2nd Place Solution for
Waymo Open Dataset Challenge - 2D Object Detection
Abstract
A practical autonomous driving system urges the need to reliably and accurately detect vehicles and persons. In this report, we introduce a state-of-the-art 2D object detection system for autonomous driving scenarios. Specifically, we integrate both popular two-stage detector and one-stage detector with anchor free fashion to yield a robust detection. Furthermore, we train multiple expert models and design a greedy version of the auto ensemble scheme that automatically merges detections from different models. Notably, our overall detection system achieves 70.28 L2 mAP on the Waymo Open Dataset v1.2, ranking the 2nd place in the 2D detection track of the Waymo Open Dataset Challenges.
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/48963316-be14-440e-89aa-487fe9fb1a41/x1.png)
1 Introduction
The Waymo Open Dataset challenges attracted many participants in the field of computer vision and autonomous driving. The Waymo Open Dataset [11] that is used in the competition provides high-quality data collected by multiple LiDAR and camera sensors in real self-driving scenarios. In the 2D detection track, three classes: vehicle, pedestrian, and cyclist are annotated with tight-fitting 2D bounding boxes based on the camera images. In self-driving applications accurately and reliably detecting vehicles, cyclists and pedestrians is of paramount importance. Towards this aim, we develop a state-of-the-art 2D object detection system in this challenge.
2 Our Solution
2.1 Base Detectors
With the renaissance of deep learning based object detector, two mainstream frameworks, i.e., one-stage detector and two-stage detector, have dramatically improved both accuracy and efficiency. To fully leverage different detection frameworks, we employ the state-of-the-art two-stage detector Cascade R-CNN [7] and one-stage detector CenterNet [2] with anchor-free fashion. Cascade R-CNN employs a cascade structure for classification and box regression of proposed candidates, which is good at precisely localizing object instances. In contrast to Cascade R-CNN, CenterNet is anchor-free and treats objects as points with properties, which may be better suited for detecting small objects and objects in crowded scenes. We argue that these two different mechanisms have fair diversity on their detections so that the results can be complementary. We respectively produce detections using these two frameworks and then fuse them as the final detection results.
2.1.1 Cascade R-CNN
Cascade is a classical architecture that is demonstrated to be effective for various tasks. Among the object detection counterparts, Cascade R-CNN builds up a cascade head based on the Faster R-CNN [8] to refine detections progressively. Since the proposal boxes are refined by multiple box regression heads, Cascade R-CNN is skilled in precisely localizing object instances. In this challenge, we utilize the Cascade R-CNN as our two-stage detector counterpart considering its superiority.
2.1.2 CenterNet
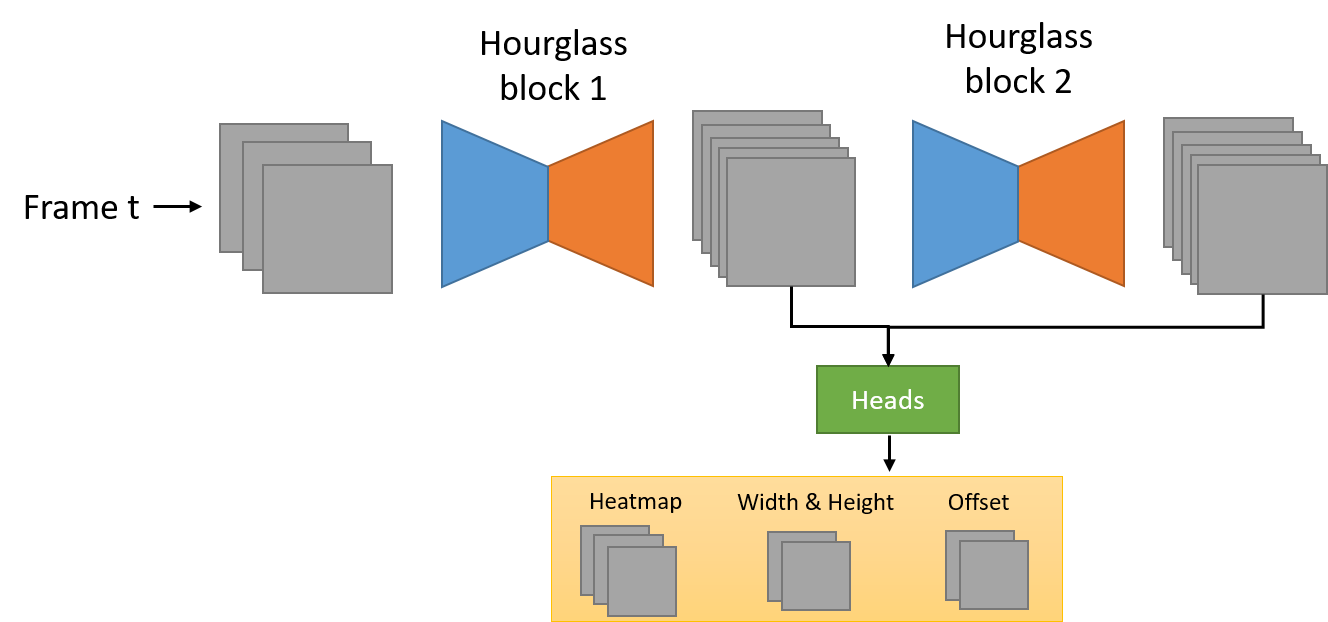
Recently, anchor-free object detectors become popular due to its simplicity and flexibility. CenterNet [2] detects objects via predicting the central location as well as spatial sizes of object instances. Since CenterNet does not need the Non-Maximum Suppression (NMS) as the post-processing step, it may be more suitable for crowded scenes where the NMS may wrongly suppress positive boxes if the threshold is not appropriately set. In this challenge, we employ CenterNet as our one-stage detector counterpart whose framework is shown in Figure 2. In contrast to the original CenterNet, we use the Gaussian kernel as in [6] which takes into account the aspect ratio of the bounding box to encode training samples.
2.2 Greedy Auto Ensemble
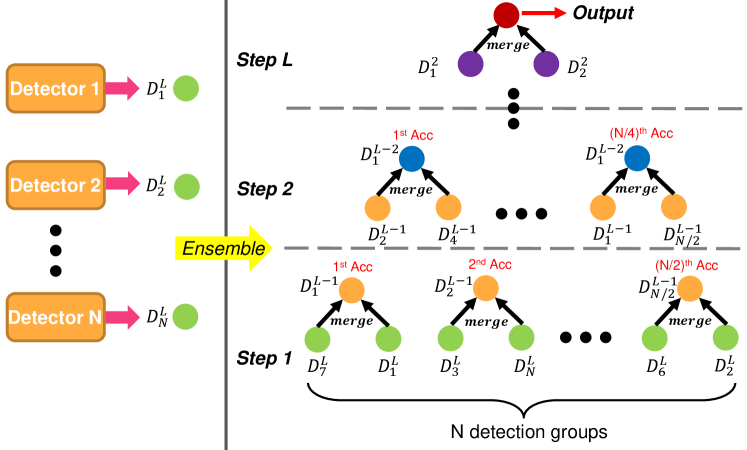
We design a greedy version of the auto ensemble scheme [5] that automatically merges multiple groups of detections according to their detection accuracies, as shown in Figure 3. We note that a group of detections represents the detection results generated from a unique detector framework or a specific inference scheme (e.g., testing with specific image scales) of the same detector framework. As in [5], we consider each group of detections as a node of a binary tree. Let be all the detection groups at the -th level of the binary tree, where is the -th group of detections and is the number of detection groups at the -th level. We denote as the number of levels of the binary tree. Note that indicates all the leaf nodes whose detection results are generated from different models and stands for the total number of detector frameworks and inference schemes used for the ensemble. For each node , it will be evaluated on the validation set and the corresponding accuracy is that is calculated based on the mAP metric. We iteratively merge every pair of children nodes into one parent node in each level of the binary tree until the root node is reached, where the root node serves as the final detection results. Different from [5], our method determines the hierarchical relations of the binary tree dynamically and greedily and therefore reduces much search space. To be more specific, at the -th level, we treat two nodes and as siblings if and are available in the candidate node set and the yields the best accuracy so far, in which is the parent node of and and is the merge operation. After merging and , we delete them from and add into .
For the merge operation , we search several candidate operations and employ the operation that yields the best accuracy. Given two nodes and , we define as:
| (1) | ||||
where is the operation set used in our method. and denotes the traditional NMS and the Adj-NMS [5] respectively. is a simplified version of non-maximum weighted (NMW) [3] that only use confidence scores as weights to merge multiple boxes into one box. In case the detection performance may be degraded after merging, we also introduce and . The overall algorithm of the greedy auto ensemble is presented in Algorithm 1.
2.3 Expert Model
Data distribution is highly imbalanced in the Waymo Open Dataset [11]. For example, there are , and instances for the vehicle and pedestrian classes but only instances for the cyclist class in the training set. As a result, the cyclist class could be overwhelmed by pedestrian or vehicle samples in training, leading to poor performance on the cyclist class. To solve this problem, we train multiple expert models for the cyclist, pedestrian, and vehicle classes, respectively. Since the Waymo Open Dataset also provides context information for each image frame such as time of the day (e.g. daytime and nighttime). We also train additional daytime and nighttime expert models using only daytime and nighttime training images, respectively.
2.4 Anchor Selection
In Cascade R-CNN, the anchors are predefined manually. By default, the aspect ratios are set to 0.5, 1, and 2. We add two more anchor aspect ratios of and for the vehicle expert model since we observe some vehicles with very elongated shapes. CenterNet is free of the anchor selection problem.

2.5 Label Smoothing
After visually inspecting the annotations, we noticed some hard examples and inaccurate or missing annotations as shown in Figure 4, which may cause problems for the training. Therefore, we employ label smoothing to handle this problem during training.
3 Experiments
3.1 Dataset and Evaluation
Dataset. The Waymo Open Dataset v1.2 [11] contains , and video sequences in the training, validation, and testing sets, respectively. Each sequence has 5 views of side left, front left, front, front right, and side right, where each camera captures - frames with the image resolution of pixels or pixels. Our models are pre-trained on the COCO dataset then fine-tuned on the Waymo Open Dataset v1.2. Due to limited computational resources, we sample frame of every frames from the training set to form a mini-train set, which is used to train the Cascade R-CNN and some CenterNet models. We also sample frame of every frames from the validation set to form a mini-val set for ablation experiments. In our solution, temporal cues are not used.
Evaluation Metrics. According to the Waymo Open Dataset Challenge 2D Detection track, we report detection results on the Level 2 Average Precision (AP) that averages over vehicle, pedestrian, and cyclist classes. The positive IoU thresholds are set to , , and for evaluating vehicles, cyclists, and pedestrians, respectively.
3.2 Implementation Details
Cascade R-CNN Detector. For the Cascade R-CNN detector, we adopt the implementation of Hybrid Task Cascade [1] in mmdetection [4] with disabled semantic segmentation and instance segmentation branches, as pixel-wise annotations are not available in this challenge. We use the ResNeXt--d [9] with deformable convolution [10] as the backbone network. We train one main model with all three classes and three expert models for vehicle, pedestrian, and cyclist classes all on the mini-train set, respectively. The main model is trained for epochs with a warm-up learning rate from -3 to -3, and the learning rate is then decayed by a factor of at the th epoch and th epoch, respectively. We train the expert models for 7 epochs with a learning rate warmed up from -5 to -4 and then decayed by a factor of at the th epoch. We also use the multi-scale training, where the long dimension is resized to pixels while the short dimension is randomly selected from pixels without changing the original aspect ratio. Label smoothing and random horizontal flipping are also applied in training. The batch size for all models is set to .
During inference, we resize the long dimension of each image to pixels and keep its original aspect ratio. We use multi-scale testing with scale factors of as well as the horizontal flipping for all models, except for the vehicle expert which only adopts the horizontal flipping. For each model, we first use the class-aware soft-NMS to filter out overlapped boxes. To merge detections generated by different models, we employ the greedy auto ensemble for the pedestrian and cyclist classes, respectively, and use the Adj-NMS for the vehicle class.
CenterNet Detector. For the CenterNet detector, the image size is set to pixels during training, and the learning rate is set to -4. To save computational resources, we first train the CenterNet detector with COCO pretrained weights on the mini-train set for 25 epochs and use it as the base model. We then fine-tune expert models based on the base model: nighttime expert, daytime expert, pedestrian+cyclist expert, respectively. We also fine-tune another expert models based on the base model using the validation set, the training set, the training set with only pedestrian and cyclist classes, and the training set with only nighttime images for 8-10 epochs. In inference, the horizontal flipping and multi-scale testing with scale factors of , , , , are used. To sum up, we train CenterNet models in total and merge their detections into one group of detections using the weighted boxes fusion (WBF)[13].
Ensemble. One-stage detector and two-stage detector each produces an independent group of detections. To merge the two groups of detections into the final result we use Adj-NMS for the vehicle and pedestrian classes, respectively, and utilize WBF for the cyclist class.
3.3 Results
To study the effect of each module used in our solution, we perform ablation experiments on the mini-val set as shown in Table 1. We first evaluate the Cascade R-CNN baseline with label smoothing that achieves AP/L2. We further improve performance from to on AP/L2 by utilizing the commonly used inference schemes of class-aware soft-NMS and multi-scale testing. To assess the greedy auto ensemble, we merge the results of baseline with those of expert models, which leads to a notable improvement of AP/L2. Finally, we fuse the detections of the Cascade R-CNN and CenterNet, which further improves AP/L2 compare to the results of CenterNet. It demonstrates the effectiveness of combining the one-stage and two-stage detectors.
The 2D detection track is quite competitive among all the five tracks in the Waymo Open Dataset Challenge. To compare our final submitted result with other competitors, we show the leaderboard of the Waymo Open Dataset Challenge - 2D Detection Track in the Table 2. It is seen that our overall detection system achieves superior detection results and ranks the 2nd place among all the competitors.
| Method | AP/L2 |
|---|---|
| Cascade R-CNN baseline | 59.71 |
| + class-aware softnms | 60.42 |
| + multi-scale testing | 61.04 |
| + GAE + Expert Models | 63.28 |
| CenterNet | 64.83 |
| Our Solution | 66.27 |
| Method Name | AP/L1 | AP/L2 |
|---|---|---|
| RW-TSDet | 79.42 | 74.43 |
| HorizonDet (Ours) | 75.56 | 70.28 |
| SPNAS-Noah | 75.03 | 69.43 |
| dereyly_alex_2 | 74.61 | 68.78 |
| dereyly_alex | 74.09 | 68.17 |
4 Conclusion
In this report, we present a state-of-the-art 2D object detection system for autonomous driving scenarios. Specifically, we utilize both popular one-stage and two-stage detectors to yield robust detections of vehicles, cyclists and pedestrians. We also employ various ensemble approaches to merge detections from various models. Our overall detection system achieved the 2nd place in the 2D detection track of the Waymo Open Dataset Challenges.
References
- [1] Kai Chen, Jiangmiao Pang, Jiaqi Wang, Yu Xiong, Xiaoxiao Li, Shuyang Sun, Wansen Feng, Ziwei Liu, Jianping Shi, Wanli Ouyang, Chen Change Loy, and Dahua Lin. Hybrid task cascade for instance segmentation. In CVPR, 2019.
- [2] Xingyi Zhou, Dequan Wang, and Philipp Krähenbühl. Objects as points. arXiv preprint arXiv:1904.07850, 2019.
- [3] Huajun Zhou, Zechao Li, Chengcheng Ning, and Jinhui Tang. CAD: scale invariant framework for real-time object detection. In ICCV Workshop, 2017.
- [4] Kai Chen, Jiaqi Wang, Jiangmiao Pang, Yuhang Cao, Yu Xiong, Xiaoxiao Li, Shuyang Sun, Wansen Feng, Ziwei Liu, Jiarui Xu, et al. MMDetection: Open MMLab Detection Toolbox and Benchmark. arXiv preprint arXiv:1906.07155, 2019.
- [5] Yu Liu, Guanglu Song, Yuhang Zang, Yan Gao, Enze Xie, Junjie Yan, Chen Change Loy, and Xiaogang Wang. 1st place solutions for openimage2019 – object detection and instance segmentation. arXiv preprint arXiv:2003.07557, 2019.
- [6] Zili Liu, Tu Zheng, Guodong Xu, Zheng Yang, Haifeng Liu, and Deng Cai. Training-time-friendly network for real-time object detection. In AAAI, 2020.
- [7] Zhaowei Cai, and Nuno Vasconcelos. Cascade r-cnn: delving into high quality object detection. In CVPR, 2018.
- [8] Shaoqing Ren, Kaiming He, Ross Girshick, and Jian Sun. Faster r-cnn: towards real-time object detection with region proposal networks. In NeurIPS, 2015.
- [9] Saining Xie, Ross Girshick, Piotr Dollár, Zhuowen Tu, and Kaiming He. Aggregated Residual Transformations for Deep Neural Networks. arXiv preprint arXiv:1611.05431, 2016
- [10] Jifeng Dai, Haozhi Qi, Yuwen Xiong, Yi Li, Guodong Zhang, Han Hu, and Yichen Wei Deformable Convolutional Networks. arXiv preprint arXiv:1703.06211, 2017
- [11] Pei Sun, Henrik Kretzschmar, Xerxes Dotiwalla, Aurelien Chouard, Vijaysai Patnaik, Paul Tsui, James Guo, Yin Zhou, Yuning Chai, Benjamin Caine, et al. Scalability in Perception for Autonomous Driving: Waymo Open Dataset arXiv preprint arXiv:1912.04838, 2019
- [12] Waymo Open Dataset Challenge 2D Detection Leaderboard. https://waymo.com/open/challenges/2d-detection/
- [13] Roman Solovyev, and Weimin Wang. Weighted Boxes Fusion: ensembling boxes for object detection models. arXiv preprint arXiv:1910.13302, 2019