61A Bot Report: AI Assistants in CS1 Save Students Homework
Time and Reduce Demands on Staff. (Now What?)
Abstract.
LLM-based chatbots enable students to get immediate, interactive help on homework assignments, but even a thoughtfully-designed bot may not serve all pedagogical goals. We report here on the development and deployment of a GPT-4-based interactive homework assistant (“61A Bot”) for students in a large CS1 course; over 2000 students made over 100,000 requests of our Bot across two semesters. Our assistant offers one-shot, contextual feedback within the command-line “autograder” students use to test their code. Our Bot wraps student code in a custom prompt that supports our pedagogical goals and avoids providing solutions directly. Analyzing student feedback, questions, and autograder data, we find reductions in homework-related question rates in our course forum, as well as reductions in homework completion time when our Bot is available. For students in the percentile, reductions can exceed 30 minutes per assignment, up to 50% less time than students at the same percentile rank in prior semesters. Finally, we discuss these observations, potential impacts on student learning, and other potential costs and benefits of AI assistance in CS1.
1. Introduction
The recent wide availability of Large Language Models (LLMs) has given students in introductory Computer Science (CS) courses a tempting alternative to asking a human TA for help on programming assignments—and potentially waiting hours to receive it. For instructors of large courses, LLMs like ChatGPT appeal by offering 24/7 access to personalized assistance that will answer nearly any student question, though not always correctly, and with other risks.
But while naively used LLMs do help students solve assigned problems, they typically do so by providing correct answers along with explanations, allowing students to avoid the process of developing solutions themselves and the learning associated with this process. A number of recent reports (Denny et al., 2023a, b; Finnie-Ansley et al., 2023; Hellas et al., 2023; Kazemitabaar et al., 2024; Liffiton et al., 2023; Wang et al., 2024) present more thoughtful approaches: new systems, also based on LLMs, geared towards offering guidance and assistance without providing direct solutions.
Both students and instructors are reported to find these systems helpful (Kazemitabaar et al., 2024; Liffiton et al., 2023). Recent studies of deployed LLM-based assistants have included analyses of what affordances are most appreciated and what kinds of functionality students are most likely to use (Kazemitabaar et al., 2024; Denny et al., 2024); how to effectively design systems with guardrails to reduce instances of solution-sharing (Liffiton et al., 2023); and what kinds of error messages are most correlated with reductions in error rates (Wang et al., 2024). There is a growing interest in understanding the landscape of these new systems and their impacts on students learning computer science (Prather et al., 2024)—but while much is known about how these systems are designed and what seems to work well, comparatively less has been reported on how these systems impact specific courses.
In this experience report, we first present our own assistant, a low-friction “61A Bot” with 24/7 availability that offers feedback on every run of an “autograder” that students use liberally to test their code-in-progress. Our Bot constructs a GPT-4 request using our custom prompt, homework question text, student code, and autograder error output (where available), returning its response to students. The prompt is itself designed to steer towards feedback that mirrors how we ourselves typically approach student questions, aligned with recent work in this area (Markel and Guo, 2021): identifying whether the student understands the question, which concepts students might need reinforcement on, and whether they have a plan, and then helping students by providing conceptual, debugging, or planning support as appropriate.
Then, we examine our Bot’s impact on our CS1 course, UC Berkeley’s CS 61A—a large (-student) Python-based course targeted at CS majors. Ultimately, we ask: What impact does this deployment have on our course, on students and on staff? First, we find that students assess a majority of Bot-provided hints as being helpful, in line with prior work. Second, through a retrospective observational study aimed at quantifying impacts, we find that requests for homework help to our course forum drop dramatically (75%) after our Bot is deployed, and that students spend substantially less time completing their homework—25-50% less time, often more than 30 minutes faster, for students at the same percentile rank in completion time across prior semesters.
We note that while these impacts do not necessarily imply improvements in student learning outcomes, speeding up homework completion times without increasing learning could still be a positive outcome: the time saved on completing traditional assignments could be harnessed by instructors to increase learning in other ways. In our final section, we discuss some of the costs and potential benefits of deploying LLM-based assistance in CS1, exploring possible learning impacts, reductions in the visibility of student challenges to staff, and opportunities for future research.
Our work makes three main contributions. First, it offers a rich description of our low-friction CS1 assistant and its deployment in our course. Second, we detail findings of students’ subjective experiences based on student surveys over two semesters. Third, we share results from a retrospective, observational analysis of student homework completion patterns, identifying quantitative impacts our Bot had on staff demand and students’ homework experiences.
2. Background & Related Work
Generative models such as ChatGPT,111https://chat.openai.com/ OpenAI Codex (Chen et al., 2021), Amazon CodeWhisperer,222https://aws.amazon.com/codewhisperer/ and GitHub Copilot333https://copilot.github.com/ offer promising opportunities for enriching the learning experience of students. These models have already been leveraged by educators in different areas of Computing education (Finnie-Ansley et al., 2022; Denny et al., 2023b; Hellas et al., 2023; Denny et al., 2023a), where they accelerate content generation and seem to be impacting the relevant skills students gain in introductory CS courses. Researchers have studied LLMs in areas such as generating code explanations (Leinonen et al., 2023a; Becker et al., 2023; MacNeil et al., 2023b; Liu et al., 2024a), providing personalized immediate feedback (Bassner et al., 2024), enhancing programming error messages (Leinonen et al., 2023b; Wang et al., 2024), generating discussion forum responses (Mitra et al., 2024; Liu et al., 2024b), and automatic creation of personalized programming exercises and tutorials (Sarsa et al., 2022; Yuan et al., 2023; Reeves et al., 2023) to enhance the comprehensiveness of course materials.
However, the integration of LLMs in CS1 instruction comes with challenges. Students could become overly reliant on automation (a concern at least as old as calculators (Demana and Waits, 2000)), potentially hindering their development of critical problem-solving skills—though recent work suggests these negative effects can be avoided, at least for programming assistance (Kazemitabaar et al., 2023). Taken to an extreme, the resulting absence of human interaction could have negative effects, alongside other ethical concerns related to plagiarism and the responsible use of LLM-generated code. To maximize the benefits of LLMs while mitigating these challenges, a thoughtful and balanced approach to their incorporation into CS1 courses is essential (Mirhosseini et al., 2023; MacNeil et al., 2023a; Denny et al., 2024).
Through deployments of LLMs as intelligent tutors, students can receive immediate, personalized support and guidance, which would ideally foster a deeper understanding of coding concepts and promote self-paced learning—just as with pre-LLM Intelligent Tutoring Systems (e.g., (Suzuki et al., 2017); see (Crow et al., 2018) for a review). The ability of LLMs to generate tailored resources, such as new, personalized tutorials and newly-generated code examples, not only expands the available learning materials but also accommodates students’ varying learning preferences—though these generated materials are not always better (Pardos and Bhandari, 2023). Educators should integrate LLMs as complementary tools, striking a balance between automation and human interaction while emphasizing the development of critical problem-solving skills and responsible coding practices, ultimately serving students better in their CS education.
Researchers are also increasingly integrating LLM-based chatbots in courses (Liu et al., 2024a; Wu et al., 2022) and online educational websites (Ofgang, 2023) to provide immediate personalized feedback, and in tools in supporting students’ development of programming skills (Prather et al., 2023; Finnie-Ansley et al., 2023; Cipriano and Alves, 2023). These include CodeHelp (Liffiton et al., 2023; Sheese et al., 2024) and CodeAid (Kazemitabaar et al., 2024), two systems (and deployments) that bear a number of similarities to our own—though those systems enable students to ask questions, while ours (we believe uniquely) integrates feedback directly into the tool students already use to execute that code, and then builds on the student’s history of prior assistant hints and code changes in response.
Our work here builds on these prior efforts in the design of 61A Bot, differing primarily in its integration mode (embedded within an autograder students must run anyway), and the lack of conversational interaction. Our evaluation validates prior findings on engagement and satisfaction, and additionally offers a unique perspective of the impact of our Bot on student assignment completion times compared with historical course baselines.
3. Design & Deployment
Our deployment focused on providing students help with homework problems in part to address frequent student feedback from prior terms about long wait times for TA support for homework problems. In particular, we chose to focus primarily on the kinds of debugging assistance our staff are often asked for. Three concerns—hallucinations, students sharing personal information with a third party, and the harms from an unmonitored chat interaction—led us to a one-shot “Get Help” design rather thanc“chat”. This meant eschewing the valuable pedagogical approach of having students explain their understanding of the problem.
Following a common tutoring pattern (Markel and Guo, 2021), we designed a prompt that would try to assess student conceptual knowledge, based on the provided code, and offer syntactical, logical, or even template-code suggestions—but not solutions. This prompt explicitly includes a sequence of questions to consider in response to the student code:
-
(1)
Is the student missing conceptual knowledge?
-
(2)
Is their current code on the right track?
-
(3)
How close are they to a solution?
-
(4)
Were they able to follow previous advice?
-
(5)
Do they have a reasonable plan?
Though we avoided students explicitly writing natural language “chat” messages to the bot, we did want some degree of continuity—which we achieved by also including up to three prior (student code, Bot advice) exchanges, if available (enabling question 4).
In addition to the steps above, the prompt also includes a per-problem instruction block, which we used for about 10% of problems, and more general instructions such as Do not give the student the answer or any code. and Limit your response to a sentence or two at most. Our full prompt, along with our server and VS Code extension, are open source and available online at https://github.com/zamfi/61a-bot.

3.1. Course Details & Deployment
Our course covers most of the typical CS1 content, plus a few additional topics, and we report here on the CS1 portion of our course. These modules are taught using Python, to a student population made up predominantly of CS majors and intended majors ( majors/intended), with substantial prior preparation ( any prior CS course, including high school). These demographics are broadly consistent across the semesters we examine historically in this report, and variations do not correlate with the results described here. (Typical Fall and typical Spring semester students differ demographically due to how course requirements are structured at our institution; we treat those as separate populations.) In our course, content is typically introduced in lecture, and then reinforced in three assignment types: first, “labs,” which include a mixture of notional machine reinforcement (e.g., tracing, “What would Python do?”) and traditional homework problems, completed in small groups without access to 61A Bot. These are followed by “homework,” which students complete individually with access to 61A Bot. Finally, students complete “projects” that bring together multiple concepts towards a single goal, over a few weeks, again without access to 61A Bot. In addition, students were prohibited by course policy from using ChatGPT or other similar AI-based systems for help across all assignment types—but we do not have the means to enforce this.
3.1.1. Using 61A Bot
Students primarily (93%) access our Bot through an autograder444 OK Client, https://github.com/okpy/ok-client in the command line which provides the result of running the student’s code on a set of test cases; if any fail, the student is then asked whether they would like to receive feedback on their code from 61A Bot (see Figure 1). If they do, the autograder collects the student’s code, any errors from executing test cases, and constructs a request from these. Alternatively, students choosing to use VS Code555Visual Studio Code, https://code.visualstudio.com can install an extension to enable a “Get Help” button in the toolbar that works similarly.
Requests thus include: our prompt, along with any problem-specific notes; the text of the specific homework problem the student is requesting help for (one of 4-6 problems within an assignment); up to 3 pairs of prior-code/Bot-response text (from any prior requests); the student’s current code; and, finally, any error text from failed test cases. These requests are sent to a server run by our instructional staff, which passes it to GPT-4 and logs the request and GPT-4’s response for further analysis.
Students are informed when installing the software that, in using our assistant, all code they write will be sent to OpenAI via Microsoft Azure,666https://ai.azure.com/ and that they should not include any content in their code files (e.g., comments) that they do not want to share.
3.1.2. Deployment Timeline
We piloted and continued development on 61A Bot throughout the academic year 2023-2024. In Fall 2023, we deployed an initial pilot of 61A Bot to a section of 400 students. This was followed by a full-scale deployment in week 10 (after the CS1 portion of our course) for the approximately 1400 students across both sections of the course. In conjunction with the wider deployment, we also enabled access through the autograder tool students could already run from the command line to validate their code against a set of test cases. In Spring 2024, all 900 enrolled students had access to both modalities of the Bot from the start of the semester. Our qualitative analysis thus draws on both semesters, while our quantitative analysis is focused on the full deployment in Spring 2024 where we can compare like-for-like with a full-term deployment and historically comparable student populations.
4. Outcomes
Students’ adoption of 61A Bot was immediate, and usage exploded once we integrated access into our autograder. In this section, we detail usage patterns and changes in reliance on course staff, report on student assessments of their experiences, and finally offer an investigation of the possible impacts of 61A Bot on homework completion times. Unless otherwise noted, statistical accounts in this section come exclusively from Spring 2024, the semester in which our fully-developed Bot was deployed for all students (see §3.1.2 for deployment details).
4.1. Usage & Reliance on Staff
Usage patterns show that students are returning to 61A Bot multiple times as they engage in homework: across our pilot and full deployment semesters, over 2000 students made a total of 105,689 requests of our bot. The median student in our full deployment semester made 25 requests to our bot, rising to 80 requests for the student at the 95th percentile. As expected, usage increases as the assignment deadline nears and is concentrated in the late afternoons and evenings—a pattern similar to the usage reported in (Liffiton et al., 2023; Kazemitabaar et al., 2024)—with a peak request rate of 291 requests/hour.
This engagement correlates with a reduction in help requests on our online discussion forum for students to receive asynchronous help. There is a substantial (30%) decrease in the number of questions asked (scaled to total enrollment) throughout the semester from Spring 2023 to Spring 2024, from 1741 to 1185 questions per thousand students. The impact on homework-specific questions is even larger, showing a 75% decrease from 344 homework questions per thousand students in Spring ’23 to 88 in ’24—see Table 1. (We include scaled question counts for Fall 2022 and Fall 2023 as data points illustrating the level of consistency across semesters.)
| Fa22 | Sp23 | Fa23 | Sp24 | |
|---|---|---|---|---|
| # Students | 1656 | 1169 | 1407 | 872 |
| # Questions | 1853 | 2035 | 1823 | 1033 |
| per 1000 students | 1119 | 1741 | 1296 | 1185 |
| # HW Questions | 234 | 402 | 177 | 77 |
| per 1000 students | 141 | 344 | 126 | 88 |
4.2. Student Reception
Student feedback suggests that students also found the Bot helpful. We solicited this feedback in two ways: First, we queried students for their assessment of each individual hint, which we received for approximately 27% () of queries.777These counts reflect queries from only those students who gave consent for their data to be used for research, and only during the CS1 portion of our course. Of these, 70% () were rated as “helpful,” with 45% of those, , reporting that the problem was now resolved. A further 10% () were rated as “not helpful, but made sense,” while the final 20% () were rated as insensible, misleading, or wrong.
Second, we formally surveyed students on their usage and perceptions of the Bot. In Fall 2023, we conducted a non-anonymous survey at the end of the semester to which 49% () of students responded. Students were asked to rate how much they used the Bot and how helpful they found it on a scale from 1 to 5. As expected, those who reported more usage also found it more helpful.
In Spring 2024, we conducted a non-anonymous survey at the end of the semester, to which 89% () of students responded. On a scale from 1 to 5, we asked students to rate their Bot usage, Bot helpfulness, Bot reliability, and overall satisfaction with the Bot. Finally, we asked them whether or not they recommend that the Bot be available to students in future semesters. The results from these surveys can be found in Figure 2.
Note that these results include both our partial- (Fall 2023) and full-deployment (Spring 2024) semesters; the Fall 2023 results thus reflect usage only post-deployment. Additionally, these surveys were non-anonymous to track individual participation (for pedagogical goals independent of this project); because of this non-anonymity, however, we did not ask whether students relied on ChatGPT or other prohibited (by course policy) methods of support, reasoning that we were unlikely to be able to rely on such results.

In the Spring 2024 survey, we also asked two optional free-response questions: What did students like the most and least about learning with the Bot? We include a representative response for each here: Most liked:
“What I loved about the bot is that it allowed me to get feedback when I didn’t have access to a tutor. Accordingly, instead of banging my head against the wall for hours, I was able to get feedback about what I was doing wrong and correct the mistakes. For me personally, I would have had a lot more success in this class if I would have had access to the bot for labs. (Labs on average took me about 2 and a half hours to complete, and sometimes longer if I didn’t have access to a tutor).”
Least liked:
“Sometimes the answers were slightly vague. Of course, the bot can’t simply spit out the answer, but sometimes it was frustrating how it would say ‘you’re on the right track, but there seems to be a conceptual misunderstanding with __’ — the explanations for the blank could be a bit jargon-filled and didn’t always directly help me resolve the misunderstanding due to imprecise language.”
Students generally appreciated 61A Bot’s accessibility, debugging capabilities, and time savings. However, the hints were sometimes too vague for the students to make changes, while other times, the Bot was too specific and gave away too much. Despite our attempts to steer GPT-4 towards rephrasing and a broader diversity of responses to repeat inputs, these incidents still occur.
4.3. Effects on Homework
To understand the effects of 61A Bot on students in our course, we compare student performance from our semester of full deployment, Spring 2024 (SP24), with performance from prior Spring semesters (see §3.1), going back through Spring 2021 (SP21)—comprising a total of 1,643,613 data points from 6,034 students. (Our IRB does not allow differential access to tools in courses, preventing a randomized control trial.)
Though 61A Bot is available to students for homework assignments, it is not available for lab assignments nor for projects (see §3.1). To the extent that performance differences on homework assignments between pre- and post-deployment semesters are inconsistent with performance differences on lab assignments and projects, some of this difference may be attributable to the use of the Bot. There is some variation in course staff, individual lectures, and specific problems within labs and homework assignments over time in our course; where problems have changed more than trivially in content or sequencing, we have omitted them from our comparisons. The specific assignments we report on here are otherwise representative of the full set of assignments.









∗ denotes differences significant at the level.
4.3.1. Data & Analytical Method
Our course “autograder” records every attempt a student makes to test their code, storing a “snapshot” of student code on our instructional servers, along with a student identifier and a timestamp; we use these to reconstruct a history of student progress. Autograder use is unlimited, and students typically revise their programs repeatedly until they are ready to submit their final code. Nearly all students submit code that successfully passes all test cases, so examining the final submitted code artifact alone does not necessarily provide useful insight into impacts. Thus the metric we consider here is time to completion, rather than passing test cases or other measures of code quality.
We calculate an approximate total completion time by summing the timestamp deltas between snapshots. To account for students completing the homework across multiple sessions, we ignore time deltas above a 60-minute threshold—a value chosen somewhat arbitrarily, but we confirm that the results we report here are robust to values in the range of 20 to 120 minutes.888An independent analysis of snapshot counts were consistent with the findings we report here, as expected from (Piech et al., 2012); we report times as we found them more straightforward to reason about. For clarity, we aggregate individual repeated problems into “assignments,” e.g., “HW 1.” Occasionally, one assignment in a particular semester differs sufficiently from other semesters that we omit it entirely.999We chose to aggregate in this way for clarity; our reported analyses are robust to aggregation method and problem selection, as well as many other factors elided here for space.
We then report the distribution of student assignment completion times using Cumulative Distribution Function (CDF) plots for specific homework assignments, labs, and projects. This CDF can be read as “What fraction of students (y-axis) complete the homework in less than some number of minutes (x-axis)?”, capturing how long students take to complete these assignments across the full distribution of completion times.
4.3.2. Results
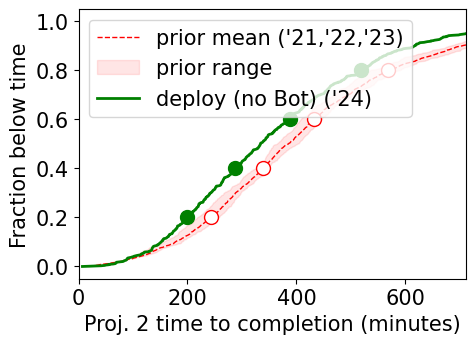
Our primary finding is that student completion times on identical homework assignments are substantially faster in our post-deployment semester, Spring 2024, compared to prior semesters (3(a)). This effect is not seen in the similar lab assignments where the Bot is not available (3(b)); a smaller, but still substantial, speedup is seen in projects (3(c)).
The data indicate that the (Bot-available) homework completion times in Spring 2024 are between faster among students in the middle percentile of completion times, when compared to students at the same percentile rank (3(a)). There is some inherent variability in completion time from year to year for a given percentile rank (e.g., the percentile ranked student); the red bands in Figure 3 show this variability. Note that the Spring 2024 homework completion times within the percentile range were lower, at a given percentile rank, than the mean completion time at that rank across prior semesters—by a factor of the range of that prior variability across Spring semesters. In contrast, no-Bot lab completion times fall within the range of the prior semesters’ variability for the first few labs. Most later labs lack enough consistency across semesters for a robust comparison, but lab 8 does offer a glimpse into one possible outcome: here, students in Spring 2024 at a given rank took more time than students at the same rank in any prior semesters.
Meanwhile, the no-Bot project completion times fall somewhere in between: Spring 2024 students completed these projects between faster than the pre-deployment mean—a speedup about half as large as the Bot-available homeworks.
5. Discussion & Future Work
Overall, our findings are consistent with a causal link between the availability of our Bot and faster homework completion times. In the context of our course (see §4.3.1), reduced completion times are likely to be a result of students reaching a correct solution more quickly, rather than stopping before reaching a correct solution, or making other mistakes, as might be the case in domains where assignments have a greater variety of possible outcomes.
Though we did not carefully examine (and don’t make claims about) student learning outcomes, we have reason to believe that students are not performing much worse after deployment. In particular, student exam performance is sufficiently inconsistent (exam coverage differs from term to term) that we did not report on it here, but it does not appear that Spring 2024 students performed much worse than in prior terms. Additionally, the differences in performance on assignments where the Bot was not available (labs and projects) were much smaller. We can’t say for certain, but we have not found much evidence for a major decrease in outcomes.
If indeed this reduction in homework time results in little or no learning loss, we can then ask: What implications does this have for CS1 courses? Are there other costs unrelated to learning loss? And what other benefits might accrue?
On the costs side, with most homework help requests going through an LLM, our human TAs may struggle more to stay on top of common challenges among students, leading to a looser feedback loop. However, this challenge could be addressed with new tools that help TAs aggregate over automated help requests—but now with LLM-generated hints and student feedback on whether those hints are helpful. That is, of course, assuming CS1 courses do not elect to reduce staff in response. Given the mode of access of 61A Bot, one likely change in student learning is a reduction in the ability to understand error traces. With an easy way to get natural language feedback on failed test cases, students are less incentivized to read traces, let alone understand them.
However, instructors could use this extra student time to cover more material, such as debugging techniques or reading traces. Or, students could continue to simply spend less time on the course. Similarly, TAs could spend less time debugging straightforward homework errors and more time focused on other forms of support.
These factors all point to a need for more research to better understand the actual costs and to inform decisions made in the hope of realizing actual benefits beyond saved student and TA time.
We ourselves plan to also explore new opportunities to extend 61A Bot in future work, in particular in tracking student progress over time, and in providing concept support though worked examples and links to our online textbook.
5.1. Limitations & Threats to Validity
Differences in prior preparation could explain why students complete homework more quickly in Spring 2024—but any such differences would also have to explain the lack of a decrease in lab completion times. In fact, the consistency in early lab completion times over the 4 semesters we examined suggests that our student populations do not differ significantly in prior ability.
Similarly, differences in course content delivery, staffing, structure, etc., would be expected to impact both labs and homeworks, as lectures and discussion sections for given topics come before labs and homeworks. No additional homework support was provided in Spring 2024 beyond 61A Bot—no hints or support unique to Spring 2024 were offered in lecture or group sessions.
Finally, our study is entirely observational, and there could be other causes for the effects we observe—perhaps students are using ChatGPT for their homework or projects despite the prohibition on ChatGPT use and the availability of 61A Bot. (ChatGPT was originally released in November 2022, but we observed no similar effect in Spring 2023 compared with prior terms.)
6. Conclusions
Our results suggest that 61A Bot reduces demands on staff and helps students complete homework more quickly, with oversized impacts for students who spent the most time on homework—a benefit that might even disproportionately support goals towards inclusion in CS. But, ideally, this type of scaffolding should recede over time as learners become more confident (Soloway et al., 1994). 61A Bot has not yet clearly achieved this goal.
Guidelines around the inclusion of AI-based course materials and tools suggest that these should only be incorporated when we have a good understanding that their benefits outweigh their costs (Bala et al., 2023). Yet even if the primary outcome of 61A Bot is limited to a reduction in homework completion time with no other benefits, we believe that 61A Bot clears this bar—but that further research into improving outcomes and mitigating the costs we have started to expose is critical and urgent.
Acknowledgements.
This work was made possible by a few generous sources of support: an Inclusion Research Award from Google, and support for 61A Bot’s use of Azure’s OpenAI API by Microsoft. We would also like to extend our graitiude to our anonymous reviewers for their helpful feedback, as well as to our student participants in this experiment.References
- (1)
- Bala et al. (2023) Kavita Bala, Alex Colvin, Morten H. Christiansen, Allison Weiner Heinemann, Sarah Kreps, Lionel Levine, Christina Liang, David Mimno, Sasha Rush, Deirdre Snyder, Wendy E. Tarlow, Felix Thoemmes, Rob Vanderlan, Andrea Stevenson Won, Alan Zehnder, and Malte Ziewitz. 2023. Generative Artificial Intelligence for Education and Pedagogy | Center for Teaching Innovation. https://teaching.cornell.edu/generative-artificial-intelligence/cu-committee-report-generative-artificial-intelligence-education
- Bassner et al. (2024) Patrick Bassner, Eduard Frankford, and Stephan Krusche. 2024. Iris: An AI-Driven Virtual Tutor for Computer Science Education. In Proceedings of the 2024 on Innovation and Technology in Computer Science Education V. 1 (Milan, Italy) (ITiCSE 2024). Association for Computing Machinery, New York, NY, USA, 394–400. https://doi.org/10.1145/3649217.3653543
- Becker et al. (2023) Brett A Becker, Paul Denny, James Finnie-Ansley, Andrew Luxton-Reilly, James Prather, and Eddie Antonio Santos. 2023. Programming Is Hard–Or at Least It Used to Be: Educational Opportunities And Challenges of AI Code Generation. (2023).
- Chen et al. (2021) Mark Chen, Jerry Tworek, Heewoo Jun, Qiming Yuan, Henrique Ponde de Oliveira Pinto, Jared Kaplan, Harri Edwards, Yuri Burda, Nicholas Joseph, Greg Brockman, et al. 2021. Evaluating large language models trained on code. arXiv preprint arXiv:2107.03374 (2021).
- Cipriano and Alves (2023) Bruno Pereira Cipriano and Pedro Alves. 2023. GPT-3 vs Object Oriented Programming Assignments: An Experience Report. In Proceedings of the 2023 Conference on Innovation and Technology in Computer Science Education V. 1. 61–67.
- Crow et al. (2018) Tyne Crow, Andrew Luxton-Reilly, and Burkhard Wuensche. 2018. Intelligent tutoring systems for programming education: a systematic review. In Proceedings of the 20th Australasian Computing Education Conference. 53–62.
- Demana and Waits (2000) Franklin Demana and BK Waits. 2000. Calculators in mathematics teaching and learning. Past, present, and future. In Learning Mathematics for a New Century (2000), 51–66.
- Denny et al. (2023a) Paul Denny, Brett A Becker, Juho Leinonen, and James Prather. 2023a. Chat Overflow: Artificially Intelligent Models for Computing Education-renAIssance or apocAIypse?. In Proceedings of the 2023 Conference on Innovation and Technology in Computer Science Education V. 1. 3–4.
- Denny et al. (2024) Paul Denny, Stephen MacNeil, Jaromir Savelka, Leo Porter, and Andrew Luxton-Reilly. 2024. Desirable Characteristics for AI Teaching Assistants in Programming Education. In Proceedings of the 2024 on Innovation and Technology in Computer Science Education V. 1 (Milan, Italy) (ITiCSE 2024). Association for Computing Machinery, New York, NY, USA, 408–414. https://doi.org/10.1145/3649217.3653574
- Denny et al. (2023b) Paul Denny, James Prather, Brett A Becker, James Finnie-Ansley, Arto Hellas, Juho Leinonen, Andrew Luxton-Reilly, Brent N Reeves, Eddie Antonio Santos, and Sami Sarsa. 2023b. Computing Education in the Era of Generative AI. arXiv preprint arXiv:2306.02608 (2023).
- Finnie-Ansley et al. (2022) James Finnie-Ansley, Paul Denny, Brett A Becker, Andrew Luxton-Reilly, and James Prather. 2022. The robots are coming: Exploring the implications of openai codex on introductory programming. In Proceedings of the 24th Australasian Computing Education Conference. 10–19.
- Finnie-Ansley et al. (2023) James Finnie-Ansley, Paul Denny, Andrew Luxton-Reilly, Eddie Antonio Santos, James Prather, and Brett A Becker. 2023. My AI Wants to Know if This Will Be on the Exam: Testing OpenAI’s Codex on CS2 Programming Exercises. In Proceedings of the 25th Australasian Computing Education Conference. 97–104.
- Hellas et al. (2023) Arto Hellas, Juho Leinonen, Sami Sarsa, Charles Koutcheme, Lilja Kujanpää, and Juha Sorva. 2023. Exploring the Responses of Large Language Models to Beginner Programmers’ Help Requests. In Proceedings of the 2023 ACM Conference on International Computing Education Research V.1.
- Kazemitabaar et al. (2023) Majeed Kazemitabaar, Justin Chow, Carl Ka To Ma, Barbara J Ericson, David Weintrop, and Tovi Grossman. 2023. Studying the effect of AI Code Generators on Supporting Novice Learners in Introductory Programming. In Proceedings of the 2023 CHI Conference on Human Factors in Computing Systems. 1–23.
- Kazemitabaar et al. (2024) Majeed Kazemitabaar, Runlong Ye, Xiaoning Wang, Austin Zachary Henley, Paul Denny, Michelle Craig, and Tovi Grossman. 2024. CodeAid: Evaluating a Classroom Deployment of an LLM-based Programming Assistant that Balances Student and Educator Needs. In Proceedings of the CHI Conference on Human Factors in Computing Systems (CHI ’24).
- Leinonen et al. (2023a) Juho Leinonen, Paul Denny, Stephen MacNeil, Sami Sarsa, Seth Bernstein, Joanne Kim, Andrew Tran, and Arto Hellas. 2023a. Comparing Code Explanations Created by Students and Large Language Models. In Proceedings of the 2023 Conference on Innovation and Technology in Computer Science Education V. 1. ACM, 124–130.
- Leinonen et al. (2023b) Juho Leinonen, Arto Hellas, Sami Sarsa, Brent Reeves, Paul Denny, James Prather, and Brett A Becker. 2023b. Using Large Language Models to Enhance Programming Error Messages. In Proceedings of the 54th ACM Technical Symposium on Computer Science Education V. 1. ACM.
- Liffiton et al. (2023) Mark Liffiton, Brad Sheese, Jaromir Savelka, and Paul Denny. 2023. CodeHelp: Using Large Language Models with Guardrails for Scalable Support in Programming Classes. arXiv:2308.06921 [cs.CY]
- Liu et al. (2024a) Rongxin Liu, Carter Zenke, Charlie Liu, Andrew Holmes, Patrick Thornton, and David J. Malan. 2024a. Teaching CS50 with AI: Leveraging Generative Artificial Intelligence in Computer Science Education. In Proceedings of the 55th ACM Technical Symposium on Computer Science Education V. 1 (Portland, OR, USA) (SIGCSE 2024). Association for Computing Machinery, New York, NY, USA, 750–756. https://doi.org/10.1145/3626252.3630938
- Liu et al. (2024b) Rongxin Liu, Carter Zenke, Charlie Liu, Andrew Holmes, Patrick Thornton, and David J. Malan. 2024b. Teaching CS50 with AI: Leveraging Generative Artificial Intelligence in Computer Science Education. In Proceedings of the 55th ACM Technical Symposium on Computer Science Education V. 2 (Portland, OR, USA) (SIGCSE 2024). Association for Computing Machinery, New York, NY, USA, 1927.
- MacNeil et al. (2023a) Stephen MacNeil, Joanne Kim, Juho Leinonen, Paul Denny, Seth Bernstein, Brett A Becker, Michel Wermelinger, Arto Hellas, Andrew Tran, Sami Sarsa, et al. 2023a. The Implications of Large Language Models for CS Teachers and Students. In Proc. of the 54th ACM Technical Symposium on Computer Science Education, Vol. 2.
- MacNeil et al. (2023b) Stephen MacNeil, Andrew Tran, Arto Hellas, Joanne Kim, Sami Sarsa, Paul Denny, Seth Bernstein, and Juho Leinonen. 2023b. Experiences from using code explanations generated by large language models in a web software development e-book. In Proceedings of the 54th ACM Technical Symposium on Computer Science Education V. 1. 931–937.
- Markel and Guo (2021) Julia M Markel and Philip J Guo. 2021. Inside the mind of a CS undergraduate TA: A firsthand account of undergraduate peer tutoring in computer labs. In Proceedings of the 52nd ACM Technical Symposium on Computer Science Education. 502–508.
- Mirhosseini et al. (2023) Samim Mirhosseini, Austin Z Henley, and Chris Parnin. 2023. What is your biggest pain point? an investigation of cs instructor obstacles, workarounds, and desires. In Proceedings of the 54th ACM Technical Symposium on Computer Science Education V. 1. 291–297.
- Mitra et al. (2024) Chancharik Mitra, Mihran Miroyan, Rishi Jain, Vedant Kumud, Gireeja Ranade, and Narges Norouzi. 2024. Elevating Learning Experiences: Leveraging Large Language Models as Student-Facing Assistants in Discussion Forums. In Proceedings of the 55th ACM Technical Symposium on Computer Science Education V. 2 (Portland, OR, USA) (SIGCSE 2024).
- Ofgang (2023) Erik Ofgang. 2023. What is Khanmigo? The GPT-4 learning tool explained by Sal Khan. Tech & Learn (2023).
- Pardos and Bhandari (2023) Zachary A Pardos and Shreya Bhandari. 2023. Learning gain differences between ChatGPT and human tutor generated algebra hints. arXiv preprint arXiv:2302.06871 (2023).
- Piech et al. (2012) Chris Piech, Mehran Sahami, Daphne Koller, Steve Cooper, and Paulo Blikstein. 2012. Modeling how students learn to program. In Proceedings of the 43rd ACM technical symposium on Computer Science Education. 153–160.
- Prather et al. (2024) James Prather, Juho Leinonen, Natalie Kiesler, Jamie Gorson Benario, Sam Lau, Stephen MacNeil, Narges Norouzi, Simone Opel, Virginia Pettit, Leo Porter, et al. 2024. How Instructors Incorporate Generative AI into Teaching Computing. In Proceedings of the 2024 on Innovation and Technology in Computer Science Education V. 2. 771–772.
- Prather et al. (2023) James Prather, Brent N Reeves, Paul Denny, Brett A Becker, Juho Leinonen, Andrew Luxton-Reilly, Garrett Powell, James Finnie-Ansley, and Eddie Antonio Santos. 2023. ” It’s Weird That it Knows What I Want”: Usability and Interactions with Copilot for Novice Programmers. arXiv preprint arXiv:2304.02491 (2023).
- Reeves et al. (2023) Brent Reeves, Sami Sarsa, James Prather, Paul Denny, Brett A Becker, Arto Hellas, Bailey Kimmel, Garrett Powell, and Juho Leinonen. 2023. Evaluating the Performance of Code Generation Models for Solving Parsons Problems With Small Prompt Variations. In Proceedings of the 2023 Conference on Innovation and Technology in Computer Science Education V. 1. 299–305.
- Sarsa et al. (2022) Sami Sarsa, Paul Denny, Arto Hellas, and Juho Leinonen. 2022. Automatic generation of programming exercises and code explanations using large language models. In Proceedings of the 2022 ACM Conference on International Computing Education Research-Volume 1. 27–43.
- Sheese et al. (2024) Brad Sheese, Mark Liffiton, Jaromir Savelka, and Paul Denny. 2024. Patterns of Student Help-Seeking When Using a Large Language Model-Powered Programming Assistant. In Proceedings of the 26th Australasian Computing Education Conference. 49–57.
- Soloway et al. (1994) Elliot Soloway, Mark Guzdial, and Kenneth E. Hay. 1994. Learner-centered design: the challenge for HCI in the 21st century. Interactions 1 (1994), 36–48.
- Suzuki et al. (2017) Ryo Suzuki, Gustavo Soares, Andrew Head, Elena Glassman, Ruan Reis, Melina Mongiovi, Loris D’Antoni, and Bjoern Hartmann. 2017. Tracediff: Debugging unexpected code behavior using trace divergences. In 2017 IEEE Symposium on Visual Languages and Human-Centric Computing (VL/HCC). IEEE, 107–115.
- Wang et al. (2024) Sierra Wang, John Mitchell, and Chris Piech. 2024. A Large Scale RCT on Effective Error Messages in CS1. In Proceedings of the 55th ACM Technical Symposium on Computer Science Education V. 1 (Portland, OR, USA) (SIGCSE 2024). 1395–1401.
- Wu et al. (2022) Yu-Chieh Wu, Andrew Petersen, and Lisa Zhang. 2022. Student Reactions to Bots on Course Q&A Platform. In Proceedings of the 27th ACM Conference on on Innovation and Technology in Computer Science Education Vol. 2. 621–621.
- Yuan et al. (2023) Zhiqiang Yuan, Junwei Liu, Qiancheng Zi, Mingwei Liu, Xin Peng, and Yiling Lou. 2023. Evaluating instruction-tuned large language models on code comprehension and generation. arXiv preprint arXiv:2308.01240 (2023).