A Bayesian framework for patient-level partitioned survival cost-utility analysis
Abstract
Patient-level health economic data collected alongside clinical trials are an important component of the process of technology appraisal, with a view to informing resource allocation decisions. For end of life treatments, such as cancer treatments, modelling of cost-effectiveness/utility data may involve some form of partitioned survival analysis, where measures of health-related quality of life and survival time for both pre- and post-progression periods are combined to generate some aggregate measure of clinical benefits (e.g. quality-adjusted survival). In addition, resource use data are often collected from health records on different services from which different cost components are obtained (e.g. treatment, hospital or adverse events costs). A critical problem in these analyses is that both effectiveness and cost data present some complexities, including non-normality, spikes, and missingness, that should be addressed using appropriate methods. Bayesian modelling provides a powerful tool which has become more and more popular in the recent health economics and statistical literature to jointly handle these issues in a relatively easy way. This paper presents a general Bayesian framework that takes into account the complex relationships of trial-based partitioned survival cost-utility data, potentially providing a more adequate evidence for policymakers to inform the decision-making process. Our approach is motivated by, and applied to, a working example based on data from a trial assessing the cost-effectiveness of a new treatment for patients with advanced non-small-cell lung cancer.
Keywords: Bayesian statistics, economic evaluations, partitioned survival cost-utility analysis, STAN, hurdle models, missing data
1 Introduction
Constraints on healthcare resource, particularly during times of economic turmoil and instability, result in governments taking a hard look at all public expenditure, including the medicines budget. As a result, in many countries, government bodies who are responsible for the assessment of the costs relative to the effects of specific treatments now require evidence of economic value as part of their reimbursement decision-making. For example, in the United Kingdom (England and Wales), this assessment is made by the National Institute for Clinical Health Excellence (NICE) 1. The statistical analysis of health economic data has become an increasingly important component of clinical trials, which provide one of the earliest opportunities to generate economic data that can be used for decision-making 2.
The standard analysis of individual-level data involves the comparison of two interventions for which suitable measures of effectiveness and costs are collected on each patient enrolled in the trial, often at different time points throughout the follow-up period. Depending on the economic perspective of the analysis, different types of resource use data (e.g. hospital visits, consultations, scans, number of doses, etc.) are collected for each patient and time point using electronic health records, self-reported questionnaires or a combination of both. Service use information is combined with unit prices taken from national sources to derive patient-level costs associated with each type of service and the total costs over the trial duration are obtained by summing up all cost components at each time. The effectiveness is often measured in terms of preference-based health-related quality of life instruments (e.g. the EQ-5D questionnaires 3) and are combined with national tariff systems to value the patients’ health states in terms of utility scores, measured on a scale from (worst imaginable health) to (perfect health), using the preferences of a sample of the public 4. States considered worse than death are also possible and are associated with values below . Finally, a single metric, called Quality-Adjusted Life Years (QALYs), is calculated by aggregating the utility scores over the trial duration and represents the health outcome of choice in the economic analysis. A common approach for calculating a QALY is to compute the Area Under the Curve (AUC) 5:.
| (1) |
where is the utility score for the -th patient in treatment at the -th time in the trial, while is the fraction of the time unit (typically year) which is covered between time and . For example, if measurements in the trial are collected at monthly intervals, then . We note that for patients who die at some point in the trial, which is often the case for cancer trials, assumptions have to be made about their utility values at all time points after the time of death so that their QALYs can be computed using Equation 1. In many cases, a utility of is typically associated with a state of death at a given time point and is carried over until the last follow-up, which may cause an underestimation of the AUC. However, this assumption may not be unreasonable, because often disease progression precedes death, and the health state is expected to be worse (even worse than death) around this time 6.
The AUC method is a relatively simple approach but assumes an absence of missing values/censoring. When the primary end point of the trial is survival, such as in cancer trials where patients may be either dead or still alive at the end of the study (often censored), a possible way to deal with censoring is to combine the information from both utility and survival for each patient. More specifically, it is possible to multiply each patient’s observed survival at time by his/her corresponding utility values at the same time to formulate a QALY end point on an AUC scale, also known as Quality Adjusted Survival (QAS), that is
| (2) |
where and are the utility and the survival time for the -th patient in treatment at the -th time. Equation 2 can be thought as a time to event analysis using the QALY as the analysis end point, given that it is still in a time measurement, albeit weighted 7. When some utility scores are missing (e.g. due to incomplete questionnaire), the empirical values can be replaced with predicted individual-level utilities which are generated from some model. This allows to extrapolate the utility scores for those patients still alive in the future, predict the values at different time points within the follow-up period, and adjust for possible imbalances between treatments in some baseline variables. However, care should be taken that predictions are computed sensibly: if a patient died at time , then his/her predicted utility estimates from at and all subsequent times should be equal to zero.
1.1 Partitioned Survival Cost-Utility Analysis
One important aspect, particularly in cancer trials, is that survival time can change rapidly after the disease has progressed. Therefore, inferences about mean utilities should take into account the specific features of pre- and post-progression responses as well as their dependence relationships. This is the rationale behind partitioned survival analysis, which involves the partitioning of survival data for the time to event end point, typically Overall Survival (OS), into two components: Progression Free Survival (PFS) and Post-Progression Survival (PPS), where . Hence, QAS based on the AUC approach can alternatively be computed during the pre- and post-progression periods by multiplying each survival component by the pre- and post-progression utilities. The partitioning of health-related quality of life data based on different components of survival time forms the basis for what is known as Partitioned Survival Cost-Utility Analysis, where patient-level QAS based on OS data () can be expressed as
| (3) |
where and are the QAS computed as in Equation 2 using patient-level utilities and survival times for pre- and post-progression periods, respectively. In most analyses, the different survival components in Equation 3 are separately modelled using parametric regression models to allow for extrapolation 6, 8. However, in many cancer trials, direct modelling of is not possible since utility data are collected only up to progression, while utilities after disease progressions are extrapolated based on some modelling assumptions and OS or PFS data 9. However, if PPS is collected, it is generally recommended to use whatever of these data are available to improve the estimate of .
It is important to note that the calculation of QAS in Equation 2 and Equation 3 assumes an absence of censoring. In practice, however, some of the patients may be still alive at the end of the trial (censored), which may hinder the validity of standard approaches for calculating QAS data. Indeed, on a QALY scale, survival times may be altered (by the utility weights), resulting in informative censoring (i.e. related to survival time), which makes the standard Kaplan-Meier analysis invalid 7. For the rest of the paper and in the analysis of our case study, we will assume that no informative censoring occurs (in the case study of patients had died at the time of the analysis) so that standard partitioned survival cost-utility analysis methods for computing QAS data can be assumed to be valid. In Section 6 we will discuss the potential implications associated with informative censoring on these types of analyses as well as some alternative approaches that can be used to overcome the limitations associated with standard approaches in this context.
1.2 Modelling of Patient-Level Cost-Utility Data
Statistical modelling for trial-based cost-effectiveness/utility data has received much attention in both the health economics and the statistical literature in recent years 10, 11, increasingly often under a Bayesian statistical approach 12, 13, 14. From the statistical point of view, this is a challenging problem because of the generally complex relationships linking the measure of effectiveness (e.g. QALYs) and the associated costs. First, the presence of a bivariate outcome requires the use of appropriate methods taking into account correlation 15, 16, 17. Second, both utility and cost data are characterised by empirical distributions that are highly skewed and simplifying assumptions, such as (bivariate) normality of the underlying distributions, are usually not granted. The adoption of parametric distributions that can account for skewness (e.g. beta for the utilities and gamma or log-normal distributions for the costs) has been suggested to improve the fit of the model 18, 19, 20. Third, data may exhibit spikes at one or both of the boundaries of the range for the underlying distribution, e.g. null costs and perfect health (i.e. utility of one), that are difficult to capture with standard parametric models 21, 20. The use of more flexible formulations, known as hurdle models, has been recommended to explicitly account for these "structural" values 22, 23, 24. These models consist in a mixture between a point mass distribution (the spike) and a parametric model fit to the natural range of the relevant variable without the boundary values. Finally, individual-level data from clinical trials are almost invariably affected by the problem of missing data. Analyses that are limited to individuals with fully-observed data (complete case analysis) are inefficient and assume that the completers are a random sample of all individuals, an assumption known as Missing Completely At Random (MCAR), which may yield biased inferences 25. Alternative and more efficient approaches, such as multiple imputation and likelihood-based methods 25, 26, rely on the less restrictive assumption that all observed data can be used to explain fully the reason for why some observations are missing, an assumption known as Missing At Random (MAR). However, the possibility that unobserved data influence the mechanism by which the missing values arise, an assumption known as Missing Not At Random (MNAR), can never be ruled out and will introduce bias when inferences are based on the observed data alone. Content-specific knowledge and tailored modelling approaches can be used to make inferences under MNAR and, within a Bayesian approach, informative prior distributions represent a powerful tool for conducting sensitivity analysis to different missingness assumptions 27.
In this paper, we aim at extending the current methods for modelling trial-based partitioned survival cost-utility data, taking advantage of the flexibility of Bayesian methods, and specify a joint probabilistic model for the health economic outcomes. We propose a general framework that is able to account for the multiple types of complexities affecting individual level data (correlation, missingness, skewness and structural values), while also explicitly modelling the dependence relationships between different types of quality of life and cost components. The paper is structured as follows: first, in Section 2, we set out our modelling framework. In Section 3 we present the case study used as motivating example and describe the data, while Section 4 defines the general structure of the model used in the analysis and how it is tailored to deal with the different characteristics of the data. Section 5 presents and discusses the statistical and health economic results of the analysis. Finally, Section 6 summarises our conclusions.
2 Methods
Consider a clinical trial in which patient-level information on a set of suitably defined effectiveness and cost variables has been collected at time points on individuals, who have been allocated to intervention groups. We assume that the primary endpoint of the trial is OS, while secondary endpoints include PFS, a self-reported health-related quality of life questionnaire (e.g. EQ-5D) and health records on different types of services (e.g. drug frequency and dosage, hospital visits, etc.) for each individual. We denote with the set of effectiveness variables for the -th individual in treatment of the trial, which are obtained by combining survival time and utility scores (e.g. QAS). We assume that utility data are collected up to and beyond progression so that both and can be obtained from the observed data without extrapolation. We denote the full set of effectiveness variables as , formed by the pre- and post-progression components. Next, we denote with the set of patient-level cost variables, obtained by combining the resource use data on different services over the duration of the trial with a unit prices for each type of service. The full set of cost variables can therefore be expressed as . Finally, it is also common to have some patient-level information on a set of additional variables (for example on age, sex or potential co-morbidities) which may be included in the economic analysis. Without loss of generality, we assume in the following that only two interventions are compared: is some standard (e.g. currently recommended or applied by the health care provider), and is a new intervention being suggested to potentially replace the standard.
The objective of the economic evaluations is to perform a patient-level partitioned survival cost-utility analysis by specifying a joint model , indexed by a set of parameters comprising the marginal mean effectiveness and cost parameters on which inference has to be made to inform the decision-making process. Different approaches can be used to specify . Here, we take advantage of the flexibility granted by the Bayesian framework and express the joint distribution as
| (4) |
where is the marginal distribution of the effectiveness and is the conditional distribution of the costs given the effectiveness. Note that it is always possible to specify the joint distribution using the reverse factorisation but, following previous works 28, 23, we describe our approach through a marginal distribution for the effectiveness and a conditional distribution for the costs. In the following, we describe how the two factors on the right-hand side of Equation 4 are specified.
2.1 Marginal Model for the Effectiveness
For each individual and treatment, we specify a marginal distribution of the effectiveness variables using the conditional factorisation:
| (5) |
where are the treatment-specific effectiveness parameters formed by the two distinct sets that index the marginal distribution of and the conditional distribution of . The sets of parameters can be expressed in terms of some location and ancillary parameters, the latter typically comprising some standard deviations . Often, interest is in the modelling of the location parameters as a function of other variables. This is typically achieved through a generalised linear structure and some link function that relates the expected value of the response to the linear predictors in the model. For example, we can use some parametric model to specify the distribution of the two effectiveness variables as
| (6) |
where and denote some generic parametric distribution (e.g. normal) used to model and , respectively. The locations of the two models in Equation 6 are then modelled as:
| (7) |
where is the link function, and are the sets of regression parameters indexing the two models, while the notation indicates that other terms (e.g. quantifying the effect of relevant covariates ) may or may not be included in each model. In the absence of covariates or assuming that a centred version is used, the quantities and can be interpreted as the population mean effectiveness for and , respectively.
2.2 Conditional Model for the Costs Given the Effectiveness
For the conditional distribution of the costs given the effectiveness, we use a similar approach to the one of and factor as the product of a sequence of conditional distributions:
| (8) |
where are the treatment-specific cost parameters that index the conditional distributions of the cost variables, with being the number of cost components. These parameters can also be expressed in terms of a series of location and ancillary parameters, the latter typically including a vector of standard deviations . We can model the univariate distributions of the cost variables using some parametric forms:
| (9) |
where denote the parametric distributions used to model the patient-level cost data for the cost components. The location of each variable can then be modelled as a function of other variables using the generalised linear forms:
| (10) |
where are the sets of regression parameters indexing the models. Assuming other covariates are also either centred or absent, the quantities in Equation 10 can be interpreted as the population mean cost components.
Figure 1 provides a visual representation of the general modelling framework described above.
FIGURE 1
The effectiveness and cost distributions are represented in terms of combined "modules"- the red and blue boxes - in which the random quantities are linked through logical relationships. The links both within and between the variables in the modules ensure the full characterisation of the uncertainty in the model. Notably, this is general enough to be extended to any suitable distributional assumption, as well as to handle covariates in either or both the modules. In the following section, we first introduce and describe the case study that we use as motivating example. Next, we present the modelling specification for the effectiveness and cost data chosen in our analysis. The model is specified so to take into account different issues of the individual-level data, including correlation between variables, missingness, skewness and presence of structural values.
3 Example: The TOPICAL trial
The TOPICAL study is a double-blind, randomised, placebo-controlled, phase III trial, conducted in the UK in predominantly elderly patients with non-small-cell lung cancer receiving best supportive care considered unfit for chemotherapy because of poor performance status and/or multiple medical comorbidities 29. Subjects were randomly assigned to receive a control (oral placebo) () or erlotinib ( mg per day, ) until disease progression or unacceptable toxicity. All patients were allowed to receive immediate or delayed palliative chest radiotherapy and/or radiotherapy to metastatic sites as appropriate. The original trial investigated patients in the active treatment and in the placebo group, with time of interest for the cost-effectiveness analysis being year. Patient-level QAS, cost are measured and available to us, for a subsample of patients ( in the placebo and in the erlotinib group, respectively).
The primary end point of the trial was OS; secondary end points were PFS (defined as the time between randomisation and progression or death), and health-related quality of life measured by the EQ-5D-3L questionnaire which was collected at monthly intervals. Patient-level QAS for both PFS () and PPS () were determined using the EQ-5D utilities over time for pre- and post-progression periods and multiplied by corresponding survival times. Since all patients in our dataset progressed/died by the time of the analysis, no extrapolation of OS and PFS was carried out but utility data were obtained prospectively up to and beyond progression 30. The costs are from three main components: 1) drug (erlotinib), radiotherapy, additional anticancer treatments - denoted with ; 2) patient management (e.g. hospital visits) - denoted with ; 3) and managing important treatment related-adverse events (e.g. rash) - denoted with . Resource use was collected monthly on the case report forms and combined with unit prices from published sources to derive the costs for each component. Figure 2 and Figure 3 show the histograms of the distributions of the different components of the observed QAS and cost data in both treatment groups, respectively. The number of observations, the empirical mean and standard deviations for each variable are reported in the graphs.
FIGURE 2
The observed distributions of and show a considerable degree of skewness in both treatment groups, especially for post-progression QAS data. Although are defined on a similar range of values, can take both negative and positive values, while has a lower bound at zero, with about of the individuals in each group being associated with this boundary (structural value).
FIGIRE 3
The observed distributions of , and show a high degree of skewness, especially in the intervention group. All data are defined on a positive range but each component has a different variability, with in the intervention being the component associated with the largest standard deviation. The proportions of individuals who are associated with a structural zero for each cost component are: (only in the control group) for , (in each group) for , and (in each group) for . The total number of individuals with fully-observed data for all variables (completers) is , while among those with partially-observed data () the majority were associated with unobserved values for either , or or a combination of these (). A detailed presentation of the missingness patterns and numbers of individuals in each pattern for these data is reported in Appendix A. We note that missingness in is only due to incomplete EQ-5D questionnaires (and thus utility scores) and not censoring of survival time, since all patients progressed/died by the time of the analysis. Missingness in is due to incomplete information from the case report forms on resource use.
4 Application to the TOPICAL study
4.1 Model Specification
Throughout, we refer to our motivating example to demonstrate the flexibility of our approach in dealing with the different issues affecting the cost-utility data; we note that these are likely to be encountered in many practical cases, thus making our arguments applicable in general. We start by modelling with a Gumbel distribution using an identify link function for the mean:
| (11) |
where and are the mean and standard deviation of . We choose the Gumbel distribution since it was the parametric model associated with the best fit to the observed among those assessed (which included Logistic and Normal distributions). The Gumbel distribution has already been recommended for modelling utility data as it is defined on the real line while also being able to capture skewness 31.We parameterise the Gumbel distribution in terms of mean and standard deviation to facilitate the specification of the priors on the parameters, compared with using the canonical location (real) and scale parameters. More specifically, the mean and standard deviation of the Gumbel distribution are linked to the canonical parameters through the relationships: and , where is the Euler’s constant.
When choosing the model for it is important to take into account the considerable proportion of people associated with a zero value in the empirical distributions of both treatment groups (Figure 2), which may otherwise lead to biased inferences. We propose to handle this using a hurdle approach, where the distribution of is expressed as a mixture of a point mass distribution at zero and a parametric model for the natural range of the variable excluding the zeros. Specifically, for each subject we define an indicator variable taking value if the -th individual is associated with and otherwise (i.e. ). We then model the conditional distribution of with a Bernoulli distribution using a logit link function for the probability of being associated with a zero:
| (12) |
where is the probability associated with , which is expressed as a linear function of on the logit scale via the intercept and slope regression parameters and , respectively. Other covariates which are thought to be strongly associated with the chance of having a zero can also be included in the logistic regression to improve the estimation of the probability parameter. However, in our analysis, the inclusion of any of the baseline variables available in the trial did not lead to substantial changes in the inferences, while also not improving the fit of the model to the observed data compared with Equation 12. Therefore, we decided to remove these variables and keep the current specification for the model of . We model with an Exponential distribution using a log link function for the conditional mean:
| (13) |
where and are the intercept and slope mean regression parameters for , defined on the log scale. Again, the choice of the Exponential distribution was made according to the fit to the observed after comparing alternative model specifications (including Weibull and Normal distributions). We note that the canonical rate parameter of the Exponential distribution can be retrieved from the mean parameter through the relationship: .
Using a similar modelling structure to that of , we specify the models for the conditional distributions of the cost variables . We use a hurdle approach to handle the "structural" zero components for each variable, and fit Lognormal distributions to the positive costs (chosen in light of the better fit to the observed data compared with Gamma distributions). For each modelled cost variable, we checked whether the inclusion of any of the available baseline covariates from the trial could lead to some model improvement in terms of fit to the observed data or parameter estimates. However, results from the different model specifications suggest that there is no substantial gain from including these variables, which were therefore removed. We model the conditional distribution of the zero drug cost indicators and drug cost variables given as:
| (14) |
where is the probability of having , while and are the mean and standard deviation parameter for on the log scale. The regression parameters and capture the dependence between drug costs and the effectiveness variables for the zero and non-zero components, respectively. The conditional distribution of the zero hospital cost indicators and hospital cost variables given and is specified as:
| (15) |
where is the probability of having , while and are the mean and standard deviation parameter for on the log scale. The regression parameters and capture the dependence between hospital costs, the effectiveness and the drug cost variables for the zero and non-zero components, respectively. Finally, we specify the conditional distribution of the zero adverse event cost indicators and adverse events cost variables given , and as:
| (16) |
where is the probability of having , while and are the mean and standard deviation parameter for on the log scale. The regression parameters and capture the dependence between adverse events costs, hospital costs, the effectiveness and the drug cost variables for the zero and non-zero components, respectively. We note that we included the drug and hospital cost variables on the log scale in both logit and log linear regressions in Equation 15 and Equation 16 as this lead to an improvement of the model fit compared with using the costs on the original scale. For all parameters in the model we specify vague prior distributions: a normal distribution with a large variance on the appropriate scale for the regression parameters, e.g. , and a uniform distribution over a large positive range for the standard deviations, e.g. .
We note that, although the proposed model requires the specification of a relatively large number of parameters, which may make the model difficult to interpret, this, however, does not ultimately affect the final analysis, which exclusively focuses on the marginal effectiveness and cost means ( and ). These quantities can be retrieved by centering each variable in the effectiveness and cost modules as shown in Section 2. However, this procedure may become difficult to implement in practice when dealing with non-standard parametric specifications, such as the hurdle models, which make the identification of such parameters cumbersome. An alternative, although more computationally intensive, approach to overcome this problem is Monte Carlo integration, which allows to retrieve the marginal mean estimates for each variable by randomly drawing a large number of samples from the posterior distribution of the model and then take the expectation over these sampled values as an approximation to the marginal means.
The procedure is defined as follows. First, we fit the model to the full data, typically using some Markov Chain Monte Carlo (MCMC) methods 32 and imputing the missing values based on their predictive distributions conditional on the observed data via some data augmentation procedure 33. Second, at each iteration of the posterior distribution, we generate a large number of samples for each component of and based on the posterior values for the parameters of the effectiveness and cost models in the MCMC output. Third, we approximate the posterior distribution of the marginal means by taking the expectation over the sampled values at each iteration. Finally, we derive the overall marginal means by summing up the marginal mean estimates for the different components of the effectiveness and costs, that is:
| (17) |
where and are the pre- and post-progression mean QAS, while , and are the mean for the three different components (drug, hospital and adverse events) in the TOPICAL trial.
4.2 Computation
We fitted the model in STAN 34 which is a software specifically designed for the analysis of Bayesian models using a type of MCMC algorithm known as Hamiltonian Monte Carlo 32, and which is interfaced with R through the package rstan 35. Samples from the posterior distribution of the parameters of interest generated by STAN and saved to the R work space are then used to produce summary statistics and plots. We ran two chains with iterations per chain, using a burn-in of , for a total sample of iterations for posterior inference. For each unknown quantity in the model, we assessed convergence and autocorrelation of the MCMC simulations by using diagnostic measures including density and trace plots, the potential scale reduction factor and the effective sample size 36. A summary of the results from these convergence checks for the parameters of the model are provided in Appendix B, while the STAN code used to fit the model is provided in the supplementary material.
4.3 Model Assessment
We compute two relative measures of predictive accuracy to assess the fit of the proposed model specification (denoted as "original") with respect to a second parametric specification (denoted as "alternative"), where we replace the Gumbel distribution for with a Logistic distribution, the Exponential distribution for with a Weibull distribution, and the Lognormal distributions for with Gamma distributions. We specifically rely on the Widely Applicable Information Criterion (WAIC) 37 and the Leave-One-Out Information Criterion (LOOIC) 38, which provide estimates for the pointwise out-of-sample prediction accuracy from a fitted Bayesian model using the log-likelihood evaluated at the posterior simulations of the parameter values. Both measures can be viewed as an improvement on the popular Deviance Information Criterion (DIC) 39 in that they use the entire posterior distribution, are invariant to parametrisation, and are asymptotically equal to Bayesian cross-validation 40. These information criteria are obtained based on the model deviance and a penalty for model complexity known as effective number of parameters ( ) and, when comparing a set of models based on the same data, the one associated with the lowest WAIC or LOOIC is the best-performing, among those assessed.
Results between the two alternative specifications are reported in Table 1.
TABLE 1
For both criteria, the values associated with the "original" specification of the model are systematically lower compared with those from the "alternative" parameterisation, and result in an overall better fit to the data for the first model. We have explored different configurations of distribution assignment among those shown in Table 1 for the effectiveness and cost variables (including also the Normal distribution which, however, was always associated with the worst fit). The results from these comparisons suggest that the "original" specification of the model remains the one associated with the best performance.
We additionally assess the absolute fit of the model using the observed and replicated data. The latter are generated from the posterior predictive distributions of the models using the posterior samples of the parameters indexing the distributions of each effectiveness and cost variable. We use the posterior estimates from these parameters to jointly sample replications of the data which are then used for model assessment. We computed different types of graphical posterior predictive checks, either in terms of the entire distributions using density and cumulative density plots, or in terms of the marginal mean estimates between the real and replicated data, which are provided in Appendix C. Overall these checks suggest a relatively good fit of the model for each modelled variable.
5 Results
This section discusses the results of the model from a twofold perspective: first, focus is given to summarising the posterior distribution of the main quantities of interest, namely the marginal means of each component of the effectiveness () and cost () variables and the marginal means for the aggregated variables, namely ; second, the economic results are discussed by computing the probability that the new intervention is cost-effective with respect to the control.
5.1 Posterior Estimates
Figure 4 compares the posterior means (squares) together with the (thick lines) and (thin lines) highest posterior density (HPD) credible intervals for the marginal means of each effectiveness and cost components, obtained from fitting the model to all cases under a MAR assumption. Results associated with the control () and intervention () group are indicated with red and blue colours, respectively.
FIGURE 4
Posterior QAS means are on average higher for the PFS compared with the PPS component in both treatment groups. However, both and HPD intervals suggest that the estimates associated with the intervention group have a much higher degree of variability compared with those from the control, especially for the PPS component. The posterior cost means for each component show that the intervention group is associated with systematically higher values with respect to the control, especially for the drug costs which by far cover most of the total costs in the intervention. HPD intervals for mean costs show a relatively high degree of skewness with posterior mean estimates being closer to the upper bounds of the intervals compared to the lower bounds.
We derived the aggregated QAS and cost means for each treatment group by summing up the posterior mean estimates of the different components for each type of variable. We then computed the incremental mean estimates between the two groups, denoted with and , together with the Incremental Cost Effectiveness Ratio (ICER), representing the cost per QAS gained between the two interventions. Table 2 shows selected posterior summaries, including means, medians, standard deviations and HPD intervals, for the marginal and incremental mean estimates associated with the two intervention groups.
TABLE 2
Overall, the posterior results indicate that the new intervention is associated with systematically higher QAS and costs compared to the control, with a positive mean QAS increment of , a positive mean cost increment of , and with intervals that exclude zero for both quantities. We note that posterior estimates for the marginal means in the control group show a considerably lower degree of variability (standard deviations of and ) compared with those from the intervention group (standard deviations of and ). Finally, the additional cost per unit of QAS gained is estimated to be roughly for compared to .
5.2 Economic Evaluation
We complete the analysis by assessing the probability of cost-effectiveness for the new intervention with respect to the control. A general advantage of using a Bayesian approach is that the economic analysis can be easily performed without the need to use ad-hoc methods to represent uncertainty around point estimates (e.g. bootstrapping). Indeed, once the statistical model is fitted to the data, the samples from the posterior distributions of the parameters of interest can be used to compute different types of summary measures of cost-effectiveness.
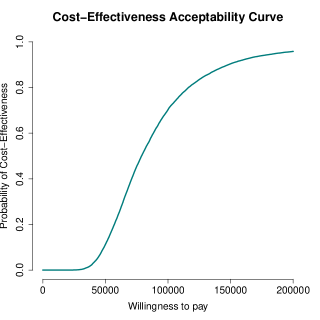
We specifically rely on the examination of the cost-effectiveness plane (CEP) 41 and the cost-effectiveness acceptability curve (CEAC) 42 to summarise the economic analysis. Figure 5 (panel a) shows the plot of the CEP, which is a graphical representation of the joint distribution for the mean effectiveness and costs increments between the two treatment groups. The slope of the straight line crossing the plane is the "willingness-to-pay’" threshold (which is often indicated as ). This can be considered as the amount of budget that the decision maker is willing to spend to increase the health outcome of unit and effectively is used to trade clinical benefits for money. Current recommendations for generic interventions suggest a value of between ; however, for end of life treatments, such as cancer treatments, the recommended threshold values are typically higher and lie in a range between or above 43. Points lying below this straight line fall in the so-called sustainability area 14 and suggest that the new intervention is more cost-effective than the control.
FIGIRE 5
Almost all samples fall in the north-east quadrant of the plane. This suggests that the intervention is likely to be more effective and more expensive compared with the control. At , the ICER (and the majority of the samples) falls outside the sustainability area, and therefore indicates that the intervention is unlikely to be considered cost-effective at the chosen value of . Figure 5 (panel b) shows the CEAC, which is obtained by computing the proportion of points lying in the sustainability area on varying the willingness-to-pay threshold . The CEAC estimates the probability of cost-effectiveness, thus providing a simple summary of the uncertainty that is associated with the "optimal" decision making that is suggested by the ICER. The graph shows how, starting from null to relatively small probabilities of cost-effectiveness for , as the value of the willingness to pay threshold is increased, the chance that the new intervention becomes cost-effective rises up to near full certainty for . We note that these cost-effectiveness conclusions should be interpreted with care, due to limitations associated with the data analysed which are explicitly discussed in Section 6 (e.g. based on a subset of the original data). However, this does not affect the generalisability of our framework, which implements a flexible modelling approach for handling the typical characteristics of trial-based partitioned survival economic data.
6 Discussion
In this paper, we have proposed a general framework for partitioned survival cost-utility analysis using patient level data (e.g. from a trial), which takes into account the correlation between costs and effectiveness, skewness in the distribution of the observed data, the presence of structural zeros, and missing data. Although alternative approaches have been proposed in the literature to handle the statistical issues affecting cost-effectiveness data, they had either considered only some of these issues separately 44, 20, 22 or did not specifically focus on partitioned survival analyses 23, 24. The approach developed in Section 2 uses a flexible structure and allows the distributions of different components of the effectiveness and costs to be modelled so to handle the typical idiosyncrasies that affect each variable, all within a joint probabilistic framework. This is a key advantage of the Bayesian approach compared with other approaches, especially in health economic evaluations where the main objective is not statistical inference per se, but rather to assess the uncertainty in the decision-making process, induced by the uncertainty in the model inputs 45, 46.
The economic results from our case study should be interpreted with caution and some potential limitations in terms of the generalisability of the proposed framework to other studies should be highlighted. First, our analysis of TOPICAL is based on a subset of the individuals in the original trial (made available to us) and therefore it is difficult to draw any cost-effectiveness conclusions about the trial from this analysis. Second, although the results are obtained under a MAR assumption, which is typically considered more plausible than just focussing on the complete cases, missingness assumptions can never be checked from the data at hand. It is possible that the assumption of MAR is not tenable, which may therefore introduce some bias. It is generally recommended that departures from MAR are explored in sensitivity analysis to assess the robustness of the conclusions to some plausible MNAR scenarios 27. However, given the limitations of our analysis in terms of the interpretation of the trial results and the lack of any external information to guide the choice of the MNAR departures, we decided not to pursue such analyses here. We note that different approaches are available to conduct sensitivity analysis to MNAR, some of which can be implemented within a Bayesian framework, for example through the elicitation of expert’s opinions using prior distributions 27, 47. Finally, while the computation of QAS based on utility and survival data from TOPICAL can be assumed to be valid (since of individuals in the trial have progressed/died by the time of the analysis), it is generally known that this calculation may be invalid if the survival time for some patients is not observed, as it may introduce informative censoring which distorts the inferences 7. Alternative approaches have been proposed to overcome this problem, which mostly rely on the separate calculation of population-level summary measures for the utility and survival components (e.g. using linear mixed models for the utilities and Kaplan-Meier estimates for the survival times) which are then combined together to generate QAS estimates 6.
In conclusions, although our approach may not be applicable to all cases, the data analysed are very much representative of the “typical” data used in partitioned survival cost-utility analysis alongside clinical trials. Thus, it is highly likely that the same features apply to many real cases. This is a very important, if somewhat overlooked problem, as methods that do not take into account the complexities affecting patient-level data, while being easier to implement and well established among practitioners, may ultimately mislead cost-effectiveness conclusions and bias the decision-making process.
Acknowledgements
We wish to thank the UCL CRUK Cancer Trials Centre for providing a subset of data from the TOPICAL trial.
References
- Earnshaw and Lewis 2008 Julia Earnshaw and Gavin Lewis. Nice guide to the methods of technology appraisal, 2008.
- Glick et al. 2014 Henry A Glick, Jalpa A Doshi, Seema S Sonnad, and Daniel Polsky. Economic evaluation in clinical trials. OUP Oxford, 2014.
- Van Reenen and Oppe 2015 M. Van Reenen and M. Oppe. EQ-5D-3L User Guide Basic information on how to use the EQ-5D-3L instrument. https://euroqol.org/wp-content/uploads/2016/09/EQ-5D-3L_UserGuide_2015.pdf, 2015.
- Dolan 1997 Paul Dolan. Modeling valuations for euroqol health states. Medical care, pages 1095–1108, 1997.
- Drummond et al. 2005 MF. Drummond, MJ. Schulpher, K. Claxton, GL. Stoddart, and GW. Torrance. Methods for the economic evaluation of health care programmes. 3rd ed. Oxford university press, Oxford, 2005.
- Khan 2015 Iftekhar Khan. Design & Analysis of clinical trials for Economic Evaluation & Reimbursement: an applied approach using SAS & STATA. Chapman and Hall/CRC, 2015.
- Glasziou et al. 1990 PP Glasziou, RJ Simes, and RD Gelber. Quality adjusted survival analysis. Statistics in medicine, 9(11):1259–1276, 1990.
- Gelber et al. 1995 Richard D Gelber, Bernard F Cole, Shari Gelber, and Aron Goldhirsch. Comparing treatments using quality-adjusted survival: the q-twist method. The American Statistician, 49(2):161–169, 1995.
- Williams et al. 2017 Claire Williams, James D Lewsey, Daniel F Mackay, and Andrew H Briggs. Estimation of survival probabilities for use in cost-effectiveness analyses: a comparison of a multi-state modeling survival analysis approach with partitioned survival and markov decision-analytic modeling. Medical Decision Making, 37(4):427–439, 2017.
- Willan and Briggs 2006 Andrew R Willan and Andrew H Briggs. Statistical analysis of cost-effectiveness data, volume 37. John Wiley & Sons, 2006.
- Ramsey et al. 2015 Scott D Ramsey, Richard J Willke, Henry Glick, Shelby D Reed, Federico Augustovski, Bengt Jonsson, Andrew Briggs, and Sean D Sullivan. Cost-effectiveness analysis alongside clinical trials ii—an ispor good research practices task force report. Value in Health, 18(2):161–172, 2015.
- O’Hagan et al. 2001 Anthony O’Hagan, John W Stevens, and Jacques Montmartin. Bayesian cost-effectiveness analysis from clinical trial data. Statistics in medicine, 20(5):733–753, 2001.
- Spiegelhalter et al. 2004 David J Spiegelhalter, Keith R Abrams, and Jonathan P Myles. Bayesian approaches to clinical trials and health-care evaluation, volume 13. John Wiley & Sons, 2004.
- Baio 2012 G. Baio. Bayesian Methods in Health Economics. Chapman and Hall/CRC, University College London London, UK, 2012.
- Nixon and Thompson 2005 RM. Nixon and SG. Thompson. Methods for incorporating covariate adjustment, subgroup analysis and between-centre differences into cost-effectiveness evaluations. Health Economics, 14:1217–1229, 2005.
- Grieve et al. 2010 R. Grieve, R. Nixon, G. Simon, and SG. Thompson. Bayesian hierarchical models for cost-effectiveness analyses that use data from cluster randomized trials. Medical Decision Making, 30:163–175, 2010.
- Gomes et al. 2012 R. Gomes, ESW. Ng, R. Grieve, R. Nixon, ESW. NG, J. Carpenter, and SG. Thompson. Developing appropriate methods for cost-effectiveness analysis of cluster randomized trials. Medical Decision Making, 32:350–361, 2012.
- O’Hagan and Stevens 2003 A. O’Hagan and JW. Stevens. Assessing and comparing costs: how robust are the bootstrap and methods based on asymptotic normality? Health Economics, 12:33–49, 2003.
- Thompson and Nixon 2005 SG. Thompson and RM. Nixon. How sensitive are cost-effectiveness analyses to choice of parametric distributions? Medical Decision Making, 4:416–423, 2005.
- Basu et al. 2007 A. Basu, JJ. Heckman, S. Navarro-Lozano, and S. Urzua. Use of instrumental variables in the presence of heterogeneity and self-selection: An application in breast cancer patients. Health Econometrics and Data Group, HEDG Working Paper 07/07, 2007.
- Mihaylova et al. 2011 Borislava Mihaylova, Andrew Briggs, Anthony O’Hagan, and Simon G Thompson. Review of statistical methods for analysing healthcare resources and costs. Health economics, 20(8):897–916, 2011.
- Baio 2014 Gianluca Baio. Bayesian models for cost-effectiveness analysis in the presence of structural zero costs. Statistics in medicine, 33(11):1900–1913, 2014.
- Gabrio et al. 2019a Andrea Gabrio, Alexina J Mason, and Gianluca Baio. A full bayesian model to handle structural ones and missingness in economic evaluations from individual-level data. Statistics in medicine, 38(8):1399–1420, 2019a.
- Gabrio et al. 2019b Andrea Gabrio, Michael J Daniels, and Gianluca Baio. A bayesian parametric approach to handle missing longitudinal outcome data in trial-based health economic evaluations. Journal of the Royal Statistical Society: Series A (Statistics in Society), 2019b.
- Rubin 1987 DB. Rubin. Multiple Imputation for Nonresponse in Surveys. John Wiley and Sons, New York,USA, 1987.
- Molenberghs et al. 2014 Geert Molenberghs, Garrett Fitzmaurice, Michael G Kenward, Anastasios Tsiatis, and Geert Verbeke. Handbook of missing data methodology. Chapman and Hall/CRC, 2014.
- Daniels and Hogan 2008 MJ. Daniels and JW. Hogan. Missing Data in Longitudinal Studies: Strategies for Bayesian Modeling and Sensitivity Analysis. Chapman and Hall, New York, 2008.
- Lambert et al. 2008 Paul C Lambert, Lucinda J Billingham, Nicola J Cooper, Alex J Sutton, and Keith R Abrams. Estimating the cost-effectiveness of an intervention in a clinical trial when partial cost information is available: a bayesian approach. Health economics, 17(1):67–81, 2008.
- Lee et al. 2012 Siow Ming Lee, Iftekhar Khan, Sunil Upadhyay, Conrad Lewanski, Stephen Falk, Geraldine Skailes, Ernie Marshall, Penella J Woll, Matthew Hatton, Rohit Lal, et al. First-line erlotinib in patients with advanced non-small-cell lung cancer unsuitable for chemotherapy (topical): a double-blind, placebo-controlled, phase 3 trial. The lancet oncology, 13(11):1161–1170, 2012.
- Khan et al. 2015 Iftekhar Khan, Stephen Morris, Allan Hackshaw, and Siow-Ming Lee. Cost-effectiveness of first-line erlotinib in patients with advanced non-small-cell lung cancer unsuitable for chemotherapy. BMJ open, 5(7):e006733, 2015.
- Gomes et al. 2019 Manuel Gomes, Rosalba Radice, Jose Camarena Brenes, and Giampiero Marra. Copula selection models for non-gaussian outcomes that are missing not at random. Statistics in medicine, 38(3):480–496, 2019.
- Brooks et al. 2011 Steve Brooks, Andrew Gelman, Galin Jones, and Xiao-Li Meng. Handbook of markov chain monte carlo. CRC press, 2011.
- Tanner and Wong 1987 Martin A Tanner and Wing Hung Wong. The calculation of posterior distributions by data augmentation. Journal of the American statistical Association, 82(398):528–540, 1987.
- Carpenter et al. 2017 Bob Carpenter, Andrew Gelman, Matthew D Hoffman, Daniel Lee, Ben Goodrich, Michael Betancourt, Marcus Brubaker, Jiqiang Guo, Peter Li, and Allen Riddell. Stan: A probabilistic programming language. Journal of statistical software, 76(1), 2017.
- Team et al. 2016 Stan Developent Team et al. Rstan: the r interface to stan. R package version, 2(1), 2016.
- Gelman et al. 2004 A. Gelman, J. Carlin, H. Stern, and D. Rubin. Bayesian Data Analysis - 2nd edition. Chapman and Hall, New York, NY, 2004.
- Watanabe 2010 Sumio Watanabe. Asymptotic equivalence of bayes cross validation and widely applicable information criterion in singular learning theory. Journal of Machine Learning Research, 11(Dec):3571–3594, 2010.
- Vehtari et al. 2017 Aki Vehtari, Andrew Gelman, and Jonah Gabry. Practical bayesian model evaluation using leave-one-out cross-validation and waic. Statistics and computing, 27(5):1413–1432, 2017.
- Spiegelhalter et al. 2002 David J Spiegelhalter, Nicola G Best, Bradley P Carlin, and Angelika Van Der Linde. Bayesian measures of model complexity and fit. Journal of the royal statistical society: Series b (statistical methodology), 64(4):583–639, 2002.
- Gelman et al. 2014 Andrew Gelman, Jessica Hwang, and Aki Vehtari. Understanding predictive information criteria for bayesian models. Statistics and computing, 24(6):997–1016, 2014.
- Black 1990 WC. Black. A graphic representation of cost-effectiveness. Medical Decision Making, 10:212–214, 1990.
- Van Hout et al. 1994 BA. Van Hout, MJ. Al, GS. Gordon, FFH. Rutten, and KM. Kuntz. Costs, effects and c/e-ratios alongside a clinical trial. Health Economics, 3:309–319, 1994.
- NICE 2013 NICE. Guide to the Methods of Technological Appraisal. NICE, London, 2013.
- O’Hagan and Stevens 2001 A. O’Hagan and JW. Stevens. A framework for cost-effectiveness analysis from clinical trial data. Health Economics, 10:303–315, 2001.
- Claxton 1999 Karl Claxton. The irrelevance of inference: a decision-making approach to the stochastic evaluation of health care technologies. Journal of health economics, 18(3):341–364, 1999.
- Claxton et al. 2005 K. Claxton, M. Sculpher, C. McCabe, A. Briggs, R. Hakehurst, M. Buxton, J. Brazier, and T. O’Hagan. Probabilistic sensitivity analysis for nice technology assessment: not an optional extra. Heath Economics, 27:339–347, 2005.
- Mason et al. 2018 Alexina J Mason, Manuel Gomes, Richard Grieve, and James R Carpenter. A bayesian framework for health economic evaluation in studies with missing data. Health economics, 27(11):1670–1683, 2018.
- Gabry and Mahr 2018 Jonah Gabry and T Mahr. bayesplot: Plotting for bayesian models. r package version 1.6. 0, 2018.
Appendix A Missingness Patterns in TOPICAL
TABLE 3
Appendix B MCMC Convergence
This section reports some summary diagnostics of the MCMC algorithm, including density and trace plots, for all key parameters of the model fitted to the TOPICAL data. For all parameters, no substantial issue in convergence is detected. All plots were generated from R using functions in the package bayesplot 48, which provides a variety of tools to perform diagnostic and posterior predictive checks for Bayesian models.
FIGURE 6
FIGURE 7
FIGURE 8
FIGURE 9
Appendix C Posterior Predictive Checks
This section reports some graphical posterior predictive checks, including empirical density, cumulative density and mean plots, for all variables of the model fitted to each treatment group in the TOPICAL trial. In all cases, no substantial discrepancy between the observed and predicted data is detected which suggests a generally good fit of the model. All plots were generated from R using functions in the package bayesplot 48, which provides a variety of tools to perform diagnostic and posterior predictive checks for Bayesian models.
FIGURE 10
FIGURE 11
FIGURE 12
FIGIRE 13
FIGURE 14











| Original | Alternative | |||||
| variable | Distribution | WAIC() | LOOIC() | Distribution | WAIC() | LOOIC() |
| Gumbel | -109(11) | -107(12) | Logistic | -68(8) | -68(8) | |
| Exponential | 34(10) | 35(10) | Weibull | 36(8) | 38(9) | |
| Lognormal | 3283(16) | 3286(17) | Gamma | 3361(26) | 3365(28) | |
| Lognormal | 3437(15) | 3438(15) | Gamma | 3659(15) | 3660(16) | |
| Lognormal | 3208(22) | 3211(23) | Gamma | 3437(38) | 3433(36) | |
| Total | 9853(74) | 9863(77) | 10425(95) | 10428(97) | ||


| Parameter | mean | median | sd | 95% CI | |
| Control | |||||
| 0.24 | 0.23 | 0.02 | 0.20 | 0.27 | |
| 3059 | 3001 | 424 | 2329 | 3898 | |
| Intervention | |||||
| 0.38 | 0.38 | 0.05 | 0.29 | 0.47 | |
| 14519 | 14055 | 2628 | 10235 | 19681 | |
| Incremental | |||||
| 0.14 | 0.14 | 0.05 | 0.05 | 0.24 | |
| 11460 | 11013 | 2666 | 7282 | 16983 | |
| ICER | 79233 | ||||