[label1]organization=Department of Applied Mathematics, University of Colorado Boulder, city=Boulder, postcode=80309, state=CO, country=United States of America \affiliation[label2]organization=College of Information Sciences and Technology, Pennsylvania State University, city=University Park, postcode=16802, state=PA, country=United States of America
A competitive baseline for deep learning enhanced data assimilation using conditional Gaussian ensemble Kalman filtering
Abstract
Ensemble Kalman Filtering (EnKF) is a popular technique for data assimilation, with far ranging applications. However, the vanilla EnKF framework is not well-defined when perturbations are nonlinear. We study two non-linear extensions of the vanilla EnKF - dubbed the conditional-Gaussian EnKF (CG-EnKF) and the normal score EnKF (NS-EnKF) - which sidestep assumptions of linearity by constructing the Kalman gain matrix with the ‘conditional Gaussian’ update formula in place of the traditional one. We then compare these models against a state-of-the-art deep learning based particle filter called the score filter (SF). This model uses an expensive score diffusion model for estimating densities and also requires a strong assumption on the perturbation operator for validity. In our comparison, we find that CG-EnKF and NS-EnKF dramatically outperform SF for a canonical problem in high-dimensional multiscale data assimilation given by the Lorenz-96 system. Our analysis also demonstrates that the CG-EnKF and NS-EnKF can handle highly non-Gaussian additive noise perturbations, with the latter typically outperforming the former.
1 Introduction
Data assimilation (DA) refers to a class of techniques that combine observations with a model in order to improve predictions of the state of some dynamical system. DA is used in a wide variety of applications, including atmospheric and ocean sciences (Slivinski et al., 2019, Hu et al., 2023) , hydrology (Zhou et al., 2011), geosciences (Pandya et al., 2022).
One important problem encompassed under DA is the Bayesian filtering problem. This refers to the task of finding the posterior on the current state given all past and current observations. One method to solve the Bayesian filtering problem (heretofore referred to as simply the filtering problem) is to perform Kalman filtering. It has been shown that the Kalman filter exactly solves the Bayesian filtering problem (Jazwinski, 1970) when all dynamics and observations are linear and all distributions involved are Gaussian. Due to the computational cost of Kalman filtering, they are not often used in practical applications (Ahmed et al., 2020). In response to this, Evensen (1994) developed a Monte-Carlo based approximation to the Kalman filter, dubbed the ensemble Kalman filter (EnKF), which has since proven incredibly popular (Evensen, 2003), (Ahmed et al., 2020).
EnKF is generally expected not to converge to the correct Bayesian posterior in nonlinear, non Gaussian systems (Grooms, 2022) and has engendered a host of extensions as possible remedies to this limitation. The first under consideration in this work is the version of EnKF used in Grooms (2022). Since this version is not the traditional version of EnKF, we refer to it as ‘conditional Gaussian’ EnKF, or CG-EnKF. We name it so because Grooms (2022) referred to the specific update formula used in this filter as ’the conditional Gaussian’ formula. This formula is different from the classic EnKF update step and, as we shall see, is applicable for nonlinear perturbations. Regardless, both the classic EnKF update and the conditional Gaussian update assume that the observations and priors have a joint Gaussian distribution (from which either the EnKF or conditional Gaussian update formulas may be derived). Zhou et al. (2011) proposed the so-called normal-score ensemble Kalman (NS-EnKF) filter to try to relax the Gaussian assumption on the prior. This model uses the normal-score transform to map data from its current, non-atomic (or continuous) distribution to a standard normal distribution. In other words, Zhou et al. (2011) transforms the ensemble to a latent space that satisfies the Gaussian assumption. Such an idea was combined with the update formula for CG-EnKF in Grooms (2022), which we refer to as NS-EnKF (as opposed to the NS-EnKF described by Zhou et al. (2011)).
There has also been a concerted effort to use machine learning (ML) techniques in DA, as covered in the reviews by Buizza et al. (2022) and Cheng (2023). Indeed, both reviews discuss combining a neural network with EnKF to iteratively emulate hidden dynamics and predict future states. Nevertheless, ML algorithms are typically far too expensive for practical applications. Chattopadhyay et al. (2023) navigates this issue by using a pre-trained model to compute covariance matrices for EnKF which accelerate EnKF significantly. Absent from Chattopadhyay et al. (2023) is an attempt to deal with nonlinear, non-Gaussian perturbations to the data.
Another leading method to solve the Bayesian filtering problem is particle filtering (van Leeuwen et al., 2019). This refers to a class of Monte-Carlo methods that use sequential importance sampling and estimate the density of the samples themselves van Leeuwen et al. (2019), Grooms (2022). Importantly, particle filters do not assume a linear perturbation of the noise (although they do assume Gaussian additive noise) Bao et al. (2024). Classical particle filters suffer from the ‘curse of dimensionality’, so Bao et al. (2024) proposed Score Filter (SF) for greater performance. SF is a particle filter proposed by Bao et al. (2024) which combines state of the art generative modelling with deep learning algorithms with the particle filter to solve the filtering problem. From Bao et al. (2024), it is clear that SF outperforms vanilla EnKF in a variety of DA problems.
The goal of this paper is to compare the efficacy of CG-EnKF and NS-EnKF against SF. We stress that NS-EnKF can handle highly non-Gaussian noise perturbations, while SF cannot. This is because NS-EnKF ensures the typical assumptions for EnKF hold by transforming variables into a latent space. We produce a comprehensive study comparing each technique on solving the filtering problem on the Lorenz-96 (L96) system which is a benchmark for validating DA algorithms across disciplines (Bao et al., 2024, Grooms, 2022, Ahmed et al., 2020).
Our paper is structured as follows:
-
1.
In Section we provide a brief overview of ensemble Kalman filtering and point out an inconsistency in many Kalman filtering implementations.
-
2.
In Section we summarize SF and discuss some potential drawbacks on a theoretical level.
-
3.
In Section we provide a comprehensive study on performing DA with the Lorenz-96 system. CG-EnKF clearly outperforms SF on solving these test problems.
2 Ensemble Kalman Filtering
Consider a model and let be a trajectory produced by for some corresponding initial condition. In other words, along some fine discretization , we have . For simplicity, we let for some . Suppose we have access to an ‘observation’ operator which allows us to access a perturbed value from the ground truth trajectory. In practice, this may be an experimental device to collect data and can be expensive to use. As such, the observations may only be available on a much coarser time grid than that of . The driving question in data assimilation is: how may we most efficiently and effectively reconstruct using measurements and the model ?
Ensemble Kalman filtering aims to solve this problem by first assuming that the observation operator takes the form
| (2.1) |
where is a Gaussian distributed noise term with mean and covariance matrix . We shall denote this by . Suppose we have access to observations (obtained through ) on the coarse time grid . We wish to produce an ensemble of trajectories which approximate . To do this, we set some initial condition and propagate the ensemble through the model until reaching . For consistency with Evensen (2003), we shall call this the forecast ensemble, and denote it by . To be precise, the forecast ensemble is produced by the recursion
| (2.2) |
At time , we perform the Kalman filter update. First, we compute the covariance of the ensemble . Next, we need an ‘observation ensemble’ defined by
| (2.3) |
where each . With these ingredients, we compute the analysis ensemble by
| (2.4) |
This formulation was derived in (Evensen, 2003, Section 3.4.3) and the interested reader is encouraged to consult that source. To keep in line with Evensen (2003), we will define the Kalman gain matrix by
| (2.5) |
and for shorthand, we denote the right hand side of (2.4) with the operator . Using this notation, we produce the analysis ensemble by
| (2.6) |
In order to propagate beyond such that , we simply push the analysis ensemble through the model, that is
| (2.7) |
Then, push the forecast ensemble until time point and perform another Kalman filter step. This is repeated until the final time step at time . The complete process is detailed in Algorithm 1
A key point to recognize in this framework is that the initial condition of the ensemble need not be the initial condition of the trajectory. This proves particularly useful when one has access to observations of a trajectory but does not know the initial condition corresponding to that trajectory (Ahmed et al., 2020, Chapter 8).
It is important to point out that the ensemble Kalman filter is a Monte-Carlo based extension of the classic Kalman filter Evensen (2003). Under the assumption that all dynamics and observations are linear and all distributions are Gaussian, then the Kalman filter exactly solves the Bayesian filtering problem (Grooms, 2022, Katzfuss et al., 2016). One such adjustment possible, as in (Evensen, 2003, 19), is to replace with the sample covariance of the errors.
To understand the necessity of the Gaussianity assumption, let us follow a similar analysis carried out in Grooms (2022). Suppose the analysis and forecast ensembles at time are sampled from the random variables and , respectively, and that the observation is sampled from . is often defined by
| (2.8) |
Under the assumption that the joint random variable is Gaussian, then (2.8) reduces to
| (2.9) |
Let be the sample covariance matrix of the observation ensemble and let be the sample covariance matrix of the joint ensemble . Grooms (2022, 10) shows that the Kalman filter update 2.4 can be expressed as
| (2.10) |
where is a reference observation vector. Under the assumptions for EnKF (i.e., (2.1)), Grooms (2022) shows that (2.10) immediately recovers the classic EnKF update formula (2.4). Observe that (2.10) does not explicitly require a well-defined linear operator , in contrast to (2.4). As such, one may still apply (2.10) when the perturbation is nonlinear. Nevertheless, (2.10) only achieves the ideal update (2.8) when is jointly Gaussian, an assumption that clearly does not always hold.
A technique to sidestep the Gaussian assumption, introduced in Zhou et al. (2011), is to explicitly transform all variables to a Gaussian distribution. In particular, before performing the Kalman filter update (2.4), both observations and the ensemble are mapped to a sample that is normally distributed. Such a model is called the normal-score ensemble Kalman filter (NS-EnKF). The normal score transform is a kind of Gausian anamorphosis technique, wherein a random scalar variable whose law is non-atomic can be transformed to a random Gaussian variable by the mapping
| (2.11) |
where is the cumulative distribution function (cdf) of and is the cumulative distribution function for the standard normal distribution.
NS-EnKF as proposed in Zhou et al. (2011) only normal-score transforms the ensemble and adds Gaussian noise to the observation. Indeed, transforming the observations introduces an inconsistency in the current EnKF framework - the matrices and no longer become well defined. If the observation is transformed after its perturbation (as in our case), then what does the covariance matrix become in the latent space? We know that the observations should be transformed to a Gaussian distribution in order to satisfy the assumptions of the Kalman filter, but the update (2.4) does not make sense. The authors of Hansen et al. (2024) normal-score transform the observations as well, but they add Gaussian noise in the latent space. As such, they cannot account for non-Gaussian observation errors. While this inconsistency is not discussed in either Zhou et al. (2011) or Hansen et al. (2024), we do believe it is worth acknowledging. In many practical applications, the user does not know the perturbation operator . It is important to devise an algorithm that treats as a black box operator and does not rely on it in any latent space.
Grooms (2022) sidesteps this issue by normal-score transforming both the forecast and observations ensemble (that is, apply (2.11) on each dimension for each element in either ensemble) and then applying (2.10) in the latent space. Such models are referred to as ‘GA-PL’ and ‘GA-KDE’ in that paper, but we will simply use a KDE-based technique and refer to it as NS-EnKF.
We shall denote the normal-score transform on the ensemble by . The observation cdf is created using both the perturbed observations and a perturbed ensemble . We shall denote the normal-score transform on the observations by . The intuition behind this approach is that ensemble states transformed by the observation operator should come from the same distribution as the observations . This agrees with the method described by Grooms (2022) and lets us make a more robust normal-score transform. Nevertheless, the normal-score transform can only be applied on a per-dimension basis. By its very definition, it is a univariate transform.
In our implementation, we took to be the original observation vector at that time. One can further modify (2.10) by incorporating localization and inflation. For the latter, we multiply the forecast ensemble by a positive inflation factor before assimilation
| (2.12) |
We define to be the forecast mean, that is
| (2.13) |
Please refer to Grooms (2022) for a more complete discussion of localization. For the former, define a localization matrix and rather than using the covariance matrices and directly, we use the update formula
| (2.14) |
where refers to the Hadamard (entry-wise) product. Choosing a localization matrix is a nontrivial task, but is outside the scope of this paper. Please refer to Janjić et al. (2011) for a complete review of localization. For simplicity, let us denote the operation on the right hand side of (2.14) with , for ‘conditional Gaussian update’.
As discussed in Grooms (2022), this update can also be used with the transformed ensemble and observations, as seen in Algorithm 2. After performing the update, one can invert the normal score transform and recover an analysis ensemble in the state space. Crucially, localization and inflation are performed on the latent space.
It should also be noted that the update in (2.10) no longer requires the observation matrix . According to Grooms (2022), it is applicable for a wide range of observation operators , instead of a strictly linear one. As seen in Grooms (2022), both EnKF and NS-EnKF can be generalized for nonlinear using the conditional Gaussian update (2.10). Algorithm 2 details NS-EnKF using the conditional Gaussian update, but the CG-EnKF is implemented analogously, except without normal-score transformations.
3 Score Filter
As previously discussed, there are many limitations in the vanilla EnKF approach detailed in Algorithm 1. Bao et al. (2024) uses these limitations to justify Score Filter (SF). SF is a kind of particle filter, which in contrast to Kalman filters, aims to solve the filtering problem by sequential importance sampling (Grooms, 2022). In particular, classic particle filters construct an empirical measure that weakly converges to the correct posterior when the ensemble size tends to infinity Grooms (2022). However, as discussed in both Grooms (2022) and Bao et al. (2024), the classical particle filter attains prohibitively slow convergence in high dimensional data, thereby suffering from the ‘curse of dimensionality’.
SF aims to avoid the curse of dimensionality by using a diffusion model to sample from the Bayesian posterior Bao et al. (2024). Indeed, diffusion models have proven remarkably successful in sampling from various high dimensional data. We encourage the interested reader to consult Yang et al. (2023) for a survey on diffusion models and their success in solving a vast array of generative modelling problems. One particular class of diffusion models are score-based, in that the model learns a score function with which to evolve particles through a stochastic differential equation (SDE) (Song et al., 2021). SF uses this kind of diffusion model for their posterior sampling (Bao et al., 2024). We use the rest of this section to summarize the workflow of SF and discuss its strengths and limitations. We also note a notational difference from Bao et al. (2024). Keep in mind that analysis and forecast in this paper refers to the posterior and prior in Bao et al. (2024).
For simplicity, let us assume , that is, we perform a filtering step at each time point in the discretization. As in the Kalman filtering case, let us start with a forecast ensemble produced by the model from an analysis ensemble and observation . We would like to obtain using the ideal update (2.8). However, instead of directly computing , particle filters to obtain the density of , dubbed the posterior density. The prior density is that corresponding to . In classic particle filters, the prior density is often merely the empirical density of the forecast ensemble. In SF, the forecast (prior) and analysis (posterior) densities are implicitly obtained using a score-based diffusion model. The corresponding score functions are denoted by and , respectively.
Given a forecast ensemble , one can train a diffusion model to learn a score function . In particular, using this score function, it is possible to generate an arbitrary number of realizations of , assuming ideal training. For our purpose, we will denote as the forward SDE operator for the score-based diffusion model (please consult Bao et al. (2024) for the specific form of the forward-backward SDEs used). Let be forward evolution process, that is, it satisfies
| (3.1) | ||||
where is some pre-specified random variable with a known distribution. In the case of SF, is taken to be a standard normal random variable. While it is known that diffusion models do not always attain through the forward diffusion (3.1) (Chen et al., 2023), SF assumes that it does (which is a common assumption). Recall that under ideal training, the score function should satisfy
| (3.2) |
where is the density of .
Samples of are produced by following the corresponding backward SDE. SF then uses a clever update technique (Bao et al., 2024, Equation 20) on the score function to obtain . To be precise, the new score function is defined by
| (3.3) |
where is a score likelihood function (that is, proportional to a likelihood function). With , one can now generate an arbitrary collection of realizations of . However, it should be pointed out that SF was derived in the case of additive Gaussian perturbations. That is, the perturbation operator takes the form
| (3.4) |
for some and smooth function . For this case, Bao et al. (2024) use the score likelihood
| (3.5) |
in their simulations, where superscripts denote the th element of each vector and . When , then = 0. It should be noted that Bao et al. (2024) did not give an explicit formula for this log likelihood in their paper. Rather, this function was gleamed through a careful consideration of the code used to generate their figures111Please refer to https://github.com/zezhongzhang/Score-based-Filter for the code implementation of Bao et al. (2024).. We believe that a proper justification for such a likelihood function is lacking and this lack of clarity is an apparent drawback of SF.
A pseudo-code implementation is given in Algorithm 3. Unfortunately, this expanded generality comes at the cost of both training a neural network and solving an SDE at each time step. As we shall see in the next section, this results in a far more expensive algorithm as compared to CG-EnKF or NS-EnKF.
4 Experimental Results
SF versus EnKF. We test the previously discussed methodologies on assimilating data with the -dimensional Lorenz-96 system. In other words, the true trajectory, is the solution of the system of equations
| (4.1) | ||||
Similar to Bao et al. (2024), we experiment with a cubic observation model, that is, the perturbation operator is
| (4.2) |
where the exponentiation occurs element-wise. We also take a linear observation model for further comparison
| (4.3) |
We assimilate perturbed trajectories from (4.1) using CG-EnKF, NS-EnKF, and SF. In every experiment, we generate a trajectory from (4.1) for second of simulation time. We discretize the time interval into equally spaced time steps and filter at each time step, for simplicity, let us refer to the discretization by . The goal is to directly compare the assimilation algorithms using classical statistics (that is, CG-EnKF and NS-EnKF) against SF. It is trivially true that vanilla EnKF cannot assimilate trajectories with perturbations of the form (4.2), as per our previous discussion. While Bao et al. (2024) uses that fact to propose SF, we wish to examine whether CG-EnKF and NS-EnKF can solve this problem.
In both Kalman filter algorithms, we use the localization matrix
| (4.4) |
where
| (4.5) |
and is the localization radius, following the same convention as Grooms (2022). We took in our experiments. We also took inflation factor for both filtering implementations. The goal of this experiment is not to obtain the best possible CG-EnKF or NS-EnKF implementation to solve the problem. Rather, we want to use a näive implementation of CG-EnKF and NS-EnKF and compare their performance against that of SF on a well studied benchmark problem. We base our implementations of CG-EnKF and NS-EnKF off the publicly available implementations used in Grooms (2022).
For SF, we train the diffusion model for epochs at each assimilation cycle. That is, the prior score function is trained for epochs for each in the discretization . We use the exact same score diffusion model as in Bao et al. (2024), the reason being we wish to provide a fair comparison between SF and the Kalman filters in consideration.
The first statistic we use to validate results is the root mean squared error (RMSE). At some time , we compute forecast RMSE (FRMSE) by the formula
| (4.6) |
For some time , we compute analysis RMSE (ARMSE) by
| (4.7) |









| Experiment | Mean FCRPS | Mean ACRPS | FRMSE | ARMSE | Time (s) |
|---|---|---|---|---|---|
| CG-EnKF | 0.0365 | 0.0343 | 0.0706 | 0.0702 | 4.6840 |
| NS-EnKF | 0.0444 | 0.0421 | 0.0868 | 0.0865 | 33.982 |
| SF | 0.1467 | 0.1656 | 0.0631 | 0.0631 | 1119.6 |
| Experiment | Mean FCRPS | Mean ACRPS | FRMSE | ARMSE | Time (s) |
|---|---|---|---|---|---|
| CG-EnKF | 0.1384 | 0.1370 | 0.2369 | 0.2376 | 4.1376 |
| NS-EnKF | 0.1364 | 0.1349 | 0.2330 | 0.2335 | 42.125 |
| SF | 0.1766 | 0.2096 | 0.0471 | 0.0471 | 1157.3 |
The second statistic we consider is the continuous ranked probability score (CRPS), for both the forecast states and the analysis states. At a high level, the CRPS measures the quality of a probabilistic estimate. A CRPS of for a given probabilistic estimate is the best possible score attainable, although not even the true Bayesian posterior will have a CRPS of Grooms (2022). The interested reader is encouraged to consult Hersbach (2000) for a thorough explanation of the CRPS.
Lastly, we measure the wallclock time each implementation took to run on a standard laptop CPU. It should be noted that Bao et al. (2024) did not include compute time in their results and there may be discrepancies based on code optimization and hardware specifications.






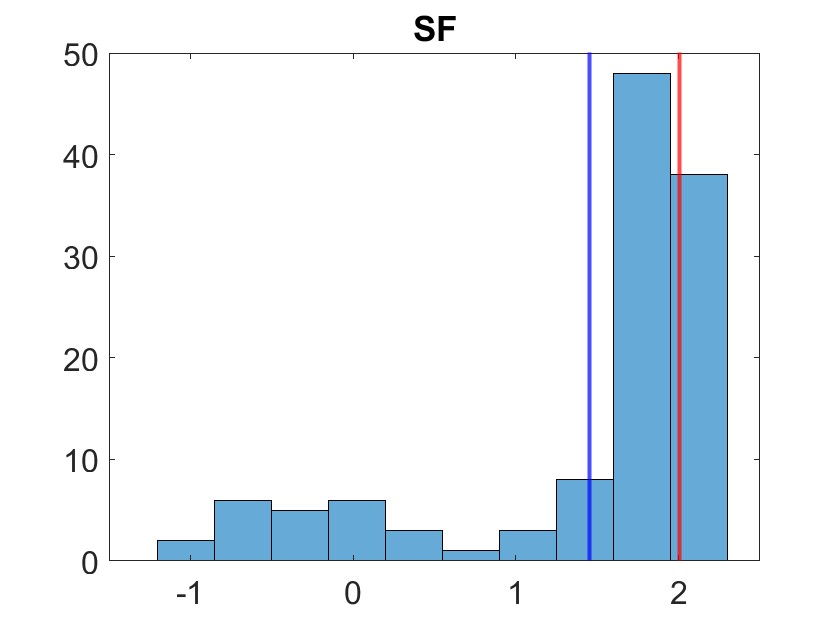


We plot the mean analysis trajectories for the first, th, and th dimensions in 1. The analysis ensemble is also compared against the true value for each model at various times in 2. From these two figures, we may qualitatively observe stronger performance in CG-EnKF and NS-EnKF over SF. Indeed, the analysis ensemble should resemble a dirac distribution about the true value, which we observe for CG-EnKF and NS-EnKF in 2. Such a quality is clearly not true for SF in the selected time points.
The quantitative results presented in Table 1 validate our qualitative observation. Furthermore, they elucidate the time complexities of the varying algorithms. Indeed, CG-EnKF solved the problem in under three seconds, or roughly times faster than . We remark that SF was implemented in Python whereas our CG-EnKF and NS-EnKF implementations are in MATLAB, but MATLAB’s slight superiority in matrix operations is not sufficient in itself to account for the vast difference in compute time. It is well known that training neural networks and solving SDEs are expensive, both of which are necessary for each time step of SF. Moreoever, we can observe in Tables 1 and 2 that the analysis statistics are typically better than the forecast statistics for CG-EnKF and NS-EnKF, whereas for SF, they are often worse.
More Experiments with EnKF. Next, we test the efficacy of our implementations of CG-EnKF and NS-EnKF with a variety of perturbations and noises. With the exception of the cubic observations model, we ran comparative results using the vanilla EnKF as described in Algorithm 1. In Table 3, this implementation is referred to as ‘V-EnKF’. We ran experiments on the -dimensional Lorenz-96 system for filter steps, with each filter step occurring on every time point along the discretization. We start the ODE trajectory at and begin assimilation at in ODE time.
| Observation | Experiment | FCRPS | ACRPS | FRMSE | ARMSE | Inflation | Time(s) |
| Linear | CG-EnKF | 0.1904 | 0.1752 | 0.3469 | 0.3163 | 1 | 156.292 |
| NS-EnKF | 0.1825 | 0.1695 | 0.3325 | 0.2838 | 1.05 | 3012.8 | |
| V-EnKF | 0.1676 | 0.1548 | 0.3094 | 0.2838 | 1 | 181.219 | |
| Exponential | CG-EnKF | 0.1959 | 0.1802 | 0.3556 | 0.3240 | 1 | 215.52 |
| NS-EnKF | 0.1411 | 0.1307 | 0.2591 | 0.2387 | 1.05 | 2791.6 | |
| V-EnKF | 0.1711 | 0.1575 | 0.3163 | 0.2895 | 1 | 215.52 | |
| Bimodal | CG-EnKF | 0.9627 | 0.9072 | 1.7272 | 1.6185 | 1 | 182.03 |
| NS-EnKF | 0.7112 | 0.6648 | 1.2878 | 1.1978 | 1 | 2734.7 | |
| V-EnKF | 0.8383 | 0.7880 | 1.5233 | 1.4251 | 1 | 155.08 | |
| Cubic | CG-EnKF | 0.0044 | 0.0040 | 0.0080 | 0.0073 | 1 | 155.08 |
| NS-EnKF | 0.0036 | 0.0036 | 0.0072 | 0.0066 | 1.05 | 2412.0 | |
| Pareto | NS-EnKF | 0.2556 | 0.2362 | 0.4750 | 0.4381 | 1.05 | 3436.1 |









In addition to linear and cubic observations as before, we also consider ‘Exponential’ and ‘Bimodal’, where the former simply adds exponentially distributed noise term with mean and the latter adds a bimodal distributed noise term, with modes at and . As before, all experiments were run on a single CPU.
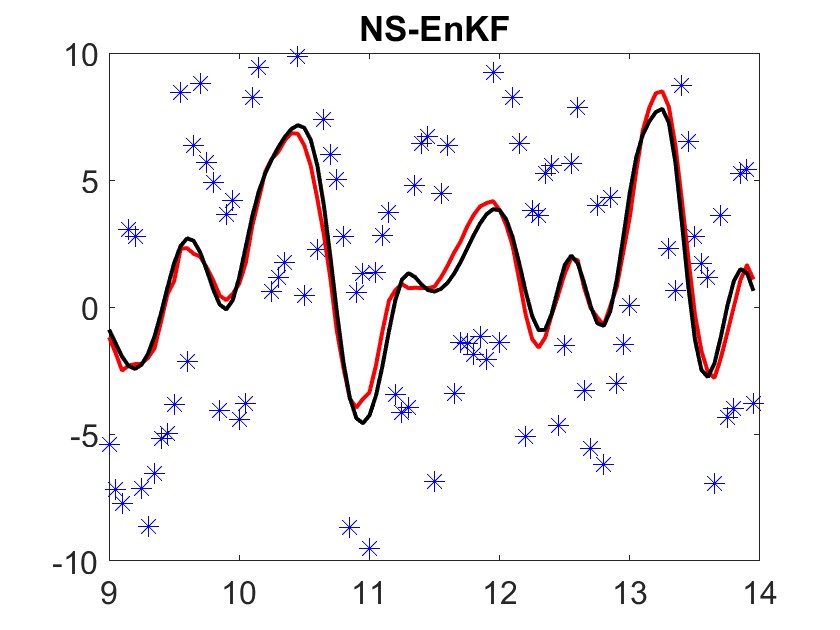
The first steps of the first dimension of the assimilated trajectories are shown in Figure 4. Table 3 gives the summary statistics throughout the entire assimilation. We note that CG-EnKF and NS-EnKF perform very well across all noise types. Furthermore, the cost in wallclock time is reasonable.
We also tried to solve the filtering problem when the additive noise has Pareto distribution. These numbers were generated using MATLAB’s gprnd with parameters , , and (following MATLAB’s parameter naming convention). While our vanilla EnKF and CG-EnKF implementations blew up while trying to solve this problem, we did find that NS-EnKF could properly assimilate trajectories. The first 100 time steps of the first dimension of the assimilated trajectory is shown in Figure 3. The summary statistics for this experiment are given in the last row of Table 3.
Since SF cannot assimilate non-Gaussian additive noise (as per the discussion in the previous section), we did not include that model in our analysis for this set of experiments. We can also expect SF to take an inordinate amount of time to assimilate this problem within a reasonable range of accuracy. For instance, if assimilations took around minutes, as in Table 1, then we may expect assimilations to take around minutes (or over hours). Clearly, SF more expensive than EnKF and performed worse in our experiments.
5 Conclusion
This paper reviews two nonlinear extensions to the vanilla EnKF and compares them against a state of the art, machine learning based, algorithm called SF, for solving the Bayesian filtering problem. We perform data assimilation on a very simple system with nonlinear perturbations and find that the classic extensions, CG-EnKF and NS-EnKF, vastly outperform SF across multiple metrics such as accuracy and computational efficiency. Not only are CG-EnKF and NS-EnKF far cheaper to implement than SF, but they also beat SF in solving the filtering problem itself. Furthermore, SF as proposed by Bao et al. (2024) cannot assimilate non-Gaussian observation perturbations: the likelihood function (3.5) explicitly requires this assumption (see also (Bao et al., 2024, Section 2).
In contrast, CG-EnKF and NS-EnKF were able to assimilate non-Gaussian additive noise to a very satisfactory level of accuracy, as shown in Table 3. Furthermore, these models were executed with a very reasonable computational cost, for example, CG-EnKF often assimilated trajectories in under three minutes. We believe CG-EnKF is a competitive approach to solve the Bayesian filtering problem and should be considered as a highly competitive baseline when developing novel (and potentially expensive) deep learning based methods for data assimilation.
Acknowledgements
ZM acknowledges support from the NSF Mathematical Sciences Graduate Internship. RM acknowledges support from DOE Office of Science, Advanced Scientific Computing Research grant DE-FOA-0002493 (Data-intensive scientific machine learning) and the ARO Early Career Program award for Modeling of Complex Systems.
References
- Ahmed et al. (2020) S. E. Ahmed, S. Pawar, and O. San. Pyda: A hands-on introduction to dynamical data assimilation with python. Fluids, 5(4), 2020. ISSN 2311-5521. doi: 10.3390/fluids5040225. URL https://www.mdpi.com/2311-5521/5/4/225.
- Bao et al. (2024) F. Bao, Z. Zhang, and G. Zhang. A score-based filter for nonlinear data assimilation. Journal of Computational Physics, 514:113207, 2024. ISSN 0021-9991. doi: https://doi.org/10.1016/j.jcp.2024.113207. URL https://www.sciencedirect.com/science/article/pii/S002199912400456X.
- Buizza et al. (2022) C. Buizza, C. Quilodrán Casas, P. Nadler, J. Mack, S. Marrone, Z. Titus, C. Le Cornec, E. Heylen, T. Dur, L. Baca Ruiz, C. Heaney, J. A. Díaz Lopez, K. S. Kumar, and R. Arcucci. Data learning: Integrating data assimilation and machine learning. Journal of Computational Science, 58:101525, 2022. ISSN 1877-7503. doi: https://doi.org/10.1016/j.jocs.2021.101525. URL https://www.sciencedirect.com/science/article/pii/S1877750321001861.
- Chattopadhyay et al. (2023) A. Chattopadhyay, E. Nabizadeh, E. Bach, and P. Hassanzadeh. Deep learning-enhanced ensemble-based data assimilation for high-dimensional nonlinear dynamical systems. Journal of Computational Physics, 477:111918, 2023. ISSN 0021-9991. doi: https://doi.org/10.1016/j.jcp.2023.111918. URL https://www.sciencedirect.com/science/article/pii/S002199912300013X.
- Chen et al. (2023) T. Chen, G.-H. Liu, and E. A. Theodorou. Likelihood training of schrödinger bridge using forward-backward sdes theory, 2023. URL https://arxiv.org/abs/2110.11291.
- Cheng (2023) S. Cheng. Machine learning with data assimilation and uncertainty quantification for dynamical systems: A review, 2023. ISSN 2329-9266. URL https://www.ieee-jas.net/en/article/doi/10.1109/JAS.2023.123537.
- Evensen (1994) G. Evensen. Sequential data assimilation with a nonlinear quasi-geostrophic model using monte carlo methods to forecast error statistics. Journal of Geophysical Research, 99:10143–10162, 1994. URL https://api.semanticscholar.org/CorpusID:16213443.
- Evensen (2003) G. Evensen. The ensemble kalman filter: theoretical formulation and practical implementation. Ocean Dynamics, 2003.
- Grooms (2022) I. Grooms. A comparison of nonlinear extensions to the ensemble Kalman filter. Comput. Geosci., 26(3):633–650, 2022. ISSN 1420-0597,1573-1499. doi: 10.1007/s10596-022-10141-x. URL https://doi.org/10.1007/s10596-022-10141-x.
- Hansen et al. (2024) J. J. Hansen, D. Brouzet, and M. Ihme. A normal-score ensemble kalman filter for 1d shock waves. AIAA SCITECH 2024 Forum, 2024.
- Hersbach (2000) H. Hersbach. Decomposition of the continuous ranked probability score for ensemble prediction systems. Weather and Forecasting, 15(5):559 – 570, 2000. doi: 10.1175/1520-0434(2000)015<0559:DOTCRP>2.0.CO;2. URL https://journals.ametsoc.org/view/journals/wefo/15/5/1520-0434_2000_015_0559_dotcrp_2_0_co_2.xml.
- Hu et al. (2023) G. Hu, S. L. Dance, R. N. Bannister, H. G. Chipilski, O. Guillet, B. Macpherson, M. Weissmann, and N. Yussouf. Progress, challenges, and future steps in data assimilation for convection-permitting numerical weather prediction: Report on the virtual meeting held on 10 and 12 november 2021. Atmospheric Science Letters, 24(1):e1130, 2023. doi: https://doi.org/10.1002/asl.1130. URL https://rmets.onlinelibrary.wiley.com/doi/abs/10.1002/asl.1130.
- Janjić et al. (2011) T. Janjić, L. Nerger, A. Albertella, J. Schröter, and S. Skachko. On domain localization in ensemble-based kalman filter algorithms. Monthly Weather Review, 139(7):2046 – 2060, 2011. doi: 10.1175/2011MWR3552.1. URL https://journals.ametsoc.org/view/journals/mwre/139/7/2011mwr3552.1.xml.
- Jazwinski (1970) A. H. Jazwinski. Stochastic Processes and Filtering Theory. Academic Press, 1970.
- Katzfuss et al. (2016) M. Katzfuss, J. R. Stroud, and C. K. Wikle. Understanding the ensemble Kalman filter. Amer. Statist., 70(4):350–357, 2016. ISSN 0003-1305,1537-2731. doi: 10.1080/00031305.2016.1141709. URL https://doi.org/10.1080/00031305.2016.1141709.
- Pandya et al. (2022) D. Pandya, B. Vachharajani, and R. Srivastava. A review of data assimilation techniques: Applications in engineering and agriculture. Materials Today: Proceedings, 62:7048–7052, 2022. ISSN 2214-7853. doi: https://doi.org/10.1016/j.matpr.2022.01.122. URL https://www.sciencedirect.com/science/article/pii/S2214785322001511. International Conference on Additive Manufacturing and Advanced Materials (AM2).
- Slivinski et al. (2019) L. C. Slivinski, G. P. Compo, J. S. Whitaker, P. D. Sardeshmukh, B. S. Giese, C. McColl, R. Allan, X. Yin, R. Vose, H. Titchner, J. Kennedy, L. J. Spencer, L. Ashcroft, S. Brönnimann, M. Brunet, D. Camuffo, R. Cornes, T. A. Cram, R. Crouthamel, F. Domínguez-Castro, J. E. Freeman, J. Gergis, E. Hawkins, P. D. Jones, S. Jourdain, A. Kaplan, H. Kubota, F. L. Blancq, T.-C. Lee, A. Lorrey, J. Luterbacher, M. Maugeri, C. J. Mock, G. K. Moore, R. Przybylak, C. Pudmenzky, C. Reason, V. C. Slonosky, C. A. Smith, B. Tinz, B. Trewin, M. A. Valente, X. L. Wang, C. Wilkinson, K. Wood, and P. Wyszyński. Towards a more reliable historical reanalysis: Improvements for version 3 of the twentieth century reanalysis system. Quarterly Journal of the Royal Meteorological Society, 145(724):2876–2908, 2019. doi: https://doi.org/10.1002/qj.3598. URL https://rmets.onlinelibrary.wiley.com/doi/abs/10.1002/qj.3598.
- Song et al. (2021) Y. Song, J. Sohl-Dickstein, D. P. Kingma, A. Kumar, S. Ermon, and B. Poole. Score-based generative modeling through stochastic differential equations, 2021. URL https://arxiv.org/abs/2011.13456.
- van Leeuwen et al. (2019) P. J. van Leeuwen, H. R. Künsch, L. Nerger, R. Potthast, and S. Reich. Particle filters for high-dimensional geoscience applications: A review. Quarterly Journal of the Royal Meteorological Society, 145(723):2335–2365, 2019. doi: https://doi.org/10.1002/qj.3551. URL https://rmets.onlinelibrary.wiley.com/doi/abs/10.1002/qj.3551.
- Yang et al. (2023) L. Yang, Z. Zhang, Y. Song, S. Hong, R. Xu, Y. Zhao, W. Zhang, B. Cui, and M.-H. Yang. Diffusion models: A comprehensive survey of methods and applications, 2023.
- Zhou et al. (2011) H. Zhou, J. J. Gómez-Hernández, H.-J. Hendricks Franssen, and L. Li. An approach to handling non-gaussianity of parameters and state variables in ensemble kalman filtering. Advances in Water Resources, 34(7):844–864, 2011. ISSN 0309-1708. doi: https://doi.org/10.1016/j.advwatres.2011.04.014. URL https://www.sciencedirect.com/science/article/pii/S0309170811000789.