\ul
22institutetext: AIBEE Inc., Palo Alto, CA 94306, USA
22email: {rlweng,wgchoi,amirabs}@aibee.com
3SD: Self-Supervised Saliency Detection With No Labels
Abstract
We present a conceptually simple self-supervised method for saliency detection. Our method generates and uses pseudo-ground truth labels for training. The generated pseudo-GT labels don’t require any kind of human annotations (e.g., pixel-wise labels or weak labels like scribbles). Recent works show that features extracted from classification tasks provide important saliency cues like structure and semantic information of salient objects in the image. Our method, called 3SD, exploits this idea by adding a branch for a self-supervised classification task in parallel with salient object detection, to obtain class activation maps (CAM maps). These CAM maps along with the edges of the input image are used to generate the pseudo-GT saliency maps to train our 3SD network. Specifically, we propose a contrastive learning-based training on multiple image patches for the classification task. We show the multi-patch classification with contrastive loss improves the quality of the CAM maps compared to naive classification on the entire image. Experiments on six benchmark datasets demonstrate that without any labels, our 3SD method outperforms all existing weakly supervised and unsupervised methods, and its performance is on par with the fully-supervised methods. Code is available at :https://github.com/rajeevyasarla/3SD
Keywords:
saliency object detection, self-supervised classification, CAM map, gated edge, pseudo-GT.
1 Introduction
Salient object detection (SOD) task is defined as pixel-wise segmentation of interesting regions that capture human attention in an image. It is widely used as a prior to improve many computer vision tasks such as visual tracking, segmentation, etc. Early methods based on hand-crafted features like histograms [28], boundary connectivity [56], high-dimensional color transforms[20], may fail in producing high-quality saliency maps on cluttered images where the foreground object is similar to the background. In recent years, deep convolutional neural networks (CNNs), and in particular fully convolutional networks (FCN)[27] have provided excellent image segmentation and salient object detection performance.
In general, the CNN-based salient object detection methods can be classified into three groups: (i) fully-supervised methods (that require large-scale datasets with pixel-wise annotations), (ii) weakly supervised, and (iii) unsupervised or self-supervised methods (that don’t require actual pixel-wise annotations of salient object detection). The main drawback of the fully-supervised methods [34, 42, 33, 40, 25] is that they require a large amount of pixel-wise annotations of salient objects which is time-consuming and expensive. On the other hand, to minimize human efforts in labeling datasets, weakly-supervised approaches [21, 46] have been proposed which address saliency detection either by using weak sparse labels such as image class labels [21] or image captions [46]. Alternatively, Zhang et al. [49] present a weakly-supervised SOD method based on scribble annotations. Pia et al.[32] propose a learnable directive filter based method that extracts saliency cues using multiple labels from the attentions. Note, Pia et al.[32] and MSW [46] rely on the features or attention maps obtained from a classification task, and might fail to produce high-quality pseudo-GTs since the classification task is trained with global class label or image caption. For example, Fig. 1 shows that the outputs of [46, 32] are not sharp and miss fine details like legs and ears. Although these weakly-supervised methods reduce the amount of labeling required for SOD, they still require labeling resources to obtain image captions [46], image class labels [21, 32], or accurate scribble annotations[49]. On the other hand, unsupervised methods [50, 30, 48] devise a refinement procedure or generative based approach (noise-aware), that utilizes the hand crafted features, and/or noisy annotations. Note that performance of these unsupervised methods highly rely on the noisy annotation, and might struggle to produce high-quality saliency maps if they fail to recover the underlying semantics from the noisy annotations. For instance, we can observe in Fig. 1 saliency outputs of [50, 30, 48] miss parts like legs and ears.
In an attempt to overcome these issues, we propose our Self-Supervised Saliency Detection (3SD) method. Our framework follows the conventional encoder-decoder structure to generate saliency map. In terms of encoder, we present a novel encoder architecture which consists of a local encoder and global context encoder. The local encoder learns pixel-wise relationship among neighbourhood while the global encoder encodes the global context. The outputs of these encoders are concatenated and subsequently fed to the decoder stream. By fusing both local features and global context we are able to extract both fine-grain contour details as well as adhere to the underlying object structure.
For the decoder, we follow the literature [3] by adding an auxiliary classification task to capture important saliency cues like semantics and segmentation of the salient object in the image, which can be extracted in the form of class activation map (CAM map). However, performing a self-supervised classification with single global class label might result in low-quality class activation map (illustrated in Fig. 2f, where the CAM map is incomplete). To address this issue, we propose a contrastive learning [5] based patch-wise self-supervision for the classification task, where we perform patch-wise ( pixels in our implementation) classification and train it with proposed self-supervised contrastive loss. Specifically, positive patches (patches similar to the salient object) and negative patches (patches dissimilar to the salient object) are identified. Positive patches are pulled together, and they are pushed away from the negative patches. In this way, the network strives to learn the attentions or semantic information that are responsible for classifying the salient object at a fine-grain patch level.
With the novel designs of encoder and decoder, our 3SD is able to generate high-quality CAM maps (see Fig. 2). While the generated CAM maps provide salient object information, they might not have proper boundary corresponding to the salient object. To deal with this issue, we fuse CAM map with a gated edge map of the input image to generate the pseudo-GT salient map (Fig. 2d).





(a) (b) (c) (d) (e)





(f) (g) (h) (i) (j)
Fig. 1 compares sample results of the proposed 3SD with the existing SOTA weakly, unsupervised [47, 50, 46, 48, 49] and SOTA fully-supervised [40] methods. One can clearly observe that [47, 50, 46, 48, 49] fail to produce sharp edges and proper saliency maps. In contrast, our method is able to provide sharper and better results. To summarize, the main contributions of our paper are as follows:
-
•
We propose a self-supervised 3SD method that requires no human annotations for training an SOD model. Our 3SD method is trained using high-quality pseudo-GT saliency maps generated from CAM maps using a novel self-supervised classification task.
-
•
We present a patch-wise self-supervised contrastive learning paradigm, which substantially improves the quality of pseudo-GT saliency maps and boosts 3SD performance.
-
•
We construct a novel encoder architecture for SOD that attends features locally (pixel-level understanding), and globally (patch-level understanding).
-
•
Extensive experiments on six benchmark datasets show that the proposed 3SD method outperforms the SOTA weakly/unsupervised methods.
2 Related Work
Classical image processing methods address SOD using histograms [28], boundary connectivity [56], high-dimensional color transforms [20], hand-crafted features like foreground consistency [51], and similarity in superpixels [53]. In recent years, various supervised CNN-based methods have been proposed for SOD [52, 29, 39, 41, 42, 12, 34, 40] which extensively study architectural changes, attention mechanisms, multi-scale contextual information extraction, boundary-aware designs, label decoupling, etc. In contrast, our 3SD method is a self-supervised method trained using pseudo-GT data. In what follows, we will review recent weakly/unsupervised SOD methods as well as the self-supervised methods.
Weakly supervised SOD methods: To reduce human efforts and expenses in pixel-level labeling and annotations, various weakly methods have been proposed. These methods use high-level labels such as image class labels and image captions [21, 46], and scribble annotations [49]. Dai et al.[7], Khorea et al.[19] follow a bounding-box label approach to solve weakly-supervised segmentation task. Wang et al.[38] extract cues using image-level labels for foreground salient objects. Hsu et al.[18] propose a category-based saliency map generator using image-level labels. [4, 21, 31] propose a CRF-based method for weakly supervised SOD. Zeng et al.[46] train a network with multiple source labels like category labels, and captions of the images to perform saliency detection. Zhang et al.[49] introduce scribble annotations for SOD. Unlike these methods, the proposed 3SD method doesn’t require any kind of human annotations, noisy labels, scribble annotations, or hand-crafted features to perform SOD.
Unsupervised SOD methods: Zhang et al.[47] devise a fusion process that employs unsupervised saliency models to generate supervision. Nguyen et al.[30] propose an incrementally refinement technique that employs noisy pseudo labels generated from different handcrafted methods. Zhang et al.[50] and Zhang et al.[48] propose a saliency prediction network and noise modeling module that jointly learn from the noisy labels generated from multiple “weak” and “noisy” unsupervised handcrafted saliency methods. Unlike these unsupervised methods that highly rely on the noisy annotations, we propose a novel pseudo-GT generation technique using patchwise contrastive learning based self-supervised classification task.
Self-supervised/Contrastive learning methods: Several approaches explore discriminative approaches for self-supervised instance classification [9, 43]. These methods treat each image as a different class. The main limitation of these approaches is that they require comparing features from images for discrimination which can be complex in a large-scale dataset. To address this challenge, Grillet al.[13] introduce metric learning, called BOYL, where better representations of the features are learned by matching the outputs of momentum encoders. Subsequently, Caron et al.[3] propose the DINO method that is based on mean Teacher [36] self-distillation without labels. Recently, [15, 5, 16, 37] propose self-supervised contrastive learning based methods where the losses are inspired by noise-contrastive estimation[14], triplet loss[17], and N-pair loss[35]. Motivated by [1, 5], we perform patch-wise contrastive learning within the self-supervised classification framework to obtain high-quality CAM maps, leading to good-quality pseudo-GTs.

3 Proposed Method
The proposed 3SD method is a fully self-supervised approach that doesn’t require any human annotations or noisy labels. As shown in Fig. 3, our method 3SD consists of a base network (BN) and a pseudo label generator. The base network outputs the saliency map along with the class labels which are used to generate the CAM map. BN utilizes self-supervised classification task to extract the semantic information for CAM map. The pseudo label generator fuses gated edge of the input image with CAM map to compute the pseudo-GT for training. In this section, we will discuss: (i) construction of the base network (BN), and (ii) pseudo-label generator.
3.1 Base Network
We construct our framework with two encoders (local encoder and global encoder ) and two decoders (saliency decoder and classification decoder ) as shown in Fig. 3. Both local features and global context are vital for SOD task. To learn the pixel-wise relationship with local features, the local encoder is constructed using similar structure as U2Net [33]. Specifically, has nested two-level U-structure network with ResUBlock to capture contextual information at different scales. Even-though learns the inter-dependency between neighboring pixels in the receptive field size (approximately ), it fails to capture the global context for high-resolution images. To remedy this issue, we introduce a transformer based encoder to model long-range relationship across patches (inspired by ViT[8]). By combining the outputs of both encoders, our 3SD is able to capture the local fine-grain details and reason globally. This combined encoded features are fed to saliency decoder to obtain saliency map, and classification decoder to obtain class label map as output. We use the similar architecture proposed in [33] for saliency decoder . Our major contribution is on the classification decoder . In contrast to conventional single-image-single-label classification design, our decoder performs self-supervised learning in patch wise. To enhance the feature representation and fully exploit the semantics, patches belonging to the object are encouraged to be differentiated from background patches using our novel contrastive learning paradigm. More details about , , , and are provided in the supplementary document.
As shown in Fig. 3, given an input image, BN predicts the salient object , and patch-wise class logits map . It is trained in a fully self-supervised way using our proposed pseudo-label generator, which is described in the next subsection.


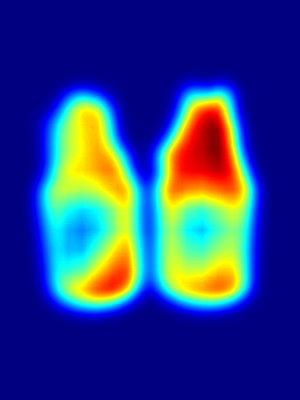














(a) (b) (c) (d) (e) (f)
3.2 Pseudo-label generator
The main goal of 3SD is to train an SOD network without any GT-labels of salient objects. To achieve this, 3SD should be able to extract structural or semantic information of the object in the image. From the earlier works [32, 21] it is evident that attention maps from classification task provide important cues for salient object detection. In contrast to [32, 21] which require image class and/or caption labels, we train our BN with student-teacher based knowledge-distillation technique, and found the features from encoders of BN contain structural or semantic information of the salient object in the image. These semantics are the key to generate high-quality CAM maps [55]. But as shown in Fig. 4, the quality of CAM maps obtained from the self-supervised image-wise classification task when trained with single global class label, might not be high enough to produce pseudo-GT. This is due to the fact that single label classification task does not need to attend to all object regions. Instead, classification task drives the model to focus on the discriminative object parts. To address this issue, we propose a contrastive learning based patch-wise classification on the image patches as shown in Fig. 5. Patch-wise learning drives 3SD to capture local structures that constitute the object. Fig. 4 (b)-(e) show CAM map comparison between different classification tasks. Finally, by guiding the CAM map with the edge information of the input image, we obtain high-quality pseudo-GT (). This pseudo-GT is taken as the training labels to update the parameters of the 3SD network.
3.2.1 Self-supervised classification.
Student-teacher based knowledge distillation is a well-known learning paradigm that is commonly used for self-supervised classification tasks. As shown in Fig. 4, self-supervised classification task as done in [3] fails to produce high quality pseudo-GTs. This is because image-wise self-supervised classification with one global class only requires a few important activations in the salient object, leading to incomplete saliency map. To overcome this hurdle, our proposed self-supervised classification contains (i) global level self-supervision using loss, and (ii) patch-wise contrastive learning based self-supervision using loss.

In our 3SD, student and teacher networks share the same architecture as the BN, and we denote student and teacher networks as and , respectively with and as their corresponding parameters. Given an input image, we compute class logits maps and for both networks, as well as their corresponding softmax probability output and . Meanwhile, we obtain image wise class logits for student model: , where is patch in the image. Similar expression holds for the teacher’s logits . Given a fixed teacher network , we match the image-level class probability distribution and by minimizing the cross-entropy loss to update the parameters of the student network :
| (1) |
where . Note that is used to update the student network’s parameters with stochastic gradient descent. The teacher weights are updated using exponential moving average (EMA) update rule as in [3, 13], i.e., , with following a cosine schedule from 0.996 to 1 during training. Additionally, in order to improve quality of CAM maps we perform patchwise contrastive learning for the classification task, where we identify the top positive patches (patches similar to salient object) and negative patches (patches dissimilar to salient object) from and . Using these positive and negative pairs we construct the following contrastive learning [5] based loss,
| (2) |
where and are the set of positive and negative patches from respectively, and and are the set of positive and negative patches from respectively. Concretely, and are extracted from by comparing with using normalized dot product. Similarly, and are obtained from . From Fig. 4, we can observe that addition of loss drives the student network to extract class-sensitive local features across the whole object region, which results in better quality CAM maps.
In summary, the following steps are performed in self-supervised classification task to learn student network weights: (i) Augment the image with two different augmentations and randomly crop the images to obtain (local crop or smaller resolution) and (global crop or smaller resolution) as shown in Fig. 5. (ii) Fix the teacher network’s parameters. (iii) Pass as input to the student network and as input to the teacher network, to obtain output class logits maps and , respectively. (iv) Match the outputs by minimizing the loss and update the student network’s parameters . (v) Additionally, we extract positive and negative patches from and , and update the student network’s parameters using . (v) Finally, employ the EMA update rule to update the teacher network’s parameters . Fig. 5 shows the overview diagram of these steps in updating the student network’s parameters.
3.2.2 Pseudo-GT
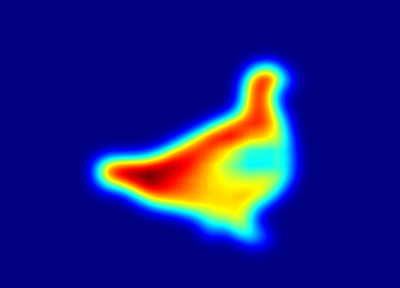
When 3SD is trained with self-supervised classification, features from classification decoder explicitly contain the structural or semantic information of the salient object in the image. Hence, we compute CAM (using technique from [55]) to obtain this semantic information of the salient object. We can clearly observe in Fig. 6 (c) and (d), that the obtained CAM map doesn’t depict a proper or sharp boundary. To overcome this problem, we compute edge map using the RCF edge detection network [26]. Then we dilate the thresholded CAM map and gate the edge map to obtain the edges of the salient objects. This design effectively removes the background edges. Pseudo-GT () is then defined as the union of the gated edge map and the CAM map, i.e., , where is the CAM map and is the gated edge. Fig. 6 (g) and (h) show the pseudo-GT () and the thresholded version of the pseudo-GT () (with threshold 0.5). We compute cross-entropy between the pseudo-GT () and the salient object prediction output of 3SD,
|
|
(3) |
where are pixel coordinates, and are height and width of the image. We minimize and update the 3SD parameters to perform SOD.




(a) (b) (c) (d)




(e) (f) (g) (h)
3.3 Loss
To improve the boundary estimation for SOD, we further introduce the gated structure-aware loss () proposed by [49]. Gated structure-aware () is defined as follows,
| (4) |
where , are pixel coordinates, are horizontal and vertical directions, is derivative operation, and is the gate for the structure loss (see Fig. 6(e)).
The overall loss function used for training the 3SD network is defined as follows,
| (5) |
We set in all our experiments.
4 Experiments and results
In this section, we present the details of various experiments conducted on six benchmarks to demonstrate the effectiveness of the proposed 3SD method. Additionally, we perform extensive ablation studies which shows the factors and parameters that influence the performance of the proposed 3SD method.
4.1 Datasets
Training dataset: We use images from the DUTS-TR dataset which is the training dataset of DUTS [38]. Note that we only use the images to train 3SD, i.e., we don’t use the corresponding salient object annotations. The DUTS-TR dataset contains 10,553 images, and it is the largest and most commonly used dataset for training SOD.
Evaluation datasets: We evaluate the performance of 3SD on six benchmark test datasets: (i) The DUTS-TE testing dataset (5,019 images) [38], (ii) DUT-OMRON (5,168 test images) [45], (iii) HKU-IS [22] (4,447 test images), (iv) PASCAL-S [23] (850 test images), (v) ECSSD [44] (1,000 images), and (vi) THUR [6] (6,233 images).
4.2 Comparison methods and metrics
We compare the performance of 3SD with seven SOTA weakly/unsupervised methods [47, 21, 50, 46, 49, 48], and eleven SOTA fully-supervised methods [52, 29, 39, 24, 54, 41, 42, 12, 34, 33, 40]. We use the following five evaluation metrics for comparison: structure measure [10] (), saliency structure measure [49] (), mean F-score (), mean E-measure[11] (), and mean absolute error (). Additionally, we plot precision vs. recall curves to show the effectiveness of our 3SD method.
4.3 Implementation Details
Given a training image, we randomly crop pixels and use it for training 3SD. As explained in the earlier sections, we perform patch-wise contrastive learning based self-supervised classification without labels. Specifically, we learn the teacher centers ( dimension vector) to sharpen the teacher’s output before computing . Here, we sharpen the teachers output class logits map with as shown in Fig 5 ( i.e. ). In all of our experiments, we perform patch-wise self-supervised classification in our 3SD method. For augmentations, we use the augmentations of BYOL [13] (Gaussian blur solarization, and color jittering) and multi-crop [2] with bi-cubic interpolation to resize the crop. In our 3SD method, the student and teacher networks share the same architecture as BN with different weights. Initially, we train the student and teacher networks for self-supervised classification as explained in section 3.2 for 30 epochs. Later, we perform patch-wise self-supervised classification and pseudo-GT based salient object detection in an iterative manner as explained in the algorithm provided in the supplementary document. We set as 10 for all our experiments. We train 3SD for 150 epochs using a stochastic gradient descent optimizer with batch-size 8 and learning rate 0.001. Following DUTS [38], we set classes in all of our experiments. The student network () in 3SD is used for all evaluations during inference. Algorithm 1 shows steps involved in training our 3SD method.
4.4 Comparisons
Quantitative results: As shown in Table 1, our 3SD method consistently outperforms the SOTA weakly/unsupervised methods on all datasets and in all metrics. This shows training with our pseudo-GT generation is superior to the existing weakly/unsupervised SOD techniques. Moreover, although 3SD is not trained with any human annotations or weak labels (e.g. image captions, handcrafted features, or scribble annotations), its performance is on par with fully-supervised methods. In some cases the performance of 3SD is even better than some fully-supervised methods like [29, 24, 54]. Similar behaviors can be observed in the precision vs. recall curves shown in Fig. 8. Curves corresponding to our method are close to the SOTA fully-supervised methods, while the curves corresponding to the SOTA weakly/unsupervised methods are far below our 3SD method.
Qualitative results: Fig. 7 illustrates the qualitative comparisons of our 3SD method with SOTA methods on 4 sample images from DUTS-TE, DUT-OMRON, HKU-IS, and ECSSD. It can be seen that the outputs of [47, 46, 49, 48] are blurred or incomplete, and include parts of non-salient objects. In contrast, 3SD outputs are accurate, clear, and sharp. For example, output saliency maps of [47, 46, 49, 48] in the second row of Fig. 7 miss parts of legs for the horses. And, output saliency maps of [47, 46, 49, 48] in the third row of Fig. 7 contains artifacts or parts of non-salient objects. In contrast, saliency maps of our 3SD method delineate legs for the horses properly, and are free of artifacts. More qualitative comparisons are provided in the supplementary material.
| Fully supervised | Weakly supervised | Un-supervised | ||||||||||||||||||||
| Dataset | Metric | PiCANet[24] CVPR18 | MSNet[41] CVPR19 | CPD[42] CVPR19 | BASNet[34] CVPR19 | U2Net[33] PR2020 | LDF[40] CVPR20 |
|
BN (ours) | WSS[38] CVPR17 | WSI[21] AAAI18 |
|
Scrible_S[49] CVPR20 | MFNet[32] ICCV21 | SBF[47] ICCV17 | MNL[50] CVPR18 | EDNS[48] ECCV20 | 3SD (ours) | ||||
| 0.851 | 0.851 | 0.867 | 0.866 | 0.861 | 0.881 | 0.885 | 0.883 | 0.748 | 0.697 | 0.759 | 0.793 | 0.775 | 0.739 | 0.813 | 0.828 | \ul0.844 | ||||||
| 0.635 | 0.582 | 0.462 | 0.400 | 0.365 | 0.384 | 0.347 | 0.358 | 0.780 | 0.879 | 0.829 | 0.603 | 0.610 | 0.808 | 0.712 | 0.628 | \ul0.443 | ||||||
| 0.757 | 0.792 | 0.8246 | 0.823 | 0.804 | 0.855 | 0.870 | 0.829 | 0.633 | 0.569 | 0.648 | 0.746 | 0.770 | 0.622 | 0.725 | 0.747 | \ul0.765 | ||||||
| 0.853 | 0.883 | 0.902 | 0.896 | 0.897 | 0.910 | 0.939 | 0.913 | 0.806 | 0.690 | 0.742 | 0.865 | 0.839 | 0.763 | 0.853 | 0.859 | \ul0.875 | ||||||
| DUTS-TE | 0.062 | 0.050 | 0.043 | 0.048 | 0.044 | 0.034 | 0.037 | 0.036 | 0.100 | 0.116 | 0.091 | 0.062 | 0.076 | 0.107 | 0.075 | 0.060 | \ul0.044 | |||||
| 0.826 | 0.809 | 0.818 | 0.836 | 0.842 | 0.847 | 0.839 | 0.843 | 0.730 | 0.759 | 0.756 | 0.771 | 0.742 | 0.731 | 0.733 | 0.791 | \ul0.803 | ||||||
| 0.685 | 0.642 | 0.549 | 0.480 | 0.438 | 0.432 | 0.455 | 0.429 | 0.830 | 0.839 | 0.890 | 0.655 | 0.658 | 0.812 | 0.776 | 0.689 | \ul0.501 | ||||||
| 0.710 | 0.709 | 0.739 | 0.767 | 0.757 | 0.773 | 0.800 | 0.777 | 0.590 | 0.641 | 0.597 | 0.702 | 0.646 | 0.612 | 0.597 | 0.701 | \ul0.735 | ||||||
| 0.823 | 0.830 | 0.845 | 0.865 | 0.867 | 0.873 | 0.883 | 0.869 | 0.729 | 0.761 | 0.728 | 0.835 | 0.803 | 0.763 | 0.712 | 0.816 | \ul0.845 | ||||||
| DUT-OMRON | 0.072 | 0.064 | 0.057 | 0.057 | 0.054 | 0.051 | 0.058 | 0.049 | 0.110 | 0.100 | 0.109 | 0.068 | 0.087 | 0.108 | 0.103 | 0.070 | \ul0.660 | |||||
| 0.906 | 0.907 | 0.904 | 0.909 | 0.916 | 0.919 | 0.919 | 0.918 | 0.822 | 0.808 | 0.818 | 0.855 | 0.846 | 0.812 | 0.860 | 0.890 | \ul0.904 | ||||||
| 0.561 | 0.498 | 0.421 | 0.359 | 0.325 | 0.337 | 0.338 | 0.321 | 0.752 | 0.782 | 0.830 | 0.537 | 0.522 | 0.734 | 0.627 | 0.567 | \ul0.381 | ||||||
| 0.854 | 0.878 | 0.895 | 0.903 | 0.890 | 0.914 | 0.922 | 0.918 | 0.773 | 0.763 | 0.734 | 0.857 | 0.851 | 0.783 | 0.820 | 0.878 | \ul0.885 | ||||||
| 0.909 | 0.930 | 0.940 | 0.943 | 0.945 | 0.954 | 0.962 | 0.959 | 0.819 | 0.800 | 0.786 | 0.923 | 0.921 | 0.855 | 0.858 | 0.919 | \ul0.935 | ||||||
| HKU-IS | 0.047 | 0.039 | 0.033 | 0.032 | 0.031 | 0.027 | 0.030 | 0.024 | 0.079 | 0.089 | 0.084 | 0.047 | 0.059 | 0.075 | 0.065 | 0.043 | \ul0.039 | |||||
| 0.848 | 0.844 | 0.848 | 0.838 | 0.844 | 0.851 | 0.863 | 0.856 | - | - | 0.697 | 0.742 | 0.770 | 0.712 | 0.728 | 0.750 | \ul0.761 | ||||||
| 0.704 | 0.671 | 0.616 | 0.582 | 0.513 | 0.512 | 0.504 | 0.509 | 0.831 | 0.855 | 0.870 | 0.665 | 0.679 | 0.815 | 0.776 | 0.739 | \ul0.531 | ||||||
| 0.799 | 0.813 | 0.822 | 0.821 | 0.797 | 0.848 | 0.829 | 0.832 | 0.698 | 0.653 | 0.685 | 0.788 | 0.751 | 0.735 | 0.748 | 0.759 | \ul0.763 | ||||||
| 0.804 | 0.822 | 0.819 | 0.821 | 0.831 | 0.865 | 0.865 | 0.849 | 0.690 | 0.647 | 0.693 | 0.798 | 0.817 | 0.746 | 0.741 | 0.794 | \ul0.810 | ||||||
| PASCAL | 0.129 | 0.119 | 0.122 | 0.122 | 0.074 | 0.060 | 0.067 | 0.068 | 0.184 | 0.206 | 0.178 | 0.140 | 0.115 | 0.167 | 0.158 | 0.142 | \ul0.137 | |||||
| 0.867 | 0.905 | 0.905 | 0.910 | 0.918 | 0.912 | 0.917 | 0.924 | 0.808 | 0.805 | 0.825 | 0.854 | 0.834 | 0.813 | 0.845 | 0.860 | 0.883 | ||||||
| 0.592 | 0.542 | 0.434 | 0.364 | 0.321 | 0.323 | 0.348 | 0.319 | 0.808 | 0.801 | 0.851 | 0.550 | 0.581 | 0.759 | 0.681 | 0.600 | \ul0.387 | ||||||
| 0.871 | 0.885 | 0.907 | 0.913 | 0.910 | 0.930 | 0.929 | 0.933 | 0.767 | 0.762 | 0.761 | 0.865 | 0.854 | 0.782 | 0.810 | 0.852 | \ul0.887 | ||||||
| 0.909 | 0.922 | 0.932 | 0.938 | 0.936 | 0.925 | 0.945 | 0.940 | 0.796 | 0.792 | 0.787 | 0.908 | 0.885 | 0.835 | 0.836 | 0.883 | \ul0.928 | ||||||
| ECSSD | 0.054 | 0.048 | 0.043 | 0.040 | 0.033 | 0.034 | 0.034 | 0.032 | 0.108 | 0.068 | 0.098 | 0.061 | 0.084 | 0.096 | 0.090 | 0.071 | \ul0.049 | |||||
| - | 0.819 | 0.831 | 0.823 | 0.828 | 0.847 | - | 0.852 | 0.775 | - | - | 0.794 | - | 0.762 | 0.804 | 0.810 | \ul0.827 | ||||||
| 0.659 | 0.620 | 0.525 | 0.489 | 0.531 | 0.469 | - | 0.464 | 0.788 | - | - | 0.596 | - | 0.785 | 0.717 | 0.656 | \ul0.487 | ||||||
| 0.710 | 0.718 | 0.750 | 0.737 | 0.749 | 0.764 | - | 0.769 | 0.653 | - | - | 0.718 | - | 0.627 | 0.691 | 0.719 | \ul0.746 | ||||||
| 0.821 | 0.829 | 0.851 | 0.841 | 0.843 | 0.842 | - | 0.846 | 0.775 | - | - | 0.837 | - | 0.770 | 0.807 | 0.838 | \ul0.840 | ||||||
| THUR | 0.084 | 0.079 | 0.094 | 0.073 | 0.075 | 0.064 | - | 0.061 | 0.097 | - | - | 0.077 | - | 0.107 | 0.086 | 0.070 | \ul0.064 | |||||
| Parameters | Size in MB | 197 | - | 183 | 349 | 176 | 98 | 82 | 219 | 53 | - | 119 | 68 | 47 | 376 | 170 | - | 219 | ||||









































4.5 Ablation study
The goal of these ablation experiments is to analyze the components in the pseudo-GT generation that effect the performance of 3SD. We perform seven experiments, patch-wise contrastive learning based self-supervised classification experiments (PCL16: , PCL24: , PCL32: , PCL48: pixels), self-supervised classification with one global class label (GCL), PCM: generating pseudo-GT without using the edge map (using CM as ), PGE: generating pseudo-GT without using the CAM map CM (using as ), CMG: training 3SD with the pseudo-GT () and without .
Impact of patch-wise contrastive learning based self-supervised classification: As can be seen from Table 2, PG (global class wise classification) fails to produce proper CAM maps (see Fig. 4) which results in lower performance when compared to patch-wise contrastive learning based self-supervised classification with patch-size PCL16, PCL24, PCL32, PCL40 ( respectively). From Table 2 and Fig. 4, it is evident that when we increase the patch size in patch-wise self-supervised classification from to , we obtain better quality CAM maps which in turn results in better pseudo-GT and as a result better SOD performance. We obtained the best performance using setting of . Note that, larger patch doesn’t improve the performance of 3SD method.
Impact of Pseudo-GT: As explained in the section 3.2, pseudo-GT is defined as . Here we perform experiments to validate the important role played by CAM () map and gated edge () in the construction of the pseudo-GT. From Table 2 columns PCM and PGE, we can clearly observe a huge improvement in performance when we use as the pseudo-GT instead of . This shows that obtained from patch-wise self-supervised classification contains more consistent semantic information than gated edge (). Furthermore in the LPG column of Table 2, the combination of both and brings in further increase of the performance. The PCL32 column in Table 2 corresponds to the case where we train 3SD with the pseudo-GT (), with additional boundary aware loss (). In this case, we found a small improvement in the performance. Results corresponding to this ablation experiments are also shown in a bar-graph in Fig. 9.
BaseNetwork (BN): We perform three experiments to evaluate the effectiveness of the constructed Base Network (BN). We use the following definitions in this experiment: 1) B0: BN with one encoder (local encoder ) and one decoder(saliency decoder ). 2) B1: BN with two encoders( and ), and one decoder() (adding global encoder () to BN). 3) B2: Using two encoders and two decoders (adding classification decoder to BN), as shown in Fig. 3. For this experiment, B0, B1, B2 methods are trained in supervised fashion using the actual ground-truth labels with cross-entropy loss. As can be seen from Table 2, we obtain an improvement when we add transformer based global encoder () to BN (B1 in Table 2). This implies that is efficient in capturing patch-wise relations to obtain better saliency maps. Furthermore, adding a classification decoder improves BN’s performance (B2 in Table 2).

| Self or Unsupervised |
|
|||||||||||||
| Dataset | Metrics | PCL16 | PCL24 | PCL32 | PCL48 | GCL | PCM | PGE | LPG | B0 | B1 | B2 | ||
| 0.832 | 0.841 | 0.844 | 0.842 | 0.804 | 0.791 | 0.712 | 0.828 | 0.836 | 0.861 | 0.883 | ||||
| 0.451 | 0.438 | 0.443 | 0.432 | 0.463 | 0.621 | 0.658 | 0.501 | 0.368 | 0.364 | 0.358 | ||||
| 0.759 | 0.762 | 0.765 | 0.760 | 0.748 | 0.738 | 0.652 | 0.756 | 0.798 | 0.807 | 0.829 | ||||
| 0.866 | 0.874 | 0.875 | 0.869 | 0.844 | 0.832 | 0.740 | 0.858 | 0.884 | 0.897 | 0.913 | ||||
| DUTS-TE | 0.047 | 0.044 | 0.044 | 0.052 | 0.058 | 0.072 | 0.119 | 0.052 | 0.052 | 0.046 | 0.036 | |||
| 0.792 | 0.796 | 0.803 | 0.795 | 0.782 | 0.767 | 0.672 | 0.783 | 0.828 | 0.832 | 0.843 | ||||
| 0.504 | 0.501 | 0.501 | 0.508 | 0.511 | 0.701 | 0.687 | 0.518 | 0.460 | 0.451 | 0.429 | ||||
| 0.726 | 0.738 | 0.735 | 0.732 | 0.715 | 0.691 | 0.614 | 0.718 | 0.747 | 0.756 | 0.777 | ||||
| 0.832 | 0.838 | 0.845 | 0.840 | 0.826 | 0.810 | 0.731 | 0.817 | 0.854 | 0.859 | 0.869 | ||||
| DUT-OMRON | 0.062 | 0.062 | 0.060 | 0.062 | 0.070 | 0.077 | 0.130 | 0.063 | 0.060 | 0.054 | 0.049 | |||
| 0.878 | 0.881 | 0.883 | 0.879 | 0.869 | 0.852 | 0.770 | 0.876 | 0.895 | 0.905 | 0.924 | ||||
| 0.395 | 0.389 | 0.387 | 0.391 | 0.410 | 0.590 | 0.662 | 0.400 | 0.346 | 0.332 | 0.319 | ||||
| 0.881 | 0.891 | 0.897 | 0.894 | 0.873 | 0.843 | 0.756 | 0.892 | 0.891 | 0.905 | 0.933 | ||||
| 0.921 | 0.926 | 0.928 | 0.928 | 0.904 | 0.869 | 0.854 | 0.922 | 0.929 | 0.934 | 0.940 | ||||
| ECSSD | 0.050 | 0.049 | 0.049 | 0.049 | 0.052 | 0.077 | 0.128 | 0.049 | 0.047 | 0.043 | 0.032 | |||
| 0.862 | 0.891 | 0.904 | 0.896 | 0.863 | 0.841 | 0.747 | 0.892 | 0.890 | 0.902 | 0.918 | ||||
| 0.389 | 0.384 | 0.381 | 0.383 | 0.394 | 0.543 | 0.657 | 0.397 | 0.354 | 0.338 | 0.321 | ||||
| 0.864 | 0.881 | 0.885 | 0.883 | 0.859 | 0.849 | 0.734 | 0.878 | 0.893 | 0.903 | 0.918 | ||||
| 0.920 | 0.928 | 0.935 | 0.932 | 0.916 | 0.901 | 0.829 | 0.931 | 0.941 | 0.946 | 0.959 | ||||
| HKU-IS | 0.042 | 0.038 | 0.039 | 0.040 | 0.048 | 0.055 | 0.125 | 0.040 | 0.035 | 0.031 | 0.024 | |||
5 Conclusion
We presented a Self-Supervised Saliency Detection method (3SD), which doesn’t require any labels, i.e., neither human annotations nor weak labels like image captions, handcrafted features or scribble annotations. The cornerstone of successful self-supervised SOD approach is generation of high-quality of pseudo-GTs. Our novel patch-wise contrastive learning paradigm effectively captures the semantics of salient objects. And this is the key of our superior performance verified on six benchmarks.
References
- [1] Brendel, W., Bethge, M.: Approximating cnns with bag-of-local-features models works surprisingly well on imagenet. arXiv preprint arXiv:1904.00760 (2019)
- [2] Caron, M., Misra, I., Mairal, J., Goyal, P., Bojanowski, P., Joulin, A.: Unsupervised learning of visual features by contrasting cluster assignments. arXiv preprint arXiv:2006.09882 (2020)
- [3] Caron, M., Touvron, H., Misra, I., Jégou, H., Mairal, J., Bojanowski, P., Joulin, A.: Emerging properties in self-supervised vision transformers. arXiv preprint arXiv:2104.14294 (2021)
- [4] Chen, L.C., Papandreou, G., Kokkinos, I., Murphy, K., Yuille, A.L.: Deeplab: Semantic image segmentation with deep convolutional nets, atrous convolution, and fully connected crfs. TPAMI 40(4), 834–848 (2017)
- [5] Chen, T., Kornblith, S., Norouzi, M., Hinton, G.: A simple framework for contrastive learning of visual representations. In: ICML. pp. 1597–1607. PMLR (2020)
- [6] Cheng, M.M., Mitra, N.J., Huang, X., Hu, S.M.: Salientshape: group saliency in image collections. The visual computer 30(4), 443–453 (2014)
- [7] Dai, J., He, K., Sun, J.: Boxsup: Exploiting bounding boxes to supervise convolutional networks for semantic segmentation. In: ICCV. pp. 1635–1643 (2015)
- [8] Dosovitskiy, A., Beyer, L., Kolesnikov, A., Weissenborn, D., Zhai, X., Unterthiner, T., Dehghani, M., Minderer, M., Heigold, G., Gelly, S., et al.: An image is worth 16x16 words: Transformers for image recognition at scale. arXiv preprint arXiv:2010.11929 (2020)
- [9] Dosovitskiy, A., Fischer, P., Springenberg, J.T., Riedmiller, M., Brox, T.: Discriminative unsupervised feature learning with exemplar convolutional neural networks. TPAMI 38(9), 1734–1747 (2015)
- [10] Fan, D.P., Cheng, M.M., Liu, Y., Li, T., Borji, A.: Structure-measure: A new way to evaluate foreground maps. In: ICCV. pp. 4548–4557 (2017)
- [11] Fan, D.P., Gong, C., Cao, Y., Ren, B., Cheng, M.M., Borji, A.: Enhanced-alignment measure for binary foreground map evaluation. arXiv preprint arXiv:1805.10421 (2018)
- [12] Feng, M., Lu, H., Ding, E.: Attentive feedback network for boundary-aware salient object detection. In: CVPR. pp. 1623–1632 (2019)
- [13] Grill, J.B., Strub, F., Altché, F., Tallec, C., Richemond, P.H., Buchatskaya, E., Doersch, C., Pires, B.A., Guo, Z.D., Azar, M.G., Piot, B., Kavukcuoglu, K., Munos, R., Valko, M.: Bootstrap your own latent: A new approach to self-supervised learning. NIPS (2020)
- [14] Gutmann, M., Hyvärinen, A.: Noise-contrastive estimation: A new estimation principle for unnormalized statistical models. In: Proceedings of the thirteenth international conference on artificial intelligence and statistics. pp. 297–304 (2010)
- [15] He, K., Fan, H., Wu, Y., Xie, S., Girshick, R.: Momentum contrast for unsupervised visual representation learning. In: CVPR. pp. 9729–9738 (2020)
- [16] Henaff, O.: Data-efficient image recognition with contrastive predictive coding. In: ICML. pp. 4182–4192. PMLR (2020)
- [17] Hermans, A., Beyer, L., Leibe, B.: In defense of the triplet loss for person re-identification. arXiv preprint arXiv:1703.07737 (2017)
- [18] Hsu12, K.J., Lin, Y.Y., Chuang, Y.Y.: Weakly supervised saliency detection with a category-driven map generator. BMVC (2017)
- [19] Khoreva, A., Benenson, R., Hosang, J., Hein, M., Schiele, B.: Simple does it: Weakly supervised instance and semantic segmentation. In: CVPR. pp. 876–885 (2017)
- [20] Kim, J., Han, D., Tai, Y.W., Kim, J.: Salient region detection via high-dimensional color transform. In: CVPR. pp. 883–890 (2014)
- [21] Li, G., Xie, Y., Lin, L.: Weakly supervised salient object detection using image labels. In: AAAI. pp. 7024–7031 (2018)
- [22] Li, G., Yu, Y.: Visual saliency based on multiscale deep features. In: CVPR. pp. 5455–5463 (2015)
- [23] Li, Y., Hou, X., Koch, C., Rehg, J.M., Yuille, A.L.: The secrets of salient object segmentation. In: CVPR. pp. 280–287 (2014)
- [24] Liu, N., Han, J., Yang, M.H.: Picanet: Learning pixel-wise contextual attention for saliency detection. In: CVPR. pp. 3089–3098 (2018)
- [25] Liu, N., Zhang, N., Wan, K., Shao, L., Han, J.: Visual saliency transformer. In: CVPR. pp. 4722–4732 (2021)
- [26] Liu, Y., Cheng, M.M., Hu, X., Wang, K., Bai, X.: Richer convolutional features for edge detection. In: CVPR. pp. 3000–3009 (2017)
- [27] Long, J., Shelhamer, E., Darrell, T.: Fully convolutional networks for semantic segmentation. In: CVPR. pp. 3431–3440 (2015)
- [28] Lu, S., Tan, C., Lim, J.H.: Robust and efficient saliency modeling from image co-occurrence histograms. TPAMI 36(1), 195–201 (2013)
- [29] Luo, Z., Mishra, A., Achkar, A., Eichel, J., Li, S., Jodoin, P.M.: Non-local deep features for salient object detection. In: CVPR. pp. 6609–6617 (2017)
- [30] Nguyen, D.T., Dax, M., Mummadi, C.K., Ngo, T.P.N., Nguyen, T.H.P., Lou, Z., Brox, T.: Deepusps: Deep robust unsupervised saliency prediction with self-supervision. arXiv preprint arXiv:1909.13055 (2019)
- [31] Obukhov, A., Georgoulis, S., Dai, D., Van Gool, L.: Gated crf loss for weakly supervised semantic image segmentation. arXiv preprint arXiv:1906.04651 (2019)
- [32] Piao, Y., Wang, J., Zhang, M., Lu, H.: Mfnet: Multi-filter directive network for weakly supervised salient object detection. In: ICCV. pp. 4136–4145 (October 2021)
- [33] Qin, X., Zhang, Z., Huang, C., Dehghan, M., Zaiane, O.R., Jagersand, M.: U2-net: Going deeper with nested u-structure for salient object detection. Pattern Recognition 106, 107404 (2020)
- [34] Qin, X., Zhang, Z., Huang, C., Gao, C., Dehghan, M., Jagersand, M.: Basnet: Boundary-aware salient object detection. In: CVPR. pp. 7479–7489 (June 2019)
- [35] Sohn, K.: Improved deep metric learning with multi-class n-pair loss objective. NIPS 29 (2016)
- [36] Tarvainen, A., Valpola, H.: Mean teachers are better role models: Weight-averaged consistency targets improve semi-supervised deep learning results. arXiv preprint arXiv:1703.01780 (2017)
- [37] Tian, Y., Krishnan, D., Isola, P.: Contrastive multiview coding. In: ECCV. pp. 776–794. Springer (2020)
- [38] Wang, L., Lu, H., Wang, Y., Feng, M., Wang, D., Yin, B., Ruan, X.: Learning to detect salient objects with image-level supervision. In: CVPR. pp. 136–145 (2017)
- [39] Wang, T., Zhang, L., Wang, S., Lu, H., Yang, G., Ruan, X., Borji, A.: Detect globally, refine locally: A novel approach to saliency detection. In: CVPR. pp. 3127–3135 (2018)
- [40] Wei, J., Wang, S., Wu, Z., Su, C., Huang, Q., Tian, Q.: Label decoupling framework for salient object detection. In: CVPR. pp. 13022–13031 (June 2020)
- [41] Wu, R., Feng, M., Guan, W., Wang, D., Lu, H., Ding, E.: A mutual learning method for salient object detection with intertwined multi-supervision. In: CVPR. pp. 8150–8159 (2019)
- [42] Wu, Z., Su, L., Huang, Q.: Cascaded partial decoder for fast and accurate salient object detection. In: CVPR. pp. 3907–3916 (2019)
- [43] Wu, Z., Xiong, Y., Yu, S.X., Lin, D.: Unsupervised feature learning via non-parametric instance discrimination. In: CVPR. pp. 3733–3742 (2018)
- [44] Yan, Q., Xu, L., Shi, J., Jia, J.: Hierarchical saliency detection. In: CVPR. pp. 1155–1162 (2013)
- [45] Yang, C., Zhang, L., Lu, H., Ruan, X., Yang, M.H.: Saliency detection via graph-based manifold ranking. In: CVPR. pp. 3166–3173 (2013)
- [46] Zeng, Y., Zhuge, Y., Lu, H., Zhang, L., Qian, M., Yu, Y.: Multi-source weak supervision for saliency detection. In: CVPR. pp. 6074–6083 (2019)
- [47] Zhang, D., Han, J., Zhang, Y.: Supervision by fusion: Towards unsupervised learning of deep salient object detector. In: ICCV. pp. 4048–4056 (2017)
- [48] Zhang, J., Xie, J., Barnes, N.: Learning noise-aware encoder-decoder from noisy labels by alternating back-propagation for saliency detection. In: ECCV. pp. 349–366. Springer (2020)
- [49] Zhang, J., Yu, X., Li, A., Song, P., Liu, B., Dai, Y.: Weakly-supervised salient object detection via scribble annotations. In: CVPR. pp. 12546–12555 (2020)
- [50] Zhang, J., Zhang, T., Dai, Y., Harandi, M., Hartley, R.: Deep unsupervised saliency detection: A multiple noisy labeling perspective. In: CVPR. pp. 9029–9038 (2018)
- [51] Zhang, J., Ehinger, K.A., Wei, H., Zhang, K., Yang, J.: A novel graph-based optimization framework for salient object detection. Pattern Recognition 64, 39–50 (2017)
- [52] Zhang, P., Wang, D., Lu, H., Wang, H., Yin, B.: Learning uncertain convolutional features for accurate saliency detection. In: ICCV. pp. 212–221 (2017)
- [53] Zhang, Q., Huo, Z., Liu, Y., Pan, Y., Shan, C., Han, J.: Salient object detection employing a local tree-structured low-rank representation and foreground consistency. Pattern Recognition 92, 119–134 (2019)
- [54] Zhang, X., Wang, T., Qi, J., Lu, H., Wang, G.: Progressive attention guided recurrent network for salient object detection. In: CVPR. pp. 714–722 (2018)
- [55] Zhou, B., Khosla, A., Lapedriza, A., Oliva, A., Torralba, A.: Learning deep features for discriminative localization. In: CVPR. pp. 2921–2929 (2016)
- [56] Zhu, W., Liang, S., Wei, Y., Sun, J.: Saliency optimization from robust background detection. In: CVPR. pp. 2814–2821 (2014)