5G Network on Wings: A Deep Reinforcement Learning Approach to the UAV-based Integrated Access and Backhaul
Abstract
Fast and reliable wireless communication has become a critical demand in human life. In the case of mission-critical (MC) scenarios, for instance, when natural disasters strike, providing ubiquitous connectivity becomes challenging by using traditional wireless networks. In this context, unmanned aerial vehicle (UAV) based aerial networks offer a promising alternative for fast, flexible, and reliable wireless communications. Due to unique characteristics such as mobility, flexible deployment, and rapid reconfiguration, drones can readily change location dynamically to provide on-demand communications to users on the ground in emergency scenarios. As a result, the usage of UAV base stations (UAV-BSs) has been considered an appropriate approach for providing rapid connection in MC scenarios. In this paper, we study how to control multiple UAV-BSs in both static and dynamic environments. We use a system-level simulator to model an MC scenario in which a macro BS of a cellular network is out of service and multiple UAV-BSs are deployed using integrated access and backhaul (IAB) technology to provide coverage for users in the disaster area. With the data collected from the system-level simulation, a deep reinforcement learning algorithm is developed to jointly optimize the three-dimensional placement of these multiple UAV-BSs, which adapt their 3-D locations to the on-ground user movement. The evaluation results show that the proposed algorithm can support the autonomous navigation of the UAV-BSs to meet the MC service requirements in terms of user throughput and drop rate.
Index Terms:
Reinforcement Learning, Multi-Agent, Integrated access and backhaul (IAB), 5G NR, wireless backhaul, UAV-BSI Introduction
Traditional cellular infrastructure provides fast and reliable connectivity in most use cases. However, when a natural disaster happens, such traditional wireless base stations (BSs) can be damaged and therefore they cannot provide mission-critical (MC) services to the users in the disaster area. In this context, further enhancements of the cellular networks are needed to enable temporary connectivity and on-demand coverage for MC users in various challenging scenarios.
Vehicular networking can be enabled by various vehicle types including not only cars but also buses, trucks and UAVs. By equipping with a cellular tower and transceiver on a truck or trailer, cell-on-wheels have fewer cruising duration constraints and can transmit with a higher power to provide a relatively large coverage area [1]. However, cell-on-wheel placement may be less flexible for MC operations in rural areas with complex environments, such as forest firefighting, mountain search and rescue. UAV-BS (cell-on-wings) on the other hand, can be deployed in a more flexible and mobile manner. Specifically, UAVs can be used to carry deployable BSs to provide additional or on-demand coverage to users, thanks to their good mobility and higher chances of light-of-sight (LOS) propagation. However, there are a number of challenges when implementing UAV-BS assisted wireless communication networks in practice [2][3]. The system performance and user experience are significantly impacted by the deployment and configuration of UAV-BSs, including the UAV’s 3-D position, operation time, antenna capabilities, transmit power, etc [4]. Using wireless backhaul, UAV-BSs can connect to the on-ground BSs (e.g., cell-on-wheels or macro BSs) and be integrated into the cellular system. Hence, it is necessary to jointly optimize the configuration parameters for the access links (between UAV-BS and on-ground users) and the backhaul links (between UAV-BSs and on-ground BSs), when optimizing UAV-BS based wireless communication systems. The optimization problem becomes even more complicated when considering different system loads and user movement on the ground. In some cases where multiple UAV-BSs are needed to cover a wide area, the complexity of providing reliable and scalable backhaul links will further increase.
Despite the fact that there are numerous applications for UAV-based reinforcement learning algorithms, the fundamental drawback of classic RL is its low performance in a changing environment. If the environment changes (the environmental values observed by the agent change), the agent usually has to retrain the entire algorithm to keep up with the environmental changes [5][6]. In our case, user mobility would have a major impact on the system performance in terms of MC user throughput and drop rate. As a result, to ensure good service quality, a triggering mechanism needs to be implemented for algorithm adaptation and analysis. The dynamic environment, in this case, indicates that the states (user throughout and drop rate) that the agent observed will vary substantially due to wireless communication environment changes and user movement.
I-A Related Work
In recent years, UAV-BS assisted wireless communication networks have attracted significant attention from both industry and academia [7, 8, 9, 10, 11]. To guarantee a robust wireless connection between the UAV-BSs and the core network, more and more research work has started working on improving the wireless backhaul link [12, 13, 14, 15, 16]. Authors in [12] assume that all the UAV-BSs are flying at a fixed height, and a robust backbone network among UAV-BSs is guaranteed by ensuring that there is always at least one path between any UAV-BS and a BS on the ground. Then they investigate the rapid UAV deployment problem by minimizing the number of UAVs to provide on-demand coverage for as many users as possible. In [13], optimal 3-D deployment of a UAV-BS is investigated to maximize the number of connected users with different service requirements by considering the limitation of wireless backhaul links. In [14], the limitation of backhaul and access capacities is also considered, and a heuristic algorithm is proposed to optimize the UAV navigation and bandwidth allocation. Similar to [13], the authors in [16] also investigate a coverage improvement problem enabled by UAV-BS with backhaul limitation but with a machine learning (ML) based solution.
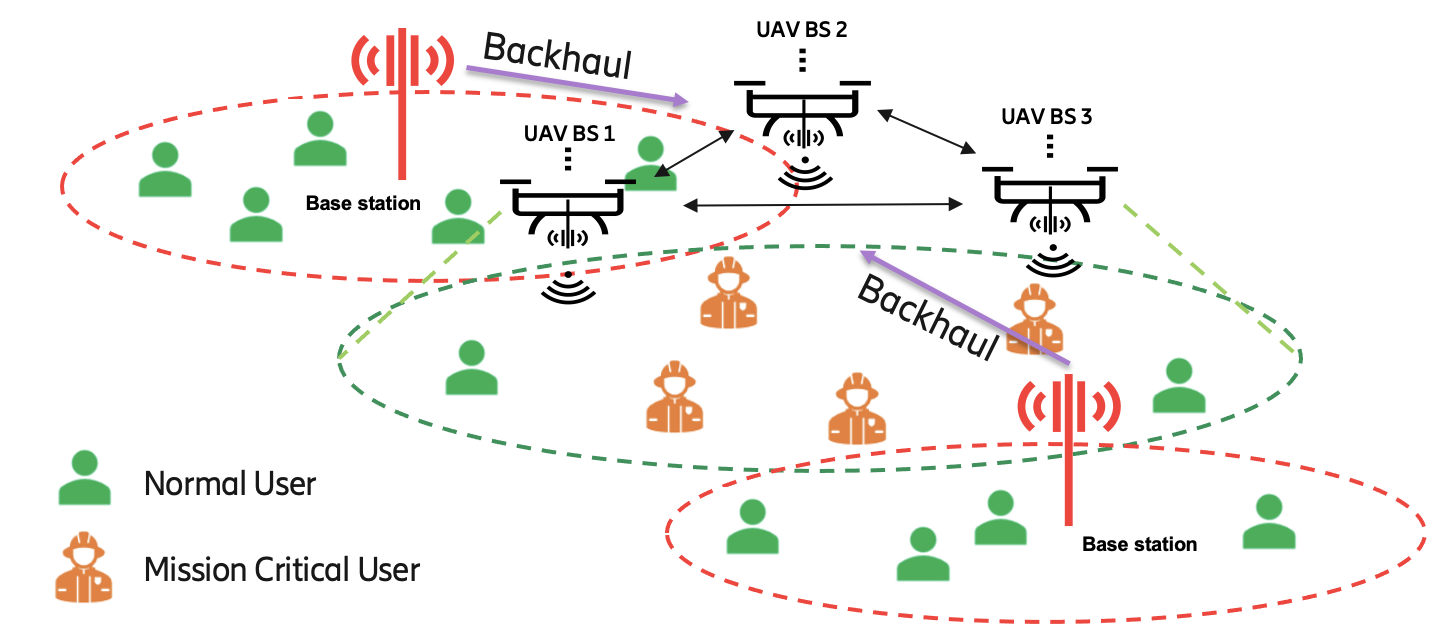
Enabled by 5G new radio (NR), the integrated access and backhaul (IAB) feature can be applied to wirelessly integrate multiple UAV-BSs to an existing cellular network seamlessly [17]. Figure 1 shows an example of UAV-BS assisted network deployment using IAB technology. The macro-BSs who have connections with the core network are serving the normal users, and some of them can also be acting as donor-BSs, who can provide wireless backhaul connections to the flying UAV-BS. Based on the wireless backhaul link, the UAV-BS is acting as an IAB node, which can be deployed at different locations to provide on-demand services to MC users and/or normal users who are out of the coverage of the existing mobile network. To evaluate the performance of the UAV-assisted wireless system enabled by IAB, authors in [15] propose a dedicated dynamic algorithm based on the particle swarm optimization (PSO) method to optimize the throughput and user fairness. By intertwining different spatial configurations of the UAVs with the spatial distribution of ground users, [18] proposes an interference management algorithm to jointly optimize the access and backhaul transmissions. Their results prove that both coverage and capacity can be improved.
Due to the characteristics of revealing implicit features in large amounts of data, the ML methodology draws growing attention and has been extensively applied in various fields. As a sub-field of ML, agent-based reinforcement learning (RL) features in interacting with the external environment and providing an optimized action strategy. Hence, it has been used to solve complicated optimization problems that are difficult to be addressed by traditional methods. As two of the promising technologies for the next-generation wireless communication networks, it is natural to combine ML with deployable UAV-BS to solve high complexity optimization problems [19, 20].
Specifically, ML is frequently used to solve problems on deployment [21, 16, 22], scheduling [23, 24, 25, 26], trajectory [27, 28, 29, 30] and navigation [31, 32, 33, 34] in UAV assisted network. In [21], a deep RL-based method is proposed for UAV control to improve coverage, fairness, and energy efficiency in a multi-UAV scenario. To solve the scheduling problem in a high mobility environment, the authors in [23] develop a dynamic time-division duplex (TDD) configuration method to perform intelligent scheduling. Based on the experience replay mechanism of deep Q-learning, the proposed algorithm can adaptively adjust the TDD configuration and improve the throughput and packet loss rate. From the perspective of distributed learning, [24] proposes a framework based on asynchronous federated learning in a multi-UAV network, which enables local training without transmitting a significant amount of data to a central server. In this framework, an asynchronous algorithm is introduced to jointly optimize UAV deployment and scheduling with enhanced learning efficiency.
For ML-based trajectory and navigation, the authors in [27] investigate a trajectory strategy for a UAV-BS by formulating the uplink rate optimization problem as a Markov decision process without user-side information. To enable UAV autonomous navigation in large-scale complex environments, an online deep RL-based method is proposed in [31] by mapping UAV’s measurement into control signals. Furthermore, to guarantee that the UAV always navigates towards the optimal direction, authors in [32] enhance the deep RL algorithm by introducing a sparse reward scheme and the proposed method outperforms some existing algorithms.
Additionally, the limited battery life of a UAV restricts its flying time, which in turn affects the service availability that can be provided by the UAV. Therefore, many works have been focusing on designing energy-efficient UAV deployment or configuration schemes either with non-ML [7, 35, 36] or ML methodologies [30, 37, 38].
I-B Contributions
In this paper, we consider a scenario with multiple macro BSs covering a large area, but due to disaster, one of the macro BSs is damaged, which creates a coverage hole where the first responders execute their MC operations. The deployable UAV-BSs are set up to fill the coverage hole and provide temporary connectivity for these MC users. Compared with the related works and our previous paper[39], we propose in this paper a novel RL algorithm combined with adaptive exploration and value-based action selection algorithms to autonomously and efficiently deploy the UAV-BSs based on the requirements. Furthermore, to extend the algorithm in a scalable manner, a decentralized architecture is proposed for the collaboration of multiple UAV-BSs. More specifically, the contributions of this paper include the following aspects:
-
1)
We propose the framework to support applying RL algorithm for the considered use case in an IAB network architecture.
-
2)
We applied two strategies, i.e., adaptive exploration control and value-based action selection for the RL algorithm so that the algorithm itself can adapt to a dynamic environment (e.g., MC user movement) in a fast and efficient way.
-
3)
We demonstrated deployment in a decentralized method for supporting multiple UAV-BSs deployment to respond to varied industrial scenarios.
-
4)
We validate the proposed RL algorithm in a continuously changing environment with consecutive MC user movement phases. Our results show that the proposed algorithm can create a generalized model and assist in updating the decision-making on UAV-BSs and navigation in a dynamic environment.
The remainder of this paper is structured as follows. Section II introduces the system model considered in this paper. In section III, we propose a framework to enable ML in an IAB network architecture. Section IV discusses our proposed ML algorithm. Section V presents the system-level simulation results and evaluates the proposed RL algorithm. In Section VI, we summarize our findings and discuss future works.
II System Model and Problem Formulation
II-A System Description
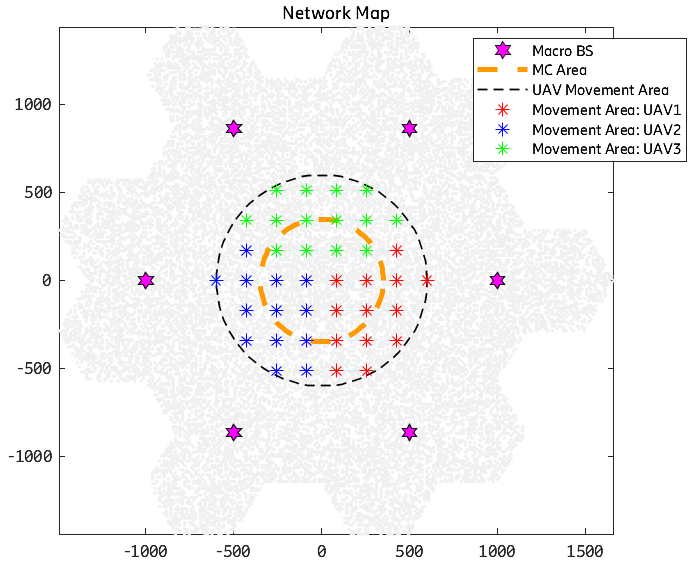
For the system model, we consider a multi-cell mobile cellular network, consisting of a public network and a deployable network, as shown in Figure 2. Initially, seven macro-BSs are serving users uniformly distributed in the whole area. However, one of the macro-BSs in the center of the scenario is damaged due to, e.g., a natural disaster that creates a coverage hole. For users in the central emergency area with a predefined radius, they might have very limited or no connectivity with the public network. Hence, multiple UAV-BSs, which are integrated into the public network using IAB technology, can be set up to provide temporary or additional coverage to the users in this emergency area, which is also the research target of this paper. In this paper, the UAV-BSs are limited only to stay at the discrete points indicated by the colored stars in Figure 2. In the considered scenario, there are two types of users: The users located in the MC area are marked as MC users, while the others are normal users. User equipment (UE), either an MC user or a normal user, can select either a macro-BS or a UAV-BS as its serving-BS, based on the wireless link qualities between the UE and these BSs.
For the traffic pattern design, we apply a dynamic traffic model. All the users are randomly dropped in the scenario. For each time slot, the users are activated with a predefined arrival rate. Only these activated users can be scheduled and initiate fixed-size data transmission based on the link quality (both access and backhaul links) and system load for downlink and uplink, respectively. When the data transmission is completed, the user will leave the system and wait to be activated again. Then the user throughput can be calculated with actually served traffic and consumed time to deliver the traffic.
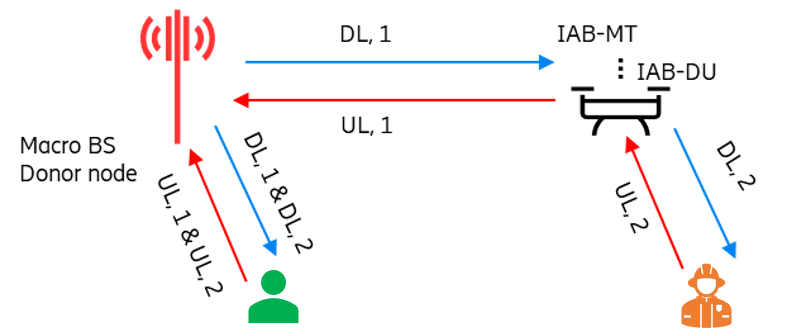
As mentioned before, the UAV-BSs work as the IAB nodes in the current scenario. They will measure the wireless link to all macro-BSs and select one with the best link quality as their donor-BSs. Once the wireless backhaul link between the UAV-BSs and their donor-BSs are established, the three sectors of the UAV-BSs will share this wireless backhaul link and provide access service to both normal users and MC users. For the users served by the UAV-BSs, the corresponding throughput depends not only on the access link but also on the wireless backhaul link. While selecting the access links, the users with too bad link quality, for instance, below a certain threshold, will be dropped. To reduce the complexity and the load-bearing of the UAV-BSs, it is assumed that the same antenna configuration is applied for both access and backhaul antennas of the UAV-BSs.
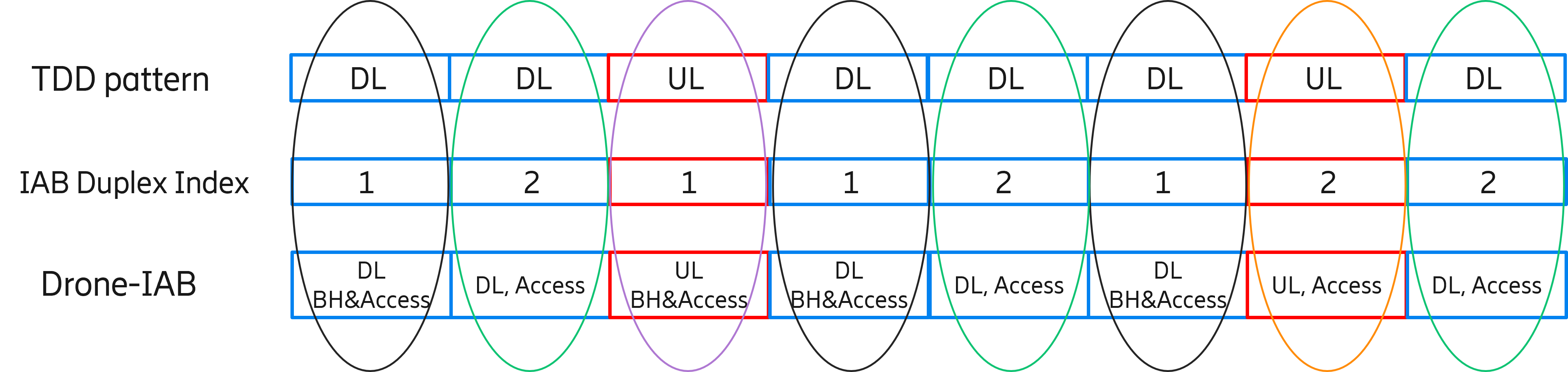
The system operates under a TDD model, and the time slot pattern consists of downlink (DL), DL, uplink (UL), and DL, which is repeated with a periodicity of 2 ms [40]. The system bandwidth is 100 MHz, and it is shared between backhaul and access links. The time slots assigned for UL/DL Access/Backhaul links are shown in Figure 1(b) and (c). Two full TDD periods are required to cover all eight UL/DL Access/Backhaul combinations, which lead to four interference cases, denoted as: DL1, DL2, UL1, and UL2. As shown in Figure 1(b), for the UAV-IAB node, DL1 and UL1 are reserved for backhaul link transmission, while DL2 and UL2 are reserved for providing access services for users. For the donor-BS and all other macro-BSs, all the time slots can be used for access link transmission.
II-B Transmission Model
For the public network in this paper, we use an urban-macro propagation model [41], while a refined aerial model from 3GPP standardization is used for UAV-BS [42]. It is assumed that the network consists of macro-BS, UAV-BSs and users, denoted by , and . The whole available bandwidth is divided into K sub-channels and each one has a bandwidth denoted by . Assuming that the coordinates of the UAV-BS and the user are and , respectively. Based on 3GPP channel model[41], the following formula is applied to represent the probability of LOS propagation between UAV-BS and user :
| (1) |
where,
| (2) |
denotes the height of user n with meter as a unit and is the horizontal distance between UAV-BS and user . is a 2D distance threshold and its value is 18 meters. The path loss between UAV-BS and user in the case of LOS propagation and NLOS propagation can also be derived based on [41]:
| (3) |
| (4) |
where denotes the distance between the antennas of UAV-BS and user , while is the carrier frequency. Hence the average path loss between UAV-BS and user can be denoted as:
| (5) |
Similarly, denotes the average path loss between macro-BS and user , while denotes the average path loss between macro-BS and UAV-BS . To indicate whether a sub-channel is occupied by a UAV-BS/macro-BS to serve the users, an occupy indicator is defined and setting as 1 implies that the sub-channel is occupied by UAV-BS/macro-BS . Meanwhile, another indicator is defined where indicating that user is served by UAV-BS . Hence, the SINR between UAV-BS and user on sub-channel can be denoted as:
| (6) |
where represents the transmit power of interfering node and is the power spectral density of the additive Gaussian noise. When the UAV-BSs are serving users, the interference may not only come from the other UAV-BSs serving users but also from the macro-BSs serving other UAV-BSs/users. Therefore, generally denotes the path loss between user/UAV-BS and interfering node (UAV-BS/macro-BS) . Based on the above-mentioned expressions, the achieved throughput for MC user can be obtained by:
| (7) |
where is the user drop indicator. The user with an SINR lower than will be dropped and its corresponding user drop indicator equals zero. For the drop rate of MC users which will be used in the following sections, it is defined as:
| (8) |
where is the number of MC users.
II-C Problem Formulation
In a multi-network scenario consisting of both existing BSs on the ground and temporarily deployed UAV-BS, the deployment of the UAV-BS play a critical role in guaranteeing the performance of the target users/services (e.g., MC users/services). It can also impact the overall system performance. As the UAV-BS is connected to the core network using wireless backhaul, it is important to ensure the good quality of both the backhaul and access links when performing this system optimization. Furthermore, the optimal solution depends on many factors like network traffic load distribution, quality of service (QoS) requirements and user movements on the ground. Therefore, jointly optimizing these parameters of UAV-BS is a complex system-level optimization problem that needs to be solved in a dynamic changing environment.
In order to best serve target users while also maintaining a good backhaul link quality between UAV-BSs and their donor-BSs, we aim to solve the following research problems: 1) Design an RL algorithm to jointly optimize the 3-D locations of the UAV-BSs. 2) Find the movement strategy of a UAV-BS to accommodate the dynamically changing user distribution.
Based on the system model introduced in the previous sub-section, the target problem we intend to solve is optimizing the 3-D locations of the UAV-BSs to maximize a weighted sum of the following system key performance metrics for the MC users:
-
•
Backhaul link rate for UAV-BS: On one hand, the backhaul link rate reflects the link quality when the UAV-BS is served as a user via its donor-BS. On the other hand, it also affects the end-to-end throughput performance of its associated users since the throughput of UAV-served users is calculated by considering the quality of both the access link and backhaul link.
-
•
The 5-percentile and 50-percentile of the cumulative distribution function (CDF) of MC user throughput: The 5-percentile MC user throughput represents the performance of the cell-edge MC users, i.e., the MC users with the ”worst” throughput performance, while the 50% throughput indicates the average MC user performance in the simulation area.
-
•
Drop rate for MC users: The ratio of MC users that cannot be served with the required services. This is an important performance metric for MC scenarios, since for MC users, keeping reliable connectivity broadly is more important than guaranteeing high-demand services for specific users in most MC cases.
III ML-based Solution
In this section, we describe how we transform and model the considered use case in an ML environment. Three important components, including the state space, action space, and reward function, are constructed in order to design an RL algorithm to jointly optimize the 3-D position of multiple UAV-BSs in an IAB network.
III-A Modeling of ML Environment
III-A1 State Space
In our case, a UAV-BS state at a given time instance has three dimensions, namely the UAV-BS’s 3-D position.
We use to denote the 3-D position of a UAV-BS at time . Then, a UAV-BS’s state at a given time instance is denoted as . Table I shows the candidate values for each UAV-BS:
| 3-D position Space | UAV1 Candidate Values |
| meters | |
| meters | |
| meters | |
| 3-D position Space | UAV2 Candidate Values |
| meters | |
| meters | |
| meters | |
| 3-D position Space | UAV3 Candidate Values |
| meters | |
| meters | |
| meters |
It should be noted in Table I that the available height range for all UAV-BSs is limited between 10 m and 20 m, rather than deploying the UAV-BSs into a higher altitude. The reason is that, in the scenario considered in this paper, the UAV-BSs tend to stay at a lower height to maintain good backhaul links to on-ground donor-BS and also provide better access links to serve on-ground MC users, which makes the current height range selection reasonable.
The candidate values of 2-D space location and axis cover the disaster area shown in Figure 2. The location options are selected by three deployed UAV-BSs. The 2-D MC area has been divided into 3 parts, with each UAV-BS covering one part of the area. For UAV1, and axis options are and meters. For UAV2, and axis options are and meters. For UAV3, and axis options are and meters. And the height options for all three UAV-BSs in the axis are meters. As a result, the total number of state combinations in this environment is 18928. The computation complexity will be linearly increased based on the total number of input states combination.
III-A2 Action Space
In order to enable a UAV-BS to control its state, for each state dimension, we defined three potential action options and the UAV-BSs choose an action from three candidate options. These three alternative action options are denoted by the three digits: , where “-1” indicates that a UAV-BS decreases the status value at this state dimension by one step from its current value; “0” indicates that a UAV-BS does not need to take any action at this state dimension and keeps its current value; ”1” indicates that a UAV-BS increases the status value at this state dimension by one step from its current value.
For example, if the x-axis value of the UAV1 (i.e. the value of the dimension) equals 257 meters, an action coded by “-1” for this dimension means that the UAV-BS will select an action to reduce position value to 85 meters, an action coded by “0” implies that the UAV-BS will hold the current position ( meters), and an action coded by “1” implies that the UAV-BS will increase the position value to meters. The same policy is applied to all dimensions of the state space.
Since there are three action alternatives for each space state, the action pool for 3-D position space, the pool has 27 action candidates that may be programmed to an action list =[(-1, -1, -1), (-1, -1, 0), (-1, -1, 1), (-1, 0, -1) …, (1, 1, 1)]. As a result, if we combine the action of the 3-D position space, at any given moment , a UAV-BS can thus choose an action from these 27 alternatives. Figure 3 depicts a state transition from the specified state meters.

III-A3 Reward Function Design
It is more critical to serve as many MC users as possible with appropriate service quality than to maximize the peak rate of a subset of MC users. As a result, the aggregated reward metrics are produced for the reward function design of the reinforcement learning algorithm to take into account both the impact of other drones’ actions as well as the quality of local services. Therefore, the reward is calculated using the average of the performance indicators of local and neighbouring agents. We have selected six key performance metrics for each local agent to highlight the local quality of service for MC users, including:
-
•
The drop rates of MC users for UL and DL (), which reflect the percentage of unserved MC users.
-
•
The 50% throughput values of MC users for both UL and DL (), which represent the average performance of the MC users, and
-
•
The 5% throughput values of MC users for both UL and DL (), which represent the “worst” performance of the MC users.
The reward function is built as a weighted sum of these six feature values to balance these critical performance indicators, as shown below. The reason why backhaul link rate is not considered here is that the values of the six features all rely on the quality of backhaul link between the UAV-BS and its donor-BS. Before the model, all characteristics are normalised using min-max normalization, thus the values are constrained within the range .
| (9) |
Furthermore, we set to normalize the reward value such that is between . To emphasize the significance of supporting all MC users, we assign higher weights to user drop rates and 5% MC-user throughput metrics. This is because, in the MC use cases, we must first prioritize that all users have access to the communication service rather than focusing on optimizing the communication quality of a small subset. In this paper, our method uses the weight values , and . In order to know the influence of each UAV-BS, the reward function will also aggregate the reward values of the neighbour agents. Hence, the following is the reward function which is applied in the algorithm:
| (10) |
Assuming that is the set of register neighbours, represents the current agent’s local system performance and the indicates the local system performance of its neighbour ID .
III-B RL Algorithm Design
In this section, we design an RL algorithm to solve the optimization problem of the considered use case. RL is distinct from supervised and unsupervised learning in the field of ML in that supervised learning is performed from a training set with annotations provided by an external supervisor (task-driven), whereas unsupervised learning is typically a process of discovering the implicit structure in unannotated data (data-driven). RL is suitable for this case since the method provides a unique feature: the trade-off between exploration and exploitation, in which an intelligence agent must benefit from prior experience while still subjecting itself to trial and error, allowing for a larger action selection space in the future (i.e., learning from mistakes).
In order to achieve better self-control decisions for our scenario, we applied deep Q-network (DQN) as our base RL algorithm. The algorithm was first proposed by Mnih et al. in [43][44] by combining convolutional neural networks with Q-learning algorithms [45] in traditional RL. The approach has been frequently used in gaming and static environments. However, the original approach is incapable of adapting to our MC situation due to environmental changes. To address these issues, we have proposed two significant schemes in our autonomous UAV-BSs control algorithm (Algorithm 1): adaptive exploration control and value-based action selection.
capacity
of weights
dimensions and execute the actions
with respect to the online parameters
III-B1 Adaptive Exploration (AE)
Because of the environmental changes, the original DQN model needs to be updated to accommodate feature value changes. As a result, we create a dynamic exploration probability triggered by a substantial decline in reward value. Following the completion of each learning iteration, the final reward value is checked and compared to the pre-defined reward drop and upper reward thresholds. Based on the outcome, the exploration probability will be adjusted.
Each UAV-BS initially explores the state space and then performs Q-value iterations at each training episode. When deciding whether to take an action that gives the maximum reward value or randomly explore a new state, a -greedy exploration is used. The parameter determines the likelihood of exploration. Each training step’s data is saved in a replay batch . Each row of holds the tuple , which represents the current state, action, reward, and next state for a training step. Samples will be chosen at random and used to update the Q value model.
The most recent reward value is reviewed and compared to a pre-defined reward-drop threshold and an upper reward threshold. Then, the exploration probability is updated by checking the following three conditions: (Algorithm 2):
-
•
If the most recent reward value is less than the prior reward, and the difference is greater than the reward drop threshold, the exploration probability is increased to 0.1.
-
•
If the most recent reward value exceeds the higher reward threshold, we can conclude that the algorithm has already located the optimal zone capable of delivering a reliable connection to MC users. The likelihood of exploration will be matched to the probability of completion.
-
•
Otherwise, the exploration probability will multiply by an exploration decay and fall linearly after each learning cycle.
to 0.1
from the same consequence 3-D position
action pool
from the opposite consequence 3-D position
action pool

For the hyper-parameters of the deep Q-network, we explored various sets of combinations in order to achieve acceptable results. During the training, the discount factor is set to 0.99, the learning rate is set to and the number of training iterations equals 1000.
III-B2 Value-Based Action Selection (VAS)
Although the -greedy algorithm can strike a reasonable balance between exploration and exploitation, in some cases the approach utilized for exploration is redundant and time-consuming. The algorithm will choose actions at random throughout the searching stage, which may lengthen the search time. However, when dealing with a large action and state space, random action selection is clearly not an effective strategy and may cause decision-making to be delayed, which is unacceptable in most time-critical businesses. Therefore, we propose a novel value-based action selection strategy (Algorithm 3) which can lead to fast decision-making for a UAV-BS when determining its 3-D space location.
As described in the previous section, an agent’s 3-D position state at a given time instance is denoted as . Since each position state has three dimensions and each state dimension has three action options, the action pool contains in total 27 action candidates that can be programmed to a list of action space . Each element in this list can then be regarded as an action vector.
Figure 4 depicts a probable set of next actions with the same or opposite consequence. The consequence is defined as the reward value (or monitored performance metrics) change after an action has been executed. The algorithm will analyze the outcome of past actions. If the prior action decision has a positive outcome (the reward value increases or monitored performance metrics become better) as defined above, the algorithm will choose actions from a pool of following actions with the same consequence. The dot product between two action vectors determines the result. If the dot product is larger than 0, this action vector can be assumed to have the same outcome as the prior action option.
If the previous action decision results in a negative consequence (the reward value decreases or monitored performance metrics become worse), the algorithm will select actions from the pool consisting of potential next actions with the opposite consequence. The opposite consequence is determined by the dot product of two action vectors that is smaller than or equal to 0. The actions in this pool will result in an opposite consequence compared with the previous action decision. Assume that the previous action vector is while the next potential action vector is :
| (11) |
In Figure 4, the red vector represents the previous action decision. The angle between the previous action vector (red vector) and the green vectors is less than , which can be represented by a dot product greater than zero. As a result, the green vectors represent actions that may result in the same consequence as the red vector. Similarly, the angle between the previous action vector (red vector) and the brown vectors is greater than or equal to , which is represented by a dot product value less than 0. As a result, the brown vectors may have the opposite consequence.
During the UAV-BSs deployment, the algorithm monitors a set of critical system performance values (the reward value). Based on the current and a set of previous performance values, the algorithm will evaluate the consequences caused by the previous action. The algorithm will thus select the action set which will potentially result in positive consequences.
III-C Decentralized Reinforcement Learning
In some circumstances, a single UAV is not capable to be extended to cover a larger area. As shown in Figure 1(a), multiple UAV-BSs are deployed to work together to service the MC users. An extensible decentralized method for deploying numerous UAV-BSs is therefore designed. The concept is illustrated in Figure 5 where we relocate the central server operation function from the central entity and attach it to the edge entity on UAV, as opposed to the typical single-agent reinforcement learning algorithms, to achieve decentralized characteristics.

The system has two different kinds of data for exchanging information, namely the system-related data (including location information and system KPIs) and the model data. The location will communicate with nearby drones regarding the connection performance and UAV-BS system-related data. These kinds of data can assist each drone in understanding how their movements affect the others and in being aware of one another’s surroundings. Following each UAV-BS decision, the information will be continuously exchanged and used as a guide for the subsequent choice. The local model of each UAV-BS will be shared with its neighbours via the model data channel, which is indicated by the green line. Each UAV-BS has a separate procedure to train, communicate, and receive model weights and service metrics during the learning process. Each UAV-BS will share their learning experiences as a result, and the others can gain information from the experiences of the others. After multiple training epochs, the UAV-BSs can swap their model with their neighbours under the control of a frequency parameter. The process is described in Algorithm 1. The procedures can be summarized as follows:
-
Step 1:
Each training episode will begin with each UAV-BS exploring and locating its neighbours before moving on to exploring the environment and doing Q-value iterations. When deciding whether to choose the best action or to randomly explore the new state, a -greedy exploration is used. The parameter specifies the likelihood of exploration.
-
Step 2:
After making a choice, each UAV-BS will notify its neighbours of the state and local performance indicators. The agent will simultaneously listen to the other neighbours, and get ready to receive their states and local performance metrics . A global system metric value that can direct each UAV-BS to take future actions will be formed when all metrics have been received and the reward has been calculated based on the reward function .
-
Step 3:
A replay batch contains the data for each training stage. The tuple , or the current state, action, reward, and next state for a training step, is contained in each row of . For the purpose of updating the Q value model, samples will be chosen at random. The current state reward pairs will also be distributed to the other agents after each decision round.
-
Step 4:
A UAV-BS will send the updated model results, , to its registered neighbours for model aggregation after it has reached the predetermined exchanging iteration. Each UAV-BS will simultaneously listen to its neighbours in order to receive models and service metrics.
-
Step 5:
Each node executes aggregation by averaging all updated models depending on the aggregation function, , after receiving all the models from the registered neighbours.
-
Step 6:
The updated model is used by the edge device to replace the outdated one and to carry out additional local training. We’ll repeat the steps from above.
IV Simulation Results and Analysis
In this section, the simulation configuration and scenario deployment are introduced firstly. Then, we investigate the impact of the 3-D location of multiple UAV-BSs on the performance of MC users in terms of backhaul link rate, throughput, and drop rate based on system-level simulations. Finally, we present the results of proposed RL algorithms for autonomous UAV-BS navigation.
IV-A Simulation Configuration
To evaluate the performance of the proposed RL algorithm in solving the formulated problem, we build a multi-cell scenario by considering the predefined system model, and a simulation is executed with a system-level simulator. With the output of the simulation, the proposed RL algorithm can be applied for UAV-BS to build a well-trained model, based on which the optimal UAV-BS position and antenna configuration can be found rapidly.
In the simulation, we drop 500 users in the area as shown in Figure 2. The circle area with a 350m radius around the UAV-BS is defined as the MC area. The users located in the MC area are marked as MC users, while the others are normal users. All users follow an arrival model and only arrived users can be considered as activated. To investigate how a well-trained RL model performs in a dynamic environment, we design a set of different user distributions to simulate the case of slow-moving users.
The detailed simulation parameters are shown in Table II.
| Parameter | Value |
| Carrier Frequency | 3.5 GHz |
| Bandwidth | 100 MHz |
| Duplex Mode | TDD |
| TDD DL/UL Configuration | DDUD |
| Inter-Site-Distance (ISD) | 750-1000 m |
| Radius of MC Area | 350 m |
| Number of BSs | Macro-BS: 6; UAV-BS: 1 |
| BS Transmit Power | Macro-BS: 46 dBm; UAV-BS: 40 dBm |
| Noise Figure | 7 dB |
| BS Height | Macro-BS: 32 m; UAV-BS: 10-300 m |
| Number of Sectors per Site | 3 |
| Number of MC&Normal Users | 500 |
| User Arriving Rate per Simulation Area | 270 users/s |
| User Speed | 3 km/s |
| Minimum Distance between BS and Users | 30 m |
| Simulation Time | 2 s |
IV-B System-level Performance Evaluation
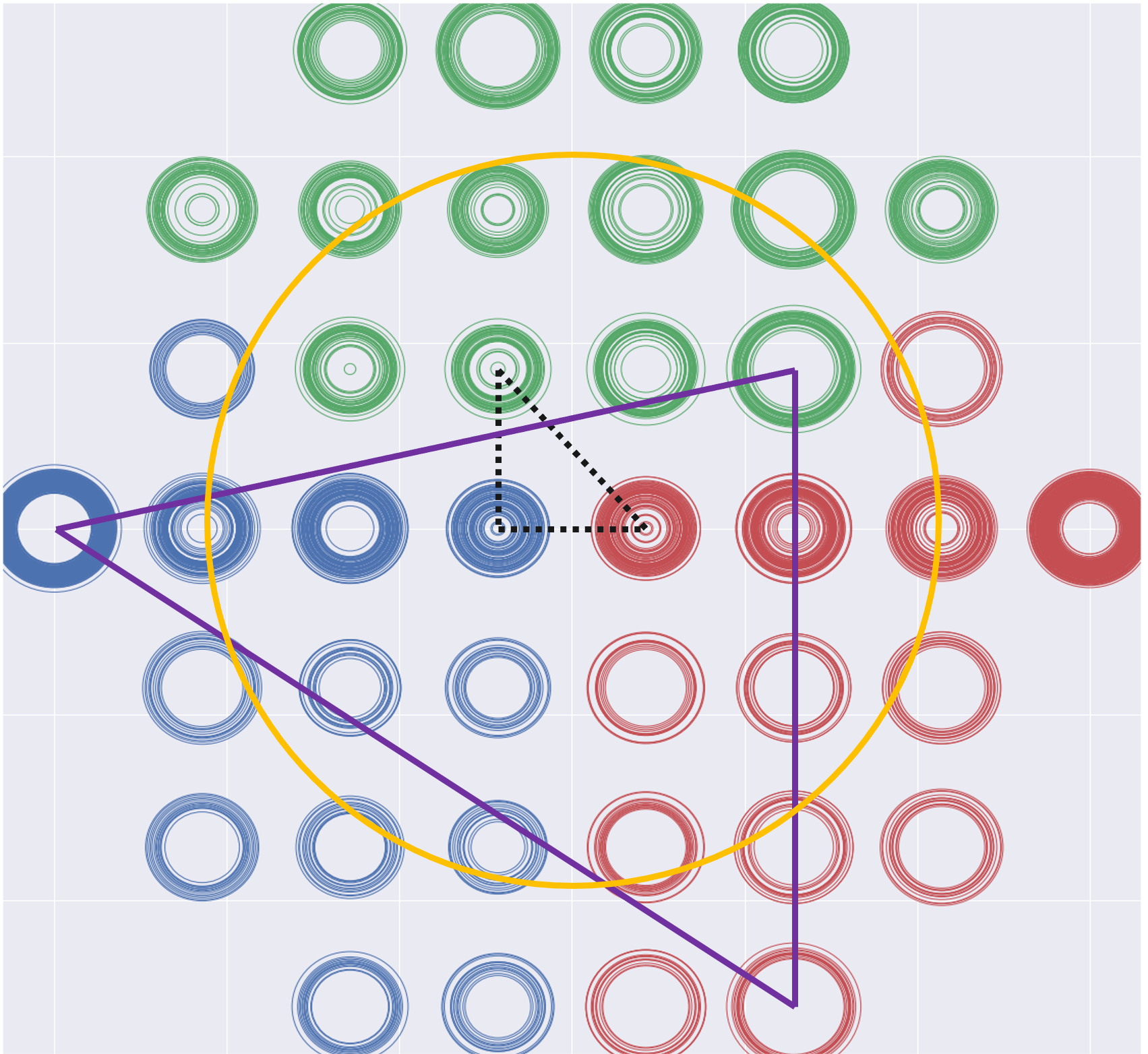
To evaluate the impact of UAV-BSs’ positions on the user performance, Figure 6 shows the range of achieved average backhaul link rate when the three UAV-BSs are deployed at different candidate positions as indicated in Figure 2. Around the MC area, 40 candidate 2D-positions of UAV-BS (colored stars shown in Figure 6) are selected and indicated by the centers of the circles in Figure 6. Each colored UAV-BS can only be deployed at the position with the same color. The radius of the circles denotes the normalized average backhaul link rate of three UAV-BSs. For instance, when one UAV-BS is deployed at one candidate position in blue, the other two UAV-BSs can be placed at the all possible combination of green and red candidate positions. This explains why there are multiple circles at each candidate’s UAV position. Hence the range of the circle radius at one candidate position denotes the lower and higher bounds of the backhaul link rate when the UAV-BS is placed at the current location. After connecting the locations with the lowest or highest backhaul link rate, two triangles can be observed, where the black dashed circle indicates the positions of three UAV-BSs with the lowest average backhaul link rate, while the solid purple triangle indicates the positions of three UAV-BSs with the highest average backhaul link rate. Based on the distribution pattern of three UAV-BSs, it seems that the optimal UAV-BSs’ positions to maximize the backhaul link rate tend to be near the edge of the MC area. This is because the UAV-BSs can keep good backhaul link quality when located near the donor-BSs.
Based on the above assumptions, the optimal UAV-BSs’ positions are different for different performance metrics considered in the reward function. Hence, optimizing the performance metrics in the reward function to achieve the global optimization by adjusting UAV-BSs’ positions is a complicated problem, for which ML-based solutions can be applied to find the implicit structure from the collected data.
IV-C Machine Learning Performance Evaluation
In this section, we present the experimental results of Decentralized Reinforcement Learning with Adaptive Exploration and Value-based Action Selection (DecRL-AE&VAS) for autonomously controlling multiple UAV-BSs. For the UAV-BSs deployment, different from the single UAV case introduced in the previous section, more candidate positions are allocated around the MC area for the multi-UAV case. As shown in Figure 2, the available positions for each UAV-BS don’t overlap with others, which means each UAV-BS is covering a certain geographical area with a total of 18928 combinations. The result is evaluated using two criteria: (1) six features (specified in Section IV - Modeling of ML Environment) that demonstrate link service quality, and (2) model learning quality in each phase as demonstrated by system reward value. The results are compared to several baseline models. As we described before, the experiment contains five validation phases incorporating MC user mobility. When entering a new phase, the algorithms will use the data collected during the new phase to learn and update themselves. During the simulation, the DecRL-AE&VAS method trains the model from scratch in the training phase and then continuously improves itself in the succeeding validation phases. The previously learnt experience will not be removed for the subsequent sessions.
There are two baseline methods used to compare the performance of DecRL-AE&VAS and demonstrate the effectiveness of the decentralized architecture and the convergent efficiency in the training phase, namely, baseline CRL and baseline IRL method. For the baseline IRL algorithm, these baseline models are explicitly trained using each edge UAV-BS. There will not be any model or information exchange between the edge and central nodes during training, in contrast to decentralized reinforcement learning. The service quality performance can be compared to the decentralized reinforcement Learning model to demonstrate how it can outperform those locally trained individual models. For the baseline CRL, this baseline model is trained using the centralized learning strategy. Prior to model training, all data from the edge are collected into a single server and learn the action strategy step by step.
In the validation phase, in order to prove the performance in a dynamic environment, two baselines are utilized, namely, the retrained DecRL and baseline CRL. The retrained DecRL algorithm removes the past information and randomizes the ML model parameters but with the same decentralized setup. When entering a new phase, the algorithm will retrain the model from scratch. The difference between retrained DecRL and DecRL-AE&VAS is the utilization of AE and VAS strategies. These strategies have been proven to be useful when deploying UAV-BSs into dynamic environments. Last but not the least, the baseline CRL algorithm in the validation phases will constantly learn and employ the new data when entering the new phase but with a centralized algorithm which controls all deployed UAV-BSs but without improved strategies.
For the hyper-parameters of our method, we explored various sets of combinations in order to achieve acceptable results. During the training, the network architecture for a DQN is set to , the exploration probability decay is set to 0.995, the learning rate is set to and the number of learning iterations at the training phase and validation phases equals 1500 and 500.
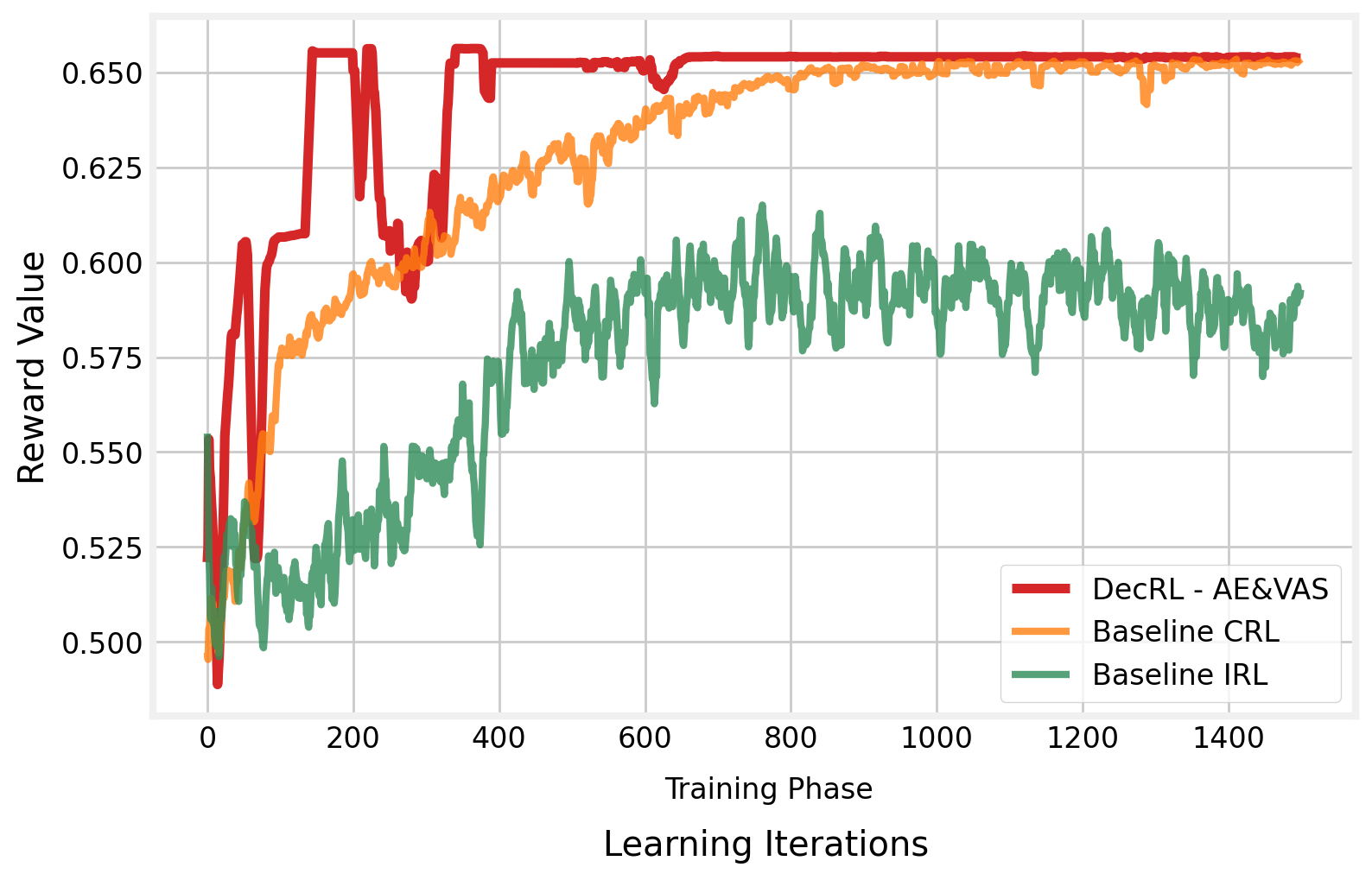
We first analyze the algorithm’s convergence performance during the model training phase. Figure 8 depicts the reward value as a function of the number of learning iterations. Compared to the baseline CRL algorithm, we can see that the VAS method can help the UAV-BS quickly discover the near-optimal position and converge at a high-quality level.
Training the algorithm in a decentralized way can also be converged and reach a high reward value before 400 training rounds. The convergent reward value of the DecRL-AE&VAS is approximately 5% higher than that of the centralized training method in the initial learning iterations which results in higher training efficiency. When compared to the independent learning method, the algorithm does not converge after 1500 learning iterations. It is difficult for agents to share knowledge and collaborate since the algorithm stops them from exchanging information. Throughout the training procedure, the Baseline IRL algorithm performs poorly. Because the reward value represents the overall system performance of the three UAV-BSs, we can conclude that the DecRL-AE&VAS algorithm enables the UAV-BSs to provide the best wireless connection service when compared to the other two frequently utilized baseline approaches in the training phase.
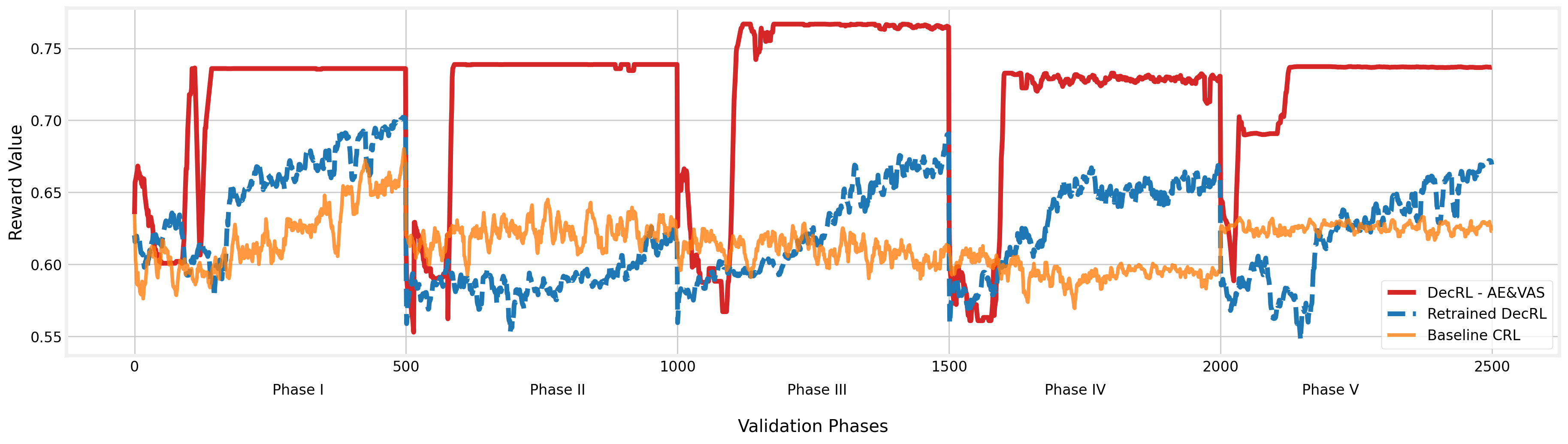
When entering the validation phases (Figure 7 Phase I - V), the proposed algorithm can learn from the past and finally reach the optimal state that provides the highest reward value in the validation scenarios using the AE method. Even if the environment has changed and the quality has dropped dramatically, the algorithm can assist the UAV-BS in quickly adjusting and returning to ideal performance. When we look at the baseline CRL approach, the method failed to respond to environmental changes in a short period due to the slow-paced state exploration. When we compared the baseline results to the retrained DecRL and DecRL-AE&VAS, the results showed that our suggested VAS-AE approach can enable UAV-BS quickly converge in most of the validation phases. However, with the retrained DecRL, a significant impact may occur on the algorithm and service stability if not using previous existing knowledge. When we integrated RL with adaptive exploration and the value-based action selection strategy, the algorithm showed the best performance in terms of convergence speed, the ability to adapt to environmental changes and stable service quality of our suggested DecRL-AE&VAS method.
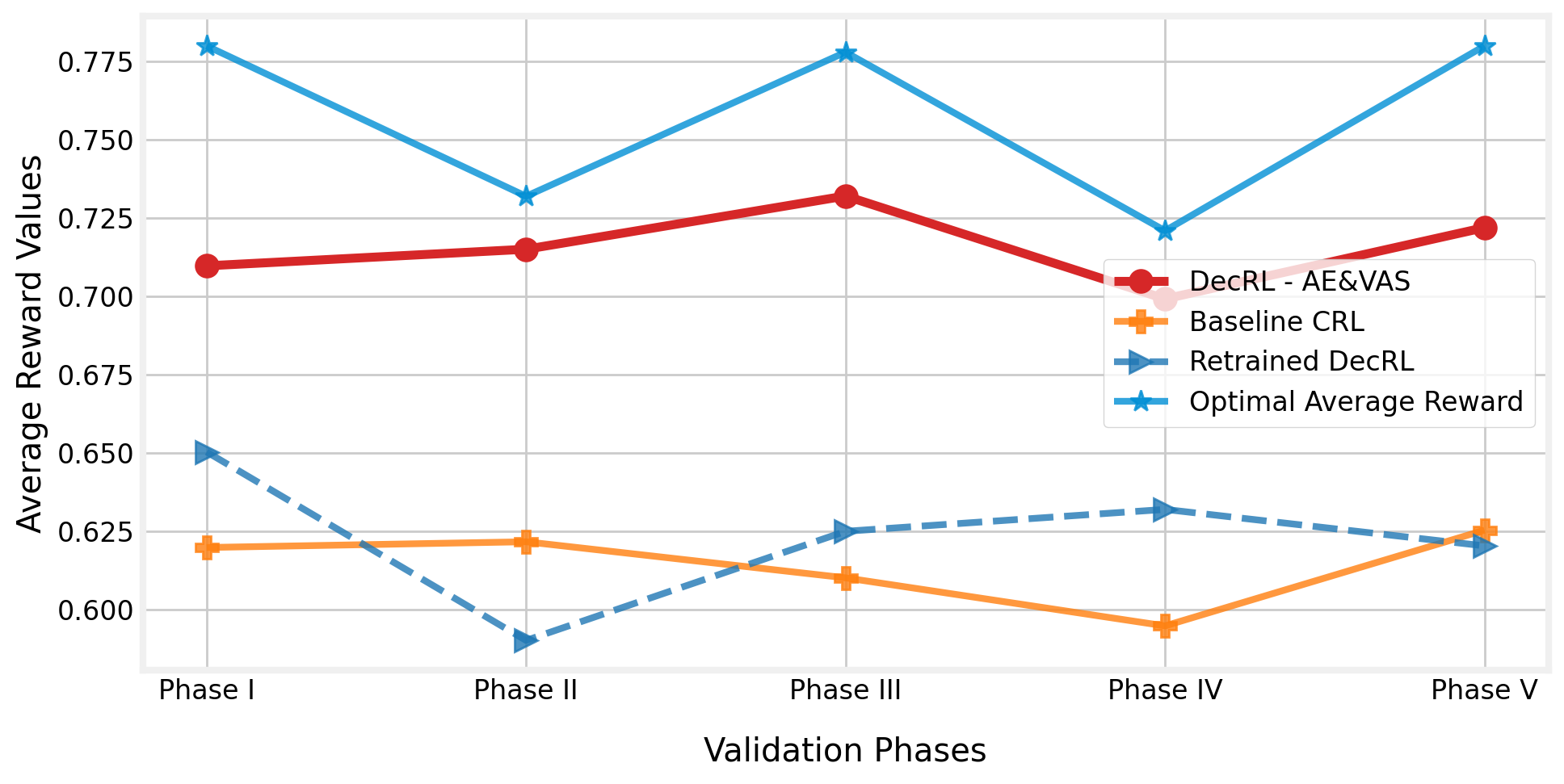
The average reward value changes during the validation phases are depicted in Figure 9. Because the reward value encompasses all of the essential criteria that must be evaluated during the deployment of the UAV-BS, the value clearly demonstrates the model’s quality at each stage. As shown in the figure, our proposed DecRL-AE&VAS method can assist the UAV-BS in maintaining the ideal service quality, but the baseline model failed to discover a state that can give reliable and satisfactory service to MC users. The suggested DecRL-AE&VAS algorithm gives a reward value (a weighted sum of the six assessed performance measures) of only about 5% to 6% less than the global best solution in each validation phase.
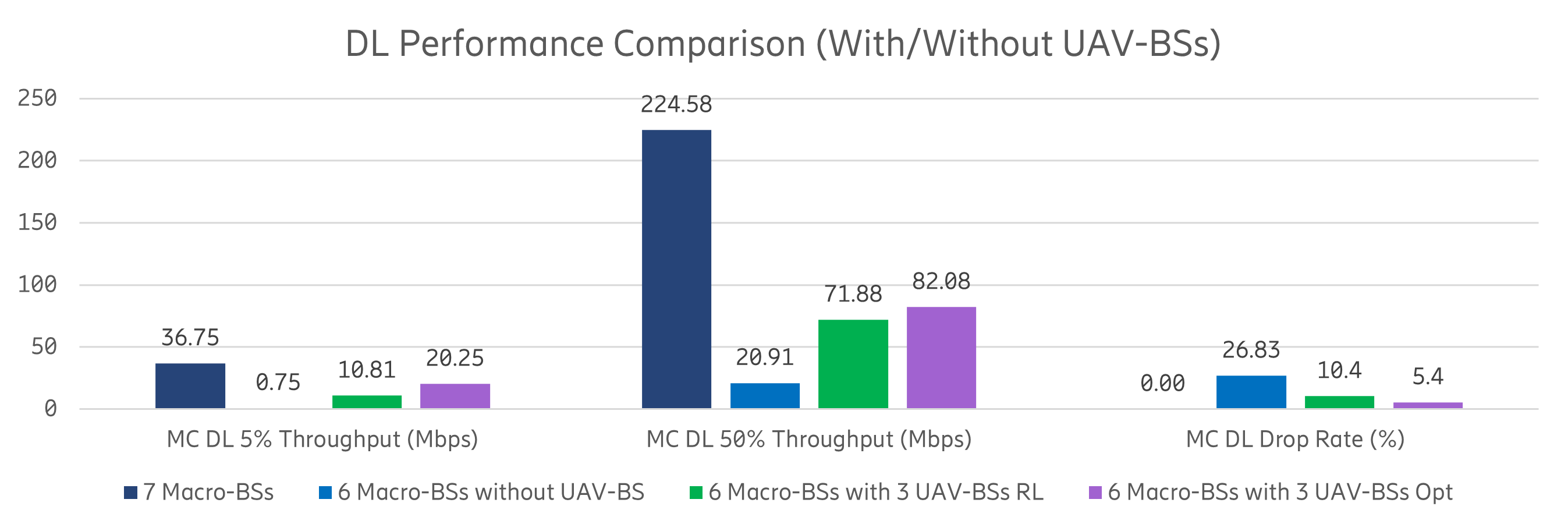
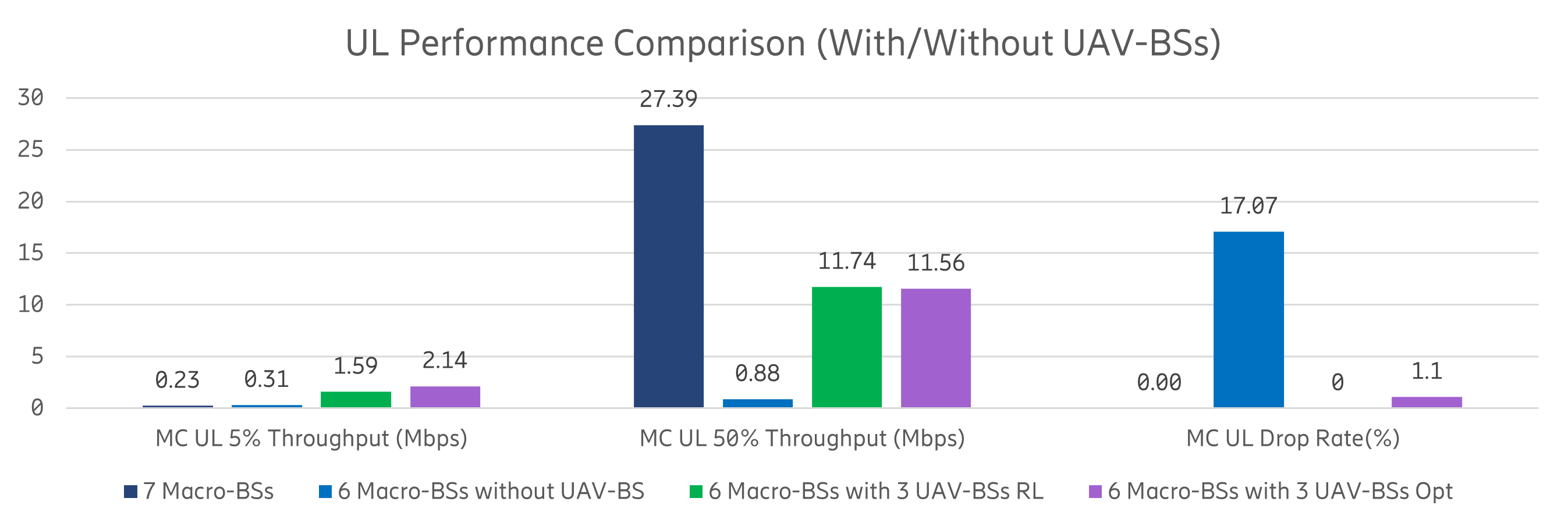
In conclusion, we show that, when compared to the baseline RL approaches, the DecRL-AE&VAS model can efficiently assist the UAV-BS in finding the near-optimal location and converging at a high-quality level. Utilizing the model-sharing and information-exchange technique, the proposed algorithm can learn from the past and eventually arrive at the optimal state that provides the best reward value, the proposed DecRL-AE&VAS method can achieve the same or even higher levels of system quality than the Baseline CRL approach in both training and validation phases. Because the reward value shows the system’s performance, we may conclude that the DecRL-AE&VAS can help UAV-BS provide better service than the other baseline models. Our findings show that the algorithm has the capacity to link MC users swiftly and adequately, allowing drone systems to self-learn without centralized interaction. In Figure 10, we also demonstrate the effectiveness after deploying multiple UAV-BSs in the MC use case. The ”7 Macro-BSs” denotes the scenario where 7 marco-BSs are serving the whole scenario, while the ”6 Macro-BSs without UAV-BS” denotes the scenario where one macro-BS is broken and no UAV-BS is deployed. The case ”6 Macro-BSs with 3 UAV-BSs RL” describes the situation that 3 UAV-BSs are deployed to fill the coverage hole created in case ”6 Macro-BSs without UAV-BS”. The results in case ”6 Macro-BSs with 3 UAV-BSs Opt” is derived based on grid search to be compared with the RL case. It can be observed that when one macro-BS brokes down, the MC users are experiencing severe performance degradation. Compared with the ”6 Macro-BSs without UAV-BS” case, deploying 3 UAV-BSs as in the case ”6 Macro-BSs with 3 UAV-BSs RL” can improve about 80% system performance (including 5%, 50% throughput and drop rate) for MC users in both DL and UL. Furthermore, the suggested DecRL-AE&VAS algorithm gives a throughput of 10 Mbps and a drop rate of only about 2% to 3% less than the global best solution indicated in the ”6 Macro-BSs with 3 UAV-BSs Opt” case. In conclusion, deploying UAV-BS can greatly improve the performance of MC users who are experiencing coverage loss. However, due to the BS capability difference, deploying 3 UAV-BS, in this case, can not guarantee that the MC users have similar performance in the case when no emergency happens. The only exception is that the UL 5% throughput performance of MC users served by 3 UAV-BSs is better than that served by one macro-BS before the disaster happens. This is because three UAV-BSs can be deployed in dispersed locations which increases the probability for an MC user to be close to its serving BS and the UL 5% throughput performance of MC users is improved accordingly.
V Conclusions and Future Work
In this paper, we presented a data collection system and machine learning applications for an MC use case, a novel RL algorithm, as well as a decentralized architecture to autonomously pilot multiple UAV-BS in order to offer users temporary wireless access. Two novel strategies, i.e., adaptive exploration and value-based action selection, are developed to help the proposed RL algorithms work efficiently in a dynamic real-world context, incorporating MC user movements and a decentralized architecture to support multi UAV-BSs deployment. Note that the number of participated UAV-BSs can be further extended based on the industrial requirements due to the characteristics of the decentralized architecture. We show that the proposed RL algorithm can monitor the MC service performance and quickly respond to environmental changes via self-adapting exploration probability. In addition, it requires far fewer model training iterations by reusing previous experiences and the value-based action selection strategy. Therefore, the proposed method can well serve the MC users by autonomously navigating multiple UAV-BSs despite environmental changes.
In the future, we will consider separating the configuration for access and backhaul antennas of the UAV-BS, as well as modelling drone rotation in the horizontal domain as an additional parameter for the UAV-BS configuration. We also intend to examine other hyper-parameters and reward function combinations based on different service requirements. Last but not least, we will also investigate the energy efficiency problem for deploying UAVs with machine learning components in the real-world context.
References
- [1] H. Shakhatreh, K. Hayajneh, K. Bani-Hani, A. Sawalmeh, and M. Anan, “Cell on wheels-unmanned aerial vehicle system for providing wireless coverage in emergency situations,” Complexity, vol. 2021, 2021.
- [2] Y. Zeng, R. Zhang, and T. J. Lim, “Wireless communications with unmanned aerial vehicles: Opportunities and challenges,” IEEE Communications Magazine, vol. 54, no. 5, pp. 36–42, 2016.
- [3] J. Li, X. Lin, K. K. Nagalapur, Z. Qi, A. Lahuerta-Lavieja, T. Chapman, S. Agneessens, H. Sahlin, D. Guldbrand, and J. Åkesson, “Towards providing connectivity when and where it counts: An overview of deployable 5G networks,” arXiv preprint arXiv:2110.05360, 2021.
- [4] Z. Qi, A. Lahuerta-Lavieja, J. Li, and K. K. Nagalapur, “Deployable networks for public safety in 5g and beyond: A coverage and interference study,” in 2021 IEEE 4th 5G World Forum (5GWF), 2021, pp. 346–351.
- [5] G. Dulac-Arnold, D. Mankowitz, and T. Hester, “Challenges of real-world reinforcement learning,” arXiv preprint arXiv:1904.12901, 2019.
- [6] Z. Ding and H. Dong, “Challenges of reinforcement learning,” in Deep Reinforcement Learning. Springer, 2020, pp. 249–272.
- [7] J. Li, K. K. Nagalapur, E. Stare, S. Dwivedi, S. A. Ashraf, P.-E. Eriksson, U. Engström, W.-H. Lee, and T. Lohmar, “5G new radio for public safety mission critical communications,” IEEE Communications Standards Magazine, vol. 6, no. 4, pp. 48–55, 2022.
- [8] S. A. R. Naqvi, S. A. Hassan, H. Pervaiz, and Q. Ni, “Drone-aided communication as a key enabler for 5G and resilient public safety networks,” IEEE Communications Magazine, vol. 56, no. 1, pp. 36–42, 2018.
- [9] K. P. Morison and J. Calahorrano. (2020) FirstNet Case Study: How FirstNet Deployables are Supporting Public Safety. [Online]. Available: https://www.policeforum.org/assets/FirstNetDeployables.pdf
- [10] A. Merwaday, A. Tuncer, A. Kumbhar, and I. Guvenc, “Improved throughput coverage in natural disasters: Unmanned aerial base stations for public-safety communications,” IEEE Vehicular Technology Magazine, vol. 11, no. 4, pp. 53–60, 2016.
- [11] L. Ferranti, L. Bonati, S. D’Oro, and T. Melodia, “SkyCell: A prototyping platform for 5G aerial base stations,” in 2020 IEEE 21st International Symposium on “A World of Wireless, Mobile and Multimedia Networks”(WoWMoM). IEEE, 2020, pp. 329–334.
- [12] H. Wang, H. Zhao, W. Wu, J. Xiong, D. Ma, and J. Wei, “Deployment algorithms of flying base stations: 5G and beyond with UAVs,” IEEE Internet of Things Journal, vol. 6, no. 6, pp. 10 009–10 027, 2019.
- [13] E. Kalantari, M. Z. Shakir, H. Yanikomeroglu, and A. Yongacoglu, “Backhaul-aware robust 3D drone placement in 5G+ wireless networks,” in 2017 IEEE international conference on communications workshops (ICC workshops). IEEE, 2017, pp. 109–114.
- [14] C. T. Cicek, H. Gultekin, B. Tavli, and H. Yanikomeroglu, “Backhaul-aware optimization of UAV base station location and bandwidth allocation for profit maximization,” IEEE Access, vol. 8, pp. 154 573–154 588, 2020.
- [15] N. Tafintsev, D. Moltchanov, M. Gerasimenko, M. Gapeyenko, J. Zhu, S.-p. Yeh, N. Himayat, S. Andreev, Y. Koucheryavy, and M. Valkama, “Aerial access and backhaul in mmWave B5G systems: Performance dynamics and optimization,” IEEE Communications Magazine, vol. 58, no. 2, pp. 93–99, 2020.
- [16] S. A. Al-Ahmed, M. Z. Shakir, and S. A. R. Zaidi, “Optimal 3D UAV base station placement by considering autonomous coverage hole detection, wireless backhaul and user demand,” Journal of Communications and Networks, vol. 22, no. 6, pp. 467–475, 2020.
- [17] C. Madapatha, B. Makki, C. Fang, O. Teyeb, E. Dahlman, M.-S. Alouini, and T. Svensson, “On integrated access and backhaul networks: Current status and potentials,” IEEE Open Journal of the Communications Society, vol. 1, pp. 1374–1389, 2020.
- [18] A. Fouda, A. S. Ibrahim, I. Güvenç, and M. Ghosh, “Interference management in UAV-assisted integrated access and backhaul cellular networks,” IEEE Access, vol. 7, pp. 104 553–104 566, 2019.
- [19] M.-A. Lahmeri, M. A. Kishk, and M.-S. Alouini, “Artificial intelligence for UAV-enabled wireless networks: A survey,” IEEE Open Journal of the Communications Society, vol. 2, pp. 1015–1040, 2021.
- [20] A. Ly and Y.-D. Yao, “A review of deep learning in 5G research: Channel coding, massive MIMO, multiple access, resource allocation, and network security,” IEEE Open Journal of the Communications Society, vol. 2, pp. 396–408, 2021.
- [21] C. H. Liu, Z. Chen, J. Tang, J. Xu, and C. Piao, “Energy-efficient UAV control for effective and fair communication coverage: A deep reinforcement learning approach,” IEEE Journal on Selected Areas in Communications, vol. 36, no. 9, pp. 2059–2070, 2018.
- [22] C. Madapatha, B. Makki, A. Muhammad, E. Dahlman, M.-S. Alouini, and T. Svensson, “On topology optimization and routing in integrated access and backhaul networks: A genetic algorithm-based approach,” IEEE Open Journal of the Communications Society, vol. 2, pp. 2273–2291, 2021.
- [23] F. Tang, Y. Zhou, and N. Kato, “Deep reinforcement learning for dynamic uplink/downlink resource allocation in high mobility 5G HetNet,” IEEE Journal on Selected Areas in Communications, vol. 38, no. 12, pp. 2773–2782, 2020.
- [24] H. Yang, J. Zhao, Z. Xiong, K.-Y. Lam, S. Sun, and L. Xiao, “Privacy-preserving federated learning for UAV-enabled networks: Learning-based joint scheduling and resource management,” IEEE Journal on Selected Areas in Communications, vol. 39, no. 10, pp. 3144–3159, 2021.
- [25] C. Zhou, W. Wu, H. He, P. Yang, F. Lyu, N. Cheng, and X. Shen, “Deep reinforcement learning for delay-oriented IoT task scheduling in sagin,” IEEE Transactions on Wireless Communications, vol. 20, no. 2, pp. 911–925, 2021.
- [26] S. Tan, C. Dun, F. Jin, and K. Xu, “UAV control in smart city based on space-air-ground integrated network,” in 2021 International Conference on Internet, Education and Information Technology (IEIT), 2021, pp. 324–328.
- [27] L. Zhang, A. Celik, S. Dang, and B. Shihada, “Energy-efficient trajectory optimization for UAV-assisted IoT networks,” IEEE Transactions on Mobile Computing, pp. 1–1, 2021.
- [28] S. Yin, S. Zhao, Y. Zhao, and F. R. Yu, “Intelligent trajectory design in UAV-aided communications with reinforcement learning,” IEEE Transactions on Vehicular Technology, vol. 68, no. 8, pp. 8227–8231, 2019.
- [29] S. Yin and F. R. Yu, “Resource allocation and trajectory design in UAV-aided cellular networks based on multi-agent reinforcement learning,” IEEE Internet of Things Journal, pp. 1–1, 2021.
- [30] H. Wu, F. Lyu, C. Zhou, J. Chen, L. Wang, and X. Shen, “Optimal UAV caching and trajectory in aerial-assisted vehicular networks: A learning-based approach,” IEEE Journal on Selected Areas in Communications, vol. 38, no. 12, pp. 2783–2797, 2020.
- [31] C. Wang, J. Wang, Y. Shen, and X. Zhang, “Autonomous navigation of UAVs in large-scale complex environments: A deep reinforcement learning approach,” IEEE Transactions on Vehicular Technology, vol. 68, no. 3, pp. 2124–2136, 2019.
- [32] C. Wang, J. Wang, J. Wang, and X. Zhang, “Deep-reinforcement-learning-based autonomous UAV navigation with sparse rewards,” IEEE Internet of Things Journal, vol. 7, no. 7, pp. 6180–6190, 2020.
- [33] H. Huang, Y. Yang, H. Wang, Z. Ding, H. Sari, and F. Adachi, “Deep reinforcement learning for UAV navigation through massive MIMO technique,” IEEE Transactions on Vehicular Technology, vol. 69, no. 1, pp. 1117–1121, 2020.
- [34] Y. Zeng, X. Xu, S. Jin, and R. Zhang, “Simultaneous navigation and radio mapping for cellular-connected UAV with deep reinforcement learning,” IEEE Transactions on Wireless Communications, vol. 20, no. 7, pp. 4205–4220, 2021.
- [35] Y. Zeng and R. Zhang, “Energy-efficient UAV communication with trajectory optimization,” IEEE Transactions on Wireless Communications, vol. 16, no. 6, pp. 3747–3760, 2017.
- [36] S. Ahmed, M. Z. Chowdhury, and Y. M. Jang, “Energy-efficient UAV relaying communications to serve ground nodes,” IEEE Communications Letters, vol. 24, no. 4, pp. 849–852, 2020.
- [37] C. Zhao, J. Liu, M. Sheng, W. Teng, Y. Zheng, and J. Li, “Multi-UAV trajectory planning for energy-efficient content coverage: A decentralized learning-based approach,” IEEE Journal on Selected Areas in Communications, vol. 39, no. 10, pp. 3193–3207, 2021.
- [38] B. Zhu, E. Bedeer, H. H. Nguyen, R. Barton, and J. Henry, “UAV trajectory planning in wireless sensor networks for energy consumption minimization by deep reinforcement learning,” IEEE Transactions on Vehicular Technology, vol. 70, no. 9, pp. 9540–9554, 2021.
- [39] H. Zhang, J. Li, Z. Qi, X. Lin, A. Aronsson, J. Bosch, and H. H. Olsson, “Autonomous navigation and configuration of integrated access backhauling for UAV base station using reinforcement learning,” arXiv preprint arXiv:2112.07313, 2021.
- [40] 3GPP—, “Radio Resource Control (RRC) protocol specification,” 3rd Generation Partnership Project (3GPP), Technical Specification (TS) 38.331, 03 2022, version 16.8.0. [Online]. Available: https://www.3gpp.org/ftp/Specs/archive/38_series/38.331/38331-g80.zip
- [41] 3GPP-, “Study on channel model for frequencies from 0.5 to 100 GHz,” 3rd Generation Partnership Project (3GPP), Technical Report (TR) 38.901, 1 2020, version 16.1.0. [Online]. Available: https://www.3gpp.org/ftp//Specs/archive/38_series/38.901/38901-g10.zip
- [42] 3GPP–, “Study on Enhanced LTE Support for Aerial Vehicles,” 3rd Generation Partnership Project (3GPP), Technical Report (TR) 36.777, 12 2017, version 15.0.0. [Online]. Available: https://www.3gpp.org/ftp//Specs/archive/36_series/36.777/36777-f00.zip
- [43] V. Mnih, K. Kavukcuoglu, D. Silver, A. Graves, I. Antonoglou, D. Wierstra, and M. Riedmiller, “Playing Atari with deep reinforcement learning,” arXiv preprint arXiv:1312.5602, 2013.
- [44] V. Mnih, K. Kavukcuoglu, D. Silver, A. A. Rusu, J. Veness, M. G. Bellemare, A. Graves, M. Riedmiller, A. K. Fidjeland, G. Ostrovski et al., “Human-level control through deep reinforcement learning,” nature, vol. 518, no. 7540, pp. 529–533, 2015.
- [45] C. J. C. H. Watkins, “Learning from delayed rewards,” 1989.