3D Visual Tracking Framework with Deep Learning for Asteroid Exploration
Abstract
3D visual tracking is significant to deep space exploration programs, which can guarantee spacecraft to flexibly approach the target. In this paper, we focus on the studied accurate and real-time method for 3D tracking. Considering the fact that there are almost no public dataset for this topic, A new large-scale 3D asteroid tracking dataset is presented, including binocular video sequences, depth maps, and point clouds of diverse asteroids with various shapes and textures. Benefitting from the power and convenience of simulation platform, all the 2D and 3D annotations are automatically generated. Meanwhile, we propose a deep-learning based 3D tracking framework, named as Track3D, which involves 2D monocular tracker and a novel light-weight amodal axis-aligned bounding-box network, A3BoxNet. The evaluation results demonstrate that Track3D achieves state-of-the-art 3D tracking performance in both accuracy and precision, comparing to a baseline algorithm. Moreover, our framework has great generalization ability to 2D monocular tracking performance.
Index Terms:
3D visual tracking, Asteroid tracking, 3D tracking dataset, amodal bounding-box estimation, 2D visual trackingI Introduction
Millions of asteroids exist in solar system, many the shattered remnants of planetesimals, bodies within the young Sun’s solar nebula that never grew large enough to become planets [1]. The vast majority of known asteroids orbit within the main asteroid belt located between the orbits of Mars and Jupiter. To further investigate how planets formed and how life began, as well as improve our understanding to asteroids that could impact Earth, some deep exploration programs were proposed, e.g. Hayabusa[2, 3], Hayabusa2[4, 5], and OSIRIS-Rex[6, 7]. The program objectives involve orbiting observation, autonomous landing, geological sampling, and so on.
Two near-Earth asteroids, Itokawa [3] and Ryugu [4], with complex 6-DoF motion are shown in Fig. 1. It is obvious that 3D visual tracking system is important to explore these two asteroids, which can provide object location, size, and pose. It’s also of great significance to spacecraft autonomous navigation, asteroid sample collection, and universe origin study. However, state-of-the-art 4-DoF trackers [8, 9, 10] presented for automous driving are confused about heading angle of asteroid, which makes inaccurate 3D bounding-box estimation. Besides, some 6-DoF tracking methods [11, 12, 13] under strong assumptions are also impractical to track asteroid. To be honest, constructing an end-to-end deep network that predicts 6-DoF states of asteroid is pretty difficult. We therefore decompose 3D asteroid tracking problem into 3-DoF tracking and pose estimation. And this paper merely focus on the 3-DoF tracking part.









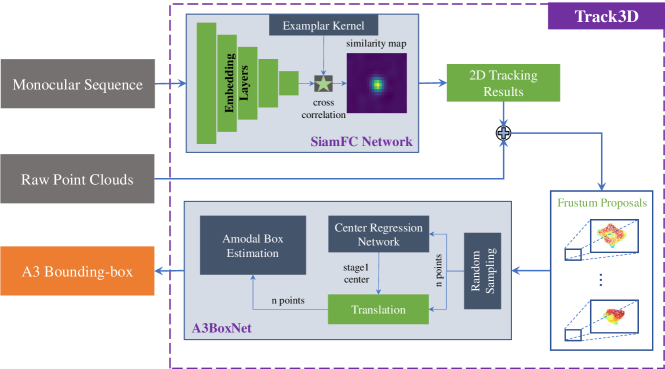
Inspired by the idea of 2D-driven 3D perception, we present a novel deep-learning based 3D asteroid tracking framework, Track3D. As shown in Fig. 2, it mainly consists of 2D monocular tracker and a light-weight amodal axis-aligned bounding-box network, A3BoxNet, which can predict accurate target center and size purely relied on partial object point cloud. Extensive experiments show that Track3D reaches state-of-the-art 3D tracking results (0.669 at 77 FPS) and has great generalization ability to 2D monocular tracker. Moreover, we discover that our framework with 2D-3D tracking fusion strategy can make significant improvement on 2D tracking performance.
However, there are few studies on 3D asteroid tracking, as well as relevant dataset, which have greatly hindered the development of asteroid exploration. To this end, we construct the first large-scale 3D asteroid tracking dataset, by acquiring 148,500 binocular images, depth maps, and point clouds of diverse asteroids in various shapes and textures with physics engine. Benefitting from the power and convenience of physics engine, all the 2D and 3D annotations are automatically generated. Meanwhile, we also provide an evaluation toolkit, which includes 2D monocular and 3D tracking evaluation algorithms.
Our contributions in this paper are summarized as follows:
-
•
Considering different types of asteroid with various shapes and textures, we construct the first large-scale 3D asteroid tracking dataset, including 148,500 binocular images, depth maps, and point clouds.
-
•
The first 3-DoF asteroid tracking framework, Track3D, is also presented, which involves an 2D monocular tracker and A3BoxNet network. The experimental results show the impressive advancement and generalization of our framework, even based on poor 2D tracking algorithm.
-
•
We propose a novel light-weight amodal bounding-box estimation network, A3BoxNet, which can predict accurate axis-aligned bounding-box of target merely with partial object point cloud. Randomly sampling 1024 points as network input, A3BoxNet can even achieve 0.712 and 0.345 with up to 281.5 FPS real-time performance.
The rest of this paper is ordered in the subsequent sections. In Section II, we review some related works from two aspects: visual tracking in aerospace domain and 3D object tracking. In Section III, the constructing details of 3D asteroid tracking dataset are presented, involving simulation platform, annotation, and evaluation metrics. We also propose a novel deep-learning based 3D tracking framework in Section IV, which consists of 2D monocular tracker, and a light-weight amodal bounding-box estimation network, A3BoxNet. Section V introduces more details about 3D tracking framework performance and ablation study. Finally, we make a conclusion in Section VI.

II Related Work
II-A Visual Tracking in Aerospace
The goal of visual tracking is to precisely and robustly perceive real-time states (e.g. location, velocity and size) of an instereted target in complex and dynamic environment. As the basis for pose estimation, behavior understanding, and scene interpretation, visual object tracking has wide application in space debris removel [14, 15], space robotic inspection [16], spacecraft rendezvous and docking [17, 18].
At present, most of visual trackers in aerospace domain mainly focus on feature-based method. Huang [15] proposed a novel feature tracking algorithm. Firstly, it extracted features by SURF detector. And then, the pyramid-Kanade-Lucas-Tomasi (P-KLT) algorithm was adopted to match key-points between two adjacent frames. Finally, accurate target bounding box is obtained with Greedy Snake method. A feature-tracking scheme was also presented in [19] that combines traditional feature-point detector and frame-wise matching to track a non-cooperative and unknown satellite. Felicetti [20] put forward an active space debris visual tracking method, in which the chaser satellite can keep the moving object in field of view of optical camera by continuously pose correction. Those feature-based trackers heavily relied on the manually designed feature detector and cannot handle extreme cases in space (e.g. illumination variation, scale variation, fast motion, rotation, truncation, and background clutters).
With many challenges and benchmarks emerging, such as OTB2015 [21], YouTube-BB [22], ILSVRC-VID [23], GOT-10K [24], and Visual Object Tracking challenges [25, 26], the development of generic object tracking is far beyond imagination [27]. Especially, deep learning based trackers [28, 29, 30, 31, 32, 33, 34] have dominated the whole tracking community in recent years, because of its striking performance. Generic object trackers often follow one protocol that no prior knowledges is available. This hypothesis is naturally suitable for asteroid visual tracking, because of high uncertainty of vision tasks in space. In paper [35], most of state-of-the-art generic trackers had been evaluated on space non-cooperative object visual tracking (SNCOVT) dataset, which provides firm research foundation for our work.
However, recent visual trackers mainly cope with RGB [36, 37, 38], RGB-Thermal [39, 40, 41], and RGB-Depth [42] video sequences, which only provides poor target information in 2D space and heavily restricts practical applications of visual tracking. In contrast, 3D visual tracking is more promising and competitive. To this end, we propose a novel deep-learning based 3D tracking framework for asteroid exploration.
| category | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 | 13 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| X | 1 | 1/2 | 1/3 | 2/3 | 1 | 1 | 1 | 1 | 1/2 | 2/3 | 1/2 | 2/3 | 1 | 1 |
| Y | 1 | 1 | 1 | 1 | 1/2 | 2/3 | 1 | 1 | 1/2 | 2/3 | 1 | 1 | 1/2 | 2/3 |
| Z | 1 | 1 | 1 | 1 | 1 | 1 | 1/2 | 2/3 | 1 | 1 | 1/2 | 2/3 | 1/2 | 2/3 |
II-B 3D Object Tracking
Although there are plenty of related works [11, 43, 12, 44, 13, 45, 8, 9, 10], the concept of 3D object tracking remains ambiguous. Hence that, we first define that 3D object tracking is to obtain 3D information of any target in real-time by leveraging various visual sensors, given initaial states at the beginning. According to the degrees of freedom of tracking result, all the 3D trackers can be concluded into three categories: 3-DoF, 4-DoF, and 6-DoF Tracker. Obviously, the more degrees of freedom, the more difficult 3D tracking task is.
3-DoF tracking means that both 3D location and size of object (i.e. 3D axis-aligned bounding-box) should be estimated. However, most of researches only considered predicting 3D object center. In paper [43], a color-augmented search algorithm was presented to obtain the position and velocity of vehicle. Asvadi et al. [44] utilized two parallel mean-shift localizers in image and pcd space, and made fusion for two localizations by Kalman filter. This algorithm can effectively achieve low 3D center error. To the best of our knowledge, the framework proposed in this paper is the first real 3-DoF tracker that can be applied for collision avoidance, 3D reconstruction, and pose estimation.
Comparing with 3-DoF methods, 4-DoF tracker often needs to predict an extra heading angle of target, which is original from 3D tracking requirement in autonomous driving. Giancola et al. [8] presented a novel 3D siamese tracker with the regularization of point cloud completion. However, the exhaustively searching for candidate shapes in this method would consume high computational cost. Qi et al. [9] also proposed point-wise tracking paradigm, P2B, which addressed 3D object tracking by potential center localization, 3D target proposal and verification. Since this method purely uses point cloud data as input, it is vulnerable to initial object point cloud and only achieves 0.562 at 40 FPS on KITTI tracking dataset [46].
In paper [11, 12], 6-DoF tracking task was considered as joint 2D segmentation and 3D pose estimation problem, and the method looked for the pose that best segmented the target object from the background. Crivellaro et al. [13] present a novel 6-DoF tracking framework with monocular image, including expensive 2D detector, local pose estimation and extended kalman filter. However, the non-textured 3D model of target should be given in this method, which heavily limits the scope of its application. To be honest, the asteroid tracking is one of 6-DoF tracking tasks. We think it is very hard to construct an end-to-end network that can directly and precisely predict the 6-DoF object states. Therefore, we decompose asteroid tracking problem into 3-DoF tracking and pose estimation. It is worthwhile noting that this paper simply focus on the 3-DoF tracking task of asteroid.
III 3D Asteroid Tracking Dataset
To promote the research on 3D tracking for asteroid, we construct a large-scale 3D asteroid tracking dataset, including binocular video sequences, depth maps and point clouds. In addition, 3D tracking evaluation toolkit is also provided for performance analysis. More details about 3D asteroid tracking dataset are introduced in this section.
III-A Dataset Construction
There is no doubt that collecting real data to create large-scale 3D asteroid tracking dataset is impractical, like KITTI dataset [46] and Princeton RGB-D Tracking dataset [42]. Meanwhile, constructing dataset by ground simulation [35] is very expensive and limited. Inspired by UAV123 dataset [47], we therefore consider to collect rich 3D tracking data by virtual physics engine, V-rep. The power and convenience of physics engine make automatic data labelling possible, which greatly reduces constructing cost and improves annotation accuracy.
The critical foundation of dataset constructing based on physics engine is 3D modeling of asteroids with diverse shapes and textures. We create three types of 3D asteroid model (i.e. Asteroid04, 05, and 06) with 6 different textures, which are illustrated at the left of Fig. 3. From point of our view, one asteroid model with diferent textures can be considered as different fine-grained categories. In addition, we introduce 9 simulated space scenes into dataset construction. All the 3D asteroid models have been controlled by scripts to carry out random 6-DoF motion in simulated scenes.
The detailed setup of vision sensors for data collection can be seen at upper right corner of Fig 3. Only two perspective vision cameras are equipmented with 0.4-meter baseline in x-axis direction on observer spacecraft, which can not only acquire binocular video sequences during simulation, but also achieve aligned depth maps and point clouds from camera buffer by the API of physics engine. The camera matrix is very vital for our 3D tracking framework in which point clouds should be projected to image plane, however, V-rep merely provides perspective angle and resolution . To this end, we compute camera intrinsic matrix following Eq. 1 (more derived details are given in Appendix A):
| (1) |
At final, we collect 360 sequences for training and 135 sequences for testing set. Each sequence has 300 frames binocular images, depth maps, and point clouds. Following the protocol proposed in [24], there is no overlap on fine-grained categories between training and testing set. The screenshots of 3D asteroid tracking testing set with 2D and 3D annotations are shown in Fig. 3.



III-B Dataset Statistics
In actual, our framework predicts the object size class and normalized size residuals, rather outputs an axis-aligned 3D bounding-box directly. Therefore, size classes should be predefined and the number of samples in each category has better to be balanced. To this end, we make a statistic analysis for size category of axis-aligned 3D bounding-boxes in 3D asteroid tracking dataset and define 14 default size categories summarized in Table I. The final distribution of size classes can be seen in Fig. 4a.
Meanwhile, the distribution of object volumes and motion speeds are shown in Fig. 4b and 4c, respectively. Because of random asteroid rotation and manual shape modification, the volume of samples is widely distributed (16 to 1600 ). It is worthwhile noting that object volume metioned here is the volume of axis-aligned 3D bounding-box, instead the real one. In addition, as we mentioned above that all the 3D asteroid models are controlled by scripts to carry out random 6-DoF motion, Fig. 4c clearly demonstrates that the random translation of object obeys normal distribution.
III-C Evaluation Metrics
The main metric utilized to analyse 2D tracking performance is average overlap, , which is also widely applied in visual tracking benchmarks like OTB[21], VOT[26], and GOT-10k [24]. In this paper, we also introduce this metric to evaluate 2D monocular tracker and 3D tracking results in bird’s eye view (i.e. and ). Furthermore, We extend average overlap measurement to evaluate 3D tracking accuracy, named as :
| (2) | ||||
in which, is the sequences number in 3D asteroid tracking test set, denotes the length of s-th sequence, and denotes the region overlap between axis-aligned 3D annotation and 3D tracking result at t-th frame. It is worthwhile noting that tracking restart mechanism is introduced to 3D tracking evaluation. That is 3D tracker is allowed to reinitialize, once the Intersection-over-Union (IoU) of 3D tracking result is zero.
Besides average overlap metric, we also adopt success rate, , as our indicator, which denotes the percentage of successfully tracked frames where the overlap exceeds a threshold. In this work, we take 0.5 as threshold to measure the success rate of one tracker. However, at a specific threshold is not representative, we further introduce success plot presented by [21] into our evaluation tool.
Another intuitive technique index of tracker is location precision. Therefore, we propose 3D average center error metric () that measures the mean distance between all the predicted trajectories and ground-truth trajectories:
| (3) |
where and are the predictions and ground-truths of s-th sequence, which consist of a series of object center in 3D space. is formulated as:
| (4) |
in which, denotes Euclidean distance.


IV 3D Tracking Framework
Inspired by the 2D-drieven 3D perception, we propose a deep-learning based 3D tracking framework shown in Fig. 5, which involves 2D monocular tracker, SiamFC [28] and a novel light-weight amodal axis-aligned bounding-box network, A3BoxNet. Although binocular images and depth maps are also provided in our 3D asteroid tracking dataset, it is worthwhile noting that Track3D only utilizes monocular video sequence and corresponding point clouds, which reduces the complexity of 3D tracking framework and more conforms to real applications in aerospace. In addition, we will introduce a simple but effective 2D-3D tracking fusion strategy in the following subsections.
IV-A SiamFC
The SiamFC algorithm utilizes full convolutional layers as an embedding layer, denoted as embedding function . The exemplar image and multi-scale search images are mapped to a high-dimensional feature space with , which can be trained by a general large-scale dataset. And then similarity score maps are generated by cross-correlation between exemplar kernal and the tensors of multi-scale search images, where the 2D tracking result can be reached after post-processing.
For this algorithm, the key is to learn discriminative embedding function . In this work, we train the backbone of SiamFC from scratch on ILSVRC-VID [23] with 50 epochs and further fine-tune it on our 3D asteroid tracking training set. Benefitting from the strong generalization ability of Siamese network, SiamFC can achieve a decent 2D tracking performance. Although there are multifarious deep-learning based 2D monocular trackers, like SiamRPN++ [30], Ocean [36], STARK [37], TransT [38], which greatly outperform SiamFC in tracking accuracy, we think weak dependence on high-performance 2D monocular tracker can effectively guarantee the generalization ability of our framework and improve its running speed.
Once tracking result is acquired from 2D monocular tracker, it can be used for frustum proposal extraction from raw points set , as shown in Fig. 5. We first crop out points from raw point cloud , and then compute the projected point cloud in image plane with camera matrix . Therefore, we can achieve the frustum proposal by the indices of points which belong to region in .


| name | FPS | |||||
|---|---|---|---|---|---|---|
| (pixel) | (meter) | |||||
| SiamFC | 0.513 | 29.986 | - | - | - | 101.3 |
| A3BoxNet | - | - | 0.798 | 0.721 | 0.345 | 281.5 |
| 3D Tracking Baseline | 0.568 | 23.767 | 0.309 | 0.165 | 0.876 | 103.1 |
| Track3D | 0.541 | 26.741 | 0.756 | 0.669 | 0.570 | 77.0 |
IV-B A3BoxNet
In this work, we assume that there are no other objects in the range of LiDAR perception, that is, all of the points in frustum proposal belong to tracked target, which conforms to practical scenario in space. Therefore, we propose a novel light-weight amodal axis-aligned bounding-box network, A3BoxNet, which makes directly prediction on frumstum proposal and no point segmentation is considered into. Fig. 2 clearly shows that our A3BoxNet mainly consists of two modules: center regression network and amodal box estimation network. The former one is responsible for the estimation of stage-1 object center. Another is to predict object center residuals, object size category, and normalized size residuals. It is worthwhile noting that both center regression network and amodal box estimation network are only support fixed number of input points. To this end, we add random sampling at the beginning of A3BoxNet.
The architecture of center regression network and amodal box estimation network are both illustrated in Fig. 6a and 6b. It can be clearly seen that there is no significant difference between two networks which are both derived from PointNet [48]. In A3BoxNet, we use a number of MLP for high-level features extraction. And max-pooling layer is introduced to aggregate global features with symmetric property that is critical for unsorted point sets. The global feautres concatenated with one-hot vector of coarse-grained asteroid category can be further used for predicting stage-1 center, stage-2 center, and object size.
We visualize the center predction progress of A3BoxNet in Fig. 7. The frustum proposal have been normalized by substracting the centroid of point sets firstly, which can improve the translation invariance of A3BoxNet and speed up convergence rate during training. In addtion, it shows that after two stage prediction, estimated object center is very close to the ground-truth. The predicted center is formulateds as follows:
| (5) |
where is the centroid of point cloud in frustum proposal, is the output of center regression network, is the center residuals predicted by amodal box estimation network.
Except for estimating the center residuals of object, our amodal box estimation network also classifies object size to 14 predefined categories (see in Table I) as well as predicts normalized size residuals ( scores for size classification, for size residuals regression). At final, we remap the predicted size category and normalized size residual to original scale by multiplying the largest length of enclosing bounding-box of point clouds.
To train our A3BoxNet, we use a joint loss function to simultaneously optimize both two submodules:
| (6) |
in which,
| (7) |
more details about optimization function of A3BoxNet are given in Appendix B. In addition, A3BoxNet is trained on 3D asteroid tracking dataset with 25 epoches and 32 batch size. All the inputs are fixed number of point sets that randomly sampled from object point cloud.
IV-C 2D-3D Tracking Fusion Strategy
We believe the fusion of 3D tracking and 2D monocular tracking results can make significant improvement on 2D tracking performance. To this end, we propose a simple and effective 2D-3D tracking fusion strategy (as shown in Fig. 8). At first, we calculate the projection of center cross-section plane of 3D bounding-box in image plane, . And then, 2D monocular tracking result is weighted with :
| (8) |
in this work, we set and .




| sequence 0001 | sequence 0022 | sequence 0031 | sequence 0052 |
|---|---|---|---|








V Experiments
In this section, we have introduced a simple 3D tracking baseline algorithm as comparison and implemented extensive experiments with Track3D on 3D asteroid tracking dataset to demonstrate the advancement and effectiveness of our framework. We also find out that our framework with 2D-3D fusion strategy can not only handle 3D tracking challenge, but also make improvement on 2D tracking performance. In addition, valuable ablation study is also considered. All the experiments are carried out with Intel [email protected] CPU and Nvidia RTX 2080Ti GPU.
V-A Framework Performance
Considering that there are a few researh results in the scope of 3-DoF tracking at present, therefore, we replace the A3BoxNet of our framework with minimum enclosing 3D bounding-box algorithm (i.e. computing the length of aixs-aligned 3D bounding-box by ) to realise a simple 3D tracking baseline as comparison. Both 2D and 3D tracking evaluation results of 3D tracking baseline are summarized at 3rd row in Table II. And its success plots are shown in Fig. 9a. We find out that the 3D tracking baseline with 2D-3D fusion strategy improves 2D monocular tracking performance about 10.5%, however, it achieves quite poor performance in 3D space.
The overall performance of deep-learning based 3D tracking framework, also named as Track3D, is illustrated in Fig. 9b. It reaches excellent evaluation results on 3D asteroid tracking test set (0.669 and 0.570 ) with high real-time performance (77.0 FPS). We visualize part of tracking results of Track3D in Fig. 10, which demonstrates the effectiveness of our 3D tracking method. It clearly shows that our framework can estimate accurate 3D bounding-box even under extreme truncation (see 150-th frame of sequence 0001 in Fig. 10). The 3D trajectory plots in Fig. 11 also intuitively show our framework predicts precise 3D object location, which greatly outperforms 3D tracking baseline. In addition, it can be seen in the first colum of Table II that Track3D with 2D-3D fusion strategy can also make significant improvement on 2D tracking performance.
V-B Module Performance
Extensive experiments are implemented in this subsection that explore how two main modules of Track3D (i.e. 2D monocular tracker and A3BoxNet) make influences on final 3D tracking performance, which points the way to design effective 3D tracking framework for future work.
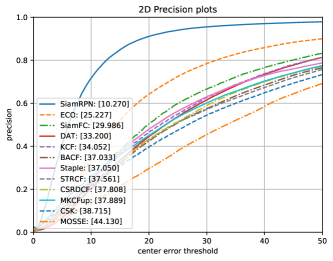
Firstly, plenty of classic monocular trackers have been evaluated on left video sequences of 3D asteroid tracking dataset, such as SiamFC [28], SiamRPN [49], ECO [50], Staple [51], KCF [52], DAT [53], BACF [54], STRCF [55], MKCFup [56], CSRDCF [57], CSK [58], and MOSSE [59]. The evaluation results are illustrated in Fig. 12 which straightforward shows the accuracy of 12 monocular trackers are distributed in a large range from 0.375 to 0.746. SiamFC adopted in our framework only achieves intermediate 2D tracking performance in both accuracy and precision metrics.
And then, we evaluate the whole framework under different monocular trackers respectively and plot 3D success and precision curves in Fig. 13a and 13b. We found that 3D evaluation curves become much dense comparing with 2D curves of Fig. 11, which denotes that 2D monocular trackers just have slight influence on 3D tracking performance of our framework. In other words, Track3D can still work even based on poor 2D monocular tracker. We further plot the relationship between 2D tracking performance and framework accuracy in Fig. 14, which intuitively demonstrates the generalization ability of Track3D.


Meanwhile, We evaluate amodal bounding-box estimation network, A3BoxNet, on 3D asteroid tracking dataset by randomly sampling 1024 points from frustum proposal. Its performance is also illustrated in Fig. 15. It can be clearly seen that our A3BoxNet predicts high accurate axis-aligned bounding-box purely with partial object points. Furthermore, our network is able to run at 281.5 FPS, which totally satisfies the requirement of application on edge computing device.

| name | |||
|---|---|---|---|
| A3BoxNet | 0.721 | 0.798 | 0.345 |
| without category | 0.715 | 0.792 | 0.316 |
We also study how the number of input points affects the performance of amodal axis-aligned bounding-box network. We retrain the A3BoxNet by randomly sampling different numbers of point set (e.g. 512, 1024, 2048, 3072, and 4096 points) from object point clouds in 3D asteroid tracking training set. And all the models are trained from scratch with 25 epoches and 32 batch size. The evaluation results are plotted in Fig. 16, which clearly shows accuracy and precision of A3BoxNet have contradictory with the number of input points. Once the accuracy of model increasing, the corresponding precision will decrease.
Besides, the influence of object category on A3BoxNet is further studied. We remove one-hot vector of object category in center regression network and amodal box estimation network, and retrain A3BoxNet from scratch with 1024 point sets. The performance comparison between original A3BoxNet and A3BoxNet without category information is summarized in Table III, which proves the object category can make a slight improvement on the 3D accuracy of A3BoxNet.
VI Conclusion
In this work, we construct the first large-scale 3D asteroid tracking dataset, which involves 148,500 binocular images, depth maps, and point clouds. All the 2D and 3D annotations are automatically generated, which greatly guarantees the quality of tracking dataset and reduce the cost of data collection. The 3D asteroid tracking dataset will be public on website (http://aius.hit.edu.cn/12920/list.htm). Meanwhile, we propose a deep-learning based 3D visual tracking framework, Track3D, which mainly consists of classic 2D monocular tracker and a novel light-weight amodal axis-aligned bounding-box network. The state-of-the-art 3D tracking performance and great generalization ability of our framework have been demonstrated by sufficient experiments. We also find that Track3D with 2D-3D tracking fusion strategy also makes improvement on 2D tracking performance. In future work, We will further apply our Track3D method to normoal cases like automous driving and robot picking.
Appendix A The perspective camera matrix
In section III, we have mentioned that camera matrix is very important for Track3D to extract frustum proposal. However, physics engine V-rep only provides perspective angle and resolution . To this end, we derive the camera matrix by perspective projection principle, which is also illustrated in Fig. 3.
Suppose that the virtual focus of perspective camera in both x and y axes are , the size of image plane is , and an object point in camera coordinate system is projected at in image plane. Fig. 3 clearly shows that:
| (9) |
and,
| (10) |
Meanwhile, the transformation from image coordinate system to pixel coordinate system in x axis is formulated as:
| (11) | ||||
Substitute Eq. 9 and 10 into Eq. 11, it can be obtained:
| (12) |
in which, the parameter is eliminated. Similarly, the transformation in y-axis direction from camera coordinate system to pixel coordinate system is also obtained:
| (13) |
We further rewrite Eq. 12 and 13 in homogeneous matrix form:
| (14) |
To eliminate the variable in the transformation matrix, we multiply both sides of Eq. 14 by :
| (15) |
Because we set left camera coordinate system as reference frame, the camera matrix of left perspective camera can be formulated as:
| (16) |
Appendix B Traning objectives
In this work, we utilize a joint loss function to optimize A3BoxNet:
| (17) |
where, adopt huber loss function:
| (18) |
in which , is 3D center label, is the centroid of points in frustum proposal, and is the prediction of center regression network.
In addition,
| (19) |
where utilizes softmax cross entropy loss function:
| (20) |
in which is dimensional one-hot vector of size category label, is the partial outputs of amodal box estimation network, of which dimension is also .
Furthermore, and both use huber loss function. is formulated as:
| (21) |
in which, , is 3D center residuals predicted by amodal box estimation network. And is as follows:
| (22) |
where , and are the size and size residual label, respectively. is normalized size residual corresponding to the size category predicted by amodal box estimation network.
Acknowledgment
This work was kindly supported by the National Key R&D Program of China through grant 2019YFB1312001.
References
- [1] S. Kortenkamp, Asteroids, Comets, and Meteoroids. Capstone, 2011.
- [2] A. Fujiwara, J. Kawaguchi, D. K. Yeomans, M. Abe, T. Mukai, T. Okada et al., “The Rubble-Pile Asteroid Itokawa as Observed by Hayabusa,” Science, vol. 312, no. 5778, pp. 1330–1334, Jun. 2006, publisher: American Association for the Advancement of Science Section: Special Reports.
- [3] M. Yoshikawa, A. Fujiwara, and J. Kawaguchi, “Hayabusa and its adventure around the tiny asteroid Itokawa,” Proceedings of the International Astronomical Union, vol. 2, no. 14, pp. 323–324, Aug. 2006, publisher: Cambridge University Press.
- [4] S. Sugita, R. Honda, T. Morota, S. Kameda, H. Sawada, E. Tatsumi et al., “The geomorphology, color, and thermal properties of Ryugu: Implications for parent-body processes,” Science, vol. 364, no. 6437, Apr. 2019, publisher: American Association for the Advancement of Science Section: Research Article.
- [5] S.-i. Watanabe, Y. Tsuda, M. Yoshikawa, S. Tanaka et al., “Hayabusa2 Mission Overview,” Space Science Reviews, vol. 208, no. 1, pp. 3–16, Jul. 2017.
- [6] D. Lauretta, S. Balram-Knutson, E. Beshore, W. Boynton, C. D. d’Aubigny, D. DellaGiustina, H. Enos, D. Golish, C. Hergenrother, E. Howell et al., “Osiris-rex: sample return from asteroid (101955) bennu,” Space Science Reviews, vol. 212, no. 1, pp. 925–984, 2017.
- [7] D. Golish, C. D. d’Aubigny, B. Rizk, D. DellaGiustina, P. Smith, K. Becker, N. Shultz, T. Stone, M. Barker, E. Mazarico et al., “Ground and in-flight calibration of the osiris-rex camera suite,” Space science reviews, vol. 216, no. 1, pp. 1–31, 2020.
- [8] S. Giancola, J. Zarzar, and B. Ghanem, “Leveraging shape completion for 3D siamese tracking,” in Proc. IEEE Comput. Soc. Conf. Comput. Vis. Pattern Recognit., vol. 2019-June, 2019, pp. 1359–1368.
- [9] H. Qi, C. Feng, Z. Cao, F. Zhao, and Y. Xiao, “P2B: Point-to-Box Network for 3D Object Tracking in Point Clouds,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2020, pp. 6329–6338.
- [10] T. Yin, X. Zhou, and P. Krahenbuhl, “Center-Based 3D Object Detection and Tracking,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2021, pp. 11 784–11 793.
- [11] V. A. Prisacariu and I. D. Reid, “PWP3D: Real-Time Segmentation and Tracking of 3D Objects,” International Journal of Computer Vision, vol. 98, no. 3, pp. 335–354, 2012-07-01.
- [12] V. A. Prisacariu, A. V. Segal, and I. Reid, “Simultaneous monocular 2d segmentation, 3d pose recovery and 3d reconstruction,” in Asian conference on computer vision. Springer, 2012, pp. 593–606.
- [13] A. Crivellaro, M. Rad, Y. Verdie, K. M. Yi, P. Fua, and V. Lepetit, “Robust 3D Object Tracking from Monocular Images Using Stable Parts,” IEEE Transactions on Pattern Analysis and Machine Intelligence, vol. 40, no. 6, pp. 1465–1479, 2018.
- [14] G. S. Aglietti, B. Taylor, S. Fellowes, T. Salmon, I. Retat, A. Hall, T. Chabot, A. Pisseloup, C. Cox, A. Mafficini et al., “The active space debris removal mission removedebris. part 2: in orbit operations,” Acta Astronautica, vol. 168, pp. 310–322, 2020.
- [15] P. Huang, F. Zhang, J. Cai, D. Wang, Z. Meng, and J. Guo, “Dexterous tethered space robot: Design, measurement, control, and experiment,” IEEE Transactions on Aerospace and Electronic Systems, vol. 53, no. 3, pp. 1452–1468, 2017.
- [16] D. Fourie, B. E. Tweddle, S. Ulrich, and A. Saenz-Otero, “Flight results of vision-based navigation for autonomous spacecraft inspection of unknown objects,” Journal of spacecraft and rockets, vol. 51, no. 6, pp. 2016–2026, 2014.
- [17] A. Petit, E. Marchand, and K. Kanani, “Vision-based space autonomous rendezvous: A case study,” in 2011 IEEE/RSJ International Conference on Intelligent Robots and Systems. IEEE, 2011, pp. 619–624.
- [18] S. Sharma, C. Beierle, and S. D’Amico, “Pose estimation for non-cooperative spacecraft rendezvous using convolutional neural networks,” in 2018 IEEE Aerospace Conference, 2018-03, pp. 1–12.
- [19] R. Volpe, G. B. Palmerini, and M. Sabatini, “A passive camera based determination of a non-cooperative and unknown satellite’s pose and shape,” Acta Astronautica, vol. 151, pp. 805–817, 2018.
- [20] L. Felicetti and M. R. Emami, “Image-based attitude maneuvers for space debris tracking,” Aerospace science and technology, vol. 76, pp. 58–71, 2018.
- [21] Y. Wu, J. Lim, and M.-H. Yang, “Object Tracking Benchmark,” IEEE Transactions on Pattern Analysis and Machine Intelligence, vol. 37, no. 9, pp. 1834–1848, 2015-09.
- [22] E. Real, J. Shlens, S. Mazzocchi, X. Pan, and V. Vanhoucke, “Youtube-boundingboxes: A large high-precision human-annotated data set for object detection in video,” in proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 2017, pp. 5296–5305.
- [23] O. Russakovsky, J. Deng, H. Su, J. Krause, S. Satheesh, S. Ma, Z. Huang, A. Karpathy, A. Khosla, M. Bernstein, A. C. Berg, and L. Fei-Fei, “ImageNet Large Scale Visual Recognition Challenge,” International Journal of Computer Vision, vol. 115, no. 3, pp. 211–252, 2015-12-01.
- [24] L. Huang, X. Zhao, and K. Huang, “GOT-10k: A Large High-Diversity Benchmark for Generic Object Tracking in the Wild,” IEEE Transactions on Pattern Analysis and Machine Intelligence, pp. 1–1, 2019.
- [25] M. Kristan, A. Leonardis, J. Matas, M. Felsberg, R. Pflugfelder, L. Cehovin Zajc, T. Vojir, G. Hager, A. Lukezic, A. Eldesokey, and G. Fernandez, “The Visual Object Tracking VOT2017 Challenge Results,” in Proceedings of the IEEE International Conference on Computer Vision Workshops, 2017, pp. 1949–1972.
- [26] M. Kristan, J. Matas, A. Leonardis, M. Felsberg, R. Pflugfelder, J.-K. Kamarainen, L. ˇCehovin Zajc, O. Drbohlav, A. Lukezic, A. Berg et al., “The seventh visual object tracking vot2019 challenge results,” in Proceedings of the IEEE/CVF International Conference on Computer Vision Workshops, 2019, pp. 0–0.
- [27] X. Lan, S. Zhang, P. C. Yuen, and R. Chellappa, “Learning Common and Feature-Specific Patterns: A Novel Multiple-Sparse-Representation-Based Tracker,” IEEE Transactions on Image Processing, vol. 27, no. 4, pp. 2022–2037, 2018-04.
- [28] L. Bertinetto, J. Valmadre, J. F. Henriques, A. Vedaldi, and P. H. Torr, “Fully-convolutional siamese networks for object tracking,” in European conference on computer vision. Springer, 2016, pp. 850–865.
- [29] Q. Wang, L. Zhang, L. Bertinetto, W. Hu, and P. H. Torr, “Fast online object tracking and segmentation: A unifying approach,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2019, pp. 1328–1338.
- [30] B. Li, W. Wu, Q. Wang, F. Zhang, J. Xing, and J. Yan, “Siamrpn++: Evolution of siamese visual tracking with very deep networks,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2019, pp. 4282–4291.
- [31] M. Danelljan, G. Bhat, F. S. Khan, and M. Felsberg, “Atom: Accurate tracking by overlap maximization,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2019, pp. 4660–4669.
- [32] Z. Zhang and H. Peng, “Deeper and Wider Siamese Networks for Real-Time Visual Tracking,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2019, pp. 4591–4600.
- [33] Z. Chen, B. Zhong, G. Li, S. Zhang, and R. Ji, “Siamese box adaptive network for visual tracking,” in Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2020, pp. 6668–6677.
- [34] M. Ondrašovič and P. Tarábek, “Siamese Visual Object Tracking: A Survey,” IEEE Access, vol. 9, pp. 110 149–110 172, 2021.
- [35] D. Zhou, G. Sun, J. Song, and W. Yao, “2D vision-based tracking algorithm for general space non-cooperative objects,” Acta Astronautica, vol. 188, pp. 193–202, 2021-11-01.
- [36] Z. Zhang, H. Peng, J. Fu, B. Li, and W. Hu, “Ocean: Object-aware anchor-free tracking,” in Computer Vision–ECCV 2020: 16th European Conference, Glasgow, UK, August 23–28, 2020, Proceedings, Part XXI 16. Springer, 2020, pp. 771–787.
- [37] B. Yan, H. Peng, J. Fu, D. Wang, and H. Lu, “Learning spatio-temporal transformer for visual tracking,” arXiv preprint arXiv:2103.17154, 2021.
- [38] X. Chen, B. Yan, J. Zhu, D. Wang, X. Yang, and H. Lu, “Transformer Tracking,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2021, pp. 8126–8135.
- [39] X. Lan, M. Ye, S. Zhang, H. Zhou, and P. C. Yuen, “Modality-correlation-aware sparse representation for RGB-infrared object tracking,” Pattern Recognition Letters, vol. 130, pp. 12–20, 2020-02-01.
- [40] X. Lan, M. Ye, R. Shao, B. Zhong, P. C. Yuen, and H. Zhou, “Learning Modality-Consistency Feature Templates: A Robust RGB-Infrared Tracking System,” IEEE Transactions on Industrial Electronics, vol. 66, no. 12, pp. 9887–9897, 2019-12.
- [41] X. Lan, W. Zhang, S. Zhang, D. K. Jain, and H. Zhou, “Robust Multi-modality Anchor Graph-based Label Prediction for RGB-Infrared Tracking,” IEEE Transactions on Industrial Informatics, pp. 1–1, 2019.
- [42] S. Song and J. Xiao, “Tracking Revisited Using RGBD Camera: Unified Benchmark and Baselines,” in Proceedings of the IEEE International Conference on Computer Vision, 2013, pp. 233–240.
- [43] D. Held, J. Levinson, and S. Thrun, “Precision tracking with sparse 3D and dense color 2D data,” in 2013 IEEE International Conference on Robotics and Automation, 2013, pp. 1138–1145.
- [44] A. Asvadi, P. Girão, P. Peixoto, and U. Nunes, “3D object tracking using RGB and LIDAR data,” in 2016 IEEE 19th International Conference on Intelligent Transportation Systems (ITSC), 2016, pp. 1255–1260.
- [45] U. Kart, A. Lukezic, M. Kristan, J.-K. Kamarainen, and J. Matas, “Object Tracking by Reconstruction With View-Specific Discriminative Correlation Filters,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2019, pp. 1339–1348.
- [46] A. Geiger, P. Lenz, and R. Urtasun, “Are we ready for autonomous driving? The KITTI vision benchmark suite,” in 2012 IEEE Conference on Computer Vision and Pattern Recognition, 2012, pp. 3354–3361.
- [47] M. Mueller, N. Smith, and B. Ghanem, “A benchmark and simulator for uav tracking,” in European conference on computer vision. Springer, 2016, pp. 445–461.
- [48] C. R. Qi, W. Liu, C. Wu, H. Su, and L. J. Guibas, “Frustum pointnets for 3d object detection from rgb-d data,” in Proceedings of the IEEE conference on computer vision and pattern recognition, 2018, pp. 918–927.
- [49] B. Li, J. Yan, W. Wu, Z. Zhu, and X. Hu, “High Performance Visual Tracking With Siamese Region Proposal Network,” in Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 2018, pp. 8971–8980.
- [50] M. Danelljan, G. Bhat, F. Shahbaz Khan, and M. Felsberg, “ECO: Efficient Convolution Operators for Tracking,” in Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 2017, pp. 6638–6646.
- [51] L. Bertinetto, J. Valmadre, S. Golodetz, O. Miksik, and P. H. Torr, “Staple: Complementary learners for real-time tracking,” in Proc. IEEE Comput. Soc. Conf. Comput. Vis. Pattern Recognit., 2016.
- [52] J. F. Henriques, R. Caseiro, P. Martins, and J. Batista, “High-Speed Tracking with Kernelized Correlation Filters,” IEEE Transactions on Pattern Analysis and Machine Intelligence, vol. 37, no. 3, pp. 583–596, 2015-03-01.
- [53] H. Possegger, T. Mauthner, and H. Bischof, “In defense of color-based model-free tracking,” in Proc. IEEE Comput. Soc. Conf. Comput. Vis. Pattern Recognit., 2015.
- [54] H. Kiani Galoogahi, A. Fagg, and S. Lucey, “Learning Background-Aware Correlation Filters for Visual Tracking,” in Proceedings of the IEEE International Conference on Computer Vision, 2017, pp. 1135–1143.
- [55] F. Li, C. Tian, W. Zuo, L. Zhang, and M.-H. Yang, “Learning Spatial-Temporal Regularized Correlation Filters for Visual Tracking,” in Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 2018, pp. 4904–4913.
- [56] M. Tang, B. Yu, F. Zhang, and J. Wang, “High-Speed Tracking With Multi-Kernel Correlation Filters,” in Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 2018, pp. 4874–4883.
- [57] A. Lukezic, T. Vojir, L. Cehovin Zajc, J. Matas, and M. Kristan, “Discriminative Correlation Filter With Channel and Spatial Reliability,” in Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 2017, pp. 6309–6318.
- [58] J. F. Henriques, R. Caseiro, P. Martins, and J. Batista, “Exploiting the Circulant Structure of Tracking-by-Detection with Kernels,” in Computer Vision – ECCV 2012, ser. Lecture Notes in Computer Science, A. Fitzgibbon, S. Lazebnik, P. Perona, Y. Sato, and C. Schmid, Eds. Springer, 2012, pp. 702–715.
- [59] D. S. Bolme, J. R. Beveridge, B. A. Draper, and Y. M. Lui, “Visual object tracking using adaptive correlation filters,” in 2010 IEEE Computer Society Conference on Computer Vision and Pattern Recognition, 2010, pp. 2544–2550.
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/63ba995b-f367-4a5c-b4fc-bf4d60f3f4cb/x44.png) |
Dong Zhou was born in Hunan, China, in 1996. He received the B.S degree in automation from Harbin Engineering University, Harbin, China, in 2018. He is currently working toward the Ph.D. degree in the Department of Control Science and Engineering, Harbin Institute of Technology, Harbin, China. His research interests include space non-cooperative object visual tracking, 3D computer vision, and deep learning. |
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/63ba995b-f367-4a5c-b4fc-bf4d60f3f4cb/x45.png) |
Guanghui Sun was born in Henan Province, China, in 1983. He received the B.S. degree in Automation from Harbin Institute of Technology, Harbin, China, in 2005, and the M.S. and Ph.D. degrees in Control Science and Engineering from Harbin Institute of Technology, Harbin, China, in 2007 and 2010, respectively. He is currently a professor with Department of Control Science and Engineering in Harbin Institute of Technology, Harbin, China. His research interests include machine learning, computer vision, and aerospace technology. |
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/63ba995b-f367-4a5c-b4fc-bf4d60f3f4cb/x46.png) |
Xiaopeng Hong received the Ph.D. degree in computer application and technology from the Harbin Institute of Technology, China, in 2010. He was a Docent with Center for Machine Vision and Signal Analysis, University of Oulu, Finland, where he had been a Scientist Researcher from 2011 to 2018. He is currently a Distinguished Research Fellow with Xi’an Jiaotong University, China. He has published over 30 articles in mainstream journals and conferences such as the IEEE T-PAMI, T-IP, CVPR, ICCV, AAAI, and ACM UbiComp. His current research interests include multi-modal learning, affective computing, intelligent medical examination, and human-computer interaction. |