3DAttGAN: A 3D Attention-based Generative Adversarial Network for Joint Space-Time Video Super-Resolution
Abstract
In many applications, including surveillance, entertainment, and restoration, there is a need to increase both the spatial resolution and the frame rate of a video sequence. The aim is to improve visual quality, refine details, and create a more realistic viewing experience. Existing space-time video super-resolution methods do not effectively use spatio-temporal information. To address this limitation, we propose a generative adversarial network for joint space-time video super-resolution. The generative network consists of three operations: shallow feature extraction, deep feature extraction, and reconstruction. It uses three-dimensional (3D) convolutions to process temporal and spatial information simultaneously and includes a novel 3D attention mechanism to extract the most important channel and spatial information. The discriminative network uses a two-branch structure to handle details and motion information, making the generated results more accurate. Experimental results on the Vid4, Vimeo-90K, and REDS datasets demonstrate the effectiveness of the proposed method. The source code is publicly available at https://github.com/FCongRui/3DAttGan.git.
Index Terms:
video space-time super-resolution, generative adversarial network, 3D attention mechanism, quality enhancement.I Introduction
Video super resolution (VSR) aims at estimating high-resolution (HR) frames from low-resolution (LR) ones. VSR has many applications, including face recognition [1], small object recognition [2], and 4K ultra-high-definition (UHD) video [3]. Usually, VSR refers to spatial super-resolution (SSR). The aim is to generate an HR video sequence from a corresponding LR video sequence. To achieve SSR, two main types of methods are used: model-based methods and learning-based methods. In model-based SSR methods, e.g., [4, 5, 6, 7], the LR frames are modeled as blurred and downsampled versions of the HR frames. Using this model, it is possible to estimate the HR frames with an inverse calculation. However, as the SSR problem is ill posed, regularization techniques are necessary to effectively reconstruct the HR frames. To incorporate specific image features into the HR estimate, prior information is often used. For instance, in the Bayesian framework, the SSR problem can be statistically modeled and regularized with the integration of smoothness and sparsity priors. In contrast to model-based schemes, learning-based schemes such as deep neural networks (DNNs) do not derive an analytical SSR model. Instead, they leverage large training datasets containing both HR and LR videos to learn how to solve the VSR problem.
Besides SSR, there are two other kinds of VSR: temporal super-resolution (TSR) and space-time super-resolution (STSR). In TSR, a video frame is interpolated between existing video frames (Fig. 1(b)). On the other hand, in STSR, a video with high space-time resolution is generated from a given video with low space-time resolution (Fig. 1(c)). In this paper, we focus on STSR.

Existing STSR methods usually achieve spatial and temporal super-resolution independently by applying TSR and SSR alternately. This approach is not only time consuming but also inefficient as it is difficult to take advantage of the high temporal resolution if SSR is applied first and to take advantage of the high spatial resolution if TSR is applied first. A higher spatial representation can help improve motion estimation accuracy, which is important for TSR, while a higher temporal resolution can enhance the accuracy of SSR by capturing finer details in successive frames due to their similarity.
To harness the potential of the spatial and temporal features for VSR, we propose a generative adversarial neural network (GAN) with a 3D attention mechanism that simultaneously generates high-spatial-resolution and high-frame-rate video frames from low-spatial-resolution and low-frame-rate input video frames.
We use 3D convolution operations to process temporal and spatial information simultaneously and extend the standard 2D attention mechanism to 3D to make it suitable for STSR. Our generative network consists of shallow feature extraction, deep feature extraction, and reconstruction. Multiple residual attention blocks with a 3D attention mechanism are superimposed to enhance the accuracy of spatial and temporal feature extraction. The discriminative network is used to distinguish between the outputs of STSR and real HR videos. It includes two branches; one evaluates details, and the other assesses temporal information using motion consistency analysis. The contributions of the paper can be summarized as follows.
-
We propose a novel generative adversarial network to simultaneously enhance the spatial and temporal resolution of input videos. Our network has less complexity than state-of-the-art STSR methods and outperforms them in areas of rich texture and high motion.
-
We propose a 3D attention mechanism that uses 3D convolutions to extract important temporal and spatial information simultaneously. Current STSR attention mechanisms are designed for 2D convolutional networks and cannot be directly applied to 3D convolutions due to inconsistent dimensions.
-
We design two discriminator strategies that significantly enhance the performance of the proposed generator. One strategy focuses on the spatial detail characteristics of video frames, while the other emphasizes the temporal motion information. This is the first time that a two-branch discriminator is proposed for video STSR.
The remainder of this paper is organized as follows. Section II gives an overview of learning-based VSR. Section III provides a detailed description of the proposed network. Experimental results, including an ablation study, are presented in Section IV. Finally, Section V provides a summary of the paper.
II Related work
II-A Video spatial super-resolution
Video SSR improves the quality of low-resolution videos by upscaling them to higher resolutions. The methods based on deep learning use external references to construct models while simultaneously approximating complex nonlinear functions. SRCNN [8], one of the pioneering convolutional neural networks (CNN), is a simple three-layer end-to-end model. Video SSR methods take advantage of the temporal correlations by merging spatial information over adjacent frames and estimate the inter-frame motion to obtain references. Unlike single image super-resolution, VSR can exploit motion information between consecutive frames to recover lost high-frequency details in the current frame.
Tian et al. [9] proposed a temporal deformable alignment network (TDAN) that can align the reference image and supporting frames without requiring optical flow estimation. Wang et al. [10] proposed a video super-resolution network, EDVR, that uses enhanced deformable convolutions. EDVR comprises a pyramid, cascading, and deformable (PCD) alignment module to effectively address the motions, as well as a temporal and spatial attention (TSA) fusion module that emphasizes crucial features for subsequent restoration. Chan et al. [11] proposed a concise pipeline for VSR called BasicVSR, which leverages bidirectional propagation to enhance information gathering, and uses a method based on optical flow to estimate the correspondence between adjacent frames for accurate feature alignment. Building on SRGAN [12], which uses a modified version of the VGG [13] network as the discriminator, ESRGAN [14] incorporates a residual-in-residual dense block and uses a relativistic average GAN (RaGAN) [15] to evaluate the authenticity of images. VSRResNet [16] relies on a discriminator architecture during GAN training and uses two regularizers: a feature-space loss and a pixel-space loss. For video super-resolution, temporally coherent GAN (TecoGAN) [17] was the first method to introduce a spatiotemporal discriminator that takes into account temporal and spatial coherence. TecoGAN is based on frame recurrent video super resolution (FRVSR) [18], which uses the HR estimate from the preceding frame for super-resolving the next frame. Wen et al. [19] proposed an end-to-end deep convolutional network for video super-resolution that dynamically generates spatially adaptive filters to improve temporal alignment. Yi et al. [20] introduced a progressive fusion network for video super-resolution that effectively fuses temporal information, incorporates multi-scale structures, hybrid convolutions, and non-local operations, improving both performance and complexity. Li et al. [21] presented a novel approach for efficient video resolution upscaling by leveraging spatial-temporal information to divide videos into chunks, reducing model size and storage requirements while achieving real-time video super-resolution with high quality. Qiu et al. [22] introduced Frequency-Transformer for Video Super-Resolution (FTVSR++). The method operates in a combined space-time-frequency domain, distinguishes real visual texture from artifacts, and incorporates dual frequency attention. Meng et al. [23] introduced an approach to enhance video super-resolution by leveraging similar patches across distant frames through long-term cross-scale aggregation. The method is adaptable as post-processing for any super-resolution technique.
II-B Video temporal super-resolution
Video TSR mitigates motion artifacts and reduces judder by interpolating frames between existing ones, proving valuable for slow-motion effects creation and enhancing overall video playback quality. Video TSR is similar to video frame interpolation (VFI). The objective is to predict one or multiple frames between two input frames. While traditional methods typically use dense optical flow interpolation, recent methods often use DNNs for middle frame prediction.
Liu et al.. [24] proposed a deep voxel flow (DVF) network, which combines the advantages of classic flow-based methods with those of learning-based methods. Bao et al. [25] introduced a network that uses an adaptive warping layer to process video data through a combination of optical flow-based warping and learned interpolation kernel-based sampling of input frames. Xue et al. [26] presented ToFlow, a tailored flow representation for video processing tasks, achieved through a neural network incorporating motion estimation and video processing components. Bao et al. [27] introduced a VFI approach that generates more realistic intermediate flows by prioritizing closer objects over distant ones using a depth-aware flow projection layer. The cycle consistency network proposed by Liu et al. [28] measures the quality of synthesized frames by evaluating their ability to reconstruct the input frames accurately, thus increasing their reliability. Park et al. [29] proposed a VFI method that identifies and exploits the position and strength of complicated motion to generate intermediate frames. Lee et al. [30] proposed a method called “adaptive collaboration of flows (AdaCoF)” that can generate a target pixel by referring to a variable number of pixels from any position. Kong et al. [31] introduced a Progressive Motion Context Refine Network for efficient frame interpolation. The network predicts motion fields and image context jointly, simplifying the task by reusing existing textures from adjacent input frames. It achieves favorable results with a reduced model size and running time. Liu et al. [32] proposed a novel trajectory-aware transformer for video frame interpolation. The method formulates the warped features with inconsistent motions as query tokens and uses relevant regions in a motion trajectory from two original consecutive frames as keys and values. Park et al. [33] introduced BiFormer, a 4K video frame interpolator, which uses a bilateral transformer to predict global motion fields, refines them using blockwise bilateral cost volumes, and synthesizes intermediate frames. Plack et al. [34] presented a novel transformer-based video frame interpolation network that estimates both the interpolated frame and its expected error. The method improves visual quality, provides error maps for identifying problematic frames, and supports partial rendering passes to enhance frame quality while reducing processing time. Zhu et al. [35] presented MFNet, a frame interpolation network that focuses on motion regions and uses methods such as adaptive motion region separation, fine-grained approximation of intermediate streams, and lightweight bi-directional optical stream fusion.
II-C Video space-time super-resolution
Video STSR enhances both spatial and temporal resolutions. Video STSR is a very challenging inverse problem as LR frames lack detailed texture and motion information. The common approach to STSR for videos is to alternate between SSR and TSR. However, this approach leads to excessive complexity. A better approach is to generate videos that have both HR and high-frame-rate simultaneously. However, existing methods do not fully exploit the temporal and spatial characteristics across video frames.
Shechtman et al. [36] proposed a method that creates an STSR video of a scene by combining information from a number of LR videos of the same scene. The method is based on modeling each LR video as a blurred version of the HR video in space and time. Mudenagudi et al. [37] formulated video STSR as a reconstruction problem in a Markov random field-maximum a posteriori framework and used graph-cut optimization to solve the problem. Takeda et al. [38] exploited MASK regression, a method that uses local spatial orientations and motion vectors to construct adaptive filters at every position of interest. Shahar et al. [39] combined information from multiple space-time patches to super resolve input videos. Haris et al. [40] developed a CNN that super-resolves video jointly in space and time, incorporating direct lateral connections between multiple resolutions to present multi-scale features during training. Kang et al. [41] proposed a weighting scheme for efficient video processing, where all input frames are fused without the need for explicit motion compensation. Dutta et al. [42] used quadratic modeling for LR interpolation and reused flowmaps and blending masks for both LR and HR synthesis. Xiang et al. [43] proposed a deformable feature interpolation network to capture local temporal characteristics when interpolating LR frame features. They also introduced a deformable ConvLSTM to align and gather time information, leading to improved utilization of global temporal contexts. Xu et al. [44] introduced a method that uses a temporal modulation block (TMB) to control feature interpolation and a locally-temporal feature comparison (LFC) module to capture time-based information in video processing. Zhang et al. [45] proposed cross-frame transformers instead of traditional convolutions divided the input feature sequence into query, key, and value matrices,along with a multi-level residual reconstruction module. This approach allows for the use of the maximum similarity and similarity coefficient matrices obtained though the cross-frame transformer.
III Proposed method
Given a low resolution video with frames, the STSR task is to generate the corresponding HR video frames with frames, where the superscripts “low” and “high” denote spatial resolutions.

The proposed 3D attention-based GAN (3DAttGAN) is shown in Fig. 2. The generative network consists of shallow feature extraction, deep feature extraction, and reconstruction. In the generative network, all the convolution operations are 3D convolutions. In the deep feature extraction module, a 3D attention mechanism is used to effectively capture temporal and spatial features. The discriminative network uses two criteria, one for the detail features and the other for the motion features, to accurately distinguish between STSR and HR.
III-A Proposed 3D Attention Mechanism
Attention has a significant impact on human perception [46, 47]. For example, humans can selectively focus on important visual features using partial glimpses for more efficient processing of visual structures [48]. The attention mechanism in a neural network is similar in essence to human visual attention, as it aims to select the most critical information for a given task from a vast amount of data.
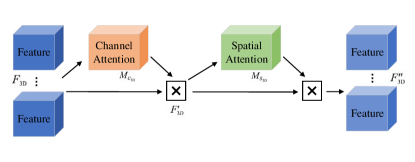
The convolutional block attention module (CBAM) [49] is a lightweight and effective module that can be directly applied to feed-forward convolutional neural networks. The module comprises two components: channel attention and spatial attention. CBAM generates attention maps on channel and spatial dimensions from the input feature map. It then uses these maps to adaptively refine the features via element-wise multiplication.
To fully exploit temporal and spatial information, we propose a 3D channel-spatial attention mechanism (3D CSA), as shown in Fig. 3. Traditional attention mechanisms are designed for 2D convolutional neural networks and cannot be directly applied to 3D convolutions due to inconsistent dimensions. 3D convolutional networks have a depth dimension, and changes in depth should be considered when extracting spatial and depth features.
For the features of an intermediate 3D convolution layer , 3D CSA deduces the channel attention feature map and the spatial attention feature map in sequence.
The 3D CSA channel attention module identifies the channels that play a significant role in the final results in the fused 3D network, i.e., it selects the key features for prediction. The process is illustrated in Fig. 4.

First, the input features are separately processed by maximum pooling and average pooling based on width , height and depth . The 3D convolutional features are computed by element-wise addition. Next, a sigmoid activation is applied. By multiplying the generated channel feature map with the input feature , the final channel feature is generated as
| (1) |
where and are 3D mean pooling and 3D maximum pooling operations, respectively, and is a sigmoid operation.
The 3D spatial attention model of 3D CSA focuses on the pixels in the image that have a significant impact in prediction. The attention feature extraction process is shown in Fig. 5. The spatial attention module takes the feature of the channel attention module as input and applies channel-based 3D maximum pooling and 3D average pooling operations. Next, the two extracted features are merged. Then, the dimension is reduced by the convolution operation, and the spatial attention feature map is generated through a sigmoid function. That is,
| (2) |
where denotes the convolution operation.

Finally, the output feature map and the input are multiplied pointwise to generate the final feature . The overall process can be expressed as
| (3) | ||||
where represents pointwise multiplication.
III-B Proposed Generative Adversarial Network
Generative adversarial networks (GANs) [50] are highly efficient models that can learn complex probability distributions from a given prior distribution. GANs were initially developed for the purpose of generating images [50]. Since then, GANs have been used for many generative tasks, including audio synthesis, 3D modeling, and image-to-image translation tasks. The exceptional generative capability of the GANs has been used to generate high-quality images for various reconstruction tasks, e.g., [51, 52, 53].
GANs and Variational Autoencoders (VAEs) are two commonly used generative models in image and video processing. GANs are better suited for tasks that demand extremely high-quality details, whereas VAEs are more suitable for tasks that emphasize stability and interpretability. GANs operate by training a generator and a discriminator network to produce high-quality images or videos. They excel in super-resolution tasks, yielding sharper images by capturing fine textures and structures. On the other hand, VAEs may produce blurry results in super-resolution tasks, as they tend to generate smoother images with less focus on details. VAEs typically impose higher quality requirements on input images or videos, potentially necessitating more training data and complex network architectures to achieve high-quality super-resolution results. Our objective is to obtain higher quality videos, including fine details and textures. Therefore, we have opted for GANs instead of VAEs.

Our goal is to improve the resolution of LR video frames. Fig. 6 shows the histogram distribution of various images. The distribution of the same image is roughly the same across different resolutions, while the distribution between different images varies widely. When we super-resolve a video, the SR video and the original video are in similar domains, which facilitates convergence of the neural network. In the proposed STSR task, GANs can automatically learn the data distribution through generative adversarial training, enabling the generation of content that closely matches the input data.
III-B1 Generative Network
The generative network is the core of our video STSR method. We use a 3D convolution to achieve STSR and a 3D attention mechanism to further improve the results. The network architecture is shown in Fig. 7.
Shallow feature extraction uses a single-layer 3D convolution to extract features from the input video frame. This results in a small overlap area in the receptive field, which enables the network to extract fine details. Shallow feature extraction is followed by deep feature extraction through multiple residual attention convolution blocks (RABs). Each RAB consists of a 3D convolution, an activation function, and a 3D CSA module. As the input contains both spatial and temporal information, a 3D convolution is used to effectively extract the corresponding features simultaneously. The activation function uses a parametric rectified linear unit(PReLU) [54] which can improve the fitting ability of the model and mitigate the overfitting risk without extra parameters. 3D CSA dynamically selects important information from the input features by adapting the weight of each feature.

The deep feature extraction module is composed of RABs, as shown in Fig. 7. The output of the -th RAB is
| (4) | ||||
where , denotes the feature extraction operator of the RAB, is the input feature of the RAB, denotes the 3D convolution followed by a PReLU activation operation, and is the 3D CSA operator.
The reconstruction module is mainly composed of ConvTranspose3d and Conv3d. ConvTranspose3d upsamples the features to the required resolution and activates them, while Conv3d reconstructs the video frames. ConvTranspose3d is illustrated in Fig. 8. When both space and time resolutions are increased, STSR is achieved. When only the former is increased, SSR is achieved. When only the latter is increased, TSR is achieved.

III-B2 Discriminative Network

The proposed discriminator (Fig. 9) aims to accurately distinguish between SR and true HR frames. There are two discriminant criteria: the characteristics of the video frame itself and the motion information between frames. The discriminator is composed of two branches. The top branch is used for detailed texture judgment, while the bottom branch compares motion information. The top branch extracts detailed information from each video frame, while the bottom branch processes two successive video frames to obtain their optical flow motion information. As the two branches of the discriminator deal with the texture detail and motion information separately, a 2D convolution is used for all the convolution layers of the discriminator. The activation function used is a leaky rectified linear unit (LeakyReLU) layer. A full connection layer is used to integrate the outputs of the two branches. Finally, a sigmoid function is used to judge whether the input video is a real HR video or not.
III-B3 Loss function
The loss function is the sum of two loss functions: for SR loss and for the GAN discriminator loss. calculates the L2 distance between the prediction result and the ground truth :
| (5) |
Inspired by least squares GAN (LSGAN) [55], we use the least-squares loss instead of the cross-entropy loss as the loss function for the discriminator. The least-squares discriminator loss incentivizes the discriminator to produce continuous outputs that closely align with the true distribution. This fosters the production of smoother discriminator outputs, enhancing the discriminator’s ability to assess the quality of the generated samples more effectively. Conventional GANs may face the issue of mode collapse during training. The utilization of the least-squares loss mitigates this problem, rendering the generator more inclined to generate diverse samples. Simultaneously, the least-squares loss typically exhibits greater stability and is less susceptible to the vanishing gradient problem throughout the training process. Consequently, this facilitates the training of GANs and generally results in higher-quality generated samples.
The discriminator loss function is thus [55]
| (6) | ||||
where is the discriminator, the generated sample and the real sample are coded as respectively, represents random noise that follows a Gaussian distribution , and is the distribution of .
IV Experimental Results
| Method (SSR+TSR/STSR) | PSNR↑ | SSIM↑ | Method (TSR+SSR/STSR) | PSNR↑ | SSIM↑ |
| DBPN [59]+ToFlow [26] | 29.87 | 0.905 | ToFlow [26]+DBPN [59] | 28.82 | 0.887 |
| TDAN [9]+ToFlow [26] | 30.41 | 0.918 | ToFlow [26]+TDAN [9] | 29.65 | 0.908 |
| BasicVSR [11]+ToFlow [26] | 30.58 | 0.924 | ToFlow [26]+BasicVSR [11] | 30.22 | 0.915 |
| LatticeNet [61]+ToFlow [26] | 30.84 | 0.928 | ToFlow [26]+LatticeNet [61] | 30.62 | 0.924 |
| SwinIR [62]+ToFlow [26] | 30.91 | 0.929 | ToFlow [26]+SwinIR [62] | 30.73 | 0.926 |
| DBPN [59]+DAIN [27] | 30.25 | 0.916 | DAIN [27]+DBPN [59] | 29.42 | 0.906 |
| BasicVSR [11]+DAIN [27] | 30.72 | 0.925 | DAIN [27]+BasicVSR [11] | 30.45 | 0.919 |
| LatticeNet [61]+CAIN [64] | 30.95 | 0.929 | CAIN [64]+LatticeNet [61] | 30.82 | 0.922 |
| SwinIR [62]+EDSC [65] | 30.98 | 0.930 | EDSC [65]+SwinIR [62] | 30.84 | 0.928 |
| STVUN [41] | 29.68 | 0.908 | STARnet [40] | 30.81 | 0.924 |
| TMNet [44] | 30.92 | 0.928 | Ours | 31.86 | 0.945 |
IV-A Data sets and training configuration
The proposed network was trained using the training-subset of Vimeo-90K dataset [56] which includes more than 60000 videos of size 7 (number of frames) 448 (spatial width) 256 (spatial height). The Vid4 dataset [57] and the Vimeo-90K [56] testing dataset were used for testing. For training, we first generated LR videos by spatial and temporal subsampling. Specifically, the spatial resolution was down-sampled to 11264 through bi-cubic interpolation, while the even frames were deleted. To evaluate the quality of the generated full-resolution videos, we used the peak signal-to-noise ratio (PSNR) and the structural similarity index (SSIM) [58]. As the proposed STSR method can generate high spatial-resolution (SSR) and high frame-rate (TSR) videos simultaneously, the SSR and TSR results are also presented.
The proposed model was developed on the PyTorch platform and trained with a 2080Ti GPU. In the implementation, we randomly cropped the videos for training to patches of size 32324 and used ground truth video patches of size (324)(324)7 as the labels.
IV-B Comparison with state-of-the-art methods
As benchmarks for STSR methods, we used the state-of-the-art (SOTA) STSR methods STARnet [40], STVUN [41], and TMNet [44], as well as a combination of SOTA SSR and TSR methods. If the source code of the SOTA method was available, we used it; otherwise, we implemented the method ourselves. In this way, all comparison methods were trained and tested in the same way as our method. For these combinations, we used DBPN [59], TDAN [9], BasicVSR [11], LatticeNet [61] and SwinIR [62] for SSR, and ToFlow [26], DAIN [27], CAIN [64] and EDSC [65] for TSR. Table I shows the results for Vimeo-90K. We can see that the combination of SSR+TSR performs better than TSR+SSR. We can also see that the proposed method had both the highest PSNR (31.68 dB on average) and SSIM (0.945).
To further verify the effectiveness of proposed method, we tested it on the REDS dataset [63]. The experimental results are shown in Table II. As can be seen from the table, the proposed method consistently maintained the best performance. To evaluate the performance under at motion conditions, we divided, as in [26], the Vimeo-90K dataset into three groups based on the level of motion: fast, medium, and slow. These groups comprise 1225, 4977, and 1613 video clips, respectively. The gains were largest in the fast motion group (0.94 dB on average), see Table III.
| Method | PSNR | SSIM | Method | PSNR | SSIM |
| STVUN [41] | 27.35 | 0.872 | STARnet [40] | 28.48 | 0.881 |
| TMNet [44] | 28.73 | 0.887 | Ours | 29.21 | 0.893 |
| Method | Fast motion | Medium motion | Slow motion | |||
| PSNR | SSIM | PSNR | SSIM | PSNR | SSIM | |
| STARnet [40] | 30.63 | 0.924 | 30.74 | 0.928 | 30.86 | 0.931 |
| TMNet [44] | 30.89 | 0.930 | 30.97 | 0.938 | 31.04 | 0.940 |
| Ours | 31.83 | 0.943 | 31.85 | 0.945 | 31.88 | 0.948 |
| Method | Bicubic | DBPN [59] | RBPN [60] | TDAN [9] | BasicVSR [11] | SwinIR [62] | Ours | Ours-SSR |
| PSNR | 27.89 | 29.83 | 30.97 | 32.42 | 33.02 | 33.16 | 32.55 | 33.23 |
| SSIM | 0.887 | 0.913 | 0.938 | 0.943 | 0.957 | 0.959 | 0.942 | 0.961 |
| Method | DVF [24] | ToFlow [26] | MEMC-Net [25] | DAIN [27] | EDSC | Ours-TSR |
| PSNR | 31.54 | 33.73 | 34.29 | 34.71 | 34.83 | 34.93 |
| SSIM | 0.946 | 0.968 | 0.974 | 0.976 | 0.976 | 0.978 |
| Methods | ToFlow-DBPN | DBPN-ToFlow | DBPN-DAIN | DBPN_MI-DAIN | DAIN-RBPN | RBPN-DAIN | TDAN-DAIN | STARnet | Ours |
| Parameters | 20.2M | 20.2M | 38.4M | 40.2M | 36.7M | 36.7M | 26.2M | 19.2M | 20.3M |
| Runtime(s) | 3.44 | 3.85 | 3.26 | 3.42 | 3.71 | 4.26 | 3.52 | 3.25 | 3.14 |
Our method allows us to achieve SSR in two ways. The first one (named Ours in Table IV) is to consider SSR as a byproduct of STSR. The second one (named Ours-SSR in Table IV) is to convert our STSR method into an SSR one by keeping the same temporal resolution and modifying only the spatial resolution in Convtranspose3d. Table IV compares these two approaches to five SOTA methods (DBPN [59], RBPN [60], TDAN [9], BasicVSR [11]), and SwinIR [62]. The results show that the first approach did not give competitive results. However, the second approach achieved better results than the current SOTA SSR methods.
Similarly, keeping the same spatial resolution and modifying only the temporal resolution in Convtranspose3d (named Ours-TSR in Table V) allowed us to outperform five TSR methods (DVF [24], ToFlow [26], MEMC Net [25], DAIN [27], and EDSC [65]), see Table V.
To synthesize high-quality video frames, SSR and TSR networks often require very complex reconstruction blocks. Therefore, the two-stage STSR networks have a huge number of parameters, leading to a high computational cost. Table VI compares the number of network parameters and processing time of various methods. Since our method consists of two networks (a generator and a discriminator), it includes more parameters than methods like STARnet that consist of a single network. However, because the generator is simpler than these networks, and our method only uses the generator in the testing phase, its running time is shorter.
Finally, Fig. 12 compares the visual results. The proposed method can provide better visual quality, especially for videos with rich textures and fast motion.
IV-C Ablation study
IV-C1 Effectivness of 3D CSA
Attention mechanisms not only guide the model’s focus, but also enhance the representation of relevant information. The aim is to enhance representation capacity with the help of an attention mechanism that prioritizes salient features and disregards irrelevant ones. Fig. 10 shows the feature map and the heat map generated by 3D CSA. Fig. 10(a) shows that in a low motion sequence, feature extraction is mainly focused on areas with complex textures, such as faces and contours, while less attention is paid to the background area. The results show that 3D CSA can effectively extract important information from spatial features. Fig. 10(b) corresponds to a video frame with large motion. We can clearly see that the large motion is prominently represented. The result shows that 3D CSA can also effectively capture motion information in video frames.


| Method | STSR | SSR | TSR | |||
| PSNR | SSIM | PSNR | SSIM | PSNR | SSIM | |
| w/o | 30.21 | 0.8342 | 31.15 | 0.8794 | 28.95 | 0.8197 |
| with | 30.90 | 0.8985 | 31.80 | 0.9222 | 29.62 | 0.8750 |
IV-C2 Effect of the number of RABs
The proposed RAB, which includes 3D CSA, is the most important part of the proposed generator network. To assess the impact of RAB, we experimentally studied the influence of the number of RABs, as shown in Tables VIII and IX. In general, the quality improved with more RABs. For the test set Vimeo90K, when the number of RABs was increased from 3 to 7, the improvement was 0.51 dB for STSR, 0.95 dB for SSR, and 0.19 dB for TSR. When the number of RABs was raised from 9 to 12, the improvements were 0.46 dB for STSR, 0.56 dB for SSR, and 0.39 dB for TSR. For the Vid4 test set, the overall performance did not improve beyond a certain number of RABs. Specifically, when the number of RABs was raised from 9 to 12, the improvement was only 0.01 dB for STSR, 0.01 dB for SSR, and 0.02 dB for TSR. This may be because the network reaches an overfitting state for Vid4 when the number of RABs reaches a certain level. Consequently, when the number of RABs further increases, the network’s performance starts to stagnate. To balance computational cost and performance, we set the number of RABs to 9 for Vid4 and 12 for Vimeo90K.
| RABs | STSR | SSR | TSR | |||
| PSNR | SSIM | PSNR | SSIM | PSNR | SSIM | |
| 3 | 29.80 | 0.8775 | 30.29 | 0.8863 | 28.85 | 0.8249 |
| 7 | 30.31 | 0.8824 | 31.24 | 0.9065 | 29.04 | 0.8670 |
| 9 | 30.90 | 0.8985 | 31.80 | 0.9222 | 29.62 | 0.8750 |
| 12 | 31.36 | 0.9002 | 32.36 | 0.9324 | 30.01 | 0.8824 |
| RABs | STSR | SSR | TSR | |||
| PSNR | SSIM | PSNR | SSIM | PSNR | SSIM | |
| 3 | 29.75 | 0.8734 | 30.16 | 0.8572 | 28.56 | 0.8175 |
| 7 | 30.56 | 0.8804 | 31.02 | 0.8867 | 28.94 | 0.8256 |
| 9 | 30.71 | 0.8955 | 31.86 | 0.9013 | 29.48 | 0.8376 |
| 12 | 30.72 | 0.8953 | 31.87 | 0.9014 | 29.50 | 0.8398 |
IV-C3 Effectiveness of the discriminator
To evaluate the efficacy of our generative adversarial structure, we compared the results of the generator without the proposed discriminator (only generator), with only the top branch of the proposed discriminator (only discriminator 1), with only the bottom branch of the proposed discriminator (only discriminator 2), and with the proposed GAN structure (full GAN). The results of this experiment are given in Table X. From this table, we can see that the full GAN structure improved the performance of the structure based on only the generator by 0.5 dB, 0.59 dB, and 0.37 dB for STSR, SSR and TSR, respectively, confirming the efficacy of the proposed design. Comparing the results in the middle two rows of Table X, we see that better SSR results were obtained when only the top branch of the discriminator was used, and better TSR results were obtained when only the bottom branch of the discriminator was used. The results motivate the structure of the discriminator, with a top branch for texture features and a bottom one for motion information.
| Method | STSR | SSR | TSR | |||
| PSNR | SSIM | PSNR | SSIM | PSNR | SSIM | |
| only generator | 31.36 | 0.9002 | 32.36 | 0.9324 | 30.01 | 0.8824 |
| only discriminator 1 | 31.61 | 0.9232 | 32.84 | 0.9378 | 30.23 | 0.8931 |
| only discriminator 2 | 31.69 | 0.9258 | 32.82 | 0.9369 | 30.29 | 0.8942 |
| full GAN | 31.86 | 0.9445 | 32.95 | 0.9421 | 30.38 | 0.8952 |

V Conclusion
We proposed a GAN to reconstruct HR video frames from LR video frames. Unlike previous video STSR methods, the proposed network uses 3D convolutions and a 3D attention mechanism. The generator consists of three parts: shallow feature extraction, deep feature extraction, and reconstruction. In the deep feature extraction part, a 3D CSA is used to enhance important features. The discriminator uses a two-branch structure to deal with details and motion, which further improves the network performance. Experimental results verify the validity of the proposed method. The gains over prior methods are more prominent in regions with rich texture and large motion. In the future, we plan to enhance the performance of our method by leveraging the distinctive features inherent to large motion. Furthermore, we plan to explore combinations with other techniques, such as optical flow estimation.
References
- [1] E. Zangeneh, M. Rahmati, and Y. Mohsenzadeh, “Low resolution face recognition using a two-branch deep convolutional neural network architecture,” Expert Systems with Applications, vol. 139, p. 112854, 2020.
- [2] J. Noh, W. Bae, W. Lee, J. Seo, and G. Kim, “Better to follow, follow to be better: Towards precise supervision of feature super-resolution for small object detection,” in Proceedings of the IEEE/CVF International Conference on Computer Vision, 2019, pp. 9725–9734.
- [3] S. Y. Kim, J. Oh, and M. Kim, “Deep sr-itm: Joint learning of superresolution and inverse tone-mapping for 4k uhd hdr applications,” in Proceedings of the IEEE/CVF International Conference on Computer Vision, 2019, pp. 3116–3125.
- [4] S. D. Babacan, R. Molina, and A. K. Katsaggelos, “Variational Bayesian super resolution,” IEEE Trans. Image Process., vol. 20, no. 4, pp. 984–999, Apr. 2011.
- [5] S. P. Belekos, N. P. Galatsanos, and A. K. Katsaggelos, “Maximum a posteriori video super-resolution using a new multichannel image prior,” IEEE Trans. Image Process., vol. 19, no. 6, pp. 1451–1464, Jun. 2010.
- [6] C. Liu and D. Sun, “On Bayesian adaptive video super resolution,” IEEE Trans. Pattern Anal. Mach. Intell., vol. 36, no. 2, pp. 346–360, Feb. 2014.
- [7] A. K. Katsaggelos, R. Molina, and J. Mateos, “Super resolution of images and video,” Synth. Lectures Image, Video, Multimedia Process., vol. 1, no. 1, pp. 1–134, 2007.
- [8] 12. C. Dong, C. C. Loy, K. He, and X. Tang, “Image super-resolution using deep convolutional networks,” IEEE Trans. Pattern Anal. Mach. Intell., vol. 38, no. 2, pp. 295 307, Feb. 2016.
- [9] Y. Tian, Y. Zhang, Y. Fu, and C. Xu, “TDAN: Temporally-Deformable Alignment Network for Video Super-Resolution,” in IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2020, pp. 3357-3366.
- [10] X. Wang, K. C. K. Chan, K. Yu, C. Dong and C. C. Loy, “EDVR: Video restoration with enhanced deformable convolutional networks,” in Proc. IEEE Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), 2019, pp. 1954-1963.
- [11] K. C. K. Chan, X. Wang, K. Yu, C. Dong and C. C. Loy, “BasicVSR: The Search for Essential Components in Video Super-Resolution and Beyond,” 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pp. 4945-4954, 2021.
- [12] C. Ledig, L. Theis, F. Huszar, J. Caballero, A. Cunningham, A. Acosta, A. Aitken, A. Tejani, J. Totz, Z. Wang, and W. Shi, “Photo-realistic single image super-resolution using a generative adversarial network,” in Proc. IEEE Conf. Comput. Vis. Pattern Recognit. (CVPR), Jul. 2017, pp. 4681 4690.
- [13] K. Simonyan and A. Zisserman, “Very deep convolutional networks for large-scale image recognition,” 2014, arXiv:1409.1556. [Online]. Available: http://arxiv.org/abs/1409.1556
- [14] X. Wang, K. Yu, S. Wu, J. Gu, Y. Liu, C. Dong, Y. Qiao, and C. C. Loy, “ESRGAN: Enhanced super-resolution generative adversarial networks,” in Proc. Eur. Conf. Comput. Vis. (ECCV), 2018, pp. 1-16.
- [15] A. Jolicoeur-Martineau, “The relativistic discriminator: A key element missing from standard GAN,” 2018, arXiv:1807.00734. [Online]. Available: http://arxiv.org/abs/1807.00734
- [16] A. Lucas, S. López-Tapia, R. Molina and A. K. Katsaggelos, “Generative Adversarial Networks and Perceptual Losses for Video Super-Resolution,” in IEEE Transactions on Image Processing, vol. 28, no. 7, pp. 3312-3327, July 2019.
- [17] Chu M, Xie Y, Mayer J, Leal-Taixé L, and Thuerey N, “Learning temporal coherence via self-supervision for GAN-based video generation,” in ACM Trans Graph 39(4):75, 2020
- [18] M. S. M. Sajjadi, R. Vemulapalli, and M. Brown, “Frame-recurrent video super-resolution,” in Proc. IEEE/CVF Conf. Comput. Vis. Pattern Recognit., Jun. 2018, pp. 6626 6634.
- [19] W. Wen, W. Ren, Y. Shi, Y. Nie, J. Zhang and X. Cao, “Video Super-Resolution via a Spatio-Temporal Alignment Network,” in IEEE Transactions on Image Processing, vol. 31, pp. 1761-1773, 2022.
- [20] P. Yi, Z. Wang, K. Jiang, J. Jiang, T. Lu, and J. Ma, “A Progressive Fusion Generative Adversarial Network for Realistic and Consistent Video Super-Resolution,” IEEE Transactions on Pattern Analysis and Machine Intelligence, vol. 44, no. 5, pp. 2264–2280, May 2022.
- [21] G. Li, J. Ji, M. Qin, W. Niu, B. Ren, F. Afghah, L. Guo, and X. Ma, “Towards High-Quality and Efficient Video Super-Resolution via Spatial-Temporal Data Overfitting,” in 2023 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Jun. 2023, pp. 10259–10269,2023.
- [22] Z. Qiu, H. Yang, J. Fu, D. Liu, C. Xu, and D. Fu, “Learning Degradation-Robust Spatiotemporal Frequency-Transformer for Video Super-Resolution,” IEEE Transactions on Pattern Analysis and Machine Intelligence, pp. 1–17, 2023.
- [23] G. Meng, Y. Wu, and Q. Chen, “Improving Video Super-Resolution with Long-Term Self-Exemplars,” in 2023 IEEE International Conference on Robotics and Automation (ICRA), May 2023, pp. 5992–5998,2023.
- [24] Z. Liu, R. A. Yeh, X. Tang, Y. Liu and A. Agarwala, “Video frame synthesis using deep voxel flow,” in Proc. IEEE International Conference on Computer Vision (ICCV), 2017, pp. 4473-4481.
- [25] W. Bao, W. Lai, X. Zhang, Z. Gao and M. Yang, “MEMC-Net: Motion estimation and motion compensation driven neural network for video interpolation and enhancement,” IEEE Transactions on Pattern Analysis and Machine Intelligence, pp. 1-1, 2019.
- [26] Tianfan Xue, Baian Chen, Jiajun Wu, Donglai Wei, and William T Freeman, “Video enhancement with task-oriented flow,” International Journal of Computer Vision (IJCV), 127(8):1106–1125, 2019.
- [27] W. Bao, W. Lai, C. Ma, X. Zhang, Z. Gao and M. Yang, “Depth-Aware video frame interpolation,” in Proc. IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2019, pp. 3698-3707.
- [28] Y. L. Liu, Y. T. Liao, Y. Y. Lin and Y. Y. Chuang, “Deep video frame interpolation using cyclic frame generation,” in Proceedings of the AAAI Conference on Artificial Intelligence, 33. 8794-8802. 10.1609, 2019.
- [29] M. Park, H. G. Kim, S. Lee and Y. M. Ro, “Robust Video Frame Interpolation With Exceptional Motion Map,” in IEEE Transactions on Circuits and Systems for Video Technology, vol. 31, no. 2, pp. 754-764, Feb. 2021.
- [30] H. Lee, T. Kim, T. -y. Chung, D. Pak, Y. Ban and S. Lee, “AdaCoF: Adaptive Collaboration of Flows for Video Frame Interpolation,” 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pp. 5315-5324, 2020.
- [31] L. Kong, J. Liu, and J. Yang, “Progressive Motion Context Refine Network for Efficient Video Frame Interpolation,” IEEE Signal Processing Letters, vol. 29, pp. 2338–2342, 2022.
- [32] C. Liu, H. Yang, J. Fu, and X. Qian, “TTVFI: Learning Trajectory-Aware Transformer for Video Frame Interpolation,” IEEE Transactions on Image Processing, vol. 32, pp. 4728–4741, 2023.
- [33] J. Park, J. Kim, and C.-S. Kim, “BiFormer: Learning Bilateral Motion Estimation via Bilateral Transformer for 4K Video Frame Interpolation,” in 2023 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Jun. 2023, pp. 1568–1577.
- [34] M. Plack, M. B. Hullin, K. M. Briedis, M. Gross, A. Djelouah, and C. Schroers, “Frame Interpolation Transformer and Uncertainty Guidance,” in 2023 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Jun. 2023, pp. 9811–9821.
- [35] G. Zhu, Z. Qin, Y. Ding, Y. Liu, and Z. Qin, “MFNet:Real-time motion focus network for video frame interpolation,” IEEE Transactions on Multimedia, pp. 1–13, 2023.
- [36] E. Shechtman, Y. Caspi, and M. Irani, “Increasing space-time resolution in video,” In Proceedings of the 7th European Conference on Computer Vision-Part I (ECCV ’02), 753–768, 2002.
- [37] U. Mudenagudi, S. Banerjee and P. K. Kalra, “Space-time super-resolution using graph-cut optimization,” IEEE Transactions on Pattern Analysis and Machine Intelligence, vol. 33, no. 5, pp. 995-1008, May 2011.
- [38] H. Takeda, P. V. Beek, and P. Milanfar, “Spatiotemporal video upscaling using motion-assisted steering kernel (mask) regression,” In High-Quality Visual Experience, pages 245–274. Springer, 2010.
- [39] O. Shahar, A. Faktor and M. Irani, “Space-time super-resolution from a single video,” in Proc. IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2011, pp. 3353-3360.
- [40] M. Haris, G. Shakhnarovich, and N. Ukita, “Space-Time-Aware Multi-Resolution Video Enhancement,” 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 2020, pp. 2856-2865.
- [41] J. Kang, Y. Jo, S. W. Oh, V.Peter, and S. J. Kim, “Deep Space-Time Video Upsampling Networks,” in European Conference on Computer Vision (ECCV) 2020, vol 11, pp. 701-717, 2020.
- [42] S. Dutta, N. A. Shah, and A. Mittal, “Efficient Space-time Video Super Resolution using Low-Resolution Flow and Mask Upsampling,” 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), pp. 314-323, 2021.
- [43] X. Xiang, Y. Tian, Y. Zhang, Y. Fu, J. P. Allebach, and C. Xu, “Zooming Slow-Mo: Fast and Accurate One-Stage Space-Time Video Super-Resolution,” 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pp. 3367-3376, 2020.
- [44] G. Xu, J. Xu, Z. Li, L. Wang, X. Sun, and M. -M. Cheng, “Temporal Modulation Network for Controllable Space-Time Video Super-Resolution,” 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pp. 6384-6393, 2021.
- [45] W. Zhang, M. Zhou, C. Ji, X. Sui, and J. Bai, “Cross-Frame Transformer-Based Spatio-Temporal Video Super-Resolution,” IEEE Transactions on Broadcasting, vol. 68, no. 2, pp. 359–369, Jun. 2022.
- [46] L. Itti, C. Koch, and E. Niebur, “A model of saliency-based visual attention for rapid scene analysis,” IEEE Transactions on Pattern Analysis & Machine Intelligence, no. 11, pp. 1254–1259, 1998.
- [47] R. A. Rensink, “The dynamic representation of scenes,” Visual cognition, vol. 7, no. 1-3, pp. 17–42, 2000.
- [48] H. Larochelle and G. E. Hinton, “Learning to combine foveal glimpses with a third-order boltzmann machine,” in Advances in neural information processing systems, 2010, pp. 1243–1251.
- [49] Woo. Sanghyun, Park. JongChan, Lee. Joon-Young, and Kweon, Inso,“CBAM: Convolutional Block Attention Module,” in 15th European Conference(ECCV) Part VII, Munich, Germany, September 8–14, 2018.
- [50] I. Goodfellow et al., “Generative adversarial nets,” in Proc. Adv. Neural Inf. Process. Syst., 2014, pp. 2672–2680.
- [51] P. Isola, J.-Y. Zhu, T. Zhou, and A. A. Efros, “Image-to-image translation with conditional adversarial networks,” in Proc. IEEE Conf. Comput. Vis. Pattern Recognit. (CVPR), Jul. 2017, pp. 5967–5976.
- [52] C. Ledig et al. (2016). “Photo-realistic single image super-resolution using a generative adversarial network.” [Online]. Available: https:// arxiv.org/abs/1609.04802
- [53] T. M. Quan, T. Nguyen-Duc, and W.-K. Jeong. (2017). “Compressed sensing MRI reconstruction using a generative adversarial network with a cyclic loss.” [Online]. Available: https://arxiv.org/abs/1709.00753
- [54] K. He, X. Zhang, S. Ren and J. Sun, “Delving Deep into Rectifiers: Surpassing Human-Level Performance on ImageNet Classification,” 2015 IEEE International Conference on Computer Vision (ICCV), 2015, pp. 1026-1034.
- [55] X. Mao, Q. Li, H. Xie, R. Y. Lau, Z. Wang, and S. Paul Smolley,“Least squares generative adversarial networks,” in Proceedings of the IEEE international conference on computer vision, 2017, pp. 2794–2802. III-D2
- [56] H. Takeda, P. V. Beek, and P. Milanfar, “Spatiotemporal video upscaling using motion-assisted steering kernel (mask) regression,” In High-Quality Visual Experience, pages 245–274. Springer, 2010.
- [57] O. Shahar, A. Faktor and M. Irani, “Space-time super-resolution from a single video,” in Proc. IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2011, pp. 3353-3360.
- [58] Zhou Wang, Alan C Bovik, Hamid R Sheikh, Eero P Simoncelli, et al. “Image quality assessment: from error visibility to structural similarity,” IEEE Transactions on Image Processing, 13(4):600–612, 2004.
- [59] Muhammad Haris, Greg Shakhnarovich, and Norimichi Ukita. “Deep back-projection networks for single image super-resolution,” IEEE Transactions on Pattern Analysis and Machine Intelligence, vol. 43, no. 12, pp. 4323-4337, 1 Dec. 2021.
- [60] Muhammad Haris, Greg Shakhnarovich, and Norimichi Ukita. “Recurrent back-projection network for video super resolution,” In Proc. IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2019.
- [61] X. Luo, Y. Xie, Y. Zhang, Y. Qu, C. Li, and Y. Fu, “Latticenet: Towards lightweight image super-resolution with lattice block”, in Computer Vision–ECCV 2020: 16th European Conference, Glasgow, UK, August 23–28, 2020.
- [62] J. Liang, J. Cao, G. Sun, and K. Zhang, “Swinir: Image restoration using swin transformer”, Proceedings of the IEEE/CVF international conference on computer vision, 2021.
- [63] S. Son, S. Lee, S. Nah, R. Timofte, and K.M. Lee, “NTIRE 2021 Challenge on Video Super-Resolution,” 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), Nashville, TN, USA, 2021, pp. 166-181.
- [64] M. Choi, H. Kim, B. Ham, N. Xu, and K.M. Lee, “Channel attention is all you need for video frame interpolation”, Proceedings of the AAAI Conference on Artificial Intelligence. Vol. 34. No. 07. 2020.
- [65] X. Cheng and Z. Chen, “Multiple video frame interpolation via enhanced deformable separable convolution.” IEEE Transactions on Pattern Analysis and Machine Intelligence 44.10 (2021): 7029-7045.