A Comprehensive Review of Latent Space Dynamics Identification Algorithms for Intrusive and Non-Intrusive Reduced-Order-Modeling
Abstract
Numerical solvers of partial differential equations (PDEs) have been widely employed for simulating physical systems. However, the computational cost remains a major bottleneck in various scientific and engineering applications, which has motivated the development of reduced-order models (ROMs). Recently, machine-learning-based ROMs have gained significant popularity and are promising for addressing some limitations of traditional ROM methods, especially for advection dominated systems. In this chapter, we focus on a particular framework known as Latent Space Dynamics Identification (LaSDI), which transforms the high-fidelity data, governed by a PDE, to simpler and low-dimensional latent-space data, governed by ordinary differential equations (ODEs). These ODEs can be learned and subsequently interpolated to make ROM predictions. Each building block of LaSDI can be easily modulated depending on the application, which makes the LaSDI framework highly flexible. In particular, we present strategies to enforce the laws of thermodynamics into LaSDI models (tLaSDI), enhance robustness in the presence of noise through the weak form (WLaSDI), select high-fidelity training data efficiently through active learning (gLaSDI, GPLaSDI), and quantify the ROM prediction uncertainty through Gaussian processes (GPLaSDI). We demonstrate the performance of different LaSDI approaches on Burgers equation, a non-linear heat conduction problem, and a plasma physics problem, showing that LaSDI algorithms can achieve relative errors of less than a few percent and up to thousands of times speed-ups.
Keywords:
Reduce-Order-Modeling Auto-encoder Latent–Space Identification Partial Differential Equation Active Learning†Corresponding author: [email protected]
1 Introduction
In recent years, there has been an impressive growth in the development of numerical simulation methods to comprehend physical phenomena, resulting in enhanced accuracy and level of sophistication. Alongside this, there have been substantial advancements in computational hardware, making it more powerful and cost-effective. Consequently, numerical simulations have become widely adopted in numerous areas, such as engineering design, digital twins, decision-making processes [58, 38, 2, 12, 75], and a range of fields including aerospace, automotive, electronics, physics, and biology. [20, 23, 44, 54, 57, 71, 70, 63].
In the realms of engineering and physics, computational simulations frequently involve the resolution of partial differential equations (PDEs) using various numerical approaches, such as finite difference/volume/element methods, particle methods, and others. Although these techniques are known for their precision and ability to produce detailed simulations when implemented appropriately, they require substantial computational resources. This becomes particularly true in complex, time-sensitive multiscale problems that deal with intricate physical phenomenons (for instance, turbulent fluid flows, the dynamics of plasma in fusion devices, and astrodynamic flows) on high resolution grids and meshes. As a result, conducting numerous high-fidelity simulations with these advanced solvers can present considerable computational challenges, especially in scenarios involving uncertainty quantification [6, 64, 67], inverse problems [6, 26, 24, 67], design optimization [73, 74], and optimal control [18].
The computational challenges in high-fidelity simulations have led to the creation of reduced-order models (ROMs). ROMs aim to streamline the complex calculations of the full-order model (the detailed high-fidelity simulation) by reducing the complexity of the problem. While the accuracy of ROMs may slightly drop compared to the full-order-model, they can be considerably faster which makes them very attractive in situations where a small compromise in accuracy is acceptable. Many ROM methods are based on projecting data snapshots from the full-order model.
Methods like proper orthogonal decomposition (POD), the reduced basis method, and the balanced truncation method, which are linear projection techniques, have become increasingly popular in the field of reduced-order modeling (ROM) [5, 60, 62]. These approaches have demonstrated effectiveness in a range of applications, including fluid dynamics [46, 17, 65, 36, 19, 16, 51, 43]. Recently, non-linear projection techniques [41, 40, 47, 22], particularly those using auto-encoders [34, 21], have started to gain traction as an alternative, as these methods achieved higher performance in problems characterized by dominant advection [41, 25, 31].
Projection-based ROM methods driven by data are broadly divided into two categories: intrusive and non-intrusive. Intrusive ROMs, which are informed by the underlying physics, need direct access to the governing equations [60, 22, 40, 47, 17, 36, 19, 43, 50]. This aspect contributes to the sturdiness of their predictions and often requires a smaller amount of data from the full-order model (FOM). However, they also necessitate access to the FOM solver and specific details of implementation, like the discretized residual of the PDE. On the other hand, non-intrusive ROMs do not depend on the governing equations and are solely based on data-driven methods. These typically employ interpolation techniques to associate parameters with their respective ROM predictions [69, 49, 15, 45]. Being entirely black-box in nature, however, these methods often lack interpretability and robustness, sometimes facing challenges in accurate generalization and showing limitations in performance.
To address these issues, newer strategies are integrating projection methods with latent space dynamics learning. In these approaches, the latent space is considered as a dynamical system governed by a set of ordinary differential equations (ODEs). By precisely identifying these ODEs, it becomes possible to forecast the dynamics within the latent space and then map them back into the space of full-order solutions.
Several techniques have been developed to learn governing equations from data, including the popular method known as Sparse Identification of Non-Linear Dynamics (SINDy) [11]. SINDy works by forming a collection of potential terms for the governing ordinary differential equations (ODEs) and uses linear regression to calculate the relevant coefficients. This approach has been widely used and laid the groundwork for the development of various SINDy-based algorithms including both regression-based [61, 53, 52, 10, 39, 68, 35] and neural network approaches [27, 14, 9, 66].
Champion et al. [13] introduced a method to identify sets of governing ODEs directly in the latent space of an auto-encoder. Although this method shows promise, the identified ODEs are not parameterized based on simulation parameters, which limits its applicability across different scenarios. Conversely, Bai and Peng suggested a similar technique [4], but with a linear projection using proper orthogonal decomposition (POD), and they incorporated parameterization of the latent space ODEs. This enhancement allows for ROM predictions at any point in the parameter space. However, their approach faces challenges when applied to advection-dominated problems due to the limitations of POD.
More recently, a framework originally proposed by Fries et al. [25], Latent Space Dynamics Identification (LaSDI) was proposed. Building on the work of Champion et al. and Bai and Peng, the main idea of the LaSDI algorithm is to identify the sets of ODEs governing the auto-encoder latent space, each corresponding to one training data point from the full-order model (FOM). Then, the coefficients of each set of ODEs are interpolated with respect to the FOM parameters, which allows for estimating the set of latent space governing equations for any new parameter in the parameter space. Integrating the ODEs and passing them to the decoder allows to reconstruct the ROM prediction. This initial work laid the foundation for many follow-up LaSDI-based algorithms [25, 31, 8, 7, 32, 72]. Directly building on LaSDI [25], Greedy-LaSDI (gLaSDI) [31] introduced additional constrains to the auto-encoder training loss, enhancing the model’s robustness. gLaSDI also introduced a novel active learning strategy, based on the PDE residual error (intrusive ROM), to acquire additional FOM data during training where it is the most needed. Subsequently, Gaussian Process LaSDI (GPLaSDI) was also introduced [8]. GPLaSDI builds on the elements introduced in gLaSDI, but also employs Gaussian process for interpolating the latent space governing ODEs. This allows for a purely data-driven active learning strategy (non-intrusive ROM), as well as predicting meaningful confidence bounds over the ROM predictions. More recently, WLaSDI [72], short for Weak form-LaSDI introduced a weak formulation to accurately learn the ODE dynamics of the latent space in the presence of substantial noise. Intriguingly, even when there is no noise, using WLaSDI yields a more accurate ROM in many cases. Thermodynamics-LaSDI (tLaSDI) [56] was also proposed, and introduces physical constrains to enforce the first and second laws of thermodynamics within the latent space, for enhanced accuracy.
In this chapter, we provide a comprehensive review of LaSDI algorithms. First, We go through the key LaSDI building blocks (sections 2.1, 2.2, 2.3, 2.6, 2.7 and 2.8) and also introduce elements more specific to WLaSDI (section 2.4), tLaSDI (section 2.5), gLaSDI (section 3.1) and GPLaSDI (section 3.2). Finally, We present results demonstrating the performance of the different LaSDI methods on various examples (sections 4.1, 4.2 and 4.3). Note that in this chapter, the term LaSDI usually refers the set of different LaSDI algorithms, but may (when specified) also refer to the original LaSDI paper [25].
2 Latent Space Dynamics Identification
2.1 Governing Equation of Physical Systems
In this chapter, we consider physical phenomenons described by governing PDEs with the following form:
| (1) |
In Equation (1), the solution may represent either a scalar or vector field over the time-space domain . The spatial domain can be of any dimension, and the differential operator might include a mix of linear and/or non-linear combinations of spatial derivatives and source terms. The governing equations, along with their initial and boundary conditions, are influenced by a set of parameters, represented by a vector . The parameter space is designated as and can have any dimension (for instance, a 2D-parameter space with is considered in subsequent sections). For a specific parameter vector , it’s assumed that we can access the corresponding discretized solution of Equation (1), denoted as . Here, is a matrix composed of sequential snapshots at each time step , arranged as . This solution is acquired either through a full-order model solver or an experiment. In this chapter, all the FOM solutions are compiled into a order tensor dataset , where and are the number of time steps and degrees of freedom, respectively, and is the number of available FOM solutions.
2.2 Auto-encoders
An auto-encoder [34, 28] is a type of neural network specifically tailored for compressing large datasets by diminishing their dimensions through nonlinear transformation. It comprises two interconnected neural networks: the encoder, labeled as and parameterized by , and the decoder, labeled as and parameterized by . The encoder processes an input data snapshot and generates a compressed version in a latent space. Here, denotes the latent dimension, i.e., the number of variables in the latent space. This number is chosen based on design preferences, typically ensuring . Similar to the matrix , we concatenate the latent representations at each time step into a matrix . The latent variables for each time step and for each parameter are compiled into a third-order tensor , similar in structure to the tensor . The decoder takes each as input and generates a reconstructed version of , denoted as .
| (2) | ||||
and are learned using a numerical optimization algorithm that minimizes the norm of the difference between the set of input solutions and the set of reconstructed solutions . The reconstruction loss is defined as:
| (3) | ||||
It should be noted that the auto-encoder acts as a non-linear data projection. Alternatively, a linear projection method, such as POD, may be employed. This option alleviates the cost of training an auto-encoder, but it may result in lower accuracy, especially for advection-dominated problems. A more detailed comparison between auto-encoders and POD is outlined in LaSDI [25] and WLaSDI [72].
2.3 Identification of Latent Space Dynamics
The encoder’s role is to compress high-dimensional physical data, such as solutions of PDEs that span both space and time, into a more compact array of discrete and abstract latent variables, defined over the time dimension. As a result, the latent space can effectively be viewed as a dynamical system, but now governed by ordinary differential equations (ODEs). This feature is a key element in LaSDI algorithms. For each discrete time step, the behavior of the latent variables within this latent space can be represented by a specific equation form. At each time step, the dynamics of the latent variables in the latent space can be described by an equation of the following form:
| (4) |
where represents a Dynamics Identification (DI) function governing the latent space dynamics, which can be defined as a system of ODEs and identified using the Sparse Identification of Nonlinear Dynamics (SINDy) method [11]. SINDy involves creating a library, , which is composed of linear and nonlinear potential terms that could be part of the ODEs. This method is based on the premise that the time derivatives of , denoted as , can be represented as a linear combination of these selected terms. Consequently, the equation that describes the system’s behavior on the right-hand side can be estimated in the following manner:
| (5) |
where denotes an ODE coefficient matrix associated with . The selection of terms in is a design choice. To capture the latent space dynamics more accurately, it may be desirable to include a broad variety of terms, although this may lead to sets of ODE more challenging and longer to solve numerically. can be written explicitly as:
| (6) |
where are basis functions that output arbitrary linear and/or non-linear transformations of each terms in to build the SINDy library. represents the latent variable for parameter at time step . Sparse linear regressions are performed between and for each . The resulting coefficients associated with each SINDy term are stored in a vector . The system of SINDy regressions can be expressed as:
| (7) |
Each set of coefficients is compiled into a coefficient matrix . Since a unique set of ODEs controls the dynamics within the latent space for each parameter vector , several SINDy regressions are conducted simultaneously to identify the respective sets of ODE coefficients , where . The ensemble of ODE coefficient matrices , corresponding to each ODE system, is learned by minimizing the mean-squared-error loss specific to SINDy.
| (8) | ||||
The time derivatives may be computed using a finite difference [8] or, alternatively, using the chain rule [25, 31]:
| (9) |
The aforementioned approach is a local DI method where each parameter has its own coefficient matrix. During testing, the local SINDy of training parameters can be exploited to estimate the SINDy associated with the testing parameter. More details will be presented in Section 2.7. Alternatively, a global DI approach can also be adopted in which only one coefficient matrix is employed to model the latent space dynamics for all parameters.
2.4 Weak-form Identification
The coefficient matrix referenced in equation (5) can alternatively be determined using weak-form equation learning methods. This approach replaces the need to directly approximate pointwise derivatives from data (in the presence of noise, this is a particularly challenging task). Instead, the variance-reduction nature of the weak-form facilitates a more robust and accurate system recovery. In this section, we present WLaSDI [72], a direct extension of LaSDI [25] that leverages the weak-form equation learning technique.
We begin by transforming equation (7) into the weak-form through multiplication by an absolutely continuous test function and integrating it over the time domain:
Integration by parts yields:
Choosing to be compactly supported in , i.e., , we have:
| (10) |
We use the trapezoidal rule to discretize the integrals in equation (10) numerically and assume that observations of the system’s state have a uniform time step of .1††1It is possible to use a non-uniform time interval, but this necessitates modifications to the test function matrices. Let be the set of compactly supported test functions placed uniformly along the time domain, we define the test function matrices:
| (11) |
From there, we have
| (12) |
for and . By solving the least square problem, we identify the coefficient vector subject to:
| (13) |
The weak-SINDy loss can then be defined as:
| (14) |
The test functions employed in weak-form equation learning include high order polynomial or bump functions. For further details about how to choose these test functions, please refer to [10, 52, 53].
2.5 Thermodynamics-informed Latent Space Dynamics Identification (tLaSDI)
tLaSDI [56] utilizes a neural network-based model to embed the General Equation for Non-Equilibrium Reversible-Irreversible Coupling (GENERIC) formalism [29, 55] into the latent space dynamics. The GENERIC formalism is a mathematical framework that covers both conservative and dissipative systems, offering a general description of beyond-equilibrium thermodynamic systems. This formalism models dynamical systems through four key functions – the scalar functions and that representing the system’s total energy and entropy, respectively, and two matrix-valued functions, and , referred to as the Poisson and friction matrices, respectively.
| (15) |
The degeneracy and structural conditions ensure the first and second laws of thermodynamics, i.e., the properties of energy conservation and non-decreasing entropy, and .
2.5.1 GFINNs
Several neural network-based models were proposed to incorporate the GENERIC formalism [33, 48, 76]. While other alternatives are equally applicable, tLaSDI utilizes the model proposed in [76], namely, GENERIC Formalism Informed Neural Networks (GFINNs). We direct readers to refer to [76] for more details. The GFINNs consists of neural networks – , , and – that represent , , and in equation (15), respectively. These neural networks are constructed to exactly satisfy the degeneracy conditions in (15) while also being sufficiently expressive to capture the underlying dynamics from data. We denote the GFINNs by , where represents the neural network parameters in the model.
We note that GFINNs are global DI model and do not have parameter dependence. Instead, tLaSDI lets the network parameters of the encoder and the decoder depend on parameters by employing hypernetworks [30].
The hypernetwork is a neural network that takes a parameter as input and outputs the network parameters of another neural network. In tLaSDI, two distinct hypernetworks and are utilized to output the network parameters of the encoder and decoder. The network parameters for encoder and decoder at parameter are denoted as and , respectively.
2.6 Training Loss
In LaSDI [25], the auto-encoder and SINDy are trained separately. Hower, for enhanced accuracy and robustness when identifying the latent space dynamics, in gLaSDI [31], the auto-encoder and SINDy are trained simultaneously. gLaSDI also introduced an additional loss term: the mean-squared-error of the velocity, computed through the chain rule:
| (18) |
| (19) |
In GPLaSDI [8], a penalty is also added to the SINDy coefficients. This enforce smaller values of the ODE coefficients, which leads to better conditioned ODEs. The LaSDI training loss, weighted with hyperparameters , , and is:
| (20) | ||||
where may be either the vanilla SINDy loss (equation (8)) or the weak SINDy loss (equation (14)). In tLaSDI, the latent space dynamics is not learned through SINDy, so the training loss has a slightly different (yet equivalent) formalism:
| (21) | ||||
where , , and are hyperparameters (analog to , , and in equation (20)). The first and second terms of are analog to and in the gLaSDI training loss, respectively. Furthermore, the Jacobian loss is defined as
| (22) |
The loss components are based on the error estimates of ROM approximation provided in [56].
2.7 Parameterized Latent Space Dynamics Interpolation
The auto-encoder learns a latent space dynamical representation of each training parameter. In the local Dynamics Identification (DI) approach, a set of SINDy’s or weak-SINDy’s learns the ODEs governing the latent space dynamics of training parameters. However, the set of ODE coefficients associated with a new parameter (distinct from the set of training parameters ) remains unknown. It can be estimated by finding an interpolant of the learned ODE coefficients, given and , . Several interpolants have been proposed in the literature, and we briefly cover three of them here, RBF interpolation, as used in LaSDI [25], NN, as used in gLaSDI [31], and Gaussian process regression (GP), as introduced in GPLaSDI [8].
2.7.1 RBF Interpolation
Let us consider a domain . may be a subset of the parameter space (local Dynamics Identification), or the full space (global Dynamics Identification). The interpolated ODE coefficient matrix can be expressed as:
| (23) |
is a radial basis function (RBF). For example in LaSDI [25], a multiquadric function is used:
| (24) |
is the euclidian distance between and , is a length-scale typically chosen as the average distance between each and the coefficients are computed by solving a linear system depending on the set of matrices associated with each parameter .
2.7.2 Nearest-Neighbours Interpolation
Similarly to RBF interpolation, in NN interpolation, the ODE coefficient matrix can be written as:
| (25) |
is the set of indices of the -nearest-neighbours of (i.e. associated with training parameters ). The interpolation basis are defined as:
| (26) |
where is the Mahalanobis distance. Here, partition of unity is satisfied () and convexity preservation is guaranteed [31].
2.7.3 Gaussian Process Regression
In a Gaussian process regression [59], the fitting function is stochastic and is assumed to follow a prior Gaussian probability distribution:
| (27) |
is an arbitrary covariance kernel, function of the input data (i.e. the set of parameters ) and some trainable hyper-parameters. In GPLaSDI [8], the kernel is chosen as a squared-exponential function. Using both Bayes’ Rule and the sum and product rules of probability, it can be shown that the predictive distribution of the interpolated set of ODE coefficients, , follows a Gaussian distribution:
| (28) |
and are the predictive mean and standard deviation, which depend on , , , and the kernel function. It should be emphasized that unlike RBF and NN regression, is here not deterministic and may thus take an infinity of possible values. Since it follows a Gaussian distribution, we may only consider its most likely value, the mean (), with some confidence interval defined by .
2.8 Predicting Solutions
Once the auto-encoder has been properly trained and the latent space governing ODEs have been learned (section 2.2, 2.3, 2.4 and 2.6), ROM prediction for an arbitrary test parameter is straightforward and can be made through the following steps:
-
1.
Estimate by interpolating the set of learned ODE coefficients using one of the interpolator introduced in section 2.7. If using GP regression, in-lieu of , a sample from the predictive distribution may be used: , , with an arbitrary number of samples.
-
2.
Build and solve the set of ODEs associated with (equation (5)) using a standard numerical integrator. The initial condition can be computed using the encoder (), where is a function of . The approximate latent-space solution is noted .
-
3.
Make a forward pass through the decoder to map the ROM prediction back into the full-order space.
Note that if using GP regression to interpolate the latent space governing equations, step 1, 2 and 3 may be repeated for a finite number of samples. The ROM prediction can then be taken as the average prediction over all the samples (). Similarly, the standard deviation can also be computed to estimate prediction uncertainty. In tLaSDI, the prediction do not involve interpolation methods as GFINN is a global DI model independent of parameters. The tLaSDI prediction for a test parameter can be conducted through the following analog steps:
-
1.
Evaluate the network parameters of the encoder and decoder using corresponding hypernetworks, i.e., and .
-
2.
Solve the latent space dynamics (equation (15)) represented by GFINNs using a numerical integrator. The initial condition is given by . The approximate solution is denoted as .
-
3.
Use the decoder to return the prediction in the full-order space, i.e., .
3 Greedy Sampling
One key aspect of LaSDI algorithms is to train an auto-encoder and learn the governing dynamics in the latent space. To that end, choosing the appropriate training data is crucial. In LaSDI [25] and WLaSDI [72], each FOM solution data point is associated with equispaced parameters , located on a grid within the parameter space . While this approach is simple, easy to implement, and may provide satisfactory performance, more sophisticated approaches have been proposed in gLaSDI [31] and GPLaSDI [8]. In these two papers, an active learning strategy is employed, where instead of having access to the entire training dataset upfront, the training data is collected on the fly. This allows for collecting only the data that is the most needed while maximizing model performances. In this section, we present the key aspects of these two methods. The general greedy sampling framework is described in algorithm 1
3.1 Residual-Based Greedy Sampling (gLaSDI)
For a given test parameter, the ROM prediction error may be estimated using the time-averaged PDE residual of the FOM governing equation:
| (29) |
refers to the discretized residual of the governing PDE (equation (1)). is the number of time steps used to estimate the residual. When is expensive to evaluate, it may be desirable to evaluate the residual only at a handfull of time steps, and we may thus consider .
In gLaSDI [31], the training process is initialized using a limited number () of training FOM simulations. The training is then paused every epochs, and the (current) LaSDI model is used to make predictions at a finite number of test parameters ( is a discretized representation of the parameter space). Each prediction is plugged into equation (29) to compute the residual error, and the next sampling parameter can be selected as the one associated with the ROM solution yielding the largest residual:
| (30) |
A high-fidelity simulation can then be run for parameter , and the resulting solution is added to the training dataset before resuming the training process. This operation may be repeated until the budget for running FOM simulations has been exhausted, or the ROM predictions have become sufficiently accurate. The residual-based greedy sampling is also employed in tLaSDI [56] following the algorithm proposed in [31].
3.2 Uncertainty-Based Greedy Sampling (GPLaSDI)
As described in section 2.8, when using GP interpolation, the uncertainty in the latent space dynamics may be propagated through the decoder, and the ROM prediction variance can be computed for any time step :
| (31) |
represent the latent space dynamics solved for a sampled ODE coefficient matrix (equation (28)). The variance at each time step can be computed and the variance across time and space is written .
An uncertainty based strategy for picking the next sampling parameter can now easily be implemented. The general approach is very similar to the residual-based greedy sampling strategy presented in section 3.1, but instead of picking the parameter yielding the largest residual error, we pick the parameter yielding the largest ROM variance (at any point in time and space):
| (32) |
Note that in order to properly quantify the ROM variance (), for each , the GP predictive distribution needs to be sampled times, and the corresponding ODE needs to be solved and fed to the decoder. Therefore, this approach requires more ROM prediction than the residual-based greedy sampling approach. However, this approach does not require to evaluate the PDE residual at any time. Thus, GPLaSDI is non-intrusive and may be particularly suitable when the residual is difficult to implement, expensive to evaluate, or simply unknown (e.g. legacy codes for high-fidelity simulations).
4 Application
We now briefly summarize results and examples originally introduced in [25, 31, 72, 8, 56], and cover in particular the 1D Burgers equation (section 4.1), the non-linear heat equation (section 4.2), and a two-stream plasma instability problem (section 4.3). In each of the following section, the error metric used is the maximum relative error defined as:
| (33) |
where the quantities with a tilde are predictions.
4.1 1D Burgers Equation
In this first application, we use a simple benchmark problem to compare the different LaSDI algorithms introduced in the previous two sections. We consider the following inviscid 1D Burgers equation:
| (34) |
The initial condition is parameterized by , and the parameter space is defined as :
| (35) |
The parameter space is discretized into a square grid with a stepping of , resulting in a total of 441 grid points ( values in each dimension). The high-fidelity solver employs a classic backward Euler time integration, and a finite difference discretization in space ( and ).
4.1.1 LaSDI vs. gLaSDI
We first compare the performances of LaSDI trained with pre-selected data, or data selected on the fly using residual-based greedy sampling (gLaSDI) [31]. For the encoder, we employ a 1001-100-5 fully-connected hidden layers/hidden units architecture (), with sigmoid activation functions, and a symmetric architecture for the decoder. The loss hyperparameters are taken as , , and . We also consider training epochs, with a greedy sampling rate. The SINDy library is restricted to linear terms and the ODE coefficients are interpolated with NN interpolation ( and are employed during gLaSDI training and evaluation, respectively, and is employed for LaSDI). The four corner parameters of are used to generate the initial training data points (, , and ) At the end of the training, a total of 25 training data points are being used.
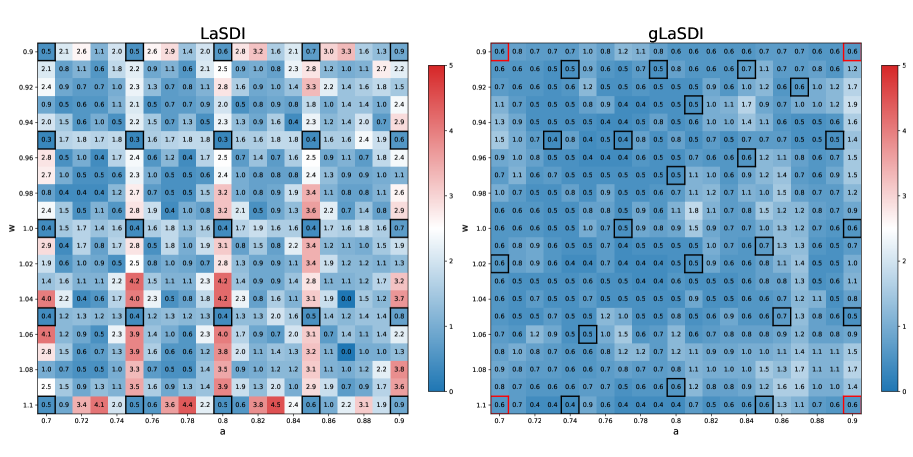
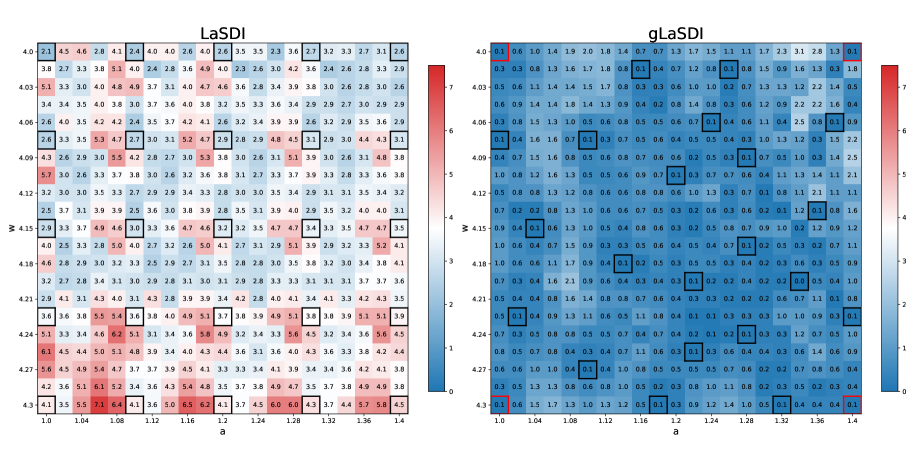
Figure 1 shows a comparison between LaSDI and gLaSDI maximum relative error across the parameter space. Both achieve excellent accuracy: at most error for LaSDI (trained on a parameter grid), and at most error for gLaSDI. Since gLaSDI selects training data based on the worst residual error, areas of the parameter space yielding large prediction errors will eventually concentrate more data, helping to capture the correct physics more accurately and faster.
4.1.2 GPLaSDI vs. gLaSDI
We now compare the performance of variance-based greedy sampling (GPLaSDI) and residual-based greedy sampling (gLaSDI). We consider a similar auto-encoder architecture as in the previous experiment (1001-100-5-100-1001), and use , , and for the loss hyperparameters. Like earlier, we restrict the SINDy library to linear terms only. Since GPLaSDI employs Gaussian processes for interpolating the latent space ODEs, we also interpolate the latent space ODEs in gLaSDI with GPs for a more fair comparison. Even if GPs are employed along with gLaSDI here, the uncertainty information is not exploited and the additional training data is selected solely through the residual error (as in the previous experiment). In GPLaSDI, we employ ODE samples to compute the ROM prediction variance, and train both models for epochs with sampling rate (13 training data points are collected on the fly, along with the 4 initialization corner points).
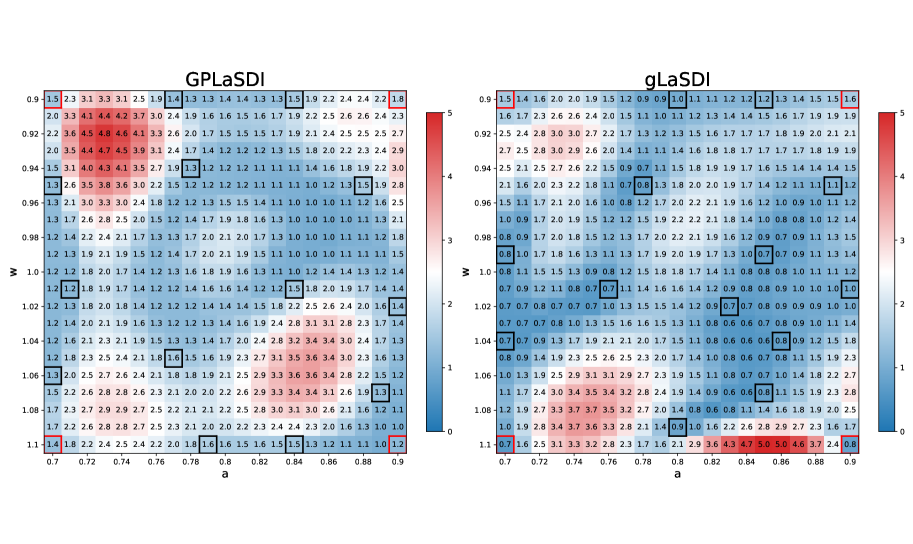
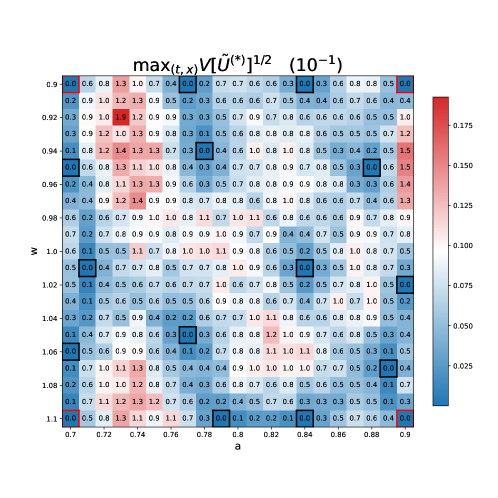
Figure 2 shows a comparison between GPLaSDI and gLaSDI. Both cases achieve very similar performance (at most and error for GPLaSDI and gLaSDI respectively). One might expect gLaSDI to perform generally better than GPLaSDI, because the former has direct access to physics information (through the PDE residual), while GPLaSDI is purely data-driven. Here however, GPLaSDI is able to achieve similar performance than gLaSDI. This indicates that in the present case, sampling new data for parameters yielding the largest ROM variance or the largest residual error is equivalent. Figure 3 shows the maximum ROM standard deviation across time and space, for each parameter of the discretized parameter space. There is a strong correlation between GPLaSDI’s maximum relative error and maximum standard deviation, which is consistent with the expectation that reducing the prediction uncertainty should also reduce the error.
4.1.3 LaSDI vs. Weak-LaSDI
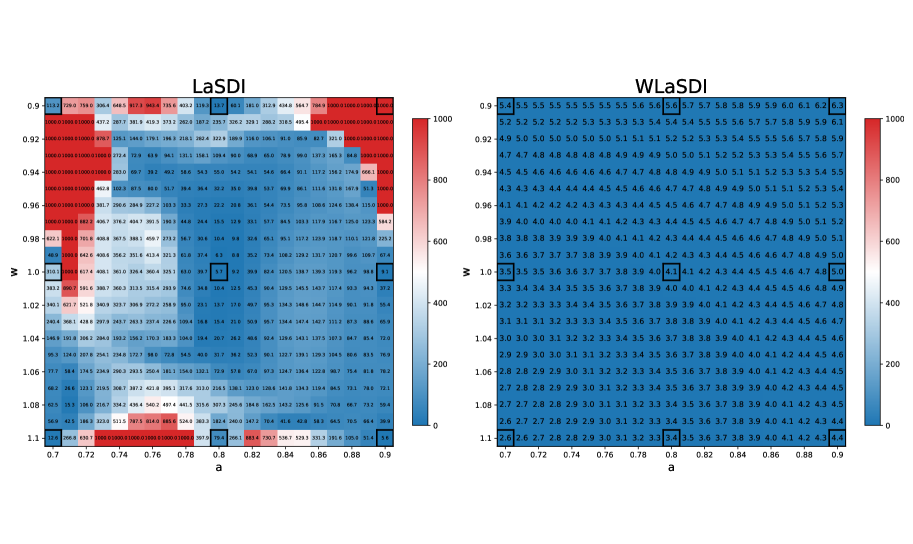
In this experiment, we evaluate the performance of LaSDI and WLaSDI, comparing them under a fixed number of training data points. Active learning is intentionally excluded, as the primary goal is to demonstrate the robustness of the weak-form in comparison with the strong form. A shallow-masked auto-encoder architecture is utilized [42] for the nonlinear ROM creation. The training data contains 9 high-fidelity simulations (of the inviscid Burgers’ equation) corresponding to the combination of each value of and where and . We consider 2 cases: Figure 4 illustrates the difference between LaSDI and WLaSDI without any added noise, whereas Figure 5 demonstrates the difference between LaSDI and WLaSDI with added Gaussian white noise. The ODE coefficients governing the latent space dynamics are interpolated using Radial basis function interpolation. To ensure a fair comparison, the type of radial basis function and the radius are kept consistent between LaSDI and WLaSDI. Note that in both cases, the relative error is bounded below by the error of the autoencoder. Exploring better autoencoder architecture may lead to improvements. In the noise-free case, the projection error introduced by the autoencoder is about across the parameter space. Meanwhile, for the noisy case, it is about .
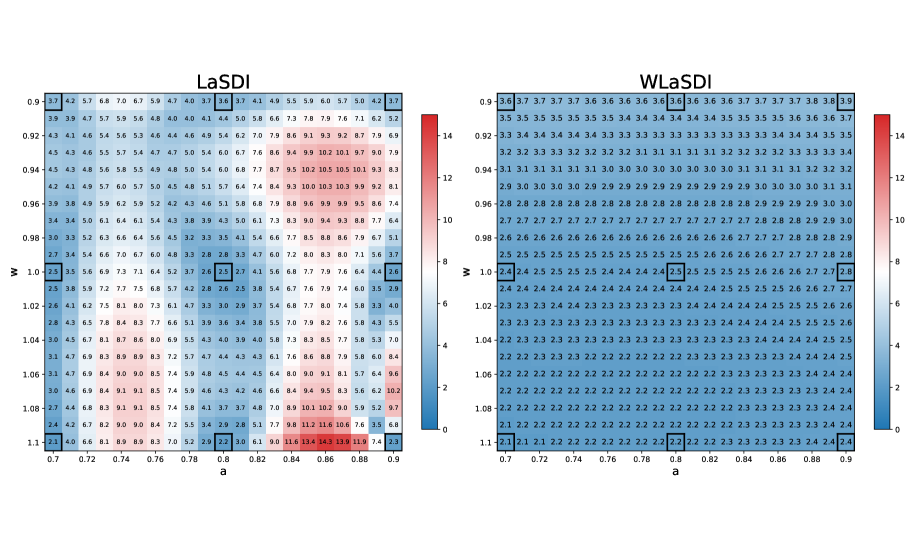
For Figure 4, the depicted results show the maximum relative error across the parameter space when employing LaSDI and WLaSDI without any noise. In the case of LaSDI, the error varies between and , while WLaSDI demonstrates a lower error, remaining below (nearly achieving the minimum possible error, given the autoencoder architecture limitations). Figure 5 depicts the same comparison, but for data with noise. In the noisy scenario, LaSDI frequently returns values with errors in excess of (any value exceeding is capped at in Figure 5), whereas WLaSDI maintains a more controlled error, staying below . In these instances, the strong form requires approximately seconds, while the weak-form computation takes about seconds. Therefore, for a tenfold increase in computation time, the error is reduced by two to three orders of magnitude (at the noise level).
The perturbations in the data introduced by the noise propagate through the encoder, making it challenging to approximate the time derivative of the latent space. By eliminating the need to approximate the pointwise derivative as well as leveraging the variance-reduction nature of the integral, the weak form allows for more accurate identification of the governing ODEs.
Given its robustness against noise, WLaSDI is particularly well suited for building numerical models based solely on experimental data2 ††2 Note that the weak version of SDI methods would also be effective in attempting to find a ROM from models with a stochastic component, like a Particle-In-Cell simulation. especially when combined with GPLaSDI for efficient data sampling.
4.1.4 tLaSDI vs. gLaSDI
In this last experiment, we compare the performance of tLaSDI and gLaSDI utilizing different temporal and parameter domains, specifically , . Due to the extended temporal domain, the solutions exhibit stiff behaviors as time approaches the final time (). The training data are discretized with the spatial and time spacing , , which are subsampled from the high-fidelity data with and . We used the auto-encoder architecture (201-100-10-100-201) for both methods. The sigmoid and ReLU activation functions are used to train auto-encoders of gLaSDI and tLaSDI respectively. In tLaSDI, all neural networks within GFINNs consist of layers and neurons in each hidden layer, and the hyperbolic tangent activation function is employed to train them. The loss hyperparameters for gLaSDI are set to , , and . For tLaSDI, the loss weights , , and are employed. Both methods utilize the residual-based greedy sampling for training epochs with a sampling rate . A total of training data points are collected on the fly, in addition to initial samples at the corners of parameter space. For gLaSDI, quadratic polynomials are used for the SINDy library, and the ODE coefficients are interpolated with NN interpolation with and during training and evaluation, respectively.
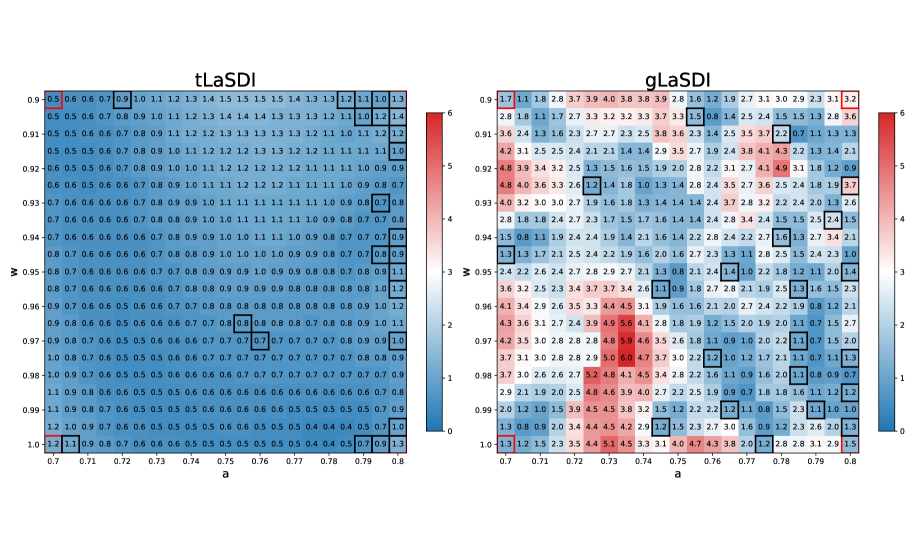
Figure 6 depicts a comparison between tLaSDI and gLaSDI in terms of maximum relative errors over the parameter domain. Both algorithms achieve high prediction accuracy (at most for tLaSDI and for gLaSDI). The sampled parameters for tLaSDI tend to cluster near the domain boundaries. For both methods, a higher concentration of training data is observed in regions of large amplitudes () that correspond to the solutions exhibiting stiffer behavior. This demonstrates that both methods effectively select training data points using the greedy sampling strategy to accurately predict solutions exhibiting stiff patterns. The effective prediction performance of tLaSDI is due to its loss function and incorporation of laws of physics (thermodynamics) in the latent space.
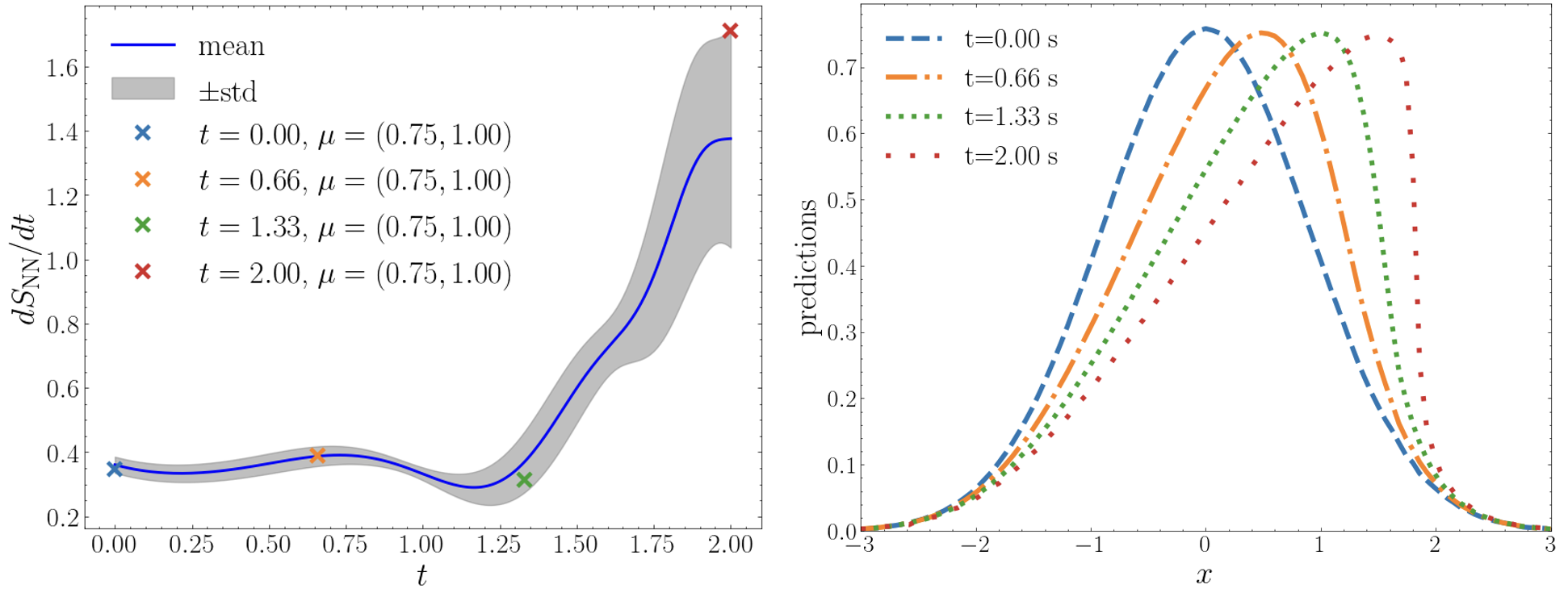
tLaSDI constructs a thermodynamic structure in the latent space dynamics which provides the neural network based entropy function in the latent space. Figure 7 illustrates the entropy production rate with respect to time. The mean over all the test parameters is reported and the shared area represents one standard deviation away from the mean. As promised by GFINNs, we observe that the entropy increases as the rate is always non-negative. The entropy production rate has the largest value at the final time , which happens to be the time where the full-state solution exhibits the stiffest pattern. See the right of Figure 7 for the tLaSDI prediction at varying times.
4.2 2D Non-Linear Heat Equation with Residual-based Greedy Sampling
In this second example, we consider the non-linear heat equation in 2D introduced in gLaSDI [31]:
| (36) |
The diffusion coefficients are chosen as and . The initial condition is parameterized by , and the parameter space is defined as :
| (37) |
The parameter space is discretized into a square grid with stepping and , resulting in a total of 441 grid points ( values in each dimension). To generate the high-fidelity data, we rely on a finite element code, MFEM [3], and we discretize the spatial domain with 1024 first-order square elements. For time integration, we employ a backward Euler scheme ().
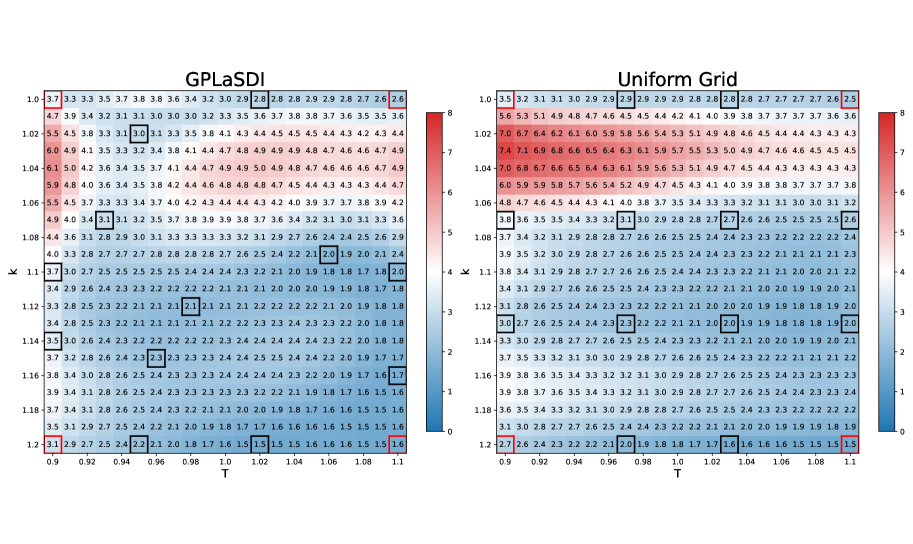
The encoder employs a 1089-100-3 fully-connected hidden layers/hidden units architecture (), with sigmoid activation functions, and a symmetric architecture for the decoder. The loss hyperparameters are taken as , , and . We also consider training epochs, with a greedy sampling rate. The ODE coefficients are interpolated with NN interpolation ( and are employed during gLaSDI training and evaluation, respectively, and is employed for LaSDI). The four corner parameters of are used to generate the initial training data points (, , and ) At the end of the training, there are a total of 25 training data points. We compare the performance of gLaSDI (residual-based greedy sampling) with LaSDI trained on a uniform parameter grid.
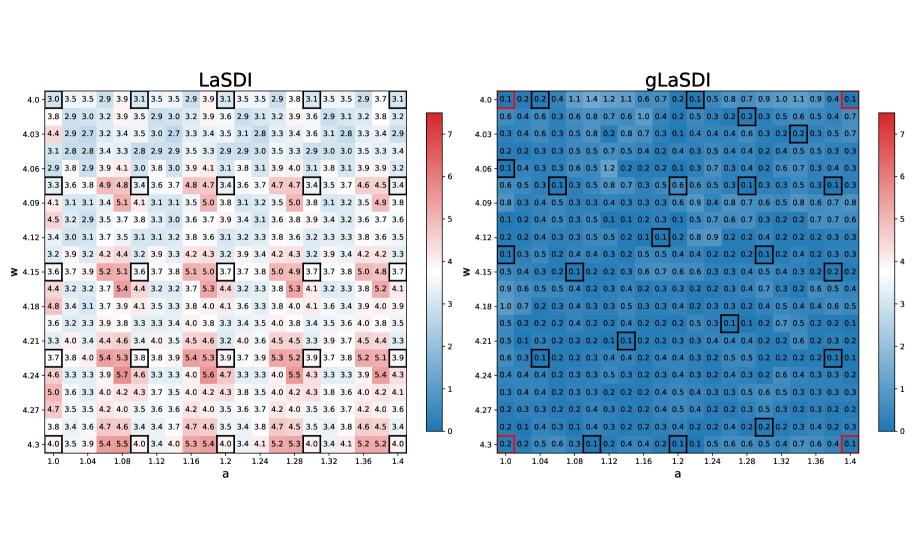
Figure 8 illustrates the maximum relative error when using LaSDI and gLaSDI, with a SINDy library restricted to linear terms only. As already observed with the 1D Burgers equation example, gLaSDI clearly outperforms LaSDI by selecting the most appropriate training data. gLaSDI achieves at most maximum relative error, whereas LaSDI maximum relative error can be as high as . The choice of candidate terms used in the SINDy library is purely arbitrary. Thus, we do not have to restrict it to linear terms only. Figure 9 shows the maximum relative error for the same experiment, but this time using both linear and quadratic candidate terms in the SINDy library. Interestingly, a slight deterioration of performances is noticed (at most and error for gLaSDI and LaSDI, respectively). This indicates that while a broader selection of SINDy candidate terms may theoretically capture the latent space dynamics more accurately, it is not always the case in practice. A simpler set of candidate (e.g. linear terms) may sometime be sufficient. In fact, increasing the number of SINDy candidate terms means that more ODE coefficients need to be interpolated, so the potential for interpolation error increases accordingly. gLaSDI achieves speed-up (with linear and quadratic SINDy library), and speed-up (with linear SINDy library only). As a result, restricting the SINDy library to linear terms not only achieves better performance in this example, it is also faster. This is not surprising since in the later case, less ODE coefficients need to be interpolated, and the ODE are simpler to integrate numerically.
4.3 1D-1V Vlasov Equation with Variance-based Greedy Sampling
In this last example, we introduce a GPLaSDI example to showcase the variance based active learning strategy. We consider the simplified 1D–1V Vlasov–Poisson equation, for which implementing the residual-based sampling strategy is cumbersome:
| (38) |
is the plasma distribution function, dependant on a spatial coordinate and a velocity coordinate , and is the electrostatic potential. This model describes collisionless electrostatic plasma dynamics within a 1-dimensional space, and is representative of more complex plasma behaviors occuring in nuclear fusion reactors. Due to the velocity variable, this equation can be seen (and solved) as a 2D-PDE. The initial condition is a two-stream instability problem described by the following expression:
| (39) |
We consider two simulation parameters, and (). The parameter space is discretized over a grid , with a step size of . The initial training data contains the four corners of the parameter space (). To generate the FOM data, we employ HyPar [1], a conservative finite difference PDE code with a WENO spatial discretization [37] and the classical fourth–order Runge–Kutta time integration scheme (). The auto-encoder employs fully connected layers with softplus activation functions, and latent space variables. The SINDy library is restricted to linear and constant terms, which we have found to be sufficient for modeling the latent space dynamics (in this example, WLaSDI is not used). GPLaSDI is trained with epochs, and a FOM data sampling rate every epochs (resulting in adding 12 data points during training, for a total of 16 training points). More details on the models hyperparameters can be found in [8].
For baseline comparison, we also trained the same model but with pre-selected training parameters. The 16 training data points are associated with parameters located along a uniform grid. All the training hyperparameters are kept identical and the baseline model also employs GPs for interpolating the latent space ODE coefficients. Figure 10 presents the maximum relative error for each point in the parameter space obtained using GPLaSDI and the baseline model. With GPLaSDI, the worst maximum relative error is , and in most regions of the parameter space, the error remains within the range of . The highest errors are concentrated towards smaller values of (typically ). Compared to uniform sampling, GPLaSDI outperforms the baseline model, which achieves a maximum relative error of . It is clear that the variance-based sampling reduces the error faster by selecting data where it is needed the most.
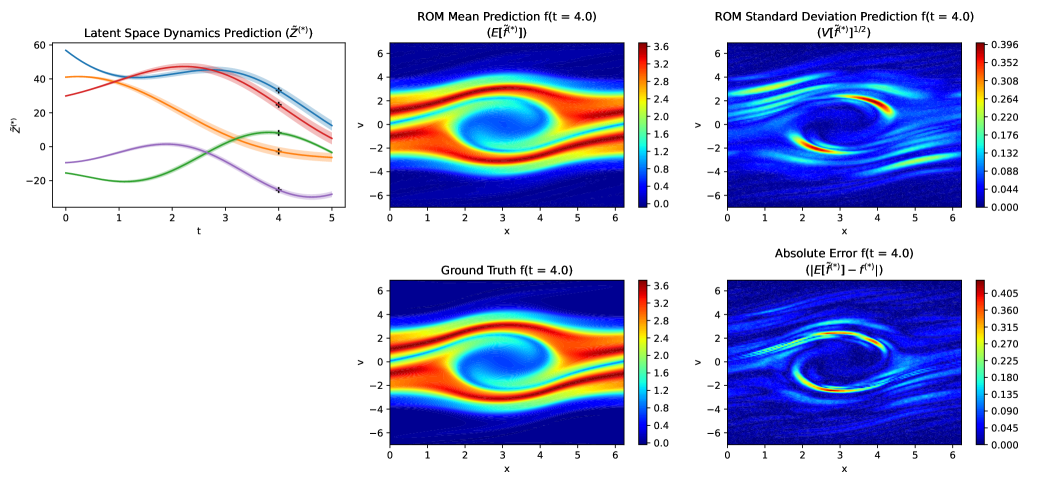
Figure 11 displays the latent space dynamics, including the predicted and ground truth values of , the absolute error, and the predictive standard deviation. The results correspond to the least favorable case () at . The standard deviation of the reduced-order model (ROM) exhibits qualitative similarity to the absolute error, and the error generally falls within about 1-standard-deviation. This shows that GPLaSDI is able to output meaningful confidence intervals with well quantified uncertainty.
In separate test runs, the FOM requires an average wall clock run–time of seconds when utilizing four cores, and seconds when using a single core. In contrast, the ROM model achieves an average run–time of seconds, resulting in a remarkable average speed-up of ( when compared to the parallel FOM). Note that this speed-up is obtained using the mean prediction only, and thus does not permits uncertainty quantification (i.e. rather than sampling multiple times , we take ).
5 Conclusion
In this chapter, we have summarized the key building blocks that can be used and interchanged to develop LaSDI-based ROMs. By training an auto-encoder over high-fidelity data, we can effectively compress complex physics described by a PDE into simpler latent dynamics described by coupled ODEs. The latent space dynamics can be identified during the auto-encoder training using SINDy, Weak-SINDy, or the GENERIC framework. Interpolation can be applied to exploit the local latent space dynamics of training parameters for the prediction of testing parameters. Finally, active learning can be employed through either the residual-based error (gLaSDI for intrusive ROM) or the prediction uncertainty (GPLaSDI for non-intrusive ROM). LaSDI algorithms achieve remarkable performance, both in terms of accuracy (typically less than a - maximum relative error) and efficiency (up to a few thousand times speed-up). The LaSDI framework can be applied to a wide variety of non-equilibrium physical problems, as we demonstrated with the Burgers equation, the non-linear heat equation, and the Vlasov equation. Recent development and extension have enabled LaSDI to be robust against noisy data (WLaSDI), to rigorously respect the laws of thermodynamics (tLaSDI), efficiently sample training data (gLaSDI, GPLaSDI), and provide meaningful prediction confidence intervals (GPLaSDI).
5.0.1 Acknowledgements
This work received support from the U.S. Department of Energy, Office of Science, Office of Advanced Scientific Computing Research, as part of the CHaRMNET Mathematical Multifaceted Integrated Capability Center (MMICC) program, under Award Number DE-SC0023164 to YC at Lawrence Livermore National Laboratory, and under Award Number DE-SC0023346 to DMB at the University of Colorado Boulder. The LLNL Lab Directed Research and Development Program is acknowledged for funding support of this research under Project No. 21-SI-006. JP was supported by a KIAS Individual Grant (AP095601) via the Center for AI and Natural Sciences at Korea Institute for Advanced Study. YS was partially supported for this work by the NRF grant funded by the Ministry of Science and ICT of Korea (RS-2023-00219980). Livermore National Laboratory is operated by Lawrence Livermore National Security, LLC, for the U.S. Department of Energy, National Nuclear Security Administration under Contract DE-AC52-07NA27344. IM release number: LLNL-BOOK-861682.
References
- [1] HyPar Repository, https://bitbucket.org/deboghosh/hypar
- [2] Review of digital twin about concepts, technologies, and industrial applications. Journal of Manufacturing Systems 58, 346–361 (2020). https://doi.org/10.1016/J.JMSY.2020.06.017
- [3] Anderson, R., Andrej, J., Barker, A., Bramwell, J., Camier, J.S., Cerveny, J., Dobrev, V., Dudouit, Y., Fisher, A., Kolev, T., Pazner, W., Stowell, M., Tomov, V., Akkerman, I., Dahm, J., Medina, D., Zampini, S.: MFEM: A modular finite element methods library. Computers & Mathematics with Applications 81, 42–74 (2021). https://doi.org/10.1016/j.camwa.2020.06.009
- [4] Bai, Z., Peng, L.: Non-intrusive nonlinear model reduction via machine learning approximations to low-dimensional operators (2021). https://doi.org/10.48550/ARXIV.2106.09658, https://arxiv.org/abs/2106.09658
- [5] Berkooz, G., Holmes, P., Lumley, J.L.: The proper orthogonal decomposition in the analysis of turbulent flows. Annual Review of Fluid Mechanics 25(1), 539–575 (1993). https://doi.org/10.1146/annurev.fl.25.010193.002543, https://doi.org/10.1146/annurev.fl.25.010193.002543
- [6] Biegler, L., Biros, G., Ghattas, O., Heinkenschloss, M., Keyes, D., Mallick, B., Marzouk, Y., Tenorio, L., van Bloemen Waanders, B., Willcox, K.: Large-scale inverse problems and quantification of uncertainty (2010). https://doi.org/10.1002/9780470685853, http://hdl.handle.net/10754/656260
- [7] Bonneville, C., Choi, Y., Ghosh, D., Belof, J.L.: Data-driven autoencoder numerical solver with uncertainty quantification for fast physical simulations (2023)
- [8] Bonneville, C., Choi, Y., Ghosh, D., Belof, J.L.: Gplasdi: Gaussian process-based interpretable latent space dynamics identification through deep autoencoder. Computer Methods in Applied Mechanics and Engineering 418, 116535 (2024). https://doi.org/https://doi.org/10.1016/j.cma.2023.116535, https://www.sciencedirect.com/science/article/pii/S004578252300659X
- [9] Bonneville, C., Earls, C.: Bayesian deep learning for partial differential equation parameter discovery with sparse and noisy data. Journal of Computational Physics: X 16, 100115 (2022). https://doi.org/https://doi.org/10.1016/j.jcpx.2022.100115, https://www.sciencedirect.com/science/article/pii/S2590055222000117
- [10] Bortz, D.M., Messenger, D.A., Dukic, V.: Direct Estimation of Parameters in ODE Models Using WENDy: Weak-form Estimation of Nonlinear Dynamics. Bull. Math. Biol. 85(110) (2023). https://doi.org/DOI:10.1007/S11538-023-01208-6
- [11] Brunton, S.L., Proctor, J.L., Kutz, J.N.: Discovering governing equations from data by sparse identification of nonlinear dynamical systems. Proceedings of the National Academy of Sciences 113(15), 3932–3937 (2016). https://doi.org/10.1073/pnas.1517384113, https://www.pnas.org/doi/abs/10.1073/pnas.1517384113
- [12] Calder, M., Craig, C., Culley, D., Cani, R., Donnelly, C., Douglas, R., Edmonds, B., Gascoigne, J., Gilbert, N., Hargrove, C., Hinds, D., Lane, D., Mitchell, D., Pavey, G., Robertson, D., Rosewell, B., Sherwin, S., Walport, M., Wilson, A.: Computational modelling for decision-making: Where, why, what, who and how. Royal Society Open Science 5, 172096 (06 2018). https://doi.org/10.1098/rsos.172096
- [13] Champion, K., Lusch, B., Kutz, J.N., Brunton, S.L.: Data-driven discovery of coordinates and governing equations. Proceedings of the National Academy of Sciences 116(45), 22445–22451 (2019). https://doi.org/10.1073/pnas.1906995116, https://www.pnas.org/doi/abs/10.1073/pnas.1906995116
- [14] Chen, Z., Liu, Y., Sun, H.: Physics-informed learning of governing equations from scarce data. Nature Communications 12(1) (oct 2021). https://doi.org/10.1038/s41467-021-26434-1, https://doi.org/10.1038/s41467-021-26434-1
- [15] Cheng, K., Zimmermann, R.: Sliced gradient-enhanced kriging for high-dimensional function approximation and aerodynamic modeling (04 2022)
- [16] Cheung, S.W., Choi, Y., Copeland, D.M., Huynh, K.: Local lagrangian reduced-order modeling for rayleigh-taylor instability by solution manifold decomposition (2022). https://doi.org/10.48550/ARXIV.2201.07335, https://arxiv.org/abs/2201.07335
- [17] Choi, Y., Coombs, D., Anderson, R.: Sns: A solution-based nonlinear subspace method for time-dependent model order reduction. SIAM Journal on Scientific Computing 42(2), A1116–A1146 (2020). https://doi.org/10.1137/19M1242963, https://doi.org/10.1137/19M1242963
- [18] Choi, Y., Farhat, C., Murray, W., Saunders, M.: A practical factorization of a schur complement for pde-constrained distributed optimal control (2013). https://doi.org/10.48550/ARXIV.1312.5653, https://arxiv.org/abs/1312.5653
- [19] Copeland, D.M., Cheung, S.W., Huynh, K., Choi, Y.: Reduced order models for lagrangian hydrodynamics. Computer Methods in Applied Mechanics and Engineering 388, 114259 (jan 2022). https://doi.org/10.1016/j.cma.2021.114259, https://doi.org/10.1016/j.cma.2021.114259
- [20] Cummings, R.M., Mason, W.H., Morton, S.A., McDaniel, D.R.: Applied Computational Aerodynamics: A Modern Engineering Approach. Cambridge Aerospace Series, Cambridge University Press (2015). https://doi.org/10.1017/CBO9781107284166
- [21] DeMers, D., Cottrell, G.: Non-linear dimensionality reduction. In: Hanson, S., Cowan, J., Giles, C. (eds.) Advances in Neural Information Processing Systems. vol. 5. Morgan-Kaufmann (1992), https://proceedings.neurips.cc/paper/1992/file/cdc0d6e63aa8e41c89689f54970bb35f-Paper.pdf
- [22] Diaz, A.N., Choi, Y., Heinkenschloss, M.: A fast and accurate domain-decomposition nonlinear manifold reduced order model (2023)
- [23] Diston, D.: Computational Modelling and Simulation of Aircraft and the Environment: Platform Kinematics and Synthetic Environment, Aerospace Series, vol. 1. John Wiley & Sons Ltd, United Kingdom, 1 edn. (Apr 2009). https://doi.org/10.1002/9780470744130
- [24] Fountoulakis, V., Earls, C.: Duct heights inferred from radar sea clutter using proper orthogonal bases. Radio Science 51(10), 1614–1626 (2016). https://doi.org/https://doi.org/10.1002/2016RS005998, https://agupubs.onlinelibrary.wiley.com/doi/abs/10.1002/2016RS005998
- [25] Fries, W.D., He, X., Choi, Y.: LaSDI: Parametric latent space dynamics identification. Computer Methods in Applied Mechanics and Engineering 399, 115436 (sep 2022). https://doi.org/10.1016/j.cma.2022.115436, https://doi.org/10.1016/j.cma.2022.115436
- [26] Galbally, D., Fidkowski, K., Willcox, K., Ghattas, O.: Non-linear model reduction for uncertainty quantification in large-scale inverse problems. International Journal for Numerical Methods in Engineering 81(12), 1581–1608 (2010). https://doi.org/https://doi.org/10.1002/nme.2746, https://onlinelibrary.wiley.com/doi/abs/10.1002/nme.2746
- [27] Gao, L.M., Kutz, J.N.: Bayesian autoencoders for data-driven discovery of coordinates, governing equations and fundamental constants (2022). https://doi.org/10.48550/ARXIV.2211.10575, https://arxiv.org/abs/2211.10575
- [28] Goodfellow, I., Bengio, Y., Courville, A.: Deep Learning. MIT Press (2016), http://www.deeplearningbook.org
- [29] Grmela, M., Öttinger, H.C.: Dynamics and thermodynamics of complex fluids. i. development of a general formalism. Physical Review E 56(6), 6620 (1997)
- [30] Ha, D., Dai, A.M., Le, Q.V.: Hypernetworks. In: International Conference on Learning Representations (2017), https://openreview.net/forum?id=rkpACe1lx
- [31] He, X., Choi, Y., Fries, W.D., Belof, J., Chen, J.S.: gLaSDI: Parametric physics-informed greedy latent space dynamics identification 489, 112267 (2023). https://doi.org/10.1016/j.jcp.2023.112267, https://www.sciencedirect.com/science/article/abs/pii/S0021999123003625
- [32] He, X., Choi, Y., Fries, W.D., Belof, J.L., Chen, J.S.: Certified data-driven physics-informed greedy auto-encoder simulator (2022)
- [33] Hernandez, Q., Badias, A., Gonzalez, D., Chinesta, F., Cueto, E.: Structure-preserving neural networks. Journal of Computational Physics 426, 109950 (2021)
- [34] Hinton, G.E., Salakhutdinov, R.R.: Reducing the dimensionality of data with neural networks. Science 313(5786), 504–507 (2006). https://doi.org/10.1126/science.1127647, https://www.science.org/doi/abs/10.1126/science.1127647
- [35] Hirsh, S.M., Barajas-Solano, D.A., Kutz, J.N.: Sparsifying priors for bayesian uncertainty quantification in model discovery. Royal Society Open Science 9(2), 211823 (2022). https://doi.org/10.1098/rsos.211823, https://royalsocietypublishing.org/doi/abs/10.1098/rsos.211823
- [36] Iliescu, T., Wang, Z.: Variational multiscale proper orthogonal decomposition: Navier-stokes equations. Numerical Methods for Partial Differential Equations 30(2), 641–663 (2014). https://doi.org/https://doi.org/10.1002/num.21835, https://onlinelibrary.wiley.com/doi/abs/10.1002/num.21835
- [37] Jiang, G.S., Shu, C.W.: Efficient implementation of weighted ENO schemes. Journal of Computational Physics 126(1), 202–228 (1996). https://doi.org/10.1006/jcph.1996.0130
- [38] Jones, D., Snider, C., Nassehi, A., Yon, J., Hicks, B.: Characterising the digital twin: A systematic literature review. CIRP Journal of Manufacturing Science and Technology 29, 36–52 (2020). https://doi.org/https://doi.org/10.1016/j.cirpj.2020.02.002, https://www.sciencedirect.com/science/article/pii/S1755581720300110
- [39] Kang, S.H., Liao, W., Liu, Y.: IDENT: Identifying Differential Equations with Numerical Time Evolution. J Sci Comput 87(1), 1 (Apr 2021). https://doi.org/10.1007/s10915-020-01404-9
- [40] Kim, Y., Choi, Y., Widemann, D., Zohdi, T.: Efficient nonlinear manifold reduced order model (2020). https://doi.org/10.48550/ARXIV.2011.07727, https://arxiv.org/abs/2011.07727
- [41] Kim, Y., Choi, Y., Widemann, D., Zohdi, T.: A fast and accurate physics-informed neural network reduced order model with shallow masked autoencoder (2020). https://doi.org/10.48550/ARXIV.2009.11990, https://arxiv.org/abs/2009.11990
- [42] Kim, Y., Choi, Y., Widemann, D., Zohdi, T.: A fast and accurate physics-informed neural network reduced order model with shallow masked autoencoder. Journal of Computational Physics 451, 110841 (Feb 2022). https://doi.org/10.1016/j.jcp.2021.110841
- [43] Kim, Y., Wang, K., Choi, Y.: Efficient space–time reduced order model for linear dynamical systems in python using less than 120 lines of code. Mathematics 9(14) (2021). https://doi.org/10.3390/math9141690, https://www.mdpi.com/2227-7390/9/14/1690
- [44] Kurec, K., Remer, M., Broniszewski, J., Bibik, P., Tudruj, S., Piechna, J.: Advanced modeling and simulation of vehicle active aerodynamic safety. Journal of Advanced Transportation 2019, 1–17 (02 2019). https://doi.org/10.1155/2019/7308590
- [45] Kutz, J.N.: Deep learning in fluid dynamics. Journal of Fluid Mechanics 814, 1–4 (2017). https://doi.org/10.1017/jfm.2016.803
- [46] Lauzon, J.T., Cheung, S.W., Shin, Y., Choi, Y., Copeland, D.M., Huynh, K.: S-opt: A points selection algorithm for hyper-reduction in reduced order models (2022). https://doi.org/10.48550/ARXIV.2203.16494, https://arxiv.org/abs/2203.16494
- [47] Lee, K., Carlberg, K.T.: Model reduction of dynamical systems on nonlinear manifolds using deep convolutional autoencoders. Journal of Computational Physics 404, 108973 (2020). https://doi.org/https://doi.org/10.1016/j.jcp.2019.108973, https://www.sciencedirect.com/science/article/pii/S0021999119306783
- [48] Lee, K., Trask, N., Stinis, P.: Machine learning structure preserving brackets for forecasting irreversible processes. Advances in Neural Information Processing Systems 34, 5696–5707 (2021)
- [49] Marjavaara, D.: Cfd driven optimization of hydraulic turbine draft tubes using surrogate models (2006)
- [50] McBane, S., Choi, Y., Willcox, K.: Stress-constrained topology optimization of lattice-like structures using component-wise reduced order models. Computer Methods in Applied Mechanics and Engineering 400, 115525 (2022)
- [51] McLaughlin, B., Peterson, J., Ye, M.: Stabilized reduced order models for the advection–diffusion–reaction equation using operator splitting. Computers & Mathematics with Applications 71(11), 2407–2420 (2016). https://doi.org/https://doi.org/10.1016/j.camwa.2016.01.032, https://www.sciencedirect.com/science/article/pii/S0898122116300281, proceedings of the conference on Advances in Scientific Computing and Applied Mathematics. A special issue in honor of Max Gunzburger’s 70th birthday
- [52] Messenger, D.A., Bortz, D.M.: Weak SINDy For Partial Differential Equations. J. Comput. Phys. 443, 110525 (Oct 2021). https://doi.org/10.1016/j.jcp.2021.110525
- [53] Messenger, D.A., Bortz, D.M.: Weak SINDy: Galerkin-Based Data-Driven Model Selection. Multiscale Model. Simul. 19(3), 1474–1497 (2021). https://doi.org/10.1137/20M1343166
- [54] Muhammad, A., Shanono, I.H.: Simulation of a car crash using ansys. In: 2019 15th International Conference on Electronics, Computer and Computation (ICECCO). pp. 1–5 (2019). https://doi.org/10.1109/ICECCO48375.2019.9043275
- [55] Öttinger, H.C.: Beyond equilibrium thermodynamics. John Wiley & Sons, Hoboken, NJ (2005)
- [56] Park, J.S.R., Cheung, S.W., Choi, Y., Shin, Y.: tLaSDI: Thermodynamics-informed latent space dynamics identification (2024), https://arxiv.org/abs/2403.05848
- [57] Peterson, A.F., Ray, S.L., Mittra, R.:
- [58] Raczynski, S.: Modeling and simulation : the computer science of illusion / Stanislaw Raczynski. RSP Series in Computer Simulation and Modeling, John Wiley & Sons, Ltd, Hertfordshire, England ; (2006 - 2006)
- [59] Rasmussen, C.E., Williams, C.K.I.: Gaussian processes for machine learning. Adaptive computation and machine learning, MIT Press (2006)
- [60] Rozza, G., Huynh, D., Patera, A.: Reduced basis approximation and a posteriori error estimation for affinely parametrized elliptic coercive partial differential equations. Archives of Computational Methods in Engineering 15, 1–47 (09 2007). https://doi.org/10.1007/BF03024948
- [61] Rudy, S.H., Brunton, S.L., Proctor, J.L., Kutz, J.N.: Data-driven discovery of partial differential equations. Science Advances 3(4), e1602614 (2017). https://doi.org/10.1126/sciadv.1602614, https://www.science.org/doi/abs/10.1126/sciadv.1602614
- [62] Safonov, M.G., Chiang, R.Y.: A schur method for balanced model reduction. 1988 American Control Conference pp. 1036–1040 (1988)
- [63] Schwartz, R.: Biological Modeling and Simulation. MIT Press (2008)
- [64] Smith, R.C.: Uncertainty quantification - theory, implementation, and applications. In: Computational science and engineering (2013)
- [65] Stabile, G., Rozza, G.: Finite volume POD-galerkin stabilised reduced order methods for the parametrised incompressible navier–stokes equations. Computers & Fluids 173, 273–284 (sep 2018). https://doi.org/10.1016/j.compfluid.2018.01.035, https://doi.org/10.1016/j.compfluid.2018.01.035
- [66] Stephany, R., Earls, C.: Pde-read: Human-readable partial differential equation discovery using deep learning. Neural Networks 154, 360–382 (2022). https://doi.org/https://doi.org/10.1016/j.neunet.2022.07.008, https://www.sciencedirect.com/science/article/pii/S0893608022002660
- [67] Sternfels, R., Earls, C.J.: Reduced-order model tracking and interpolation to solve pde-based bayesian inverse problems. Inverse Problems 29(7), 075014 (jun 2013). https://doi.org/10.1088/0266-5611/29/7/075014, https://dx.doi.org/10.1088/0266-5611/29/7/075014
- [68] Tang, M., Liao, W., Kuske, R., Kang, S.H.: WeakIdent: Weak formulation for Identifying Differential Equation using Narrow-fit and Trimming. J. Comput. Phys. p. 112069 (Mar 2023). https://doi.org/10.1016/j.jcp.2023.112069
- [69] Tapia, G., Khairallah, S.A., Matthews, M.J., King, W.E., Elwany, A.: Gaussian process-based surrogate modeling framework for process planning in laser powder-bed fusion additive manufacturing of 316l stainless steel. International Journal of Advanced Manufacturing Technology 94(9-12) (9 2017). https://doi.org/10.1007/s00170-017-1045-z
- [70] Thijssen, J.: Computational Physics. Cambridge University Press, 2 edn. (2007). https://doi.org/10.1017/CBO9781139171397
- [71] Thomas Rylander, Par Ingelström, A.B.: Computational Electromagnetics. Springer (2013)
- [72] Tran, A., He, X., Messenger, D.A., Choi, Y., Bortz, D.M.: Weak-Form Latent Space Dynamics Identification. Comput. Methods Appl. Mech. Eng. (accepted) (2024)
- [73] Wang, S., Sturler, E.d., Paulino, G.H.: Large-scale topology optimization using preconditioned krylov subspace methods with recycling. International Journal for Numerical Methods in Engineering 69(12), 2441–2468 (2007). https://doi.org/https://doi.org/10.1002/nme.1798, https://onlinelibrary.wiley.com/doi/abs/10.1002/nme.1798
- [74] White, D., Choi, Y., Kudo, J.: A dual mesh method with adaptivity for stress-constrained topology optimization. Structural and Multidisciplinary Optimization 61 (02 2020). https://doi.org/10.1007/s00158-019-02393-6
- [75] Winsberg, E.: Computer Simulations in Science. In: Zalta, E.N., Nodelman, U. (eds.) The Stanford Encyclopedia of Philosophy. Metaphysics Research Lab, Stanford University, Winter 2022 edn. (2022)
- [76] Zhang, Z., Shin, Y., Karniadakis, G.E.: GFINNs: Generic formalism informed neural networks for deterministic and stochastic dynamical systems. Philosophical Transactions of the Royal Society A 380(2229), 20210207 (2022)