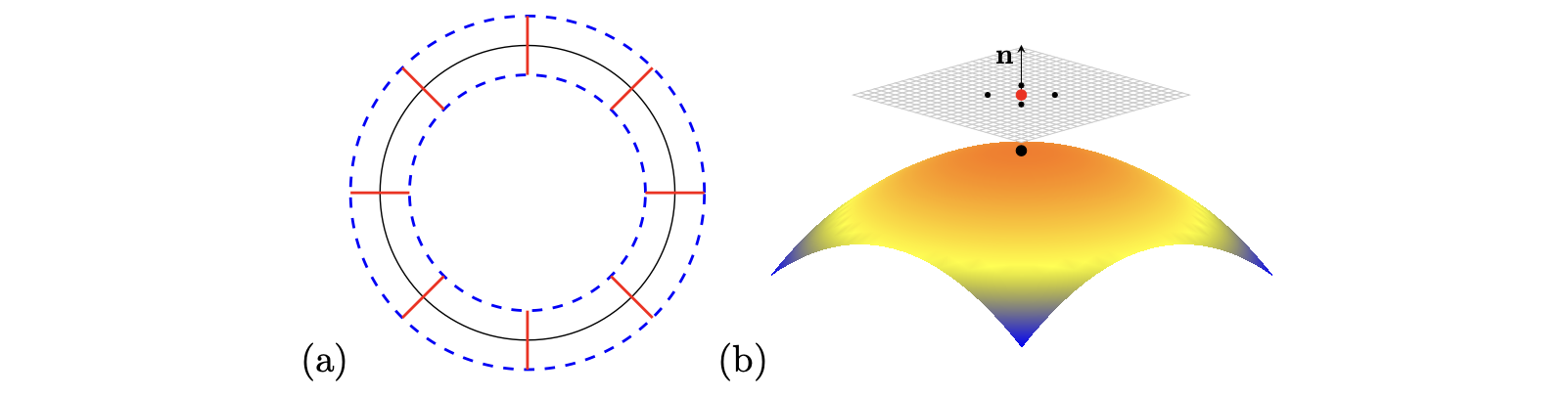
We first gather a subset of sample points within a small neighborhood of . Within this neighborhood, we introduce a set of basis functions, each centered at a predefined location denoted by for . These locations are referred to as the ghost sample points associated with the center location . A typical arrangement is illustrated in Figure 1. The selection of these locations offers considerable flexibility. This work suggests two simple choices for allocating these ghost sample points. The first one is to have (i.e., ) evenly distributed on the boundary of a ball centered at with the radius given by the average distance from the sample points to the center. The second one is to have them uniformly located in a small neighborhood centered at the center point. Figure 8(b) shows a distribution with 49 ghost sample points uniformly placed in a disc. This allows these ghost sample points to spread widely and evenly in the local neighborhood. Indeed, one might randomly select a certain fraction of sample points as ghost sample points and determine a stable local approximation of the function using cross-validation. This approach, however, might significantly increase computational time and will not be further investigated here.
The method for selecting these ghost sample points in higher dimensions can also be quite natural. For instance, in three dimensions, we might opt for a sphere of a given radius and uniformly distribute ghost sample points on its surface. Determining these locations can be achieved using Thomson’s solution, conceptualizing each ghost sample point as a charged particle that repels others according to Coulomb’s law. Explicit coordinates of some configurations are available and can be easily found in the public domain.
Next, we introduce a radial basis function with each ghost sample point and reconstruct the underlying function based on the space spanned by these basis functions. The major difference from the typical RBF approach is that we propose choosing so that the typical interpolation problem at becomes a least-squares problem. Specifically, we reconstruct the function in the following form:
| (1) |
and aim to determine the unknown coefficients and by minimizing the sum of mismatches at the sample locations , along with the extra polynomial constraints as in RBF-FD. However, since we are considering a least-squares problem after all, our approach might seem to work even if we do not incorporate extra polynomials into the set of basis functions. There are two reasons why we propose to include them. Firstly, this allows our method to approach the standard RBF-FD as approaches and approaches . Therefore, our method recovers all the desirable properties, including the stability behavior of RBF-FD. The more significant reason, however, relates to the consistency of the approximation, which will be fully discussed later in Section 3.
The choice of the mismatch in with is clearly not unique. However, emphasizing local information might be more desirable by imposing soft constraints in applications where the samples contain noise. For instance, we can introduce a weight function such as to assign fewer weights to those sample points far away from the center point. Then, the corresponding minimization problem becomes . However, the current paper will not further investigate this moving least-squares-type approach.
Mathematically, we find the least-squares solution to
where
The size of the matrices P and are given by and , where is the total number of monomials of degree up to added to the set of basis functions. For example, if we include polynomials in 2 variables ( and ) up to degree , we have a total of elements of . When we have 3 variables (, and ), we have elements of for polynomials up to degree .
We introduce the second set of linear equations to mimic the conventional RBF-FD method. In particular, if we choose and , the approach reduces back to the original RBF-FD method with the addition of polynomial basis functions. In this paper, however, we choose , and the system becomes overdetermined since there are in total unknown coefficients, but the system contains equations. The least-squares coefficients and can be obtained by
where is the pseudoinverse of matrix .
Finally, we consider computing the derivative of the reconstruction. We denote the differential operator by . Then, applying the operator to the reconstruction and evaluating it at , we have with and determined by solving the above least-squares problem. Alternatively, we could rewrite the above procedure and solve the following explicit problem given by where the weights are given by the first components in
2.2 The Constrained Least-Squares Ghost Sample Points (CLS-GSP) Method
The LS-GSP method introduced in the above section works reasonably well even if the given sampling locations are badly distributed. However, we observe that the approximation to any linear operator might be inaccurate. A similar behavior has been observed in [23, 22, 33]. The main reason is that the least-squares approach does not necessarily provide enough weighting from the center location. This has motivated the development of the modified virtual grid difference method (MVGD) [33], in which we explicitly increase the least-squares weighting at the center location.
In this work, we propose to enforce that the least-squares reconstruction has to pass through the function value exactly. Mathematically, this constraint implies:
Without loss of generality, we assume for the remaining discussion. Otherwise, we could make a translation to transform the center point to the origin. The above equation then implies . By subtracting this equation from equation (1), the CLS-GSP method will fit the function by:
We emphasize that the set of polynomial bases in CLS-GSP now excludes the constant basis corresponding to the index . Therefore, when we substitute into the right-hand side, the least-squares approximation gives the exact function value regardless of the values of and .
Following a similar practice in the RBF community, we impose additional constraints
for each to improve the conditioning of the ultimate least-squares system. Now, we replace the previous set of basis functions by the following modified basis , we obtain the coefficients and by finding the least-squares solution of the following overdetermined system of size :
where we are abusing the notations of and given by
The solution can again be found by taking the pseudoinverse of the matrix.
Finally, applying a differential operator to a function defined at , we have where are determined by the first components in
2.3 Comparisons with Some Other Approaches
While our proposed ghost sample points methods incorporate RBF and virtual grids, they differ from typical RBF approaches and our previously developed MVGD method [33]. Here, we now provide a detailed comparison of these approaches.
Conventional RBF algorithms utilize point clouds for interpolation of the underlying function. Subsequently, the interpolant undergoes analytical differentiation. In contrast, LS-GSP or CLS-GSP employs least-squares to reconstruct the underlying function by specifying the basis functions at predetermined locations, which may not align with the data points. Although RBF-FD narrows its focus to a subset of locations within the point cloud for interpolation, the basis functions remain centered at this subset. Consequently, the quality of interpolation could be heavily contingent upon the quality of the provided point cloud sampling and the subsampling step during neighborhood selection.
While MVGD also employs least-squares fitting, it utilizes a polynomial basis for local approximation of the underlying function. Subsequently, finite difference techniques are applied to determine higher-order derivatives of the function, with any center function value substituted by the data value. For instance, assuming represents the local least-squares approximation of the underlying function at , the Laplacian of the function is given by , where controls the size of the virtual grid, and denotes the given function value at data point . There exist multiple distinctions from the method proposed in this work. Firstly, we substitute the polynomial least-squares fitting with an RBF basis centered at well-chosen locations. Consequently, the set of virtual grids (ghost sample points) is not utilized for finite difference calculations; instead, it already plays a role in the least-squares process. Secondly, unlike MVGD, CLS-GSP does not replace the finite difference value with any function value to enhance the diagonal dominance property; rather, we introduce a hard constraint to ensure that the least-squares reconstruction aligns with the function value at the centered location.
3 A Consistency Analysis
To facilitate our discussion, we focus on the standard Laplace operator due to its significance in numerous applications. While our discussion is limited to two dimensions, extending our approach to higher dimensions is straightforward. The consistency of any other linear differential operator can be similarly extended, although we will not delve into those details here.
In this section, we demonstrate the consistency of the CLS-GSP method. Under some regularity conditions, we will analytically show that the CLS-GSP method provides a consistent estimation of the standard Laplacian of a function with order , where is the order of polynomial basis included in the CLS-GSP method.
3.1 Approximating the Laplace Operator
Following the discussion above, the Laplace operator is approximated by
| (2) |
The vector has length , where is the number of sample points and is the number of elements in the polynomial basis up to the -th order in the representation. In approximating the derivative of , on the other hand, we use only the first elements in . In particular, if we include only the linear basis ( and ), we have the following system:
and the following system if we include up to the quadratic basis ( and ),
3.2 Consistency
In the following discussion on consistency, we fix the number of sample points , where , while shrinking these points towards the origin by taking with approaching 0. We define . For the ghost sample points chosen evenly distributed on the boundary of a ball, since the radius of this ball equals the average of for , the radius (denoted by ) shrinks to 0 at a rate of . For the second type of distribution where the ghost sample points are chosen evenly within a disc, we can also assume that the radius of the disc is given by the average distance from the sample points to the origin. This also gives the same estimates that .
Definition 1.
An estimation of a quantity is said to be consistent of order if as approaches 0.
The remaining part of this section aims to demonstrate the following consistent property of the approximation to the Laplacian using the CLS-GSP method proposed in the previous section.
Theorem 1.
Assume . Additionally, we assume that the RBF function has the form with the shape parameter , where . If the sample points are taken with , keeping constant, and the polynomial basis contains elements up to order , then the approximation (2) is consistent of order , i.e., as approaches to 0.
The rest of this section is to prove Theorem 1. To begin with, we need the following two lemmas.
Lemma 1.
Denote the first entries and the remaining elements of in (2) by and , respectively, so that
If the matrix is of full rank given by , the weights satisfies .
Proof.
Since is full rank, the transpose is also full rank. This implies that the solution must be a particular solution to the underdetermined system given by
The second row of the submatrix implies . This completes the proof. ∎
Lemma 2.
Assume the RBF function has the form with where is the shape parameter. If both matrices and are full rank, we have as approaches to 0 for any vector norm while keeping as constant.
We found that most of the commonly used RBFs are in the form of with a twice differentiable . These include the IQ, the MQ, the GA, and the IMQ.
Proof.
We first rewrite the definition of and obtain
Therefore, it is sufficient to show the following two conditions: and . For the first condition, we apply the following expansion of the pseudoinverse and take and . If the shape parameter satisfies as goes to 0 (i.e. ), we found that will be independent of and the remaining part (without the zeroth order polynomial) is of order . This implies
For the second condition, we first examine . For each component, we have
Now, since and where is the dimension, we obtain
Now, the condition with implies and . These are all functions in the form of . Therefore, if we have a constant , the quantity can be expressed as a constant divided by . As all the ghost sample points shrink to the origin with speed , the average radius is a constant multiple of . This implies that the condition being a constant is the same as keeping constant. Therefore, the quantity can also be expressed as a constant divided by , and when approaches zero with a constant .
For the term , we notice that out of all possible polynomials in the basis, only two polynomials in the basis (given by and ) whose Laplacian is nonzero. In particular,
For example, in the two-dimensional space, if we take the basis to be respectively, then
Combining these two results, we have
∎
Now, we are ready to present the proof of Theorem 1.
Theorem 1.
We write where for . We first expand all around the origin up to the -th order derivatives. For example, if up to second order polynomial is included in the case of two dimensions , we have
where the first and second order derivatives are evaluated at the origin and the third order derivatives are evaluated at some point inside the circle enclosing all the sample points. This expansion can be easily extended to higher dimensions. Note that the coefficient of all derivatives of (up to the -th order derivatives) are simply given by components in . Using Lemma 1 and an intermediate result in Lemma 2, we have
for up to the highest degree in the polynomial basis. Therefore, if we include up to -th order polynomial basis, then can be expressed as
Hence, we have bounded above by
In general, for higher dimensions, we apply Taylor’s expansion for the multivariable function up the -th order and cancel out all the lower order terms not in the form of . Finally, we obtain the error bounded for given by
with being the -th component of the -th sampling point . Now, based on Lemma 2, we have . Moreover, since sample points shrink to the center with speed , we have . Therefore, we obtain the estimate . ∎
Note that this error bound depends explicitly on the number of data points used in the approximation (i.e., ). It might seem that more data would yield less accuracy. However, we are considering the behavior of the approximation for a fixed number of data points. The situation is more complicated when comparing the corresponding behavior for two sets with different numbers of data points. If more data points are collected in the reconstruction, one has to go further away from the center to search for more neighbors, making the approximation less local. Therefore, intuitively, it indeed yields less accuracy. However, if we can control the average radius of these data points from the center as we increase , one may be able to derive a tighter bound for the summation independent of . It is, therefore, less conclusive whether the error bounds will actually increase as we increase .
4 Numerical Examples
In this section, we will design several numerical examples to demonstrate the effectiveness and performance of the proposed CLS-GSP method in various applications.
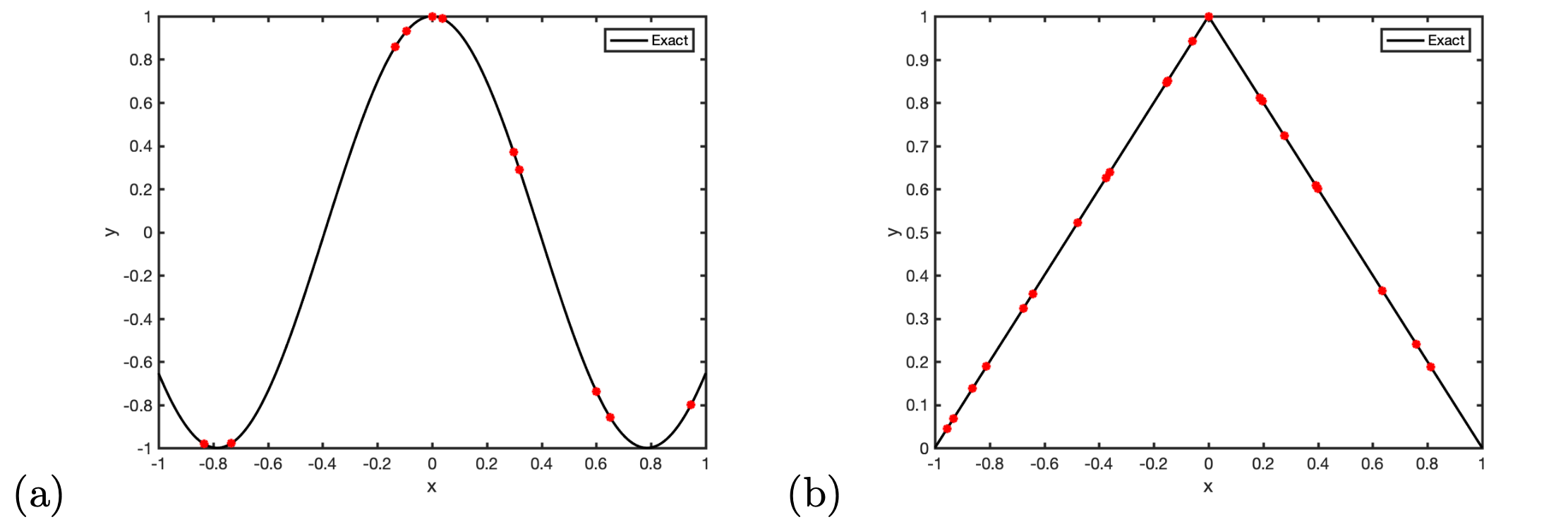
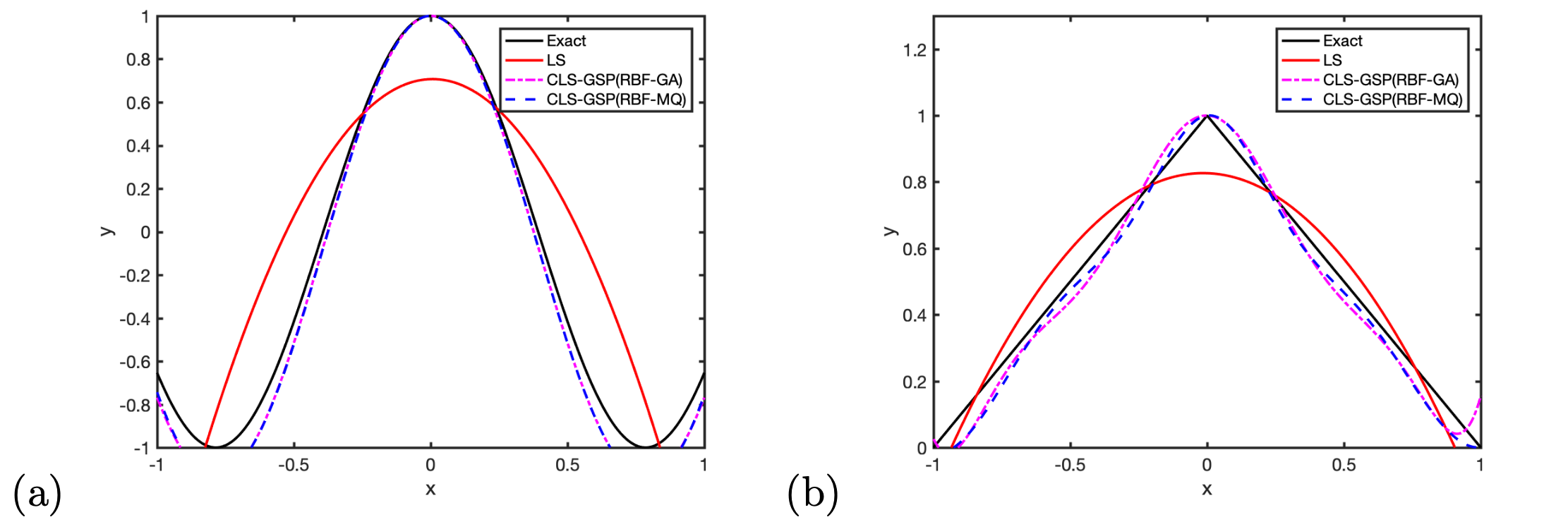
4.1 Local Reconstruction
This section demonstrates the performance of the local reconstruction in our proposed CLS-GSP method. We randomly generate sample points between with the center at the origin. In the first example, we consider a smooth function , as shown in Figure 2(a), and also a non-smooth function which has a kink at the origin, as shown in Figure 2(b). To emphasize the importance of the RBF kernels, we will compare our performance with the standard second-order polynomial least-squares polynomial approach, as shown in Figure 3. The solution from the standard polynomial least-squares method is a little drastic since the method tries to balance the error from all sampling locations. The result is especially unsatisfactory since some sample points are far from the center . Nevertheless, our CLS-GSP method, using either the Gaussian or the Multiquadric basis, can recover the function well, especially in the area near the center , even if the samples are not localized.
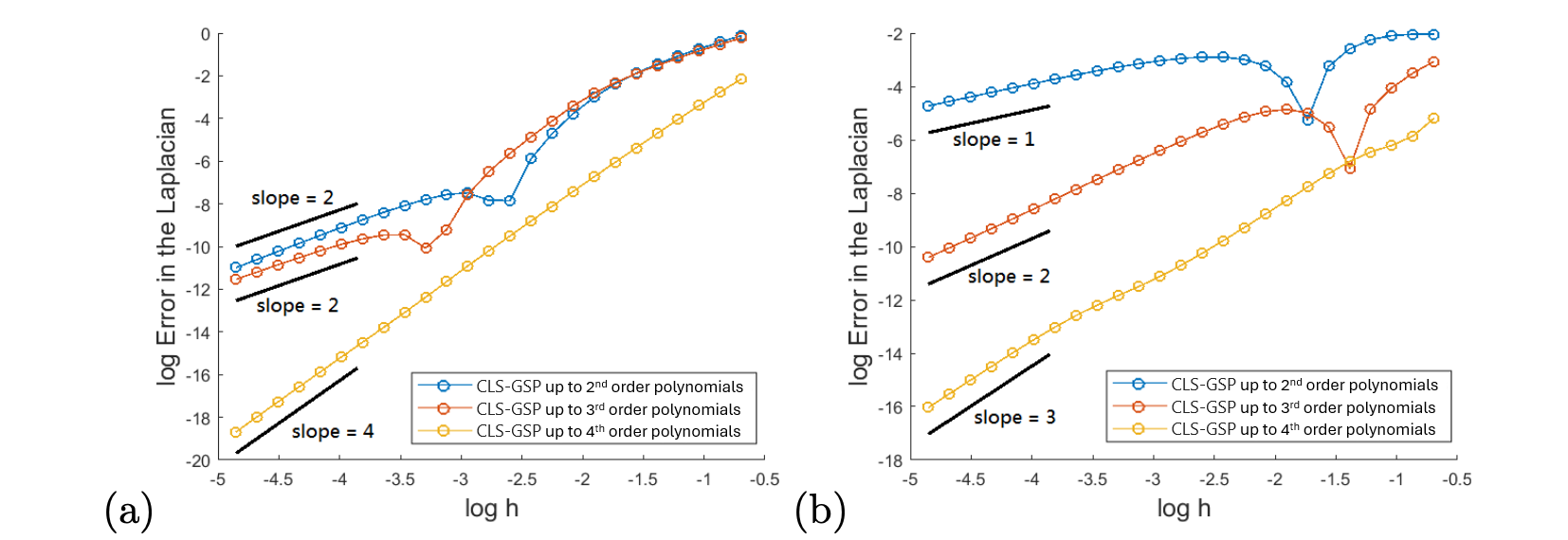
4.2 Consistency in Approximating the Laplacian
In the second example, we demonstrate the consistency of our CLS-GSP method applied to the Laplace operator, , in . We examine the Laplacian of two functions: and , at where the exact Laplacian is given by and , respectively. We generate random sample points around the center and take 8 ghost sample points uniformly on a circle centered at the origin given by , where is chosen to be the average distance of the sample points from the origin. We apply our CLS-GSP method using Gaussian kernels (GA) and polynomial basis up to the second, third, and fourth order. The approximation to the Laplacian is calculated using expression (2).
In the first test function , we refine the scaling parameter as defined in Section 3.2 while fixing where is the shape parameter. The log-Error plot is shown in Figure 4(a). According to Theorem 1, we expect our computed Laplacian to have -th order consistency when up to -th order polynomial bases are included. In Figure 4(a), when is small, the slopes of the log-Error plot are approximately , , and when , and , respectively. This indicates an extra consistent order when up to the second- or fourth-order polynomial bases are included. All the third-order and fifth-order partial derivatives of at the origin are zero. This leads to the vanishing of the leading-order term. However, considering the second test function , the consistent behavior is different from . Figure 4(b) shows the log-Error for different , when is fixed to be . The slopes are approximately , , and when , and , respectively. This observation aligns with Theorem 1 as some high-order derivatives of are non-zero.
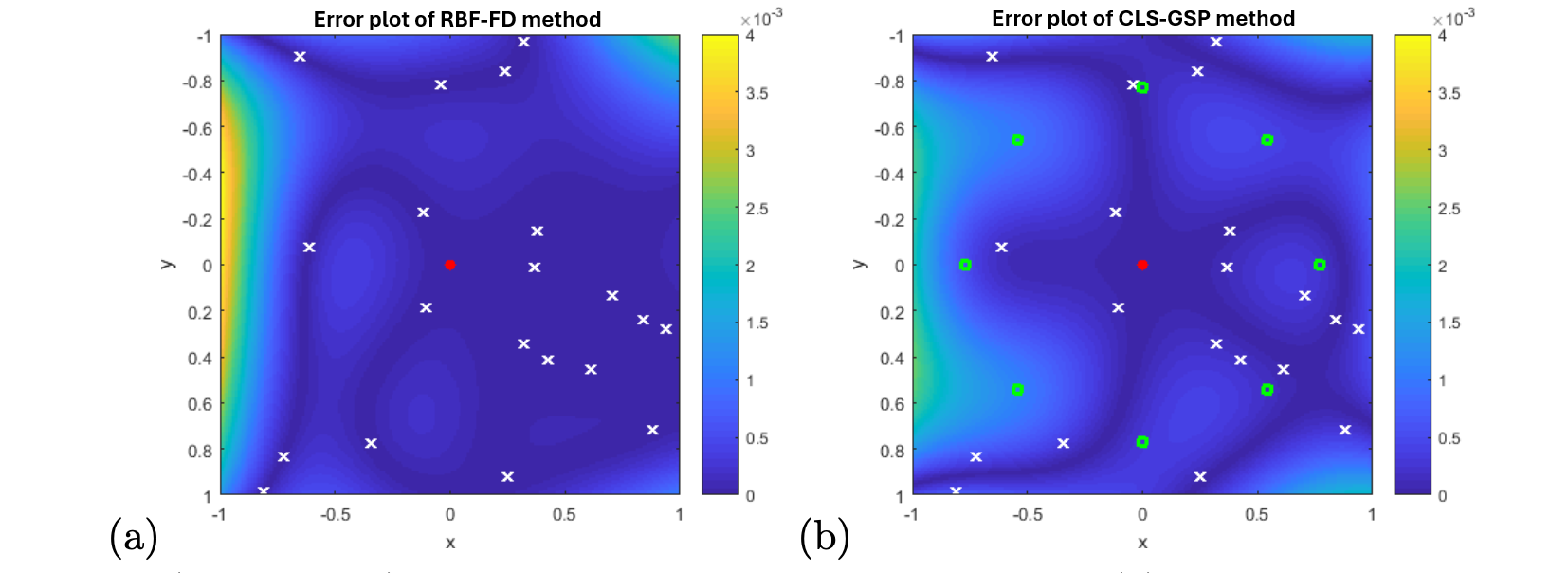
| Error | Rank | Error | Rank | |
|---|---|---|---|---|
| in RBF-FD | in CLS-GSP | |||
4.3 Sensitivity of the Shape Parameter
In this section, we test the sensitivity of the shape parameter in both the RBF-FD and CLS-GSP methods. The condition for a certain matrix to be full rank, as required in Lemma 1 and Theorem 1, depends on the choice of the shape parameter in the basis function. In this example, we generate sample points in and examine the performance of both the RBF-FD method and the CLS-GSP method with different types of basis functions and different values of the shape parameter . The underlying function is given by . The exact Laplacian at the origin is . We include the polynomial basis up to the second order in both methods. The ghost points in our proposed CLS-GSP are chosen to be , where is the average distance of the sample points from the origin.
Figure 5 illustrates the error in the approximation obtained by both the conventional RBF and our CLS-GSP approach. Remarkably, with only 8 basis functions in our CLS-GSP approach, we achieve an approximation of comparable accuracy to the typical RBF approach, which requires 20 basis elements. To test the sensitivity, we maintain the same set of sampling points while varying the parameter . Given that all four commonly used RBFs listed are functions of , it is natural to select such that remains constant. In our test case, we fix such that , where . To determine the optimal choice of the shape parameter, we analyze the error in the numerical Laplacian at the origin and monitor the rank of the matrices
in the RBF-FD method and the CLS-GSP method, respectively. We compute the rank numerically by counting the number of singular values greater than the tolerance . The results are shown in Table 1 for the IQ-RBF case. Initially, we observe that both methods yield large errors when is extremely large. Conversely, if the shape parameter is extremely small, both methods encounter a rank-deficiency problem, resulting in a large error in the numerical Laplacian.
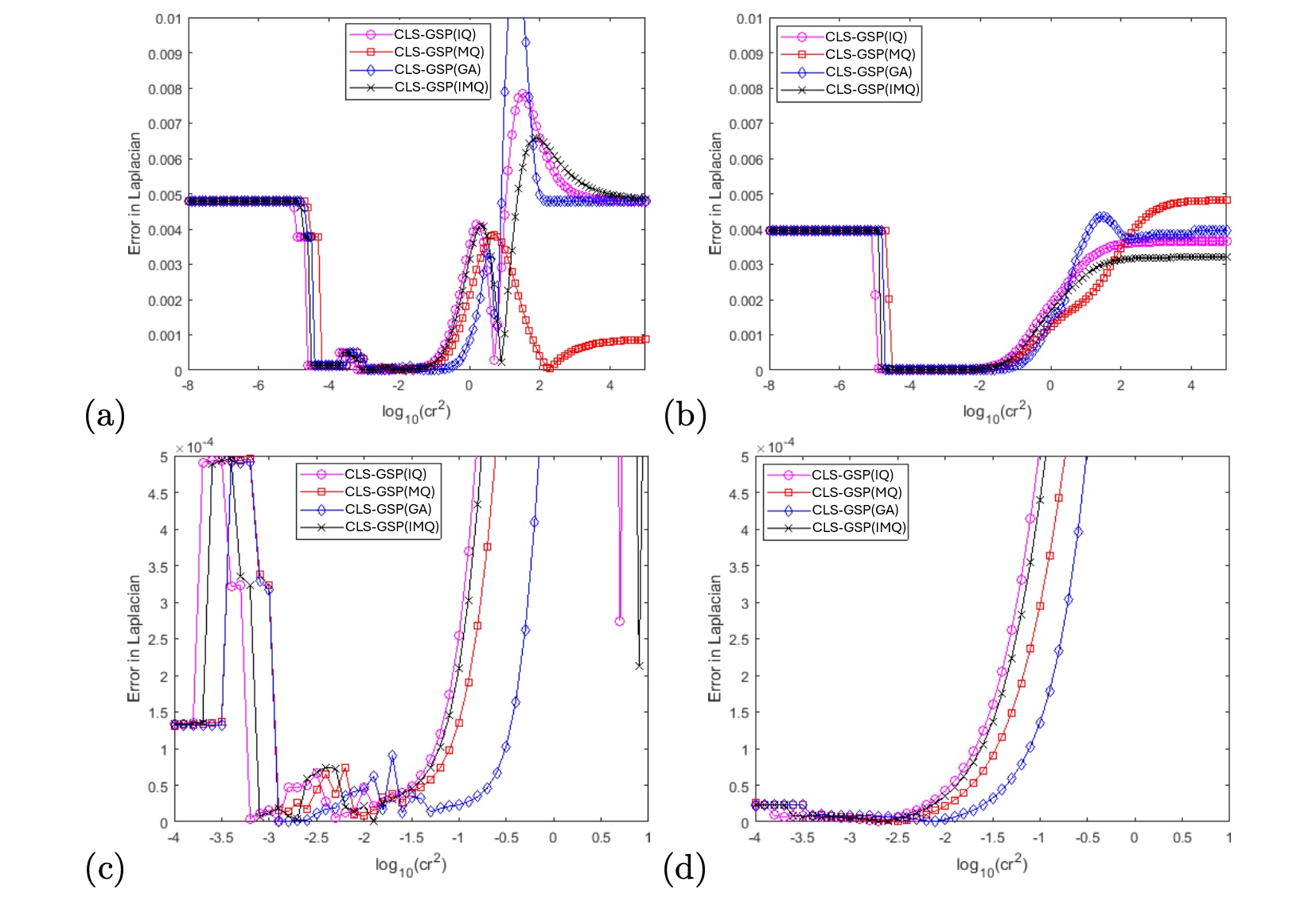
We repeated the same experiments to determine a suitable range of shape parameter but replaced the IQ-type basis with the MQ-, GA-, and IMQ-types, respectively. Figure 6(a-b) illustrates the errors in the numerical Laplacian as we vary the quantity . Our proposed CLS-GSP method generally approximates the Laplacian more accurately than the RBF-FD method. Further zooming in on the region , as shown in Figure 6(c-d), reveals that the fluctuation in the error in our proposed CLS-GSP method is smaller than that obtained by the RBF-FD method. This indicates that the CLS-GSP method is less sensitive to small changes in the shape parameter .
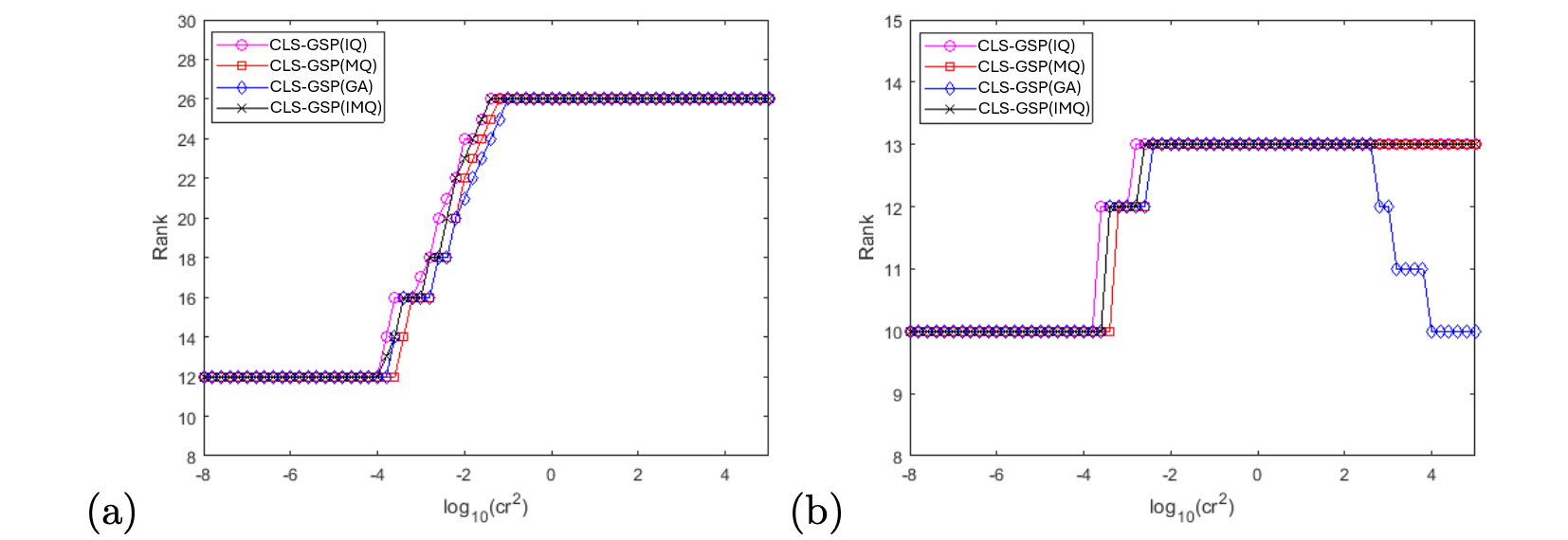
Figure 7 illustrates the rank of the corresponding matrices in both methods versus the choice of the shape parameter . Across all types of basis functions, the RBF-FD method exhibits a rank deficiency problem (with full rank being ) when drops below roughly . In contrast, our proposed CLS-GSP method (specifically the GA-type) encounters a rank deficiency problem (with full rank being ) only when drops below approximately . As discussed in the analysis in Section 3, achieving a full-rank matrix is crucial for obtaining the consistency result. Hence, our proposed CLS-GSP method offers a broader range of the shape parameter to ensure the necessary consistency in the numerical approximation of the required derivative.
Regarding the behavior of the GA-type basis functions, it is evident that the rank of the matrix decreases as we increase the parameter and, consequently, the shape parameter . This phenomenon arises because the support of the Gaussian basis functions becomes excessively narrow with larger values of . Specifically, when is around 2, the corresponding shape parameter is approximately 170. This indicates that the standard deviation of each Gaussian basis function is roughly 0.05. Comparing this scale to the domain size, which is , it becomes clear that the GA-type basis functions struggle to provide an accurate approximation to the underlying function.
4.4 Two Dimensional Poisson Equations
In this example, we apply the CLS-GSP method to solve Poisson’s equation in different 2D domains, defined by the equation:
To mitigate one-sided stencils near the boundary , we incorporate a layer of boundary nodes outside the domain . In our approach, we presume that the function is specified not only on the boundary but also analytically defined in the exterior, ensuring precise values when necessary. If is solely provided by an explicit expression on , we determine the function value on these boundary nodes through a normal extension, ensuring , where represents the outward normal along . This is achieved by projecting the boundary nodes onto the boundary. Furthermore, if data points are available on the boundary, the value assigned to a boundary node can be determined through additional interpolation on .
Let denote the number of meshless sample points in the computational domain, and represent the number of boundary nodes outside the domain. Consequently, we obtain a DM of the Laplacian operator given by: , where is an matrix associated solely with the sample points within the computational domain, and is an matrix containing the coefficients associated with the boundary nodes in . This operator operates on all points and provides the numerical Laplacian at the sample points within the computational domain. Set
where are sample points in and are boundary nodes in . Therefore, the solution at the interior sample points, denoted by , can be computed using , which implies that we solve .
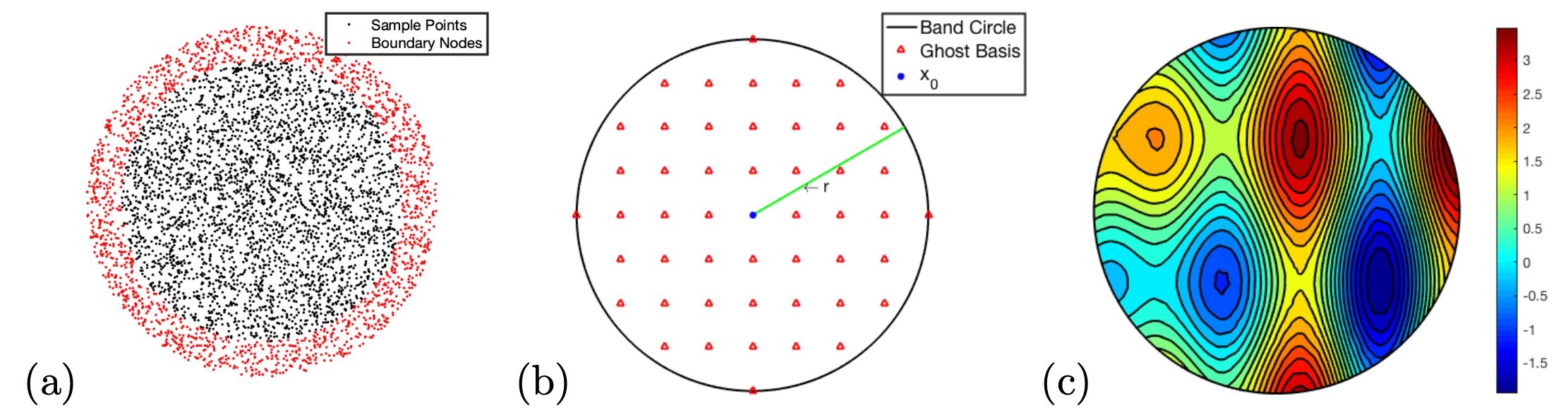
In the first domain, we consider a simple disc . Both functions and are determined from the exact solution given by . We select random points from and random boundary nides from in the boundary domain . These points are plotted in Figure 8(a). Some sample points are located very close, which could cause instability problems with a straightforward implementation of the RBF-FD method based on the -nearest neighbors. In this example, we choose (i.e., we have 60 local neighbors for each sample point ) to generate the weights vector of the Laplacian matrix at . We choose 49 ghost basis samples uniformly within a distance of , as shown in Figure 8(b). The numerical solution is presented in Figure 8(c), and the error in the solution is around .
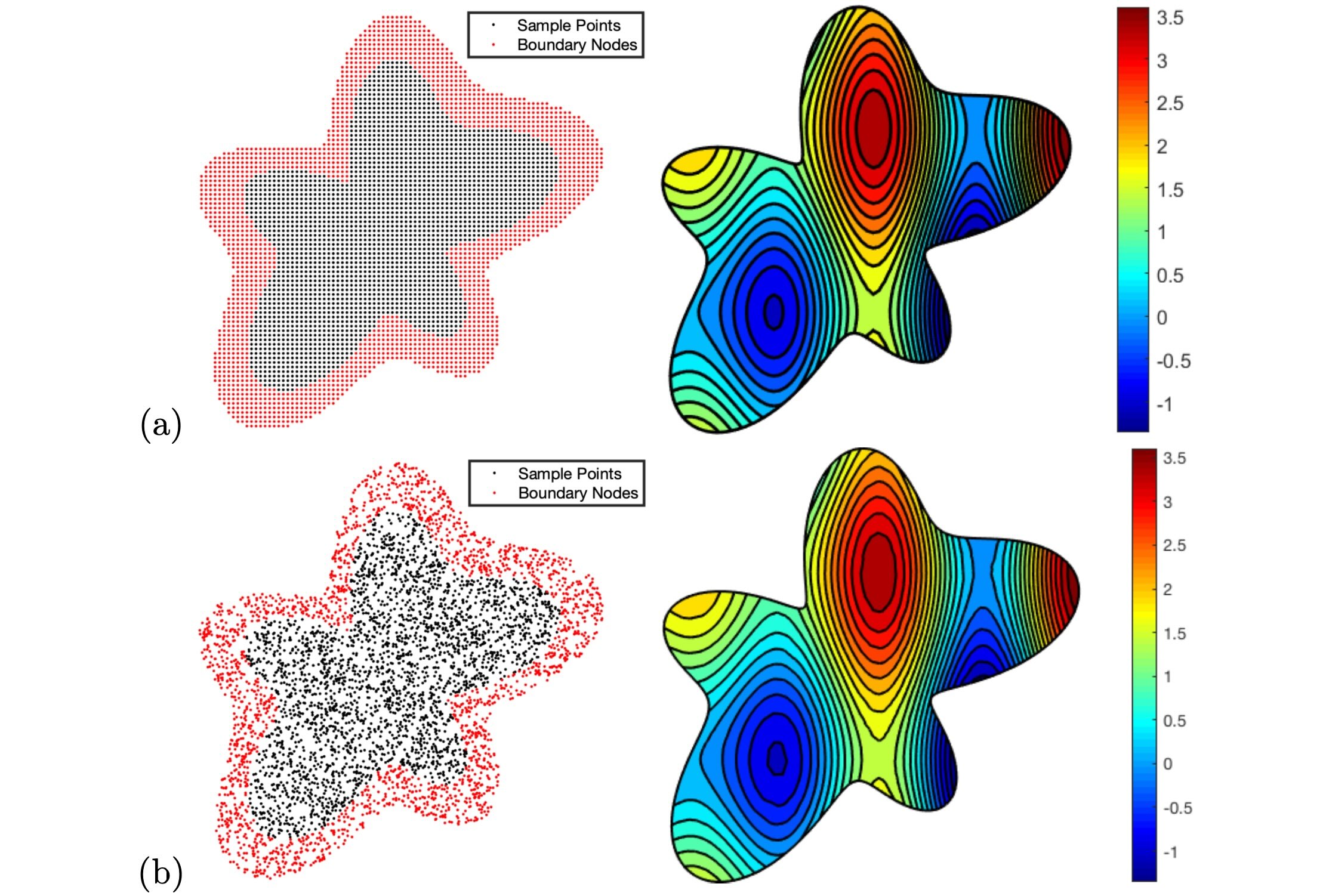
In the second test domain, we consider an irregular flower shape given by . The functions and are again determined from the same exact solution. In this example, we test on two different sets of sample points. In the first sampling, we select 2677 samples uniformly inside the computational domain with 2066 boundary nodes chosen in . The second case uses 2782 random samples in with 2782 boundary nodes in . Figure 9 shows our computed solution in this irregular domain using the uniform samples (in (a)) and the random samples (in (b)). The error of these solutions is around and for the uniform and the random samplings, respectively.
4.5 The Laplace-Beltrami Operator
There are several methods for approximating the Laplace-Beltrami (LB) operator on manifolds. One Eulerian approach involves extending the manifold to with the constraint , where denotes the normal on the manifold , as illustrated in Figure 10(a). Various methods have been developed within this Eulerian framework. For instance, an earlier approach by Green [17] utilized the level set method [28] and the projection method. The closest point method (CPM) [26, 30, 25] has also been applied to this problem. Following the basic embedding concept outlined in [35] for surface eikonal equations, we have devised a similar straightforward embedding approach for the LB eigenproblem, as detailed in [21]. Additionally, methods like RBF-OGr [29] and RBF-FD are utilized within the RBF community. Another approach is the Lagrangian framework, which explicitly deals with sample points on the manifold. In this approach, neighbor points for each sample point are projected onto the local tangent plane of the manifold. Subsequently, these methods use the standard Laplacian on the tangent plane to compute the Laplace-Beltrami operator, incorporating local geometric information. A graphical illustration is provided in Figure 10(b). This technique finds widespread use in point cloud data analysis, as seen in methods proposed in [1], as well as in some local mesh methods developed in [24, 20]. Other methods, such as the grid-based particle method (GBPM) and the cell-based particle method (CBPM) [23, 22, 19], and a virtual grid method [33], also employ similar principles.
In this example, we focus on approximating the Laplace-Beltrami operator on a two-dimensional surface embedded in and parameterized by . The Laplace-Beltrami operator acting on a function is defined as: . Here, the metric is given by , and the Jacobian of the metric is denoted as . The matrix represents the inverse of . It’s important to note that the Laplace-Beltrami operator is geometrically intrinsic, meaning it’s independent of the parametrization. Thus, computations based on local parametrization remain valid and retain geometric intrinsic properties.
4.5.1 Eigenvalues of the LB Operator
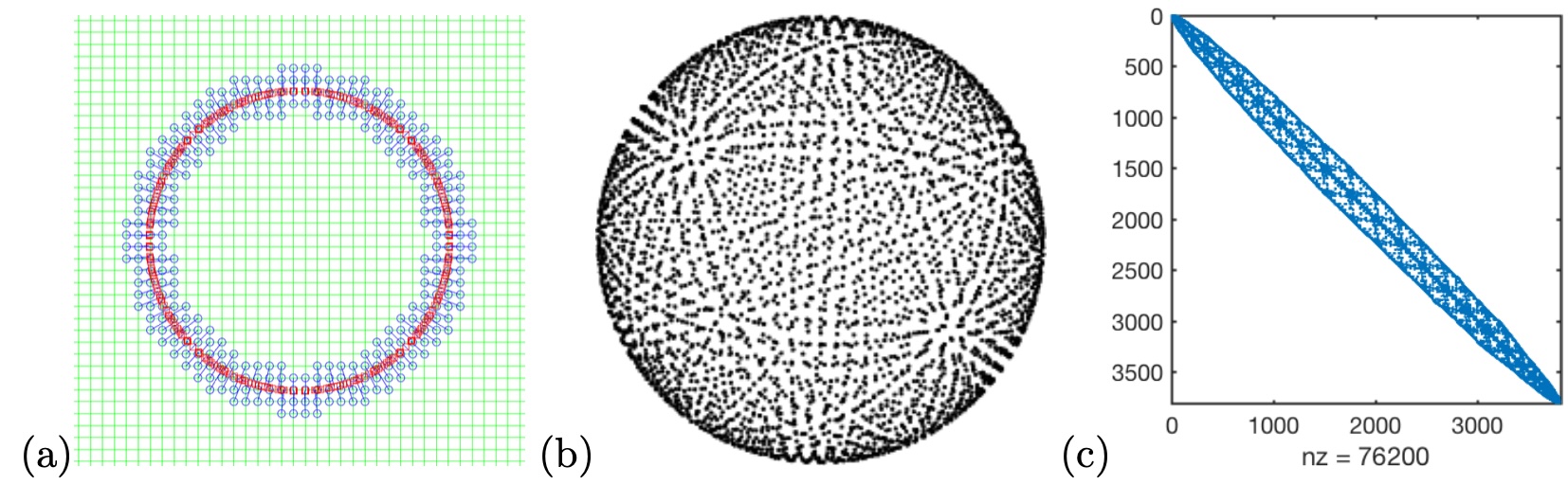
In this example, we have employed the GBPM or CPM to sample the sphere. This involves selecting points closest to the underlying mesh points near the interface. The illustration in Figure 11(a) plots a typical point cloud sampling of the interface/surface using GBPM. Here, the underlying mesh is shown with solid lines, while all active grids near the interface (plotted as a circle) are represented by blue circles. The associated closest points on the interface are marked with red squares, and solid line links show the correspondence between each pair. It’s worth noting that the resulting point cloud from GBPM may exhibit non-uniformity, as the two closest points to two mesh points can be very close or even identical. A crucial parameter in generating the GBPM/CPM point cloud is the width of the computational band, which we have set to in our numerical example. This implies that for each grid point within a distance less than from the interface, we compute its projection onto the manifold. These projected points serve as sample points for representing the interface.
Here, we compute the eigenvalues of the Laplace-Beltrami operator on the unit sphere represented by the GBPM sampling. The sample points are shown in Figure 11(b).
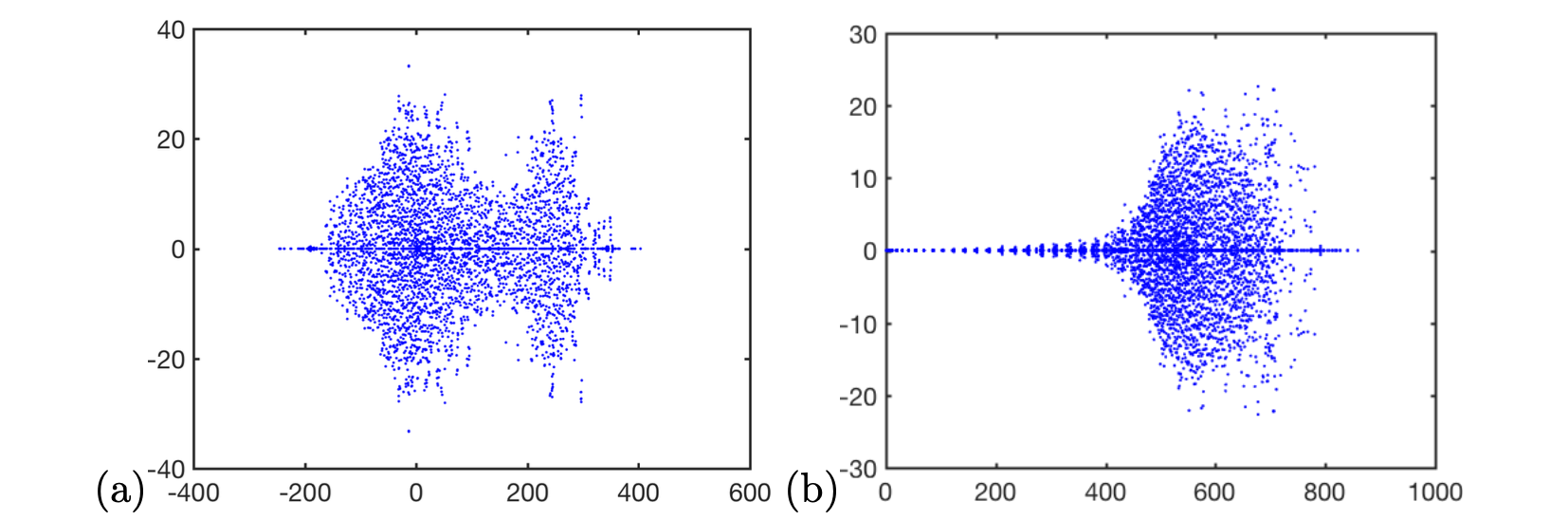
First, we construct the DM of the operator using our proposed CLS-GSP method, denoted as . Then, we compute all the eigenvalues and eigenvectors of the matrix using the MATLAB function eig. These eigenvalues and eigenvectors can serve as a good discrete approximation to the eigenvalues and eigenfunctions of the continuous eigenvalue problem . After obtaining these computed eigenvalues, we can plot them onto the complex plane. Figure 12 shows the eigenvalues of from (a) the least-squares method as in the GBPM [22], and (b) our proposed CLS-GSP method.
In many applications, having the real part of all eigenvalues of the Laplace-Beltrami operator staying non-negative is important. For example, when solving the diffusion equation on the manifold , an eigenvalue of the Laplace-Beltrami operator with a negative real part can lead to instability in the numerical solution. In the GBPM sampling, two sample points can collide at the same place on the surface, leading to their corresponding projection points being arbitrarily close to the tangent plane. However, our proposed CLS-GSP works better in this example. All eigenvalues from our proposed CLS-GSP are on the right-hand side of the complex plane, showing that the real part of all eigenvalues is non-negative.
| Samples | ||||
|---|---|---|---|---|
| Samples | ||||
|---|---|---|---|---|
4.5.2 Convergence of the Eigenvalues of the Laplace-Beltrami Operator
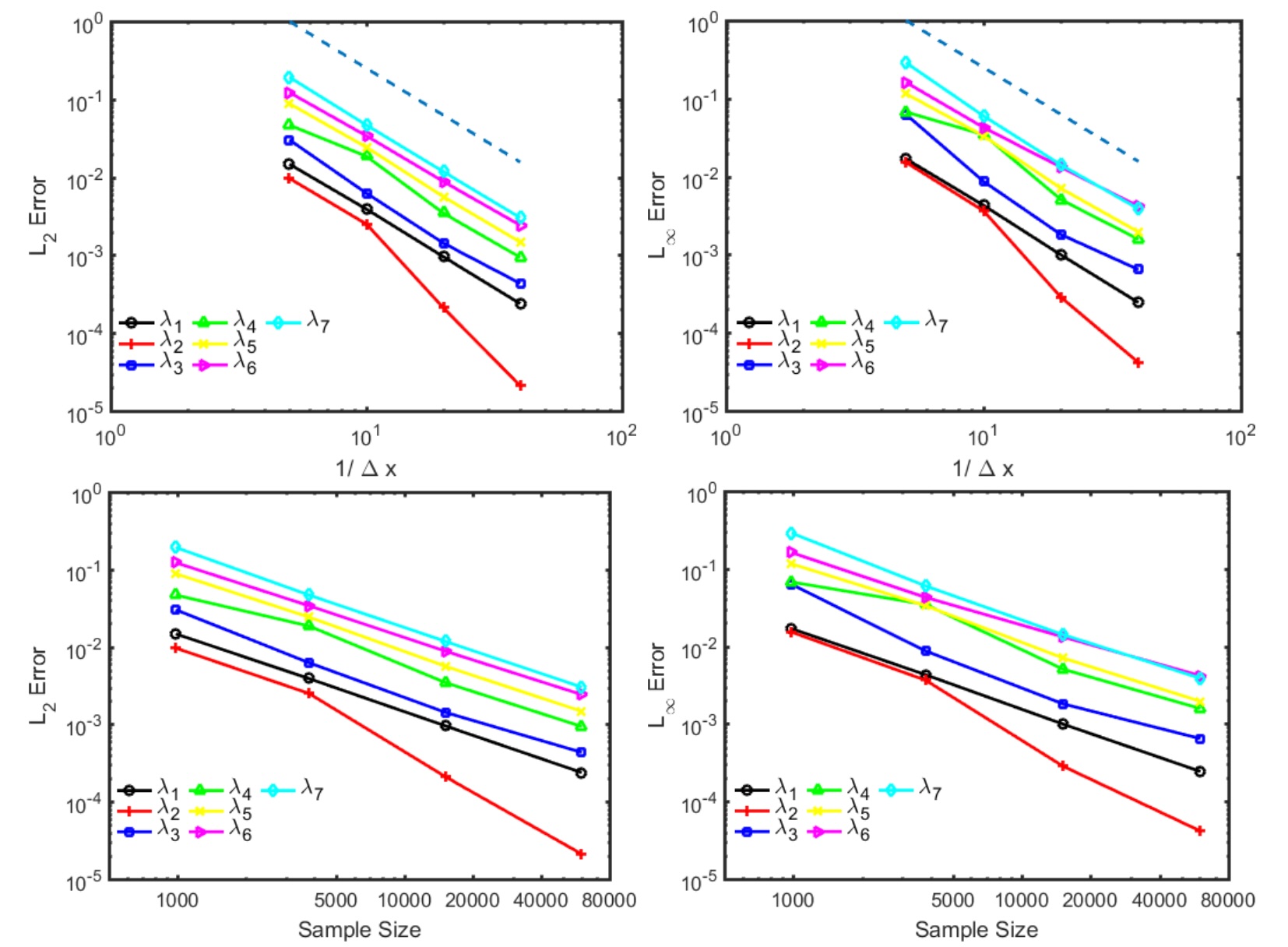
In this part, we test the convergence of the computed eigenvalues of the LB operator on the unit sphere. On the unit sphere, the exact value of the -th eigenvalue can be analytically computed and is given by with multiplicity . We use the following normalized and errors to measure our algorithm’s performance: and . Figure 13 shows that the convergence rate of our algorithm is approximately second order in both error measures. It also shows that the error decreases when the GBPM sample size is increased. Tables 2 and 3 show the details of the errors measured in different discretizations.
4.5.3 Eigenfunctions of the LB Operator on Manifolds
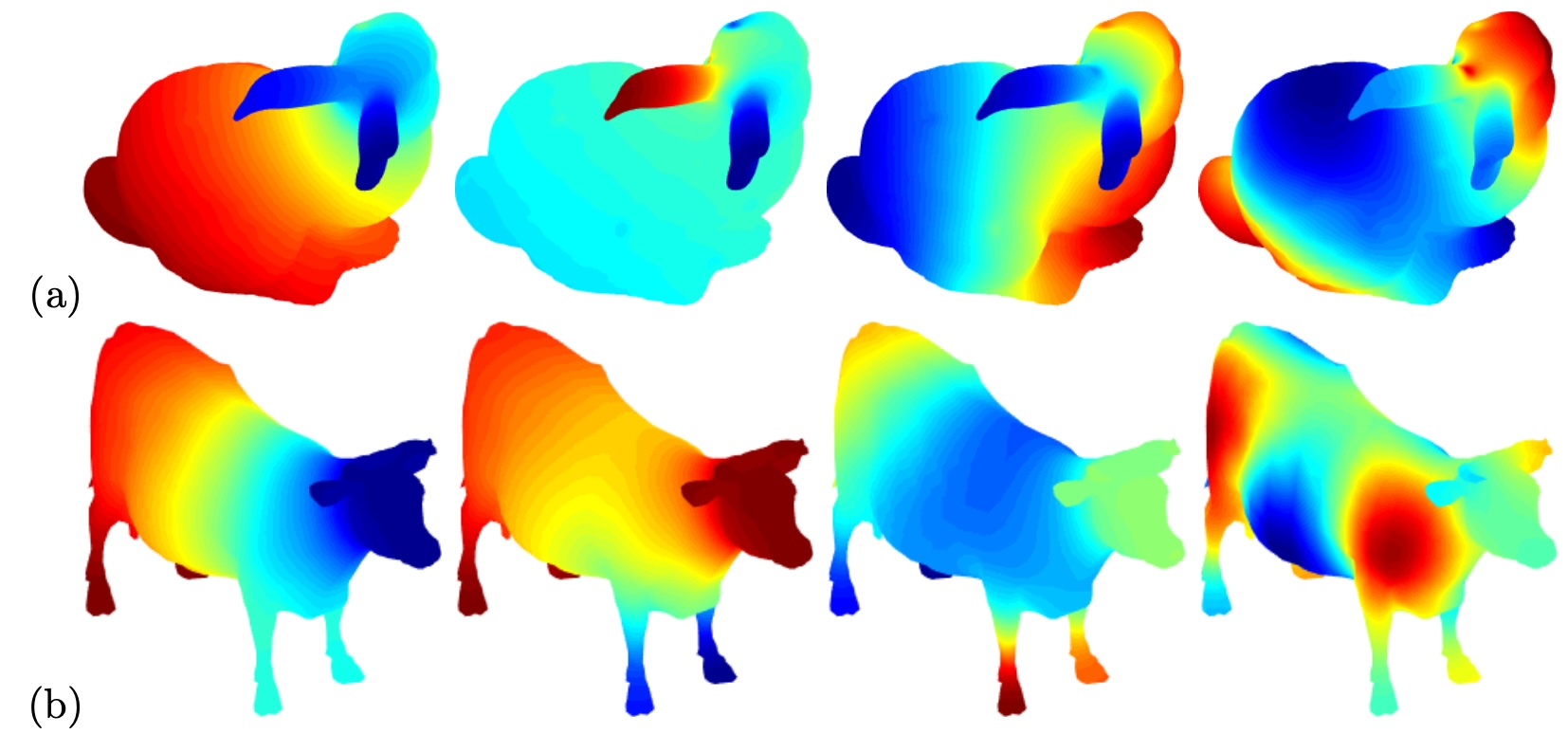
Our method’s ability in handling manifolds, as represented by various samplings, is a significant advantage. Figure 14 illustrates the first few eigenfunctions of two-point cloud datasets obtained from the Stanford 3D scanning repository and the public domain, showcasing the applicability of your approach across different datasets.
5 Conclusion
This paper introduced the constrained least-squares ghost sample points (CLS-GSP) method for approximating differential operators on domains sampled by a random set of sample points. Unlike traditional RBF interpolation methods, we formulated the problem as a least-squares one, offering more flexibility in allocating basis locations, especially when sample points are close or overlap. Additionally, we enhanced the approach presented in previous work by enforcing the local reconstruction to pass through the center data point, improving the accuracy and diagonal dominance of the resulting DM.
Given the challenge of designing optimal sample locations, we addressed the issue by introducing the concept of consistency and analyzing the behavior of the pointwise consistency error as sample locations approach the center. By incorporating polynomial basis functions up to the -th order into the CLS-GSP basis, we demonstrated the method’s consistency in estimating the Laplacian of a function with an order of .
Numerical experiments showcased the accuracy and stability of the proposed CLS-GSP method. Notably, the discretized Laplace-Beltrami operator obtained using CLS-GSP has eigenvalues with positive real parts, indicating stability for solving the diffusion equation on a manifold. Our approach presents a promising framework for robust numerical algorithms in manifold-based applications.
Acknowledgment
The work of Leung was supported in part by the Hong Kong RGC grant 16302223.
References
- [1] M. Belkin, J. Sun, and Y. Wang. Constructing Laplace operator from point clouds in rd. In Proceedings of the twentieth Annual ACM-SIAM Symposium on Discrete Algorithms, pages 1031–1040. Society for Industrial and Applied Mathematics, 2009.
- [2] T. Belytschko, Y. Krongauz, D. Organ, M. Fleming, and P. Krysl. Meshless methods: An overview and recent developments. Comput. Meth. Appl. Mech. Engrg., 139:3–47, 1996.
- [3] JJ. Benito, F. Urena, and L. Gavete. Influence of several factors in the generalized finite difference method. Applied Mathematical Modelling, 25(12):1039–1053, 2001.
- [4] JJ. Benito, F. Urena, and L. Gavete. Solving parabolic and hyperbolic equations by the generalized finite difference method. Journal of computational and applied mathematics, 209(2):208–233, 2007.
- [5] M.D. Buhmann. Radial Basis Functions. Cambridge University Press, 2003.
- [6] M.D. Buhmann and D. Nira. Spectral convergence of multiquadric interpolation. Proceedings of the Edinburgh Mathematical Society, 36(2):319–333, 1993.
- [7] S. G. Chen, M. H. Chi, and J. Y. Wu. High-Order Algorithms for Laplace–Beltrami Operators and Geometric Invariants over Curved Surfaces. J. Sci. Comput., 65:839–865, 2015.
- [8] S.-G. Chen and J.-Y. Wu. Discrete conservation laws on curved surfaces. SIAM J. Sci. Comput., 35(2):A719–A739, 2013.
- [9] S.-G. Chen and J.-Y. Wu. Discrete conservation laws on evolving surfaces. SIAM J. Sci. Comput., 38(3):A1725–A1742, 2016.
- [10] G.E. Fasshauer. Meshfree approximation methods with MATLAB. World Scientific, 2007.
- [11] N. Flyer and E. Lehto. Rotational transport on a sphere: Local node refinement with radialbasis functions. J. Comp. Phys., 229:1954–1969, 2010.
- [12] B. Fornberg. Generation of finite difference formulas on arbitrarily spaced grids. Mathematics of computation, 51(184):699–706, 1988.
- [13] B. Fornberg. A practical guide to pseudospectral methods. Cambridge University Press, 1996.
- [14] B. Fornberg. Classroom note: Calculation of weights in finite difference formulas. SIAM review, 40(3):685–691, 1998.
- [15] B. Fornberg and N. Flyer. Accuracy of radial basis function interpolation and derivative approximations on 1-D infinite grids. Advances in Computational Mathematics, 23(1-2):5–20, 2005.
- [16] B. Fornberg, N. Flyer, and J.M. Russell. Comparisons between pseudospectral and radial basis function derivative approximations. IMA J. Numer. Anal., pages 1–28, 2008.
- [17] J.B. Greer. An improvement of a recent Eulerian method for solving PDEs on general geometries. J. Sci. Comp., 29(3):321–352, 2005.
- [18] R. Hardy. Multiquadratic equations of topography and other irregular surface. Journal of Geophysical Research, 76:1905–1915, 1971.
- [19] S. Hon, S. Leung, and H.-K. Zhao. A cell based particle method for modeling dynamic interfaces. J. Comp. Phys., 272:279–306, 2014.
- [20] R. Lai, J. Liang, and H. Zhao. A local mesh method for solving pdes on point clouds. Inverse Problems and Imaging, 7(3):737–755, 2013.
- [21] Y.K. Lee and S. Leung. A Simple Embedding Method for the Laplace-Beltrami Eigenvalue Problem on Implicit Surfaces. Comm. App. Math. and Comp., 2023.
- [22] S. Leung, J. Lowengrub, and H.K. Zhao. A grid based particle method for high order geometrical motions and local inextensible flows. J. Comput. Phys., 230:2540–2561, 2011.
- [23] S. Leung and H.K. Zhao. A grid based particle method for moving interface problems. J. Comput. Phys., 228:2993–3024, 2009.
- [24] J. Liang, R. Lai, T.W. Wong, and H. Zhao. Geometric understanding of point clouds using Laplace-Beltrami operator. Computer Vision and Pattern Recongnition (CVPR), pages 214–221, 2012.
- [25] C.B. Macdonald, J. Brandman, and S. Ruuth. Solving eigenvalue problems on curved surfaces using the closest point method. J. Comp. Phys., 230:7944–7956, 2011.
- [26] C.B. Macdonald and S.J. Ruuth. Level set equations on surfaces via the closest point method. J. Sci. Comput., 35:219–240, 2008.
- [27] V.P. Nguyen, T. Rabczuk, S. Bordas, and M. Duflot. Meshless methods: A review and computer implementation aspects. Mathematics and Computers in Simulation, 79:763–813, 2008.
- [28] S. J. Osher and J. A. Sethian. Fronts propagating with curvature dependent speed: algorithms based on Hamilton-Jacobi formulations. J. Comput. Phys., 79:12–49, 1988.
- [29] C. Piret. The orthogonal gradients method: A radial basis functions method for solving partial differential equations on arbitrary surfaces. J. Comput. Phys., 231:4662–4675, 2012.
- [30] S.J. Ruuth and B. Merriman. A simple embedding method for solving partial differential equations on surfaces. J. Comput. Phys., 227:1943–1961, 2008.
- [31] C. Shu, H. Ding, and K. S. Yeo. Local radial basis function-based differential quadrature method and its application to solve two-dimensional incompressible navier-stokes equations. Comput. Meth. Appl. Mech. Engrg., 192:941–954, 2003.
- [32] J. G. Wang and G. R. Liu. A point interpolation meshless method based on radial basis functions. Int. J. Num. Meth. Eng., 54:1623–1648, 2002.
- [33] M. Wang, S. Leung, and H. Zhao. Modified Virtual Grid Difference (MVGD) for Discretizing the Laplace-Beltrami Operator on Point Clouds. SIAM J. Sci. Comput., 40(1):A1–A21, 2018.
- [34] H. Wendland. Scattered data approximation. Cambridge University Press, 2005.
- [35] T. Wong and S. Leung. A fast sweeping method for eikonal equations on implicit surfaces. J. Sci. Comput., 67:837–859, 2016.
- [36] G. B. Wright. Radial basis function interpolation: Numerical and analytical developments. Ph.D. thesis, University of Colorado, Boulder, 2003.
- [37] J.-Y. Wu, M.-H. Chi, and S.-G. Chen. A local tangential lifting differential method for triangular meshes. Mathematics and Computers in Simulation, 80:2386–2402, 2010.
- [38] N. Ying. Numerical Methods for Partial Differential Equations from Interface Problems. HKUST PhD Thesis, 2017.