A Benchmark for Multi-speaker Anonymization
Abstract
Privacy-preserving voice protection approaches primarily suppress privacy-related information derived from paralinguistic attributes while preserving the linguistic content. Existing solutions focus particularly on single-speaker scenarios. However, they lack practicality for real-world applications, i.e., multi-speaker scenarios. In this paper, we present an initial attempt to provide a multi-speaker anonymization benchmark by defining the task and evaluation protocol, proposing benchmarking solutions, and discussing the privacy leakage of overlapping conversations. Specifically, ideal multi-speaker anonymization should preserve the number of speakers and the turn-taking structure of the conversation, ensuring accurate context conveyance while maintaining privacy. To achieve that, a cascaded system uses spectral-clustering-based speaker diarization to aggregate the speech of each speaker and disentanglement-based speaker anonymization with a selection-based speaker anonymizer to conceal speaker privacy and preserve speech content. Additionally, we propose two conversation-level speaker vector anonymization methods to improve the utility further. Both methods aim to make the original and corresponding pseudo-speaker identities of each speaker unlinkable while preserving or even improving the distinguishability among pseudo-speakers in a conversation. The first method minimizes the differential similarity across speaker pairs in the original and anonymized conversations to maintain original speaker relationships in the anonymized version. The other method minimizes the aggregated similarity across anonymized speakers to achieve better differentiation between speakers. Experiments conducted on both non-overlap simulated and real-world datasets demonstrate the effectiveness of the multi-speaker anonymization system with the proposed speaker anonymizers. Additionally, we analyzed overlapping speech regarding privacy leakage and provide potential solutions111Code and audio samples are available at https://github.com/xiaoxiaomiao323/MSA.
Index Terms:
Single-speaker anonymization, multi-speaker anonymization, conversation-level anonymizerI Introduction
Speech data is clearly defined as personally identifiable data under the EU General Data Protection Regulation (GDPR) [1]. Its rich information content, apart from the spoken language itself, encompasses attributes like age, gender, emotion, identity, geographical origin, and health status. Failure to implement voice privacy protection measures and directly sharing raw audio data with social platforms or third-party companies may result in privacy leakage [2, 3]. In the worst-case scenario, attackers could exploit advanced generative artificial intelligence technologies to clone or manipulate the original speakers’ audio for voice authentication systems for illegal purposes [4, 5, 6]. Another area of concern involves deducing additional paralinguistic information from the raw speech, leading to the creation of applications such as targeted advertisements [7] based on factors like customer age, gender, and accent.
One mainstream idea in the academic community to solve this problem is to implement a user-centric voice protection solution on the raw datasets before data sharing. In recent years, efforts to protect voice privacy have primarily concentrated on techniques like noise addition [8], voice transformation [9], voice conversion [10, 11, 12, 13], and speech synthesis [14]. However, researchers perform these studies in diverse settings, making them incomparable.
The VoicePrivacy Challenge (VPC) held in 2020 [15], 2022 [16], and 2024 [17] provided a formal definition of the speaker anonymization task, common datasets, evaluation protocols, evaluation metrics, and baseline systems, promoting the development of privacy preservation techniques for speech technology. Given an input speech waveform uttered by a single speaker, an ideal speaker anonymization system in VPC should protect speaker identity information (privacy) while maintaining linguistic and prosodic content (stress, intonation, and rhythm) to enable various downstream tasks (utility).
The primary baseline of VPC aims to separate speaker identity information from linguistic and prosodic content, generating anonymized speech where only identity information is removed. It extracts three types of features from an original speech recording: (i) a speaker vector encoding speaker identity information [18], (ii) content features capturing linguistic content [19], and (iii) pitch features conveying prosodic information. To hide the speaker identity of the original speaker, a speaker anonymizer searches for several farthest speaker vectors from the original speaker vector in an external speaker vector pool, then averages randomly-selected ones as the anonymized speaker vector [14, 20, 21]. Anonymized speech is finally generated by synthesizing speech from original content and pitch features along with the anonymized speaker vector [22].
Following the VPC protocol, several works have proposed improvements from various aspects. These include (i) enhancing disentanglement to prevent privacy leakage from content and prosody features [23, 24, 25, 26], (ii) improving the speaker anonymizer to generate natural and distinctive anonymized speaker vectors that protect speaker privacy against various attackers [27, 28, 29], (iii) modifying not only speaker identity but other privacy-related paralinguistic attributes such as age, gender, and accent to enable more flexible anonymization [30, 31], (iv) exploring language-robust speaker anonymization that supports anonymizing unseen languages without severe language mismatch [32, 33, 28].
Although these efforts have driven forward the development of speaker anonymization techniques, all of them mainly focus on single-speaker scenarios—the input utterance is assumed to contain the voice of a single speaker. This paper refers to this as single-speaker anonymization (SSA).
Compared with SSA, real-world meetings and interview scenarios usually contain multiple speakers, which are more realistic and complex. These scenarios call for a multi-speaker anonymization (MSA) system that anonymizes every speaker’s voice (privacy) while keeping the anonymized voices distinctive throughout the conversation (utility).
At the time of writing, no work explores MSA due to several challenges. First, we lack evaluation metrics to assess the goodness of privacy protection and utility preservation. Second, there is no publicly available MSA tool for anonymizing conversations directly, and current speaker anonymizers used in SSA are insufficient to maintain distinctive relationships within conversations. Thus, this work aims to establish a benchmark for MSA, covering the task definition, evaluation metrics, and baseline solutions. We further discuss privacy leakage when speech from different speakers overlaps in a conversation.
The contributions of this work are as follows:
-
•
We define the criteria for MSA and introduce metrics to assess its effectiveness in terms of privacy and utility, including content, naturalness, and speaker distinctiveness preservation.
-
•
We develop a cascaded MSA system that can handle conversations involving multiple speakers. To achieve this, we use a speaker diarization technique to aggregate the speech of each speaker and apply the spectral-clustering-based method to guarantee the correctness of speaker diarization. Following segmentation, each speaker segment undergoes individual anonymization using the disentanglement-based anonymization method with a selection-based speaker anonymizer.
-
•
We improve the selection-based speaker anonymizer by proposing two conversation-level selection strategies to generate anonymized speaker vectors. Specifically, the first strategy aims to preserve the relationships between different pairs of speakers in the anonymized conversation as closely as possible to those in the corresponding original conversation, while the second aims to reduce the overall similarity among anonymized speakers. These strategies strive for the unlinkability between the original and corresponding pseudo-speaker identities for each speaker while preserving distinguishability among pseudo-speakers within a conversation.
-
•
We validate the effectiveness of the proposed MSA systems on both simulated and real-world non-overlapping conversations involving various numbers of speakers and background noises. Additionally, we analyze overlapping conversations for potential privacy leakage and propose possible lightweight solutions.
| Goals | SSA | MSA | |
| Input | Single-speaker original speech | Multi-speaker original conversation | |
| Output | Single-speaker anonymized speech | Multi-speaker anonymized conversation | |
| Privacy | Conceal each original speaker’s identity | ||
| Utility | Content | Maintain content | |
| Naturalness | Maintain naturalness | ||
| Speaker distinctiveness | Depends on downstream tasks | Speakers within one conversation should be distinctive, and turn-taking structure should remain consistent | |
II Related Work on
Single-speaker Anonymization
This section reviews SSA, which serves as the foundation for this study, including the goals outlined in VPC [15, 16, 17], as well as traditional and advanced SSA approaches.
II-A Goals of Single-speaker Anonymization
The goals for SSA are listed on the left side of Table I. The input of SSA is single-speaker original speech, and the output is anonymized speech. Specifically, VPC treats the SSA task as a game between users and attackers. Suppose users publish their anonymized speech after applying the SSA system to their original private speech, which involves only one speaker. This anonymized speech should conceal speaker identity when facing different attackers while keeping other characteristics unchanged to maintain intelligibility and naturalness, enabling downstream tasks to be achieved.
For privacy evaluation, assume attackers have different levels of prior knowledge about the speaker anonymization approach applied by the users. The attackers then use this prior knowledge to determine the speaker identity in the users’ anonymized speech.
For utility evaluation, the primary downstream task for anonymized speech was automatic speech recognition (ASR) model training, where preserving speech content, intelligibility, and naturalness in anonymized speech is paramount. The other utility metrics, such as speaker distinctiveness preservation, depend on downstream tasks. For example, when using SSA to generate a privacy-friendly synthetic automatic speaker verification (ASV) dataset [34], speaker distinctiveness should be preserved. This means that the anonymized voices of all speakers must be distinguishable from each other and should not change over time. Hence, speaker-level anonymization [15] is applied, where all utterances from the same speaker in the dataset are converted to the same pseudo-speaker, while utterances from different speakers have different pseudo-speakers. This process requires the original speaker labels.
In VPC 2024 [17], in addition to ASR, emotion analysis is considered as another downstream task. Preserving emotion traits in anonymized speech became essential while speaker distinctiveness is not necessary. In line with the considered application scenarios, utterance-level anonymization [17] is applied, where each utterance is assigned to a pseudo-speaker independently of other utterances. The pseudo-speaker assignment process does not rely on speaker labels, typically resulting in a different pseudo-speaker for each utterance. Note that assigning a single pseudo-speaker to all utterances also satisfies this definition.
II-B Single-speaker Anonymization Approaches
II-B1 Single-speaker anonymization approaches from VPC
Following VPC baseline models, SSA approaches can be categorized into digital signal processing- and disentanglement-based methods. Digital signal processing methods perceptively modify speech to conceal the original speaker’s identity. For instance, VPC provided one baseline where the speaker attributes are altered using the McAdams coefficient to shift the spectral envelope [15, 16, 17]. However, this approach may distort the content, even though the speaker’s privacy is being protected, making it less effective than disentanglement-based methods [15, 16, 17].
Two hypotheses underlie disentanglement-based approaches. First, speech can be explicitly decomposed into content, speaker identity, and prosodic representations, where speaker identity is a time-invariant representation across the utterance, while content and prosody are time-varying. This enables the modification of content and other paralinguistic attributes independently. Second, the representation of speaker identity carries most of the speaker’s private information; modifying the original speaker representation can hide the majority of speaker identity information. The modified speaker embeddings are finally combined with the original content and prosody representations to generate anonymized speech.
Because disentanglement-based SSAs show superior effectiveness in preserving speaker privacy and maintaining utility, the majority of speaker anonymization studies have adopted a similar disentanglement-based framework, with improvements made from several perspectives.
II-B2 Improved speech disentanglement
Several works argue that the disentanglement of linguistic information extracted from the content encoder and prosody still contains original speaker information. To address this, modifications are made to the content and prosody. For instance, [23] removed speaker information from pitch and linguistic information by introducing differentially private noise. [24] modified pitch and speech duration to remove the speaker identity information residual in pitch contours and their dynamics. [25, 26] enhanced the disentanglement by removing speaker information from the acoustic model using vector quantization. [35] proposed a neural audio codec-based approach, known for generating high-quality synthetic speech when combined with language models, effectively bottlenecking speaker-related information to enhance privacy protection.
II-B3 Improved speaker anonymizer
A widely-used selection-based speaker anonymizer [20, 21] replaced an original speaker vector with a mean vector (pseudo-speaker vector) of a set of randomly-selected speaker vectors from an external pool of English speakers. Previous research [15, 16] has demonstrated that anonymized voices generated by selection-based anonymizers have limited variability due to the average operation on speaker vectors. There have been recent attempts to preserve speaker distinctiveness. One of the top SSA systems [27] submitted to VPC 2022 utilized a generative adversarial network (GAN) to generate artificial speaker embeddings. This GAN was trained to turn random noise into artificial speaker embeddings that follow a similar distribution as the original speaker vectors. Another interesting work [28] is based on an orthogonal householder neural network (OHNN), which rotates the original speaker vectors into anonymized speaker vectors while ensuring they maintain the distribution over the original speaker vector space to preserve the naturalness of the original speech. The most recent work [29] models a matrix related to speaker identity and transforms it into an anonymized singular value transformation-assisted matrix to conceal the original speaker identity, generating more natural and distinctive anonymized speech.
II-B4 Flexible attribute anonymization
SSA, as defined by VPC, focuses solely on removing speaker identity from the original speech while leaving the linguistic content and other paralinguistic attributes unchanged like age, gender, emotion, and dialect. However, these paralinguistic attributes, which also contain sensitive personal information, could potentially disclose a speaker’s privacy, including geographical background, social identity, and health status [30, 31]. Researchers have explored techniques aimed at protecting voice privacy by concealing various privacy-related characteristics, such as age, gender, and accent from speech signals.
II-B5 Language-robust speaker anonymization
Another aspect of research aims at a SSA solution that can be applied to speech for unseen language. Self-supervised learning (SSL)-based speaker anonymization has been proposed [32, 28, 30], which utilizes an SSL-based content encoder to extract general context representations regardless of the input speech language. The entire system requires no text labels or other language-specific resources, enabling the system to anonymize speech data from unseen languages.
Applying SSA techniques directly in conversations would convert multi-speaker interactions into a single pseudo-speaker, thereby completely erasing the turn-taking information crucial for MSA. However, most SSAs can be extended to handle the multi-speaker conditions with additional components. In this work, we select SSL-based SSA as the backbone, as it has been verified to maintain good intelligibility, naturalness, and applicability across multiple languages [32, 33, 28]. This will be detailed in Section IV-B.

III Goals and Evaluation Metrics for Multi-speaker Anonymization
This section defines the goals of MSA, along with highlighting the differences from the SSA goals described in Section II-A. Various metrics are then established to assess MSA effectiveness in terms of privacy and utility.
III-A Comparison of Goals for Single-speaker and Multi-speaker Anonymization
An ideal MSA system should ensure safeguarding each speaker’s privacy and preserving content and naturalness, which is similar to SSA. Additionally, it should maintain the original number of speakers and the conversational turn-taking structure, thereby accurately conveying the context. Table I summarizes and compares the goals for SSA and MSA across four perspectives: input type, output type, privacy, and utility.
The common objectives includes privacy protection, speech content preservation, and speech naturalness preservation. The differences are highlighted in grey cells. For input type, SSA takes a single-speaker original speech, while MSA takes a multi-speaker original conversation. Accordingly, their output types are a single-speaker anonymized speech and a multi-speaker anonymized conversation, respectively. In terms of speaker distinctiveness, SSA highlights that the preservation of speaker distinctiveness depends on downstream tasks involving a single speaker in each utterance, such as ASV or emotion recognition as described in Section II-A. However, MSA emphasizes preserving speaker distinctiveness within a single conversation, especially in scenarios where speaker labels are unknown, ensuring that all segments from the same speaker are attributed consistently to a single pseudo-speaker while maintaining the original number of speakers before and after anonymization to retain the logical context of the conversation.
As the input types are different, unfortunately, both utterance-level and speaker-level anonymization used in SSA cannot be directly applied to MSA. For example, an input conversation with multiple speakers’ voices would be anonymized into a single pseudo-voice, resulting in a complete loss of turn-taking information from the original conversation. Therefore, it is essential to identify segments from different speakers and anonymize each speaker’s segments individually to keep the utility of the anonymized conversation. The proposed solutions will be illustrated in Sections IV-B and V.
III-B Evaluation Metrics
The Fig. 1 illustrates the evaluation process for MSA. We use one privacy metric to assess privacy protection and three utility metrics to assess content preservation, naturalness, and speaker distinctiveness in anonymized conversations, respectively. All metric computations rely on pre-trained evaluation models. Notably, except for speaker distinctiveness, which is assessed on anonymized conversations, the computation of other metrics is conducted on single-speaker segments aggregated using diarization results from both the original and anonymized conversations.
III-B1 Privacy metrics
To evaluate the effectiveness of speaker privacy protection in anonymized speech, we take the viewpoint of the attacker who uses an ASV model () to guess the speaker identity from the anonymized speech. Given an unanonymized (original) reference utterance from a targeted user, the attacker uses the ASV model to measure how similar an anonymized utterance is to the reference in terms of speaker identity. The similarity (i.e., the ASV score) should be low for a well anonymized utterance. However, if there is some leakage of the speaker identity in the anonymized utterance, the ASV score may be higher than the ASV threshold, leading the attacker to accept the hypothesis that the anonymized utterance and the reference are uttered from the same speaker. The ‘success’ rate of the attacker’s guess is equivalent to the ASV false accept rate (FAR). The pair of an anonymized utterance and unanonymized reference is considered to be negative data, while that of an unanonymized utterance and reference from the same speaker is considered to be positive data. Similar metrics have been used in other security fields, e.g., membership inference attack [36, 37].
To further explain the FAR, we first define three types of enrollment and test pairs that are used to compute the FAR. Given original (O) and anonymized (A) conversations, is the -th original conversation with speakers and . is the aggregated single-speaker segment for speaker in original conversation . Similarly, is the -th anonymized conversation. is the aggregated single-speaker segment for speaker in anonymized conversation .
-
•
O-O positive pairs: is split in half, denoted by and , to form positive pairs for each conversation, and then traverses all conversations. This traversal process uses the union of sets to encompass all positive pairs:
(1) -
•
O-O negative pairs: different speaker segments from each conversation that traverse all conversations form negative pairs :
(2) -
•
O-A pairs: the original single-speaker segment and its corresponding anonymized segment form as O-A pairs:
(3)
is then utilized to select a threshold corresponding to the equal error rate (EER), where the FAR and the false rejection rate (FRR) are equivalent, using and from the original conversation. Subsequently, is input to to calculate cosine similarity and compute the FAR. This FAR is determined as the number of false acceptances (under the threshold identified using original segments) divided by the total number of .
A lower FAR indicates that identifies anonymized test segments as dissimilar to their corresponding original enrollment segments, suggesting that most anonymized conversations conceal speaker identities, thereby safeguarding the speakers’ privacy.
III-B2 Utility metrics
Word error rate
To assess how well speech content is preserved in anonymized speech, the word error rate (WER) is computed by using an ASR evaluation model denoted as . A lower WER, similar to that of the original speech, indicates a good speech content preservation ability.
Predicted mean opinion score
To assess how well speech naturalness is preserved in anonymized speech, the predicted mean opinion score (PMOS) is computed by a mean opinion score (MOS) prediction network [38] denoted as . A higher PMOS, similar to that of the original speech, indicates a good speech naturalness preservation ability.
Diarization error rate
To assess how well the speaker distinctiveness is preserved in anonymized conversations, the diarization error rate (DER) is computed by a speaker diarization (SD) evaluation model denoted as . Anonymized conversations with similar speaking turns and speaker distinctiveness to the original speech will achieve a DER similar to the original ones. Conversely, higher or lower DER than those of original conversations means worse or better distinctiveness preservation, respectively.

IV A Cascaded Multi-speaker
Anonymization System
Given the absence of publicly accessible MSA tools for users to directly use in anonymizing conversations, this section addresses this gap by proposing a cascaded MSA system, as shown in Fig. 2.
The original conversation speech is fed into the SD module to generate rich transcription time-marked (RTTM) information for each speaker. The RTTM data is crucial as it serves as a foundation for aggregating the speech of each speaker and reconstructing the conversation sequentially. Subsequently, the individual single-speaker speech aggregated on the basis of RTTM data is anonymized to the same pseudo-speaker, while the speech from different speakers is anonymized into distinct pseudo-speakers222speaker-level anonymization. Notably, the background audio remains unaltered to preserve the authenticity and realism of the conversation. In this work, the widely-used spectral-based SD and the SSL-based SSA approach with selection-based anonymizer are chosen to establish a basic MSA framework333Note that this pipeline is not limited to a specific SD and speaker anonymization method.. The details of each component are provided in the following.
IV-A Speaker Diarization
The spectral clustering-based SD system involves multiple stages [39, 40], as illustrated in Fig. 2. First, a voice activity detection (VAD) system is used to filter out the non-speech regions. The active speech regions are then split into short fixed-length segments with a specific overlapping ratio. Subsequently, a pre-trained speaker embedding extractor is used to extract speaker vectors for each segment. Following this, a scoring backend, such as cosine scoring or probabilistic linear discriminant analysis (PLDA) [41, 42], is applied to compute similarity scores between pairs of segments. A clustering algorithm [43, 44, 45] is then used to assign a unique speaker label to each segment. Finally, the clustering results are summarized into the RTTM file, which contains the start time, duration, and speaker ID for each talking segment, providing the foundation for separating the speech of individual speakers.
IV-B Speaker Anonymization
Considering the goals for achieving MSA, we select the SSL-based SSA as the backbone as it has been verified to maintain good intelligibility and naturalness, and can be used for multiple languages [32, 33, 28]. After using the RTTM to aggregate the speech of each speaker and background audio, the speaker anonymization system anonymizes the speech of each speaker separately. Specifically, the system involves three steps, as shown at the bottom of Fig. 2.
Original speech disentanglement: The first step aims to disentangle the original speech into different components representing various speech attributes. This includes extracting frame-level content features via SSL-based content encoders [32, 33], frame-level F0 using the YAAPT algorithm [46], and segment-level original speaker vectors individually for each speaker via ECAPA-TDNN [47] models. This helps separate speaker identity information from linguistic and prosodic content, facilitating the concealment of speaker identity in the following step. This step aims to modify the speaker vectors for anonymization.
Speaker anonymizer: Hiding the original speaker’s identity for each speaker is crucial. Most works focus on modifying the original speaker embeddings using a speaker anonymizer, assuming that identity is mainly encoded in them. One commonly-used speaker anonymizer used in VPC baseline systems and based on an external pool is called selection-based anonymizer. It involves searching the farthest same-gender speaker vectors from an external speaker vector pool, then averaging randomly-selected ones as the anonymized speaker vector. Selecting the farthest speaker vectors as candidates to generate the anonymized speaker vector ensures that the anonymized speech does not sound like the original speaker, thus protecting the original speaker privacy. Averaging randomly-selected speaker vectors from the candidates helps prevent the leakage of speaker privacy for the pool speakers.
Anonymized speech generation: The anonymized speaker vector, original prosody, and content features are then fed into the neural vocoder HiFi-GAN [48] to generate individual anonymized segments. These segments are reconstructed into an anonymized conversation utilizing the temporal information provided in the RTTM file.

V Conversation-level Speaker Anonymizer for Multi-speaker Anonymization
The cascaded MSA described in Section IV-B, utilizing existing modules, i.e., SD and SSA, can anonymize conversations. However, the speaker anonymizer designed for SSA only considers speaker privacy protection, lacking consideration for speaker distinctiveness in conversations. This section will enhance the speaker anonymizer of the cascaded MSA by proposing two conversation-level anonymization approaches.
Given one conversation with speakers, let us denote their original speaker vectors as , where is the -dimensional segment-level speaker vector of the -th speaker444Each speaker has multiple segments in a conversation. These segments are aggregated into one single-speaker speech on the basis of diarization results, and then the speaker vector for each speaker is extracted, denoted .. Let the external pool with speaker vectors be , where and . The anonymization algorithm defines a function , which produces an anonymized vector for each . Note that the external pool is sourced from speakers different from the speakers to be anonymized555To protect the identity of the speakers in the external pool, we average the ten most similar gender-consistent speaker vectors along with the original pool speaker vector itself to generate a replacement for this pool speaker vector. This is unlike the usual settings where the speaker vectors in the external pool are unanonymized..
Our goal is to design so that the anonymized speaker vectors well conceal the speakers’ identities and stay distinctive across speakers. Before explaining how the goodness of anonymization is measured, let us define a similarity matrix , where the element is equal to the similarity between the original speaker vector and the candidate anonymized vector . A common choice is to compute the cosine similarity, i.e.,
| (4) |
Similarly, we define that measure the similarities among candidate anonymized speaker vectors.
After selecting the anonymized speaker vectors for each speaker, the similarities between the original and selected anonymized speaker vectors can be represented:
| (5) |
Additionally, and are defined to measure the similarities among original and selected anonymized speaker vectors, respectively.
As explained in Section III-A, in an ideal MSA, pseudo-speakers should meet two criteria:
-
•
Protecting privacy: to hide the original speaker identity, an original speaker vector and its anonymized version should be dissimilar. This means that should be small for and the sum of these similarities can be represented as .
-
•
Maintaining utility: to maintain speaker distinctiveness after anonymization, should be small for . Two approaches are proposed to achieve good utility.
-
Differential similarity (DS): This approach maintains the utility by minimizing the difference between the similarity of the original speaker pair (e.g., and and that of the corresponding anonymized speaker pair (e.g., and ), calculated as .
-
Aggregated similarity (AS): This approach directly minimizes the similarities across anonymized speakers , to achieve better differentiation between speakers, calculated as .
-
Fig. 3 illustrates the aforementioned DS and AS approaches when . Combining both privacy and utility constraints leads to two loss functions:
| (6) |
and
| (7) |
To minimize the loss function (either Eq.(6) or Eq.(7)), we design an and describe it in the python-like Algorithm 1. Note that we perform gender-dependent anonymization in this implementation. This is done by separating the input and into gender-dependent subsets and execute Algorithm 1 separately for female and male. This guarantees that the gender of each speaker remains the same before and after anonymization. When no gender annotation is available, a pre-trained gender recognition model predicts the gender.
VI Evaluation
In this section, we primarily evaluate the proposed system on non-overlapping datasets using various privacy and utility metrics described in Section III-B. This includes assessments on simulated datasets with different numbers of speakers, both clean and noisy speech, as well as real-world conversations. Finally, we analyze the potential privacy leakage in overlapping segments.
| Notation | Optimization level | Speaker anonymizer |
| [28] | Speaker-level | OHNN |
| [32] | Speaker-level | Selection-based |
| Conversation-level | Minimum | |
| Conversation-level | Minimum |
VI-A System Configurations
VI-A1 Multi-speaker anonymization configurations
All the MSAs examined in this work are based on cascaded structures, utilizing SD and SSL-based speaker anonymization with various speaker anonymizers, all of which are well-pretrained models. The proposed conversation-level speaker anonymizer is a selection procedure with specific conditions, eliminating the need for additional training.
For SD, we apply the efficient and robust spectrum clustering-based approach, which is implemented with the WeSpeaker Toolkit 666https://github.com/wenet-e2e/wespeaker/tree/master [49]. It first performs Silero-VAD 777https://github.com/snakers4/silero-vad to remove the silent segments, then splits the long audio into the 1.5-second segments. Note that these segments have 0.75 seconds of overlapping. Each segment is fed into the speaker recognition model, which is a context-aware masking-based structure [50] pre-trained on the VoxCeleb2 dataset [51]. After that, spectral clustering [39, 40] is performed to aggregate the segments into several speakers by analyzing the similarity metrics. The diarization results are saved into the RTTM file, which summarizes the timestamp of each speaker’s active speech segments.
Table II lists the notations for the different MSA approaches that were examined. and are the cascaded MSAs using speaker-level speaker anonymizers designed for SSA. and are those using the proposed conversation-level speaker anonymizers. Specifically, all approaches share the same backbone, utilizing the YAAPT algorithm [46] to extract the fundamental frequency (F0); the ECAPA-TDNN architecture, with 512 channels in the convolutional frame layers [47], provides 192-dimensional speaker identity representations; the HuBERT-based soft content encoder [52] uses a convolutional neural network (CNN) encoder along with the first and sixth transformer layers from the pre-trained HuBERT base model. It downsamples a raw audio signal into a continuous 768-dimensional representation, subsequently mapped to a 200-dimensional vector using a projection layer to predict discrete speech units. These units are derived by discretizing the intermediate 768-dimensional representations through k-means clustering888https://github.com/pytorch/fairseq/tree/main/examples/textless_nlp/gslm/speech2unit [53, 54]. The configuration of HiFi-GAN is consistent with [53]. Additional training procedures are detailed in [32].
, the state-of-the-art speaker-level speaker anonymizer that achieves good speaker distinctiveness for single-speaker utterances, uses an OHNN-based anonymizer trained on authentic VoxCeleb2, utilizing random orthogonal Householder reflections with a random seed of 50 for parameter initialization. An additive loss function is used, combining weighted angular margin softmax and cosine similarity. Training details are available in [28].
, the commonly-used speaker anonymizer, uses a selection-based strategy that identifies the 200 farthest same-gender speaker vectors from an external speaker vector pool (specifically LibriTTS-train-other-500 [55]), subsequently averaging 10 randomly-selected ones as the pseudo-speaker vector99910 vectors instead of the default setting of 100 used in VPC, as it has been demonstrated that averaging 100 (large number) vectors significantly reduces the distinctiveness of anonymized speakers [17]..
Both and are based on the same external speaker vector pool as . , . The gender recognition model used before selecting an anonymized speaker vector from the pool is a fine-tuned version of wav2vec2-xls-r-300m101010https://huggingface.co/facebook/wav2vec2-xls-r-300m on Librispeech-clean-100. It achieves 99% accuracy on the LibriSpeech test-clean subset.
| # Spk | # Utt | Duration (s) | Speech ratio (%) |
| 2 | 1121 | 3.04 / 14.70 / 76.28 | 64.37 / 93.21 / 100.00 |
| 3 | 821 | 4.23 / 21.18 / 101.50 | 67.35 / 94.68 / 100.00 |
| 4 | 623 | 8.27 / 29.02 / 123.01 | 82.97 / 95.41 / 100.00 |
| 5 | 500 | 12.30 / 36.32 / 100.38 | 80.48 / 95.64 / 99.89 |
| # Spk | # Utt | Duration (s) | Speech ratio (%) |
| 1 / 2.85 / 9 | 56 | 21.99 / 149.03 / 426.14 | 10.73 / 86.66 / 99.75 |
VI-B Evaluation Setup
VI-B1 Evaluation datasets
Simulated datasets
We simulated four different subsets using the LibriSpeech test-clean subset, which includes 5 hours of audio from 40 speakers [56]. Detailed information about the simulation data is presented in Table III. Each subset contains a fixed number of speakers, with the number varying from 2 to 5 across different subsets. The total duration for each subset is 5 hours, and there is no overlap between speakers.
In addition to the clean subsets, we also simulated another four corresponding subsets augmented with background noises from the MUSAN collection [57], scaled with a randomly-selected signal-to-noise ratio (SNR) from dB. Furthermore, with a 50% probability, we randomly selected room impulse responses (RIR) [58] to introduce reverberation, simulating far-field audio.
Real-world dataset
VI-B2 Evaluation models
is the publicly available ECAPA-TDNN model111111https://huggingface.co/speechbrain/spkrec-ecapa-voxceleb, trained on VoxCeleb1 [60] and 2 [51]. is a model fine-tuned on LibriSpeech-train-960 [56] from wav2vec2-large-960h-lv60-self121212https://huggingface.co/facebook/wav2vec2-large-960h-lv60-self, using a SpeechBrain [61] recipe131313https://huggingface.co/speechbrain/asr-wav2vec2-librispeech. is the same speaker diarization model used in MSA. For [38], is a model fine-tuned on the Blizzard Challenge for TTS [62] and the Voice Conversion Challenge [63] from wav2vec2-base141414https://huggingface.co/facebook/wav2vec2-base by mean-pooling the model’s output embeddings, adding a linear output layer, and training with L1 loss. We utilized the predicted MOS instead of human perception-based MOS from listening tests due to time and cost constraints. The predicted MOS is reasonably well-aligned with human perception [38]. In our previous work [28], we demonstrated that the ranking of the predicted MOS of original and anonymized speech, generated by different speaker anonymization systems, is consistent with those from listening tests conducted by VPC [15]. This observation holds for clean datasets, and therefore we only computed PMOS for clean simulated datasets in the following experiments.
Note that except for the DER computation, where takes the conversation as input, the other metrics’ computations require RTTM to split the original and anonymized conversation into single-speaker segments. In real MSA applications, we assume there is no RTTM available. MSA produces predicted RTTM using the SD model and then uses this RTTM to split and reconstruct the audio. In our experiments, we also provide the results using real RTTM (ground truth) as the upper baseline.



| Clean | Noise | |||||||||
| Resyn | Resyn | |||||||||
| 2-spk | 99.52 | 2.90 | 0.04 | 3.12 | 3.12 | 96.18 | 1.98 | 0.57 | 1.36 | 1.93 |
| 3-spk | 99.35 | 2.71 | 0.40 | 2.46 | 2.46 | 95.15 | 2.18 | 0.93 | 1.33 | 1.74 |
| 4-spk | 99.48 | 3.06 | 0.24 | 2.54 | 2.70 | 94.77 | 2.54 | 0.72 | 1.61 | 1.53 |
| 5-spk | 99.56 | 3.19 | 0.48 | 2.54 | 1.98 | 94.31 | 2.42 | 1.01 | 1.53 | 1.29 |
| Clean | Noise | |||||||||
| Resyn | Resyn | |||||||||
| 2-spk | 98.97 | 4.31 | 1.03 | 2.06 | 2.21 | 94.60 | 1.49 | 0.56 | 1.42 | 1.15 |
| 3-spk | 98.95 | 4.30 | 1.05 | 1.81 | 1.35 | 95.72 | 2.10 | 0.45 | 1.40 | 0.91 |
| 4-spk | 99.35 | 6.69 | 1.11 | 2.58 | 1.89 | 97.69 | 4.13 | 1.86 | 1.38 | 1.69 |
| 5-spk | 99.72 | 8.66 | 2.70 | 3.45 | 2.47 | 98.92 | 3.61 | 1.22 | 1.81 | 1.26 |
VI-C Experimental Results on non-overlapping conversations
VI-C1 Examination of the proposed conversational-level speaker anonymizers
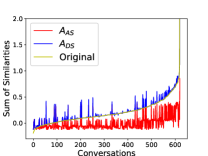
First, we examine whether and learn as the optimization objectives. Fig. 4 plots the sum of similarities for all speaker pair combinations per conversation, with each pair consisting of two different speakers, for the original data, , and using predicted RTTM on clean simulation datasets. Overall, the sum of similarities for is the lowest across all scenarios with different numbers of speakers, ensuring better speaker distinctiveness of anonymized speakers. mimics the original conversation distribution, and the sum of similarity for each conversation matches that of the original conversation. However, as the number of speakers increases, it becomes more difficult to obtain a similar sum, resulting in more fluctuations and outliers.





| Original | |||||
| Clean | 1.89 | 2.49 | 2.50 | 2.50 | 2.51 |
| Noise | 5.58 | 13.44 | 13.69 | 13.70 | 13.70 |
| Clean | Noise | |||||||||||
| Original | Resyn | Original | Resyn | |||||||||
| 2-spk | 4.26 | 4.26 | 5.88 | 5.04 | 4.45 | 4.33 | 4.97 | 4.01 | 6.53 | 7.01 | 4.96 | 4.87 |
| 3-spk | 10.38 | 10.38 | 11.43 | 11.46 | 10.73 | 10.92 | 10.80 | 10.86 | 12.30 | 13.00 | 11.61 | 10.39 |
| 4-spk | 13.15 | 13.63 | 14.86 | 15.92 | 14.02 | 13.88 | 14.41 | 13.89 | 15.49 | 17.88 | 14.83 | 13.91 |
| 5-spk | 15.55 | 16.22 | 17.67 | 18.54 | 15.43 | 14.90 | 16.90 | 16.12 | 17.84 | 21.86 | 16.36 | 16.18 |
| Clean | Noise | |||||||||||
| Original | Resyn | Original | Resyn | |||||||||
| 2-spk | 4.26 | 5.51 | 14.82 | 7.06 | 5.92 | 5.86 | 4.97 | 6.00 | 15.82 | 7.69 | 6.11 | 6.43 |
| 3-spk | 10.38 | 11.30 | 19.82 | 13.20 | 11.61 | 11.91 | 10.80 | 11.88 | 22.37 | 13.33 | 12.22 | 11.79 |
| 4-spk | 13.15 | 14.67 | 27.04 | 17.08 | 14.90 | 14.74 | 14.41 | 15.17 | 28.89 | 18.16 | 15.59 | 15.91 |
| 5-spk | 15.55 | 16.63 | 33.17 | 19.98 | 17.46 | 17.15 | 16.90 | 17.98 | 34.45 | 21.12 | 18.64 | 17.69 |


VI-C2 Results on simulated datasets
Privacy Protection
Tables V and VI show the FARs for simulation datasets using real and predicted RTTM, respectively. Both tables exhibit similar trends: resynthesized speech without any protection/anonymization achieves nearly 100% FAR, indicating complete leakage of the original speaker identity. With different MSAs, FARs can be reduced to less than 3%, indicating effective speaker identity protection. To further visualize privacy protection ability, Fig. 5 plots the cosine similarities between pairs of speaker vectors extracted from original and anonymized segments for clean simulation datasets. The cosine similarity distributions of the original-anonymized pairs (yellow) have much less overlap with original-original pairs (red) in the right four subfigures, demonstrating the strong privacy protection offered by different anonymization methods.
Content preservation
The first row of Table VII shows the WERs on the original LibriSpeech test-clean subset used to simulate the conversation and its anonymized audios using different speaker vector anonymization methods. The second row presents the results for the noisy dataset, which adds background noises to the original LibriSpeech test-clean subset. All anonymized audios obtain higher WERs than those of original audios. For the clean condition, the absolute difference between the original (1.89%) and different anonymized audios (around 2.50%) is about 0.61%. For the noisy condition, this difference increases to about , as is trained on clean speech, leading to more mismatches when decoding noisy speech. The differences among different anonymization methods are minor and the speech content is preserved at an acceptable level after anonymization.
Speaker distinctiveness preservation
Tables VIII and IX show the DERs for simulation datasets using real and predicted RTTM, respectively. Common conclusions from these tables include the following. (i) Resynthesized speech achieves DERs very similar to those of the original conversation, having almost no speaker distinctiveness loss. (ii) Noisy conversations achieve higher DERs compared with the same condition of clean conversations. (iii) As expected, a general progression in performance exists: and optimize the similarities among each speaker within one conversation, yielding lower DERs than and , which are designed for SSA that neglects such similarities when anonymizing speech. (iv) In general, achieves the best DERs among different anonymization methods, nearly similar to or slightly better than the corresponding original conversation, as it maximizes the similarities among each anonymized speaker, thereby obtaining better speaker distinctiveness after anonymization.
However, a few differences are observed. (i) Compared with real RTTM, using predicted RTTM increases the DERs overall because the segments for each speaker predicted by the SD system have errors where several frames are split to the wrong speaker. These cascading errors in turn affect DERs and typically introduce speaker confusion errors. (ii) The OHNN system achieves much worse DERs when using predicted RTTM. One potential reason is that the OHNN anonymizer is NN-based and very sensitive to input frames; even slight differences in input frames may result in anonymized speaker vectors belonging to entirely different speakers, leading to speaker confusion errors and increased DERs. Conversely, , , and anonymized vectors on the basis of different similarity criteria, making them more robust to slight differences in RTTM.
Naturalness preservation
Fig. 6 plots the PMOS on original, resynthesized, and anonymized segments split from clean simulation datasets using real RTTM (right) and predicted RTTM (left). The first observation is that compared with using real RTTM, using predicted/inaccurate RTTM, which introduces discontinuous speaker segments, slightly decreases the overall naturalness. Additionally, there is a general trend in performance: the original speech performs best, followed by resynthesized speech. Next are , , and , which use different speaker vector selection strategies based on the same external pool, achieving similar PMOS and performing better than the .
In summary, the proposed MSA systems using and achieve the overall best performance in terms of various privacy and utility metrics.
| RTTM | Resyn | ||||
| Real | 99.77 | 0.58 | 1.75 | 0.70 | 0.00 |
| Predict | 99.16 | 2.51 | 6.23 | 0.38 | 0.15 |
| RTTM | Original | Resyn | ||||
| Real | 10.00 | 12.65 | 14.50 | 15.21 | 14.48 | 13.75 |
| Predict | 13.34 | 15.51 | 16.54 | 15.25 | 13.72 |



VI-C3 Results on VoxConverse datasets
Tables X and XI list the FARs and DERs for the VoxConverse test dataset, respectively151515We omit WER and PMOS computations since VoxConverse dataset lacks a text transcript and includes real-world noise.. The trends of FARs and DERs for both original and anonymized speech generated with different MSA systems are remarkably similar to those observed on the simulation test sets. Specifically, using and achieves less than 1% FARs, showing almost perfect privacy protection ability. For DERs, achieves about 13.7% whether predicted or real RTTM is used, and is close to the original conversation, which achieved 10%, showing good speaker distinctiveness preservation.
VI-D Discussion on overlapping speech
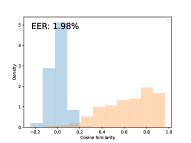
Until now, we have verified the effectiveness of proposed MSA systems on non-overlapping conversations. It is interesting to explore scenarios where overlapping segments exist, with a specific focus on the privacy risks to speakers in adjacent overlapping segments—both preceding and succeeding speakers. We consider the same attacker as in non-overlapping scenarios who uses to infer the adjacent speaker identities from the anonymized overlapping segments161616Note that a stronger attacker may infer the original speaker’s identity after separating overlapping segments, we leave it as a future work.. Specifically, we select 97 conversations from VoxConverse with overlaps and attempt to answer the following three questions. Does the overlapping segment reveal the privacy of nearby single speakers? We crop overlapping segments from the 97 selected conversations and extract the connected preceding and following single-speaker segments. Overlapping segments and either preceding or following single-speaker segments are taken as negative pairs. The single-speaker segments, split in half, are taken as positive pairs, as shown in Fig. 7a. Fig. 7b plots the cosine similarity between overlapping segments and their nearby single-speaker segments, including preceding and following single-speaker segments (blue), as well as the cosine similarity for segments from the same speaker (orange). We treated the former as negative pairs and the latter as positive pairs to compute the EER. Ideally, an EER of 0% indicates the overlapping segments do not leak adjacent speaker identity information. However, an EER of 13.40% was obtained, suggesting a low level of privacy leakage.
Is the level of speaker privacy leakage related to the overlap length? Fig. 7c plots how the similarity of overlapping segments to nearby single-speaker segments changes with the length of the overlaps. There is a light trend that longer overlap lengths result in higher cosine similarity, indicating more speaker privacy leakage.
What can be done to avoid privacy leakage from overlapping segments? One intuitive approach is to detect overlapping segments, apply speech separation to them, anonymize, and then reconstruct. However, this method is resource-intensive. Considering human speaking habits, overlapping segments typically do not convey too much important information. If something important is said, the speaker usually repeats it. Thus, one quick solution is to detect the overlap region and remove it entirely. Another method is to detect the overlap region and shuffle the segments along the time axis. Fig. 7d plots the cosine similarity, which is similar to Figure 7b, but with the overlapping segments shuffled along the timestamp. This shuffle reduces the EER from 13.40% to 1.98% as shown in Fig. 7d.
VII Conclusion and Future Work
This paper established a benchmark for MSA, providing a flexible solution for anonymizing speech from different speakers. We developed a cascaded MSA system that uses spectral-clustering-based SD to accurately segment speakers. Each segment is then anonymized individually using a disentanglement-based method before being concatenated to reconstruct the full conversation. Additionally, we enhanced the selection-based speaker anonymizer, a critical component of the disentanglement-based method, by proposing two conversation-level selection strategies. These strategies generate anonymized speaker vectors that improve speaker distinctiveness while ensuring the unlinkability of original and pseudo-speaker identities, and maintaining the distinguishability of pseudo-speakers within a conversation. We confirmed the effectiveness of the proposed MSA systems on both simulated and real-world non-overlapping conversations with various numbers of speakers and background noises. Finally, we discussed the potential privacy leakage caused by overlapping segments and provided possible lightweight solutions.
In this study, we consider that the attacker does not have knowledge or access to the MSA system and use an ASV evaluation model to identify the original speaker identity from anonymized speech. In addition, in the overlapping discussion in Section VI-D, we assume the attacker infers nearby speaker identities from overlapping segments, rather than separating overlapping segments first and then inferring original speakers. However, in real-life scenarios, a stronger attacker might possess prior knowledge of the MSA system, as well as the ability to separate overlapping segments and identify original speakers. Thus, in future work, we will investigate an end-to-end MSA approach that can handle both non-overlapping and overlapping conversations simultaneously, with an uncertain number of speakers, and evaluate its privacy protection abilities under various attack scenarios.
References
- [1] “General data protection regulation (GDPR),” https://gdpr.eu/what-is-gdpr.
- [2] S. K. Ergünay, E. Khoury, A. Lazaridis, and S. Marcel, “On the vulnerability of speaker verification to realistic voice spoofing,” in Proc. BTAS. IEEE, 2015, pp. 1–6.
- [3] V. Vestman, T. Kinnunen, R. G. Hautamäki, and M. Sahidullah, “Voice mimicry attacks assisted by automatic speaker verification,” Computer Speech & Language, vol. 59, pp. 36–54, 2020.
- [4] T. Kinnunen and H. Li, “An overview of text-independent speaker recognition: From features to supervectors,” Speech communication, vol. 52, no. 1, pp. 12–40, 2010.
- [5] J. H. Hansen and T. Hasan, “Speaker recognition by machines and humans: A tutorial review,” IEEE Signal processing magazine, vol. 32, no. 6, pp. 74–99, 2015.
- [6] Z. Bai and X.-L. Zhang, “Speaker recognition based on deep learning: An overview,” Neural Networks, 2021.
- [7] L. Kamb, “Lawsuit claims amazon using alexa to target ads at customers,” [Online; accessed 6-May-2024]. [Online]. Available: https://www.axios.com/local/seattle/2022/06/16/lawsuit-amazon-alexatarget-ads-customers
- [8] K. Hashimoto, J. Yamagishi, and I. Echizen, “Privacy-preserving sound to degrade automatic speaker verification performance,” in Proc. ICASSP. IEEE, 2016, pp. 5500–5504.
- [9] J. Qian, H. Du, J. Hou, L. Chen, T. Jung, X. Li, Y. Wang, and Y. Deng, “Voicemask: Anonymize and sanitize voice input on mobile devices,” ArXiv, vol. abs/1711.11460, 2017.
- [10] C. Magarinos, P. Lopez-Otero, L. Docio-Fernandez, E. Rodriguez-Banga, D. Erro, and C. Garcia-Mateo, “Reversible speaker de-identification using pre-trained transformation functions,” Computer Speech & Language, vol. 46, pp. 36–52, 2017.
- [11] Q. Jin, A. R. Toth, T. Schultz, and A. W. Black, “Voice convergin: Speaker de-identification by voice transformation,” in Proc. ICASSP. IEEE, 2009, pp. 3909–3912.
- [12] J. Qian, H. Du, J. Hou, L. Chen, T. Jung, and X.-Y. Li, “Hidebehind: Enjoy voice input with voiceprint unclonability and anonymity,” in Proceedings of the 16th ACM Conference on Embedded Networked Sensor Systems, 2018, pp. 82–94.
- [13] C.-y. Huang, Y. Y. Lin, H.-y. Lee, and L.-s. Lee, “Defending your voice: Adversarial attack on voice conversion,” in Proc. Spoken Language Technology Workshop (SLT). IEEE, 2021, pp. 552–559.
- [14] F. Fang, X. Wang, J. Yamagishi, I. Echizen, M. Todisco, N. Evans, and J.-F. Bonastre, “Speaker anonymization using x-vector and neural waveform models,” Proc. 10th ISCA Speech Synthesis Workshop, pp. 155–160, 9 2019.
- [15] N. Tomashenko, X. Wang, E. Vincent, J. Patino, B. M. L. Srivastava, P.-G. Noé, A. Nautsch, N. Evans, J. Yamagishi, B. O’Brien et al., “The VoicePrivacy 2020 challenge: Results and findings,” Computer Speech & Language, 2022.
- [16] N. Tomashenko, X. Wang, X. Miao, H. Nourtel, P. Champion, M. Todisco, E. Vincent, N. Evans, J. Yamagishi, and J. F. Bonastre, “The VoicePrivacy 2022 Challenge evaluation plan,” arXiv preprint arXiv:2203.12468, 2022.
- [17] N. Tomashenko, X. Miao, P. Champion, S. Meyer, X. Wang, E. Vincent, M. Panariello, N. Evans, J. Yamagishi, and M. Todisco, “The voiceprivacy 2024 challenge evaluation plan,” arXiv preprint arXiv:2404.02677, 2024.
- [18] D. Snyder, D. Garcia-Romero, G. Sell, D. Povey, and S. Khudanpur, “X-vectors: Robust dnn embeddings for speaker recognition,” in Proc. ICASSP. IEEE, 2018, pp. 5329–5333.
- [19] D. Povey, G. Cheng, Y. Wang, K. Li, H. Xu, M. Yarmohammadi, and S. Khudanpur, “Semi-orthogonal low-rank matrix factorization for deep neural networks.” in Proc. Interspeech, 2018, pp. 3743–3747.
- [20] B. M. L. Srivastava, N. A. Tomashenko, X. Wang, E. Vincent, J. Yamagishi, M. Maouche, A. Bellet, and M. Tommasi, “Design choices for x-vector based speaker anonymization,” in Proc. Interspeech, 2020, pp. 1713–1717.
- [21] B. M. L. Srivastava, M. Maouche, M. Sahidullah, E. Vincent, A. Bellet, M. Tommasi, N. Tomashenko, X. Wang, and J. Yamagishi, “Privacy and utility of x-vector based speaker anonymization,” IEEE/ACM Transactions on Audio, Speech, and Language Processing, vol. 30, pp. 2383–2395, 2022.
- [22] X. Wang, S. Takaki, and J. Yamagishi, “Neural source-filter-based waveform model for statistical parametric speech synthesis,” in Proc. ICASSP. IEEE, 2019, pp. 5916–5920.
- [23] A. S. Shamsabadi, B. M. L. Srivastava, A. Bellet, N. Vauquier, E. Vincent, M. Maouche, M. Tommasi, and N. Papernot, “Differentially private speaker anonymization,” Proceedings on Privacy Enhancing Technologies, vol. 2023, no. 1, Jan. 2023. [Online]. Available: https://hal.inria.fr/hal-03588932
- [24] C. O. Mawalim, K. Galajit, J. Karnjana, S. Kidani, and M. Unoki, “Speaker anonymization by modifying fundamental frequency and x-vector singular value,” Computer Speech & Language, vol. 73, p. 101326, 2022.
- [25] C. Pierre, A. Larcher, and D. Jouvet, “Are disentangled representations all you need to build speaker anonymization systems?” in Proc. Interspeech, 2022, pp. 2793–2797.
- [26] P. Champion, “Anonymizing speech: Evaluating and designing speaker anonymization techniques,” arXiv preprint arXiv:2308.04455, 2023.
- [27] S. Meyer, F. Lux, J. Koch, P. Denisov, P. Tilli, and N. T. Vu, “Prosody is not identity: A speaker anonymization approach using prosody cloning,” in Proc. IEEE ICASSP. IEEE, 2023, pp. 1–5.
- [28] X. Miao, X. Wang, E. Cooper, J. Yamagishi, and N. Tomashenko, “Speaker anonymization using orthogonal householder neural network,” IEEE/ACM Trans. Audio, Speech, and Language Processing, vol. 31, pp. 3681–3695, 2023.
- [29] J. Yao, Q. Wang, P. Guo, Z. Ning, and L. Xie, “Distinctive and natural speaker anonymization via singular value transformation-assisted matrix,” Accepted by IEEE/ACM Transactions on Audio, Speech, and Language Processing, 2024.
- [30] Z. Shaohu, L. Zhouyu, and D. Anupam, “Voicepm: A robust privacy measurement on voice anonymity,” in Proc. 16th ACM Conference on Security and Privacy in Wireless and Mobile Networks (WiSec), 2023, p. 215–226.
- [31] P.-G. Noé, X. Miao, X. Wang, J. Yamagishi, J.-F. Bonastre, and D. Matrouf, “Hiding speaker’s sex in speech using zero-evidence speaker representation in an analysis/synthesis pipeline,” in Proc. ICASSP. IEEE, 2023, pp. 1–5.
- [32] X. Miao, X. Wang, E. Cooper, J. Yamagishi, and N. Tomashenko, “Language-Independent Speaker Anonymization Approach Using Self-Supervised Pre-Trained Models,” in Proc. The Speaker and Language Recognition Workshop (Odyssey 2022), 2022, pp. 279–286.
- [33] ——, “Analyzing Language-Independent Speaker Anonymization Framework under Unseen Conditions,” in Proc. Interspeech, 2022, pp. 4426–4430.
- [34] X. Miao, X. Wang, E. Cooper, J. Yamagishi, N. Evans, M. Todisco, J.-F. Bonastre, and M. Rouvier, “Synvox2: Towards a privacy-friendly voxceleb2 dataset,” in Proc. ICASSP. IEEE, 2024, pp. 11 421–11 425.
- [35] M. Panariello, F. Nespoli, M. Todisco, and N. Evans, “Speaker anonymization using neural audio codec language models,” in Proc. ICASSP, 2024, pp. 4725–4729.
- [36] N. Carlini, S. Chien, M. Nasr, S. Song, A. Terzis, and F. Tramèr, “Membership Inference Attacks From First Principles,” in Proc. IEEE Symposium on Security and Privacy (SP). San Francisco, CA, USA: IEEE, May 2022, pp. 1897–1914.
- [37] M. Nasr, J. Hayes, T. Steinke, B. Balle, F. Tramèr, M. Jagielski, N. Carlini, and A. Terzis, “Tight auditing of differentially private machine learning,” in Proc. USENIX Security Symposium, 2023, pp. 1631–1648.
- [38] E. Cooper, W.-C. Huang, T. Toda, and J. Yamagishi, “Generalization ability of MOS prediction networks,” in Proc. ICASSP. IEEE, 2022, pp. 8442–8446.
- [39] S. H. Shum, N. Dehak, R. Dehak, and J. R. Glass, “Unsupervised methods for speaker diarization: An integrated and iterative approach,” IEEE Transactions on Audio, Speech, and Language Processing, vol. 21, no. 10, pp. 2015–2028, 2013.
- [40] G. Sell and D. Garcia-Romero, “Speaker diarization with plda i-vector scoring and unsupervised calibration,” in Proc. Spoken Language Technology Workshop (SLT). IEEE, 2014, pp. 413–417.
- [41] P. Rajan, A. Afanasyev, V. Hautamäki, and T. Kinnunen, “From single to multiple enrollment i-vectors: Practical plda scoring variants for speaker verification,” Digital Signal Processing, vol. 31, pp. 93–101, 2014.
- [42] J. Villalba, M. Diez, A. Varona, and E. Lleida, “Handling recordings acquired simultaneously over multiple channels with plda,” in Proc. Interspeech, 2013.
- [43] G. Sell, D. Snyder, A. McCree, D. Garcia-Romero, J. Villalba, M. Maciejewski, V. Manohar, N. Dehak, D. Povey, S. Watanabe et al., “Diarization is hard: Some experiences and lessons learned for the jhu team in the inaugural dihard challenge.” in Proc. Interspeech, 2018, pp. 2808–2812.
- [44] Q. Wang, C. Downey, L. Wan, P. A. Mansfield, and I. L. Moreno, “Speaker diarization with lstm,” in Proc. ICASSP. IEEE, 2018, pp. 5239–5243.
- [45] Q. Lin, R. Yin, M. Li, H. Bredin, and C. Barras, “LSTM Based Similarity Measurement with Spectral Clustering for Speaker Diarization,” in Proc. Interspeech, 2019, pp. 366–370.
- [46] K. Kasi and S. A. Zahorian, “Yet another algorithm for pitch tracking,” in Proc. ICASSP, vol. 1, 2002, pp. I–361.
- [47] B. Desplanques, J. Thienpondt, and K. Demuynck, “ECAPA-TDNN: Emphasized Channel Attention, Propagation and Aggregation in TDNN Based Speaker Verification,” in Proc. Interspeech, 2020, pp. 3830–3834.
- [48] J. Kong, J. Kim, and J. Bae, “Hifi-gan: Generative adversarial networks for efficient and high fidelity speech synthesis,” in Proc. NeurIPS, 2020, pp. 17 022–17 033.
- [49] H. Wang, C. Liang, S. Wang, Z. Chen, B. Zhang, X. Xiang, Y. Deng, and Y. Qian, “Wespeaker: A research and production oriented speaker embedding learning toolkit,” in Proc. ICASSP. IEEE, 2023, pp. 1–5.
- [50] H. Wang, S. Zheng, Y. Chen, L. Cheng, and Q. Chen, “CAM++: A Fast and Efficient Network for Speaker Verification Using Context-Aware Masking,” in Proc. INTERSPEECH, 2023, pp. 5301–5305.
- [51] J. S. Chung, A. Nagrani, and A. Zisserman, “Voxceleb2: Deep speaker recognition,” in Proc. Interspeech, 2018, pp. 1086–1090.
- [52] B. van Niekerk, M.-A. Carbonneau, J. Zaïdi, M. Baas, H. Seuté, and H. Kamper, “A comparison of discrete and soft speech units for improved voice conversion,” in Proc. ICASSP. IEEE, 2022, pp. 6562–6566.
- [53] A. Polyak, Y. Adi, J. Copet, E. Kharitonov, K. Lakhotia, W.-N. Hsu, A. Mohamed, and E. Dupoux, “Speech Resynthesis from Discrete Disentangled Self-Supervised Representations,” in Proc. Interspeech, 2021.
- [54] K. Lakhotia, E. Kharitonov, W.-N. Hsu, Y. Adi, A. Polyak, B. Bolte, T.-A. Nguyen, J. Copet, A. Baevski, A. Mohamed et al., “On generative spoken language modeling from raw audio,” Transactions of the Association for Computational Linguistics, vol. 9, pp. 1336–1354, 2021.
- [55] H. Zen, V. Dang, R. Clark, Y. Zhang, R. J. Weiss, Y. Jia, Z. Chen, and Y. Wu, “LibriTTS: A corpus derived from LibriSpeech for text-to-speech,” arXiv preprint arXiv:1904.02882, 2019.
- [56] V. Panayotov, G. Chen, D. Povey, and S. Khudanpur, “Librispeech: an ASR corpus based on public domain audio books,” in Proc. ICASSP. IEEE, 2015, pp. 5206–5210.
- [57] D. Snyder, G. Chen, and D. Povey, “MUSAN: A Music, Speech, and Noise Corpus,” 2015, arXiv:1510.08484v1.
- [58] T. Ko, V. Peddinti, D. Povey, M. L. Seltzer, and S. Khudanpur, “A study on data augmentation of reverberant speech for robust speech recognition,” in Proc. ICASSP, 2017, pp. 5220–5224.
- [59] J. S. Chung, J. Huh, A. Nagrani, T. Afouras, and A. Zisserman, “Spot the Conversation: Speaker Diarisation in the Wild,” in Proc. Interspeech, 2020, pp. 299–303.
- [60] A. Nagrani, J. S. Chung, and A. Zisserman, “Voxceleb: A large-scale speaker identification dataset,” in Proc. Interspeech, 2017, pp. 2616–2620.
- [61] M. Ravanelli, T. Parcollet, P. Plantinga, A. Rouhe, S. Cornell, L. Lugosch, C. Subakan, N. Dawalatabad, A. Heba, J. Zhong, J.-C. Chou, S.-L. Yeh, S.-W. Fu, C.-F. Liao, E. Rastorgueva, F. Grondin, W. Aris, H. Na, Y. Gao, R. D. Mori, and Y. Bengio, “SpeechBrain: A general-purpose speech toolkit,” 2021, arXiv:2106.04624.
- [62] S. King and V. Karaiskos, “The blizzard challenge 2016,” Blizzard Challenge 2016, 2016.
- [63] R. K. Das, T. Kinnunen, W.-C. Huang, Z.-H. Ling, J. Yamagishi, Z. Yi, X. Tian, and T. Toda, “Predictions of Subjective Ratings and Spoofing Assessments of Voice Conversion Challenge 2020 Submissions,” in Proc. Joint Workshop for the Blizzard Challenge and Voice Conversion Challenge 2020, 2020, pp. 99–120.